Hi All,
Thanks a lot for the feedback so far!
Respin after recent comments from Peter.
Patches [1-3] unmodified since v5, patch 4 is new and the other ones
have been updated to address feedback.
The previous summary that still applies:
On Sunday, March 4, 2018 11:21:30 PM CET Rafael J. Wysocki wrote:
>
> The problem is that if we stop the sched tick in
> tick_nohz_idle_enter() and then the idle governor predicts short idle
> duration, we lose regardless of whether or not it is right.
>
> If it is right, we've lost already, because we stopped the tick
> unnecessarily. If it is not right, we'll lose going forward, because
> the idle state selected by the governor is going to be too shallow and
> we'll draw too much power (that has been reported recently to actually
> happen often enough for people to care).
>
> This patch series is an attempt to improve the situation and the idea
> here is to make the decision whether or not to stop the tick deeper in
> the idle loop and in particular after running the idle state selection
> in the path where the idle governor is invoked. This way the problem
> can be avoided, because the idle duration predicted by the idle governor
> can be used to decide whether or not to stop the tick so that the tick
> is only stopped if that value is large enough (and, consequently, the
> idle state selected by the governor is deep enough).
>
> The series tires to avoid adding too much new code, rather reorder the
> existing code and make it more fine-grained.
>
> Patch 1 prepares the tick-sched code for the subsequent modifications and it
> doesn't change the code's functionality (at least not intentionally).
>
> Patch 2 starts pushing the tick stopping decision deeper into the idle
> loop, but that is limited to do_idle() and tick_nohz_irq_exit().
>
> Patch 3 makes cpuidle_idle_call() decide whether or not to stop the tick
> and sets the stage for the subsequent changes.
Patch 4 is a new one just for the TICK_USEC definition changes.
Patch 5 adds a bool pointer argument to cpuidle_select() and the ->select
governor callback allowing them to return a "nohz" hint on whether or not to
stop the tick to the caller. It also adds code to decide what value to
return as "nohz" to the menu governor and modifies its correction factor
computations to take running tick into account if need be.
Patch 6 reorders the idle state selection with respect to the stopping of
the tick and causes the additional "nohz" hint from cpuidle_select() to be
used for deciding whether or not to stop the tick.
Patch 7 causes the menu governor to refine the state selection in case the
tick is not going to be stopped and the already selected state may not fit
before the next tick time.
Patch 8 Deals with the situation in which the tick was stopped previously,
but the idle governor still predicts short idle.
This series is complementary to the poll_idle() patch at
https://patchwork.kernel.org/patch/10282237/
and I have update the idle-loop branch in my tree
git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
idle-loop
with the new patches.
Thanks,
Rafael
From: Rafael J. Wysocki <[email protected]>
Push the decision whether or not to stop the tick somewhat deeper
into the idle loop.
Stopping the tick upfront leads to unpleasant outcomes in case the
idle governor doesn't agree with the nohz code on the duration of the
upcoming idle period. Specifically, if the tick has been stopped and
the idle governor predicts short idle, the situation is bad regardless
of whether or not the prediction is accurate. If it is accurate, the
tick has been stopped unnecessarily which means excessive overhead.
If it is not accurate, the CPU is likely to spend too much time in
the (shallow, because short idle has been predicted) idle state
selected by the governor [1].
As the first step towards addressing this problem, change the code
to make the tick stopping decision inside of the loop in do_idle().
In particular, do not stop the tick in the cpu_idle_poll() code path.
Also don't do that in tick_nohz_irq_exit() which doesn't really have
enough information on whether or not to stop the tick.
Link: https://marc.info/?l=linux-pm&m=150116085925208&w=2 # [1]
Link: https://tu-dresden.de/zih/forschung/ressourcen/dateien/projekte/haec/powernightmares.pdf
Suggested-by: Frederic Weisbecker <[email protected]>
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
include/linux/tick.h | 2 ++
kernel/sched/idle.c | 9 ++++++---
kernel/time/tick-sched.c | 26 ++++++++++++++++++--------
3 files changed, 26 insertions(+), 11 deletions(-)
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -221,13 +221,13 @@ static void do_idle(void)
__current_set_polling();
tick_nohz_idle_enter();
- tick_nohz_idle_stop_tick_protected();
while (!need_resched()) {
check_pgt_cache();
rmb();
if (cpu_is_offline(cpu)) {
+ tick_nohz_idle_stop_tick_protected();
cpuhp_report_idle_dead();
arch_cpu_idle_dead();
}
@@ -241,10 +241,13 @@ static void do_idle(void)
* broadcast device expired for us, we don't want to go deep
* idle as we know that the IPI is going to arrive right away.
*/
- if (cpu_idle_force_poll || tick_check_broadcast_expired())
+ if (cpu_idle_force_poll || tick_check_broadcast_expired()) {
+ tick_nohz_idle_restart_tick();
cpu_idle_poll();
- else
+ } else {
+ tick_nohz_idle_stop_tick();
cpuidle_idle_call();
+ }
arch_cpu_idle_exit();
}
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -984,12 +984,10 @@ void tick_nohz_irq_exit(void)
{
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
- if (ts->inidle) {
+ if (ts->inidle)
tick_nohz_start_idle(ts);
- __tick_nohz_idle_stop_tick(ts);
- } else {
+ else
tick_nohz_full_update_tick(ts);
- }
}
/**
@@ -1050,6 +1048,20 @@ static void tick_nohz_account_idle_ticks
#endif
}
+static void __tick_nohz_idle_restart_tick(struct tick_sched *ts, ktime_t now)
+{
+ tick_nohz_restart_sched_tick(ts, now);
+ tick_nohz_account_idle_ticks(ts);
+}
+
+void tick_nohz_idle_restart_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, ktime_get());
+}
+
/**
* tick_nohz_idle_exit - restart the idle tick from the idle task
*
@@ -1074,10 +1086,8 @@ void tick_nohz_idle_exit(void)
if (ts->idle_active)
tick_nohz_stop_idle(ts, now);
- if (ts->tick_stopped) {
- tick_nohz_restart_sched_tick(ts, now);
- tick_nohz_account_idle_ticks(ts);
- }
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, now);
local_irq_enable();
}
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -115,6 +115,7 @@ enum tick_dep_bits {
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
extern void tick_nohz_idle_stop_tick(void);
+extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
@@ -135,6 +136,7 @@ static inline void tick_nohz_idle_stop_t
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
static inline void tick_nohz_idle_stop_tick(void) { }
+static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
From: Rafael J. Wysocki <[email protected]>
Since the subsequent changes will need a TICK_USEC definition
analogous to TICK_NSEC, rename the existing TICK_USEC as
USER_TICK_USEC, update its users and redefine TICK_USEC
accordingly.
Suggested-by: Peter Zijlstra <[email protected]>
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
drivers/net/ethernet/sfc/mcdi.c | 2 +-
include/linux/jiffies.h | 7 +++++--
kernel/time/ntp.c | 2 +-
3 files changed, 7 insertions(+), 4 deletions(-)
Index: linux-pm/include/linux/jiffies.h
===================================================================
--- linux-pm.orig/include/linux/jiffies.h
+++ linux-pm/include/linux/jiffies.h
@@ -62,8 +62,11 @@ extern int register_refined_jiffies(long
/* TICK_NSEC is the time between ticks in nsec assuming SHIFTED_HZ */
#define TICK_NSEC ((NSEC_PER_SEC+HZ/2)/HZ)
-/* TICK_USEC is the time between ticks in usec assuming fake USER_HZ */
-#define TICK_USEC ((1000000UL + USER_HZ/2) / USER_HZ)
+/* TICK_USEC is the time between ticks in usec assuming SHIFTED_HZ */
+#define TICK_USEC ((USEC_PER_SEC + HZ/2) / HZ)
+
+/* USER_TICK_USEC is the time between ticks in usec assuming fake USER_HZ */
+#define USER_TICK_USEC ((1000000UL + USER_HZ/2) / USER_HZ)
#ifndef __jiffy_arch_data
#define __jiffy_arch_data
Index: linux-pm/drivers/net/ethernet/sfc/mcdi.c
===================================================================
--- linux-pm.orig/drivers/net/ethernet/sfc/mcdi.c
+++ linux-pm/drivers/net/ethernet/sfc/mcdi.c
@@ -375,7 +375,7 @@ static int efx_mcdi_poll(struct efx_nic
* because generally mcdi responses are fast. After that, back off
* and poll once a jiffy (approximately)
*/
- spins = TICK_USEC;
+ spins = USER_TICK_USEC;
finish = jiffies + MCDI_RPC_TIMEOUT;
while (1) {
Index: linux-pm/kernel/time/ntp.c
===================================================================
--- linux-pm.orig/kernel/time/ntp.c
+++ linux-pm/kernel/time/ntp.c
@@ -31,7 +31,7 @@
/* USER_HZ period (usecs): */
-unsigned long tick_usec = TICK_USEC;
+unsigned long tick_usec = USER_TICK_USEC;
/* SHIFTED_HZ period (nsecs): */
unsigned long tick_nsec;
From: Rafael J. Wysocki <[email protected]>
Push the decision whether or not to stop the tick somewhat deeper
into the idle loop.
Stopping the tick upfront leads to unpleasant outcomes in case the
idle governor doesn't agree with the nohz code on the duration of the
upcoming idle period. Specifically, if the tick has been stopped and
the idle governor predicts short idle, the situation is bad regardless
of whether or not the prediction is accurate. If it is accurate, the
tick has been stopped unnecessarily which means excessive overhead.
If it is not accurate, the CPU is likely to spend too much time in
the (shallow, because short idle has been predicted) idle state
selected by the governor [1].
As the first step towards addressing this problem, change the code
to make the tick stopping decision inside of the loop in do_idle().
In particular, do not stop the tick in the cpu_idle_poll() code path.
Also don't do that in tick_nohz_irq_exit() which doesn't really have
enough information on whether or not to stop the tick.
Link: https://marc.info/?l=linux-pm&m=150116085925208&w=2 # [1]
Link: https://tu-dresden.de/zih/forschung/ressourcen/dateien/projekte/haec/powernightmares.pdf
Suggested-by: Frederic Weisbecker <[email protected]>
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
include/linux/tick.h | 2 ++
kernel/sched/idle.c | 9 ++++++---
kernel/time/tick-sched.c | 26 ++++++++++++++++++--------
3 files changed, 26 insertions(+), 11 deletions(-)
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -221,13 +221,13 @@ static void do_idle(void)
__current_set_polling();
tick_nohz_idle_enter();
- tick_nohz_idle_stop_tick_protected();
while (!need_resched()) {
check_pgt_cache();
rmb();
if (cpu_is_offline(cpu)) {
+ tick_nohz_idle_stop_tick_protected();
cpuhp_report_idle_dead();
arch_cpu_idle_dead();
}
@@ -241,10 +241,13 @@ static void do_idle(void)
* broadcast device expired for us, we don't want to go deep
* idle as we know that the IPI is going to arrive right away.
*/
- if (cpu_idle_force_poll || tick_check_broadcast_expired())
+ if (cpu_idle_force_poll || tick_check_broadcast_expired()) {
+ tick_nohz_idle_restart_tick();
cpu_idle_poll();
- else
+ } else {
+ tick_nohz_idle_stop_tick();
cpuidle_idle_call();
+ }
arch_cpu_idle_exit();
}
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -984,12 +984,10 @@ void tick_nohz_irq_exit(void)
{
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
- if (ts->inidle) {
+ if (ts->inidle)
tick_nohz_start_idle(ts);
- __tick_nohz_idle_stop_tick(ts);
- } else {
+ else
tick_nohz_full_update_tick(ts);
- }
}
/**
@@ -1050,6 +1048,20 @@ static void tick_nohz_account_idle_ticks
#endif
}
+static void __tick_nohz_idle_restart_tick(struct tick_sched *ts, ktime_t now)
+{
+ tick_nohz_restart_sched_tick(ts, now);
+ tick_nohz_account_idle_ticks(ts);
+}
+
+void tick_nohz_idle_restart_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, ktime_get());
+}
+
/**
* tick_nohz_idle_exit - restart the idle tick from the idle task
*
@@ -1074,10 +1086,8 @@ void tick_nohz_idle_exit(void)
if (ts->idle_active)
tick_nohz_stop_idle(ts, now);
- if (ts->tick_stopped) {
- tick_nohz_restart_sched_tick(ts, now);
- tick_nohz_account_idle_ticks(ts);
- }
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, now);
local_irq_enable();
}
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -115,6 +115,7 @@ enum tick_dep_bits {
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
extern void tick_nohz_idle_stop_tick(void);
+extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
@@ -135,6 +136,7 @@ static inline void tick_nohz_idle_stop_t
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
static inline void tick_nohz_idle_stop_tick(void) { }
+static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
From: Rafael J. Wysocki <[email protected]>
Prepare the scheduler tick code for reworking the idle loop to
avoid stopping the tick in some cases.
The idea is to split the nohz idle entry call to decouple the idle
time stats accounting and preparatory work from the actual tick stop
code, in order to later be able to delay the tick stop once we reach
more power-knowledgeable callers.
Move away the tick_nohz_start_idle() invocation from
__tick_nohz_idle_enter(), rename the latter to
__tick_nohz_idle_stop_tick() and define tick_nohz_idle_stop_tick()
as a wrapper around it for calling it from the outside.
Make tick_nohz_idle_enter() only call tick_nohz_start_idle() instead
of calling the entire __tick_nohz_idle_enter(), add another wrapper
disabling and enabling interrupts around tick_nohz_idle_stop_tick()
and make the current callers of tick_nohz_idle_enter() call it too
to retain their current functionality.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
arch/x86/xen/smp_pv.c | 1 +
include/linux/tick.h | 12 ++++++++++++
kernel/sched/idle.c | 1 +
kernel/time/tick-sched.c | 46 +++++++++++++++++++++++++---------------------
4 files changed, 39 insertions(+), 21 deletions(-)
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -114,6 +114,7 @@ enum tick_dep_bits {
#ifdef CONFIG_NO_HZ_COMMON
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
+extern void tick_nohz_idle_stop_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
@@ -122,9 +123,18 @@ extern unsigned long tick_nohz_get_idle_
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
extern u64 get_cpu_idle_time_us(int cpu, u64 *last_update_time);
extern u64 get_cpu_iowait_time_us(int cpu, u64 *last_update_time);
+
+static inline void tick_nohz_idle_stop_tick_protected(void)
+{
+ local_irq_disable();
+ tick_nohz_idle_stop_tick();
+ local_irq_enable();
+}
+
#else /* !CONFIG_NO_HZ_COMMON */
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
+static inline void tick_nohz_idle_stop_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
@@ -134,6 +144,8 @@ static inline ktime_t tick_nohz_get_slee
}
static inline u64 get_cpu_idle_time_us(int cpu, u64 *unused) { return -1; }
static inline u64 get_cpu_iowait_time_us(int cpu, u64 *unused) { return -1; }
+
+static inline void tick_nohz_idle_stop_tick_protected(void) { }
#endif /* !CONFIG_NO_HZ_COMMON */
#ifdef CONFIG_NO_HZ_FULL
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -539,14 +539,11 @@ static void tick_nohz_stop_idle(struct t
sched_clock_idle_wakeup_event();
}
-static ktime_t tick_nohz_start_idle(struct tick_sched *ts)
+static void tick_nohz_start_idle(struct tick_sched *ts)
{
- ktime_t now = ktime_get();
-
- ts->idle_entrytime = now;
+ ts->idle_entrytime = ktime_get();
ts->idle_active = 1;
sched_clock_idle_sleep_event();
- return now;
}
/**
@@ -911,19 +908,21 @@ static bool can_stop_idle_tick(int cpu,
return true;
}
-static void __tick_nohz_idle_enter(struct tick_sched *ts)
+static void __tick_nohz_idle_stop_tick(struct tick_sched *ts)
{
- ktime_t now, expires;
+ ktime_t expires;
int cpu = smp_processor_id();
- now = tick_nohz_start_idle(ts);
-
if (can_stop_idle_tick(cpu, ts)) {
int was_stopped = ts->tick_stopped;
ts->idle_calls++;
- expires = tick_nohz_stop_sched_tick(ts, now, cpu);
+ /*
+ * The idle entry time should be a sufficient approximation of
+ * the current time at this point.
+ */
+ expires = tick_nohz_stop_sched_tick(ts, ts->idle_entrytime, cpu);
if (expires > 0LL) {
ts->idle_sleeps++;
ts->idle_expires = expires;
@@ -937,16 +936,19 @@ static void __tick_nohz_idle_enter(struc
}
/**
- * tick_nohz_idle_enter - stop the idle tick from the idle task
+ * tick_nohz_idle_stop_tick - stop the idle tick from the idle task
*
* When the next event is more than a tick into the future, stop the idle tick
- * Called when we start the idle loop.
- *
- * The arch is responsible of calling:
+ */
+void tick_nohz_idle_stop_tick(void)
+{
+ __tick_nohz_idle_stop_tick(this_cpu_ptr(&tick_cpu_sched));
+}
+
+/**
+ * tick_nohz_idle_enter - prepare for entering idle on the current CPU
*
- * - rcu_idle_enter() after its last use of RCU before the CPU is put
- * to sleep.
- * - rcu_idle_exit() before the first use of RCU after the CPU is woken up.
+ * Called when we start the idle loop.
*/
void tick_nohz_idle_enter(void)
{
@@ -965,7 +967,7 @@ void tick_nohz_idle_enter(void)
ts = this_cpu_ptr(&tick_cpu_sched);
ts->inidle = 1;
- __tick_nohz_idle_enter(ts);
+ tick_nohz_start_idle(ts);
local_irq_enable();
}
@@ -982,10 +984,12 @@ void tick_nohz_irq_exit(void)
{
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
- if (ts->inidle)
- __tick_nohz_idle_enter(ts);
- else
+ if (ts->inidle) {
+ tick_nohz_start_idle(ts);
+ __tick_nohz_idle_stop_tick(ts);
+ } else {
tick_nohz_full_update_tick(ts);
+ }
}
/**
Index: linux-pm/arch/x86/xen/smp_pv.c
===================================================================
--- linux-pm.orig/arch/x86/xen/smp_pv.c
+++ linux-pm/arch/x86/xen/smp_pv.c
@@ -425,6 +425,7 @@ static void xen_pv_play_dead(void) /* us
* data back is to call:
*/
tick_nohz_idle_enter();
+ tick_nohz_idle_stop_tick_protected();
cpuhp_online_idle(CPUHP_AP_ONLINE_IDLE);
}
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -221,6 +221,7 @@ static void do_idle(void)
__current_set_polling();
tick_nohz_idle_enter();
+ tick_nohz_idle_stop_tick_protected();
while (!need_resched()) {
check_pgt_cache();
From: Rafael J. Wysocki <[email protected]>
In order to address the issue with short idle duration predictions
by the idle governor after the tick has been stopped, reorder the
code in cpuidle_idle_call() so that the governor idle state selection
runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
by cpuidle_select() to decide whether or not to stop the tick.
This isn't straightforward, because menu_select() invokes
tick_nohz_get_sleep_length() to get the time to the next timer
event and the number returned by the latter comes from
__tick_nohz_idle_enter(). Fortunately, however, it is possible
to compute that number without actually stopping the tick and with
the help of the existing code.
Namely, notice that tick_nohz_stop_sched_tick() already computes the
next timer event time to reprogram the scheduler tick hrtimer and
that time can be used as a proxy for the actual next timer event
time in the idle duration predicition. Moreover, it is possible
to split tick_nohz_stop_sched_tick() into two separate routines,
one computing the time to the next timer event and the other
simply stopping the tick when the time to the next timer event
is known.
Accordingly, split tick_nohz_stop_sched_tick() into
tick_nohz_next_event() and tick_nohz_stop_tick() and use the
former in tick_nohz_get_sleep_length(). Add two new extra fields,
timer_expires and timer_expires_base, to struct tick_sched for
passing data between these two new functions and to indicate that
tick_nohz_next_event() has run and tick_nohz_stop_tick() can be
called now. Also drop the now redundant sleep_length field from
there.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v5 -> v7:
* Rebase on top of the new [5/8].
---
include/linux/tick.h | 2
kernel/sched/idle.c | 11 ++-
kernel/time/tick-sched.c | 156 +++++++++++++++++++++++++++++++----------------
kernel/time/tick-sched.h | 6 +
4 files changed, 120 insertions(+), 55 deletions(-)
Index: linux-pm/kernel/time/tick-sched.h
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.h
+++ linux-pm/kernel/time/tick-sched.h
@@ -38,7 +38,8 @@ enum tick_nohz_mode {
* @idle_exittime: Time when the idle state was left
* @idle_sleeptime: Sum of the time slept in idle with sched tick stopped
* @iowait_sleeptime: Sum of the time slept in idle with sched tick stopped, with IO outstanding
- * @sleep_length: Duration of the current idle sleep
+ * @timer_expires: Anticipated timer expiration time (in case sched tick is stopped)
+ * @timer_expires_base: Base time clock monotonic for @timer_expires
* @do_timer_lst: CPU was the last one doing do_timer before going idle
*/
struct tick_sched {
@@ -58,8 +59,9 @@ struct tick_sched {
ktime_t idle_exittime;
ktime_t idle_sleeptime;
ktime_t iowait_sleeptime;
- ktime_t sleep_length;
unsigned long last_jiffies;
+ u64 timer_expires;
+ u64 timer_expires_base;
u64 next_timer;
ktime_t idle_expires;
int do_timer_last;
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -190,13 +190,18 @@ static void cpuidle_idle_call(void)
} else {
bool stop_tick = true;
- tick_nohz_idle_stop_tick();
- rcu_idle_enter();
-
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
next_state = cpuidle_select(drv, dev, &stop_tick);
+
+ if (stop_tick)
+ tick_nohz_idle_stop_tick();
+ else
+ tick_nohz_idle_retain_tick();
+
+ rcu_idle_enter();
+
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -652,13 +652,10 @@ static inline bool local_timer_softirq_p
return local_softirq_pending() & TIMER_SOFTIRQ;
}
-static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
- ktime_t now, int cpu)
+static ktime_t tick_nohz_next_event(struct tick_sched *ts, int cpu)
{
- struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
u64 basemono, next_tick, next_tmr, next_rcu, delta, expires;
unsigned long seq, basejiff;
- ktime_t tick;
/* Read jiffies and the time when jiffies were updated last */
do {
@@ -667,6 +664,7 @@ static ktime_t tick_nohz_stop_sched_tick
basejiff = jiffies;
} while (read_seqretry(&jiffies_lock, seq));
ts->last_jiffies = basejiff;
+ ts->timer_expires_base = basemono;
/*
* Keep the periodic tick, when RCU, architecture or irq_work
@@ -711,31 +709,24 @@ static ktime_t tick_nohz_stop_sched_tick
* next period, so no point in stopping it either, bail.
*/
if (!ts->tick_stopped) {
- tick = 0;
+ ts->timer_expires = 0;
goto out;
}
}
/*
- * If this CPU is the one which updates jiffies, then give up
- * the assignment and let it be taken by the CPU which runs
- * the tick timer next, which might be this CPU as well. If we
- * don't drop this here the jiffies might be stale and
- * do_timer() never invoked. Keep track of the fact that it
- * was the one which had the do_timer() duty last. If this CPU
- * is the one which had the do_timer() duty last, we limit the
- * sleep time to the timekeeping max_deferment value.
+ * If this CPU is the one which had the do_timer() duty last, we limit
+ * the sleep time to the timekeeping max_deferment value.
* Otherwise we can sleep as long as we want.
*/
delta = timekeeping_max_deferment();
- if (cpu == tick_do_timer_cpu) {
- tick_do_timer_cpu = TICK_DO_TIMER_NONE;
- ts->do_timer_last = 1;
- } else if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
- delta = KTIME_MAX;
- ts->do_timer_last = 0;
- } else if (!ts->do_timer_last) {
- delta = KTIME_MAX;
+ if (cpu != tick_do_timer_cpu) {
+ if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
+ delta = KTIME_MAX;
+ ts->do_timer_last = 0;
+ } else if (!ts->do_timer_last) {
+ delta = KTIME_MAX;
+ }
}
#ifdef CONFIG_NO_HZ_FULL
@@ -750,14 +741,40 @@ static ktime_t tick_nohz_stop_sched_tick
else
expires = KTIME_MAX;
- expires = min_t(u64, expires, next_tick);
- tick = expires;
+ ts->timer_expires = min_t(u64, expires, next_tick);
+
+out:
+ return ts->timer_expires;
+}
+
+static void tick_nohz_stop_tick(struct tick_sched *ts, int cpu)
+{
+ struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
+ u64 basemono = ts->timer_expires_base;
+ u64 expires = ts->timer_expires;
+ ktime_t tick = expires;
+
+ /* Make sure we won't be trying to stop it twice in a row. */
+ ts->timer_expires_base = 0;
+
+ /*
+ * If this CPU is the one which updates jiffies, then give up
+ * the assignment and let it be taken by the CPU which runs
+ * the tick timer next, which might be this CPU as well. If we
+ * don't drop this here the jiffies might be stale and
+ * do_timer() never invoked. Keep track of the fact that it
+ * was the one which had the do_timer() duty last.
+ */
+ if (cpu == tick_do_timer_cpu) {
+ tick_do_timer_cpu = TICK_DO_TIMER_NONE;
+ ts->do_timer_last = 1;
+ }
/* Skip reprogram of event if its not changed */
if (ts->tick_stopped && (expires == ts->next_tick)) {
/* Sanity check: make sure clockevent is actually programmed */
if (tick == KTIME_MAX || ts->next_tick == hrtimer_get_expires(&ts->sched_timer))
- goto out;
+ return;
WARN_ON_ONCE(1);
printk_once("basemono: %llu ts->next_tick: %llu dev->next_event: %llu timer->active: %d timer->expires: %llu\n",
@@ -791,7 +808,7 @@ static ktime_t tick_nohz_stop_sched_tick
if (unlikely(expires == KTIME_MAX)) {
if (ts->nohz_mode == NOHZ_MODE_HIGHRES)
hrtimer_cancel(&ts->sched_timer);
- goto out;
+ return;
}
hrtimer_set_expires(&ts->sched_timer, tick);
@@ -800,15 +817,23 @@ static ktime_t tick_nohz_stop_sched_tick
hrtimer_start_expires(&ts->sched_timer, HRTIMER_MODE_ABS_PINNED);
else
tick_program_event(tick, 1);
-out:
- /*
- * Update the estimated sleep length until the next timer
- * (not only the tick).
- */
- ts->sleep_length = ktime_sub(dev->next_event, now);
- return tick;
}
+static void tick_nohz_retain_tick(struct tick_sched *ts)
+{
+ ts->timer_expires_base = 0;
+}
+
+#ifdef CONFIG_NO_HZ_FULL
+static void tick_nohz_stop_sched_tick(struct tick_sched *ts, int cpu)
+{
+ if (tick_nohz_next_event(ts, cpu))
+ tick_nohz_stop_tick(ts, cpu);
+ else
+ tick_nohz_retain_tick(ts);
+}
+#endif /* CONFIG_NO_HZ_FULL */
+
static void tick_nohz_restart_sched_tick(struct tick_sched *ts, ktime_t now)
{
/* Update jiffies first */
@@ -844,7 +869,7 @@ static void tick_nohz_full_update_tick(s
return;
if (can_stop_full_tick(cpu, ts))
- tick_nohz_stop_sched_tick(ts, ktime_get(), cpu);
+ tick_nohz_stop_sched_tick(ts, cpu);
else if (ts->tick_stopped)
tick_nohz_restart_sched_tick(ts, ktime_get());
#endif
@@ -870,10 +895,8 @@ static bool can_stop_idle_tick(int cpu,
return false;
}
- if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE)) {
- ts->sleep_length = NSEC_PER_SEC / HZ;
+ if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE))
return false;
- }
if (need_resched())
return false;
@@ -913,25 +936,33 @@ static void __tick_nohz_idle_stop_tick(s
ktime_t expires;
int cpu = smp_processor_id();
- if (can_stop_idle_tick(cpu, ts)) {
+ /*
+ * If tick_nohz_get_sleep_length() ran tick_nohz_next_event(), the
+ * tick timer expiration time is known already.
+ */
+ if (ts->timer_expires_base)
+ expires = ts->timer_expires;
+ else if (can_stop_idle_tick(cpu, ts))
+ expires = tick_nohz_next_event(ts, cpu);
+ else
+ return;
+
+ ts->idle_calls++;
+
+ if (expires > 0LL) {
int was_stopped = ts->tick_stopped;
- ts->idle_calls++;
+ tick_nohz_stop_tick(ts, cpu);
- /*
- * The idle entry time should be a sufficient approximation of
- * the current time at this point.
- */
- expires = tick_nohz_stop_sched_tick(ts, ts->idle_entrytime, cpu);
- if (expires > 0LL) {
- ts->idle_sleeps++;
- ts->idle_expires = expires;
- }
+ ts->idle_sleeps++;
+ ts->idle_expires = expires;
if (!was_stopped && ts->tick_stopped) {
ts->idle_jiffies = ts->last_jiffies;
nohz_balance_enter_idle(cpu);
}
+ } else {
+ tick_nohz_retain_tick(ts);
}
}
@@ -945,6 +976,11 @@ void tick_nohz_idle_stop_tick(void)
__tick_nohz_idle_stop_tick(this_cpu_ptr(&tick_cpu_sched));
}
+void tick_nohz_idle_retain_tick(void)
+{
+ tick_nohz_retain_tick(this_cpu_ptr(&tick_cpu_sched));
+}
+
/**
* tick_nohz_idle_enter - prepare for entering idle on the current CPU
*
@@ -957,7 +993,7 @@ void tick_nohz_idle_enter(void)
lockdep_assert_irqs_enabled();
/*
* Update the idle state in the scheduler domain hierarchy
- * when tick_nohz_stop_sched_tick() is called from the idle loop.
+ * when tick_nohz_stop_tick() is called from the idle loop.
* State will be updated to busy during the first busy tick after
* exiting idle.
*/
@@ -966,6 +1002,9 @@ void tick_nohz_idle_enter(void)
local_irq_disable();
ts = this_cpu_ptr(&tick_cpu_sched);
+
+ WARN_ON_ONCE(ts->timer_expires_base);
+
ts->inidle = 1;
tick_nohz_start_idle(ts);
@@ -1005,15 +1044,31 @@ bool tick_nohz_idle_got_tick(void)
}
/**
- * tick_nohz_get_sleep_length - return the length of the current sleep
+ * tick_nohz_get_sleep_length - return the expected length of the current sleep
*
* Called from power state control code with interrupts disabled
*/
ktime_t tick_nohz_get_sleep_length(void)
{
+ struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+ int cpu = smp_processor_id();
+ /*
+ * The idle entry time is expected to be a sufficient approximation of
+ * the current time at this point.
+ */
+ ktime_t now = ts->idle_entrytime;
+
+ WARN_ON_ONCE(!ts->inidle);
+
+ if (can_stop_idle_tick(cpu, ts)) {
+ ktime_t next_event = tick_nohz_next_event(ts, cpu);
+
+ if (next_event)
+ return ktime_sub(next_event, now);
+ }
- return ts->sleep_length;
+ return ktime_sub(dev->next_event, now);
}
/**
@@ -1091,6 +1146,7 @@ void tick_nohz_idle_exit(void)
local_irq_disable();
WARN_ON_ONCE(!ts->inidle);
+ WARN_ON_ONCE(ts->timer_expires_base);
ts->inidle = 0;
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -115,6 +115,7 @@ enum tick_dep_bits {
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
extern void tick_nohz_idle_stop_tick(void);
+extern void tick_nohz_idle_retain_tick(void);
extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
@@ -137,6 +138,7 @@ static inline void tick_nohz_idle_stop_t
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
static inline void tick_nohz_idle_stop_tick(void) { }
+static inline void tick_nohz_idle_retain_tick(void) { }
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
From: Rafael J. Wysocki <[email protected]>
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0, or
(2) the selected state is a polling one, or
(3) the expected idle period duration is within the tick period
range.
In addition to that, the correction factor computations in the menu
governor need to take the possibility that the tick may not be
stopped into account to avoid artificially small correction factor
values. To that end, add a mechanism to record tick wakeups, as
suggested by Peter Zijlstra, and use it to modify the menu_update()
behavior when tick wakeup occurs. Namely, make it add a (sufficiently
large) constant value to the correction factor in these cases (instead
of increasing the correction factor by a value based on the
measured idle time).
Since the value returned through the new argument pointer of
cpuidle_select() is not used by its caller yet, this change by
itself is not expected to alter the functionality of the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v5 -> v7:
* Rename the new cpuidle_select() arg (and some related things) from
"nohz" to "stop_tick" (as requested by Peter).
* Use TICK_USEC from the previous patch.
* Record tick wakeups (as suggested by Peter) and use them to take the
tick into account in menu_update().
---
drivers/cpuidle/cpuidle.c | 10 +++-
drivers/cpuidle/governors/ladder.c | 3 -
drivers/cpuidle/governors/menu.c | 81 ++++++++++++++++++++++++++-----------
include/linux/cpuidle.h | 8 ++-
include/linux/tick.h | 2
kernel/sched/idle.c | 4 +
kernel/time/tick-sched.c | 20 +++++++++
7 files changed, 98 insertions(+), 30 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *stop_tick)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool stop_tick = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &stop_tick);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @stop_tick: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @stop_tick is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, stop_tick);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -123,6 +123,7 @@
struct menu_device {
int last_state_idx;
int needs_update;
+ int tick_wakeup;
unsigned int next_timer_us;
unsigned int predicted_us;
@@ -279,8 +280,10 @@ again:
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @stop_tick: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +306,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *stop_tick = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +359,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = data->predicted_us;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -369,15 +375,30 @@ static int menu_select(struct cpuidle_dr
idx = i; /* first enabled state */
if (s->target_residency > data->predicted_us)
break;
- if (s->exit_latency > latency_req)
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons, use
+ * the target residency of the selected state as the
+ * expected idle duration so that the tick is retained
+ * as long as that target residency is low enough.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or if the
+ * expected idle duration is shorter than the tick period length.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC)
+ *stop_tick = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
@@ -397,6 +418,7 @@ static void menu_reflect(struct cpuidle_
data->last_state_idx = index;
data->needs_update = 1;
+ data->tick_wakeup = tick_nohz_idle_got_tick();
}
/**
@@ -427,31 +449,44 @@ static void menu_update(struct cpuidle_d
* assume the state was never reached and the exit latency is 0.
*/
- /* measured value */
- measured_us = cpuidle_get_last_residency(dev);
-
- /* Deduct exit latency */
- if (measured_us > 2 * target->exit_latency)
- measured_us -= target->exit_latency;
- else
- measured_us /= 2;
-
- /* Make sure our coefficients do not exceed unity */
- if (measured_us > data->next_timer_us)
- measured_us = data->next_timer_us;
-
/* Update our correction ratio */
new_factor = data->correction_factor[data->bucket];
new_factor -= new_factor / DECAY;
- if (data->next_timer_us > 0 && measured_us < MAX_INTERESTING)
- new_factor += RESOLUTION * measured_us / data->next_timer_us;
- else
+ if (data->tick_wakeup) {
/*
- * we were idle so long that we count it as a perfect
- * prediction
+ * If the CPU was woken up by the tick, it might have been idle
+ * for a much longer time if the tick had been stopped. That
+ * time cannot be determined, so asssume that it would have been
+ * long, but not as long as the original return value of
+ * tick_nohz_get_sleep_length(). Use a number between 0.5 and
+ * 1, something like 0.75 (which is easy enough to get), that
+ * should work on the average.
*/
- new_factor += RESOLUTION;
+ new_factor += RESOLUTION / 2 + RESOLUTION / 4;
+ } else {
+ /* measured value */
+ measured_us = cpuidle_get_last_residency(dev);
+
+ /* Deduct exit latency */
+ if (measured_us > 2 * target->exit_latency)
+ measured_us -= target->exit_latency;
+ else
+ measured_us /= 2;
+
+ /* Make sure our coefficients do not exceed unity */
+ if (measured_us > data->next_timer_us)
+ measured_us = data->next_timer_us;
+
+ if (data->next_timer_us > 0 && measured_us < MAX_INTERESTING)
+ new_factor += RESOLUTION * measured_us / data->next_timer_us;
+ else
+ /*
+ * we were idle so long that we count it as a perfect
+ * prediction
+ */
+ new_factor += RESOLUTION;
+ }
/*
* We don't want 0 as factor; we always want at least
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -991,6 +991,20 @@ void tick_nohz_irq_exit(void)
}
/**
+ * tick_nohz_idle_got_tick - Check whether or not the tick handler has run
+ */
+bool tick_nohz_idle_got_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->inidle > 1) {
+ ts->inidle = 1;
+ return true;
+ }
+ return false;
+}
+
+/**
* tick_nohz_get_sleep_length - return the length of the current sleep
*
* Called from power state control code with interrupts disabled
@@ -1101,6 +1115,9 @@ static void tick_nohz_handler(struct clo
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
dev->next_event = KTIME_MAX;
tick_sched_do_timer(now);
@@ -1198,6 +1215,9 @@ static enum hrtimer_restart tick_sched_t
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
tick_sched_do_timer(now);
/*
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -119,6 +119,7 @@ extern void tick_nohz_idle_restart_tick(
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
+extern bool tick_nohz_idle_got_tick(void);
extern ktime_t tick_nohz_get_sleep_length(void);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
@@ -139,6 +140,7 @@ static inline void tick_nohz_idle_stop_t
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
+static inline bool tick_nohz_idle_got_tick(void) { return false; }
static inline ktime_t tick_nohz_get_sleep_length(void)
{
From: Rafael J. Wysocki <[email protected]>
If the scheduler tick has been stopped already and the governor
selects a shallow idle state, the CPU can spend a long time in that
state if the selection is based on an inaccurate prediction of idle
time. That effect turns out to be relevant, so it needs to be
mitigated.
To that end, modify the menu governor to discard the result of the
idle time prediction if the tick is stopped and the predicted idle
time is less than the tick period length, unless the tick timer is
going to expire soon.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v5 -> v7:
* Rebase on top of the new [5-7/8].
Note that the problem tackled here may be addressed in a couple of other
ways in principle.
---
drivers/cpuidle/governors/menu.c | 29 ++++++++++++++++++++++-------
1 file changed, 22 insertions(+), 7 deletions(-)
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -352,13 +352,28 @@ static int menu_select(struct cpuidle_dr
*/
data->predicted_us = min(data->predicted_us, expected_interval);
- /*
- * Use the performance multiplier and the user-configurable
- * latency_req to determine the maximum exit latency.
- */
- interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
- if (latency_req > interactivity_req)
- latency_req = interactivity_req;
+ if (tick_nohz_tick_stopped()) {
+ /*
+ * If the tick is already stopped, the cost of possible short
+ * idle duration misprediction is much higher, because the CPU
+ * may be stuck in a shallow idle state for a long time as a
+ * result of it. In that case say we might mispredict and try
+ * to force the CPU into a state for which we would have stopped
+ * the tick, unless the tick timer is going to expire really
+ * soon anyway.
+ */
+ if (data->predicted_us < TICK_USEC)
+ data->predicted_us = min_t(unsigned int, TICK_USEC,
+ ktime_to_us(delta_next));
+ } else {
+ /*
+ * Use the performance multiplier and the user-configurable
+ * latency_req to determine the maximum exit latency.
+ */
+ interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
+ if (latency_req > interactivity_req)
+ latency_req = interactivity_req;
+ }
expected_interval = data->predicted_us;
/*
From: Rafael J. Wysocki <[email protected]>
Subject: [PATCH] cpuidle: menu: Refine idle state selection for running tick
If the tick isn't stopped, the target residency of the state selected
by the menu governor may be greater than the actual time to the next
tick and that means lost energy.
To avoid that, make tick_nohz_get_sleep_length() return the current
time to the next event (before stopping the tick) in addition to the
estimated one via an extra pointer argument and make menu_select()
use that value to refine the state selection when necessary.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v5 -> v7:
* Rebase on top of the new [5-6/8].
* Rename the new argument of tick_nohz_get_sleep_length() to
"delta_next" (as requested by Peter).
---
drivers/cpuidle/governors/menu.c | 22 ++++++++++++++++++++--
include/linux/tick.h | 7 ++++---
kernel/time/tick-sched.c | 7 +++++--
3 files changed, 29 insertions(+), 7 deletions(-)
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -121,7 +121,7 @@ extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
extern bool tick_nohz_idle_got_tick(void);
-extern ktime_t tick_nohz_get_sleep_length(void);
+extern ktime_t tick_nohz_get_sleep_length(ktime_t *delta_next);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
extern u64 get_cpu_idle_time_us(int cpu, u64 *last_update_time);
@@ -144,9 +144,10 @@ static inline void tick_nohz_idle_enter(
static inline void tick_nohz_idle_exit(void) { }
static inline bool tick_nohz_idle_got_tick(void) { return false; }
-static inline ktime_t tick_nohz_get_sleep_length(void)
+static inline ktime_t tick_nohz_get_sleep_length(ktime_t *delta_next)
{
- return NSEC_PER_SEC / HZ;
+ *delta_next = NSEC_PER_SEC / HZ;
+ return *delta_next;
}
static inline u64 get_cpu_idle_time_us(int cpu, u64 *unused) { return -1; }
static inline u64 get_cpu_iowait_time_us(int cpu, u64 *unused) { return -1; }
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -1045,10 +1045,11 @@ bool tick_nohz_idle_got_tick(void)
/**
* tick_nohz_get_sleep_length - return the expected length of the current sleep
+ * @delta_next: duration until the next event if the tick cannot be stopped
*
* Called from power state control code with interrupts disabled
*/
-ktime_t tick_nohz_get_sleep_length(void)
+ktime_t tick_nohz_get_sleep_length(ktime_t *delta_next)
{
struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
@@ -1061,6 +1062,8 @@ ktime_t tick_nohz_get_sleep_length(void)
WARN_ON_ONCE(!ts->inidle);
+ *delta_next = ktime_sub(dev->next_event, now);
+
if (can_stop_idle_tick(cpu, ts)) {
ktime_t next_event = tick_nohz_next_event(ts, cpu);
@@ -1068,7 +1071,7 @@ ktime_t tick_nohz_get_sleep_length(void)
return ktime_sub(next_event, now);
}
- return ktime_sub(dev->next_event, now);
+ return *delta_next;
}
/**
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -295,6 +295,7 @@ static int menu_select(struct cpuidle_dr
unsigned int expected_interval;
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
+ ktime_t delta_next;
if (data->needs_update) {
menu_update(drv, dev);
@@ -312,7 +313,7 @@ static int menu_select(struct cpuidle_dr
}
/* determine the expected residency time, round up */
- data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
+ data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length(&delta_next));
get_iowait_load(&nr_iowaiters, &cpu_load);
data->bucket = which_bucket(data->next_timer_us, nr_iowaiters);
@@ -396,9 +397,26 @@ static int menu_select(struct cpuidle_dr
* expected idle duration is shorter than the tick period length.
*/
if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
- expected_interval < TICK_USEC)
+ expected_interval < TICK_USEC) {
*stop_tick = false;
+ if (!tick_nohz_tick_stopped()) {
+ unsigned int delta_next_us = ktime_to_us(delta_next);
+
+ /*
+ * Because the tick is not going to be stopped, make
+ * sure that the target residency of the state to be
+ * returned is within the time to the next timer event
+ * including the tick.
+ */
+ while (idx > 0 &&
+ (drv->states[idx].target_residency > delta_next_us ||
+ drv->states[idx].disabled ||
+ dev->states_usage[idx].disable))
+ idx--;
+ }
+ }
+
data->last_state_idx = idx;
return data->last_state_idx;
I am just trying to catch up. Switching to 4.16-rc6 and
this new patch set.
I think this patch 3/8 is incorrect, and is actually
patch 2/8 repeated.
I'll see if I can just apply the old v5 patch 3/7,
and move on.
On 2018.03.20 08:16 Rafael J. Wysocki wrote:
...[snip]...
From: Rafael J. Wysocki <[email protected]>
Make cpuidle_idle_call() decide whether or not to stop the tick.
First, the cpuidle_enter_s2idle() path deals with the tick (and with
the entire timekeeping for that matter) by itself and it doesn't need
the tick to be stopped beforehand.
Second, to address the issue with short idle duration predictions
by the idle governor after the tick has been stopped, it will be
necessary to change the ordering of cpuidle_select() with respect
to tick_nohz_idle_stop_tick(). To prepare for that, put a
tick_nohz_idle_stop_tick() call in the same branch in which
cpuidle_select() is called.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
The correct patch this time.
---
kernel/sched/idle.c | 19 +++++++++++++++----
1 file changed, 15 insertions(+), 4 deletions(-)
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -146,13 +146,15 @@ static void cpuidle_idle_call(void)
}
/*
- * Tell the RCU framework we are entering an idle section,
- * so no more rcu read side critical sections and one more
+ * The RCU framework needs to be told that we are entering an idle
+ * section, so no more rcu read side critical sections and one more
* step to the grace period
*/
- rcu_idle_enter();
if (cpuidle_not_available(drv, dev)) {
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
default_idle_call();
goto exit_idle;
}
@@ -169,16 +171,26 @@ static void cpuidle_idle_call(void)
if (idle_should_enter_s2idle() || dev->use_deepest_state) {
if (idle_should_enter_s2idle()) {
+ rcu_idle_enter();
+
entered_state = cpuidle_enter_s2idle(drv, dev);
if (entered_state > 0) {
local_irq_enable();
goto exit_idle;
}
+
+ rcu_idle_exit();
}
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
@@ -245,7 +257,6 @@ static void do_idle(void)
tick_nohz_idle_restart_tick();
cpu_idle_poll();
} else {
- tick_nohz_idle_stop_tick();
cpuidle_idle_call();
}
arch_cpu_idle_exit();
On Tue, Mar 20, 2018 at 6:52 PM, Doug Smythies <[email protected]> wrote:
> I am just trying to catch up. Switching to 4.16-rc6 and
> this new patch set.
>
> I think this patch 3/8 is incorrect, and is actually
> patch 2/8 repeated.
Yes, it is, sorry about that.
I've just sent the correct one in a reply to this message.
> I'll see if I can just apply the old v5 patch 3/7,
> and move on.
It should apply, it hasn't changed since v5.
Thanks!
From: Rafael J. Wysocki <[email protected]>
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0, or
(2) the selected state is a polling one, or
(3) the expected idle period duration is within the tick period
range.
In addition to that, the correction factor computations in the menu
governor need to take the possibility that the tick may not be
stopped into account to avoid artificially small correction factor
values. To that end, add a mechanism to record tick wakeups, as
suggested by Peter Zijlstra, and use it to modify the menu_reflect()
behavior when tick wakeup occurs. Namely, if the CPU is woken up by
the tick, the predicted idle duration is likely too short, so make
menu_reflect() try to compensate by bumping up the correction factor
with a (sufficiently large) constant value.
Since the value returned through the new argument pointer of
cpuidle_select() is not used by its caller yet, this change by
itself is not expected to alter the functionality of the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
Another variant of patch [5/8] to test.
This one doesn't run menu_update() at all on tick wakeups, but simply
bumps up the correction factor alone then.
It may give better results, but please test and compare.
I have created a git branch with this variant for easier testing:
git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
idle-loop-v7.1
---
drivers/cpuidle/cpuidle.c | 10 ++++++-
drivers/cpuidle/governors/ladder.c | 3 +-
drivers/cpuidle/governors/menu.c | 49 +++++++++++++++++++++++++++++++++----
include/linux/cpuidle.h | 8 +++---
include/linux/tick.h | 2 +
kernel/sched/idle.c | 4 ++-
kernel/time/tick-sched.c | 20 +++++++++++++++
7 files changed, 84 insertions(+), 12 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *stop_tick)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool stop_tick = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &stop_tick);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @stop_tick: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @stop_tick is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, stop_tick);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -279,8 +279,10 @@ again:
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @stop_tick: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +305,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *stop_tick = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +358,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = data->predicted_us;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -369,15 +374,30 @@ static int menu_select(struct cpuidle_dr
idx = i; /* first enabled state */
if (s->target_residency > data->predicted_us)
break;
- if (s->exit_latency > latency_req)
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons, use
+ * the target residency of the selected state as the
+ * expected idle duration so that the tick is retained
+ * as long as that target residency is low enough.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or if the
+ * expected idle duration is shorter than the tick period length.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC)
+ *stop_tick = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
@@ -396,7 +416,26 @@ static void menu_reflect(struct cpuidle_
struct menu_device *data = this_cpu_ptr(&menu_devices);
data->last_state_idx = index;
- data->needs_update = 1;
+ if (tick_nohz_idle_got_tick()) {
+ unsigned int new_factor = data->correction_factor[data->bucket];
+
+ /*
+ * Only update the correction factor, don't update the repeating
+ * pattern data to avoid polluting it with the tick period
+ * length which is an artificial addition.
+ */
+ new_factor -= new_factor / DECAY;
+ /*
+ * If the CPU was woken up by the tick, the predicted idle time
+ * was likely too short. Try to compensate by bumping up the
+ * correction factor. Use 0.75 * RESOLUTION (which is easy
+ * enough to get) that should work on the average.
+ */
+ new_factor += RESOLUTION / 2 + RESOLUTION / 4;
+ data->correction_factor[data->bucket] = new_factor;
+ } else {
+ data->needs_update = 1;
+ }
}
/**
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -991,6 +991,20 @@ void tick_nohz_irq_exit(void)
}
/**
+ * tick_nohz_idle_got_tick - Check whether or not the tick handler has run
+ */
+bool tick_nohz_idle_got_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->inidle > 1) {
+ ts->inidle = 1;
+ return true;
+ }
+ return false;
+}
+
+/**
* tick_nohz_get_sleep_length - return the length of the current sleep
*
* Called from power state control code with interrupts disabled
@@ -1101,6 +1115,9 @@ static void tick_nohz_handler(struct clo
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
dev->next_event = KTIME_MAX;
tick_sched_do_timer(now);
@@ -1198,6 +1215,9 @@ static enum hrtimer_restart tick_sched_t
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
tick_sched_do_timer(now);
/*
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -119,6 +119,7 @@ extern void tick_nohz_idle_restart_tick(
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
+extern bool tick_nohz_idle_got_tick(void);
extern ktime_t tick_nohz_get_sleep_length(void);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
@@ -139,6 +140,7 @@ static inline void tick_nohz_idle_stop_t
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
+static inline bool tick_nohz_idle_got_tick(void) { return false; }
static inline ktime_t tick_nohz_get_sleep_length(void)
{
On Wed, Mar 21, 2018 at 7:48 AM, Rafael J. Wysocki <[email protected]> wrote:
> From: Rafael J. Wysocki <[email protected]>
>
> Add a new pointer argument to cpuidle_select() and to the ->select
> cpuidle governor callback to allow a boolean value indicating
> whether or not the tick should be stopped before entering the
> selected state to be returned from there.
>
> Make the ladder governor ignore that pointer (to preserve its
> current behavior) and make the menu governor return 'false" through
> it if:
> (1) the idle exit latency is constrained at 0, or
> (2) the selected state is a polling one, or
> (3) the expected idle period duration is within the tick period
> range.
>
> In addition to that, the correction factor computations in the menu
> governor need to take the possibility that the tick may not be
> stopped into account to avoid artificially small correction factor
> values. To that end, add a mechanism to record tick wakeups, as
> suggested by Peter Zijlstra, and use it to modify the menu_reflect()
> behavior when tick wakeup occurs. Namely, if the CPU is woken up by
> the tick, the predicted idle duration is likely too short, so make
> menu_reflect() try to compensate by bumping up the correction factor
> with a (sufficiently large) constant value.
>
> Since the value returned through the new argument pointer of
> cpuidle_select() is not used by its caller yet, this change by
> itself is not expected to alter the functionality of the code.
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
>
> Another variant of patch [5/8] to test.
>
> This one doesn't run menu_update() at all on tick wakeups, but simply
> bumps up the correction factor alone then.
I have overlooked one thing in this patch and in the original v7 of it.
Namely, tick wakeups occurring when the return value of
tick_nohz_get_sleep_length() is within the tick boundary should be
treated as normal wakeups, because the nohz code itself doesn't stop
the tick then even without this patch series.
I'll rework this patch for that and will send an update shortly.
Thanks!
On Tue, 2018-03-20 at 16:12 +0100, Rafael J. Wysocki wrote:
> Hi All,
>
> Thanks a lot for the feedback so far!
>
> Respin after recent comments from Peter.
>
> Patches [1-3] unmodified since v5, patch 4 is new and the other ones
> have been updated to address feedback.
>
> The previous summary that still applies:
For some reason I see increased CPU utilization
with this patch series (75% -> 85%) with the same
rate of requests being handled by the vanilla
kernel and a kernel with these patches applied.
I am running a bisect in the series to see what
change could possibly cause that, and also digging
through system statistics to see whether it might
be something as perverse as not mistakenly choosing
deeper C-states on one core causing other cores to
miss out on turbo mode...
--
All Rights Reversed.
From: Rafael J. Wysocki <[email protected]>
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0, or
(2) the selected state is a polling one, or
(3) the expected idle period duration is within the tick period
range.
In addition to that, the correction factor computations in the menu
governor need to take the possibility that the tick may not be
stopped into account to avoid artificially small correction factor
values. To that end, add a mechanism to record tick wakeups, as
suggested by Peter Zijlstra, and use it to modify the menu_reflect()
behavior when tick wakeup occurs. Namely, if the CPU is woken up by
the tick and the return value of tick_nohz_get_sleep_length() is not
within the tick boundary, the predicted idle duration is likely too
short, so make menu_reflect() try to compensate for that by bumping
up the correction factor with a (sufficiently large) constant value.
Since the value returned through the new argument pointer of
cpuidle_select() is not used by its caller yet, this change by
itself is not expected to alter the functionality of the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
This fixes the bug in the v7.1 of patch [5/8] (and in the original v7 of it
for that matter) by which tick wakeups occurring for tick_nohz_get_sleep_length()
return values within the tick boundary were treated in a special way
incorrectly.
It doesn't run menu_update() on tick wakeups occurring when the return
value of tick_nohz_get_sleep_length() is not within the tick boundary, but
simply bumps up the correction factor alone then.
From the theoretical standpoint this is my favorite version of patch [5/8]
so far, as there's a clear (to me at least) reason for all of the changes.
Of course, the constant value used for bumping up the correction factor in
menu_reflect() is a matter of speculation at this point, but this is the
only remaining sort of moving part I can see. And it can be adjusted later. :-)
Still, the theory needs to meet practice and we'll see what comes out of that ...
Thanks!
---
drivers/cpuidle/cpuidle.c | 10 +++++-
drivers/cpuidle/governors/ladder.c | 3 +
drivers/cpuidle/governors/menu.c | 57 +++++++++++++++++++++++++++++++++----
include/linux/cpuidle.h | 8 +++--
include/linux/tick.h | 2 +
kernel/sched/idle.c | 4 +-
kernel/time/tick-sched.c | 20 ++++++++++++
7 files changed, 92 insertions(+), 12 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *stop_tick)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool stop_tick = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &stop_tick);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @stop_tick: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @stop_tick is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, stop_tick);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -279,8 +279,10 @@ again:
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @stop_tick: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +305,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *stop_tick = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +358,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = data->predicted_us;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -369,15 +374,30 @@ static int menu_select(struct cpuidle_dr
idx = i; /* first enabled state */
if (s->target_residency > data->predicted_us)
break;
- if (s->exit_latency > latency_req)
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons, use
+ * the target residency of the selected state as the
+ * expected idle duration so that the tick is retained
+ * as long as that target residency is low enough.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or if the
+ * expected idle duration is shorter than the tick period length.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC)
+ *stop_tick = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
@@ -396,7 +416,34 @@ static void menu_reflect(struct cpuidle_
struct menu_device *data = this_cpu_ptr(&menu_devices);
data->last_state_idx = index;
- data->needs_update = 1;
+ /*
+ * Tick wakeups occurring when the tick_nohz_get_sleep_length() return
+ * value is within the tick boundary should be treated as regular ones,
+ * as the nohz code itself doesn't stop the tick then.
+ */
+ if (tick_nohz_idle_got_tick() && data->next_timer_us > TICK_USEC) {
+ unsigned int new_factor = data->correction_factor[data->bucket];
+
+ /*
+ * Only update the correction factor, don't update the repeating
+ * pattern data to avoid polluting it with the tick period
+ * length which is a design artifact here.
+ */
+ new_factor -= new_factor / DECAY;
+ /*
+ * The nohz code said that there wouldn't be any wakeups
+ * within the tick boundary (if the tick wasn't stopped), but
+ * menu_select() had a differing opinion. Yet, the CPU was
+ * woken up by the tick, so menu_select() was not quite right.
+ * Try to make it do a better job next time by bumping up the
+ * correction factor. Use 0.75 * RESOLUTION (which is easy
+ * enough to get) that should work fine on the average.
+ */
+ new_factor += RESOLUTION / 2 + RESOLUTION / 4;
+ data->correction_factor[data->bucket] = new_factor;
+ } else {
+ data->needs_update = 1;
+ }
}
/**
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -991,6 +991,20 @@ void tick_nohz_irq_exit(void)
}
/**
+ * tick_nohz_idle_got_tick - Check whether or not the tick handler has run
+ */
+bool tick_nohz_idle_got_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->inidle > 1) {
+ ts->inidle = 1;
+ return true;
+ }
+ return false;
+}
+
+/**
* tick_nohz_get_sleep_length - return the length of the current sleep
*
* Called from power state control code with interrupts disabled
@@ -1101,6 +1115,9 @@ static void tick_nohz_handler(struct clo
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
dev->next_event = KTIME_MAX;
tick_sched_do_timer(now);
@@ -1198,6 +1215,9 @@ static enum hrtimer_restart tick_sched_t
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
tick_sched_do_timer(now);
/*
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -119,6 +119,7 @@ extern void tick_nohz_idle_restart_tick(
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
+extern bool tick_nohz_idle_got_tick(void);
extern ktime_t tick_nohz_get_sleep_length(void);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
@@ -139,6 +140,7 @@ static inline void tick_nohz_idle_stop_t
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
+static inline bool tick_nohz_idle_got_tick(void) { return false; }
static inline ktime_t tick_nohz_get_sleep_length(void)
{
On Wednesday, March 21, 2018 1:31:07 PM CET Rik van Riel wrote:
> On Tue, 2018-03-20 at 16:12 +0100, Rafael J. Wysocki wrote:
> > Hi All,
> >
> > Thanks a lot for the feedback so far!
> >
> > Respin after recent comments from Peter.
> >
> > Patches [1-3] unmodified since v5, patch 4 is new and the other ones
> > have been updated to address feedback.
> >
> > The previous summary that still applies:
Thanks for the testing!
> For some reason I see increased CPU utilization
> with this patch series (75% -> 85%) with the same
> rate of requests being handled by the vanilla
> kernel and a kernel with these patches applied.
>
> I am running a bisect in the series to see what
> change could possibly cause that,
The first 4 patches in the v7 should not change functionality by
themselves.
If you replace the original [5/8] with the v7.2 of it I've just
posted (https://patchwork.kernel.org/patch/10299429/), then it
should not change functionality by itself too.
Then you only have 3 patches to check. :-)
> and also digging
> through system statistics to see whether it might
> be something as perverse as not mistakenly choosing
> deeper C-states on one core causing other cores to
> miss out on turbo mode...
I have no idea ATM. And what's the workload?
On Tue, Mar 20, 2018 at 4:45 PM, Rafael J. Wysocki <[email protected]> wrote:
> From: Rafael J. Wysocki <[email protected]>
>
> Add a new pointer argument to cpuidle_select() and to the ->select
> cpuidle governor callback to allow a boolean value indicating
> whether or not the tick should be stopped before entering the
> selected state to be returned from there.
>
> Make the ladder governor ignore that pointer (to preserve its
> current behavior) and make the menu governor return 'false" through
> it if:
> (1) the idle exit latency is constrained at 0, or
> (2) the selected state is a polling one, or
> (3) the expected idle period duration is within the tick period
> range.
>
> In addition to that, the correction factor computations in the menu
> governor need to take the possibility that the tick may not be
> stopped into account to avoid artificially small correction factor
> values. To that end, add a mechanism to record tick wakeups, as
> suggested by Peter Zijlstra, and use it to modify the menu_update()
> behavior when tick wakeup occurs. Namely, make it add a (sufficiently
> large) constant value to the correction factor in these cases (instead
> of increasing the correction factor by a value based on the
> measured idle time).
>
> Since the value returned through the new argument pointer of
> cpuidle_select() is not used by its caller yet, this change by
> itself is not expected to alter the functionality of the code.
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
>
> v5 -> v7:
> * Rename the new cpuidle_select() arg (and some related things) from
> "nohz" to "stop_tick" (as requested by Peter).
> * Use TICK_USEC from the previous patch.
> * Record tick wakeups (as suggested by Peter) and use them to take the
> tick into account in menu_update().
[cut]
> @@ -427,31 +449,44 @@ static void menu_update(struct cpuidle_d
> * assume the state was never reached and the exit latency is 0.
> */
>
> - /* measured value */
> - measured_us = cpuidle_get_last_residency(dev);
> -
> - /* Deduct exit latency */
> - if (measured_us > 2 * target->exit_latency)
> - measured_us -= target->exit_latency;
> - else
> - measured_us /= 2;
> -
> - /* Make sure our coefficients do not exceed unity */
> - if (measured_us > data->next_timer_us)
> - measured_us = data->next_timer_us;
> -
> /* Update our correction ratio */
> new_factor = data->correction_factor[data->bucket];
> new_factor -= new_factor / DECAY;
>
> - if (data->next_timer_us > 0 && measured_us < MAX_INTERESTING)
> - new_factor += RESOLUTION * measured_us / data->next_timer_us;
> - else
> + if (data->tick_wakeup) {
This should check if data->next_timer_us is greater than TICK_USEC
too, but also the measured_us computation needs to go before it (or
uninitialized measured_us will be used later on if this branch is
executed).
So please disregard this one entirely and take the v7.2 replacement
instead of it: https://patchwork.kernel.org/patch/10299429/
The current versions (including the above) is in the git branch at
git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
idle-loop-v7.2
> /*
> - * we were idle so long that we count it as a perfect
> - * prediction
> + * If the CPU was woken up by the tick, it might have been idle
> + * for a much longer time if the tick had been stopped. That
> + * time cannot be determined, so asssume that it would have been
> + * long, but not as long as the original return value of
> + * tick_nohz_get_sleep_length(). Use a number between 0.5 and
> + * 1, something like 0.75 (which is easy enough to get), that
> + * should work on the average.
> */
> - new_factor += RESOLUTION;
> + new_factor += RESOLUTION / 2 + RESOLUTION / 4;
> + } else {
> + /* measured value */
> + measured_us = cpuidle_get_last_residency(dev);
> +
> + /* Deduct exit latency */
> + if (measured_us > 2 * target->exit_latency)
> + measured_us -= target->exit_latency;
> + else
> + measured_us /= 2;
> +
> + /* Make sure our coefficients do not exceed unity */
> + if (measured_us > data->next_timer_us)
> + measured_us = data->next_timer_us;
> +
> + if (data->next_timer_us > 0 && measured_us < MAX_INTERESTING)
> + new_factor += RESOLUTION * measured_us / data->next_timer_us;
> + else
> + /*
> + * we were idle so long that we count it as a perfect
> + * prediction
> + */
> + new_factor += RESOLUTION;
> + }
>
> /*
> * We don't want 0 as factor; we always want at least
On Wed, 2018-03-21 at 14:55 +0100, Rafael J. Wysocki wrote:
> On Wednesday, March 21, 2018 1:31:07 PM CET Rik van Riel wrote:
> > On Tue, 2018-03-20 at 16:12 +0100, Rafael J. Wysocki wrote:
> > > Hi All,
> > >
> > > Thanks a lot for the feedback so far!
> > >
> > > Respin after recent comments from Peter.
> > >
> > > Patches [1-3] unmodified since v5, patch 4 is new and the other
> > > ones
> > > have been updated to address feedback.
> > >
> > > The previous summary that still applies:
>
> Thanks for the testing!
>
> > For some reason I see increased CPU utilization
> > with this patch series (75% -> 85%) with the same
> > rate of requests being handled by the vanilla
> > kernel and a kernel with these patches applied.
> >
> > I am running a bisect in the series to see what
> > change could possibly cause that,
>
> The first 4 patches in the v7 should not change functionality by
> themselves.
>
> If you replace the original [5/8] with the v7.2 of it I've just
> posted (https://patchwork.kernel.org/patch/10299429/), then it
> should not change functionality by itself too.
>
> Then you only have 3 patches to check. :-)
I kicked off a test with your v7.2 series first.
I have the idle poll loop rework in the mix, too.
I will check the last 3 patches bit by bit through
today, and will let you know which causes the issue.
I will also try to figure out what the issue is,
if I can :)
> > and also digging
> > through system statistics to see whether it might
> > be something as perverse as not mistakenly choosing
> > deeper C-states on one core causing other cores to
> > miss out on turbo mode...
>
> I have no idea ATM. And what's the workload?
The workload is memcache style, with equal
queries coming in to both the system running
the control kernel, and the system running
the test kernel.
On the control system, CPU utilization is
around 75%, while on the test system it is
up to 85% - for the same number of queries.
--
All Rights Reversed.
On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>
> So please disregard this one entirely and take the v7.2 replacement
> instead of it:https://patchwork.kernel.org/patch/10299429/
>
> The current versions (including the above) is in the git branch at
>
> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> idle-loop-v7.2
With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
as with v5: several cores which just keep the sched tick enabled.
Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
full sched tick.
The resulting power consumption is ~105 W instead of ~ 70 W.
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
I have briefly ran v7 and I believe it was also affected.
On 2018.03.21 11:00 Thomas Ilsche wrote:
> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>>
>> So please disregard this one entirely and take the v7.2 replacement
>> instead of it:https://patchwork.kernel.org/patch/10299429/
>>
>> The current versions (including the above) is in the git branch at
>>
>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>> idle-loop-v7.2
>
> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
> as with v5: several cores which just keep the sched tick enabled.
> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
> full sched tick.
> The resulting power consumption is ~105 W instead of ~ 70 W.
>
> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
>
> I have briefly ran v7 and I believe it was also affected.
I am not able to repeat your issues anymore.
Idle powers were fine with V7, on my test computer.
I have not done thorough idle tests with V7.2, but they looked O.K.
As for the high frequency loop stuff, I no longer see any issues there
either. I tried several loops frequencies, and did one for a couple of hours.
I'll try again later today, as there is a test running now (frequency sweep)
that takes about 4 hours.
... Doug
On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche
<[email protected]> wrote:
> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>>
>>
>> So please disregard this one entirely and take the v7.2 replacement
>> instead of it:https://patchwork.kernel.org/patch/10299429/
>>
>> The current versions (including the above) is in the git branch at
>>
>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>> idle-loop-v7.2
>
>
> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
> as with v5: several cores which just keep the sched tick enabled.
> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
> full sched tick.
> The resulting power consumption is ~105 W instead of ~ 70 W.
>
> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
>
> I have briefly ran v7 and I believe it was also affected.
Then it looks like menu_select() stubbornly thinks that the idle
duration will be within the tick boundary on those cores.
That may be because the bumping up of the correction factor in
menu_reflect() is too conservative or it may be necessary to do
something radical to measured_us in menu_update() in case of a tick
wakeup combined with a large next_timer_us value.
For starters, please see if the attached patch (on top of the
idle-loop-v7.2 git branch) changes this behavior in any way.
On 2018.03.21 15:15 Rafael J. Wysocki wrote:
> On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche wrote:
>> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>>>
>>>
>>> So please disregard this one entirely and take the v7.2 replacement
>>> instead of it:https://patchwork.kernel.org/patch/10299429/
>>>
>>> The current versions (including the above) is in the git branch at
>>>
>>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>>> idle-loop-v7.2
>>
>> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
>> as with v5: several cores which just keep the sched tick enabled.
>> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
>> full sched tick.
>> The resulting power consumption is ~105 W instead of ~ 70 W.
>>
>> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
>>
>> I have briefly ran v7 and I believe it was also affected.
>
> Then it looks like menu_select() stubbornly thinks that the idle
> duration will be within the tick boundary on those cores.
>
> That may be because the bumping up of the correction factor in
> menu_reflect() is too conservative or it may be necessary to do
> something radical to measured_us in menu_update() in case of a tick
> wakeup combined with a large next_timer_us value.
>
> For starters, please see if the attached patch (on top of the
> idle-loop-v7.2 git branch) changes this behavior in any way.
O.K. I am seeing some weirdness.
On my system with both V7.2 and V7.2 plus this patch, I observe
A spike in Idle State 1 residency every 34+ minutes. And slightly
higher average idle power than before. (I might not have done V7
idle tests long enough).
It can be seen in the frequency sweep I did earlier today, with V7.2:
http://fast.smythies.com/rjw_freq_sweep_72_combined.png
Despite the note on the graph that says it might be real, I don't think
it is (I forgot to delete the note).
With V7.2+ sometimes the event occurs at 17 minute intervals.
Here is a idle graph (for reference: we have seen idle package power
pretty steady at ~3.7 watts before).
http://fast.smythies.com/rjw_v72p_idle.png
... Doug
On 2018-03-21 23:15, Rafael J. Wysocki wrote:
> On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche
> <[email protected]> wrote:
>> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>>>
>>>
>>> So please disregard this one entirely and take the v7.2 replacement
>>> instead of it:https://patchwork.kernel.org/patch/10299429/
>>>
>>> The current versions (including the above) is in the git branch at
>>>
>>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>>> idle-loop-v7.2
>>
>>
>> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
>> as with v5: several cores which just keep the sched tick enabled.
>> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
>> full sched tick.
>> The resulting power consumption is ~105 W instead of ~ 70 W.
>>
>> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
>>
>> I have briefly ran v7 and I believe it was also affected.
>
> Then it looks like menu_select() stubbornly thinks that the idle
> duration will be within the tick boundary on those cores.
>
> That may be because the bumping up of the correction factor in
> menu_reflect() is too conservative or it may be necessary to do
> something radical to measured_us in menu_update() in case of a tick
> wakeup combined with a large next_timer_us value.
>
> For starters, please see if the attached patch (on top of the
> idle-loop-v7.2 git branch) changes this behavior in any way.
>
The patch on top of idle-loop-v7.2 doesn't improve idle behavior on
SKL-SP. Overall it is pretty erratic, I have not seen any regular
patterns. Sometimes only few cpus are affected, here's a screenshot of
almost all cpus being affected after a short burst workload.
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_reflect_skl_sp_idle.png
On 2018.03.21 23:25 Doug Smythies wrote:
> On 2018.03.21 15:15 Rafael J. Wysocki wrote:
>> On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche wrote:
>>> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
>>>>
>>>> So please disregard this one entirely and take the v7.2 replacement
>>>> instead of it:https://patchwork.kernel.org/patch/10299429/
>>>>
>>>> The current versions (including the above) is in the git branch at
>>>>
>>>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>>>> idle-loop-v7.2
>>>
>>> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
>>> as with v5: several cores which just keep the sched tick enabled.
>>> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
>>> full sched tick.
>>> The resulting power consumption is ~105 W instead of ~ 70 W.
>>>
>>> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
>>>
>>> I have briefly ran v7 and I believe it was also affected.
I am not seeing any issues at all with V7.
>>
>> Then it looks like menu_select() stubbornly thinks that the idle
>> duration will be within the tick boundary on those cores.
>>
>> That may be because the bumping up of the correction factor in
>> menu_reflect() is too conservative or it may be necessary to do
>> something radical to measured_us in menu_update() in case of a tick
>> wakeup combined with a large next_timer_us value.
>>
>> For starters, please see if the attached patch (on top of the
>> idle-loop-v7.2 git branch) changes this behavior in any way.
>
> O.K. I am seeing some weirdness.
> On my system with both V7.2 and V7.2 plus this patch, I observe
> A spike in Idle State 1 residency every 34+ minutes. And slightly
> higher average idle power than before.
> (I might not have done V7 idle tests long enough).
I re-did the idle test on V7, and for longer.
It is great.
See line added to the idle graph for V7.2+:
http://fast.smythies.com/rjw_v72p_v7_idle.png
>
> It can be seen in the frequency sweep I did earlier today, with V7.2:
>
> http://fast.smythies.com/rjw_freq_sweep_72_combined.png
>
> Despite the note on the graph that says it might be real, I don't think
> it is (I forgot to delete the note).
>
> With V7.2+ sometimes the event occurs at 17 minute intervals.
> Here is a idle graph (for reference: we have seen idle package power
> pretty steady at ~3.7 watts before).
Now shown on the new graph. Link above.
>
> http://fast.smythies.com/rjw_v72p_idle.png
... Doug
On Thursday, March 22, 2018 4:41:54 PM CET Doug Smythies wrote:
> On 2018.03.21 23:25 Doug Smythies wrote:
> > On 2018.03.21 15:15 Rafael J. Wysocki wrote:
> >> On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche wrote:
> >>> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
> >>>>
> >>>> So please disregard this one entirely and take the v7.2 replacement
> >>>> instead of it:https://patchwork.kernel.org/patch/10299429/
> >>>>
> >>>> The current versions (including the above) is in the git branch at
> >>>>
> >>>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> >>>> idle-loop-v7.2
> >>>
> >>> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
> >>> as with v5: several cores which just keep the sched tick enabled.
> >>> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
> >>> full sched tick.
> >>> The resulting power consumption is ~105 W instead of ~ 70 W.
> >>>
> >>> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
> >>>
> >>> I have briefly ran v7 and I believe it was also affected.
>
> I am not seeing any issues at all with V7.
>
> >>
> >> Then it looks like menu_select() stubbornly thinks that the idle
> >> duration will be within the tick boundary on those cores.
> >>
> >> That may be because the bumping up of the correction factor in
> >> menu_reflect() is too conservative or it may be necessary to do
> >> something radical to measured_us in menu_update() in case of a tick
> >> wakeup combined with a large next_timer_us value.
> >>
> >> For starters, please see if the attached patch (on top of the
> >> idle-loop-v7.2 git branch) changes this behavior in any way.
> >
> > O.K. I am seeing some weirdness.
> > On my system with both V7.2 and V7.2 plus this patch, I observe
> > A spike in Idle State 1 residency every 34+ minutes. And slightly
> > higher average idle power than before.
> > (I might not have done V7 idle tests long enough).
>
> I re-did the idle test on V7, and for longer.
> It is great.
> See line added to the idle graph for V7.2+:
>
> http://fast.smythies.com/rjw_v72p_v7_idle.png
>
> >
> > It can be seen in the frequency sweep I did earlier today, with V7.2:
> >
> > http://fast.smythies.com/rjw_freq_sweep_72_combined.png
> >
> > Despite the note on the graph that says it might be real, I don't think
> > it is (I forgot to delete the note).
> >
> > With V7.2+ sometimes the event occurs at 17 minute intervals.
> > Here is a idle graph (for reference: we have seen idle package power
> > pretty steady at ~3.7 watts before).
>
> Now shown on the new graph. Link above.
Thanks for the data!
I will send another update of patch [5/8] shortly which is closer to the
original v7 of it than the v7.[1-2].
On Thursday, March 22, 2018 2:18:59 PM CET Thomas Ilsche wrote:
> On 2018-03-21 23:15, Rafael J. Wysocki wrote:
> > On Wed, Mar 21, 2018 at 6:59 PM, Thomas Ilsche
> > <[email protected]> wrote:
> >> On 2018-03-21 15:36, Rafael J. Wysocki wrote:
> >>>
> >>>
> >>> So please disregard this one entirely and take the v7.2 replacement
> >>> instead of it:https://patchwork.kernel.org/patch/10299429/
> >>>
> >>> The current versions (including the above) is in the git branch at
> >>>
> >>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> >>> idle-loop-v7.2
> >>
> >>
> >> With v7.2 (tested on SKL-SP from git) I see similar behavior in idle
> >> as with v5: several cores which just keep the sched tick enabled.
> >> Worse yet, some go only in C1 (not even C1E!?) despite sleeping the
> >> full sched tick.
> >> The resulting power consumption is ~105 W instead of ~ 70 W.
> >>
> >> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_skl_sp_idle.png
> >>
> >> I have briefly ran v7 and I believe it was also affected.
> >
> > Then it looks like menu_select() stubbornly thinks that the idle
> > duration will be within the tick boundary on those cores.
> >
> > That may be because the bumping up of the correction factor in
> > menu_reflect() is too conservative or it may be necessary to do
> > something radical to measured_us in menu_update() in case of a tick
> > wakeup combined with a large next_timer_us value.
> >
> > For starters, please see if the attached patch (on top of the
> > idle-loop-v7.2 git branch) changes this behavior in any way.
> >
>
> The patch on top of idle-loop-v7.2 doesn't improve idle behavior on
> SKL-SP. Overall it is pretty erratic, I have not seen any regular
> patterns. Sometimes only few cpus are affected, here's a screenshot of
> almost all cpus being affected after a short burst workload.
>
> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_2_reflect_skl_sp_idle.png
Thanks for the information!
I will post a v7.3 of patch [5/8] shortly that appears to give good results
for me. It may be selectig deep states quite aggressively, but let's see.
From: Rafael J. Wysocki <[email protected]>
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0, or
(2) the selected state is a polling one, or
(3) the expected idle period duration is within the tick period
range.
In addition to that, the correction factor computations in the menu
governor need to take the possibility that the tick may not be
stopped into account to avoid artificially small correction factor
values. To that end, add a mechanism to record tick wakeups, as
suggested by Peter Zijlstra, and use it to modify the menu_update()
behavior when tick wakeup occurs. Namely, if the CPU is woken up by
the tick and the return value of tick_nohz_get_sleep_length() is not
within the tick boundary, the predicted idle duration is likely too
short, so make menu_update() try to compensate for that by updating
the governor statistics as though the CPU was idle for a long time.
Since the value returned through the new argument pointer of
cpuidle_select() is not used by its caller yet, this change by
itself is not expected to alter the functionality of the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
One more revision here.
From the Thomas Ilsche's testing on the Skylake server it looks like
data->intervals[] need to be updated along with the correction factor
on tick wakeups that occur when next_timer_us is above the tick boundary.
The difference between this and the original v7 (of patch [5/8]) is
what happens in menu_update(). This time next_timer_us is checked
properly and if that is above the tick boundary and a tick wakeup occurs,
the function simply sets mesured_us to a large constant and uses that to
update both the correction factor and data->intervals[] (the particular
value used in this patch was found through a bit of experimentation).
Let's see how this works for Thomas and Doug.
For easier testing there is a git branch containing this patch (and the
rest of the series) at:
git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
idle-loop-v7.3
Thanks!
---
drivers/cpuidle/cpuidle.c | 10 +++++-
drivers/cpuidle/governors/ladder.c | 3 +
drivers/cpuidle/governors/menu.c | 59 +++++++++++++++++++++++++++++--------
include/linux/cpuidle.h | 8 +++--
include/linux/tick.h | 2 +
kernel/sched/idle.c | 4 +-
kernel/time/tick-sched.c | 20 ++++++++++++
7 files changed, 87 insertions(+), 19 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *stop_tick)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *stop_tick);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool stop_tick = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &stop_tick);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @stop_tick: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @stop_tick is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, stop_tick);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -123,6 +123,7 @@
struct menu_device {
int last_state_idx;
int needs_update;
+ int tick_wakeup;
unsigned int next_timer_us;
unsigned int predicted_us;
@@ -279,8 +280,10 @@ again:
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @stop_tick: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *stop_tick)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +306,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *stop_tick = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +359,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = data->predicted_us;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -369,15 +375,30 @@ static int menu_select(struct cpuidle_dr
idx = i; /* first enabled state */
if (s->target_residency > data->predicted_us)
break;
- if (s->exit_latency > latency_req)
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons, use
+ * the target residency of the selected state as the
+ * expected idle duration so that the tick is retained
+ * as long as that target residency is low enough.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or if the
+ * expected idle duration is shorter than the tick period length.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC)
+ *stop_tick = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
@@ -397,6 +418,7 @@ static void menu_reflect(struct cpuidle_
data->last_state_idx = index;
data->needs_update = 1;
+ data->tick_wakeup = tick_nohz_idle_got_tick();
}
/**
@@ -427,14 +449,27 @@ static void menu_update(struct cpuidle_d
* assume the state was never reached and the exit latency is 0.
*/
- /* measured value */
- measured_us = cpuidle_get_last_residency(dev);
-
- /* Deduct exit latency */
- if (measured_us > 2 * target->exit_latency)
- measured_us -= target->exit_latency;
- else
- measured_us /= 2;
+ if (data->tick_wakeup && data->next_timer_us > TICK_USEC) {
+ /*
+ * The nohz code said that there wouldn't be any events within
+ * the tick boundary (if the tick was stopped), but the idle
+ * duration predictor had a differing opinion. Since the CPU
+ * was woken up by a tick (that wasn't stopped after all), the
+ * predictor was not quite right, so assume that the CPU could
+ * have been idle long (but not forever) to help the idle
+ * duration predictor do a better job next time.
+ */
+ measured_us = 9 * MAX_INTERESTING / 10;
+ } else {
+ /* measured value */
+ measured_us = cpuidle_get_last_residency(dev);
+
+ /* Deduct exit latency */
+ if (measured_us > 2 * target->exit_latency)
+ measured_us -= target->exit_latency;
+ else
+ measured_us /= 2;
+ }
/* Make sure our coefficients do not exceed unity */
if (measured_us > data->next_timer_us)
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -991,6 +991,20 @@ void tick_nohz_irq_exit(void)
}
/**
+ * tick_nohz_idle_got_tick - Check whether or not the tick handler has run
+ */
+bool tick_nohz_idle_got_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->inidle > 1) {
+ ts->inidle = 1;
+ return true;
+ }
+ return false;
+}
+
+/**
* tick_nohz_get_sleep_length - return the length of the current sleep
*
* Called from power state control code with interrupts disabled
@@ -1101,6 +1115,9 @@ static void tick_nohz_handler(struct clo
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
dev->next_event = KTIME_MAX;
tick_sched_do_timer(now);
@@ -1198,6 +1215,9 @@ static enum hrtimer_restart tick_sched_t
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
tick_sched_do_timer(now);
/*
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -119,6 +119,7 @@ extern void tick_nohz_idle_restart_tick(
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
+extern bool tick_nohz_idle_got_tick(void);
extern ktime_t tick_nohz_get_sleep_length(void);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
@@ -139,6 +140,7 @@ static inline void tick_nohz_idle_stop_t
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
+static inline bool tick_nohz_idle_got_tick(void) { return false; }
static inline ktime_t tick_nohz_get_sleep_length(void)
{
On 2018.03.22 10:40 Rafael J. Wysocki wrote:
...[snip]...
>The difference between this and the original v7 (of patch [5/8]) is
> what happens in menu_update(). This time next_timer_us is checked
> properly and if that is above the tick boundary and a tick wakeup occurs,
> the function simply sets mesured_us to a large constant and uses that to
> update both the correction factor and data->intervals[] (the particular
> value used in this patch was found through a bit of experimentation).
>
> Let's see how this works for Thomas and Doug.
System idle test done for 74 minutes.
After boot and after the system settles down for a couple of minutes,
Processor package power is constant at 3.7 Watts. (great)
Not worth a new graph to show a flat line.
V7.3 average package power = 3.68 Watts.
V7 average package power = 3.68 Watts
V7.2+ average package power = 4.06 Watts (+10%)
> For easier testing there is a git branch containing this patch (and the
> rest of the series) at:
>
> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> idle-loop-v7.3
Thanks. I used this git branch this time and for the first time.
Much easier.
... Doug
On 2018-03-20 16:45, Rafael J. Wysocki wrote:
> From: Rafael J. Wysocki <[email protected]>
>
> In order to address the issue with short idle duration predictions
> by the idle governor after the tick has been stopped, reorder the
> code in cpuidle_idle_call() so that the governor idle state selection
> runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
> by cpuidle_select() to decide whether or not to stop the tick.
>
> This isn't straightforward, because menu_select() invokes
> tick_nohz_get_sleep_length() to get the time to the next timer
> event and the number returned by the latter comes from
> __tick_nohz_idle_enter(). Fortunately, however, it is possible
> to compute that number without actually stopping the tick and with
> the help of the existing code.
I think something is wrong with the new tick_nohz_get_sleep_length.
It seems to return a value that is too large, ignoring immanent
non-sched timer.
I tested idle-loop-v7.3. It looks very similar to my previous results
on the first idle-loop-git-version [1]. Idle and traditional synthetic
powernightmares are mostly good. But it selects too deep C-states
for short idle periods, which is bad for power consumption [2].
I tracked this down with additional tests using
__attribute__((optimize("O0"))) menu_select
and perf probe. With this the behavior seems slightly different, but it
shows that data->next_timer_us is:
v4.16-rc6: the expected ~500 us [3]
idle-loop-v7.3: many milliseconds to minutes [4].
This leads to the governor to wrongly selecting C6.
Checking with 372be9e and 6ea0577, I can confirm that the change is
introduced by this patch.
[1] https://lkml.org/lkml/2018/3/20/238
[2] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_3_skl_sp.png
[3] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/next_timer_us-v4.16-rc6.png
[4] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/next_timer_us-idle-loop-v7.3.png
> Namely, notice that tick_nohz_stop_sched_tick() already computes the
> next timer event time to reprogram the scheduler tick hrtimer and
> that time can be used as a proxy for the actual next timer event
> time in the idle duration predicition. Moreover, it is possible
> to split tick_nohz_stop_sched_tick() into two separate routines,
> one computing the time to the next timer event and the other
> simply stopping the tick when the time to the next timer event
> is known.
>
> Accordingly, split tick_nohz_stop_sched_tick() into
> tick_nohz_next_event() and tick_nohz_stop_tick() and use the
> former in tick_nohz_get_sleep_length(). Add two new extra fields,
> timer_expires and timer_expires_base, to struct tick_sched for
> passing data between these two new functions and to indicate that
> tick_nohz_next_event() has run and tick_nohz_stop_tick() can be
> called now. Also drop the now redundant sleep_length field from
> there.
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
>
> v5 -> v7:
> * Rebase on top of the new [5/8].
>
> ---
> include/linux/tick.h | 2
> kernel/sched/idle.c | 11 ++-
> kernel/time/tick-sched.c | 156 +++++++++++++++++++++++++++++++----------------
> kernel/time/tick-sched.h | 6 +
> 4 files changed, 120 insertions(+), 55 deletions(-)
>
> Index: linux-pm/kernel/time/tick-sched.h
> ===================================================================
> --- linux-pm.orig/kernel/time/tick-sched.h
> +++ linux-pm/kernel/time/tick-sched.h
> @@ -38,7 +38,8 @@ enum tick_nohz_mode {
> * @idle_exittime: Time when the idle state was left
> * @idle_sleeptime: Sum of the time slept in idle with sched tick stopped
> * @iowait_sleeptime: Sum of the time slept in idle with sched tick stopped, with IO outstanding
> - * @sleep_length: Duration of the current idle sleep
> + * @timer_expires: Anticipated timer expiration time (in case sched tick is stopped)
> + * @timer_expires_base: Base time clock monotonic for @timer_expires
> * @do_timer_lst: CPU was the last one doing do_timer before going idle
> */
> struct tick_sched {
> @@ -58,8 +59,9 @@ struct tick_sched {
> ktime_t idle_exittime;
> ktime_t idle_sleeptime;
> ktime_t iowait_sleeptime;
> - ktime_t sleep_length;
> unsigned long last_jiffies;
> + u64 timer_expires;
> + u64 timer_expires_base;
> u64 next_timer;
> ktime_t idle_expires;
> int do_timer_last;
> Index: linux-pm/kernel/sched/idle.c
> ===================================================================
> --- linux-pm.orig/kernel/sched/idle.c
> +++ linux-pm/kernel/sched/idle.c
> @@ -190,13 +190,18 @@ static void cpuidle_idle_call(void)
> } else {
> bool stop_tick = true;
>
> - tick_nohz_idle_stop_tick();
> - rcu_idle_enter();
> -
> /*
> * Ask the cpuidle framework to choose a convenient idle state.
> */
> next_state = cpuidle_select(drv, dev, &stop_tick);
> +
> + if (stop_tick)
> + tick_nohz_idle_stop_tick();
> + else
> + tick_nohz_idle_retain_tick();
> +
> + rcu_idle_enter();
> +
> entered_state = call_cpuidle(drv, dev, next_state);
> /*
> * Give the governor an opportunity to reflect on the outcome
> Index: linux-pm/kernel/time/tick-sched.c
> ===================================================================
> --- linux-pm.orig/kernel/time/tick-sched.c
> +++ linux-pm/kernel/time/tick-sched.c
> @@ -652,13 +652,10 @@ static inline bool local_timer_softirq_p
> return local_softirq_pending() & TIMER_SOFTIRQ;
> }
>
> -static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
> - ktime_t now, int cpu)
> +static ktime_t tick_nohz_next_event(struct tick_sched *ts, int cpu)
> {
> - struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
> u64 basemono, next_tick, next_tmr, next_rcu, delta, expires;
> unsigned long seq, basejiff;
> - ktime_t tick;
>
> /* Read jiffies and the time when jiffies were updated last */
> do {
> @@ -667,6 +664,7 @@ static ktime_t tick_nohz_stop_sched_tick
> basejiff = jiffies;
> } while (read_seqretry(&jiffies_lock, seq));
> ts->last_jiffies = basejiff;
> + ts->timer_expires_base = basemono;
>
> /*
> * Keep the periodic tick, when RCU, architecture or irq_work
> @@ -711,31 +709,24 @@ static ktime_t tick_nohz_stop_sched_tick
> * next period, so no point in stopping it either, bail.
> */
> if (!ts->tick_stopped) {
> - tick = 0;
> + ts->timer_expires = 0;
> goto out;
> }
> }
>
> /*
> - * If this CPU is the one which updates jiffies, then give up
> - * the assignment and let it be taken by the CPU which runs
> - * the tick timer next, which might be this CPU as well. If we
> - * don't drop this here the jiffies might be stale and
> - * do_timer() never invoked. Keep track of the fact that it
> - * was the one which had the do_timer() duty last. If this CPU
> - * is the one which had the do_timer() duty last, we limit the
> - * sleep time to the timekeeping max_deferment value.
> + * If this CPU is the one which had the do_timer() duty last, we limit
> + * the sleep time to the timekeeping max_deferment value.
> * Otherwise we can sleep as long as we want.
> */
> delta = timekeeping_max_deferment();
> - if (cpu == tick_do_timer_cpu) {
> - tick_do_timer_cpu = TICK_DO_TIMER_NONE;
> - ts->do_timer_last = 1;
> - } else if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
> - delta = KTIME_MAX;
> - ts->do_timer_last = 0;
> - } else if (!ts->do_timer_last) {
> - delta = KTIME_MAX;
> + if (cpu != tick_do_timer_cpu) {
> + if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
> + delta = KTIME_MAX;
> + ts->do_timer_last = 0;
> + } else if (!ts->do_timer_last) {
> + delta = KTIME_MAX;
> + }
> }
>
> #ifdef CONFIG_NO_HZ_FULL
> @@ -750,14 +741,40 @@ static ktime_t tick_nohz_stop_sched_tick
> else
> expires = KTIME_MAX;
>
> - expires = min_t(u64, expires, next_tick);
> - tick = expires;
> + ts->timer_expires = min_t(u64, expires, next_tick);
> +
> +out:
> + return ts->timer_expires;
> +}
> +
> +static void tick_nohz_stop_tick(struct tick_sched *ts, int cpu)
> +{
> + struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
> + u64 basemono = ts->timer_expires_base;
> + u64 expires = ts->timer_expires;
> + ktime_t tick = expires;
> +
> + /* Make sure we won't be trying to stop it twice in a row. */
> + ts->timer_expires_base = 0;
> +
> + /*
> + * If this CPU is the one which updates jiffies, then give up
> + * the assignment and let it be taken by the CPU which runs
> + * the tick timer next, which might be this CPU as well. If we
> + * don't drop this here the jiffies might be stale and
> + * do_timer() never invoked. Keep track of the fact that it
> + * was the one which had the do_timer() duty last.
> + */
> + if (cpu == tick_do_timer_cpu) {
> + tick_do_timer_cpu = TICK_DO_TIMER_NONE;
> + ts->do_timer_last = 1;
> + }
>
> /* Skip reprogram of event if its not changed */
> if (ts->tick_stopped && (expires == ts->next_tick)) {
> /* Sanity check: make sure clockevent is actually programmed */
> if (tick == KTIME_MAX || ts->next_tick == hrtimer_get_expires(&ts->sched_timer))
> - goto out;
> + return;
>
> WARN_ON_ONCE(1);
> printk_once("basemono: %llu ts->next_tick: %llu dev->next_event: %llu timer->active: %d timer->expires: %llu\n",
> @@ -791,7 +808,7 @@ static ktime_t tick_nohz_stop_sched_tick
> if (unlikely(expires == KTIME_MAX)) {
> if (ts->nohz_mode == NOHZ_MODE_HIGHRES)
> hrtimer_cancel(&ts->sched_timer);
> - goto out;
> + return;
> }
>
> hrtimer_set_expires(&ts->sched_timer, tick);
> @@ -800,15 +817,23 @@ static ktime_t tick_nohz_stop_sched_tick
> hrtimer_start_expires(&ts->sched_timer, HRTIMER_MODE_ABS_PINNED);
> else
> tick_program_event(tick, 1);
> -out:
> - /*
> - * Update the estimated sleep length until the next timer
> - * (not only the tick).
> - */
> - ts->sleep_length = ktime_sub(dev->next_event, now);
> - return tick;
> }
>
> +static void tick_nohz_retain_tick(struct tick_sched *ts)
> +{
> + ts->timer_expires_base = 0;
> +}
> +
> +#ifdef CONFIG_NO_HZ_FULL
> +static void tick_nohz_stop_sched_tick(struct tick_sched *ts, int cpu)
> +{
> + if (tick_nohz_next_event(ts, cpu))
> + tick_nohz_stop_tick(ts, cpu);
> + else
> + tick_nohz_retain_tick(ts);
> +}
> +#endif /* CONFIG_NO_HZ_FULL */
> +
> static void tick_nohz_restart_sched_tick(struct tick_sched *ts, ktime_t now)
> {
> /* Update jiffies first */
> @@ -844,7 +869,7 @@ static void tick_nohz_full_update_tick(s
> return;
>
> if (can_stop_full_tick(cpu, ts))
> - tick_nohz_stop_sched_tick(ts, ktime_get(), cpu);
> + tick_nohz_stop_sched_tick(ts, cpu);
> else if (ts->tick_stopped)
> tick_nohz_restart_sched_tick(ts, ktime_get());
> #endif
> @@ -870,10 +895,8 @@ static bool can_stop_idle_tick(int cpu,
> return false;
> }
>
> - if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE)) {
> - ts->sleep_length = NSEC_PER_SEC / HZ;
> + if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE))
> return false;
> - }
>
> if (need_resched())
> return false;
> @@ -913,25 +936,33 @@ static void __tick_nohz_idle_stop_tick(s
> ktime_t expires;
> int cpu = smp_processor_id();
>
> - if (can_stop_idle_tick(cpu, ts)) {
> + /*
> + * If tick_nohz_get_sleep_length() ran tick_nohz_next_event(), the
> + * tick timer expiration time is known already.
> + */
> + if (ts->timer_expires_base)
> + expires = ts->timer_expires;
> + else if (can_stop_idle_tick(cpu, ts))
> + expires = tick_nohz_next_event(ts, cpu);
> + else
> + return;
> +
> + ts->idle_calls++;
> +
> + if (expires > 0LL) {
> int was_stopped = ts->tick_stopped;
>
> - ts->idle_calls++;
> + tick_nohz_stop_tick(ts, cpu);
>
> - /*
> - * The idle entry time should be a sufficient approximation of
> - * the current time at this point.
> - */
> - expires = tick_nohz_stop_sched_tick(ts, ts->idle_entrytime, cpu);
> - if (expires > 0LL) {
> - ts->idle_sleeps++;
> - ts->idle_expires = expires;
> - }
> + ts->idle_sleeps++;
> + ts->idle_expires = expires;
>
> if (!was_stopped && ts->tick_stopped) {
> ts->idle_jiffies = ts->last_jiffies;
> nohz_balance_enter_idle(cpu);
> }
> + } else {
> + tick_nohz_retain_tick(ts);
> }
> }
>
> @@ -945,6 +976,11 @@ void tick_nohz_idle_stop_tick(void)
> __tick_nohz_idle_stop_tick(this_cpu_ptr(&tick_cpu_sched));
> }
>
> +void tick_nohz_idle_retain_tick(void)
> +{
> + tick_nohz_retain_tick(this_cpu_ptr(&tick_cpu_sched));
> +}
> +
> /**
> * tick_nohz_idle_enter - prepare for entering idle on the current CPU
> *
> @@ -957,7 +993,7 @@ void tick_nohz_idle_enter(void)
> lockdep_assert_irqs_enabled();
> /*
> * Update the idle state in the scheduler domain hierarchy
> - * when tick_nohz_stop_sched_tick() is called from the idle loop.
> + * when tick_nohz_stop_tick() is called from the idle loop.
> * State will be updated to busy during the first busy tick after
> * exiting idle.
> */
> @@ -966,6 +1002,9 @@ void tick_nohz_idle_enter(void)
> local_irq_disable();
>
> ts = this_cpu_ptr(&tick_cpu_sched);
> +
> + WARN_ON_ONCE(ts->timer_expires_base);
> +
> ts->inidle = 1;
> tick_nohz_start_idle(ts);
>
> @@ -1005,15 +1044,31 @@ bool tick_nohz_idle_got_tick(void)
> }
>
> /**
> - * tick_nohz_get_sleep_length - return the length of the current sleep
> + * tick_nohz_get_sleep_length - return the expected length of the current sleep
> *
> * Called from power state control code with interrupts disabled
> */
> ktime_t tick_nohz_get_sleep_length(void)
> {
> + struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
> struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
> + int cpu = smp_processor_id();
> + /*
> + * The idle entry time is expected to be a sufficient approximation of
> + * the current time at this point.
> + */
> + ktime_t now = ts->idle_entrytime;
> +
> + WARN_ON_ONCE(!ts->inidle);
> +
> + if (can_stop_idle_tick(cpu, ts)) {
> + ktime_t next_event = tick_nohz_next_event(ts, cpu);
> +
> + if (next_event)
> + return ktime_sub(next_event, now);
> + }
>
> - return ts->sleep_length;
> + return ktime_sub(dev->next_event, now);
> }
>
> /**
> @@ -1091,6 +1146,7 @@ void tick_nohz_idle_exit(void)
> local_irq_disable();
>
> WARN_ON_ONCE(!ts->inidle);
> + WARN_ON_ONCE(ts->timer_expires_base);
>
> ts->inidle = 0;
>
> Index: linux-pm/include/linux/tick.h
> ===================================================================
> --- linux-pm.orig/include/linux/tick.h
> +++ linux-pm/include/linux/tick.h
> @@ -115,6 +115,7 @@ enum tick_dep_bits {
> extern bool tick_nohz_enabled;
> extern int tick_nohz_tick_stopped(void);
> extern void tick_nohz_idle_stop_tick(void);
> +extern void tick_nohz_idle_retain_tick(void);
> extern void tick_nohz_idle_restart_tick(void);
> extern void tick_nohz_idle_enter(void);
> extern void tick_nohz_idle_exit(void);
> @@ -137,6 +138,7 @@ static inline void tick_nohz_idle_stop_t
> #define tick_nohz_enabled (0)
> static inline int tick_nohz_tick_stopped(void) { return 0; }
> static inline void tick_nohz_idle_stop_tick(void) { }
> +static inline void tick_nohz_idle_retain_tick(void) { }
> static inline void tick_nohz_idle_restart_tick(void) { }
> static inline void tick_nohz_idle_enter(void) { }
> static inline void tick_nohz_idle_exit(void) { }
>
On Tuesday, March 27, 2018 11:50:02 PM CEST Thomas Ilsche wrote:
> On 2018-03-20 16:45, Rafael J. Wysocki wrote:
> > From: Rafael J. Wysocki <[email protected]>
> >
> > In order to address the issue with short idle duration predictions
> > by the idle governor after the tick has been stopped, reorder the
> > code in cpuidle_idle_call() so that the governor idle state selection
> > runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
> > by cpuidle_select() to decide whether or not to stop the tick.
> >
> > This isn't straightforward, because menu_select() invokes
> > tick_nohz_get_sleep_length() to get the time to the next timer
> > event and the number returned by the latter comes from
> > __tick_nohz_idle_enter(). Fortunately, however, it is possible
> > to compute that number without actually stopping the tick and with
> > the help of the existing code.
>
> I think something is wrong with the new tick_nohz_get_sleep_length.
> It seems to return a value that is too large, ignoring immanent
> non-sched timer.
That's a very useful hint, let me have a look.
> I tested idle-loop-v7.3. It looks very similar to my previous results
> on the first idle-loop-git-version [1]. Idle and traditional synthetic
> powernightmares are mostly good.
OK
> But it selects too deep C-states for short idle periods, which is bad
> for power consumption [2].
That still needs to be improved, then.
> I tracked this down with additional tests using
> __attribute__((optimize("O0"))) menu_select
> and perf probe. With this the behavior seems slightly different, but it
> shows that data->next_timer_us is:
> v4.16-rc6: the expected ~500 us [3]
> idle-loop-v7.3: many milliseconds to minutes [4].
> This leads to the governor to wrongly selecting C6.
>
> Checking with 372be9e and 6ea0577, I can confirm that the change is
> introduced by this patch.
Yes, that's where the most intrusive reordering happens.
Thanks for the feedback!
On Wed, Mar 28, 2018 at 12:10 AM, Rafael J. Wysocki <[email protected]> wrote:
> On Tuesday, March 27, 2018 11:50:02 PM CEST Thomas Ilsche wrote:
>> On 2018-03-20 16:45, Rafael J. Wysocki wrote:
>> > From: Rafael J. Wysocki <[email protected]>
>> >
>> > In order to address the issue with short idle duration predictions
>> > by the idle governor after the tick has been stopped, reorder the
>> > code in cpuidle_idle_call() so that the governor idle state selection
>> > runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
>> > by cpuidle_select() to decide whether or not to stop the tick.
>> >
>> > This isn't straightforward, because menu_select() invokes
>> > tick_nohz_get_sleep_length() to get the time to the next timer
>> > event and the number returned by the latter comes from
>> > __tick_nohz_idle_enter(). Fortunately, however, it is possible
>> > to compute that number without actually stopping the tick and with
>> > the help of the existing code.
>>
>> I think something is wrong with the new tick_nohz_get_sleep_length.
>> It seems to return a value that is too large, ignoring immanent
>> non-sched timer.
>
> That's a very useful hint, let me have a look.
>
>> I tested idle-loop-v7.3. It looks very similar to my previous results
>> on the first idle-loop-git-version [1]. Idle and traditional synthetic
>> powernightmares are mostly good.
>
> OK
>
>> But it selects too deep C-states for short idle periods, which is bad
>> for power consumption [2].
>
> That still needs to be improved, then.
>
>> I tracked this down with additional tests using
>> __attribute__((optimize("O0"))) menu_select
>> and perf probe. With this the behavior seems slightly different, but it
>> shows that data->next_timer_us is:
>> v4.16-rc6: the expected ~500 us [3]
>> idle-loop-v7.3: many milliseconds to minutes [4].
>> This leads to the governor to wrongly selecting C6.
>>
>> Checking with 372be9e and 6ea0577, I can confirm that the change is
>> introduced by this patch.
>
> Yes, that's where the most intrusive reordering happens.
Overall, this is an interesting conundrum, because the case in
question is when the tick should never be stopped at all during the
workload and the code's behavior in that case should not change, so
the change was not intentional.
Now, from walking through the code, as long as can_stop_idle_tick()
returns 'true' all should be fine or at least I don't see why there is
any difference in behavior in that case.
However, if can_stop_idle_tick() returns 'false' (for example, because
need_resched() returns 'true' when it is evaluated), the behavior *is*
different in a couple of ways. I sort of know how that can be
addressed, but I'd like to reproduce your results here.
Are you still using the same workload as before to trigger this behavior?
On 2018-03-28 10:13, Rafael J. Wysocki wrote:
> On Wed, Mar 28, 2018 at 12:10 AM, Rafael J. Wysocki <[email protected]> wrote:
>> On Tuesday, March 27, 2018 11:50:02 PM CEST Thomas Ilsche wrote:
>>> On 2018-03-20 16:45, Rafael J. Wysocki wrote:
>>>> From: Rafael J. Wysocki <[email protected]>
>>>>
>>>> In order to address the issue with short idle duration predictions
>>>> by the idle governor after the tick has been stopped, reorder the
>>>> code in cpuidle_idle_call() so that the governor idle state selection
>>>> runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
>>>> by cpuidle_select() to decide whether or not to stop the tick.
>>>>
>>>> This isn't straightforward, because menu_select() invokes
>>>> tick_nohz_get_sleep_length() to get the time to the next timer
>>>> event and the number returned by the latter comes from
>>>> __tick_nohz_idle_enter(). Fortunately, however, it is possible
>>>> to compute that number without actually stopping the tick and with
>>>> the help of the existing code.
>>>
>>> I think something is wrong with the new tick_nohz_get_sleep_length.
>>> It seems to return a value that is too large, ignoring immanent
>>> non-sched timer.
>>
>> That's a very useful hint, let me have a look.
>>
>>> I tested idle-loop-v7.3. It looks very similar to my previous results
>>> on the first idle-loop-git-version [1]. Idle and traditional synthetic
>>> powernightmares are mostly good.
>>
>> OK
>>
>>> But it selects too deep C-states for short idle periods, which is bad
>>> for power consumption [2].
>>
>> That still needs to be improved, then.
>>
>>> I tracked this down with additional tests using
>>> __attribute__((optimize("O0"))) menu_select
>>> and perf probe. With this the behavior seems slightly different, but it
>>> shows that data->next_timer_us is:
>>> v4.16-rc6: the expected ~500 us [3]
>>> idle-loop-v7.3: many milliseconds to minutes [4].
>>> This leads to the governor to wrongly selecting C6.
>>>
>>> Checking with 372be9e and 6ea0577, I can confirm that the change is
>>> introduced by this patch.
>>
>> Yes, that's where the most intrusive reordering happens.
>
> Overall, this is an interesting conundrum, because the case in
> question is when the tick should never be stopped at all during the
> workload and the code's behavior in that case should not change, so
> the change was not intentional.
>
> Now, from walking through the code, as long as can_stop_idle_tick()
> returns 'true' all should be fine or at least I don't see why there is
> any difference in behavior in that case.
>
> However, if can_stop_idle_tick() returns 'false' (for example, because
> need_resched() returns 'true' when it is evaluated), the behavior *is*
> different in a couple of ways. I sort of know how that can be
> addressed, but I'd like to reproduce your results here.
>
> Are you still using the same workload as before to trigger this behavior?
>
Yes, the exact code I use is as follows
$ gcc poller.c -O3 -fopenmp -o poller_omp
$ GOMP_CPU_AFFINITY=0-35 ./poller_omp 500
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int sleep_us = 10000;
if (argc == 2) {
sleep_us = atoi(argv[1]);
}
#pragma omp parallel
{
while (1) {
usleep(sleep_us);
}
}
}
On 2018-03-22 18:40, Rafael J. Wysocki wrote:
> From: Rafael J. Wysocki <[email protected]>
>
> Add a new pointer argument to cpuidle_select() and to the ->select
> cpuidle governor callback to allow a boolean value indicating
> whether or not the tick should be stopped before entering the
> selected state to be returned from there.
>
> Make the ladder governor ignore that pointer (to preserve its
> current behavior) and make the menu governor return 'false" through
> it if:
> (1) the idle exit latency is constrained at 0, or
> (2) the selected state is a polling one, or
> (3) the expected idle period duration is within the tick period
> range.
>
> In addition to that, the correction factor computations in the menu
> governor need to take the possibility that the tick may not be
> stopped into account to avoid artificially small correction factor
> values. To that end, add a mechanism to record tick wakeups, as
> suggested by Peter Zijlstra, and use it to modify the menu_update()
> behavior when tick wakeup occurs. Namely, if the CPU is woken up by
> the tick and the return value of tick_nohz_get_sleep_length() is not
> within the tick boundary, the predicted idle duration is likely too
> short, so make menu_update() try to compensate for that by updating
> the governor statistics as though the CPU was idle for a long time.
>
> Since the value returned through the new argument pointer of
> cpuidle_select() is not used by its caller yet, this change by
> itself is not expected to alter the functionality of the code.
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
>
> One more revision here.
>
> From the Thomas Ilsche's testing on the Skylake server it looks like
> data->intervals[] need to be updated along with the correction factor
> on tick wakeups that occur when next_timer_us is above the tick boundary.
>
> The difference between this and the original v7 (of patch [5/8]) is
> what happens in menu_update(). This time next_timer_us is checked
> properly and if that is above the tick boundary and a tick wakeup occurs,
> the function simply sets mesured_us to a large constant and uses that to
> update both the correction factor and data->intervals[] (the particular
> value used in this patch was found through a bit of experimentation).
>
> Let's see how this works for Thomas and Doug.
>
> For easier testing there is a git branch containing this patch (and the
> rest of the series) at:
>
> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> idle-loop-v7.3
>
> Thanks!
Besides the other issue with tick_nohz_get_sleep_length, v7.3
generally works well in idle. So far I don't see anything
statistically noticeable, but I saw one peculiar anomaly. After all
cores woke up simultaneously to schedule some kworker task, some of
them kept the sched tick up, even stayed in shallow sleep state for a
while, without having any tasks scheduled. Gradually they chose deeper
sleep states and stopped their sched ticks. After 23 ms (1000 Hz
kernel), they all went back to deep sleep.
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_3_skl_sp_anomaly.png
I have only seen this once so far and can't reproduce it yet, so this
particular instance may not be an issue in practice. However my
fundamental concerns about the policy whether to disable the sched
tick remain:
Mixing the precise timer and vague heuristic for the decision is
dangerous. The timer should not be wrong, heuristic may be.
Decisions should use actual time points rather than the generic tick
duration and residency time. e.g.
expected_interval < delta_next_us
vs
expected_interval < TICK_USEC
For some cases the unmodified sched tick is not efficient as fallback.
Is it feasible to
1) enable the sched tick when it's currently disabled instead of
blindly choosing a different C state?
2) modify the next upcoming sched tick to be better suitable as
fallback timer?
I think with the infrastructure changes it should be possible to
implement the policy I envisioned previously
(https://marc.info/?l=linux-pm&m=151384941425947&w=2), which is based
on the ordering of timers and the heuristically predicted idle time.
If the sleep_length issue is fixed and I have some mechanism for a
modifiable fallback timer, I'll try to demonstrate that on top of your
changes.
>
> ---
> drivers/cpuidle/cpuidle.c | 10 +++++-
> drivers/cpuidle/governors/ladder.c | 3 +
> drivers/cpuidle/governors/menu.c | 59 +++++++++++++++++++++++++++++--------
> include/linux/cpuidle.h | 8 +++--
> include/linux/tick.h | 2 +
> kernel/sched/idle.c | 4 +-
> kernel/time/tick-sched.c | 20 ++++++++++++
> 7 files changed, 87 insertions(+), 19 deletions(-)
>
> Index: linux-pm/include/linux/cpuidle.h
> ===================================================================
> --- linux-pm.orig/include/linux/cpuidle.h
> +++ linux-pm/include/linux/cpuidle.h
> @@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
> struct cpuidle_device *dev);
>
> extern int cpuidle_select(struct cpuidle_driver *drv,
> - struct cpuidle_device *dev);
> + struct cpuidle_device *dev,
> + bool *stop_tick);
> extern int cpuidle_enter(struct cpuidle_driver *drv,
> struct cpuidle_device *dev, int index);
> extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
> @@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
> struct cpuidle_device *dev)
> {return true; }
> static inline int cpuidle_select(struct cpuidle_driver *drv,
> - struct cpuidle_device *dev)
> + struct cpuidle_device *dev, bool *stop_tick)
> {return -ENODEV; }
> static inline int cpuidle_enter(struct cpuidle_driver *drv,
> struct cpuidle_device *dev, int index)
> @@ -250,7 +251,8 @@ struct cpuidle_governor {
> struct cpuidle_device *dev);
>
> int (*select) (struct cpuidle_driver *drv,
> - struct cpuidle_device *dev);
> + struct cpuidle_device *dev,
> + bool *stop_tick);
> void (*reflect) (struct cpuidle_device *dev, int index);
> };
>
> Index: linux-pm/kernel/sched/idle.c
> ===================================================================
> --- linux-pm.orig/kernel/sched/idle.c
> +++ linux-pm/kernel/sched/idle.c
> @@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
> next_state = cpuidle_find_deepest_state(drv, dev);
> call_cpuidle(drv, dev, next_state);
> } else {
> + bool stop_tick = true;
> +
> tick_nohz_idle_stop_tick();
> rcu_idle_enter();
>
> /*
> * Ask the cpuidle framework to choose a convenient idle state.
> */
> - next_state = cpuidle_select(drv, dev);
> + next_state = cpuidle_select(drv, dev, &stop_tick);
> entered_state = call_cpuidle(drv, dev, next_state);
> /*
> * Give the governor an opportunity to reflect on the outcome
> Index: linux-pm/drivers/cpuidle/cpuidle.c
> ===================================================================
> --- linux-pm.orig/drivers/cpuidle/cpuidle.c
> +++ linux-pm/drivers/cpuidle/cpuidle.c
> @@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
> *
> * @drv: the cpuidle driver
> * @dev: the cpuidle device
> + * @stop_tick: indication on whether or not to stop the tick
> *
> * Returns the index of the idle state. The return value must not be negative.
> + *
> + * The memory location pointed to by @stop_tick is expected to be written the
> + * 'false' boolean value if the scheduler tick should not be stopped before
> + * entering the returned state.
> */
> -int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
> +int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
> + bool *stop_tick)
> {
> - return cpuidle_curr_governor->select(drv, dev);
> + return cpuidle_curr_governor->select(drv, dev, stop_tick);
> }
>
> /**
> Index: linux-pm/drivers/cpuidle/governors/ladder.c
> ===================================================================
> --- linux-pm.orig/drivers/cpuidle/governors/ladder.c
> +++ linux-pm/drivers/cpuidle/governors/ladder.c
> @@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
> * ladder_select_state - selects the next state to enter
> * @drv: cpuidle driver
> * @dev: the CPU
> + * @dummy: not used
> */
> static int ladder_select_state(struct cpuidle_driver *drv,
> - struct cpuidle_device *dev)
> + struct cpuidle_device *dev, bool *dummy)
> {
> struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
> struct device *device = get_cpu_device(dev->cpu);
> Index: linux-pm/drivers/cpuidle/governors/menu.c
> ===================================================================
> --- linux-pm.orig/drivers/cpuidle/governors/menu.c
> +++ linux-pm/drivers/cpuidle/governors/menu.c
> @@ -123,6 +123,7 @@
> struct menu_device {
> int last_state_idx;
> int needs_update;
> + int tick_wakeup;
>
> unsigned int next_timer_us;
> unsigned int predicted_us;
> @@ -279,8 +280,10 @@ again:
> * menu_select - selects the next idle state to enter
> * @drv: cpuidle driver containing state data
> * @dev: the CPU
> + * @stop_tick: indication on whether or not to stop the tick
> */
> -static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
> +static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
> + bool *stop_tick)
> {
> struct menu_device *data = this_cpu_ptr(&menu_devices);
> struct device *device = get_cpu_device(dev->cpu);
> @@ -303,8 +306,10 @@ static int menu_select(struct cpuidle_dr
> latency_req = resume_latency;
>
> /* Special case when user has set very strict latency requirement */
> - if (unlikely(latency_req == 0))
> + if (unlikely(latency_req == 0)) {
> + *stop_tick = false;
> return 0;
> + }
>
> /* determine the expected residency time, round up */
> data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
> @@ -354,6 +359,7 @@ static int menu_select(struct cpuidle_dr
> if (latency_req > interactivity_req)
> latency_req = interactivity_req;
>
> + expected_interval = data->predicted_us;
> /*
> * Find the idle state with the lowest power while satisfying
> * our constraints.
> @@ -369,15 +375,30 @@ static int menu_select(struct cpuidle_dr
> idx = i; /* first enabled state */
> if (s->target_residency > data->predicted_us)
> break;
> - if (s->exit_latency > latency_req)
> + if (s->exit_latency > latency_req) {
> + /*
> + * If we break out of the loop for latency reasons, use
> + * the target residency of the selected state as the
> + * expected idle duration so that the tick is retained
> + * as long as that target residency is low enough.
> + */
> + expected_interval = drv->states[idx].target_residency;
> break;
> -
> + }
> idx = i;
> }
>
> if (idx == -1)
> idx = 0; /* No states enabled. Must use 0. */
>
> + /*
> + * Don't stop the tick if the selected state is a polling one or if the
> + * expected idle duration is shorter than the tick period length.
> + */
> + if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
> + expected_interval < TICK_USEC)
> + *stop_tick = false;
> +
> data->last_state_idx = idx;
>
> return data->last_state_idx;
> @@ -397,6 +418,7 @@ static void menu_reflect(struct cpuidle_
>
> data->last_state_idx = index;
> data->needs_update = 1;
> + data->tick_wakeup = tick_nohz_idle_got_tick();
> }
>
> /**
> @@ -427,14 +449,27 @@ static void menu_update(struct cpuidle_d
> * assume the state was never reached and the exit latency is 0.
> */
>
> - /* measured value */
> - measured_us = cpuidle_get_last_residency(dev);
> -
> - /* Deduct exit latency */
> - if (measured_us > 2 * target->exit_latency)
> - measured_us -= target->exit_latency;
> - else
> - measured_us /= 2;
> + if (data->tick_wakeup && data->next_timer_us > TICK_USEC) {
> + /*
> + * The nohz code said that there wouldn't be any events within
> + * the tick boundary (if the tick was stopped), but the idle
> + * duration predictor had a differing opinion. Since the CPU
> + * was woken up by a tick (that wasn't stopped after all), the
> + * predictor was not quite right, so assume that the CPU could
> + * have been idle long (but not forever) to help the idle
> + * duration predictor do a better job next time.
> + */
> + measured_us = 9 * MAX_INTERESTING / 10;
> + } else {
> + /* measured value */
> + measured_us = cpuidle_get_last_residency(dev);
> +
> + /* Deduct exit latency */
> + if (measured_us > 2 * target->exit_latency)
> + measured_us -= target->exit_latency;
> + else
> + measured_us /= 2;
> + }
>
> /* Make sure our coefficients do not exceed unity */
> if (measured_us > data->next_timer_us)
> Index: linux-pm/kernel/time/tick-sched.c
> ===================================================================
> --- linux-pm.orig/kernel/time/tick-sched.c
> +++ linux-pm/kernel/time/tick-sched.c
> @@ -991,6 +991,20 @@ void tick_nohz_irq_exit(void)
> }
>
> /**
> + * tick_nohz_idle_got_tick - Check whether or not the tick handler has run
> + */
> +bool tick_nohz_idle_got_tick(void)
> +{
> + struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
> +
> + if (ts->inidle > 1) {
> + ts->inidle = 1;
> + return true;
> + }
> + return false;
> +}
> +
> +/**
> * tick_nohz_get_sleep_length - return the length of the current sleep
> *
> * Called from power state control code with interrupts disabled
> @@ -1101,6 +1115,9 @@ static void tick_nohz_handler(struct clo
> struct pt_regs *regs = get_irq_regs();
> ktime_t now = ktime_get();
>
> + if (ts->inidle)
> + ts->inidle = 2;
> +
> dev->next_event = KTIME_MAX;
>
> tick_sched_do_timer(now);
> @@ -1198,6 +1215,9 @@ static enum hrtimer_restart tick_sched_t
> struct pt_regs *regs = get_irq_regs();
> ktime_t now = ktime_get();
>
> + if (ts->inidle)
> + ts->inidle = 2;
> +
> tick_sched_do_timer(now);
>
> /*
> Index: linux-pm/include/linux/tick.h
> ===================================================================
> --- linux-pm.orig/include/linux/tick.h
> +++ linux-pm/include/linux/tick.h
> @@ -119,6 +119,7 @@ extern void tick_nohz_idle_restart_tick(
> extern void tick_nohz_idle_enter(void);
> extern void tick_nohz_idle_exit(void);
> extern void tick_nohz_irq_exit(void);
> +extern bool tick_nohz_idle_got_tick(void);
> extern ktime_t tick_nohz_get_sleep_length(void);
> extern unsigned long tick_nohz_get_idle_calls(void);
> extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
> @@ -139,6 +140,7 @@ static inline void tick_nohz_idle_stop_t
> static inline void tick_nohz_idle_restart_tick(void) { }
> static inline void tick_nohz_idle_enter(void) { }
> static inline void tick_nohz_idle_exit(void) { }
> +static inline bool tick_nohz_idle_got_tick(void) { return false; }
>
> static inline ktime_t tick_nohz_get_sleep_length(void)
> {
>
On Wed, Mar 28, 2018 at 10:38 AM, Thomas Ilsche
<[email protected]> wrote:
> On 2018-03-28 10:13, Rafael J. Wysocki wrote:
>>
>> On Wed, Mar 28, 2018 at 12:10 AM, Rafael J. Wysocki <[email protected]>
>> wrote:
>>>
>>> On Tuesday, March 27, 2018 11:50:02 PM CEST Thomas Ilsche wrote:
>>>>
>>>> On 2018-03-20 16:45, Rafael J. Wysocki wrote:
>>>>>
>>>>> From: Rafael J. Wysocki <[email protected]>
>>>>>
>>>>> In order to address the issue with short idle duration predictions
>>>>> by the idle governor after the tick has been stopped, reorder the
>>>>> code in cpuidle_idle_call() so that the governor idle state selection
>>>>> runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
>>>>> by cpuidle_select() to decide whether or not to stop the tick.
>>>>>
>>>>> This isn't straightforward, because menu_select() invokes
>>>>> tick_nohz_get_sleep_length() to get the time to the next timer
>>>>> event and the number returned by the latter comes from
>>>>> __tick_nohz_idle_enter(). Fortunately, however, it is possible
>>>>> to compute that number without actually stopping the tick and with
>>>>> the help of the existing code.
>>>>
>>>>
>>>> I think something is wrong with the new tick_nohz_get_sleep_length.
>>>> It seems to return a value that is too large, ignoring immanent
>>>> non-sched timer.
>>>
>>>
>>> That's a very useful hint, let me have a look.
>>>
>>>> I tested idle-loop-v7.3. It looks very similar to my previous results
>>>> on the first idle-loop-git-version [1]. Idle and traditional synthetic
>>>> powernightmares are mostly good.
>>>
>>>
>>> OK
>>>
>>>> But it selects too deep C-states for short idle periods, which is bad
>>>> for power consumption [2].
>>>
>>>
>>> That still needs to be improved, then.
>>>
>>>> I tracked this down with additional tests using
>>>> __attribute__((optimize("O0"))) menu_select
>>>> and perf probe. With this the behavior seems slightly different, but it
>>>> shows that data->next_timer_us is:
>>>> v4.16-rc6: the expected ~500 us [3]
>>>> idle-loop-v7.3: many milliseconds to minutes [4].
>>>> This leads to the governor to wrongly selecting C6.
>>>>
>>>> Checking with 372be9e and 6ea0577, I can confirm that the change is
>>>> introduced by this patch.
>>>
>>>
>>> Yes, that's where the most intrusive reordering happens.
>>
>>
>> Overall, this is an interesting conundrum, because the case in
>> question is when the tick should never be stopped at all during the
>> workload and the code's behavior in that case should not change, so
>> the change was not intentional.
>>
>> Now, from walking through the code, as long as can_stop_idle_tick()
>> returns 'true' all should be fine or at least I don't see why there is
>> any difference in behavior in that case.
>>
>> However, if can_stop_idle_tick() returns 'false' (for example, because
>> need_resched() returns 'true' when it is evaluated), the behavior *is*
>> different in a couple of ways. I sort of know how that can be
>> addressed, but I'd like to reproduce your results here.
>>
>> Are you still using the same workload as before to trigger this behavior?
>>
>
> Yes, the exact code I use is as follows
>
> $ gcc poller.c -O3 -fopenmp -o poller_omp
> $ GOMP_CPU_AFFINITY=0-35 ./poller_omp 500
>
> #include <stdlib.h>
> #include <stdio.h>
> #include <unistd.h>
>
> int main(int argc, char *argv[])
> {
> int sleep_us = 10000;
> if (argc == 2) {
> sleep_us = atoi(argv[1]);
> }
>
> #pragma omp parallel
> {
> while (1) {
> usleep(sleep_us);
> }
> }
> }
So I do
$ for cpu in 0 1 2 3; do taskset -c $cpu sh -c 'while true; do usleep
500; done' & done
which is a shell kind of imitation of the above and I cannot see this
issue at all.
I count the number of times data->next_timer_us in menu_select() is
greater than TICK_USEC and while this "workload" is running, that
number is exactly 0.
I'll try with a C program still.
On Wed, Mar 28, 2018 at 12:37 PM, Rafael J. Wysocki <[email protected]> wrote:
> On Wed, Mar 28, 2018 at 10:38 AM, Thomas Ilsche
> <[email protected]> wrote:
>> On 2018-03-28 10:13, Rafael J. Wysocki wrote:
>>>
[cut]
>
> So I do
>
> $ for cpu in 0 1 2 3; do taskset -c $cpu sh -c 'while true; do usleep
> 500; done' & done
>
> which is a shell kind of imitation of the above and I cannot see this
> issue at all.
>
> I count the number of times data->next_timer_us in menu_select() is
> greater than TICK_USEC and while this "workload" is running, that
> number is exactly 0.
>
> I'll try with a C program still.
And with a C program I see data->next_timer_us greater than TICK_USEC
while it is running, so let me dig deeper.
On 2018-03-28 12:56, Rafael J. Wysocki wrote:
> On Wed, Mar 28, 2018 at 12:37 PM, Rafael J. Wysocki <[email protected]> wrote:
>> On Wed, Mar 28, 2018 at 10:38 AM, Thomas Ilsche
>> <[email protected]> wrote:
>>> On 2018-03-28 10:13, Rafael J. Wysocki wrote:
>>>>
>
> [cut]
>
>>
>> So I do
>>
>> $ for cpu in 0 1 2 3; do taskset -c $cpu sh -c 'while true; do usleep
>> 500; done' & done
>>
>> which is a shell kind of imitation of the above and I cannot see this
>> issue at all.
>>
>> I count the number of times data->next_timer_us in menu_select() is
>> greater than TICK_USEC and while this "workload" is running, that
>> number is exactly 0.
>>
>> I'll try with a C program still.
>
> And with a C program I see data->next_timer_us greater than TICK_USEC
> while it is running, so let me dig deeper.
>
I can confirm that a shell-loop behaves differently like you describe.
Even if it's just a shell-loop calling "main{usleep(500);}" binary.
On 2018.03.28 08:15 Thomas Ilsche wrote:
> On 2018-03-28 12:56, Rafael J. Wysocki wrote:
>> On Wed, Mar 28, 2018 at 12:37 PM, Rafael J. Wysocki <[email protected]> wrote:
>>> On Wed, Mar 28, 2018 at 10:38 AM, Thomas Ilsche
>>> <[email protected]> wrote:
>>>> On 2018-03-28 10:13, Rafael J. Wysocki wrote:
>>>>>
>>
>> [cut]
>>
>>>
>>> So I do
>>>
>>> $ for cpu in 0 1 2 3; do taskset -c $cpu sh -c 'while true; do usleep
>>> 500; done' & done
>>>
>>> which is a shell kind of imitation of the above and I cannot see this
>>> issue at all.
>>>
>>> I count the number of times data->next_timer_us in menu_select() is
>>> greater than TICK_USEC and while this "workload" is running, that
>>> number is exactly 0.
>>>
>>> I'll try with a C program still.
>>
>> And with a C program I see data->next_timer_us greater than TICK_USEC
>> while it is running, so let me dig deeper.
>>
>
> I can confirm that a shell-loop behaves differently like you describe.
> Even if it's just a shell-loop calling "main{usleep(500);}" binary.
I normally use the C program method.
The timer there returns with the need_sched() flag set.
I do not seem to have usleep on my system, but when using sleep in a
shell loop, the timer returns without the need_resched() flag set.
Most of my test results involving varying the value of
POLL_IDLE_COUNT are total garbage, because I was using the
C program method, and thus exiting the poll_idle loop based
on the need_resched() flag and not the POLL_IDLE_COUNT
setting.
I don't know if I can re-do the work, because I
do not have a good way to get my system to use Idle
State 0 with any real workflow, and I seem to get into
side effect issues when I disable other idle states to
force more use of idle state 0.
... Doug
On Wed, Mar 28, 2018 at 10:41 PM, Doug Smythies <[email protected]> wrote:
> On 2018.03.28 08:15 Thomas Ilsche wrote:
>> On 2018-03-28 12:56, Rafael J. Wysocki wrote:
>>> On Wed, Mar 28, 2018 at 12:37 PM, Rafael J. Wysocki <[email protected]> wrote:
>>>> On Wed, Mar 28, 2018 at 10:38 AM, Thomas Ilsche
>>>> <[email protected]> wrote:
>>>>> On 2018-03-28 10:13, Rafael J. Wysocki wrote:
>>>>>>
>>>
>>> [cut]
>>>
>>>>
>>>> So I do
>>>>
>>>> $ for cpu in 0 1 2 3; do taskset -c $cpu sh -c 'while true; do usleep
>>>> 500; done' & done
>>>>
>>>> which is a shell kind of imitation of the above and I cannot see this
>>>> issue at all.
>>>>
>>>> I count the number of times data->next_timer_us in menu_select() is
>>>> greater than TICK_USEC and while this "workload" is running, that
>>>> number is exactly 0.
>>>>
>>>> I'll try with a C program still.
>>>
>>> And with a C program I see data->next_timer_us greater than TICK_USEC
>>> while it is running, so let me dig deeper.
>>>
>>
>> I can confirm that a shell-loop behaves differently like you describe.
>> Even if it's just a shell-loop calling "main{usleep(500);}" binary.
>
> I normally use the C program method.
> The timer there returns with the need_sched() flag set.
I found the problem, but addressing it will not be straightforward,
which is kind of unfortunate.
Namely, get_next_timer_interrupt() doesn't take high resolution timers
into account if they are enabled (which I overlooked), but they
obviously need to be taken into account in
tick_nohz_get_sleep_length(), so calling tick_nohz_next_event() in
there is not sufficient.
Moreover, it needs to know the next highres timer not including the
tick and that's not so easy to get. It is doable, though, AFAICS.
On Wednesday, March 28, 2018 11:14:36 AM CEST Thomas Ilsche wrote:
> On 2018-03-22 18:40, Rafael J. Wysocki wrote:
> > From: Rafael J. Wysocki <[email protected]>
> >
> > Add a new pointer argument to cpuidle_select() and to the ->select
> > cpuidle governor callback to allow a boolean value indicating
> > whether or not the tick should be stopped before entering the
> > selected state to be returned from there.
> >
> > Make the ladder governor ignore that pointer (to preserve its
> > current behavior) and make the menu governor return 'false" through
> > it if:
> > (1) the idle exit latency is constrained at 0, or
> > (2) the selected state is a polling one, or
> > (3) the expected idle period duration is within the tick period
> > range.
> >
> > In addition to that, the correction factor computations in the menu
> > governor need to take the possibility that the tick may not be
> > stopped into account to avoid artificially small correction factor
> > values. To that end, add a mechanism to record tick wakeups, as
> > suggested by Peter Zijlstra, and use it to modify the menu_update()
> > behavior when tick wakeup occurs. Namely, if the CPU is woken up by
> > the tick and the return value of tick_nohz_get_sleep_length() is not
> > within the tick boundary, the predicted idle duration is likely too
> > short, so make menu_update() try to compensate for that by updating
> > the governor statistics as though the CPU was idle for a long time.
> >
> > Since the value returned through the new argument pointer of
> > cpuidle_select() is not used by its caller yet, this change by
> > itself is not expected to alter the functionality of the code.
> >
> > Signed-off-by: Rafael J. Wysocki <[email protected]>
> > ---
> >
> > One more revision here.
> >
> > From the Thomas Ilsche's testing on the Skylake server it looks like
> > data->intervals[] need to be updated along with the correction factor
> > on tick wakeups that occur when next_timer_us is above the tick boundary.
> >
> > The difference between this and the original v7 (of patch [5/8]) is
> > what happens in menu_update(). This time next_timer_us is checked
> > properly and if that is above the tick boundary and a tick wakeup occurs,
> > the function simply sets mesured_us to a large constant and uses that to
> > update both the correction factor and data->intervals[] (the particular
> > value used in this patch was found through a bit of experimentation).
> >
> > Let's see how this works for Thomas and Doug.
> >
> > For easier testing there is a git branch containing this patch (and the
> > rest of the series) at:
> >
> > git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> > idle-loop-v7.3
> >
> > Thanks!
>
> Besides the other issue with tick_nohz_get_sleep_length, v7.3
> generally works well in idle.
Great, thanks!
> So far I don't see anything
> statistically noticeable, but I saw one peculiar anomaly. After all
> cores woke up simultaneously to schedule some kworker task, some of
> them kept the sched tick up, even stayed in shallow sleep state for a
> while, without having any tasks scheduled. Gradually they chose deeper
> sleep states and stopped their sched ticks. After 23 ms (1000 Hz
> kernel), they all went back to deep sleep.
>
> https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v7_3_skl_sp_anomaly.png
>
> I have only seen this once so far and can't reproduce it yet, so this
> particular instance may not be an issue in practice.
OK
> However my fundamental concerns about the policy whether to disable the sched
> tick remain:
>
> Mixing the precise timer and vague heuristic for the decision is
> dangerous. The timer should not be wrong, heuristic may be.
Well, I wouldn't say "dangerous". It may be suboptimal, but even that is not
a given. Besides ->
> Decisions should use actual time points rather than the generic tick
> duration and residency time. e.g.
> expected_interval < delta_next_us
> vs
> expected_interval < TICK_USEC
-> the role of this check is to justify taking the overhead of stopping the
tick and it certainly is justifiable if the governor doesn't anticipate any
wakeups (timer or not) in the TICK_USEC range. It may be justifiable in
other cases too, but that's a matter of some more complex checks and may not
be worth the extra complexity at all.
> For some cases the unmodified sched tick is not efficient as fallback.
> Is it feasible to
> 1) enable the sched tick when it's currently disabled instead of
> blindly choosing a different C state?
It is not "blindly" if you will. It is very much "consciously". :-)
Restarting the tick from within menu_select() wouldn't work IMO and
restarting it from cpuidle_idle_call() every time it was stopped might
be wasteful.
It could be done, but AFAICS if the CPU in deep idle is woken up by an
occasional interrupt that doesn't set need_resched, it is more likely
to go into deep idle again than to go into shallow idle at that point.
> 2) modify the next upcoming sched tick to be better suitable as
> fallback timer?
Im not sure what you mean.
> I think with the infrastructure changes it should be possible to
> implement the policy I envisioned previously
> (https://marc.info/?l=linux-pm&m=151384941425947&w=2), which is based
> on the ordering of timers and the heuristically predicted idle time.
> If the sleep_length issue is fixed and I have some mechanism for a
> modifiable fallback timer, I'll try to demonstrate that on top of your
> changes.
Sure. I'm not against adding more complexity to this in principle, but there
needs to be a good enough justification for it.
As I said in one of the previous messages, if simple code gets the job done,
the extra complexity may just not be worth it. That's why I went for very
simple code here. Still, if there is a clear case for making it more complex,
that can be done.
Thanks!
>> However my fundamental concerns about the policy whether to disable the sched
>> tick remain:
>>
>> Mixing the precise timer and vague heuristic for the decision is
>> dangerous. The timer should not be wrong, heuristic may be.
>
> Well, I wouldn't say "dangerous". It may be suboptimal, but even that is not
> a given. Besides ->
>
>> Decisions should use actual time points rather than the generic tick
>> duration and residency time. e.g.
>> expected_interval < delta_next_us
>> vs
>> expected_interval < TICK_USEC
>
> -> the role of this check is to justify taking the overhead of stopping the
> tick and it certainly is justifiable if the governor doesn't anticipate any
> wakeups (timer or not) in the TICK_USEC range. It may be justifiable in
> other cases too, but that's a matter of some more complex checks and may not
> be worth the extra complexity at all.
I tried that change. It's just just a bit bulky because I
cache the result of ktime_to_us(delta_next) early.
diff --git a/drivers/cpuidle/governors/menu.c b/drivers/cpuidle/governors/menu.c
index a6eca02..cad87bf 100644
--- a/drivers/cpuidle/governors/menu.c
+++ b/drivers/cpuidle/governors/menu.c
@@ -296,6 +296,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
ktime_t delta_next;
+ unsigned long delta_next_us;
if (data->needs_update) {
menu_update(drv, dev);
@@ -314,6 +315,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length(&delta_next));
+ delta_next_us = ktime_to_us(delta_next);
get_iowait_load(&nr_iowaiters, &cpu_load);
data->bucket = which_bucket(data->next_timer_us, nr_iowaiters);
@@ -364,7 +366,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
*/
if (data->predicted_us < TICK_USEC)
data->predicted_us = min_t(unsigned int, TICK_USEC,
- ktime_to_us(delta_next));
+ delta_next_us);
} else {
/*
* Use the performance multiplier and the user-configurable
@@ -412,9 +414,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
* expected idle duration is shorter than the tick period length.
*/
if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
- expected_interval < TICK_USEC) {
- unsigned int delta_next_us = ktime_to_us(delta_next);
-
+ expected_interval < delta_next_us) {
*stop_tick = false;
if (!tick_nohz_tick_stopped() && idx > 0 &&
This works as a I expect in the sense of stopping the tick more often
and allowing deeper sleep states in some cases. However, it
drastically *increases* the power consumption for some affected
workloads test system (SKL-SP).
So while I believe this generally improves the behavior - I can't
recommend it based on the practical implications. Below are some
details for the curious:
power consumption for various workload configurations with 250 Hz
kernels 4.16.0, v9, v9+delta_next patch:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_250_Hz_power.png
Practically v9 has the best power consumption in most cases.
The following detailed looks are with 1000 Hz kernels.
v9 with a synchronized 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_poll_sync.png
v9 with a staggered 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_poll_stagger.png
Both show that the sched tick is kept on and this causes more requests
to C1E than C6
v9+delta_next with a synchronized 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_delta_poll_sync.png
v9+delta_next with a staggered 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_delta_poll_stagger.png
No more sched tick, no more C1E requests, but increased power.
Besides:
- the hardware reports 0 residency in C6 (both core and PKG) for
both v9 and v9+delta_next_us.
- the increased power consumption comes after a ramp-up of ~200 ms
for the staggered and ~2 s for the synchronized workload.
For reference traces from an unmodified 4.16.0:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v4.16.0_poll_sync.png
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v4.16.0_poll_stagger.png
It behaves similar to the delta_next patch but does not show the
increased power consumption in this exact workload configuration.
I couldn't help to dig into the effect a bit more and am able to
reproduce it even under unmodified kernels with staggered sleep cycles
between ~1.2 ms and ~2.5 ms where power is increased by > 40 W.
Anyway, this effect seems to be beyond what the governor should
consider. It is an example where it doesn't seem possible to decide
for the optimal C state without considering the state of other cores
and such unexpected hardware behavior.
And these are only the results from one system and a limited set of
workload configurations.
>> For some cases the unmodified sched tick is not efficient as fallback.
>> Is it feasible to
>> 1) enable the sched tick when it's currently disabled instead of
>> blindly choosing a different C state?
>
> It is not "blindly" if you will. It is very much "consciously". :-)
>
> Restarting the tick from within menu_select() wouldn't work IMO and
> restarting it from cpuidle_idle_call() every time it was stopped might
> be wasteful.
>
> It could be done, but AFAICS if the CPU in deep idle is woken up by an
> occasional interrupt that doesn't set need_resched, it is more likely
> to go into deep idle again than to go into shallow idle at that point.
>
>> 2) modify the next upcoming sched tick to be better suitable as
>> fallback timer?
>
> Im not sure what you mean.
>
>> I think with the infrastructure changes it should be possible to
>> implement the policy I envisioned previously
>> (https://marc.info/?l=linux-pm&m=151384941425947&w=2), which is based
>> on the ordering of timers and the heuristically predicted idle time.
>> If the sleep_length issue is fixed and I have some mechanism for a
>> modifiable fallback timer, I'll try to demonstrate that on top of your
>> changes.
>
> Sure. I'm not against adding more complexity to this in principle, but there
> needs to be a good enough justification for it.
>
> As I said in one of the previous messages, if simple code gets the job done,
> the extra complexity may just not be worth it. That's why I went for very
> simple code here. Still, if there is a clear case for making it more complex,
> that can be done.
>
> Thanks!
>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
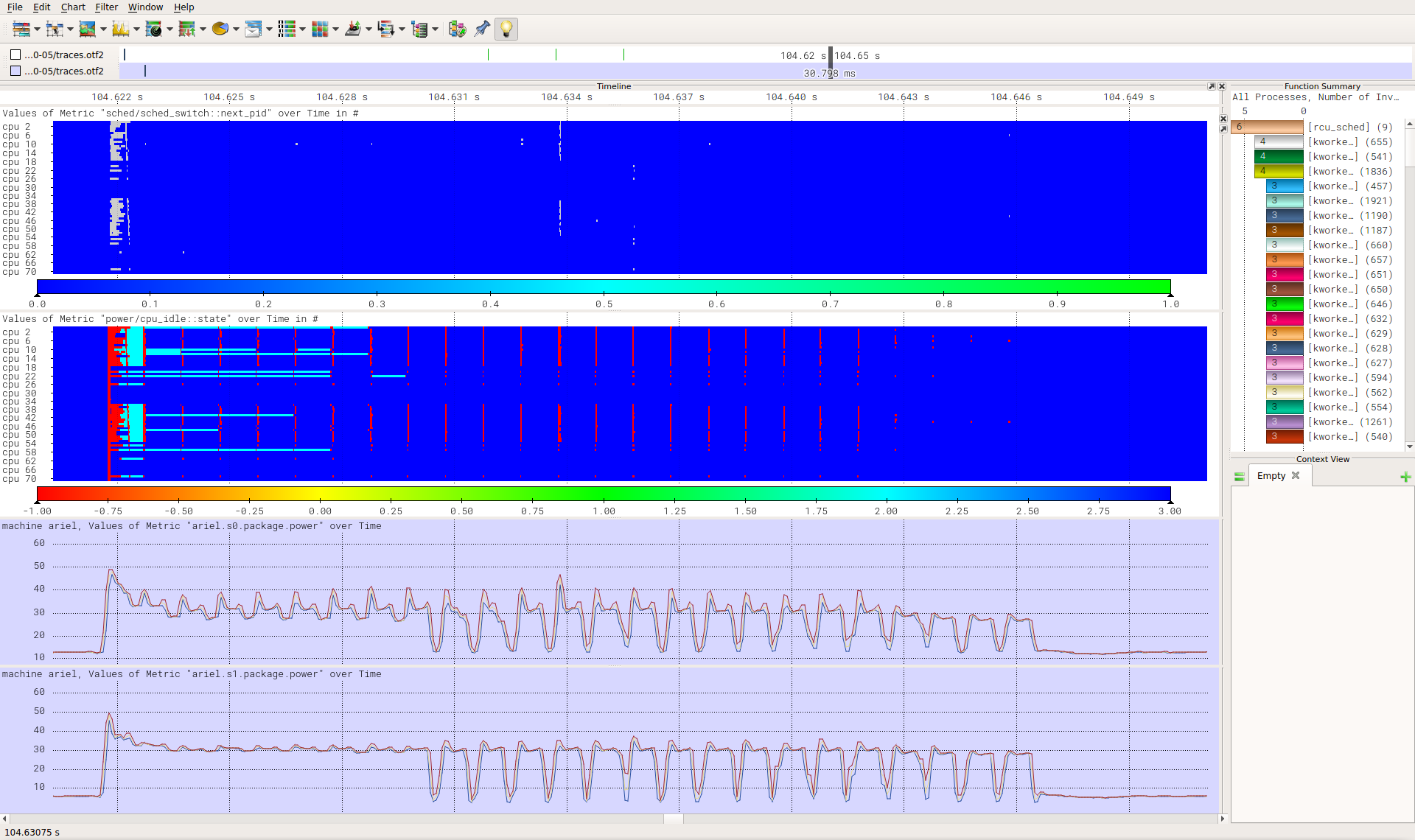{kind=link}
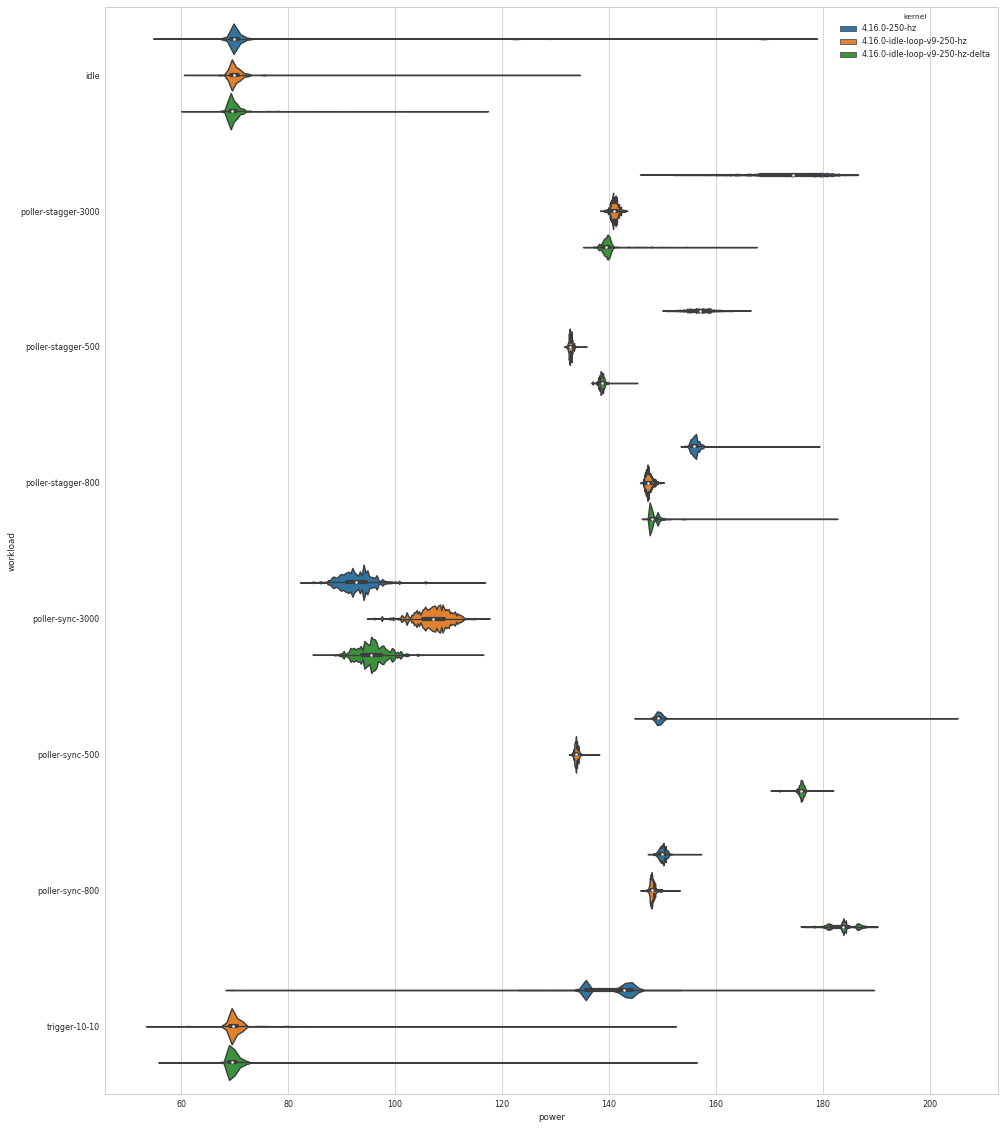{kind=link}
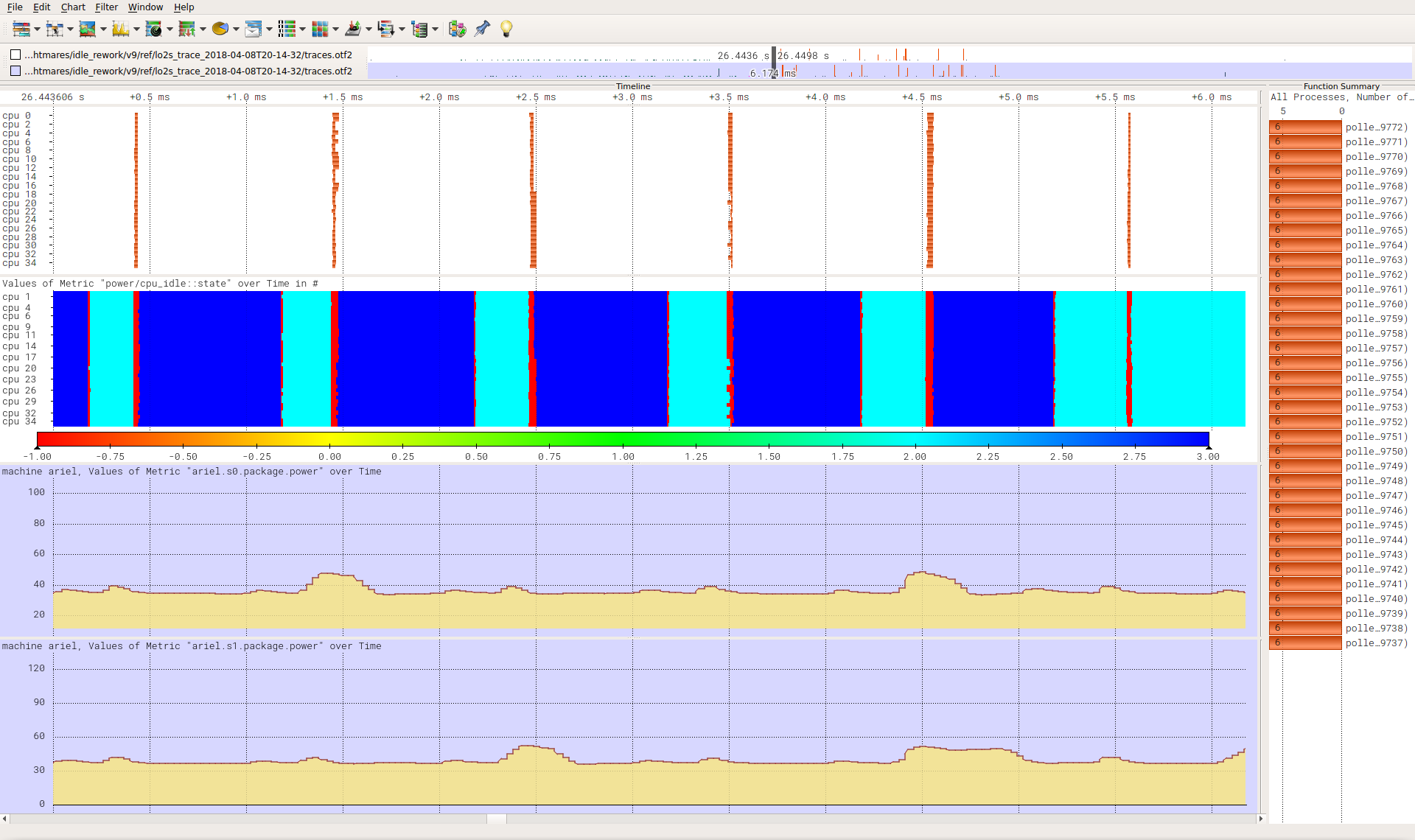{kind=link}
{kind=link}
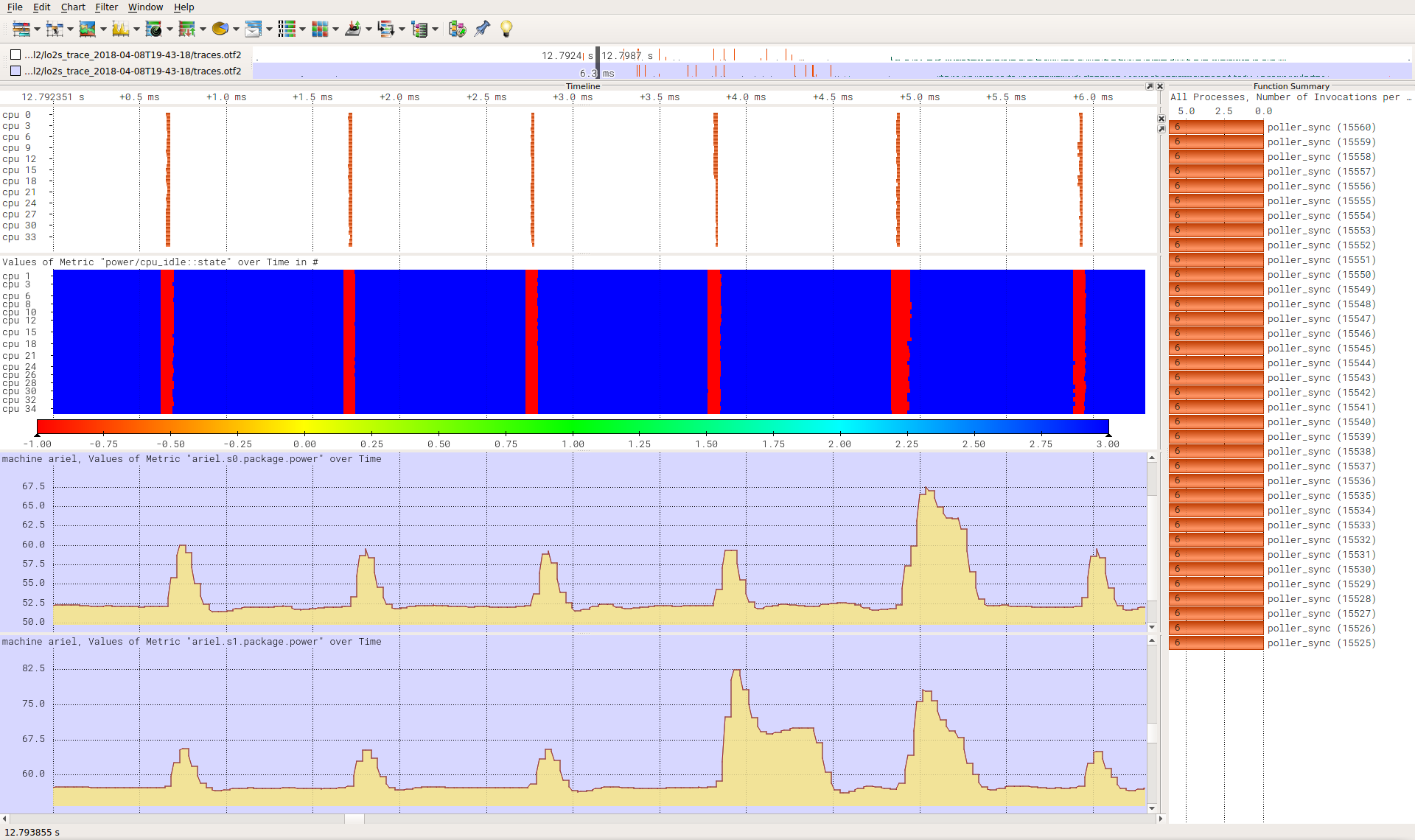{kind=link}
{kind=link}
{kind=link}
{kind=link}