Robert Olsson noticed dst cache overflows while doing DoS stress testing in a
2.6 based router setup a few months and davem, alexey, robert and I
have been discussing this privately since then (198 mails, no less!!).
Recently, I set up an environment to test Robert's problem and have
been characterizing it. My setup is -
pktgen box --- in router out --
eth0 eth0 <-> dumm0
10.0.0.1 10.0.0.2 5.0.0.1
The router box is a 2-way P4 xeon 2.4 GHz with 256MB memory. I use
Robert's pktgen script -
CLONE_SKB="clone_skb 1"
PKT_SIZE="pkt_size 60"
#COUNT="count 0"
COUNT="count 10000000"
IPG="ipg 0"
PGDEV=/proc/net/pktgen/eth0
echo "Configuring $PGDEV"
pgset "$COUNT"
pgset "$CLONE_SKB"
pgset "$PKT_SIZE"
pgset "$IPG"
pgset "flag IPDST_RND"
pgset "dst_min 5.0.0.0"
pgset "dst_max 5.255.255.255"
pgset "flows 32768"
pgset "flowlen 10"
With this, wthin a few seconds of starting pktgen, I get dst cache
overflow messages. I use the following instrumentation patch
to look at what's happening -
http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/patches/15-rcu-debug.patch
I tried both vanilla 2.6.0 and 2.6.0 + throttle-rcu patch which limits
RCU to 4 updates per RCU tasklet. The results are here -
http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/gracedata/cpu-grace.png
This graph shows the maximum grace period during ~4ms time buckets on x-axis.
Couple of things are clear from this -
1. RCU grace periods of upto 300ms are seen. 300ms + 100Kpps packet
amounts to about 30000 pending dst entries which result in route cache
overflow.
2. throttle-rcu is only marginally better (10% less worst case grace period).
So, what causes RCU to stall for 300ms odd time ? I did some measurements
using the following patch -
http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/patches/25-softirq-debug.patch
It applies on top of the 15-rcu-debug patch. This counts the number of
softirqs (in effect and approximation) during ~4ms time buckets. The
result is here -
http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/softirq/cpu-softirq.png
The rcu grace period spikes are always accompanied by softirq frequency
spikes. So, this indicates that it is the large number of quick-running
softirqs that cause userland starvation which in turn result in RCU
delays. This raises a fundamental question - should we work around
this by providing a quiescent point at the end of every softirq handler
(giving softirqs its own RCU mechanism) or should we address a wider
problem, the system getting overwhelmed by heavy softirq load, and
try to implement a real softirq throttling mechanism that balances
cpu use.
Robert demonstrated to us sometime ago with a small
timestamping user program to show that it can get starved for
more than 6 seconds in his system. So userland starvation is an
issue.
Thanks
Dipankar
On Tue, Mar 30, 2004 at 12:15:50AM +0530, Dipankar Sarma wrote:
> Robert Olsson noticed dst cache overflows while doing DoS stress testing in a
> 2.6 based router setup a few months and davem, alexey, robert and I
> have been discussing this privately since then (198 mails, no less!!).
> Recently, I set up an environment to test Robert's problem and have
> been characterizing it. My setup is -
>
> pktgen box --- in router out --
> eth0 eth0 <-> dumm0
>
> 10.0.0.1 10.0.0.2 5.0.0.1
>
> The router box is a 2-way P4 xeon 2.4 GHz with 256MB memory. I use
> Robert's pktgen script -
>
> CLONE_SKB="clone_skb 1"
> PKT_SIZE="pkt_size 60"
> #COUNT="count 0"
> COUNT="count 10000000"
> IPG="ipg 0"
>
> PGDEV=/proc/net/pktgen/eth0
> echo "Configuring $PGDEV"
> pgset "$COUNT"
> pgset "$CLONE_SKB"
> pgset "$PKT_SIZE"
> pgset "$IPG"
> pgset "flag IPDST_RND"
> pgset "dst_min 5.0.0.0"
> pgset "dst_max 5.255.255.255"
> pgset "flows 32768"
> pgset "flowlen 10"
>
> With this, wthin a few seconds of starting pktgen, I get dst cache
> overflow messages. I use the following instrumentation patch
> to look at what's happening -
>
> http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/patches/15-rcu-debug.patch
> I tried both vanilla 2.6.0 and 2.6.0 + throttle-rcu patch which limits
> RCU to 4 updates per RCU tasklet. The results are here -
>
> http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/gracedata/cpu-grace.png
>
> This graph shows the maximum grace period during ~4ms time buckets on x-axis.
>
> Couple of things are clear from this -
>
> 1. RCU grace periods of upto 300ms are seen. 300ms + 100Kpps packet
> amounts to about 30000 pending dst entries which result in route cache
> overflow.
>
> 2. throttle-rcu is only marginally better (10% less worst case grace period).
>
> So, what causes RCU to stall for 300ms odd time ? I did some measurements
> using the following patch -
>
> http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/patches/25-softirq-debug.patch
>
> It applies on top of the 15-rcu-debug patch. This counts the number of
> softirqs (in effect and approximation) during ~4ms time buckets. The
> result is here -
>
> http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/softirq/cpu-softirq.png
>
> The rcu grace period spikes are always accompanied by softirq frequency
> spikes. So, this indicates that it is the large number of quick-running
> softirqs that cause userland starvation which in turn result in RCU
> delays. This raises a fundamental question - should we work around
> this by providing a quiescent point at the end of every softirq handler
> (giving softirqs its own RCU mechanism) or should we address a wider
> problem, the system getting overwhelmed by heavy softirq load, and
> try to implement a real softirq throttling mechanism that balances
> cpu use.
>
> Robert demonstrated to us sometime ago with a small
> timestamping user program to show that it can get starved for
> more than 6 seconds in his system. So userland starvation is an
> issue.
softirqs are already capable of being offloaded to scheduler-friendy
kernel threads to avoid starvation, if this wasn't the case NAPI would
have no way to work in the first place and everything else would fall
apart too, not just the rcu-route-cache. I don't think high latencies
and starvation are the same thing, starvation means for "indefinite
time" and you can't hang userspace for indefinite time using softirqs.
For sure the irq based load, and in turn softirqs too, can take a large
amount of cpu (though not 100%, this is why it cannot be called
starvation).
the only real starvation you can claim is in presence of an _hard_irq
flood, not a softirq one. Ingo had some patch for the hardirq
throttling, unfortunately those pathes were mixed with irrelevant
softirq changes, but the hardirq part of these patches was certainly
valid (though in most business environments I imagine if one is under
hardirq attack in the local ethernet, the last worry is probably the
throttling of hardirqs ;)
The softirq issue you mention simply shows how these softirqs keeps
being served with slightly higher prio than the regular kernel code,
and by doing so they make more progress than regular kernel code during
spike of softirq load. The problem with rcu based softirq load, is that
these softirqs requires the scheduler to keep going or they overflow if
they keep running instead of the scheduler. They require the scheduler
to keep up with the softirq load. This has never been the case so far,
and serving softirq as fast as possible is normally a good thing for
server/firewalls, the small unfariness (note unfariness != starvation)
it generates has never been an issue, because so far the softirq never
required the scheduler to work in order to do their work, rcu changed
this in the routing cache specific case.
So you're simply asking the ksoftirqd offloading to become more
aggressive, and to make the softirq even more scheduler friendly,
something I never had a reason to do yet, since ksoftirqd already
eliminates the starvation issue, and secondly because I did care about
the performance of softirq first (delaying softirqs is derimental for
performance if it happens frequently w/o this kind of flood-load). I
even got a patch for 2.4 doing this kind of changes to the softirqd for
similar reasons on embedded systems where the cpu spent on the softirqs
would been way too much under attack. I had to back it out since it was
causing drop of performance in specweb or something like that and nobody
but the embdedded people needed it. But now here we've a case where it
makes even more sense since the hardirq aren't strictly related to this
load, this load with the rcu-routing-cache is just about letting the
scheduler go together witn an intensive softirq load. So we can try
again with a truly userspace throttling of the softirqs (and in 2.4 I
didn't change the nice from 19 to -20 so maybe this will just work
perfectly).
btw, the set_current_state(TASK_INTERRUPTIBLE) before
kthread_should_stop seems overkill w.r.t. smp locking, plus the code is
written in the wrong way around, all set_current_state are in the wrong
place. It's harmless but I cleaned up that bit as well.
I would suggest to give this untested patch a try and see if it fixes
your problem completely or not:
--- sles/kernel/softirq.c.~1~ 2004-03-29 19:05:17.140586072 +0200
+++ sles/kernel/softirq.c 2004-03-30 00:28:11.097296968 +0200
@@ -58,6 +58,14 @@ static inline void wakeup_softirqd(void)
wake_up_process(tsk);
}
+static inline int local_softirqd_running(void)
+{
+ /* Interrupts are disabled: no need to stop preemption */
+ struct task_struct *tsk = __get_cpu_var(ksoftirqd);
+
+ return tsk && tsk->state == TASK_RUNNING;
+}
+
/*
* We restart softirq processing MAX_SOFTIRQ_RESTART times,
* and we fall back to softirqd after that.
@@ -71,13 +79,15 @@ static inline void wakeup_softirqd(void)
asmlinkage void do_softirq(void)
{
- int max_restart = MAX_SOFTIRQ_RESTART;
+ int max_restart;
__u32 pending;
unsigned long flags;
- if (in_interrupt())
+ if (in_interrupt() || local_softirqd_running())
return;
+ max_restart = MAX_SOFTIRQ_RESTART;
+
local_irq_save(flags);
pending = local_softirq_pending();
@@ -308,16 +318,14 @@ void __init softirq_init(void)
static int ksoftirqd(void * __bind_cpu)
{
- set_user_nice(current, 19);
+ set_user_nice(current, -20);
current->flags |= PF_IOTHREAD;
- set_current_state(TASK_INTERRUPTIBLE);
-
while (!kthread_should_stop()) {
- if (!local_softirq_pending())
+ if (!local_softirq_pending()) {
+ __set_current_state(TASK_INTERRUPTIBLE);
schedule();
-
- __set_current_state(TASK_RUNNING);
+ }
while (local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
@@ -331,20 +339,16 @@ static int ksoftirqd(void * __bind_cpu)
cond_resched();
}
- __set_current_state(TASK_INTERRUPTIBLE);
}
- __set_current_state(TASK_RUNNING);
return 0;
wait_to_die:
preempt_enable();
/* Wait for kthread_stop */
- __set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
- schedule();
__set_current_state(TASK_INTERRUPTIBLE);
+ schedule();
}
- __set_current_state(TASK_RUNNING);
return 0;
}
On Tue, Mar 30, 2004 at 01:07:12AM +0000, Andrea Arcangeli wrote:
> btw, the set_current_state(TASK_INTERRUPTIBLE) before
> kthread_should_stop seems overkill w.r.t. smp locking, plus the code is
> written in the wrong way around, all set_current_state are in the wrong
> place. It's harmless but I cleaned up that bit as well.
I think set_current_state(TASK_INTERRUPTIBLE) before kthread_should_stop()
_is_ required, otherwise kthread_stop can fail to destroy a kthread.
kthread_stop does:
1. kthread_stop_info.k = k;
2. wake_up_process(k);
and if ksoftirqd were to do :
a. while (!kthread_should_stop()) {
b. __set_current_state(TASK_INTERRUPTIBLE);
c. schedule();
}
There is a (narrow) possibility here that a) happens _after_ 1) as well as
b) _after_ 2).
In such a case kthread_stop would have failed to wake up the kthread!
The same race is avoided if ksoftirqd does:
a. __set_current_state(TASK_INTERRUPTIBLE);
b. while (!kthread_should_stop()) {
c. schedule();
d. __set_current_state(TASK_INTERRUPTIBLE);
}
e. __set_current_state(TASK_RUNNING);
In this case, even if b) happens _after_ 1) and c) _after_ 2), schedule
simply returns immediately because task's state would have been set to
TASK_RUNNING by 2). It goes back to the kthread_should_stop() check and
exits!
--
Thanks and Regards,
Srivatsa Vaddagiri,
Linux Technology Center,
IBM Software Labs,
Bangalore, INDIA - 560017
On Tue, Mar 30, 2004 at 10:36:14AM +0530, Srivatsa Vaddagiri wrote:
> kthread_stop does:
>
> 1. kthread_stop_info.k = k;
> 2. wake_up_process(k);
>
> and if ksoftirqd were to do :
>
> a. while (!kthread_should_stop()) {
> b. __set_current_state(TASK_INTERRUPTIBLE);
> c. schedule();
> }
>
>
> There is a (narrow) possibility here that a) happens _after_ 1) as well as
> b) _after_ 2).
hmm .. I meant a) happening _before_ 1) and b) happening _after_ 2) ..
>
> a. __set_current_state(TASK_INTERRUPTIBLE);
> b. while (!kthread_should_stop()) {
> c. schedule();
> d. __set_current_state(TASK_INTERRUPTIBLE);
> }
>
> e. __set_current_state(TASK_RUNNING);
>
> In this case, even if b) happens _after_ 1) and c) _after_ 2),
Again I meant "even if b) happens _before_ 1) and c) _after_ 2) !!
> schedule simply returns immediately because task's state would have been set
> to TASK_RUNNING by 2). It goes back to the kthread_should_stop() check and
> exits!
--
Thanks and Regards,
Srivatsa Vaddagiri,
Linux Technology Center,
IBM Software Labs,
Bangalore, INDIA - 560017
On Tue, Mar 30, 2004 at 12:29:26AM +0200, Andrea Arcangeli wrote:
> the only real starvation you can claim is in presence of an _hard_irq
> flood, not a softirq one. Ingo had some patch for the hardirq
> throttling, unfortunately those pathes were mixed with irrelevant
> softirq changes, but the hardirq part of these patches was certainly
> valid (though in most business environments I imagine if one is under
> hardirq attack in the local ethernet, the last worry is probably the
> throttling of hardirqs ;)
Hmm.. What about firewalls and routers on the internet ? Shouldn't
they care ?
> So you're simply asking the ksoftirqd offloading to become more
> aggressive, and to make the softirq even more scheduler friendly,
> something I never had a reason to do yet, since ksoftirqd already
> eliminates the starvation issue, and secondly because I did care about
> the performance of softirq first (delaying softirqs is derimental for
> performance if it happens frequently w/o this kind of flood-load). I
> even got a patch for 2.4 doing this kind of changes to the softirqd for
> similar reasons on embedded systems where the cpu spent on the softirqs
> would been way too much under attack. I had to back it out since it was
> causing drop of performance in specweb or something like that and nobody
> but the embdedded people needed it. But now here we've a case where it
> makes even more sense since the hardirq aren't strictly related to this
> load, this load with the rcu-routing-cache is just about letting the
> scheduler go together witn an intensive softirq load. So we can try
> again with a truly userspace throttling of the softirqs (and in 2.4 I
> didn't change the nice from 19 to -20 so maybe this will just work
> perfectly).
Tried it and it didn't work. I still got dst cache overflows. I will dig
out more numbers about what what happened - is ksoftirqd a pig still or
we are mostly doing short softirq bursts on the back of a hardirq
flood.
Thanks
Dipankar
On Tue, Mar 30, 2004 at 11:05:15AM +0530, Srivatsa Vaddagiri wrote:
> On Tue, Mar 30, 2004 at 10:36:14AM +0530, Srivatsa Vaddagiri wrote:
> > kthread_stop does:
> >
> > 1. kthread_stop_info.k = k;
> > 2. wake_up_process(k);
> >
> > and if ksoftirqd were to do :
> >
> > a. while (!kthread_should_stop()) {
> > b. __set_current_state(TASK_INTERRUPTIBLE);
> > c. schedule();
> > }
> >
> >
> > There is a (narrow) possibility here that a) happens _after_ 1) as well as
> > b) _after_ 2).
>
> hmm .. I meant a) happening _before_ 1) and b) happening _after_ 2) ..
>
> >
> > a. __set_current_state(TASK_INTERRUPTIBLE);
> > b. while (!kthread_should_stop()) {
> > c. schedule();
> > d. __set_current_state(TASK_INTERRUPTIBLE);
> > }
> >
> > e. __set_current_state(TASK_RUNNING);
> >
> > In this case, even if b) happens _after_ 1) and c) _after_ 2),
>
> Again I meant "even if b) happens _before_ 1) and c) _after_ 2) !!
>
> > schedule simply returns immediately because task's state would have been set
> > to TASK_RUNNING by 2). It goes back to the kthread_should_stop() check and
> > exits!
you're right, I had a private email exchange with Andrew about this
yesterday, he promptly pointed it out too. But my point is that the
previous code was broken too, it wasn't me breaking the code, I only
simplified already broken code instead of fixing it for real. His tree
should get the proper fixes soon. All those __ in front of the
set_current_state in that function made the ordering worthless and
that's why I cleaned them up.
The softirq part in the patch however is orthogonal to the above races,
so I didn't post an update since it didn't impact testing.
On Tue, Mar 30, 2004 at 08:13:24PM +0530, Dipankar Sarma wrote:
> On Tue, Mar 30, 2004 at 12:29:26AM +0200, Andrea Arcangeli wrote:
> > So you're simply asking the ksoftirqd offloading to become more
> > aggressive, and to make the softirq even more scheduler friendly,
> > something I never had a reason to do yet, since ksoftirqd already
> > eliminates the starvation issue, and secondly because I did care about
> > the performance of softirq first (delaying softirqs is derimental for
> > performance if it happens frequently w/o this kind of flood-load). I
> > even got a patch for 2.4 doing this kind of changes to the softirqd for
> > similar reasons on embedded systems where the cpu spent on the softirqs
> > would been way too much under attack. I had to back it out since it was
> > causing drop of performance in specweb or something like that and nobody
> > but the embdedded people needed it. But now here we've a case where it
> > makes even more sense since the hardirq aren't strictly related to this
> > load, this load with the rcu-routing-cache is just about letting the
> > scheduler go together witn an intensive softirq load. So we can try
> > again with a truly userspace throttling of the softirqs (and in 2.4 I
> > didn't change the nice from 19 to -20 so maybe this will just work
> > perfectly).
>
> Tried it and it didn't work. I still got dst cache overflows. I will dig
> out more numbers about what what happened - is ksoftirqd a pig still or
> we are mostly doing short softirq bursts on the back of a hardirq
> flood.
It doesn't look as if we are processing much from ksoftirqd at
all in this case. I did the following instrumentation -
if (in_interrupt() && local_softirqd_running())
return;
max_restart = MAX_SOFTIRQ_RESTART;
local_irq_save(flags);
if (rcu_trace) {
int cpu = smp_processor_id();
per_cpu(softirq_count, cpu)++;
if (local_softirqd_running() && current == __get_cpu_var(ksoftirqd))
per_cpu(ksoftirqd_count, cpu)++;
else if (!in_interrupt())
per_cpu(other_softirq_count, cpu)++;
}
pending = local_softirq_pending();
A look at the softirq_count, ksoftirqd_count and other_softirq_count shows -
CPU 0 : 638240 554 637686
CPU 1 : 102316 1 102315
CPU 2 : 675696 557 675139
CPU 3 : 102305 0 102305
So, it doesn't seem supprising that your ksoftirqd offloading didn't
really help much. The softirq frequency and grace period graph
looks pretty much same without that patch -
http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/andrea/cpu-softirq.png
We are simply calling do_softirq() too much it seems and not letting
other things run on the system. Perhaps we need to look at real
throttling of softirqs ?
Thanks
Dipankar
Hello!
> > Robert demonstrated to us sometime ago with a small
> > timestamping user program to show that it can get starved for
> > more than 6 seconds in his system. So userland starvation is an
> > issue.
>
> softirqs are already capable of being offloaded to scheduler-friendy
> kernel threads to avoid starvation, if this wasn't the case NAPI would
> have no way to work in the first place and everything else would fall
> apart too, not just the rcu-route-cache. I don't think high latencies
> and starvation are the same thing, starvation means for "indefinite
> time" and you can't hang userspace for indefinite time using softirqs.
> For sure the irq based load, and in turn softirqs too, can take a large
> amount of cpu (though not 100%, this is why it cannot be called
> starvation).
>
> the only real starvation you can claim is in presence of an _hard_irq
> flood, not a softirq one.
There are no hardirqs in the case under investigation, remember?
What's about the problem it really splits to two ones:
1. The _new_ problem when bad latency of rcu hurts core
functionality. This is precise description:
> to keep up with the softirq load. This has never been the case so far,
> and serving softirq as fast as possible is normally a good thing for
> server/firewalls, the small unfariness (note unfariness != starvation)
> it generates has never been an issue, because so far the softirq never
> required the scheduler to work in order to do their work, rcu changed
> this in the routing cache specific case.
We had one full solution for this issue not changing anything
in scheduler/softirq relationship: to run rcu task for the things
sort of dst cache not from process context, but essentially as part
of do_softirq(). Simple, stupid and apparently solves new problems
which rcu created.
Another solution is just to increase memory consumption limits
to deal with current rcu latency. F.e. 300ms latency just requires
additional space for pps*300ms objects, which are handled by RCU.
The problem with this is that pps is the thing which increases
when cpu power grows and that 300ms is not a mathematically established
limit too.
> So you're simply asking the ksoftirqd offloading to become more
> aggressive,
It is the second challenge.
Andrea, it is experimenatl fact: this "small unfariness" stalls process
contexts for >=6 seconds and gives them microscopic slices. We could live
with this (provided RCU problem is solved in some way). Essentially,
the only trouble for me was that we could use existing rcu bits to make
offloading to ksoftirqd more smart (not aggressive, _smart_). The absense
of RCU quiescent states looks too close to absence of forward progress
in process contexts, it was anticipating similarity. The dumb throttling
do_softirq made not from ksoftirqd context when starvation is detected
which we tested the last summer is not only ugly, it really might hurt
router performance, you are right here too. It is the challenge:
or we proceed with this idea and invent something, or we just forget
about this concentrating on RCU.
Alexey
On Wed, Mar 31, 2004 at 12:05:05AM +0400, [email protected] wrote:
> What's about the problem it really splits to two ones:
>
> 1. The _new_ problem when bad latency of rcu hurts core
> functionality. This is precise description:
Which essentially happens due to userland starvation during a
softirq flood.
>
> > to keep up with the softirq load. This has never been the case so far,
> > and serving softirq as fast as possible is normally a good thing for
> > server/firewalls, the small unfariness (note unfariness != starvation)
> > it generates has never been an issue, because so far the softirq never
> > required the scheduler to work in order to do their work, rcu changed
> > this in the routing cache specific case.
>
> We had one full solution for this issue not changing anything
> in scheduler/softirq relationship: to run rcu task for the things
> sort of dst cache not from process context, but essentially as part
> of do_softirq(). Simple, stupid and apparently solves new problems
> which rcu created.
Can you be a little bit more specific about this solution ? There
were a number of them discussed during our private emails and I
can't tell which one you are talking about.
> Another solution is just to increase memory consumption limits
> to deal with current rcu latency. F.e. 300ms latency just requires
> additional space for pps*300ms objects, which are handled by RCU.
> The problem with this is that pps is the thing which increases
> when cpu power grows and that 300ms is not a mathematically established
> limit too.
I don't think increasing memory consumption limit is a good idea.
> Andrea, it is experimenatl fact: this "small unfariness" stalls process
> contexts for >=6 seconds and gives them microscopic slices. We could live
> with this (provided RCU problem is solved in some way). Essentially,
> the only trouble for me was that we could use existing rcu bits to make
> offloading to ksoftirqd more smart (not aggressive, _smart_). The absense
> of RCU quiescent states looks too close to absence of forward progress
> in process contexts, it was anticipating similarity. The dumb throttling
> do_softirq made not from ksoftirqd context when starvation is detected
> which we tested the last summer is not only ugly, it really might hurt
> router performance, you are right here too. It is the challenge:
> or we proceed with this idea and invent something, or we just forget
> about this concentrating on RCU.
Exactly. And the throttling will likely not be enough by ksoftirqd
as indicated by my earlier experiments. We have potential fixes
for RCU through a call_rcu_bh() interface where completion of a
softirq handler is a quiescent state. I am working on forward porting
that old patch from our discussion last year and testing in my
environment. That should increase the number of quiescent state
points significantly and hopefully reduce the grace period significantly.
But this does nothing to help userland starvation.
Thanks
Dipankar
On Wed, Mar 31, 2004 at 01:23:15AM +0530, Dipankar Sarma wrote:
> It doesn't look as if we are processing much from ksoftirqd at
> all in this case. I did the following instrumentation -
>
> if (in_interrupt() && local_softirqd_running())
> return;
> max_restart = MAX_SOFTIRQ_RESTART;
> local_irq_save(flags);
>
> if (rcu_trace) {
> int cpu = smp_processor_id();
> per_cpu(softirq_count, cpu)++;
> if (local_softirqd_running() && current == __get_cpu_var(ksoftirqd))
> per_cpu(ksoftirqd_count, cpu)++;
> else if (!in_interrupt())
> per_cpu(other_softirq_count, cpu)++;
> }
> pending = local_softirq_pending();
>
> A look at the softirq_count, ksoftirqd_count and other_softirq_count shows -
>
> CPU 0 : 638240 554 637686
> CPU 1 : 102316 1 102315
> CPU 2 : 675696 557 675139
> CPU 3 : 102305 0 102305
>
> So, it doesn't seem supprising that your ksoftirqd offloading didn't
> really help much. The softirq frequency and grace period graph
> looks pretty much same without that patch -
>
> http://lse.sourceforge.net/locking/rcu/rtcache/pktgen/andrea/cpu-softirq.png
>
> We are simply calling do_softirq() too much it seems and not letting
> other things run on the system. Perhaps we need to look at real
> throttling of softirqs ?
>
I see what's going on now, yes my patch cannot help. the workload is
simply generating too much hardirq load, and it's like if we don't use
softirq at all but that we process the packet inside the hardirq for
this matter. As far as RCU is concerned it's like if there a no softirq
at all but that we process everything in the hardirq.
so what you're looking after is a new feature then:
1) rate limit the hardirqs
2) rate limit only part of the irq load (i.e. the softirq, that's handy
since it's already splitted out) to scheduler-aware context (not
inside irq context anymore)
3) stop processing packets in irqs in the first place (NAPI or similar)
however I start to think they can be all wrong, and that rcu is simply
not suitable for purerely irq usages like this. w/o rcu there would be
no need of the scheduler keeping up with the irq load, and in some usage
I can imagine that it is a feature to prioritize heavily on the
irq load vs scheduler-aware context.
On Tue, Mar 30, 2004 at 10:47:32PM +0200, Andrea Arcangeli wrote:
> I see what's going on now, yes my patch cannot help. the workload is
> simply generating too much hardirq load, and it's like if we don't use
> softirq at all but that we process the packet inside the hardirq for
> this matter. As far as RCU is concerned it's like if there a no softirq
> at all but that we process everything in the hardirq.
>
> so what you're looking after is a new feature then:
>
> 1) rate limit the hardirqs
> 2) rate limit only part of the irq load (i.e. the softirq, that's handy
> since it's already splitted out) to scheduler-aware context (not
> inside irq context anymore)
There were a number of somewhat ugly softirq limiting patches that
Robert tried out (not spitting them to scheduler-aware context) and some
combination of that worked well in Robert's setup. I will see if I can
revive that. That said, we would need to find out how badly we affect network
performance with that thing.
> 3) stop processing packets in irqs in the first place (NAPI or similar)
>
> however I start to think they can be all wrong, and that rcu is simply
> not suitable for purerely irq usages like this. w/o rcu there would be
> no need of the scheduler keeping up with the irq load, and in some usage
> I can imagine that it is a feature to prioritize heavily on the
> irq load vs scheduler-aware context.
Not necessarily, we can do a call_rcu_bh() just for softirqs with
softirq handler completion as a quiescent state. That will likely
help with the route cache overflow problem atleast.
Thanks
Dipankar
On Wed, Mar 31, 2004 at 12:05:05AM +0400, [email protected] wrote:
> Hello!
>
> > > Robert demonstrated to us sometime ago with a small
> > > timestamping user program to show that it can get starved for
> > > more than 6 seconds in his system. So userland starvation is an
> > > issue.
> >
> > softirqs are already capable of being offloaded to scheduler-friendy
> > kernel threads to avoid starvation, if this wasn't the case NAPI would
> > have no way to work in the first place and everything else would fall
> > apart too, not just the rcu-route-cache. I don't think high latencies
> > and starvation are the same thing, starvation means for "indefinite
> > time" and you can't hang userspace for indefinite time using softirqs.
> > For sure the irq based load, and in turn softirqs too, can take a large
> > amount of cpu (though not 100%, this is why it cannot be called
> > starvation).
> >
> > the only real starvation you can claim is in presence of an _hard_irq
> > flood, not a softirq one.
>
> There are no hardirqs in the case under investigation, remember?
no hardirqs? there must be tons of hardirqs if ksoftirqd never runs.
>
> What's about the problem it really splits to two ones:
>
> 1. The _new_ problem when bad latency of rcu hurts core
> functionality. This is precise description:
>
> > to keep up with the softirq load. This has never been the case so far,
> > and serving softirq as fast as possible is normally a good thing for
> > server/firewalls, the small unfariness (note unfariness != starvation)
> > it generates has never been an issue, because so far the softirq never
> > required the scheduler to work in order to do their work, rcu changed
> > this in the routing cache specific case.
>
> We had one full solution for this issue not changing anything
> in scheduler/softirq relationship: to run rcu task for the things
> sort of dst cache not from process context, but essentially as part
> of do_softirq(). Simple, stupid and apparently solves new problems
> which rcu created.
I don't understand exactly the details of how this works but I trust you ;)
> Another solution is just to increase memory consumption limits
> to deal with current rcu latency. F.e. 300ms latency just requires
> additional space for pps*300ms objects, which are handled by RCU.
> The problem with this is that pps is the thing which increases
> when cpu power grows and that 300ms is not a mathematically established
> limit too.
I consider this more a workaround than a solution ;). It also depends
how much boost you get from the rcu scalability in smp to evaluate if
the above solution could be worthwhile, I don't know the exact numbers
myself.
> > So you're simply asking the ksoftirqd offloading to become more
> > aggressive,
>
> It is the second challenge.
>
> Andrea, it is experimenatl fact: this "small unfariness" stalls process
> contexts for >=6 seconds and gives them microscopic slices. We could live
> with this (provided RCU problem is solved in some way). Essentially,
yes, we could live with this if it wasn't for RCU not making any
progress and the irq load depending on the RCU to make progress.
> the only trouble for me was that we could use existing rcu bits to make
> offloading to ksoftirqd more smart (not aggressive, _smart_). The absense
> of RCU quiescent states looks too close to absence of forward progress
> in process contexts, it was anticipating similarity. The dumb throttling
> do_softirq made not from ksoftirqd context when starvation is detected
> which we tested the last summer is not only ugly, it really might hurt
> router performance, you are right here too. It is the challenge:
> or we proceed with this idea and invent something, or we just forget
> about this concentrating on RCU.
So basically you're suggesting to use the rcu grace period "timeout" to
choose when to defer the softirq load to userspace, right? That should
work. I mean, it will need some instrumentation to define the "timeout",
but it's very similar to the patch I already posted, rather than
local_softirqd_running() we'll check for rcu_timed_out() and we'll
wakeup ksofitrqd in that case and we'll return immediatly from
do_softirq. That will still risk to lose some packet from the backlog
though, since we'll process softirqs at a slower peace (but that's
partly the feature).
That sounds a bit too rcu centric though, I mean, if we do this, maybe
we should make it indipendent from rcu, and we could detect a too long
time spent in softirq load, and we can offload softirqs in function of
that instead of the rcu_timed_out() thing.
On Wed, Mar 31, 2004 at 02:36:48AM +0530, Dipankar Sarma wrote:
> Not necessarily, we can do a call_rcu_bh() just for softirqs with
> softirq handler completion as a quiescent state. That will likely
> help with the route cache overflow problem atleast.
cute, I like this. You're right all we care about is a quiscient point
against softirq context (this should work fine against regular kernel
context under local_bh_disable too). This really sounds a smart and
optimal and finegriend solution to me. The only thing I'm concerned
about is if it slowdown further the fast paths, but I can imagine that
you can implement it purerly with tasklets and no change to the fast
paths (I mean, I wouldn't enjoy further instrumentations like the stuff
you had to add to the scheduler especially in the preempt case). I mean,
you've just to run 1 magic takklet per cpu then you declare the
quiscient point. The only annoyance will be the queueing of these
tasklets in every cpu, that may need IPIs or some nasty locking. Of
course we should use the higher prio tasklets, so they run before the
other softirqs.
Is this the suggestion from Alexey or did he suggest something else? the
details of his suggestion weren't clear to me.
after call_rcu_bh everything else w.r.t. softirq/scheduler will return
low prio. I mean, the everything else will return a "irq load
(hardirq+softirq) runs on top of kernel context and they're not
accounted by the scheduler" like it has always been in the last thousand
kernel releases ;) that may need solving eventually, but still the
routing cache sounds optimal with the call_rcu_bh.
Andrea Arcangeli writes:
> I see what's going on now, yes my patch cannot help. the workload is
> simply generating too much hardirq load, and it's like if we don't use
> softirq at all but that we process the packet inside the hardirq for
> this matter. As far as RCU is concerned it's like if there a no softirq
> at all but that we process everything in the hardirq.
>
> so what you're looking after is a new feature then:
>
> 1) rate limit the hardirqs
> 2) rate limit only part of the irq load (i.e. the softirq, that's handy
> since it's already splitted out) to scheduler-aware context (not
> inside irq context anymore)
> 3) stop processing packets in irqs in the first place (NAPI or similar)
Hello!
No Andrea it pure softirq workload. Interfaces runs with irq disabled
at this load w. NAPI. Softirq's are run from spin_unlock_bh etc when
doing route lookup and GC. And the more fine-grained locking we do the
the more do_softirq's are run.
Cheers.
--ro
On Tue, 30 Mar 2004 23:14:50 +0200
Andrea Arcangeli <[email protected]> wrote:
> > There are no hardirqs in the case under investigation, remember?
>
> no hardirqs? there must be tons of hardirqs if ksoftirqd never runs.
NAPI should be kicking in for this workload, and I know for a fact it is
for Robert's case. There should only be a few thousand hard irqs per
second.
Until the RX ring is depleted the device's hardirqs will not be re-
enabled.
On Tue, Mar 30, 2004 at 01:30:00PM -0800, David S. Miller wrote:
> On Tue, 30 Mar 2004 23:14:50 +0200
> Andrea Arcangeli <[email protected]> wrote:
>
> > > There are no hardirqs in the case under investigation, remember?
> >
> > no hardirqs? there must be tons of hardirqs if ksoftirqd never runs.
>
> NAPI should be kicking in for this workload, and I know for a fact it is
> for Robert's case. There should only be a few thousand hard irqs per
> second.
>
> Until the RX ring is depleted the device's hardirqs will not be re-
> enabled.
then Dipankar is reproducing with a workload that is completely
different. I've only seen the emails from Dipankar so I couldn't know it
was a NAPI load.
He posted these numbers:
softirq_count, ksoftirqd_count and other_softirq_count shows -
CPU 0 : 638240 554 637686
CPU 1 : 102316 1 102315
CPU 2 : 675696 557 675139
CPU 3 : 102305 0 102305
that means nothing runs in ksoftirqd for Dipankar, so he cannot be using
NAPI.
Either that or I'm misreading his numbers, or his stats results are wrong.
On Tue, 30 Mar 2004 23:37:42 +0200
Andrea Arcangeli <[email protected]> wrote:
> that means nothing runs in ksoftirqd for Dipankar, so he cannot be using
> NAPI.
>
> Either that or I'm misreading his numbers, or his stats results are wrong.
If these numbers are with your "if (ksoftirqd_pending()) return;" thing
at the top of do_softirq() then I must agree with you.
Otherwise, keep in mind what I said, and also as Robert mentioned every
single local_bh_enable() is going to call do_softirq() if the count falls
to zero.
On Tue, Mar 30, 2004 at 02:22:10PM -0800, David S. Miller wrote:
> Otherwise, keep in mind what I said, and also as Robert mentioned every
> single local_bh_enable() is going to call do_softirq() if the count falls
> to zero.
I was less concerned about the do_sofitrq in local_bh_enable, since that
runs in a scheduler-aware context, so at least the timeslice is
definitely accounted for and it'll schedule at some point (unlike with
an hardirq flood). Actually the length of the default timeslice matters
too here, lowering the max timeslice to 10msec would certainly reduce
the effect.
call_rcu_bh will fix the local_bh_enable too. The only problem with
call_rcu_bh is how to queue the tasklets in every cpu (an IPI sounds
overkill at high frequency, because effectively here we're running the rcu
callbacks in a potential fast path). OTOH if we've to add a spinlock to
queue the tasklet, then we might as well take a spinlock in the routing
cache in the first place (at least for this workload).
Andrea Arcangeli writes:
> He posted these numbers:
>
> softirq_count, ksoftirqd_count and other_softirq_count shows -
>
> CPU 0 : 638240 554 637686
> CPU 1 : 102316 1 102315
> CPU 2 : 675696 557 675139
> CPU 3 : 102305 0 102305
>
> that means nothing runs in ksoftirqd for Dipankar, so he cannot be using
> NAPI.
>
> Either that or I'm misreading his numbers, or his stats results are wrong.
Well we have to ask Dipankar... But I'll buy a beer if it's not on. :)
Anyway w. NAPI enabled. 2 * 304 kpps DoS flows into eth0, eth2. Flows
are 2 * 10 Millions 64 byte pkts. 32 k buckets routehash. Full Internet
routing means ~130 k routes. Linux 2.6.4 2*2.66 MHz XEON.
26: 896 0 IO-APIC-level eth0
27: 25197 0 IO-APIC-level eth1
28: 8 579 IO-APIC-level eth2
29: 10 26112 IO-APIC-level eth3
T-put is seen on output dev. eth1, eth3. So about 16% of incoming load,
eth0 1500 0 1577468 9631270 9631270 8422828 237 0 0 0 BRU
eth1 1500 0 42 0 0 0 1573355 0 0 0 BRU
eth2 1500 0 1636154 9603432 9603432 8363849 41 0 0 0 BRU
eth3 1500 0 54 0 0 0 1632274 0 0 0 BRU
And lots of
.
.
printk: 1898 messages suppressed.
dst cache overflow
printk: 829 messages suppressed.
dst cache overflow
Cheers.
--ro
On Tue, 2004-03-30 at 15:06, Srivatsa Vaddagiri wrote:
> On Tue, Mar 30, 2004 at 01:07:12AM +0000, Andrea Arcangeli wrote:
> > btw, the set_current_state(TASK_INTERRUPTIBLE) before
> > kthread_should_stop seems overkill w.r.t. smp locking, plus the code is
> > written in the wrong way around, all set_current_state are in the wrong
> > place. It's harmless but I cleaned up that bit as well.
>
> I think set_current_state(TASK_INTERRUPTIBLE) before kthread_should_stop()
> _is_ required, otherwise kthread_stop can fail to destroy a kthread.
The problem is that kthread_stop used to send a signal to the kthread,
which meant we didn't have to beware of races (since it would never
sleep any more): kthread_should_stop() was called signal_pending 8)
Andrew hated the signal mechanism, so I abandoned it, but didn't go back
and fix all the users. It's tempting to send a signal anyway to make
life simpler, though, although that might set a bad example for others.
Rusty.
--
Anyone who quotes me in their signature is an idiot -- Rusty Russell
On Tue, Mar 30, 2004 at 11:29:44PM +0200, Robert Olsson wrote:
> Andrea Arcangeli writes:
> > I see what's going on now, yes my patch cannot help. the workload is
> > simply generating too much hardirq load, and it's like if we don't use
> > softirq at all but that we process the packet inside the hardirq for
> > this matter. As far as RCU is concerned it's like if there a no softirq
> > at all but that we process everything in the hardirq.
> >
> > so what you're looking after is a new feature then:
> >
> > 1) rate limit the hardirqs
> > 2) rate limit only part of the irq load (i.e. the softirq, that's handy
> > since it's already splitted out) to scheduler-aware context (not
> > inside irq context anymore)
> > 3) stop processing packets in irqs in the first place (NAPI or similar)
>
> No Andrea it pure softirq workload. Interfaces runs with irq disabled
> at this load w. NAPI. Softirq's are run from spin_unlock_bh etc when
> doing route lookup and GC. And the more fine-grained locking we do the
> the more do_softirq's are run.
Not lookup, we don't take the lock in lookup. Probably route
insertions which will happen very frequently in this case.
Thanks
Dipankar
On Tue, Mar 30, 2004 at 11:37:42PM +0200, Andrea Arcangeli wrote:
> On Tue, Mar 30, 2004 at 01:30:00PM -0800, David S. Miller wrote:
> > On Tue, 30 Mar 2004 23:14:50 +0200
> > Andrea Arcangeli <[email protected]> wrote:
> >
> > > > There are no hardirqs in the case under investigation, remember?
> > >
> > > no hardirqs? there must be tons of hardirqs if ksoftirqd never runs.
> >
> > NAPI should be kicking in for this workload, and I know for a fact it is
> > for Robert's case. There should only be a few thousand hard irqs per
> > second.
> >
> > Until the RX ring is depleted the device's hardirqs will not be re-
> > enabled.
>
> then Dipankar is reproducing with a workload that is completely
> different. I've only seen the emails from Dipankar so I couldn't know it
> was a NAPI load.
>
> He posted these numbers:
>
> softirq_count, ksoftirqd_count and other_softirq_count shows -
>
> CPU 0 : 638240 554 637686
> CPU 1 : 102316 1 102315
> CPU 2 : 675696 557 675139
> CPU 3 : 102305 0 102305
>
> that means nothing runs in ksoftirqd for Dipankar, so he cannot be using
> NAPI.
And I am not. I am still on 2.6.0 and there seems to be no NAPI support
for the e100 there. Should I try 2.6.4 where e100 has NAPI support ?
Anyway, even without softirqs on the back of hardirqs, there are
other ways of softirq overload as seen in Robert's setup.
Thanks
Dipankar
Cheers.
--ro
On Wed, Mar 31, 2004 at 08:46:09PM +0200, Robert Olsson wrote:
Content-Description: message body text
> Before run
>
> total droppped tsquz throttl bh_enbl ksoftird irqexit other
> 00000000 00000000 00000000 00000000 000000e8 0000017e 00030411 00000000
> 00000000 00000000 00000000 00000000 000000ae 00000277 00030349 00000000
>
> After DoS (See description from previous mail)
>
> total droppped tsquz throttl bh_enbl ksoftird irqexit other
> 00164c55 00000000 000021de 00000000 000000fc 0000229f 0003443c 00000000
> 001695e7 00000000 0000224d 00000000 00000162 0000236f 000342f7 00000000
>
> So the major part of softirq's are run from irqexit and therefor out of
> scheduler control. This even with RX polling (eth0, eth2) We still have
> some TX interrupts plus timer interrupts now at 1000Hz. Which probably
> reduces the number of softirq's that ksoftirqd runs.
So, NAPI or not we get userland stalls due to packetflooding.
Looking at some of the old patches we discussed privately, it seems
this is what was done earlier -
1. Use rcu-softirq.patch which provides call_rcu_bh() for softirqs
only.
2. Limit non-ksoftirqd softirqs - get a measure of userland stall (using
an api rcu_grace_period(cpu)) and if it is too long, expire
the timeslice of the current process and start sending everything to
ksoftirqd.
By reducing the softirq time at the back of a hardirq or local_bh_enable(),
we should be able to bring a bit more fairness. I am working on the
patches, will test and publish later.
Thanks
Dipankar
On Wed, Mar 31, 2004 at 12:49:02AM +0200, Andrea Arcangeli wrote:
> On Tue, Mar 30, 2004 at 02:22:10PM -0800, David S. Miller wrote:
> > Otherwise, keep in mind what I said, and also as Robert mentioned every
> > single local_bh_enable() is going to call do_softirq() if the count falls
> > to zero.
>
> I was less concerned about the do_sofitrq in local_bh_enable, since that
> runs in a scheduler-aware context, so at least the timeslice is
> definitely accounted for and it'll schedule at some point (unlike with
> an hardirq flood). Actually the length of the default timeslice matters
> too here, lowering the max timeslice to 10msec would certainly reduce
> the effect.
That is there in my list of things to test.
> call_rcu_bh will fix the local_bh_enable too. The only problem with
> call_rcu_bh is how to queue the tasklets in every cpu (an IPI sounds
> overkill at high frequency, because effectively here we're running the rcu
> callbacks in a potential fast path). OTOH if we've to add a spinlock to
> queue the tasklet, then we might as well take a spinlock in the routing
> cache in the first place (at least for this workload).
I don't do any of this. I just have a separate quiescent state counter
for softirq RCU. It is incremented for regular quiescent points
like cswitch, userland, idle loop as well as at the completion
of each softirq handler. call_rcu_bh() uses its own queues.
Everything else works like call_rcu().
Thanks
Dipankar
On Thu, Apr 01, 2004 at 02:07:50AM +0530, Dipankar Sarma wrote:
> On Wed, Mar 31, 2004 at 08:46:09PM +0200, Robert Olsson wrote:
> Content-Description: message body text
> > Before run
> >
> > total droppped tsquz throttl bh_enbl ksoftird irqexit other
> > 00000000 00000000 00000000 00000000 000000e8 0000017e 00030411 00000000
> > 00000000 00000000 00000000 00000000 000000ae 00000277 00030349 00000000
> >
> > After DoS (See description from previous mail)
> >
> > total droppped tsquz throttl bh_enbl ksoftird irqexit other
> > 00164c55 00000000 000021de 00000000 000000fc 0000229f 0003443c 00000000
> > 001695e7 00000000 0000224d 00000000 00000162 0000236f 000342f7 00000000
> >
> > So the major part of softirq's are run from irqexit and therefor out of
> > scheduler control. This even with RX polling (eth0, eth2) We still have
> > some TX interrupts plus timer interrupts now at 1000Hz. Which probably
> > reduces the number of softirq's that ksoftirqd runs.
>
> So, NAPI or not we get userland stalls due to packetflooding.
indeed, the most of the softirq load happens within irqs even with NAPI
as we were talking about, so Alexey and DaveM were wrong about the
hardirq load being non significant.
Maybe the problem is simply that NAPI should be tuned more aggressively,
it may have to poll for a longer time before giving up.
> Looking at some of the old patches we discussed privately, it seems
> this is what was done earlier -
>
> 1. Use rcu-softirq.patch which provides call_rcu_bh() for softirqs
> only.
this is the one I prefer if it performs.
> 2. Limit non-ksoftirqd softirqs - get a measure of userland stall (using
> an api rcu_grace_period(cpu)) and if it is too long, expire
> the timeslice of the current process and start sending everything to
> ksoftirqd.
yep, this may be desiderable eventually just to be fair with tasks, but
I believe it's partly an orthogonal with the rcu grace period length.
> By reducing the softirq time at the back of a hardirq or local_bh_enable(),
> we should be able to bring a bit more fairness. I am working on the
> patches, will test and publish later.
I consider this as the approch number 2 too.
On Wed, Mar 31, 2004 at 11:28:17PM +0200, Andrea Arcangeli wrote:
> On Thu, Apr 01, 2004 at 02:07:50AM +0530, Dipankar Sarma wrote:
> > So, NAPI or not we get userland stalls due to packetflooding.
>
> indeed, the most of the softirq load happens within irqs even with NAPI
> as we were talking about, so Alexey and DaveM were wrong about the
> hardirq load being non significant.
>
> Maybe the problem is simply that NAPI should be tuned more aggressively,
> it may have to poll for a longer time before giving up.
Perhaps yes, but we still have softirqs from local_bh_enable()s to
deal with.
> > Looking at some of the old patches we discussed privately, it seems
> > this is what was done earlier -
> >
> > 1. Use rcu-softirq.patch which provides call_rcu_bh() for softirqs
> > only.
>
> this is the one I prefer if it performs.
I just tried the attached patch (forward ported and some aggressive
things deleted) and there was no route cache overflow during
pktgen testing. So, this is a good approach, however this is
not going to solve userland stalls.
Robert, btw, this rcu-softirq patch is slightly different
from the earlier one in the sense that now every softirq
handler completion is a quiescent point. Earlier each iteration
of softirqs was a quiescent point. So this has more quiescent
points.
>
> > 2. Limit non-ksoftirqd softirqs - get a measure of userland stall (using
> > an api rcu_grace_period(cpu)) and if it is too long, expire
> > the timeslice of the current process and start sending everything to
> > ksoftirqd.
>
> yep, this may be desiderable eventually just to be fair with tasks, but
> I believe it's partly an orthogonal with the rcu grace period length.
Yes, it is. Delaying softirqs will delay RCU grace periods. But it
will also affect i/o throughput. So this is a balancing act anyway.
> > By reducing the softirq time at the back of a hardirq or local_bh_enable(),
> > we should be able to bring a bit more fairness. I am working on the
> > patches, will test and publish later.
>
> I consider this as the approch number 2 too.
Well, I don't really have #1 and #2. I think we need to understand
if there are the situations where such stalls are unacceptable
and if so fix softirqs for them. RCU OOMs we can probably work
around anyway.
Thanks
Dipankar
Provide a new call_rcu_bh() interface that can be used in softirq
only situations. Completion of a softirq handler is considered
a quiescent point apart from regular quiescent points. If there
is any read from process context, then it must be protected
by rcu_read_lock/unlock_bh().
include/linux/rcupdate.h | 40 ++++++---
kernel/rcupdate.c | 207 ++++++++++++++++++++++++++++-------------------
kernel/softirq.c | 12 ++
net/decnet/dn_route.c | 6 -
net/ipv4/route.c | 28 +++---
5 files changed, 183 insertions(+), 110 deletions(-)
diff -puN include/linux/rcupdate.h~rcu-softirq include/linux/rcupdate.h
--- linux-2.6.0-rtcache/include/linux/rcupdate.h~rcu-softirq 2004-04-01 00:07:48.000000000 +0530
+++ linux-2.6.0-rtcache-dipankar/include/linux/rcupdate.h 2004-04-01 02:01:32.000000000 +0530
@@ -99,38 +99,56 @@ struct rcu_data {
};
DECLARE_PER_CPU(struct rcu_data, rcu_data);
+DECLARE_PER_CPU(struct rcu_data, rcu_bh_data);
extern struct rcu_ctrlblk rcu_ctrlblk;
-
+extern struct rcu_ctrlblk rcu_bh_ctrlblk;
+
#define RCU_qsctr(cpu) (per_cpu(rcu_data, (cpu)).qsctr)
-#define RCU_last_qsctr(cpu) (per_cpu(rcu_data, (cpu)).last_qsctr)
-#define RCU_batch(cpu) (per_cpu(rcu_data, (cpu)).batch)
#define RCU_nxtlist(cpu) (per_cpu(rcu_data, (cpu)).nxtlist)
-#define RCU_curlist(cpu) (per_cpu(rcu_data, (cpu)).curlist)
-
+#define RCU_bh_qsctr(cpu) (per_cpu(rcu_bh_data, (cpu)).qsctr)
+#define RCU_bh_nxtlist(cpu) (per_cpu(rcu_bh_data, (cpu)).nxtlist)
+
#define RCU_QSCTR_INVALID 0
-static inline int rcu_pending(int cpu)
+static inline int __rcu_pending(int cpu, struct rcu_ctrlblk *rcp,
+ struct rcu_data *rdp)
{
- if ((!list_empty(&RCU_curlist(cpu)) &&
- rcu_batch_before(RCU_batch(cpu), rcu_ctrlblk.curbatch)) ||
- (list_empty(&RCU_curlist(cpu)) &&
- !list_empty(&RCU_nxtlist(cpu))) ||
- cpu_isset(cpu, rcu_ctrlblk.rcu_cpu_mask))
+ if ((!list_empty(&rdp->curlist) &&
+ rcu_batch_before(rdp->batch, rcp->curbatch)) ||
+ (list_empty(&rdp->curlist) &&
+ !list_empty(&rdp->nxtlist)) ||
+ cpu_isset(cpu, rcp->rcu_cpu_mask))
return 1;
else
return 0;
}
+static inline int rcu_pending_bh(int cpu)
+{
+ return __rcu_pending(cpu, &rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
+}
+static inline int rcu_pending(int cpu)
+{
+ return __rcu_pending(cpu, &rcu_ctrlblk, &per_cpu(rcu_data, cpu)) ||
+ __rcu_pending(cpu, &rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
+}
#define rcu_read_lock() preempt_disable()
#define rcu_read_unlock() preempt_enable()
+#define rcu_read_lock_bh() local_bh_disable()
+#define rcu_read_unlock_bh() local_bh_enable()
extern void rcu_init(void);
extern void rcu_check_callbacks(int cpu, int user);
+extern void rcu_process_callbacks_bh(int cpu);
/* Exported interfaces */
extern void FASTCALL(call_rcu(struct rcu_head *head,
void (*func)(void *arg), void *arg));
+extern void FASTCALL(call_rcu_bh(struct rcu_head *head,
+ void (*func)(void *arg), void *arg));
extern void synchronize_kernel(void);
+extern struct rcu_ctrlblk rcu_ctrlblk;
+
#endif /* __KERNEL__ */
#endif /* __LINUX_RCUPDATE_H */
diff -puN kernel/rcupdate.c~rcu-softirq kernel/rcupdate.c
--- linux-2.6.0-rtcache/kernel/rcupdate.c~rcu-softirq 2004-04-01 00:07:48.000000000 +0530
+++ linux-2.6.0-rtcache-dipankar/kernel/rcupdate.c 2004-04-01 00:53:29.000000000 +0530
@@ -51,6 +51,11 @@ struct rcu_ctrlblk rcu_ctrlblk =
.maxbatch = 1, .rcu_cpu_mask = CPU_MASK_NONE };
DEFINE_PER_CPU(struct rcu_data, rcu_data) = { 0L };
+struct rcu_ctrlblk rcu_bh_ctrlblk =
+ { .mutex = SPIN_LOCK_UNLOCKED, .curbatch = 1,
+ .maxbatch = 1, .rcu_cpu_mask = 0 };
+DEFINE_PER_CPU(struct rcu_data, rcu_bh_data) = { 0L };
+
/* Fake initialization required by compiler */
static DEFINE_PER_CPU(struct tasklet_struct, rcu_tasklet) = {NULL};
#define RCU_tasklet(cpu) (per_cpu(rcu_tasklet, cpu))
@@ -79,6 +84,30 @@ void call_rcu(struct rcu_head *head, voi
local_irq_restore(flags);
}
+/**
+ * call_rcu_bh - Queue an RCU update request that is used only from softirqs
+ * @head: structure to be used for queueing the RCU updates.
+ * @func: actual update function to be invoked after the grace period
+ * @arg: argument to be passed to the update function
+ *
+ * The update function will be invoked as soon as all CPUs have performed
+ * a context switch or been seen in the idle loop or in a user process or
+ * or has exited a softirq handler that it may have been executing.
+ * The read-side of critical section that use call_rcu_bh() for updation must
+ * be protected by rcu_read_lock()/rcu_read_unlock().
+ */
+void call_rcu_bh(struct rcu_head *head, void (*func)(void *arg), void *arg)
+{
+ int cpu;
+
+ head->func = func;
+ head->arg = arg;
+ local_bh_disable();
+ cpu = smp_processor_id();
+ list_add_tail(&head->list, &RCU_bh_nxtlist(cpu));
+ local_bh_enable();
+}
+
/*
* Invoke the completed RCU callbacks. They are expected to be in
* a per-cpu list.
@@ -101,16 +130,16 @@ static void rcu_do_batch(struct list_hea
* active batch and the batch to be registered has not already occurred.
* Caller must hold the rcu_ctrlblk lock.
*/
-static void rcu_start_batch(long newbatch)
+static void rcu_start_batch(struct rcu_ctrlblk *rcp, long newbatch)
{
- if (rcu_batch_before(rcu_ctrlblk.maxbatch, newbatch)) {
- rcu_ctrlblk.maxbatch = newbatch;
- }
- if (rcu_batch_before(rcu_ctrlblk.maxbatch, rcu_ctrlblk.curbatch) ||
- !cpus_empty(rcu_ctrlblk.rcu_cpu_mask)) {
- return;
- }
- rcu_ctrlblk.rcu_cpu_mask = cpu_online_map;
+ if (rcu_batch_before(rcp->maxbatch, newbatch)) {
+ rcp->maxbatch = newbatch;
+ }
+ if (rcu_batch_before(rcp->maxbatch, rcp->curbatch) ||
+ !cpus_empty(rcp->rcu_cpu_mask)) {
+ return;
+ }
+ rcp->rcu_cpu_mask = cpu_online_map;
}
/*
@@ -118,41 +147,73 @@ static void rcu_start_batch(long newbatc
* switch). If so and if it already hasn't done so in this RCU
* quiescent cycle, then indicate that it has done so.
*/
-static void rcu_check_quiescent_state(void)
+static void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
+ struct rcu_data *rdp)
{
- int cpu = smp_processor_id();
-
- if (!cpu_isset(cpu, rcu_ctrlblk.rcu_cpu_mask))
- return;
-
- /*
- * Races with local timer interrupt - in the worst case
- * we may miss one quiescent state of that CPU. That is
- * tolerable. So no need to disable interrupts.
- */
- if (RCU_last_qsctr(cpu) == RCU_QSCTR_INVALID) {
- RCU_last_qsctr(cpu) = RCU_qsctr(cpu);
- return;
- }
- if (RCU_qsctr(cpu) == RCU_last_qsctr(cpu))
- return;
-
- spin_lock(&rcu_ctrlblk.mutex);
- if (!cpu_isset(cpu, rcu_ctrlblk.rcu_cpu_mask))
- goto out_unlock;
-
- cpu_clear(cpu, rcu_ctrlblk.rcu_cpu_mask);
- RCU_last_qsctr(cpu) = RCU_QSCTR_INVALID;
- if (!cpus_empty(rcu_ctrlblk.rcu_cpu_mask))
- goto out_unlock;
-
- rcu_ctrlblk.curbatch++;
- rcu_start_batch(rcu_ctrlblk.maxbatch);
-
+ int cpu = smp_processor_id();
+
+ if (!cpu_isset(cpu, rcp->rcu_cpu_mask))
+ return;
+
+ if (rdp->last_qsctr == RCU_QSCTR_INVALID) {
+ rdp->last_qsctr = rdp->qsctr;
+ return;
+ }
+ if (rdp->qsctr == rdp->last_qsctr)
+ return;
+
+ spin_lock(&rcp->mutex);
+ if (!cpu_isset(cpu, rcp->rcu_cpu_mask))
+ goto out_unlock;
+
+ cpu_clear(cpu, rcp->rcu_cpu_mask);
+ rdp->last_qsctr = RCU_QSCTR_INVALID;
+ if (!cpus_empty(rcp->rcu_cpu_mask))
+ goto out_unlock;
+
+ rcp->curbatch++;
+ rcu_start_batch(rcp, rcp->maxbatch);
+
out_unlock:
- spin_unlock(&rcu_ctrlblk.mutex);
+ spin_unlock(&rcp->mutex);
+}
+
+static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
+ struct rcu_data *rdp)
+{
+ LIST_HEAD(list);
+
+ if (!list_empty(&rdp->curlist) &&
+ rcu_batch_after(rcp->curbatch, rdp->batch)) {
+ list_splice(&rdp->curlist, &list);
+ INIT_LIST_HEAD(&rdp->curlist);
+ }
+
+ local_irq_disable();
+ if (!list_empty(&rdp->nxtlist) && list_empty(&rdp->curlist)) {
+ list_splice(&rdp->nxtlist, &rdp->curlist);
+ INIT_LIST_HEAD(&rdp->nxtlist);
+ local_irq_enable();
+
+ /*
+ * start the next batch of callbacks
+ */
+ spin_lock(&rcp->mutex);
+ rdp->batch = rcp->curbatch + 1;
+ rcu_start_batch(rcp, rdp->batch);
+ spin_unlock(&rcp->mutex);
+ } else {
+ local_irq_enable();
+ }
+ rcu_check_quiescent_state(rcp, rdp);
+ if (!list_empty(&list))
+ rcu_do_batch(&list);
+}
+
+void rcu_process_callbacks_bh(int cpu)
+{
+ __rcu_process_callbacks(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
}
-
/*
* This does the RCU processing work from tasklet context.
@@ -160,59 +221,38 @@ out_unlock:
static void rcu_process_callbacks(unsigned long unused)
{
int cpu = smp_processor_id();
- LIST_HEAD(list);
-
- if (!list_empty(&RCU_curlist(cpu)) &&
- rcu_batch_after(rcu_ctrlblk.curbatch, RCU_batch(cpu))) {
- list_splice(&RCU_curlist(cpu), &list);
- INIT_LIST_HEAD(&RCU_curlist(cpu));
- }
-
- local_irq_disable();
- if (!list_empty(&RCU_nxtlist(cpu)) && list_empty(&RCU_curlist(cpu))) {
- list_splice(&RCU_nxtlist(cpu), &RCU_curlist(cpu));
- INIT_LIST_HEAD(&RCU_nxtlist(cpu));
- local_irq_enable();
-
- /*
- * start the next batch of callbacks
- */
- spin_lock(&rcu_ctrlblk.mutex);
- RCU_batch(cpu) = rcu_ctrlblk.curbatch + 1;
- rcu_start_batch(RCU_batch(cpu));
- spin_unlock(&rcu_ctrlblk.mutex);
- } else {
- local_irq_enable();
- }
- rcu_check_quiescent_state();
- if (!list_empty(&list))
- rcu_do_batch(&list);
+ __rcu_process_callbacks(&rcu_ctrlblk, &per_cpu(rcu_data, cpu));
+ __rcu_process_callbacks(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
}
void rcu_check_callbacks(int cpu, int user)
{
- if (user ||
- (idle_cpu(cpu) && !in_softirq() &&
- hardirq_count() <= (1 << HARDIRQ_SHIFT)))
- RCU_qsctr(cpu)++;
- tasklet_schedule(&RCU_tasklet(cpu));
-}
-
-static void __devinit rcu_online_cpu(int cpu)
-{
- memset(&per_cpu(rcu_data, cpu), 0, sizeof(struct rcu_data));
- tasklet_init(&RCU_tasklet(cpu), rcu_process_callbacks, 0UL);
- INIT_LIST_HEAD(&RCU_nxtlist(cpu));
- INIT_LIST_HEAD(&RCU_curlist(cpu));
+ if (user ||
+ (idle_cpu(cpu) && !in_softirq() &&
+ hardirq_count() <= (1 << HARDIRQ_SHIFT))) {
+ RCU_qsctr(cpu)++;
+ RCU_bh_qsctr(cpu)++;
+ } else if (!in_softirq())
+ RCU_bh_qsctr(cpu)++;
+ tasklet_schedule(&RCU_tasklet(cpu));
+}
+
+static void __devinit rcu_online_cpu(struct rcu_data *rdp)
+{
+ memset(rdp, 0, sizeof(*rdp));
+ INIT_LIST_HEAD(&rdp->nxtlist);
+ INIT_LIST_HEAD(&rdp->curlist);
}
-
+
static int __devinit rcu_cpu_notify(struct notifier_block *self,
unsigned long action, void *hcpu)
{
long cpu = (long)hcpu;
switch (action) {
case CPU_UP_PREPARE:
- rcu_online_cpu(cpu);
+ rcu_online_cpu(&per_cpu(rcu_data, cpu));
+ rcu_online_cpu(&per_cpu(rcu_bh_data, cpu));
+ tasklet_init(&RCU_tasklet(cpu), rcu_process_callbacks, 0UL);
break;
/* Space reserved for CPU_OFFLINE :) */
default:
@@ -264,4 +304,5 @@ void synchronize_kernel(void)
EXPORT_SYMBOL(call_rcu);
+EXPORT_SYMBOL(call_rcu_bh);
EXPORT_SYMBOL(synchronize_kernel);
diff -puN kernel/softirq.c~rcu-softirq kernel/softirq.c
--- linux-2.6.0-rtcache/kernel/softirq.c~rcu-softirq 2004-04-01 00:07:48.000000000 +0530
+++ linux-2.6.0-rtcache-dipankar/kernel/softirq.c 2004-04-01 02:19:00.000000000 +0530
@@ -73,6 +73,7 @@ asmlinkage void do_softirq(void)
int max_restart = MAX_SOFTIRQ_RESTART;
__u32 pending;
unsigned long flags;
+ int cpu;
if (in_interrupt())
return;
@@ -85,6 +86,7 @@ asmlinkage void do_softirq(void)
struct softirq_action *h;
local_bh_disable();
+ cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
local_softirq_pending() = 0;
@@ -94,8 +96,10 @@ restart:
h = softirq_vec;
do {
- if (pending & 1)
+ if (pending & 1) {
h->action(h);
+ RCU_bh_qsctr(cpu)++;
+ }
h++;
pending >>= 1;
} while (pending);
@@ -107,6 +111,7 @@ restart:
goto restart;
if (pending)
wakeup_softirqd();
+
__local_bh_enable();
}
@@ -117,6 +122,11 @@ EXPORT_SYMBOL(do_softirq);
void local_bh_enable(void)
{
+ int cpu = smp_processor_id();
+
+ if (softirq_count() == (1 << SOFTIRQ_SHIFT)) {
+ RCU_bh_qsctr(cpu)++;
+ }
__local_bh_enable();
WARN_ON(irqs_disabled());
if (unlikely(!in_interrupt() &&
diff -puN net/decnet/dn_route.c~rcu-softirq net/decnet/dn_route.c
--- linux-2.6.0-rtcache/net/decnet/dn_route.c~rcu-softirq 2004-04-01 00:07:48.000000000 +0530
+++ linux-2.6.0-rtcache-dipankar/net/decnet/dn_route.c 2004-04-01 00:07:48.000000000 +0530
@@ -146,14 +146,16 @@ static __inline__ unsigned dn_hash(unsig
static inline void dnrt_free(struct dn_route *rt)
{
- call_rcu(&rt->u.dst.rcu_head, (void (*)(void *))dst_free, &rt->u.dst);
+ call_rcu_bh(&rt->u.dst.rcu_head, (void (*)(void *))dst_free,
+ &rt->u.dst);
}
static inline void dnrt_drop(struct dn_route *rt)
{
if (rt)
dst_release(&rt->u.dst);
- call_rcu(&rt->u.dst.rcu_head, (void (*)(void *))dst_free, &rt->u.dst);
+ call_rcu_bh(&rt->u.dst.rcu_head, (void (*)(void *))dst_free,
+ &rt->u.dst);
}
static void dn_dst_check_expire(unsigned long dummy)
diff -puN net/ipv4/route.c~rcu-softirq net/ipv4/route.c
--- linux-2.6.0-rtcache/net/ipv4/route.c~rcu-softirq 2004-04-01 00:07:48.000000000 +0530
+++ linux-2.6.0-rtcache-dipankar/net/ipv4/route.c 2004-04-01 02:02:31.000000000 +0530
@@ -224,11 +224,11 @@ static struct rtable *rt_cache_get_first
struct rt_cache_iter_state *st = seq->private;
for (st->bucket = rt_hash_mask; st->bucket >= 0; --st->bucket) {
- rcu_read_lock();
+ rcu_read_lock_bh();
r = rt_hash_table[st->bucket].chain;
if (r)
break;
- rcu_read_unlock();
+ rcu_read_unlock_bh();
}
return r;
}
@@ -240,10 +240,10 @@ static struct rtable *rt_cache_get_next(
smp_read_barrier_depends();
r = r->u.rt_next;
while (!r) {
- rcu_read_unlock();
+ rcu_read_unlock_bh();
if (--st->bucket < 0)
break;
- rcu_read_lock();
+ rcu_read_lock_bh();
r = rt_hash_table[st->bucket].chain;
}
return r;
@@ -279,7 +279,7 @@ static void *rt_cache_seq_next(struct se
static void rt_cache_seq_stop(struct seq_file *seq, void *v)
{
if (v && v != SEQ_START_TOKEN)
- rcu_read_unlock();
+ rcu_read_unlock_bh();
}
static int rt_cache_seq_show(struct seq_file *seq, void *v)
@@ -437,13 +437,15 @@ static struct file_operations rt_cpu_seq
static __inline__ void rt_free(struct rtable *rt)
{
- call_rcu(&rt->u.dst.rcu_head, (void (*)(void *))dst_free, &rt->u.dst);
+ call_rcu_bh(&rt->u.dst.rcu_head, (void (*)(void *))dst_free,
+ &rt->u.dst);
}
static __inline__ void rt_drop(struct rtable *rt)
{
ip_rt_put(rt);
- call_rcu(&rt->u.dst.rcu_head, (void (*)(void *))dst_free, &rt->u.dst);
+ call_rcu_bh(&rt->u.dst.rcu_head, (void (*)(void *))dst_free,
+ &rt->u.dst);
}
static __inline__ int rt_fast_clean(struct rtable *rth)
@@ -2223,7 +2225,7 @@ int __ip_route_output_key(struct rtable
hash = rt_hash_code(flp->fl4_dst, flp->fl4_src ^ (flp->oif << 5), flp->fl4_tos);
- rcu_read_lock();
+ rcu_read_lock_bh();
for (rth = rt_hash_table[hash].chain; rth; rth = rth->u.rt_next) {
smp_read_barrier_depends();
if (rth->fl.fl4_dst == flp->fl4_dst &&
@@ -2239,13 +2241,13 @@ int __ip_route_output_key(struct rtable
dst_hold(&rth->u.dst);
rth->u.dst.__use++;
RT_CACHE_STAT_INC(out_hit);
- rcu_read_unlock();
+ rcu_read_unlock_bh();
*rp = rth;
return 0;
}
RT_CACHE_STAT_INC(out_hlist_search);
}
- rcu_read_unlock();
+ rcu_read_unlock_bh();
return ip_route_output_slow(rp, flp);
}
@@ -2455,7 +2457,7 @@ int ip_rt_dump(struct sk_buff *skb, str
if (h < s_h) continue;
if (h > s_h)
s_idx = 0;
- rcu_read_lock();
+ rcu_read_lock_bh();
for (rt = rt_hash_table[h].chain, idx = 0; rt;
rt = rt->u.rt_next, idx++) {
smp_read_barrier_depends();
@@ -2466,12 +2468,12 @@ int ip_rt_dump(struct sk_buff *skb, str
cb->nlh->nlmsg_seq,
RTM_NEWROUTE, 1) <= 0) {
dst_release(xchg(&skb->dst, NULL));
- rcu_read_unlock();
+ rcu_read_unlock_bh();
goto done;
}
dst_release(xchg(&skb->dst, NULL));
}
- rcu_read_unlock();
+ rcu_read_unlock_bh();
}
done:
_
On Wed, Mar 31, 2004 at 11:31:09PM +0200, Andrea Arcangeli wrote:
> On Thu, Apr 01, 2004 at 02:16:11AM +0530, Dipankar Sarma wrote:
> > I don't do any of this. I just have a separate quiescent state counter
> > for softirq RCU. It is incremented for regular quiescent points
> > like cswitch, userland, idle loop as well as at the completion
> > of each softirq handler. call_rcu_bh() uses its own queues.
> > Everything else works like call_rcu().
>
> the point is that you want this counter to increase in every cpu quick,
> that's why I was thinking at posting the tasklet, if the counter doesn't
> increase from softirq, you fallback in the grace period length of the
> non-bh rcu.
>
> maybe the softirq load is so high in all cpus that just the additional
> counter will fix it w/o having to post any additional tasklet (I very
> much hope so but especially with irq binding I don't see it happening,
> however with irq binding you may have a call_rcu_bh_cpuset). You should
> give it a try and see if it just works.
Ah, forcing CPUs for quiescent state is my last WMD if I have to use it ever :)
Thanks
Dipankar
On Thu, Apr 01, 2004 at 02:16:11AM +0530, Dipankar Sarma wrote:
> I don't do any of this. I just have a separate quiescent state counter
> for softirq RCU. It is incremented for regular quiescent points
> like cswitch, userland, idle loop as well as at the completion
> of each softirq handler. call_rcu_bh() uses its own queues.
> Everything else works like call_rcu().
the point is that you want this counter to increase in every cpu quick,
that's why I was thinking at posting the tasklet, if the counter doesn't
increase from softirq, you fallback in the grace period length of the
non-bh rcu.
maybe the softirq load is so high in all cpus that just the additional
counter will fix it w/o having to post any additional tasklet (I very
much hope so but especially with irq binding I don't see it happening,
however with irq binding you may have a call_rcu_bh_cpuset). You should
give it a try and see if it just works.
Andrea Arcangeli writes:
> Maybe the problem is simply that NAPI should be tuned more aggressively,
> it may have to poll for a longer time before giving up.
It cannot poll much more... 20 Million packets were injected in total
there were 250 RX irq's. Most from my ssh sessions. There are some TX
interrupts... it's another story
Packet flooding is just our way to generate load and kernel locking must
work with and without irq's. As far as I understand the real problem is
when do_softirq is run from irqexit etc.
Some thoughts...
If we tag the different do_softirq sources (look in my testpatch) we can
control the softirqs better. For example; do_softirq's from irqexit etc
could be given low a "max_restart" this to move processing to ksoftird
maybe even dynamic.
Cheers.
--ro
On Thu, Apr 01, 2004 at 12:36:00AM +0200, Robert Olsson wrote:
>
> Andrea Arcangeli writes:
>
> > Maybe the problem is simply that NAPI should be tuned more aggressively,
> > it may have to poll for a longer time before giving up.
>
> It cannot poll much more... 20 Million packets were injected in total
> there were 250 RX irq's. Most from my ssh sessions. There are some TX
> interrupts... it's another story
I didn't focus much on the irq count, but now that I look at it, it
looks like the biggest source of softirq in irq context is the timer
irq, not the network irq. That explains the problem and why NAPI
couldn't avoid the softirq load in irq context, NAPI avoids the network
irqs, but the softirqs keeps running in irq context.
So lowering HZ to 100 should mitigate the problem significantly.
But I feel like we should change the softirq code so that the irqexit
runs only the softirq setup by the current (or nested) irq handler. This
way the timer irq will stop executing the softirqs posted by the network
stack and it may very well fix the problem completely. This definitely
will help fairness too.
> Packet flooding is just our way to generate load and kernel locking must
> work with and without irq's. As far as I understand the real problem is
> when do_softirq is run from irqexit etc.
yes, but it's run from the _timer_ irq as far as I can tell. Changing
the softirq code so that the irqexit only processes softirqs posted in
the irq handlers should fix it.
> If we tag the different do_softirq sources (look in my testpatch) we can
> control the softirqs better. For example; do_softirq's from irqexit etc
> could be given low a "max_restart" this to move processing to ksoftird
> maybe even dynamic.
max_restart is needed exactly to avoid irqexit load to be offloaded to
regular kernel context, so that's basically saying that we should
disable max_restart but that's not a good solution for some non-NAPI
workload.
Hello!
> > We had one full solution for this issue not changing anything
> > in scheduler/softirq relationship: to run rcu task for the things
> > sort of dst cache not from process context, but essentially as part
> > of do_softirq(). Simple, stupid and apparently solves new problems
> > which rcu created.
>
> Can you be a little bit more specific about this solution ?
It is about that your suggestion, which you outlined below :-)
> as indicated by my earlier experiments. We have potential fixes
> for RCU through a call_rcu_bh() interface where completion of a
> softirq handler is a quiescent state. I am working on forward porting
> that old patch from our discussion last year and testing in my
> environment. That should increase the number of quiescent state
> points significantly and hopefully reduce the grace period significantly.
> But this does nothing to help userland starvation.
Alexey
Hello!
> I didn't focus much on the irq count, but now that I look at it, it
> looks like the biggest source of softirq in irq context is the timer
> irq, not the network irq. That explains the problem and why NAPI
> couldn't avoid the softirq load in irq context, NAPI avoids the network
> irqs, but the softirqs keeps running in irq context.
>
> So lowering HZ to 100 should mitigate the problem significantly.
Plus local_bh_enable(), which was actually the first source discovered
by Robert year ago. It does not contribute now, but Robert could turn it on
starting some non-trivial process context workload.
We have lots of places where we do local_bh_disable/enable() several times
in row and each of them triggers full do_softirq() run without schedule()
in between. See?
The thing which I want to say is: source of do_softirq() does not matter.
All of them happening outside of ksoftirqd are equally bad, unaccountable,
uncontrollable and will show up in some situation.
What's about some accounting do_softirq() in some way as a starting point?
F.e. one way is to account all timer ticks happened while do_softirq()
to ksoftirqd instead of current process (I am not sure that this is even
possible without race conditions). Or something like that.
Alexey
On Thu, Apr 01, 2004 at 10:43:45AM +0400, [email protected] wrote:
> What's about some accounting do_softirq() in some way as a starting point?
> F.e. one way is to account all timer ticks happened while do_softirq()
> to ksoftirqd instead of current process (I am not sure that this is even
> possible without race conditions). Or something like that.
This sounds reasonable. However as a start I was thinking at having
hardirq run only the softirq they posted actively, and local_bh_enable
run only the softirq that have been posted by the critical section (not
from hardirqs happening on top of it). And leave everything else for
ksoftirqd. this will complicate the bitmask setting and bitmask
management but it sounds doable.
This will still leave some unfariness under an irq driven flood (partly
a feature to provide as usual the lowest possible latency for stuff like
not busy routers where NAPI isn't needed) but at least it avoids hardirq
to overload excessively the task that happens to run with bh disabled
most of the time, and it will^Wshould allow NAPI to offload the softirq
to ksoftirqd completely.
comments?
Andrea Arcangeli writes:
> But I feel like we should change the softirq code so that the irqexit
> runs only the softirq setup by the current (or nested) irq handler. This
> way the timer irq will stop executing the softirqs posted by the network
> stack and it may very well fix the problem completely. This definitely
> will help fairness too.
How would softirq's scheduled be softirq's be run?
For a definitive solution a think Alexey analysis make sense:
"All of them happening outside of ksoftirqd are equally bad, unaccountable,
uncontrollable and will show up in some situation."
FYI. I did some more experiments:
Simple sycall test: user app = ank-time-loop (does gettimeofday in a loop)
=========================================================================
Before
total droppped tsquz throttl bh_enbl ksoftird irqexit other
00000099 00000000 00000000 00000000 0000005d 00000005 000163a2 00000000
00000008 00000000 00000000 00000000 00000009 00000000 000162f6 00000000
ank-time-loop
After 10 sec.
000000c0 00000000 00000000 00000000 0000005d 00000005 0001c3d2 00000000
00000008 00000000 00000000 00000000 00000009 00000000 0001c2f3 00000000
So syscalls "in this context" seems to do_softirq() via irqexit.
Route DoS while BGP tables are loading. ank-time-loop is running.
================================================================
total droppped tsquz throttl bh_enbl ksoftird irqexit other
000000c2 00000000 00000000 00000000 00000042 00000005 0001aef8 00000000
00000008 00000000 00000000 00000000 00000017 00000001 0001adba 00000000
After run:
000b3a10 00000000 00000eda 00000000 000006f6 0000052e 00041c06 00000000
000b0500 00000000 00000ec1 00000000 0000075e 00000197 000419f2 00000000
Most softirq's are run from irqexit but we see local_bh_enable is running
softirq's too. And only a minority of softirq's is running under scheduler
control. As discussed we before with 100Hz timer we would expect lower
rates from irqexit.
Cheers.
--ro
Dipankar Sarma writes:
> Robert, btw, this rcu-softirq patch is slightly different
> from the earlier one in the sense that now every softirq
> handler completion is a quiescent point. Earlier each iteration
> of softirqs was a quiescent point. So this has more quiescent
> points.
Hello!
Yes it seems reduce RCU latency in our setup as well. It does not eliminate
overflows but reduces with ~50% and increases the throughput a bit. dst cache
overflow depends on RCU-delay + gc_min_interval and the number of entries
freed per sec so this means RCU has improved. Also the user app doing gettimeofday
seems to be better scheduled. The worst starvation improved from ~7.5 to ~4.4 sec.
Cheers.
--ro
Setup as described before.
Without patch
=============
2 * 283 kpps (eth0, eth2) 32768 flows and 10 pkts flow
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flags
eth0 1500 0 5419435 8802471 8802471 4580569 44 0 0 0 BRU
eth1 1500 0 45 0 0 0 5417465 0 0 0 BRU
eth2 1500 0 5372943 8849348 8849348 4627060 44 0 0 0 BRU
eth3 1500 0 46 0 0 0 5371007 0 0 0 BRU
/proc/net/rt_cache_stat (3:rd last is ovfr)
000034d0 0046284e 000c8986 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000bf952 000bf173 000007b8 000007b3 0081b228 00000000
000034d0 004559f4 000ca247 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000c369c 000c2edf 00000799 00000792 008057a4 00000000
User app max delay 7.5 Sec
WIth RCU patch
===============
2 * 284 kpps 32768 flows and 10 pkts flow
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flags
eth0 1500 0 5838522 8704663 8704663 4161481 44 0 0 0 BRU
eth1 1500 0 45 0 0 0 5837586 0 0 0 BRU
eth2 1500 0 5957987 8643714 8643714 4042016 44 0 0 0 BRU
eth3 1500 0 46 0 0 0 5957051 0 0 0 BRU
/proc/net/rt_cache_stat
0002dcb5 004b6add 000dac08 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000d029a 000cfec3 000003aa 000003a9 008c80b2 00000000
0002dcb5 004d2db5 000dbbda 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000cfa51 000cf67e 000003b1 000003aa 008eb195 00000000
User app max delay 4.4 Sec
On Mon, Apr 05, 2004 at 07:11:52PM +0200, Robert Olsson wrote:
>
> Dipankar Sarma writes:
>
> > Robert, btw, this rcu-softirq patch is slightly different
> > from the earlier one in the sense that now every softirq
> > handler completion is a quiescent point. Earlier each iteration
> > of softirqs was a quiescent point. So this has more quiescent
> > points.
>
> Hello!
>
> Yes it seems reduce RCU latency in our setup as well. It does not eliminate
> overflows but reduces with ~50% and increases the throughput a bit. dst cache
> overflow depends on RCU-delay + gc_min_interval and the number of entries
> freed per sec so this means RCU has improved. Also the user app doing gettimeofday
> seems to be better scheduled. The worst starvation improved from ~7.5 to ~4.4 sec.
Looks better atleast. Can you apply the following patch (rs-throttle-rcu)
on top of rcu-softirq.patch in your tree and see if helps a little bit more ?
Please make sure to set the kernel paramenters rcupdate.maxbatch to 4
and rcupdate.plugticks to 0. You can make sure of those parameters
by looking at dmesg (rcu prints them out during boot). I just merged
it, but have not tested this patch yet.
Thanks
Dipankar
Throttle rcu by forcing a limit on how many callbacks per softirq
and also implement a configurable plug. Applies on top of the
rcu-softirq (hence rs-) patch.
include/linux/list.h | 21 +++++++++++++++++++++
include/linux/rcupdate.h | 7 ++++++-
kernel/rcupdate.c | 33 +++++++++++++++++++++++++--------
kernel/sched.c | 2 ++
4 files changed, 54 insertions(+), 9 deletions(-)
diff -puN include/linux/list.h~rs-throttle-rcu include/linux/list.h
--- linux-2.6.4-rcu/include/linux/list.h~rs-throttle-rcu 2004-04-06 02:05:13.000000000 +0530
+++ linux-2.6.4-rcu-dipankar/include/linux/list.h 2004-04-06 02:05:13.000000000 +0530
@@ -251,6 +251,27 @@ static inline void list_splice(struct li
__list_splice(list, head);
}
+static inline void __list_splice_tail(struct list_head *list,
+ struct list_head *head)
+{
+ struct list_head *first = list->next;
+ struct list_head *last = list->prev;
+ struct list_head *at = head->prev;
+
+ first->prev = at;
+ at->next = first;
+ head->prev = last;
+ last->next = head;
+}
+
+
+static inline void list_splice_tail(struct list_head *list,
+ struct list_head *head)
+{
+ if (!list_empty(list))
+ __list_splice_tail(list, head);
+}
+
/**
* list_splice_init - join two lists and reinitialise the emptied list.
* @list: the new list to add.
diff -puN include/linux/rcupdate.h~rs-throttle-rcu include/linux/rcupdate.h
--- linux-2.6.4-rcu/include/linux/rcupdate.h~rs-throttle-rcu 2004-04-06 02:05:13.000000000 +0530
+++ linux-2.6.4-rcu-dipankar/include/linux/rcupdate.h 2004-04-06 02:27:29.000000000 +0530
@@ -96,10 +96,12 @@ struct rcu_data {
long batch; /* Batch # for current RCU batch */
struct list_head nxtlist;
struct list_head curlist;
+ struct list_head donelist;
};
DECLARE_PER_CPU(struct rcu_data, rcu_data);
DECLARE_PER_CPU(struct rcu_data, rcu_bh_data);
+DECLARE_PER_CPU(int, rcu_plugticks);
extern struct rcu_ctrlblk rcu_ctrlblk;
extern struct rcu_ctrlblk rcu_bh_ctrlblk;
@@ -107,6 +109,8 @@ extern struct rcu_ctrlblk rcu_bh_ctrlblk
#define RCU_nxtlist(cpu) (per_cpu(rcu_data, (cpu)).nxtlist)
#define RCU_bh_qsctr(cpu) (per_cpu(rcu_bh_data, (cpu)).qsctr)
#define RCU_bh_nxtlist(cpu) (per_cpu(rcu_bh_data, (cpu)).nxtlist)
+
+#define RCU_plugticks(cpu) (per_cpu(rcu_plugticks, (cpu)))
#define RCU_QSCTR_INVALID 0
@@ -117,7 +121,8 @@ static inline int __rcu_pending(int cpu,
rcu_batch_before(rdp->batch, rcp->curbatch)) ||
(list_empty(&rdp->curlist) &&
!list_empty(&rdp->nxtlist)) ||
- cpu_isset(cpu, rcp->rcu_cpu_mask))
+ cpu_isset(cpu, rcp->rcu_cpu_mask) ||
+ (!list_empty(&rdp->donelist) && RCU_plugticks(cpu) == 0))
return 1;
else
return 0;
diff -puN kernel/rcupdate.c~rs-throttle-rcu kernel/rcupdate.c
--- linux-2.6.4-rcu/kernel/rcupdate.c~rs-throttle-rcu 2004-04-06 02:05:13.000000000 +0530
+++ linux-2.6.4-rcu-dipankar/kernel/rcupdate.c 2004-04-06 02:47:10.000000000 +0530
@@ -39,6 +39,7 @@
#include <asm/atomic.h>
#include <asm/bitops.h>
#include <linux/module.h>
+#include <linux/moduleparam.h>
#include <linux/completion.h>
#include <linux/percpu.h>
#include <linux/notifier.h>
@@ -59,6 +60,10 @@ DEFINE_PER_CPU(struct rcu_data, rcu_bh_d
/* Fake initialization required by compiler */
static DEFINE_PER_CPU(struct tasklet_struct, rcu_tasklet) = {NULL};
#define RCU_tasklet(cpu) (per_cpu(rcu_tasklet, cpu))
+DEFINE_PER_CPU(int, rcu_plugticks) = 0;
+
+static int maxbatch = 1000000;
+static int plugticks = 4;
/**
* call_rcu - Queue an RCU update request.
@@ -112,16 +117,23 @@ void call_rcu_bh(struct rcu_head *head,
* Invoke the completed RCU callbacks. They are expected to be in
* a per-cpu list.
*/
-static void rcu_do_batch(struct list_head *list)
+static void rcu_do_batch(int cpu, struct list_head *list)
{
struct list_head *entry;
struct rcu_head *head;
+ int count = 0;
while (!list_empty(list)) {
entry = list->next;
list_del(entry);
head = list_entry(entry, struct rcu_head, list);
head->func(head->arg);
+ if (++count >= maxbatch) {
+ RCU_plugticks(cpu) = plugticks;
+ if (!RCU_plugticks(cpu))
+ tasklet_hi_schedule(&RCU_tasklet(cpu));
+ break;
+ }
}
}
@@ -178,7 +190,7 @@ out_unlock:
spin_unlock(&rcp->mutex);
}
-static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
+static void __rcu_process_callbacks(int cpu, struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
LIST_HEAD(list);
@@ -186,6 +198,7 @@ static void __rcu_process_callbacks(stru
if (!list_empty(&rdp->curlist) &&
rcu_batch_after(rcp->curbatch, rdp->batch)) {
list_splice(&rdp->curlist, &list);
+ list_splice_tail(&rdp->curlist, &rdp->donelist);
INIT_LIST_HEAD(&rdp->curlist);
}
@@ -206,13 +219,13 @@ static void __rcu_process_callbacks(stru
local_irq_enable();
}
rcu_check_quiescent_state(rcp, rdp);
- if (!list_empty(&list))
- rcu_do_batch(&list);
+ if (!list_empty(&rdp->donelist) && !RCU_plugticks(cpu))
+ rcu_do_batch(cpu, &rdp->donelist);
}
void rcu_process_callbacks_bh(int cpu)
{
- __rcu_process_callbacks(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
+ __rcu_process_callbacks(cpu, &rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
}
/*
@@ -221,8 +234,8 @@ void rcu_process_callbacks_bh(int cpu)
static void rcu_process_callbacks(unsigned long unused)
{
int cpu = smp_processor_id();
- __rcu_process_callbacks(&rcu_ctrlblk, &per_cpu(rcu_data, cpu));
- __rcu_process_callbacks(&rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
+ __rcu_process_callbacks(cpu, &rcu_ctrlblk, &per_cpu(rcu_data, cpu));
+ __rcu_process_callbacks(cpu, &rcu_bh_ctrlblk, &per_cpu(rcu_bh_data, cpu));
}
void rcu_check_callbacks(int cpu, int user)
@@ -234,7 +247,7 @@ void rcu_check_callbacks(int cpu, int us
RCU_bh_qsctr(cpu)++;
} else if (!in_softirq())
RCU_bh_qsctr(cpu)++;
- tasklet_schedule(&RCU_tasklet(cpu));
+ tasklet_hi_schedule(&RCU_tasklet(cpu));
}
static void __devinit rcu_online_cpu(struct rcu_data *rdp)
@@ -242,6 +255,7 @@ static void __devinit rcu_online_cpu(str
memset(rdp, 0, sizeof(*rdp));
INIT_LIST_HEAD(&rdp->nxtlist);
INIT_LIST_HEAD(&rdp->curlist);
+ INIT_LIST_HEAD(&rdp->donelist);
}
static int __devinit rcu_cpu_notify(struct notifier_block *self,
@@ -277,6 +291,7 @@ void __init rcu_init(void)
(void *)(long)smp_processor_id());
/* Register notifier for non-boot CPUs */
register_cpu_notifier(&rcu_nb);
+ printk("RCU: maxbatch = %d, plugticks = %d\n", maxbatch, plugticks);
}
@@ -302,6 +317,8 @@ void synchronize_kernel(void)
wait_for_completion(&completion);
}
+module_param(maxbatch, int, 0);
+module_param(plugticks, int, 0);
EXPORT_SYMBOL(call_rcu);
EXPORT_SYMBOL(call_rcu_bh);
diff -puN kernel/sched.c~rs-throttle-rcu kernel/sched.c
--- linux-2.6.4-rcu/kernel/sched.c~rs-throttle-rcu 2004-04-06 02:05:13.000000000 +0530
+++ linux-2.6.4-rcu-dipankar/kernel/sched.c 2004-04-06 02:05:13.000000000 +0530
@@ -1486,6 +1486,8 @@ void scheduler_tick(int user_ticks, int
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_ticks);
+ if (RCU_plugticks(cpu))
+ RCU_plugticks(cpu)--;
/* note: this timer irq context must be accounted for as well */
if (hardirq_count() - HARDIRQ_OFFSET) {
_
Cheers.
--ro
On Tue, Apr 06, 2004 at 02:55:19PM +0200, Robert Olsson wrote:
Content-Description: message body text
> Dipankar Sarma writes:
> > Looks better atleast. Can you apply the following patch (rs-throttle-rcu)
> > on top of rcu-softirq.patch in your tree and see if helps a little bit more ?
> > Please make sure to set the kernel paramenters rcupdate.maxbatch to 4
> > and rcupdate.plugticks to 0. You can make sure of those parameters
> > by looking at dmesg (rcu prints them out during boot). I just merged
> > it, but have not tested this patch yet.
>
> OK!
>
> Well not tested yet but I don't think we will get rid overflow totally in my
> setup. I've done a little experimental patch so *all* softirq's are run via
> ksoftirqd.
Robert, you should try out rs-throttle-rcu.patch. The idea is that
we don't run too many callbacks in a single rcu. In my setup,
at 100kpps, I see as many as 30000 rcu callbacks in a single
tasklet handler. That is likely hurting even the softirq-only
RCU grace periods. Setting rcupdate.maxbatch=4 will do only 4 per
tasklet thus providing more quiescent points to the system.
Thanks
Dipankar
Dipankar Sarma writes:
> Robert, you should try out rs-throttle-rcu.patch. The idea is that
> we don't run too many callbacks in a single rcu. In my setup,
> at 100kpps, I see as many as 30000 rcu callbacks in a single
> tasklet handler. That is likely hurting even the softirq-only
> RCU grace periods. Setting rcupdate.maxbatch=4 will do only 4 per
> tasklet thus providing more quiescent points to the system.
Hello!
No bad things happens, lots of overflows and drop in performance
and the userland app can stall for 32 sec. We seems to spin in
softirq to much and still don't get things done.
Cheers.
--ro
Without patch
=============
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flags
eth0 1500 0 5568922 8823920 8823920 4431083 46 0 0 0 BRU
eth1 1500 0 45 0 0 0 5567591 0 0 0 BRU
eth2 1500 0 5742954 8731915 8731915 4257049 42 0 0 0 BRU
eth3 1500 0 46 0 0 0 5741617 0 0 0 BRU
/proc/net/rt_cache_stat [overflow 3:rd last]
00009e0f 004809d5 000cefee 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000c8c85 000c8725 0000053a 00000533 0085c6f6 00000000
00009e0f 004aa57e 000cfc18 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000c4920 000c43b8 00000541 0000053d 0088c546 00000000
With patch
===========
RCU: maxbatch = 4, plugticks = 0
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flags
eth0 1500 0 922395 9792296 9792296 9077609 45 0 0 0 BRU
eth1 1500 0 47 0 0 0 909892 0 0 0 BRU
eth2 1500 0 922586 9789706 9789706 9077417 45 0 0 0 BRU
eth3 1500 0 48 0 0 0 909992 0 0 0 BRU
/proc/net/rt_cache_stat [overflow 3:rd last]
00000018 000bc6e3 00024c63 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00021077 0001df2f 000030e2 000030d9 0011ed4d 00000000
00000018 000bc27d 0002518a 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00020d75 0001dbba 0000313c 00003135 00122fc9 00000000
On Wed, Apr 07, 2004 at 05:23:28PM +0200, Robert Olsson wrote:
> Dipankar Sarma writes:
>
> > Robert, you should try out rs-throttle-rcu.patch. The idea is that
> > we don't run too many callbacks in a single rcu. In my setup,
> > at 100kpps, I see as many as 30000 rcu callbacks in a single
> > tasklet handler. That is likely hurting even the softirq-only
> > RCU grace periods. Setting rcupdate.maxbatch=4 will do only 4 per
> > tasklet thus providing more quiescent points to the system.
>
> Hello!
>
> No bad things happens, lots of overflows and drop in performance
> and the userland app can stall for 32 sec. We seems to spin in
> softirq to much and still don't get things done.
Argh!! Andrea, this means that throttling rcu callbacks with
back-to-back rcu tasklets for better scheduling latency is bad
for this kind of DoS situation. I think we will have to address
the softirq limiting question.
That said, Robert, one last experiment - if you are running UP,
can you try the following patchset (should apply on top of vanilla
2.6.x) ? This implements direct invocation of callbacks instead
of waiting for rcu grace periods in UP kernel. This would be a
good data point to understand what happens.
Thanks
Dipankar
Hello!
> setup. I've done a little experimental patch so *all* softirq's are run via
> ksoftirqd.
BTW what's about performance in this extremal situation?
Also, Robert, let's count the numbers again. With this change you should
have latency much less 100msec when priority of ksoftirqd is high.
So, rcu problem must be solved at current flow rates.
This enforces me to suspect we have another source of overflows.
F.e. one silly place could be that you set gc_min_interval via sysctl,
which uses second resolution (yup :-(). With one second you get maximal
ip_rt_max_size/1 second flow rate, it is _not_ a lot.
Alexey
Hello!
> This sounds reasonable. However as a start I was thinking at having
> hardirq run only the softirq they posted actively, and local_bh_enable
> run only the softirq that have been posted by the critical section (not
> from hardirqs happening on top of it).
To all that I remember Ingo insisted that the run from local_bh_enable()
is necessary for softirqs triggered by hardirqs while softirqs are disabled.
Otherwise he observed random delays and redundant scheduler activity
breaking at least tux fast path.
Alexey
[email protected] writes:
> BTW what's about performance in this extremal situation?
First I used the patch to defer all softirq's to ksoftirq with call_rcu_bh()
patch. Sofar this has been the best combination giving both pure sofirq
performance and also good response from the userland apps.
I also tried other TCP apps netperf and could note any performance
degradation which I was expecting.
> Also, Robert, let's count the numbers again. With this change you should
> have latency much less 100msec when priority of ksoftirqd is high.
> So, rcu problem must be solved at current flow rates.
> This enforces me to suspect we have another source of overflows.
Certainly. I said to Dipankar we should not expect all overflows to disappear
the setup I use now. But the call_rcu_bh() patch improved things so it cured
some latency caused by RCU. But I don't think we can do much better now in
terms dst overflow.
> F.e. one silly place could be that you set gc_min_interval via sysctl,
I should not...
> which uses second resolution (yup :-(). With one second you get maximal
> ip_rt_max_size/1 second flow rate, it is _not_ a lot.
From /proc
gc_min_interval = 0
max_size = 262144
Cheers.
--ro
{kind=link}
{kind=link}
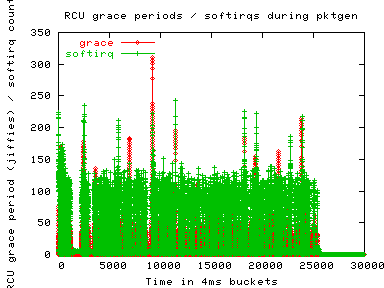{kind=link}