Some of the patches in the previous series, that were bugfixes or code
cleanups, are already committed, so the series is a little bit
smaller.
Previous performance graph was wrong because I had a bunch of
debugging options enabled when performing the tests. The following
graph contains a more accurate comparison:
http://xenbits.xen.org/people/royger/plot_indirect_read4k.png
Also, the default number of segments per indirect request has been set
to 32 in order to map them all persistently, but this can be changed
at runtime by the user.
Roger Pau Monne (7):
xen-blkback: print stats about persistent grants
xen-blkback: use balloon pages for all mappings
xen-blkback: implement LRU mechanism for persistent grants
xen-blkback: move pending handles list from blkbk to pending_req
xen-blkback: make the queue of free requests per backend
xen-blkback: expand map/unmap functions
xen-block: implement indirect descriptors
Documentation/ABI/stable/sysfs-bus-xen-backend | 15 +
drivers/block/xen-blkback/blkback.c | 833 +++++++++++++++---------
drivers/block/xen-blkback/common.h | 120 ++++-
drivers/block/xen-blkback/xenbus.c | 32 +
drivers/block/xen-blkfront.c | 490 ++++++++++++---
include/xen/interface/io/blkif.h | 26 +
6 files changed, 1122 insertions(+), 394 deletions(-)
git://xenbits.xen.org/people/royger/linux.git xen-block-indirect-v1
Using balloon pages for all granted pages allows us to simplify the
logic in blkback, especially in the xen_blkbk_map function, since now
we can decide if we want to map a grant persistently or not after we
have actually mapped it. This could not be done before because
persistent grants used ballooned pages, whereas non-persistent grants
used pages from the kernel.
This patch also introduces several changes, the first one is that the
list of free pages is no longer global, now each blkback instance has
it's own list of free pages that can be used to map grants. Also, a
run time parameter (max_buffer_pages) has been added in order to tune
the maximum number of free pages each blkback instance will keep in
it's buffer.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: [email protected]
Cc: Konrad Rzeszutek Wilk <[email protected]>
---
Changes since RFC:
* Fix typos in commit message.
* Minor fixes in code.
---
Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
drivers/block/xen-blkback/common.h | 5 +
drivers/block/xen-blkback/xenbus.c | 3 +
4 files changed, 165 insertions(+), 116 deletions(-)
diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
index 3d5951c..e04afe0 100644
--- a/Documentation/ABI/stable/sysfs-bus-xen-backend
+++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
@@ -73,3 +73,11 @@ KernelVersion: 3.0
Contact: Konrad Rzeszutek Wilk <[email protected]>
Description:
Number of sectors written by the frontend.
+
+What: /sys/module/xen_blkback/parameters/max_buffer_pages
+Date: March 2013
+KernelVersion: 3.10
+Contact: Roger Pau Monné <[email protected]>
+Description:
+ Maximum number of free pages to keep in each block
+ backend buffer.
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index f7526db..8a1892a 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
module_param_named(reqs, xen_blkif_reqs, int, 0);
MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
+/*
+ * Maximum number of unused free pages to keep in the internal buffer.
+ * Setting this to a value too low will reduce memory used in each backend,
+ * but can have a performance penalty.
+ *
+ * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
+ * be set to a lower value that might degrade performance on some intensive
+ * IO workloads.
+ */
+
+static int xen_blkif_max_buffer_pages = 704;
+module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
+MODULE_PARM_DESC(max_buffer_pages,
+"Maximum number of free pages to keep in each block backend buffer");
+
/* Run-time switchable: /sys/module/blkback/parameters/ */
static unsigned int log_stats;
module_param(log_stats, int, 0644);
@@ -82,10 +97,14 @@ struct pending_req {
int status;
struct list_head free_list;
DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
+ struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
};
#define BLKBACK_INVALID_HANDLE (~0)
+/* Number of free pages to remove on each call to free_xenballooned_pages */
+#define NUM_BATCH_FREE_PAGES 10
+
struct xen_blkbk {
struct pending_req *pending_reqs;
/* List of all 'pending_req' available */
@@ -93,8 +112,6 @@ struct xen_blkbk {
/* And its spinlock. */
spinlock_t pending_free_lock;
wait_queue_head_t pending_free_wq;
- /* The list of all pages that are available. */
- struct page **pending_pages;
/* And the grant handles that are available. */
grant_handle_t *pending_grant_handles;
};
@@ -143,14 +160,66 @@ static inline int vaddr_pagenr(struct pending_req *req, int seg)
BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
}
-#define pending_page(req, seg) pending_pages[vaddr_pagenr(req, seg)]
+static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
+{
+ unsigned long flags;
+
+ spin_lock_irqsave(&blkif->free_pages_lock, flags);
+ if (list_empty(&blkif->free_pages)) {
+ BUG_ON(blkif->free_pages_num != 0);
+ spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
+ return alloc_xenballooned_pages(1, page, false);
+ }
+ BUG_ON(blkif->free_pages_num == 0);
+ page[0] = list_first_entry(&blkif->free_pages, struct page, lru);
+ list_del(&page[0]->lru);
+ blkif->free_pages_num--;
+ spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
+
+ return 0;
+}
+
+static inline void put_free_pages(struct xen_blkif *blkif, struct page **page,
+ int num)
+{
+ unsigned long flags;
+ int i;
+
+ spin_lock_irqsave(&blkif->free_pages_lock, flags);
+ for (i = 0; i < num; i++)
+ list_add(&page[i]->lru, &blkif->free_pages);
+ blkif->free_pages_num += num;
+ spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
+}
-static inline unsigned long vaddr(struct pending_req *req, int seg)
+static inline void shrink_free_pagepool(struct xen_blkif *blkif, int num)
{
- unsigned long pfn = page_to_pfn(blkbk->pending_page(req, seg));
- return (unsigned long)pfn_to_kaddr(pfn);
+ /* Remove requested pages in batches of NUM_BATCH_FREE_PAGES */
+ struct page *page[NUM_BATCH_FREE_PAGES];
+ unsigned long flags;
+ unsigned int num_pages = 0;
+
+ spin_lock_irqsave(&blkif->free_pages_lock, flags);
+ while (blkif->free_pages_num > num) {
+ BUG_ON(list_empty(&blkif->free_pages));
+ page[num_pages] = list_first_entry(&blkif->free_pages,
+ struct page, lru);
+ list_del(&page[num_pages]->lru);
+ blkif->free_pages_num--;
+ if (++num_pages == NUM_BATCH_FREE_PAGES) {
+ spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
+ free_xenballooned_pages(num_pages, page);
+ spin_lock_irqsave(&blkif->free_pages_lock, flags);
+ num_pages = 0;
+ }
+ }
+ spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
+ if (num_pages != 0)
+ free_xenballooned_pages(num_pages, page);
}
+#define vaddr(page) ((unsigned long)pfn_to_kaddr(page_to_pfn(page)))
+
#define pending_handle(_req, _seg) \
(blkbk->pending_grant_handles[vaddr_pagenr(_req, _seg)])
@@ -170,7 +239,7 @@ static void make_response(struct xen_blkif *blkif, u64 id,
(n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
-static void add_persistent_gnt(struct rb_root *root,
+static int add_persistent_gnt(struct rb_root *root,
struct persistent_gnt *persistent_gnt)
{
struct rb_node **new = &(root->rb_node), *parent = NULL;
@@ -186,14 +255,15 @@ static void add_persistent_gnt(struct rb_root *root,
else if (persistent_gnt->gnt > this->gnt)
new = &((*new)->rb_right);
else {
- pr_alert(DRV_PFX " trying to add a gref that's already in the tree\n");
- BUG();
+ pr_alert_ratelimited(DRV_PFX " trying to add a gref that's already in the tree\n");
+ return -EINVAL;
}
}
/* Add new node and rebalance tree. */
rb_link_node(&(persistent_gnt->node), parent, new);
rb_insert_color(&(persistent_gnt->node), root);
+ return 0;
}
static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
@@ -215,7 +285,8 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
return NULL;
}
-static void free_persistent_gnts(struct rb_root *root, unsigned int num)
+static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
+ unsigned int num)
{
struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
@@ -240,7 +311,7 @@ static void free_persistent_gnts(struct rb_root *root, unsigned int num)
ret = gnttab_unmap_refs(unmap, NULL, pages,
segs_to_unmap);
BUG_ON(ret);
- free_xenballooned_pages(segs_to_unmap, pages);
+ put_free_pages(blkif, pages, segs_to_unmap);
segs_to_unmap = 0;
}
@@ -422,13 +493,17 @@ int xen_blkif_schedule(void *arg)
if (do_block_io_op(blkif))
blkif->waiting_reqs = 1;
+ shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
+
if (log_stats && time_after(jiffies, blkif->st_print))
print_stats(blkif);
}
+ shrink_free_pagepool(blkif, 0);
+
/* Free all persistent grant pages */
if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
- free_persistent_gnts(&blkif->persistent_gnts,
+ free_persistent_gnts(blkif, &blkif->persistent_gnts,
blkif->persistent_gnt_c);
BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
@@ -457,23 +532,25 @@ static void xen_blkbk_unmap(struct pending_req *req)
struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
unsigned int i, invcount = 0;
grant_handle_t handle;
+ struct xen_blkif *blkif = req->blkif;
int ret;
for (i = 0; i < req->nr_pages; i++) {
if (!test_bit(i, req->unmap_seg))
continue;
handle = pending_handle(req, i);
+ pages[invcount] = req->pages[i];
if (handle == BLKBACK_INVALID_HANDLE)
continue;
- gnttab_set_unmap_op(&unmap[invcount], vaddr(req, i),
+ gnttab_set_unmap_op(&unmap[invcount], vaddr(pages[invcount]),
GNTMAP_host_map, handle);
pending_handle(req, i) = BLKBACK_INVALID_HANDLE;
- pages[invcount] = virt_to_page(vaddr(req, i));
invcount++;
}
ret = gnttab_unmap_refs(unmap, NULL, pages, invcount);
BUG_ON(ret);
+ put_free_pages(blkif, pages, invcount);
}
static int xen_blkbk_map(struct blkif_request *req,
@@ -488,7 +565,6 @@ static int xen_blkbk_map(struct blkif_request *req,
struct xen_blkif *blkif = pending_req->blkif;
phys_addr_t addr = 0;
int i, j;
- bool new_map;
int nseg = req->u.rw.nr_segments;
int segs_to_map = 0;
int ret = 0;
@@ -517,68 +593,16 @@ static int xen_blkbk_map(struct blkif_request *req,
* We are using persistent grants and
* the grant is already mapped
*/
- new_map = false;
- } else if (use_persistent_gnts &&
- blkif->persistent_gnt_c <
- max_mapped_grant_pages(blkif->blk_protocol)) {
- /*
- * We are using persistent grants, the grant is
- * not mapped but we have room for it
- */
- new_map = true;
- persistent_gnt = kmalloc(
- sizeof(struct persistent_gnt),
- GFP_KERNEL);
- if (!persistent_gnt)
- return -ENOMEM;
- if (alloc_xenballooned_pages(1, &persistent_gnt->page,
- false)) {
- kfree(persistent_gnt);
- return -ENOMEM;
- }
- persistent_gnt->gnt = req->u.rw.seg[i].gref;
- persistent_gnt->handle = BLKBACK_INVALID_HANDLE;
-
- pages_to_gnt[segs_to_map] =
- persistent_gnt->page;
- addr = (unsigned long) pfn_to_kaddr(
- page_to_pfn(persistent_gnt->page));
-
- add_persistent_gnt(&blkif->persistent_gnts,
- persistent_gnt);
- blkif->persistent_gnt_c++;
- pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
- persistent_gnt->gnt, blkif->persistent_gnt_c,
- max_mapped_grant_pages(blkif->blk_protocol));
- } else {
- /*
- * We are either using persistent grants and
- * hit the maximum limit of grants mapped,
- * or we are not using persistent grants.
- */
- if (use_persistent_gnts &&
- !blkif->vbd.overflow_max_grants) {
- blkif->vbd.overflow_max_grants = 1;
- pr_alert(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
- blkif->domid, blkif->vbd.handle);
- }
- new_map = true;
- pages[i] = blkbk->pending_page(pending_req, i);
- addr = vaddr(pending_req, i);
- pages_to_gnt[segs_to_map] =
- blkbk->pending_page(pending_req, i);
- }
-
- if (persistent_gnt) {
pages[i] = persistent_gnt->page;
persistent_gnts[i] = persistent_gnt;
} else {
+ if (get_free_page(blkif, &pages[i]))
+ goto out_of_memory;
+ addr = vaddr(pages[i]);
+ pages_to_gnt[segs_to_map] = pages[i];
persistent_gnts[i] = NULL;
- }
-
- if (new_map) {
flags = GNTMAP_host_map;
- if (!persistent_gnt &&
+ if (!use_persistent_gnts &&
(pending_req->operation != BLKIF_OP_READ))
flags |= GNTMAP_readonly;
gnttab_set_map_op(&map[segs_to_map++], addr,
@@ -599,47 +623,71 @@ static int xen_blkbk_map(struct blkif_request *req,
*/
bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
for (i = 0, j = 0; i < nseg; i++) {
- if (!persistent_gnts[i] ||
- persistent_gnts[i]->handle == BLKBACK_INVALID_HANDLE) {
+ if (!persistent_gnts[i]) {
/* This is a newly mapped grant */
BUG_ON(j >= segs_to_map);
if (unlikely(map[j].status != 0)) {
pr_debug(DRV_PFX "invalid buffer -- could not remap it\n");
- map[j].handle = BLKBACK_INVALID_HANDLE;
+ pending_handle(pending_req, i) =
+ BLKBACK_INVALID_HANDLE;
ret |= 1;
- if (persistent_gnts[i]) {
- rb_erase(&persistent_gnts[i]->node,
- &blkif->persistent_gnts);
- blkif->persistent_gnt_c--;
- kfree(persistent_gnts[i]);
- persistent_gnts[i] = NULL;
- }
+ j++;
+ continue;
}
+ pending_handle(pending_req, i) = map[j].handle;
}
- if (persistent_gnts[i]) {
- if (persistent_gnts[i]->handle ==
- BLKBACK_INVALID_HANDLE) {
+ if (persistent_gnts[i])
+ goto next;
+ if (use_persistent_gnts &&
+ blkif->persistent_gnt_c <
+ max_mapped_grant_pages(blkif->blk_protocol)) {
+ /*
+ * We are using persistent grants, the grant is
+ * not mapped but we have room for it
+ */
+ persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
+ GFP_KERNEL);
+ if (!persistent_gnt) {
/*
- * If this is a new persistent grant
- * save the handler
+ * If we don't have enough memory to
+ * allocate the persistent_gnt struct
+ * map this grant non-persistenly
*/
- persistent_gnts[i]->handle = map[j++].handle;
+ j++;
+ goto next;
}
- pending_handle(pending_req, i) =
- persistent_gnts[i]->handle;
-
- if (ret)
- continue;
- } else {
- pending_handle(pending_req, i) = map[j++].handle;
- bitmap_set(pending_req->unmap_seg, i, 1);
-
- if (ret)
- continue;
+ persistent_gnt->gnt = map[j].ref;
+ persistent_gnt->handle = map[j].handle;
+ persistent_gnt->page = pages[i];
+ if (add_persistent_gnt(&blkif->persistent_gnts,
+ persistent_gnt)) {
+ kfree(persistent_gnt);
+ j++;
+ goto next;
+ }
+ blkif->persistent_gnt_c++;
+ pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
+ persistent_gnt->gnt, blkif->persistent_gnt_c,
+ max_mapped_grant_pages(blkif->blk_protocol));
+ j++;
+ goto next;
}
+ if (use_persistent_gnts && !blkif->vbd.overflow_max_grants) {
+ blkif->vbd.overflow_max_grants = 1;
+ pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
+ blkif->domid, blkif->vbd.handle);
+ }
+ bitmap_set(pending_req->unmap_seg, i, 1);
+ j++;
+next:
seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
}
return ret;
+
+out_of_memory:
+ pr_alert(DRV_PFX "%s: out of memory\n", __func__);
+ put_free_pages(blkif, pages_to_gnt, segs_to_map);
+ return -ENOMEM;
}
static int dispatch_discard_io(struct xen_blkif *blkif,
@@ -863,7 +911,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
int operation;
struct blk_plug plug;
bool drain = false;
- struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct page **pages = pending_req->pages;
switch (req->operation) {
case BLKIF_OP_READ:
@@ -1090,22 +1138,14 @@ static int __init xen_blkif_init(void)
xen_blkif_reqs, GFP_KERNEL);
blkbk->pending_grant_handles = kmalloc(sizeof(blkbk->pending_grant_handles[0]) *
mmap_pages, GFP_KERNEL);
- blkbk->pending_pages = kzalloc(sizeof(blkbk->pending_pages[0]) *
- mmap_pages, GFP_KERNEL);
- if (!blkbk->pending_reqs || !blkbk->pending_grant_handles ||
- !blkbk->pending_pages) {
+ if (!blkbk->pending_reqs || !blkbk->pending_grant_handles) {
rc = -ENOMEM;
goto out_of_memory;
}
for (i = 0; i < mmap_pages; i++) {
blkbk->pending_grant_handles[i] = BLKBACK_INVALID_HANDLE;
- blkbk->pending_pages[i] = alloc_page(GFP_KERNEL);
- if (blkbk->pending_pages[i] == NULL) {
- rc = -ENOMEM;
- goto out_of_memory;
- }
}
rc = xen_blkif_interface_init();
if (rc)
@@ -1130,13 +1170,6 @@ static int __init xen_blkif_init(void)
failed_init:
kfree(blkbk->pending_reqs);
kfree(blkbk->pending_grant_handles);
- if (blkbk->pending_pages) {
- for (i = 0; i < mmap_pages; i++) {
- if (blkbk->pending_pages[i])
- __free_page(blkbk->pending_pages[i]);
- }
- kfree(blkbk->pending_pages);
- }
kfree(blkbk);
blkbk = NULL;
return rc;
diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
index 60103e2..6c73c38 100644
--- a/drivers/block/xen-blkback/common.h
+++ b/drivers/block/xen-blkback/common.h
@@ -220,6 +220,11 @@ struct xen_blkif {
struct rb_root persistent_gnts;
unsigned int persistent_gnt_c;
+ /* buffer of free pages to map grant refs */
+ spinlock_t free_pages_lock;
+ int free_pages_num;
+ struct list_head free_pages;
+
/* statistics */
unsigned long st_print;
unsigned long long st_rd_req;
diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
index 8bfd1bc..24f7f6d 100644
--- a/drivers/block/xen-blkback/xenbus.c
+++ b/drivers/block/xen-blkback/xenbus.c
@@ -118,6 +118,9 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
blkif->st_print = jiffies;
init_waitqueue_head(&blkif->waiting_to_free);
blkif->persistent_gnts.rb_node = NULL;
+ spin_lock_init(&blkif->free_pages_lock);
+ INIT_LIST_HEAD(&blkif->free_pages);
+ blkif->free_pages_num = 0;
return blkif;
}
--
1.7.7.5 (Apple Git-26)
This mechanism allows blkback to change the number of grants
persistently mapped at run time.
The algorithm uses a simple LRU mechanism that removes (if needed) the
persistent grants that have not been used since the last LRU run, or
if all grants have been used it removes the first grants in the list
(that are not in use).
The algorithm allows the user to change the maximum number of
persistent grants, by changing max_persistent_grants in sysfs.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: Konrad Rzeszutek Wilk <[email protected]>
Cc: [email protected]
---
Changes since RFC:
* Offload part of the purge work to a kworker thread.
* Add documentation about sysfs tunable.
---
Documentation/ABI/stable/sysfs-bus-xen-backend | 7 +
drivers/block/xen-blkback/blkback.c | 278 +++++++++++++++++++-----
drivers/block/xen-blkback/common.h | 12 +
drivers/block/xen-blkback/xenbus.c | 2 +
4 files changed, 240 insertions(+), 59 deletions(-)
diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
index e04afe0..7595b38 100644
--- a/Documentation/ABI/stable/sysfs-bus-xen-backend
+++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
@@ -81,3 +81,10 @@ Contact: Roger Pau Monné <[email protected]>
Description:
Maximum number of free pages to keep in each block
backend buffer.
+
+What: /sys/module/xen_blkback/parameters/max_persistent_grants
+Date: March 2013
+KernelVersion: 3.10
+Contact: Roger Pau Monné <[email protected]>
+Description:
+ Maximum number of grants to map persistently in blkback.
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index 8a1892a..fd1dd38 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -78,6 +78,44 @@ module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
MODULE_PARM_DESC(max_buffer_pages,
"Maximum number of free pages to keep in each block backend buffer");
+/*
+ * Maximum number of grants to map persistently in blkback. For maximum
+ * performance this should be the total numbers of grants that can be used
+ * to fill the ring, but since this might become too high, specially with
+ * the use of indirect descriptors, we set it to a value that provides good
+ * performance without using too much memory.
+ *
+ * When the list of persistent grants is full we clean it using a LRU
+ * algorithm.
+ */
+
+static int xen_blkif_max_pgrants = 352;
+module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
+MODULE_PARM_DESC(max_persistent_grants,
+ "Maximum number of grants to map persistently");
+
+/*
+ * The LRU mechanism to clean the lists of persistent grants needs to
+ * be executed periodically. The time interval between consecutive executions
+ * of the purge mechanism is set in ms.
+ */
+
+static int xen_blkif_lru_interval = 100;
+module_param_named(lru_interval, xen_blkif_lru_interval, int, 0);
+MODULE_PARM_DESC(lru_interval,
+"Execution interval (in ms) of the LRU mechanism to clean the list of persistent grants");
+
+/*
+ * When the persistent grants list is full we will remove unused grants
+ * from the list. The percent number of grants to be removed at each LRU
+ * execution.
+ */
+
+static int xen_blkif_lru_percent_clean = 5;
+module_param_named(lru_percent_clean, xen_blkif_lru_percent_clean, int, 0);
+MODULE_PARM_DESC(lru_percent_clean,
+"Number of persistent grants to unmap when the list is full");
+
/* Run-time switchable: /sys/module/blkback/parameters/ */
static unsigned int log_stats;
module_param(log_stats, int, 0644);
@@ -96,8 +134,8 @@ struct pending_req {
unsigned short operation;
int status;
struct list_head free_list;
- DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
};
#define BLKBACK_INVALID_HANDLE (~0)
@@ -119,36 +157,6 @@ struct xen_blkbk {
static struct xen_blkbk *blkbk;
/*
- * Maximum number of grant pages that can be mapped in blkback.
- * BLKIF_MAX_SEGMENTS_PER_REQUEST * RING_SIZE is the maximum number of
- * pages that blkback will persistently map.
- * Currently, this is:
- * RING_SIZE = 32 (for all known ring types)
- * BLKIF_MAX_SEGMENTS_PER_REQUEST = 11
- * sizeof(struct persistent_gnt) = 48
- * So the maximum memory used to store the grants is:
- * 32 * 11 * 48 = 16896 bytes
- */
-static inline unsigned int max_mapped_grant_pages(enum blkif_protocol protocol)
-{
- switch (protocol) {
- case BLKIF_PROTOCOL_NATIVE:
- return __CONST_RING_SIZE(blkif, PAGE_SIZE) *
- BLKIF_MAX_SEGMENTS_PER_REQUEST;
- case BLKIF_PROTOCOL_X86_32:
- return __CONST_RING_SIZE(blkif_x86_32, PAGE_SIZE) *
- BLKIF_MAX_SEGMENTS_PER_REQUEST;
- case BLKIF_PROTOCOL_X86_64:
- return __CONST_RING_SIZE(blkif_x86_64, PAGE_SIZE) *
- BLKIF_MAX_SEGMENTS_PER_REQUEST;
- default:
- BUG();
- }
- return 0;
-}
-
-
-/*
* Little helpful macro to figure out the index and virtual address of the
* pending_pages[..]. For each 'pending_req' we have have up to
* BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
@@ -239,13 +247,19 @@ static void make_response(struct xen_blkif *blkif, u64 id,
(n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
-static int add_persistent_gnt(struct rb_root *root,
+static int add_persistent_gnt(struct xen_blkif *blkif,
struct persistent_gnt *persistent_gnt)
{
- struct rb_node **new = &(root->rb_node), *parent = NULL;
+ struct rb_node **new = NULL, *parent = NULL;
struct persistent_gnt *this;
+ if (blkif->persistent_gnt_c >= xen_blkif_max_pgrants) {
+ if (!blkif->vbd.overflow_max_grants)
+ blkif->vbd.overflow_max_grants = 1;
+ return -EBUSY;
+ }
/* Figure out where to put new node */
+ new = &blkif->persistent_gnts.rb_node;
while (*new) {
this = container_of(*new, struct persistent_gnt, node);
@@ -259,19 +273,23 @@ static int add_persistent_gnt(struct rb_root *root,
return -EINVAL;
}
}
-
+ bitmap_zero(persistent_gnt->flags, PERSISTENT_GNT_FLAGS_SIZE);
+ set_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
/* Add new node and rebalance tree. */
rb_link_node(&(persistent_gnt->node), parent, new);
- rb_insert_color(&(persistent_gnt->node), root);
+ rb_insert_color(&(persistent_gnt->node), &blkif->persistent_gnts);
+ blkif->persistent_gnt_c++;
+ atomic_inc(&blkif->persistent_gnt_in_use);
return 0;
}
-static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
+static struct persistent_gnt *get_persistent_gnt(struct xen_blkif *blkif,
grant_ref_t gref)
{
struct persistent_gnt *data;
- struct rb_node *node = root->rb_node;
+ struct rb_node *node = NULL;
+ node = blkif->persistent_gnts.rb_node;
while (node) {
data = container_of(node, struct persistent_gnt, node);
@@ -279,12 +297,25 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
node = node->rb_left;
else if (gref > data->gnt)
node = node->rb_right;
- else
+ else {
+ WARN_ON(test_bit(PERSISTENT_GNT_ACTIVE, data->flags));
+ set_bit(PERSISTENT_GNT_ACTIVE, data->flags);
+ atomic_inc(&blkif->persistent_gnt_in_use);
return data;
+ }
}
return NULL;
}
+static void put_persistent_gnt(struct xen_blkif *blkif,
+ struct persistent_gnt *persistent_gnt)
+{
+ WARN_ON(!test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags));
+ set_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
+ clear_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
+ atomic_dec(&blkif->persistent_gnt_in_use);
+}
+
static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
unsigned int num)
{
@@ -322,6 +353,122 @@ static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
BUG_ON(num != 0);
}
+static void unmap_purged_grants(struct work_struct *work)
+{
+ struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct persistent_gnt *persistent_gnt;
+ int ret, segs_to_unmap = 0;
+ struct xen_blkif *blkif =
+ container_of(work, typeof(*blkif), persistent_purge_work);
+
+ while(!list_empty(&blkif->persistent_purge_list)) {
+ persistent_gnt = list_first_entry(&blkif->persistent_purge_list,
+ struct persistent_gnt,
+ remove_node);
+ list_del(&persistent_gnt->remove_node);
+
+ gnttab_set_unmap_op(&unmap[segs_to_unmap],
+ vaddr(persistent_gnt->page),
+ GNTMAP_host_map,
+ persistent_gnt->handle);
+
+ pages[segs_to_unmap] = persistent_gnt->page;
+
+ if (++segs_to_unmap == BLKIF_MAX_SEGMENTS_PER_REQUEST) {
+ ret = gnttab_unmap_refs(unmap, NULL, pages,
+ segs_to_unmap);
+ BUG_ON(ret);
+ put_free_pages(blkif, pages, segs_to_unmap);
+ segs_to_unmap = 0;
+ }
+ kfree(persistent_gnt);
+ }
+ if (segs_to_unmap > 0) {
+ ret = gnttab_unmap_refs(unmap, NULL, pages, segs_to_unmap);
+ BUG_ON(ret);
+ put_free_pages(blkif, pages, segs_to_unmap);
+ }
+}
+
+static void purge_persistent_gnt(struct xen_blkif *blkif)
+{
+ struct persistent_gnt *persistent_gnt;
+ struct rb_node *n;
+ int num_clean, total;
+ bool scan_used = false;
+ struct rb_root *root;
+
+ if (blkif->persistent_gnt_c < xen_blkif_max_pgrants ||
+ (blkif->persistent_gnt_c == xen_blkif_max_pgrants &&
+ !blkif->vbd.overflow_max_grants)) {
+ return;
+ }
+
+ if (work_pending(&blkif->persistent_purge_work)) {
+ pr_alert_ratelimited(DRV_PFX "Scheduled work from previous purge is still pending, cannot purge list\n");
+ return;
+ }
+
+ num_clean = (xen_blkif_max_pgrants / 100) * xen_blkif_lru_percent_clean;
+ num_clean = blkif->persistent_gnt_c - xen_blkif_max_pgrants + num_clean;
+ num_clean = num_clean > blkif->persistent_gnt_c ?
+ blkif->persistent_gnt_c : num_clean;
+ if (num_clean >
+ (blkif->persistent_gnt_c -
+ atomic_read(&blkif->persistent_gnt_in_use)))
+ return;
+
+ total = num_clean;
+
+ pr_debug(DRV_PFX "Going to purge %d persistent grants\n", num_clean);
+
+ INIT_LIST_HEAD(&blkif->persistent_purge_list);
+ root = &blkif->persistent_gnts;
+purge_list:
+ foreach_grant_safe(persistent_gnt, n, root, node) {
+ BUG_ON(persistent_gnt->handle ==
+ BLKBACK_INVALID_HANDLE);
+
+ if (test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags))
+ continue;
+ if (!scan_used &&
+ (test_bit(PERSISTENT_GNT_USED, persistent_gnt->flags)))
+ continue;
+
+ rb_erase(&persistent_gnt->node, root);
+ list_add(&persistent_gnt->remove_node,
+ &blkif->persistent_purge_list);
+ if (--num_clean == 0)
+ goto finished;
+ }
+ /*
+ * If we get here it means we also need to start cleaning
+ * grants that were used since last purge in order to cope
+ * with the requested num
+ */
+ if (!scan_used) {
+ pr_debug(DRV_PFX "Still missing %d purged frames\n", num_clean);
+ scan_used = true;
+ goto purge_list;
+ }
+finished:
+ /* Remove the "used" flag from all the persistent grants */
+ foreach_grant_safe(persistent_gnt, n, root, node) {
+ BUG_ON(persistent_gnt->handle ==
+ BLKBACK_INVALID_HANDLE);
+ clear_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
+ }
+ blkif->persistent_gnt_c -= (total - num_clean);
+ blkif->vbd.overflow_max_grants = 0;
+
+ /* We can defer this work */
+ INIT_WORK(&blkif->persistent_purge_work, unmap_purged_grants);
+ schedule_work(&blkif->persistent_purge_work);
+ pr_debug(DRV_PFX "Purged %d/%d\n", (total - num_clean), total);
+ return;
+}
+
/*
* Retrieve from the 'pending_reqs' a free pending_req structure to be used.
*/
@@ -453,12 +600,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
static void print_stats(struct xen_blkif *blkif)
{
pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
- " | ds %4llu | pg: %4u/%4u\n",
+ " | ds %4llu | pg: %4u/%4d\n",
current->comm, blkif->st_oo_req,
blkif->st_rd_req, blkif->st_wr_req,
blkif->st_f_req, blkif->st_ds_req,
blkif->persistent_gnt_c,
- max_mapped_grant_pages(blkif->blk_protocol));
+ xen_blkif_max_pgrants);
blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
blkif->st_rd_req = 0;
blkif->st_wr_req = 0;
@@ -470,6 +617,7 @@ int xen_blkif_schedule(void *arg)
{
struct xen_blkif *blkif = arg;
struct xen_vbd *vbd = &blkif->vbd;
+ unsigned long timeout;
xen_blkif_get(blkif);
@@ -479,13 +627,21 @@ int xen_blkif_schedule(void *arg)
if (unlikely(vbd->size != vbd_sz(vbd)))
xen_vbd_resize(blkif);
- wait_event_interruptible(
+ timeout = msecs_to_jiffies(xen_blkif_lru_interval);
+
+ timeout = wait_event_interruptible_timeout(
blkif->wq,
- blkif->waiting_reqs || kthread_should_stop());
- wait_event_interruptible(
+ blkif->waiting_reqs || kthread_should_stop(),
+ timeout);
+ if (timeout == 0)
+ goto purge_gnt_list;
+ timeout = wait_event_interruptible_timeout(
blkbk->pending_free_wq,
!list_empty(&blkbk->pending_free) ||
- kthread_should_stop());
+ kthread_should_stop(),
+ timeout);
+ if (timeout == 0)
+ goto purge_gnt_list;
blkif->waiting_reqs = 0;
smp_mb(); /* clear flag *before* checking for work */
@@ -493,6 +649,14 @@ int xen_blkif_schedule(void *arg)
if (do_block_io_op(blkif))
blkif->waiting_reqs = 1;
+purge_gnt_list:
+ if (blkif->vbd.feature_gnt_persistent &&
+ time_after(jiffies, blkif->next_lru)) {
+ purge_persistent_gnt(blkif);
+ blkif->next_lru = jiffies +
+ msecs_to_jiffies(xen_blkif_lru_interval);
+ }
+
shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
if (log_stats && time_after(jiffies, blkif->st_print))
@@ -504,7 +668,7 @@ int xen_blkif_schedule(void *arg)
/* Free all persistent grant pages */
if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
free_persistent_gnts(blkif, &blkif->persistent_gnts,
- blkif->persistent_gnt_c);
+ blkif->persistent_gnt_c);
BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
blkif->persistent_gnt_c = 0;
@@ -536,8 +700,10 @@ static void xen_blkbk_unmap(struct pending_req *req)
int ret;
for (i = 0; i < req->nr_pages; i++) {
- if (!test_bit(i, req->unmap_seg))
+ if (req->persistent_gnts[i] != NULL) {
+ put_persistent_gnt(blkif, req->persistent_gnts[i]);
continue;
+ }
handle = pending_handle(req, i);
pages[invcount] = req->pages[i];
if (handle == BLKBACK_INVALID_HANDLE)
@@ -559,8 +725,8 @@ static int xen_blkbk_map(struct blkif_request *req,
struct page *pages[])
{
struct gnttab_map_grant_ref map[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
struct page *pages_to_gnt[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct persistent_gnt **persistent_gnts = pending_req->persistent_gnts;
struct persistent_gnt *persistent_gnt = NULL;
struct xen_blkif *blkif = pending_req->blkif;
phys_addr_t addr = 0;
@@ -572,9 +738,6 @@ static int xen_blkbk_map(struct blkif_request *req,
use_persistent_gnts = (blkif->vbd.feature_gnt_persistent);
- BUG_ON(blkif->persistent_gnt_c >
- max_mapped_grant_pages(pending_req->blkif->blk_protocol));
-
/*
* Fill out preq.nr_sects with proper amount of sectors, and setup
* assign map[..] with the PFN of the page in our domain with the
@@ -585,7 +748,7 @@ static int xen_blkbk_map(struct blkif_request *req,
if (use_persistent_gnts)
persistent_gnt = get_persistent_gnt(
- &blkif->persistent_gnts,
+ blkif,
req->u.rw.seg[i].gref);
if (persistent_gnt) {
@@ -621,7 +784,6 @@ static int xen_blkbk_map(struct blkif_request *req,
* so that when we access vaddr(pending_req,i) it has the contents of
* the page from the other domain.
*/
- bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
for (i = 0, j = 0; i < nseg; i++) {
if (!persistent_gnts[i]) {
/* This is a newly mapped grant */
@@ -639,11 +801,10 @@ static int xen_blkbk_map(struct blkif_request *req,
if (persistent_gnts[i])
goto next;
if (use_persistent_gnts &&
- blkif->persistent_gnt_c <
- max_mapped_grant_pages(blkif->blk_protocol)) {
+ blkif->persistent_gnt_c < xen_blkif_max_pgrants) {
/*
* We are using persistent grants, the grant is
- * not mapped but we have room for it
+ * not mapped but we might have room for it.
*/
persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
GFP_KERNEL);
@@ -659,16 +820,16 @@ static int xen_blkbk_map(struct blkif_request *req,
persistent_gnt->gnt = map[j].ref;
persistent_gnt->handle = map[j].handle;
persistent_gnt->page = pages[i];
- if (add_persistent_gnt(&blkif->persistent_gnts,
+ if (add_persistent_gnt(blkif,
persistent_gnt)) {
kfree(persistent_gnt);
j++;
goto next;
}
- blkif->persistent_gnt_c++;
+ persistent_gnts[i] = persistent_gnt;
pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
persistent_gnt->gnt, blkif->persistent_gnt_c,
- max_mapped_grant_pages(blkif->blk_protocol));
+ xen_blkif_max_pgrants);
j++;
goto next;
}
@@ -677,7 +838,6 @@ static int xen_blkbk_map(struct blkif_request *req,
pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
blkif->domid, blkif->vbd.handle);
}
- bitmap_set(pending_req->unmap_seg, i, 1);
j++;
next:
seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
index 6c73c38..f43782c 100644
--- a/drivers/block/xen-blkback/common.h
+++ b/drivers/block/xen-blkback/common.h
@@ -182,12 +182,17 @@ struct xen_vbd {
struct backend_info;
+#define PERSISTENT_GNT_FLAGS_SIZE 2
+#define PERSISTENT_GNT_ACTIVE 0
+#define PERSISTENT_GNT_USED 1
struct persistent_gnt {
struct page *page;
grant_ref_t gnt;
grant_handle_t handle;
+ DECLARE_BITMAP(flags, PERSISTENT_GNT_FLAGS_SIZE);
struct rb_node node;
+ struct list_head remove_node;
};
struct xen_blkif {
@@ -219,6 +224,12 @@ struct xen_blkif {
/* tree to store persistent grants */
struct rb_root persistent_gnts;
unsigned int persistent_gnt_c;
+ atomic_t persistent_gnt_in_use;
+ unsigned long next_lru;
+
+ /* used by the kworker that offload work from the persistent purge */
+ struct list_head persistent_purge_list;
+ struct work_struct persistent_purge_work;
/* buffer of free pages to map grant refs */
spinlock_t free_pages_lock;
@@ -262,6 +273,7 @@ int xen_blkif_xenbus_init(void);
irqreturn_t xen_blkif_be_int(int irq, void *dev_id);
int xen_blkif_schedule(void *arg);
+int xen_blkif_purge_persistent(void *arg);
int xen_blkbk_flush_diskcache(struct xenbus_transaction xbt,
struct backend_info *be, int state);
diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
index 24f7f6d..e0fd92a 100644
--- a/drivers/block/xen-blkback/xenbus.c
+++ b/drivers/block/xen-blkback/xenbus.c
@@ -98,6 +98,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
err = PTR_ERR(blkif->xenblkd);
blkif->xenblkd = NULL;
xenbus_dev_error(blkif->be->dev, err, "start xenblkd");
+ return;
}
}
@@ -121,6 +122,7 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
spin_lock_init(&blkif->free_pages_lock);
INIT_LIST_HEAD(&blkif->free_pages);
blkif->free_pages_num = 0;
+ atomic_set(&blkif->persistent_gnt_in_use, 0);
return blkif;
}
--
1.7.7.5 (Apple Git-26)
Moving grant ref handles from blkbk to pending_req will allow us to
get rid of the shared blkbk structure.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: Konrad Rzeszutek Wilk <[email protected]>
Cc: [email protected]
---
drivers/block/xen-blkback/blkback.c | 16 ++++------------
1 files changed, 4 insertions(+), 12 deletions(-)
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index fd1dd38..e6542d5 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -136,6 +136,7 @@ struct pending_req {
struct list_head free_list;
struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
};
#define BLKBACK_INVALID_HANDLE (~0)
@@ -150,8 +151,6 @@ struct xen_blkbk {
/* And its spinlock. */
spinlock_t pending_free_lock;
wait_queue_head_t pending_free_wq;
- /* And the grant handles that are available. */
- grant_handle_t *pending_grant_handles;
};
static struct xen_blkbk *blkbk;
@@ -229,7 +228,7 @@ static inline void shrink_free_pagepool(struct xen_blkif *blkif, int num)
#define vaddr(page) ((unsigned long)pfn_to_kaddr(page_to_pfn(page)))
#define pending_handle(_req, _seg) \
- (blkbk->pending_grant_handles[vaddr_pagenr(_req, _seg)])
+ (_req->grant_handles[_seg])
static int do_block_io_op(struct xen_blkif *blkif);
@@ -1280,7 +1279,7 @@ static void make_response(struct xen_blkif *blkif, u64 id,
static int __init xen_blkif_init(void)
{
- int i, mmap_pages;
+ int i;
int rc = 0;
if (!xen_domain())
@@ -1292,21 +1291,15 @@ static int __init xen_blkif_init(void)
return -ENOMEM;
}
- mmap_pages = xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST;
blkbk->pending_reqs = kzalloc(sizeof(blkbk->pending_reqs[0]) *
xen_blkif_reqs, GFP_KERNEL);
- blkbk->pending_grant_handles = kmalloc(sizeof(blkbk->pending_grant_handles[0]) *
- mmap_pages, GFP_KERNEL);
- if (!blkbk->pending_reqs || !blkbk->pending_grant_handles) {
+ if (!blkbk->pending_reqs) {
rc = -ENOMEM;
goto out_of_memory;
}
- for (i = 0; i < mmap_pages; i++) {
- blkbk->pending_grant_handles[i] = BLKBACK_INVALID_HANDLE;
- }
rc = xen_blkif_interface_init();
if (rc)
goto failed_init;
@@ -1329,7 +1322,6 @@ static int __init xen_blkif_init(void)
pr_alert(DRV_PFX "%s: out of memory\n", __func__);
failed_init:
kfree(blkbk->pending_reqs);
- kfree(blkbk->pending_grant_handles);
kfree(blkbk);
blkbk = NULL;
return rc;
--
1.7.7.5 (Apple Git-26)
Indirect descriptors introduce a new block operation
(BLKIF_OP_INDIRECT) that passes grant references instead of segments
in the request. This grant references are filled with arrays of
blkif_request_segment_aligned, this way we can send more segments in a
request.
The proposed implementation sets the maximum number of indirect grefs
(frames filled with blkif_request_segment_aligned) to 256 in the
backend and 32 in the frontend. The value in the frontend has been
chosen experimentally, and the backend value has been set to a sane
value that allows expanding the maximum number of indirect descriptors
in the frontend if needed.
The migration code has changed from the previous implementation, in
which we simply remapped the segments on the shared ring. Now the
maximum number of segments allowed in a request can change depending
on the backend, so we have to requeue all the requests in the ring and
in the queue and split the bios in them if they are bigger than the
new maximum number of segments.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: Konrad Rzeszutek Wilk <[email protected]>
Cc: [email protected]
---
drivers/block/xen-blkback/blkback.c | 136 +++++++---
drivers/block/xen-blkback/common.h | 82 ++++++-
drivers/block/xen-blkback/xenbus.c | 8 +
drivers/block/xen-blkfront.c | 490 +++++++++++++++++++++++++++++------
include/xen/interface/io/blkif.h | 26 ++
5 files changed, 621 insertions(+), 121 deletions(-)
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index f8c838e..f16a7c9 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -69,7 +69,7 @@ MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
* IO workloads.
*/
-static int xen_blkif_max_buffer_pages = 704;
+static int xen_blkif_max_buffer_pages = 1024;
module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
MODULE_PARM_DESC(max_buffer_pages,
"Maximum number of free pages to keep in each block backend buffer");
@@ -85,7 +85,7 @@ MODULE_PARM_DESC(max_buffer_pages,
* algorithm.
*/
-static int xen_blkif_max_pgrants = 352;
+static int xen_blkif_max_pgrants = 1056;
module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
MODULE_PARM_DESC(max_persistent_grants,
"Maximum number of grants to map persistently");
@@ -631,10 +631,6 @@ purge_gnt_list:
return 0;
}
-struct seg_buf {
- unsigned int offset;
- unsigned int nsec;
-};
/*
* Unmap the grant references, and also remove the M2P over-rides
* used in the 'pending_req'.
@@ -808,29 +804,71 @@ out_of_memory:
return -ENOMEM;
}
-static int xen_blkbk_map_seg(struct blkif_request *req,
- struct pending_req *pending_req,
+static int xen_blkbk_map_seg(struct pending_req *pending_req,
struct seg_buf seg[],
struct page *pages[])
{
- int i, rc;
- grant_ref_t grefs[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ int rc;
- for (i = 0; i < req->u.rw.nr_segments; i++)
- grefs[i] = req->u.rw.seg[i].gref;
-
- rc = xen_blkbk_map(pending_req->blkif, grefs,
+ rc = xen_blkbk_map(pending_req->blkif, pending_req->grefs,
pending_req->persistent_gnts,
pending_req->grant_handles, pending_req->pages,
- req->u.rw.nr_segments,
+ pending_req->nr_pages,
(pending_req->operation != BLKIF_OP_READ));
- if (rc)
- return rc;
- for (i = 0; i < req->u.rw.nr_segments; i++)
- seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
+ return rc;
+}
- return 0;
+static int xen_blkbk_parse_indirect(struct blkif_request *req,
+ struct pending_req *pending_req,
+ struct seg_buf seg[],
+ struct phys_req *preq)
+{
+ struct persistent_gnt **persistent =
+ pending_req->indirect_persistent_gnts;
+ struct page **pages = pending_req->indirect_pages;
+ struct xen_blkif *blkif = pending_req->blkif;
+ int indirect_grefs, rc, n, nseg, i;
+ struct blkif_request_segment_aligned *segments = NULL;
+
+ nseg = pending_req->nr_pages;
+ indirect_grefs = (nseg + SEGS_PER_INDIRECT_FRAME - 1) /
+ SEGS_PER_INDIRECT_FRAME;
+
+ rc = xen_blkbk_map(blkif, req->u.indirect.indirect_grefs,
+ persistent, pending_req->indirect_handles,
+ pages, indirect_grefs, true);
+ if (rc)
+ goto unmap;
+
+ for (n = 0, i = 0; n < nseg; n++) {
+ if ((n % SEGS_PER_INDIRECT_FRAME) == 0) {
+ /* Map indirect segments */
+ if (segments)
+ kunmap_atomic(segments);
+ segments =
+ kmap_atomic(pages[n/SEGS_PER_INDIRECT_FRAME]);
+ }
+ i = n % SEGS_PER_INDIRECT_FRAME;
+ pending_req->grefs[n] = segments[i].gref;
+ seg[n].nsec = segments[i].last_sect -
+ segments[i].first_sect + 1;
+ seg[n].offset = (segments[i].first_sect << 9);
+ if ((segments[i].last_sect >= (PAGE_SIZE >> 9)) ||
+ (segments[i].last_sect <
+ segments[i].first_sect)) {
+ rc = -EINVAL;
+ goto unmap;
+ }
+ preq->nr_sects += seg[n].nsec;
+ }
+
+unmap:
+ if (segments)
+ kunmap_atomic(segments);
+ xen_blkbk_unmap(blkif, pending_req->indirect_handles,
+ pages, persistent, indirect_grefs);
+ return rc;
}
static int dispatch_discard_io(struct xen_blkif *blkif,
@@ -1003,6 +1041,7 @@ __do_block_io_op(struct xen_blkif *blkif)
case BLKIF_OP_WRITE:
case BLKIF_OP_WRITE_BARRIER:
case BLKIF_OP_FLUSH_DISKCACHE:
+ case BLKIF_OP_INDIRECT:
if (dispatch_rw_block_io(blkif, &req, pending_req))
goto done;
break;
@@ -1049,17 +1088,28 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
struct pending_req *pending_req)
{
struct phys_req preq;
- struct seg_buf seg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct seg_buf *seg = pending_req->seg;
unsigned int nseg;
struct bio *bio = NULL;
- struct bio *biolist[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct bio **biolist = pending_req->biolist;
int i, nbio = 0;
int operation;
struct blk_plug plug;
bool drain = false;
struct page **pages = pending_req->pages;
+ unsigned short req_operation;
+
+ req_operation = req->operation == BLKIF_OP_INDIRECT ?
+ req->u.indirect.indirect_op : req->operation;
+ if ((req->operation == BLKIF_OP_INDIRECT) &&
+ (req_operation != BLKIF_OP_READ) &&
+ (req_operation != BLKIF_OP_WRITE)) {
+ pr_debug(DRV_PFX "Invalid indirect operation (%u)\n",
+ req_operation);
+ goto fail_response;
+ }
- switch (req->operation) {
+ switch (req_operation) {
case BLKIF_OP_READ:
blkif->st_rd_req++;
operation = READ;
@@ -1081,33 +1131,47 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
}
/* Check that the number of segments is sane. */
- nseg = req->u.rw.nr_segments;
+ nseg = req->operation == BLKIF_OP_INDIRECT ?
+ req->u.indirect.nr_segments : req->u.rw.nr_segments;
if (unlikely(nseg == 0 && operation != WRITE_FLUSH) ||
- unlikely(nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
+ unlikely((req->operation != BLKIF_OP_INDIRECT) &&
+ (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) ||
+ unlikely((req->operation == BLKIF_OP_INDIRECT) &&
+ (nseg > MAX_INDIRECT_SEGMENTS))) {
pr_debug(DRV_PFX "Bad number of segments in request (%d)\n",
nseg);
/* Haven't submitted any bio's yet. */
goto fail_response;
}
- preq.sector_number = req->u.rw.sector_number;
preq.nr_sects = 0;
pending_req->blkif = blkif;
pending_req->id = req->u.rw.id;
- pending_req->operation = req->operation;
+ pending_req->operation = req_operation;
pending_req->status = BLKIF_RSP_OKAY;
pending_req->nr_pages = nseg;
- for (i = 0; i < nseg; i++) {
- seg[i].nsec = req->u.rw.seg[i].last_sect -
- req->u.rw.seg[i].first_sect + 1;
- if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
- (req->u.rw.seg[i].last_sect < req->u.rw.seg[i].first_sect))
+ if (req->operation != BLKIF_OP_INDIRECT) {
+ preq.dev = req->u.rw.handle;
+ preq.sector_number = req->u.rw.sector_number;
+ for (i = 0; i < nseg; i++) {
+ pending_req->grefs[i] = req->u.rw.seg[i].gref;
+ seg[i].nsec = req->u.rw.seg[i].last_sect -
+ req->u.rw.seg[i].first_sect + 1;
+ seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
+ if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
+ (req->u.rw.seg[i].last_sect <
+ req->u.rw.seg[i].first_sect))
+ goto fail_response;
+ preq.nr_sects += seg[i].nsec;
+ }
+ } else {
+ preq.dev = req->u.indirect.handle;
+ preq.sector_number = req->u.indirect.sector_number;
+ if (xen_blkbk_parse_indirect(req, pending_req, seg, &preq))
goto fail_response;
- preq.nr_sects += seg[i].nsec;
-
}
if (xen_vbd_translate(&preq, blkif, operation) != 0) {
@@ -1144,7 +1208,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
* the hypercall to unmap the grants - that is all done in
* xen_blkbk_unmap.
*/
- if (xen_blkbk_map_seg(req, pending_req, seg, pages))
+ if (xen_blkbk_map_seg(pending_req, seg, pages))
goto fail_flush;
/*
@@ -1210,7 +1274,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
pending_req->nr_pages);
fail_response:
/* Haven't submitted any bio's yet. */
- make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
+ make_response(blkif, req->u.rw.id, req_operation, BLKIF_RSP_ERROR);
free_req(blkif, pending_req);
msleep(1); /* back off a bit */
return -EIO;
diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
index debff44..30bffcc 100644
--- a/drivers/block/xen-blkback/common.h
+++ b/drivers/block/xen-blkback/common.h
@@ -50,6 +50,17 @@
__func__, __LINE__, ##args)
+/*
+ * This is the maximum number of segments that would be allowed in indirect
+ * requests. This value will also be passed to the frontend.
+ */
+#define MAX_INDIRECT_SEGMENTS 256
+
+#define SEGS_PER_INDIRECT_FRAME \
+(PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
+#define MAX_INDIRECT_GREFS \
+((MAX_INDIRECT_SEGMENTS + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
+
/* Not a real protocol. Used to generate ring structs which contain
* the elements common to all protocols only. This way we get a
* compiler-checkable way to use common struct elements, so we can
@@ -83,12 +94,23 @@ struct blkif_x86_32_request_other {
uint64_t id; /* private guest value, echoed in resp */
} __attribute__((__packed__));
+struct blkif_x86_32_request_indirect {
+ uint8_t indirect_op;
+ uint16_t nr_segments;
+ uint64_t id;
+ blkif_sector_t sector_number;
+ blkif_vdev_t handle;
+ uint16_t _pad1;
+ grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
+} __attribute__((__packed__));
+
struct blkif_x86_32_request {
uint8_t operation; /* BLKIF_OP_??? */
union {
struct blkif_x86_32_request_rw rw;
struct blkif_x86_32_request_discard discard;
struct blkif_x86_32_request_other other;
+ struct blkif_x86_32_request_indirect indirect;
} u;
} __attribute__((__packed__));
@@ -127,12 +149,24 @@ struct blkif_x86_64_request_other {
uint64_t id; /* private guest value, echoed in resp */
} __attribute__((__packed__));
+struct blkif_x86_64_request_indirect {
+ uint8_t indirect_op;
+ uint16_t nr_segments;
+ uint32_t _pad1; /* offsetof(blkif_..,u.indirect.id)==8 */
+ uint64_t id;
+ blkif_sector_t sector_number;
+ blkif_vdev_t handle;
+ uint16_t _pad2;
+ grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
+} __attribute__((__packed__));
+
struct blkif_x86_64_request {
uint8_t operation; /* BLKIF_OP_??? */
union {
struct blkif_x86_64_request_rw rw;
struct blkif_x86_64_request_discard discard;
struct blkif_x86_64_request_other other;
+ struct blkif_x86_64_request_indirect indirect;
} u;
} __attribute__((__packed__));
@@ -257,6 +291,11 @@ struct xen_blkif {
wait_queue_head_t waiting_to_free;
};
+struct seg_buf {
+ unsigned long offset;
+ unsigned int nsec;
+};
+
/*
* Each outstanding request that we've passed to the lower device layers has a
* 'pending_req' allocated to it. Each buffer_head that completes decrements
@@ -271,9 +310,16 @@ struct pending_req {
unsigned short operation;
int status;
struct list_head free_list;
- struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct page *pages[MAX_INDIRECT_SEGMENTS];
+ struct persistent_gnt *persistent_gnts[MAX_INDIRECT_SEGMENTS];
+ grant_handle_t grant_handles[MAX_INDIRECT_SEGMENTS];
+ grant_ref_t grefs[MAX_INDIRECT_SEGMENTS];
+ /* Indirect descriptors */
+ struct persistent_gnt *indirect_persistent_gnts[MAX_INDIRECT_GREFS];
+ struct page *indirect_pages[MAX_INDIRECT_GREFS];
+ grant_handle_t indirect_handles[MAX_INDIRECT_GREFS];
+ struct seg_buf seg[MAX_INDIRECT_SEGMENTS];
+ struct bio *biolist[MAX_INDIRECT_SEGMENTS];
};
@@ -312,7 +358,7 @@ struct xenbus_device *xen_blkbk_xenbus(struct backend_info *be);
static inline void blkif_get_x86_32_req(struct blkif_request *dst,
struct blkif_x86_32_request *src)
{
- int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
+ int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
dst->operation = src->operation;
switch (src->operation) {
case BLKIF_OP_READ:
@@ -335,6 +381,19 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
dst->u.discard.sector_number = src->u.discard.sector_number;
dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
break;
+ case BLKIF_OP_INDIRECT:
+ dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
+ dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
+ dst->u.indirect.handle = src->u.indirect.handle;
+ dst->u.indirect.id = src->u.indirect.id;
+ dst->u.indirect.sector_number = src->u.indirect.sector_number;
+ barrier();
+ if (j > dst->u.indirect.nr_segments)
+ j = dst->u.indirect.nr_segments;
+ for (i = 0; i < j; i++)
+ dst->u.indirect.indirect_grefs[i] =
+ src->u.indirect.indirect_grefs[i];
+ break;
default:
/*
* Don't know how to translate this op. Only get the
@@ -348,7 +407,7 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
static inline void blkif_get_x86_64_req(struct blkif_request *dst,
struct blkif_x86_64_request *src)
{
- int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
+ int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
dst->operation = src->operation;
switch (src->operation) {
case BLKIF_OP_READ:
@@ -371,6 +430,19 @@ static inline void blkif_get_x86_64_req(struct blkif_request *dst,
dst->u.discard.sector_number = src->u.discard.sector_number;
dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
break;
+ case BLKIF_OP_INDIRECT:
+ dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
+ dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
+ dst->u.indirect.handle = src->u.indirect.handle;
+ dst->u.indirect.id = src->u.indirect.id;
+ dst->u.indirect.sector_number = src->u.indirect.sector_number;
+ barrier();
+ if (j > dst->u.indirect.nr_segments)
+ j = dst->u.indirect.nr_segments;
+ for (i = 0; i < j; i++)
+ dst->u.indirect.indirect_grefs[i] =
+ src->u.indirect.indirect_grefs[i];
+ break;
default:
/*
* Don't know how to translate this op. Only get the
diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
index bf7344f..172cf89 100644
--- a/drivers/block/xen-blkback/xenbus.c
+++ b/drivers/block/xen-blkback/xenbus.c
@@ -703,6 +703,14 @@ again:
goto abort;
}
+ err = xenbus_printf(xbt, dev->nodename, "max-indirect-segments", "%u",
+ MAX_INDIRECT_SEGMENTS);
+ if (err) {
+ xenbus_dev_fatal(dev, err, "writing %s/max-indirect-segments",
+ dev->nodename);
+ goto abort;
+ }
+
err = xenbus_printf(xbt, dev->nodename, "sectors", "%llu",
(unsigned long long)vbd_sz(&be->blkif->vbd));
if (err) {
diff --git a/drivers/block/xen-blkfront.c b/drivers/block/xen-blkfront.c
index a894f88..ecbc26a 100644
--- a/drivers/block/xen-blkfront.c
+++ b/drivers/block/xen-blkfront.c
@@ -74,12 +74,30 @@ struct grant {
struct blk_shadow {
struct blkif_request req;
struct request *request;
- struct grant *grants_used[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct grant **grants_used;
+ struct grant **indirect_grants;
+};
+
+struct split_bio {
+ struct bio *bio;
+ atomic_t pending;
+ int err;
};
static DEFINE_MUTEX(blkfront_mutex);
static const struct block_device_operations xlvbd_block_fops;
+/*
+ * Maximum number of segments in indirect requests, the actual value used by
+ * the frontend driver is the minimum of this value and the value provided
+ * by the backend driver.
+ */
+
+static int xen_blkif_max_segments = 32;
+module_param_named(max_segments, xen_blkif_max_segments, int, 0);
+MODULE_PARM_DESC(max_segments,
+"Maximum number of segments in indirect requests");
+
#define BLK_RING_SIZE __CONST_RING_SIZE(blkif, PAGE_SIZE)
/*
@@ -98,7 +116,7 @@ struct blkfront_info
enum blkif_state connected;
int ring_ref;
struct blkif_front_ring ring;
- struct scatterlist sg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct scatterlist *sg;
unsigned int evtchn, irq;
struct request_queue *rq;
struct work_struct work;
@@ -114,6 +132,8 @@ struct blkfront_info
unsigned int discard_granularity;
unsigned int discard_alignment;
unsigned int feature_persistent:1;
+ unsigned int max_indirect_segments;
+ unsigned int sector_size;
int is_ready;
};
@@ -142,6 +162,14 @@ static DEFINE_SPINLOCK(minor_lock);
#define DEV_NAME "xvd" /* name in /dev */
+#define SEGS_PER_INDIRECT_FRAME \
+ (PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
+#define INDIRECT_GREFS(_segs) \
+ ((_segs + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
+#define MIN(_a, _b) ((_a) < (_b) ? (_a) : (_b))
+
+static int blkfront_setup_indirect(struct blkfront_info *info);
+
static int get_id_from_freelist(struct blkfront_info *info)
{
unsigned long free = info->shadow_free;
@@ -358,7 +386,8 @@ static int blkif_queue_request(struct request *req)
struct blkif_request *ring_req;
unsigned long id;
unsigned int fsect, lsect;
- int i, ref;
+ int i, ref, n;
+ struct blkif_request_segment_aligned *segments = NULL;
/*
* Used to store if we are able to queue the request by just using
@@ -369,21 +398,27 @@ static int blkif_queue_request(struct request *req)
grant_ref_t gref_head;
struct grant *gnt_list_entry = NULL;
struct scatterlist *sg;
+ int nseg, max_grefs;
if (unlikely(info->connected != BLKIF_STATE_CONNECTED))
return 1;
- /* Check if we have enought grants to allocate a requests */
- if (info->persistent_gnts_c < BLKIF_MAX_SEGMENTS_PER_REQUEST) {
+ max_grefs = info->max_indirect_segments ?
+ info->max_indirect_segments +
+ INDIRECT_GREFS(info->max_indirect_segments) :
+ BLKIF_MAX_SEGMENTS_PER_REQUEST;
+
+ /* Check if we have enough grants to allocate a requests */
+ if (info->persistent_gnts_c < max_grefs) {
new_persistent_gnts = 1;
if (gnttab_alloc_grant_references(
- BLKIF_MAX_SEGMENTS_PER_REQUEST - info->persistent_gnts_c,
+ max_grefs - info->persistent_gnts_c,
&gref_head) < 0) {
gnttab_request_free_callback(
&info->callback,
blkif_restart_queue_callback,
info,
- BLKIF_MAX_SEGMENTS_PER_REQUEST);
+ max_grefs);
return 1;
}
} else
@@ -394,42 +429,74 @@ static int blkif_queue_request(struct request *req)
id = get_id_from_freelist(info);
info->shadow[id].request = req;
- ring_req->u.rw.id = id;
- ring_req->u.rw.sector_number = (blkif_sector_t)blk_rq_pos(req);
- ring_req->u.rw.handle = info->handle;
-
- ring_req->operation = rq_data_dir(req) ?
- BLKIF_OP_WRITE : BLKIF_OP_READ;
-
- if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
- /*
- * Ideally we can do an unordered flush-to-disk. In case the
- * backend onlysupports barriers, use that. A barrier request
- * a superset of FUA, so we can implement it the same
- * way. (It's also a FLUSH+FUA, since it is
- * guaranteed ordered WRT previous writes.)
- */
- ring_req->operation = info->flush_op;
- }
-
if (unlikely(req->cmd_flags & (REQ_DISCARD | REQ_SECURE))) {
/* id, sector_number and handle are set above. */
ring_req->operation = BLKIF_OP_DISCARD;
ring_req->u.discard.nr_sectors = blk_rq_sectors(req);
+ ring_req->u.discard.id = id;
+ ring_req->u.discard.sector_number =
+ (blkif_sector_t)blk_rq_pos(req);
if ((req->cmd_flags & REQ_SECURE) && info->feature_secdiscard)
ring_req->u.discard.flag = BLKIF_DISCARD_SECURE;
else
ring_req->u.discard.flag = 0;
} else {
- ring_req->u.rw.nr_segments = blk_rq_map_sg(req->q, req,
- info->sg);
- BUG_ON(ring_req->u.rw.nr_segments >
- BLKIF_MAX_SEGMENTS_PER_REQUEST);
-
- for_each_sg(info->sg, sg, ring_req->u.rw.nr_segments, i) {
+ BUG_ON(info->max_indirect_segments == 0 &&
+ req->nr_phys_segments > BLKIF_MAX_SEGMENTS_PER_REQUEST);
+ BUG_ON(info->max_indirect_segments &&
+ req->nr_phys_segments > info->max_indirect_segments);
+ nseg = blk_rq_map_sg(req->q, req, info->sg);
+ ring_req->u.rw.id = id;
+ if (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST) {
+ /*
+ * The indirect operation can only be a BLKIF_OP_READ or
+ * BLKIF_OP_WRITE
+ */
+ BUG_ON(req->cmd_flags & (REQ_FLUSH | REQ_FUA));
+ ring_req->operation = BLKIF_OP_INDIRECT;
+ ring_req->u.indirect.indirect_op = rq_data_dir(req) ?
+ BLKIF_OP_WRITE : BLKIF_OP_READ;
+ ring_req->u.indirect.sector_number =
+ (blkif_sector_t)blk_rq_pos(req);
+ ring_req->u.indirect.handle = info->handle;
+ ring_req->u.indirect.nr_segments = nseg;
+ } else {
+ ring_req->u.rw.sector_number =
+ (blkif_sector_t)blk_rq_pos(req);
+ ring_req->u.rw.handle = info->handle;
+ ring_req->operation = rq_data_dir(req) ?
+ BLKIF_OP_WRITE : BLKIF_OP_READ;
+ if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
+ /*
+ * Ideally we can do an unordered flush-to-disk. In case the
+ * backend onlysupports barriers, use that. A barrier request
+ * a superset of FUA, so we can implement it the same
+ * way. (It's also a FLUSH+FUA, since it is
+ * guaranteed ordered WRT previous writes.)
+ */
+ ring_req->operation = info->flush_op;
+ }
+ ring_req->u.rw.nr_segments = nseg;
+ }
+ for_each_sg(info->sg, sg, nseg, i) {
fsect = sg->offset >> 9;
lsect = fsect + (sg->length >> 9) - 1;
+ if ((ring_req->operation == BLKIF_OP_INDIRECT) &&
+ (i % SEGS_PER_INDIRECT_FRAME == 0)) {
+ if (segments)
+ kunmap_atomic(segments);
+
+ n = i / SEGS_PER_INDIRECT_FRAME;
+ gnt_list_entry = get_grant(&gref_head, info);
+ info->shadow[id].indirect_grants[n] =
+ gnt_list_entry;
+ segments = kmap_atomic(
+ pfn_to_page(gnt_list_entry->pfn));
+ ring_req->u.indirect.indirect_grefs[n] =
+ gnt_list_entry->gref;
+ }
+
gnt_list_entry = get_grant(&gref_head, info);
ref = gnt_list_entry->gref;
@@ -461,13 +528,23 @@ static int blkif_queue_request(struct request *req)
kunmap_atomic(bvec_data);
kunmap_atomic(shared_data);
}
-
- ring_req->u.rw.seg[i] =
- (struct blkif_request_segment) {
- .gref = ref,
- .first_sect = fsect,
- .last_sect = lsect };
+ if (ring_req->operation != BLKIF_OP_INDIRECT) {
+ ring_req->u.rw.seg[i] =
+ (struct blkif_request_segment) {
+ .gref = ref,
+ .first_sect = fsect,
+ .last_sect = lsect };
+ } else {
+ n = i % SEGS_PER_INDIRECT_FRAME;
+ segments[n] =
+ (struct blkif_request_segment_aligned) {
+ .gref = ref,
+ .first_sect = fsect,
+ .last_sect = lsect };
+ }
}
+ if (segments)
+ kunmap_atomic(segments);
}
info->ring.req_prod_pvt++;
@@ -542,7 +619,8 @@ wait:
flush_requests(info);
}
-static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
+static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size,
+ unsigned int segments)
{
struct request_queue *rq;
struct blkfront_info *info = gd->private_data;
@@ -571,7 +649,7 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
blk_queue_max_segment_size(rq, PAGE_SIZE);
/* Ensure a merged request will fit in a single I/O ring slot. */
- blk_queue_max_segments(rq, BLKIF_MAX_SEGMENTS_PER_REQUEST);
+ blk_queue_max_segments(rq, segments);
/* Make sure buffer addresses are sector-aligned. */
blk_queue_dma_alignment(rq, 511);
@@ -588,13 +666,14 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
static void xlvbd_flush(struct blkfront_info *info)
{
blk_queue_flush(info->rq, info->feature_flush);
- printk(KERN_INFO "blkfront: %s: %s: %s %s\n",
+ printk(KERN_INFO "blkfront: %s: %s: %s %s %s\n",
info->gd->disk_name,
info->flush_op == BLKIF_OP_WRITE_BARRIER ?
"barrier" : (info->flush_op == BLKIF_OP_FLUSH_DISKCACHE ?
"flush diskcache" : "barrier or flush"),
info->feature_flush ? "enabled" : "disabled",
- info->feature_persistent ? "using persistent grants" : "");
+ info->feature_persistent ? "using persistent grants" : "",
+ info->max_indirect_segments ? "using indirect descriptors" : "");
}
static int xen_translate_vdev(int vdevice, int *minor, unsigned int *offset)
@@ -734,7 +813,9 @@ static int xlvbd_alloc_gendisk(blkif_sector_t capacity,
gd->driverfs_dev = &(info->xbdev->dev);
set_capacity(gd, capacity);
- if (xlvbd_init_blk_queue(gd, sector_size)) {
+ if (xlvbd_init_blk_queue(gd, sector_size,
+ info->max_indirect_segments ? :
+ BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
del_gendisk(gd);
goto release;
}
@@ -818,6 +899,7 @@ static void blkif_free(struct blkfront_info *info, int suspend)
{
struct grant *persistent_gnt;
struct grant *n;
+ int i, j, segs;
/* Prevent new requests being issued until we fix things up. */
spin_lock_irq(&info->io_lock);
@@ -843,6 +925,47 @@ static void blkif_free(struct blkfront_info *info, int suspend)
}
BUG_ON(info->persistent_gnts_c != 0);
+ kfree(info->sg);
+ info->sg = NULL;
+ for (i = 0; i < BLK_RING_SIZE; i++) {
+ /*
+ * Clear persistent grants present in requests already
+ * on the shared ring
+ */
+ if (!info->shadow[i].request)
+ goto free_shadow;
+
+ segs = info->shadow[i].req.operation == BLKIF_OP_INDIRECT ?
+ info->shadow[i].req.u.indirect.nr_segments :
+ info->shadow[i].req.u.rw.nr_segments;
+ for (j = 0; j < segs; j++) {
+ persistent_gnt = info->shadow[i].grants_used[j];
+ gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
+ __free_page(pfn_to_page(persistent_gnt->pfn));
+ kfree(persistent_gnt);
+ }
+
+ if (info->shadow[i].req.operation != BLKIF_OP_INDIRECT)
+ /*
+ * If this is not an indirect operation don't try to
+ * free indirect segments
+ */
+ goto free_shadow;
+
+ for (j = 0; j < INDIRECT_GREFS(segs); j++) {
+ persistent_gnt = info->shadow[i].indirect_grants[j];
+ gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
+ __free_page(pfn_to_page(persistent_gnt->pfn));
+ kfree(persistent_gnt);
+ }
+
+free_shadow:
+ kfree(info->shadow[i].grants_used);
+ info->shadow[i].grants_used = NULL;
+ kfree(info->shadow[i].indirect_grants);
+ info->shadow[i].indirect_grants = NULL;
+ }
+
/* No more gnttab callback work. */
gnttab_cancel_free_callback(&info->callback);
spin_unlock_irq(&info->io_lock);
@@ -873,6 +996,10 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
char *bvec_data;
void *shared_data;
unsigned int offset = 0;
+ int nseg;
+
+ nseg = s->req.operation == BLKIF_OP_INDIRECT ?
+ s->req.u.indirect.nr_segments : s->req.u.rw.nr_segments;
if (bret->operation == BLKIF_OP_READ) {
/*
@@ -885,7 +1012,7 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
BUG_ON((bvec->bv_offset + bvec->bv_len) > PAGE_SIZE);
if (bvec->bv_offset < offset)
i++;
- BUG_ON(i >= s->req.u.rw.nr_segments);
+ BUG_ON(i >= nseg);
shared_data = kmap_atomic(
pfn_to_page(s->grants_used[i]->pfn));
bvec_data = bvec_kmap_irq(bvec, &flags);
@@ -897,10 +1024,17 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
}
}
/* Add the persistent grant into the list of free grants */
- for (i = 0; i < s->req.u.rw.nr_segments; i++) {
+ for (i = 0; i < nseg; i++) {
list_add(&s->grants_used[i]->node, &info->persistent_gnts);
info->persistent_gnts_c++;
}
+ if (s->req.operation == BLKIF_OP_INDIRECT) {
+ for (i = 0; i < INDIRECT_GREFS(nseg); i++) {
+ list_add(&s->indirect_grants[i]->node,
+ &info->persistent_gnts);
+ info->persistent_gnts_c++;
+ }
+ }
}
static irqreturn_t blkif_interrupt(int irq, void *dev_id)
@@ -1034,14 +1168,6 @@ static int setup_blkring(struct xenbus_device *dev,
SHARED_RING_INIT(sring);
FRONT_RING_INIT(&info->ring, sring, PAGE_SIZE);
- sg_init_table(info->sg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
-
- /* Allocate memory for grants */
- err = fill_grant_buffer(info, BLK_RING_SIZE *
- BLKIF_MAX_SEGMENTS_PER_REQUEST);
- if (err)
- goto fail;
-
err = xenbus_grant_ring(dev, virt_to_mfn(info->ring.sring));
if (err < 0) {
free_page((unsigned long)sring);
@@ -1223,13 +1349,84 @@ static int blkfront_probe(struct xenbus_device *dev,
return 0;
}
+/*
+ * This is a clone of md_trim_bio, used to split a bio into smaller ones
+ */
+static void trim_bio(struct bio *bio, int offset, int size)
+{
+ /* 'bio' is a cloned bio which we need to trim to match
+ * the given offset and size.
+ * This requires adjusting bi_sector, bi_size, and bi_io_vec
+ */
+ int i;
+ struct bio_vec *bvec;
+ int sofar = 0;
+
+ size <<= 9;
+ if (offset == 0 && size == bio->bi_size)
+ return;
+
+ bio->bi_sector += offset;
+ bio->bi_size = size;
+ offset <<= 9;
+ clear_bit(BIO_SEG_VALID, &bio->bi_flags);
+
+ while (bio->bi_idx < bio->bi_vcnt &&
+ bio->bi_io_vec[bio->bi_idx].bv_len <= offset) {
+ /* remove this whole bio_vec */
+ offset -= bio->bi_io_vec[bio->bi_idx].bv_len;
+ bio->bi_idx++;
+ }
+ if (bio->bi_idx < bio->bi_vcnt) {
+ bio->bi_io_vec[bio->bi_idx].bv_offset += offset;
+ bio->bi_io_vec[bio->bi_idx].bv_len -= offset;
+ }
+ /* avoid any complications with bi_idx being non-zero*/
+ if (bio->bi_idx) {
+ memmove(bio->bi_io_vec, bio->bi_io_vec+bio->bi_idx,
+ (bio->bi_vcnt - bio->bi_idx) * sizeof(struct bio_vec));
+ bio->bi_vcnt -= bio->bi_idx;
+ bio->bi_idx = 0;
+ }
+ /* Make sure vcnt and last bv are not too big */
+ bio_for_each_segment(bvec, bio, i) {
+ if (sofar + bvec->bv_len > size)
+ bvec->bv_len = size - sofar;
+ if (bvec->bv_len == 0) {
+ bio->bi_vcnt = i;
+ break;
+ }
+ sofar += bvec->bv_len;
+ }
+}
+
+static void split_bio_end(struct bio *bio, int error)
+{
+ struct split_bio *split_bio = bio->bi_private;
+
+ if (error)
+ split_bio->err = error;
+
+ if (atomic_dec_and_test(&split_bio->pending)) {
+ split_bio->bio->bi_phys_segments = 0;
+ bio_endio(split_bio->bio, split_bio->err);
+ kfree(split_bio);
+ }
+ bio_put(bio);
+}
static int blkif_recover(struct blkfront_info *info)
{
int i;
- struct blkif_request *req;
+ struct request *req, *n;
struct blk_shadow *copy;
- int j;
+ int rc;
+ struct bio *bio, *cloned_bio;
+ struct bio_list bio_list, merge_bio;
+ unsigned int segs;
+ int pending, offset, size;
+ struct split_bio *split_bio;
+ struct list_head requests;
/* Stage 1: Make a safe copy of the shadow state. */
copy = kmemdup(info->shadow, sizeof(info->shadow),
@@ -1244,36 +1441,64 @@ static int blkif_recover(struct blkfront_info *info)
info->shadow_free = info->ring.req_prod_pvt;
info->shadow[BLK_RING_SIZE-1].req.u.rw.id = 0x0fffffff;
- /* Stage 3: Find pending requests and requeue them. */
+ rc = blkfront_setup_indirect(info);
+ if (rc) {
+ kfree(copy);
+ return rc;
+ }
+
+ segs = info->max_indirect_segments ? : BLKIF_MAX_SEGMENTS_PER_REQUEST;
+ blk_queue_max_segments(info->rq, segs);
+ bio_list_init(&bio_list);
+ INIT_LIST_HEAD(&requests);
for (i = 0; i < BLK_RING_SIZE; i++) {
/* Not in use? */
if (!copy[i].request)
continue;
- /* Grab a request slot and copy shadow state into it. */
- req = RING_GET_REQUEST(&info->ring, info->ring.req_prod_pvt);
- *req = copy[i].req;
-
- /* We get a new request id, and must reset the shadow state. */
- req->u.rw.id = get_id_from_freelist(info);
- memcpy(&info->shadow[req->u.rw.id], ©[i], sizeof(copy[i]));
-
- if (req->operation != BLKIF_OP_DISCARD) {
- /* Rewrite any grant references invalidated by susp/resume. */
- for (j = 0; j < req->u.rw.nr_segments; j++)
- gnttab_grant_foreign_access_ref(
- req->u.rw.seg[j].gref,
- info->xbdev->otherend_id,
- pfn_to_mfn(copy[i].grants_used[j]->pfn),
- 0);
+ /*
+ * Get the bios in the request so we can re-queue them.
+ */
+ if (copy[i].request->cmd_flags &
+ (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
+ /*
+ * Flush operations don't contain bios, so
+ * we need to requeue the whole request
+ */
+ list_add(©[i].request->queuelist, &requests);
+ continue;
}
- info->shadow[req->u.rw.id].req = *req;
-
- info->ring.req_prod_pvt++;
+ merge_bio.head = copy[i].request->bio;
+ merge_bio.tail = copy[i].request->biotail;
+ bio_list_merge(&bio_list, &merge_bio);
+ copy[i].request->bio = NULL;
+ blk_put_request(copy[i].request);
}
kfree(copy);
+ /*
+ * Empty the queue, this is important because we might have
+ * requests in the queue with more segments than what we
+ * can handle now.
+ */
+ spin_lock_irq(&info->io_lock);
+ while ((req = blk_fetch_request(info->rq)) != NULL) {
+ if (req->cmd_flags &
+ (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
+ list_add(&req->queuelist, &requests);
+ continue;
+ }
+ merge_bio.head = req->bio;
+ merge_bio.tail = req->biotail;
+ bio_list_merge(&bio_list, &merge_bio);
+ req->bio = NULL;
+ if (req->cmd_flags & (REQ_FLUSH | REQ_FUA))
+ pr_alert("diskcache flush request found!\n");
+ __blk_put_request(info->rq, req);
+ }
+ spin_unlock_irq(&info->io_lock);
+
xenbus_switch_state(info->xbdev, XenbusStateConnected);
spin_lock_irq(&info->io_lock);
@@ -1281,14 +1506,50 @@ static int blkif_recover(struct blkfront_info *info)
/* Now safe for us to use the shared ring */
info->connected = BLKIF_STATE_CONNECTED;
- /* Send off requeued requests */
- flush_requests(info);
-
/* Kick any other new requests queued since we resumed */
kick_pending_request_queues(info);
+ list_for_each_entry_safe(req, n, &requests, queuelist) {
+ /* Requeue pending requests (flush or discard) */
+ list_del_init(&req->queuelist);
+ BUG_ON(req->nr_phys_segments > segs);
+ blk_requeue_request(info->rq, req);
+ }
spin_unlock_irq(&info->io_lock);
+ while ((bio = bio_list_pop(&bio_list)) != NULL) {
+ /* Traverse the list of pending bios and re-queue them */
+ if (bio_segments(bio) > segs) {
+ /*
+ * This bio has more segments than what we can
+ * handle, we have to split it.
+ */
+ pending = (bio_segments(bio) + segs - 1) / segs;
+ split_bio = kzalloc(sizeof(*split_bio), GFP_NOIO);
+ BUG_ON(split_bio == NULL);
+ atomic_set(&split_bio->pending, pending);
+ split_bio->bio = bio;
+ for (i = 0; i < pending; i++) {
+ offset = (i * segs * PAGE_SIZE) >> 9;
+ size = MIN((segs * PAGE_SIZE) >> 9,
+ (bio->bi_size >> 9) - offset);
+ cloned_bio = bio_clone(bio, GFP_NOIO);
+ BUG_ON(cloned_bio == NULL);
+ trim_bio(cloned_bio, offset, size);
+ cloned_bio->bi_private = split_bio;
+ cloned_bio->bi_end_io = split_bio_end;
+ submit_bio(cloned_bio->bi_rw, cloned_bio);
+ }
+ /*
+ * Now we have to wait for all those smaller bios to
+ * end, so we can also end the "parent" bio.
+ */
+ continue;
+ }
+ /* We don't need to split this bio */
+ submit_bio(bio->bi_rw, bio);
+ }
+
return 0;
}
@@ -1308,8 +1569,12 @@ static int blkfront_resume(struct xenbus_device *dev)
blkif_free(info, info->connected == BLKIF_STATE_CONNECTED);
err = talk_to_blkback(dev, info);
- if (info->connected == BLKIF_STATE_SUSPENDED && !err)
- err = blkif_recover(info);
+
+ /*
+ * We have to wait for the backend to switch to
+ * connected state, since we want to read which
+ * features it supports.
+ */
return err;
}
@@ -1387,6 +1652,62 @@ static void blkfront_setup_discard(struct blkfront_info *info)
kfree(type);
}
+static int blkfront_setup_indirect(struct blkfront_info *info)
+{
+ unsigned int indirect_segments, segs;
+ int err, i;
+
+ err = xenbus_gather(XBT_NIL, info->xbdev->otherend,
+ "max-indirect-segments", "%u", &indirect_segments,
+ NULL);
+ if (err) {
+ info->max_indirect_segments = 0;
+ segs = BLKIF_MAX_SEGMENTS_PER_REQUEST;
+ } else {
+ info->max_indirect_segments = MIN(indirect_segments,
+ xen_blkif_max_segments);
+ segs = info->max_indirect_segments;
+ }
+ info->sg = kzalloc(sizeof(info->sg[0]) * segs, GFP_KERNEL);
+ if (info->sg == NULL)
+ goto out_of_memory;
+ sg_init_table(info->sg, segs);
+
+ err = fill_grant_buffer(info,
+ (segs + INDIRECT_GREFS(segs)) * BLK_RING_SIZE);
+ if (err)
+ goto out_of_memory;
+
+ for (i = 0; i < BLK_RING_SIZE; i++) {
+ info->shadow[i].grants_used = kzalloc(
+ sizeof(info->shadow[i].grants_used[0]) * segs,
+ GFP_NOIO);
+ if (info->max_indirect_segments)
+ info->shadow[i].indirect_grants = kzalloc(
+ sizeof(info->shadow[i].indirect_grants[0]) *
+ INDIRECT_GREFS(segs),
+ GFP_NOIO);
+ if ((info->shadow[i].grants_used == NULL) ||
+ (info->max_indirect_segments &&
+ (info->shadow[i].indirect_grants == NULL)))
+ goto out_of_memory;
+ }
+
+
+ return 0;
+
+out_of_memory:
+ kfree(info->sg);
+ info->sg = NULL;
+ for (i = 0; i < BLK_RING_SIZE; i++) {
+ kfree(info->shadow[i].grants_used);
+ info->shadow[i].grants_used = NULL;
+ kfree(info->shadow[i].indirect_grants);
+ info->shadow[i].indirect_grants = NULL;
+ }
+ return -ENOMEM;
+}
+
/*
* Invoked when the backend is finally 'ready' (and has told produced
* the details about the physical device - #sectors, size, etc).
@@ -1414,8 +1735,9 @@ static void blkfront_connect(struct blkfront_info *info)
set_capacity(info->gd, sectors);
revalidate_disk(info->gd);
- /* fall through */
+ return;
case BLKIF_STATE_SUSPENDED:
+ blkif_recover(info);
return;
default:
@@ -1436,6 +1758,7 @@ static void blkfront_connect(struct blkfront_info *info)
info->xbdev->otherend);
return;
}
+ info->sector_size = sector_size;
info->feature_flush = 0;
info->flush_op = 0;
@@ -1483,6 +1806,13 @@ static void blkfront_connect(struct blkfront_info *info)
else
info->feature_persistent = persistent;
+ err = blkfront_setup_indirect(info);
+ if (err) {
+ xenbus_dev_fatal(info->xbdev, err, "setup_indirect at %s",
+ info->xbdev->otherend);
+ return;
+ }
+
err = xlvbd_alloc_gendisk(sectors, info, binfo, sector_size);
if (err) {
xenbus_dev_fatal(info->xbdev, err, "xlvbd_add at %s",
diff --git a/include/xen/interface/io/blkif.h b/include/xen/interface/io/blkif.h
index ffd4652..893bee2 100644
--- a/include/xen/interface/io/blkif.h
+++ b/include/xen/interface/io/blkif.h
@@ -102,6 +102,8 @@ typedef uint64_t blkif_sector_t;
*/
#define BLKIF_OP_DISCARD 5
+#define BLKIF_OP_INDIRECT 6
+
/*
* Maximum scatter/gather segments per request.
* This is carefully chosen so that sizeof(struct blkif_ring) <= PAGE_SIZE.
@@ -109,6 +111,16 @@ typedef uint64_t blkif_sector_t;
*/
#define BLKIF_MAX_SEGMENTS_PER_REQUEST 11
+#define BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST 8
+
+struct blkif_request_segment_aligned {
+ grant_ref_t gref; /* reference to I/O buffer frame */
+ /* @first_sect: first sector in frame to transfer (inclusive). */
+ /* @last_sect: last sector in frame to transfer (inclusive). */
+ uint8_t first_sect, last_sect;
+ uint16_t _pad; /* padding to make it 8 bytes, so it's cache-aligned */
+} __attribute__((__packed__));
+
struct blkif_request_rw {
uint8_t nr_segments; /* number of segments */
blkif_vdev_t handle; /* only for read/write requests */
@@ -147,12 +159,26 @@ struct blkif_request_other {
uint64_t id; /* private guest value, echoed in resp */
} __attribute__((__packed__));
+struct blkif_request_indirect {
+ uint8_t indirect_op;
+ uint16_t nr_segments;
+#ifdef CONFIG_X86_64
+ uint32_t _pad1; /* offsetof(blkif_...,u.indirect.id) == 8 */
+#endif
+ uint64_t id;
+ blkif_sector_t sector_number;
+ blkif_vdev_t handle;
+ uint16_t _pad2;
+ grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
+} __attribute__((__packed__));
+
struct blkif_request {
uint8_t operation; /* BLKIF_OP_??? */
union {
struct blkif_request_rw rw;
struct blkif_request_discard discard;
struct blkif_request_other other;
+ struct blkif_request_indirect indirect;
} u;
} __attribute__((__packed__));
--
1.7.7.5 (Apple Git-26)
Remove the last dependency from blkbk by moving the list of free
requests to blkif. This change reduces the contention on the list of
available requests.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: Konrad Rzeszutek Wilk <[email protected]>
Cc: [email protected]
---
Changes since RFC:
* Replace kzalloc with kcalloc.
---
drivers/block/xen-blkback/blkback.c | 125 +++++++----------------------------
drivers/block/xen-blkback/common.h | 27 ++++++++
drivers/block/xen-blkback/xenbus.c | 19 +++++
3 files changed, 70 insertions(+), 101 deletions(-)
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index e6542d5..a1c9dad 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -50,18 +50,14 @@
#include "common.h"
/*
- * These are rather arbitrary. They are fairly large because adjacent requests
- * pulled from a communication ring are quite likely to end up being part of
- * the same scatter/gather request at the disc.
- *
- * ** TRY INCREASING 'xen_blkif_reqs' IF WRITE SPEEDS SEEM TOO LOW **
- *
- * This will increase the chances of being able to write whole tracks.
- * 64 should be enough to keep us competitive with Linux.
+ * This is the number of requests that will be pre-allocated for each backend.
+ * For better performance this is set to RING_SIZE (32), so requests
+ * in the ring will never have to wait for a free pending_req.
*/
-static int xen_blkif_reqs = 64;
+
+int xen_blkif_reqs = 32;
module_param_named(reqs, xen_blkif_reqs, int, 0);
-MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
+MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
/*
* Maximum number of unused free pages to keep in the internal buffer.
@@ -120,53 +116,11 @@ MODULE_PARM_DESC(lru_percent_clean,
static unsigned int log_stats;
module_param(log_stats, int, 0644);
-/*
- * Each outstanding request that we've passed to the lower device layers has a
- * 'pending_req' allocated to it. Each buffer_head that completes decrements
- * the pendcnt towards zero. When it hits zero, the specified domain has a
- * response queued for it, with the saved 'id' passed back.
- */
-struct pending_req {
- struct xen_blkif *blkif;
- u64 id;
- int nr_pages;
- atomic_t pendcnt;
- unsigned short operation;
- int status;
- struct list_head free_list;
- struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
-};
-
#define BLKBACK_INVALID_HANDLE (~0)
/* Number of free pages to remove on each call to free_xenballooned_pages */
#define NUM_BATCH_FREE_PAGES 10
-struct xen_blkbk {
- struct pending_req *pending_reqs;
- /* List of all 'pending_req' available */
- struct list_head pending_free;
- /* And its spinlock. */
- spinlock_t pending_free_lock;
- wait_queue_head_t pending_free_wq;
-};
-
-static struct xen_blkbk *blkbk;
-
-/*
- * Little helpful macro to figure out the index and virtual address of the
- * pending_pages[..]. For each 'pending_req' we have have up to
- * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
- * 10 and would index in the pending_pages[..].
- */
-static inline int vaddr_pagenr(struct pending_req *req, int seg)
-{
- return (req - blkbk->pending_reqs) *
- BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
-}
-
static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
{
unsigned long flags;
@@ -471,18 +425,18 @@ finished:
/*
* Retrieve from the 'pending_reqs' a free pending_req structure to be used.
*/
-static struct pending_req *alloc_req(void)
+static struct pending_req *alloc_req(struct xen_blkif *blkif)
{
struct pending_req *req = NULL;
unsigned long flags;
- spin_lock_irqsave(&blkbk->pending_free_lock, flags);
- if (!list_empty(&blkbk->pending_free)) {
- req = list_entry(blkbk->pending_free.next, struct pending_req,
+ spin_lock_irqsave(&blkif->pending_free_lock, flags);
+ if (!list_empty(&blkif->pending_free)) {
+ req = list_entry(blkif->pending_free.next, struct pending_req,
free_list);
list_del(&req->free_list);
}
- spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
+ spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
return req;
}
@@ -490,17 +444,17 @@ static struct pending_req *alloc_req(void)
* Return the 'pending_req' structure back to the freepool. We also
* wake up the thread if it was waiting for a free page.
*/
-static void free_req(struct pending_req *req)
+static void free_req(struct xen_blkif *blkif, struct pending_req *req)
{
unsigned long flags;
int was_empty;
- spin_lock_irqsave(&blkbk->pending_free_lock, flags);
- was_empty = list_empty(&blkbk->pending_free);
- list_add(&req->free_list, &blkbk->pending_free);
- spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
+ spin_lock_irqsave(&blkif->pending_free_lock, flags);
+ was_empty = list_empty(&blkif->pending_free);
+ list_add(&req->free_list, &blkif->pending_free);
+ spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
if (was_empty)
- wake_up(&blkbk->pending_free_wq);
+ wake_up(&blkif->pending_free_wq);
}
/*
@@ -635,8 +589,8 @@ int xen_blkif_schedule(void *arg)
if (timeout == 0)
goto purge_gnt_list;
timeout = wait_event_interruptible_timeout(
- blkbk->pending_free_wq,
- !list_empty(&blkbk->pending_free) ||
+ blkif->pending_free_wq,
+ !list_empty(&blkif->pending_free) ||
kthread_should_stop(),
timeout);
if (timeout == 0)
@@ -883,7 +837,7 @@ static int dispatch_other_io(struct xen_blkif *blkif,
struct blkif_request *req,
struct pending_req *pending_req)
{
- free_req(pending_req);
+ free_req(blkif, pending_req);
make_response(blkif, req->u.other.id, req->operation,
BLKIF_RSP_EOPNOTSUPP);
return -EIO;
@@ -943,7 +897,7 @@ static void __end_block_io_op(struct pending_req *pending_req, int error)
if (atomic_read(&pending_req->blkif->drain))
complete(&pending_req->blkif->drain_complete);
}
- free_req(pending_req);
+ free_req(pending_req->blkif, pending_req);
}
}
@@ -986,7 +940,7 @@ __do_block_io_op(struct xen_blkif *blkif)
break;
}
- pending_req = alloc_req();
+ pending_req = alloc_req(blkif);
if (NULL == pending_req) {
blkif->st_oo_req++;
more_to_do = 1;
@@ -1020,7 +974,7 @@ __do_block_io_op(struct xen_blkif *blkif)
goto done;
break;
case BLKIF_OP_DISCARD:
- free_req(pending_req);
+ free_req(blkif, pending_req);
if (dispatch_discard_io(blkif, &req))
goto done;
break;
@@ -1222,7 +1176,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
fail_response:
/* Haven't submitted any bio's yet. */
make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
- free_req(pending_req);
+ free_req(blkif, pending_req);
msleep(1); /* back off a bit */
return -EIO;
@@ -1279,51 +1233,20 @@ static void make_response(struct xen_blkif *blkif, u64 id,
static int __init xen_blkif_init(void)
{
- int i;
int rc = 0;
if (!xen_domain())
return -ENODEV;
- blkbk = kzalloc(sizeof(struct xen_blkbk), GFP_KERNEL);
- if (!blkbk) {
- pr_alert(DRV_PFX "%s: out of memory!\n", __func__);
- return -ENOMEM;
- }
-
-
- blkbk->pending_reqs = kzalloc(sizeof(blkbk->pending_reqs[0]) *
- xen_blkif_reqs, GFP_KERNEL);
-
- if (!blkbk->pending_reqs) {
- rc = -ENOMEM;
- goto out_of_memory;
- }
-
rc = xen_blkif_interface_init();
if (rc)
goto failed_init;
- INIT_LIST_HEAD(&blkbk->pending_free);
- spin_lock_init(&blkbk->pending_free_lock);
- init_waitqueue_head(&blkbk->pending_free_wq);
-
- for (i = 0; i < xen_blkif_reqs; i++)
- list_add_tail(&blkbk->pending_reqs[i].free_list,
- &blkbk->pending_free);
-
rc = xen_blkif_xenbus_init();
if (rc)
goto failed_init;
- return 0;
-
- out_of_memory:
- pr_alert(DRV_PFX "%s: out of memory\n", __func__);
failed_init:
- kfree(blkbk->pending_reqs);
- kfree(blkbk);
- blkbk = NULL;
return rc;
}
diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
index f43782c..debff44 100644
--- a/drivers/block/xen-blkback/common.h
+++ b/drivers/block/xen-blkback/common.h
@@ -236,6 +236,14 @@ struct xen_blkif {
int free_pages_num;
struct list_head free_pages;
+ /* Allocation of pending_reqs */
+ struct pending_req *pending_reqs;
+ /* List of all 'pending_req' available */
+ struct list_head pending_free;
+ /* And its spinlock. */
+ spinlock_t pending_free_lock;
+ wait_queue_head_t pending_free_wq;
+
/* statistics */
unsigned long st_print;
unsigned long long st_rd_req;
@@ -249,6 +257,25 @@ struct xen_blkif {
wait_queue_head_t waiting_to_free;
};
+/*
+ * Each outstanding request that we've passed to the lower device layers has a
+ * 'pending_req' allocated to it. Each buffer_head that completes decrements
+ * the pendcnt towards zero. When it hits zero, the specified domain has a
+ * response queued for it, with the saved 'id' passed back.
+ */
+struct pending_req {
+ struct xen_blkif *blkif;
+ u64 id;
+ int nr_pages;
+ atomic_t pendcnt;
+ unsigned short operation;
+ int status;
+ struct list_head free_list;
+ struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+};
+
#define vbd_sz(_v) ((_v)->bdev->bd_part ? \
(_v)->bdev->bd_part->nr_sects : \
diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
index e0fd92a..bf7344f 100644
--- a/drivers/block/xen-blkback/xenbus.c
+++ b/drivers/block/xen-blkback/xenbus.c
@@ -30,6 +30,8 @@ struct backend_info {
char *mode;
};
+extern int xen_blkif_reqs;
+
static struct kmem_cache *xen_blkif_cachep;
static void connect(struct backend_info *);
static int connect_ring(struct backend_info *);
@@ -105,6 +107,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
static struct xen_blkif *xen_blkif_alloc(domid_t domid)
{
struct xen_blkif *blkif;
+ int i;
blkif = kmem_cache_zalloc(xen_blkif_cachep, GFP_KERNEL);
if (!blkif)
@@ -124,6 +127,21 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
blkif->free_pages_num = 0;
atomic_set(&blkif->persistent_gnt_in_use, 0);
+ blkif->pending_reqs = kcalloc(xen_blkif_reqs,
+ sizeof(blkif->pending_reqs[0]),
+ GFP_KERNEL);
+ if (!blkif->pending_reqs) {
+ kmem_cache_free(xen_blkif_cachep, blkif);
+ return ERR_PTR(-ENOMEM);
+ }
+ INIT_LIST_HEAD(&blkif->pending_free);
+ spin_lock_init(&blkif->pending_free_lock);
+ init_waitqueue_head(&blkif->pending_free_wq);
+
+ for (i = 0; i < xen_blkif_reqs; i++)
+ list_add_tail(&blkif->pending_reqs[i].free_list,
+ &blkif->pending_free);
+
return blkif;
}
@@ -205,6 +223,7 @@ static void xen_blkif_free(struct xen_blkif *blkif)
{
if (!atomic_dec_and_test(&blkif->refcnt))
BUG();
+ kfree(blkif->pending_reqs);
kmem_cache_free(xen_blkif_cachep, blkif);
}
--
1.7.7.5 (Apple Git-26)
Preparatory change for implementing indirect descriptors. Change
xen_blkbk_{map/unmap} in order to be able to map/unmap a random amount
of grants (previously it was limited to
BLKIF_MAX_SEGMENTS_PER_REQUEST). Also, remove the usage of pending_req
in the map/unmap functions, so we can map/unmap grants without needing
to pass a pending_req.
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: Konrad Rzeszutek Wilk <[email protected]>
Cc: [email protected]
---
drivers/block/xen-blkback/blkback.c | 133 ++++++++++++++++++++++-------------
1 files changed, 84 insertions(+), 49 deletions(-)
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index a1c9dad..f8c838e 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -181,10 +181,6 @@ static inline void shrink_free_pagepool(struct xen_blkif *blkif, int num)
#define vaddr(page) ((unsigned long)pfn_to_kaddr(page_to_pfn(page)))
-#define pending_handle(_req, _seg) \
- (_req->grant_handles[_seg])
-
-
static int do_block_io_op(struct xen_blkif *blkif);
static int dispatch_rw_block_io(struct xen_blkif *blkif,
struct blkif_request *req,
@@ -643,50 +639,57 @@ struct seg_buf {
* Unmap the grant references, and also remove the M2P over-rides
* used in the 'pending_req'.
*/
-static void xen_blkbk_unmap(struct pending_req *req)
+static void xen_blkbk_unmap(struct xen_blkif *blkif,
+ grant_handle_t handles[],
+ struct page *pages[],
+ struct persistent_gnt *persistent_gnts[],
+ int num)
{
struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+ struct page *unmap_pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
unsigned int i, invcount = 0;
- grant_handle_t handle;
- struct xen_blkif *blkif = req->blkif;
int ret;
- for (i = 0; i < req->nr_pages; i++) {
- if (req->persistent_gnts[i] != NULL) {
- put_persistent_gnt(blkif, req->persistent_gnts[i]);
+ for (i = 0; i < num; i++) {
+ if (persistent_gnts[i] != NULL) {
+ put_persistent_gnt(blkif, persistent_gnts[i]);
continue;
}
- handle = pending_handle(req, i);
- pages[invcount] = req->pages[i];
- if (handle == BLKBACK_INVALID_HANDLE)
+ if (handles[i] == BLKBACK_INVALID_HANDLE)
continue;
- gnttab_set_unmap_op(&unmap[invcount], vaddr(pages[invcount]),
- GNTMAP_host_map, handle);
- pending_handle(req, i) = BLKBACK_INVALID_HANDLE;
- invcount++;
+ unmap_pages[invcount] = pages[i];
+ gnttab_set_unmap_op(&unmap[invcount], vaddr(pages[i]),
+ GNTMAP_host_map, handles[i]);
+ handles[i] = BLKBACK_INVALID_HANDLE;
+ if (++invcount == BLKIF_MAX_SEGMENTS_PER_REQUEST) {
+ ret = gnttab_unmap_refs(unmap, NULL, unmap_pages,
+ invcount);
+ BUG_ON(ret);
+ put_free_pages(blkif, unmap_pages, invcount);
+ invcount = 0;
+ }
+ }
+ if (invcount) {
+ ret = gnttab_unmap_refs(unmap, NULL, unmap_pages, invcount);
+ BUG_ON(ret);
+ put_free_pages(blkif, unmap_pages, invcount);
}
-
- ret = gnttab_unmap_refs(unmap, NULL, pages, invcount);
- BUG_ON(ret);
- put_free_pages(blkif, pages, invcount);
}
-static int xen_blkbk_map(struct blkif_request *req,
- struct pending_req *pending_req,
- struct seg_buf seg[],
- struct page *pages[])
+static int xen_blkbk_map(struct xen_blkif *blkif, grant_ref_t grefs[],
+ struct persistent_gnt *persistent_gnts[],
+ grant_handle_t handles[],
+ struct page *pages[],
+ int num, bool ro)
{
struct gnttab_map_grant_ref map[BLKIF_MAX_SEGMENTS_PER_REQUEST];
struct page *pages_to_gnt[BLKIF_MAX_SEGMENTS_PER_REQUEST];
- struct persistent_gnt **persistent_gnts = pending_req->persistent_gnts;
struct persistent_gnt *persistent_gnt = NULL;
- struct xen_blkif *blkif = pending_req->blkif;
phys_addr_t addr = 0;
int i, j;
- int nseg = req->u.rw.nr_segments;
int segs_to_map = 0;
int ret = 0;
+ int last_map = 0, map_until = 0;
int use_persistent_gnts;
use_persistent_gnts = (blkif->vbd.feature_gnt_persistent);
@@ -696,13 +699,14 @@ static int xen_blkbk_map(struct blkif_request *req,
* assign map[..] with the PFN of the page in our domain with the
* corresponding grant reference for each page.
*/
- for (i = 0; i < nseg; i++) {
+again:
+ for (i = map_until; i < num; i++) {
uint32_t flags;
if (use_persistent_gnts)
persistent_gnt = get_persistent_gnt(
blkif,
- req->u.rw.seg[i].gref);
+ grefs[i]);
if (persistent_gnt) {
/*
@@ -718,13 +722,15 @@ static int xen_blkbk_map(struct blkif_request *req,
pages_to_gnt[segs_to_map] = pages[i];
persistent_gnts[i] = NULL;
flags = GNTMAP_host_map;
- if (!use_persistent_gnts &&
- (pending_req->operation != BLKIF_OP_READ))
+ if (!use_persistent_gnts && ro)
flags |= GNTMAP_readonly;
gnttab_set_map_op(&map[segs_to_map++], addr,
- flags, req->u.rw.seg[i].gref,
+ flags, grefs[i],
blkif->domid);
}
+ map_until = i + 1;
+ if (segs_to_map == BLKIF_MAX_SEGMENTS_PER_REQUEST)
+ break;
}
if (segs_to_map) {
@@ -737,22 +743,20 @@ static int xen_blkbk_map(struct blkif_request *req,
* so that when we access vaddr(pending_req,i) it has the contents of
* the page from the other domain.
*/
- for (i = 0, j = 0; i < nseg; i++) {
+ for (i = last_map, j = 0; i < map_until; i++) {
if (!persistent_gnts[i]) {
/* This is a newly mapped grant */
BUG_ON(j >= segs_to_map);
if (unlikely(map[j].status != 0)) {
pr_debug(DRV_PFX "invalid buffer -- could not remap it\n");
- pending_handle(pending_req, i) =
- BLKBACK_INVALID_HANDLE;
+ handles[i] = BLKBACK_INVALID_HANDLE;
ret |= 1;
- j++;
- continue;
+ goto next;
}
- pending_handle(pending_req, i) = map[j].handle;
+ handles[i] = map[j].handle;
}
if (persistent_gnts[i])
- goto next;
+ continue;
if (use_persistent_gnts &&
blkif->persistent_gnt_c < xen_blkif_max_pgrants) {
/*
@@ -767,7 +771,6 @@ static int xen_blkbk_map(struct blkif_request *req,
* allocate the persistent_gnt struct
* map this grant non-persistenly
*/
- j++;
goto next;
}
persistent_gnt->gnt = map[j].ref;
@@ -776,14 +779,12 @@ static int xen_blkbk_map(struct blkif_request *req,
if (add_persistent_gnt(blkif,
persistent_gnt)) {
kfree(persistent_gnt);
- j++;
goto next;
}
persistent_gnts[i] = persistent_gnt;
pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
persistent_gnt->gnt, blkif->persistent_gnt_c,
xen_blkif_max_pgrants);
- j++;
goto next;
}
if (use_persistent_gnts && !blkif->vbd.overflow_max_grants) {
@@ -791,10 +792,14 @@ static int xen_blkbk_map(struct blkif_request *req,
pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
blkif->domid, blkif->vbd.handle);
}
- j++;
next:
- seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
+ j++;
}
+ segs_to_map = 0;
+ last_map = map_until;
+ if (map_until != num)
+ goto again;
+
return ret;
out_of_memory:
@@ -803,6 +808,31 @@ out_of_memory:
return -ENOMEM;
}
+static int xen_blkbk_map_seg(struct blkif_request *req,
+ struct pending_req *pending_req,
+ struct seg_buf seg[],
+ struct page *pages[])
+{
+ int i, rc;
+ grant_ref_t grefs[BLKIF_MAX_SEGMENTS_PER_REQUEST];
+
+ for (i = 0; i < req->u.rw.nr_segments; i++)
+ grefs[i] = req->u.rw.seg[i].gref;
+
+ rc = xen_blkbk_map(pending_req->blkif, grefs,
+ pending_req->persistent_gnts,
+ pending_req->grant_handles, pending_req->pages,
+ req->u.rw.nr_segments,
+ (pending_req->operation != BLKIF_OP_READ));
+ if (rc)
+ return rc;
+
+ for (i = 0; i < req->u.rw.nr_segments; i++)
+ seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
+
+ return 0;
+}
+
static int dispatch_discard_io(struct xen_blkif *blkif,
struct blkif_request *req)
{
@@ -889,7 +919,10 @@ static void __end_block_io_op(struct pending_req *pending_req, int error)
* the proper response on the ring.
*/
if (atomic_dec_and_test(&pending_req->pendcnt)) {
- xen_blkbk_unmap(pending_req);
+ xen_blkbk_unmap(pending_req->blkif, pending_req->grant_handles,
+ pending_req->pages,
+ pending_req->persistent_gnts,
+ pending_req->nr_pages);
make_response(pending_req->blkif, pending_req->id,
pending_req->operation, pending_req->status);
xen_blkif_put(pending_req->blkif);
@@ -1111,7 +1144,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
* the hypercall to unmap the grants - that is all done in
* xen_blkbk_unmap.
*/
- if (xen_blkbk_map(req, pending_req, seg, pages))
+ if (xen_blkbk_map_seg(req, pending_req, seg, pages))
goto fail_flush;
/*
@@ -1172,7 +1205,9 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
return 0;
fail_flush:
- xen_blkbk_unmap(pending_req);
+ xen_blkbk_unmap(blkif, pending_req->grant_handles,
+ pending_req->pages, pending_req->persistent_gnts,
+ pending_req->nr_pages);
fail_response:
/* Haven't submitted any bio's yet. */
make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
--
1.7.7.5 (Apple Git-26)
Signed-off-by: Roger Pau Monné <[email protected]>
Cc: [email protected]
Cc: Konrad Rzeszutek Wilk <[email protected]>
---
drivers/block/xen-blkback/blkback.c | 6 ++++--
1 files changed, 4 insertions(+), 2 deletions(-)
diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
index dd5b2fe..f7526db 100644
--- a/drivers/block/xen-blkback/blkback.c
+++ b/drivers/block/xen-blkback/blkback.c
@@ -382,10 +382,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
static void print_stats(struct xen_blkif *blkif)
{
pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
- " | ds %4llu\n",
+ " | ds %4llu | pg: %4u/%4u\n",
current->comm, blkif->st_oo_req,
blkif->st_rd_req, blkif->st_wr_req,
- blkif->st_f_req, blkif->st_ds_req);
+ blkif->st_f_req, blkif->st_ds_req,
+ blkif->persistent_gnt_c,
+ max_mapped_grant_pages(blkif->blk_protocol));
blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
blkif->st_rd_req = 0;
blkif->st_wr_req = 0;
--
1.7.7.5 (Apple Git-26)
On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
> Using balloon pages for all granted pages allows us to simplify the
> logic in blkback, especially in the xen_blkbk_map function, since now
> we can decide if we want to map a grant persistently or not after we
> have actually mapped it. This could not be done before because
> persistent grants used ballooned pages, whereas non-persistent grants
> used pages from the kernel.
>
> This patch also introduces several changes, the first one is that the
> list of free pages is no longer global, now each blkback instance has
> it's own list of free pages that can be used to map grants. Also, a
> run time parameter (max_buffer_pages) has been added in order to tune
> the maximum number of free pages each blkback instance will keep in
> it's buffer.
>
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: [email protected]
> Cc: Konrad Rzeszutek Wilk <[email protected]>
Sorry for the late review. Some comments.
> ---
> Changes since RFC:
> * Fix typos in commit message.
> * Minor fixes in code.
> ---
> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
> drivers/block/xen-blkback/common.h | 5 +
> drivers/block/xen-blkback/xenbus.c | 3 +
> 4 files changed, 165 insertions(+), 116 deletions(-)
>
> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
> index 3d5951c..e04afe0 100644
> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
> @@ -73,3 +73,11 @@ KernelVersion: 3.0
> Contact: Konrad Rzeszutek Wilk <[email protected]>
> Description:
> Number of sectors written by the frontend.
> +
> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
> +Date: March 2013
> +KernelVersion: 3.10
> +Contact: Roger Pau Monn? <[email protected]>
> +Description:
> + Maximum number of free pages to keep in each block
> + backend buffer.
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index f7526db..8a1892a 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
> module_param_named(reqs, xen_blkif_reqs, int, 0);
> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>
> +/*
> + * Maximum number of unused free pages to keep in the internal buffer.
> + * Setting this to a value too low will reduce memory used in each backend,
> + * but can have a performance penalty.
> + *
> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
> + * be set to a lower value that might degrade performance on some intensive
> + * IO workloads.
> + */
> +
> +static int xen_blkif_max_buffer_pages = 704;
> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> +MODULE_PARM_DESC(max_buffer_pages,
> +"Maximum number of free pages to keep in each block backend buffer");
> +
> /* Run-time switchable: /sys/module/blkback/parameters/ */
> static unsigned int log_stats;
> module_param(log_stats, int, 0644);
> @@ -82,10 +97,14 @@ struct pending_req {
> int status;
> struct list_head free_list;
> DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> };
>
> #define BLKBACK_INVALID_HANDLE (~0)
>
> +/* Number of free pages to remove on each call to free_xenballooned_pages */
> +#define NUM_BATCH_FREE_PAGES 10
> +
> struct xen_blkbk {
> struct pending_req *pending_reqs;
> /* List of all 'pending_req' available */
> @@ -93,8 +112,6 @@ struct xen_blkbk {
> /* And its spinlock. */
> spinlock_t pending_free_lock;
> wait_queue_head_t pending_free_wq;
> - /* The list of all pages that are available. */
> - struct page **pending_pages;
> /* And the grant handles that are available. */
> grant_handle_t *pending_grant_handles;
> };
> @@ -143,14 +160,66 @@ static inline int vaddr_pagenr(struct pending_req *req, int seg)
> BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
> }
>
> -#define pending_page(req, seg) pending_pages[vaddr_pagenr(req, seg)]
> +static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
> +{
> + unsigned long flags;
> +
> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
I am curious to why you need to use the irqsave variant one here, as
> + if (list_empty(&blkif->free_pages)) {
> + BUG_ON(blkif->free_pages_num != 0);
> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> + return alloc_xenballooned_pages(1, page, false);
This function is using an mutex.
which would imply it is OK to have an non-irq variant of spinlock?
> + }
> + BUG_ON(blkif->free_pages_num == 0);
> + page[0] = list_first_entry(&blkif->free_pages, struct page, lru);
> + list_del(&page[0]->lru);
> + blkif->free_pages_num--;
> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> +
> + return 0;
> +}
> +
> +static inline void put_free_pages(struct xen_blkif *blkif, struct page **page,
> + int num)
> +{
> + unsigned long flags;
> + int i;
> +
> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
> + for (i = 0; i < num; i++)
> + list_add(&page[i]->lru, &blkif->free_pages);
> + blkif->free_pages_num += num;
> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> +}
>
> -static inline unsigned long vaddr(struct pending_req *req, int seg)
> +static inline void shrink_free_pagepool(struct xen_blkif *blkif, int num)
> {
> - unsigned long pfn = page_to_pfn(blkbk->pending_page(req, seg));
> - return (unsigned long)pfn_to_kaddr(pfn);
> + /* Remove requested pages in batches of NUM_BATCH_FREE_PAGES */
> + struct page *page[NUM_BATCH_FREE_PAGES];
> + unsigned long flags;
> + unsigned int num_pages = 0;
> +
> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
> + while (blkif->free_pages_num > num) {
> + BUG_ON(list_empty(&blkif->free_pages));
> + page[num_pages] = list_first_entry(&blkif->free_pages,
> + struct page, lru);
> + list_del(&page[num_pages]->lru);
> + blkif->free_pages_num--;
> + if (++num_pages == NUM_BATCH_FREE_PAGES) {
> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> + free_xenballooned_pages(num_pages, page);
> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
> + num_pages = 0;
> + }
> + }
> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> + if (num_pages != 0)
> + free_xenballooned_pages(num_pages, page);
> }
>
> +#define vaddr(page) ((unsigned long)pfn_to_kaddr(page_to_pfn(page)))
> +
> #define pending_handle(_req, _seg) \
> (blkbk->pending_grant_handles[vaddr_pagenr(_req, _seg)])
>
> @@ -170,7 +239,7 @@ static void make_response(struct xen_blkif *blkif, u64 id,
> (n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
>
>
> -static void add_persistent_gnt(struct rb_root *root,
> +static int add_persistent_gnt(struct rb_root *root,
> struct persistent_gnt *persistent_gnt)
> {
> struct rb_node **new = &(root->rb_node), *parent = NULL;
> @@ -186,14 +255,15 @@ static void add_persistent_gnt(struct rb_root *root,
> else if (persistent_gnt->gnt > this->gnt)
> new = &((*new)->rb_right);
> else {
> - pr_alert(DRV_PFX " trying to add a gref that's already in the tree\n");
> - BUG();
> + pr_alert_ratelimited(DRV_PFX " trying to add a gref that's already in the tree\n");
> + return -EINVAL;
> }
> }
>
> /* Add new node and rebalance tree. */
> rb_link_node(&(persistent_gnt->node), parent, new);
> rb_insert_color(&(persistent_gnt->node), root);
> + return 0;
> }
>
> static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> @@ -215,7 +285,8 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> return NULL;
> }
>
> -static void free_persistent_gnts(struct rb_root *root, unsigned int num)
> +static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
> + unsigned int num)
> {
> struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> @@ -240,7 +311,7 @@ static void free_persistent_gnts(struct rb_root *root, unsigned int num)
> ret = gnttab_unmap_refs(unmap, NULL, pages,
> segs_to_unmap);
> BUG_ON(ret);
> - free_xenballooned_pages(segs_to_unmap, pages);
> + put_free_pages(blkif, pages, segs_to_unmap);
> segs_to_unmap = 0;
> }
>
> @@ -422,13 +493,17 @@ int xen_blkif_schedule(void *arg)
> if (do_block_io_op(blkif))
> blkif->waiting_reqs = 1;
>
> + shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
That threw me off the first time I saw it. I somehow thought it meant
to shrink all xen_blkif_max_buffer_pages, not the value "above" it.
Might need a comment saying: "/* Shrink if we have more than xen_blkif_max_buffer_pages. */"
> +
> if (log_stats && time_after(jiffies, blkif->st_print))
> print_stats(blkif);
> }
>
> + shrink_free_pagepool(blkif, 0);
Add a little comment by the zero please that says: /* All */
> +
> /* Free all persistent grant pages */
> if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
> - free_persistent_gnts(&blkif->persistent_gnts,
> + free_persistent_gnts(blkif, &blkif->persistent_gnts,
> blkif->persistent_gnt_c);
>
> BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
> @@ -457,23 +532,25 @@ static void xen_blkbk_unmap(struct pending_req *req)
> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> unsigned int i, invcount = 0;
> grant_handle_t handle;
> + struct xen_blkif *blkif = req->blkif;
> int ret;
>
> for (i = 0; i < req->nr_pages; i++) {
> if (!test_bit(i, req->unmap_seg))
> continue;
> handle = pending_handle(req, i);
> + pages[invcount] = req->pages[i];
> if (handle == BLKBACK_INVALID_HANDLE)
> continue;
> - gnttab_set_unmap_op(&unmap[invcount], vaddr(req, i),
> + gnttab_set_unmap_op(&unmap[invcount], vaddr(pages[invcount]),
> GNTMAP_host_map, handle);
> pending_handle(req, i) = BLKBACK_INVALID_HANDLE;
> - pages[invcount] = virt_to_page(vaddr(req, i));
> invcount++;
> }
>
> ret = gnttab_unmap_refs(unmap, NULL, pages, invcount);
> BUG_ON(ret);
> + put_free_pages(blkif, pages, invcount);
> }
>
> static int xen_blkbk_map(struct blkif_request *req,
> @@ -488,7 +565,6 @@ static int xen_blkbk_map(struct blkif_request *req,
> struct xen_blkif *blkif = pending_req->blkif;
> phys_addr_t addr = 0;
> int i, j;
> - bool new_map;
> int nseg = req->u.rw.nr_segments;
> int segs_to_map = 0;
> int ret = 0;
> @@ -517,68 +593,16 @@ static int xen_blkbk_map(struct blkif_request *req,
> * We are using persistent grants and
> * the grant is already mapped
> */
> - new_map = false;
> - } else if (use_persistent_gnts &&
> - blkif->persistent_gnt_c <
> - max_mapped_grant_pages(blkif->blk_protocol)) {
> - /*
> - * We are using persistent grants, the grant is
> - * not mapped but we have room for it
> - */
> - new_map = true;
> - persistent_gnt = kmalloc(
> - sizeof(struct persistent_gnt),
> - GFP_KERNEL);
> - if (!persistent_gnt)
> - return -ENOMEM;
> - if (alloc_xenballooned_pages(1, &persistent_gnt->page,
> - false)) {
> - kfree(persistent_gnt);
> - return -ENOMEM;
> - }
> - persistent_gnt->gnt = req->u.rw.seg[i].gref;
> - persistent_gnt->handle = BLKBACK_INVALID_HANDLE;
> -
> - pages_to_gnt[segs_to_map] =
> - persistent_gnt->page;
> - addr = (unsigned long) pfn_to_kaddr(
> - page_to_pfn(persistent_gnt->page));
> -
> - add_persistent_gnt(&blkif->persistent_gnts,
> - persistent_gnt);
> - blkif->persistent_gnt_c++;
> - pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
> - persistent_gnt->gnt, blkif->persistent_gnt_c,
> - max_mapped_grant_pages(blkif->blk_protocol));
> - } else {
> - /*
> - * We are either using persistent grants and
> - * hit the maximum limit of grants mapped,
> - * or we are not using persistent grants.
> - */
> - if (use_persistent_gnts &&
> - !blkif->vbd.overflow_max_grants) {
> - blkif->vbd.overflow_max_grants = 1;
> - pr_alert(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
> - blkif->domid, blkif->vbd.handle);
> - }
> - new_map = true;
> - pages[i] = blkbk->pending_page(pending_req, i);
> - addr = vaddr(pending_req, i);
> - pages_to_gnt[segs_to_map] =
> - blkbk->pending_page(pending_req, i);
> - }
> -
> - if (persistent_gnt) {
Nice :-)
> pages[i] = persistent_gnt->page;
> persistent_gnts[i] = persistent_gnt;
> } else {
> + if (get_free_page(blkif, &pages[i]))
> + goto out_of_memory;
> + addr = vaddr(pages[i]);
> + pages_to_gnt[segs_to_map] = pages[i];
> persistent_gnts[i] = NULL;
> - }
> -
> - if (new_map) {
> flags = GNTMAP_host_map;
> - if (!persistent_gnt &&
> + if (!use_persistent_gnts &&
> (pending_req->operation != BLKIF_OP_READ))
> flags |= GNTMAP_readonly;
> gnttab_set_map_op(&map[segs_to_map++], addr,
> @@ -599,47 +623,71 @@ static int xen_blkbk_map(struct blkif_request *req,
> */
> bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> for (i = 0, j = 0; i < nseg; i++) {
> - if (!persistent_gnts[i] ||
> - persistent_gnts[i]->handle == BLKBACK_INVALID_HANDLE) {
> + if (!persistent_gnts[i]) {
> /* This is a newly mapped grant */
> BUG_ON(j >= segs_to_map);
> if (unlikely(map[j].status != 0)) {
> pr_debug(DRV_PFX "invalid buffer -- could not remap it\n");
> - map[j].handle = BLKBACK_INVALID_HANDLE;
> + pending_handle(pending_req, i) =
> + BLKBACK_INVALID_HANDLE;
You can make that on one line. The 80 character limit is not that ... strict anymore.
Here is what Ingo said about it:
https://lkml.org/lkml/2012/2/3/101
> ret |= 1;
> - if (persistent_gnts[i]) {
> - rb_erase(&persistent_gnts[i]->node,
> - &blkif->persistent_gnts);
> - blkif->persistent_gnt_c--;
> - kfree(persistent_gnts[i]);
> - persistent_gnts[i] = NULL;
> - }
> + j++;
> + continue;
The old code had abit of different logic for the non-persistent error path.
It would do:
598 if (!persistent_gnts[i] ||
..
602 if (unlikely(map[j].status != 0)) {
605 ret |= 1;
.. then later.. for the !persisten_gnts case:
634 } else {
635 pending_handle(pending_req, i) = map[j].handle;
636 bitmap_set(pending_req->unmap_seg, i, 1);
637
638 if (ret) {
639 j++;
640 continue;
641 }
> }
> + pending_handle(pending_req, i) = map[j].handle;
Which means that for this code, we skip the 635 (which is OK as you have done the
"pending_handle(pending_req, i) = BLKBACK_INVALID_HANDLE", but what the 636 case
(that is the bitmap_set)?
It presumarily is OK, as the 'pending_handle(pending_req, i)' ends up being
set to BLKBACK_INVALID_HANDLE, so the loop in xen_blkbk_unmap will still skip
over it?
This I think warrants a little comment saying: "We can skip the bitmap_set' as
xen_blkbk_unmap can handle BLKBACK_INVALID_HANDLE'.
But then that begs the question - why do we even need the bitmap_set code path anymore?
> }
> - if (persistent_gnts[i]) {
> - if (persistent_gnts[i]->handle ==
> - BLKBACK_INVALID_HANDLE) {
> + if (persistent_gnts[i])
> + goto next;
> + if (use_persistent_gnts &&
> + blkif->persistent_gnt_c <
> + max_mapped_grant_pages(blkif->blk_protocol)) {
> + /*
> + * We are using persistent grants, the grant is
> + * not mapped but we have room for it
> + */
> + persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
> + GFP_KERNEL);
> + if (!persistent_gnt) {
> /*
> - * If this is a new persistent grant
> - * save the handler
> + * If we don't have enough memory to
> + * allocate the persistent_gnt struct
> + * map this grant non-persistenly
> */
> - persistent_gnts[i]->handle = map[j++].handle;
> + j++;
> + goto next;
So you are doing this by assuming that get_persistent_gnt in the earlier loop
failed, which means you have in effect done this:
map[segs_to_map++]
Doing the next label will set:
seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
OK, that sounds right. Is this then:
bitmap_set(pending_req->unmap_seg, i, 1);
even needed? The "pending_handle(pending_req, i) = map[j].handle;" had already been
done in the /* This is a newly mapped grant */ if case, so we are set there.
Perhaps you could update the comment from saying 'map this grant' (which
implies doing it NOW as opposed to have done it already), and say:
/*
.. continue using the grant non-persistently. Note that
we mapped it in the earlier loop and the earlier if conditional
sets pending_handle(pending_req, i) = map[j].handle.
*/
> }
> - pending_handle(pending_req, i) =
> - persistent_gnts[i]->handle;
> -
> - if (ret)
> - continue;
> - } else {
> - pending_handle(pending_req, i) = map[j++].handle;
> - bitmap_set(pending_req->unmap_seg, i, 1);
> -
> - if (ret)
> - continue;
> + persistent_gnt->gnt = map[j].ref;
> + persistent_gnt->handle = map[j].handle;
> + persistent_gnt->page = pages[i];
Oh boy, that is a confusing. i and j. Keep loosing track which one is which.
It lookis right.
> + if (add_persistent_gnt(&blkif->persistent_gnts,
> + persistent_gnt)) {
> + kfree(persistent_gnt);
I would also say 'persisten_gnt = NULL' for extra measure of safety
> + j++;
Perhaps the 'j' variable can be called 'map_idx' ? By this point I am pretty
sure I know what the 'i' and 'j' variables are used for, but if somebody new
is trying to grok this code they might spend some 5 minutes trying to figure
this out.
> + goto next;
> + }
> + blkif->persistent_gnt_c++;
> + pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
> + persistent_gnt->gnt, blkif->persistent_gnt_c,
> + max_mapped_grant_pages(blkif->blk_protocol));
> + j++;
> + goto next;
> }
> + if (use_persistent_gnts && !blkif->vbd.overflow_max_grants) {
> + blkif->vbd.overflow_max_grants = 1;
> + pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
> + blkif->domid, blkif->vbd.handle);
> + }
> + bitmap_set(pending_req->unmap_seg, i, 1);
> + j++;
> +next:
> seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
> }
> return ret;
> +
> +out_of_memory:
> + pr_alert(DRV_PFX "%s: out of memory\n", __func__);
> + put_free_pages(blkif, pages_to_gnt, segs_to_map);
> + return -ENOMEM;
> }
>
> static int dispatch_discard_io(struct xen_blkif *blkif,
> @@ -863,7 +911,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> int operation;
> struct blk_plug plug;
> bool drain = false;
> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct page **pages = pending_req->pages;
>
> switch (req->operation) {
> case BLKIF_OP_READ:
> @@ -1090,22 +1138,14 @@ static int __init xen_blkif_init(void)
> xen_blkif_reqs, GFP_KERNEL);
> blkbk->pending_grant_handles = kmalloc(sizeof(blkbk->pending_grant_handles[0]) *
> mmap_pages, GFP_KERNEL);
> - blkbk->pending_pages = kzalloc(sizeof(blkbk->pending_pages[0]) *
> - mmap_pages, GFP_KERNEL);
>
> - if (!blkbk->pending_reqs || !blkbk->pending_grant_handles ||
> - !blkbk->pending_pages) {
> + if (!blkbk->pending_reqs || !blkbk->pending_grant_handles) {
> rc = -ENOMEM;
> goto out_of_memory;
> }
>
> for (i = 0; i < mmap_pages; i++) {
> blkbk->pending_grant_handles[i] = BLKBACK_INVALID_HANDLE;
> - blkbk->pending_pages[i] = alloc_page(GFP_KERNEL);
> - if (blkbk->pending_pages[i] == NULL) {
> - rc = -ENOMEM;
> - goto out_of_memory;
> - }
> }
> rc = xen_blkif_interface_init();
> if (rc)
> @@ -1130,13 +1170,6 @@ static int __init xen_blkif_init(void)
> failed_init:
> kfree(blkbk->pending_reqs);
> kfree(blkbk->pending_grant_handles);
> - if (blkbk->pending_pages) {
> - for (i = 0; i < mmap_pages; i++) {
> - if (blkbk->pending_pages[i])
> - __free_page(blkbk->pending_pages[i]);
> - }
> - kfree(blkbk->pending_pages);
> - }
> kfree(blkbk);
> blkbk = NULL;
> return rc;
> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
> index 60103e2..6c73c38 100644
> --- a/drivers/block/xen-blkback/common.h
> +++ b/drivers/block/xen-blkback/common.h
> @@ -220,6 +220,11 @@ struct xen_blkif {
> struct rb_root persistent_gnts;
> unsigned int persistent_gnt_c;
>
> + /* buffer of free pages to map grant refs */
> + spinlock_t free_pages_lock;
> + int free_pages_num;
> + struct list_head free_pages;
> +
> /* statistics */
> unsigned long st_print;
> unsigned long long st_rd_req;
> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
> index 8bfd1bc..24f7f6d 100644
> --- a/drivers/block/xen-blkback/xenbus.c
> +++ b/drivers/block/xen-blkback/xenbus.c
> @@ -118,6 +118,9 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> blkif->st_print = jiffies;
> init_waitqueue_head(&blkif->waiting_to_free);
> blkif->persistent_gnts.rb_node = NULL;
> + spin_lock_init(&blkif->free_pages_lock);
> + INIT_LIST_HEAD(&blkif->free_pages);
> + blkif->free_pages_num = 0;
>
> return blkif;
> }
> --
> 1.7.7.5 (Apple Git-26)
>
On Wed, Mar 27, 2013 at 12:10:37PM +0100, Roger Pau Monne wrote:
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: [email protected]
> Cc: Konrad Rzeszutek Wilk <[email protected]>
Looks good.
> ---
> drivers/block/xen-blkback/blkback.c | 6 ++++--
> 1 files changed, 4 insertions(+), 2 deletions(-)
>
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index dd5b2fe..f7526db 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -382,10 +382,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
> static void print_stats(struct xen_blkif *blkif)
> {
> pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
> - " | ds %4llu\n",
> + " | ds %4llu | pg: %4u/%4u\n",
> current->comm, blkif->st_oo_req,
> blkif->st_rd_req, blkif->st_wr_req,
> - blkif->st_f_req, blkif->st_ds_req);
> + blkif->st_f_req, blkif->st_ds_req,
> + blkif->persistent_gnt_c,
> + max_mapped_grant_pages(blkif->blk_protocol));
> blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
> blkif->st_rd_req = 0;
> blkif->st_wr_req = 0;
> --
> 1.7.7.5 (Apple Git-26)
>
On Wed, Mar 27, 2013 at 12:10:39PM +0100, Roger Pau Monne wrote:
> This mechanism allows blkback to change the number of grants
> persistently mapped at run time.
>
> The algorithm uses a simple LRU mechanism that removes (if needed) the
> persistent grants that have not been used since the last LRU run, or
> if all grants have been used it removes the first grants in the list
> (that are not in use).
>
> The algorithm allows the user to change the maximum number of
> persistent grants, by changing max_persistent_grants in sysfs.
>
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: Konrad Rzeszutek Wilk <[email protected]>
> Cc: [email protected]
> ---
> Changes since RFC:
> * Offload part of the purge work to a kworker thread.
> * Add documentation about sysfs tunable.
> ---
> Documentation/ABI/stable/sysfs-bus-xen-backend | 7 +
> drivers/block/xen-blkback/blkback.c | 278 +++++++++++++++++++-----
> drivers/block/xen-blkback/common.h | 12 +
> drivers/block/xen-blkback/xenbus.c | 2 +
> 4 files changed, 240 insertions(+), 59 deletions(-)
>
> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
> index e04afe0..7595b38 100644
> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
> @@ -81,3 +81,10 @@ Contact: Roger Pau Monn? <[email protected]>
> Description:
> Maximum number of free pages to keep in each block
> backend buffer.
> +
> +What: /sys/module/xen_blkback/parameters/max_persistent_grants
> +Date: March 2013
> +KernelVersion: 3.10
> +Contact: Roger Pau Monn? <[email protected]>
> +Description:
> + Maximum number of grants to map persistently in blkback.
You are missing the other 2 paramters.
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index 8a1892a..fd1dd38 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -78,6 +78,44 @@ module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> MODULE_PARM_DESC(max_buffer_pages,
> "Maximum number of free pages to keep in each block backend buffer");
>
> +/*
> + * Maximum number of grants to map persistently in blkback. For maximum
> + * performance this should be the total numbers of grants that can be used
> + * to fill the ring, but since this might become too high, specially with
> + * the use of indirect descriptors, we set it to a value that provides good
> + * performance without using too much memory.
> + *
> + * When the list of persistent grants is full we clean it using a LRU
^- up
> + * algorithm.
Sorry for the confusion. Does this mean that the cap is 352? Or that once
we hit the cap of 352 then the LRU engine gets kicked in?
> + */
> +
> +static int xen_blkif_max_pgrants = 352;
> +module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
> +MODULE_PARM_DESC(max_persistent_grants,
> + "Maximum number of grants to map persistently");
> +
> +/*
> + * The LRU mechanism to clean the lists of persistent grants needs to
> + * be executed periodically. The time interval between consecutive executions
> + * of the purge mechanism is set in ms.
> + */
> +
> +static int xen_blkif_lru_interval = 100;
> +module_param_named(lru_interval, xen_blkif_lru_interval, int, 0);
Is the '0' intentional?
> +MODULE_PARM_DESC(lru_interval,
> +"Execution interval (in ms) of the LRU mechanism to clean the list of persistent grants");
> +
> +/*
> + * When the persistent grants list is full we will remove unused grants
> + * from the list. The percent number of grants to be removed at each LRU
> + * execution.
> + */
> +
> +static int xen_blkif_lru_percent_clean = 5;
OK, so by default if the persistent grants are at 352 pages we start trimming
5% of the list every 100ms. Are we trimming the whole list or just down
to 352 (so max_persistent_grants?).
If the latter do we stop the LRU execution at that point? If so please
enumerate that. Oh and do we stop at 352 or do we do the 5% so we end up actually
at 334?
Would it make sense to cap the engine to stop removing unused grants
down to xen_blkif_max_pgrants?
> +module_param_named(lru_percent_clean, xen_blkif_lru_percent_clean, int, 0);
Ditto here.
> +MODULE_PARM_DESC(lru_percent_clean,
> +"Number of persistent grants to unmap when the list is full");
> +
> /* Run-time switchable: /sys/module/blkback/parameters/ */
> static unsigned int log_stats;
> module_param(log_stats, int, 0644);
> @@ -96,8 +134,8 @@ struct pending_req {
> unsigned short operation;
> int status;
> struct list_head free_list;
> - DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> };
>
> #define BLKBACK_INVALID_HANDLE (~0)
> @@ -119,36 +157,6 @@ struct xen_blkbk {
> static struct xen_blkbk *blkbk;
>
> /*
> - * Maximum number of grant pages that can be mapped in blkback.
> - * BLKIF_MAX_SEGMENTS_PER_REQUEST * RING_SIZE is the maximum number of
> - * pages that blkback will persistently map.
> - * Currently, this is:
> - * RING_SIZE = 32 (for all known ring types)
> - * BLKIF_MAX_SEGMENTS_PER_REQUEST = 11
> - * sizeof(struct persistent_gnt) = 48
> - * So the maximum memory used to store the grants is:
> - * 32 * 11 * 48 = 16896 bytes
> - */
> -static inline unsigned int max_mapped_grant_pages(enum blkif_protocol protocol)
> -{
> - switch (protocol) {
> - case BLKIF_PROTOCOL_NATIVE:
> - return __CONST_RING_SIZE(blkif, PAGE_SIZE) *
> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> - case BLKIF_PROTOCOL_X86_32:
> - return __CONST_RING_SIZE(blkif_x86_32, PAGE_SIZE) *
> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> - case BLKIF_PROTOCOL_X86_64:
> - return __CONST_RING_SIZE(blkif_x86_64, PAGE_SIZE) *
> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> - default:
> - BUG();
> - }
> - return 0;
> -}
> -
> -
> -/*
> * Little helpful macro to figure out the index and virtual address of the
> * pending_pages[..]. For each 'pending_req' we have have up to
> * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
> @@ -239,13 +247,19 @@ static void make_response(struct xen_blkif *blkif, u64 id,
> (n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
>
>
> -static int add_persistent_gnt(struct rb_root *root,
> +static int add_persistent_gnt(struct xen_blkif *blkif,
> struct persistent_gnt *persistent_gnt)
> {
> - struct rb_node **new = &(root->rb_node), *parent = NULL;
> + struct rb_node **new = NULL, *parent = NULL;
> struct persistent_gnt *this;
>
> + if (blkif->persistent_gnt_c >= xen_blkif_max_pgrants) {
> + if (!blkif->vbd.overflow_max_grants)
> + blkif->vbd.overflow_max_grants = 1;
> + return -EBUSY;
> + }
> /* Figure out where to put new node */
> + new = &blkif->persistent_gnts.rb_node;
> while (*new) {
> this = container_of(*new, struct persistent_gnt, node);
>
> @@ -259,19 +273,23 @@ static int add_persistent_gnt(struct rb_root *root,
> return -EINVAL;
> }
> }
> -
> + bitmap_zero(persistent_gnt->flags, PERSISTENT_GNT_FLAGS_SIZE);
> + set_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
> /* Add new node and rebalance tree. */
> rb_link_node(&(persistent_gnt->node), parent, new);
> - rb_insert_color(&(persistent_gnt->node), root);
> + rb_insert_color(&(persistent_gnt->node), &blkif->persistent_gnts);
> + blkif->persistent_gnt_c++;
> + atomic_inc(&blkif->persistent_gnt_in_use);
> return 0;
> }
>
> -static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> +static struct persistent_gnt *get_persistent_gnt(struct xen_blkif *blkif,
> grant_ref_t gref)
> {
> struct persistent_gnt *data;
> - struct rb_node *node = root->rb_node;
> + struct rb_node *node = NULL;
>
> + node = blkif->persistent_gnts.rb_node;
> while (node) {
> data = container_of(node, struct persistent_gnt, node);
>
> @@ -279,12 +297,25 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> node = node->rb_left;
> else if (gref > data->gnt)
> node = node->rb_right;
> - else
> + else {
> + WARN_ON(test_bit(PERSISTENT_GNT_ACTIVE, data->flags));
Ouch. Is that even safe? Doesn't that mean that somebody is using this and we just
usurped it?
> + set_bit(PERSISTENT_GNT_ACTIVE, data->flags);
> + atomic_inc(&blkif->persistent_gnt_in_use);
> return data;
> + }
> }
> return NULL;
> }
>
> +static void put_persistent_gnt(struct xen_blkif *blkif,
> + struct persistent_gnt *persistent_gnt)
> +{
> + WARN_ON(!test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags));
> + set_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
> + clear_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
> + atomic_dec(&blkif->persistent_gnt_in_use);
> +}
> +
> static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
> unsigned int num)
> {
> @@ -322,6 +353,122 @@ static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
> BUG_ON(num != 0);
> }
>
Might need need to say something about locking..
> +static void unmap_purged_grants(struct work_struct *work)
> +{
> + struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct persistent_gnt *persistent_gnt;
> + int ret, segs_to_unmap = 0;
> + struct xen_blkif *blkif =
> + container_of(work, typeof(*blkif), persistent_purge_work);
> +
> + while(!list_empty(&blkif->persistent_purge_list)) {
> + persistent_gnt = list_first_entry(&blkif->persistent_purge_list,
> + struct persistent_gnt,
> + remove_node);
> + list_del(&persistent_gnt->remove_node);
> +
> + gnttab_set_unmap_op(&unmap[segs_to_unmap],
> + vaddr(persistent_gnt->page),
> + GNTMAP_host_map,
> + persistent_gnt->handle);
> +
> + pages[segs_to_unmap] = persistent_gnt->page;
> +
> + if (++segs_to_unmap == BLKIF_MAX_SEGMENTS_PER_REQUEST) {
> + ret = gnttab_unmap_refs(unmap, NULL, pages,
> + segs_to_unmap);
> + BUG_ON(ret);
> + put_free_pages(blkif, pages, segs_to_unmap);
> + segs_to_unmap = 0;
> + }
> + kfree(persistent_gnt);
> + }
> + if (segs_to_unmap > 0) {
> + ret = gnttab_unmap_refs(unmap, NULL, pages, segs_to_unmap);
> + BUG_ON(ret);
> + put_free_pages(blkif, pages, segs_to_unmap);
> + }
> +}
> +
> +static void purge_persistent_gnt(struct xen_blkif *blkif)
> +{
> + struct persistent_gnt *persistent_gnt;
> + struct rb_node *n;
> + int num_clean, total;
> + bool scan_used = false;
> + struct rb_root *root;
> +
> + if (blkif->persistent_gnt_c < xen_blkif_max_pgrants ||
> + (blkif->persistent_gnt_c == xen_blkif_max_pgrants &&
> + !blkif->vbd.overflow_max_grants)) {
> + return;
> + }
> +
> + if (work_pending(&blkif->persistent_purge_work)) {
> + pr_alert_ratelimited(DRV_PFX "Scheduled work from previous purge is still pending, cannot purge list\n");
> + return;
> + }
> +
> + num_clean = (xen_blkif_max_pgrants / 100) * xen_blkif_lru_percent_clean;
> + num_clean = blkif->persistent_gnt_c - xen_blkif_max_pgrants + num_clean;
> + num_clean = num_clean > blkif->persistent_gnt_c ?
> + blkif->persistent_gnt_c : num_clean;
I think you can do:
num_clean = min(blkif->persistent_gnt_c, num_clean);
?
> + if (num_clean >
> + (blkif->persistent_gnt_c -
> + atomic_read(&blkif->persistent_gnt_in_use)))
> + return;
> +
> + total = num_clean;
> +
> + pr_debug(DRV_PFX "Going to purge %d persistent grants\n", num_clean);
> +
> + INIT_LIST_HEAD(&blkif->persistent_purge_list);
> + root = &blkif->persistent_gnts;
> +purge_list:
> + foreach_grant_safe(persistent_gnt, n, root, node) {
> + BUG_ON(persistent_gnt->handle ==
> + BLKBACK_INVALID_HANDLE);
> +
> + if (test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags))
> + continue;
> + if (!scan_used &&
> + (test_bit(PERSISTENT_GNT_USED, persistent_gnt->flags)))
> + continue;
> +
> + rb_erase(&persistent_gnt->node, root);
> + list_add(&persistent_gnt->remove_node,
> + &blkif->persistent_purge_list);
> + if (--num_clean == 0)
> + goto finished;
The check (if num_clean > .. atomic_read) means that by the time we
get here and try to remove some of them, the blkif->persistent_gnt_in_use
might have dramatically changed.
Which would mean we could be walking the list here without collecting
any grants.
Thought on the second pass we would hopefully get the PERSISTENT_GNT_USED
but might also hit that case.
Is that a case we need to worry about? I mean if we hit it, then num_clean
is less than the total. Perhaps at that stage we should decrease
the 'xen_blkif_lru_percent_clean' to a smaller number as we are probably
going to hit the same issue next time around?
And conversely - the next time we run this code and num_clean == total
then we can increase the 'xen_blkif_lru_percent_clean' to its original
value?
That would mean we need somewhere a new value (blkif specific) that
would serve the role of being a local version of 'xen_blkif_lru_percent_clean'
that can be from 0 -> xen_blkif_lru_percent_clean?
Or is this case I am thinking of overblown and you did not hit it when
running stress-tests with this code?
> + }
> + /*
> + * If we get here it means we also need to start cleaning
> + * grants that were used since last purge in order to cope
> + * with the requested num
> + */
> + if (!scan_used) {
> + pr_debug(DRV_PFX "Still missing %d purged frames\n", num_clean);
> + scan_used = true;
> + goto purge_list;
> + }
> +finished:
> + /* Remove the "used" flag from all the persistent grants */
> + foreach_grant_safe(persistent_gnt, n, root, node) {
> + BUG_ON(persistent_gnt->handle ==
> + BLKBACK_INVALID_HANDLE);
> + clear_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
The 'used' flag does not sound right. I can't place it but I would
think another name is better.
Perhaps 'WALKED' ? 'TOUCHED' ? 'NOT_TOO_FRESH'? 'STALE'? 'WAS_ACTIVE'?
Hm, perhaps 'WAS_ACTIVE'? Or maybe the 'USED' is right.
Either way, I am not a native speaker so lets not get hanged up on this.
> + }
> + blkif->persistent_gnt_c -= (total - num_clean);
> + blkif->vbd.overflow_max_grants = 0;
> +
> + /* We can defer this work */
> + INIT_WORK(&blkif->persistent_purge_work, unmap_purged_grants);
> + schedule_work(&blkif->persistent_purge_work);
> + pr_debug(DRV_PFX "Purged %d/%d\n", (total - num_clean), total);
> + return;
> +}
> +
> /*
> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
> */
> @@ -453,12 +600,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
> static void print_stats(struct xen_blkif *blkif)
> {
> pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
> - " | ds %4llu | pg: %4u/%4u\n",
> + " | ds %4llu | pg: %4u/%4d\n",
> current->comm, blkif->st_oo_req,
> blkif->st_rd_req, blkif->st_wr_req,
> blkif->st_f_req, blkif->st_ds_req,
> blkif->persistent_gnt_c,
> - max_mapped_grant_pages(blkif->blk_protocol));
> + xen_blkif_max_pgrants);
> blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
> blkif->st_rd_req = 0;
> blkif->st_wr_req = 0;
> @@ -470,6 +617,7 @@ int xen_blkif_schedule(void *arg)
> {
> struct xen_blkif *blkif = arg;
> struct xen_vbd *vbd = &blkif->vbd;
> + unsigned long timeout;
>
> xen_blkif_get(blkif);
>
> @@ -479,13 +627,21 @@ int xen_blkif_schedule(void *arg)
> if (unlikely(vbd->size != vbd_sz(vbd)))
> xen_vbd_resize(blkif);
>
> - wait_event_interruptible(
> + timeout = msecs_to_jiffies(xen_blkif_lru_interval);
> +
> + timeout = wait_event_interruptible_timeout(
> blkif->wq,
> - blkif->waiting_reqs || kthread_should_stop());
> - wait_event_interruptible(
> + blkif->waiting_reqs || kthread_should_stop(),
> + timeout);
> + if (timeout == 0)
> + goto purge_gnt_list;
So if the system admin decided that the value of zero in xen_blkif_lru_interval
was perfect, won't we timeout immediately and keep on going to the goto statement,
and then looping around?
I think we need some sanity checking that the xen_blkif_lru_interval and
perhaps the other parameters are sane. And sadly we cannot do that
in the init function as the system admin might do this:
for fun in `ls -1 /sys/modules/xen_blkback/parameters`
do
echo 0 > /sys/modules/xen_blkback/parameters/$a
done
and reset everything to zero. Yikes.
> + timeout = wait_event_interruptible_timeout(
if (blkif->vbd.feature_gnt_persistent) {
timeout = msecs_to_jiffiers(..)
timeout = wait_event_interruptple_timeout
> blkbk->pending_free_wq,
> !list_empty(&blkbk->pending_free) ||
> - kthread_should_stop());
> + kthread_should_stop(),
> + timeout);
> + if (timeout == 0)
> + goto purge_gnt_list;
>
> blkif->waiting_reqs = 0;
> smp_mb(); /* clear flag *before* checking for work */
> @@ -493,6 +649,14 @@ int xen_blkif_schedule(void *arg)
> if (do_block_io_op(blkif))
> blkif->waiting_reqs = 1;
>
> +purge_gnt_list:
> + if (blkif->vbd.feature_gnt_persistent &&
> + time_after(jiffies, blkif->next_lru)) {
> + purge_persistent_gnt(blkif);
> + blkif->next_lru = jiffies +
> + msecs_to_jiffies(xen_blkif_lru_interval);
You can make this more than 80 characters.
> + }
> +
> shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
>
> if (log_stats && time_after(jiffies, blkif->st_print))
> @@ -504,7 +668,7 @@ int xen_blkif_schedule(void *arg)
> /* Free all persistent grant pages */
> if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
> free_persistent_gnts(blkif, &blkif->persistent_gnts,
> - blkif->persistent_gnt_c);
> + blkif->persistent_gnt_c);
>
> BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
> blkif->persistent_gnt_c = 0;
> @@ -536,8 +700,10 @@ static void xen_blkbk_unmap(struct pending_req *req)
> int ret;
>
> for (i = 0; i < req->nr_pages; i++) {
> - if (!test_bit(i, req->unmap_seg))
> + if (req->persistent_gnts[i] != NULL) {
> + put_persistent_gnt(blkif, req->persistent_gnts[i]);
> continue;
> + }
Aha, the req->unmap_seg bitmap is not used here anymore! You might want to
mention that in the commit description saying that you are also removing
this artifact as you don't need it anymore with the superior cleaning
method employed here.
> handle = pending_handle(req, i);
> pages[invcount] = req->pages[i];
> if (handle == BLKBACK_INVALID_HANDLE)
> @@ -559,8 +725,8 @@ static int xen_blkbk_map(struct blkif_request *req,
> struct page *pages[])
> {
> struct gnttab_map_grant_ref map[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> struct page *pages_to_gnt[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct persistent_gnt **persistent_gnts = pending_req->persistent_gnts;
> struct persistent_gnt *persistent_gnt = NULL;
> struct xen_blkif *blkif = pending_req->blkif;
> phys_addr_t addr = 0;
> @@ -572,9 +738,6 @@ static int xen_blkbk_map(struct blkif_request *req,
>
> use_persistent_gnts = (blkif->vbd.feature_gnt_persistent);
>
> - BUG_ON(blkif->persistent_gnt_c >
> - max_mapped_grant_pages(pending_req->blkif->blk_protocol));
> -
> /*
> * Fill out preq.nr_sects with proper amount of sectors, and setup
> * assign map[..] with the PFN of the page in our domain with the
> @@ -585,7 +748,7 @@ static int xen_blkbk_map(struct blkif_request *req,
>
> if (use_persistent_gnts)
> persistent_gnt = get_persistent_gnt(
> - &blkif->persistent_gnts,
> + blkif,
> req->u.rw.seg[i].gref);
>
> if (persistent_gnt) {
> @@ -621,7 +784,6 @@ static int xen_blkbk_map(struct blkif_request *req,
> * so that when we access vaddr(pending_req,i) it has the contents of
> * the page from the other domain.
> */
> - bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> for (i = 0, j = 0; i < nseg; i++) {
> if (!persistent_gnts[i]) {
> /* This is a newly mapped grant */
> @@ -639,11 +801,10 @@ static int xen_blkbk_map(struct blkif_request *req,
> if (persistent_gnts[i])
> goto next;
> if (use_persistent_gnts &&
> - blkif->persistent_gnt_c <
> - max_mapped_grant_pages(blkif->blk_protocol)) {
> + blkif->persistent_gnt_c < xen_blkif_max_pgrants) {
> /*
> * We are using persistent grants, the grant is
> - * not mapped but we have room for it
> + * not mapped but we might have room for it.
> */
> persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
> GFP_KERNEL);
> @@ -659,16 +820,16 @@ static int xen_blkbk_map(struct blkif_request *req,
> persistent_gnt->gnt = map[j].ref;
> persistent_gnt->handle = map[j].handle;
> persistent_gnt->page = pages[i];
> - if (add_persistent_gnt(&blkif->persistent_gnts,
> + if (add_persistent_gnt(blkif,
> persistent_gnt)) {
> kfree(persistent_gnt);
> j++;
> goto next;
> }
> - blkif->persistent_gnt_c++;
> + persistent_gnts[i] = persistent_gnt;
> pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
> persistent_gnt->gnt, blkif->persistent_gnt_c,
> - max_mapped_grant_pages(blkif->blk_protocol));
> + xen_blkif_max_pgrants);
> j++;
> goto next;
> }
> @@ -677,7 +838,6 @@ static int xen_blkbk_map(struct blkif_request *req,
> pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
> blkif->domid, blkif->vbd.handle);
> }
> - bitmap_set(pending_req->unmap_seg, i, 1);
> j++;
> next:
> seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
> index 6c73c38..f43782c 100644
> --- a/drivers/block/xen-blkback/common.h
> +++ b/drivers/block/xen-blkback/common.h
> @@ -182,12 +182,17 @@ struct xen_vbd {
>
> struct backend_info;
>
> +#define PERSISTENT_GNT_FLAGS_SIZE 2
> +#define PERSISTENT_GNT_ACTIVE 0
> +#define PERSISTENT_GNT_USED 1
These might need a bit of explanation. Would it be possible to include that
here?
>
> struct persistent_gnt {
> struct page *page;
> grant_ref_t gnt;
> grant_handle_t handle;
> + DECLARE_BITMAP(flags, PERSISTENT_GNT_FLAGS_SIZE);
> struct rb_node node;
> + struct list_head remove_node;
> };
>
> struct xen_blkif {
> @@ -219,6 +224,12 @@ struct xen_blkif {
> /* tree to store persistent grants */
> struct rb_root persistent_gnts;
> unsigned int persistent_gnt_c;
> + atomic_t persistent_gnt_in_use;
> + unsigned long next_lru;
> +
> + /* used by the kworker that offload work from the persistent purge */
> + struct list_head persistent_purge_list;
> + struct work_struct persistent_purge_work;
>
> /* buffer of free pages to map grant refs */
> spinlock_t free_pages_lock;
> @@ -262,6 +273,7 @@ int xen_blkif_xenbus_init(void);
>
> irqreturn_t xen_blkif_be_int(int irq, void *dev_id);
> int xen_blkif_schedule(void *arg);
> +int xen_blkif_purge_persistent(void *arg);
>
> int xen_blkbk_flush_diskcache(struct xenbus_transaction xbt,
> struct backend_info *be, int state);
> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
> index 24f7f6d..e0fd92a 100644
> --- a/drivers/block/xen-blkback/xenbus.c
> +++ b/drivers/block/xen-blkback/xenbus.c
> @@ -98,6 +98,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
> err = PTR_ERR(blkif->xenblkd);
> blkif->xenblkd = NULL;
> xenbus_dev_error(blkif->be->dev, err, "start xenblkd");
> + return;
> }
> }
>
> @@ -121,6 +122,7 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> spin_lock_init(&blkif->free_pages_lock);
> INIT_LIST_HEAD(&blkif->free_pages);
> blkif->free_pages_num = 0;
> + atomic_set(&blkif->persistent_gnt_in_use, 0);
>
> return blkif;
> }
> --
> 1.7.7.5 (Apple Git-26)
>
On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
> Using balloon pages for all granted pages allows us to simplify the
> logic in blkback, especially in the xen_blkbk_map function, since now
> we can decide if we want to map a grant persistently or not after we
> have actually mapped it. This could not be done before because
> persistent grants used ballooned pages, whereas non-persistent grants
> used pages from the kernel.
>
> This patch also introduces several changes, the first one is that the
> list of free pages is no longer global, now each blkback instance has
> it's own list of free pages that can be used to map grants. Also, a
> run time parameter (max_buffer_pages) has been added in order to tune
> the maximum number of free pages each blkback instance will keep in
> it's buffer.
>
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: [email protected]
> Cc: Konrad Rzeszutek Wilk <[email protected]>
> ---
> Changes since RFC:
> * Fix typos in commit message.
> * Minor fixes in code.
> ---
> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
> drivers/block/xen-blkback/common.h | 5 +
> drivers/block/xen-blkback/xenbus.c | 3 +
> 4 files changed, 165 insertions(+), 116 deletions(-)
>
> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
> index 3d5951c..e04afe0 100644
> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
> @@ -73,3 +73,11 @@ KernelVersion: 3.0
> Contact: Konrad Rzeszutek Wilk <[email protected]>
> Description:
> Number of sectors written by the frontend.
> +
> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
> +Date: March 2013
> +KernelVersion: 3.10
> +Contact: Roger Pau Monn? <[email protected]>
> +Description:
> + Maximum number of free pages to keep in each block
> + backend buffer.
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index f7526db..8a1892a 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
> module_param_named(reqs, xen_blkif_reqs, int, 0);
> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>
> +/*
> + * Maximum number of unused free pages to keep in the internal buffer.
> + * Setting this to a value too low will reduce memory used in each backend,
> + * but can have a performance penalty.
> + *
> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
> + * be set to a lower value that might degrade performance on some intensive
> + * IO workloads.
> + */
> +
> +static int xen_blkif_max_buffer_pages = 704;
> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> +MODULE_PARM_DESC(max_buffer_pages,
> +"Maximum number of free pages to keep in each block backend buffer");
Just curios but have you tried setting it to zero and seen what it does? Or
to 1390193013910923?
It might be good to actually have some code to check for sane values.
<sigh> But obviously we did not do that with the xen_blkif_reqs option at all
so this is capricious of me to ask you to do that in this patchset.
But if you do find some extra time and want to send out a patch to make
this more robust, that would be much appreciated. It does not have
to be done now or with this patchset of course.
On Wed, Mar 27, 2013 at 12:10:41PM +0100, Roger Pau Monne wrote:
> Remove the last dependency from blkbk by moving the list of free
> requests to blkif. This change reduces the contention on the list of
> available requests.
>
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: Konrad Rzeszutek Wilk <[email protected]>
> Cc: [email protected]
> ---
> Changes since RFC:
> * Replace kzalloc with kcalloc.
> ---
> drivers/block/xen-blkback/blkback.c | 125 +++++++----------------------------
> drivers/block/xen-blkback/common.h | 27 ++++++++
> drivers/block/xen-blkback/xenbus.c | 19 +++++
> 3 files changed, 70 insertions(+), 101 deletions(-)
>
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index e6542d5..a1c9dad 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -50,18 +50,14 @@
> #include "common.h"
>
> /*
> - * These are rather arbitrary. They are fairly large because adjacent requests
> - * pulled from a communication ring are quite likely to end up being part of
> - * the same scatter/gather request at the disc.
> - *
> - * ** TRY INCREASING 'xen_blkif_reqs' IF WRITE SPEEDS SEEM TOO LOW **
> - *
> - * This will increase the chances of being able to write whole tracks.
> - * 64 should be enough to keep us competitive with Linux.
> + * This is the number of requests that will be pre-allocated for each backend.
> + * For better performance this is set to RING_SIZE (32), so requests
> + * in the ring will never have to wait for a free pending_req.
You might want to clarify that 'Any value less than that is sure to
cause problems.'
At which point perhaps we should have some logic to enforce that?
> */
> -static int xen_blkif_reqs = 64;
> +
> +int xen_blkif_reqs = 32;
> module_param_named(reqs, xen_blkif_reqs, int, 0);
> -MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
> +MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
Do we even need this anymore? I mean if the optimial size is 32 and going
below that is silly. Going above that is silly as well - as we won't be using
the extra count.
Can we just rip this module parameter out?
>
> /*
> * Maximum number of unused free pages to keep in the internal buffer.
> @@ -120,53 +116,11 @@ MODULE_PARM_DESC(lru_percent_clean,
> static unsigned int log_stats;
> module_param(log_stats, int, 0644);
>
> -/*
> - * Each outstanding request that we've passed to the lower device layers has a
> - * 'pending_req' allocated to it. Each buffer_head that completes decrements
> - * the pendcnt towards zero. When it hits zero, the specified domain has a
> - * response queued for it, with the saved 'id' passed back.
> - */
> -struct pending_req {
> - struct xen_blkif *blkif;
> - u64 id;
> - int nr_pages;
> - atomic_t pendcnt;
> - unsigned short operation;
> - int status;
> - struct list_head free_list;
> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> -};
> -
> #define BLKBACK_INVALID_HANDLE (~0)
>
> /* Number of free pages to remove on each call to free_xenballooned_pages */
> #define NUM_BATCH_FREE_PAGES 10
>
> -struct xen_blkbk {
> - struct pending_req *pending_reqs;
> - /* List of all 'pending_req' available */
> - struct list_head pending_free;
> - /* And its spinlock. */
> - spinlock_t pending_free_lock;
> - wait_queue_head_t pending_free_wq;
> -};
> -
> -static struct xen_blkbk *blkbk;
> -
> -/*
> - * Little helpful macro to figure out the index and virtual address of the
> - * pending_pages[..]. For each 'pending_req' we have have up to
> - * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
> - * 10 and would index in the pending_pages[..].
> - */
> -static inline int vaddr_pagenr(struct pending_req *req, int seg)
> -{
> - return (req - blkbk->pending_reqs) *
> - BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
> -}
> -
> static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
> {
> unsigned long flags;
> @@ -471,18 +425,18 @@ finished:
> /*
> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
> */
> -static struct pending_req *alloc_req(void)
> +static struct pending_req *alloc_req(struct xen_blkif *blkif)
> {
> struct pending_req *req = NULL;
> unsigned long flags;
>
> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
> - if (!list_empty(&blkbk->pending_free)) {
> - req = list_entry(blkbk->pending_free.next, struct pending_req,
> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
> + if (!list_empty(&blkif->pending_free)) {
> + req = list_entry(blkif->pending_free.next, struct pending_req,
> free_list);
> list_del(&req->free_list);
> }
> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
> return req;
> }
>
> @@ -490,17 +444,17 @@ static struct pending_req *alloc_req(void)
> * Return the 'pending_req' structure back to the freepool. We also
> * wake up the thread if it was waiting for a free page.
> */
> -static void free_req(struct pending_req *req)
> +static void free_req(struct xen_blkif *blkif, struct pending_req *req)
> {
> unsigned long flags;
> int was_empty;
>
> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
> - was_empty = list_empty(&blkbk->pending_free);
> - list_add(&req->free_list, &blkbk->pending_free);
> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
> + was_empty = list_empty(&blkif->pending_free);
> + list_add(&req->free_list, &blkif->pending_free);
> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
> if (was_empty)
> - wake_up(&blkbk->pending_free_wq);
> + wake_up(&blkif->pending_free_wq);
> }
>
> /*
> @@ -635,8 +589,8 @@ int xen_blkif_schedule(void *arg)
> if (timeout == 0)
> goto purge_gnt_list;
> timeout = wait_event_interruptible_timeout(
> - blkbk->pending_free_wq,
> - !list_empty(&blkbk->pending_free) ||
> + blkif->pending_free_wq,
> + !list_empty(&blkif->pending_free) ||
> kthread_should_stop(),
> timeout);
> if (timeout == 0)
> @@ -883,7 +837,7 @@ static int dispatch_other_io(struct xen_blkif *blkif,
> struct blkif_request *req,
> struct pending_req *pending_req)
> {
> - free_req(pending_req);
> + free_req(blkif, pending_req);
> make_response(blkif, req->u.other.id, req->operation,
> BLKIF_RSP_EOPNOTSUPP);
> return -EIO;
> @@ -943,7 +897,7 @@ static void __end_block_io_op(struct pending_req *pending_req, int error)
> if (atomic_read(&pending_req->blkif->drain))
> complete(&pending_req->blkif->drain_complete);
> }
> - free_req(pending_req);
> + free_req(pending_req->blkif, pending_req);
> }
> }
>
> @@ -986,7 +940,7 @@ __do_block_io_op(struct xen_blkif *blkif)
> break;
> }
>
> - pending_req = alloc_req();
> + pending_req = alloc_req(blkif);
> if (NULL == pending_req) {
> blkif->st_oo_req++;
> more_to_do = 1;
> @@ -1020,7 +974,7 @@ __do_block_io_op(struct xen_blkif *blkif)
> goto done;
> break;
> case BLKIF_OP_DISCARD:
> - free_req(pending_req);
> + free_req(blkif, pending_req);
> if (dispatch_discard_io(blkif, &req))
> goto done;
> break;
> @@ -1222,7 +1176,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> fail_response:
> /* Haven't submitted any bio's yet. */
> make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
> - free_req(pending_req);
> + free_req(blkif, pending_req);
> msleep(1); /* back off a bit */
> return -EIO;
>
> @@ -1279,51 +1233,20 @@ static void make_response(struct xen_blkif *blkif, u64 id,
>
> static int __init xen_blkif_init(void)
> {
> - int i;
> int rc = 0;
>
> if (!xen_domain())
> return -ENODEV;
>
> - blkbk = kzalloc(sizeof(struct xen_blkbk), GFP_KERNEL);
> - if (!blkbk) {
> - pr_alert(DRV_PFX "%s: out of memory!\n", __func__);
> - return -ENOMEM;
> - }
> -
> -
> - blkbk->pending_reqs = kzalloc(sizeof(blkbk->pending_reqs[0]) *
> - xen_blkif_reqs, GFP_KERNEL);
> -
> - if (!blkbk->pending_reqs) {
> - rc = -ENOMEM;
> - goto out_of_memory;
> - }
> -
> rc = xen_blkif_interface_init();
> if (rc)
> goto failed_init;
>
> - INIT_LIST_HEAD(&blkbk->pending_free);
> - spin_lock_init(&blkbk->pending_free_lock);
> - init_waitqueue_head(&blkbk->pending_free_wq);
> -
> - for (i = 0; i < xen_blkif_reqs; i++)
> - list_add_tail(&blkbk->pending_reqs[i].free_list,
> - &blkbk->pending_free);
> -
> rc = xen_blkif_xenbus_init();
> if (rc)
> goto failed_init;
>
> - return 0;
> -
> - out_of_memory:
> - pr_alert(DRV_PFX "%s: out of memory\n", __func__);
> failed_init:
> - kfree(blkbk->pending_reqs);
> - kfree(blkbk);
> - blkbk = NULL;
> return rc;
> }
>
> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
> index f43782c..debff44 100644
> --- a/drivers/block/xen-blkback/common.h
> +++ b/drivers/block/xen-blkback/common.h
> @@ -236,6 +236,14 @@ struct xen_blkif {
> int free_pages_num;
> struct list_head free_pages;
>
> + /* Allocation of pending_reqs */
> + struct pending_req *pending_reqs;
> + /* List of all 'pending_req' available */
> + struct list_head pending_free;
> + /* And its spinlock. */
> + spinlock_t pending_free_lock;
> + wait_queue_head_t pending_free_wq;
> +
> /* statistics */
> unsigned long st_print;
> unsigned long long st_rd_req;
> @@ -249,6 +257,25 @@ struct xen_blkif {
> wait_queue_head_t waiting_to_free;
> };
>
> +/*
> + * Each outstanding request that we've passed to the lower device layers has a
> + * 'pending_req' allocated to it. Each buffer_head that completes decrements
> + * the pendcnt towards zero. When it hits zero, the specified domain has a
> + * response queued for it, with the saved 'id' passed back.
> + */
> +struct pending_req {
> + struct xen_blkif *blkif;
> + u64 id;
> + int nr_pages;
> + atomic_t pendcnt;
> + unsigned short operation;
> + int status;
> + struct list_head free_list;
> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> +};
> +
>
> #define vbd_sz(_v) ((_v)->bdev->bd_part ? \
> (_v)->bdev->bd_part->nr_sects : \
> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
> index e0fd92a..bf7344f 100644
> --- a/drivers/block/xen-blkback/xenbus.c
> +++ b/drivers/block/xen-blkback/xenbus.c
> @@ -30,6 +30,8 @@ struct backend_info {
> char *mode;
> };
>
> +extern int xen_blkif_reqs;
How about just sticking it in 'common.h'?
> +
> static struct kmem_cache *xen_blkif_cachep;
> static void connect(struct backend_info *);
> static int connect_ring(struct backend_info *);
> @@ -105,6 +107,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
> static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> {
> struct xen_blkif *blkif;
> + int i;
>
> blkif = kmem_cache_zalloc(xen_blkif_cachep, GFP_KERNEL);
> if (!blkif)
> @@ -124,6 +127,21 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> blkif->free_pages_num = 0;
> atomic_set(&blkif->persistent_gnt_in_use, 0);
>
> + blkif->pending_reqs = kcalloc(xen_blkif_reqs,
> + sizeof(blkif->pending_reqs[0]),
> + GFP_KERNEL);
> + if (!blkif->pending_reqs) {
> + kmem_cache_free(xen_blkif_cachep, blkif);
> + return ERR_PTR(-ENOMEM);
> + }
> + INIT_LIST_HEAD(&blkif->pending_free);
> + spin_lock_init(&blkif->pending_free_lock);
> + init_waitqueue_head(&blkif->pending_free_wq);
> +
> + for (i = 0; i < xen_blkif_reqs; i++)
> + list_add_tail(&blkif->pending_reqs[i].free_list,
> + &blkif->pending_free);
> +
> return blkif;
> }
>
> @@ -205,6 +223,7 @@ static void xen_blkif_free(struct xen_blkif *blkif)
> {
> if (!atomic_dec_and_test(&blkif->refcnt))
> BUG();
For sanity, should we have something like this:
struct pending_req *p;
i = 0;
list_for_each_entry (p, &blkif->pending_free, free_list)
i++;
BUG_ON(i != xen_blkif_reqs);
As that would mean somebody did not call 'free_req' and we have a loose one laying
around.
Or perhaps just leak the offending struct and then don't do 'kfree'?
> + kfree(blkif->pending_reqs);
> kmem_cache_free(xen_blkif_cachep, blkif);
> }
>
> --
> 1.7.7.5 (Apple Git-26)
>
On Wed, Mar 27, 2013 at 12:10:43PM +0100, Roger Pau Monne wrote:
> Indirect descriptors introduce a new block operation
> (BLKIF_OP_INDIRECT) that passes grant references instead of segments
> in the request. This grant references are filled with arrays of
> blkif_request_segment_aligned, this way we can send more segments in a
> request.
>
> The proposed implementation sets the maximum number of indirect grefs
> (frames filled with blkif_request_segment_aligned) to 256 in the
> backend and 32 in the frontend. The value in the frontend has been
> chosen experimentally, and the backend value has been set to a sane
> value that allows expanding the maximum number of indirect descriptors
> in the frontend if needed.
>
> The migration code has changed from the previous implementation, in
> which we simply remapped the segments on the shared ring. Now the
> maximum number of segments allowed in a request can change depending
> on the backend, so we have to requeue all the requests in the ring and
> in the queue and split the bios in them if they are bigger than the
> new maximum number of segments.
>
> Signed-off-by: Roger Pau Monn? <[email protected]>
> Cc: Konrad Rzeszutek Wilk <[email protected]>
> Cc: [email protected]
> ---
> drivers/block/xen-blkback/blkback.c | 136 +++++++---
> drivers/block/xen-blkback/common.h | 82 ++++++-
> drivers/block/xen-blkback/xenbus.c | 8 +
> drivers/block/xen-blkfront.c | 490 +++++++++++++++++++++++++++++------
> include/xen/interface/io/blkif.h | 26 ++
> 5 files changed, 621 insertions(+), 121 deletions(-)
>
> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> index f8c838e..f16a7c9 100644
> --- a/drivers/block/xen-blkback/blkback.c
> +++ b/drivers/block/xen-blkback/blkback.c
> @@ -69,7 +69,7 @@ MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
> * IO workloads.
> */
>
> -static int xen_blkif_max_buffer_pages = 704;
> +static int xen_blkif_max_buffer_pages = 1024;
> module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> MODULE_PARM_DESC(max_buffer_pages,
> "Maximum number of free pages to keep in each block backend buffer");
> @@ -85,7 +85,7 @@ MODULE_PARM_DESC(max_buffer_pages,
> * algorithm.
> */
>
> -static int xen_blkif_max_pgrants = 352;
> +static int xen_blkif_max_pgrants = 1056;
> module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
> MODULE_PARM_DESC(max_persistent_grants,
> "Maximum number of grants to map persistently");
> @@ -631,10 +631,6 @@ purge_gnt_list:
> return 0;
> }
>
> -struct seg_buf {
> - unsigned int offset;
> - unsigned int nsec;
> -};
> /*
> * Unmap the grant references, and also remove the M2P over-rides
> * used in the 'pending_req'.
> @@ -808,29 +804,71 @@ out_of_memory:
> return -ENOMEM;
> }
>
> -static int xen_blkbk_map_seg(struct blkif_request *req,
> - struct pending_req *pending_req,
> +static int xen_blkbk_map_seg(struct pending_req *pending_req,
> struct seg_buf seg[],
> struct page *pages[])
> {
> - int i, rc;
> - grant_ref_t grefs[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + int rc;
>
> - for (i = 0; i < req->u.rw.nr_segments; i++)
> - grefs[i] = req->u.rw.seg[i].gref;
> -
> - rc = xen_blkbk_map(pending_req->blkif, grefs,
> + rc = xen_blkbk_map(pending_req->blkif, pending_req->grefs,
> pending_req->persistent_gnts,
> pending_req->grant_handles, pending_req->pages,
> - req->u.rw.nr_segments,
> + pending_req->nr_pages,
> (pending_req->operation != BLKIF_OP_READ));
> - if (rc)
> - return rc;
>
> - for (i = 0; i < req->u.rw.nr_segments; i++)
> - seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
> + return rc;
> +}
>
> - return 0;
> +static int xen_blkbk_parse_indirect(struct blkif_request *req,
> + struct pending_req *pending_req,
> + struct seg_buf seg[],
> + struct phys_req *preq)
> +{
> + struct persistent_gnt **persistent =
> + pending_req->indirect_persistent_gnts;
> + struct page **pages = pending_req->indirect_pages;
> + struct xen_blkif *blkif = pending_req->blkif;
> + int indirect_grefs, rc, n, nseg, i;
> + struct blkif_request_segment_aligned *segments = NULL;
> +
> + nseg = pending_req->nr_pages;
> + indirect_grefs = (nseg + SEGS_PER_INDIRECT_FRAME - 1) /
> + SEGS_PER_INDIRECT_FRAME;
Then 4096 + 511 / 511 = 8. OK. Looks good!
Perhaps also have
BUG_ON(indirect_grefs > BLKIF_MAX_INDIRECT_PAGES_PER_REQUEST);
just in case?
> +
> + rc = xen_blkbk_map(blkif, req->u.indirect.indirect_grefs,
> + persistent, pending_req->indirect_handles,
> + pages, indirect_grefs, true);
> + if (rc)
> + goto unmap;
> +
> + for (n = 0, i = 0; n < nseg; n++) {
> + if ((n % SEGS_PER_INDIRECT_FRAME) == 0) {
> + /* Map indirect segments */
> + if (segments)
> + kunmap_atomic(segments);
> + segments =
> + kmap_atomic(pages[n/SEGS_PER_INDIRECT_FRAME]);
You can make it in one-line.
> + }
> + i = n % SEGS_PER_INDIRECT_FRAME;
> + pending_req->grefs[n] = segments[i].gref;
> + seg[n].nsec = segments[i].last_sect -
> + segments[i].first_sect + 1;
> + seg[n].offset = (segments[i].first_sect << 9);
> + if ((segments[i].last_sect >= (PAGE_SIZE >> 9)) ||
> + (segments[i].last_sect <
> + segments[i].first_sect)) {
> + rc = -EINVAL;
> + goto unmap;
> + }
> + preq->nr_sects += seg[n].nsec;
> + }
> +
> +unmap:
> + if (segments)
> + kunmap_atomic(segments);
> + xen_blkbk_unmap(blkif, pending_req->indirect_handles,
> + pages, persistent, indirect_grefs);
> + return rc;
> }
>
> static int dispatch_discard_io(struct xen_blkif *blkif,
> @@ -1003,6 +1041,7 @@ __do_block_io_op(struct xen_blkif *blkif)
> case BLKIF_OP_WRITE:
> case BLKIF_OP_WRITE_BARRIER:
> case BLKIF_OP_FLUSH_DISKCACHE:
> + case BLKIF_OP_INDIRECT:
> if (dispatch_rw_block_io(blkif, &req, pending_req))
> goto done;
> break;
> @@ -1049,17 +1088,28 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> struct pending_req *pending_req)
> {
> struct phys_req preq;
> - struct seg_buf seg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct seg_buf *seg = pending_req->seg;
> unsigned int nseg;
> struct bio *bio = NULL;
> - struct bio *biolist[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct bio **biolist = pending_req->biolist;
> int i, nbio = 0;
> int operation;
> struct blk_plug plug;
> bool drain = false;
> struct page **pages = pending_req->pages;
> + unsigned short req_operation;
> +
> + req_operation = req->operation == BLKIF_OP_INDIRECT ?
> + req->u.indirect.indirect_op : req->operation;
> + if ((req->operation == BLKIF_OP_INDIRECT) &&
> + (req_operation != BLKIF_OP_READ) &&
> + (req_operation != BLKIF_OP_WRITE)) {
> + pr_debug(DRV_PFX "Invalid indirect operation (%u)\n",
> + req_operation);
> + goto fail_response;
> + }
>
> - switch (req->operation) {
> + switch (req_operation) {
> case BLKIF_OP_READ:
> blkif->st_rd_req++;
> operation = READ;
> @@ -1081,33 +1131,47 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> }
>
> /* Check that the number of segments is sane. */
> - nseg = req->u.rw.nr_segments;
> + nseg = req->operation == BLKIF_OP_INDIRECT ?
> + req->u.indirect.nr_segments : req->u.rw.nr_segments;
>
> if (unlikely(nseg == 0 && operation != WRITE_FLUSH) ||
> - unlikely(nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
> + unlikely((req->operation != BLKIF_OP_INDIRECT) &&
> + (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) ||
> + unlikely((req->operation == BLKIF_OP_INDIRECT) &&
> + (nseg > MAX_INDIRECT_SEGMENTS))) {
> pr_debug(DRV_PFX "Bad number of segments in request (%d)\n",
> nseg);
> /* Haven't submitted any bio's yet. */
> goto fail_response;
> }
>
> - preq.sector_number = req->u.rw.sector_number;
> preq.nr_sects = 0;
>
> pending_req->blkif = blkif;
> pending_req->id = req->u.rw.id;
> - pending_req->operation = req->operation;
> + pending_req->operation = req_operation;
> pending_req->status = BLKIF_RSP_OKAY;
> pending_req->nr_pages = nseg;
>
> - for (i = 0; i < nseg; i++) {
> - seg[i].nsec = req->u.rw.seg[i].last_sect -
> - req->u.rw.seg[i].first_sect + 1;
> - if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
> - (req->u.rw.seg[i].last_sect < req->u.rw.seg[i].first_sect))
> + if (req->operation != BLKIF_OP_INDIRECT) {
> + preq.dev = req->u.rw.handle;
> + preq.sector_number = req->u.rw.sector_number;
> + for (i = 0; i < nseg; i++) {
> + pending_req->grefs[i] = req->u.rw.seg[i].gref;
> + seg[i].nsec = req->u.rw.seg[i].last_sect -
> + req->u.rw.seg[i].first_sect + 1;
> + seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
> + if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
> + (req->u.rw.seg[i].last_sect <
> + req->u.rw.seg[i].first_sect))
> + goto fail_response;
> + preq.nr_sects += seg[i].nsec;
> + }
> + } else {
> + preq.dev = req->u.indirect.handle;
> + preq.sector_number = req->u.indirect.sector_number;
> + if (xen_blkbk_parse_indirect(req, pending_req, seg, &preq))
> goto fail_response;
> - preq.nr_sects += seg[i].nsec;
> -
> }
>
> if (xen_vbd_translate(&preq, blkif, operation) != 0) {
> @@ -1144,7 +1208,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> * the hypercall to unmap the grants - that is all done in
> * xen_blkbk_unmap.
> */
> - if (xen_blkbk_map_seg(req, pending_req, seg, pages))
> + if (xen_blkbk_map_seg(pending_req, seg, pages))
> goto fail_flush;
>
> /*
> @@ -1210,7 +1274,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> pending_req->nr_pages);
> fail_response:
> /* Haven't submitted any bio's yet. */
> - make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
> + make_response(blkif, req->u.rw.id, req_operation, BLKIF_RSP_ERROR);
> free_req(blkif, pending_req);
> msleep(1); /* back off a bit */
> return -EIO;
> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
> index debff44..30bffcc 100644
> --- a/drivers/block/xen-blkback/common.h
> +++ b/drivers/block/xen-blkback/common.h
> @@ -50,6 +50,17 @@
> __func__, __LINE__, ##args)
>
>
> +/*
> + * This is the maximum number of segments that would be allowed in indirect
> + * requests. This value will also be passed to the frontend.
> + */
> +#define MAX_INDIRECT_SEGMENTS 256
That little? We don't want to have say 512 to at least fill the full page? Or
perhaps 1024 to use two pages (and be able to comfortably do 4MB of I/O in
one request).
> +
> +#define SEGS_PER_INDIRECT_FRAME \
> +(PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
OK, so 512.
> +#define MAX_INDIRECT_GREFS \
> +((MAX_INDIRECT_SEGMENTS + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
(256 + 512 - 1) / 512 = so 1.49 or since it is an int = '1'.
Is that right? The patch comment alluded to 256?
Ah, MAX_INDIRECT_GREFS is how many pages of indirect descriptors we can do!
Somehow I thought it was related to how many indirect grant references we
have (so SEGS_PER_INDIRECT_FRAME).
How about just calling it MAX_INDIRECT_PAGES ?
This should also have some
BUILD_BUG_ON(MAX_INDIRECT_GREFS > BLKIF_MAX_INDIRECT_PAGES_PER_REQUEST)
to guard against doing something very bad.
> +
> /* Not a real protocol. Used to generate ring structs which contain
> * the elements common to all protocols only. This way we get a
> * compiler-checkable way to use common struct elements, so we can
> @@ -83,12 +94,23 @@ struct blkif_x86_32_request_other {
> uint64_t id; /* private guest value, echoed in resp */
> } __attribute__((__packed__));
>
> +struct blkif_x86_32_request_indirect {
> + uint8_t indirect_op;
> + uint16_t nr_segments;
This needs to be documented. Is there are limit to what it can be? What if
the frontend sets it to 1231231?
> + uint64_t id;
> + blkif_sector_t sector_number;
> + blkif_vdev_t handle;
> + uint16_t _pad1;
> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
And how do we figure out whether we are going to use one indirect_grefs or many?
That should be described here. (if I understand it right it would be done
via the maximum-indirect-something' variable)
> +} __attribute__((__packed__));
> +
Per my calculation the size of this structure is 55 bytes. The 64-bit is 59 bytes.
It is a bit odd, but then 1 byte is for the 'operation' in the 'blkif_x*_request',
so it comes out to 56 and 60 bytes.
Is that still the right amount ? I thought we wanted to flesh it out to be a nice
64 byte aligned so that the future patches which will make the requests be
more cache-aligned and won't have to play games?
> struct blkif_x86_32_request {
> uint8_t operation; /* BLKIF_OP_??? */
> union {
> struct blkif_x86_32_request_rw rw;
> struct blkif_x86_32_request_discard discard;
> struct blkif_x86_32_request_other other;
> + struct blkif_x86_32_request_indirect indirect;
> } u;
> } __attribute__((__packed__));
>
> @@ -127,12 +149,24 @@ struct blkif_x86_64_request_other {
> uint64_t id; /* private guest value, echoed in resp */
> } __attribute__((__packed__));
>
> +struct blkif_x86_64_request_indirect {
> + uint8_t indirect_op;
> + uint16_t nr_segments;
> + uint32_t _pad1; /* offsetof(blkif_..,u.indirect.id)==8 */
The comment is a bit off compared to the rest.
> + uint64_t id;
> + blkif_sector_t sector_number;
> + blkif_vdev_t handle;
> + uint16_t _pad2;
> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
> +} __attribute__((__packed__));
> +
> struct blkif_x86_64_request {
> uint8_t operation; /* BLKIF_OP_??? */
> union {
> struct blkif_x86_64_request_rw rw;
> struct blkif_x86_64_request_discard discard;
> struct blkif_x86_64_request_other other;
> + struct blkif_x86_64_request_indirect indirect;
> } u;
> } __attribute__((__packed__));
>
> @@ -257,6 +291,11 @@ struct xen_blkif {
> wait_queue_head_t waiting_to_free;
> };
>
> +struct seg_buf {
> + unsigned long offset;
> + unsigned int nsec;
> +};
> +
> /*
> * Each outstanding request that we've passed to the lower device layers has a
> * 'pending_req' allocated to it. Each buffer_head that completes decrements
> @@ -271,9 +310,16 @@ struct pending_req {
> unsigned short operation;
> int status;
> struct list_head free_list;
> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct page *pages[MAX_INDIRECT_SEGMENTS];
> + struct persistent_gnt *persistent_gnts[MAX_INDIRECT_SEGMENTS];
> + grant_handle_t grant_handles[MAX_INDIRECT_SEGMENTS];
> + grant_ref_t grefs[MAX_INDIRECT_SEGMENTS];
> + /* Indirect descriptors */
> + struct persistent_gnt *indirect_persistent_gnts[MAX_INDIRECT_GREFS];
> + struct page *indirect_pages[MAX_INDIRECT_GREFS];
> + grant_handle_t indirect_handles[MAX_INDIRECT_GREFS];
> + struct seg_buf seg[MAX_INDIRECT_SEGMENTS];
> + struct bio *biolist[MAX_INDIRECT_SEGMENTS];
Oh wow. That is a big structure. So 1536 for the BLKIF_MAX_SEGMENTS_PER_REQUEST
ones and 24 bytes for the ones that deail with MAX_INDIRECT_GREFS.
This could be made look nicer. For example you could do:
struct indirect {
struct page;
grant_handle_t handle;
struct persistent_gnt *gnt;
} desc[MAX_INDIRECT_GREFS];
.. and the same treatment to the BLKIF_MAX_SEGMENTS_PER_REQUEST
one.
Thought perhaps it makes more sense to do that with a later patch as a cleanup.
> };
>
>
> @@ -312,7 +358,7 @@ struct xenbus_device *xen_blkbk_xenbus(struct backend_info *be);
> static inline void blkif_get_x86_32_req(struct blkif_request *dst,
> struct blkif_x86_32_request *src)
> {
> - int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
> + int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
> dst->operation = src->operation;
> switch (src->operation) {
> case BLKIF_OP_READ:
> @@ -335,6 +381,19 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
> dst->u.discard.sector_number = src->u.discard.sector_number;
> dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
> break;
> + case BLKIF_OP_INDIRECT:
> + dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
> + dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
> + dst->u.indirect.handle = src->u.indirect.handle;
> + dst->u.indirect.id = src->u.indirect.id;
> + dst->u.indirect.sector_number = src->u.indirect.sector_number;
> + barrier();
> + if (j > dst->u.indirect.nr_segments)
> + j = dst->u.indirect.nr_segments;
How about just:
j = min(MAX_INDIRECT_GREFS, dst->u.indirect.nr_segments);
But.. you are using the 'nr_segments' and 'j' (which is 1) which is odd. j ends up
being set to 1. But you are somehow mixing 'nr_segments' and 'MAX_INDIRECT_GREFS'
which is confusing. Perhaps you meant:
if (j > min(dst->u.inderect.nr_segments, SEGS_PER_INDIRECT_FRAME) / SEGS_PER_INDIRECT_FRAME)
...
After all, the 'j' is suppose to tell you how many indirect pages to use, and that
should be driven by the total amount of nr_segments.
Thought if nr_segments is absuredly high we should detect that and do something
about it.
> + for (i = 0; i < j; i++)
> + dst->u.indirect.indirect_grefs[i] =
> + src->u.indirect.indirect_grefs[i];
> + break;
> default:
> /*
> * Don't know how to translate this op. Only get the
> @@ -348,7 +407,7 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
> static inline void blkif_get_x86_64_req(struct blkif_request *dst,
> struct blkif_x86_64_request *src)
> {
> - int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
> + int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
> dst->operation = src->operation;
> switch (src->operation) {
> case BLKIF_OP_READ:
> @@ -371,6 +430,19 @@ static inline void blkif_get_x86_64_req(struct blkif_request *dst,
> dst->u.discard.sector_number = src->u.discard.sector_number;
> dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
> break;
> + case BLKIF_OP_INDIRECT:
> + dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
> + dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
> + dst->u.indirect.handle = src->u.indirect.handle;
> + dst->u.indirect.id = src->u.indirect.id;
> + dst->u.indirect.sector_number = src->u.indirect.sector_number;
> + barrier();
> + if (j > dst->u.indirect.nr_segments)
> + j = dst->u.indirect.nr_segments;
Same here. The min is a nice macro.
> + for (i = 0; i < j; i++)
> + dst->u.indirect.indirect_grefs[i] =
> + src->u.indirect.indirect_grefs[i];
> + break;
> default:
> /*
> * Don't know how to translate this op. Only get the
> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
> index bf7344f..172cf89 100644
> --- a/drivers/block/xen-blkback/xenbus.c
> +++ b/drivers/block/xen-blkback/xenbus.c
> @@ -703,6 +703,14 @@ again:
> goto abort;
> }
>
> + err = xenbus_printf(xbt, dev->nodename, "max-indirect-segments", "%u",
> + MAX_INDIRECT_SEGMENTS);
Ahem. That should be 'feature-max-indirect-segments'.
> + if (err) {
> + xenbus_dev_fatal(dev, err, "writing %s/max-indirect-segments",
> + dev->nodename);
> + goto abort;
That is not fatal. We can continue on without having that enabled.
> + }
> +
> err = xenbus_printf(xbt, dev->nodename, "sectors", "%llu",
> (unsigned long long)vbd_sz(&be->blkif->vbd));
> if (err) {
> diff --git a/drivers/block/xen-blkfront.c b/drivers/block/xen-blkfront.c
> index a894f88..ecbc26a 100644
> --- a/drivers/block/xen-blkfront.c
> +++ b/drivers/block/xen-blkfront.c
> @@ -74,12 +74,30 @@ struct grant {
> struct blk_shadow {
> struct blkif_request req;
> struct request *request;
> - struct grant *grants_used[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct grant **grants_used;
> + struct grant **indirect_grants;
> +};
> +
> +struct split_bio {
> + struct bio *bio;
> + atomic_t pending;
> + int err;
> };
>
> static DEFINE_MUTEX(blkfront_mutex);
> static const struct block_device_operations xlvbd_block_fops;
>
> +/*
> + * Maximum number of segments in indirect requests, the actual value used by
> + * the frontend driver is the minimum of this value and the value provided
> + * by the backend driver.
> + */
> +
> +static int xen_blkif_max_segments = 32;
> +module_param_named(max_segments, xen_blkif_max_segments, int, 0);
> +MODULE_PARM_DESC(max_segments,
> +"Maximum number of segments in indirect requests");
This means a new entry in Documentation/ABI/sysfs/...
Perhaps the xen-blkfront part of the patch should be just split out to make
this easier?
Perhaps what we really should have is just the 'max' value of megabytes
we want to handle on the ring.
As right now 32 ring requests * 32 segments = 4MB. But if the user wants
to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
and since we have 32 of them = 512MB).
> +
> #define BLK_RING_SIZE __CONST_RING_SIZE(blkif, PAGE_SIZE)
>
> /*
> @@ -98,7 +116,7 @@ struct blkfront_info
> enum blkif_state connected;
> int ring_ref;
> struct blkif_front_ring ring;
> - struct scatterlist sg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> + struct scatterlist *sg;
> unsigned int evtchn, irq;
> struct request_queue *rq;
> struct work_struct work;
> @@ -114,6 +132,8 @@ struct blkfront_info
> unsigned int discard_granularity;
> unsigned int discard_alignment;
> unsigned int feature_persistent:1;
> + unsigned int max_indirect_segments;
> + unsigned int sector_size;
sector_size? That looks like it belongs to a different patch?
> int is_ready;
> };
>
> @@ -142,6 +162,14 @@ static DEFINE_SPINLOCK(minor_lock);
>
> #define DEV_NAME "xvd" /* name in /dev */
>
> +#define SEGS_PER_INDIRECT_FRAME \
> + (PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
> +#define INDIRECT_GREFS(_segs) \
> + ((_segs + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
> +#define MIN(_a, _b) ((_a) < (_b) ? (_a) : (_b))
No need. Just use 'min'
> +
> +static int blkfront_setup_indirect(struct blkfront_info *info);
> +
> static int get_id_from_freelist(struct blkfront_info *info)
> {
> unsigned long free = info->shadow_free;
> @@ -358,7 +386,8 @@ static int blkif_queue_request(struct request *req)
> struct blkif_request *ring_req;
> unsigned long id;
> unsigned int fsect, lsect;
> - int i, ref;
> + int i, ref, n;
> + struct blkif_request_segment_aligned *segments = NULL;
>
> /*
> * Used to store if we are able to queue the request by just using
> @@ -369,21 +398,27 @@ static int blkif_queue_request(struct request *req)
> grant_ref_t gref_head;
> struct grant *gnt_list_entry = NULL;
> struct scatterlist *sg;
> + int nseg, max_grefs;
>
> if (unlikely(info->connected != BLKIF_STATE_CONNECTED))
> return 1;
>
> - /* Check if we have enought grants to allocate a requests */
> - if (info->persistent_gnts_c < BLKIF_MAX_SEGMENTS_PER_REQUEST) {
> + max_grefs = info->max_indirect_segments ?
> + info->max_indirect_segments +
> + INDIRECT_GREFS(info->max_indirect_segments) :
> + BLKIF_MAX_SEGMENTS_PER_REQUEST;
> +
> + /* Check if we have enough grants to allocate a requests */
> + if (info->persistent_gnts_c < max_grefs) {
> new_persistent_gnts = 1;
> if (gnttab_alloc_grant_references(
> - BLKIF_MAX_SEGMENTS_PER_REQUEST - info->persistent_gnts_c,
> + max_grefs - info->persistent_gnts_c,
> &gref_head) < 0) {
> gnttab_request_free_callback(
> &info->callback,
> blkif_restart_queue_callback,
> info,
> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
> + max_grefs);
> return 1;
> }
> } else
> @@ -394,42 +429,74 @@ static int blkif_queue_request(struct request *req)
> id = get_id_from_freelist(info);
> info->shadow[id].request = req;
>
> - ring_req->u.rw.id = id;
> - ring_req->u.rw.sector_number = (blkif_sector_t)blk_rq_pos(req);
> - ring_req->u.rw.handle = info->handle;
> -
> - ring_req->operation = rq_data_dir(req) ?
> - BLKIF_OP_WRITE : BLKIF_OP_READ;
> -
> - if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
> - /*
> - * Ideally we can do an unordered flush-to-disk. In case the
> - * backend onlysupports barriers, use that. A barrier request
> - * a superset of FUA, so we can implement it the same
> - * way. (It's also a FLUSH+FUA, since it is
> - * guaranteed ordered WRT previous writes.)
> - */
> - ring_req->operation = info->flush_op;
> - }
> -
> if (unlikely(req->cmd_flags & (REQ_DISCARD | REQ_SECURE))) {
> /* id, sector_number and handle are set above. */
And you can also remove that comment or change it and mention that we don't
care about the 'handle' value.
> ring_req->operation = BLKIF_OP_DISCARD;
> ring_req->u.discard.nr_sectors = blk_rq_sectors(req);
> + ring_req->u.discard.id = id;
> + ring_req->u.discard.sector_number =
> + (blkif_sector_t)blk_rq_pos(req);
One line pls.
> if ((req->cmd_flags & REQ_SECURE) && info->feature_secdiscard)
> ring_req->u.discard.flag = BLKIF_DISCARD_SECURE;
> else
> ring_req->u.discard.flag = 0;
> } else {
> - ring_req->u.rw.nr_segments = blk_rq_map_sg(req->q, req,
> - info->sg);
> - BUG_ON(ring_req->u.rw.nr_segments >
> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
> -
> - for_each_sg(info->sg, sg, ring_req->u.rw.nr_segments, i) {
> + BUG_ON(info->max_indirect_segments == 0 &&
> + req->nr_phys_segments > BLKIF_MAX_SEGMENTS_PER_REQUEST);
> + BUG_ON(info->max_indirect_segments &&
> + req->nr_phys_segments > info->max_indirect_segments);
> + nseg = blk_rq_map_sg(req->q, req, info->sg);
> + ring_req->u.rw.id = id;
> + if (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST) {
> + /*
> + * The indirect operation can only be a BLKIF_OP_READ or
> + * BLKIF_OP_WRITE
> + */
> + BUG_ON(req->cmd_flags & (REQ_FLUSH | REQ_FUA));
> + ring_req->operation = BLKIF_OP_INDIRECT;
> + ring_req->u.indirect.indirect_op = rq_data_dir(req) ?
> + BLKIF_OP_WRITE : BLKIF_OP_READ;
> + ring_req->u.indirect.sector_number =
> + (blkif_sector_t)blk_rq_pos(req);
> + ring_req->u.indirect.handle = info->handle;
> + ring_req->u.indirect.nr_segments = nseg;
> + } else {
> + ring_req->u.rw.sector_number =
> + (blkif_sector_t)blk_rq_pos(req);
> + ring_req->u.rw.handle = info->handle;
> + ring_req->operation = rq_data_dir(req) ?
> + BLKIF_OP_WRITE : BLKIF_OP_READ;
> + if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
> + /*
> + * Ideally we can do an unordered flush-to-disk. In case the
> + * backend onlysupports barriers, use that. A barrier request
> + * a superset of FUA, so we can implement it the same
> + * way. (It's also a FLUSH+FUA, since it is
> + * guaranteed ordered WRT previous writes.)
> + */
Something is off with that comment.
> + ring_req->operation = info->flush_op;
> + }
> + ring_req->u.rw.nr_segments = nseg;
> + }
> + for_each_sg(info->sg, sg, nseg, i) {
> fsect = sg->offset >> 9;
> lsect = fsect + (sg->length >> 9) - 1;
>
> + if ((ring_req->operation == BLKIF_OP_INDIRECT) &&
> + (i % SEGS_PER_INDIRECT_FRAME == 0)) {
> + if (segments)
> + kunmap_atomic(segments);
> +
> + n = i / SEGS_PER_INDIRECT_FRAME;
> + gnt_list_entry = get_grant(&gref_head, info);
> + info->shadow[id].indirect_grants[n] =
> + gnt_list_entry;
One line pls
> + segments = kmap_atomic(
> + pfn_to_page(gnt_list_entry->pfn));
Ditto
> + ring_req->u.indirect.indirect_grefs[n] =
> + gnt_list_entry->gref;
Ditto.
> + }
> +
> gnt_list_entry = get_grant(&gref_head, info);
> ref = gnt_list_entry->gref;
>
> @@ -461,13 +528,23 @@ static int blkif_queue_request(struct request *req)
> kunmap_atomic(bvec_data);
> kunmap_atomic(shared_data);
> }
> -
> - ring_req->u.rw.seg[i] =
> - (struct blkif_request_segment) {
> - .gref = ref,
> - .first_sect = fsect,
> - .last_sect = lsect };
> + if (ring_req->operation != BLKIF_OP_INDIRECT) {
> + ring_req->u.rw.seg[i] =
> + (struct blkif_request_segment) {
> + .gref = ref,
> + .first_sect = fsect,
> + .last_sect = lsect };
> + } else {
> + n = i % SEGS_PER_INDIRECT_FRAME;
> + segments[n] =
> + (struct blkif_request_segment_aligned) {
> + .gref = ref,
> + .first_sect = fsect,
> + .last_sect = lsect };
> + }
> }
> + if (segments)
> + kunmap_atomic(segments);
> }
>
> info->ring.req_prod_pvt++;
> @@ -542,7 +619,8 @@ wait:
> flush_requests(info);
> }
>
> -static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
> +static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size,
> + unsigned int segments)
> {
> struct request_queue *rq;
> struct blkfront_info *info = gd->private_data;
> @@ -571,7 +649,7 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
> blk_queue_max_segment_size(rq, PAGE_SIZE);
>
> /* Ensure a merged request will fit in a single I/O ring slot. */
> - blk_queue_max_segments(rq, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> + blk_queue_max_segments(rq, segments);
>
> /* Make sure buffer addresses are sector-aligned. */
> blk_queue_dma_alignment(rq, 511);
> @@ -588,13 +666,14 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
> static void xlvbd_flush(struct blkfront_info *info)
> {
> blk_queue_flush(info->rq, info->feature_flush);
> - printk(KERN_INFO "blkfront: %s: %s: %s %s\n",
> + printk(KERN_INFO "blkfront: %s: %s: %s %s %s\n",
> info->gd->disk_name,
> info->flush_op == BLKIF_OP_WRITE_BARRIER ?
> "barrier" : (info->flush_op == BLKIF_OP_FLUSH_DISKCACHE ?
> "flush diskcache" : "barrier or flush"),
> info->feature_flush ? "enabled" : "disabled",
> - info->feature_persistent ? "using persistent grants" : "");
> + info->feature_persistent ? "using persistent grants" : "",
> + info->max_indirect_segments ? "using indirect descriptors" : "");
This is a bit of mess now:
[ 0.968241] blkfront: xvda: barrier or flush: disabled using persistent grants using indirect descriptors
Should it just be:
'persistent_grants: enabled; indirect descriptors: enabled'
?
> }
>
> static int xen_translate_vdev(int vdevice, int *minor, unsigned int *offset)
> @@ -734,7 +813,9 @@ static int xlvbd_alloc_gendisk(blkif_sector_t capacity,
> gd->driverfs_dev = &(info->xbdev->dev);
> set_capacity(gd, capacity);
>
> - if (xlvbd_init_blk_queue(gd, sector_size)) {
> + if (xlvbd_init_blk_queue(gd, sector_size,
> + info->max_indirect_segments ? :
> + BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
> del_gendisk(gd);
> goto release;
> }
> @@ -818,6 +899,7 @@ static void blkif_free(struct blkfront_info *info, int suspend)
> {
> struct grant *persistent_gnt;
> struct grant *n;
> + int i, j, segs;
>
> /* Prevent new requests being issued until we fix things up. */
> spin_lock_irq(&info->io_lock);
> @@ -843,6 +925,47 @@ static void blkif_free(struct blkfront_info *info, int suspend)
> }
> BUG_ON(info->persistent_gnts_c != 0);
>
> + kfree(info->sg);
> + info->sg = NULL;
> + for (i = 0; i < BLK_RING_SIZE; i++) {
> + /*
> + * Clear persistent grants present in requests already
> + * on the shared ring
> + */
> + if (!info->shadow[i].request)
> + goto free_shadow;
> +
> + segs = info->shadow[i].req.operation == BLKIF_OP_INDIRECT ?
> + info->shadow[i].req.u.indirect.nr_segments :
> + info->shadow[i].req.u.rw.nr_segments;
> + for (j = 0; j < segs; j++) {
> + persistent_gnt = info->shadow[i].grants_used[j];
> + gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
> + __free_page(pfn_to_page(persistent_gnt->pfn));
> + kfree(persistent_gnt);
> + }
> +
> + if (info->shadow[i].req.operation != BLKIF_OP_INDIRECT)
> + /*
> + * If this is not an indirect operation don't try to
> + * free indirect segments
> + */
> + goto free_shadow;
> +
> + for (j = 0; j < INDIRECT_GREFS(segs); j++) {
> + persistent_gnt = info->shadow[i].indirect_grants[j];
> + gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
> + __free_page(pfn_to_page(persistent_gnt->pfn));
> + kfree(persistent_gnt);
> + }
> +
> +free_shadow:
> + kfree(info->shadow[i].grants_used);
> + info->shadow[i].grants_used = NULL;
> + kfree(info->shadow[i].indirect_grants);
> + info->shadow[i].indirect_grants = NULL;
> + }
> +
> /* No more gnttab callback work. */
> gnttab_cancel_free_callback(&info->callback);
> spin_unlock_irq(&info->io_lock);
> @@ -873,6 +996,10 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
> char *bvec_data;
> void *shared_data;
> unsigned int offset = 0;
> + int nseg;
> +
> + nseg = s->req.operation == BLKIF_OP_INDIRECT ?
> + s->req.u.indirect.nr_segments : s->req.u.rw.nr_segments;
>
> if (bret->operation == BLKIF_OP_READ) {
> /*
> @@ -885,7 +1012,7 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
> BUG_ON((bvec->bv_offset + bvec->bv_len) > PAGE_SIZE);
> if (bvec->bv_offset < offset)
> i++;
> - BUG_ON(i >= s->req.u.rw.nr_segments);
> + BUG_ON(i >= nseg);
> shared_data = kmap_atomic(
> pfn_to_page(s->grants_used[i]->pfn));
> bvec_data = bvec_kmap_irq(bvec, &flags);
> @@ -897,10 +1024,17 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
> }
> }
> /* Add the persistent grant into the list of free grants */
> - for (i = 0; i < s->req.u.rw.nr_segments; i++) {
> + for (i = 0; i < nseg; i++) {
> list_add(&s->grants_used[i]->node, &info->persistent_gnts);
> info->persistent_gnts_c++;
> }
> + if (s->req.operation == BLKIF_OP_INDIRECT) {
> + for (i = 0; i < INDIRECT_GREFS(nseg); i++) {
> + list_add(&s->indirect_grants[i]->node,
> + &info->persistent_gnts);
One line pls.
> + info->persistent_gnts_c++;
> + }
> + }
> }
>
> static irqreturn_t blkif_interrupt(int irq, void *dev_id)
> @@ -1034,14 +1168,6 @@ static int setup_blkring(struct xenbus_device *dev,
> SHARED_RING_INIT(sring);
> FRONT_RING_INIT(&info->ring, sring, PAGE_SIZE);
>
> - sg_init_table(info->sg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> -
> - /* Allocate memory for grants */
> - err = fill_grant_buffer(info, BLK_RING_SIZE *
> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
> - if (err)
> - goto fail;
> -
> err = xenbus_grant_ring(dev, virt_to_mfn(info->ring.sring));
> if (err < 0) {
> free_page((unsigned long)sring);
> @@ -1223,13 +1349,84 @@ static int blkfront_probe(struct xenbus_device *dev,
> return 0;
> }
>
> +/*
> + * This is a clone of md_trim_bio, used to split a bio into smaller ones
> + */
> +static void trim_bio(struct bio *bio, int offset, int size)
> +{
> + /* 'bio' is a cloned bio which we need to trim to match
> + * the given offset and size.
> + * This requires adjusting bi_sector, bi_size, and bi_io_vec
> + */
> + int i;
> + struct bio_vec *bvec;
> + int sofar = 0;
> +
> + size <<= 9;
> + if (offset == 0 && size == bio->bi_size)
> + return;
> +
> + bio->bi_sector += offset;
> + bio->bi_size = size;
> + offset <<= 9;
> + clear_bit(BIO_SEG_VALID, &bio->bi_flags);
> +
> + while (bio->bi_idx < bio->bi_vcnt &&
> + bio->bi_io_vec[bio->bi_idx].bv_len <= offset) {
> + /* remove this whole bio_vec */
> + offset -= bio->bi_io_vec[bio->bi_idx].bv_len;
> + bio->bi_idx++;
> + }
> + if (bio->bi_idx < bio->bi_vcnt) {
> + bio->bi_io_vec[bio->bi_idx].bv_offset += offset;
> + bio->bi_io_vec[bio->bi_idx].bv_len -= offset;
> + }
> + /* avoid any complications with bi_idx being non-zero*/
> + if (bio->bi_idx) {
> + memmove(bio->bi_io_vec, bio->bi_io_vec+bio->bi_idx,
> + (bio->bi_vcnt - bio->bi_idx) * sizeof(struct bio_vec));
> + bio->bi_vcnt -= bio->bi_idx;
> + bio->bi_idx = 0;
> + }
> + /* Make sure vcnt and last bv are not too big */
> + bio_for_each_segment(bvec, bio, i) {
> + if (sofar + bvec->bv_len > size)
> + bvec->bv_len = size - sofar;
> + if (bvec->bv_len == 0) {
> + bio->bi_vcnt = i;
> + break;
> + }
> + sofar += bvec->bv_len;
> + }
> +}
> +
> +static void split_bio_end(struct bio *bio, int error)
> +{
> + struct split_bio *split_bio = bio->bi_private;
> +
> + if (error)
> + split_bio->err = error;
> +
> + if (atomic_dec_and_test(&split_bio->pending)) {
> + split_bio->bio->bi_phys_segments = 0;
> + bio_endio(split_bio->bio, split_bio->err);
> + kfree(split_bio);
> + }
> + bio_put(bio);
> +}
>
> static int blkif_recover(struct blkfront_info *info)
> {
> int i;
> - struct blkif_request *req;
> + struct request *req, *n;
> struct blk_shadow *copy;
> - int j;
> + int rc;
> + struct bio *bio, *cloned_bio;
> + struct bio_list bio_list, merge_bio;
> + unsigned int segs;
> + int pending, offset, size;
> + struct split_bio *split_bio;
> + struct list_head requests;
>
> /* Stage 1: Make a safe copy of the shadow state. */
> copy = kmemdup(info->shadow, sizeof(info->shadow),
> @@ -1244,36 +1441,64 @@ static int blkif_recover(struct blkfront_info *info)
> info->shadow_free = info->ring.req_prod_pvt;
> info->shadow[BLK_RING_SIZE-1].req.u.rw.id = 0x0fffffff;
>
> - /* Stage 3: Find pending requests and requeue them. */
> + rc = blkfront_setup_indirect(info);
> + if (rc) {
> + kfree(copy);
> + return rc;
> + }
> +
> + segs = info->max_indirect_segments ? : BLKIF_MAX_SEGMENTS_PER_REQUEST;
> + blk_queue_max_segments(info->rq, segs);
> + bio_list_init(&bio_list);
> + INIT_LIST_HEAD(&requests);
> for (i = 0; i < BLK_RING_SIZE; i++) {
> /* Not in use? */
> if (!copy[i].request)
> continue;
>
> - /* Grab a request slot and copy shadow state into it. */
> - req = RING_GET_REQUEST(&info->ring, info->ring.req_prod_pvt);
> - *req = copy[i].req;
> -
> - /* We get a new request id, and must reset the shadow state. */
> - req->u.rw.id = get_id_from_freelist(info);
> - memcpy(&info->shadow[req->u.rw.id], ©[i], sizeof(copy[i]));
> -
> - if (req->operation != BLKIF_OP_DISCARD) {
> - /* Rewrite any grant references invalidated by susp/resume. */
> - for (j = 0; j < req->u.rw.nr_segments; j++)
> - gnttab_grant_foreign_access_ref(
> - req->u.rw.seg[j].gref,
> - info->xbdev->otherend_id,
> - pfn_to_mfn(copy[i].grants_used[j]->pfn),
> - 0);
> + /*
> + * Get the bios in the request so we can re-queue them.
> + */
> + if (copy[i].request->cmd_flags &
> + (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
> + /*
> + * Flush operations don't contain bios, so
> + * we need to requeue the whole request
> + */
> + list_add(©[i].request->queuelist, &requests);
> + continue;
> }
> - info->shadow[req->u.rw.id].req = *req;
> -
> - info->ring.req_prod_pvt++;
> + merge_bio.head = copy[i].request->bio;
> + merge_bio.tail = copy[i].request->biotail;
> + bio_list_merge(&bio_list, &merge_bio);
> + copy[i].request->bio = NULL;
> + blk_put_request(copy[i].request);
> }
>
> kfree(copy);
>
> + /*
> + * Empty the queue, this is important because we might have
> + * requests in the queue with more segments than what we
> + * can handle now.
> + */
> + spin_lock_irq(&info->io_lock);
> + while ((req = blk_fetch_request(info->rq)) != NULL) {
> + if (req->cmd_flags &
> + (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
> + list_add(&req->queuelist, &requests);
> + continue;
> + }
> + merge_bio.head = req->bio;
> + merge_bio.tail = req->biotail;
> + bio_list_merge(&bio_list, &merge_bio);
> + req->bio = NULL;
> + if (req->cmd_flags & (REQ_FLUSH | REQ_FUA))
> + pr_alert("diskcache flush request found!\n");
> + __blk_put_request(info->rq, req);
> + }
> + spin_unlock_irq(&info->io_lock);
> +
> xenbus_switch_state(info->xbdev, XenbusStateConnected);
>
> spin_lock_irq(&info->io_lock);
> @@ -1281,14 +1506,50 @@ static int blkif_recover(struct blkfront_info *info)
> /* Now safe for us to use the shared ring */
> info->connected = BLKIF_STATE_CONNECTED;
>
> - /* Send off requeued requests */
> - flush_requests(info);
> -
> /* Kick any other new requests queued since we resumed */
> kick_pending_request_queues(info);
>
> + list_for_each_entry_safe(req, n, &requests, queuelist) {
> + /* Requeue pending requests (flush or discard) */
> + list_del_init(&req->queuelist);
> + BUG_ON(req->nr_phys_segments > segs);
> + blk_requeue_request(info->rq, req);
> + }
> spin_unlock_irq(&info->io_lock);
>
> + while ((bio = bio_list_pop(&bio_list)) != NULL) {
> + /* Traverse the list of pending bios and re-queue them */
> + if (bio_segments(bio) > segs) {
> + /*
> + * This bio has more segments than what we can
> + * handle, we have to split it.
> + */
> + pending = (bio_segments(bio) + segs - 1) / segs;
> + split_bio = kzalloc(sizeof(*split_bio), GFP_NOIO);
> + BUG_ON(split_bio == NULL);
> + atomic_set(&split_bio->pending, pending);
> + split_bio->bio = bio;
> + for (i = 0; i < pending; i++) {
> + offset = (i * segs * PAGE_SIZE) >> 9;
> + size = MIN((segs * PAGE_SIZE) >> 9,
> + (bio->bi_size >> 9) - offset);
> + cloned_bio = bio_clone(bio, GFP_NOIO);
> + BUG_ON(cloned_bio == NULL);
> + trim_bio(cloned_bio, offset, size);
> + cloned_bio->bi_private = split_bio;
> + cloned_bio->bi_end_io = split_bio_end;
> + submit_bio(cloned_bio->bi_rw, cloned_bio);
> + }
> + /*
> + * Now we have to wait for all those smaller bios to
> + * end, so we can also end the "parent" bio.
> + */
> + continue;
> + }
> + /* We don't need to split this bio */
> + submit_bio(bio->bi_rw, bio);
> + }
> +
> return 0;
> }
>
> @@ -1308,8 +1569,12 @@ static int blkfront_resume(struct xenbus_device *dev)
> blkif_free(info, info->connected == BLKIF_STATE_CONNECTED);
>
> err = talk_to_blkback(dev, info);
> - if (info->connected == BLKIF_STATE_SUSPENDED && !err)
> - err = blkif_recover(info);
> +
> + /*
> + * We have to wait for the backend to switch to
> + * connected state, since we want to read which
> + * features it supports.
> + */
>
> return err;
> }
> @@ -1387,6 +1652,62 @@ static void blkfront_setup_discard(struct blkfront_info *info)
> kfree(type);
> }
>
> +static int blkfront_setup_indirect(struct blkfront_info *info)
> +{
> + unsigned int indirect_segments, segs;
> + int err, i;
> +
> + err = xenbus_gather(XBT_NIL, info->xbdev->otherend,
> + "max-indirect-segments", "%u", &indirect_segments,
That I believe has to be 'feature-max-indirect-segments'
> + NULL);
> + if (err) {
> + info->max_indirect_segments = 0;
> + segs = BLKIF_MAX_SEGMENTS_PER_REQUEST;
> + } else {
> + info->max_indirect_segments = MIN(indirect_segments,
> + xen_blkif_max_segments);
> + segs = info->max_indirect_segments;
> + }
> + info->sg = kzalloc(sizeof(info->sg[0]) * segs, GFP_KERNEL);
> + if (info->sg == NULL)
> + goto out_of_memory;
> + sg_init_table(info->sg, segs);
> +
> + err = fill_grant_buffer(info,
> + (segs + INDIRECT_GREFS(segs)) * BLK_RING_SIZE);
> + if (err)
> + goto out_of_memory;
> +
> + for (i = 0; i < BLK_RING_SIZE; i++) {
> + info->shadow[i].grants_used = kzalloc(
> + sizeof(info->shadow[i].grants_used[0]) * segs,
> + GFP_NOIO);
> + if (info->max_indirect_segments)
> + info->shadow[i].indirect_grants = kzalloc(
> + sizeof(info->shadow[i].indirect_grants[0]) *
> + INDIRECT_GREFS(segs),
> + GFP_NOIO);
> + if ((info->shadow[i].grants_used == NULL) ||
> + (info->max_indirect_segments &&
> + (info->shadow[i].indirect_grants == NULL)))
> + goto out_of_memory;
> + }
> +
> +
> + return 0;
> +
> +out_of_memory:
> + kfree(info->sg);
> + info->sg = NULL;
> + for (i = 0; i < BLK_RING_SIZE; i++) {
> + kfree(info->shadow[i].grants_used);
> + info->shadow[i].grants_used = NULL;
> + kfree(info->shadow[i].indirect_grants);
> + info->shadow[i].indirect_grants = NULL;
> + }
> + return -ENOMEM;
> +}
> +
> /*
> * Invoked when the backend is finally 'ready' (and has told produced
> * the details about the physical device - #sectors, size, etc).
> @@ -1414,8 +1735,9 @@ static void blkfront_connect(struct blkfront_info *info)
> set_capacity(info->gd, sectors);
> revalidate_disk(info->gd);
>
> - /* fall through */
> + return;
How come?
> case BLKIF_STATE_SUSPENDED:
> + blkif_recover(info);
> return;
>
> default:
> @@ -1436,6 +1758,7 @@ static void blkfront_connect(struct blkfront_info *info)
> info->xbdev->otherend);
> return;
> }
> + info->sector_size = sector_size;
>
> info->feature_flush = 0;
> info->flush_op = 0;
> @@ -1483,6 +1806,13 @@ static void blkfront_connect(struct blkfront_info *info)
> else
> info->feature_persistent = persistent;
>
> + err = blkfront_setup_indirect(info);
> + if (err) {
> + xenbus_dev_fatal(info->xbdev, err, "setup_indirect at %s",
> + info->xbdev->otherend);
> + return;
> + }
> +
> err = xlvbd_alloc_gendisk(sectors, info, binfo, sector_size);
> if (err) {
> xenbus_dev_fatal(info->xbdev, err, "xlvbd_add at %s",
> diff --git a/include/xen/interface/io/blkif.h b/include/xen/interface/io/blkif.h
> index ffd4652..893bee2 100644
> --- a/include/xen/interface/io/blkif.h
> +++ b/include/xen/interface/io/blkif.h
> @@ -102,6 +102,8 @@ typedef uint64_t blkif_sector_t;
> */
> #define BLKIF_OP_DISCARD 5
>
> +#define BLKIF_OP_INDIRECT 6
> +
Ahem! There needs to be more about this. For example which 'feature-X' sets it,
what kind of operations are permitted, etc.
> /*
> * Maximum scatter/gather segments per request.
> * This is carefully chosen so that sizeof(struct blkif_ring) <= PAGE_SIZE.
> @@ -109,6 +111,16 @@ typedef uint64_t blkif_sector_t;
> */
> #define BLKIF_MAX_SEGMENTS_PER_REQUEST 11
>
> +#define BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST 8
> +
> +struct blkif_request_segment_aligned {
> + grant_ref_t gref; /* reference to I/O buffer frame */
> + /* @first_sect: first sector in frame to transfer (inclusive). */
> + /* @last_sect: last sector in frame to transfer (inclusive). */
> + uint8_t first_sect, last_sect;
> + uint16_t _pad; /* padding to make it 8 bytes, so it's cache-aligned */
> +} __attribute__((__packed__));
> +
> struct blkif_request_rw {
> uint8_t nr_segments; /* number of segments */
> blkif_vdev_t handle; /* only for read/write requests */
> @@ -147,12 +159,26 @@ struct blkif_request_other {
> uint64_t id; /* private guest value, echoed in resp */
> } __attribute__((__packed__));
>
> +struct blkif_request_indirect {
> + uint8_t indirect_op;
> + uint16_t nr_segments;
> +#ifdef CONFIG_X86_64
> + uint32_t _pad1; /* offsetof(blkif_...,u.indirect.id) == 8 */
> +#endif
> + uint64_t id;
> + blkif_sector_t sector_number;
> + blkif_vdev_t handle;
> + uint16_t _pad2;
> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
> +} __attribute__((__packed__));
> +
> struct blkif_request {
> uint8_t operation; /* BLKIF_OP_??? */
> union {
> struct blkif_request_rw rw;
> struct blkif_request_discard discard;
> struct blkif_request_other other;
> + struct blkif_request_indirect indirect;
> } u;
> } __attribute__((__packed__));
>
> --
> 1.7.7.5 (Apple Git-26)
>
On 09/04/13 16:47, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
>> Using balloon pages for all granted pages allows us to simplify the
>> logic in blkback, especially in the xen_blkbk_map function, since now
>> we can decide if we want to map a grant persistently or not after we
>> have actually mapped it. This could not be done before because
>> persistent grants used ballooned pages, whereas non-persistent grants
>> used pages from the kernel.
>>
>> This patch also introduces several changes, the first one is that the
>> list of free pages is no longer global, now each blkback instance has
>> it's own list of free pages that can be used to map grants. Also, a
>> run time parameter (max_buffer_pages) has been added in order to tune
>> the maximum number of free pages each blkback instance will keep in
>> it's buffer.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: [email protected]
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>
> Sorry for the late review. Some comments.
Thanks for the review.
>> ---
>> Changes since RFC:
>> * Fix typos in commit message.
>> * Minor fixes in code.
>> ---
>> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
>> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
>> drivers/block/xen-blkback/common.h | 5 +
>> drivers/block/xen-blkback/xenbus.c | 3 +
>> 4 files changed, 165 insertions(+), 116 deletions(-)
>>
>> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> index 3d5951c..e04afe0 100644
>> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
>> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> @@ -73,3 +73,11 @@ KernelVersion: 3.0
>> Contact: Konrad Rzeszutek Wilk <[email protected]>
>> Description:
>> Number of sectors written by the frontend.
>> +
>> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
>> +Date: March 2013
>> +KernelVersion: 3.10
>> +Contact: Roger Pau Monn? <[email protected]>
>> +Description:
>> + Maximum number of free pages to keep in each block
>> + backend buffer.
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index f7526db..8a1892a 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
>> module_param_named(reqs, xen_blkif_reqs, int, 0);
>> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>>
>> +/*
>> + * Maximum number of unused free pages to keep in the internal buffer.
>> + * Setting this to a value too low will reduce memory used in each backend,
>> + * but can have a performance penalty.
>> + *
>> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
>> + * be set to a lower value that might degrade performance on some intensive
>> + * IO workloads.
>> + */
>> +
>> +static int xen_blkif_max_buffer_pages = 704;
>> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
>> +MODULE_PARM_DESC(max_buffer_pages,
>> +"Maximum number of free pages to keep in each block backend buffer");
>> +
>> /* Run-time switchable: /sys/module/blkback/parameters/ */
>> static unsigned int log_stats;
>> module_param(log_stats, int, 0644);
>> @@ -82,10 +97,14 @@ struct pending_req {
>> int status;
>> struct list_head free_list;
>> DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> };
>>
>> #define BLKBACK_INVALID_HANDLE (~0)
>>
>> +/* Number of free pages to remove on each call to free_xenballooned_pages */
>> +#define NUM_BATCH_FREE_PAGES 10
>> +
>> struct xen_blkbk {
>> struct pending_req *pending_reqs;
>> /* List of all 'pending_req' available */
>> @@ -93,8 +112,6 @@ struct xen_blkbk {
>> /* And its spinlock. */
>> spinlock_t pending_free_lock;
>> wait_queue_head_t pending_free_wq;
>> - /* The list of all pages that are available. */
>> - struct page **pending_pages;
>> /* And the grant handles that are available. */
>> grant_handle_t *pending_grant_handles;
>> };
>> @@ -143,14 +160,66 @@ static inline int vaddr_pagenr(struct pending_req *req, int seg)
>> BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
>> }
>>
>> -#define pending_page(req, seg) pending_pages[vaddr_pagenr(req, seg)]
>> +static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
>> +{
>> + unsigned long flags;
>> +
>> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
>
> I am curious to why you need to use the irqsave variant one here, as
>> + if (list_empty(&blkif->free_pages)) {
>> + BUG_ON(blkif->free_pages_num != 0);
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> + return alloc_xenballooned_pages(1, page, false);
>
> This function is using an mutex.
>
> which would imply it is OK to have an non-irq variant of spinlock?
Yes, the only one that probably needs irqsave is put_free_pages, which
is not using any mutexes and could indeed be called from irq context.
>
>> + }
>> + BUG_ON(blkif->free_pages_num == 0);
>> + page[0] = list_first_entry(&blkif->free_pages, struct page, lru);
>> + list_del(&page[0]->lru);
>> + blkif->free_pages_num--;
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> +
>> + return 0;
>> +}
>> +
>> +static inline void put_free_pages(struct xen_blkif *blkif, struct page **page,
>> + int num)
>> +{
>> + unsigned long flags;
>> + int i;
>> +
>> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
>> + for (i = 0; i < num; i++)
>> + list_add(&page[i]->lru, &blkif->free_pages);
>> + blkif->free_pages_num += num;
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> +}
>>
>> -static inline unsigned long vaddr(struct pending_req *req, int seg)
>> +static inline void shrink_free_pagepool(struct xen_blkif *blkif, int num)
>> {
>> - unsigned long pfn = page_to_pfn(blkbk->pending_page(req, seg));
>> - return (unsigned long)pfn_to_kaddr(pfn);
>> + /* Remove requested pages in batches of NUM_BATCH_FREE_PAGES */
>> + struct page *page[NUM_BATCH_FREE_PAGES];
>> + unsigned long flags;
>> + unsigned int num_pages = 0;
>> +
>> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
>> + while (blkif->free_pages_num > num) {
>> + BUG_ON(list_empty(&blkif->free_pages));
>> + page[num_pages] = list_first_entry(&blkif->free_pages,
>> + struct page, lru);
>> + list_del(&page[num_pages]->lru);
>> + blkif->free_pages_num--;
>> + if (++num_pages == NUM_BATCH_FREE_PAGES) {
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> + free_xenballooned_pages(num_pages, page);
>> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
>> + num_pages = 0;
>> + }
>> + }
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> + if (num_pages != 0)
>> + free_xenballooned_pages(num_pages, page);
>> }
>>
>> +#define vaddr(page) ((unsigned long)pfn_to_kaddr(page_to_pfn(page)))
>> +
>> #define pending_handle(_req, _seg) \
>> (blkbk->pending_grant_handles[vaddr_pagenr(_req, _seg)])
>>
>> @@ -170,7 +239,7 @@ static void make_response(struct xen_blkif *blkif, u64 id,
>> (n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
>>
>>
>> -static void add_persistent_gnt(struct rb_root *root,
>> +static int add_persistent_gnt(struct rb_root *root,
>> struct persistent_gnt *persistent_gnt)
>> {
>> struct rb_node **new = &(root->rb_node), *parent = NULL;
>> @@ -186,14 +255,15 @@ static void add_persistent_gnt(struct rb_root *root,
>> else if (persistent_gnt->gnt > this->gnt)
>> new = &((*new)->rb_right);
>> else {
>> - pr_alert(DRV_PFX " trying to add a gref that's already in the tree\n");
>> - BUG();
>> + pr_alert_ratelimited(DRV_PFX " trying to add a gref that's already in the tree\n");
>> + return -EINVAL;
>> }
>> }
>>
>> /* Add new node and rebalance tree. */
>> rb_link_node(&(persistent_gnt->node), parent, new);
>> rb_insert_color(&(persistent_gnt->node), root);
>> + return 0;
>> }
>>
>> static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
>> @@ -215,7 +285,8 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
>> return NULL;
>> }
>>
>> -static void free_persistent_gnts(struct rb_root *root, unsigned int num)
>> +static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
>> + unsigned int num)
>> {
>> struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> @@ -240,7 +311,7 @@ static void free_persistent_gnts(struct rb_root *root, unsigned int num)
>> ret = gnttab_unmap_refs(unmap, NULL, pages,
>> segs_to_unmap);
>> BUG_ON(ret);
>> - free_xenballooned_pages(segs_to_unmap, pages);
>> + put_free_pages(blkif, pages, segs_to_unmap);
>> segs_to_unmap = 0;
>> }
>>
>> @@ -422,13 +493,17 @@ int xen_blkif_schedule(void *arg)
>> if (do_block_io_op(blkif))
>> blkif->waiting_reqs = 1;
>>
>> + shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
>
> That threw me off the first time I saw it. I somehow thought it meant
> to shrink all xen_blkif_max_buffer_pages, not the value "above" it.
>
> Might need a comment saying: "/* Shrink if we have more than xen_blkif_max_buffer_pages. */"
>
>
>> +
>> if (log_stats && time_after(jiffies, blkif->st_print))
>> print_stats(blkif);
>> }
>>
>> + shrink_free_pagepool(blkif, 0);
>
> Add a little comment by the zero please that says: /* All */
Done.
>
>> +
>> /* Free all persistent grant pages */
>> if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
>> - free_persistent_gnts(&blkif->persistent_gnts,
>> + free_persistent_gnts(blkif, &blkif->persistent_gnts,
>> blkif->persistent_gnt_c);
>>
>> BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
>> @@ -457,23 +532,25 @@ static void xen_blkbk_unmap(struct pending_req *req)
>> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> unsigned int i, invcount = 0;
>> grant_handle_t handle;
>> + struct xen_blkif *blkif = req->blkif;
>> int ret;
>>
>> for (i = 0; i < req->nr_pages; i++) {
>> if (!test_bit(i, req->unmap_seg))
>> continue;
>> handle = pending_handle(req, i);
>> + pages[invcount] = req->pages[i];
>> if (handle == BLKBACK_INVALID_HANDLE)
>> continue;
>> - gnttab_set_unmap_op(&unmap[invcount], vaddr(req, i),
>> + gnttab_set_unmap_op(&unmap[invcount], vaddr(pages[invcount]),
>> GNTMAP_host_map, handle);
>> pending_handle(req, i) = BLKBACK_INVALID_HANDLE;
>> - pages[invcount] = virt_to_page(vaddr(req, i));
>> invcount++;
>> }
>>
>> ret = gnttab_unmap_refs(unmap, NULL, pages, invcount);
>> BUG_ON(ret);
>> + put_free_pages(blkif, pages, invcount);
>> }
>>
>> static int xen_blkbk_map(struct blkif_request *req,
>> @@ -488,7 +565,6 @@ static int xen_blkbk_map(struct blkif_request *req,
>> struct xen_blkif *blkif = pending_req->blkif;
>> phys_addr_t addr = 0;
>> int i, j;
>> - bool new_map;
>> int nseg = req->u.rw.nr_segments;
>> int segs_to_map = 0;
>> int ret = 0;
>> @@ -517,68 +593,16 @@ static int xen_blkbk_map(struct blkif_request *req,
>> * We are using persistent grants and
>> * the grant is already mapped
>> */
>> - new_map = false;
>> - } else if (use_persistent_gnts &&
>> - blkif->persistent_gnt_c <
>> - max_mapped_grant_pages(blkif->blk_protocol)) {
>> - /*
>> - * We are using persistent grants, the grant is
>> - * not mapped but we have room for it
>> - */
>> - new_map = true;
>> - persistent_gnt = kmalloc(
>> - sizeof(struct persistent_gnt),
>> - GFP_KERNEL);
>> - if (!persistent_gnt)
>> - return -ENOMEM;
>> - if (alloc_xenballooned_pages(1, &persistent_gnt->page,
>> - false)) {
>> - kfree(persistent_gnt);
>> - return -ENOMEM;
>> - }
>> - persistent_gnt->gnt = req->u.rw.seg[i].gref;
>> - persistent_gnt->handle = BLKBACK_INVALID_HANDLE;
>> -
>> - pages_to_gnt[segs_to_map] =
>> - persistent_gnt->page;
>> - addr = (unsigned long) pfn_to_kaddr(
>> - page_to_pfn(persistent_gnt->page));
>> -
>> - add_persistent_gnt(&blkif->persistent_gnts,
>> - persistent_gnt);
>> - blkif->persistent_gnt_c++;
>> - pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
>> - persistent_gnt->gnt, blkif->persistent_gnt_c,
>> - max_mapped_grant_pages(blkif->blk_protocol));
>> - } else {
>> - /*
>> - * We are either using persistent grants and
>> - * hit the maximum limit of grants mapped,
>> - * or we are not using persistent grants.
>> - */
>> - if (use_persistent_gnts &&
>> - !blkif->vbd.overflow_max_grants) {
>> - blkif->vbd.overflow_max_grants = 1;
>> - pr_alert(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
>> - blkif->domid, blkif->vbd.handle);
>> - }
>> - new_map = true;
>> - pages[i] = blkbk->pending_page(pending_req, i);
>> - addr = vaddr(pending_req, i);
>> - pages_to_gnt[segs_to_map] =
>> - blkbk->pending_page(pending_req, i);
>> - }
>> -
>> - if (persistent_gnt) {
>
> Nice :-)
>
>> pages[i] = persistent_gnt->page;
>> persistent_gnts[i] = persistent_gnt;
>> } else {
>> + if (get_free_page(blkif, &pages[i]))
>> + goto out_of_memory;
>> + addr = vaddr(pages[i]);
>> + pages_to_gnt[segs_to_map] = pages[i];
>> persistent_gnts[i] = NULL;
>> - }
>> -
>> - if (new_map) {
>> flags = GNTMAP_host_map;
>> - if (!persistent_gnt &&
>> + if (!use_persistent_gnts &&
>> (pending_req->operation != BLKIF_OP_READ))
>> flags |= GNTMAP_readonly;
>> gnttab_set_map_op(&map[segs_to_map++], addr,
>> @@ -599,47 +623,71 @@ static int xen_blkbk_map(struct blkif_request *req,
>> */
>> bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> for (i = 0, j = 0; i < nseg; i++) {
>> - if (!persistent_gnts[i] ||
>> - persistent_gnts[i]->handle == BLKBACK_INVALID_HANDLE) {
>> + if (!persistent_gnts[i]) {
>> /* This is a newly mapped grant */
>> BUG_ON(j >= segs_to_map);
>> if (unlikely(map[j].status != 0)) {
>> pr_debug(DRV_PFX "invalid buffer -- could not remap it\n");
>> - map[j].handle = BLKBACK_INVALID_HANDLE;
>> + pending_handle(pending_req, i) =
>> + BLKBACK_INVALID_HANDLE;
>
> You can make that on one line. The 80 character limit is not that ... strict anymore.
> Here is what Ingo said about it:
> https://lkml.org/lkml/2012/2/3/101
OK, good to know.
>> ret |= 1;
>> - if (persistent_gnts[i]) {
>> - rb_erase(&persistent_gnts[i]->node,
>> - &blkif->persistent_gnts);
>> - blkif->persistent_gnt_c--;
>> - kfree(persistent_gnts[i]);
>> - persistent_gnts[i] = NULL;
>> - }
>> + j++;
>> + continue;
>
> The old code had abit of different logic for the non-persistent error path.
> It would do:
>
> 598 if (!persistent_gnts[i] ||
> ..
> 602 if (unlikely(map[j].status != 0)) {
>
> 605 ret |= 1;
> .. then later.. for the !persisten_gnts case:
>
> 634 } else {
> 635 pending_handle(pending_req, i) = map[j].handle;
> 636 bitmap_set(pending_req->unmap_seg, i, 1);
> 637
> 638 if (ret) {
> 639 j++;
> 640 continue;
> 641 }
>> }
>> + pending_handle(pending_req, i) = map[j].handle;
>
> Which means that for this code, we skip the 635 (which is OK as you have done the
> "pending_handle(pending_req, i) = BLKBACK_INVALID_HANDLE", but what the 636 case
> (that is the bitmap_set)?
That's done in line 678:
678 bitmap_set(pending_req->unmap_seg, i, 1);
that is only reached if the grant is not mapped persistently. If the
grant is not mapped at all (so pending_handle ==
BLKBACK_INVALID_HANDLE), it doesn't really matter to set unmap_seg bit,
since we cannot unmap the grant.
>
> It presumarily is OK, as the 'pending_handle(pending_req, i)' ends up being
> set to BLKBACK_INVALID_HANDLE, so the loop in xen_blkbk_unmap will still skip
> over it?
>
> This I think warrants a little comment saying: "We can skip the bitmap_set' as
> xen_blkbk_unmap can handle BLKBACK_INVALID_HANDLE'.
Sure, I've added the following comment:
/*
* No need to set unmap_seg bit, since
* we can not unmap this grant because
* the handle is invalid.
*/
>
> But then that begs the question - why do we even need the bitmap_set code path anymore?
To know which grants are mapped persistenly, so we don't unmap them in
xen_blkbk_unmap.
>> }
>> - if (persistent_gnts[i]) {
>> - if (persistent_gnts[i]->handle ==
>> - BLKBACK_INVALID_HANDLE) {
>> + if (persistent_gnts[i])
>> + goto next;
>> + if (use_persistent_gnts &&
>> + blkif->persistent_gnt_c <
>> + max_mapped_grant_pages(blkif->blk_protocol)) {
>> + /*
>> + * We are using persistent grants, the grant is
>> + * not mapped but we have room for it
>> + */
>> + persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
>> + GFP_KERNEL);
>> + if (!persistent_gnt) {
>> /*
>> - * If this is a new persistent grant
>> - * save the handler
>> + * If we don't have enough memory to
>> + * allocate the persistent_gnt struct
>> + * map this grant non-persistenly
>> */
>> - persistent_gnts[i]->handle = map[j++].handle;
>> + j++;
>> + goto next;
>
> So you are doing this by assuming that get_persistent_gnt in the earlier loop
> failed, which means you have in effect done this:
> map[segs_to_map++]
>
> Doing the next label will set:
> seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
>
> OK, that sounds right. Is this then:
>
> bitmap_set(pending_req->unmap_seg, i, 1);
>
> even needed? The "pending_handle(pending_req, i) = map[j].handle;" had already been
> done in the /* This is a newly mapped grant */ if case, so we are set there.
We need to mark this grant as non-persistent, so we unmap it on
xen_blkbk_unmap.
>
> Perhaps you could update the comment from saying 'map this grant' (which
> implies doing it NOW as opposed to have done it already), and say:
>
> /*
> .. continue using the grant non-persistently. Note that
> we mapped it in the earlier loop and the earlier if conditional
> sets pending_handle(pending_req, i) = map[j].handle.
> */
>
>
>
>> }
>> - pending_handle(pending_req, i) =
>> - persistent_gnts[i]->handle;
>> -
>> - if (ret)
>> - continue;
>> - } else {
>> - pending_handle(pending_req, i) = map[j++].handle;
>> - bitmap_set(pending_req->unmap_seg, i, 1);
>> -
>> - if (ret)
>> - continue;
>> + persistent_gnt->gnt = map[j].ref;
>> + persistent_gnt->handle = map[j].handle;
>> + persistent_gnt->page = pages[i];
>
> Oh boy, that is a confusing. i and j. Keep loosing track which one is which.
> It lookis right.
>
>> + if (add_persistent_gnt(&blkif->persistent_gnts,
>> + persistent_gnt)) {
>> + kfree(persistent_gnt);
>
> I would also say 'persisten_gnt = NULL' for extra measure of safety
Done.
>
>
>> + j++;
>
> Perhaps the 'j' variable can be called 'map_idx' ? By this point I am pretty
> sure I know what the 'i' and 'j' variables are used for, but if somebody new
> is trying to grok this code they might spend some 5 minutes trying to figure
> this out.
Yes, I agree that i and j are not the best names, I propose to call j
new_map_idx, and i seg_idx.
>
>> + goto next;
>> + }
>> + blkif->persistent_gnt_c++;
>> + pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
>> + persistent_gnt->gnt, blkif->persistent_gnt_c,
>> + max_mapped_grant_pages(blkif->blk_protocol));
>> + j++;
>> + goto next;
>> }
>> + if (use_persistent_gnts && !blkif->vbd.overflow_max_grants) {
>> + blkif->vbd.overflow_max_grants = 1;
>> + pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
>> + blkif->domid, blkif->vbd.handle);
>> + }
>> + bitmap_set(pending_req->unmap_seg, i, 1);
>> + j++;
>> +next:
>> seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
>> }
>> return ret;
>> +
>> +out_of_memory:
>> + pr_alert(DRV_PFX "%s: out of memory\n", __func__);
>> + put_free_pages(blkif, pages_to_gnt, segs_to_map);
>> + return -ENOMEM;
>> }
>>
>> static int dispatch_discard_io(struct xen_blkif *blkif,
>> @@ -863,7 +911,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> int operation;
>> struct blk_plug plug;
>> bool drain = false;
>> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct page **pages = pending_req->pages;
>>
>> switch (req->operation) {
>> case BLKIF_OP_READ:
>> @@ -1090,22 +1138,14 @@ static int __init xen_blkif_init(void)
>> xen_blkif_reqs, GFP_KERNEL);
>> blkbk->pending_grant_handles = kmalloc(sizeof(blkbk->pending_grant_handles[0]) *
>> mmap_pages, GFP_KERNEL);
>> - blkbk->pending_pages = kzalloc(sizeof(blkbk->pending_pages[0]) *
>> - mmap_pages, GFP_KERNEL);
>>
>> - if (!blkbk->pending_reqs || !blkbk->pending_grant_handles ||
>> - !blkbk->pending_pages) {
>> + if (!blkbk->pending_reqs || !blkbk->pending_grant_handles) {
>> rc = -ENOMEM;
>> goto out_of_memory;
>> }
>>
>> for (i = 0; i < mmap_pages; i++) {
>> blkbk->pending_grant_handles[i] = BLKBACK_INVALID_HANDLE;
>> - blkbk->pending_pages[i] = alloc_page(GFP_KERNEL);
>> - if (blkbk->pending_pages[i] == NULL) {
>> - rc = -ENOMEM;
>> - goto out_of_memory;
>> - }
>> }
>> rc = xen_blkif_interface_init();
>> if (rc)
>> @@ -1130,13 +1170,6 @@ static int __init xen_blkif_init(void)
>> failed_init:
>> kfree(blkbk->pending_reqs);
>> kfree(blkbk->pending_grant_handles);
>> - if (blkbk->pending_pages) {
>> - for (i = 0; i < mmap_pages; i++) {
>> - if (blkbk->pending_pages[i])
>> - __free_page(blkbk->pending_pages[i]);
>> - }
>> - kfree(blkbk->pending_pages);
>> - }
>> kfree(blkbk);
>> blkbk = NULL;
>> return rc;
>> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
>> index 60103e2..6c73c38 100644
>> --- a/drivers/block/xen-blkback/common.h
>> +++ b/drivers/block/xen-blkback/common.h
>> @@ -220,6 +220,11 @@ struct xen_blkif {
>> struct rb_root persistent_gnts;
>> unsigned int persistent_gnt_c;
>>
>> + /* buffer of free pages to map grant refs */
>> + spinlock_t free_pages_lock;
>> + int free_pages_num;
>> + struct list_head free_pages;
>> +
>> /* statistics */
>> unsigned long st_print;
>> unsigned long long st_rd_req;
>> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
>> index 8bfd1bc..24f7f6d 100644
>> --- a/drivers/block/xen-blkback/xenbus.c
>> +++ b/drivers/block/xen-blkback/xenbus.c
>> @@ -118,6 +118,9 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
>> blkif->st_print = jiffies;
>> init_waitqueue_head(&blkif->waiting_to_free);
>> blkif->persistent_gnts.rb_node = NULL;
>> + spin_lock_init(&blkif->free_pages_lock);
>> + INIT_LIST_HEAD(&blkif->free_pages);
>> + blkif->free_pages_num = 0;
>>
>> return blkif;
>> }
>> --
>> 1.7.7.5 (Apple Git-26)
>>
>> Perhaps you could update the comment from saying 'map this grant' (which
>> implies doing it NOW as opposed to have done it already), and say:
>>
>> /*
>> .. continue using the grant non-persistently. Note that
>> we mapped it in the earlier loop and the earlier if conditional
>> sets pending_handle(pending_req, i) = map[j].handle.
>> */
>>
>>
>>
>>> }
>>> - pending_handle(pending_req, i) =
>>> - persistent_gnts[i]->handle;
>>> -
>>> - if (ret)
>>> - continue;
>>> - } else {
>>> - pending_handle(pending_req, i) = map[j++].handle;
>>> - bitmap_set(pending_req->unmap_seg, i, 1);
>>> -
>>> - if (ret)
>>> - continue;
>>> + persistent_gnt->gnt = map[j].ref;
>>> + persistent_gnt->handle = map[j].handle;
>>> + persistent_gnt->page = pages[i];
>>
>> Oh boy, that is a confusing. i and j. Keep loosing track which one is which.
>> It lookis right.
>>
>>> + if (add_persistent_gnt(&blkif->persistent_gnts,
>>> + persistent_gnt)) {
>>> + kfree(persistent_gnt);
>>
>> I would also say 'persisten_gnt = NULL' for extra measure of safety
This loop was not completely right, I failed to set the unmap_seg bit if
we tried to map the grant persistently and failed, we would just jump to
next without doing:
bitmap_set(pending_req->unmap_seg, seg_idx, 1);
On 09/04/13 17:46, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
>> Using balloon pages for all granted pages allows us to simplify the
>> logic in blkback, especially in the xen_blkbk_map function, since now
>> we can decide if we want to map a grant persistently or not after we
>> have actually mapped it. This could not be done before because
>> persistent grants used ballooned pages, whereas non-persistent grants
>> used pages from the kernel.
>>
>> This patch also introduces several changes, the first one is that the
>> list of free pages is no longer global, now each blkback instance has
>> it's own list of free pages that can be used to map grants. Also, a
>> run time parameter (max_buffer_pages) has been added in order to tune
>> the maximum number of free pages each blkback instance will keep in
>> it's buffer.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: [email protected]
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>> ---
>> Changes since RFC:
>> * Fix typos in commit message.
>> * Minor fixes in code.
>> ---
>> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
>> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
>> drivers/block/xen-blkback/common.h | 5 +
>> drivers/block/xen-blkback/xenbus.c | 3 +
>> 4 files changed, 165 insertions(+), 116 deletions(-)
>>
>> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> index 3d5951c..e04afe0 100644
>> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
>> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> @@ -73,3 +73,11 @@ KernelVersion: 3.0
>> Contact: Konrad Rzeszutek Wilk <[email protected]>
>> Description:
>> Number of sectors written by the frontend.
>> +
>> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
>> +Date: March 2013
>> +KernelVersion: 3.10
>> +Contact: Roger Pau Monn? <[email protected]>
>> +Description:
>> + Maximum number of free pages to keep in each block
>> + backend buffer.
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index f7526db..8a1892a 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
>> module_param_named(reqs, xen_blkif_reqs, int, 0);
>> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>>
>> +/*
>> + * Maximum number of unused free pages to keep in the internal buffer.
>> + * Setting this to a value too low will reduce memory used in each backend,
>> + * but can have a performance penalty.
>> + *
>> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
>> + * be set to a lower value that might degrade performance on some intensive
>> + * IO workloads.
>> + */
>> +
>> +static int xen_blkif_max_buffer_pages = 704;
>> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
>> +MODULE_PARM_DESC(max_buffer_pages,
>> +"Maximum number of free pages to keep in each block backend buffer");
>
>
> Just curios but have you tried setting it to zero and seen what it does? Or
> to 1390193013910923?
I have not tried it, but setting it to 0 will just mean that we clean
the buffer of unused balloon pages at every iteration of
xen_blkif_schedule, which implies a performance degradation. On the
other hand, setting it to 1390193013910923 will mean that the buffer is
possibly never cleaned, so we could have RING_SIZE * MAX_SEGMENTS unused
balloon pages in the buffer, shouldn't be harmful either if the system
has enough memory.
>
> It might be good to actually have some code to check for sane values.
>
> <sigh> But obviously we did not do that with the xen_blkif_reqs option at all
> so this is capricious of me to ask you to do that in this patchset.
>
> But if you do find some extra time and want to send out a patch to make
> this more robust, that would be much appreciated. It does not have
> to be done now or with this patchset of course.
Instead of using xen_blkif_max_buffer_pages directly we could use
something similar to:
min(xen_blkif_max_buffer_pages, (RING_SIZE * MAX_SEGMENTS))
On 09/04/13 16:47, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
>> Using balloon pages for all granted pages allows us to simplify the
>> logic in blkback, especially in the xen_blkbk_map function, since now
>> we can decide if we want to map a grant persistently or not after we
>> have actually mapped it. This could not be done before because
>> persistent grants used ballooned pages, whereas non-persistent grants
>> used pages from the kernel.
>>
>> This patch also introduces several changes, the first one is that the
>> list of free pages is no longer global, now each blkback instance has
>> it's own list of free pages that can be used to map grants. Also, a
>> run time parameter (max_buffer_pages) has been added in order to tune
>> the maximum number of free pages each blkback instance will keep in
>> it's buffer.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: [email protected]
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>
> Sorry for the late review. Some comments.
>> ---
>> Changes since RFC:
>> * Fix typos in commit message.
>> * Minor fixes in code.
>> ---
>> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
>> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
>> drivers/block/xen-blkback/common.h | 5 +
>> drivers/block/xen-blkback/xenbus.c | 3 +
>> 4 files changed, 165 insertions(+), 116 deletions(-)
>>
>> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> index 3d5951c..e04afe0 100644
>> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
>> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> @@ -73,3 +73,11 @@ KernelVersion: 3.0
>> Contact: Konrad Rzeszutek Wilk <[email protected]>
>> Description:
>> Number of sectors written by the frontend.
>> +
>> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
>> +Date: March 2013
>> +KernelVersion: 3.10
>> +Contact: Roger Pau Monn? <[email protected]>
>> +Description:
>> + Maximum number of free pages to keep in each block
>> + backend buffer.
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index f7526db..8a1892a 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
>> module_param_named(reqs, xen_blkif_reqs, int, 0);
>> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>>
>> +/*
>> + * Maximum number of unused free pages to keep in the internal buffer.
>> + * Setting this to a value too low will reduce memory used in each backend,
>> + * but can have a performance penalty.
>> + *
>> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
>> + * be set to a lower value that might degrade performance on some intensive
>> + * IO workloads.
>> + */
>> +
>> +static int xen_blkif_max_buffer_pages = 704;
>> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
>> +MODULE_PARM_DESC(max_buffer_pages,
>> +"Maximum number of free pages to keep in each block backend buffer");
>> +
>> /* Run-time switchable: /sys/module/blkback/parameters/ */
>> static unsigned int log_stats;
>> module_param(log_stats, int, 0644);
>> @@ -82,10 +97,14 @@ struct pending_req {
>> int status;
>> struct list_head free_list;
>> DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> };
>>
>> #define BLKBACK_INVALID_HANDLE (~0)
>>
>> +/* Number of free pages to remove on each call to free_xenballooned_pages */
>> +#define NUM_BATCH_FREE_PAGES 10
>> +
>> struct xen_blkbk {
>> struct pending_req *pending_reqs;
>> /* List of all 'pending_req' available */
>> @@ -93,8 +112,6 @@ struct xen_blkbk {
>> /* And its spinlock. */
>> spinlock_t pending_free_lock;
>> wait_queue_head_t pending_free_wq;
>> - /* The list of all pages that are available. */
>> - struct page **pending_pages;
>> /* And the grant handles that are available. */
>> grant_handle_t *pending_grant_handles;
>> };
>> @@ -143,14 +160,66 @@ static inline int vaddr_pagenr(struct pending_req *req, int seg)
>> BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
>> }
>>
>> -#define pending_page(req, seg) pending_pages[vaddr_pagenr(req, seg)]
>> +static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
>> +{
>> + unsigned long flags;
>> +
>> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
>
> I am curious to why you need to use the irqsave variant one here, as
>> + if (list_empty(&blkif->free_pages)) {
>> + BUG_ON(blkif->free_pages_num != 0);
>> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
>> + return alloc_xenballooned_pages(1, page, false);
>
> This function is using an mutex.
>
> which would imply it is OK to have an non-irq variant of spinlock?
Sorry, the previous response is wrong, I need to use irqsave in order to
disable interrupts, since put_free_pages is called from interrupt
context and it could create a race if for example, put_free_pages is
called while we are inside shrink_free_pagepool.
On 09/04/13 17:42, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:39PM +0100, Roger Pau Monne wrote:
>> This mechanism allows blkback to change the number of grants
>> persistently mapped at run time.
>>
>> The algorithm uses a simple LRU mechanism that removes (if needed) the
>> persistent grants that have not been used since the last LRU run, or
>> if all grants have been used it removes the first grants in the list
>> (that are not in use).
>>
>> The algorithm allows the user to change the maximum number of
>> persistent grants, by changing max_persistent_grants in sysfs.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>> Cc: [email protected]
>> ---
>> Changes since RFC:
>> * Offload part of the purge work to a kworker thread.
>> * Add documentation about sysfs tunable.
>> ---
>> Documentation/ABI/stable/sysfs-bus-xen-backend | 7 +
>> drivers/block/xen-blkback/blkback.c | 278 +++++++++++++++++++-----
>> drivers/block/xen-blkback/common.h | 12 +
>> drivers/block/xen-blkback/xenbus.c | 2 +
>> 4 files changed, 240 insertions(+), 59 deletions(-)
>>
>> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> index e04afe0..7595b38 100644
>> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
>> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
>> @@ -81,3 +81,10 @@ Contact: Roger Pau Monn? <[email protected]>
>> Description:
>> Maximum number of free pages to keep in each block
>> backend buffer.
>> +
>> +What: /sys/module/xen_blkback/parameters/max_persistent_grants
>> +Date: March 2013
>> +KernelVersion: 3.10
>> +Contact: Roger Pau Monn? <[email protected]>
>> +Description:
>> + Maximum number of grants to map persistently in blkback.
>
> You are missing the other 2 paramters.
Since the other two parameters are not "public", in the sense that you
need to change the source in order to use them, I have not added them to
the list of parameters.
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index 8a1892a..fd1dd38 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -78,6 +78,44 @@ module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
>> MODULE_PARM_DESC(max_buffer_pages,
>> "Maximum number of free pages to keep in each block backend buffer");
>>
>> +/*
>> + * Maximum number of grants to map persistently in blkback. For maximum
>> + * performance this should be the total numbers of grants that can be used
>> + * to fill the ring, but since this might become too high, specially with
>> + * the use of indirect descriptors, we set it to a value that provides good
>> + * performance without using too much memory.
>> + *
>> + * When the list of persistent grants is full we clean it using a LRU
> ^- up
>
>> + * algorithm.
>
> Sorry for the confusion. Does this mean that the cap is 352? Or that once
> we hit the cap of 352 then the LRU engine gets kicked in?
This means that we can add up to 352 grants without the LRU kicking in,
if we try to add 353, then the LRU would kick in.
>
>> + */
>> +
>> +static int xen_blkif_max_pgrants = 352;
>> +module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
>> +MODULE_PARM_DESC(max_persistent_grants,
>> + "Maximum number of grants to map persistently");
>> +
>> +/*
>> + * The LRU mechanism to clean the lists of persistent grants needs to
>> + * be executed periodically. The time interval between consecutive executions
>> + * of the purge mechanism is set in ms.
>> + */
>> +
>> +static int xen_blkif_lru_interval = 100;
>> +module_param_named(lru_interval, xen_blkif_lru_interval, int, 0);
>
> Is the '0' intentional?
I didn't plan to make them public, because I'm not sure of the benefit
of exporting those, but they are there so if someone wants to really
tune this parameters it can be done without much trouble. The same with
lru_percent_clean. Would you prefer to make those public?
>
>> +MODULE_PARM_DESC(lru_interval,
>> +"Execution interval (in ms) of the LRU mechanism to clean the list of persistent grants");
>> +
>> +/*
>> + * When the persistent grants list is full we will remove unused grants
>> + * from the list. The percent number of grants to be removed at each LRU
>> + * execution.
>> + */
>> +
>> +static int xen_blkif_lru_percent_clean = 5;
>
> OK, so by default if the persistent grants are at 352 pages we start trimming
> 5% of the list every 100ms. Are we trimming the whole list or just down
> to 352 (so max_persistent_grants?).
In the case that we have here, max_persistent_grants is set to
RING_SIZE*MAX_SEGMENTS, so the LRU would never kick in. If we set this
to something lower, then the LRU would kick in and remove 5% of
max_persistent_grants at each execution.
>
> If the latter do we stop the LRU execution at that point? If so please
> enumerate that. Oh and do we stop at 352 or do we do the 5% so we end up actually
> at 334?
>
> Would it make sense to cap the engine to stop removing unused grants
> down to xen_blkif_max_pgrants?
If I got your question right, I think this is already done by the
current implementation, it will only start removing grants the moment we
try to use more than max_persistent_grants, but not when using exactly
max_persistent_grants.
>
>> +module_param_named(lru_percent_clean, xen_blkif_lru_percent_clean, int, 0);
>
> Ditto here.
>
>> +MODULE_PARM_DESC(lru_percent_clean,
>> +"Number of persistent grants to unmap when the list is full");
>> +
>> /* Run-time switchable: /sys/module/blkback/parameters/ */
>> static unsigned int log_stats;
>> module_param(log_stats, int, 0644);
>> @@ -96,8 +134,8 @@ struct pending_req {
>> unsigned short operation;
>> int status;
>> struct list_head free_list;
>> - DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> };
>>
>> #define BLKBACK_INVALID_HANDLE (~0)
>> @@ -119,36 +157,6 @@ struct xen_blkbk {
>> static struct xen_blkbk *blkbk;
>>
>> /*
>> - * Maximum number of grant pages that can be mapped in blkback.
>> - * BLKIF_MAX_SEGMENTS_PER_REQUEST * RING_SIZE is the maximum number of
>> - * pages that blkback will persistently map.
>> - * Currently, this is:
>> - * RING_SIZE = 32 (for all known ring types)
>> - * BLKIF_MAX_SEGMENTS_PER_REQUEST = 11
>> - * sizeof(struct persistent_gnt) = 48
>> - * So the maximum memory used to store the grants is:
>> - * 32 * 11 * 48 = 16896 bytes
>> - */
>> -static inline unsigned int max_mapped_grant_pages(enum blkif_protocol protocol)
>> -{
>> - switch (protocol) {
>> - case BLKIF_PROTOCOL_NATIVE:
>> - return __CONST_RING_SIZE(blkif, PAGE_SIZE) *
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> - case BLKIF_PROTOCOL_X86_32:
>> - return __CONST_RING_SIZE(blkif_x86_32, PAGE_SIZE) *
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> - case BLKIF_PROTOCOL_X86_64:
>> - return __CONST_RING_SIZE(blkif_x86_64, PAGE_SIZE) *
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> - default:
>> - BUG();
>> - }
>> - return 0;
>> -}
>> -
>> -
>> -/*
>> * Little helpful macro to figure out the index and virtual address of the
>> * pending_pages[..]. For each 'pending_req' we have have up to
>> * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
>> @@ -239,13 +247,19 @@ static void make_response(struct xen_blkif *blkif, u64 id,
>> (n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
>>
>>
>> -static int add_persistent_gnt(struct rb_root *root,
>> +static int add_persistent_gnt(struct xen_blkif *blkif,
>> struct persistent_gnt *persistent_gnt)
>> {
>> - struct rb_node **new = &(root->rb_node), *parent = NULL;
>> + struct rb_node **new = NULL, *parent = NULL;
>> struct persistent_gnt *this;
>>
>> + if (blkif->persistent_gnt_c >= xen_blkif_max_pgrants) {
>> + if (!blkif->vbd.overflow_max_grants)
>> + blkif->vbd.overflow_max_grants = 1;
>> + return -EBUSY;
>> + }
>> /* Figure out where to put new node */
>> + new = &blkif->persistent_gnts.rb_node;
>> while (*new) {
>> this = container_of(*new, struct persistent_gnt, node);
>>
>> @@ -259,19 +273,23 @@ static int add_persistent_gnt(struct rb_root *root,
>> return -EINVAL;
>> }
>> }
>> -
>> + bitmap_zero(persistent_gnt->flags, PERSISTENT_GNT_FLAGS_SIZE);
>> + set_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
>> /* Add new node and rebalance tree. */
>> rb_link_node(&(persistent_gnt->node), parent, new);
>> - rb_insert_color(&(persistent_gnt->node), root);
>> + rb_insert_color(&(persistent_gnt->node), &blkif->persistent_gnts);
>> + blkif->persistent_gnt_c++;
>> + atomic_inc(&blkif->persistent_gnt_in_use);
>> return 0;
>> }
>>
>> -static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
>> +static struct persistent_gnt *get_persistent_gnt(struct xen_blkif *blkif,
>> grant_ref_t gref)
>> {
>> struct persistent_gnt *data;
>> - struct rb_node *node = root->rb_node;
>> + struct rb_node *node = NULL;
>>
>> + node = blkif->persistent_gnts.rb_node;
>> while (node) {
>> data = container_of(node, struct persistent_gnt, node);
>>
>> @@ -279,12 +297,25 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
>> node = node->rb_left;
>> else if (gref > data->gnt)
>> node = node->rb_right;
>> - else
>> + else {
>> + WARN_ON(test_bit(PERSISTENT_GNT_ACTIVE, data->flags));
>
> Ouch. Is that even safe? Doesn't that mean that somebody is using this and we just
> usurped it?
It is not safe for sure regarding data integrity, but a buggy frontend
can send a request with the same grant for all the segments, and now
that you make me think of it, this should be ratelimited to prevent a
malicious frontend from flooding the Dom0.
>> + set_bit(PERSISTENT_GNT_ACTIVE, data->flags);
>> + atomic_inc(&blkif->persistent_gnt_in_use);
>> return data;
>> + }
>> }
>> return NULL;
>> }
>>
>> +static void put_persistent_gnt(struct xen_blkif *blkif,
>> + struct persistent_gnt *persistent_gnt)
>> +{
>> + WARN_ON(!test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags));
>> + set_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
>> + clear_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
>> + atomic_dec(&blkif->persistent_gnt_in_use);
>> +}
>> +
>> static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
>> unsigned int num)
>> {
>> @@ -322,6 +353,122 @@ static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
>> BUG_ON(num != 0);
>> }
>>
>
> Might need need to say something about locking..
I've added the following comment:
/*
* We don't need locking around the persistent grant helpers
* because blkback uses a single-thread for each backed, so we
* can be sure that this functions will never be called recursively.
*
* The only exception to that is put_persistent_grant, that can be called
* from interrupt context (by xen_blkbk_unmap), so we have to use atomic
* bit operations to modify the flags of a persistent grant and to count
* the number of used grants.
*/
>
>> +static void unmap_purged_grants(struct work_struct *work)
>> +{
>> + struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct persistent_gnt *persistent_gnt;
>> + int ret, segs_to_unmap = 0;
>> + struct xen_blkif *blkif =
>> + container_of(work, typeof(*blkif), persistent_purge_work);
>> +
>> + while(!list_empty(&blkif->persistent_purge_list)) {
>> + persistent_gnt = list_first_entry(&blkif->persistent_purge_list,
>> + struct persistent_gnt,
>> + remove_node);
>> + list_del(&persistent_gnt->remove_node);
>> +
>> + gnttab_set_unmap_op(&unmap[segs_to_unmap],
>> + vaddr(persistent_gnt->page),
>> + GNTMAP_host_map,
>> + persistent_gnt->handle);
>> +
>> + pages[segs_to_unmap] = persistent_gnt->page;
>> +
>> + if (++segs_to_unmap == BLKIF_MAX_SEGMENTS_PER_REQUEST) {
>> + ret = gnttab_unmap_refs(unmap, NULL, pages,
>> + segs_to_unmap);
>> + BUG_ON(ret);
>> + put_free_pages(blkif, pages, segs_to_unmap);
>> + segs_to_unmap = 0;
>> + }
>> + kfree(persistent_gnt);
>> + }
>> + if (segs_to_unmap > 0) {
>> + ret = gnttab_unmap_refs(unmap, NULL, pages, segs_to_unmap);
>> + BUG_ON(ret);
>> + put_free_pages(blkif, pages, segs_to_unmap);
>> + }
>> +}
>> +
>> +static void purge_persistent_gnt(struct xen_blkif *blkif)
>> +{
>> + struct persistent_gnt *persistent_gnt;
>> + struct rb_node *n;
>> + int num_clean, total;
>> + bool scan_used = false;
>> + struct rb_root *root;
>> +
>> + if (blkif->persistent_gnt_c < xen_blkif_max_pgrants ||
>> + (blkif->persistent_gnt_c == xen_blkif_max_pgrants &&
>> + !blkif->vbd.overflow_max_grants)) {
>> + return;
>> + }
>> +
>> + if (work_pending(&blkif->persistent_purge_work)) {
>> + pr_alert_ratelimited(DRV_PFX "Scheduled work from previous purge is still pending, cannot purge list\n");
>> + return;
>> + }
>> +
>> + num_clean = (xen_blkif_max_pgrants / 100) * xen_blkif_lru_percent_clean;
>> + num_clean = blkif->persistent_gnt_c - xen_blkif_max_pgrants + num_clean;
>> + num_clean = num_clean > blkif->persistent_gnt_c ?
>> + blkif->persistent_gnt_c : num_clean;
>
> I think you can do:
> num_clean = min(blkif->persistent_gnt_c, num_clean);
> ?
D'oh! sure, thanks for spotting that.
>> + if (num_clean >
>> + (blkif->persistent_gnt_c -
>> + atomic_read(&blkif->persistent_gnt_in_use)))
>> + return;
>> +
>> + total = num_clean;
>> +
>> + pr_debug(DRV_PFX "Going to purge %d persistent grants\n", num_clean);
>> +
>> + INIT_LIST_HEAD(&blkif->persistent_purge_list);
>> + root = &blkif->persistent_gnts;
>> +purge_list:
>> + foreach_grant_safe(persistent_gnt, n, root, node) {
>> + BUG_ON(persistent_gnt->handle ==
>> + BLKBACK_INVALID_HANDLE);
>> +
>> + if (test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags))
>> + continue;
>> + if (!scan_used &&
>> + (test_bit(PERSISTENT_GNT_USED, persistent_gnt->flags)))
>> + continue;
>> +
>> + rb_erase(&persistent_gnt->node, root);
>> + list_add(&persistent_gnt->remove_node,
>> + &blkif->persistent_purge_list);
>> + if (--num_clean == 0)
>> + goto finished;
>
> The check (if num_clean > .. atomic_read) means that by the time we
> get here and try to remove some of them, the blkif->persistent_gnt_in_use
> might have dramatically changed.
>
> Which would mean we could be walking the list here without collecting
> any grants.
Not really -- at this point, we can assure that there will be no calls
to get_persistent_grant (because we are executing this code from
xen_blkif_schedule), there can only be calls to put_persistent_gnt,
which means that the number of currently used grants will go down, but
never up, so we will always be able to remove the requested number of
grants.
>
> Thought on the second pass we would hopefully get the PERSISTENT_GNT_USED
> but might also hit that case.
>
> Is that a case we need to worry about? I mean if we hit it, then num_clean
> is less than the total. Perhaps at that stage we should decrease
> the 'xen_blkif_lru_percent_clean' to a smaller number as we are probably
> going to hit the same issue next time around?
I haven't really thought about that, because even on busy blkbacks I've
been able to execute the LRU without problems.
>
> And conversely - the next time we run this code and num_clean == total
> then we can increase the 'xen_blkif_lru_percent_clean' to its original
> value?
>
> That would mean we need somewhere a new value (blkif specific) that
> would serve the role of being a local version of 'xen_blkif_lru_percent_clean'
> that can be from 0 -> xen_blkif_lru_percent_clean?
>
> Or is this case I am thinking of overblown and you did not hit it when
> running stress-tests with this code?
Not really, the only case I can think might be problematic is for
example when you have xen_blkif_max_pgrants == 352 and reduce it to 10,
then if blkback is very busy it might take some time to find a window
where only 10 persistent grants are used.
>
>
>
>> + }
>> + /*
>> + * If we get here it means we also need to start cleaning
>> + * grants that were used since last purge in order to cope
>> + * with the requested num
>> + */
>> + if (!scan_used) {
>> + pr_debug(DRV_PFX "Still missing %d purged frames\n", num_clean);
>> + scan_used = true;
>> + goto purge_list;
>> + }
>> +finished:
>> + /* Remove the "used" flag from all the persistent grants */
>> + foreach_grant_safe(persistent_gnt, n, root, node) {
>> + BUG_ON(persistent_gnt->handle ==
>> + BLKBACK_INVALID_HANDLE);
>> + clear_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
>
> The 'used' flag does not sound right. I can't place it but I would
> think another name is better.
>
> Perhaps 'WALKED' ? 'TOUCHED' ? 'NOT_TOO_FRESH'? 'STALE'? 'WAS_ACTIVE'?
>
> Hm, perhaps 'WAS_ACTIVE'? Or maybe the 'USED' is right.
>
> Either way, I am not a native speaker so lets not get hanged up on this.
I'm not a native speaker either, maybe WAS_ACTIVE is a better
definittion? Or UTILIZED?
>
>> + }
>> + blkif->persistent_gnt_c -= (total - num_clean);
>> + blkif->vbd.overflow_max_grants = 0;
>> +
>> + /* We can defer this work */
>> + INIT_WORK(&blkif->persistent_purge_work, unmap_purged_grants);
>> + schedule_work(&blkif->persistent_purge_work);
>> + pr_debug(DRV_PFX "Purged %d/%d\n", (total - num_clean), total);
>> + return;
>> +}
>> +
>> /*
>> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
>> */
>> @@ -453,12 +600,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
>> static void print_stats(struct xen_blkif *blkif)
>> {
>> pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
>> - " | ds %4llu | pg: %4u/%4u\n",
>> + " | ds %4llu | pg: %4u/%4d\n",
>> current->comm, blkif->st_oo_req,
>> blkif->st_rd_req, blkif->st_wr_req,
>> blkif->st_f_req, blkif->st_ds_req,
>> blkif->persistent_gnt_c,
>> - max_mapped_grant_pages(blkif->blk_protocol));
>> + xen_blkif_max_pgrants);
>> blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
>> blkif->st_rd_req = 0;
>> blkif->st_wr_req = 0;
>> @@ -470,6 +617,7 @@ int xen_blkif_schedule(void *arg)
>> {
>> struct xen_blkif *blkif = arg;
>> struct xen_vbd *vbd = &blkif->vbd;
>> + unsigned long timeout;
>>
>> xen_blkif_get(blkif);
>>
>> @@ -479,13 +627,21 @@ int xen_blkif_schedule(void *arg)
>> if (unlikely(vbd->size != vbd_sz(vbd)))
>> xen_vbd_resize(blkif);
>>
>> - wait_event_interruptible(
>> + timeout = msecs_to_jiffies(xen_blkif_lru_interval);
>> +
>> + timeout = wait_event_interruptible_timeout(
>> blkif->wq,
>> - blkif->waiting_reqs || kthread_should_stop());
>> - wait_event_interruptible(
>> + blkif->waiting_reqs || kthread_should_stop(),
>> + timeout);
>> + if (timeout == 0)
>> + goto purge_gnt_list;
>
> So if the system admin decided that the value of zero in xen_blkif_lru_interval
> was perfect, won't we timeout immediately and keep on going to the goto statement,
> and then looping around?
Yes, we would go looping around purge_gnt_list.
>
> I think we need some sanity checking that the xen_blkif_lru_interval and
> perhaps the other parameters are sane. And sadly we cannot do that
> in the init function as the system admin might do this:
>
> for fun in `ls -1 /sys/modules/xen_blkback/parameters`
> do
> echo 0 > /sys/modules/xen_blkback/parameters/$a
> done
>
> and reset everything to zero. Yikes.
That's one of the reasons why xen_blkif_lru_interval is not public, but
anyway if someone is so "clever" to export xen_blkif_lru_interval and
then change it to 0...
>
>
>> + timeout = wait_event_interruptible_timeout(
>
> if (blkif->vbd.feature_gnt_persistent) {
> timeout = msecs_to_jiffiers(..)
> timeout = wait_event_interruptple_timeout
>> blkbk->pending_free_wq,
>> !list_empty(&blkbk->pending_free) ||
>> - kthread_should_stop());
>> + kthread_should_stop(),
>> + timeout);
>> + if (timeout == 0)
>> + goto purge_gnt_list;
>>
>> blkif->waiting_reqs = 0;
>> smp_mb(); /* clear flag *before* checking for work */
>> @@ -493,6 +649,14 @@ int xen_blkif_schedule(void *arg)
>> if (do_block_io_op(blkif))
>> blkif->waiting_reqs = 1;
>>
>> +purge_gnt_list:
>> + if (blkif->vbd.feature_gnt_persistent &&
>> + time_after(jiffies, blkif->next_lru)) {
>> + purge_persistent_gnt(blkif);
>> + blkif->next_lru = jiffies +
>> + msecs_to_jiffies(xen_blkif_lru_interval);
>
> You can make this more than 80 characters.
>
>> + }
>> +
>> shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
>>
>> if (log_stats && time_after(jiffies, blkif->st_print))
>> @@ -504,7 +668,7 @@ int xen_blkif_schedule(void *arg)
>> /* Free all persistent grant pages */
>> if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
>> free_persistent_gnts(blkif, &blkif->persistent_gnts,
>> - blkif->persistent_gnt_c);
>> + blkif->persistent_gnt_c);
>>
>> BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
>> blkif->persistent_gnt_c = 0;
>> @@ -536,8 +700,10 @@ static void xen_blkbk_unmap(struct pending_req *req)
>> int ret;
>>
>> for (i = 0; i < req->nr_pages; i++) {
>> - if (!test_bit(i, req->unmap_seg))
>> + if (req->persistent_gnts[i] != NULL) {
>> + put_persistent_gnt(blkif, req->persistent_gnts[i]);
>> continue;
>> + }
>
> Aha, the req->unmap_seg bitmap is not used here anymore! You might want to
> mention that in the commit description saying that you are also removing
> this artifact as you don't need it anymore with the superior cleaning
> method employed here.
Yes, since we are storing the persistent grants used inside the request
struct (to be able to mark them as "unused" when unmapping), we no
longer need the bitmap.
>
>
>
>> handle = pending_handle(req, i);
>> pages[invcount] = req->pages[i];
>> if (handle == BLKBACK_INVALID_HANDLE)
>> @@ -559,8 +725,8 @@ static int xen_blkbk_map(struct blkif_request *req,
>> struct page *pages[])
>> {
>> struct gnttab_map_grant_ref map[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> struct page *pages_to_gnt[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct persistent_gnt **persistent_gnts = pending_req->persistent_gnts;
>> struct persistent_gnt *persistent_gnt = NULL;
>> struct xen_blkif *blkif = pending_req->blkif;
>> phys_addr_t addr = 0;
>> @@ -572,9 +738,6 @@ static int xen_blkbk_map(struct blkif_request *req,
>>
>> use_persistent_gnts = (blkif->vbd.feature_gnt_persistent);
>>
>> - BUG_ON(blkif->persistent_gnt_c >
>> - max_mapped_grant_pages(pending_req->blkif->blk_protocol));
>> -
>> /*
>> * Fill out preq.nr_sects with proper amount of sectors, and setup
>> * assign map[..] with the PFN of the page in our domain with the
>> @@ -585,7 +748,7 @@ static int xen_blkbk_map(struct blkif_request *req,
>>
>> if (use_persistent_gnts)
>> persistent_gnt = get_persistent_gnt(
>> - &blkif->persistent_gnts,
>> + blkif,
>> req->u.rw.seg[i].gref);
>>
>> if (persistent_gnt) {
>> @@ -621,7 +784,6 @@ static int xen_blkbk_map(struct blkif_request *req,
>> * so that when we access vaddr(pending_req,i) it has the contents of
>> * the page from the other domain.
>> */
>> - bitmap_zero(pending_req->unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> for (i = 0, j = 0; i < nseg; i++) {
>> if (!persistent_gnts[i]) {
>> /* This is a newly mapped grant */
>> @@ -639,11 +801,10 @@ static int xen_blkbk_map(struct blkif_request *req,
>> if (persistent_gnts[i])
>> goto next;
>> if (use_persistent_gnts &&
>> - blkif->persistent_gnt_c <
>> - max_mapped_grant_pages(blkif->blk_protocol)) {
>> + blkif->persistent_gnt_c < xen_blkif_max_pgrants) {
>> /*
>> * We are using persistent grants, the grant is
>> - * not mapped but we have room for it
>> + * not mapped but we might have room for it.
>> */
>> persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
>> GFP_KERNEL);
>> @@ -659,16 +820,16 @@ static int xen_blkbk_map(struct blkif_request *req,
>> persistent_gnt->gnt = map[j].ref;
>> persistent_gnt->handle = map[j].handle;
>> persistent_gnt->page = pages[i];
>> - if (add_persistent_gnt(&blkif->persistent_gnts,
>> + if (add_persistent_gnt(blkif,
>> persistent_gnt)) {
>> kfree(persistent_gnt);
>> j++;
>> goto next;
>> }
>> - blkif->persistent_gnt_c++;
>> + persistent_gnts[i] = persistent_gnt;
>> pr_debug(DRV_PFX " grant %u added to the tree of persistent grants, using %u/%u\n",
>> persistent_gnt->gnt, blkif->persistent_gnt_c,
>> - max_mapped_grant_pages(blkif->blk_protocol));
>> + xen_blkif_max_pgrants);
>> j++;
>> goto next;
>> }
>> @@ -677,7 +838,6 @@ static int xen_blkbk_map(struct blkif_request *req,
>> pr_debug(DRV_PFX " domain %u, device %#x is using maximum number of persistent grants\n",
>> blkif->domid, blkif->vbd.handle);
>> }
>> - bitmap_set(pending_req->unmap_seg, i, 1);
>> j++;
>> next:
>> seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
>> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
>> index 6c73c38..f43782c 100644
>> --- a/drivers/block/xen-blkback/common.h
>> +++ b/drivers/block/xen-blkback/common.h
>> @@ -182,12 +182,17 @@ struct xen_vbd {
>>
>> struct backend_info;
>>
>> +#define PERSISTENT_GNT_FLAGS_SIZE 2
>> +#define PERSISTENT_GNT_ACTIVE 0
>> +#define PERSISTENT_GNT_USED 1
>
> These might need a bit of explanation. Would it be possible to include that
> here?
Sure.
/* Number of available flags */
#define PERSISTENT_GNT_FLAGS_SIZE 2
/* This persistent grant is currently in use */
#define PERSISTENT_GNT_ACTIVE 0
/*
* This persistent grant has been used, this flag is set when we remove the
* PERSISTENT_GNT_ACTIVE, to know that this grant has been used recently.
*/
#define PERSISTENT_GNT_USED 1
>
>>
>> struct persistent_gnt {
>> struct page *page;
>> grant_ref_t gnt;
>> grant_handle_t handle;
>> + DECLARE_BITMAP(flags, PERSISTENT_GNT_FLAGS_SIZE);
>> struct rb_node node;
>> + struct list_head remove_node;
>> };
>>
>> struct xen_blkif {
>> @@ -219,6 +224,12 @@ struct xen_blkif {
>> /* tree to store persistent grants */
>> struct rb_root persistent_gnts;
>> unsigned int persistent_gnt_c;
>> + atomic_t persistent_gnt_in_use;
>> + unsigned long next_lru;
>> +
>> + /* used by the kworker that offload work from the persistent purge */
>> + struct list_head persistent_purge_list;
>> + struct work_struct persistent_purge_work;
>>
>> /* buffer of free pages to map grant refs */
>> spinlock_t free_pages_lock;
>> @@ -262,6 +273,7 @@ int xen_blkif_xenbus_init(void);
>>
>> irqreturn_t xen_blkif_be_int(int irq, void *dev_id);
>> int xen_blkif_schedule(void *arg);
>> +int xen_blkif_purge_persistent(void *arg);
>>
>> int xen_blkbk_flush_diskcache(struct xenbus_transaction xbt,
>> struct backend_info *be, int state);
>> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
>> index 24f7f6d..e0fd92a 100644
>> --- a/drivers/block/xen-blkback/xenbus.c
>> +++ b/drivers/block/xen-blkback/xenbus.c
>> @@ -98,6 +98,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
>> err = PTR_ERR(blkif->xenblkd);
>> blkif->xenblkd = NULL;
>> xenbus_dev_error(blkif->be->dev, err, "start xenblkd");
>> + return;
>> }
>> }
>>
>> @@ -121,6 +122,7 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
>> spin_lock_init(&blkif->free_pages_lock);
>> INIT_LIST_HEAD(&blkif->free_pages);
>> blkif->free_pages_num = 0;
>> + atomic_set(&blkif->persistent_gnt_in_use, 0);
>>
>> return blkif;
>> }
>> --
>> 1.7.7.5 (Apple Git-26)
>>
On 09/04/13 18:13, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:41PM +0100, Roger Pau Monne wrote:
>> Remove the last dependency from blkbk by moving the list of free
>> requests to blkif. This change reduces the contention on the list of
>> available requests.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>> Cc: [email protected]
>> ---
>> Changes since RFC:
>> * Replace kzalloc with kcalloc.
>> ---
>> drivers/block/xen-blkback/blkback.c | 125 +++++++----------------------------
>> drivers/block/xen-blkback/common.h | 27 ++++++++
>> drivers/block/xen-blkback/xenbus.c | 19 +++++
>> 3 files changed, 70 insertions(+), 101 deletions(-)
>>
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index e6542d5..a1c9dad 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -50,18 +50,14 @@
>> #include "common.h"
>>
>> /*
>> - * These are rather arbitrary. They are fairly large because adjacent requests
>> - * pulled from a communication ring are quite likely to end up being part of
>> - * the same scatter/gather request at the disc.
>> - *
>> - * ** TRY INCREASING 'xen_blkif_reqs' IF WRITE SPEEDS SEEM TOO LOW **
>> - *
>> - * This will increase the chances of being able to write whole tracks.
>> - * 64 should be enough to keep us competitive with Linux.
>> + * This is the number of requests that will be pre-allocated for each backend.
>> + * For better performance this is set to RING_SIZE (32), so requests
>> + * in the ring will never have to wait for a free pending_req.
>
> You might want to clarify that 'Any value less than that is sure to
> cause problems.'
>
> At which point perhaps we should have some logic to enforce that?
>> */
>> -static int xen_blkif_reqs = 64;
>> +
>> +int xen_blkif_reqs = 32;
>> module_param_named(reqs, xen_blkif_reqs, int, 0);
>> -MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
>> +MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
>
>
> Do we even need this anymore? I mean if the optimial size is 32 and going
> below that is silly. Going above that is silly as well - as we won't be using
> the extra count.
>
> Can we just rip this module parameter out?
Wiped out, it doesn't make sense.
>
>>
>> /*
>> * Maximum number of unused free pages to keep in the internal buffer.
>> @@ -120,53 +116,11 @@ MODULE_PARM_DESC(lru_percent_clean,
>> static unsigned int log_stats;
>> module_param(log_stats, int, 0644);
>>
>> -/*
>> - * Each outstanding request that we've passed to the lower device layers has a
>> - * 'pending_req' allocated to it. Each buffer_head that completes decrements
>> - * the pendcnt towards zero. When it hits zero, the specified domain has a
>> - * response queued for it, with the saved 'id' passed back.
>> - */
>> -struct pending_req {
>> - struct xen_blkif *blkif;
>> - u64 id;
>> - int nr_pages;
>> - atomic_t pendcnt;
>> - unsigned short operation;
>> - int status;
>> - struct list_head free_list;
>> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> -};
>> -
>> #define BLKBACK_INVALID_HANDLE (~0)
>>
>> /* Number of free pages to remove on each call to free_xenballooned_pages */
>> #define NUM_BATCH_FREE_PAGES 10
>>
>> -struct xen_blkbk {
>> - struct pending_req *pending_reqs;
>> - /* List of all 'pending_req' available */
>> - struct list_head pending_free;
>> - /* And its spinlock. */
>> - spinlock_t pending_free_lock;
>> - wait_queue_head_t pending_free_wq;
>> -};
>> -
>> -static struct xen_blkbk *blkbk;
>> -
>> -/*
>> - * Little helpful macro to figure out the index and virtual address of the
>> - * pending_pages[..]. For each 'pending_req' we have have up to
>> - * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
>> - * 10 and would index in the pending_pages[..].
>> - */
>> -static inline int vaddr_pagenr(struct pending_req *req, int seg)
>> -{
>> - return (req - blkbk->pending_reqs) *
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
>> -}
>> -
>> static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
>> {
>> unsigned long flags;
>> @@ -471,18 +425,18 @@ finished:
>> /*
>> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
>> */
>> -static struct pending_req *alloc_req(void)
>> +static struct pending_req *alloc_req(struct xen_blkif *blkif)
>> {
>> struct pending_req *req = NULL;
>> unsigned long flags;
>>
>> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
>> - if (!list_empty(&blkbk->pending_free)) {
>> - req = list_entry(blkbk->pending_free.next, struct pending_req,
>> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
>> + if (!list_empty(&blkif->pending_free)) {
>> + req = list_entry(blkif->pending_free.next, struct pending_req,
>> free_list);
>> list_del(&req->free_list);
>> }
>> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
>> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
>> return req;
>> }
>>
>> @@ -490,17 +444,17 @@ static struct pending_req *alloc_req(void)
>> * Return the 'pending_req' structure back to the freepool. We also
>> * wake up the thread if it was waiting for a free page.
>> */
>> -static void free_req(struct pending_req *req)
>> +static void free_req(struct xen_blkif *blkif, struct pending_req *req)
>> {
>> unsigned long flags;
>> int was_empty;
>>
>> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
>> - was_empty = list_empty(&blkbk->pending_free);
>> - list_add(&req->free_list, &blkbk->pending_free);
>> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
>> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
>> + was_empty = list_empty(&blkif->pending_free);
>> + list_add(&req->free_list, &blkif->pending_free);
>> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
>> if (was_empty)
>> - wake_up(&blkbk->pending_free_wq);
>> + wake_up(&blkif->pending_free_wq);
>> }
>>
>> /*
>> @@ -635,8 +589,8 @@ int xen_blkif_schedule(void *arg)
>> if (timeout == 0)
>> goto purge_gnt_list;
>> timeout = wait_event_interruptible_timeout(
>> - blkbk->pending_free_wq,
>> - !list_empty(&blkbk->pending_free) ||
>> + blkif->pending_free_wq,
>> + !list_empty(&blkif->pending_free) ||
>> kthread_should_stop(),
>> timeout);
>> if (timeout == 0)
>> @@ -883,7 +837,7 @@ static int dispatch_other_io(struct xen_blkif *blkif,
>> struct blkif_request *req,
>> struct pending_req *pending_req)
>> {
>> - free_req(pending_req);
>> + free_req(blkif, pending_req);
>> make_response(blkif, req->u.other.id, req->operation,
>> BLKIF_RSP_EOPNOTSUPP);
>> return -EIO;
>> @@ -943,7 +897,7 @@ static void __end_block_io_op(struct pending_req *pending_req, int error)
>> if (atomic_read(&pending_req->blkif->drain))
>> complete(&pending_req->blkif->drain_complete);
>> }
>> - free_req(pending_req);
>> + free_req(pending_req->blkif, pending_req);
>> }
>> }
>>
>> @@ -986,7 +940,7 @@ __do_block_io_op(struct xen_blkif *blkif)
>> break;
>> }
>>
>> - pending_req = alloc_req();
>> + pending_req = alloc_req(blkif);
>> if (NULL == pending_req) {
>> blkif->st_oo_req++;
>> more_to_do = 1;
>> @@ -1020,7 +974,7 @@ __do_block_io_op(struct xen_blkif *blkif)
>> goto done;
>> break;
>> case BLKIF_OP_DISCARD:
>> - free_req(pending_req);
>> + free_req(blkif, pending_req);
>> if (dispatch_discard_io(blkif, &req))
>> goto done;
>> break;
>> @@ -1222,7 +1176,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> fail_response:
>> /* Haven't submitted any bio's yet. */
>> make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
>> - free_req(pending_req);
>> + free_req(blkif, pending_req);
>> msleep(1); /* back off a bit */
>> return -EIO;
>>
>> @@ -1279,51 +1233,20 @@ static void make_response(struct xen_blkif *blkif, u64 id,
>>
>> static int __init xen_blkif_init(void)
>> {
>> - int i;
>> int rc = 0;
>>
>> if (!xen_domain())
>> return -ENODEV;
>>
>> - blkbk = kzalloc(sizeof(struct xen_blkbk), GFP_KERNEL);
>> - if (!blkbk) {
>> - pr_alert(DRV_PFX "%s: out of memory!\n", __func__);
>> - return -ENOMEM;
>> - }
>> -
>> -
>> - blkbk->pending_reqs = kzalloc(sizeof(blkbk->pending_reqs[0]) *
>> - xen_blkif_reqs, GFP_KERNEL);
>> -
>> - if (!blkbk->pending_reqs) {
>> - rc = -ENOMEM;
>> - goto out_of_memory;
>> - }
>> -
>> rc = xen_blkif_interface_init();
>> if (rc)
>> goto failed_init;
>>
>> - INIT_LIST_HEAD(&blkbk->pending_free);
>> - spin_lock_init(&blkbk->pending_free_lock);
>> - init_waitqueue_head(&blkbk->pending_free_wq);
>> -
>> - for (i = 0; i < xen_blkif_reqs; i++)
>> - list_add_tail(&blkbk->pending_reqs[i].free_list,
>> - &blkbk->pending_free);
>> -
>> rc = xen_blkif_xenbus_init();
>> if (rc)
>> goto failed_init;
>>
>> - return 0;
>> -
>> - out_of_memory:
>> - pr_alert(DRV_PFX "%s: out of memory\n", __func__);
>> failed_init:
>> - kfree(blkbk->pending_reqs);
>> - kfree(blkbk);
>> - blkbk = NULL;
>> return rc;
>> }
>>
>> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
>> index f43782c..debff44 100644
>> --- a/drivers/block/xen-blkback/common.h
>> +++ b/drivers/block/xen-blkback/common.h
>> @@ -236,6 +236,14 @@ struct xen_blkif {
>> int free_pages_num;
>> struct list_head free_pages;
>>
>> + /* Allocation of pending_reqs */
>> + struct pending_req *pending_reqs;
>> + /* List of all 'pending_req' available */
>> + struct list_head pending_free;
>> + /* And its spinlock. */
>> + spinlock_t pending_free_lock;
>> + wait_queue_head_t pending_free_wq;
>> +
>> /* statistics */
>> unsigned long st_print;
>> unsigned long long st_rd_req;
>> @@ -249,6 +257,25 @@ struct xen_blkif {
>> wait_queue_head_t waiting_to_free;
>> };
>>
>> +/*
>> + * Each outstanding request that we've passed to the lower device layers has a
>> + * 'pending_req' allocated to it. Each buffer_head that completes decrements
>> + * the pendcnt towards zero. When it hits zero, the specified domain has a
>> + * response queued for it, with the saved 'id' passed back.
>> + */
>> +struct pending_req {
>> + struct xen_blkif *blkif;
>> + u64 id;
>> + int nr_pages;
>> + atomic_t pendcnt;
>> + unsigned short operation;
>> + int status;
>> + struct list_head free_list;
>> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> +};
>> +
>>
>> #define vbd_sz(_v) ((_v)->bdev->bd_part ? \
>> (_v)->bdev->bd_part->nr_sects : \
>> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
>> index e0fd92a..bf7344f 100644
>> --- a/drivers/block/xen-blkback/xenbus.c
>> +++ b/drivers/block/xen-blkback/xenbus.c
>> @@ -30,6 +30,8 @@ struct backend_info {
>> char *mode;
>> };
>>
>> +extern int xen_blkif_reqs;
>
> How about just sticking it in 'common.h'?
Done, I've replaced it with a define instead of a variable.
>
>> +
>> static struct kmem_cache *xen_blkif_cachep;
>> static void connect(struct backend_info *);
>> static int connect_ring(struct backend_info *);
>> @@ -105,6 +107,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
>> static struct xen_blkif *xen_blkif_alloc(domid_t domid)
>> {
>> struct xen_blkif *blkif;
>> + int i;
>>
>> blkif = kmem_cache_zalloc(xen_blkif_cachep, GFP_KERNEL);
>> if (!blkif)
>> @@ -124,6 +127,21 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
>> blkif->free_pages_num = 0;
>> atomic_set(&blkif->persistent_gnt_in_use, 0);
>>
>> + blkif->pending_reqs = kcalloc(xen_blkif_reqs,
>> + sizeof(blkif->pending_reqs[0]),
>> + GFP_KERNEL);
>> + if (!blkif->pending_reqs) {
>> + kmem_cache_free(xen_blkif_cachep, blkif);
>> + return ERR_PTR(-ENOMEM);
>> + }
>> + INIT_LIST_HEAD(&blkif->pending_free);
>> + spin_lock_init(&blkif->pending_free_lock);
>> + init_waitqueue_head(&blkif->pending_free_wq);
>> +
>> + for (i = 0; i < xen_blkif_reqs; i++)
>> + list_add_tail(&blkif->pending_reqs[i].free_list,
>> + &blkif->pending_free);
>> +
>> return blkif;
>> }
>>
>> @@ -205,6 +223,7 @@ static void xen_blkif_free(struct xen_blkif *blkif)
>> {
>> if (!atomic_dec_and_test(&blkif->refcnt))
>> BUG();
>
> For sanity, should we have something like this:
> struct pending_req *p;
> i = 0;
> list_for_each_entry (p, &blkif->pending_free, free_list)
> i++;
>
> BUG_ON(i != xen_blkif_reqs);
>
> As that would mean somebody did not call 'free_req' and we have a loose one laying
> around.
>
> Or perhaps just leak the offending struct and then don't do 'kfree'?
I prefer the BUG instead of leaking the struct, if we are indeed still
using a request better notice and fix it :)
>
>> + kfree(blkif->pending_reqs);
>> kmem_cache_free(xen_blkif_cachep, blkif);
>> }
>>
>> --
>> 1.7.7.5 (Apple Git-26)
>>
On 09/04/13 20:49, Konrad Rzeszutek Wilk wrote:
> On Wed, Mar 27, 2013 at 12:10:43PM +0100, Roger Pau Monne wrote:
>> Indirect descriptors introduce a new block operation
>> (BLKIF_OP_INDIRECT) that passes grant references instead of segments
>> in the request. This grant references are filled with arrays of
>> blkif_request_segment_aligned, this way we can send more segments in a
>> request.
>>
>> The proposed implementation sets the maximum number of indirect grefs
>> (frames filled with blkif_request_segment_aligned) to 256 in the
>> backend and 32 in the frontend. The value in the frontend has been
>> chosen experimentally, and the backend value has been set to a sane
>> value that allows expanding the maximum number of indirect descriptors
>> in the frontend if needed.
>>
>> The migration code has changed from the previous implementation, in
>> which we simply remapped the segments on the shared ring. Now the
>> maximum number of segments allowed in a request can change depending
>> on the backend, so we have to requeue all the requests in the ring and
>> in the queue and split the bios in them if they are bigger than the
>> new maximum number of segments.
>>
>> Signed-off-by: Roger Pau Monn? <[email protected]>
>> Cc: Konrad Rzeszutek Wilk <[email protected]>
>> Cc: [email protected]
>> ---
>> drivers/block/xen-blkback/blkback.c | 136 +++++++---
>> drivers/block/xen-blkback/common.h | 82 ++++++-
>> drivers/block/xen-blkback/xenbus.c | 8 +
>> drivers/block/xen-blkfront.c | 490 +++++++++++++++++++++++++++++------
>> include/xen/interface/io/blkif.h | 26 ++
>> 5 files changed, 621 insertions(+), 121 deletions(-)
>>
>> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
>> index f8c838e..f16a7c9 100644
>> --- a/drivers/block/xen-blkback/blkback.c
>> +++ b/drivers/block/xen-blkback/blkback.c
>> @@ -69,7 +69,7 @@ MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
>> * IO workloads.
>> */
>>
>> -static int xen_blkif_max_buffer_pages = 704;
>> +static int xen_blkif_max_buffer_pages = 1024;
>> module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
>> MODULE_PARM_DESC(max_buffer_pages,
>> "Maximum number of free pages to keep in each block backend buffer");
>> @@ -85,7 +85,7 @@ MODULE_PARM_DESC(max_buffer_pages,
>> * algorithm.
>> */
>>
>> -static int xen_blkif_max_pgrants = 352;
>> +static int xen_blkif_max_pgrants = 1056;
>> module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
>> MODULE_PARM_DESC(max_persistent_grants,
>> "Maximum number of grants to map persistently");
>> @@ -631,10 +631,6 @@ purge_gnt_list:
>> return 0;
>> }
>>
>> -struct seg_buf {
>> - unsigned int offset;
>> - unsigned int nsec;
>> -};
>> /*
>> * Unmap the grant references, and also remove the M2P over-rides
>> * used in the 'pending_req'.
>> @@ -808,29 +804,71 @@ out_of_memory:
>> return -ENOMEM;
>> }
>>
>> -static int xen_blkbk_map_seg(struct blkif_request *req,
>> - struct pending_req *pending_req,
>> +static int xen_blkbk_map_seg(struct pending_req *pending_req,
>> struct seg_buf seg[],
>> struct page *pages[])
>> {
>> - int i, rc;
>> - grant_ref_t grefs[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + int rc;
>>
>> - for (i = 0; i < req->u.rw.nr_segments; i++)
>> - grefs[i] = req->u.rw.seg[i].gref;
>> -
>> - rc = xen_blkbk_map(pending_req->blkif, grefs,
>> + rc = xen_blkbk_map(pending_req->blkif, pending_req->grefs,
>> pending_req->persistent_gnts,
>> pending_req->grant_handles, pending_req->pages,
>> - req->u.rw.nr_segments,
>> + pending_req->nr_pages,
>> (pending_req->operation != BLKIF_OP_READ));
>> - if (rc)
>> - return rc;
>>
>> - for (i = 0; i < req->u.rw.nr_segments; i++)
>> - seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
>> + return rc;
>> +}
>>
>> - return 0;
>> +static int xen_blkbk_parse_indirect(struct blkif_request *req,
>> + struct pending_req *pending_req,
>> + struct seg_buf seg[],
>> + struct phys_req *preq)
>> +{
>> + struct persistent_gnt **persistent =
>> + pending_req->indirect_persistent_gnts;
>> + struct page **pages = pending_req->indirect_pages;
>> + struct xen_blkif *blkif = pending_req->blkif;
>> + int indirect_grefs, rc, n, nseg, i;
>> + struct blkif_request_segment_aligned *segments = NULL;
>> +
>> + nseg = pending_req->nr_pages;
>> + indirect_grefs = (nseg + SEGS_PER_INDIRECT_FRAME - 1) /
>> + SEGS_PER_INDIRECT_FRAME;
>
> Then 4096 + 511 / 511 = 8. OK. Looks good!
>
> Perhaps also have
> BUG_ON(indirect_grefs > BLKIF_MAX_INDIRECT_PAGES_PER_REQUEST);
>
> just in case?
Since we already have a check for the number of segments in
dispatch_rw_block_io:
unlikely((req->operation == BLKIF_OP_INDIRECT) &&
(nseg > MAX_INDIRECT_SEGMENTS)))
Adding a BUG should be safe.
>
>> +
>> + rc = xen_blkbk_map(blkif, req->u.indirect.indirect_grefs,
>> + persistent, pending_req->indirect_handles,
>> + pages, indirect_grefs, true);
>> + if (rc)
>> + goto unmap;
>> +
>> + for (n = 0, i = 0; n < nseg; n++) {
>> + if ((n % SEGS_PER_INDIRECT_FRAME) == 0) {
>> + /* Map indirect segments */
>> + if (segments)
>> + kunmap_atomic(segments);
>> + segments =
>> + kmap_atomic(pages[n/SEGS_PER_INDIRECT_FRAME]);
>
> You can make it in one-line.
>
>
>> + }
>> + i = n % SEGS_PER_INDIRECT_FRAME;
>> + pending_req->grefs[n] = segments[i].gref;
>> + seg[n].nsec = segments[i].last_sect -
>> + segments[i].first_sect + 1;
>> + seg[n].offset = (segments[i].first_sect << 9);
>> + if ((segments[i].last_sect >= (PAGE_SIZE >> 9)) ||
>> + (segments[i].last_sect <
>> + segments[i].first_sect)) {
>> + rc = -EINVAL;
>> + goto unmap;
>> + }
>> + preq->nr_sects += seg[n].nsec;
>> + }
>> +
>> +unmap:
>> + if (segments)
>> + kunmap_atomic(segments);
>> + xen_blkbk_unmap(blkif, pending_req->indirect_handles,
>> + pages, persistent, indirect_grefs);
>> + return rc;
>> }
>>
>> static int dispatch_discard_io(struct xen_blkif *blkif,
>> @@ -1003,6 +1041,7 @@ __do_block_io_op(struct xen_blkif *blkif)
>> case BLKIF_OP_WRITE:
>> case BLKIF_OP_WRITE_BARRIER:
>> case BLKIF_OP_FLUSH_DISKCACHE:
>> + case BLKIF_OP_INDIRECT:
>> if (dispatch_rw_block_io(blkif, &req, pending_req))
>> goto done;
>> break;
>> @@ -1049,17 +1088,28 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> struct pending_req *pending_req)
>> {
>> struct phys_req preq;
>> - struct seg_buf seg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct seg_buf *seg = pending_req->seg;
>> unsigned int nseg;
>> struct bio *bio = NULL;
>> - struct bio *biolist[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct bio **biolist = pending_req->biolist;
>> int i, nbio = 0;
>> int operation;
>> struct blk_plug plug;
>> bool drain = false;
>> struct page **pages = pending_req->pages;
>> + unsigned short req_operation;
>> +
>> + req_operation = req->operation == BLKIF_OP_INDIRECT ?
>> + req->u.indirect.indirect_op : req->operation;
>> + if ((req->operation == BLKIF_OP_INDIRECT) &&
>> + (req_operation != BLKIF_OP_READ) &&
>> + (req_operation != BLKIF_OP_WRITE)) {
>> + pr_debug(DRV_PFX "Invalid indirect operation (%u)\n",
>> + req_operation);
>> + goto fail_response;
>> + }
>>
>> - switch (req->operation) {
>> + switch (req_operation) {
>> case BLKIF_OP_READ:
>> blkif->st_rd_req++;
>> operation = READ;
>> @@ -1081,33 +1131,47 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> }
>>
>> /* Check that the number of segments is sane. */
>> - nseg = req->u.rw.nr_segments;
>> + nseg = req->operation == BLKIF_OP_INDIRECT ?
>> + req->u.indirect.nr_segments : req->u.rw.nr_segments;
>>
>> if (unlikely(nseg == 0 && operation != WRITE_FLUSH) ||
>> - unlikely(nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
>> + unlikely((req->operation != BLKIF_OP_INDIRECT) &&
>> + (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) ||
>> + unlikely((req->operation == BLKIF_OP_INDIRECT) &&
>> + (nseg > MAX_INDIRECT_SEGMENTS))) {
>> pr_debug(DRV_PFX "Bad number of segments in request (%d)\n",
>> nseg);
>> /* Haven't submitted any bio's yet. */
>> goto fail_response;
>> }
>>
>> - preq.sector_number = req->u.rw.sector_number;
>> preq.nr_sects = 0;
>>
>> pending_req->blkif = blkif;
>> pending_req->id = req->u.rw.id;
>> - pending_req->operation = req->operation;
>> + pending_req->operation = req_operation;
>> pending_req->status = BLKIF_RSP_OKAY;
>> pending_req->nr_pages = nseg;
>>
>> - for (i = 0; i < nseg; i++) {
>> - seg[i].nsec = req->u.rw.seg[i].last_sect -
>> - req->u.rw.seg[i].first_sect + 1;
>> - if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
>> - (req->u.rw.seg[i].last_sect < req->u.rw.seg[i].first_sect))
>> + if (req->operation != BLKIF_OP_INDIRECT) {
>> + preq.dev = req->u.rw.handle;
>> + preq.sector_number = req->u.rw.sector_number;
>> + for (i = 0; i < nseg; i++) {
>> + pending_req->grefs[i] = req->u.rw.seg[i].gref;
>> + seg[i].nsec = req->u.rw.seg[i].last_sect -
>> + req->u.rw.seg[i].first_sect + 1;
>> + seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
>> + if ((req->u.rw.seg[i].last_sect >= (PAGE_SIZE >> 9)) ||
>> + (req->u.rw.seg[i].last_sect <
>> + req->u.rw.seg[i].first_sect))
>> + goto fail_response;
>> + preq.nr_sects += seg[i].nsec;
>> + }
>> + } else {
>> + preq.dev = req->u.indirect.handle;
>> + preq.sector_number = req->u.indirect.sector_number;
>> + if (xen_blkbk_parse_indirect(req, pending_req, seg, &preq))
>> goto fail_response;
>> - preq.nr_sects += seg[i].nsec;
>> -
>> }
>>
>> if (xen_vbd_translate(&preq, blkif, operation) != 0) {
>> @@ -1144,7 +1208,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> * the hypercall to unmap the grants - that is all done in
>> * xen_blkbk_unmap.
>> */
>> - if (xen_blkbk_map_seg(req, pending_req, seg, pages))
>> + if (xen_blkbk_map_seg(pending_req, seg, pages))
>> goto fail_flush;
>>
>> /*
>> @@ -1210,7 +1274,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
>> pending_req->nr_pages);
>> fail_response:
>> /* Haven't submitted any bio's yet. */
>> - make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
>> + make_response(blkif, req->u.rw.id, req_operation, BLKIF_RSP_ERROR);
>> free_req(blkif, pending_req);
>> msleep(1); /* back off a bit */
>> return -EIO;
>> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
>> index debff44..30bffcc 100644
>> --- a/drivers/block/xen-blkback/common.h
>> +++ b/drivers/block/xen-blkback/common.h
>> @@ -50,6 +50,17 @@
>> __func__, __LINE__, ##args)
>>
>>
>> +/*
>> + * This is the maximum number of segments that would be allowed in indirect
>> + * requests. This value will also be passed to the frontend.
>> + */
>> +#define MAX_INDIRECT_SEGMENTS 256
>
> That little? We don't want to have say 512 to at least fill the full page? Or
> perhaps 1024 to use two pages (and be able to comfortably do 4MB of I/O in
> one request).
Yes, we can set this to a different value, but what really matters is
the value used in blkfront.
Also, from what I've found, setting this to a higher value only improves
performance if the maximum number of persistent grants is also
increased. For example allowing requests with 512 segments and only
using 1056 persistent grants (so we are only persistently mapping 7% of
all the possible grants) will be a performance degradation in comparison
to using only 32 segments per request and 1056 persistent grants (100%
of the grants mapped persistently).
>
>> +
>> +#define SEGS_PER_INDIRECT_FRAME \
>> +(PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
>
> OK, so 512.
>
>> +#define MAX_INDIRECT_GREFS \
>> +((MAX_INDIRECT_SEGMENTS + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
>
>
> (256 + 512 - 1) / 512 = so 1.49 or since it is an int = '1'.
>
> Is that right? The patch comment alluded to 256?
>
> Ah, MAX_INDIRECT_GREFS is how many pages of indirect descriptors we can do!
> Somehow I thought it was related to how many indirect grant references we
> have (so SEGS_PER_INDIRECT_FRAME).
>
> How about just calling it MAX_INDIRECT_PAGES ?
Yes, that's a better name.
>
> This should also have some
>
> BUILD_BUG_ON(MAX_INDIRECT_GREFS > BLKIF_MAX_INDIRECT_PAGES_PER_REQUEST)
>
> to guard against doing something very bad.
>
>
>> +
>> /* Not a real protocol. Used to generate ring structs which contain
>> * the elements common to all protocols only. This way we get a
>> * compiler-checkable way to use common struct elements, so we can
>> @@ -83,12 +94,23 @@ struct blkif_x86_32_request_other {
>> uint64_t id; /* private guest value, echoed in resp */
>> } __attribute__((__packed__));
>>
>> +struct blkif_x86_32_request_indirect {
>> + uint8_t indirect_op;
>> + uint16_t nr_segments;
>
> This needs to be documented. Is there are limit to what it can be? What if
> the frontend sets it to 1231231?
This is checked in dispatch_rw_block_io:
if (unlikely(nseg == 0 && operation != WRITE_FLUSH) ||
unlikely((req->operation != BLKIF_OP_INDIRECT) &&
(nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) ||
unlikely((req->operation == BLKIF_OP_INDIRECT) &&
(nseg > MAX_INDIRECT_SEGMENTS))) {
pr_debug(DRV_PFX "Bad number of segments in request (%d)\n",
nseg);
/* Haven't submitted any bio's yet. */
goto fail_response;
}
And the value of MAX_INDIRECT_SEGMENTS is exported to the frontend in
xenstore, so the frontend does:
max_indirect_segments = min(MAX_INDIRECT_SEGMENTS, front_max_segments);
To know how many segments it can safely use in an indirect op.
>
>> + uint64_t id;
>> + blkif_sector_t sector_number;
>> + blkif_vdev_t handle;
>> + uint16_t _pad1;
>> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
>
> And how do we figure out whether we are going to use one indirect_grefs or many?
> That should be described here. (if I understand it right it would be done
> via the maximum-indirect-something' variable)
I've added the following comment:
/*
* The maximum number of indirect segments (and pages) that will
* be used is determined by MAX_INDIRECT_SEGMENTS, this value
* is also exported to the guest (via xenstore max-indirect-segments
* entry), so the frontend knows how many indirect segments the
* backend supports.
*/
>
>
>> +} __attribute__((__packed__));
>> +
>
> Per my calculation the size of this structure is 55 bytes. The 64-bit is 59 bytes.
>
> It is a bit odd, but then 1 byte is for the 'operation' in the 'blkif_x*_request',
> so it comes out to 56 and 60 bytes.
>
> Is that still the right amount ? I thought we wanted to flesh it out to be a nice
> 64 byte aligned so that the future patches which will make the requests be
> more cache-aligned and won't have to play games?
Yes, I've added a uint32_t for 64bits and a uint64_t for 32bits, that
makes it 64bytes aligned in both cases.
>
>> struct blkif_x86_32_request {
>> uint8_t operation; /* BLKIF_OP_??? */
>> union {
>> struct blkif_x86_32_request_rw rw;
>> struct blkif_x86_32_request_discard discard;
>> struct blkif_x86_32_request_other other;
>> + struct blkif_x86_32_request_indirect indirect;
>> } u;
>> } __attribute__((__packed__));
>>
>> @@ -127,12 +149,24 @@ struct blkif_x86_64_request_other {
>> uint64_t id; /* private guest value, echoed in resp */
>> } __attribute__((__packed__));
>>
>> +struct blkif_x86_64_request_indirect {
>> + uint8_t indirect_op;
>> + uint16_t nr_segments;
>> + uint32_t _pad1; /* offsetof(blkif_..,u.indirect.id)==8 */
>
> The comment is a bit off compared to the rest.
>
>> + uint64_t id;
>> + blkif_sector_t sector_number;
>> + blkif_vdev_t handle;
>> + uint16_t _pad2;
>> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
>> +} __attribute__((__packed__));
>> +
>> struct blkif_x86_64_request {
>> uint8_t operation; /* BLKIF_OP_??? */
>> union {
>> struct blkif_x86_64_request_rw rw;
>> struct blkif_x86_64_request_discard discard;
>> struct blkif_x86_64_request_other other;
>> + struct blkif_x86_64_request_indirect indirect;
>> } u;
>> } __attribute__((__packed__));
>>
>> @@ -257,6 +291,11 @@ struct xen_blkif {
>> wait_queue_head_t waiting_to_free;
>> };
>>
>> +struct seg_buf {
>> + unsigned long offset;
>> + unsigned int nsec;
>> +};
>> +
>> /*
>> * Each outstanding request that we've passed to the lower device layers has a
>> * 'pending_req' allocated to it. Each buffer_head that completes decrements
>> @@ -271,9 +310,16 @@ struct pending_req {
>> unsigned short operation;
>> int status;
>> struct list_head free_list;
>> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct page *pages[MAX_INDIRECT_SEGMENTS];
>> + struct persistent_gnt *persistent_gnts[MAX_INDIRECT_SEGMENTS];
>> + grant_handle_t grant_handles[MAX_INDIRECT_SEGMENTS];
>> + grant_ref_t grefs[MAX_INDIRECT_SEGMENTS];
>> + /* Indirect descriptors */
>> + struct persistent_gnt *indirect_persistent_gnts[MAX_INDIRECT_GREFS];
>> + struct page *indirect_pages[MAX_INDIRECT_GREFS];
>> + grant_handle_t indirect_handles[MAX_INDIRECT_GREFS];
>> + struct seg_buf seg[MAX_INDIRECT_SEGMENTS];
>> + struct bio *biolist[MAX_INDIRECT_SEGMENTS];
>
> Oh wow. That is a big structure. So 1536 for the BLKIF_MAX_SEGMENTS_PER_REQUEST
> ones and 24 bytes for the ones that deail with MAX_INDIRECT_GREFS.
>
> This could be made look nicer. For example you could do:
>
> struct indirect {
> struct page;
> grant_handle_t handle;
> struct persistent_gnt *gnt;
> } desc[MAX_INDIRECT_GREFS];
>
> .. and the same treatment to the BLKIF_MAX_SEGMENTS_PER_REQUEST
> one.
>
> Thought perhaps it makes more sense to do that with a later patch as a cleanup.
This was similar to what Jan was suggesting, but I would prefer to leave
that for a latter patch.
>> };
>>
>>
>> @@ -312,7 +358,7 @@ struct xenbus_device *xen_blkbk_xenbus(struct backend_info *be);
>> static inline void blkif_get_x86_32_req(struct blkif_request *dst,
>> struct blkif_x86_32_request *src)
>> {
>> - int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> + int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
>> dst->operation = src->operation;
>> switch (src->operation) {
>> case BLKIF_OP_READ:
>> @@ -335,6 +381,19 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
>> dst->u.discard.sector_number = src->u.discard.sector_number;
>> dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
>> break;
>> + case BLKIF_OP_INDIRECT:
>> + dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
>> + dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
>> + dst->u.indirect.handle = src->u.indirect.handle;
>> + dst->u.indirect.id = src->u.indirect.id;
>> + dst->u.indirect.sector_number = src->u.indirect.sector_number;
>> + barrier();
>> + if (j > dst->u.indirect.nr_segments)
>> + j = dst->u.indirect.nr_segments;
>
> How about just:
> j = min(MAX_INDIRECT_GREFS, dst->u.indirect.nr_segments);
>
> But.. you are using the 'nr_segments' and 'j' (which is 1) which is odd. j ends up
> being set to 1. But you are somehow mixing 'nr_segments' and 'MAX_INDIRECT_GREFS'
> which is confusing. Perhaps you meant:
>
> if (j > min(dst->u.inderect.nr_segments, SEGS_PER_INDIRECT_FRAME) / SEGS_PER_INDIRECT_FRAME)
> ...
>
> After all, the 'j' is suppose to tell you how many indirect pages to use, and that
> should be driven by the total amount of nr_segments.
>
> Thought if nr_segments is absuredly high we should detect that and do something
> about it.
This is indeed not right, I've added a macro to calculate the number of
indirect pages based on the number of segments, so now if looks like:
j = min(MAX_INDIRECT_PAGES,
INDIRECT_PAGES(dst->u.indirect.nr_segments));
>
>> + for (i = 0; i < j; i++)
>> + dst->u.indirect.indirect_grefs[i] =
>> + src->u.indirect.indirect_grefs[i];
>> + break;
>> default:
>> /*
>> * Don't know how to translate this op. Only get the
>> @@ -348,7 +407,7 @@ static inline void blkif_get_x86_32_req(struct blkif_request *dst,
>> static inline void blkif_get_x86_64_req(struct blkif_request *dst,
>> struct blkif_x86_64_request *src)
>> {
>> - int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> + int i, n = BLKIF_MAX_SEGMENTS_PER_REQUEST, j = MAX_INDIRECT_GREFS;
>> dst->operation = src->operation;
>> switch (src->operation) {
>> case BLKIF_OP_READ:
>> @@ -371,6 +430,19 @@ static inline void blkif_get_x86_64_req(struct blkif_request *dst,
>> dst->u.discard.sector_number = src->u.discard.sector_number;
>> dst->u.discard.nr_sectors = src->u.discard.nr_sectors;
>> break;
>> + case BLKIF_OP_INDIRECT:
>> + dst->u.indirect.indirect_op = src->u.indirect.indirect_op;
>> + dst->u.indirect.nr_segments = src->u.indirect.nr_segments;
>> + dst->u.indirect.handle = src->u.indirect.handle;
>> + dst->u.indirect.id = src->u.indirect.id;
>> + dst->u.indirect.sector_number = src->u.indirect.sector_number;
>> + barrier();
>> + if (j > dst->u.indirect.nr_segments)
>> + j = dst->u.indirect.nr_segments;
>
> Same here. The min is a nice macro.
Done.
>> + for (i = 0; i < j; i++)
>> + dst->u.indirect.indirect_grefs[i] =
>> + src->u.indirect.indirect_grefs[i];
>> + break;
>> default:
>> /*
>> * Don't know how to translate this op. Only get the
>> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
>> index bf7344f..172cf89 100644
>> --- a/drivers/block/xen-blkback/xenbus.c
>> +++ b/drivers/block/xen-blkback/xenbus.c
>> @@ -703,6 +703,14 @@ again:
>> goto abort;
>> }
>>
>> + err = xenbus_printf(xbt, dev->nodename, "max-indirect-segments", "%u",
>> + MAX_INDIRECT_SEGMENTS);
>
> Ahem. That should be 'feature-max-indirect-segments'.
Done, replaced all occurences of 'max-indirect-segments' with
'feature-max-indirect-segments'.
>
>> + if (err) {
>> + xenbus_dev_fatal(dev, err, "writing %s/max-indirect-segments",
>> + dev->nodename);
>> + goto abort;
>
> That is not fatal. We can continue on without having that enabled.
OK, removed the abort.
>
>> + }
>> +
>> err = xenbus_printf(xbt, dev->nodename, "sectors", "%llu",
>> (unsigned long long)vbd_sz(&be->blkif->vbd));
>> if (err) {
>> diff --git a/drivers/block/xen-blkfront.c b/drivers/block/xen-blkfront.c
>> index a894f88..ecbc26a 100644
>> --- a/drivers/block/xen-blkfront.c
>> +++ b/drivers/block/xen-blkfront.c
>> @@ -74,12 +74,30 @@ struct grant {
>> struct blk_shadow {
>> struct blkif_request req;
>> struct request *request;
>> - struct grant *grants_used[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct grant **grants_used;
>> + struct grant **indirect_grants;
>> +};
>> +
>> +struct split_bio {
>> + struct bio *bio;
>> + atomic_t pending;
>> + int err;
>> };
>>
>> static DEFINE_MUTEX(blkfront_mutex);
>> static const struct block_device_operations xlvbd_block_fops;
>>
>> +/*
>> + * Maximum number of segments in indirect requests, the actual value used by
>> + * the frontend driver is the minimum of this value and the value provided
>> + * by the backend driver.
>> + */
>> +
>> +static int xen_blkif_max_segments = 32;
>> +module_param_named(max_segments, xen_blkif_max_segments, int, 0);
>> +MODULE_PARM_DESC(max_segments,
>> +"Maximum number of segments in indirect requests");
>
> This means a new entry in Documentation/ABI/sysfs/...
I think I should just not allow this to be exported, since we cannot
change it at run-time, so if a user changes the 0 to something else, and
changes the value... nothing will happen (because this is only used
before the device is connected).
>
> Perhaps the xen-blkfront part of the patch should be just split out to make
> this easier?
>
> Perhaps what we really should have is just the 'max' value of megabytes
> we want to handle on the ring.
>
> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
> and since we have 32 of them = 512MB).
I've just set that to something that brings a performance benefit
without having to map an insane number of persistent grants in blkback.
Yes, the values are correct, but the device request queue (rq) is only
able to provide read requests with 64 segments or write requests with
128 segments. I haven't been able to get larger requests, even when
setting this to 512 or higer.
>
>> +
>> #define BLK_RING_SIZE __CONST_RING_SIZE(blkif, PAGE_SIZE)
>>
>> /*
>> @@ -98,7 +116,7 @@ struct blkfront_info
>> enum blkif_state connected;
>> int ring_ref;
>> struct blkif_front_ring ring;
>> - struct scatterlist sg[BLKIF_MAX_SEGMENTS_PER_REQUEST];
>> + struct scatterlist *sg;
>> unsigned int evtchn, irq;
>> struct request_queue *rq;
>> struct work_struct work;
>> @@ -114,6 +132,8 @@ struct blkfront_info
>> unsigned int discard_granularity;
>> unsigned int discard_alignment;
>> unsigned int feature_persistent:1;
>> + unsigned int max_indirect_segments;
>> + unsigned int sector_size;
>
> sector_size? That looks like it belongs to a different patch?
Yes, this sector_size clearly doesn't belong here.
>> int is_ready;
>> };
>>
>> @@ -142,6 +162,14 @@ static DEFINE_SPINLOCK(minor_lock);
>>
>> #define DEV_NAME "xvd" /* name in /dev */
>>
>> +#define SEGS_PER_INDIRECT_FRAME \
>> + (PAGE_SIZE/sizeof(struct blkif_request_segment_aligned))
>> +#define INDIRECT_GREFS(_segs) \
>> + ((_segs + SEGS_PER_INDIRECT_FRAME - 1)/SEGS_PER_INDIRECT_FRAME)
>> +#define MIN(_a, _b) ((_a) < (_b) ? (_a) : (_b))
>
> No need. Just use 'min'
>
>> +
>> +static int blkfront_setup_indirect(struct blkfront_info *info);
>> +
>> static int get_id_from_freelist(struct blkfront_info *info)
>> {
>> unsigned long free = info->shadow_free;
>> @@ -358,7 +386,8 @@ static int blkif_queue_request(struct request *req)
>> struct blkif_request *ring_req;
>> unsigned long id;
>> unsigned int fsect, lsect;
>> - int i, ref;
>> + int i, ref, n;
>> + struct blkif_request_segment_aligned *segments = NULL;
>>
>> /*
>> * Used to store if we are able to queue the request by just using
>> @@ -369,21 +398,27 @@ static int blkif_queue_request(struct request *req)
>> grant_ref_t gref_head;
>> struct grant *gnt_list_entry = NULL;
>> struct scatterlist *sg;
>> + int nseg, max_grefs;
>>
>> if (unlikely(info->connected != BLKIF_STATE_CONNECTED))
>> return 1;
>>
>> - /* Check if we have enought grants to allocate a requests */
>> - if (info->persistent_gnts_c < BLKIF_MAX_SEGMENTS_PER_REQUEST) {
>> + max_grefs = info->max_indirect_segments ?
>> + info->max_indirect_segments +
>> + INDIRECT_GREFS(info->max_indirect_segments) :
>> + BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> +
>> + /* Check if we have enough grants to allocate a requests */
>> + if (info->persistent_gnts_c < max_grefs) {
>> new_persistent_gnts = 1;
>> if (gnttab_alloc_grant_references(
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST - info->persistent_gnts_c,
>> + max_grefs - info->persistent_gnts_c,
>> &gref_head) < 0) {
>> gnttab_request_free_callback(
>> &info->callback,
>> blkif_restart_queue_callback,
>> info,
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> + max_grefs);
>> return 1;
>> }
>> } else
>> @@ -394,42 +429,74 @@ static int blkif_queue_request(struct request *req)
>> id = get_id_from_freelist(info);
>> info->shadow[id].request = req;
>>
>> - ring_req->u.rw.id = id;
>> - ring_req->u.rw.sector_number = (blkif_sector_t)blk_rq_pos(req);
>> - ring_req->u.rw.handle = info->handle;
>> -
>> - ring_req->operation = rq_data_dir(req) ?
>> - BLKIF_OP_WRITE : BLKIF_OP_READ;
>> -
>> - if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
>> - /*
>> - * Ideally we can do an unordered flush-to-disk. In case the
>> - * backend onlysupports barriers, use that. A barrier request
>> - * a superset of FUA, so we can implement it the same
>> - * way. (It's also a FLUSH+FUA, since it is
>> - * guaranteed ordered WRT previous writes.)
>> - */
>> - ring_req->operation = info->flush_op;
>> - }
>> -
>> if (unlikely(req->cmd_flags & (REQ_DISCARD | REQ_SECURE))) {
>> /* id, sector_number and handle are set above. */
>
> And you can also remove that comment or change it and mention that we don't
> care about the 'handle' value.
>> ring_req->operation = BLKIF_OP_DISCARD;
>> ring_req->u.discard.nr_sectors = blk_rq_sectors(req);
>> + ring_req->u.discard.id = id;
>> + ring_req->u.discard.sector_number =
>> + (blkif_sector_t)blk_rq_pos(req);
>
> One line pls.
Both comments fixed.
>
>
>> if ((req->cmd_flags & REQ_SECURE) && info->feature_secdiscard)
>> ring_req->u.discard.flag = BLKIF_DISCARD_SECURE;
>> else
>> ring_req->u.discard.flag = 0;
>> } else {
>> - ring_req->u.rw.nr_segments = blk_rq_map_sg(req->q, req,
>> - info->sg);
>> - BUG_ON(ring_req->u.rw.nr_segments >
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> -
>> - for_each_sg(info->sg, sg, ring_req->u.rw.nr_segments, i) {
>> + BUG_ON(info->max_indirect_segments == 0 &&
>> + req->nr_phys_segments > BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> + BUG_ON(info->max_indirect_segments &&
>> + req->nr_phys_segments > info->max_indirect_segments);
>> + nseg = blk_rq_map_sg(req->q, req, info->sg);
>> + ring_req->u.rw.id = id;
>> + if (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST) {
>> + /*
>> + * The indirect operation can only be a BLKIF_OP_READ or
>> + * BLKIF_OP_WRITE
>> + */
>> + BUG_ON(req->cmd_flags & (REQ_FLUSH | REQ_FUA));
>> + ring_req->operation = BLKIF_OP_INDIRECT;
>> + ring_req->u.indirect.indirect_op = rq_data_dir(req) ?
>> + BLKIF_OP_WRITE : BLKIF_OP_READ;
>> + ring_req->u.indirect.sector_number =
>> + (blkif_sector_t)blk_rq_pos(req);
>> + ring_req->u.indirect.handle = info->handle;
>> + ring_req->u.indirect.nr_segments = nseg;
>> + } else {
>> + ring_req->u.rw.sector_number =
>> + (blkif_sector_t)blk_rq_pos(req);
>> + ring_req->u.rw.handle = info->handle;
>> + ring_req->operation = rq_data_dir(req) ?
>> + BLKIF_OP_WRITE : BLKIF_OP_READ;
>> + if (req->cmd_flags & (REQ_FLUSH | REQ_FUA)) {
>> + /*
>> + * Ideally we can do an unordered flush-to-disk. In case the
>> + * backend onlysupports barriers, use that. A barrier request
>> + * a superset of FUA, so we can implement it the same
>> + * way. (It's also a FLUSH+FUA, since it is
>> + * guaranteed ordered WRT previous writes.)
>> + */
>
>
> Something is off with that comment.
Yes, because I just moved the comment around, I didn't want to change
it, so I indented it differently to fit within 80 cols, now that I know
we can use longer lines I will align it normally.
>> + ring_req->operation = info->flush_op;
>> + }
>> + ring_req->u.rw.nr_segments = nseg;
>> + }
>> + for_each_sg(info->sg, sg, nseg, i) {
>> fsect = sg->offset >> 9;
>> lsect = fsect + (sg->length >> 9) - 1;
>>
>> + if ((ring_req->operation == BLKIF_OP_INDIRECT) &&
>> + (i % SEGS_PER_INDIRECT_FRAME == 0)) {
>> + if (segments)
>> + kunmap_atomic(segments);
>> +
>> + n = i / SEGS_PER_INDIRECT_FRAME;
>> + gnt_list_entry = get_grant(&gref_head, info);
>> + info->shadow[id].indirect_grants[n] =
>> + gnt_list_entry;
>
> One line pls
>> + segments = kmap_atomic(
>> + pfn_to_page(gnt_list_entry->pfn));
>
> Ditto
>> + ring_req->u.indirect.indirect_grefs[n] =
>> + gnt_list_entry->gref;
>
> Ditto.
I've fixed this, and some that were a couple of lines up.
>> + }
>> +
>> gnt_list_entry = get_grant(&gref_head, info);
>> ref = gnt_list_entry->gref;
>>
>> @@ -461,13 +528,23 @@ static int blkif_queue_request(struct request *req)
>> kunmap_atomic(bvec_data);
>> kunmap_atomic(shared_data);
>> }
>> -
>> - ring_req->u.rw.seg[i] =
>> - (struct blkif_request_segment) {
>> - .gref = ref,
>> - .first_sect = fsect,
>> - .last_sect = lsect };
>> + if (ring_req->operation != BLKIF_OP_INDIRECT) {
>> + ring_req->u.rw.seg[i] =
>> + (struct blkif_request_segment) {
>> + .gref = ref,
>> + .first_sect = fsect,
>> + .last_sect = lsect };
>> + } else {
>> + n = i % SEGS_PER_INDIRECT_FRAME;
>> + segments[n] =
>> + (struct blkif_request_segment_aligned) {
>> + .gref = ref,
>> + .first_sect = fsect,
>> + .last_sect = lsect };
>> + }
>> }
>> + if (segments)
>> + kunmap_atomic(segments);
>> }
>>
>> info->ring.req_prod_pvt++;
>> @@ -542,7 +619,8 @@ wait:
>> flush_requests(info);
>> }
>>
>> -static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
>> +static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size,
>> + unsigned int segments)
>> {
>> struct request_queue *rq;
>> struct blkfront_info *info = gd->private_data;
>> @@ -571,7 +649,7 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
>> blk_queue_max_segment_size(rq, PAGE_SIZE);
>>
>> /* Ensure a merged request will fit in a single I/O ring slot. */
>> - blk_queue_max_segments(rq, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> + blk_queue_max_segments(rq, segments);
>>
>> /* Make sure buffer addresses are sector-aligned. */
>> blk_queue_dma_alignment(rq, 511);
>> @@ -588,13 +666,14 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
>> static void xlvbd_flush(struct blkfront_info *info)
>> {
>> blk_queue_flush(info->rq, info->feature_flush);
>> - printk(KERN_INFO "blkfront: %s: %s: %s %s\n",
>> + printk(KERN_INFO "blkfront: %s: %s: %s %s %s\n",
>> info->gd->disk_name,
>> info->flush_op == BLKIF_OP_WRITE_BARRIER ?
>> "barrier" : (info->flush_op == BLKIF_OP_FLUSH_DISKCACHE ?
>> "flush diskcache" : "barrier or flush"),
>> info->feature_flush ? "enabled" : "disabled",
>> - info->feature_persistent ? "using persistent grants" : "");
>> + info->feature_persistent ? "using persistent grants" : "",
>> + info->max_indirect_segments ? "using indirect descriptors" : "");
>
> This is a bit of mess now:
>
>
> [ 0.968241] blkfront: xvda: barrier or flush: disabled using persistent grants using indirect descriptors
>
> Should it just be:
>
> 'persistent_grants: enabled; indirect descriptors: enabled'
>
> ?
Agreed. If you don't mind I will change the wording for both persistent
grants and indirect descriptors in this same patch.
>> }
>>
>> static int xen_translate_vdev(int vdevice, int *minor, unsigned int *offset)
>> @@ -734,7 +813,9 @@ static int xlvbd_alloc_gendisk(blkif_sector_t capacity,
>> gd->driverfs_dev = &(info->xbdev->dev);
>> set_capacity(gd, capacity);
>>
>> - if (xlvbd_init_blk_queue(gd, sector_size)) {
>> + if (xlvbd_init_blk_queue(gd, sector_size,
>> + info->max_indirect_segments ? :
>> + BLKIF_MAX_SEGMENTS_PER_REQUEST)) {
>> del_gendisk(gd);
>> goto release;
>> }
>> @@ -818,6 +899,7 @@ static void blkif_free(struct blkfront_info *info, int suspend)
>> {
>> struct grant *persistent_gnt;
>> struct grant *n;
>> + int i, j, segs;
>>
>> /* Prevent new requests being issued until we fix things up. */
>> spin_lock_irq(&info->io_lock);
>> @@ -843,6 +925,47 @@ static void blkif_free(struct blkfront_info *info, int suspend)
>> }
>> BUG_ON(info->persistent_gnts_c != 0);
>>
>> + kfree(info->sg);
>> + info->sg = NULL;
>> + for (i = 0; i < BLK_RING_SIZE; i++) {
>> + /*
>> + * Clear persistent grants present in requests already
>> + * on the shared ring
>> + */
>> + if (!info->shadow[i].request)
>> + goto free_shadow;
>> +
>> + segs = info->shadow[i].req.operation == BLKIF_OP_INDIRECT ?
>> + info->shadow[i].req.u.indirect.nr_segments :
>> + info->shadow[i].req.u.rw.nr_segments;
>> + for (j = 0; j < segs; j++) {
>> + persistent_gnt = info->shadow[i].grants_used[j];
>> + gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
>> + __free_page(pfn_to_page(persistent_gnt->pfn));
>> + kfree(persistent_gnt);
>> + }
>> +
>> + if (info->shadow[i].req.operation != BLKIF_OP_INDIRECT)
>> + /*
>> + * If this is not an indirect operation don't try to
>> + * free indirect segments
>> + */
>> + goto free_shadow;
>> +
>> + for (j = 0; j < INDIRECT_GREFS(segs); j++) {
>> + persistent_gnt = info->shadow[i].indirect_grants[j];
>> + gnttab_end_foreign_access(persistent_gnt->gref, 0, 0UL);
>> + __free_page(pfn_to_page(persistent_gnt->pfn));
>> + kfree(persistent_gnt);
>> + }
>> +
>> +free_shadow:
>> + kfree(info->shadow[i].grants_used);
>> + info->shadow[i].grants_used = NULL;
>> + kfree(info->shadow[i].indirect_grants);
>> + info->shadow[i].indirect_grants = NULL;
>> + }
>> +
>> /* No more gnttab callback work. */
>> gnttab_cancel_free_callback(&info->callback);
>> spin_unlock_irq(&info->io_lock);
>> @@ -873,6 +996,10 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
>> char *bvec_data;
>> void *shared_data;
>> unsigned int offset = 0;
>> + int nseg;
>> +
>> + nseg = s->req.operation == BLKIF_OP_INDIRECT ?
>> + s->req.u.indirect.nr_segments : s->req.u.rw.nr_segments;
>>
>> if (bret->operation == BLKIF_OP_READ) {
>> /*
>> @@ -885,7 +1012,7 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
>> BUG_ON((bvec->bv_offset + bvec->bv_len) > PAGE_SIZE);
>> if (bvec->bv_offset < offset)
>> i++;
>> - BUG_ON(i >= s->req.u.rw.nr_segments);
>> + BUG_ON(i >= nseg);
>> shared_data = kmap_atomic(
>> pfn_to_page(s->grants_used[i]->pfn));
>> bvec_data = bvec_kmap_irq(bvec, &flags);
>> @@ -897,10 +1024,17 @@ static void blkif_completion(struct blk_shadow *s, struct blkfront_info *info,
>> }
>> }
>> /* Add the persistent grant into the list of free grants */
>> - for (i = 0; i < s->req.u.rw.nr_segments; i++) {
>> + for (i = 0; i < nseg; i++) {
>> list_add(&s->grants_used[i]->node, &info->persistent_gnts);
>> info->persistent_gnts_c++;
>> }
>> + if (s->req.operation == BLKIF_OP_INDIRECT) {
>> + for (i = 0; i < INDIRECT_GREFS(nseg); i++) {
>> + list_add(&s->indirect_grants[i]->node,
>> + &info->persistent_gnts);
>
> One line pls.
>
>> + info->persistent_gnts_c++;
>> + }
>> + }
>> }
>>
>> static irqreturn_t blkif_interrupt(int irq, void *dev_id)
>> @@ -1034,14 +1168,6 @@ static int setup_blkring(struct xenbus_device *dev,
>> SHARED_RING_INIT(sring);
>> FRONT_RING_INIT(&info->ring, sring, PAGE_SIZE);
>>
>> - sg_init_table(info->sg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> -
>> - /* Allocate memory for grants */
>> - err = fill_grant_buffer(info, BLK_RING_SIZE *
>> - BLKIF_MAX_SEGMENTS_PER_REQUEST);
>> - if (err)
>> - goto fail;
>> -
>> err = xenbus_grant_ring(dev, virt_to_mfn(info->ring.sring));
>> if (err < 0) {
>> free_page((unsigned long)sring);
>> @@ -1223,13 +1349,84 @@ static int blkfront_probe(struct xenbus_device *dev,
>> return 0;
>> }
>>
>> +/*
>> + * This is a clone of md_trim_bio, used to split a bio into smaller ones
>> + */
>> +static void trim_bio(struct bio *bio, int offset, int size)
>> +{
>> + /* 'bio' is a cloned bio which we need to trim to match
>> + * the given offset and size.
>> + * This requires adjusting bi_sector, bi_size, and bi_io_vec
>> + */
>> + int i;
>> + struct bio_vec *bvec;
>> + int sofar = 0;
>> +
>> + size <<= 9;
>> + if (offset == 0 && size == bio->bi_size)
>> + return;
>> +
>> + bio->bi_sector += offset;
>> + bio->bi_size = size;
>> + offset <<= 9;
>> + clear_bit(BIO_SEG_VALID, &bio->bi_flags);
>> +
>> + while (bio->bi_idx < bio->bi_vcnt &&
>> + bio->bi_io_vec[bio->bi_idx].bv_len <= offset) {
>> + /* remove this whole bio_vec */
>> + offset -= bio->bi_io_vec[bio->bi_idx].bv_len;
>> + bio->bi_idx++;
>> + }
>> + if (bio->bi_idx < bio->bi_vcnt) {
>> + bio->bi_io_vec[bio->bi_idx].bv_offset += offset;
>> + bio->bi_io_vec[bio->bi_idx].bv_len -= offset;
>> + }
>> + /* avoid any complications with bi_idx being non-zero*/
>> + if (bio->bi_idx) {
>> + memmove(bio->bi_io_vec, bio->bi_io_vec+bio->bi_idx,
>> + (bio->bi_vcnt - bio->bi_idx) * sizeof(struct bio_vec));
>> + bio->bi_vcnt -= bio->bi_idx;
>> + bio->bi_idx = 0;
>> + }
>> + /* Make sure vcnt and last bv are not too big */
>> + bio_for_each_segment(bvec, bio, i) {
>> + if (sofar + bvec->bv_len > size)
>> + bvec->bv_len = size - sofar;
>> + if (bvec->bv_len == 0) {
>> + bio->bi_vcnt = i;
>> + break;
>> + }
>> + sofar += bvec->bv_len;
>> + }
>> +}
>> +
>> +static void split_bio_end(struct bio *bio, int error)
>> +{
>> + struct split_bio *split_bio = bio->bi_private;
>> +
>> + if (error)
>> + split_bio->err = error;
>> +
>> + if (atomic_dec_and_test(&split_bio->pending)) {
>> + split_bio->bio->bi_phys_segments = 0;
>> + bio_endio(split_bio->bio, split_bio->err);
>> + kfree(split_bio);
>> + }
>> + bio_put(bio);
>> +}
>>
>> static int blkif_recover(struct blkfront_info *info)
>> {
>> int i;
>> - struct blkif_request *req;
>> + struct request *req, *n;
>> struct blk_shadow *copy;
>> - int j;
>> + int rc;
>> + struct bio *bio, *cloned_bio;
>> + struct bio_list bio_list, merge_bio;
>> + unsigned int segs;
>> + int pending, offset, size;
>> + struct split_bio *split_bio;
>> + struct list_head requests;
>>
>> /* Stage 1: Make a safe copy of the shadow state. */
>> copy = kmemdup(info->shadow, sizeof(info->shadow),
>> @@ -1244,36 +1441,64 @@ static int blkif_recover(struct blkfront_info *info)
>> info->shadow_free = info->ring.req_prod_pvt;
>> info->shadow[BLK_RING_SIZE-1].req.u.rw.id = 0x0fffffff;
>>
>> - /* Stage 3: Find pending requests and requeue them. */
>> + rc = blkfront_setup_indirect(info);
>> + if (rc) {
>> + kfree(copy);
>> + return rc;
>> + }
>> +
>> + segs = info->max_indirect_segments ? : BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> + blk_queue_max_segments(info->rq, segs);
>> + bio_list_init(&bio_list);
>> + INIT_LIST_HEAD(&requests);
>> for (i = 0; i < BLK_RING_SIZE; i++) {
>> /* Not in use? */
>> if (!copy[i].request)
>> continue;
>>
>> - /* Grab a request slot and copy shadow state into it. */
>> - req = RING_GET_REQUEST(&info->ring, info->ring.req_prod_pvt);
>> - *req = copy[i].req;
>> -
>> - /* We get a new request id, and must reset the shadow state. */
>> - req->u.rw.id = get_id_from_freelist(info);
>> - memcpy(&info->shadow[req->u.rw.id], ©[i], sizeof(copy[i]));
>> -
>> - if (req->operation != BLKIF_OP_DISCARD) {
>> - /* Rewrite any grant references invalidated by susp/resume. */
>> - for (j = 0; j < req->u.rw.nr_segments; j++)
>> - gnttab_grant_foreign_access_ref(
>> - req->u.rw.seg[j].gref,
>> - info->xbdev->otherend_id,
>> - pfn_to_mfn(copy[i].grants_used[j]->pfn),
>> - 0);
>> + /*
>> + * Get the bios in the request so we can re-queue them.
>> + */
>> + if (copy[i].request->cmd_flags &
>> + (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
>> + /*
>> + * Flush operations don't contain bios, so
>> + * we need to requeue the whole request
>> + */
>> + list_add(©[i].request->queuelist, &requests);
>> + continue;
>> }
>> - info->shadow[req->u.rw.id].req = *req;
>> -
>> - info->ring.req_prod_pvt++;
>> + merge_bio.head = copy[i].request->bio;
>> + merge_bio.tail = copy[i].request->biotail;
>> + bio_list_merge(&bio_list, &merge_bio);
>> + copy[i].request->bio = NULL;
>> + blk_put_request(copy[i].request);
>> }
>>
>> kfree(copy);
>>
>> + /*
>> + * Empty the queue, this is important because we might have
>> + * requests in the queue with more segments than what we
>> + * can handle now.
>> + */
>> + spin_lock_irq(&info->io_lock);
>> + while ((req = blk_fetch_request(info->rq)) != NULL) {
>> + if (req->cmd_flags &
>> + (REQ_FLUSH | REQ_FUA | REQ_DISCARD | REQ_SECURE)) {
>> + list_add(&req->queuelist, &requests);
>> + continue;
>> + }
>> + merge_bio.head = req->bio;
>> + merge_bio.tail = req->biotail;
>> + bio_list_merge(&bio_list, &merge_bio);
>> + req->bio = NULL;
>> + if (req->cmd_flags & (REQ_FLUSH | REQ_FUA))
>> + pr_alert("diskcache flush request found!\n");
>> + __blk_put_request(info->rq, req);
>> + }
>> + spin_unlock_irq(&info->io_lock);
>> +
>> xenbus_switch_state(info->xbdev, XenbusStateConnected);
>>
>> spin_lock_irq(&info->io_lock);
>> @@ -1281,14 +1506,50 @@ static int blkif_recover(struct blkfront_info *info)
>> /* Now safe for us to use the shared ring */
>> info->connected = BLKIF_STATE_CONNECTED;
>>
>> - /* Send off requeued requests */
>> - flush_requests(info);
>> -
>> /* Kick any other new requests queued since we resumed */
>> kick_pending_request_queues(info);
>>
>> + list_for_each_entry_safe(req, n, &requests, queuelist) {
>> + /* Requeue pending requests (flush or discard) */
>> + list_del_init(&req->queuelist);
>> + BUG_ON(req->nr_phys_segments > segs);
>> + blk_requeue_request(info->rq, req);
>> + }
>> spin_unlock_irq(&info->io_lock);
>>
>> + while ((bio = bio_list_pop(&bio_list)) != NULL) {
>> + /* Traverse the list of pending bios and re-queue them */
>> + if (bio_segments(bio) > segs) {
>> + /*
>> + * This bio has more segments than what we can
>> + * handle, we have to split it.
>> + */
>> + pending = (bio_segments(bio) + segs - 1) / segs;
>> + split_bio = kzalloc(sizeof(*split_bio), GFP_NOIO);
>> + BUG_ON(split_bio == NULL);
>> + atomic_set(&split_bio->pending, pending);
>> + split_bio->bio = bio;
>> + for (i = 0; i < pending; i++) {
>> + offset = (i * segs * PAGE_SIZE) >> 9;
>> + size = MIN((segs * PAGE_SIZE) >> 9,
>> + (bio->bi_size >> 9) - offset);
>> + cloned_bio = bio_clone(bio, GFP_NOIO);
>> + BUG_ON(cloned_bio == NULL);
>> + trim_bio(cloned_bio, offset, size);
>> + cloned_bio->bi_private = split_bio;
>> + cloned_bio->bi_end_io = split_bio_end;
>> + submit_bio(cloned_bio->bi_rw, cloned_bio);
>> + }
>> + /*
>> + * Now we have to wait for all those smaller bios to
>> + * end, so we can also end the "parent" bio.
>> + */
>> + continue;
>> + }
>> + /* We don't need to split this bio */
>> + submit_bio(bio->bi_rw, bio);
>> + }
>> +
>> return 0;
>> }
>>
>> @@ -1308,8 +1569,12 @@ static int blkfront_resume(struct xenbus_device *dev)
>> blkif_free(info, info->connected == BLKIF_STATE_CONNECTED);
>>
>> err = talk_to_blkback(dev, info);
>> - if (info->connected == BLKIF_STATE_SUSPENDED && !err)
>> - err = blkif_recover(info);
>> +
>> + /*
>> + * We have to wait for the backend to switch to
>> + * connected state, since we want to read which
>> + * features it supports.
>> + */
>>
>> return err;
>> }
>> @@ -1387,6 +1652,62 @@ static void blkfront_setup_discard(struct blkfront_info *info)
>> kfree(type);
>> }
>>
>> +static int blkfront_setup_indirect(struct blkfront_info *info)
>> +{
>> + unsigned int indirect_segments, segs;
>> + int err, i;
>> +
>> + err = xenbus_gather(XBT_NIL, info->xbdev->otherend,
>> + "max-indirect-segments", "%u", &indirect_segments,
>
> That I believe has to be 'feature-max-indirect-segments'
Yes, I've changed it in blkfront and blkback.
>
>> + NULL);
>> + if (err) {
>> + info->max_indirect_segments = 0;
>> + segs = BLKIF_MAX_SEGMENTS_PER_REQUEST;
>> + } else {
>> + info->max_indirect_segments = MIN(indirect_segments,
>> + xen_blkif_max_segments);
>> + segs = info->max_indirect_segments;
>> + }
>> + info->sg = kzalloc(sizeof(info->sg[0]) * segs, GFP_KERNEL);
>> + if (info->sg == NULL)
>> + goto out_of_memory;
>> + sg_init_table(info->sg, segs);
>> +
>> + err = fill_grant_buffer(info,
>> + (segs + INDIRECT_GREFS(segs)) * BLK_RING_SIZE);
>> + if (err)
>> + goto out_of_memory;
>> +
>> + for (i = 0; i < BLK_RING_SIZE; i++) {
>> + info->shadow[i].grants_used = kzalloc(
>> + sizeof(info->shadow[i].grants_used[0]) * segs,
>> + GFP_NOIO);
>> + if (info->max_indirect_segments)
>> + info->shadow[i].indirect_grants = kzalloc(
>> + sizeof(info->shadow[i].indirect_grants[0]) *
>> + INDIRECT_GREFS(segs),
>> + GFP_NOIO);
>> + if ((info->shadow[i].grants_used == NULL) ||
>> + (info->max_indirect_segments &&
>> + (info->shadow[i].indirect_grants == NULL)))
>> + goto out_of_memory;
>> + }
>> +
>> +
>> + return 0;
>> +
>> +out_of_memory:
>> + kfree(info->sg);
>> + info->sg = NULL;
>> + for (i = 0; i < BLK_RING_SIZE; i++) {
>> + kfree(info->shadow[i].grants_used);
>> + info->shadow[i].grants_used = NULL;
>> + kfree(info->shadow[i].indirect_grants);
>> + info->shadow[i].indirect_grants = NULL;
>> + }
>> + return -ENOMEM;
>> +}
>> +
>> /*
>> * Invoked when the backend is finally 'ready' (and has told produced
>> * the details about the physical device - #sectors, size, etc).
>> @@ -1414,8 +1735,9 @@ static void blkfront_connect(struct blkfront_info *info)
>> set_capacity(info->gd, sectors);
>> revalidate_disk(info->gd);
>>
>> - /* fall through */
>> + return;
>
> How come?
We cannot fall thought anymore, because now we call blkif_recover in
order to recover after performing the suspension, in the past this was
just a return so we could fall thought.
We need to perform the recover at this point because we need to know if
the backend supports indirect descriptors, and how many. In the past we
used to perform the recover before the backend announced it's features,
but now we need to know if the backend supports indirect segments or not.
>
>> case BLKIF_STATE_SUSPENDED:
>> + blkif_recover(info);
>> return;
>>
>> default:
>> @@ -1436,6 +1758,7 @@ static void blkfront_connect(struct blkfront_info *info)
>> info->xbdev->otherend);
>> return;
>> }
>> + info->sector_size = sector_size;
>>
>> info->feature_flush = 0;
>> info->flush_op = 0;
>> @@ -1483,6 +1806,13 @@ static void blkfront_connect(struct blkfront_info *info)
>> else
>> info->feature_persistent = persistent;
>>
>> + err = blkfront_setup_indirect(info);
>> + if (err) {
>> + xenbus_dev_fatal(info->xbdev, err, "setup_indirect at %s",
>> + info->xbdev->otherend);
>> + return;
>> + }
>> +
>> err = xlvbd_alloc_gendisk(sectors, info, binfo, sector_size);
>> if (err) {
>> xenbus_dev_fatal(info->xbdev, err, "xlvbd_add at %s",
>> diff --git a/include/xen/interface/io/blkif.h b/include/xen/interface/io/blkif.h
>> index ffd4652..893bee2 100644
>> --- a/include/xen/interface/io/blkif.h
>> +++ b/include/xen/interface/io/blkif.h
>> @@ -102,6 +102,8 @@ typedef uint64_t blkif_sector_t;
>> */
>> #define BLKIF_OP_DISCARD 5
>>
>> +#define BLKIF_OP_INDIRECT 6
>> +
>
> Ahem! There needs to be more about this. For example which 'feature-X' sets it,
> what kind of operations are permitted, etc.
>
>> /*
>> * Maximum scatter/gather segments per request.
>> * This is carefully chosen so that sizeof(struct blkif_ring) <= PAGE_SIZE.
>> @@ -109,6 +111,16 @@ typedef uint64_t blkif_sector_t;
>> */
>> #define BLKIF_MAX_SEGMENTS_PER_REQUEST 11
>>
>> +#define BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST 8
>> +
>> +struct blkif_request_segment_aligned {
>> + grant_ref_t gref; /* reference to I/O buffer frame */
>> + /* @first_sect: first sector in frame to transfer (inclusive). */
>> + /* @last_sect: last sector in frame to transfer (inclusive). */
>> + uint8_t first_sect, last_sect;
>> + uint16_t _pad; /* padding to make it 8 bytes, so it's cache-aligned */
>> +} __attribute__((__packed__));
>> +
>> struct blkif_request_rw {
>> uint8_t nr_segments; /* number of segments */
>> blkif_vdev_t handle; /* only for read/write requests */
>> @@ -147,12 +159,26 @@ struct blkif_request_other {
>> uint64_t id; /* private guest value, echoed in resp */
>> } __attribute__((__packed__));
>>
>> +struct blkif_request_indirect {
>> + uint8_t indirect_op;
>> + uint16_t nr_segments;
>> +#ifdef CONFIG_X86_64
>> + uint32_t _pad1; /* offsetof(blkif_...,u.indirect.id) == 8 */
>> +#endif
>> + uint64_t id;
>> + blkif_sector_t sector_number;
>> + blkif_vdev_t handle;
>> + uint16_t _pad2;
>> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
>> +} __attribute__((__packed__));
>> +
>> struct blkif_request {
>> uint8_t operation; /* BLKIF_OP_??? */
>> union {
>> struct blkif_request_rw rw;
>> struct blkif_request_discard discard;
>> struct blkif_request_other other;
>> + struct blkif_request_indirect indirect;
>> } u;
>> } __attribute__((__packed__));
>>
>> --
>> 1.7.7.5 (Apple Git-26)
>>
> /*
> * No need to set unmap_seg bit, since
> * we can not unmap this grant because
> * the handle is invalid.
> */
>
> >
> > But then that begs the question - why do we even need the bitmap_set code path anymore?
>
> To know which grants are mapped persistenly, so we don't unmap them in
> xen_blkbk_unmap.
Aha! I missed that part.
>
> >> }
> >> - if (persistent_gnts[i]) {
> >> - if (persistent_gnts[i]->handle ==
> >> - BLKBACK_INVALID_HANDLE) {
> >> + if (persistent_gnts[i])
> >> + goto next;
> >> + if (use_persistent_gnts &&
> >> + blkif->persistent_gnt_c <
> >> + max_mapped_grant_pages(blkif->blk_protocol)) {
> >> + /*
> >> + * We are using persistent grants, the grant is
> >> + * not mapped but we have room for it
> >> + */
> >> + persistent_gnt = kmalloc(sizeof(struct persistent_gnt),
> >> + GFP_KERNEL);
> >> + if (!persistent_gnt) {
> >> /*
> >> - * If this is a new persistent grant
> >> - * save the handler
> >> + * If we don't have enough memory to
> >> + * allocate the persistent_gnt struct
> >> + * map this grant non-persistenly
> >> */
> >> - persistent_gnts[i]->handle = map[j++].handle;
> >> + j++;
> >> + goto next;
> >
> > So you are doing this by assuming that get_persistent_gnt in the earlier loop
> > failed, which means you have in effect done this:
> > map[segs_to_map++]
> >
> > Doing the next label will set:
> > seg[i].offset = (req->u.rw.seg[i].first_sect << 9);
> >
> > OK, that sounds right. Is this then:
> >
> > bitmap_set(pending_req->unmap_seg, i, 1);
> >
> > even needed? The "pending_handle(pending_req, i) = map[j].handle;" had already been
> > done in the /* This is a newly mapped grant */ if case, so we are set there.
>
> We need to mark this grant as non-persistent, so we unmap it on
> xen_blkbk_unmap.
And then this makes sense.
>
> >
> > Perhaps you could update the comment from saying 'map this grant' (which
> > implies doing it NOW as opposed to have done it already), and say:
> >
> > /*
> > .. continue using the grant non-persistently. Note that
> > we mapped it in the earlier loop and the earlier if conditional
> > sets pending_handle(pending_req, i) = map[j].handle.
> > */
> >
> >
> >
> >> }
> >> - pending_handle(pending_req, i) =
> >> - persistent_gnts[i]->handle;
> >> -
> >> - if (ret)
> >> - continue;
> >> - } else {
> >> - pending_handle(pending_req, i) = map[j++].handle;
> >> - bitmap_set(pending_req->unmap_seg, i, 1);
> >> -
> >> - if (ret)
> >> - continue;
> >> + persistent_gnt->gnt = map[j].ref;
> >> + persistent_gnt->handle = map[j].handle;
> >> + persistent_gnt->page = pages[i];
> >
> > Oh boy, that is a confusing. i and j. Keep loosing track which one is which.
> > It lookis right.
> >
> >> + if (add_persistent_gnt(&blkif->persistent_gnts,
> >> + persistent_gnt)) {
> >> + kfree(persistent_gnt);
> >
> > I would also say 'persisten_gnt = NULL' for extra measure of safety
>
> Done.
>
> >
> >
> >> + j++;
> >
> > Perhaps the 'j' variable can be called 'map_idx' ? By this point I am pretty
> > sure I know what the 'i' and 'j' variables are used for, but if somebody new
> > is trying to grok this code they might spend some 5 minutes trying to figure
> > this out.
>
> Yes, I agree that i and j are not the best names, I propose to call j
> new_map_idx, and i seg_idx.
Sounds good.
On Mon, Apr 15, 2013 at 11:14:29AM +0200, Roger Pau Monn? wrote:
> On 09/04/13 16:47, Konrad Rzeszutek Wilk wrote:
> > On Wed, Mar 27, 2013 at 12:10:38PM +0100, Roger Pau Monne wrote:
> >> Using balloon pages for all granted pages allows us to simplify the
> >> logic in blkback, especially in the xen_blkbk_map function, since now
> >> we can decide if we want to map a grant persistently or not after we
> >> have actually mapped it. This could not be done before because
> >> persistent grants used ballooned pages, whereas non-persistent grants
> >> used pages from the kernel.
> >>
> >> This patch also introduces several changes, the first one is that the
> >> list of free pages is no longer global, now each blkback instance has
> >> it's own list of free pages that can be used to map grants. Also, a
> >> run time parameter (max_buffer_pages) has been added in order to tune
> >> the maximum number of free pages each blkback instance will keep in
> >> it's buffer.
> >>
> >> Signed-off-by: Roger Pau Monn? <[email protected]>
> >> Cc: [email protected]
> >> Cc: Konrad Rzeszutek Wilk <[email protected]>
> >
> > Sorry for the late review. Some comments.
> >> ---
> >> Changes since RFC:
> >> * Fix typos in commit message.
> >> * Minor fixes in code.
> >> ---
> >> Documentation/ABI/stable/sysfs-bus-xen-backend | 8 +
> >> drivers/block/xen-blkback/blkback.c | 265 +++++++++++++-----------
> >> drivers/block/xen-blkback/common.h | 5 +
> >> drivers/block/xen-blkback/xenbus.c | 3 +
> >> 4 files changed, 165 insertions(+), 116 deletions(-)
> >>
> >> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> index 3d5951c..e04afe0 100644
> >> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> @@ -73,3 +73,11 @@ KernelVersion: 3.0
> >> Contact: Konrad Rzeszutek Wilk <[email protected]>
> >> Description:
> >> Number of sectors written by the frontend.
> >> +
> >> +What: /sys/module/xen_blkback/parameters/max_buffer_pages
> >> +Date: March 2013
> >> +KernelVersion: 3.10
> >> +Contact: Roger Pau Monn? <[email protected]>
> >> +Description:
> >> + Maximum number of free pages to keep in each block
> >> + backend buffer.
> >> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> >> index f7526db..8a1892a 100644
> >> --- a/drivers/block/xen-blkback/blkback.c
> >> +++ b/drivers/block/xen-blkback/blkback.c
> >> @@ -63,6 +63,21 @@ static int xen_blkif_reqs = 64;
> >> module_param_named(reqs, xen_blkif_reqs, int, 0);
> >> MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
> >>
> >> +/*
> >> + * Maximum number of unused free pages to keep in the internal buffer.
> >> + * Setting this to a value too low will reduce memory used in each backend,
> >> + * but can have a performance penalty.
> >> + *
> >> + * A sane value is xen_blkif_reqs * BLKIF_MAX_SEGMENTS_PER_REQUEST, but can
> >> + * be set to a lower value that might degrade performance on some intensive
> >> + * IO workloads.
> >> + */
> >> +
> >> +static int xen_blkif_max_buffer_pages = 704;
> >> +module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> >> +MODULE_PARM_DESC(max_buffer_pages,
> >> +"Maximum number of free pages to keep in each block backend buffer");
> >> +
> >> /* Run-time switchable: /sys/module/blkback/parameters/ */
> >> static unsigned int log_stats;
> >> module_param(log_stats, int, 0644);
> >> @@ -82,10 +97,14 @@ struct pending_req {
> >> int status;
> >> struct list_head free_list;
> >> DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> >> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> };
> >>
> >> #define BLKBACK_INVALID_HANDLE (~0)
> >>
> >> +/* Number of free pages to remove on each call to free_xenballooned_pages */
> >> +#define NUM_BATCH_FREE_PAGES 10
> >> +
> >> struct xen_blkbk {
> >> struct pending_req *pending_reqs;
> >> /* List of all 'pending_req' available */
> >> @@ -93,8 +112,6 @@ struct xen_blkbk {
> >> /* And its spinlock. */
> >> spinlock_t pending_free_lock;
> >> wait_queue_head_t pending_free_wq;
> >> - /* The list of all pages that are available. */
> >> - struct page **pending_pages;
> >> /* And the grant handles that are available. */
> >> grant_handle_t *pending_grant_handles;
> >> };
> >> @@ -143,14 +160,66 @@ static inline int vaddr_pagenr(struct pending_req *req, int seg)
> >> BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
> >> }
> >>
> >> -#define pending_page(req, seg) pending_pages[vaddr_pagenr(req, seg)]
> >> +static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
> >> +{
> >> + unsigned long flags;
> >> +
> >> + spin_lock_irqsave(&blkif->free_pages_lock, flags);
> >
> > I am curious to why you need to use the irqsave variant one here, as
> >> + if (list_empty(&blkif->free_pages)) {
> >> + BUG_ON(blkif->free_pages_num != 0);
> >> + spin_unlock_irqrestore(&blkif->free_pages_lock, flags);
> >> + return alloc_xenballooned_pages(1, page, false);
> >
> > This function is using an mutex.
> >
> > which would imply it is OK to have an non-irq variant of spinlock?
>
> Sorry, the previous response is wrong, I need to use irqsave in order to
> disable interrupts, since put_free_pages is called from interrupt
> context and it could create a race if for example, put_free_pages is
> called while we are inside shrink_free_pagepool.
OK, but you can mix the irq and non-irq spinlocks variants.
On Mon, Apr 15, 2013 at 01:19:38PM +0200, Roger Pau Monn? wrote:
> On 09/04/13 17:42, Konrad Rzeszutek Wilk wrote:
> > On Wed, Mar 27, 2013 at 12:10:39PM +0100, Roger Pau Monne wrote:
> >> This mechanism allows blkback to change the number of grants
> >> persistently mapped at run time.
> >>
> >> The algorithm uses a simple LRU mechanism that removes (if needed) the
> >> persistent grants that have not been used since the last LRU run, or
> >> if all grants have been used it removes the first grants in the list
> >> (that are not in use).
> >>
> >> The algorithm allows the user to change the maximum number of
> >> persistent grants, by changing max_persistent_grants in sysfs.
> >>
> >> Signed-off-by: Roger Pau Monn? <[email protected]>
> >> Cc: Konrad Rzeszutek Wilk <[email protected]>
> >> Cc: [email protected]
> >> ---
> >> Changes since RFC:
> >> * Offload part of the purge work to a kworker thread.
> >> * Add documentation about sysfs tunable.
> >> ---
> >> Documentation/ABI/stable/sysfs-bus-xen-backend | 7 +
> >> drivers/block/xen-blkback/blkback.c | 278 +++++++++++++++++++-----
> >> drivers/block/xen-blkback/common.h | 12 +
> >> drivers/block/xen-blkback/xenbus.c | 2 +
> >> 4 files changed, 240 insertions(+), 59 deletions(-)
> >>
> >> diff --git a/Documentation/ABI/stable/sysfs-bus-xen-backend b/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> index e04afe0..7595b38 100644
> >> --- a/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> +++ b/Documentation/ABI/stable/sysfs-bus-xen-backend
> >> @@ -81,3 +81,10 @@ Contact: Roger Pau Monn? <[email protected]>
> >> Description:
> >> Maximum number of free pages to keep in each block
> >> backend buffer.
> >> +
> >> +What: /sys/module/xen_blkback/parameters/max_persistent_grants
> >> +Date: March 2013
> >> +KernelVersion: 3.10
> >> +Contact: Roger Pau Monn? <[email protected]>
> >> +Description:
> >> + Maximum number of grants to map persistently in blkback.
> >
> > You are missing the other 2 paramters.
>
> Since the other two parameters are not "public", in the sense that you
> need to change the source in order to use them, I have not added them to
> the list of parameters.
OK, can we just get rid of them?
>
> >> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> >> index 8a1892a..fd1dd38 100644
> >> --- a/drivers/block/xen-blkback/blkback.c
> >> +++ b/drivers/block/xen-blkback/blkback.c
> >> @@ -78,6 +78,44 @@ module_param_named(max_buffer_pages, xen_blkif_max_buffer_pages, int, 0644);
> >> MODULE_PARM_DESC(max_buffer_pages,
> >> "Maximum number of free pages to keep in each block backend buffer");
> >>
> >> +/*
> >> + * Maximum number of grants to map persistently in blkback. For maximum
> >> + * performance this should be the total numbers of grants that can be used
> >> + * to fill the ring, but since this might become too high, specially with
> >> + * the use of indirect descriptors, we set it to a value that provides good
> >> + * performance without using too much memory.
> >> + *
> >> + * When the list of persistent grants is full we clean it using a LRU
> > ^- up
> >
> >> + * algorithm.
> >
> > Sorry for the confusion. Does this mean that the cap is 352? Or that once
> > we hit the cap of 352 then the LRU engine gets kicked in?
>
> This means that we can add up to 352 grants without the LRU kicking in,
> if we try to add 353, then the LRU would kick in.
>
> >
> >> + */
> >> +
> >> +static int xen_blkif_max_pgrants = 352;
> >> +module_param_named(max_persistent_grants, xen_blkif_max_pgrants, int, 0644);
> >> +MODULE_PARM_DESC(max_persistent_grants,
> >> + "Maximum number of grants to map persistently");
> >> +
> >> +/*
> >> + * The LRU mechanism to clean the lists of persistent grants needs to
> >> + * be executed periodically. The time interval between consecutive executions
> >> + * of the purge mechanism is set in ms.
> >> + */
> >> +
> >> +static int xen_blkif_lru_interval = 100;
> >> +module_param_named(lru_interval, xen_blkif_lru_interval, int, 0);
> >
> > Is the '0' intentional?
>
> I didn't plan to make them public, because I'm not sure of the benefit
> of exporting those, but they are there so if someone wants to really
> tune this parameters it can be done without much trouble. The same with
> lru_percent_clean. Would you prefer to make those public?
Nope. Rather remove them altogether. Or if you want them to tweak a bit
then use the xen_init_debugfs().. and setup a 'blkback' DebugFS directory
with these.
>
> >
> >> +MODULE_PARM_DESC(lru_interval,
> >> +"Execution interval (in ms) of the LRU mechanism to clean the list of persistent grants");
> >> +
> >> +/*
> >> + * When the persistent grants list is full we will remove unused grants
> >> + * from the list. The percent number of grants to be removed at each LRU
> >> + * execution.
> >> + */
> >> +
> >> +static int xen_blkif_lru_percent_clean = 5;
> >
> > OK, so by default if the persistent grants are at 352 pages we start trimming
> > 5% of the list every 100ms. Are we trimming the whole list or just down
> > to 352 (so max_persistent_grants?).
>
> In the case that we have here, max_persistent_grants is set to
> RING_SIZE*MAX_SEGMENTS, so the LRU would never kick in. If we set this
> to something lower, then the LRU would kick in and remove 5% of
> max_persistent_grants at each execution.
And then stop. Later on (on the next time it goes in the LRU system) it would
not even bother removing as the count is below max_persistent_grants.
>
> >
> > If the latter do we stop the LRU execution at that point? If so please
> > enumerate that. Oh and do we stop at 352 or do we do the 5% so we end up actually
> > at 334?
> >
> > Would it make sense to cap the engine to stop removing unused grants
> > down to xen_blkif_max_pgrants?
>
> If I got your question right, I think this is already done by the
> current implementation, it will only start removing grants the moment we
> try to use more than max_persistent_grants, but not when using exactly
> max_persistent_grants.
Right. I think it makes sense to enumerate that in the documentation part here.
>
> >
> >> +module_param_named(lru_percent_clean, xen_blkif_lru_percent_clean, int, 0);
> >
> > Ditto here.
> >
> >> +MODULE_PARM_DESC(lru_percent_clean,
> >> +"Number of persistent grants to unmap when the list is full");
> >> +
> >> /* Run-time switchable: /sys/module/blkback/parameters/ */
> >> static unsigned int log_stats;
> >> module_param(log_stats, int, 0644);
> >> @@ -96,8 +134,8 @@ struct pending_req {
> >> unsigned short operation;
> >> int status;
> >> struct list_head free_list;
> >> - DECLARE_BITMAP(unmap_seg, BLKIF_MAX_SEGMENTS_PER_REQUEST);
> >> struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> };
> >>
> >> #define BLKBACK_INVALID_HANDLE (~0)
> >> @@ -119,36 +157,6 @@ struct xen_blkbk {
> >> static struct xen_blkbk *blkbk;
> >>
> >> /*
> >> - * Maximum number of grant pages that can be mapped in blkback.
> >> - * BLKIF_MAX_SEGMENTS_PER_REQUEST * RING_SIZE is the maximum number of
> >> - * pages that blkback will persistently map.
> >> - * Currently, this is:
> >> - * RING_SIZE = 32 (for all known ring types)
> >> - * BLKIF_MAX_SEGMENTS_PER_REQUEST = 11
> >> - * sizeof(struct persistent_gnt) = 48
> >> - * So the maximum memory used to store the grants is:
> >> - * 32 * 11 * 48 = 16896 bytes
> >> - */
> >> -static inline unsigned int max_mapped_grant_pages(enum blkif_protocol protocol)
> >> -{
> >> - switch (protocol) {
> >> - case BLKIF_PROTOCOL_NATIVE:
> >> - return __CONST_RING_SIZE(blkif, PAGE_SIZE) *
> >> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> >> - case BLKIF_PROTOCOL_X86_32:
> >> - return __CONST_RING_SIZE(blkif_x86_32, PAGE_SIZE) *
> >> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> >> - case BLKIF_PROTOCOL_X86_64:
> >> - return __CONST_RING_SIZE(blkif_x86_64, PAGE_SIZE) *
> >> - BLKIF_MAX_SEGMENTS_PER_REQUEST;
> >> - default:
> >> - BUG();
> >> - }
> >> - return 0;
> >> -}
> >> -
> >> -
> >> -/*
> >> * Little helpful macro to figure out the index and virtual address of the
> >> * pending_pages[..]. For each 'pending_req' we have have up to
> >> * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
> >> @@ -239,13 +247,19 @@ static void make_response(struct xen_blkif *blkif, u64 id,
> >> (n) = (&(pos)->node != NULL) ? rb_next(&(pos)->node) : NULL)
> >>
> >>
> >> -static int add_persistent_gnt(struct rb_root *root,
> >> +static int add_persistent_gnt(struct xen_blkif *blkif,
> >> struct persistent_gnt *persistent_gnt)
> >> {
> >> - struct rb_node **new = &(root->rb_node), *parent = NULL;
> >> + struct rb_node **new = NULL, *parent = NULL;
> >> struct persistent_gnt *this;
> >>
> >> + if (blkif->persistent_gnt_c >= xen_blkif_max_pgrants) {
> >> + if (!blkif->vbd.overflow_max_grants)
> >> + blkif->vbd.overflow_max_grants = 1;
> >> + return -EBUSY;
> >> + }
> >> /* Figure out where to put new node */
> >> + new = &blkif->persistent_gnts.rb_node;
> >> while (*new) {
> >> this = container_of(*new, struct persistent_gnt, node);
> >>
> >> @@ -259,19 +273,23 @@ static int add_persistent_gnt(struct rb_root *root,
> >> return -EINVAL;
> >> }
> >> }
> >> -
> >> + bitmap_zero(persistent_gnt->flags, PERSISTENT_GNT_FLAGS_SIZE);
> >> + set_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
> >> /* Add new node and rebalance tree. */
> >> rb_link_node(&(persistent_gnt->node), parent, new);
> >> - rb_insert_color(&(persistent_gnt->node), root);
> >> + rb_insert_color(&(persistent_gnt->node), &blkif->persistent_gnts);
> >> + blkif->persistent_gnt_c++;
> >> + atomic_inc(&blkif->persistent_gnt_in_use);
> >> return 0;
> >> }
> >>
> >> -static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> >> +static struct persistent_gnt *get_persistent_gnt(struct xen_blkif *blkif,
> >> grant_ref_t gref)
> >> {
> >> struct persistent_gnt *data;
> >> - struct rb_node *node = root->rb_node;
> >> + struct rb_node *node = NULL;
> >>
> >> + node = blkif->persistent_gnts.rb_node;
> >> while (node) {
> >> data = container_of(node, struct persistent_gnt, node);
> >>
> >> @@ -279,12 +297,25 @@ static struct persistent_gnt *get_persistent_gnt(struct rb_root *root,
> >> node = node->rb_left;
> >> else if (gref > data->gnt)
> >> node = node->rb_right;
> >> - else
> >> + else {
> >> + WARN_ON(test_bit(PERSISTENT_GNT_ACTIVE, data->flags));
> >
> > Ouch. Is that even safe? Doesn't that mean that somebody is using this and we just
> > usurped it?
>
> It is not safe for sure regarding data integrity, but a buggy frontend
> can send a request with the same grant for all the segments, and now
> that you make me think of it, this should be ratelimited to prevent a
> malicious frontend from flooding the Dom0.
<nods>
>
> >> + set_bit(PERSISTENT_GNT_ACTIVE, data->flags);
> >> + atomic_inc(&blkif->persistent_gnt_in_use);
> >> return data;
> >> + }
> >> }
> >> return NULL;
> >> }
> >>
> >> +static void put_persistent_gnt(struct xen_blkif *blkif,
> >> + struct persistent_gnt *persistent_gnt)
> >> +{
> >> + WARN_ON(!test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags));
> >> + set_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
> >> + clear_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags);
> >> + atomic_dec(&blkif->persistent_gnt_in_use);
> >> +}
> >> +
> >> static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
> >> unsigned int num)
> >> {
> >> @@ -322,6 +353,122 @@ static void free_persistent_gnts(struct xen_blkif *blkif, struct rb_root *root,
> >> BUG_ON(num != 0);
> >> }
> >>
> >
> > Might need need to say something about locking..
>
> I've added the following comment:
>
> /*
> * We don't need locking around the persistent grant helpers
> * because blkback uses a single-thread for each backed, so we
> * can be sure that this functions will never be called recursively.
> *
> * The only exception to that is put_persistent_grant, that can be called
> * from interrupt context (by xen_blkbk_unmap), so we have to use atomic
> * bit operations to modify the flags of a persistent grant and to count
> * the number of used grants.
> */
>
Great. Thanks.
> >
> >> +static void unmap_purged_grants(struct work_struct *work)
> >> +{
> >> + struct gnttab_unmap_grant_ref unmap[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + struct persistent_gnt *persistent_gnt;
> >> + int ret, segs_to_unmap = 0;
> >> + struct xen_blkif *blkif =
> >> + container_of(work, typeof(*blkif), persistent_purge_work);
> >> +
> >> + while(!list_empty(&blkif->persistent_purge_list)) {
> >> + persistent_gnt = list_first_entry(&blkif->persistent_purge_list,
> >> + struct persistent_gnt,
> >> + remove_node);
> >> + list_del(&persistent_gnt->remove_node);
> >> +
> >> + gnttab_set_unmap_op(&unmap[segs_to_unmap],
> >> + vaddr(persistent_gnt->page),
> >> + GNTMAP_host_map,
> >> + persistent_gnt->handle);
> >> +
> >> + pages[segs_to_unmap] = persistent_gnt->page;
> >> +
> >> + if (++segs_to_unmap == BLKIF_MAX_SEGMENTS_PER_REQUEST) {
> >> + ret = gnttab_unmap_refs(unmap, NULL, pages,
> >> + segs_to_unmap);
> >> + BUG_ON(ret);
> >> + put_free_pages(blkif, pages, segs_to_unmap);
> >> + segs_to_unmap = 0;
> >> + }
> >> + kfree(persistent_gnt);
> >> + }
> >> + if (segs_to_unmap > 0) {
> >> + ret = gnttab_unmap_refs(unmap, NULL, pages, segs_to_unmap);
> >> + BUG_ON(ret);
> >> + put_free_pages(blkif, pages, segs_to_unmap);
> >> + }
> >> +}
> >> +
> >> +static void purge_persistent_gnt(struct xen_blkif *blkif)
> >> +{
> >> + struct persistent_gnt *persistent_gnt;
> >> + struct rb_node *n;
> >> + int num_clean, total;
> >> + bool scan_used = false;
> >> + struct rb_root *root;
> >> +
> >> + if (blkif->persistent_gnt_c < xen_blkif_max_pgrants ||
> >> + (blkif->persistent_gnt_c == xen_blkif_max_pgrants &&
> >> + !blkif->vbd.overflow_max_grants)) {
> >> + return;
> >> + }
> >> +
> >> + if (work_pending(&blkif->persistent_purge_work)) {
> >> + pr_alert_ratelimited(DRV_PFX "Scheduled work from previous purge is still pending, cannot purge list\n");
> >> + return;
> >> + }
> >> +
> >> + num_clean = (xen_blkif_max_pgrants / 100) * xen_blkif_lru_percent_clean;
> >> + num_clean = blkif->persistent_gnt_c - xen_blkif_max_pgrants + num_clean;
> >> + num_clean = num_clean > blkif->persistent_gnt_c ?
> >> + blkif->persistent_gnt_c : num_clean;
> >
> > I think you can do:
> > num_clean = min(blkif->persistent_gnt_c, num_clean);
> > ?
>
> D'oh! sure, thanks for spotting that.
>
> >> + if (num_clean >
> >> + (blkif->persistent_gnt_c -
> >> + atomic_read(&blkif->persistent_gnt_in_use)))
> >> + return;
> >> +
> >> + total = num_clean;
> >> +
> >> + pr_debug(DRV_PFX "Going to purge %d persistent grants\n", num_clean);
> >> +
> >> + INIT_LIST_HEAD(&blkif->persistent_purge_list);
> >> + root = &blkif->persistent_gnts;
> >> +purge_list:
> >> + foreach_grant_safe(persistent_gnt, n, root, node) {
> >> + BUG_ON(persistent_gnt->handle ==
> >> + BLKBACK_INVALID_HANDLE);
> >> +
> >> + if (test_bit(PERSISTENT_GNT_ACTIVE, persistent_gnt->flags))
> >> + continue;
> >> + if (!scan_used &&
> >> + (test_bit(PERSISTENT_GNT_USED, persistent_gnt->flags)))
> >> + continue;
> >> +
> >> + rb_erase(&persistent_gnt->node, root);
> >> + list_add(&persistent_gnt->remove_node,
> >> + &blkif->persistent_purge_list);
> >> + if (--num_clean == 0)
> >> + goto finished;
> >
> > The check (if num_clean > .. atomic_read) means that by the time we
> > get here and try to remove some of them, the blkif->persistent_gnt_in_use
> > might have dramatically changed.
> >
> > Which would mean we could be walking the list here without collecting
> > any grants.
>
> Not really -- at this point, we can assure that there will be no calls
> to get_persistent_grant (because we are executing this code from
> xen_blkif_schedule), there can only be calls to put_persistent_gnt,
> which means that the number of currently used grants will go down, but
> never up, so we will always be able to remove the requested number of
> grants.
<nods>
>
> >
> > Thought on the second pass we would hopefully get the PERSISTENT_GNT_USED
> > but might also hit that case.
> >
> > Is that a case we need to worry about? I mean if we hit it, then num_clean
> > is less than the total. Perhaps at that stage we should decrease
> > the 'xen_blkif_lru_percent_clean' to a smaller number as we are probably
> > going to hit the same issue next time around?
>
> I haven't really thought about that, because even on busy blkbacks I've
> been able to execute the LRU without problems.
OK. Then lets not worry about it.
>
> >
> > And conversely - the next time we run this code and num_clean == total
> > then we can increase the 'xen_blkif_lru_percent_clean' to its original
> > value?
> >
> > That would mean we need somewhere a new value (blkif specific) that
> > would serve the role of being a local version of 'xen_blkif_lru_percent_clean'
> > that can be from 0 -> xen_blkif_lru_percent_clean?
> >
> > Or is this case I am thinking of overblown and you did not hit it when
> > running stress-tests with this code?
>
> Not really, the only case I can think might be problematic is for
> example when you have xen_blkif_max_pgrants == 352 and reduce it to 10,
> then if blkback is very busy it might take some time to find a window
> where only 10 persistent grants are used.
>
> >
> >
> >
> >> + }
> >> + /*
> >> + * If we get here it means we also need to start cleaning
> >> + * grants that were used since last purge in order to cope
> >> + * with the requested num
> >> + */
> >> + if (!scan_used) {
> >> + pr_debug(DRV_PFX "Still missing %d purged frames\n", num_clean);
> >> + scan_used = true;
> >> + goto purge_list;
> >> + }
> >> +finished:
> >> + /* Remove the "used" flag from all the persistent grants */
> >> + foreach_grant_safe(persistent_gnt, n, root, node) {
> >> + BUG_ON(persistent_gnt->handle ==
> >> + BLKBACK_INVALID_HANDLE);
> >> + clear_bit(PERSISTENT_GNT_USED, persistent_gnt->flags);
> >
> > The 'used' flag does not sound right. I can't place it but I would
> > think another name is better.
> >
> > Perhaps 'WALKED' ? 'TOUCHED' ? 'NOT_TOO_FRESH'? 'STALE'? 'WAS_ACTIVE'?
> >
> > Hm, perhaps 'WAS_ACTIVE'? Or maybe the 'USED' is right.
> >
> > Either way, I am not a native speaker so lets not get hanged up on this.
>
> I'm not a native speaker either, maybe WAS_ACTIVE is a better
> definittion? Or UTILIZED?
<shrugs> Either way. Up to you.
>
> >
> >> + }
> >> + blkif->persistent_gnt_c -= (total - num_clean);
> >> + blkif->vbd.overflow_max_grants = 0;
> >> +
> >> + /* We can defer this work */
> >> + INIT_WORK(&blkif->persistent_purge_work, unmap_purged_grants);
> >> + schedule_work(&blkif->persistent_purge_work);
> >> + pr_debug(DRV_PFX "Purged %d/%d\n", (total - num_clean), total);
> >> + return;
> >> +}
> >> +
> >> /*
> >> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
> >> */
> >> @@ -453,12 +600,12 @@ irqreturn_t xen_blkif_be_int(int irq, void *dev_id)
> >> static void print_stats(struct xen_blkif *blkif)
> >> {
> >> pr_info("xen-blkback (%s): oo %3llu | rd %4llu | wr %4llu | f %4llu"
> >> - " | ds %4llu | pg: %4u/%4u\n",
> >> + " | ds %4llu | pg: %4u/%4d\n",
> >> current->comm, blkif->st_oo_req,
> >> blkif->st_rd_req, blkif->st_wr_req,
> >> blkif->st_f_req, blkif->st_ds_req,
> >> blkif->persistent_gnt_c,
> >> - max_mapped_grant_pages(blkif->blk_protocol));
> >> + xen_blkif_max_pgrants);
> >> blkif->st_print = jiffies + msecs_to_jiffies(10 * 1000);
> >> blkif->st_rd_req = 0;
> >> blkif->st_wr_req = 0;
> >> @@ -470,6 +617,7 @@ int xen_blkif_schedule(void *arg)
> >> {
> >> struct xen_blkif *blkif = arg;
> >> struct xen_vbd *vbd = &blkif->vbd;
> >> + unsigned long timeout;
> >>
> >> xen_blkif_get(blkif);
> >>
> >> @@ -479,13 +627,21 @@ int xen_blkif_schedule(void *arg)
> >> if (unlikely(vbd->size != vbd_sz(vbd)))
> >> xen_vbd_resize(blkif);
> >>
> >> - wait_event_interruptible(
> >> + timeout = msecs_to_jiffies(xen_blkif_lru_interval);
> >> +
> >> + timeout = wait_event_interruptible_timeout(
> >> blkif->wq,
> >> - blkif->waiting_reqs || kthread_should_stop());
> >> - wait_event_interruptible(
> >> + blkif->waiting_reqs || kthread_should_stop(),
> >> + timeout);
> >> + if (timeout == 0)
> >> + goto purge_gnt_list;
> >
> > So if the system admin decided that the value of zero in xen_blkif_lru_interval
> > was perfect, won't we timeout immediately and keep on going to the goto statement,
> > and then looping around?
>
> Yes, we would go looping around purge_gnt_list.
>
> >
> > I think we need some sanity checking that the xen_blkif_lru_interval and
> > perhaps the other parameters are sane. And sadly we cannot do that
> > in the init function as the system admin might do this:
> >
> > for fun in `ls -1 /sys/modules/xen_blkback/parameters`
> > do
> > echo 0 > /sys/modules/xen_blkback/parameters/$a
> > done
> >
> > and reset everything to zero. Yikes.
>
> That's one of the reasons why xen_blkif_lru_interval is not public, but
> anyway if someone is so "clever" to export xen_blkif_lru_interval and
> then change it to 0...
Right. Lets not make it possible then.
>
> >
> >
> >> + timeout = wait_event_interruptible_timeout(
> >
> > if (blkif->vbd.feature_gnt_persistent) {
> > timeout = msecs_to_jiffiers(..)
> > timeout = wait_event_interruptple_timeout
> >> blkbk->pending_free_wq,
> >> !list_empty(&blkbk->pending_free) ||
> >> - kthread_should_stop());
> >> + kthread_should_stop(),
> >> + timeout);
> >> + if (timeout == 0)
> >> + goto purge_gnt_list;
> >>
> >> blkif->waiting_reqs = 0;
> >> smp_mb(); /* clear flag *before* checking for work */
> >> @@ -493,6 +649,14 @@ int xen_blkif_schedule(void *arg)
> >> if (do_block_io_op(blkif))
> >> blkif->waiting_reqs = 1;
> >>
> >> +purge_gnt_list:
> >> + if (blkif->vbd.feature_gnt_persistent &&
> >> + time_after(jiffies, blkif->next_lru)) {
> >> + purge_persistent_gnt(blkif);
> >> + blkif->next_lru = jiffies +
> >> + msecs_to_jiffies(xen_blkif_lru_interval);
> >
> > You can make this more than 80 characters.
> >
> >> + }
> >> +
> >> shrink_free_pagepool(blkif, xen_blkif_max_buffer_pages);
> >>
> >> if (log_stats && time_after(jiffies, blkif->st_print))
> >> @@ -504,7 +668,7 @@ int xen_blkif_schedule(void *arg)
> >> /* Free all persistent grant pages */
> >> if (!RB_EMPTY_ROOT(&blkif->persistent_gnts))
> >> free_persistent_gnts(blkif, &blkif->persistent_gnts,
> >> - blkif->persistent_gnt_c);
> >> + blkif->persistent_gnt_c);
> >>
> >> BUG_ON(!RB_EMPTY_ROOT(&blkif->persistent_gnts));
> >> blkif->persistent_gnt_c = 0;
> >> @@ -536,8 +700,10 @@ static void xen_blkbk_unmap(struct pending_req *req)
> >> int ret;
> >>
> >> for (i = 0; i < req->nr_pages; i++) {
> >> - if (!test_bit(i, req->unmap_seg))
> >> + if (req->persistent_gnts[i] != NULL) {
> >> + put_persistent_gnt(blkif, req->persistent_gnts[i]);
> >> continue;
> >> + }
> >
> > Aha, the req->unmap_seg bitmap is not used here anymore! You might want to
> > mention that in the commit description saying that you are also removing
> > this artifact as you don't need it anymore with the superior cleaning
> > method employed here.
>
> Yes, since we are storing the persistent grants used inside the request
> struct (to be able to mark them as "unused" when unmapping), we no
> longer need the bitmap.
Good. Lets just mention it also in the git commit.
On Mon, Apr 15, 2013 at 03:50:38PM +0200, Roger Pau Monn? wrote:
> On 09/04/13 18:13, Konrad Rzeszutek Wilk wrote:
> > On Wed, Mar 27, 2013 at 12:10:41PM +0100, Roger Pau Monne wrote:
> >> Remove the last dependency from blkbk by moving the list of free
> >> requests to blkif. This change reduces the contention on the list of
> >> available requests.
> >>
> >> Signed-off-by: Roger Pau Monn? <[email protected]>
> >> Cc: Konrad Rzeszutek Wilk <[email protected]>
> >> Cc: [email protected]
> >> ---
> >> Changes since RFC:
> >> * Replace kzalloc with kcalloc.
> >> ---
> >> drivers/block/xen-blkback/blkback.c | 125 +++++++----------------------------
> >> drivers/block/xen-blkback/common.h | 27 ++++++++
> >> drivers/block/xen-blkback/xenbus.c | 19 +++++
> >> 3 files changed, 70 insertions(+), 101 deletions(-)
> >>
> >> diff --git a/drivers/block/xen-blkback/blkback.c b/drivers/block/xen-blkback/blkback.c
> >> index e6542d5..a1c9dad 100644
> >> --- a/drivers/block/xen-blkback/blkback.c
> >> +++ b/drivers/block/xen-blkback/blkback.c
> >> @@ -50,18 +50,14 @@
> >> #include "common.h"
> >>
> >> /*
> >> - * These are rather arbitrary. They are fairly large because adjacent requests
> >> - * pulled from a communication ring are quite likely to end up being part of
> >> - * the same scatter/gather request at the disc.
> >> - *
> >> - * ** TRY INCREASING 'xen_blkif_reqs' IF WRITE SPEEDS SEEM TOO LOW **
> >> - *
> >> - * This will increase the chances of being able to write whole tracks.
> >> - * 64 should be enough to keep us competitive with Linux.
> >> + * This is the number of requests that will be pre-allocated for each backend.
> >> + * For better performance this is set to RING_SIZE (32), so requests
> >> + * in the ring will never have to wait for a free pending_req.
> >
> > You might want to clarify that 'Any value less than that is sure to
> > cause problems.'
> >
> > At which point perhaps we should have some logic to enforce that?
> >> */
> >> -static int xen_blkif_reqs = 64;
> >> +
> >> +int xen_blkif_reqs = 32;
> >> module_param_named(reqs, xen_blkif_reqs, int, 0);
> >> -MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate");
> >> +MODULE_PARM_DESC(reqs, "Number of blkback requests to allocate per backend");
> >
> >
> > Do we even need this anymore? I mean if the optimial size is 32 and going
> > below that is silly. Going above that is silly as well - as we won't be using
> > the extra count.
> >
> > Can we just rip this module parameter out?
>
> Wiped out, it doesn't make sense.
>
> >
> >>
> >> /*
> >> * Maximum number of unused free pages to keep in the internal buffer.
> >> @@ -120,53 +116,11 @@ MODULE_PARM_DESC(lru_percent_clean,
> >> static unsigned int log_stats;
> >> module_param(log_stats, int, 0644);
> >>
> >> -/*
> >> - * Each outstanding request that we've passed to the lower device layers has a
> >> - * 'pending_req' allocated to it. Each buffer_head that completes decrements
> >> - * the pendcnt towards zero. When it hits zero, the specified domain has a
> >> - * response queued for it, with the saved 'id' passed back.
> >> - */
> >> -struct pending_req {
> >> - struct xen_blkif *blkif;
> >> - u64 id;
> >> - int nr_pages;
> >> - atomic_t pendcnt;
> >> - unsigned short operation;
> >> - int status;
> >> - struct list_head free_list;
> >> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> -};
> >> -
> >> #define BLKBACK_INVALID_HANDLE (~0)
> >>
> >> /* Number of free pages to remove on each call to free_xenballooned_pages */
> >> #define NUM_BATCH_FREE_PAGES 10
> >>
> >> -struct xen_blkbk {
> >> - struct pending_req *pending_reqs;
> >> - /* List of all 'pending_req' available */
> >> - struct list_head pending_free;
> >> - /* And its spinlock. */
> >> - spinlock_t pending_free_lock;
> >> - wait_queue_head_t pending_free_wq;
> >> -};
> >> -
> >> -static struct xen_blkbk *blkbk;
> >> -
> >> -/*
> >> - * Little helpful macro to figure out the index and virtual address of the
> >> - * pending_pages[..]. For each 'pending_req' we have have up to
> >> - * BLKIF_MAX_SEGMENTS_PER_REQUEST (11) pages. The seg would be from 0 through
> >> - * 10 and would index in the pending_pages[..].
> >> - */
> >> -static inline int vaddr_pagenr(struct pending_req *req, int seg)
> >> -{
> >> - return (req - blkbk->pending_reqs) *
> >> - BLKIF_MAX_SEGMENTS_PER_REQUEST + seg;
> >> -}
> >> -
> >> static inline int get_free_page(struct xen_blkif *blkif, struct page **page)
> >> {
> >> unsigned long flags;
> >> @@ -471,18 +425,18 @@ finished:
> >> /*
> >> * Retrieve from the 'pending_reqs' a free pending_req structure to be used.
> >> */
> >> -static struct pending_req *alloc_req(void)
> >> +static struct pending_req *alloc_req(struct xen_blkif *blkif)
> >> {
> >> struct pending_req *req = NULL;
> >> unsigned long flags;
> >>
> >> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
> >> - if (!list_empty(&blkbk->pending_free)) {
> >> - req = list_entry(blkbk->pending_free.next, struct pending_req,
> >> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
> >> + if (!list_empty(&blkif->pending_free)) {
> >> + req = list_entry(blkif->pending_free.next, struct pending_req,
> >> free_list);
> >> list_del(&req->free_list);
> >> }
> >> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
> >> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
> >> return req;
> >> }
> >>
> >> @@ -490,17 +444,17 @@ static struct pending_req *alloc_req(void)
> >> * Return the 'pending_req' structure back to the freepool. We also
> >> * wake up the thread if it was waiting for a free page.
> >> */
> >> -static void free_req(struct pending_req *req)
> >> +static void free_req(struct xen_blkif *blkif, struct pending_req *req)
> >> {
> >> unsigned long flags;
> >> int was_empty;
> >>
> >> - spin_lock_irqsave(&blkbk->pending_free_lock, flags);
> >> - was_empty = list_empty(&blkbk->pending_free);
> >> - list_add(&req->free_list, &blkbk->pending_free);
> >> - spin_unlock_irqrestore(&blkbk->pending_free_lock, flags);
> >> + spin_lock_irqsave(&blkif->pending_free_lock, flags);
> >> + was_empty = list_empty(&blkif->pending_free);
> >> + list_add(&req->free_list, &blkif->pending_free);
> >> + spin_unlock_irqrestore(&blkif->pending_free_lock, flags);
> >> if (was_empty)
> >> - wake_up(&blkbk->pending_free_wq);
> >> + wake_up(&blkif->pending_free_wq);
> >> }
> >>
> >> /*
> >> @@ -635,8 +589,8 @@ int xen_blkif_schedule(void *arg)
> >> if (timeout == 0)
> >> goto purge_gnt_list;
> >> timeout = wait_event_interruptible_timeout(
> >> - blkbk->pending_free_wq,
> >> - !list_empty(&blkbk->pending_free) ||
> >> + blkif->pending_free_wq,
> >> + !list_empty(&blkif->pending_free) ||
> >> kthread_should_stop(),
> >> timeout);
> >> if (timeout == 0)
> >> @@ -883,7 +837,7 @@ static int dispatch_other_io(struct xen_blkif *blkif,
> >> struct blkif_request *req,
> >> struct pending_req *pending_req)
> >> {
> >> - free_req(pending_req);
> >> + free_req(blkif, pending_req);
> >> make_response(blkif, req->u.other.id, req->operation,
> >> BLKIF_RSP_EOPNOTSUPP);
> >> return -EIO;
> >> @@ -943,7 +897,7 @@ static void __end_block_io_op(struct pending_req *pending_req, int error)
> >> if (atomic_read(&pending_req->blkif->drain))
> >> complete(&pending_req->blkif->drain_complete);
> >> }
> >> - free_req(pending_req);
> >> + free_req(pending_req->blkif, pending_req);
> >> }
> >> }
> >>
> >> @@ -986,7 +940,7 @@ __do_block_io_op(struct xen_blkif *blkif)
> >> break;
> >> }
> >>
> >> - pending_req = alloc_req();
> >> + pending_req = alloc_req(blkif);
> >> if (NULL == pending_req) {
> >> blkif->st_oo_req++;
> >> more_to_do = 1;
> >> @@ -1020,7 +974,7 @@ __do_block_io_op(struct xen_blkif *blkif)
> >> goto done;
> >> break;
> >> case BLKIF_OP_DISCARD:
> >> - free_req(pending_req);
> >> + free_req(blkif, pending_req);
> >> if (dispatch_discard_io(blkif, &req))
> >> goto done;
> >> break;
> >> @@ -1222,7 +1176,7 @@ static int dispatch_rw_block_io(struct xen_blkif *blkif,
> >> fail_response:
> >> /* Haven't submitted any bio's yet. */
> >> make_response(blkif, req->u.rw.id, req->operation, BLKIF_RSP_ERROR);
> >> - free_req(pending_req);
> >> + free_req(blkif, pending_req);
> >> msleep(1); /* back off a bit */
> >> return -EIO;
> >>
> >> @@ -1279,51 +1233,20 @@ static void make_response(struct xen_blkif *blkif, u64 id,
> >>
> >> static int __init xen_blkif_init(void)
> >> {
> >> - int i;
> >> int rc = 0;
> >>
> >> if (!xen_domain())
> >> return -ENODEV;
> >>
> >> - blkbk = kzalloc(sizeof(struct xen_blkbk), GFP_KERNEL);
> >> - if (!blkbk) {
> >> - pr_alert(DRV_PFX "%s: out of memory!\n", __func__);
> >> - return -ENOMEM;
> >> - }
> >> -
> >> -
> >> - blkbk->pending_reqs = kzalloc(sizeof(blkbk->pending_reqs[0]) *
> >> - xen_blkif_reqs, GFP_KERNEL);
> >> -
> >> - if (!blkbk->pending_reqs) {
> >> - rc = -ENOMEM;
> >> - goto out_of_memory;
> >> - }
> >> -
> >> rc = xen_blkif_interface_init();
> >> if (rc)
> >> goto failed_init;
> >>
> >> - INIT_LIST_HEAD(&blkbk->pending_free);
> >> - spin_lock_init(&blkbk->pending_free_lock);
> >> - init_waitqueue_head(&blkbk->pending_free_wq);
> >> -
> >> - for (i = 0; i < xen_blkif_reqs; i++)
> >> - list_add_tail(&blkbk->pending_reqs[i].free_list,
> >> - &blkbk->pending_free);
> >> -
> >> rc = xen_blkif_xenbus_init();
> >> if (rc)
> >> goto failed_init;
> >>
> >> - return 0;
> >> -
> >> - out_of_memory:
> >> - pr_alert(DRV_PFX "%s: out of memory\n", __func__);
> >> failed_init:
> >> - kfree(blkbk->pending_reqs);
> >> - kfree(blkbk);
> >> - blkbk = NULL;
> >> return rc;
> >> }
> >>
> >> diff --git a/drivers/block/xen-blkback/common.h b/drivers/block/xen-blkback/common.h
> >> index f43782c..debff44 100644
> >> --- a/drivers/block/xen-blkback/common.h
> >> +++ b/drivers/block/xen-blkback/common.h
> >> @@ -236,6 +236,14 @@ struct xen_blkif {
> >> int free_pages_num;
> >> struct list_head free_pages;
> >>
> >> + /* Allocation of pending_reqs */
> >> + struct pending_req *pending_reqs;
> >> + /* List of all 'pending_req' available */
> >> + struct list_head pending_free;
> >> + /* And its spinlock. */
> >> + spinlock_t pending_free_lock;
> >> + wait_queue_head_t pending_free_wq;
> >> +
> >> /* statistics */
> >> unsigned long st_print;
> >> unsigned long long st_rd_req;
> >> @@ -249,6 +257,25 @@ struct xen_blkif {
> >> wait_queue_head_t waiting_to_free;
> >> };
> >>
> >> +/*
> >> + * Each outstanding request that we've passed to the lower device layers has a
> >> + * 'pending_req' allocated to it. Each buffer_head that completes decrements
> >> + * the pendcnt towards zero. When it hits zero, the specified domain has a
> >> + * response queued for it, with the saved 'id' passed back.
> >> + */
> >> +struct pending_req {
> >> + struct xen_blkif *blkif;
> >> + u64 id;
> >> + int nr_pages;
> >> + atomic_t pendcnt;
> >> + unsigned short operation;
> >> + int status;
> >> + struct list_head free_list;
> >> + struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> +};
> >> +
> >>
> >> #define vbd_sz(_v) ((_v)->bdev->bd_part ? \
> >> (_v)->bdev->bd_part->nr_sects : \
> >> diff --git a/drivers/block/xen-blkback/xenbus.c b/drivers/block/xen-blkback/xenbus.c
> >> index e0fd92a..bf7344f 100644
> >> --- a/drivers/block/xen-blkback/xenbus.c
> >> +++ b/drivers/block/xen-blkback/xenbus.c
> >> @@ -30,6 +30,8 @@ struct backend_info {
> >> char *mode;
> >> };
> >>
> >> +extern int xen_blkif_reqs;
> >
> > How about just sticking it in 'common.h'?
>
> Done, I've replaced it with a define instead of a variable.
>
> >
> >> +
> >> static struct kmem_cache *xen_blkif_cachep;
> >> static void connect(struct backend_info *);
> >> static int connect_ring(struct backend_info *);
> >> @@ -105,6 +107,7 @@ static void xen_update_blkif_status(struct xen_blkif *blkif)
> >> static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> >> {
> >> struct xen_blkif *blkif;
> >> + int i;
> >>
> >> blkif = kmem_cache_zalloc(xen_blkif_cachep, GFP_KERNEL);
> >> if (!blkif)
> >> @@ -124,6 +127,21 @@ static struct xen_blkif *xen_blkif_alloc(domid_t domid)
> >> blkif->free_pages_num = 0;
> >> atomic_set(&blkif->persistent_gnt_in_use, 0);
> >>
> >> + blkif->pending_reqs = kcalloc(xen_blkif_reqs,
> >> + sizeof(blkif->pending_reqs[0]),
> >> + GFP_KERNEL);
> >> + if (!blkif->pending_reqs) {
> >> + kmem_cache_free(xen_blkif_cachep, blkif);
> >> + return ERR_PTR(-ENOMEM);
> >> + }
> >> + INIT_LIST_HEAD(&blkif->pending_free);
> >> + spin_lock_init(&blkif->pending_free_lock);
> >> + init_waitqueue_head(&blkif->pending_free_wq);
> >> +
> >> + for (i = 0; i < xen_blkif_reqs; i++)
> >> + list_add_tail(&blkif->pending_reqs[i].free_list,
> >> + &blkif->pending_free);
> >> +
> >> return blkif;
> >> }
> >>
> >> @@ -205,6 +223,7 @@ static void xen_blkif_free(struct xen_blkif *blkif)
> >> {
> >> if (!atomic_dec_and_test(&blkif->refcnt))
> >> BUG();
> >
> > For sanity, should we have something like this:
> > struct pending_req *p;
> > i = 0;
> > list_for_each_entry (p, &blkif->pending_free, free_list)
> > i++;
> >
> > BUG_ON(i != xen_blkif_reqs);
> >
> > As that would mean somebody did not call 'free_req' and we have a loose one laying
> > around.
> >
> > Or perhaps just leak the offending struct and then don't do 'kfree'?
>
> I prefer the BUG instead of leaking the struct, if we are indeed still
> using a request better notice and fix it :)
OK. Lets leave it with a BUG.
>
> >
> >> + kfree(blkif->pending_reqs);
> >> kmem_cache_free(xen_blkif_cachep, blkif);
> >> }
> >>
> >> --
> >> 1.7.7.5 (Apple Git-26)
> >>
>
> >> +struct blkif_x86_32_request_indirect {
> >> + uint8_t indirect_op;
> >> + uint16_t nr_segments;
> >
> > This needs to be documented. Is there are limit to what it can be? What if
> > the frontend sets it to 1231231?
>
> This is checked in dispatch_rw_block_io:
>
> if (unlikely(nseg == 0 && operation != WRITE_FLUSH) ||
> unlikely((req->operation != BLKIF_OP_INDIRECT) &&
> (nseg > BLKIF_MAX_SEGMENTS_PER_REQUEST)) ||
> unlikely((req->operation == BLKIF_OP_INDIRECT) &&
> (nseg > MAX_INDIRECT_SEGMENTS))) {
> pr_debug(DRV_PFX "Bad number of segments in request (%d)\n",
> nseg);
I am wondering whether we should make that pr_err ..?
> /* Haven't submitted any bio's yet. */
> goto fail_response;
> }
>
> And the value of MAX_INDIRECT_SEGMENTS is exported to the frontend in
> xenstore, so the frontend does:
>
> max_indirect_segments = min(MAX_INDIRECT_SEGMENTS, front_max_segments);
>
> To know how many segments it can safely use in an indirect op.
<nods>
>
> >
> >> + uint64_t id;
> >> + blkif_sector_t sector_number;
> >> + blkif_vdev_t handle;
> >> + uint16_t _pad1;
> >> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
> >
> > And how do we figure out whether we are going to use one indirect_grefs or many?
> > That should be described here. (if I understand it right it would be done
> > via the maximum-indirect-something' variable)
>
> I've added the following comment:
>
> /*
> * The maximum number of indirect segments (and pages) that will
> * be used is determined by MAX_INDIRECT_SEGMENTS, this value
> * is also exported to the guest (via xenstore max-indirect-segments
.. feature-max-indirect-segments..
> * entry), so the frontend knows how many indirect segments the
> * backend supports.
> */
>
Great!
> >
> >
> >> +} __attribute__((__packed__));
> >> +
> >
> > Per my calculation the size of this structure is 55 bytes. The 64-bit is 59 bytes.
> >
> > It is a bit odd, but then 1 byte is for the 'operation' in the 'blkif_x*_request',
> > so it comes out to 56 and 60 bytes.
> >
> > Is that still the right amount ? I thought we wanted to flesh it out to be a nice
> > 64 byte aligned so that the future patches which will make the requests be
> > more cache-aligned and won't have to play games?
>
> Yes, I've added a uint32_t for 64bits and a uint64_t for 32bits, that
> makes it 64bytes aligned in both cases.
Thanks
>
> >
> >> struct blkif_x86_32_request {
> >> uint8_t operation; /* BLKIF_OP_??? */
> >> union {
> >> struct blkif_x86_32_request_rw rw;
> >> struct blkif_x86_32_request_discard discard;
> >> struct blkif_x86_32_request_other other;
> >> + struct blkif_x86_32_request_indirect indirect;
> >> } u;
> >> } __attribute__((__packed__));
> >>
> >> @@ -127,12 +149,24 @@ struct blkif_x86_64_request_other {
> >> uint64_t id; /* private guest value, echoed in resp */
> >> } __attribute__((__packed__));
> >>
> >> +struct blkif_x86_64_request_indirect {
> >> + uint8_t indirect_op;
> >> + uint16_t nr_segments;
> >> + uint32_t _pad1; /* offsetof(blkif_..,u.indirect.id)==8 */
> >
> > The comment is a bit off compared to the rest.
> >
> >> + uint64_t id;
> >> + blkif_sector_t sector_number;
> >> + blkif_vdev_t handle;
> >> + uint16_t _pad2;
> >> + grant_ref_t indirect_grefs[BLKIF_MAX_INDIRECT_GREFS_PER_REQUEST];
> >> +} __attribute__((__packed__));
> >> +
> >> struct blkif_x86_64_request {
> >> uint8_t operation; /* BLKIF_OP_??? */
> >> union {
> >> struct blkif_x86_64_request_rw rw;
> >> struct blkif_x86_64_request_discard discard;
> >> struct blkif_x86_64_request_other other;
> >> + struct blkif_x86_64_request_indirect indirect;
> >> } u;
> >> } __attribute__((__packed__));
> >>
> >> @@ -257,6 +291,11 @@ struct xen_blkif {
> >> wait_queue_head_t waiting_to_free;
> >> };
> >>
> >> +struct seg_buf {
> >> + unsigned long offset;
> >> + unsigned int nsec;
> >> +};
> >> +
> >> /*
> >> * Each outstanding request that we've passed to the lower device layers has a
> >> * 'pending_req' allocated to it. Each buffer_head that completes decrements
> >> @@ -271,9 +310,16 @@ struct pending_req {
> >> unsigned short operation;
> >> int status;
> >> struct list_head free_list;
> >> - struct page *pages[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> - struct persistent_gnt *persistent_gnts[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> - grant_handle_t grant_handles[BLKIF_MAX_SEGMENTS_PER_REQUEST];
> >> + struct page *pages[MAX_INDIRECT_SEGMENTS];
> >> + struct persistent_gnt *persistent_gnts[MAX_INDIRECT_SEGMENTS];
> >> + grant_handle_t grant_handles[MAX_INDIRECT_SEGMENTS];
> >> + grant_ref_t grefs[MAX_INDIRECT_SEGMENTS];
> >> + /* Indirect descriptors */
> >> + struct persistent_gnt *indirect_persistent_gnts[MAX_INDIRECT_GREFS];
> >> + struct page *indirect_pages[MAX_INDIRECT_GREFS];
> >> + grant_handle_t indirect_handles[MAX_INDIRECT_GREFS];
> >> + struct seg_buf seg[MAX_INDIRECT_SEGMENTS];
> >> + struct bio *biolist[MAX_INDIRECT_SEGMENTS];
> >
> > Oh wow. That is a big structure. So 1536 for the BLKIF_MAX_SEGMENTS_PER_REQUEST
> > ones and 24 bytes for the ones that deail with MAX_INDIRECT_GREFS.
> >
> > This could be made look nicer. For example you could do:
> >
> > struct indirect {
> > struct page;
> > grant_handle_t handle;
> > struct persistent_gnt *gnt;
> > } desc[MAX_INDIRECT_GREFS];
> >
> > .. and the same treatment to the BLKIF_MAX_SEGMENTS_PER_REQUEST
> > one.
> >
> > Thought perhaps it makes more sense to do that with a later patch as a cleanup.
>
> This was similar to what Jan was suggesting, but I would prefer to leave
> that for a latter patch.
<nods>
.. snip..
> >> +/*
> >> + * Maximum number of segments in indirect requests, the actual value used by
> >> + * the frontend driver is the minimum of this value and the value provided
> >> + * by the backend driver.
> >> + */
> >> +
> >> +static int xen_blkif_max_segments = 32;
> >> +module_param_named(max_segments, xen_blkif_max_segments, int, 0);
> >> +MODULE_PARM_DESC(max_segments,
> >> +"Maximum number of segments in indirect requests");
> >
> > This means a new entry in Documentation/ABI/sysfs/...
>
> I think I should just not allow this to be exported, since we cannot
> change it at run-time, so if a user changes the 0 to something else, and
> changes the value... nothing will happen (because this is only used
> before the device is connected).
OK, lets then not make it a module_param_named.
>
> >
> > Perhaps the xen-blkfront part of the patch should be just split out to make
> > this easier?
> >
> > Perhaps what we really should have is just the 'max' value of megabytes
> > we want to handle on the ring.
> >
> > As right now 32 ring requests * 32 segments = 4MB. But if the user wants
> > to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
> > and since we have 32 of them = 512MB).
>
> I've just set that to something that brings a performance benefit
> without having to map an insane number of persistent grants in blkback.
>
> Yes, the values are correct, but the device request queue (rq) is only
> able to provide read requests with 64 segments or write requests with
> 128 segments. I haven't been able to get larger requests, even when
> setting this to 512 or higer.
What are you using to drive the requests? 'fio'?
.. snip..
> >> @@ -588,13 +666,14 @@ static int xlvbd_init_blk_queue(struct gendisk *gd, u16 sector_size)
> >> static void xlvbd_flush(struct blkfront_info *info)
> >> {
> >> blk_queue_flush(info->rq, info->feature_flush);
> >> - printk(KERN_INFO "blkfront: %s: %s: %s %s\n",
> >> + printk(KERN_INFO "blkfront: %s: %s: %s %s %s\n",
> >> info->gd->disk_name,
> >> info->flush_op == BLKIF_OP_WRITE_BARRIER ?
> >> "barrier" : (info->flush_op == BLKIF_OP_FLUSH_DISKCACHE ?
> >> "flush diskcache" : "barrier or flush"),
> >> info->feature_flush ? "enabled" : "disabled",
> >> - info->feature_persistent ? "using persistent grants" : "");
> >> + info->feature_persistent ? "using persistent grants" : "",
> >> + info->max_indirect_segments ? "using indirect descriptors" : "");
> >
> > This is a bit of mess now:
> >
> >
> > [ 0.968241] blkfront: xvda: barrier or flush: disabled using persistent grants using indirect descriptors
> >
> > Should it just be:
> >
> > 'persistent_grants: enabled; indirect descriptors: enabled'
> >
> > ?
>
> Agreed. If you don't mind I will change the wording for both persistent
> grants and indirect descriptors in this same patch.
That is OK.
.. snip..
> >> * Invoked when the backend is finally 'ready' (and has told produced
> >> * the details about the physical device - #sectors, size, etc).
> >> @@ -1414,8 +1735,9 @@ static void blkfront_connect(struct blkfront_info *info)
> >> set_capacity(info->gd, sectors);
> >> revalidate_disk(info->gd);
> >>
> >> - /* fall through */
> >> + return;
> >
> > How come?
>
> We cannot fall thought anymore, because now we call blkif_recover in
> order to recover after performing the suspension, in the past this was
> just a return so we could fall thought.
>
> We need to perform the recover at this point because we need to know if
> the backend supports indirect descriptors, and how many. In the past we
> used to perform the recover before the backend announced it's features,
> but now we need to know if the backend supports indirect segments or not.
OK. Can you put that nice explanation as a comment in there please?
On 17/04/13 16:25, Konrad Rzeszutek Wilk wrote:
>>> Perhaps the xen-blkfront part of the patch should be just split out to make
>>> this easier?
>>>
>>> Perhaps what we really should have is just the 'max' value of megabytes
>>> we want to handle on the ring.
>>>
>>> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
>>> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
>>> and since we have 32 of them = 512MB).
>>
>> I've just set that to something that brings a performance benefit
>> without having to map an insane number of persistent grants in blkback.
>>
>> Yes, the values are correct, but the device request queue (rq) is only
>> able to provide read requests with 64 segments or write requests with
>> 128 segments. I haven't been able to get larger requests, even when
>> setting this to 512 or higer.
>
> What are you using to drive the requests? 'fio'?
Yes, I've tried fio with several "bs=" values, but it doesn't seem to
change the size of the underlying requests. Have you been able to get
bigger requests?
On Wed, Apr 17, 2013 at 07:04:51PM +0200, Roger Pau Monn? wrote:
> On 17/04/13 16:25, Konrad Rzeszutek Wilk wrote:
> >>> Perhaps the xen-blkfront part of the patch should be just split out to make
> >>> this easier?
> >>>
> >>> Perhaps what we really should have is just the 'max' value of megabytes
> >>> we want to handle on the ring.
> >>>
> >>> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
> >>> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
> >>> and since we have 32 of them = 512MB).
> >>
> >> I've just set that to something that brings a performance benefit
> >> without having to map an insane number of persistent grants in blkback.
> >>
> >> Yes, the values are correct, but the device request queue (rq) is only
> >> able to provide read requests with 64 segments or write requests with
> >> 128 segments. I haven't been able to get larger requests, even when
> >> setting this to 512 or higer.
> >
> > What are you using to drive the requests? 'fio'?
>
> Yes, I've tried fio with several "bs=" values, but it doesn't seem to
> change the size of the underlying requests. Have you been able to get
> bigger requests?
Martin, Jens,
Any way to drive more than 128 segments?
On Wed, Apr 17 2013, Konrad Rzeszutek Wilk wrote:
> On Wed, Apr 17, 2013 at 07:04:51PM +0200, Roger Pau Monn? wrote:
> > On 17/04/13 16:25, Konrad Rzeszutek Wilk wrote:
> > >>> Perhaps the xen-blkfront part of the patch should be just split out to make
> > >>> this easier?
> > >>>
> > >>> Perhaps what we really should have is just the 'max' value of megabytes
> > >>> we want to handle on the ring.
> > >>>
> > >>> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
> > >>> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
> > >>> and since we have 32 of them = 512MB).
> > >>
> > >> I've just set that to something that brings a performance benefit
> > >> without having to map an insane number of persistent grants in blkback.
> > >>
> > >> Yes, the values are correct, but the device request queue (rq) is only
> > >> able to provide read requests with 64 segments or write requests with
> > >> 128 segments. I haven't been able to get larger requests, even when
> > >> setting this to 512 or higer.
> > >
> > > What are you using to drive the requests? 'fio'?
> >
> > Yes, I've tried fio with several "bs=" values, but it doesn't seem to
> > change the size of the underlying requests. Have you been able to get
> > bigger requests?
>
> Martin, Jens,
> Any way to drive more than 128 segments?
If the driver is bio based, then there's a natural size constraint on
the number of vecs in the bio. So to get truly large requests, the
driver would need to merge incoming sequential IOs (similar to how it's
done for rq based drivers).
--
Jens Axboe
On 18/04/13 14:43, Jens Axboe wrote:
> On Wed, Apr 17 2013, Konrad Rzeszutek Wilk wrote:
>> On Wed, Apr 17, 2013 at 07:04:51PM +0200, Roger Pau Monn? wrote:
>>> On 17/04/13 16:25, Konrad Rzeszutek Wilk wrote:
>>>>>> Perhaps the xen-blkfront part of the patch should be just split out to make
>>>>>> this easier?
>>>>>>
>>>>>> Perhaps what we really should have is just the 'max' value of megabytes
>>>>>> we want to handle on the ring.
>>>>>>
>>>>>> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
>>>>>> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
>>>>>> and since we have 32 of them = 512MB).
>>>>>
>>>>> I've just set that to something that brings a performance benefit
>>>>> without having to map an insane number of persistent grants in blkback.
>>>>>
>>>>> Yes, the values are correct, but the device request queue (rq) is only
>>>>> able to provide read requests with 64 segments or write requests with
>>>>> 128 segments. I haven't been able to get larger requests, even when
>>>>> setting this to 512 or higer.
>>>>
>>>> What are you using to drive the requests? 'fio'?
>>>
>>> Yes, I've tried fio with several "bs=" values, but it doesn't seem to
>>> change the size of the underlying requests. Have you been able to get
>>> bigger requests?
>>
>> Martin, Jens,
>> Any way to drive more than 128 segments?
>
> If the driver is bio based, then there's a natural size constraint on
> the number of vecs in the bio. So to get truly large requests, the
> driver would need to merge incoming sequential IOs (similar to how it's
> done for rq based drivers).
When you say rq based drivers, you mean drivers with a request queue?
We are already using a request queue in blkfront, and I'm setting the
maximum number of segments per request using:
blk_queue_max_segments(<rq>, <segments>);
But even when setting <segments> to 256 or 512, I only get read requests
with 64 segments and write requests with 128 segments from the queue.
On Thu, Apr 18 2013, Roger Pau Monn? wrote:
> On 18/04/13 14:43, Jens Axboe wrote:
> > On Wed, Apr 17 2013, Konrad Rzeszutek Wilk wrote:
> >> On Wed, Apr 17, 2013 at 07:04:51PM +0200, Roger Pau Monn? wrote:
> >>> On 17/04/13 16:25, Konrad Rzeszutek Wilk wrote:
> >>>>>> Perhaps the xen-blkfront part of the patch should be just split out to make
> >>>>>> this easier?
> >>>>>>
> >>>>>> Perhaps what we really should have is just the 'max' value of megabytes
> >>>>>> we want to handle on the ring.
> >>>>>>
> >>>>>> As right now 32 ring requests * 32 segments = 4MB. But if the user wants
> >>>>>> to se the max: 32 * 4096 = so 512MB (right? each request would handle now 16MB
> >>>>>> and since we have 32 of them = 512MB).
> >>>>>
> >>>>> I've just set that to something that brings a performance benefit
> >>>>> without having to map an insane number of persistent grants in blkback.
> >>>>>
> >>>>> Yes, the values are correct, but the device request queue (rq) is only
> >>>>> able to provide read requests with 64 segments or write requests with
> >>>>> 128 segments. I haven't been able to get larger requests, even when
> >>>>> setting this to 512 or higer.
> >>>>
> >>>> What are you using to drive the requests? 'fio'?
> >>>
> >>> Yes, I've tried fio with several "bs=" values, but it doesn't seem to
> >>> change the size of the underlying requests. Have you been able to get
> >>> bigger requests?
> >>
> >> Martin, Jens,
> >> Any way to drive more than 128 segments?
> >
> > If the driver is bio based, then there's a natural size constraint on
> > the number of vecs in the bio. So to get truly large requests, the
> > driver would need to merge incoming sequential IOs (similar to how it's
> > done for rq based drivers).
>
> When you say rq based drivers, you mean drivers with a request queue?
>
> We are already using a request queue in blkfront, and I'm setting the
> maximum number of segments per request using:
>
> blk_queue_max_segments(<rq>, <segments>);
>
> But even when setting <segments> to 256 or 512, I only get read requests
> with 64 segments and write requests with 128 segments from the queue.
What kernel are you testing? The plugging is usually what will trigger a
run of the queue, for rq based drivers. What does your fio job look
like?
--
Jens Axboe
On 18/04/13 16:26, Jens Axboe wrote:
>>>>>>> I've just set that to something that brings a performance benefit
>>>>>>> without having to map an insane number of persistent grants in blkback.
>>>>>>>
>>>>>>> Yes, the values are correct, but the device request queue (rq) is only
>>>>>>> able to provide read requests with 64 segments or write requests with
>>>>>>> 128 segments. I haven't been able to get larger requests, even when
>>>>>>> setting this to 512 or higer.
>>>>>>
>>>>>> What are you using to drive the requests? 'fio'?
>>>>>
>>>>> Yes, I've tried fio with several "bs=" values, but it doesn't seem to
>>>>> change the size of the underlying requests. Have you been able to get
>>>>> bigger requests?
>>>>
>>>> Martin, Jens,
>>>> Any way to drive more than 128 segments?
>>>
>>> If the driver is bio based, then there's a natural size constraint on
>>> the number of vecs in the bio. So to get truly large requests, the
>>> driver would need to merge incoming sequential IOs (similar to how it's
>>> done for rq based drivers).
>>
>> When you say rq based drivers, you mean drivers with a request queue?
>>
>> We are already using a request queue in blkfront, and I'm setting the
>> maximum number of segments per request using:
>>
>> blk_queue_max_segments(<rq>, <segments>);
>>
>> But even when setting <segments> to 256 or 512, I only get read requests
>> with 64 segments and write requests with 128 segments from the queue.
>
> What kernel are you testing? The plugging is usually what will trigger a
> run of the queue, for rq based drivers. What does your fio job look
> like?
>
I'm currently testing on top of Konrad for-jens-3.9 branch, which is
3.8.0-rc7. This is how my fio job looks like:
[read]
rw=read
size=900m
bs=4k
directory=/root/fio
loops=100000
I've tried several bs sizes; 4k, 16k, 128k, 1m, 10m, and as far as I can
see requests from the queue don't have more than 64 segments.
Also tried a simple dd with several bs sizes and got the same result.
On Thu, Apr 18 2013, Roger Pau Monn? wrote:
> On 18/04/13 16:26, Jens Axboe wrote:
> >>>>>>> I've just set that to something that brings a performance benefit
> >>>>>>> without having to map an insane number of persistent grants in blkback.
> >>>>>>>
> >>>>>>> Yes, the values are correct, but the device request queue (rq) is only
> >>>>>>> able to provide read requests with 64 segments or write requests with
> >>>>>>> 128 segments. I haven't been able to get larger requests, even when
> >>>>>>> setting this to 512 or higer.
> >>>>>>
> >>>>>> What are you using to drive the requests? 'fio'?
> >>>>>
> >>>>> Yes, I've tried fio with several "bs=" values, but it doesn't seem to
> >>>>> change the size of the underlying requests. Have you been able to get
> >>>>> bigger requests?
> >>>>
> >>>> Martin, Jens,
> >>>> Any way to drive more than 128 segments?
> >>>
> >>> If the driver is bio based, then there's a natural size constraint on
> >>> the number of vecs in the bio. So to get truly large requests, the
> >>> driver would need to merge incoming sequential IOs (similar to how it's
> >>> done for rq based drivers).
> >>
> >> When you say rq based drivers, you mean drivers with a request queue?
> >>
> >> We are already using a request queue in blkfront, and I'm setting the
> >> maximum number of segments per request using:
> >>
> >> blk_queue_max_segments(<rq>, <segments>);
> >>
> >> But even when setting <segments> to 256 or 512, I only get read requests
> >> with 64 segments and write requests with 128 segments from the queue.
> >
> > What kernel are you testing? The plugging is usually what will trigger a
> > run of the queue, for rq based drivers. What does your fio job look
> > like?
> >
>
> I'm currently testing on top of Konrad for-jens-3.9 branch, which is
> 3.8.0-rc7. This is how my fio job looks like:
>
> [read]
> rw=read
> size=900m
> bs=4k
> directory=/root/fio
> loops=100000
>
> I've tried several bs sizes; 4k, 16k, 128k, 1m, 10m, and as far as I can
> see requests from the queue don't have more than 64 segments.
>
> Also tried a simple dd with several bs sizes and got the same result.
So you're running normal buffered IO. Most of the IO should be coming
out of read-ahead, you could try tweaking the size of the window.
--
Jens Axboe
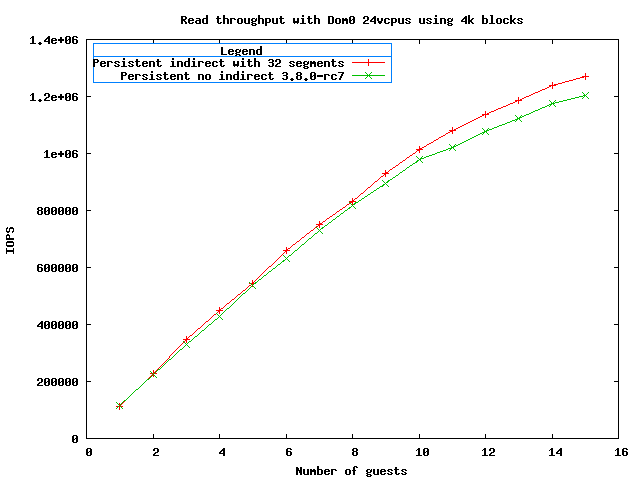{kind=link}