On Fri, 10 Nov 2006 12:17:45 -0700
Erik Andersen <[email protected]> wrote:
> I have a Pegasos2 powerpc system acting as my home server. With
> 2.6.16.x it was 100% stable and I had months of uptime, rebooting
> only to periodically apply security updates to the kernel.
>
> With 2.6.17 and 2.6.18, after an uptime of no more than 2 days,
> and usually much less, I get a kernel panic, with nothing in the
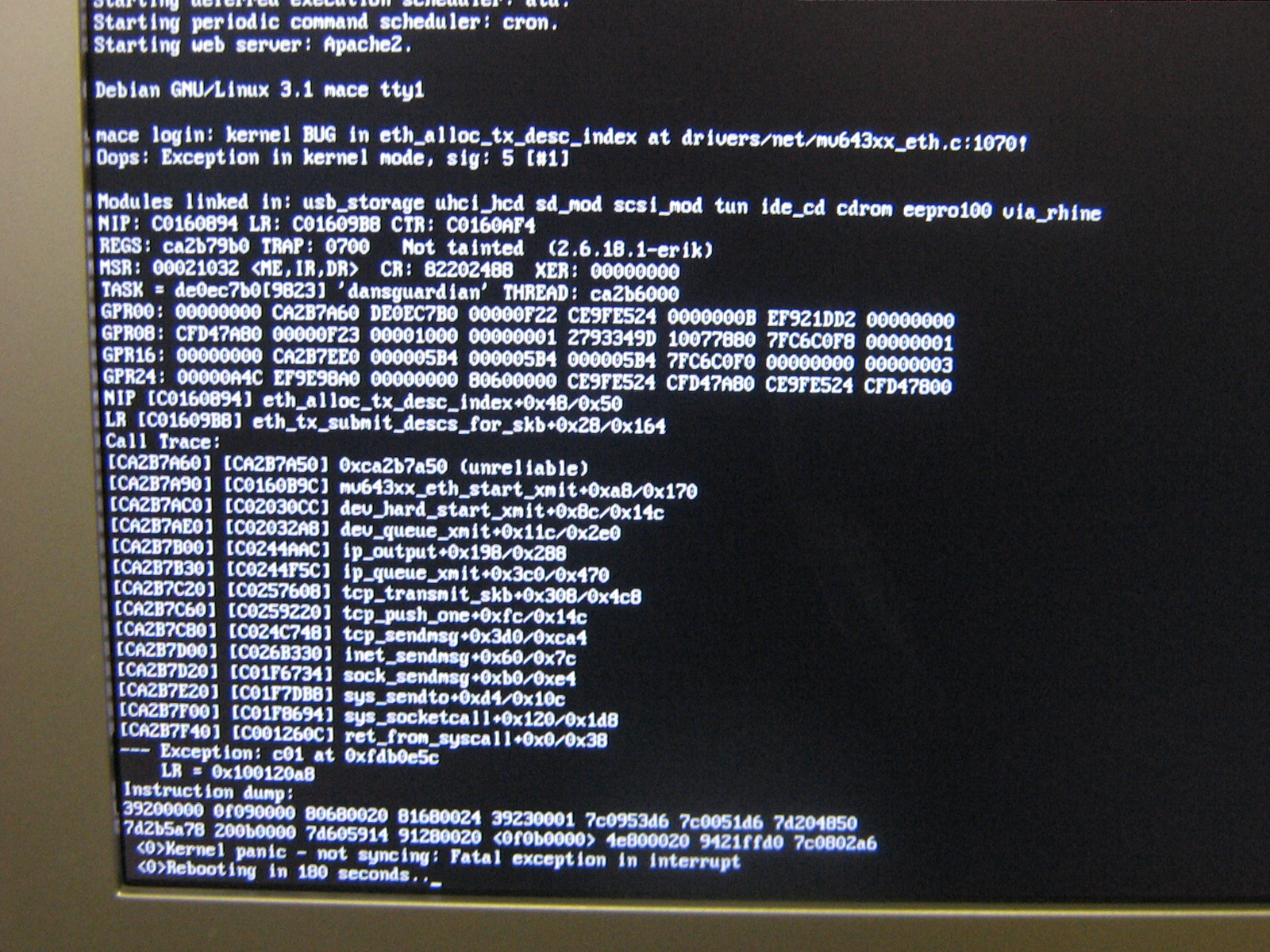
> log. I finally caught it in the act, and took a picture.
> http://codepoet.org/oops.jpg
>
> A quick transcription of the Oops in the screenshot follows:
> --------------------------------------------
>
The code int mv643xx_eth_start_xmit is not safe on SMP it was checking for space outside of lock.
Does the following (untested) fix it?
0. Fix race where space check is outside of lock.
1. Eliminate bogus BUG_ON()'s
2. Use proper transmit routine return values
3. Cleanup potential kernel log overrun if hit with unaligned frags
4. Compare with actual space needed rather than worst case
5. Use correct return code for case of linearize() failure.
---
drivers/net/mv643xx_eth.c | 30 ++++++++++++++----------------
1 files changed, 14 insertions(+), 16 deletions(-)
diff --git a/drivers/net/mv643xx_eth.c b/drivers/net/mv643xx_eth.c
index 9997081..4052bfe 100644
--- a/drivers/net/mv643xx_eth.c
+++ b/drivers/net/mv643xx_eth.c
@@ -1191,25 +1191,23 @@ static int mv643xx_eth_start_xmit(struct
struct net_device_stats *stats = &mp->stats;
unsigned long flags;
- BUG_ON(netif_queue_stopped(dev));
- BUG_ON(skb == NULL);
-
- if (mp->tx_ring_size - mp->tx_desc_count < MAX_DESCS_PER_SKB) {
- printk(KERN_ERR "%s: transmit with queue full\n", dev->name);
- netif_stop_queue(dev);
- return 1;
- }
-
- if (has_tiny_unaligned_frags(skb)) {
- if (__skb_linearize(skb)) {
- stats->tx_dropped++;
+ if (has_tiny_unaligned_frags(skb) && __skb_linearize(skb)) {
+ stats->tx_dropped++;
+ if (net_ratelimit())
printk(KERN_DEBUG "%s: failed to linearize tiny "
- "unaligned fragment\n", dev->name);
- return 1;
- }
+ "unaligned fragment\n", dev->name);
+ return NETDEV_TX_OK;
}
spin_lock_irqsave(&mp->lock, flags);
+ if (mp->tx_ring_size - mp->tx_desc_count < skb_shinfo(skb)->nr_frags + 1) {
+ if (!netif_queue_stopped(dev)) {
+ printk(KERN_ERR "%s: transmit with queue full\n", dev->name);
+ netif_stop_queue(dev);
+ }
+ spin_unlock_irqrestore(&mp->lock, flags);
+ return NETDEV_TX_BUSY;;
+ }
eth_tx_submit_descs_for_skb(mp, skb);
stats->tx_bytes = skb->len;
@@ -1221,7 +1219,7 @@ static int mv643xx_eth_start_xmit(struct
spin_unlock_irqrestore(&mp->lock, flags);
- return 0; /* success */
+ return NETDEV_TX_OK;
}
/*
--
1.4.1
--
Stephen Hemminger <[email protected]>
On Fri Nov 10, 2006 at 11:54:44AM -0800, Stephen Hemminger wrote:
> The code int mv643xx_eth_start_xmit is not safe on SMP it was
> checking for space outside of lock.
Hmm. I do not have CONFIG_SMP enabled... But then I suppose the
function is not reentrant either, so networking from N apps would
eventually result in a collision where it would blow up. That
seems consistant with what I was seeing.
> Does the following (untested) fix it?
Thanks! It at least applies cleanly and compiles...
Will let you know if it seems fixed.
-Erik
--
Erik B. Andersen http://codepoet-consulting.com/
--This message was written using 73% post-consumer electrons--
On Fri Nov 10, 2006 at 11:54:44AM -0800, Stephen Hemminger wrote:
> The code int mv643xx_eth_start_xmit is not safe on SMP it was
> checking for space outside of lock. Does the following
> (untested) fix it?
With your patch applied, I got the exact same oops a few minutes
ago while trying to rsync about a GB of stuff...
-Erik
--
Erik B. Andersen http://codepoet-consulting.com/
--This message was written using 73% post-consumer electrons--
{kind=link}