Hi,
We recently upgraded a machine from 3.14.5 to 3.17.1, and a Perl script we're
running to poll SNMP suddenly needed ten times as much time to complete.
ps shows that it keeps being in state D (ie., I/O), and strace with -ttT
shows this curious pattern:
02:11:33.106973 socket(PF_NETLINK, SOCK_RAW, 0) = 42 <0.000013>
02:11:33.107013 bind(42, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 0 <0.000010>
02:11:33.107051 getsockname(42, {sa_family=AF_NETLINK, pid=1128, groups=00000000}, [12]) = 0 <0.000008>
02:11:33.107094 sendto(42, "\24\0\0\0\26\0\1\3\265^@T\0\0\0\0\0\0\0\0", 20, 0, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 20 <0.000015>
02:11:33.107146 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"L\0\0\0\24\0\2\0\265^@Th\4\0\0\2\10\200\376\1\0\0\0\10\0\1\0\177\0\0\1"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 332 <0.000016>
02:11:33.107208 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"H\0\0\0\24\0\2\0\265^@Th\4\0\0\n\200\200\376\1\0\0\0\24\0\1\0\0\0\0\0"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 936 <0.000010>
02:11:33.107262 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"\24\0\0\0\3\0\2\0\265^@Th\4\0\0\0\0\0\0\1\0\0\0\24\0\1\0\0\0\0\0"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 20 <0.000009>
02:11:33.107313 close(42) = 0 <0.057092>
02:11:33.164529 open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 42 <0.000080>
<more stuff...>
Debugging with gdb indicates that this is from getaddrinfo calls, which the
program (for, well, Perl reasons) uses as part of DNS reverse lookups.
getaddrinfo wants to look at the list of interfaces on the system
(__check_pf in glibc), which calls out to netlink via getifaddrs.
Note specifically the call to close(), which takes 57 ms to complete.
This doesn't happen on every single getaddrinfo call, but more like 50% of
them. I've tried on another machine, running 3.16.3, and we don't see
anything like it.
I've distilled it down to this Perl script:
#! /usr/bin/perl
use strict;
use warnings;
use Socket::GetAddrInfo;
for my $i (1..1000) {
my ($err, @res) = Socket::GetAddrInfo::getaddrinfo("127.0.0.1", undef, { flags => Socket::GetAddrInfo::AI_NUMERICHOST });
}
On my 3.16.3 machine, this completes in 26 ms. On the 3.17.1 machine:
65 _seconds_! According to the stack, this is what it's doing:
[<ffffffff810766b7>] wait_rcu_gp+0x48/0x4f
[<ffffffff81078be5>] synchronize_sched+0x29/0x2b
[<ffffffff813aacdb>] synchronize_net+0x19/0x1b
[<ffffffff813d313e>] netlink_release+0x25b/0x2b7
[<ffffffff8139af07>] sock_release+0x1a/0x79
[<ffffffff8139b1f4>] sock_close+0xd/0x11
[<ffffffff8111feca>] __fput+0xdf/0x184
[<ffffffff8111ff9f>] ____fput+0x9/0xb
[<ffffffff81051610>] task_work_run+0x7c/0x94
[<ffffffff810026b2>] do_notify_resume+0x55/0x66
[<ffffffff8146feda>] int_signal+0x12/0x17
[<ffffffffffffffff>] 0xffffffffffffffff
strace indicates it starts off nicely, then goes completely off:
cirkus:~> time strace -e close -ttT perl test.pl
02:20:39.292060 close(3) = 0 <0.000041>
02:20:39.292407 close(3) = 0 <0.000037>
02:20:39.292660 close(3) = 0 <0.000010>
02:20:39.292883 close(3) = 0 <0.000009>
02:20:39.293100 close(3) = 0 <0.000009>
[some more fast ones...]
02:20:39.311421 close(4) = 0 <0.000009>
02:20:39.311927 close(3) = 0 <0.000011>
02:20:39.312188 close(3) = 0 <0.072224>
02:20:39.384979 close(3) = 0 <0.059658>
02:20:39.445378 close(3) = 0 <0.048205>
02:20:39.494213 close(3) = 0 <0.060195>
^C
Is there a way to fix this? Somehow I doubt we're the only ones calling
getaddrinfo in this way. :-)
/* Steinar */
--
Homepage: http://www.sesse.net/
On Fri, Oct 17, 2014 at 02:21:32AM +0200, Steinar H. Gunderson wrote:
> Hi,
>
> We recently upgraded a machine from 3.14.5 to 3.17.1, and a Perl script we're
> running to poll SNMP suddenly needed ten times as much time to complete.
e341694e3eb57fcda9f1adc7bfea42fe080d8d7a looks like it might cause something
like this (it certainly added the synchronize_net() call). Cc-ing people on
that commit; quoting the entire rest of the message for reference.
> ps shows that it keeps being in state D (ie., I/O), and strace with -ttT
> shows this curious pattern:
>
> 02:11:33.106973 socket(PF_NETLINK, SOCK_RAW, 0) = 42 <0.000013>
> 02:11:33.107013 bind(42, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 0 <0.000010>
> 02:11:33.107051 getsockname(42, {sa_family=AF_NETLINK, pid=1128, groups=00000000}, [12]) = 0 <0.000008>
> 02:11:33.107094 sendto(42, "\24\0\0\0\26\0\1\3\265^@T\0\0\0\0\0\0\0\0", 20, 0, {sa_family=AF_NETLINK, pid=0, groups=00000000}, 12) = 20 <0.000015>
> 02:11:33.107146 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"L\0\0\0\24\0\2\0\265^@Th\4\0\0\2\10\200\376\1\0\0\0\10\0\1\0\177\0\0\1"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 332 <0.000016>
> 02:11:33.107208 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"H\0\0\0\24\0\2\0\265^@Th\4\0\0\n\200\200\376\1\0\0\0\24\0\1\0\0\0\0\0"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 936 <0.000010>
> 02:11:33.107262 recvmsg(42, {msg_name(12)={sa_family=AF_NETLINK, pid=0, groups=00000000}, msg_iov(1)=[{"\24\0\0\0\3\0\2\0\265^@Th\4\0\0\0\0\0\0\1\0\0\0\24\0\1\0\0\0\0\0"..., 4096}], msg_controllen=0, msg_flags=0}, 0) = 20 <0.000009>
> 02:11:33.107313 close(42) = 0 <0.057092>
> 02:11:33.164529 open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 42 <0.000080>
> <more stuff...>
>
> Debugging with gdb indicates that this is from getaddrinfo calls, which the
> program (for, well, Perl reasons) uses as part of DNS reverse lookups.
> getaddrinfo wants to look at the list of interfaces on the system
> (__check_pf in glibc), which calls out to netlink via getifaddrs.
> Note specifically the call to close(), which takes 57 ms to complete.
>
> This doesn't happen on every single getaddrinfo call, but more like 50% of
> them. I've tried on another machine, running 3.16.3, and we don't see
> anything like it.
>
> I've distilled it down to this Perl script:
>
> #! /usr/bin/perl
> use strict;
> use warnings;
> use Socket::GetAddrInfo;
>
> for my $i (1..1000) {
> my ($err, @res) = Socket::GetAddrInfo::getaddrinfo("127.0.0.1", undef, { flags => Socket::GetAddrInfo::AI_NUMERICHOST });
> }
>
> On my 3.16.3 machine, this completes in 26 ms. On the 3.17.1 machine:
> 65 _seconds_! According to the stack, this is what it's doing:
>
> [<ffffffff810766b7>] wait_rcu_gp+0x48/0x4f
> [<ffffffff81078be5>] synchronize_sched+0x29/0x2b
> [<ffffffff813aacdb>] synchronize_net+0x19/0x1b
> [<ffffffff813d313e>] netlink_release+0x25b/0x2b7
> [<ffffffff8139af07>] sock_release+0x1a/0x79
> [<ffffffff8139b1f4>] sock_close+0xd/0x11
> [<ffffffff8111feca>] __fput+0xdf/0x184
> [<ffffffff8111ff9f>] ____fput+0x9/0xb
> [<ffffffff81051610>] task_work_run+0x7c/0x94
> [<ffffffff810026b2>] do_notify_resume+0x55/0x66
> [<ffffffff8146feda>] int_signal+0x12/0x17
> [<ffffffffffffffff>] 0xffffffffffffffff
>
> strace indicates it starts off nicely, then goes completely off:
>
> cirkus:~> time strace -e close -ttT perl test.pl
> 02:20:39.292060 close(3) = 0 <0.000041>
> 02:20:39.292407 close(3) = 0 <0.000037>
> 02:20:39.292660 close(3) = 0 <0.000010>
> 02:20:39.292883 close(3) = 0 <0.000009>
> 02:20:39.293100 close(3) = 0 <0.000009>
> [some more fast ones...]
> 02:20:39.311421 close(4) = 0 <0.000009>
> 02:20:39.311927 close(3) = 0 <0.000011>
> 02:20:39.312188 close(3) = 0 <0.072224>
> 02:20:39.384979 close(3) = 0 <0.059658>
> 02:20:39.445378 close(3) = 0 <0.048205>
> 02:20:39.494213 close(3) = 0 <0.060195>
> ^C
>
> Is there a way to fix this? Somehow I doubt we're the only ones calling
> getaddrinfo in this way. :-)
>
> /* Steinar */
--
Homepage: http://www.sesse.net/
On 10/17/14 at 02:34am, Steinar H. Gunderson wrote:
> On Fri, Oct 17, 2014 at 02:21:32AM +0200, Steinar H. Gunderson wrote:
> > Hi,
> >
> > We recently upgraded a machine from 3.14.5 to 3.17.1, and a Perl script we're
> > running to poll SNMP suddenly needed ten times as much time to complete.
>
> e341694e3eb57fcda9f1adc7bfea42fe080d8d7a looks like it might cause something
> like this (it certainly added the synchronize_net() call). Cc-ing people on
> that commit; quoting the entire rest of the message for reference.
I think the only option at this point is to re-add the nltable lock to
netlink_lookup() so we can drop the synchronize_net() until we find a
way to RCUify socket destruction. I will cook up a patch today unless
somebody can come up with a smarter way to work around needing the
synchronize_net().
On Fri, 2014-10-17 at 07:25 +0100, Thomas Graf wrote:
> On 10/17/14 at 02:34am, Steinar H. Gunderson wrote:
> > On Fri, Oct 17, 2014 at 02:21:32AM +0200, Steinar H. Gunderson wrote:
> > > Hi,
> > >
> > > We recently upgraded a machine from 3.14.5 to 3.17.1, and a Perl script we're
> > > running to poll SNMP suddenly needed ten times as much time to complete.
> >
> > e341694e3eb57fcda9f1adc7bfea42fe080d8d7a looks like it might cause something
> > like this (it certainly added the synchronize_net() call). Cc-ing people on
> > that commit; quoting the entire rest of the message for reference.
>
> I think the only option at this point is to re-add the nltable lock to
> netlink_lookup() so we can drop the synchronize_net() until we find a
> way to RCUify socket destruction. I will cook up a patch today unless
> somebody can come up with a smarter way to work around needing the
> synchronize_net().
I had a patch to add conditional RCUify socket destruction for some kind
of sockets (opt-in at protocol level).
I needed this to remove too expensive UDP socket refcount inc/dec (so
get rid of SLAB_DESTROY_BY_RCU, and instead use call_rcu() or kfree_rcu
thing)
But I couldn't finish and submit this for 3.18, and I believe I got it
wrong anyway. Cant remember exact details right now, maybe later in the
day, once my headache is better.
From: Eric Dumazet <[email protected]>
Date: Fri, 17 Oct 2014 09:28:03 -0700
> On Fri, 2014-10-17 at 07:25 +0100, Thomas Graf wrote:
>> On 10/17/14 at 02:34am, Steinar H. Gunderson wrote:
>> > On Fri, Oct 17, 2014 at 02:21:32AM +0200, Steinar H. Gunderson wrote:
>> > > Hi,
>> > >
>> > > We recently upgraded a machine from 3.14.5 to 3.17.1, and a Perl script we're
>> > > running to poll SNMP suddenly needed ten times as much time to complete.
>> >
>> > e341694e3eb57fcda9f1adc7bfea42fe080d8d7a looks like it might cause something
>> > like this (it certainly added the synchronize_net() call). Cc-ing people on
>> > that commit; quoting the entire rest of the message for reference.
>>
>> I think the only option at this point is to re-add the nltable lock to
>> netlink_lookup() so we can drop the synchronize_net() until we find a
>> way to RCUify socket destruction. I will cook up a patch today unless
>> somebody can come up with a smarter way to work around needing the
>> synchronize_net().
>
> I had a patch to add conditional RCUify socket destruction for some kind
> of sockets (opt-in at protocol level).
>
> I needed this to remove too expensive UDP socket refcount inc/dec (so
> get rid of SLAB_DESTROY_BY_RCU, and instead use call_rcu() or kfree_rcu
> thing)
>
> But I couldn't finish and submit this for 3.18, and I believe I got it
> wrong anyway. Cant remember exact details right now, maybe later in the
> day, once my headache is better.
Can I ask a serious question? What is the synchronize_net() in AF_NETLINK
exactly needed for?
On Fri, 2014-10-17 at 12:30 -0400, David Miller wrote:
> Can I ask a serious question? What is the synchronize_net() in AF_NETLINK
> exactly needed for?
__netlink_lookup() calls rhashtable_lookup_compare()
So you really want that any object found in this lookup respects
rcu grace period before being freed.
RCU contract is pretty clear about deletions of objects.
On Fri, Oct 17, 2014 at 02:34:30AM +0200, Steinar H. Gunderson wrote:
> e341694e3eb57fcda9f1adc7bfea42fe080d8d7a looks like it might cause something
> like this (it certainly added the synchronize_net() call). Cc-ing people on
> that commit; quoting the entire rest of the message for reference.
I see there's discussion on what to do with this; thanks. :-)
FWIW, I've verified that reverting these four patches (in that order) fixes
the problem:
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/patch/net/netlink/af_netlink.c?id=9ce12eb16ffb143f3a509da86283ddd0b10bcdb3
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/patch/net/netlink/af_netlink.c?id=6c8f7e70837468da4e658080d4448930fb597e1b
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/patch/net/netlink/af_netlink.c?id=67a24ac18b0262178ba9f05501b2c6e6731d449a
https://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/patch/net/netlink/af_netlink.c?id=e341694e3eb57fcda9f1adc7bfea42fe080d8d7a
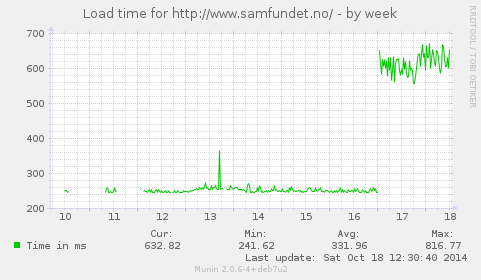
My Perl script is seemingly not the only affected program on the system;
witness the average page load times for our PHP-based home page:
http://home.samfundet.no/~sesse/web_load_time_samfundet_no-week.png
/* Steinar */
--
Homepage: http://www.sesse.net/
On Fri, Oct 17, 2014 at 07:25:17AM +0100, Thomas Graf wrote:
> I think the only option at this point is to re-add the nltable lock to
> netlink_lookup() so we can drop the synchronize_net() until we find a
> way to RCUify socket destruction. I will cook up a patch today unless
> somebody can come up with a smarter way to work around needing the
> synchronize_net().
Did you end up with a patch? We'd like to reboot the server in question
soon-ish, but it's an open question whether we should go to 3.16.x, revert
exactly the patches in question or something else.
/* Steinar */
--
Homepage: http://www.sesse.net/
On 10/21/14 at 03:25pm, Steinar H. Gunderson wrote:
> On Fri, Oct 17, 2014 at 07:25:17AM +0100, Thomas Graf wrote:
> > I think the only option at this point is to re-add the nltable lock to
> > netlink_lookup() so we can drop the synchronize_net() until we find a
> > way to RCUify socket destruction. I will cook up a patch today unless
> > somebody can come up with a smarter way to work around needing the
> > synchronize_net().
>
> Did you end up with a patch? We'd like to reboot the server in question
> soon-ish, but it's an open question whether we should go to 3.16.x, revert
> exactly the patches in question or something else.
I'm currently testing the patch below and will submit with proper
tested by attributions later today.
>From 3605e498c0b025054d17cc2943cae70d3df2a427 Mon Sep 17 00:00:00 2001
Message-Id: <3605e498c0b025054d17cc2943cae70d3df2a427.1413834710.git.tgraf@suug.ch>
From: Thomas Graf <[email protected]>
Date: Fri, 17 Oct 2014 11:33:44 +0200
Subject: [PATCH] netlink: Re-add locking to netlink_lookup() and seq walker
The synchronize_rcu() in netlink_release() introduces unacceptable
latency. Reintroduce minimal lookup so we can drop the
synchronize_rcu() until socket destruction has been RCUfied.
Signed-off-by: Thomas Graf <[email protected]>
---
net/netlink/af_netlink.c | 37 +++++++++++++++++++++++++------------
1 file changed, 25 insertions(+), 12 deletions(-)
diff --git a/net/netlink/af_netlink.c b/net/netlink/af_netlink.c
index 7a186e7..f1de72d 100644
--- a/net/netlink/af_netlink.c
+++ b/net/netlink/af_netlink.c
@@ -96,6 +96,14 @@ static DECLARE_WAIT_QUEUE_HEAD(nl_table_wait);
static int netlink_dump(struct sock *sk);
static void netlink_skb_destructor(struct sk_buff *skb);
+/* nl_table locking explained:
+ * Lookup and traversal are protected with nl_sk_hash_lock or nl_table_lock
+ * combined with an RCU read-side lock. Insertion and removal are protected
+ * with nl_sk_hash_lock while using RCU list modification primitives and may
+ * run in parallel to nl_table_lock protected lookups. Destruction of the
+ * Netlink socket may only occur *after* nl_table_lock has been acquired
+ * either during or after the socket has been removed from the list.
+ */
DEFINE_RWLOCK(nl_table_lock);
EXPORT_SYMBOL_GPL(nl_table_lock);
static atomic_t nl_table_users = ATOMIC_INIT(0);
@@ -109,10 +117,10 @@ EXPORT_SYMBOL_GPL(nl_sk_hash_lock);
static int lockdep_nl_sk_hash_is_held(void)
{
#ifdef CONFIG_LOCKDEP
- return (debug_locks) ? lockdep_is_held(&nl_sk_hash_lock) : 1;
-#else
- return 1;
+ if (debug_locks)
+ return lockdep_is_held(&nl_sk_hash_lock) || lockdep_is_held(&nl_table_lock);
#endif
+ return 1;
}
static ATOMIC_NOTIFIER_HEAD(netlink_chain);
@@ -1028,11 +1036,13 @@ static struct sock *netlink_lookup(struct net *net, int protocol, u32 portid)
struct netlink_table *table = &nl_table[protocol];
struct sock *sk;
+ read_lock(&nl_table_lock);
rcu_read_lock();
sk = __netlink_lookup(table, portid, net);
if (sk)
sock_hold(sk);
rcu_read_unlock();
+ read_unlock(&nl_table_lock);
return sk;
}
@@ -1257,9 +1267,6 @@ static int netlink_release(struct socket *sock)
}
netlink_table_ungrab();
- /* Wait for readers to complete */
- synchronize_net();
-
kfree(nlk->groups);
nlk->groups = NULL;
@@ -1281,6 +1288,7 @@ static int netlink_autobind(struct socket *sock)
retry:
cond_resched();
+ netlink_table_grab();
rcu_read_lock();
if (__netlink_lookup(table, portid, net)) {
/* Bind collision, search negative portid values. */
@@ -1288,9 +1296,11 @@ retry:
if (rover > -4097)
rover = -4097;
rcu_read_unlock();
+ netlink_table_ungrab();
goto retry;
}
rcu_read_unlock();
+ netlink_table_ungrab();
err = netlink_insert(sk, net, portid);
if (err == -EADDRINUSE)
@@ -2921,14 +2931,16 @@ static struct sock *netlink_seq_socket_idx(struct seq_file *seq, loff_t pos)
}
static void *netlink_seq_start(struct seq_file *seq, loff_t *pos)
- __acquires(RCU)
+ __acquires(nl_table_lock) __acquires(RCU)
{
+ read_lock(&nl_table_lock);
rcu_read_lock();
return *pos ? netlink_seq_socket_idx(seq, *pos - 1) : SEQ_START_TOKEN;
}
static void *netlink_seq_next(struct seq_file *seq, void *v, loff_t *pos)
{
+ struct rhashtable *ht;
struct netlink_sock *nlk;
struct nl_seq_iter *iter;
struct net *net;
@@ -2943,19 +2955,19 @@ static void *netlink_seq_next(struct seq_file *seq, void *v, loff_t *pos)
iter = seq->private;
nlk = v;
- rht_for_each_entry_rcu(nlk, nlk->node.next, node)
+ i = iter->link;
+ ht = &nl_table[i].hash;
+ rht_for_each_entry(nlk, nlk->node.next, ht, node)
if (net_eq(sock_net((struct sock *)nlk), net))
return nlk;
- i = iter->link;
j = iter->hash_idx + 1;
do {
- struct rhashtable *ht = &nl_table[i].hash;
const struct bucket_table *tbl = rht_dereference_rcu(ht->tbl, ht);
for (; j < tbl->size; j++) {
- rht_for_each_entry_rcu(nlk, tbl->buckets[j], node) {
+ rht_for_each_entry(nlk, tbl->buckets[j], ht, node) {
if (net_eq(sock_net((struct sock *)nlk), net)) {
iter->link = i;
iter->hash_idx = j;
@@ -2971,9 +2983,10 @@ static void *netlink_seq_next(struct seq_file *seq, void *v, loff_t *pos)
}
static void netlink_seq_stop(struct seq_file *seq, void *v)
- __releases(RCU)
+ __releases(RCU) __releases(nl_table_lock)
{
rcu_read_unlock();
+ read_unlock(&nl_table_lock);
}
--
1.9.3
On Tue, Oct 21, 2014 at 02:31:44PM +0100, Thomas Graf wrote:
> I'm currently testing the patch below and will submit with proper
> tested by attributions later today.
We applied this patch in a reboot today (on top of 3.17.1), and so far,
things seem to be going much better.
/* Steinar */
--
Homepage: http://www.sesse.net/
On Fri, Oct 24, 2014 at 01:37:51AM +0200, Steinar H. Gunderson wrote:
>> I'm currently testing the patch below and will submit with proper
>> tested by attributions later today.
> We applied this patch in a reboot today (on top of 3.17.1), and so far,
> things seem to be going much better.
I see 3.17.2 is out. Am I right in that this patch didn't make it?
/* Steinar */
--
Homepage: http://www.sesse.net/
From: "Steinar H. Gunderson" <[email protected]>
Date: Sun, 2 Nov 2014 22:55:36 +0100
> On Fri, Oct 24, 2014 at 01:37:51AM +0200, Steinar H. Gunderson wrote:
>>> I'm currently testing the patch below and will submit with proper
>>> tested by attributions later today.
>> We applied this patch in a reboot today (on top of 3.17.1), and so far,
>> things seem to be going much better.
>
> I see 3.17.2 is out. Am I right in that this patch didn't make it?
It got queued up for -stable after I submitted networking patches
for 3.17.2, so yes.
{kind=link}