Andrea, after playing with this for a week or two, I'm quite a bit
more confident that it's not causing much harm. Seems a fairly
low-risk feature. Could we stick these somewhere so they'll at
least hit linux-next for the 2.6.40 cycle perhaps?
--
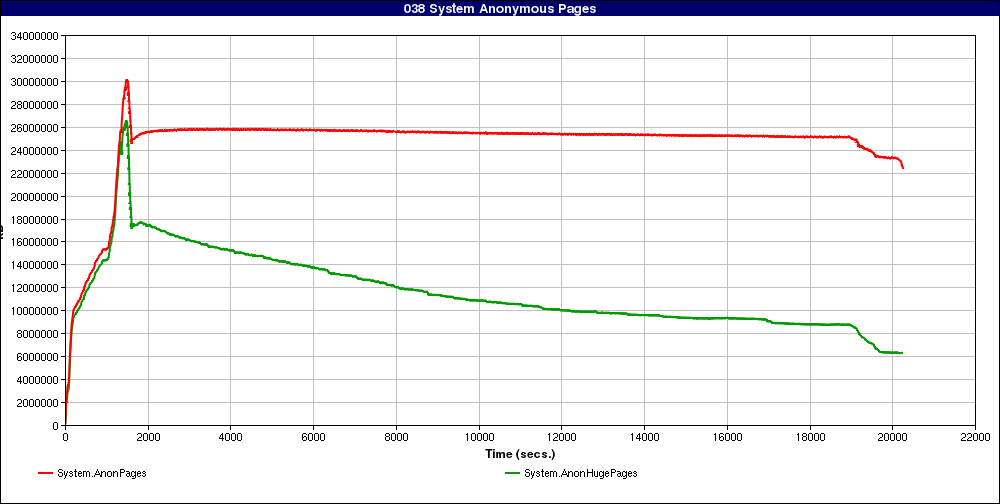
I'm working on some more reports that transparent huge pages and
KSM do not play nicely together. Basically, whenever THP's are
present along with KSM, there is a lot of attrition over time,
and we do not see much overall progress keeping THP's around:
http://sr71.net/~dave/ibm/038_System_Anonymous_Pages.png
(That's Karl Rister's graph, thanks Karl!)
However, I realized that we do not currently have a nice way to
find out where individual THP's might be on the system. We
have an overall count, but no way of telling which processes or
VMAs they might be in.
I started to implement this in the /proc/$pid/smaps code, but
quickly realized that the lib/pagewalk.c code unconditionally
splits THPs up. This set reworks that code a bit and, in the
end, gives you a per-map count of the numbers of huge pages.
It also makes it possible for page walks to _not_ split THPs.
This patch adds an argument to the new smaps_pte_entry()
function to let it account in things other than PAGE_SIZE
units. I changed all of the PAGE_SIZE sites, even though
not all of them can be reached for transparent huge pages,
just so this will continue to work without changes as THPs
are improved.
Acked-by: Johannes Weiner <[email protected]>
Signed-off-by: Dave Hansen <[email protected]>
---
linux-2.6.git-dave/fs/proc/task_mmu.c | 24 ++++++++++++------------
1 file changed, 12 insertions(+), 12 deletions(-)
diff -puN fs/proc/task_mmu.c~give-smaps_pte_range-a-size-arg fs/proc/task_mmu.c
--- linux-2.6.git/fs/proc/task_mmu.c~give-smaps_pte_range-a-size-arg 2011-02-09 11:41:43.407557537 -0800
+++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:43.423557525 -0800
@@ -335,7 +335,7 @@ struct mem_size_stats {
static void smaps_pte_entry(pte_t ptent, unsigned long addr,
- struct mm_walk *walk)
+ unsigned long ptent_size, struct mm_walk *walk)
{
struct mem_size_stats *mss = walk->private;
struct vm_area_struct *vma = mss->vma;
@@ -343,7 +343,7 @@ static void smaps_pte_entry(pte_t ptent,
int mapcount;
if (is_swap_pte(ptent)) {
- mss->swap += PAGE_SIZE;
+ mss->swap += ptent_size;
return;
}
@@ -355,25 +355,25 @@ static void smaps_pte_entry(pte_t ptent,
return;
if (PageAnon(page))
- mss->anonymous += PAGE_SIZE;
+ mss->anonymous += ptent_size;
- mss->resident += PAGE_SIZE;
+ mss->resident += ptent_size;
/* Accumulate the size in pages that have been accessed. */
if (pte_young(ptent) || PageReferenced(page))
- mss->referenced += PAGE_SIZE;
+ mss->referenced += ptent_size;
mapcount = page_mapcount(page);
if (mapcount >= 2) {
if (pte_dirty(ptent) || PageDirty(page))
- mss->shared_dirty += PAGE_SIZE;
+ mss->shared_dirty += ptent_size;
else
- mss->shared_clean += PAGE_SIZE;
- mss->pss += (PAGE_SIZE << PSS_SHIFT) / mapcount;
+ mss->shared_clean += ptent_size;
+ mss->pss += (ptent_size << PSS_SHIFT) / mapcount;
} else {
if (pte_dirty(ptent) || PageDirty(page))
- mss->private_dirty += PAGE_SIZE;
+ mss->private_dirty += ptent_size;
else
- mss->private_clean += PAGE_SIZE;
- mss->pss += (PAGE_SIZE << PSS_SHIFT);
+ mss->private_clean += ptent_size;
+ mss->pss += (ptent_size << PSS_SHIFT);
}
}
@@ -389,7 +389,7 @@ static int smaps_pte_range(pmd_t *pmd, u
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; pte++, addr += PAGE_SIZE)
- smaps_pte_entry(*pte, addr, walk);
+ smaps_pte_entry(*pte, addr, PAGE_SIZE, walk);
pte_unmap_unlock(pte - 1, ptl);
cond_resched();
return 0;
_
We will use smaps_pte_entry() in a moment to handle both small
and transparent large pages. But, we must break it out of
smaps_pte_range() first.
Acked-by: Johannes Weiner <[email protected]>
Signed-off-by: Dave Hansen <[email protected]>
---
linux-2.6.git-dave/fs/proc/task_mmu.c | 85 ++++++++++++++++++----------------
1 file changed, 46 insertions(+), 39 deletions(-)
diff -puN fs/proc/task_mmu.c~break-out-smaps_pte_entry fs/proc/task_mmu.c
--- linux-2.6.git/fs/proc/task_mmu.c~break-out-smaps_pte_entry 2011-02-09 11:41:42.895557919 -0800
+++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:42.911557907 -0800
@@ -333,56 +333,63 @@ struct mem_size_stats {
u64 pss;
};
-static int smaps_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
- struct mm_walk *walk)
+
+static void smaps_pte_entry(pte_t ptent, unsigned long addr,
+ struct mm_walk *walk)
{
struct mem_size_stats *mss = walk->private;
struct vm_area_struct *vma = mss->vma;
- pte_t *pte, ptent;
- spinlock_t *ptl;
struct page *page;
int mapcount;
- split_huge_page_pmd(walk->mm, pmd);
-
- pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
- for (; addr != end; pte++, addr += PAGE_SIZE) {
- ptent = *pte;
+ if (is_swap_pte(ptent)) {
+ mss->swap += PAGE_SIZE;
+ return;
+ }
- if (is_swap_pte(ptent)) {
- mss->swap += PAGE_SIZE;
- continue;
- }
+ if (!pte_present(ptent))
+ return;
- if (!pte_present(ptent))
- continue;
+ page = vm_normal_page(vma, addr, ptent);
+ if (!page)
+ return;
+
+ if (PageAnon(page))
+ mss->anonymous += PAGE_SIZE;
+
+ mss->resident += PAGE_SIZE;
+ /* Accumulate the size in pages that have been accessed. */
+ if (pte_young(ptent) || PageReferenced(page))
+ mss->referenced += PAGE_SIZE;
+ mapcount = page_mapcount(page);
+ if (mapcount >= 2) {
+ if (pte_dirty(ptent) || PageDirty(page))
+ mss->shared_dirty += PAGE_SIZE;
+ else
+ mss->shared_clean += PAGE_SIZE;
+ mss->pss += (PAGE_SIZE << PSS_SHIFT) / mapcount;
+ } else {
+ if (pte_dirty(ptent) || PageDirty(page))
+ mss->private_dirty += PAGE_SIZE;
+ else
+ mss->private_clean += PAGE_SIZE;
+ mss->pss += (PAGE_SIZE << PSS_SHIFT);
+ }
+}
- page = vm_normal_page(vma, addr, ptent);
- if (!page)
- continue;
+static int smaps_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
+ struct mm_walk *walk)
+{
+ struct mem_size_stats *mss = walk->private;
+ struct vm_area_struct *vma = mss->vma;
+ pte_t *pte;
+ spinlock_t *ptl;
- if (PageAnon(page))
- mss->anonymous += PAGE_SIZE;
+ split_huge_page_pmd(walk->mm, pmd);
- mss->resident += PAGE_SIZE;
- /* Accumulate the size in pages that have been accessed. */
- if (pte_young(ptent) || PageReferenced(page))
- mss->referenced += PAGE_SIZE;
- mapcount = page_mapcount(page);
- if (mapcount >= 2) {
- if (pte_dirty(ptent) || PageDirty(page))
- mss->shared_dirty += PAGE_SIZE;
- else
- mss->shared_clean += PAGE_SIZE;
- mss->pss += (PAGE_SIZE << PSS_SHIFT) / mapcount;
- } else {
- if (pte_dirty(ptent) || PageDirty(page))
- mss->private_dirty += PAGE_SIZE;
- else
- mss->private_clean += PAGE_SIZE;
- mss->pss += (PAGE_SIZE << PSS_SHIFT);
- }
- }
+ pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
+ for (; addr != end; pte++, addr += PAGE_SIZE)
+ smaps_pte_entry(*pte, addr, walk);
pte_unmap_unlock(pte - 1, ptl);
cond_resched();
return 0;
_
This adds code to explicitly detect and handle
pmd_trans_huge() pmds. It then passes HPAGE_SIZE units
in to the smap_pte_entry() function instead of PAGE_SIZE.
This means that using /proc/$pid/smaps now will no longer
cause THPs to be broken down in to small pages.
Signed-off-by: Dave Hansen <[email protected]>
Acked-by: Johannes Weiner <[email protected]>
Acked-by: David Rientjes <[email protected]>
---
linux-2.6.git-dave/fs/proc/task_mmu.c | 14 ++++++++++++--
1 file changed, 12 insertions(+), 2 deletions(-)
diff -puN fs/proc/task_mmu.c~teach-smaps_pte_range-about-thp-pmds fs/proc/task_mmu.c
--- linux-2.6.git/fs/proc/task_mmu.c~teach-smaps_pte_range-about-thp-pmds 2011-02-09 11:41:43.919557155 -0800
+++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:43.927557149 -0800
@@ -1,5 +1,6 @@
#include <linux/mm.h>
#include <linux/hugetlb.h>
+#include <linux/huge_mm.h>
#include <linux/mount.h>
#include <linux/seq_file.h>
#include <linux/highmem.h>
@@ -7,6 +8,7 @@
#include <linux/slab.h>
#include <linux/pagemap.h>
#include <linux/mempolicy.h>
+#include <linux/rmap.h>
#include <linux/swap.h>
#include <linux/swapops.h>
@@ -385,8 +387,16 @@ static int smaps_pte_range(pmd_t *pmd, u
pte_t *pte;
spinlock_t *ptl;
- split_huge_page_pmd(walk->mm, pmd);
-
+ if (pmd_trans_huge(*pmd)) {
+ if (pmd_trans_splitting(*pmd)) {
+ spin_unlock(&walk->mm->page_table_lock);
+ wait_split_huge_page(vma->anon_vma, pmd);
+ spin_lock(&walk->mm->page_table_lock);
+ } else {
+ smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
+ return 0;
+ }
+ }
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; pte++, addr += PAGE_SIZE)
smaps_pte_entry(*pte, addr, PAGE_SIZE, walk);
_
Now that the mere act of _looking_ at /proc/$pid/smaps will not
destroy transparent huge pages, tell how much of the VMA is
actually mapped with them.
This way, we can make sure that we're getting THPs where we
expect to see them.
Signed-off-by: Dave Hansen <[email protected]>
Acked-by: David Rientjes <[email protected]>
---
linux-2.6.git-dave/fs/proc/task_mmu.c | 4 ++++
1 file changed, 4 insertions(+)
diff -puN fs/proc/task_mmu.c~teach-smaps-thp fs/proc/task_mmu.c
--- linux-2.6.git/fs/proc/task_mmu.c~teach-smaps-thp 2011-02-09 11:41:44.423556779 -0800
+++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:52.611550670 -0800
@@ -331,6 +331,7 @@ struct mem_size_stats {
unsigned long private_dirty;
unsigned long referenced;
unsigned long anonymous;
+ unsigned long anonymous_thp;
unsigned long swap;
u64 pss;
};
@@ -394,6 +395,7 @@ static int smaps_pte_range(pmd_t *pmd, u
spin_lock(&walk->mm->page_table_lock);
} else {
smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
+ mss->anonymous_thp += HPAGE_SIZE;
return 0;
}
}
@@ -435,6 +437,7 @@ static int show_smap(struct seq_file *m,
"Private_Dirty: %8lu kB\n"
"Referenced: %8lu kB\n"
"Anonymous: %8lu kB\n"
+ "AnonHugePages: %8lu kB\n"
"Swap: %8lu kB\n"
"KernelPageSize: %8lu kB\n"
"MMUPageSize: %8lu kB\n"
@@ -448,6 +451,7 @@ static int show_smap(struct seq_file *m,
mss.private_dirty >> 10,
mss.referenced >> 10,
mss.anonymous >> 10,
+ mss.anonymous_thp >> 10,
mss.swap >> 10,
vma_kernel_pagesize(vma) >> 10,
vma_mmu_pagesize(vma) >> 10,
_
v2 - rework if() block, and remove now redundant split_huge_page()
Right now, if a mm_walk has either ->pte_entry or ->pmd_entry
set, it will unconditionally split any transparent huge pages
it runs in to. In practice, that means that anyone doing a
cat /proc/$pid/smaps
will unconditionally break down every huge page in the process
and depend on khugepaged to re-collapse it later. This is
fairly suboptimal.
This patch changes that behavior. It teaches each ->pmd_entry
handler (there are five) that they must break down the THPs
themselves. Also, the _generic_ code will never break down
a THP unless a ->pte_entry handler is actually set.
This means that the ->pmd_entry handlers can now choose to
deal with THPs without breaking them down.
Signed-off-by: Dave Hansen <[email protected]>
---
linux-2.6.git-dave/fs/proc/task_mmu.c | 6 ++++++
linux-2.6.git-dave/include/linux/mm.h | 3 +++
linux-2.6.git-dave/mm/memcontrol.c | 5 +++--
linux-2.6.git-dave/mm/pagewalk.c | 24 ++++++++++++++++++++----
4 files changed, 32 insertions(+), 6 deletions(-)
diff -puN fs/proc/task_mmu.c~pagewalk-dont-always-split-thp fs/proc/task_mmu.c
--- linux-2.6.git/fs/proc/task_mmu.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.299558364 -0800
+++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:42.319558349 -0800
@@ -343,6 +343,8 @@ static int smaps_pte_range(pmd_t *pmd, u
struct page *page;
int mapcount;
+ split_huge_page_pmd(walk->mm, pmd);
+
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; pte++, addr += PAGE_SIZE) {
ptent = *pte;
@@ -467,6 +469,8 @@ static int clear_refs_pte_range(pmd_t *p
spinlock_t *ptl;
struct page *page;
+ split_huge_page_pmd(walk->mm, pmd);
+
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; pte++, addr += PAGE_SIZE) {
ptent = *pte;
@@ -623,6 +627,8 @@ static int pagemap_pte_range(pmd_t *pmd,
pte_t *pte;
int err = 0;
+ split_huge_page_pmd(walk->mm, pmd);
+
/* find the first VMA at or above 'addr' */
vma = find_vma(walk->mm, addr);
for (; addr != end; addr += PAGE_SIZE) {
diff -puN include/linux/mm.h~pagewalk-dont-always-split-thp include/linux/mm.h
--- linux-2.6.git/include/linux/mm.h~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.303558361 -0800
+++ linux-2.6.git-dave/include/linux/mm.h 2011-02-09 11:41:42.323558346 -0800
@@ -899,6 +899,9 @@ unsigned long unmap_vmas(struct mmu_gath
* @pgd_entry: if set, called for each non-empty PGD (top-level) entry
* @pud_entry: if set, called for each non-empty PUD (2nd-level) entry
* @pmd_entry: if set, called for each non-empty PMD (3rd-level) entry
+ * this handler is required to be able to handle
+ * pmd_trans_huge() pmds. They may simply choose to
+ * split_huge_page() instead of handling it explicitly.
* @pte_entry: if set, called for each non-empty PTE (4th-level) entry
* @pte_hole: if set, called for each hole at all levels
* @hugetlb_entry: if set, called for each hugetlb entry
diff -puN mm/memcontrol.c~pagewalk-dont-always-split-thp mm/memcontrol.c
--- linux-2.6.git/mm/memcontrol.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.311558355 -0800
+++ linux-2.6.git-dave/mm/memcontrol.c 2011-02-09 11:41:42.327558343 -0800
@@ -4737,7 +4737,8 @@ static int mem_cgroup_count_precharge_pt
pte_t *pte;
spinlock_t *ptl;
- VM_BUG_ON(pmd_trans_huge(*pmd));
+ split_huge_page_pmd(walk->mm, pmd);
+
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; pte++, addr += PAGE_SIZE)
if (is_target_pte_for_mc(vma, addr, *pte, NULL))
@@ -4899,8 +4900,8 @@ static int mem_cgroup_move_charge_pte_ra
pte_t *pte;
spinlock_t *ptl;
+ split_huge_page_pmd(walk->mm, pmd);
retry:
- VM_BUG_ON(pmd_trans_huge(*pmd));
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
for (; addr != end; addr += PAGE_SIZE) {
pte_t ptent = *(pte++);
diff -puN mm/pagewalk.c~pagewalk-dont-always-split-thp mm/pagewalk.c
--- linux-2.6.git/mm/pagewalk.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.315558352 -0800
+++ linux-2.6.git-dave/mm/pagewalk.c 2011-02-09 11:41:42.331558340 -0800
@@ -33,19 +33,35 @@ static int walk_pmd_range(pud_t *pud, un
pmd = pmd_offset(pud, addr);
do {
+ again:
next = pmd_addr_end(addr, end);
- split_huge_page_pmd(walk->mm, pmd);
- if (pmd_none_or_clear_bad(pmd)) {
+ if (pmd_none(*pmd)) {
if (walk->pte_hole)
err = walk->pte_hole(addr, next, walk);
if (err)
break;
continue;
}
+ /*
+ * This implies that each ->pmd_entry() handler
+ * needs to know about pmd_trans_huge() pmds
+ */
if (walk->pmd_entry)
err = walk->pmd_entry(pmd, addr, next, walk);
- if (!err && walk->pte_entry)
- err = walk_pte_range(pmd, addr, next, walk);
+ if (err)
+ break;
+
+ /*
+ * Check this here so we only break down trans_huge
+ * pages when we _need_ to
+ */
+ if (!walk->pte_entry)
+ continue;
+
+ split_huge_page_pmd(walk->mm, pmd);
+ if (pmd_none_or_clear_bad(pmd))
+ goto again;
+ err = walk_pte_range(pmd, addr, next, walk);
if (err)
break;
} while (pmd++, addr = next, addr != end);
_
On Wed, Feb 09, 2011 at 11:54:06AM -0800, Dave Hansen wrote:
> Andrea, after playing with this for a week or two, I'm quite a bit
> more confident that it's not causing much harm. Seems a fairly
> low-risk feature. Could we stick these somewhere so they'll at
> least hit linux-next for the 2.6.40 cycle perhaps?
I think they're good to go in mmotm already and to be merged ASAP.
The only minor issue I have is the increment, to become per-cpu. Are
we going to change its location then or it's still read through sysfs?
On Wed, Feb 09, 2011 at 11:54:07AM -0800, Dave Hansen wrote:
>
> v2 - rework if() block, and remove now redundant split_huge_page()
>
> Right now, if a mm_walk has either ->pte_entry or ->pmd_entry
> set, it will unconditionally split any transparent huge pages
> it runs in to. In practice, that means that anyone doing a
>
> cat /proc/$pid/smaps
>
> will unconditionally break down every huge page in the process
> and depend on khugepaged to re-collapse it later. This is
> fairly suboptimal.
>
> This patch changes that behavior. It teaches each ->pmd_entry
> handler (there are five) that they must break down the THPs
> themselves. Also, the _generic_ code will never break down
> a THP unless a ->pte_entry handler is actually set.
>
> This means that the ->pmd_entry handlers can now choose to
> deal with THPs without breaking them down.
>
> Signed-off-by: Dave Hansen <[email protected]>
> ---
>
> linux-2.6.git-dave/fs/proc/task_mmu.c | 6 ++++++
> linux-2.6.git-dave/include/linux/mm.h | 3 +++
> linux-2.6.git-dave/mm/memcontrol.c | 5 +++--
> linux-2.6.git-dave/mm/pagewalk.c | 24 ++++++++++++++++++++----
> 4 files changed, 32 insertions(+), 6 deletions(-)
>
> diff -puN fs/proc/task_mmu.c~pagewalk-dont-always-split-thp fs/proc/task_mmu.c
> --- linux-2.6.git/fs/proc/task_mmu.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.299558364 -0800
> +++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:42.319558349 -0800
> @@ -343,6 +343,8 @@ static int smaps_pte_range(pmd_t *pmd, u
> struct page *page;
> int mapcount;
>
> + split_huge_page_pmd(walk->mm, pmd);
> +
> pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
> for (; addr != end; pte++, addr += PAGE_SIZE) {
> ptent = *pte;
> @@ -467,6 +469,8 @@ static int clear_refs_pte_range(pmd_t *p
> spinlock_t *ptl;
> struct page *page;
>
> + split_huge_page_pmd(walk->mm, pmd);
> +
> pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
> for (; addr != end; pte++, addr += PAGE_SIZE) {
> ptent = *pte;
> @@ -623,6 +627,8 @@ static int pagemap_pte_range(pmd_t *pmd,
> pte_t *pte;
> int err = 0;
>
> + split_huge_page_pmd(walk->mm, pmd);
> +
> /* find the first VMA at or above 'addr' */
> vma = find_vma(walk->mm, addr);
> for (; addr != end; addr += PAGE_SIZE) {
> diff -puN include/linux/mm.h~pagewalk-dont-always-split-thp include/linux/mm.h
> --- linux-2.6.git/include/linux/mm.h~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.303558361 -0800
> +++ linux-2.6.git-dave/include/linux/mm.h 2011-02-09 11:41:42.323558346 -0800
> @@ -899,6 +899,9 @@ unsigned long unmap_vmas(struct mmu_gath
> * @pgd_entry: if set, called for each non-empty PGD (top-level) entry
> * @pud_entry: if set, called for each non-empty PUD (2nd-level) entry
> * @pmd_entry: if set, called for each non-empty PMD (3rd-level) entry
> + * this handler is required to be able to handle
> + * pmd_trans_huge() pmds. They may simply choose to
> + * split_huge_page() instead of handling it explicitly.
> * @pte_entry: if set, called for each non-empty PTE (4th-level) entry
> * @pte_hole: if set, called for each hole at all levels
> * @hugetlb_entry: if set, called for each hugetlb entry
> diff -puN mm/memcontrol.c~pagewalk-dont-always-split-thp mm/memcontrol.c
> --- linux-2.6.git/mm/memcontrol.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.311558355 -0800
> +++ linux-2.6.git-dave/mm/memcontrol.c 2011-02-09 11:41:42.327558343 -0800
> @@ -4737,7 +4737,8 @@ static int mem_cgroup_count_precharge_pt
> pte_t *pte;
> spinlock_t *ptl;
>
> - VM_BUG_ON(pmd_trans_huge(*pmd));
> + split_huge_page_pmd(walk->mm, pmd);
> +
> pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
> for (; addr != end; pte++, addr += PAGE_SIZE)
> if (is_target_pte_for_mc(vma, addr, *pte, NULL))
> @@ -4899,8 +4900,8 @@ static int mem_cgroup_move_charge_pte_ra
> pte_t *pte;
> spinlock_t *ptl;
>
> + split_huge_page_pmd(walk->mm, pmd);
> retry:
> - VM_BUG_ON(pmd_trans_huge(*pmd));
> pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
> for (; addr != end; addr += PAGE_SIZE) {
> pte_t ptent = *(pte++);
Before we goto this retry, there is at a cond_resched(). Just to confirm,
we are depending on mmap_sem to prevent khugepaged promoting this back to
a hugepage, right? I don't see a problem with that but I want to be
sure.
> diff -puN mm/pagewalk.c~pagewalk-dont-always-split-thp mm/pagewalk.c
> --- linux-2.6.git/mm/pagewalk.c~pagewalk-dont-always-split-thp 2011-02-09 11:41:42.315558352 -0800
> +++ linux-2.6.git-dave/mm/pagewalk.c 2011-02-09 11:41:42.331558340 -0800
> @@ -33,19 +33,35 @@ static int walk_pmd_range(pud_t *pud, un
>
> pmd = pmd_offset(pud, addr);
> do {
> + again:
> next = pmd_addr_end(addr, end);
> - split_huge_page_pmd(walk->mm, pmd);
> - if (pmd_none_or_clear_bad(pmd)) {
> + if (pmd_none(*pmd)) {
> if (walk->pte_hole)
> err = walk->pte_hole(addr, next, walk);
> if (err)
> break;
> continue;
> }
> + /*
> + * This implies that each ->pmd_entry() handler
> + * needs to know about pmd_trans_huge() pmds
> + */
> if (walk->pmd_entry)
> err = walk->pmd_entry(pmd, addr, next, walk);
> - if (!err && walk->pte_entry)
> - err = walk_pte_range(pmd, addr, next, walk);
> + if (err)
> + break;
> +
> + /*
> + * Check this here so we only break down trans_huge
> + * pages when we _need_ to
> + */
> + if (!walk->pte_entry)
> + continue;
> +
> + split_huge_page_pmd(walk->mm, pmd);
> + if (pmd_none_or_clear_bad(pmd))
> + goto again;
> + err = walk_pte_range(pmd, addr, next, walk);
> if (err)
> break;
> } while (pmd++, addr = next, addr != end);
--
Mel Gorman
SUSE Labs
On Wed, Feb 09, 2011 at 11:54:08AM -0800, Dave Hansen wrote:
>
> We will use smaps_pte_entry() in a moment to handle both small
> and transparent large pages. But, we must break it out of
> smaps_pte_range() first.
>
> Acked-by: Johannes Weiner <[email protected]>
> Signed-off-by: Dave Hansen <[email protected]>
Acked-by: Mel Gorman <[email protected]>
--
Mel Gorman
SUSE Labs
On Wed, Feb 09, 2011 at 11:54:10AM -0800, Dave Hansen wrote:
>
> This patch adds an argument to the new smaps_pte_entry()
> function to let it account in things other than PAGE_SIZE
> units. I changed all of the PAGE_SIZE sites, even though
> not all of them can be reached for transparent huge pages,
> just so this will continue to work without changes as THPs
> are improved.
>
> Acked-by: Johannes Weiner <[email protected]>
> Signed-off-by: Dave Hansen <[email protected]>
Acked-by: Mel Gorman <[email protected]>
--
Mel Gorman
SUSE Labs
On Wed, Feb 09, 2011 at 11:54:11AM -0800, Dave Hansen wrote:
>
> This adds code to explicitly detect and handle
> pmd_trans_huge() pmds. It then passes HPAGE_SIZE units
> in to the smap_pte_entry() function instead of PAGE_SIZE.
>
> This means that using /proc/$pid/smaps now will no longer
> cause THPs to be broken down in to small pages.
>
> Signed-off-by: Dave Hansen <[email protected]>
> Acked-by: Johannes Weiner <[email protected]>
> Acked-by: David Rientjes <[email protected]>
Acked-by: Mel Gorman <[email protected]>
--
Mel Gorman
SUSE Labs
On Wed, Feb 09, 2011 at 11:54:13AM -0800, Dave Hansen wrote:
>
> Now that the mere act of _looking_ at /proc/$pid/smaps will not
> destroy transparent huge pages, tell how much of the VMA is
> actually mapped with them.
>
> This way, we can make sure that we're getting THPs where we
> expect to see them.
>
> Signed-off-by: Dave Hansen <[email protected]>
> Acked-by: David Rientjes <[email protected]>
> ---
>
> linux-2.6.git-dave/fs/proc/task_mmu.c | 4 ++++
> 1 file changed, 4 insertions(+)
>
> diff -puN fs/proc/task_mmu.c~teach-smaps-thp fs/proc/task_mmu.c
> --- linux-2.6.git/fs/proc/task_mmu.c~teach-smaps-thp 2011-02-09 11:41:44.423556779 -0800
> +++ linux-2.6.git-dave/fs/proc/task_mmu.c 2011-02-09 11:41:52.611550670 -0800
> @@ -331,6 +331,7 @@ struct mem_size_stats {
> unsigned long private_dirty;
> unsigned long referenced;
> unsigned long anonymous;
> + unsigned long anonymous_thp;
> unsigned long swap;
> u64 pss;
> };
> @@ -394,6 +395,7 @@ static int smaps_pte_range(pmd_t *pmd, u
> spin_lock(&walk->mm->page_table_lock);
> } else {
> smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> + mss->anonymous_thp += HPAGE_SIZE;
I should have thought of this for the previous patch but should this be
HPAGE_PMD_SIZE instead of HPAGE_SIZE? Right now, they are the same value
but they are not the same thing.
> return 0;
> }
> }
> @@ -435,6 +437,7 @@ static int show_smap(struct seq_file *m,
> "Private_Dirty: %8lu kB\n"
> "Referenced: %8lu kB\n"
> "Anonymous: %8lu kB\n"
> + "AnonHugePages: %8lu kB\n"
> "Swap: %8lu kB\n"
> "KernelPageSize: %8lu kB\n"
> "MMUPageSize: %8lu kB\n"
> @@ -448,6 +451,7 @@ static int show_smap(struct seq_file *m,
> mss.private_dirty >> 10,
> mss.referenced >> 10,
> mss.anonymous >> 10,
> + mss.anonymous_thp >> 10,
> mss.swap >> 10,
> vma_kernel_pagesize(vma) >> 10,
> vma_mmu_pagesize(vma) >> 10,
> _
>
--
Mel Gorman
SUSE Labs
On Thu, Feb 10, 2011 at 11:11:25AM +0000, Mel Gorman wrote:
> Before we goto this retry, there is at a cond_resched(). Just to confirm,
> we are depending on mmap_sem to prevent khugepaged promoting this back to
> a hugepage, right? I don't see a problem with that but I want to be
> sure.
Correct, and we depend on that everywhere as wait_split_huge_page has
to run without holding spinlocks.
On Thu, Feb 10, 2011 at 02:19:28PM +0100, Andrea Arcangeli wrote:
> On Thu, Feb 10, 2011 at 11:11:25AM +0000, Mel Gorman wrote:
> > Before we goto this retry, there is at a cond_resched(). Just to confirm,
> > we are depending on mmap_sem to prevent khugepaged promoting this back to
> > a hugepage, right? I don't see a problem with that but I want to be
> > sure.
>
> Correct, and we depend on that everywhere as wait_split_huge_page has
> to run without holding spinlocks.
>
In that case;
Acked-by: Mel Gorman <[email protected]>
Thanks.
--
Mel Gorman
SUSE Labs
On Thu, 2011-02-10 at 11:20 +0000, Mel Gorman wrote:
> > @@ -394,6 +395,7 @@ static int smaps_pte_range(pmd_t *pmd, u
> > spin_lock(&walk->mm->page_table_lock);
> > } else {
> > smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> > + mss->anonymous_thp += HPAGE_SIZE;
>
> I should have thought of this for the previous patch but should this be
> HPAGE_PMD_SIZE instead of HPAGE_SIZE? Right now, they are the same value
> but they are not the same thing.
Probably. There's also a nice BUG() in HPAGE_PMD_SIZE if the THP config
option is off, which is an added bonus.
-- Dave
On Thu, Feb 10, 2011 at 07:01:55AM -0800, Dave Hansen wrote:
> On Thu, 2011-02-10 at 11:20 +0000, Mel Gorman wrote:
> > > @@ -394,6 +395,7 @@ static int smaps_pte_range(pmd_t *pmd, u
> > > spin_lock(&walk->mm->page_table_lock);
> > > } else {
> > > smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> > > + mss->anonymous_thp += HPAGE_SIZE;
> >
> > I should have thought of this for the previous patch but should this be
> > HPAGE_PMD_SIZE instead of HPAGE_SIZE? Right now, they are the same value
> > but they are not the same thing.
>
> Probably. There's also a nice BUG() in HPAGE_PMD_SIZE if the THP config
> option is off, which is an added bonus.
>
Unless Andrea has an objection, I'd prefer to see HPAGE_PMD_SIZE.
Assuming that's ok;
Acked-by: Mel Gorman <[email protected]>
for the whole series.
Thanks Dave.
--
Mel Gorman
SUSE Labs
On Wed, Feb 09, 2011 at 11:54:11AM -0800, Dave Hansen wrote:
> @@ -385,8 +387,16 @@ static int smaps_pte_range(pmd_t *pmd, u
> pte_t *pte;
> spinlock_t *ptl;
>
> - split_huge_page_pmd(walk->mm, pmd);
> -
> + if (pmd_trans_huge(*pmd)) {
> + if (pmd_trans_splitting(*pmd)) {
> + spin_unlock(&walk->mm->page_table_lock);
> + wait_split_huge_page(vma->anon_vma, pmd);
> + spin_lock(&walk->mm->page_table_lock);
the locking looks wrong, who is taking the &walk->mm->page_table_lock,
and isn't this going to deadlock on the pte_offset_map_lock for
NR_CPUS < 4, and where is it released? This spin_lock don't seem
necessary to me.
The right locking would be:
spin_lock(&walk->mm->page_table_lock);
if (pmd_trans_huge(*pmd)) {
if (pmd_trans_splitting(*pmd)) {
spin_unlock(&walk->mm->page_table_lock);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
spin_unlock(&walk->mm->page_table_lock);
return 0;
}
I think it worked because you never run into a pmd_trans_splitting pmd
yet, and you were running smaps_pte_entry lockless which could race
against split_huge_page (but it normally doesn't).
> + } else {
> + smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> + return 0;
> + }
> + }
> pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
> for (; addr != end; pte++, addr += PAGE_SIZE)
> smaps_pte_entry(*pte, addr, PAGE_SIZE, walk);
> _
>
On Thu, Feb 10, 2011 at 03:09:42PM +0000, Mel Gorman wrote:
> On Thu, Feb 10, 2011 at 07:01:55AM -0800, Dave Hansen wrote:
> > On Thu, 2011-02-10 at 11:20 +0000, Mel Gorman wrote:
> > > > @@ -394,6 +395,7 @@ static int smaps_pte_range(pmd_t *pmd, u
> > > > spin_lock(&walk->mm->page_table_lock);
> > > > } else {
> > > > smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> > > > + mss->anonymous_thp += HPAGE_SIZE;
> > >
> > > I should have thought of this for the previous patch but should this be
> > > HPAGE_PMD_SIZE instead of HPAGE_SIZE? Right now, they are the same value
> > > but they are not the same thing.
> >
> > Probably. There's also a nice BUG() in HPAGE_PMD_SIZE if the THP config
> > option is off, which is an added bonus.
> >
>
> Unless Andrea has an objection, I'd prefer to see HPAGE_PMD_SIZE.
We get there only through pmd_trans_huge, so HPAGE_PMD_SIZE is
certainly more correct, agreed.
I also think this can go in -mm after s/HPAGE_SIZE/HPAGE_PMD_SIZE/ and
after correcting the locking (see other email).
Maybe it'd be cleaner if we didn't need to cast the pmd to pte_t but I
guess this makes things simpler.
Thanks!
Andrea
On Thu, 2011-02-10 at 19:09 +0100, Andrea Arcangeli wrote:
> Maybe it'd be cleaner if we didn't need to cast the pmd to pte_t but I
> guess this makes things simpler.
Yeah, I'm not a huge fan of doing that, either. But, I'm not sure what
the alternatives are. We could basically copy smaps_pte_entry() to
smaps_pmd_entry(), and then try to make pmd variants of all of the pte
functions and macros we call in there.
I know there's a least a bit of precedent in the hugetlbfs code for
doing things like this, but it's not a _great_ excuse. :)
-- Dave
On Thu, Feb 10, 2011 at 10:20:32AM -0800, Dave Hansen wrote:
> On Thu, 2011-02-10 at 19:09 +0100, Andrea Arcangeli wrote:
> > Maybe it'd be cleaner if we didn't need to cast the pmd to pte_t but I
> > guess this makes things simpler.
>
> Yeah, I'm not a huge fan of doing that, either. But, I'm not sure what
> the alternatives are. We could basically copy smaps_pte_entry() to
> smaps_pmd_entry(), and then try to make pmd variants of all of the pte
> functions and macros we call in there.
I thought at the smaps_pmd_entry possibility too, but I would expect
it to plain duplicate a bit of code just to avoid a single cast, which
is why I thought the cast was ok in this case.
> I know there's a least a bit of precedent in the hugetlbfs code for
> doing things like this, but it's not a _great_ excuse. :)
;)
On Thu, 2011-02-10 at 19:08 +0100, Andrea Arcangeli wrote:
> the locking looks wrong, who is taking the &walk->mm->page_table_lock,
> and isn't this going to deadlock on the pte_offset_map_lock for
> NR_CPUS < 4, and where is it released? This spin_lock don't seem
> necessary to me.
>
> The right locking would be:
>
> spin_lock(&walk->mm->page_table_lock);
> if (pmd_trans_huge(*pmd)) {
> if (pmd_trans_splitting(*pmd)) {
> spin_unlock(&walk->mm->page_table_lock);
> wait_split_huge_page(vma->anon_vma, pmd);
> } else {
> smaps_pte_entry(*(pte_t *)pmd, addr, HPAGE_SIZE, walk);
> spin_unlock(&walk->mm->page_table_lock);
> return 0;
> }
I was under the assumption that the mm->page_table_lock was already held
here, but I think that's wrong. I'll go back, take another look, and
retest.
-- Dave
On Wed, 09 Feb 2011, Dave Hansen wrote:
> Andrea, after playing with this for a week or two, I'm quite a bit
> more confident that it's not causing much harm. Seems a fairly
> low-risk feature. Could we stick these somewhere so they'll at
> least hit linux-next for the 2.6.40 cycle perhaps?
>
> --
>
> I'm working on some more reports that transparent huge pages and
> KSM do not play nicely together. Basically, whenever THP's are
> present along with KSM, there is a lot of attrition over time,
> and we do not see much overall progress keeping THP's around:
>
> http://sr71.net/~dave/ibm/038_System_Anonymous_Pages.png
>
> (That's Karl Rister's graph, thanks Karl!)
>
> However, I realized that we do not currently have a nice way to
> find out where individual THP's might be on the system. We
> have an overall count, but no way of telling which processes or
> VMAs they might be in.
>
> I started to implement this in the /proc/$pid/smaps code, but
> quickly realized that the lib/pagewalk.c code unconditionally
> splits THPs up. This set reworks that code a bit and, in the
> end, gives you a per-map count of the numbers of huge pages.
> It also makes it possible for page walks to _not_ split THPs.
>
I have been running these patches on top of 2.6.38-rc4 all
morning and looked at a number of smaps files for processes
using THP areas. They don't seem to be pulled apart as my
AnonHugePages: counter in meminfo is stable.
I am noticing in smaps that KernelPageSize is wrong of areas
that have been merged into THP. For instance:
7ff852a00000-7ff852c00000 rw-p 00000000 00:00 0
Size: 2048 kB
Rss: 2048 kB
Pss: 2048 kB
Shared_Clean: 0 kB
Shared_Dirty: 0 kB
Private_Clean: 0 kB
Private_Dirty: 2048 kB
Referenced: 2048 kB
Anonymous: 2048 kB
AnonHugePages: 2048 kB
Swap: 0 kB
KernelPageSize: 4 kB
MMUPageSize: 4 kB
Locked: 0 kB
The entire mapping is contained in a THP but the
KernelPageSize shows 4kb. For cases where the mapping might
have mixed page sizes this may be okay, but for this
particular mapping the 4kb page size is wrong.
Tested-by: Eric B Munson <[email protected]>
On Tue, Feb 15, 2011 at 11:55:10AM -0500, Eric B Munson wrote:
> I am noticing in smaps that KernelPageSize is wrong of areas
> that have been merged into THP. For instance:
>
> 7ff852a00000-7ff852c00000 rw-p 00000000 00:00 0
> Size: 2048 kB
> Rss: 2048 kB
> Pss: 2048 kB
> Shared_Clean: 0 kB
> Shared_Dirty: 0 kB
> Private_Clean: 0 kB
> Private_Dirty: 2048 kB
> Referenced: 2048 kB
> Anonymous: 2048 kB
> AnonHugePages: 2048 kB
> Swap: 0 kB
> KernelPageSize: 4 kB
> MMUPageSize: 4 kB
> Locked: 0 kB
>
> The entire mapping is contained in a THP but the
> KernelPageSize shows 4kb. For cases where the mapping might
> have mixed page sizes this may be okay, but for this
> particular mapping the 4kb page size is wrong.
I'm not sure this is a bug, if the mapping grows it may become 4096k
but the new pages may be 4k. There's no such thing as a
vma_mmu_pagesize in terms of hugepages because we support graceful
fallback and collapse/split on the fly without altering the vma. So I
think 4k is correct here.
On Tue, 2011-02-15 at 18:01 +0100, Andrea Arcangeli wrote:
> > The entire mapping is contained in a THP but the
> > KernelPageSize shows 4kb. For cases where the mapping might
> > have mixed page sizes this may be okay, but for this
> > particular mapping the 4kb page size is wrong.
>
> I'm not sure this is a bug, if the mapping grows it may become 4096k
> but the new pages may be 4k. There's no such thing as a
> vma_mmu_pagesize in terms of hugepages because we support graceful
> fallback and collapse/split on the fly without altering the vma. So I
> think 4k is correct here
How about we bump MMUPageSize for mappings that are _entirely_ huge
pages, but leave it at 4k for mixed mappings? Anyone needing more
detail than that can use the new AnonHugePages count.
KernelPageSize is pretty ambiguous, and we could certainly make the
argument that the kernel is or can still deal with things in 4k blocks.
-- Dave
On Tue, Feb 15, 2011 at 09:05:25AM -0800, Dave Hansen wrote:
> On Tue, 2011-02-15 at 18:01 +0100, Andrea Arcangeli wrote:
> > > The entire mapping is contained in a THP but the
> > > KernelPageSize shows 4kb. For cases where the mapping might
> > > have mixed page sizes this may be okay, but for this
> > > particular mapping the 4kb page size is wrong.
> >
> > I'm not sure this is a bug, if the mapping grows it may become 4096k
> > but the new pages may be 4k. There's no such thing as a
> > vma_mmu_pagesize in terms of hugepages because we support graceful
> > fallback and collapse/split on the fly without altering the vma. So I
> > think 4k is correct here
>
> How about we bump MMUPageSize for mappings that are _entirely_ huge
> pages, but leave it at 4k for mixed mappings? Anyone needing more
> detail than that can use the new AnonHugePages count.
Anyone needing the detail that you ask for, already can use the
AnonHugePages count.
> KernelPageSize is pretty ambiguous, and we could certainly make the
> argument that the kernel is or can still deal with things in 4k blocks.
That's my point. We could bring it to 2m whenever
AnonHugePages==Anonymous, that's a two liner change, but I'm not
really sure if it makes sense or it provides any meaningful info.
That is a slot specific to show hugetlbfs presence and to
differentiate between 2m/1g mappings. I think remaining mutually
exclusive between AnonHugePages > 0 and MMUPageSize >4k is actually
cleaner than a two liner magic returning 2m if AnonHugePages ==
Anonymous.
On Wed, 9 Feb 2011, Andrea Arcangeli wrote:
> On Wed, Feb 09, 2011 at 11:54:06AM -0800, Dave Hansen wrote:
> > Andrea, after playing with this for a week or two, I'm quite a bit
> > more confident that it's not causing much harm. Seems a fairly
> > low-risk feature. Could we stick these somewhere so they'll at
> > least hit linux-next for the 2.6.40 cycle perhaps?
>
> I think they're good to go in mmotm already and to be merged ASAP.
>
> The only minor issue I have is the increment, to become per-cpu. Are
> we going to change its location then or it's still read through sysfs?
>
Dave, I notice these patches haven't been merged into -mm yet. Are we
waiting on another iteration or is this set ready to go?
{kind=link}