This is a series of patches that try to improve merge success rate when
VMAs are being moved, resized or otherwise modified.
Motivation
In the current kernel it is impossible to merge two anonymous VMAs
if one of them was moved. That is because VMA's page offset is
set according to the virtual address where it was created and in
order to merge two VMAs page offsets need to follow up.
Another problem when merging two faulted VMA's is their anon_vma. In
current kernel these anon_vmas have to be the one and the same.
Otherwise merge is again not allowed.
There are several places from which vma_merge() is called and therefore
several use cases that might profit from this upgrade. These include
mmap (that fills a hole between two VMAs), mremap (that moves VMA next
to another one or again perfectly fills a hole), mprotect (that modifies
protection and allows merging with a neighbor) and brk (that expands VMA
so that it is adjacent to a neighbor).
Missed merge opportunities increase the number of VMAs of a process
and in some cases can cause problems when a max count is reached.
Solution
The series solves the first problem with
page offsets by updating them when the VMA is moved to a
different virtual address (patch 4). As for the second
problem, merging of VMAs with different anon_vma is allowed under some
conditions (patch 5). Another missed opportunity in the current kernel
is when mremap enlarges an already existing VMA and it is possible to
merge with following VMA (patch 2). Patch 1 refactors function
vma_merge and makes it easier to understand and also allows relatively
seamless tracing of successful merges introduced by the patch 6. Patch
3 introduces migration waiting and rmap locking into the pagewalk
mechnism, which is necessary for patche 4 and 5.
Limitations
For both problems solution works only for VMAs that do not share
physical pages with other processes (usually child or parent
processes). This is checked by looking at anon_vma of the respective
VMA and also by looking at mapcount of individual pages. The reason
why it is not possible or at least not easy to accomplish is that
each physical page has a pointer to anon_vma and page offset. And
when this physical page is shared we cannot simply change these
parameters without affecting all of the VMAs mapping this physical
page. Good thing is that this case amounts only for about 1-3% of
all merges (measured on jemalloc (0%), redis (2.7%) and kcbench
(1.2%) tests) that fail to merge in the current kernel.
Measuring also shows slight increase in running time, jemalloc (0.3%),
redis (1%), kcbench (1%). More extensive data can be viewed at
https://home.alabanda.cz/share/results.png
Changelog
Pagewalk - previously page struct has been accessed using follow_page()
which goes through the whole pagewalk for each call. This version uses
walk_page_vma() which goes through all the necessary pages at the pte
level (vm_normal_page() is used there).
Pgoff update was previously performed at the beginning of copy_vma()
for all the pages (page->index specifically) and also for the pgoff
variable used to construct the VMA copy. Now the update of individual
pages is done later in move_page_tables(). This makes more sense because
move_page_tables() moves all the pages to the new VMA anyway and this
again spares some otherwise duplicate page walking.
Anon_vma update for mprotect cases is done in __vma_adjust(). For
mremap cases the update is done in move_page_tables() together with
the page offset update. Previously the anon_vma update was always
handled in __vma_adjust() but it was not done in all necessary cases.
More details are mentioned in the concerned patches.
Questions
Is it necessary to check mapcount of individual pages of the VMA to
determine if they are shared with other processes? Is it even possible
when VMA or respectivelly its anon_vma is not shared? So far as my
knowledge of kernel goes, it seems that checking individual pages is not
necessary and check on the level of anon_vma is suficient. KSM would
theoretically interfere with page mapcount, but it is temporarily
disabled before move_vma() in mremap syscall happens. Does anyone know
about something else that can change mapcount without anon_vma knowing?
This series of patches and documentation of the related code will
be part of my master's thesis.
This patch series is based on tag v5.18-rc2. This is a third version.
Jakub Matěna (6):
mm: refactor of vma_merge()
mm: add merging after mremap resize
mm: add migration waiting and rmap locking to pagewalk
mm: adjust page offset in mremap
mm: enable merging of VMAs with different anon_vmas
mm: add tracing for VMA merges
fs/exec.c | 2 +-
fs/proc/task_mmu.c | 4 +-
include/linux/mm.h | 4 +-
include/linux/pagewalk.h | 15 +-
include/linux/rmap.h | 19 ++-
include/trace/events/mmap.h | 83 ++++++++++
mm/internal.h | 12 ++
mm/mmap.c | 291 ++++++++++++++++++++++++++----------
mm/mremap.c | 153 ++++++++++++++-----
mm/pagewalk.c | 75 +++++++++-
mm/rmap.c | 144 ++++++++++++++++++
11 files changed, 670 insertions(+), 132 deletions(-)
--
2.35.1
Adjust page offset of a VMA when it's moved to a new location by mremap.
This is made possible for all VMAs that do not share their anonymous
pages with other processes and it is checked by going through the anon_vma
tree and looking for parent child relationship. Also and maybe
redundantly this is checked for individual struct pages belonging to the
given vma by looking at their mapcount or swap entry reference count if
the page is swapped out. This is all done in can_update_faulted_pgoff(),
is_shared_pte().
If none of the pages is shared then we proceed with the
page offset update. This means updating page offset in the copy_vma()
which is used when creating the VMA copy or possibly when deciding
whether to merge with a neighboring VMA. We also set pgoff_updatable to
true to later update page offsets of individual pages.
This is done later in move_page_tables() when moving
individual pte entries to the target VMA. The page offset update
actually forces the move to happen at the pte level by using
move_ptes(). It is necessary because the page update must happen
atomically with the move and that is not possible when moving bigger
entries like pmd or pud. We do not need to update swapped out pages,
because in that case page offset is reconstructed automatically from VMA
after the page is swapped in.
As mentioned above there is a small amount of time between checking and
actually updating the page offset of pages as well as between merging VMAs
and again updating the pages. This could potencially interfere with rmap
walk, but fortunately in that case rmap walk can use the still existing old
VMA, as it would before the mremap started. Any other potential changes
to the VMA or pages is prevented by mmap_lock, which prevents forking and
therefore also COW and hence raising the mapcount. Because pages are not
shared, but belong to only one process, there is no other process which
might fork and in that way increase mapcount of the pages in question.
If a page is shared we can't update page offset of the page, because
that would interfere with the page offset for the other processes using
the page. Page offset is basically immutable as long as the page is used
by more than one process.
Previously, adjusting page offset was possible only for not yet faulted
VMAs, even though a page offset matching the virtual address of the
anonymous VMA is necessary to successfully merge with another VMA.
Signed-off-by: Jakub Matěna <[email protected]>
---
fs/exec.c | 2 +-
include/linux/mm.h | 4 +-
include/linux/pagewalk.h | 2 +
include/linux/rmap.h | 2 +
mm/mmap.c | 113 +++++++++++++++++++++++++++++++------
mm/mremap.c | 117 +++++++++++++++++++++++++++++++++------
mm/pagewalk.c | 2 +-
mm/rmap.c | 41 ++++++++++++++
8 files changed, 244 insertions(+), 39 deletions(-)
diff --git a/fs/exec.c b/fs/exec.c
index e3e55d5e0be1..207f60fcb2b4 100644
--- a/fs/exec.c
+++ b/fs/exec.c
@@ -709,7 +709,7 @@ static int shift_arg_pages(struct vm_area_struct *vma, unsigned long shift)
* process cleanup to remove whatever mess we made.
*/
if (length != move_page_tables(vma, old_start,
- vma, new_start, length, false))
+ vma, new_start, length, false, false))
return -ENOMEM;
lru_add_drain();
diff --git a/include/linux/mm.h b/include/linux/mm.h
index e34edb775334..d8e482aef901 100644
--- a/include/linux/mm.h
+++ b/include/linux/mm.h
@@ -1951,7 +1951,7 @@ int get_cmdline(struct task_struct *task, char *buffer, int buflen);
extern unsigned long move_page_tables(struct vm_area_struct *vma,
unsigned long old_addr, struct vm_area_struct *new_vma,
unsigned long new_addr, unsigned long len,
- bool need_rmap_locks);
+ bool need_rmap_locks, bool update_pgoff);
/*
* Flags used by change_protection(). For now we make it a bitmap so
@@ -2637,7 +2637,7 @@ extern void __vma_link_rb(struct mm_struct *, struct vm_area_struct *,
extern void unlink_file_vma(struct vm_area_struct *);
extern struct vm_area_struct *copy_vma(struct vm_area_struct **,
unsigned long addr, unsigned long len, pgoff_t pgoff,
- bool *need_rmap_locks);
+ bool *need_rmap_locks, bool *update_pgoff);
extern void exit_mmap(struct mm_struct *);
static inline int check_data_rlimit(unsigned long rlim,
diff --git a/include/linux/pagewalk.h b/include/linux/pagewalk.h
index 07345df51324..11c99c8d343b 100644
--- a/include/linux/pagewalk.h
+++ b/include/linux/pagewalk.h
@@ -101,6 +101,8 @@ struct mm_walk {
void *private;
};
+int walk_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
+ struct mm_walk *walk);
int walk_page_range(struct mm_struct *mm, unsigned long start,
unsigned long end, const struct mm_walk_ops *ops,
void *private);
diff --git a/include/linux/rmap.h b/include/linux/rmap.h
index d2d5e511dd93..9fee804f47ea 100644
--- a/include/linux/rmap.h
+++ b/include/linux/rmap.h
@@ -144,6 +144,8 @@ void unlink_anon_vmas(struct vm_area_struct *);
int anon_vma_clone(struct vm_area_struct *, struct vm_area_struct *);
int anon_vma_fork(struct vm_area_struct *, struct vm_area_struct *);
+bool rbt_no_children(struct anon_vma *av);
+
static inline int anon_vma_prepare(struct vm_area_struct *vma)
{
if (likely(vma->anon_vma))
diff --git a/mm/mmap.c b/mm/mmap.c
index 4a4611443593..3ca78baaee13 100644
--- a/mm/mmap.c
+++ b/mm/mmap.c
@@ -48,6 +48,8 @@
#include <linux/pkeys.h>
#include <linux/oom.h>
#include <linux/sched/mm.h>
+#include <linux/pagewalk.h>
+#include <linux/swapops.h>
#include <linux/uaccess.h>
#include <asm/cacheflush.h>
@@ -3189,28 +3191,100 @@ int insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vma)
return 0;
}
+/*
+ * is_shared_pte() - Check if the given pte points to a page that is not shared between processes.
+ * @pte: pte to check
+ * @addr: Address where the page is mapped
+ * @end: Not used
+ * @walk: Pagewalk structure holding pointer to VMA where the page belongs
+ */
+static int is_shared_pte(pte_t *pte, unsigned long addr,
+ unsigned long end, struct mm_walk *walk)
+{
+ int err;
+ struct page *page;
+ struct vm_area_struct *old = walk->vma;
+
+ if (is_swap_pte(*pte)) {
+ swp_entry_t entry = pte_to_swp_entry(*pte);
+ struct swap_info_struct *info = swp_swap_info(entry);
+ /*
+ * If the reference count is higher than one than the swap slot is used by
+ * more than one process or the swap cache is active, which means that the
+ * page is mapped by at least one process and swapped out by at least one
+ * process, so in both cases this means the page is shared.
+ * There can also exist continuation pages if the reference count is too
+ * high to fit in just one cell. This is specified by the flag COUNT_CONTINUED,
+ * which again triggers the below condition if set.
+ */
+ return info->swap_map[swp_offset(entry)] > 1;
+ }
+
+ if (!pte_present(*pte))
+ return 0;
+ page = vm_normal_page(old, addr, *pte);
+ if (page == NULL)
+ return 0;
+ /* Check page is not shared with other processes */
+ err = page_mapcount(page) + page_swapcount(page) > 1;
+ return err;
+}
+
+/**
+ * can_update_faulted_pgoff() - Check if pgoff update is possible for faulted pages of a vma
+ * @vma: VMA which should be moved
+ * @addr: new virtual address
+ * If the vma and its pages are not shared with another process, updating
+ * the new pgoff and also updating index parameter (copy of the pgoff) in
+ * all faulted pages is possible.
+ */
+static bool can_update_faulted_pgoff(struct vm_area_struct *vma, unsigned long addr)
+{
+ const struct mm_walk_ops can_update_pgoff_ops = {
+ .pte_entry = is_shared_pte
+ };
+
+ /* Check vma is not shared with other processes */
+ if (vma->anon_vma->root != vma->anon_vma || !rbt_no_children(vma->anon_vma))
+ return 1;
+ /* walk_page_vma() returns 0 on success */
+ return !walk_page_vma(vma, &can_update_pgoff_ops, NULL, WALK_MIGRATION | WALK_LOCK_RMAP);
+}
+
/*
* Copy the vma structure to a new location in the same mm,
* prior to moving page table entries, to effect an mremap move.
*/
struct vm_area_struct *copy_vma(struct vm_area_struct **vmap,
unsigned long addr, unsigned long len, pgoff_t pgoff,
- bool *need_rmap_locks)
+ bool *need_rmap_locks, bool *update_pgoff)
{
struct vm_area_struct *vma = *vmap;
unsigned long vma_start = vma->vm_start;
struct mm_struct *mm = vma->vm_mm;
struct vm_area_struct *new_vma, *prev;
struct rb_node **rb_link, *rb_parent;
- bool faulted_in_anon_vma = true;
+ bool anon_pgoff_updated = false;
+ *need_rmap_locks = false;
+ *update_pgoff = false;
/*
- * If anonymous vma has not yet been faulted, update new pgoff
+ * Try to update new pgoff for anonymous vma
* to match new location, to increase its chance of merging.
*/
- if (unlikely(vma_is_anonymous(vma) && !vma->anon_vma)) {
- pgoff = addr >> PAGE_SHIFT;
- faulted_in_anon_vma = false;
+ if (unlikely(vma_is_anonymous(vma))) {
+ if (!vma->anon_vma) {
+ pgoff = addr >> PAGE_SHIFT;
+ anon_pgoff_updated = true;
+ } else {
+ anon_pgoff_updated = can_update_faulted_pgoff(vma, addr);
+ if (anon_pgoff_updated) {
+ /* Update pgoff of the copied VMA */
+ pgoff = addr >> PAGE_SHIFT;
+ *update_pgoff = true;
+ *need_rmap_locks = true;
+ }
+ }
}
if (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent))
@@ -3227,19 +3301,25 @@ struct vm_area_struct *copy_vma(struct vm_area_struct **vmap,
/*
* The only way we can get a vma_merge with
* self during an mremap is if the vma hasn't
- * been faulted in yet and we were allowed to
- * reset the dst vma->vm_pgoff to the
- * destination address of the mremap to allow
- * the merge to happen. mremap must change the
- * vm_pgoff linearity between src and dst vmas
- * (in turn preventing a vma_merge) to be
- * safe. It is only safe to keep the vm_pgoff
- * linear if there are no pages mapped yet.
+ * been faulted in yet or is not shared and
+ * we were allowed to reset the dst
+ * vma->vm_pgoff to the destination address of
+ * the mremap to allow the merge to happen.
+ * mremap must change the vm_pgoff linearity
+ * between src and dst vmas (in turn
+ * preventing a vma_merge) to be safe. It is
+ * only safe to keep the vm_pgoff linear if
+ * there are no pages mapped yet or the none
+ * of the pages are shared with another process.
*/
- VM_BUG_ON_VMA(faulted_in_anon_vma, new_vma);
+ VM_BUG_ON_VMA(!anon_pgoff_updated, new_vma);
*vmap = vma = new_vma;
}
- *need_rmap_locks = (new_vma->vm_pgoff <= vma->vm_pgoff);
+ /*
+ * If new_vma is located before the old vma, rmap traversal order is altered
+ * and we need to apply rmap locks on vma later.
+ */
+ *need_rmap_locks |= (new_vma->vm_pgoff <= vma->vm_pgoff);
} else {
new_vma = vm_area_dup(vma);
if (!new_vma)
@@ -3256,7 +3336,6 @@ struct vm_area_struct *copy_vma(struct vm_area_struct **vmap,
if (new_vma->vm_ops && new_vma->vm_ops->open)
new_vma->vm_ops->open(new_vma);
vma_link(mm, new_vma, prev, rb_link, rb_parent);
- *need_rmap_locks = false;
}
return new_vma;
diff --git a/mm/mremap.c b/mm/mremap.c
index 309fab7ed706..2ef444abb08a 100644
--- a/mm/mremap.c
+++ b/mm/mremap.c
@@ -24,6 +24,7 @@
#include <linux/mmu_notifier.h>
#include <linux/uaccess.h>
#include <linux/userfaultfd_k.h>
+#include <linux/pagewalk.h>
#include <linux/rmap.h>
#include <asm/cacheflush.h>
@@ -117,10 +118,66 @@ static pte_t move_soft_dirty_pte(pte_t pte)
return pte;
}
+/*
+ * update_pgoff_page() - Update page offset stored in page->index, if the page is not NULL.
+ * @addr: new address to calculate the page offset.
+ * @page: page to update
+ */
+static int update_pgoff_page(unsigned long addr, struct page *page)
+{
+ if (page != NULL) {
+ get_page(page);
+ if (!trylock_page(page)) {
+ put_page(page);
+ return -1;
+ }
+ page->index = addr >> PAGE_SHIFT;
+ unlock_page(page);
+ put_page(page);
+ }
+ return 0;
+}
+
+/*
+ * update_pgoff_pte_inner() - Wait for migration and update page offset of
+ * a page represented by pte, if the pte points to mapped page.
+ */
+static int update_pgoff_pte_inner(pte_t *old_pte, unsigned long old_addr,
+ struct vm_area_struct *vma, spinlock_t *old_ptl,
+ pmd_t *old_pmd, unsigned long new_addr)
+{
+ struct page *page;
+ /*
+ * If pte is in migration state then wait for migration
+ * and return with -1 to trigger relocking mechanism in move_ptes().
+ */
+ if (!pte_present(*old_pte)) {
+ if (!pte_none(*old_pte)) {
+ swp_entry_t entry;
+ entry = pte_to_swp_entry(*old_pte);
+ if (is_migration_entry(entry)) {
+ migration_entry_wait(vma->vm_mm, old_pmd, old_addr);
+ return -1;
+ }
+ }
+ /*
+ * If there is no migration entry, but at the same
+ * time the page is not present then the page offset
+ * will be reconstructed automatically from the
+ * VMA after the page is moved back into RAM.
+ */
+ return 0;
+ }
+
+ page = vm_normal_page(vma, old_addr, *old_pte);
+ return update_pgoff_page(new_addr, page);
+}
+
static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
unsigned long old_addr, unsigned long old_end,
struct vm_area_struct *new_vma, pmd_t *new_pmd,
- unsigned long new_addr, bool need_rmap_locks)
+ unsigned long new_addr, bool need_rmap_locks,
+ bool update_pgoff)
{
struct mm_struct *mm = vma->vm_mm;
pte_t *old_pte, *new_pte, pte;
@@ -146,6 +203,8 @@ static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
* serialize access to individual ptes, but only rmap traversal
* order guarantees that we won't miss both the old and new ptes).
*/
+
+retry:
if (need_rmap_locks)
take_rmap_locks(vma);
@@ -166,6 +225,10 @@ static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
if (pte_none(*old_pte))
continue;
+ if (update_pgoff)
+ if (update_pgoff_pte_inner(old_pte, old_addr, vma, old_ptl,
+ old_pmd, new_addr))
+ break; /* Causes unlock after for cycle and goto retry */
pte = ptep_get_and_clear(mm, old_addr, old_pte);
/*
* If we are remapping a valid PTE, make sure
@@ -194,6 +257,8 @@ static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
pte_unmap_unlock(old_pte - 1, old_ptl);
if (need_rmap_locks)
drop_rmap_locks(vma);
+ if (old_addr < old_end)
+ goto retry;
}
#ifndef arch_supports_page_table_move
@@ -422,11 +487,19 @@ static __always_inline unsigned long get_extent(enum pgt_entry entry,
* pgt_entry. Returns true if the move was successful, else false.
*/
static bool move_pgt_entry(enum pgt_entry entry, struct vm_area_struct *vma,
- unsigned long old_addr, unsigned long new_addr,
- void *old_entry, void *new_entry, bool need_rmap_locks)
+ struct vm_area_struct *new_vma, unsigned long old_addr,
+ unsigned long new_addr, void *old_entry, void *new_entry,
+ bool need_rmap_locks, bool update_pgoff)
{
bool moved = false;
+ /*
+ * In case of page offset update move must be done
+ * at the pte level using move_ptes()
+ */
+ if (update_pgoff)
+ return false;
+
/* See comment in move_ptes() */
if (need_rmap_locks)
take_rmap_locks(vma);
@@ -465,7 +538,7 @@ static bool move_pgt_entry(enum pgt_entry entry, struct vm_area_struct *vma,
unsigned long move_page_tables(struct vm_area_struct *vma,
unsigned long old_addr, struct vm_area_struct *new_vma,
unsigned long new_addr, unsigned long len,
- bool need_rmap_locks)
+ bool need_rmap_locks, bool update_pgoff)
{
unsigned long extent, old_end;
struct mmu_notifier_range range;
@@ -492,7 +565,14 @@ unsigned long move_page_tables(struct vm_area_struct *vma,
* If extent is PUD-sized try to speed up the move by moving at the
* PUD level if possible.
*/
- extent = get_extent(NORMAL_PUD, old_addr, old_end, new_addr);
+ if (update_pgoff)
+ /*
+ * In case of pgoff update, extent is set to PMD
+ * and is done using move_ptes()
+ */
+ extent = get_extent(NORMAL_PMD, old_addr, old_end, new_addr);
+ else
+ extent = get_extent(NORMAL_PUD, old_addr, old_end, new_addr);
old_pud = get_old_pud(vma->vm_mm, old_addr);
if (!old_pud)
@@ -502,15 +582,15 @@ unsigned long move_page_tables(struct vm_area_struct *vma,
break;
if (pud_trans_huge(*old_pud) || pud_devmap(*old_pud)) {
if (extent == HPAGE_PUD_SIZE) {
- move_pgt_entry(HPAGE_PUD, vma, old_addr, new_addr,
- old_pud, new_pud, need_rmap_locks);
+ move_pgt_entry(HPAGE_PUD, vma, new_vma, old_addr, new_addr,
+ old_pud, new_pud, need_rmap_locks, update_pgoff);
/* We ignore and continue on error? */
continue;
}
} else if (IS_ENABLED(CONFIG_HAVE_MOVE_PUD) && extent == PUD_SIZE) {
- if (move_pgt_entry(NORMAL_PUD, vma, old_addr, new_addr,
- old_pud, new_pud, true))
+ if (move_pgt_entry(NORMAL_PUD, vma, new_vma, old_addr, new_addr,
+ old_pud, new_pud, true, update_pgoff))
continue;
}
@@ -524,8 +604,8 @@ unsigned long move_page_tables(struct vm_area_struct *vma,
if (is_swap_pmd(*old_pmd) || pmd_trans_huge(*old_pmd) ||
pmd_devmap(*old_pmd)) {
if (extent == HPAGE_PMD_SIZE &&
- move_pgt_entry(HPAGE_PMD, vma, old_addr, new_addr,
- old_pmd, new_pmd, need_rmap_locks))
+ move_pgt_entry(HPAGE_PMD, vma, new_vma, old_addr, new_addr,
+ old_pmd, new_pmd, need_rmap_locks, update_pgoff))
continue;
split_huge_pmd(vma, old_pmd, old_addr);
if (pmd_trans_unstable(old_pmd))
@@ -536,15 +616,15 @@ unsigned long move_page_tables(struct vm_area_struct *vma,
* If the extent is PMD-sized, try to speed the move by
* moving at the PMD level if possible.
*/
- if (move_pgt_entry(NORMAL_PMD, vma, old_addr, new_addr,
- old_pmd, new_pmd, true))
+ if (move_pgt_entry(NORMAL_PMD, vma, new_vma, old_addr, new_addr,
+ old_pmd, new_pmd, true, update_pgoff))
continue;
}
if (pte_alloc(new_vma->vm_mm, new_pmd))
break;
move_ptes(vma, old_pmd, old_addr, old_addr + extent, new_vma,
- new_pmd, new_addr, need_rmap_locks);
+ new_pmd, new_addr, need_rmap_locks, update_pgoff);
}
mmu_notifier_invalidate_range_end(&range);
@@ -568,7 +648,8 @@ static unsigned long move_vma(struct vm_area_struct *vma,
unsigned long hiwater_vm;
int split = 0;
int err = 0;
- bool need_rmap_locks;
+ bool need_rmap_locks = false;
+ bool update_pgoff = false;
/*
* We'd prefer to avoid failure later on in do_munmap:
@@ -608,7 +689,7 @@ static unsigned long move_vma(struct vm_area_struct *vma,
new_pgoff = vma->vm_pgoff + ((old_addr - vma->vm_start) >> PAGE_SHIFT);
new_vma = copy_vma(&vma, new_addr, new_len, new_pgoff,
- &need_rmap_locks);
+ &need_rmap_locks, &update_pgoff);
if (!new_vma) {
if (vm_flags & VM_ACCOUNT)
vm_unacct_memory(to_account >> PAGE_SHIFT);
@@ -616,7 +697,7 @@ static unsigned long move_vma(struct vm_area_struct *vma,
}
moved_len = move_page_tables(vma, old_addr, new_vma, new_addr, old_len,
- need_rmap_locks);
+ need_rmap_locks, update_pgoff);
if (moved_len < old_len) {
err = -ENOMEM;
} else if (vma->vm_ops && vma->vm_ops->mremap) {
@@ -630,7 +711,7 @@ static unsigned long move_vma(struct vm_area_struct *vma,
* and then proceed to unmap new area instead of old.
*/
move_page_tables(new_vma, new_addr, vma, old_addr, moved_len,
- true);
+ true, update_pgoff);
vma = new_vma;
old_len = new_len;
old_addr = new_addr;
diff --git a/mm/pagewalk.c b/mm/pagewalk.c
index 0bfb8c9255f3..d603962ddd52 100644
--- a/mm/pagewalk.c
+++ b/mm/pagewalk.c
@@ -89,7 +89,7 @@ static int walk_pte_range_inner(pte_t *pte, unsigned long addr,
return err;
}
-static int walk_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
+int walk_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
struct mm_walk *walk)
{
pte_t *pte;
diff --git a/mm/rmap.c b/mm/rmap.c
index d4d95ada0946..b1bddabd21c6 100644
--- a/mm/rmap.c
+++ b/mm/rmap.c
@@ -389,6 +389,47 @@ int anon_vma_fork(struct vm_area_struct *vma, struct vm_area_struct *pvma)
return -ENOMEM;
}
+
+/*
+ * rbst_no_children() - Used by rbt_no_children to check node subtree.
+ * Check if none of the VMAs connected to the node subtree via
+ * anon_vma_chain are in child relationship to the given anon_vma.
+ * @av: anon_vma to check
+ * @node: node to check in this level
+ */
+static bool rbst_no_children(struct anon_vma *av, struct rb_node *node)
+{
+ struct anon_vma_chain *model;
+ struct anon_vma_chain *avc;
+
+ if (node == NULL) /* leaf node */
+ return true;
+ avc = container_of(node, typeof(*(model)), rb);
+ if (avc->vma->anon_vma != av)
+ /*
+ * Inequality implies avc belongs
+ * to a VMA of a child process
+ */
+ return false;
+ return (rbst_no_children(av, node->rb_left) &&
+ rbst_no_children(av, node->rb_right));
+}
+
+/*
+ * rbt_no_children() - Check if none of the VMAs connected to the given
+ * anon_vma via anon_vma_chain are in child relationship
+ * @av: anon_vma to check if it has children
+ */
+bool rbt_no_children(struct anon_vma *av)
+{
+ struct rb_node *root_node;
+
+ if (av == NULL || av->degree <= 1) /* Higher degree might not necessarily imply children */
+ return true;
+ root_node = av->rb_root.rb_root.rb_node;
+ return rbst_no_children(av, root_node);
+}
+
void unlink_anon_vmas(struct vm_area_struct *vma)
{
struct anon_vma_chain *avc, *next;
--
2.35.1
Refactor vma_merge() to make it shorter, more understandable and
suitable for tracing of successful merges that are made possible by
following patches in the series. Main change is the elimination of code
duplicity in the case of merge next check. This is done by first doing
checks and caching the results before executing the merge itself. Exit
paths are also unified.
Signed-off-by: Jakub Matěna <[email protected]>
---
mm/mmap.c | 81 +++++++++++++++++++++++++------------------------------
1 file changed, 36 insertions(+), 45 deletions(-)
diff --git a/mm/mmap.c b/mm/mmap.c
index 3aa839f81e63..4a4611443593 100644
--- a/mm/mmap.c
+++ b/mm/mmap.c
@@ -1171,7 +1171,9 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
{
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
struct vm_area_struct *area, *next;
- int err;
+ int err = -1;
+ bool merge_prev = false;
+ bool merge_next = false;
/*
* We later require that vma->vm_flags == vm_flags,
@@ -1190,66 +1192,55 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
VM_WARN_ON(area && end > area->vm_end);
VM_WARN_ON(addr >= end);
- /*
- * Can it merge with the predecessor?
- */
+ /* Can we merge the predecessor? */
if (prev && prev->vm_end == addr &&
mpol_equal(vma_policy(prev), policy) &&
can_vma_merge_after(prev, vm_flags,
anon_vma, file, pgoff,
vm_userfaultfd_ctx, anon_name)) {
- /*
- * OK, it can. Can we now merge in the successor as well?
- */
- if (next && end == next->vm_start &&
- mpol_equal(policy, vma_policy(next)) &&
- can_vma_merge_before(next, vm_flags,
- anon_vma, file,
- pgoff+pglen,
- vm_userfaultfd_ctx, anon_name) &&
- is_mergeable_anon_vma(prev->anon_vma,
- next->anon_vma, NULL)) {
- /* cases 1, 6 */
- err = __vma_adjust(prev, prev->vm_start,
- next->vm_end, prev->vm_pgoff, NULL,
- prev);
- } else /* cases 2, 5, 7 */
- err = __vma_adjust(prev, prev->vm_start,
- end, prev->vm_pgoff, NULL, prev);
- if (err)
- return NULL;
- khugepaged_enter_vma_merge(prev, vm_flags);
- return prev;
+ merge_prev = true;
+ area = prev;
}
-
- /*
- * Can this new request be merged in front of next?
- */
+ /* Can we merge the successor? */
if (next && end == next->vm_start &&
mpol_equal(policy, vma_policy(next)) &&
can_vma_merge_before(next, vm_flags,
anon_vma, file, pgoff+pglen,
vm_userfaultfd_ctx, anon_name)) {
+ merge_next = true;
+ }
+ /* Can we merge both the predecessor and the successor? */
+ if (merge_prev && merge_next &&
+ is_mergeable_anon_vma(prev->anon_vma,
+ next->anon_vma, NULL)) { /* cases 1, 6 */
+ err = __vma_adjust(prev, prev->vm_start,
+ next->vm_end, prev->vm_pgoff, NULL,
+ prev);
+ } else if (merge_prev) { /* cases 2, 5, 7 */
+ err = __vma_adjust(prev, prev->vm_start,
+ end, prev->vm_pgoff, NULL, prev);
+ } else if (merge_next) {
if (prev && addr < prev->vm_end) /* case 4 */
err = __vma_adjust(prev, prev->vm_start,
- addr, prev->vm_pgoff, NULL, next);
- else { /* cases 3, 8 */
+ addr, prev->vm_pgoff, NULL, next);
+ else /* cases 3, 8 */
err = __vma_adjust(area, addr, next->vm_end,
- next->vm_pgoff - pglen, NULL, next);
- /*
- * In case 3 area is already equal to next and
- * this is a noop, but in case 8 "area" has
- * been removed and next was expanded over it.
- */
- area = next;
- }
- if (err)
- return NULL;
- khugepaged_enter_vma_merge(area, vm_flags);
- return area;
+ next->vm_pgoff - pglen, NULL, next);
+ /*
+ * In case 3 and 4 area is already equal to next and
+ * this is a noop, but in case 8 "area" has
+ * been removed and next was expanded over it.
+ */
+ area = next;
}
- return NULL;
+ /*
+ * Cannot merge with predecessor or successor or error in __vma_adjust?
+ */
+ if (err)
+ return NULL;
+ khugepaged_enter_vma_merge(area, vm_flags);
+ return area;
}
/*
--
2.35.1
When mremap call results in expansion, it might be possible to merge the
VMA with the next VMA which might become adjacent. This patch adds
vma_merge call after the expansion is done to try and merge.
Signed-off-by: Jakub Matěna <[email protected]>
---
mm/mremap.c | 7 +++++--
1 file changed, 5 insertions(+), 2 deletions(-)
diff --git a/mm/mremap.c b/mm/mremap.c
index 303d3290b938..75cda854ec58 100644
--- a/mm/mremap.c
+++ b/mm/mremap.c
@@ -9,6 +9,7 @@
*/
#include <linux/mm.h>
+#include <linux/mm_inline.h>
#include <linux/hugetlb.h>
#include <linux/shm.h>
#include <linux/ksm.h>
@@ -1022,8 +1023,10 @@ SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
}
}
- if (vma_adjust(vma, vma->vm_start, addr + new_len,
- vma->vm_pgoff, NULL)) {
+ if (!vma_merge(mm, vma, addr + old_len, addr + new_len,
+ vma->vm_flags, vma->anon_vma, vma->vm_file,
+ vma->vm_pgoff + (old_len >> PAGE_SHIFT), vma_policy(vma),
+ vma->vm_userfaultfd_ctx, anon_vma_name(vma))) {
vm_unacct_memory(pages);
ret = -ENOMEM;
goto out;
--
2.35.1
Enable merging of a VMA even when it is linked to different
anon_vma than the VMA it is being merged to, but only if the VMA
in question does not share any pages with a parent or child process.
This enables merges that would otherwise not be possible and therefore
decrease number of VMAs of a process.
In this patch the VMA is checked only at the level of anon_vma to find
out if it shares any pages with parent or child process. This check is
performed in is_mergeable_anon_vma() which is a part of vma_merge().
In this case it is not easily possible to check mapcount of individual
pages (as opposed to previous commit "mm: adjust page offset in
mremap"), because vma_merge() does not have a
pointer to the VMA or any other means of easily accessing the page
structures. In the following two paragraphs we are using cases 1
through 8 as described in comment before vma_merge().
The update itself is done during __vma_adjust() for cases 4
through 8 and partially for case 1. Other cases must be solved
elsewhere because __vma_adjust() can only work with pages that already
reside in the location of merge, in other words if VMA already exists
in the location where merge is happening. This is not true for cases 2,
3 and partially case 1, where the next VMA is already present but the
middle part is not. Cases 1,2 and 3 are either expanding or moving VMA
to the location of the merge, but unfortunately at the time of the
merge the mapping is not there yet and therefore the page update has
to be done later. An easy way out is if the pages do not exist yet and
therefore there is nothing to update. This happens e.g. when
expanding a mapping in mmap_region() or in do_brk_flags(). On the other
hand the pages do exist and have to be updated during the mremap call
that moves already existing and possibly faulted mapping. In this case
the page update is done in move_page_tables(). It is actually quite
simple as previous commit "mm: adjust page offset in
mremap" already introduced page update and therefore only
change is updating one more parameter. If rmap walk happens between
__vma_adjust() and page update done in move_page_tables() then old VMA
and old anon_vma are used as it would happen before starting the whole
merge.
The cases 4 through 8 correspond to merges which are a result of a
mprotect call or any other flag update that does not move or resize
the mapping. Together with part of case 1 the update of physical pages
is then handled directly in __vma_adjust() as mentioned before. First
it is determined which address range should be updated, which depends
on the specific case 1, 4, 5, 6, 7 or 8. The address range is set to
variables pu_start and pu_end. Secondly the value being set to the
page->mapping must be determined. However, it is always anon_vma
belonging to the expand parameter of the __vma_adjust() call. The
reason we are updating the pages is that in the __vma_adjust() the
ranges vm_start and vm_end are updated for involved VMAs and so
physical pages can belong to different VMA and anon_vma than before.
The problem is that these two updates (VMAs and pages) should happen
atomically from the rmap walk point of view. This would normally be
solved by using rmap locks, but at the same time we must keep in mind
that page migration uses rmap walk at the start and at the end and
rmap locks might trap it in the middle. This would cause pte to not
point to actual pages but instead remain in the migration entry state,
which would block the page update.
The solution is to drop rmap lock to allow page migration to end
and page walk all the relevant pages, where we wait for possible
migration to end and update the page->mapping (aka anon_vma). After
that we again take rmap lock. This whole page update must be done
after the expand VMA is already enlarged, but the source VMA still has
its original range. This way if rmap walk happens while we are updating
the pages then rmap lock will work either with the old or the new
anon_vma and therefore also the old or new VMA.
If the page is swapped out, zero page or KSM page, then it is not
changed and the correct mapping will be reconstructed from the VMA
itself when the page returns to normal state.
Again as mentioned and explained in the previous commit "mm: adjust page offset in
mremap", the mapcount of the
pages should not change between vma_merge checks and actually merging
in __vma_adjust() as potencial fork is prevented by mmap_lock.
If one of the VMAs is not yet faulted and therefore does not have
anon_vma assigned then this patch is not needed and merge happens even
without it.
Signed-off-by: Jakub Matěna <[email protected]>
---
include/linux/pagewalk.h | 2 +
include/linux/rmap.h | 15 ++++++-
mm/mmap.c | 60 ++++++++++++++++++++++++---
mm/mremap.c | 22 +++++++---
mm/pagewalk.c | 2 +-
mm/rmap.c | 87 ++++++++++++++++++++++++++++++++++++++++
6 files changed, 176 insertions(+), 12 deletions(-)
diff --git a/include/linux/pagewalk.h b/include/linux/pagewalk.h
index 11c99c8d343b..9685d1a26f17 100644
--- a/include/linux/pagewalk.h
+++ b/include/linux/pagewalk.h
@@ -106,6 +106,8 @@ int walk_pte_range(pmd_t *pmd, unsigned long addr, unsigned long end,
int walk_page_range(struct mm_struct *mm, unsigned long start,
unsigned long end, const struct mm_walk_ops *ops,
void *private);
+int __walk_page_range(unsigned long start, unsigned long end,
+ struct mm_walk *walk);
int walk_page_range_novma(struct mm_struct *mm, unsigned long start,
unsigned long end, const struct mm_walk_ops *ops,
pgd_t *pgd,
diff --git a/include/linux/rmap.h b/include/linux/rmap.h
index 9fee804f47ea..c1ba908f92e6 100644
--- a/include/linux/rmap.h
+++ b/include/linux/rmap.h
@@ -138,6 +138,8 @@ static inline void anon_vma_unlock_read(struct anon_vma *anon_vma)
*/
void anon_vma_init(void); /* create anon_vma_cachep */
int __anon_vma_prepare(struct vm_area_struct *);
+void reconnect_pages_range(struct mm_struct *mm, unsigned long start, unsigned long end,
+ struct vm_area_struct *target, struct vm_area_struct *source);
void take_rmap_locks(struct vm_area_struct *vma);
void drop_rmap_locks(struct vm_area_struct *vma);
void unlink_anon_vmas(struct vm_area_struct *);
@@ -154,10 +156,21 @@ static inline int anon_vma_prepare(struct vm_area_struct *vma)
return __anon_vma_prepare(vma);
}
+/**
+ * anon_vma_merge() - Merge anon_vmas of the given VMAs
+ * @vma: VMA being merged to
+ * @next: VMA being merged
+ */
static inline void anon_vma_merge(struct vm_area_struct *vma,
struct vm_area_struct *next)
{
- VM_BUG_ON_VMA(vma->anon_vma != next->anon_vma, vma);
+ struct anon_vma *anon_vma1 = vma->anon_vma;
+ struct anon_vma *anon_vma2 = next->anon_vma;
+
+ VM_BUG_ON_VMA(anon_vma1 && anon_vma2 && anon_vma1 != anon_vma2 &&
+ ((anon_vma2 != anon_vma2->root)
+ || !rbt_no_children(anon_vma2)), vma);
+
unlink_anon_vmas(next);
}
diff --git a/mm/mmap.c b/mm/mmap.c
index 3ca78baaee13..e7760e378a68 100644
--- a/mm/mmap.c
+++ b/mm/mmap.c
@@ -753,6 +753,8 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
bool start_changed = false, end_changed = false;
long adjust_next = 0;
int remove_next = 0;
+ unsigned long pu_start = 0;
+ unsigned long pu_end = 0;
if (next && !insert) {
struct vm_area_struct *exporter = NULL, *importer = NULL;
@@ -778,6 +780,8 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
remove_next = 3;
VM_WARN_ON(file != next->vm_file);
swap(vma, next);
+ pu_start = start;
+ pu_end = vma->vm_end;
} else {
VM_WARN_ON(expand != vma);
/*
@@ -789,6 +793,10 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
end != next->vm_next->vm_end);
/* trim end to next, for case 6 first pass */
end = next->vm_end;
+ VM_WARN_ON(vma == NULL);
+
+ pu_start = next->vm_start;
+ pu_end = next->vm_end;
}
exporter = next;
@@ -810,6 +818,8 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
exporter = next;
importer = vma;
VM_WARN_ON(expand != importer);
+ pu_start = vma->vm_end;
+ pu_end = end;
} else if (end < vma->vm_end) {
/*
* vma shrinks, and !insert tells it's not
@@ -820,6 +830,8 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
exporter = vma;
importer = next;
VM_WARN_ON(expand != importer);
+ pu_start = end;
+ pu_end = vma->vm_end;
}
/*
@@ -863,8 +875,6 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
if (!anon_vma && adjust_next)
anon_vma = next->anon_vma;
if (anon_vma) {
- VM_WARN_ON(adjust_next && next->anon_vma &&
- anon_vma != next->anon_vma);
anon_vma_lock_write(anon_vma);
anon_vma_interval_tree_pre_update_vma(vma);
if (adjust_next)
@@ -887,6 +897,31 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
end_changed = true;
}
vma->vm_pgoff = pgoff;
+
+ /* Update the anon_vma stored in pages in the range specified by pu_start and pu_end */
+ if (anon_vma && next && anon_vma != next->anon_vma && pu_start != pu_end) {
+ struct vm_area_struct *source;
+
+ anon_vma_unlock_write(anon_vma);
+ VM_WARN_ON(expand == vma && next->anon_vma &&
+ (next->anon_vma != next->anon_vma->root
+ || !rbt_no_children(next->anon_vma)));
+ VM_WARN_ON(expand == next &&
+ (anon_vma != anon_vma->root || !rbt_no_children(anon_vma)));
+ VM_WARN_ON(expand != vma && expand != next);
+ VM_WARN_ON(expand == NULL);
+ if (expand == vma)
+ source = next;
+ else
+ source = vma;
+ /*
+ * Page walk over affected address range.
+ * Wait for migration and update page->mapping.
+ */
+ reconnect_pages_range(mm, pu_start, pu_end, expand, source);
+ anon_vma_lock_write(anon_vma);
+ }
+
if (adjust_next) {
next->vm_start += adjust_next;
next->vm_pgoff += adjust_next >> PAGE_SHIFT;
@@ -991,6 +1026,8 @@ int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
if (remove_next == 2) {
remove_next = 1;
end = next->vm_end;
+ pu_start = next->vm_start;
+ pu_end = next->vm_end;
goto again;
}
else if (next)
@@ -1067,7 +1104,20 @@ static inline int is_mergeable_anon_vma(struct anon_vma *anon_vma1,
if ((!anon_vma1 || !anon_vma2) && (!vma ||
list_is_singular(&vma->anon_vma_chain)))
return 1;
- return anon_vma1 == anon_vma2;
+ if (anon_vma1 == anon_vma2)
+ return 1;
+ /*
+ * Different anon_vma but not shared by several processes
+ */
+ else if ((anon_vma1 && anon_vma2) &&
+ (anon_vma1 == anon_vma1->root)
+ && (rbt_no_children(anon_vma1)))
+ return 1;
+ /*
+ * Different anon_vma and shared -> unmergeable
+ */
+ else
+ return 0;
}
/*
@@ -1213,8 +1263,8 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
}
/* Can we merge both the predecessor and the successor? */
if (merge_prev && merge_next &&
- is_mergeable_anon_vma(prev->anon_vma,
- next->anon_vma, NULL)) { /* cases 1, 6 */
+ is_mergeable_anon_vma(next->anon_vma,
+ prev->anon_vma, NULL)) { /* cases 1, 6 */
err = __vma_adjust(prev, prev->vm_start,
next->vm_end, prev->vm_pgoff, NULL,
prev);
diff --git a/mm/mremap.c b/mm/mremap.c
index 2ef444abb08a..3b2428288b0e 100644
--- a/mm/mremap.c
+++ b/mm/mremap.c
@@ -119,12 +119,16 @@ static pte_t move_soft_dirty_pte(pte_t pte)
}
/*
- * update_pgoff_page() - Update page offset stored in page->index, if the page is not NULL.
+ * update_pgoff_page() - Update page offset stored in page->index
+ * and anon_vma in page->mapping, if the page is not NULL.
* @addr: new address to calculate the page offset.
* @page: page to update
+ * @vma: vma to get anon_vma
*/
-static int update_pgoff_page(unsigned long addr, struct page *page)
+static int update_pgoff_page(unsigned long addr, struct page *page, struct vm_area_struct *vma)
{
+ struct anon_vma *page_anon_vma;
+ unsigned long anon_mapping;
if (page != NULL) {
get_page(page);
if (!trylock_page(page)) {
@@ -132,6 +136,13 @@ static int update_pgoff_page(unsigned long addr, struct page *page)
return -1;
}
page->index = addr >> PAGE_SHIFT;
+
+ anon_mapping = (unsigned long)READ_ONCE(page->mapping);
+ page_anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
+ if (page_anon_vma != vma->anon_vma
+ && page_anon_vma != NULL) { /* NULL in case of ZERO_PAGE or KSM page */
+ page_move_anon_rmap(page, vma); /* Update physical page's mapping */
+ }
unlock_page(page);
put_page(page);
}
@@ -144,7 +155,8 @@ static int update_pgoff_page(unsigned long addr, struct page *page)
*/
static int update_pgoff_pte_inner(pte_t *old_pte, unsigned long old_addr,
struct vm_area_struct *vma, spinlock_t *old_ptl,
- pmd_t *old_pmd, unsigned long new_addr)
+ pmd_t *old_pmd, unsigned long new_addr,
+ struct vm_area_struct *new_vma)
{
struct page *page;
/*
@@ -170,7 +182,7 @@ static int update_pgoff_pte_inner(pte_t *old_pte, unsigned long old_addr,
}
page = vm_normal_page(vma, old_addr, *old_pte);
- return update_pgoff_page(new_addr, page);
+ return update_pgoff_page(new_addr, page, new_vma);
}
static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
@@ -227,7 +239,7 @@ static void move_ptes(struct vm_area_struct *vma, pmd_t *old_pmd,
if (update_pgoff)
if (update_pgoff_pte_inner(old_pte, old_addr, vma, old_ptl,
- old_pmd, new_addr))
+ old_pmd, new_addr, new_vma))
break; /* Causes unlock after for cycle and goto retry */
pte = ptep_get_and_clear(mm, old_addr, old_pte);
/*
diff --git a/mm/pagewalk.c b/mm/pagewalk.c
index d603962ddd52..4076a5ecdec0 100644
--- a/mm/pagewalk.c
+++ b/mm/pagewalk.c
@@ -419,7 +419,7 @@ static int walk_page_test(unsigned long start, unsigned long end,
return 0;
}
-static int __walk_page_range(unsigned long start, unsigned long end,
+int __walk_page_range(unsigned long start, unsigned long end,
struct mm_walk *walk)
{
int err = 0;
diff --git a/mm/rmap.c b/mm/rmap.c
index b1bddabd21c6..7caa6ec6110a 100644
--- a/mm/rmap.c
+++ b/mm/rmap.c
@@ -73,6 +73,7 @@
#include <linux/page_idle.h>
#include <linux/memremap.h>
#include <linux/userfaultfd_k.h>
+#include <linux/pagewalk.h>
#include <asm/tlbflush.h>
@@ -389,6 +390,92 @@ int anon_vma_fork(struct vm_area_struct *vma, struct vm_area_struct *pvma)
return -ENOMEM;
}
+/*
+ * reconnect_page() - If the page is not NULL and has a non-NULL anon_vma,
+ * reconnect the page to a anon_vma of the given new VMA.
+ * @page: Page to reconnect to different anon_vma
+ * @old: Old VMA the page is connected to
+ * @new: New VMA the page will be reconnected to
+ */
+static int reconnect_page(struct page *page, struct vm_area_struct *old,
+ struct vm_area_struct *new)
+{
+ struct anon_vma *page_anon_vma;
+ unsigned long anon_mapping;
+ /* Do some checks and lock the page */
+ if (page == NULL)
+ return 0; /* Virtual memory page is not mapped */
+ get_page(page);
+ if (!trylock_page(page)) {
+ put_page(page);
+ return -1;
+ }
+ anon_mapping = (unsigned long)READ_ONCE(page->mapping);
+ page_anon_vma = (struct anon_vma *) (anon_mapping - PAGE_MAPPING_ANON);
+ if (page_anon_vma != NULL) { /* NULL in case of ZERO_PAGE or KSM page */
+ VM_WARN_ON(page_anon_vma != old->anon_vma);
+ VM_WARN_ON(old->anon_vma == new->anon_vma);
+ /* Update physical page's mapping */
+ page_move_anon_rmap(page, new);
+ }
+ unlock_page(page);
+ put_page(page);
+ return 0;
+}
+
+/*
+ * reconnect_page_pte() - Reconnect page mapped by pte from old anon_vma
+ * to new anon_vma.
+ * @pte: pte to work with
+ * @addr: Address where the page should be mapped.
+ * @end: Not used
+ * @walk: Pagewalk structure holding pointer to old and new VMAs.
+ */
+static int reconnect_page_pte(pte_t *pte, unsigned long addr,
+ unsigned long end, struct mm_walk *walk)
+{
+ struct vm_area_struct *old = walk->vma;
+ struct page *page;
+
+ /*
+ * Page's anon_vma will be reconstructed automatically from the
+ * VMA after the data will be moved back into RAM
+ */
+ if (!pte_present(*pte))
+ return 0;
+
+ page = vm_normal_page(old, addr, *pte);
+
+ if (reconnect_page(page, old, walk->private) == -1)
+ walk->action = ACTION_AGAIN;
+ return 0;
+}
+
+/*
+ * reconnect_pages_range() - Reconnect physical pages to anon_vma of target VMA
+ * @mm: Memory descriptor
+ * @start: range start
+ * @end: range end
+ * @target: VMA to newly contain all physical pages
+ * @source: VMA which contains the all physical page before reconnecting them
+ */
+void reconnect_pages_range(struct mm_struct *mm, unsigned long start, unsigned long end,
+ struct vm_area_struct *target, struct vm_area_struct *source)
+{
+ const struct mm_walk_ops reconnect_pages_ops = {
+ .pte_entry = reconnect_page_pte
+ };
+
+ struct mm_walk walk = {
+ .ops = &reconnect_pages_ops,
+ .mm = mm,
+ .private = target,
+ .flags = WALK_MIGRATION & WALK_LOCK_RMAP,
+ .vma = source
+ };
+ /* Modify page->mapping for all pages in range */
+ __walk_page_range(start, end, &walk);
+}
/*
* rbst_no_children() - Used by rbt_no_children to check node subtree.
--
2.35.1
Adds trace support for vma_merge to measure successful and unsuccessful
merges of two VMAs with distinct anon_vmas and also trace support for
merges made possible by update of page offset made possible by a previous
patch in this series.
Signed-off-by: Jakub Matěna <[email protected]>
---
include/trace/events/mmap.h | 83 +++++++++++++++++++++++++++++++++++++
mm/internal.h | 12 ++++++
mm/mmap.c | 69 ++++++++++++++++--------------
3 files changed, 133 insertions(+), 31 deletions(-)
diff --git a/include/trace/events/mmap.h b/include/trace/events/mmap.h
index 4661f7ba07c0..bad7abe4899c 100644
--- a/include/trace/events/mmap.h
+++ b/include/trace/events/mmap.h
@@ -6,6 +6,27 @@
#define _TRACE_MMAP_H
#include <linux/tracepoint.h>
+#include <../mm/internal.h>
+
+#define AV_MERGE_TYPES \
+ EM(MERGE_FAILED) \
+ EM(AV_MERGE_FAILED) \
+ EM(AV_MERGE_NULL) \
+ EM(AV_MERGE_SAME) \
+ EMe(AV_MERGE_DIFFERENT)
+
+#undef EM
+#undef EMe
+#define EM(a) TRACE_DEFINE_ENUM(a);
+#define EMe(a) TRACE_DEFINE_ENUM(a);
+
+AV_MERGE_TYPES
+
+#undef EM
+#undef EMe
+
+#define EM(a) { a, #a },
+#define EMe(a) { a, #a }
TRACE_EVENT(vm_unmapped_area,
@@ -42,6 +63,68 @@ TRACE_EVENT(vm_unmapped_area,
__entry->low_limit, __entry->high_limit, __entry->align_mask,
__entry->align_offset)
);
+
+TRACE_EVENT(vm_av_merge,
+
+ TP_PROTO(int merged, enum vma_merge_res merge_prev,
+ enum vma_merge_res merge_next, enum vma_merge_res merge_both),
+
+ TP_ARGS(merged, merge_prev, merge_next, merge_both),
+
+ TP_STRUCT__entry(
+ __field(int, merged)
+ __field(enum vma_merge_res, predecessor_different_av)
+ __field(enum vma_merge_res, successor_different_av)
+ __field(enum vma_merge_res, predecessor_with_successor_different_av)
+ __field(int, same_count)
+ __field(int, diff_count)
+ __field(int, failed_count)
+ ),
+
+ TP_fast_assign(
+ __entry->merged = merged == 0;
+ __entry->predecessor_different_av = merge_prev;
+ __entry->successor_different_av = merge_next;
+ __entry->predecessor_with_successor_different_av = merge_both;
+ __entry->same_count = (merge_prev == AV_MERGE_SAME) +
+ (merge_next == AV_MERGE_SAME) +
+ (merge_both == AV_MERGE_SAME);
+ __entry->diff_count = (merge_prev == AV_MERGE_DIFFERENT) +
+ (merge_next == AV_MERGE_DIFFERENT) +
+ (merge_both == AV_MERGE_DIFFERENT);
+ __entry->failed_count = (merge_prev == AV_MERGE_FAILED) +
+ (merge_next == AV_MERGE_FAILED) +
+ (merge_both == AV_MERGE_FAILED);
+ ),
+
+ TP_printk("merged=%d predecessor=%s successor=%s predecessor_with_successor=%s same_count=%d diff_count=%d failed_count=%d",
+ __entry->merged,
+ __print_symbolic(__entry->predecessor_different_av, AV_MERGE_TYPES),
+ __print_symbolic(__entry->successor_different_av, AV_MERGE_TYPES),
+ __print_symbolic(__entry->predecessor_with_successor_different_av, AV_MERGE_TYPES),
+ __entry->same_count, __entry->diff_count, __entry->failed_count)
+
+);
+
+TRACE_EVENT(vm_pgoff_merge,
+
+ TP_PROTO(struct vm_area_struct *vma, bool anon_pgoff_updated),
+
+ TP_ARGS(vma, anon_pgoff_updated),
+
+ TP_STRUCT__entry(
+ __field(bool, faulted)
+ __field(bool, updated)
+ ),
+
+ TP_fast_assign(
+ __entry->faulted = vma->anon_vma;
+ __entry->updated = anon_pgoff_updated;
+ ),
+
+ TP_printk("faulted=%d updated=%d\n",
+ __entry->faulted, __entry->updated)
+);
#endif
/* This part must be outside protection */
diff --git a/mm/internal.h b/mm/internal.h
index cf16280ce132..9284e779f53d 100644
--- a/mm/internal.h
+++ b/mm/internal.h
@@ -35,6 +35,18 @@ struct folio_batch;
/* Do not use these with a slab allocator */
#define GFP_SLAB_BUG_MASK (__GFP_DMA32|__GFP_HIGHMEM|~__GFP_BITS_MASK)
+/*
+ * Following values indicate reason for merge success or failure.
+ */
+enum vma_merge_res {
+ MERGE_FAILED,
+ AV_MERGE_FAILED,
+ AV_MERGE_NULL,
+ MERGE_OK = AV_MERGE_NULL,
+ AV_MERGE_SAME,
+ AV_MERGE_DIFFERENT,
+};
+
void page_writeback_init(void);
static inline void *folio_raw_mapping(struct folio *folio)
diff --git a/mm/mmap.c b/mm/mmap.c
index e7760e378a68..3cecc2efe763 100644
--- a/mm/mmap.c
+++ b/mm/mmap.c
@@ -1103,21 +1103,21 @@ static inline int is_mergeable_anon_vma(struct anon_vma *anon_vma1,
*/
if ((!anon_vma1 || !anon_vma2) && (!vma ||
list_is_singular(&vma->anon_vma_chain)))
- return 1;
+ return AV_MERGE_NULL;
if (anon_vma1 == anon_vma2)
- return 1;
+ return AV_MERGE_SAME;
/*
* Different anon_vma but not shared by several processes
*/
else if ((anon_vma1 && anon_vma2) &&
(anon_vma1 == anon_vma1->root)
&& (rbt_no_children(anon_vma1)))
- return 1;
+ return AV_MERGE_DIFFERENT;
/*
* Different anon_vma and shared -> unmergeable
*/
else
- return 0;
+ return AV_MERGE_FAILED;
}
/*
@@ -1138,12 +1138,10 @@ can_vma_merge_before(struct vm_area_struct *vma, unsigned long vm_flags,
struct vm_userfaultfd_ctx vm_userfaultfd_ctx,
struct anon_vma_name *anon_name)
{
- if (is_mergeable_vma(vma, file, vm_flags, vm_userfaultfd_ctx, anon_name) &&
- is_mergeable_anon_vma(anon_vma, vma->anon_vma, vma)) {
+ if (is_mergeable_vma(vma, file, vm_flags, vm_userfaultfd_ctx, anon_name))
if (vma->vm_pgoff == vm_pgoff)
- return 1;
- }
- return 0;
+ return is_mergeable_anon_vma(anon_vma, vma->anon_vma, vma);
+ return MERGE_FAILED;
}
/*
@@ -1160,14 +1158,13 @@ can_vma_merge_after(struct vm_area_struct *vma, unsigned long vm_flags,
struct vm_userfaultfd_ctx vm_userfaultfd_ctx,
struct anon_vma_name *anon_name)
{
- if (is_mergeable_vma(vma, file, vm_flags, vm_userfaultfd_ctx, anon_name) &&
- is_mergeable_anon_vma(anon_vma, vma->anon_vma, vma)) {
+ if (is_mergeable_vma(vma, file, vm_flags, vm_userfaultfd_ctx, anon_name)) {
pgoff_t vm_pglen;
vm_pglen = vma_pages(vma);
if (vma->vm_pgoff + vm_pglen == vm_pgoff)
- return 1;
+ return is_mergeable_anon_vma(anon_vma, vma->anon_vma, vma);
}
- return 0;
+ return MERGE_FAILED;
}
/*
@@ -1224,8 +1221,14 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
pgoff_t pglen = (end - addr) >> PAGE_SHIFT;
struct vm_area_struct *area, *next;
int err = -1;
- bool merge_prev = false;
- bool merge_next = false;
+ /*
+ * Following three variables are used to store values
+ * indicating wheather this VMA and its anon_vma can
+ * be merged and also the type of failure or success.
+ */
+ enum vma_merge_res merge_prev = MERGE_FAILED;
+ enum vma_merge_res merge_both = MERGE_FAILED;
+ enum vma_merge_res merge_next = MERGE_FAILED;
/*
* We later require that vma->vm_flags == vm_flags,
@@ -1246,32 +1249,34 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
/* Can we merge the predecessor? */
if (prev && prev->vm_end == addr &&
- mpol_equal(vma_policy(prev), policy) &&
- can_vma_merge_after(prev, vm_flags,
+ mpol_equal(vma_policy(prev), policy)) {
+ merge_prev = can_vma_merge_after(prev, vm_flags,
anon_vma, file, pgoff,
- vm_userfaultfd_ctx, anon_name)) {
- merge_prev = true;
- area = prev;
+ vm_userfaultfd_ctx, anon_name);
}
+
/* Can we merge the successor? */
if (next && end == next->vm_start &&
- mpol_equal(policy, vma_policy(next)) &&
- can_vma_merge_before(next, vm_flags,
- anon_vma, file, pgoff+pglen,
- vm_userfaultfd_ctx, anon_name)) {
- merge_next = true;
+ mpol_equal(policy, vma_policy(next))) {
+ merge_next = can_vma_merge_before(next, vm_flags,
+ anon_vma, file, pgoff+pglen,
+ vm_userfaultfd_ctx, anon_name);
}
+
/* Can we merge both the predecessor and the successor? */
- if (merge_prev && merge_next &&
- is_mergeable_anon_vma(next->anon_vma,
- prev->anon_vma, NULL)) { /* cases 1, 6 */
+ if (merge_prev >= MERGE_OK && merge_next >= MERGE_OK)
+ merge_both = is_mergeable_anon_vma(next->anon_vma, prev->anon_vma, NULL);
+
+ if (merge_both >= MERGE_OK) { /* cases 1, 6 */
err = __vma_adjust(prev, prev->vm_start,
next->vm_end, prev->vm_pgoff, NULL,
prev);
- } else if (merge_prev) { /* cases 2, 5, 7 */
+ area = prev;
+ } else if (merge_prev >= MERGE_OK) { /* cases 2, 5, 7 */
err = __vma_adjust(prev, prev->vm_start,
end, prev->vm_pgoff, NULL, prev);
- } else if (merge_next) {
+ area = prev;
+ } else if (merge_next >= MERGE_OK) {
if (prev && addr < prev->vm_end) /* case 4 */
err = __vma_adjust(prev, prev->vm_start,
addr, prev->vm_pgoff, NULL, next);
@@ -1285,7 +1290,7 @@ struct vm_area_struct *vma_merge(struct mm_struct *mm,
*/
area = next;
}
-
+ trace_vm_av_merge(err, merge_prev, merge_next, merge_both);
/*
* Cannot merge with predecessor or successor or error in __vma_adjust?
*/
@@ -3346,6 +3351,8 @@ struct vm_area_struct *copy_vma(struct vm_area_struct **vmap,
/*
* Source vma may have been merged into new_vma
*/
+ trace_vm_pgoff_merge(vma, anon_pgoff_updated);
+
if (unlikely(vma_start >= new_vma->vm_start &&
vma_start < new_vma->vm_end)) {
/*
--
2.35.1
On Mon, May 16, 2022 at 02:53:59PM +0200, Jakub Matěna wrote:
> This is a series of patches that try to improve merge success rate when
> VMAs are being moved, resized or otherwise modified.
>
> Motivation
> In the current kernel it is impossible to merge two anonymous VMAs
> if one of them was moved. That is because VMA's page offset is
> set according to the virtual address where it was created and in
> order to merge two VMAs page offsets need to follow up.
> Another problem when merging two faulted VMA's is their anon_vma. In
> current kernel these anon_vmas have to be the one and the same.
> Otherwise merge is again not allowed.
> There are several places from which vma_merge() is called and therefore
> several use cases that might profit from this upgrade. These include
> mmap (that fills a hole between two VMAs), mremap (that moves VMA next
> to another one or again perfectly fills a hole), mprotect (that modifies
> protection and allows merging with a neighbor) and brk (that expands VMA
> so that it is adjacent to a neighbor).
> Missed merge opportunities increase the number of VMAs of a process
> and in some cases can cause problems when a max count is reached.
Hm. You are talking about missed opportunities, but do you know any
workload that would measurably benefit from the change?
The changes are not trivial. And rmap code is complex enough as it is.
I expect common cases to get slower due to additional checks that do not
result in more merges. I donno, the effort looks dubious to me as of now.
--
Kirill A. Shutemov
Greeting,
FYI, we noticed the following commit (built with gcc-11):
commit: df8ef36a21db281bc4932e3d5c933d5bbb9a4217 ("[RFC PATCH v3 4/6] [PATCH 4/6] mm: adjust page offset in mremap")
url: https://github.com/intel-lab-lkp/linux/commits/Jakub-Mat-na/Removing-limitations-of-merging-anonymous-VMAs/20220516-205637
base: https://git.kernel.org/cgit/linux/kernel/git/kees/linux.git for-next/execve
patch link: https://lore.kernel.org/linux-mm/[email protected]
in testcase: stress-ng
version: stress-ng-x86_64-0.11-06_20220516
with following parameters:
nr_threads: 10%
disk: 1HDD
testtime: 60s
fs: ext4
class: vm
test: mremap
cpufreq_governor: performance
ucode: 0xb000280
on test machine: 96 threads 2 sockets Ice Lake with 256G memory
caused below changes (please refer to attached dmesg/kmsg for entire log/backtrace):
If you fix the issue, kindly add following tag
Reported-by: kernel test robot <[email protected]>
[ 75.109565][ T5714] kernel BUG at lib/list_debug.c:54!
[ 75.114893][ T5714] invalid opcode: 0000 [#1] SMP NOPTI
[ 75.120309][ T5714] CPU: 76 PID: 5714 Comm: stress-ng Not tainted 5.18.0-rc2-00007-gdf8ef36a21db #1
[ 75.129545][ T5714] RIP: 0010:__list_del_entry_valid.cold (lib/list_debug.c:54 (discriminator 3))
[ 75.136019][ T5714] Code: e8 e7 b5 fe ff 0f 0b 48 89 fe 48 c7 c7 80 80 59 82 e8 d6 b5 fe ff 0f 0b 48 89 d1 48 c7 c7 40 81 59 82 4c 89 c2 e8 c2 b5 fe ff <0f> 0b 48 89 f2 48 89 fe 48 c7 c7 f0 80 59 82 e8 ae b5 fe ff 0f 0b
All code
========
0: e8 e7 b5 fe ff callq 0xfffffffffffeb5ec
5: 0f 0b ud2
7: 48 89 fe mov %rdi,%rsi
a: 48 c7 c7 80 80 59 82 mov $0xffffffff82598080,%rdi
11: e8 d6 b5 fe ff callq 0xfffffffffffeb5ec
16: 0f 0b ud2
18: 48 89 d1 mov %rdx,%rcx
1b: 48 c7 c7 40 81 59 82 mov $0xffffffff82598140,%rdi
22: 4c 89 c2 mov %r8,%rdx
25: e8 c2 b5 fe ff callq 0xfffffffffffeb5ec
2a:* 0f 0b ud2 <-- trapping instruction
2c: 48 89 f2 mov %rsi,%rdx
2f: 48 89 fe mov %rdi,%rsi
32: 48 c7 c7 f0 80 59 82 mov $0xffffffff825980f0,%rdi
39: e8 ae b5 fe ff callq 0xfffffffffffeb5ec
3e: 0f 0b ud2
Code starting with the faulting instruction
===========================================
0: 0f 0b ud2
2: 48 89 f2 mov %rsi,%rdx
5: 48 89 fe mov %rdi,%rsi
8: 48 c7 c7 f0 80 59 82 mov $0xffffffff825980f0,%rdi
f: e8 ae b5 fe ff callq 0xfffffffffffeb5c2
14: 0f 0b ud2
[ 75.155902][ T5714] RSP: 0018:ffa000002439bc60 EFLAGS: 00010046
[ 75.162055][ T5714] RAX: 000000000000006d RBX: ff1100407ce65000 RCX: 0000000000000000
[ 75.170120][ T5714] RDX: 0000000000000000 RSI: ff11003fc891b740 RDI: ff11003fc891b740
[ 75.178188][ T5714] RBP: ffd4000084068000 R08: 0000000000000000 R09: 00000000ffff7fff
[ 75.186257][ T5714] R10: ffa000002439ba98 R11: ffffffff82bd8368 R12: ff11000108c13018
[ 75.194328][ T5714] R13: 0000000000000286 R14: 00007f0434110000 R15: ff1100407ce658c8
[ 75.202398][ T5714] FS: 00007f0437ca9740(0000) GS:ff11003fc8900000(0000) knlGS:0000000000000000
[ 75.211432][ T5714] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 75.218126][ T5714] CR2: 00007f0437f4f6dd CR3: 000000407c358002 CR4: 0000000000771ee0
[ 75.226214][ T5714] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 75.234289][ T5714] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[ 75.242364][ T5714] PKRU: 55555554
[ 75.246010][ T5714] Call Trace:
[ 75.249402][ T5714] <TASK>
[ 75.252448][ T5714] free_transhuge_page (include/linux/list.h:134 include/linux/list.h:148 mm/huge_memory.c:2634)
[ 75.257577][ T5714] release_pages (include/linux/mm.h:898 mm/swap.c:119 mm/swap.c:946)
[ 75.262277][ T5714] ? free_p4d_range (mm/memory.c:318)
[ 75.267150][ T5714] ? native_flush_tlb_local (arch/x86/include/asm/special_insns.h:48 (discriminator 9) arch/x86/mm/tlb.c:1165 (discriminator 9))
[ 75.272636][ T5714] ? flush_tlb_func (arch/x86/include/asm/paravirt.h:71 arch/x86/mm/tlb.c:1170 arch/x86/mm/tlb.c:842)
[ 75.277517][ T5714] tlb_finish_mmu (mm/mmu_gather.c:51 mm/mmu_gather.c:243 mm/mmu_gather.c:250 mm/mmu_gather.c:341)
[ 75.282228][ T5714] unmap_region (mm/mmap.c:2651 (discriminator 8))
[ 75.286765][ T5714] __do_munmap (include/linux/mm.h:2075 mm/mmap.c:2619 mm/mmap.c:2864)
[ 75.291294][ T5714] mremap_to (mm/mremap.c:898)
[ 75.295655][ T5714] __do_sys_mremap (mm/mremap.c:1042)
[ 75.300535][ T5714] do_syscall_64 (arch/x86/entry/common.c:50 arch/x86/entry/common.c:80)
[ 75.305069][ T5714] entry_SYSCALL_64_after_hwframe (arch/x86/entry/entry_64.S:115)
[ 75.311082][ T5714] RIP: 0033:0x7f0438036a4a
[ 75.315618][ T5714] Code: 73 01 c3 48 8b 0d 46 04 0c 00 f7 d8 64 89 01 48 83 c8 ff c3 66 2e 0f 1f 84 00 00 00 00 00 66 90 49 89 ca b8 19 00 00 00 0f 05 <48> 3d 01 f0 ff ff 73 01 c3 48 8b 0d 16 04 0c 00 f7 d8 64 89 01 48
All code
========
0: 73 01 jae 0x3
2: c3 retq
3: 48 8b 0d 46 04 0c 00 mov 0xc0446(%rip),%rcx # 0xc0450
a: f7 d8 neg %eax
c: 64 89 01 mov %eax,%fs:(%rcx)
f: 48 83 c8 ff or $0xffffffffffffffff,%rax
13: c3 retq
14: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
1b: 00 00 00
1e: 66 90 xchg %ax,%ax
20: 49 89 ca mov %rcx,%r10
23: b8 19 00 00 00 mov $0x19,%eax
28: 0f 05 syscall
2a:* 48 3d 01 f0 ff ff cmp $0xfffffffffffff001,%rax <-- trapping instruction
30: 73 01 jae 0x33
32: c3 retq
33: 48 8b 0d 16 04 0c 00 mov 0xc0416(%rip),%rcx # 0xc0450
3a: f7 d8 neg %eax
3c: 64 89 01 mov %eax,%fs:(%rcx)
3f: 48 rex.W
Code starting with the faulting instruction
===========================================
0: 48 3d 01 f0 ff ff cmp $0xfffffffffffff001,%rax
6: 73 01 jae 0x9
8: c3 retq
9: 48 8b 0d 16 04 0c 00 mov 0xc0416(%rip),%rcx # 0xc0426
10: f7 d8 neg %eax
12: 64 89 01 mov %eax,%fs:(%rcx)
15: 48 rex.W
[ 75.335612][ T5714] RSP: 002b:00007fffa46364f8 EFLAGS: 00000246 ORIG_RAX: 0000000000000019
[ 75.344156][ T5714] RAX: ffffffffffffffda RBX: 0000000000000064 RCX: 00007f0438036a4a
[ 75.352262][ T5714] RDX: 000000000071c400 RSI: 0000000000e38800 RDI: 00007f04339f3000
[ 75.360364][ T5714] RBP: 000000000071c400 R08: 00007f0434f46000 R09: 0000000000000000
[ 75.368466][ T5714] R10: 0000000000000003 R11: 0000000000000246 R12: 0000000000000003
[ 75.376558][ T5714] R13: 00007fffa4636580 R14: 000000000071d400 R15: 00007f0434f46000
[ 75.384650][ T5714] </TASK>
[ 75.387783][ T5714] Modules linked in: kmem dm_mod binfmt_misc device_dax nd_pmem nd_btt dax_pmem ipmi_ssif btrfs ast blake2b_generic drm_vram_helper xor drm_ttm_helper ttm raid6_pq zstd_compress drm_kms_helper libcrc32c syscopyarea nvme sysfillrect sd_mod sysimgblt nvme_core fb_sys_fops intel_rapl_msr intel_rapl_common sg x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel kvm t10_pi irqbypass crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel crc64_rocksoft_generic rapl ahci intel_cstate libahci crc64_rocksoft intel_uncore crc64 drm ioatdma libata joydev dca wmi acpi_ipmi ipmi_si ipmi_devintf ipmi_msghandler nfit libnvdimm acpi_pad acpi_power_meter ip_tables
[ 75.449256][ T5714] ---[ end trace 0000000000000000 ]---
[ 75.466176][ T5714] RIP: 0010:__list_del_entry_valid.cold (lib/list_debug.c:54 (discriminator 3))
[ 75.472732][ T5714] Code: e8 e7 b5 fe ff 0f 0b 48 89 fe 48 c7 c7 80 80 59 82 e8 d6 b5 fe ff 0f 0b 48 89 d1 48 c7 c7 40 81 59 82 4c 89 c2 e8 c2 b5 fe ff <0f> 0b 48 89 f2 48 89 fe 48 c7 c7 f0 80 59 82 e8 ae b5 fe ff 0f 0b
All code
========
0: e8 e7 b5 fe ff callq 0xfffffffffffeb5ec
5: 0f 0b ud2
7: 48 89 fe mov %rdi,%rsi
a: 48 c7 c7 80 80 59 82 mov $0xffffffff82598080,%rdi
11: e8 d6 b5 fe ff callq 0xfffffffffffeb5ec
16: 0f 0b ud2
18: 48 89 d1 mov %rdx,%rcx
1b: 48 c7 c7 40 81 59 82 mov $0xffffffff82598140,%rdi
22: 4c 89 c2 mov %r8,%rdx
25: e8 c2 b5 fe ff callq 0xfffffffffffeb5ec
2a:* 0f 0b ud2 <-- trapping instruction
2c: 48 89 f2 mov %rsi,%rdx
2f: 48 89 fe mov %rdi,%rsi
32: 48 c7 c7 f0 80 59 82 mov $0xffffffff825980f0,%rdi
39: e8 ae b5 fe ff callq 0xfffffffffffeb5ec
3e: 0f 0b ud2
Code starting with the faulting instruction
===========================================
0: 0f 0b ud2
2: 48 89 f2 mov %rsi,%rdx
5: 48 89 fe mov %rdi,%rsi
8: 48 c7 c7 f0 80 59 82 mov $0xffffffff825980f0,%rdi
f: e8 ae b5 fe ff callq 0xfffffffffffeb5c2
14: 0f 0b ud2
To reproduce:
git clone https://github.com/intel/lkp-tests.git
cd lkp-tests
sudo bin/lkp install job.yaml # job file is attached in this email
bin/lkp split-job --compatible job.yaml # generate the yaml file for lkp run
sudo bin/lkp run generated-yaml-file
# if come across any failure that blocks the test,
# please remove ~/.lkp and /lkp dir to run from a clean state.
--
0-DAY CI Kernel Test Service
https://01.org/lkp
Greeting,
FYI, we noticed the following commit (built with clang-15):
commit: d0a63efe2faccada7d878ed990e446aab96ec964 ("[RFC PATCH v3 5/6] [PATCH 5/6] mm: enable merging of VMAs with different anon_vmas")
url: https://github.com/intel-lab-lkp/linux/commits/Jakub-Mat-na/Removing-limitations-of-merging-anonymous-VMAs/20220516-205637
base: https://git.kernel.org/cgit/linux/kernel/git/kees/linux.git for-next/execve
patch link: https://lore.kernel.org/linux-mm/[email protected]
in testcase: trinity
version: trinity-static-i386-x86_64-f93256fb_2019-08-28
with following parameters:
runtime: 300s
group: group-03
test-description: Trinity is a linux system call fuzz tester.
test-url: http://codemonkey.org.uk/projects/trinity/
on test machine: qemu-system-i386 -enable-kvm -cpu SandyBridge -smp 2 -m 4G
caused below changes (please refer to attached dmesg/kmsg for entire log/backtrace):
If you fix the issue, kindly add following tag
Reported-by: kernel test robot <[email protected]>
[ 89.161564][ T3735] WARNING: CPU: 0 PID: 3735 at mm/rmap.c:416 reconnect_page_pte (rmap.c:?)
[ 89.162266][ T3735] Modules linked in: i2c_piix4
[ 89.162664][ T3735] CPU: 0 PID: 3735 Comm: trinity-c1 Not tainted 5.18.0-rc2-00008-gd0a63efe2fac #1 fe7dc62a49119a172a4e1ee5fa133e62ef344742
[ 89.163746][ T3735] EIP: reconnect_page_pte (rmap.c:?)
[ 89.164209][ T3735] Code: ff 0f 0b b8 10 84 64 c7 e8 b7 dc 15 00 48 83 78 1c 00 75 c4 ba 83 87 f9 c6 e8 86 af fe ff 0f 0b b8 10 84 64 c7 e8 9a dc 15 00 <0f> 0b 8b 47 44 3b 42 44 0f 85 48 ff ff ff 0f 0b e9 41 ff ff ff 00
All code
========
0: ff 0f decl (%rdi)
2: 0b b8 10 84 64 c7 or -0x389b7bf0(%rax),%edi
8: e8 b7 dc 15 00 callq 0x15dcc4
d: 48 83 78 1c 00 cmpq $0x0,0x1c(%rax)
12: 75 c4 jne 0xffffffffffffffd8
14: ba 83 87 f9 c6 mov $0xc6f98783,%edx
19: e8 86 af fe ff callq 0xfffffffffffeafa4
1e: 0f 0b ud2
20: b8 10 84 64 c7 mov $0xc7648410,%eax
25: e8 9a dc 15 00 callq 0x15dcc4
2a:* 0f 0b ud2 <-- trapping instruction
2c: 8b 47 44 mov 0x44(%rdi),%eax
2f: 3b 42 44 cmp 0x44(%rdx),%eax
32: 0f 85 48 ff ff ff jne 0xffffffffffffff80
38: 0f 0b ud2
3a: e9 41 ff ff ff jmpq 0xffffffffffffff80
...
Code starting with the faulting instruction
===========================================
0: 0f 0b ud2
2: 8b 47 44 mov 0x44(%rdi),%eax
5: 3b 42 44 cmp 0x44(%rdx),%eax
8: 0f 85 48 ff ff ff jne 0xffffffffffffff56
e: 0f 0b ud2
10: e9 41 ff ff ff jmpq 0xffffffffffffff56
...
[ 89.165822][ T3735] EAX: ebe211ef EBX: ee4c1df4 ECX: 00000081 EDX: ebf0f810
[ 89.166440][ T3735] ESI: e69cd260 EDI: ecbd5c30 EBP: ee4c1d50 ESP: ee4c1d44
[ 89.167002][ T3735] DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 0068 EFLAGS: 00010217
[ 89.167600][ T3735] CR0: 80050033 CR2: 00000001 CR3: 2be82000 CR4: 00040690
[ 89.168176][ T3735] Call Trace:
[ 89.168448][ T3735] ? reconnect_pages_range (rmap.c:?)
[ 89.168898][ T3735] walk_pte_range (fbdev.c:?)
[ 89.169289][ T3735] __walk_page_range (fbdev.c:?)
[ 89.169681][ T3735] reconnect_pages_range (fbdev.c:?)
[ 89.170096][ T3735] ? reconnect_pages_range (rmap.c:?)
[ 89.170528][ T3735] __vma_adjust (fbdev.c:?)
[ 89.170880][ T3735] ? lock_release (fbdev.c:?)
[ 89.171243][ T3735] vma_merge (fbdev.c:?)
[ 89.171593][ T3735] mprotect_fixup (fbdev.c:?)
[ 89.171984][ T3735] ? lock_is_held_type (fbdev.c:?)
[ 89.172421][ T3735] do_mprotect_pkey (mprotect.c:?)
[ 89.172833][ T3735] __ia32_sys_mprotect (fbdev.c:?)
[ 89.173251][ T3735] __do_fast_syscall_32 (common.c:?)
[ 89.173681][ T3735] ? irqentry_exit (fbdev.c:?)
[ 89.174079][ T3735] ? irqentry_exit_to_user_mode (fbdev.c:?)
[ 89.174559][ T3735] do_fast_syscall_32 (fbdev.c:?)
[ 89.174982][ T3735] do_SYSENTER_32 (fbdev.c:?)
[ 89.175364][ T3735] entry_SYSENTER_32 (??:?)
[ 89.175772][ T3735] EIP: 0xb7f7b509
[ 89.176080][ T3735] Code: b8 01 10 06 03 74 b4 01 10 07 03 74 b0 01 10 08 03 74 d8 01 00 00 00 00 00 00 00 00 00 00 00 00 00 51 52 55 89 e5 0f 34 cd 80 <5d> 5a 59 c3 90 90 90 90 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 44 00
All code
========
0: b8 01 10 06 03 mov $0x3061001,%eax
5: 74 b4 je 0xffffffffffffffbb
7: 01 10 add %edx,(%rax)
9: 07 (bad)
a: 03 74 b0 01 add 0x1(%rax,%rsi,4),%esi
e: 10 08 adc %cl,(%rax)
10: 03 74 d8 01 add 0x1(%rax,%rbx,8),%esi
...
20: 00 51 52 add %dl,0x52(%rcx)
23: 55 push %rbp
24: 89 e5 mov %esp,%ebp
26: 0f 34 sysenter
28: cd 80 int $0x80
2a:* 5d pop %rbp <-- trapping instruction
2b: 5a pop %rdx
2c: 59 pop %rcx
2d: c3 retq
2e: 90 nop
2f: 90 nop
30: 90 nop
31: 90 nop
32: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
39: 00 00 00
3c: 0f .byte 0xf
3d: 1f (bad)
3e: 44 rex.R
...
Code starting with the faulting instruction
===========================================
0: 5d pop %rbp
1: 5a pop %rdx
2: 59 pop %rcx
3: c3 retq
4: 90 nop
5: 90 nop
6: 90 nop
7: 90 nop
8: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
f: 00 00 00
12: 0f .byte 0xf
13: 1f (bad)
14: 44 rex.R
...
[ 89.177743][ T3735] EAX: ffffffda EBX: b3a00000 ECX: 00200000 EDX: 00000003
[ 89.178339][ T3735] ESI: b3a00000 EDI: 00200000 EBP: b7502000 ESP: bfea2918
[ 89.178937][ T3735] DS: 007b ES: 007b FS: 0000 GS: 0033 SS: 007b EFLAGS: 00000296
[ 89.179571][ T3735] irq event stamp: 1828581
[ 89.179940][ T3735] hardirqs last enabled at (1828589): __up_console_sem (printk.c:?)
[ 89.180705][ T3735] hardirqs last disabled at (1828596): __up_console_sem (printk.c:?)
[ 89.181450][ T3735] softirqs last enabled at (1822860): release_sock (fbdev.c:?)
[ 89.182112][ T3735] softirqs last disabled at (1822858): release_sock (fbdev.c:?)
[ 89.182805][ T3735] ---[ end trace 0000000000000000 ]---
[ 89.183277][ T3735] ------------[ cut here ]------------
To reproduce:
# build kernel
cd linux
cp config-5.18.0-rc2-00008-gd0a63efe2fac .config
make HOSTCC=clang-15 CC=clang-15 ARCH=i386 olddefconfig prepare modules_prepare bzImage modules
make HOSTCC=clang-15 CC=clang-15 ARCH=i386 INSTALL_MOD_PATH=<mod-install-dir> modules_install
cd <mod-install-dir>
find lib/ | cpio -o -H newc --quiet | gzip > modules.cgz
git clone https://github.com/intel/lkp-tests.git
cd lkp-tests
bin/lkp qemu -k <bzImage> -m modules.cgz job-script # job-script is attached in this email
# if come across any failure that blocks the test,
# please remove ~/.lkp and /lkp dir to run from a clean state.
--
0-DAY CI Kernel Test Service
https://01.org/lkp
On Fri, May 20, 2022 at 3:26 PM Kirill A. Shutemov <[email protected]> wrote:
>
> On Mon, May 16, 2022 at 02:54:00PM +0200, Jakub Matěna wrote:
> > Refactor vma_merge() to make it shorter, more understandable and
> > suitable for tracing of successful merges that are made possible by
> > following patches in the series. Main change is the elimination of code
> > duplicity in the case of merge next check. This is done by first doing
> > checks and caching the results before executing the merge itself. Exit
> > paths are also unified.
> >
> > Signed-off-by: Jakub Matěna <[email protected]>
>
> Okay, this looks good:
>
> Acked-by: Kirill A. Shutemov <[email protected]>
>
> I would also consider renaming 'area' to 'vma'. 'area' feels wrong to me,
> but maybe it is only me.
Well, the 'area' is taken from the original code and the name is not
the only thing wrong about it. It is actually used for two purposes,
which is definitely wrong. First purpose is to store the middle VMA
between prev and next for the use of case 8. And the second purpose is
to store the resulting VMA which is passed to
khugepaged_enter_vma_merge() and also the return value of vma_merge().
So, to me it seems that the best approach is to split it into two
variables 'mid' for the first purpose and 'res' for the second one.
>
> --
> Kirill A. Shutemov
On Fri, May 20, 2022 at 3:39 PM Kirill A. Shutemov <[email protected]> wrote:
>
> On Mon, May 16, 2022 at 02:54:01PM +0200, Jakub Matěna wrote:
> > When mremap call results in expansion, it might be possible to merge the
> > VMA with the next VMA which might become adjacent. This patch adds
> > vma_merge call after the expansion is done to try and merge.
> >
> > Signed-off-by: Jakub Matěna <[email protected]>
> > ---
> > mm/mremap.c | 7 +++++--
> > 1 file changed, 5 insertions(+), 2 deletions(-)
> >
> > diff --git a/mm/mremap.c b/mm/mremap.c
> > index 303d3290b938..75cda854ec58 100644
> > --- a/mm/mremap.c
> > +++ b/mm/mremap.c
> > @@ -9,6 +9,7 @@
> > */
> >
> > #include <linux/mm.h>
> > +#include <linux/mm_inline.h>
> > #include <linux/hugetlb.h>
> > #include <linux/shm.h>
> > #include <linux/ksm.h>
> > @@ -1022,8 +1023,10 @@ SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
> > }
> > }
> >
> > - if (vma_adjust(vma, vma->vm_start, addr + new_len,
> > - vma->vm_pgoff, NULL)) {
> > + if (!vma_merge(mm, vma, addr + old_len, addr + new_len,
> > + vma->vm_flags, vma->anon_vma, vma->vm_file,
> > + vma->vm_pgoff + (old_len >> PAGE_SHIFT), vma_policy(vma),
> > + vma->vm_userfaultfd_ctx, anon_vma_name(vma))) {
>
> Hm. Don't you need to update 'vma' with result of vma_merge()?
>
> 'vma' is used below the point and IIUC it can be use-after-free.
>
Actually, this merge call is always either case 1 or 2 as they are
defined in the vma_merge(). So, either way the 'vma' can absorb its
neighbors but never gets absorbed itself.
But you are right and I will add the update, because otherwise it
would depend on the vma_merge() implementation, which could possibly
change in the future and cause a bug.
> --
> Kirill A. Shutemov
On Mon, May 16, 2022 at 02:54:01PM +0200, Jakub Matěna wrote:
> When mremap call results in expansion, it might be possible to merge the
> VMA with the next VMA which might become adjacent. This patch adds
> vma_merge call after the expansion is done to try and merge.
>
> Signed-off-by: Jakub Matěna <[email protected]>
> ---
> mm/mremap.c | 7 +++++--
> 1 file changed, 5 insertions(+), 2 deletions(-)
>
> diff --git a/mm/mremap.c b/mm/mremap.c
> index 303d3290b938..75cda854ec58 100644
> --- a/mm/mremap.c
> +++ b/mm/mremap.c
> @@ -9,6 +9,7 @@
> */
>
> #include <linux/mm.h>
> +#include <linux/mm_inline.h>
> #include <linux/hugetlb.h>
> #include <linux/shm.h>
> #include <linux/ksm.h>
> @@ -1022,8 +1023,10 @@ SYSCALL_DEFINE5(mremap, unsigned long, addr, unsigned long, old_len,
> }
> }
>
> - if (vma_adjust(vma, vma->vm_start, addr + new_len,
> - vma->vm_pgoff, NULL)) {
> + if (!vma_merge(mm, vma, addr + old_len, addr + new_len,
> + vma->vm_flags, vma->anon_vma, vma->vm_file,
> + vma->vm_pgoff + (old_len >> PAGE_SHIFT), vma_policy(vma),
> + vma->vm_userfaultfd_ctx, anon_vma_name(vma))) {
Hm. Don't you need to update 'vma' with result of vma_merge()?
'vma' is used below the point and IIUC it can be use-after-free.
--
Kirill A. Shutemov
On Mon, May 16, 2022 at 02:54:00PM +0200, Jakub Matěna wrote:
> Refactor vma_merge() to make it shorter, more understandable and
> suitable for tracing of successful merges that are made possible by
> following patches in the series. Main change is the elimination of code
> duplicity in the case of merge next check. This is done by first doing
> checks and caching the results before executing the merge itself. Exit
> paths are also unified.
>
> Signed-off-by: Jakub Matěna <[email protected]>
Okay, this looks good:
Acked-by: Kirill A. Shutemov <[email protected]>
I would also consider renaming 'area' to 'vma'. 'area' feels wrong to me,
but maybe it is only me.
--
Kirill A. Shutemov
On 5/17/22 18:44, Kirill A. Shutemov wrote:
> On Mon, May 16, 2022 at 02:53:59PM +0200, Jakub Matěna wrote:
>> This is a series of patches that try to improve merge success rate when
>> VMAs are being moved, resized or otherwise modified.
>>
>> Motivation
>> In the current kernel it is impossible to merge two anonymous VMAs
>> if one of them was moved. That is because VMA's page offset is
>> set according to the virtual address where it was created and in
>> order to merge two VMAs page offsets need to follow up.
>> Another problem when merging two faulted VMA's is their anon_vma. In
>> current kernel these anon_vmas have to be the one and the same.
>> Otherwise merge is again not allowed.
>> There are several places from which vma_merge() is called and therefore
>> several use cases that might profit from this upgrade. These include
>> mmap (that fills a hole between two VMAs), mremap (that moves VMA next
>> to another one or again perfectly fills a hole), mprotect (that modifies
>> protection and allows merging with a neighbor) and brk (that expands VMA
>> so that it is adjacent to a neighbor).
>> Missed merge opportunities increase the number of VMAs of a process
>> and in some cases can cause problems when a max count is reached.
>
> Hm. You are talking about missed opportunities, but do you know any
> workload that would measurably benefit from the change?
We do know about a workload that originally inspired this investigation of
feasibility, but it's proprietary and will take a while to evaluate the
benefits there. We did hope that a public RFC could lead to discovering
others that also have a workload that would benefit, and might currently use
some userspace workarounds due to the existing limitations.
> The changes are not trivial. And rmap code is complex enough as it is.
True, it was one of the goals, to see how complex exactly it would be. And
an opportunity to better document related parts of mm as part of the master
thesis :)
> I expect common cases to get slower due to additional checks that do not
> result in more merges.
Stats so far have shown that merges that this enables did happen, only a few
percent cases didn't. Of course for many workloads the extra merges will not
bring much benefit. One possibility is to introduce an opt-in mode (prctl or
madvise?) for workloads that know they would benefit.
> I donno, the effort looks dubious to me as of now.
At least patches 1+2 could be considered immediately, as they don't bring
extra complexity.
A related issue which was brought to our attention is that current mremap()
implementation doesn't work on a range that spans multiple vma's. The
multiple vma's may be result of the current insufficient merging, or
otherwise. And it's tedious for userspace to discover the boundaries from
/proc/pid/maps to guide a mremap() vma by vma. More sucessful merging would
thus help, but it should be also possible to improve the mremap()
implementation, which shouldn't be as complex...
On Mon, 16 May 2022 14:54:05 +0200
Jakub Matěna <[email protected]> wrote:
> + TP_fast_assign(
> + __entry->merged = merged == 0;
> + __entry->predecessor_different_av = merge_prev;
> + __entry->successor_different_av = merge_next;
> + __entry->predecessor_with_successor_different_av = merge_both;
> + __entry->same_count = (merge_prev == AV_MERGE_SAME) +
> + (merge_next == AV_MERGE_SAME) +
> + (merge_both == AV_MERGE_SAME);
> + __entry->diff_count = (merge_prev == AV_MERGE_DIFFERENT) +
> + (merge_next == AV_MERGE_DIFFERENT) +
> + (merge_both == AV_MERGE_DIFFERENT);
> + __entry->failed_count = (merge_prev == AV_MERGE_FAILED) +
> + (merge_next == AV_MERGE_FAILED) +
> + (merge_both == AV_MERGE_FAILED);
The above looks like it can be moved into the TP_printk(), as you have the
merge_prev, next and both saved already. Why waste more ring buffer space
and execution time for information that can be derived at the time of
reading the trace event?
-- Steve
> + ),
> +
> + TP_printk("merged=%d predecessor=%s successor=%s predecessor_with_successor=%s same_count=%d diff_count=%d failed_count=%d",
> + __entry->merged,
> + __print_symbolic(__entry->predecessor_different_av, AV_MERGE_TYPES),
> + __print_symbolic(__entry->successor_different_av, AV_MERGE_TYPES),
> + __print_symbolic(__entry->predecessor_with_successor_different_av, AV_MERGE_TYPES),
> + __entry->same_count, __entry->diff_count, __entry->failed_count)
> +
> +);
> +
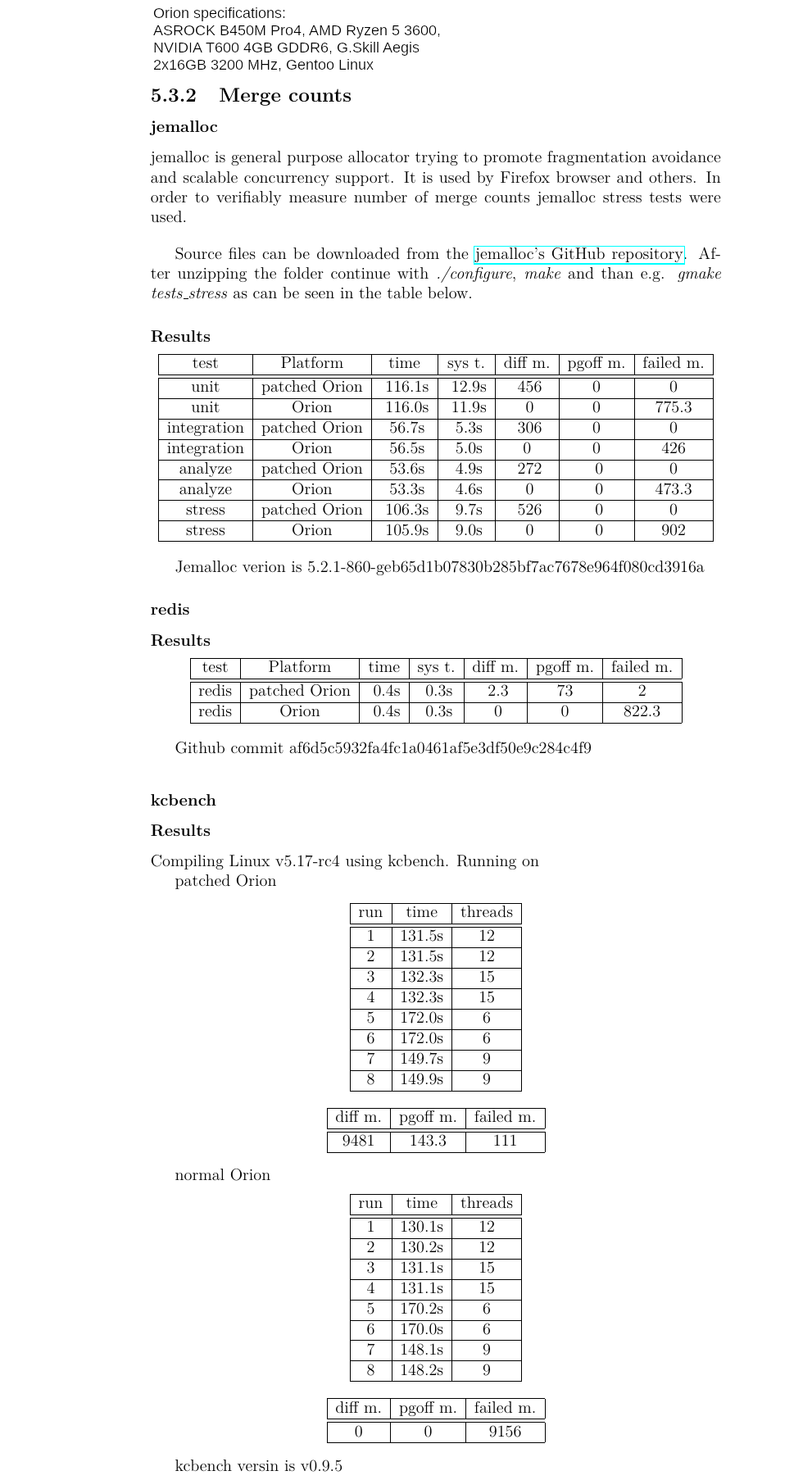{kind=link}