This still needs testing. I've tried multiple reproduction scenarios locally
but two things are tripping me. One, Simon's network card is using GFP_ATOMIC
allocations where as the one I use locally does not. Second, Simon's is a real
mail workload with network traffic and there are no decent mail simulator
benchmarks (that I could find at least) that would replicate the situation.
Still, I'm hopeful it'll stop kswapd going mad on his machine and might
also alleviate some of the "too much free memory" problem.
Changelog since V1
o Take classzone into account
o Ensure that kswapd always balances at order-09
o Reset classzone and order after reading
o Require a percentage of a node be balanced for high-order allocations,
not just any zone as ZONE_DMA could be balanced when the node in general
is a mess
Simon Kirby reported the following problem
We're seeing cases on a number of servers where cache never fully
grows to use all available memory. Sometimes we see servers with 4
GB of memory that never seem to have less than 1.5 GB free, even with
a constantly-active VM. In some cases, these servers also swap out
while this happens, even though they are constantly reading the working
set into memory. We have been seeing this happening for a long time;
I don't think it's anything recent, and it still happens on 2.6.36.
After some debugging work by Simon, Dave Hansen and others, the prevaling
theory became that kswapd is reclaiming order-3 pages requested by SLUB
too aggressive about it.
There are two apparent problems here. On the target machine, there is a small
Normal zone in comparison to DMA32. As kswapd tries to balance all zones, it
would continually try reclaiming for Normal even though DMA32 was balanced
enough for callers. The second problem is that sleeping_prematurely() uses
the requested order, not the order kswapd finally reclaimed at. This keeps
kswapd artifically awake.
This series aims to alleviate these problems but needs testing to confirm
it alleviates the actual problem and wider review to think if there is a
better alternative approach. Local tests passed but are not reproducing
the same problem unfortunately so the results are inclusive.
include/linux/mmzone.h | 3 +-
mm/page_alloc.c | 8 ++-
mm/vmscan.c | 109 ++++++++++++++++++++++++++++++++++++++++-------
3 files changed, 99 insertions(+), 21 deletions(-)
When reclaiming for high-orders, kswapd is responsible for balancing a
node but it should not reclaim excessively. It avoids excessive reclaim
by considering if any zone in a node is balanced then the node is
balanced. In the cases where there are imbalanced zone sizes (e.g.
ZONE_DMA with both ZONE_DMA32 and ZONE_NORMAL), kswapd can go to sleep
prematurely as just one small zone was balanced.
This alters the sleep logic of kswapd slightly. It counts the number of pages
that make up the balanced zones. If the total number of balanced pages is
more than a quarter of the zone, kswapd will go back to sleep. This should
keep a node balanced without reclaiming an excessive number of pages.
Signed-off-by: Mel Gorman <[email protected]>
---
mm/vmscan.c | 30 ++++++++++++++++++++++--------
1 files changed, 22 insertions(+), 8 deletions(-)
diff --git a/mm/vmscan.c b/mm/vmscan.c
index 8295c50..5680595 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2117,13 +2117,27 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
}
#endif
+/*
+ * pgdat_balanced is used when checking if a node is balanced for high-order
+ * allocations. Only zones that meet watermarks make up "balanced".
+ * The total of balanced pages must be at least 25% of the node for the
+ * node to be considered balanced. Forcing all zones to be balanced for high
+ * orders can cause excessive reclaim when there are imbalanced zones.
+ * Similarly, we do not want kswapd to go to sleep because ZONE_DMA happens
+ * to be balanced when ZONE_DMA32 is huge in comparison and unbalanced
+ */
+static bool pgdat_balanced(pg_data_t *pgdat, unsigned long balanced)
+{
+ return balanced > pgdat->node_present_pages / 4;
+}
+
/* is kswapd sleeping prematurely? */
static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining,
int classzone_idx)
{
int i;
+ unsigned long balanced = 0;
bool all_zones_ok = true;
- bool any_zone_ok = false;
/* If a direct reclaimer woke kswapd within HZ/10, it's premature */
if (remaining)
@@ -2143,7 +2157,7 @@ static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining,
classzone_idx, 0))
all_zones_ok = false;
else
- any_zone_ok = true;
+ balanced += zone->present_pages;
}
/*
@@ -2151,7 +2165,7 @@ static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining,
* kswapd to sleep. For order-0, all zones must be balanced
*/
if (order)
- return !any_zone_ok;
+ return pgdat_balanced(pgdat, balanced);
else
return !all_zones_ok;
}
@@ -2181,7 +2195,7 @@ static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
int *classzone_idx)
{
int all_zones_ok;
- int any_zone_ok;
+ unsigned long balanced;
int priority;
int i;
int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
@@ -2215,7 +2229,7 @@ loop_again:
disable_swap_token();
all_zones_ok = 1;
- any_zone_ok = 0;
+ balanced = 0;
/*
* Scan in the highmem->dma direction for the highest
@@ -2327,11 +2341,11 @@ loop_again:
*/
zone_clear_flag(zone, ZONE_CONGESTED);
if (i <= *classzone_idx)
- any_zone_ok = 1;
+ balanced += zone->present_pages;
}
}
- if (all_zones_ok || (order && any_zone_ok))
+ if (all_zones_ok || (order && pgdat_balanced(pgdat, balanced)))
break; /* kswapd: all done */
/*
* OK, kswapd is getting into trouble. Take a nap, then take
@@ -2354,7 +2368,7 @@ loop_again:
break;
}
out:
- if (!(all_zones_ok || (order && any_zone_ok))) {
+ if (!(all_zones_ok || (order && pgdat_balanced(pgdat, balanced)))) {
cond_resched();
try_to_freeze();
--
1.7.1
When kswapd is woken up for a high-order allocation, it takes account of
the highest usable zone by the caller (the classzone idx). During
allocation, this index is used to select the lowmem_reserve[] that
should be applied to the watermark calculation in zone_watermark_ok().
When balancing a node, kswapd considers the highest unbalanced zone to be the
classzone index. This will always be at least be the callers classzone_idx
and can be higher. However, sleeping_prematurely() always considers the
lowest zone (e.g. ZONE_DMA) to be the classzone index. This means that
sleeping_prematurely() can consider a zone to be balanced that is unusable
by the allocation request that originally woke kswapd. This patch changes
sleeping_prematurely() to use a classzone_idx matching the value it used
in balance_pgdat().
Signed-off-by: Mel Gorman <[email protected]>
---
mm/vmscan.c | 19 +++++++++++--------
1 files changed, 11 insertions(+), 8 deletions(-)
diff --git a/mm/vmscan.c b/mm/vmscan.c
index 193feeb..6ae1873 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2118,7 +2118,8 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
#endif
/* is kswapd sleeping prematurely? */
-static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
+static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining,
+ int classzone_idx)
{
int i;
bool all_zones_ok = true;
@@ -2139,7 +2140,7 @@ static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
continue;
if (!zone_watermark_ok(zone, order, high_wmark_pages(zone),
- 0, 0))
+ classzone_idx, 0))
all_zones_ok = false;
else
any_zone_ok = true;
@@ -2177,7 +2178,7 @@ static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
* of pages is balanced across the zones.
*/
static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
- int classzone_idx)
+ int *classzone_idx)
{
int all_zones_ok;
int any_zone_ok;
@@ -2240,6 +2241,7 @@ loop_again:
if (!zone_watermark_ok(zone, order,
high_wmark_pages(zone), 0, 0)) {
end_zone = i;
+ *classzone_idx = i;
break;
}
}
@@ -2324,7 +2326,7 @@ loop_again:
* spectulatively avoid congestion waits
*/
zone_clear_flag(zone, ZONE_CONGESTED);
- if (i <= classzone_idx)
+ if (i <= *classzone_idx)
any_zone_ok = 1;
}
@@ -2408,6 +2410,7 @@ out:
* if another caller entered the allocator slow path while kswapd
* was awake, order will remain at the higher level
*/
+ *classzone_idx = end_zone;
return order;
}
@@ -2466,8 +2469,8 @@ static int kswapd(void *p)
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
new_order = pgdat->kswapd_max_order;
- new_classzone_idx = pgdat->classzone_idx;
pgdat->kswapd_max_order = 0;
+ new_classzone_idx = pgdat->classzone_idx;
pgdat->classzone_idx = MAX_NR_ZONES - 1;
if (order < new_order || classzone_idx > new_classzone_idx) {
/*
@@ -2481,7 +2484,7 @@ static int kswapd(void *p)
long remaining = 0;
/* Try to sleep for a short interval */
- if (!sleeping_prematurely(pgdat, order, remaining)) {
+ if (!sleeping_prematurely(pgdat, order, remaining, classzone_idx)) {
remaining = schedule_timeout(HZ/10);
finish_wait(&pgdat->kswapd_wait, &wait);
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
@@ -2492,7 +2495,7 @@ static int kswapd(void *p)
* premature sleep. If not, then go fully
* to sleep until explicitly woken up
*/
- if (!sleeping_prematurely(pgdat, order, remaining)) {
+ if (!sleeping_prematurely(pgdat, order, remaining, classzone_idx)) {
trace_mm_vmscan_kswapd_sleep(pgdat->node_id);
schedule();
} else {
@@ -2518,7 +2521,7 @@ static int kswapd(void *p)
*/
if (!ret) {
trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
- order = balance_pgdat(pgdat, order, classzone_idx);
+ order = balance_pgdat(pgdat, order, &classzone_idx);
}
}
return 0;
--
1.7.1
When the allocator enters its slow path, kswapd is woken up to balance the
node. It continues working until all zones within the node are balanced. For
order-0 allocations, this makes perfect sense but for higher orders it can
have unintended side-effects. If the zone sizes are imbalanced, kswapd may
reclaim heavily within a smaller zone discarding an excessive number of
pages. The user-visible behaviour is that kswapd is awake and reclaiming
even though plenty of pages are free from a suitable zone.
This patch alters the "balance" logic for high-order reclaim allowing kswapd
to stop if any suitable zone becomes balanced to reduce the number of pages
it reclaims from other zones. kswapd still tries to ensure that order-0
watermarks for all zones are met before sleeping.
Signed-off-by: Mel Gorman <[email protected]>
---
include/linux/mmzone.h | 3 +-
mm/page_alloc.c | 8 ++++--
mm/vmscan.c | 55 +++++++++++++++++++++++++++++++++++++++++-------
3 files changed, 54 insertions(+), 12 deletions(-)
diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
index 39c24eb..7177f51 100644
--- a/include/linux/mmzone.h
+++ b/include/linux/mmzone.h
@@ -645,6 +645,7 @@ typedef struct pglist_data {
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
+ enum zone_type classzone_idx;
} pg_data_t;
#define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
@@ -660,7 +661,7 @@ typedef struct pglist_data {
extern struct mutex zonelists_mutex;
void build_all_zonelists(void *data);
-void wakeup_kswapd(struct zone *zone, int order);
+void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx);
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
int classzone_idx, int alloc_flags);
enum memmap_context {
diff --git a/mm/page_alloc.c b/mm/page_alloc.c
index e409270..82e3499 100644
--- a/mm/page_alloc.c
+++ b/mm/page_alloc.c
@@ -1915,13 +1915,14 @@ __alloc_pages_high_priority(gfp_t gfp_mask, unsigned int order,
static inline
void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
- enum zone_type high_zoneidx)
+ enum zone_type high_zoneidx,
+ enum zone_type classzone_idx)
{
struct zoneref *z;
struct zone *zone;
for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
- wakeup_kswapd(zone, order);
+ wakeup_kswapd(zone, order, classzone_idx);
}
static inline int
@@ -1998,7 +1999,8 @@ __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
goto nopage;
restart:
- wake_all_kswapd(order, zonelist, high_zoneidx);
+ wake_all_kswapd(order, zonelist, high_zoneidx,
+ zone_idx(preferred_zone));
/*
* OK, we're below the kswapd watermark and have kicked background
diff --git a/mm/vmscan.c b/mm/vmscan.c
index d31d7ce..d070d19 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2165,11 +2165,14 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
* interoperates with the page allocator fallback scheme to ensure that aging
* of pages is balanced across the zones.
*/
-static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
+static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
+ int classzone_idx)
{
int all_zones_ok;
+ int any_zone_ok;
int priority;
int i;
+ int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
unsigned long total_scanned;
struct reclaim_state *reclaim_state = current->reclaim_state;
struct scan_control sc = {
@@ -2192,7 +2195,6 @@ loop_again:
count_vm_event(PAGEOUTRUN);
for (priority = DEF_PRIORITY; priority >= 0; priority--) {
- int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
unsigned long lru_pages = 0;
int has_under_min_watermark_zone = 0;
@@ -2201,6 +2203,7 @@ loop_again:
disable_swap_token();
all_zones_ok = 1;
+ any_zone_ok = 0;
/*
* Scan in the highmem->dma direction for the highest
@@ -2310,10 +2313,12 @@ loop_again:
* spectulatively avoid congestion waits
*/
zone_clear_flag(zone, ZONE_CONGESTED);
+ if (i <= classzone_idx)
+ any_zone_ok = 1;
}
}
- if (all_zones_ok)
+ if (all_zones_ok || (order && any_zone_ok))
break; /* kswapd: all done */
/*
* OK, kswapd is getting into trouble. Take a nap, then take
@@ -2336,7 +2341,7 @@ loop_again:
break;
}
out:
- if (!all_zones_ok) {
+ if (!(all_zones_ok || (order && any_zone_ok))) {
cond_resched();
try_to_freeze();
@@ -2361,6 +2366,31 @@ out:
goto loop_again;
}
+ /*
+ * If kswapd was reclaiming at a higher order, it has the option of
+ * sleeping without all zones being balanced. Before it does, it must
+ * ensure that the watermarks for order-0 on *all* zones are met and
+ * that the congestion flags are cleared
+ */
+ if (order) {
+ for (i = 0; i <= end_zone; i++) {
+ struct zone *zone = pgdat->node_zones + i;
+
+ if (!populated_zone(zone))
+ continue;
+
+ if (zone->all_unreclaimable && priority != DEF_PRIORITY)
+ continue;
+
+ zone_clear_flag(zone, ZONE_CONGESTED);
+ if (!zone_watermark_ok(zone, order,
+ high_wmark_pages(zone), 0, 0)) {
+ order = sc.order = 0;
+ goto loop_again;
+ }
+ }
+ }
+
return sc.nr_reclaimed;
}
@@ -2380,6 +2410,7 @@ out:
static int kswapd(void *p)
{
unsigned long order;
+ int classzone_idx;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
DEFINE_WAIT(wait);
@@ -2410,19 +2441,24 @@ static int kswapd(void *p)
set_freezable();
order = 0;
+ classzone_idx = MAX_NR_ZONES - 1;
for ( ; ; ) {
unsigned long new_order;
+ int new_classzone_idx;
int ret;
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
new_order = pgdat->kswapd_max_order;
+ new_classzone_idx = pgdat->classzone_idx;
pgdat->kswapd_max_order = 0;
- if (order < new_order) {
+ pgdat->classzone_idx = MAX_NR_ZONES - 1;
+ if (order < new_order || classzone_idx > new_classzone_idx) {
/*
* Don't sleep if someone wants a larger 'order'
- * allocation
+ * allocation or has tigher zone constraints
*/
order = new_order;
+ classzone_idx = new_classzone_idx;
} else {
if (!freezing(current) && !kthread_should_stop()) {
long remaining = 0;
@@ -2451,6 +2487,7 @@ static int kswapd(void *p)
}
order = pgdat->kswapd_max_order;
+ classzone_idx = pgdat->classzone_idx;
}
finish_wait(&pgdat->kswapd_wait, &wait);
@@ -2473,7 +2510,7 @@ static int kswapd(void *p)
/*
* A zone is low on free memory, so wake its kswapd task to service it.
*/
-void wakeup_kswapd(struct zone *zone, int order)
+void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx)
{
pg_data_t *pgdat;
@@ -2483,8 +2520,10 @@ void wakeup_kswapd(struct zone *zone, int order)
pgdat = zone->zone_pgdat;
if (zone_watermark_ok(zone, order, low_wmark_pages(zone), 0, 0))
return;
- if (pgdat->kswapd_max_order < order)
+ if (pgdat->kswapd_max_order < order) {
pgdat->kswapd_max_order = order;
+ pgdat->classzone_idx = min(pgdat->classzone_idx, classzone_idx);
+ }
trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order);
if (!cpuset_zone_allowed_hardwall(zone, GFP_KERNEL))
return;
--
1.7.1
Before kswapd goes to sleep, it uses sleeping_prematurely() to check if
there was a race pushing a zone below its watermark. If the race
happened, it stays awake. However, balance_pgdat() can decide to reclaim
at a lower order if it decides that high-order reclaim is not working as
expected. This information is not passed back to sleeping_prematurely().
The impact is that kswapd remains awake reclaiming pages long after it
should have gone to sleep. This patch passes the adjusted order to
sleeping_prematurely and uses the same logic as balance_pgdat to decide
if it's ok to go to sleep.
Signed-off-by: Mel Gorman <[email protected]>
---
mm/vmscan.c | 29 +++++++++++++++++++++++------
1 files changed, 23 insertions(+), 6 deletions(-)
diff --git a/mm/vmscan.c b/mm/vmscan.c
index d070d19..193feeb 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2118,15 +2118,17 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
#endif
/* is kswapd sleeping prematurely? */
-static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
+static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
{
int i;
+ bool all_zones_ok = true;
+ bool any_zone_ok = false;
/* If a direct reclaimer woke kswapd within HZ/10, it's premature */
if (remaining)
return 1;
- /* If after HZ/10, a zone is below the high mark, it's premature */
+ /* Check the watermark levels */
for (i = 0; i < pgdat->nr_zones; i++) {
struct zone *zone = pgdat->node_zones + i;
@@ -2138,10 +2140,19 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
if (!zone_watermark_ok(zone, order, high_wmark_pages(zone),
0, 0))
- return 1;
+ all_zones_ok = false;
+ else
+ any_zone_ok = true;
}
- return 0;
+ /*
+ * For high-order requests, any zone meeting the watermark allows
+ * kswapd to sleep. For order-0, all zones must be balanced
+ */
+ if (order)
+ return !any_zone_ok;
+ else
+ return !all_zones_ok;
}
/*
@@ -2391,7 +2402,13 @@ out:
}
}
- return sc.nr_reclaimed;
+ /*
+ * Return the order we were reclaiming at so sleeping_prematurely()
+ * makes a decision on the order we were last reclaiming at. However,
+ * if another caller entered the allocator slow path while kswapd
+ * was awake, order will remain at the higher level
+ */
+ return order;
}
/*
@@ -2501,7 +2518,7 @@ static int kswapd(void *p)
*/
if (!ret) {
trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
- balance_pgdat(pgdat, order);
+ order = balance_pgdat(pgdat, order, classzone_idx);
}
}
return 0;
--
1.7.1
When kswapd wakes up, it reads its order and classzone from pgdat and
calls balance_pgdat. While its awake, it potentially reclaimes as a high
order and a low classzone index. This might have been a once-off that
was not required by subsequent callers. However, because the pgdat
values were not reset, they remain artifically high while
balance_pgdat() is running and potentially kswapd enters a second
unnecessary reclaim cycle. Reset the pgdat order and classzone index
after reading.
Signed-off-by: Mel Gorman <[email protected]>
---
mm/vmscan.c | 2 ++
1 files changed, 2 insertions(+), 0 deletions(-)
diff --git a/mm/vmscan.c b/mm/vmscan.c
index 6ae1873..8295c50 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2508,6 +2508,8 @@ static int kswapd(void *p)
order = pgdat->kswapd_max_order;
classzone_idx = pgdat->classzone_idx;
+ pgdat->kswapd_max_order = 0;
+ pgdat->classzone_idx = MAX_NR_ZONES - 1;
}
finish_wait(&pgdat->kswapd_wait, &wait);
--
1.7.1
Hi Mel,
On Fri, Dec 3, 2010 at 8:45 PM, Mel Gorman <[email protected]> wrote:
> When the allocator enters its slow path, kswapd is woken up to balance the
> node. It continues working until all zones within the node are balanced. For
> order-0 allocations, this makes perfect sense but for higher orders it can
> have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> reclaim heavily within a smaller zone discarding an excessive number of
> pages. The user-visible behaviour is that kswapd is awake and reclaiming
> even though plenty of pages are free from a suitable zone.
>
> This patch alters the "balance" logic for high-order reclaim allowing kswapd
> to stop if any suitable zone becomes balanced to reduce the number of pages
> it reclaims from other zones. kswapd still tries to ensure that order-0
> watermarks for all zones are met before sleeping.
>
> Signed-off-by: Mel Gorman <[email protected]>
<snip>
> - ? ? ? if (!all_zones_ok) {
> + ? ? ? if (!(all_zones_ok || (order && any_zone_ok))) {
> ? ? ? ? ? ? ? ?cond_resched();
>
> ? ? ? ? ? ? ? ?try_to_freeze();
> @@ -2361,6 +2366,31 @@ out:
> ? ? ? ? ? ? ? ?goto loop_again;
> ? ? ? ?}
>
> + ? ? ? /*
> + ? ? ? ?* If kswapd was reclaiming at a higher order, it has the option of
> + ? ? ? ?* sleeping without all zones being balanced. Before it does, it must
> + ? ? ? ?* ensure that the watermarks for order-0 on *all* zones are met and
> + ? ? ? ?* that the congestion flags are cleared
> + ? ? ? ?*/
> + ? ? ? if (order) {
> + ? ? ? ? ? ? ? for (i = 0; i <= end_zone; i++) {
> + ? ? ? ? ? ? ? ? ? ? ? struct zone *zone = pgdat->node_zones + i;
> +
> + ? ? ? ? ? ? ? ? ? ? ? if (!populated_zone(zone))
> + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> +
> + ? ? ? ? ? ? ? ? ? ? ? if (zone->all_unreclaimable && priority != DEF_PRIORITY)
> + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> +
> + ? ? ? ? ? ? ? ? ? ? ? zone_clear_flag(zone, ZONE_CONGESTED);
Why clear ZONE_CONGESTED?
If you have a cause, please, write down the comment.
<snip>
First impression on this patch is that it changes scanning behavior as
well as reclaiming on high order reclaim.
I can't say old behavior is right but we can't say this behavior is
right, too although this patch solves the problem. At least, we might
need some data that shows this patch doesn't have a regression. It's
not easy but I believe you can do very well as like having done until
now. I didn't see whole series so I might miss something.
--
Kind regards,
Minchan Kim
On Fri, 3 Dec 2010 11:45:30 +0000
Mel Gorman <[email protected]> wrote:
> When the allocator enters its slow path, kswapd is woken up to balance the
> node. It continues working until all zones within the node are balanced. For
> order-0 allocations, this makes perfect sense but for higher orders it can
> have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> reclaim heavily within a smaller zone discarding an excessive number of
> pages. The user-visible behaviour is that kswapd is awake and reclaiming
> even though plenty of pages are free from a suitable zone.
>
> This patch alters the "balance" logic for high-order reclaim allowing kswapd
> to stop if any suitable zone becomes balanced to reduce the number of pages
> it reclaims from other zones. kswapd still tries to ensure that order-0
> watermarks for all zones are met before sleeping.
>
> Signed-off-by: Mel Gorman <[email protected]>
a nitpick.
> ---
> include/linux/mmzone.h | 3 +-
> mm/page_alloc.c | 8 ++++--
> mm/vmscan.c | 55 +++++++++++++++++++++++++++++++++++++++++-------
> 3 files changed, 54 insertions(+), 12 deletions(-)
>
> diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
> index 39c24eb..7177f51 100644
> --- a/include/linux/mmzone.h
> +++ b/include/linux/mmzone.h
> @@ -645,6 +645,7 @@ typedef struct pglist_data {
> wait_queue_head_t kswapd_wait;
> struct task_struct *kswapd;
> int kswapd_max_order;
> + enum zone_type classzone_idx;
> } pg_data_t;
>
> #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
> @@ -660,7 +661,7 @@ typedef struct pglist_data {
>
> extern struct mutex zonelists_mutex;
> void build_all_zonelists(void *data);
> -void wakeup_kswapd(struct zone *zone, int order);
> +void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx);
> int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
> int classzone_idx, int alloc_flags);
> enum memmap_context {
> diff --git a/mm/page_alloc.c b/mm/page_alloc.c
> index e409270..82e3499 100644
> --- a/mm/page_alloc.c
> +++ b/mm/page_alloc.c
> @@ -1915,13 +1915,14 @@ __alloc_pages_high_priority(gfp_t gfp_mask, unsigned int order,
>
> static inline
> void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
> - enum zone_type high_zoneidx)
> + enum zone_type high_zoneidx,
> + enum zone_type classzone_idx)
> {
> struct zoneref *z;
> struct zone *zone;
>
> for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
> - wakeup_kswapd(zone, order);
> + wakeup_kswapd(zone, order, classzone_idx);
> }
>
> static inline int
> @@ -1998,7 +1999,8 @@ __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
> goto nopage;
>
> restart:
> - wake_all_kswapd(order, zonelist, high_zoneidx);
> + wake_all_kswapd(order, zonelist, high_zoneidx,
> + zone_idx(preferred_zone));
>
> /*
> * OK, we're below the kswapd watermark and have kicked background
> diff --git a/mm/vmscan.c b/mm/vmscan.c
> index d31d7ce..d070d19 100644
> --- a/mm/vmscan.c
> +++ b/mm/vmscan.c
> @@ -2165,11 +2165,14 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> * interoperates with the page allocator fallback scheme to ensure that aging
> * of pages is balanced across the zones.
> */
> -static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> +static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
> + int classzone_idx)
> {
> int all_zones_ok;
> + int any_zone_ok;
> int priority;
> int i;
> + int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> unsigned long total_scanned;
> struct reclaim_state *reclaim_state = current->reclaim_state;
> struct scan_control sc = {
> @@ -2192,7 +2195,6 @@ loop_again:
> count_vm_event(PAGEOUTRUN);
>
> for (priority = DEF_PRIORITY; priority >= 0; priority--) {
> - int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> unsigned long lru_pages = 0;
> int has_under_min_watermark_zone = 0;
>
> @@ -2201,6 +2203,7 @@ loop_again:
> disable_swap_token();
>
> all_zones_ok = 1;
> + any_zone_ok = 0;
>
> /*
> * Scan in the highmem->dma direction for the highest
> @@ -2310,10 +2313,12 @@ loop_again:
> * spectulatively avoid congestion waits
> */
> zone_clear_flag(zone, ZONE_CONGESTED);
> + if (i <= classzone_idx)
> + any_zone_ok = 1;
> }
>
> }
> - if (all_zones_ok)
> + if (all_zones_ok || (order && any_zone_ok))
> break; /* kswapd: all done */
> /*
> * OK, kswapd is getting into trouble. Take a nap, then take
> @@ -2336,7 +2341,7 @@ loop_again:
> break;
> }
> out:
> - if (!all_zones_ok) {
> + if (!(all_zones_ok || (order && any_zone_ok))) {
Could you add a comment ?
And this means...
all_zones_ok .... all_zone_balanced
any_zones_ok .... fallback_allocation_ok
?
Thanks,
-Kame
On Mon, Dec 06, 2010 at 08:35:18AM +0900, Minchan Kim wrote:
> Hi Mel,
>
> On Fri, Dec 3, 2010 at 8:45 PM, Mel Gorman <[email protected]> wrote:
> > When the allocator enters its slow path, kswapd is woken up to balance the
> > node. It continues working until all zones within the node are balanced. For
> > order-0 allocations, this makes perfect sense but for higher orders it can
> > have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> > reclaim heavily within a smaller zone discarding an excessive number of
> > pages. The user-visible behaviour is that kswapd is awake and reclaiming
> > even though plenty of pages are free from a suitable zone.
> >
> > This patch alters the "balance" logic for high-order reclaim allowing kswapd
> > to stop if any suitable zone becomes balanced to reduce the number of pages
> > it reclaims from other zones. kswapd still tries to ensure that order-0
> > watermarks for all zones are met before sleeping.
> >
> > Signed-off-by: Mel Gorman <[email protected]>
>
> <snip>
>
> > - ? ? ? if (!all_zones_ok) {
> > + ? ? ? if (!(all_zones_ok || (order && any_zone_ok))) {
> > ? ? ? ? ? ? ? ?cond_resched();
> >
> > ? ? ? ? ? ? ? ?try_to_freeze();
> > @@ -2361,6 +2366,31 @@ out:
> > ? ? ? ? ? ? ? ?goto loop_again;
> > ? ? ? ?}
> >
> > + ? ? ? /*
> > + ? ? ? ?* If kswapd was reclaiming at a higher order, it has the option of
> > + ? ? ? ?* sleeping without all zones being balanced. Before it does, it must
> > + ? ? ? ?* ensure that the watermarks for order-0 on *all* zones are met and
> > + ? ? ? ?* that the congestion flags are cleared
> > + ? ? ? ?*/
> > + ? ? ? if (order) {
> > + ? ? ? ? ? ? ? for (i = 0; i <= end_zone; i++) {
> > + ? ? ? ? ? ? ? ? ? ? ? struct zone *zone = pgdat->node_zones + i;
> > +
> > + ? ? ? ? ? ? ? ? ? ? ? if (!populated_zone(zone))
> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> > +
> > + ? ? ? ? ? ? ? ? ? ? ? if (zone->all_unreclaimable && priority != DEF_PRIORITY)
> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> > +
> > + ? ? ? ? ? ? ? ? ? ? ? zone_clear_flag(zone, ZONE_CONGESTED);
>
> Why clear ZONE_CONGESTED?
> If you have a cause, please, write down the comment.
>
It's because kswapd is the only mechanism that clears the congestion
flag. If it's not cleared and kswapd goes to sleep, the flag could be
left set causing hard-to-diagnose stalls. I'll add a comment.
> <snip>
>
> First impression on this patch is that it changes scanning behavior as
> well as reclaiming on high order reclaim.
It does affect scanning behaviour for high-order reclaim. Specifically,
it may stop scanning once a zone is balanced within the node. Previously
it would continue scanning until all zones were balanced. Is this what
you are thinking of or something else?
> I can't say old behavior is right but we can't say this behavior is
> right, too although this patch solves the problem. At least, we might
> need some data that shows this patch doesn't have a regression.
How do you suggest it be tested and this data be gathered? I tested a number of
workloads that keep kswapd awake but found no differences of major significant
even though it was using high-order allocations. The problem with identifying
small regressions for high-order allocations is that the state of the system
when lumpy reclaim starts is very important as it determines how much work
has to be done. I did not find major regressions in performance.
For the tests I did run;
fsmark showed nothing useful. iozone showed nothing useful either as it didn't
even wake kswapd. sysbench showed minor performance gains and losses but it
is not useful as it typically does not wake kswapd unless the database is
badly configured.
I ran postmark because it was the closest benchmark to a mail simulator I
had access to. This sucks because it's no longer representative of a mail
server and is more like a crappy filesystem benchmark. To get it closer to a
real server, there was also a program running in the background that mapped
a large anonymous segment and scanned it in blocks.
POSTMARK
postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
traceonly-v3r1 kanyzone-v2r6
Transactions per second: 2.00 ( 0.00%) 2.00 ( 0.00%)
Data megabytes read per second: 8.14 ( 0.00%) 8.59 ( 5.24%)
Data megabytes written per second: 18.94 ( 0.00%) 19.98 ( 5.21%)
Files created alone per second: 4.00 ( 0.00%) 4.00 ( 0.00%)
Files create/transact per second: 1.00 ( 0.00%) 1.00 ( 0.00%)
Files deleted alone per second: 34.00 ( 0.00%) 30.00 (-13.33%)
Files delete/transact per second: 1.00 ( 0.00%) 1.00 ( 0.00%)
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 152.4 152.92
Total Elapsed Time (seconds) 5110.96 4847.22
FTrace Reclaim Statistics: vmscan
postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
traceonly-v3r1 kanyzone-v2r6
Direct reclaims 0 0
Direct reclaim pages scanned 0 0
Direct reclaim pages reclaimed 0 0
Direct reclaim write file async I/O 0 0
Direct reclaim write anon async I/O 0 0
Direct reclaim write file sync I/O 0 0
Direct reclaim write anon sync I/O 0 0
Wake kswapd requests 0 0
Kswapd wakeups 2177 2174
Kswapd pages scanned 34690766 34691473
Kswapd pages reclaimed 34511965 34513478
Kswapd reclaim write file async I/O 32 0
Kswapd reclaim write anon async I/O 2357 2561
Kswapd reclaim write file sync I/O 0 0
Kswapd reclaim write anon sync I/O 0 0
Time stalled direct reclaim (seconds) 0.00 0.00
Time kswapd awake (seconds) 632.10 683.34
Total pages scanned 34690766 34691473
Total pages reclaimed 34511965 34513478
%age total pages scanned/reclaimed 99.48% 99.49%
%age total pages scanned/written 0.01% 0.01%
%age file pages scanned/written 0.00% 0.00%
Percentage Time Spent Direct Reclaim 0.00% 0.00%
Percentage Time kswapd Awake 12.37% 14.10%
proc vmstat: Faults
postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
traceonly-v3r1 kanyzone-v2r6
Major Faults 1979 1741
Minor Faults 13660834 13587939
Page ins 89060 74704
Page outs 69800 58884
Swap ins 1193 1499
Swap outs 2403 2562
Still, IO performance was improved (higher rates of read/write) and the test
completed significantly faster with this patch series applied. kswapd was
awake for longer and reclaimed marginally more pages with more swap-ins and
swap-outs which is unfortunate but it's somewhat balanced by fewer faults
and fewer page-ins. Basically, in terms of reclaim the figures are so close
that it is within the performance variations lumpy reclaim has depending on
the exact state of the system when reclaim starts.
> It's
> not easy but I believe you can do very well as like having done until
> now. I didn't see whole series so I might miss something.
>
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Mon, Dec 06, 2010 at 11:35:41AM +0900, KAMEZAWA Hiroyuki wrote:
> On Fri, 3 Dec 2010 11:45:30 +0000
> Mel Gorman <[email protected]> wrote:
>
> > When the allocator enters its slow path, kswapd is woken up to balance the
> > node. It continues working until all zones within the node are balanced. For
> > order-0 allocations, this makes perfect sense but for higher orders it can
> > have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> > reclaim heavily within a smaller zone discarding an excessive number of
> > pages. The user-visible behaviour is that kswapd is awake and reclaiming
> > even though plenty of pages are free from a suitable zone.
> >
> > This patch alters the "balance" logic for high-order reclaim allowing kswapd
> > to stop if any suitable zone becomes balanced to reduce the number of pages
> > it reclaims from other zones. kswapd still tries to ensure that order-0
> > watermarks for all zones are met before sleeping.
> >
> > Signed-off-by: Mel Gorman <[email protected]>
>
> a nitpick.
>
> > ---
> > include/linux/mmzone.h | 3 +-
> > mm/page_alloc.c | 8 ++++--
> > mm/vmscan.c | 55 +++++++++++++++++++++++++++++++++++++++++-------
> > 3 files changed, 54 insertions(+), 12 deletions(-)
> >
> > diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
> > index 39c24eb..7177f51 100644
> > --- a/include/linux/mmzone.h
> > +++ b/include/linux/mmzone.h
> > @@ -645,6 +645,7 @@ typedef struct pglist_data {
> > wait_queue_head_t kswapd_wait;
> > struct task_struct *kswapd;
> > int kswapd_max_order;
> > + enum zone_type classzone_idx;
> > } pg_data_t;
> >
> > #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
> > @@ -660,7 +661,7 @@ typedef struct pglist_data {
> >
> > extern struct mutex zonelists_mutex;
> > void build_all_zonelists(void *data);
> > -void wakeup_kswapd(struct zone *zone, int order);
> > +void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx);
> > int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
> > int classzone_idx, int alloc_flags);
> > enum memmap_context {
> > diff --git a/mm/page_alloc.c b/mm/page_alloc.c
> > index e409270..82e3499 100644
> > --- a/mm/page_alloc.c
> > +++ b/mm/page_alloc.c
> > @@ -1915,13 +1915,14 @@ __alloc_pages_high_priority(gfp_t gfp_mask, unsigned int order,
> >
> > static inline
> > void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
> > - enum zone_type high_zoneidx)
> > + enum zone_type high_zoneidx,
> > + enum zone_type classzone_idx)
> > {
> > struct zoneref *z;
> > struct zone *zone;
> >
> > for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
> > - wakeup_kswapd(zone, order);
> > + wakeup_kswapd(zone, order, classzone_idx);
> > }
> >
> > static inline int
> > @@ -1998,7 +1999,8 @@ __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
> > goto nopage;
> >
> > restart:
> > - wake_all_kswapd(order, zonelist, high_zoneidx);
> > + wake_all_kswapd(order, zonelist, high_zoneidx,
> > + zone_idx(preferred_zone));
> >
> > /*
> > * OK, we're below the kswapd watermark and have kicked background
> > diff --git a/mm/vmscan.c b/mm/vmscan.c
> > index d31d7ce..d070d19 100644
> > --- a/mm/vmscan.c
> > +++ b/mm/vmscan.c
> > @@ -2165,11 +2165,14 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > * interoperates with the page allocator fallback scheme to ensure that aging
> > * of pages is balanced across the zones.
> > */
> > -static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> > +static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
> > + int classzone_idx)
> > {
> > int all_zones_ok;
> > + int any_zone_ok;
> > int priority;
> > int i;
> > + int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> > unsigned long total_scanned;
> > struct reclaim_state *reclaim_state = current->reclaim_state;
> > struct scan_control sc = {
> > @@ -2192,7 +2195,6 @@ loop_again:
> > count_vm_event(PAGEOUTRUN);
> >
> > for (priority = DEF_PRIORITY; priority >= 0; priority--) {
> > - int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> > unsigned long lru_pages = 0;
> > int has_under_min_watermark_zone = 0;
> >
> > @@ -2201,6 +2203,7 @@ loop_again:
> > disable_swap_token();
> >
> > all_zones_ok = 1;
> > + any_zone_ok = 0;
> >
> > /*
> > * Scan in the highmem->dma direction for the highest
> > @@ -2310,10 +2313,12 @@ loop_again:
> > * spectulatively avoid congestion waits
> > */
> > zone_clear_flag(zone, ZONE_CONGESTED);
> > + if (i <= classzone_idx)
> > + any_zone_ok = 1;
> > }
> >
> > }
> > - if (all_zones_ok)
> > + if (all_zones_ok || (order && any_zone_ok))
> > break; /* kswapd: all done */
> > /*
> > * OK, kswapd is getting into trouble. Take a nap, then take
> > @@ -2336,7 +2341,7 @@ loop_again:
> > break;
> > }
> > out:
> > - if (!all_zones_ok) {
> > + if (!(all_zones_ok || (order && any_zone_ok))) {
>
> Could you add a comment ?
>
> And this means...
>
> all_zones_ok .... all_zone_balanced
> any_zones_ok .... fallback_allocation_ok
> ?
>
+
+ /*
+ * order-0: All zones must meet high watermark for a balanced node
+ * high-order: Any zone below pgdats classzone_idx must meet the high
+ * watermark for a balanced node
+ */
?
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Mon, 6 Dec 2010 11:32:09 +0000
Mel Gorman <[email protected]> wrote:
> On Mon, Dec 06, 2010 at 11:35:41AM +0900, KAMEZAWA Hiroyuki wrote:
> > On Fri, 3 Dec 2010 11:45:30 +0000
> > Mel Gorman <[email protected]> wrote:
> >
> > > When the allocator enters its slow path, kswapd is woken up to balance the
> > > node. It continues working until all zones within the node are balanced. For
> > > order-0 allocations, this makes perfect sense but for higher orders it can
> > > have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> > > reclaim heavily within a smaller zone discarding an excessive number of
> > > pages. The user-visible behaviour is that kswapd is awake and reclaiming
> > > even though plenty of pages are free from a suitable zone.
> > >
> > > This patch alters the "balance" logic for high-order reclaim allowing kswapd
> > > to stop if any suitable zone becomes balanced to reduce the number of pages
> > > it reclaims from other zones. kswapd still tries to ensure that order-0
> > > watermarks for all zones are met before sleeping.
> > >
> > > Signed-off-by: Mel Gorman <[email protected]>
> >
> > a nitpick.
> >
> > > ---
> > > include/linux/mmzone.h | 3 +-
> > > mm/page_alloc.c | 8 ++++--
> > > mm/vmscan.c | 55 +++++++++++++++++++++++++++++++++++++++++-------
> > > 3 files changed, 54 insertions(+), 12 deletions(-)
> > >
> > > diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
> > > index 39c24eb..7177f51 100644
> > > --- a/include/linux/mmzone.h
> > > +++ b/include/linux/mmzone.h
> > > @@ -645,6 +645,7 @@ typedef struct pglist_data {
> > > wait_queue_head_t kswapd_wait;
> > > struct task_struct *kswapd;
> > > int kswapd_max_order;
> > > + enum zone_type classzone_idx;
> > > } pg_data_t;
> > >
> > > #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
> > > @@ -660,7 +661,7 @@ typedef struct pglist_data {
> > >
> > > extern struct mutex zonelists_mutex;
> > > void build_all_zonelists(void *data);
> > > -void wakeup_kswapd(struct zone *zone, int order);
> > > +void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx);
> > > int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
> > > int classzone_idx, int alloc_flags);
> > > enum memmap_context {
> > > diff --git a/mm/page_alloc.c b/mm/page_alloc.c
> > > index e409270..82e3499 100644
> > > --- a/mm/page_alloc.c
> > > +++ b/mm/page_alloc.c
> > > @@ -1915,13 +1915,14 @@ __alloc_pages_high_priority(gfp_t gfp_mask, unsigned int order,
> > >
> > > static inline
> > > void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
> > > - enum zone_type high_zoneidx)
> > > + enum zone_type high_zoneidx,
> > > + enum zone_type classzone_idx)
> > > {
> > > struct zoneref *z;
> > > struct zone *zone;
> > >
> > > for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
> > > - wakeup_kswapd(zone, order);
> > > + wakeup_kswapd(zone, order, classzone_idx);
> > > }
> > >
> > > static inline int
> > > @@ -1998,7 +1999,8 @@ __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
> > > goto nopage;
> > >
> > > restart:
> > > - wake_all_kswapd(order, zonelist, high_zoneidx);
> > > + wake_all_kswapd(order, zonelist, high_zoneidx,
> > > + zone_idx(preferred_zone));
> > >
> > > /*
> > > * OK, we're below the kswapd watermark and have kicked background
> > > diff --git a/mm/vmscan.c b/mm/vmscan.c
> > > index d31d7ce..d070d19 100644
> > > --- a/mm/vmscan.c
> > > +++ b/mm/vmscan.c
> > > @@ -2165,11 +2165,14 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > > * interoperates with the page allocator fallback scheme to ensure that aging
> > > * of pages is balanced across the zones.
> > > */
> > > -static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> > > +static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
> > > + int classzone_idx)
> > > {
> > > int all_zones_ok;
> > > + int any_zone_ok;
> > > int priority;
> > > int i;
> > > + int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> > > unsigned long total_scanned;
> > > struct reclaim_state *reclaim_state = current->reclaim_state;
> > > struct scan_control sc = {
> > > @@ -2192,7 +2195,6 @@ loop_again:
> > > count_vm_event(PAGEOUTRUN);
> > >
> > > for (priority = DEF_PRIORITY; priority >= 0; priority--) {
> > > - int end_zone = 0; /* Inclusive. 0 = ZONE_DMA */
> > > unsigned long lru_pages = 0;
> > > int has_under_min_watermark_zone = 0;
> > >
> > > @@ -2201,6 +2203,7 @@ loop_again:
> > > disable_swap_token();
> > >
> > > all_zones_ok = 1;
> > > + any_zone_ok = 0;
> > >
> > > /*
> > > * Scan in the highmem->dma direction for the highest
> > > @@ -2310,10 +2313,12 @@ loop_again:
> > > * spectulatively avoid congestion waits
> > > */
> > > zone_clear_flag(zone, ZONE_CONGESTED);
> > > + if (i <= classzone_idx)
> > > + any_zone_ok = 1;
> > > }
> > >
> > > }
> > > - if (all_zones_ok)
> > > + if (all_zones_ok || (order && any_zone_ok))
> > > break; /* kswapd: all done */
> > > /*
> > > * OK, kswapd is getting into trouble. Take a nap, then take
> > > @@ -2336,7 +2341,7 @@ loop_again:
> > > break;
> > > }
> > > out:
> > > - if (!all_zones_ok) {
> > > + if (!(all_zones_ok || (order && any_zone_ok))) {
> >
> > Could you add a comment ?
> >
> > And this means...
> >
> > all_zones_ok .... all_zone_balanced
> > any_zones_ok .... fallback_allocation_ok
> > ?
> >
>
> +
> + /*
> + * order-0: All zones must meet high watermark for a balanced node
> + * high-order: Any zone below pgdats classzone_idx must meet the high
> + * watermark for a balanced node
> + */
>
> ?
>
!
seems good. thanks.
-kame
On Mon, Dec 6, 2010 at 7:55 PM, Mel Gorman <[email protected]> wrote:
> On Mon, Dec 06, 2010 at 08:35:18AM +0900, Minchan Kim wrote:
>> Hi Mel,
>>
>> On Fri, Dec 3, 2010 at 8:45 PM, Mel Gorman <[email protected]> wrote:
>> > When the allocator enters its slow path, kswapd is woken up to balance the
>> > node. It continues working until all zones within the node are balanced. For
>> > order-0 allocations, this makes perfect sense but for higher orders it can
>> > have unintended side-effects. If the zone sizes are imbalanced, kswapd may
>> > reclaim heavily within a smaller zone discarding an excessive number of
>> > pages. The user-visible behaviour is that kswapd is awake and reclaiming
>> > even though plenty of pages are free from a suitable zone.
>> >
>> > This patch alters the "balance" logic for high-order reclaim allowing kswapd
>> > to stop if any suitable zone becomes balanced to reduce the number of pages
>> > it reclaims from other zones. kswapd still tries to ensure that order-0
>> > watermarks for all zones are met before sleeping.
>> >
>> > Signed-off-by: Mel Gorman <[email protected]>
>>
>> <snip>
>>
>> > - ? ? ? if (!all_zones_ok) {
>> > + ? ? ? if (!(all_zones_ok || (order && any_zone_ok))) {
>> > ? ? ? ? ? ? ? ?cond_resched();
>> >
>> > ? ? ? ? ? ? ? ?try_to_freeze();
>> > @@ -2361,6 +2366,31 @@ out:
>> > ? ? ? ? ? ? ? ?goto loop_again;
>> > ? ? ? ?}
>> >
>> > + ? ? ? /*
>> > + ? ? ? ?* If kswapd was reclaiming at a higher order, it has the option of
>> > + ? ? ? ?* sleeping without all zones being balanced. Before it does, it must
>> > + ? ? ? ?* ensure that the watermarks for order-0 on *all* zones are met and
>> > + ? ? ? ?* that the congestion flags are cleared
>> > + ? ? ? ?*/
>> > + ? ? ? if (order) {
>> > + ? ? ? ? ? ? ? for (i = 0; i <= end_zone; i++) {
>> > + ? ? ? ? ? ? ? ? ? ? ? struct zone *zone = pgdat->node_zones + i;
>> > +
>> > + ? ? ? ? ? ? ? ? ? ? ? if (!populated_zone(zone))
>> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
>> > +
>> > + ? ? ? ? ? ? ? ? ? ? ? if (zone->all_unreclaimable && priority != DEF_PRIORITY)
>> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
>> > +
>> > + ? ? ? ? ? ? ? ? ? ? ? zone_clear_flag(zone, ZONE_CONGESTED);
>>
>> Why clear ZONE_CONGESTED?
>> If you have a cause, please, write down the comment.
>>
>
> It's because kswapd is the only mechanism that clears the congestion
> flag. If it's not cleared and kswapd goes to sleep, the flag could be
> left set causing hard-to-diagnose stalls. I'll add a comment.
Seems good.
>
>> <snip>
>>
>> First impression on this patch is that it changes scanning behavior as
>> well as reclaiming on high order reclaim.
>
> It does affect scanning behaviour for high-order reclaim. Specifically,
> it may stop scanning once a zone is balanced within the node. Previously
> it would continue scanning until all zones were balanced. Is this what
> you are thinking of or something else?
Yes. I mean page aging of high zones.
>
>> I can't say old behavior is right but we can't say this behavior is
>> right, too although this patch solves the problem. At least, we might
>> need some data that shows this patch doesn't have a regression.
>
> How do you suggest it be tested and this data be gathered? I tested a number of
> workloads that keep kswapd awake but found no differences of major significant
> even though it was using high-order allocations. The ?problem with identifying
> small regressions for high-order allocations is that the state of the system
> when lumpy reclaim starts is very important as it determines how much work
> has to be done. I did not find major regressions in performance.
>
> For the tests I did run;
>
> fsmark showed nothing useful. iozone showed nothing useful either as it didn't
> even wake kswapd. sysbench showed minor performance gains and losses but it
> is not useful as it typically does not wake kswapd unless the database is
> badly configured.
>
> I ran postmark because it was the closest benchmark to a mail simulator I
> had access to. This sucks because it's no longer representative of a mail
> server and is more like a crappy filesystem benchmark. To get it closer to a
> real server, there was also a program running in the background that mapped
> a large anonymous segment and scanned it in blocks.
>
> POSTMARK
> ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> Transactions per second: ? ? ? ? ? ? ? ?2.00 ( 0.00%) ? ? 2.00 ( 0.00%)
> Data megabytes read per second: ? ? ? ? 8.14 ( 0.00%) ? ? 8.59 ( 5.24%)
> Data megabytes written per second: ? ? 18.94 ( 0.00%) ? ?19.98 ( 5.21%)
> Files created alone per second: ? ? ? ? 4.00 ( 0.00%) ? ? 4.00 ( 0.00%)
> Files create/transact per second: ? ? ? 1.00 ( 0.00%) ? ? 1.00 ( 0.00%)
> Files deleted alone per second: ? ? ? ?34.00 ( 0.00%) ? ?30.00 (-13.33%)
Do you know the reason only file deletion has a big regression?
> Files delete/transact per second: ? ? ? 1.00 ( 0.00%) ? ? 1.00 ( 0.00%)
>
> MMTests Statistics: duration
> User/Sys Time Running Test (seconds) ? ? ? ? 152.4 ? ?152.92
> Total Elapsed Time (seconds) ? ? ? ? ? ? ? 5110.96 ? 4847.22
>
> FTrace Reclaim Statistics: vmscan
> ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> Direct reclaims ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?0 ? ? ? ? ?0
> Direct reclaim pages scanned ? ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Direct reclaim pages reclaimed ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Direct reclaim write file async I/O ? ? ? ? ? ? ?0 ? ? ? ? ?0
> Direct reclaim write anon async I/O ? ? ? ? ? ? ?0 ? ? ? ? ?0
> Direct reclaim write file sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Direct reclaim write anon sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Wake kswapd requests ? ? ? ? ? ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Kswapd wakeups ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?2177 ? ? ? 2174
> Kswapd pages scanned ? ? ? ? ? ? ? ? ? ? ?34690766 ? 34691473
Perhaps, in your workload, any_zone is highest zone.
If any_zone became low zone, kswapd pages scanned would have a big
difference because old behavior try to balance all zones.
Could we evaluate this situation? but I have no idea how we set up the
situation. :(
> Kswapd pages reclaimed ? ? ? ? ? ? ? ? ? ?34511965 ? 34513478
> Kswapd reclaim write file async I/O ? ? ? ? ? ? 32 ? ? ? ? ?0
> Kswapd reclaim write anon async I/O ? ? ? ? ? 2357 ? ? ? 2561
> Kswapd reclaim write file sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Kswapd reclaim write anon sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> Time stalled direct reclaim (seconds) ? ? ? ? 0.00 ? ? ? 0.00
> Time kswapd awake (seconds) ? ? ? ? ? ? ? ? 632.10 ? ? 683.34
>
> Total pages scanned ? ? ? ? ? ? ? ? ? ? ? 34690766 ?34691473
> Total pages reclaimed ? ? ? ? ? ? ? ? ? ? 34511965 ?34513478
> %age total pages scanned/reclaimed ? ? ? ? ?99.48% ? ?99.49%
> %age total pages scanned/written ? ? ? ? ? ? 0.01% ? ? 0.01%
> %age ?file pages scanned/written ? ? ? ? ? ? 0.00% ? ? 0.00%
> Percentage Time Spent Direct Reclaim ? ? ? ? 0.00% ? ? 0.00%
> Percentage Time kswapd Awake ? ? ? ? ? ? ? ?12.37% ? ?14.10%
Is "kswapd Awake" correct?
AFAIR, In your implementation, you seems to account kswapd time even
though kswapd are schedule out.
I mean, for example,
kswapd
-> time stamp start
-> balance_pgdat
-> cond_resched(kswapd schedule out)
-> app 1 start
-> app 2 start
-> kswapd schedule in
-> time stamp end.
If it's right, kswapd awake doesn't have a big meaning.
>
> proc vmstat: Faults
> ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> Major Faults ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?1979 ? ? ?1741
> Minor Faults ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?13660834 ?13587939
> Page ins ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 89060 ? ? 74704
> Page outs ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?69800 ? ? 58884
> Swap ins ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?1193 ? ? ?1499
> Swap outs ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 2403 ? ? ?2562
>
> Still, IO performance was improved (higher rates of read/write) and the test
> completed significantly faster with this patch series applied. ?kswapd was
> awake for longer and reclaimed marginally more pages with more swap-ins and
Longer wake may be due to wrong gathering of time as I said.
> swap-outs which is unfortunate but it's somewhat balanced by fewer faults
> and fewer page-ins. Basically, in terms of reclaim the figures are so close
> that it is within the performance variations lumpy reclaim has depending on
> the exact state of the system when reclaim starts.
What I wanted to see is that when if zones above any_zone isn't aging
how it affect system performance.
This patch is changing balancing mechanism of kswapd so I think the
experiment is valuable.
I don't want to make contributors to be tired by bad reviewer.
What do you think about that?
>
>> It's
>> not easy but I believe you can do very well as like having done until
>> now. I didn't see whole series so I might miss something.
>>
>
> --
> Mel Gorman
> Part-time Phd Student ? ? ? ? ? ? ? ? ? ? ? ? ?Linux Technology Center
> University of Limerick ? ? ? ? ? ? ? ? ? ? ? ? IBM Dublin Software Lab
>
--
Kind regards,
Minchan Kim
On Tue, Dec 07, 2010 at 10:32:45AM +0900, Minchan Kim wrote:
> On Mon, Dec 6, 2010 at 7:55 PM, Mel Gorman <[email protected]> wrote:
> > On Mon, Dec 06, 2010 at 08:35:18AM +0900, Minchan Kim wrote:
> >> Hi Mel,
> >>
> >> On Fri, Dec 3, 2010 at 8:45 PM, Mel Gorman <[email protected]> wrote:
> >> > When the allocator enters its slow path, kswapd is woken up to balance the
> >> > node. It continues working until all zones within the node are balanced. For
> >> > order-0 allocations, this makes perfect sense but for higher orders it can
> >> > have unintended side-effects. If the zone sizes are imbalanced, kswapd may
> >> > reclaim heavily within a smaller zone discarding an excessive number of
> >> > pages. The user-visible behaviour is that kswapd is awake and reclaiming
> >> > even though plenty of pages are free from a suitable zone.
> >> >
> >> > This patch alters the "balance" logic for high-order reclaim allowing kswapd
> >> > to stop if any suitable zone becomes balanced to reduce the number of pages
> >> > it reclaims from other zones. kswapd still tries to ensure that order-0
> >> > watermarks for all zones are met before sleeping.
> >> >
> >> > Signed-off-by: Mel Gorman <[email protected]>
> >>
> >> <snip>
> >>
> >> > - ? ? ? if (!all_zones_ok) {
> >> > + ? ? ? if (!(all_zones_ok || (order && any_zone_ok))) {
> >> > ? ? ? ? ? ? ? ?cond_resched();
> >> >
> >> > ? ? ? ? ? ? ? ?try_to_freeze();
> >> > @@ -2361,6 +2366,31 @@ out:
> >> > ? ? ? ? ? ? ? ?goto loop_again;
> >> > ? ? ? ?}
> >> >
> >> > + ? ? ? /*
> >> > + ? ? ? ?* If kswapd was reclaiming at a higher order, it has the option of
> >> > + ? ? ? ?* sleeping without all zones being balanced. Before it does, it must
> >> > + ? ? ? ?* ensure that the watermarks for order-0 on *all* zones are met and
> >> > + ? ? ? ?* that the congestion flags are cleared
> >> > + ? ? ? ?*/
> >> > + ? ? ? if (order) {
> >> > + ? ? ? ? ? ? ? for (i = 0; i <= end_zone; i++) {
> >> > + ? ? ? ? ? ? ? ? ? ? ? struct zone *zone = pgdat->node_zones + i;
> >> > +
> >> > + ? ? ? ? ? ? ? ? ? ? ? if (!populated_zone(zone))
> >> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> >> > +
> >> > + ? ? ? ? ? ? ? ? ? ? ? if (zone->all_unreclaimable && priority != DEF_PRIORITY)
> >> > + ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? continue;
> >> > +
> >> > + ? ? ? ? ? ? ? ? ? ? ? zone_clear_flag(zone, ZONE_CONGESTED);
> >>
> >> Why clear ZONE_CONGESTED?
> >> If you have a cause, please, write down the comment.
> >>
> >
> > It's because kswapd is the only mechanism that clears the congestion
> > flag. If it's not cleared and kswapd goes to sleep, the flag could be
> > left set causing hard-to-diagnose stalls. I'll add a comment.
>
> Seems good.
>
Ok.
> >
> >> <snip>
> >>
> >> First impression on this patch is that it changes scanning behavior as
> >> well as reclaiming on high order reclaim.
> >
> > It does affect scanning behaviour for high-order reclaim. Specifically,
> > it may stop scanning once a zone is balanced within the node. Previously
> > it would continue scanning until all zones were balanced. Is this what
> > you are thinking of or something else?
>
> Yes. I mean page aging of high zones.
>
When high-order node balancing is finished (aging zones as before), a
check is made to ensure that all zones are balanced for order-0. If not,
kswapd stays awake continueing to age zones as before. Zones will not age
as aggressively now that high-order balancing finishes but as part of the
bug report is too many pages being freed by kswapd, this is a good thing.
> >
> >> I can't say old behavior is right but we can't say this behavior is
> >> right, too although this patch solves the problem. At least, we might
> >> need some data that shows this patch doesn't have a regression.
> >
> > How do you suggest it be tested and this data be gathered? I tested a number of
> > workloads that keep kswapd awake but found no differences of major significant
> > even though it was using high-order allocations. The ?problem with identifying
> > small regressions for high-order allocations is that the state of the system
> > when lumpy reclaim starts is very important as it determines how much work
> > has to be done. I did not find major regressions in performance.
> >
> > For the tests I did run;
> >
> > fsmark showed nothing useful. iozone showed nothing useful either as it didn't
> > even wake kswapd. sysbench showed minor performance gains and losses but it
> > is not useful as it typically does not wake kswapd unless the database is
> > badly configured.
> >
> > I ran postmark because it was the closest benchmark to a mail simulator I
> > had access to. This sucks because it's no longer representative of a mail
> > server and is more like a crappy filesystem benchmark. To get it closer to a
> > real server, there was also a program running in the background that mapped
> > a large anonymous segment and scanned it in blocks.
> >
> > POSTMARK
> > ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> > ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> > Transactions per second: ? ? ? ? ? ? ? ?2.00 ( 0.00%) ? ? 2.00 ( 0.00%)
> > Data megabytes read per second: ? ? ? ? 8.14 ( 0.00%) ? ? 8.59 ( 5.24%)
> > Data megabytes written per second: ? ? 18.94 ( 0.00%) ? ?19.98 ( 5.21%)
> > Files created alone per second: ? ? ? ? 4.00 ( 0.00%) ? ? 4.00 ( 0.00%)
> > Files create/transact per second: ? ? ? 1.00 ( 0.00%) ? ? 1.00 ( 0.00%)
> > Files deleted alone per second: ? ? ? ?34.00 ( 0.00%) ? ?30.00 (-13.33%)
>
> Do you know the reason only file deletion has a big regression?
>
I'm guessing bad luck because it's not stable. There is a large memory
consumer running in the background. If the timing of when it got swapped
out changed, it could have regressed. It's not very stable between runs.
Sometimes the files deleted is not affected at all but every time the
read/writes per second is higher and the total time to completion is lower.
> > Files delete/transact per second: ? ? ? 1.00 ( 0.00%) ? ? 1.00 ( 0.00%)
> >
> > MMTests Statistics: duration
> > User/Sys Time Running Test (seconds) ? ? ? ? 152.4 ? ?152.92
> > Total Elapsed Time (seconds) ? ? ? ? ? ? ? 5110.96 ? 4847.22
> >
> > FTrace Reclaim Statistics: vmscan
> > ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> > ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> > Direct reclaims ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?0 ? ? ? ? ?0
> > Direct reclaim pages scanned ? ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Direct reclaim pages reclaimed ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Direct reclaim write file async I/O ? ? ? ? ? ? ?0 ? ? ? ? ?0
> > Direct reclaim write anon async I/O ? ? ? ? ? ? ?0 ? ? ? ? ?0
> > Direct reclaim write file sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Direct reclaim write anon sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Wake kswapd requests ? ? ? ? ? ? ? ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Kswapd wakeups ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?2177 ? ? ? 2174
> > Kswapd pages scanned ? ? ? ? ? ? ? ? ? ? ?34690766 ? 34691473
>
> Perhaps, in your workload, any_zone is highest zone.
> If any_zone became low zone, kswapd pages scanned would have a big
> difference because old behavior try to balance all zones.
It'll still balance the zones for order-0, the size we care most about.
> Could we evaluate this situation? but I have no idea how we set up the
> situation. :(
>
See the reset of the series. The main consequence of any_zone being a low
zone is that balancing can stop because ZONE_DMA is balanced even though it
is unusable for allocations. Patch 3 takes the classzone_idx into account
to identify when deciding if kswapd should go to sleep. The final patch in
the series replaces "any zone" with "at least 25% of the pages making up
the node must be balanced". The situation could be forced artifically by
preventing pages ever being allocated from ZONE_DMA but we wouldn't be able
to draw any sensible conclusion from it as patch 5 in the series handles it.
This is why I'm depending on Simon's reports to see if his corner case is fixed
while running other stress tests to see if anything else is noticeably worse.
> > Kswapd pages reclaimed ? ? ? ? ? ? ? ? ? ?34511965 ? 34513478
> > Kswapd reclaim write file async I/O ? ? ? ? ? ? 32 ? ? ? ? ?0
> > Kswapd reclaim write anon async I/O ? ? ? ? ? 2357 ? ? ? 2561
> > Kswapd reclaim write file sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Kswapd reclaim write anon sync I/O ? ? ? ? ? ? ? 0 ? ? ? ? ?0
> > Time stalled direct reclaim (seconds) ? ? ? ? 0.00 ? ? ? 0.00
> > Time kswapd awake (seconds) ? ? ? ? ? ? ? ? 632.10 ? ? 683.34
> >
> > Total pages scanned ? ? ? ? ? ? ? ? ? ? ? 34690766 ?34691473
> > Total pages reclaimed ? ? ? ? ? ? ? ? ? ? 34511965 ?34513478
> > %age total pages scanned/reclaimed ? ? ? ? ?99.48% ? ?99.49%
> > %age total pages scanned/written ? ? ? ? ? ? 0.01% ? ? 0.01%
> > %age ?file pages scanned/written ? ? ? ? ? ? 0.00% ? ? 0.00%
> > Percentage Time Spent Direct Reclaim ? ? ? ? 0.00% ? ? 0.00%
> > Percentage Time kswapd Awake ? ? ? ? ? ? ? ?12.37% ? ?14.10%
>
> Is "kswapd Awake" correct?
> AFAIR, In your implementation, you seems to account kswapd time even
> though kswapd are schedule out.
> I mean, for example,
>
> kswapd
> -> time stamp start
> -> balance_pgdat
> -> cond_resched(kswapd schedule out)
> -> app 1 start
> -> app 2 start
> -> kswapd schedule in
> -> time stamp end.
>
> If it's right, kswapd awake doesn't have a big meaning.
>
"Time kswapd awake" is the time between when
Trace event mm_vmscan_kswapd_wake is recorded while kswapd is asleep
Trave event mm_vmscan_kswapd_sleep is recorded just before kswapd calls
schedule() to properly go to sleep.
It's possible to receive mm_vmscan_kswapd_wake multiple times while kswapd
is asleep but it is ignored.
If kswapd schedules out normally or is stalled on direct writeback, this
time is included in the above value. Maybe a better name for this is
"kswapd active".
> >
> > proc vmstat: Faults
> > ? ? ? ? ? ?postmark-traceonly-v3r1-postmarkpostmark-kanyzone-v2r6-postmark
> > ? ? ? ? ? ? ? ?traceonly-v3r1 ? ? kanyzone-v2r6
> > Major Faults ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?1979 ? ? ?1741
> > Minor Faults ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?13660834 ?13587939
> > Page ins ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 89060 ? ? 74704
> > Page outs ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?69800 ? ? 58884
> > Swap ins ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?1193 ? ? ?1499
> > Swap outs ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 2403 ? ? ?2562
> >
> > Still, IO performance was improved (higher rates of read/write) and the test
> > completed significantly faster with this patch series applied. ?kswapd was
> > awake for longer and reclaimed marginally more pages with more swap-ins and
>
> Longer wake may be due to wrong gathering of time as I said.
>
Possibly, but I don't think so. I'm more inclined to blame the
effectively random interaction between postmark and the memory consumer
running in the background.
> > swap-outs which is unfortunate but it's somewhat balanced by fewer faults
> > and fewer page-ins. Basically, in terms of reclaim the figures are so close
> > that it is within the performance variations lumpy reclaim has depending on
> > the exact state of the system when reclaim starts.
>
> What I wanted to see is that when if zones above any_zone isn't aging
> how it affect system performance.
The only test I ran that would be affected is a streaming IO test but
it's only one aspect of memory reclaim behaviour (albeit it one that
people tend to complain about when it's broken)
> This patch is changing balancing mechanism of kswapd so I think the
> experiment is valuable.
> I don't want to make contributors to be tired by bad reviewer.
> What do you think about that?
>
About all I can report on is the streaming IO benchmarks results which
looks like;
MICRO
traceonly kanyzone
MMTests Statistics: duration
User/Sys Time Running Test (seconds) 24.23 23.93
Total Elapsed Time (seconds) 916.18 916.69
FTrace Reclaim Statistics: vmscan
traceonly kanyzone
Direct reclaims 2437 2565
Direct reclaim pages scanned 1688201 1801142
Direct reclaim write file async I/O 0 0
Direct reclaim write anon async I/O 14 0
Direct reclaim write file sync I/O 0 0
Direct reclaim write anon sync I/O 0 0
Wake kswapd requests 1333358 1417622
Kswapd wakeups 107 116
Kswapd pages scanned 15801484 15706394
Kswapd reclaim write file async I/O 44 24
Kswapd reclaim write anon async I/O 25 0
Kswapd reclaim write file sync I/O 0 0
Kswapd reclaim write anon sync I/O 0 0
Time stalled direct reclaim (seconds) 1.79 0.98
Time kswapd awake (seconds) 387.60 410.26
Total pages scanned 17489685 17507536
%age total pages scanned/reclaimed 0.00% 0.00%
%age total pages scanned/written 0.00% 0.00%
%age file pages scanned/written 0.00% 0.00%
Percentage Time Spent Direct Reclaim 6.88% 3.93%
Percentage Time kswapd Awake 42.31% 44.75%
proc vmstat: Faults
micro-traceonly-v3r1-micromicro-kanyzone-v3r1-micro
traceonly-v3r1 kanyzone-v3r1
Major Faults 1943 1808
Minor Faults 55488625 55441993
Page ins 134044 126640
Page outs 73884 69248
Swap ins 2322 1972
Swap outs 7291 6521
Total pages scanned differ by 0.1% which is not much. Time to completion
is more or less the same. Faults, paging activity and swap activity are
all slightly reduced.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Fri, Dec 03, 2010 at 11:45:29AM +0000, Mel Gorman wrote:
> This still needs testing. I've tried multiple reproduction scenarios locally
> but two things are tripping me. One, Simon's network card is using GFP_ATOMIC
> allocations where as the one I use locally does not. Second, Simon's is a real
> mail workload with network traffic and there are no decent mail simulator
> benchmarks (that I could find at least) that would replicate the situation.
> Still, I'm hopeful it'll stop kswapd going mad on his machine and might
> also alleviate some of the "too much free memory" problem.
>
> Changelog since V1
> o Take classzone into account
> o Ensure that kswapd always balances at order-09
> o Reset classzone and order after reading
> o Require a percentage of a node be balanced for high-order allocations,
> not just any zone as ZONE_DMA could be balanced when the node in general
> is a mess
>
> Simon Kirby reported the following problem
>
> We're seeing cases on a number of servers where cache never fully
> grows to use all available memory. Sometimes we see servers with 4
> GB of memory that never seem to have less than 1.5 GB free, even with
> a constantly-active VM. In some cases, these servers also swap out
> while this happens, even though they are constantly reading the working
> set into memory. We have been seeing this happening for a long time;
> I don't think it's anything recent, and it still happens on 2.6.36.
>
> After some debugging work by Simon, Dave Hansen and others, the prevaling
> theory became that kswapd is reclaiming order-3 pages requested by SLUB
> too aggressive about it.
>
> There are two apparent problems here. On the target machine, there is a small
> Normal zone in comparison to DMA32. As kswapd tries to balance all zones, it
> would continually try reclaiming for Normal even though DMA32 was balanced
> enough for callers. The second problem is that sleeping_prematurely() uses
> the requested order, not the order kswapd finally reclaimed at. This keeps
> kswapd artifically awake.
>
> This series aims to alleviate these problems but needs testing to confirm
> it alleviates the actual problem and wider review to think if there is a
> better alternative approach. Local tests passed but are not reproducing
> the same problem unfortunately so the results are inclusive.
So, we have been running the first version of this series in production
since November 26th, and this version of this series in production since
early yesterday morning. Both versions definitely solve the kswapd not
sleeping problem and do improve the use of memory for caching. There are
still problems with fragmentation causing reclaim of more page cache than
I would like, but without this patch, the system is in bad shape (it
keeps reading daemons in from disk because kswapd keeps reclaiming them).
http://0x.ca/sim/ref/2.6.36/?C=M;O=A
http://0x.ca/sim/ref/2.6.36/mel_v2_memory_day.png
http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_day.png
http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_DMA32_day.png
http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_Normal_day.png
No problem with page allocation failures or any other problem in the
weeks of testing.
Simon-
Hmm...
Wouldn't it make more sense for the fast path page allocator to allocate
weighted-round-robin (by zone size) from each zone, rather than just
starting from the highest and working down?
This would mean that each zone would get a proportional amount of
allocations and reclaiming a bit from each would likely throw out the
oldest allocations, rather than some of that and and some more recent
stuff that was allocated at the beginning of the lower zone.
For example, with the current approach, a time progression of allocations
looks like this (N=Normal, D=DMA32): 1N 2N 3N 4D 5D 6D 7D 8D 9D
...once the watermark is hit, kswapd reclaims 1 and 4, since they're
oldest in each zone, but 2 and 3 were allocated earlier.
Versus a weighted-round-robin approach: 1N 2D 3D 4N 5D 6D 7N 8D 9D
...kswapd reclaims 1 and 2, and they're oldest in time and maybe LRU.
Things probably eventually mix up enough once the system has reclaimed
and allocated more for a while with the current approach, but the
allocations are still chunky depending on how many extra things kswapd
reclaims to reach higher-order watermarks, and doesn't this always mess
with the LRU when the there are multiple usable zones?
Anyway, this approach might be horrible for some other reasons (page
allocations hoping to be sequential? bigger cache footprint?), but it
might reduce the requirements for other other workarounds, and it would
make the LRU node-wide instead of zone-wide.
Simon-
On Wed, Dec 08, 2010 at 05:55:30PM -0800, Simon Kirby wrote:
> Hmm...
>
> Wouldn't it make more sense for the fast path page allocator to allocate
> weighted-round-robin (by zone size) from each zone, rather than just
> starting from the highest and working down?
>
Unfortunately, that would cause other problems. Zones are about
addressing limitations. The DMA zone is used by callers that cannot
address above 16M. On the other extreme, the HighMem zone is used for
addresses that cannot be directly mapped at all times due to a lack of
virtual address space.
If we round-robined the zones, callers that could use HighMem or Normal
may consume memory from DMA32 or DMA causing future allocation requests
that require those zones to fail.
> This would mean that each zone would get a proportional amount of
> allocations and reclaiming a bit from each would likely throw out the
> oldest allocations, rather than some of that and and some more recent
> stuff that was allocated at the beginning of the lower zone.
>
> For example, with the current approach, a time progression of allocations
> looks like this (N=Normal, D=DMA32): 1N 2N 3N 4D 5D 6D 7D 8D 9D
>
> ...once the watermark is hit, kswapd reclaims 1 and 4, since they're
> oldest in each zone, but 2 and 3 were allocated earlier.
>
> Versus a weighted-round-robin approach: 1N 2D 3D 4N 5D 6D 7N 8D 9D
>
> ...kswapd reclaims 1 and 2, and they're oldest in time and maybe LRU.
>
> Things probably eventually mix up enough once the system has reclaimed
> and allocated more for a while with the current approach, but the
> allocations are still chunky depending on how many extra things kswapd
> reclaims to reach higher-order watermarks, and doesn't this always mess
> with the LRU when the there are multiple usable zones?
>
If addressing limitations were not a problem, we'd just have a single
zone :/
> Anyway, this approach might be horrible for some other reasons (page
> allocations hoping to be sequential? bigger cache footprint?), but it
> might reduce the requirements for other other workarounds, and it would
> make the LRU node-wide instead of zone-wide.
>
Node-wide would be preferably from a page aging perspective but as zones
are about addressing limitations, we need to be able to reclaim zones
from a specific zone quickly and not have to scan looking for suitable
pages.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Wed, Dec 08, 2010 at 05:18:08PM -0800, Simon Kirby wrote:
> On Fri, Dec 03, 2010 at 11:45:29AM +0000, Mel Gorman wrote:
>
> > This still needs testing. I've tried multiple reproduction scenarios locally
> > but two things are tripping me. One, Simon's network card is using GFP_ATOMIC
> > allocations where as the one I use locally does not. Second, Simon's is a real
> > mail workload with network traffic and there are no decent mail simulator
> > benchmarks (that I could find at least) that would replicate the situation.
> > Still, I'm hopeful it'll stop kswapd going mad on his machine and might
> > also alleviate some of the "too much free memory" problem.
> >
> > Changelog since V1
> > o Take classzone into account
> > o Ensure that kswapd always balances at order-09
> > o Reset classzone and order after reading
> > o Require a percentage of a node be balanced for high-order allocations,
> > not just any zone as ZONE_DMA could be balanced when the node in general
> > is a mess
> >
> > Simon Kirby reported the following problem
> >
> > We're seeing cases on a number of servers where cache never fully
> > grows to use all available memory. Sometimes we see servers with 4
> > GB of memory that never seem to have less than 1.5 GB free, even with
> > a constantly-active VM. In some cases, these servers also swap out
> > while this happens, even though they are constantly reading the working
> > set into memory. We have been seeing this happening for a long time;
> > I don't think it's anything recent, and it still happens on 2.6.36.
> >
> > After some debugging work by Simon, Dave Hansen and others, the prevaling
> > theory became that kswapd is reclaiming order-3 pages requested by SLUB
> > too aggressive about it.
> >
> > There are two apparent problems here. On the target machine, there is a small
> > Normal zone in comparison to DMA32. As kswapd tries to balance all zones, it
> > would continually try reclaiming for Normal even though DMA32 was balanced
> > enough for callers. The second problem is that sleeping_prematurely() uses
> > the requested order, not the order kswapd finally reclaimed at. This keeps
> > kswapd artifically awake.
> >
> > This series aims to alleviate these problems but needs testing to confirm
> > it alleviates the actual problem and wider review to think if there is a
> > better alternative approach. Local tests passed but are not reproducing
> > the same problem unfortunately so the results are inclusive.
>
> So, we have been running the first version of this series in production
> since November 26th, and this version of this series in production since
> early yesterday morning. Both versions definitely solve the kswapd not
> sleeping problem and do improve the use of memory for caching. There are
> still problems with fragmentation causing reclaim of more page cache than
> I would like, but without this patch, the system is in bad shape (it
> keeps reading daemons in from disk because kswapd keeps reclaiming them).
>
This is a plus at least. I've cc'd Andrew, Johannes and Rik so they are
aware of this result. I just released V3 of the series which is very
similar to this version with one major exception, patch 5, which alters
how sleeping_prematurely() treats zone->all_unreclaimable.
> http://0x.ca/sim/ref/2.6.36/?C=M;O=A
> http://0x.ca/sim/ref/2.6.36/mel_v2_memory_day.png
> http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_day.png
> http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_DMA32_day.png
> http://0x.ca/sim/ref/2.6.36/mel_v2_buddyinfo_Normal_day.png
>
> No problem with page allocation failures or any other problem in the
> weeks of testing.
>
As you've reported that moving slub to order-0 does not help, I don't
think slub is the only problem any more. I think V3 of the series is
worth merging just for the kswapd-being-awake- problem. If there are
still too many free pages after this is merged, the next best guess is
that it's order-1 pages for task_struct causing the problem.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Thu, Dec 09, 2010 at 11:45:06AM +0000, Mel Gorman wrote:
> On Wed, Dec 08, 2010 at 05:55:30PM -0800, Simon Kirby wrote:
> > Hmm...
> >
> > Wouldn't it make more sense for the fast path page allocator to allocate
> > weighted-round-robin (by zone size) from each zone, rather than just
> > starting from the highest and working down?
> >
>
> Unfortunately, that would cause other problems. Zones are about
> addressing limitations. The DMA zone is used by callers that cannot
> address above 16M. On the other extreme, the HighMem zone is used for
> addresses that cannot be directly mapped at all times due to a lack of
> virtual address space.
>
> If we round-robined the zones, callers that could use HighMem or Normal
> may consume memory from DMA32 or DMA causing future allocation requests
> that require those zones to fail.
Yeah, I don't mean in all cases, I mean when no particular zone is
requested; eg, __alloc_pages_nodemask() with a non-picky zone list, or
when multiple zones are allowed. This is the case for most allocations.
As soon as my 757 MB Normal fills up, the allocations come from DMA32
anyway. (Nothing ever comes from DMA because of lowmem_reserve_pages.)
> > This would mean that each zone would get a proportional amount of
> > allocations and reclaiming a bit from each would likely throw out the
> > oldest allocations, rather than some of that and and some more recent
> > stuff that was allocated at the beginning of the lower zone.
> >
> > For example, with the current approach, a time progression of allocations
> > looks like this (N=Normal, D=DMA32): 1N 2N 3N 4D 5D 6D 7D 8D 9D
> >
> > ...once the watermark is hit, kswapd reclaims 1 and 4, since they're
> > oldest in each zone, but 2 and 3 were allocated earlier.
> >
> > Versus a weighted-round-robin approach: 1N 2D 3D 4N 5D 6D 7N 8D 9D
> >
> > ...kswapd reclaims 1 and 2, and they're oldest in time and maybe LRU.
> >
> > Things probably eventually mix up enough once the system has reclaimed
> > and allocated more for a while with the current approach, but the
> > allocations are still chunky depending on how many extra things kswapd
> > reclaims to reach higher-order watermarks, and doesn't this always mess
> > with the LRU when the there are multiple usable zones?
>
> If addressing limitations were not a problem, we'd just have a single
> zone :/
Wouldn't that be nice. ;)
> > Anyway, this approach might be horrible for some other reasons (page
> > allocations hoping to be sequential? bigger cache footprint?), but it
> > might reduce the requirements for other other workarounds, and it would
> > make the LRU node-wide instead of zone-wide.
> >
>
> Node-wide would be preferably from a page aging perspective but as zones
> are about addressing limitations, we need to be able to reclaim zones
> from a specific zone quickly and not have to scan looking for suitable
> pages.
So, I'm not proposing abandoning zones, but simply changing
get_page_from_freelist() to remember where it last walked zonelist, and
try to make a (weighted) round robin out of it. It can already allocate
from any zone in this case anyway. (The implementation would be a bit
more complicated than this due to zonelist not being static, of course.)
Even if the checking of other zones happens in a buffered or chunky way
to reduce caching effects, it would still mean that all zones fill up at
roughly the same time, rather than the DMA zone filling up last. This
way, the oldest pages would all be the ones that want to be reclaimed,
rather than the a bunch of not-oldest pages being reclaimed simply
because the allocator decided to start with a higher zone to avoid
allocating from the DMA zone.
Simon-
On Thu, Dec 09, 2010 at 04:06:32PM -0800, Simon Kirby wrote:
> On Thu, Dec 09, 2010 at 11:45:06AM +0000, Mel Gorman wrote:
>
> > On Wed, Dec 08, 2010 at 05:55:30PM -0800, Simon Kirby wrote:
> > > Hmm...
> > >
> > > Wouldn't it make more sense for the fast path page allocator to allocate
> > > weighted-round-robin (by zone size) from each zone, rather than just
> > > starting from the highest and working down?
> > >
> >
> > Unfortunately, that would cause other problems. Zones are about
> > addressing limitations. The DMA zone is used by callers that cannot
> > address above 16M. On the other extreme, the HighMem zone is used for
> > addresses that cannot be directly mapped at all times due to a lack of
> > virtual address space.
> >
> > If we round-robined the zones, callers that could use HighMem or Normal
> > may consume memory from DMA32 or DMA causing future allocation requests
> > that require those zones to fail.
>
> Yeah, I don't mean in all cases, I mean when no particular zone is
> requested; eg, __alloc_pages_nodemask() with a non-picky zone list, or
> when multiple zones are allowed. This is the case for most allocations.
>
Yes, but just because caller A is not picky about the zone does not mean
caller B is not. Callers always try the highest-possible zone first so
that pages from lower zones are not used unnecessarily.
> As soon as my 757 MB Normal fills up, the allocations come from DMA32
> anyway. (Nothing ever comes from DMA because of lowmem_reserve_pages.)
>
> > > This would mean that each zone would get a proportional amount of
> > > allocations and reclaiming a bit from each would likely throw out the
> > > oldest allocations, rather than some of that and and some more recent
> > > stuff that was allocated at the beginning of the lower zone.
> > >
> > > For example, with the current approach, a time progression of allocations
> > > looks like this (N=Normal, D=DMA32): 1N 2N 3N 4D 5D 6D 7D 8D 9D
> > >
> > > ...once the watermark is hit, kswapd reclaims 1 and 4, since they're
> > > oldest in each zone, but 2 and 3 were allocated earlier.
> > >
> > > Versus a weighted-round-robin approach: 1N 2D 3D 4N 5D 6D 7N 8D 9D
> > >
> > > ...kswapd reclaims 1 and 2, and they're oldest in time and maybe LRU.
> > >
> > > Things probably eventually mix up enough once the system has reclaimed
> > > and allocated more for a while with the current approach, but the
> > > allocations are still chunky depending on how many extra things kswapd
> > > reclaims to reach higher-order watermarks, and doesn't this always mess
> > > with the LRU when the there are multiple usable zones?
> >
> > If addressing limitations were not a problem, we'd just have a single
> > zone :/
>
> Wouldn't that be nice. ;)
>
It would :)
> > > Anyway, this approach might be horrible for some other reasons (page
> > > allocations hoping to be sequential? bigger cache footprint?), but it
> > > might reduce the requirements for other other workarounds, and it would
> > > make the LRU node-wide instead of zone-wide.
> > >
> >
> > Node-wide would be preferably from a page aging perspective but as zones
> > are about addressing limitations, we need to be able to reclaim zones
> > from a specific zone quickly and not have to scan looking for suitable
> > pages.
>
> So, I'm not proposing abandoning zones, but simply changing
> get_page_from_freelist() to remember where it last walked zonelist, and
> try to make a (weighted) round robin out of it. It can already allocate
> from any zone in this case anyway. (The implementation would be a bit
> more complicated than this due to zonelist not being static, of course.)
>
I'd worry it'd still fall foul of using lower zones when it shouldn't.
> Even if the checking of other zones happens in a buffered or chunky way
> to reduce caching effects, it would still mean that all zones fill up at
> roughly the same time, rather than the DMA zone filling up last.
Well, as each zone gets filled, kswapd is woken up to reclaim some
pages. kswapd always works from the lowest to the highest zone to reduce
the likelihood a picky caller will fail its allocation. If the lower
zones have enough free pages they are ignored and kswapd reclaimed from
the higher zone.
> This
> way, the oldest pages would all be the ones that want to be reclaimed,
> rather than the a bunch of not-oldest pages being reclaimed simply
> because the allocator decided to start with a higher zone to avoid
> allocating from the DMA zone.
>
I see what you're saying - a young page can be reclaimed quickly just
because it's in the wrong zone. In cases where the highest zone is
comparatively small, it could cause serious issues. Will think about it
more but a straight round-robining of the zones used could cause
problems of its own :(
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Fri, Dec 10, 2010 at 11:28:32AM +0000, Mel Gorman wrote:
> On Thu, Dec 09, 2010 at 04:06:32PM -0800, Simon Kirby wrote:
>
> > Yeah, I don't mean in all cases, I mean when no particular zone is
> > requested; eg, __alloc_pages_nodemask() with a non-picky zone list, or
> > when multiple zones are allowed. This is the case for most allocations.
>
> Yes, but just because caller A is not picky about the zone does not mean
> caller B is not. Callers always try the highest-possible zone first so
> that pages from lower zones are not used unnecessarily.
But this is only true when the machine is booting or hasn't yet ever
fallen out of the allocator fast path (get_page_from_freelist() has never
failed).
> > So, I'm not proposing abandoning zones, but simply changing
> > get_page_from_freelist() to remember where it last walked zonelist, and
> > try to make a (weighted) round robin out of it. It can already allocate
> > from any zone in this case anyway. (The implementation would be a bit
> > more complicated than this due to zonelist not being static, of course.)
> >
>
> I'd worry it'd still fall foul of using lower zones when it shouldn't.
It would definitely increase the chance during boot, though we do live in
a hotplug world... :)
> > Even if the checking of other zones happens in a buffered or chunky way
> > to reduce caching effects, it would still mean that all zones fill up at
> > roughly the same time, rather than the DMA zone filling up last.
>
> Well, as each zone gets filled, kswapd is woken up to reclaim some
> pages. kswapd always works from the lowest to the highest zone to reduce
> the likelihood a picky caller will fail its allocation. If the lower
> zones have enough free pages they are ignored and kswapd reclaimed from
> the higher zone.
I thought I saw a patch at some point to implement this to avoid it
fighting allocations in the other same direction, but anyway, this
comment which seems to exist since 2.6.5 is interesting:
* kswapd scans the zones in the highmem->normal->dma direction. It skips
* zones which have free_pages > high_wmark_pages(zone), but once a zone is
* found to have free_pages <= high_wmark_pages(zone), we scan that zone and the
* lower zones regardless of the number of free pages in the lower zones. This
* interoperates with the page allocator fallback scheme to ensure that aging
* of pages is balanced across the zones.
Your patch series changes this behaviour, right?
> > This way, the oldest pages would all be the ones that want to be
> > reclaimed, rather than the a bunch of not-oldest pages being
> > reclaimed simply because the allocator decided to start with a
> > higher zone to avoid allocating from the DMA zone.
>
> I see what you're saying - a young page can be reclaimed quickly just
> because it's in the wrong zone. In cases where the highest zone is
> comparatively small, it could cause serious issues. Will think about it
> more but a straight round-robining of the zones used could cause
> problems of its own :(
Sure, straight doesn't make sense either. Weighted round robin based
on zone size sounds right. Maybe the algo could be borrowed from
net/netfilter/ipvs/ip_vs_wrr.c. ;)
Simon-
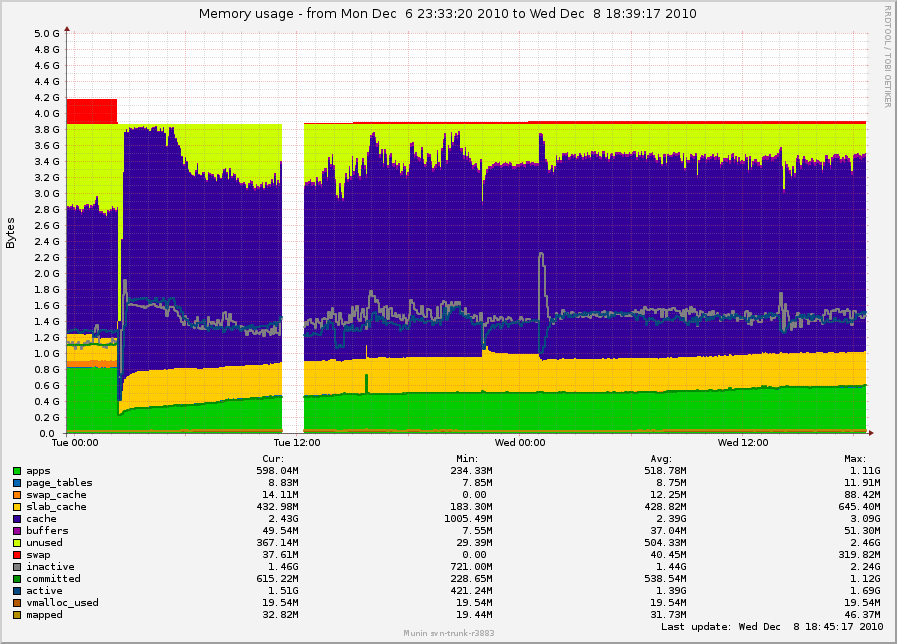{kind=link}
{kind=link}
{kind=link}
{kind=link}