Hi,
we kindly ask for some suggestions about how to trace a memory leak
which we suspect in the linux kernel version 2.6:
The machine in question is a Dell PowerEdge 2500 (4GB RAM, Dual-PIII,
AAC-raid and several e1000) running SUSE Pro 9.2 with different kernels
(2.6.8-24.11-SMP from SUSE and now a native 2.6.10 from kernel.org).
It is used as a bastion host with the usual suspects: squid, apache,
bind, xntpd, postfix, spamassassin.
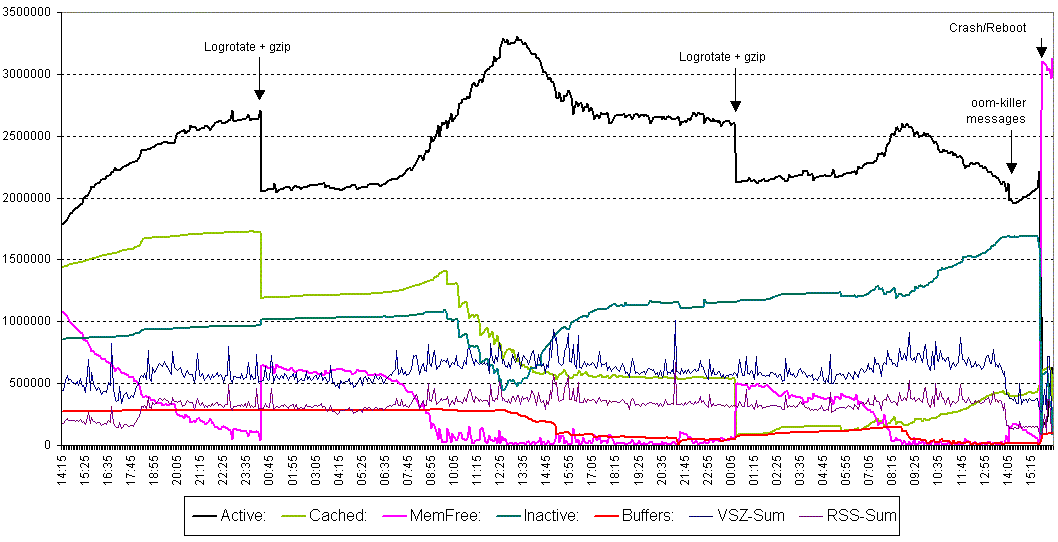
As you can see here
http://download.hennerich.de/memory-leak.gif
the userspace processes consume unchanging less then 1GB RAM for several
days (vsz-sum/rss-sum).
Nonetheless, each night (after cron started logrotate) the kernel uses
~1.2GB less for cache. After an uptime a few days, we get messages from
the oom-killer like this :
oom-killer: gfp_mask=0xd0
DMA per-cpu:
cpu 0 hot: low 2, high 6, batch 1
cpu 0 cold: low 0, high 2, batch 1
Normal per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
HighMem per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
Free pages: 131452kB (127680kB HighMem)
Active:579780 inactive:342244 dirty:0 writeback:0 unstable:0 free:32863
slab:16212 mapped:20773 pagetables:230
DMA free:68kB min:68kB low:84kB high:100kB active:6016kB inactive:6028kB
present:16384kB pages_scanned:37102 all_unreclaimable? yes
protections[]: 0 0 0
Normal free:3704kB min:3756kB low:4692kB high:5632kB active:716344kB
inactive:79172kB present:901120kB pages_scanned:2312264
all_unreclaimable? yes
protections[]: 0 0 0
HighMem free:127680kB min:512kB low:640kB high:768kB active:1596760kB
inactive:1283776kB present:3014592kB pages_scanned:0 all_unreclaimable? no
protections[]: 0 0 0
DMA: 1*4kB 0*8kB 0*16kB 2*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB
0*2048kB 0*4096kB = 68kB
Normal: 0*4kB 5*8kB 1*16kB 4*32kB 1*64kB 1*128kB 1*256kB 0*512kB 1*1024kB
1*2048kB 0*4096kB = 3704kB
HighMem: 26482*4kB 2095*8kB 110*16kB 47*32kB 19*64kB 0*128kB 0*256kB
1*512kB 0*1024kB 0*2048kB 0*4096kB = 127680kB
Swap cache: add 439887, delete 438471, find 242699/277105, race 0+0
Out of Memory: Killed process 29603 (cleanup).
(at that time we used a kernel 2.6.10 with CONFIG_SMP not set, so you
don't see the second CPU)
30 minutes later the machine swaps out some MBs (and only some few MBs),
kswapd needs CPU and the system freezes. System-load is most of the time
below 0.5, /proc/slabinfo seems to be normal.
Changing hardware (to another PowerEdge 2500) and upgrading the kernel
didn't help, only a backport to a system with a linux-2.4 changed the
behavior.
Do you have any suggestions how to isolate this problem?
Best regards Tobias Hennerich
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
[Sorry, I somehow didn't do reply-to-all in the first mail, lkml back]
> > > Out of Memory: Killed process 29603 (cleanup).
> >
> > This looks to me like someone is leaking pages. Could you please try
> > 2.6.11 and the patch I'm putting at the bottom of this mail, there'll be
> > a CONFIG_PAGE_OWNER option under kernel hacking.
> >
> > There will be a /proc/page_owner and Documentation/page_owner.c that
> > contains a program to sort the output. When it starts getting messy do:
> > cat /proc/page_owner > page_owner.txt
> > ./sort page_owner.txt sorted_page_owner.txt
> >
> > The sorted_page_owner.txt will tell us who is grabbing pages.
>
> Thank you for your mail, wonderful, exactly what I was looking for!
>
> Before we are installing the new kernel with your patch: Can you say
> anything about the performance, which this patch costs? The machine is
> used by a bigger company and I want to be prepared, if several thousand
> employees can't mail or use the web anymore...
>
I doubt you'll notice any performance overhead, however this patch eats
some memory, on your system (4GB / 4096) * 36 bytes something like 36M
of low memory.
Btw, I recalled I haven't updated my previous patch for a discontig mem
(NUMA) update I got (doesn't matter on most machines) but anyway, I've
updated it and here it is.
This updated patch has been in -mm for a while so it should have proven
itself stable.
Thanks for taking time to help shake this out.
===== fs/proc/proc_misc.c 1.113 vs edited =====
--- 1.113/fs/proc/proc_misc.c 2005-01-12 01:42:35 +01:00
+++ edited/fs/proc/proc_misc.c 2005-03-08 16:40:15 +01:00
@@ -534,6 +534,66 @@ static struct file_operations proc_sysrq
};
#endif
+#ifdef CONFIG_PAGE_OWNER
+#include <linux/bootmem.h>
+#include <linux/kallsyms.h>
+static ssize_t
+read_page_owner(struct file *file, char __user *buf, size_t count, loff_t *ppos)
+{
+ unsigned long start_pfn = min_low_pfn;
+ static unsigned long pfn;
+ struct page *page;
+ char *kbuf, *modname;
+ const char *symname;
+ int ret = 0, next_idx = 1;
+ char namebuf[128];
+ unsigned long offset = 0, symsize;
+ int i;
+
+ pfn = start_pfn + *ppos;
+ page = pfn_to_page(pfn);
+ for (; pfn < max_pfn; pfn++) {
+ if (!pfn_valid(pfn))
+ continue;
+ page = pfn_to_page(pfn);
+ if (page->order >= 0)
+ break;
+ next_idx++;
+ }
+
+ if (!pfn_valid(pfn))
+ return 0;
+
+ *ppos += next_idx;
+
+ kbuf = kmalloc(count, GFP_KERNEL);
+ if (!kbuf)
+ return -ENOMEM;
+
+ ret = snprintf(kbuf, 1024, "Page allocated via order %d\n", page->order);
+
+ for (i = 0; i < 8; i++) {
+ if (!page->trace[i])
+ break;
+ symname = kallsyms_lookup(page->trace[i], &symsize, &offset, &modname, namebuf);
+ ret += snprintf(kbuf + ret, count - ret, "[0x%lx] %s+%lu\n",
+ page->trace[i], namebuf, offset);
+ }
+
+ ret += snprintf(kbuf + ret, count -ret, "\n");
+
+ if (copy_to_user(buf, kbuf, ret))
+ ret = -EFAULT;
+
+ kfree(kbuf);
+ return ret;
+}
+
+static struct file_operations proc_page_owner_operations = {
+ .read = read_page_owner,
+};
+#endif
+
struct proc_dir_entry *proc_root_kcore;
void create_seq_entry(char *name, mode_t mode, struct file_operations *f)
@@ -610,6 +670,13 @@ void __init proc_misc_init(void)
entry = create_proc_entry("ppc_htab", S_IRUGO|S_IWUSR, NULL);
if (entry)
entry->proc_fops = &ppc_htab_operations;
+ }
+#endif
+#ifdef CONFIG_PAGE_OWNER
+ entry = create_proc_entry("page_owner", S_IWUSR | S_IRUGO, NULL);
+ if (entry) {
+ entry->proc_fops = &proc_page_owner_operations;
+ entry->size = 1024;
}
#endif
}
===== include/linux/mm.h 1.215 vs edited =====
--- 1.215/include/linux/mm.h 2005-03-05 07:41:14 +01:00
+++ edited/include/linux/mm.h 2005-03-08 16:38:02 +01:00
@@ -260,6 +260,10 @@ struct page {
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
+#ifdef CONFIG_PAGE_OWNER
+ int order;
+ unsigned long trace[8];
+#endif
};
/*
===== lib/Kconfig.debug 1.13 vs edited =====
--- 1.13/lib/Kconfig.debug 2005-01-21 06:00:21 +01:00
+++ edited/lib/Kconfig.debug 2005-03-08 16:38:02 +01:00
@@ -140,6 +140,16 @@ config DEBUG_FS
If unsure, say N.
+config PAGE_OWNER
+ bool "Track page owner"
+ depends on DEBUG_KERNEL && X86
+ help
+ This keeps track of what call chain is the owner of a page, may
+ help to find bare alloc_page(s) leaks. Eats a fair amount of memory.
+ See Documentation/page_owner.c for user-space helper.
+
+ If unsure, say N.
+
if !X86_64
config FRAME_POINTER
bool "Compile the kernel with frame pointers"
===== mm/page_alloc.c 1.258 vs edited =====
--- 1.258/mm/page_alloc.c 2005-01-31 07:20:14 +01:00
+++ edited/mm/page_alloc.c 2005-03-08 16:38:02 +01:00
@@ -688,6 +688,43 @@ int zone_watermark_ok(struct zone *z, in
return 1;
}
+#ifdef CONFIG_PAGE_OWNER
+static inline int valid_stack_ptr(struct thread_info *tinfo, void *p)
+{
+ return p > (void *)tinfo &&
+ p < (void *)tinfo + THREAD_SIZE - 3;
+}
+
+static inline void __stack_trace(struct page *page, unsigned long *stack, unsigned long bp)
+{
+ int i = 0;
+ unsigned long addr;
+ struct thread_info *tinfo = (struct thread_info *)
+ ((unsigned long)stack & (~(THREAD_SIZE - 1)));
+
+ memset(page->trace, 0, sizeof(long) * 8);
+
+#ifdef CONFIG_FRAME_POINTER
+ while (valid_stack_ptr(tinfo, (void *)bp)) {
+ addr = *(unsigned long *)(bp + sizeof(long));
+ page->trace[i] = addr;
+ if (++i >= 8)
+ break;
+ bp = *(unsigned long *)bp;
+ }
+#else
+ while (valid_stack_ptr(tinfo, stack)) {
+ addr = *stack++;
+ if (__kernel_text_address(addr)) {
+ page->trace[i] = addr;
+ if (++i >= 8)
+ break;
+ }
+ }
+#endif
+}
+#endif /* CONFIG_PAGE_OWNER */
+
/*
* This is the 'heart' of the zoned buddy allocator.
*/
@@ -851,6 +888,19 @@ nopage:
}
return NULL;
got_pg:
+
+#ifdef CONFIG_PAGE_OWNER /* huga... */
+ {
+ unsigned long address, bp;
+#ifdef X86_64
+ asm ("movq %%rbp, %0" : "=r" (bp) : );
+#else
+ asm ("movl %%ebp, %0" : "=r" (bp) : );
+#endif
+ page->order = (int) order;
+ __stack_trace(page, &address, bp);
+ }
+#endif /* CONFIG_PAGE_OWNER */
zone_statistics(zonelist, z);
return page;
}
@@ -904,6 +954,9 @@ fastcall void __free_pages(struct page *
free_hot_page(page);
else
__free_pages_ok(page, order);
+#ifdef CONFIG_PAGE_OWNER
+ page->order = -1;
+#endif
}
}
@@ -1547,6 +1600,9 @@ void __init memmap_init_zone(unsigned lo
set_page_address(page, __va(start_pfn << PAGE_SHIFT));
#endif
start_pfn++;
+#ifdef CONFIG_PAGE_OWNER
+ page->order = -1;
+#endif
}
}
--- /dev/null 2004-08-25 14:12:53.000000000 +0200
+++ linus-2.5/Documentation/page_owner.c 2005-03-08 16:27:42.000000000 +0100
@@ -0,0 +1,140 @@
+/*
+ * User-space helper to sort the output of /proc/page_owner
+ *
+ * Example use:
+ * cat /proc/page_owner > page_owner.txt
+ * ./sort page_owner.txt sorted_page_owner.txt
+*/
+
+#include <stdio.h>
+#include <stdlib.h>
+#include <sys/types.h>
+#include <sys/stat.h>
+#include <fcntl.h>
+#include <unistd.h>
+#include <string.h>
+
+struct block_list {
+ char *txt;
+ int len;
+ int num;
+};
+
+
+static struct block_list *list;
+static int list_size;
+static int max_size;
+
+struct block_list *block_head;
+
+int read_block(char *buf, FILE *fin)
+{
+ int ret = 0;
+ int hit = 0;
+ char *curr = buf;
+
+ for (;;) {
+ *curr = getc(fin);
+ if (*curr == EOF) return -1;
+
+ ret++;
+ if (*curr == '\n' && hit == 1)
+ return ret - 1;
+ else if (*curr == '\n')
+ hit = 1;
+ else
+ hit = 0;
+ curr++;
+ }
+}
+
+static int compare_txt(struct block_list *l1, struct block_list *l2)
+{
+ return strcmp(l1->txt, l2->txt);
+}
+
+static int compare_num(struct block_list *l1, struct block_list *l2)
+{
+ return l2->num - l1->num;
+}
+
+static void add_list(char *buf, int len)
+{
+ if (list_size != 0 &&
+ len == list[list_size-1].len &&
+ memcmp(buf, list[list_size-1].txt, len) == 0) {
+ list[list_size-1].num++;
+ return;
+ }
+ if (list_size == max_size) {
+ printf("max_size too small??\n");
+ exit(1);
+ }
+ list[list_size].txt = malloc(len+1);
+ list[list_size].len = len;
+ list[list_size].num = 1;
+ memcpy(list[list_size].txt, buf, len);
+ list[list_size].txt[len] = 0;
+ list_size++;
+ if (list_size % 1000 == 0) {
+ printf("loaded %d\r", list_size);
+ fflush(stdout);
+ }
+}
+
+int main(int argc, char **argv)
+{
+ FILE *fin, *fout;
+ char buf[1024];
+ int ret, i, count;
+ struct block_list *list2;
+ struct stat st;
+
+ fin = fopen(argv[1], "r");
+ fout = fopen(argv[2], "w");
+ if (!fin || !fout) {
+ printf("Usage: ./program <input> <output>\n");
+ perror("open: ");
+ exit(2);
+ }
+
+ fstat(fileno(fin), &st);
+ max_size = st.st_size / 100; /* hack ... */
+
+ list = malloc(max_size * sizeof(*list));
+
+ for(;;) {
+ ret = read_block(buf, fin);
+ if (ret < 0)
+ break;
+
+ buf[ret] = '\0';
+ add_list(buf, ret);
+ }
+
+ printf("loaded %d\n", list_size);
+
+ printf("sorting ....\n");
+
+ qsort(list, list_size, sizeof(list[0]), compare_txt);
+
+ list2 = malloc(sizeof(*list) * list_size);
+
+ printf("culling\n");
+
+ for (i=count=0;i<list_size;i++) {
+ if (count == 0 ||
+ strcmp(list2[count-1].txt, list[i].txt) != 0) {
+ list2[count++] = list[i];
+ } else {
+ list2[count-1].num += list[i].num;
+ }
+ }
+
+ qsort(list2, count, sizeof(list[0]), compare_num);
+
+ for (i=0;i<count;i++) {
+ fprintf(fout, "%d times:\n%s\n", list2[i].num, list2[i].txt);
+ }
+ return 0;
+}
Tobias Hennerich <[email protected]> wrote:
>
> we kindly ask for some suggestions about how to trace a memory leak
> which we suspect in the linux kernel version 2.6:
Please grab 2.6.11, apply the below patch, set CONFIG_PAGE_OWNER and follow
the below instructions.
From: Alexander Nyberg <[email protected]>
Introduces CONFIG_PAGE OWNER that keeps track of the call chain under which
a page was allocated. Includes a user-space helper in
Documentation/page_owner.c to sort the enormous amount of output that this
may give (thanks tridge).
Information available through /proc/page_owner
x86_64 introduces some stack noise in certain call chains so for exact
output use of x86 && CONFIG_FRAME_POINTER is suggested. Tested on x86, x86
&& CONFIG_FRAME_POINTER, x86_64
Signed-off-by: Alexander Nyberg <[email protected]>
Signed-off-by: Andrew Morton <[email protected]>
---
25-akpm/Documentation/page_owner.c | 140 +++++++++++++++++++++++++++++++++++++
25-akpm/fs/proc/proc_misc.c | 63 ++++++++++++++++
25-akpm/include/linux/mm.h | 4 +
25-akpm/lib/Kconfig.debug | 10 ++
25-akpm/mm/page_alloc.c | 56 ++++++++++++++
5 files changed, 273 insertions(+)
diff -puN /dev/null Documentation/page_owner.c
--- /dev/null 2003-09-15 06:40:47.000000000 -0700
+++ 25-akpm/Documentation/page_owner.c 2005-02-22 18:17:32.000000000 -0800
@@ -0,0 +1,140 @@
+/*
+ * User-space helper to sort the output of /proc/page_owner
+ *
+ * Example use:
+ * cat /proc/page_owner > page_owner.txt
+ * ./sort page_owner.txt sorted_page_owner.txt
+*/
+
+#include <stdio.h>
+#include <stdlib.h>
+#include <sys/types.h>
+#include <sys/stat.h>
+#include <fcntl.h>
+#include <unistd.h>
+#include <string.h>
+
+struct block_list {
+ char *txt;
+ int len;
+ int num;
+};
+
+
+static struct block_list *list;
+static int list_size;
+static int max_size;
+
+struct block_list *block_head;
+
+int read_block(char *buf, FILE *fin)
+{
+ int ret = 0;
+ int hit = 0;
+ char *curr = buf;
+
+ for (;;) {
+ *curr = getc(fin);
+ if (*curr == EOF) return -1;
+
+ ret++;
+ if (*curr == '\n' && hit == 1)
+ return ret - 1;
+ else if (*curr == '\n')
+ hit = 1;
+ else
+ hit = 0;
+ curr++;
+ }
+}
+
+static int compare_txt(struct block_list *l1, struct block_list *l2)
+{
+ return strcmp(l1->txt, l2->txt);
+}
+
+static int compare_num(struct block_list *l1, struct block_list *l2)
+{
+ return l2->num - l1->num;
+}
+
+static void add_list(char *buf, int len)
+{
+ if (list_size != 0 &&
+ len == list[list_size-1].len &&
+ memcmp(buf, list[list_size-1].txt, len) == 0) {
+ list[list_size-1].num++;
+ return;
+ }
+ if (list_size == max_size) {
+ printf("max_size too small??\n");
+ exit(1);
+ }
+ list[list_size].txt = malloc(len+1);
+ list[list_size].len = len;
+ list[list_size].num = 1;
+ memcpy(list[list_size].txt, buf, len);
+ list[list_size].txt[len] = 0;
+ list_size++;
+ if (list_size % 1000 == 0) {
+ printf("loaded %d\r", list_size);
+ fflush(stdout);
+ }
+}
+
+int main(int argc, char **argv)
+{
+ FILE *fin, *fout;
+ char buf[1024];
+ int ret, i, count;
+ struct block_list *list2;
+ struct stat st;
+
+ fin = fopen(argv[1], "r");
+ fout = fopen(argv[2], "w");
+ if (!fin || !fout) {
+ printf("Usage: ./program <input> <output>\n");
+ perror("open: ");
+ exit(2);
+ }
+
+ fstat(fileno(fin), &st);
+ max_size = st.st_size / 100; /* hack ... */
+
+ list = malloc(max_size * sizeof(*list));
+
+ for(;;) {
+ ret = read_block(buf, fin);
+ if (ret < 0)
+ break;
+
+ buf[ret] = '\0';
+ add_list(buf, ret);
+ }
+
+ printf("loaded %d\n", list_size);
+
+ printf("sorting ....\n");
+
+ qsort(list, list_size, sizeof(list[0]), compare_txt);
+
+ list2 = malloc(sizeof(*list) * list_size);
+
+ printf("culling\n");
+
+ for (i=count=0;i<list_size;i++) {
+ if (count == 0 ||
+ strcmp(list2[count-1].txt, list[i].txt) != 0) {
+ list2[count++] = list[i];
+ } else {
+ list2[count-1].num += list[i].num;
+ }
+ }
+
+ qsort(list2, count, sizeof(list[0]), compare_num);
+
+ for (i=0;i<count;i++) {
+ fprintf(fout, "%d times:\n%s\n", list2[i].num, list2[i].txt);
+ }
+ return 0;
+}
diff -puN fs/proc/proc_misc.c~page-owner-tracking-leak-detector fs/proc/proc_misc.c
--- 25/fs/proc/proc_misc.c~page-owner-tracking-leak-detector 2005-02-22 18:17:32.000000000 -0800
+++ 25-akpm/fs/proc/proc_misc.c 2005-02-22 18:17:32.000000000 -0800
@@ -534,6 +534,62 @@ static struct file_operations proc_sysrq
};
#endif
+#ifdef CONFIG_PAGE_OWNER
+#include <linux/bootmem.h>
+#include <linux/kallsyms.h>
+static ssize_t
+read_page_owner(struct file *file, char __user *buf, size_t count, loff_t *ppos)
+{
+ struct page *start = pfn_to_page(min_low_pfn);
+ static struct page *page;
+ char *kbuf, *modname;
+ const char *symname;
+ int ret = 0, next_idx = 1;
+ char namebuf[128];
+ unsigned long offset = 0, symsize;
+ int i;
+
+ page = start + *ppos;
+ for (; page < pfn_to_page(max_pfn); page++) {
+ if (page->order >= 0)
+ break;
+ next_idx++;
+ continue;
+ }
+
+ if (page >= pfn_to_page(max_pfn))
+ return 0;
+
+ *ppos += next_idx;
+
+ kbuf = kmalloc(count, GFP_KERNEL);
+ if (!kbuf)
+ return -ENOMEM;
+
+ ret = snprintf(kbuf, 1024, "Page allocated via order %d\n", page->order);
+
+ for (i = 0; i < 8; i++) {
+ if (!page->trace[i])
+ break;
+ symname = kallsyms_lookup(page->trace[i], &symsize, &offset, &modname, namebuf);
+ ret += snprintf(kbuf + ret, count - ret, "[0x%lx] %s+%lu\n",
+ page->trace[i], namebuf, offset);
+ }
+
+ ret += snprintf(kbuf + ret, count -ret, "\n");
+
+ if (copy_to_user(buf, kbuf, ret))
+ ret = -EFAULT;
+
+ kfree(kbuf);
+ return ret;
+}
+
+static struct file_operations proc_page_owner_operations = {
+ .read = read_page_owner,
+};
+#endif
+
struct proc_dir_entry *proc_root_kcore;
void create_seq_entry(char *name, mode_t mode, struct file_operations *f)
@@ -612,4 +668,11 @@ void __init proc_misc_init(void)
entry->proc_fops = &ppc_htab_operations;
}
#endif
+#ifdef CONFIG_PAGE_OWNER
+ entry = create_proc_entry("page_owner", S_IWUSR | S_IRUGO, NULL);
+ if (entry) {
+ entry->proc_fops = &proc_page_owner_operations;
+ entry->size = 1024;
+ }
+#endif
}
diff -puN include/linux/mm.h~page-owner-tracking-leak-detector include/linux/mm.h
--- 25/include/linux/mm.h~page-owner-tracking-leak-detector 2005-02-22 18:17:32.000000000 -0800
+++ 25-akpm/include/linux/mm.h 2005-02-22 18:17:32.000000000 -0800
@@ -260,6 +260,10 @@ struct page {
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
+#ifdef CONFIG_PAGE_OWNER
+ int order;
+ unsigned long trace[8];
+#endif
};
/*
diff -puN lib/Kconfig.debug~page-owner-tracking-leak-detector lib/Kconfig.debug
--- 25/lib/Kconfig.debug~page-owner-tracking-leak-detector 2005-02-22 18:17:32.000000000 -0800
+++ 25-akpm/lib/Kconfig.debug 2005-02-22 18:17:32.000000000 -0800
@@ -167,6 +167,16 @@ config DEBUG_IOREMAP
automatically, but we'd like to make it more efficient by not
having to do that.
+config PAGE_OWNER
+ bool "Track page owner"
+ depends on DEBUG_KERNEL && X86
+ help
+ This keeps track of what call chain is the owner of a page, may
+ help to find bare alloc_page(s) leaks. Eats a fair amount of memory.
+ See Documentation/page_owner.c for user-space helper.
+
+ If unsure, say N.
+
config DEBUG_FS
bool "Debug Filesystem"
depends on DEBUG_KERNEL
diff -puN mm/page_alloc.c~page-owner-tracking-leak-detector mm/page_alloc.c
--- 25/mm/page_alloc.c~page-owner-tracking-leak-detector 2005-02-22 18:17:32.000000000 -0800
+++ 25-akpm/mm/page_alloc.c 2005-02-22 18:17:32.000000000 -0800
@@ -719,6 +719,43 @@ int zone_watermark_ok(struct zone *z, in
return 1;
}
+#ifdef CONFIG_PAGE_OWNER
+static inline int valid_stack_ptr(struct thread_info *tinfo, void *p)
+{
+ return p > (void *)tinfo &&
+ p < (void *)tinfo + THREAD_SIZE - 3;
+}
+
+static inline void __stack_trace(struct page *page, unsigned long *stack, unsigned long bp)
+{
+ int i = 0;
+ unsigned long addr;
+ struct thread_info *tinfo = (struct thread_info *)
+ ((unsigned long)stack & (~(THREAD_SIZE - 1)));
+
+ memset(page->trace, 0, sizeof(long) * 8);
+
+#ifdef CONFIG_FRAME_POINTER
+ while (valid_stack_ptr(tinfo, (void *)bp)) {
+ addr = *(unsigned long *)(bp + sizeof(long));
+ page->trace[i] = addr;
+ if (++i >= 8)
+ break;
+ bp = *(unsigned long *)bp;
+ }
+#else
+ while (valid_stack_ptr(tinfo, stack)) {
+ addr = *stack++;
+ if (__kernel_text_address(addr)) {
+ page->trace[i] = addr;
+ if (++i >= 8)
+ break;
+ }
+ }
+#endif
+}
+#endif /* CONFIG_PAGE_OWNER */
+
/*
* This is the 'heart' of the zoned buddy allocator.
*/
@@ -882,6 +919,19 @@ nopage:
}
return NULL;
got_pg:
+
+#ifdef CONFIG_PAGE_OWNER /* huga... */
+ {
+ unsigned long address, bp;
+#ifdef X86_64
+ asm ("movq %%rbp, %0" : "=r" (bp) : );
+#else
+ asm ("movl %%ebp, %0" : "=r" (bp) : );
+#endif
+ page->order = (int) order;
+ __stack_trace(page, &address, bp);
+ }
+#endif /* CONFIG_PAGE_OWNER */
zone_statistics(zonelist, z);
return page;
}
@@ -935,6 +985,9 @@ fastcall void __free_pages(struct page *
free_hot_page(page);
else
__free_pages_ok(page, order);
+#ifdef CONFIG_PAGE_OWNER
+ page->order = -1;
+#endif
}
}
@@ -1578,6 +1631,9 @@ void __init memmap_init_zone(unsigned lo
set_page_address(page, __va(start_pfn << PAGE_SHIFT));
#endif
start_pfn++;
+#ifdef CONFIG_PAGE_OWNER
+ page->order = -1;
+#endif
}
}
_
Hello,
On Tue, Mar 08, 2005 at 05:38:11PM -0800, Andrew Morton wrote:
> > we kindly ask for some suggestions about how to trace a memory leak
> > which we suspect in the linux kernel version 2.6:
>
> Please grab 2.6.11, apply the below patch, set CONFIG_PAGE_OWNER and follow
> the below instructions.
thank you for you mails. We installed the patch from Alex on a test-system
last night and will switch it to the production machine this evening. The
problem will start after 48-72 hours, so we hope to send feedback
on friday.
Best regards Tobias
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
Rehi,
> > Please grab 2.6.11, apply the below patch, set CONFIG_PAGE_OWNER and follow
> > the below instructions.
>
> thank you for you mails. We installed the patch from Alex on a test-system
> last night and will switch it to the production machine this evening. The
> problem will start after 48-72 hours, so we hope to send feedback
> on friday.
Ok, we had another crash this morning after an uptime of only 36
hours 8-(.
No oom-killer this time, but we got a very high load (>40) in the
end. Our cron-job which starts the page_owner-sort every 10 minutes
didn't return the last 4 times.
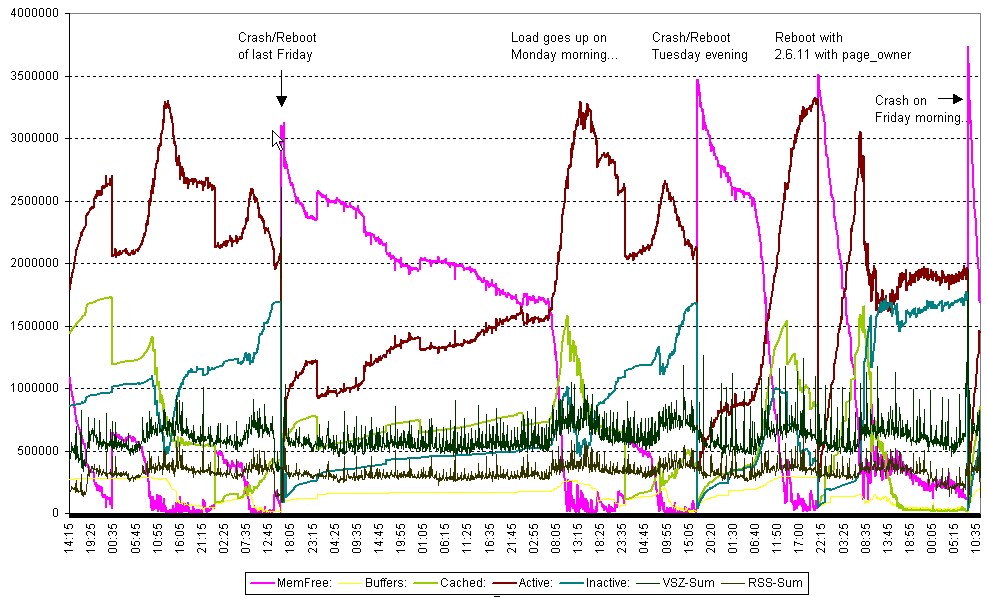
The new 2.6.11-kernel changed the graphs a little bit - values for
'MemTree' are much higher, but values for 'Cached' and 'Buffered' are
still very low.
Here the graph for the last week:
http://download.hennerich.de/memory-leak2.png
(the left part is the same like our first graph last week
http://download.hennerich.de/memory-leak.png, the weekend is well visible)
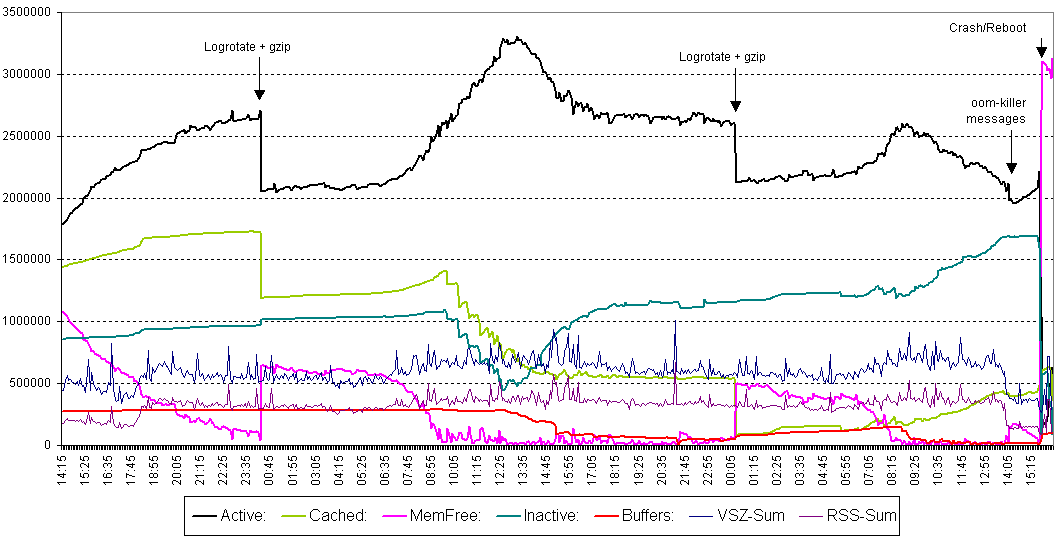
Detailed view of the last 40 hours:
http://download.hennerich.de/memory-leak3.png
Some output of the page_owner-sort:
http://download.hennerich.de/page_owner_sorted_20050310_0000.bz2
http://download.hennerich.de/page_owner_sorted_20050310_0800.bz2
http://download.hennerich.de/page_owner_sorted_20050310_1600.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0000.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0400.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0700.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0710.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0720.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0730.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0740.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0750.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0800.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0810.bz2
http://download.hennerich.de/page_owner_sorted_20050311_0820.bz2
If you need any other information, please ask...
Best regards Tobias
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
> > > Please grab 2.6.11, apply the below patch, set CONFIG_PAGE_OWNER and follow
> > > the below instructions.
> >
> > thank you for you mails. We installed the patch from Alex on a test-system
> > last night and will switch it to the production machine this evening. The
> > problem will start after 48-72 hours, so we hope to send feedback
> > on friday.
>
> Ok, we had another crash this morning after an uptime of only 36
> hours 8-(.
>
> No oom-killer this time, but we got a very high load (>40) in the
> end. Our cron-job which starts the page_owner-sort every 10 minutes
> didn't return the last 4 times.
>
> The new 2.6.11-kernel changed the graphs a little bit - values for
> 'MemTree' are much higher, but values for 'Cached' and 'Buffered' are
> still very low.
>
> Here the graph for the last week:
>
> http://download.hennerich.de/memory-leak2.png
>
> (the left part is the same like our first graph last week
> http://download.hennerich.de/memory-leak.png, the weekend is well visible)
>
> Detailed view of the last 40 hours:
>
> http://download.hennerich.de/memory-leak3.png
>
> Some output of the page_owner-sort:
>
>
> http://download.hennerich.de/page_owner_sorted_20050311_0820.bz2
Yikes something isn't right with these backtraces that page_owner is
showing. Even without frame pointers it shouldn't be this noisy.
I'm afraid I'm going to need to ask for more help, could you please
select CONFIG_FRAME_POINTER under
Kernel hacking => "Compile the kernel with frame pointers"
And when that kernel is booted, could you directly send me the output
of /proc/page_owner (sort or unsorted) so that I can see if something is
wrong with the data it's producing (just to be sure).
If it works better with CONFIG_FRAME_POINTER, i'm also going to have to
ask you to do another one of these runs that you just did.
Thanks
Alexander
Hello,
On Fri, Mar 11, 2005 at 07:23:40PM +0100, Alexander Nyberg wrote:
> Yikes something isn't right with these backtraces that page_owner is
> showing. Even without frame pointers it shouldn't be this noisy.
If you could send me some pointers to documents how to interpret
this output, i would appreciate it.
> I'm afraid I'm going to need to ask for more help, could you please
> select CONFIG_FRAME_POINTER under
> Kernel hacking => "Compile the kernel with frame pointers"
Done. Our .config looks now like this:
...
#
# Kernel hacking
#
CONFIG_DEBUG_KERNEL=y
CONFIG_MAGIC_SYSRQ=y
# CONFIG_SCHEDSTATS is not set
# CONFIG_DEBUG_SLAB is not set
CONFIG_DEBUG_PREEMPT=y
# CONFIG_DEBUG_SPINLOCK is not set
# CONFIG_DEBUG_SPINLOCK_SLEEP is not set
# CONFIG_DEBUG_KOBJECT is not set
# CONFIG_DEBUG_HIGHMEM is not set
CONFIG_DEBUG_BUGVERBOSE=y
# CONFIG_DEBUG_INFO is not set
# CONFIG_DEBUG_FS is not set
CONFIG_PAGE_OWNER=y
CONFIG_FRAME_POINTER=y
CONFIG_EARLY_PRINTK=y
CONFIG_DEBUG_STACKOVERFLOW=y
# CONFIG_KPROBES is not set
# CONFIG_DEBUG_STACK_USAGE is not set
# CONFIG_DEBUG_PAGEALLOC is not set
# CONFIG_4KSTACKS is not set
CONFIG_X86_FIND_SMP_CONFIG=y
CONFIG_X86_MPPARSE=y
...
> And when that kernel is booted, could you directly send me the output
> of /proc/page_owner (sort or unsorted) so that I can see if something is
> wrong with the data it's producing (just to be sure).
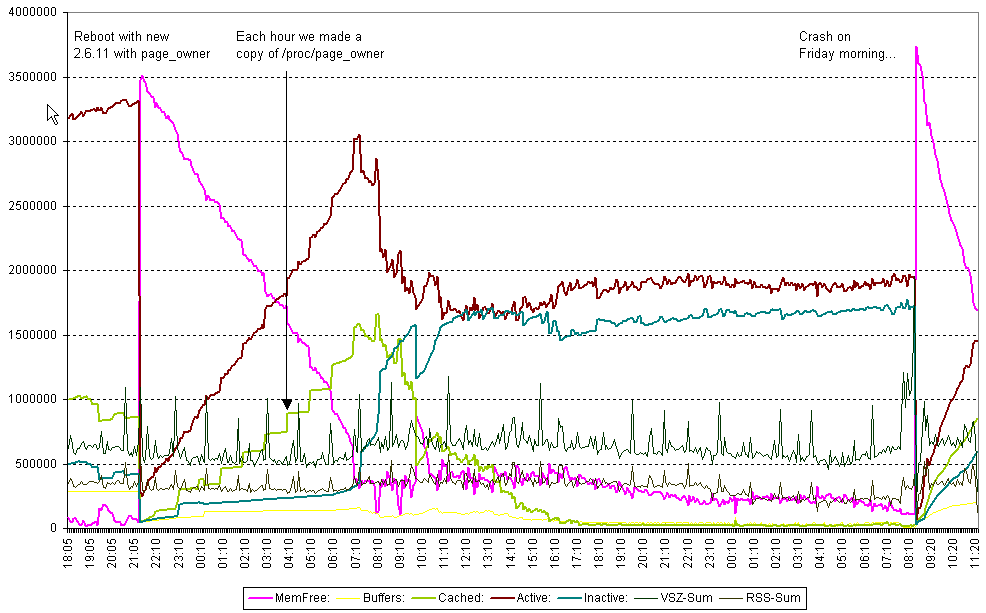
See http://download.hennerich.de/page_owner_sorted_20050312_1040.bz2
> If it works better with CONFIG_FRAME_POINTER, i'm also going to have to
> ask you to do another one of these runs that you just did.
The cronjob which generates each 10 minutes a new actual file of
page_owner_sorted is still running... and I'm afraid that we will
run into problems sooner or later again...
Best regards Tobias
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
> > Yikes something isn't right with these backtraces that page_owner is
> > showing. Even without frame pointers it shouldn't be this noisy.
>
> If you could send me some pointers to documents how to interpret
> this output, i would appreciate it.
The whole output indicates who has allocated whole pages from the page
allocator. It shows us a bit of the call trace of who allocated it. If
we see that someone has allocated abnormally much memory (considering
how much the caller 'should' have allocated) there is a good chance that
that caller is leaking memory.
This is for example good complete trace:
[0xc0148b9a] do_anonymous_page+170
[0xc0148cdb] do_no_page+75
[0xc0149128] handle_mm_fault+264
[0xc0113625] do_page_fault+501
[0xc0104a7b] error_code+43
The next one here is how it looks when it is not so good:
[0xc013962b] find_or_create_page+91
[0xc01596ac] grow_dev_page+44
[0xc015986a] __getblk_slow+170
[0xc0159c26] __getblk+54
[0xf8ac0a57] +1207
[0xf8abfccd] +61
[0xf8ac03c1] +241
[0xf8ac040a] +42
Stupid me, the 0xf8ac040a addresses are vmalloc space (modules). I need
to look into why it doesn't work with vmalloc but in the meantime, could
you please save a copy of /proc/kallsyms from the computer right away so
that I can look up those when the computer locks up (the copy needs to
be from the current run, addresses can change between reboots).
> > And when that kernel is booted, could you directly send me the output
> > of /proc/page_owner (sort or unsorted) so that I can see if something is
> > wrong with the data it's producing (just to be sure).
>
> See http://download.hennerich.de/page_owner_sorted_20050312_1040.bz2
>
> > If it works better with CONFIG_FRAME_POINTER, i'm also going to have to
> > ask you to do another one of these runs that you just did.
>
> The cronjob which generates each 10 minutes a new actual file of
> page_owner_sorted is still running... and I'm afraid that we will
> run into problems sooner or later again...
Thanks for helping to track this down.
> This is for example good complete trace:
> [0xc0148b9a] do_anonymous_page+170
> [0xc0148cdb] do_no_page+75
> [0xc0149128] handle_mm_fault+264
> [0xc0113625] do_page_fault+501
> [0xc0104a7b] error_code+43
>
> The next one here is how it looks when it is not so good:
> [0xc013962b] find_or_create_page+91
> [0xc01596ac] grow_dev_page+44
> [0xc015986a] __getblk_slow+170
> [0xc0159c26] __getblk+54
> [0xf8ac0a57] +1207
> [0xf8abfccd] +61
> [0xf8ac03c1] +241
> [0xf8ac040a] +42
>
>
> Stupid me, the 0xf8ac040a addresses are vmalloc space (modules). I need
> to look into why it doesn't work with vmalloc
Just for completeness I see what's happening, it is fixed in mainline
(went in after 2.6.11 however).
The more cumbersome way I suggested with saving /proc/kallsyms still works.
# This is a BitKeeper generated diff -Nru style patch.
#
# ChangeSet
# 2005/03/08 09:48:29-08:00 [email protected]
# [PATCH] Fix kallsyms/insmod/rmmod race
#
# The attached patch fixes a race between kallsyms and insmod/rmmod.
#
# The problem is this:
#
# (1) The various kallsyms functions poke around in the module list without any
# locking so that they can be called from the oops handler.
#
# (2) Although insmod and rmmod use locks to exclude each other, these have no
# effect on the kallsyms function.
#
# (3) Although rmmod modifies the module state with the machine "stopped", it
# hasn't removed the metadata from the module metadata list, meaning that
# as soon as the machine is "restarted", the metadata can be observed by
# kallsyms.
#
# It's not possible to say that an item in that list should be ignored if
# it's state is marked as inactive - you can't get at the state information
# because you can't trust the metadata in which it is embedded.
#
# Furthermore, list linkage information is embedded in the metadata too, so
# you can't trust that either...
#
# (4) kallsyms may be walking the module list without a lock whilst either
# insmod or rmmod are busy changing it. insmod probably isn't a problem
# since nothing is going a way, but rmmod is as it's deleting an entry.
#
# (5) Therefore nothing that uses these functions can in any way trust any
# pointers to "static" data (such as module symbol names or module names)
# that are returned.
#
# (6) On ppc64 the problems are exacerbated since the hypervisor may reschedule
# bits of the kernel, making operations that appear adjacent occur a long
# time apart.
#
# This patch fixes the race by only linking/unlinking modules into/from the
# master module list with the machine in the "stopped" state. This means that
# any "static" information can be trusted as far as the next kernel reschedule
# on any given CPU without the need to hold any locks.
#
# However, I'm not sure how this is affected by preemption. I suspect more work
# may need to be done in that case, but I'm not entirely sure.
#
# This also means that rmmod has to bump the machine into the stopped state
# twice... but since that shouldn't be a common operation, I don't think that's
# a problem.
#
# I've amended this patch to not get spinlocks whilst in the machine locked
# state - there's no point as nothing else can be holding spinlocks.
#
# Signed-Off-By: David Howells <[email protected]>
# Signed-off-by: Andrew Morton <[email protected]>
# Signed-off-by: Linus Torvalds <[email protected]>
#
# kernel/module.c
# 2005/03/07 20:41:36-08:00 [email protected] +25 -8
# Fix kallsyms/insmod/rmmod race
#
# kernel/kallsyms.c
# 2005/03/07 21:14:30-08:00 [email protected] +14 -2
# Fix kallsyms/insmod/rmmod race
#
# include/linux/stop_machine.h
# 2005/03/07 20:41:36-08:00 [email protected] +1 -1
# Fix kallsyms/insmod/rmmod race
#
diff -Nru a/include/linux/stop_machine.h b/include/linux/stop_machine.h
--- a/include/linux/stop_machine.h 2005-03-12 18:56:52 +01:00
+++ b/include/linux/stop_machine.h 2005-03-12 18:56:52 +01:00
@@ -8,7 +8,7 @@
#include <linux/cpu.h>
#include <asm/system.h>
-#ifdef CONFIG_SMP
+#if defined(CONFIG_STOP_MACHINE) && defined(CONFIG_SMP)
/**
* stop_machine_run: freeze the machine on all CPUs and run this function
* @fn: the function to run
diff -Nru a/kernel/kallsyms.c b/kernel/kallsyms.c
--- a/kernel/kallsyms.c 2005-03-12 18:56:52 +01:00
+++ b/kernel/kallsyms.c 2005-03-12 18:56:52 +01:00
@@ -146,13 +146,20 @@
return module_kallsyms_lookup_name(name);
}
-/* Lookup an address. modname is set to NULL if it's in the kernel. */
+/*
+ * Lookup an address
+ * - modname is set to NULL if it's in the kernel
+ * - we guarantee that the returned name is valid until we reschedule even if
+ * it resides in a module
+ * - we also guarantee that modname will be valid until rescheduled
+ */
const char *kallsyms_lookup(unsigned long addr,
unsigned long *symbolsize,
unsigned long *offset,
char **modname, char *namebuf)
{
unsigned long i, low, high, mid;
+ const char *msym;
/* This kernel should never had been booted. */
BUG_ON(!kallsyms_addresses);
@@ -204,7 +211,12 @@
return namebuf;
}
- return module_address_lookup(addr, symbolsize, offset, modname);
+ /* see if it's in a module */
+ msym = module_address_lookup(addr, symbolsize, offset, modname);
+ if (msym)
+ return strncpy(namebuf, msym, KSYM_NAME_LEN);
+
+ return NULL;
}
/* Replace "%s" in format with address, or returns -errno. */
diff -Nru a/kernel/module.c b/kernel/module.c
--- a/kernel/module.c 2005-03-12 18:56:52 +01:00
+++ b/kernel/module.c 2005-03-12 18:56:52 +01:00
@@ -472,7 +472,7 @@
};
/* Whole machine is stopped with interrupts off when this runs. */
-static inline int __try_stop_module(void *_sref)
+static int __try_stop_module(void *_sref)
{
struct stopref *sref = _sref;
@@ -1072,14 +1072,22 @@
kobject_unregister(&mod->mkobj.kobj);
}
+/*
+ * unlink the module with the whole machine is stopped with interrupts off
+ * - this defends against kallsyms not taking locks
+ */
+static int __unlink_module(void *_mod)
+{
+ struct module *mod = _mod;
+ list_del(&mod->list);
+ return 0;
+}
+
/* Free a module, remove from lists, etc (must hold module mutex). */
static void free_module(struct module *mod)
{
/* Delete from various lists */
- spin_lock_irq(&modlist_lock);
- list_del(&mod->list);
- spin_unlock_irq(&modlist_lock);
-
+ stop_machine_run(__unlink_module, mod, NR_CPUS);
remove_sect_attrs(mod);
mod_kobject_remove(mod);
@@ -1732,6 +1740,17 @@
goto free_hdr;
}
+/*
+ * link the module with the whole machine is stopped with interrupts off
+ * - this defends against kallsyms not taking locks
+ */
+static int __link_module(void *_mod)
+{
+ struct module *mod = _mod;
+ list_add(&mod->list, &modules);
+ return 0;
+}
+
/* This is where the real work happens */
asmlinkage long
sys_init_module(void __user *umod,
@@ -1766,9 +1785,7 @@
/* Now sew it into the lists. They won't access us, since
strong_try_module_get() will fail. */
- spin_lock_irq(&modlist_lock);
- list_add(&mod->list, &modules);
- spin_unlock_irq(&modlist_lock);
+ stop_machine_run(__link_module, mod, NR_CPUS);
/* Drop lock so they can recurse */
up(&module_mutex);
Rehi Alexander,
On Sat, Mar 12, 2005 at 04:08:05PM +0100, Alexander Nyberg wrote:
> The next one here is how it looks when it is not so good:
> [0xc013962b] find_or_create_page+91
> [0xc01596ac] grow_dev_page+44
> [0xc015986a] __getblk_slow+170
> [0xc0159c26] __getblk+54
> [0xf8ac0a57] +1207
> [0xf8abfccd] +61
> [0xf8ac03c1] +241
> [0xf8ac040a] +42
>
> Stupid me, the 0xf8ac040a addresses are vmalloc space (modules). I need
> to look into why it doesn't work with vmalloc but in the meantime, could
> you please save a copy of /proc/kallsyms from the computer right away so
> that I can look up those when the computer locks up (the copy needs to
> be from the current run, addresses can change between reboots).
See http://download.hennerich.de/kallsyms_20050312_1630.gz
> Thanks for helping to track this down.
Thanks for your support - even on Saturday! 8-)
Best regards Tobias Hennerich
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
Hello,
my brother got ill this weekend, so I'll continue this task:
> > See http://download.hennerich.de/kallsyms_20050312_1630.gz
>
> Great, just so that there is no confusion, I still need a new run
> of /proc/page_owner, the shorter time before the lockup the better.
The machine locked up this morning again. See
http://download.hennerich.de/page_owner_sorted_20050314_0740.bz2
for one of the last results of /proc/page_owner. It seems to be
obvious that the memory-leak seems to be the first entry:
$ less page_owner_sorted_20050314_0740.bz2
881397 times:
Page allocated via order 0
[0xc013962b] find_or_create_page+91
[0xf8aa9955] +613
[0xf8aaa606] +1366
[0xc015765c] vfs_write+172
[0xc015776c] sys_write+60
[0xc0103879] sysenter_past_esp+82
13358 times:
Page allocated via order 0
[0xc014817a] do_wp_page+282
[0xc014914e] handle_mm_fault+302
[0xc0113625] do_page_fault+501
[0xc0104a7b] error_code+43
The sorted table of /proc/kallsyms looks like this:
...
f8aa90e0 t reiserfs_commit_page [reiserfs]
f8aa92e0 t reiserfs_submit_file_region_for_write [reiserfs]
f8aa9550 t reiserfs_check_for_tail_and_convert [reiserfs]
f8aa96f0 t reiserfs_prepare_file_region_for_write [reiserfs]
f8aaa0b0 t reiserfs_file_write [reiserfs]
f8aaa770 t reiserfs_aio_write [reiserfs]
f8aaa779 t .text.lock.file [reiserfs]
f8aaa7c0 t reiserfs_dir_fsync [reiserfs]
f8aaa7f0 t reiserfs_readdir [reiserfs]
f8aaad70 t make_empty_dir_item_v1 [reiserfs]
f8aaae50 t make_empty_dir_item [reiserfs]
f8aaafc0 t create_virtual_node [reiserfs]
f8aab520 t check_left [reiserfs]
f8aab670 t check_right [reiserfs]
f8aab7c0 t get_num_ver [reiserfs]
...
So I guess that we have a problem with the reiser filesystem??
We are using reiserfs 3.6...
Perhaps it's important to notice that the operating system
- is no fresh installation of SuSE 9.2, but was updated from SuSE 8.2
- is installed on that special hardware via a restore with the software
Mondo-Rescue v2.03
Unfortunately we were not able up to now to reproduce the bug with
identical hardware and simulated disk-io. Only the production environment
triggers the bug.
0xf8aa9955 - 613 = 0xf8aa96f0: reiserfs_prepare_file_region_for_write
0xf8aaa606 - 1366 = 0xf8aaa0b0: reiserfs_file_write
Wild guessing: Is "reiserfs_prepare_file_region_for_write" used
to append new output to existent files only - and do we have a memory
leak inside of this function? The production machine is used as loghost
and syslog is writing several 100MB logfiles each day - which would be
a difference to the test hardware.
Best regards Timo
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
> > > See http://download.hennerich.de/kallsyms_20050312_1630.gz
> >
> > Great, just so that there is no confusion, I still need a new run
> > of /proc/page_owner, the shorter time before the lockup the better.
>
> The machine locked up this morning again. See
>
> http://download.hennerich.de/page_owner_sorted_20050314_0740.bz2
>
> for one of the last results of /proc/page_owner. It seems to be
> obvious that the memory-leak seems to be the first entry:
>
> $ less page_owner_sorted_20050314_0740.bz2
> 881397 times:
> Page allocated via order 0
> [0xc013962b] find_or_create_page+91
> [0xf8aa9955] reiserfs_prepare_file_region_for_write+613
> [0xf8aaa606] reiserfs_file_write+1366
> [0xc015765c] vfs_write+172
> [0xc015776c] sys_write+60
> [0xc0103879] sysenter_past_esp+82
[resolved addresses => names]
> 13358 times:
> Page allocated via order 0
> [0xc014817a] do_wp_page+282
> [0xc014914e] handle_mm_fault+302
> [0xc0113625] do_page_fault+501
> [0xc0104a7b] error_code+43
>
> The sorted table of /proc/kallsyms looks like this:
>
> ...
> f8aa90e0 t reiserfs_commit_page [reiserfs]
> f8aa92e0 t reiserfs_submit_file_region_for_write [reiserfs]
> f8aa9550 t reiserfs_check_for_tail_and_convert [reiserfs]
> f8aa96f0 t reiserfs_prepare_file_region_for_write [reiserfs]
> f8aaa0b0 t reiserfs_file_write [reiserfs]
> f8aaa770 t reiserfs_aio_write [reiserfs]
> f8aaa779 t .text.lock.file [reiserfs]
> f8aaa7c0 t reiserfs_dir_fsync [reiserfs]
> f8aaa7f0 t reiserfs_readdir [reiserfs]
> f8aaad70 t make_empty_dir_item_v1 [reiserfs]
> f8aaae50 t make_empty_dir_item [reiserfs]
> f8aaafc0 t create_virtual_node [reiserfs]
> f8aab520 t check_left [reiserfs]
> f8aab670 t check_right [reiserfs]
> f8aab7c0 t get_num_ver [reiserfs]
> ...
>
> So I guess that we have a problem with the reiser filesystem??
> We are using reiserfs 3.6...
>
> Perhaps it's important to notice that the operating system
>
> - is no fresh installation of SuSE 9.2, but was updated from SuSE 8.2
> - is installed on that special hardware via a restore with the software
> Mondo-Rescue v2.03
>
> Unfortunately we were not able up to now to reproduce the bug with
> identical hardware and simulated disk-io. Only the production environment
> triggers the bug.
>
>
> 0xf8aa9955 - 613 = 0xf8aa96f0: reiserfs_prepare_file_region_for_write
> 0xf8aaa606 - 1366 = 0xf8aaa0b0: reiserfs_file_write
>
> Wild guessing: Is "reiserfs_prepare_file_region_for_write" used
> to append new output to existent files only - and do we have a memory
> leak inside of this function? The production machine is used as loghost
> and syslog is writing several 100MB logfiles each day - which would be
> a difference to the test hardware.
[added Vladimir Saveliev to CC]
The only thing that stands out is big page cache. However, looking at
the previous OOM output it shows that it is zone normal that is
completely out of memory and that highmem zone has lots of free memory.
Let's see if the big sharks know what is going on...
Hello,
On Mon, Mar 14, 2005 at 03:58:12PM +0100, Alexander Nyberg wrote:
> > for one of the last results of /proc/page_owner. It seems to be
> > obvious that the memory-leak seems to be the first entry:
> >
> > $ less page_owner_sorted_20050314_0740.bz2
> > 881397 times:
> > Page allocated via order 0
> > [0xc013962b] find_or_create_page+91
> > [0xf8aa9955] reiserfs_prepare_file_region_for_write+613
> > [0xf8aaa606] reiserfs_file_write+1366
> > [0xc015765c] vfs_write+172
> > [0xc015776c] sys_write+60
> > [0xc0103879] sysenter_past_esp+82
>
> [resolved addresses => names]
> >
> > The sorted table of /proc/kallsyms looks like this:
> >
> > f8aa96f0 t reiserfs_prepare_file_region_for_write [reiserfs]
> > f8aaa0b0 t reiserfs_file_write [reiserfs]
> >
> > So I guess that we have a problem with the reiser filesystem??
> > We are using reiserfs 3.6...
>
> [added Vladimir Saveliev to CC]
>
> The only thing that stands out is big page cache. However, looking at
> the previous OOM output it shows that it is zone normal that is
> completely out of memory and that highmem zone has lots of free memory.
>
> Let's see if the big sharks know what is going on...
Hm, it seems like the big sharks are hunting other fishes at the moment...
I looked at the code myself - reiserfs_prepare_file_region_for_write
has more then 250 lines of code. I don't want to critize anyone, but
this function is a bit too long to be easily debugged.
Because we suspect the problem in reiserfs and we still have to reboot
the machine every other day, we will switch to ext3 now.
I will report if the problem disappears this way.
Best regards Tobias
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
> > > for one of the last results of /proc/page_owner. It seems to be
> > > obvious that the memory-leak seems to be the first entry:
> > >
> > > $ less page_owner_sorted_20050314_0740.bz2
> > > 881397 times:
> > > Page allocated via order 0
> > > [0xc013962b] find_or_create_page+91
> > > [0xf8aa9955] reiserfs_prepare_file_region_for_write+613
> > > [0xf8aaa606] reiserfs_file_write+1366
> > > [0xc015765c] vfs_write+172
> > > [0xc015776c] sys_write+60
> > > [0xc0103879] sysenter_past_esp+82
> >
> > [resolved addresses => names]
> > >
> > > The sorted table of /proc/kallsyms looks like this:
> > >
> > > f8aa96f0 t reiserfs_prepare_file_region_for_write [reiserfs]
> > > f8aaa0b0 t reiserfs_file_write [reiserfs]
> > >
> > > So I guess that we have a problem with the reiser filesystem??
> > > We are using reiserfs 3.6...
> >
> > [added Vladimir Saveliev to CC]
> >
> > The only thing that stands out is big page cache. However, looking at
> > the previous OOM output it shows that it is zone normal that is
> > completely out of memory and that highmem zone has lots of free memory.
> >
> > Let's see if the big sharks know what is going on...
>
> Hm, it seems like the big sharks are hunting other fishes at the moment...
>
> I looked at the code myself - reiserfs_prepare_file_region_for_write
> has more then 250 lines of code. I don't want to critize anyone, but
> this function is a bit too long to be easily debugged.
>
> Because we suspect the problem in reiserfs and we still have to reboot
> the machine every other day, we will switch to ext3 now.
Just to follow up, did the problems go away when switching to ext3?
Thanks
Alexander
Hello Alexander,
On Wed, Mar 23, 2005 at 02:41:15PM +0100, Alexander Nyberg wrote:
> > > > 881397 times:
> > > > Page allocated via order 0
> > > > [0xc013962b] find_or_create_page+91
> > > > [0xf8aa9955] reiserfs_prepare_file_region_for_write+613
> > > > [0xf8aaa606] reiserfs_file_write+1366
> > > >
> > > > So I guess that we have a problem with the reiser filesystem??
> > > > We are using reiserfs 3.6...
> > >
> > > The only thing that stands out is big page cache. However, looking at
> > > the previous OOM output it shows that it is zone normal that is
> > > completely out of memory and that highmem zone has lots of free memory.
> > >
> > > Let's see if the big sharks know what is going on...
> >
> > Because we suspect the problem in reiserfs and we still have to reboot
> > the machine every other day, we will switch to ext3 now.
>
> Just to follow up, did the problems go away when switching to ext3?
The switch has been delayed. Up to now we just reboot the machine every
48h - the administrator responsible for the machine is on holiday...
Meanwhile, I noticed, that the latest release candidate has several
changes which could be quite interesting for us:
<[email protected]>
[PATCH] orphaned pagecache memleak fix
Chris found that with data journaling a reiserfs pagecache may
be truncate while still pinned. The truncation removes the
page->mapping, but the page is still listed in the VM queues
because it still has buffers. Then during the journaling process,
a buffer is marked dirty and that sets the PG_dirty bitflag as well
(in mark_buffer_dirty). After that the page is leaked because it's
both dirty and without a mapping.
<[email protected]>
[PATCH] reiserfs: make sure data=journal buffers are cleaned on free
In data=journal mode, when blocks are freed and their buffers
are dirty, reiserfs can remove them from the transaction without
cleaning them. These buffers never get cleaned, resulting in an
unfreeable page.
On the other side we don't want to install a rc1-kernel on a important
system. Up to now we still plan to do the switch to ext3...
If someone would recommend to install a special reiserfs-patch (*not*
the 12mb of patch-2.6.12-rc1) we would consider that, too! So some
feedback from "the big sharks" is still very welcome.
Best regards Tobias
--
T+T Hennerich GmbH --- Zettachring 12a --- 70567 Stuttgart
Fon:+49(711)720714-0 Fax:+49(711)720714-44 Vanity:+49(700)HENNERICH
UNIX - Linux - Java - C Entwicklung/Beratung/Betreuung/Schulung
http://www.hennerich.de/
> > Just to follow up, did the problems go away when switching to ext3?
>
> The switch has been delayed. Up to now we just reboot the machine every
> 48h - the administrator responsible for the machine is on holiday...
>
> Meanwhile, I noticed, that the latest release candidate has several
> changes which could be quite interesting for us:
>
> <[email protected]>
> [PATCH] orphaned pagecache memleak fix
>
> Chris found that with data journaling a reiserfs pagecache may
> be truncate while still pinned. The truncation removes the
> page->mapping, but the page is still listed in the VM queues
> because it still has buffers. Then during the journaling process,
> a buffer is marked dirty and that sets the PG_dirty bitflag as well
> (in mark_buffer_dirty). After that the page is leaked because it's
> both dirty and without a mapping.
>
> <[email protected]>
> [PATCH] reiserfs: make sure data=journal buffers are cleaned on free
>
> In data=journal mode, when blocks are freed and their buffers
> are dirty, reiserfs can remove them from the transaction without
> cleaning them. These buffers never get cleaned, resulting in an
> unfreeable page.
>
> On the other side we don't want to install a rc1-kernel on a important
> system. Up to now we still plan to do the switch to ext3...
>
> If someone would recommend to install a special reiserfs-patch (*not*
> the 12mb of patch-2.6.12-rc1) we would consider that, too! So some
> feedback from "the big sharks" is still very welcome.
>
I've attached the two (small) patches that you mentioned above if you
decide to take another try with reiserfs.
Alex
{kind=link}
{kind=link}
{kind=link}
{kind=link}