I guess people who get this should just stick with 2.6.8.1?
$ dmesg
nfsd: page allocation failure. order:0, mode:0x20
[<c013923c>] __alloc_pages+0x21c/0x350
[<c0139388>] __get_free_pages+0x18/0x40
[<c013c9ef>] kmem_getpages+0x1f/0xc0
[<c013d730>] cache_grow+0xc0/0x1a0
[<c013d9db>] cache_alloc_refill+0x1cb/0x210
[<c013de41>] __kmalloc+0x71/0x80
[<c036f583>] alloc_skb+0x53/0x100
[<c031fb18>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031f81e>] e1000_clean_rx_irq+0x18e/0x440
[<c0106a2f>] handle_IRQ_event+0x6f/0x80
[<c031f3fb>] e1000_clean+0x5b/0x100
[<c0375c0a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013007b>] simplify_symbols+0x5b/0x110
[<c014019a>] shrink_list+0x30a/0x4b0
[<c01404a3>] shrink_cache+0x163/0x380
[<c0140c42>] shrink_zone+0xa2/0xd0
[<c0140cc3>] shrink_caches+0x53/0x70
[<c0140d8f>] try_to_free_pages+0xaf/0x1b0
[<c0139287>] __alloc_pages+0x267/0x350
[<c0136763>] generic_file_buffered_write+0x123/0x660
[<c013918b>] __alloc_pages+0x16b/0x350
[<c013d557>] alloc_slabmgmt+0x57/0x70
[<c027c156>] xfs_trans_unlocked_item+0x56/0x60
[<c02929cf>] xfs_write+0x78f/0xc00
[<c028de01>] linvfs_writev+0x101/0x140
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c02a5e52>] copy_from_user+0x42/0x70
[<c01542fa>] do_readv_writev+0x28a/0x2b0
[<c028dfe0>] linvfs_open+0x0/0x90
[<c01049c8>] common_interrupt+0x18/0x20
[<c0153bc0>] do_sync_write+0x0/0x110
[<c028e03a>] linvfs_open+0x5a/0x90
[<c0152da2>] dentry_open+0xd2/0x270
[<c01543d8>] vfs_writev+0x58/0x60
[<c01caf26>] nfsd_write+0xf6/0x390
[<c01049c8>] common_interrupt+0x18/0x20
[<c01d33bb>] nfsd3_proc_write+0xbb/0x120
[<c01c66c3>] nfsd_dispatch+0xa3/0x250
[<c041f4e1>] svc_process+0x6e1/0x7f0
[<c01c6463>] nfsd+0x203/0x3c0
[<c01c6260>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
I am not sure what else to do except stay with 2.6.8.1 as it did not have
these problems.
Justin Piszcz wrote:
> I guess people who get this should just stick with 2.6.8.1?
>
Does it cause any noticable problems? If not, then stay with
2.6.9.
However, it would be nice to get to the bottom of it. It might
just be happening by chance on 2.6.9 but not 2.6.8.1 though...
Anyway, how often are you getting the messages? How many
ethernet cards in the system?
Can you run a kernel with sysrq support, and do `SysRq+M`
(close to when the allocation failure happens if possible, but
otherwise on a normally running system after it has been up
for a while). Then send in the dmesg.
Thanks,
Nick
It does not cause any noticable problems that I know of, I guess it is
just a bit disturbing.
> Anyway, how often are you getting the messages?
It depends what I am doing, sometimes they happen after 20-30 minutes,
othertimes it takes a day or two.
> How many ethernet cards in the system?
There are 4 ethernet cards in the system.
1) 3c905b (on-board)
2) 3c905b (PCI)
3) 3c900 Combo (PCI)
4) Intel 82541GI/PI (PCI)
> Can you run a kernel with sysrq support, and do `SysRq+M`
> (close to when the allocation failure happens if possible, but
> otherwise on a normally running system after it has been up
> for a while). Then send in the dmesg.
Ok, I will try this.
On Mon, 25 Oct 2004, Nick Piggin wrote:
> Justin Piszcz wrote:
>> I guess people who get this should just stick with 2.6.8.1?
>>
>
> Does it cause any noticable problems? If not, then stay with
> 2.6.9.
>
> However, it would be nice to get to the bottom of it. It might
> just be happening by chance on 2.6.9 but not 2.6.8.1 though...
>
> Anyway, how often are you getting the messages? How many
> ethernet cards in the system?
>
> Can you run a kernel with sysrq support, and do `SysRq+M`
> (close to when the allocation failure happens if possible, but
> otherwise on a normally running system after it has been up
> for a while). Then send in the dmesg.
>
> Thanks,
> Nick
>
Nicj Piggin wrote:
> Does it cause any noticable problems? If not, then stay with
> 2.6.9.
>
> However, it would be nice to get to the bottom of it. It might
> just be happening by chance on 2.6.9 but not 2.6.8.1 though...
Isn't this the problem fixed by the below patch? (Sorry I didn't
get sender name when I collected it.) Some were skeptical this
would fix it but it has worked for those who tried...
Oh and BTW what is rollup.patch?
# The following patch makes it allocate skb_headlen(skb) - len instead
# of skb->len - len. When skb is linear there is no difference. When
# it's non-linear we only ever copy the bytes in the header.
#
===== net/ipv4/tcp_output.c 1.67 vs edited =====
--- 1.67/net/ipv4/tcp_output.c 2004-10-01 13:56:45 +10:00
+++ edited/net/ipv4/tcp_output.c 2004-10-17 18:58:47 +10:00
@@ -455,8 +455,12 @@
{
struct tcp_opt *tp = tcp_sk(sk);
struct sk_buff *buff;
- int nsize = skb->len - len;
+ int nsize;
u16 flags;
+
+ nsize = skb_headlen(skb) - len;
+ if (nsize < 0)
+ nsize = 0;
if (skb_cloned(skb) &&
skb_is_nonlinear(skb) &&
--Chuck Ebbert 25-Oct-04 14:54:36
No, the below patch did not fix the problem.
I am waiting for the error to re-occur then I will sysrq+M and dmesg &
send the info to the mailing list.
Rollup patch was from Nick Piggin, he stated:
Date: Sat, 23 Oct 2004 19:14:46 +1000
From: Nick Piggin <[email protected]>
To: Justin Piszcz <[email protected]>
Cc: [email protected]
Subject: Re: Page Allocation Failures Return With 2.6.9+TSO patch.
Parts/Attachments:
1 Shown 32 lines Text
2 Shown 356 lines Text
----------------------------------------
Justin Piszcz wrote:
> Kernel 2.6.9 w/TSO patch.
>
> (most likely do to the e1000/nic/issue)
>
> $ dmesg
> gaim: page allocation failure. order:4, mode:0x21
> [<c01391a7>] __alloc_pages+0x247/0x3b0
> [<c0139328>] __get_free_pages+0x18/0x40
> [<c035c33a>] sound_alloc_dmap+0xaa/0x1b0
> [<c03648c0>] ad_mute+0x20/0x40
> [<c035c70f>] open_dmap+0x1f/0x100
> [<c035cb58>] DMAbuf_open+0x178/0x1d0
> [<c035a4fa>] audio_open+0xba/0x280
> [<c015d863>] cdev_get+0x53/0xc0
> [<c035968c>] sound_open+0xac/0x110
> [<c035898e>] soundcore_open+0x1ce/0x300
> [<c03587c0>] soundcore_open+0x0/0x300
> [<c015d524>] chrdev_open+0x104/0x250
> [<c015d420>] chrdev_open+0x0/0x250
> [<c0152d82>] dentry_open+0x1d2/0x270
> [<c0152b9c>] filp_open+0x5c/0x70
> [<c01049c8>] common_interrupt+0x18/0x20
> [<c0152e75>] get_unused_fd+0x55/0xf0
> [<c0152fd9>] sys_open+0x49/0x90
> [<c010405b>] syscall_call+0x7/0xb
Ouch, 64K atomic DMA allocation.
The DMA zone barely even keeps that much total memory free.
The caller probably wants fixing, but you could try this patch...
[ Part 2: "Attached Text" ]
Pine -> 2 356 lines Text/X-PATCH (Name: "rollup.patch")
That was rollup.patch (patched 3 source files) - but this as well as the
TSO has not seemed to have fixed the problem.
On Mon, 25 Oct 2004, Chuck Ebbert wrote:
> Nicj Piggin wrote:
>
>> Does it cause any noticable problems? If not, then stay with
>> 2.6.9.
>>
>> However, it would be nice to get to the bottom of it. It might
>> just be happening by chance on 2.6.9 but not 2.6.8.1 though...
>
> Isn't this the problem fixed by the below patch? (Sorry I didn't
> get sender name when I collected it.) Some were skeptical this
> would fix it but it has worked for those who tried...
>
> Oh and BTW what is rollup.patch?
>
>
> # The following patch makes it allocate skb_headlen(skb) - len instead
> # of skb->len - len. When skb is linear there is no difference. When
> # it's non-linear we only ever copy the bytes in the header.
> #
> ===== net/ipv4/tcp_output.c 1.67 vs edited =====
> --- 1.67/net/ipv4/tcp_output.c 2004-10-01 13:56:45 +10:00
> +++ edited/net/ipv4/tcp_output.c 2004-10-17 18:58:47 +10:00
> @@ -455,8 +455,12 @@
> {
> struct tcp_opt *tp = tcp_sk(sk);
> struct sk_buff *buff;
> - int nsize = skb->len - len;
> + int nsize;
> u16 flags;
> +
> + nsize = skb_headlen(skb) - len;
> + if (nsize < 0)
> + nsize = 0;
>
> if (skb_cloned(skb) &&
> skb_is_nonlinear(skb) &&
>
> --Chuck Ebbert 25-Oct-04 14:54:36
>
Ok, thanks, one last question,
I do not explicitly set ethtool* tso, however I use dhcpcd on this
interface, does that set TSO on the interface? I have never used TSO (that
I am aware of) and I am wondering if it is something else?
On Wed, 27 Oct 2004, Andrew Morton wrote:
> Justin Piszcz <[email protected]> wrote:
>>
>> swapper: page allocation failure. order:0, mode:0x20
>> [<c0139227>] __alloc_pages+0x247/0x3b0
>> [<c02d9471>] add_interrupt_randomness+0x31/0x40
>> [<c01393a8>] __get_free_pages+0x18/0x40
>> [<c013ca2f>] kmem_getpages+0x1f/0xc0
>> [<c013d770>] cache_grow+0xc0/0x1a0
>> [<c013da1b>] cache_alloc_refill+0x1cb/0x210
>> [<c013de81>] __kmalloc+0x71/0x80
>> [<c036f8f3>] alloc_skb+0x53/0x100
>> [<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
>> [<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
>> [<c031f76b>] e1000_clean+0x5b/0x100
>> [<c0375f7a>] net_rx_action+0x6a/0xf0
>> [<c011daa1>] __do_softirq+0x41/0x90
>> [<c011db17>] do_softirq+0x27/0x30
>> [<c0106ebc>] do_IRQ+0x10c/0x130
>
> This should be harmless - networking will recover. The TSO fix was
> merged a week or so ago.
>
Justin Piszcz <[email protected]> wrote:
>
> swapper: page allocation failure. order:0, mode:0x20
> [<c0139227>] __alloc_pages+0x247/0x3b0
> [<c02d9471>] add_interrupt_randomness+0x31/0x40
> [<c01393a8>] __get_free_pages+0x18/0x40
> [<c013ca2f>] kmem_getpages+0x1f/0xc0
> [<c013d770>] cache_grow+0xc0/0x1a0
> [<c013da1b>] cache_alloc_refill+0x1cb/0x210
> [<c013de81>] __kmalloc+0x71/0x80
> [<c036f8f3>] alloc_skb+0x53/0x100
> [<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
> [<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
> [<c031f76b>] e1000_clean+0x5b/0x100
> [<c0375f7a>] net_rx_action+0x6a/0xf0
> [<c011daa1>] __do_softirq+0x41/0x90
> [<c011db17>] do_softirq+0x27/0x30
> [<c0106ebc>] do_IRQ+0x10c/0x130
This should be harmless - networking will recover. The TSO fix was
merged a week or so ago.
Ah, you are correct:
root@p500:~# ethtool -k eth0
Offload parameters for eth0:
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp segmentation offload: on
root@p500:~# ethtool -k eth1
Offload parameters for eth1:
Cannot get device rx csum settings: Operation not supported
Cannot get device tx csum settings: Operation not supported
Cannot get device scatter-gather settings: Operation not supported
Cannot get device tcp segmentation offload settings: Operation not
supported
no offload info available
root@p500:~# ethtool -k eth2
Offload parameters for eth2:
Cannot get device rx csum settings: Operation not supported
Cannot get device tx csum settings: Operation not supported
Cannot get device scatter-gather settings: Operation not supported
Cannot get device tcp segmentation offload settings: Operation not
supported
no offload info available
root@p500:~# ethtool -k eth3
Offload parameters for eth3:
Cannot get device rx csum settings: Operation not supported
Cannot get device tx csum settings: Operation not supported
Cannot get device scatter-gather settings: Operation not supported
Cannot get device tcp segmentation offload settings: Operation not
supported
no offload info available
root@p500:~#
On Thu, 28 Oct 2004, Francois Romieu wrote:
> Justin Piszcz <[email protected]> :
> [...]
>> I do not explicitly set ethtool* tso, however I use dhcpcd on this
>> interface, does that set TSO on the interface? I have never used TSO (that
>
> Hint: ethtool -k ethX
>
> --
> Ueimor
>
Justin Piszcz <[email protected]> :
[...]
> I do not explicitly set ethtool* tso, however I use dhcpcd on this
> interface, does that set TSO on the interface? I have never used TSO (that
Hint: ethtool -k ethX
--
Ueimor
After a couple days the errors have shown up again.
Can anyone help me debug this problem further?
Is there any chance Linus will freeze 2.6 and make the current development
tree 2.7? It seems like ever since around 2.6.8 things have been getting
progressively worse (page allocation failures/nvidia
breakage/XFS-oops-when-copying-over-nfs-when-the-file-is-being-written-to)?
$ uptime
17:34:32 up 2 days, 8:53, 29 users, load average: 0.29, 0.38, 0.36
jpiszcz@p500:/usr/src/linux$ grep -i sysrq .config
CONFIG_MAGIC_SYSRQ=y
I tried various combinations of sysrq+M but it did not seem to do anything
special?
Also, all of the failures below, could they possibly be causing data
corruption?
Once again, box = Dell GX1 p3 500mhz / 768MB ram (Intel 440BX/ZX/DX)
chipset.
$ lspci
00:00.0 Host bridge: Intel Corp. 440BX/ZX/DX - 82443BX/ZX/DX Host bridge
(rev 03)
00:01.0 PCI bridge: Intel Corp. 440BX/ZX/DX - 82443BX/ZX/DX AGP bridge
(rev 03)
00:07.0 ISA bridge: Intel Corp. 82371AB/EB/MB PIIX4 ISA (rev 02)
00:07.1 IDE interface: Intel Corp. 82371AB/EB/MB PIIX4 IDE (rev 01)
00:07.2 USB Controller: Intel Corp. 82371AB/EB/MB PIIX4 USB (rev 01)
00:07.3 Bridge: Intel Corp. 82371AB/EB/MB PIIX4 ACPI (rev 02)
00:0d.0 Unknown mass storage controller: Promise Technology, Inc. 20269
(rev 02)
00:0e.0 Unknown mass storage controller: Promise Technology, Inc. 20267
(rev 02)
00:0f.0 PCI bridge: Digital Equipment Corporation DECchip 21152 (rev 03)
00:11.0 Ethernet controller: 3Com Corporation 3c905B 100BaseTX [Cyclone]
(rev 24)
01:00.0 VGA compatible controller: ATI Technologies Inc 3D Rage Pro AGP
1X/2X (rev 5c)
02:09.0 Ethernet controller: Intel Corp. 82541GI/PI Gigabit Ethernet
Controller
02:0a.0 Ethernet controller: 3Com Corporation 3c905B 100BaseTX [Cyclone]
(rev 30)
02:0b.0 Ethernet controller: 3Com Corporation 3c900 Combo [Boomerang]
$ cat /proc/interrupts
CPU0
0: 204979514 XT-PIC timer
1: 2484 XT-PIC i8042
2: 0 XT-PIC cascade
5: 0 XT-PIC Crystal audio controller
8: 1 XT-PIC rtc
9: 0 XT-PIC acpi
10: 3866403 XT-PIC ide2, ide3
11: 129079320 XT-PIC ide4, ide5, eth0, eth1, eth2, eth3
12: 16198 XT-PIC i8042
15: 50 XT-PIC ide1
NMI: 0
LOC: 0
ERR: 1022
MIS: 0
$ cat /proc/ioports
0000-001f : dma1
0020-0021 : pic1
0040-0043 : timer0
0050-0053 : timer1
0060-006f : keyboard
0070-0077 : rtc
0080-008f : dma page reg
00a0-00a1 : pic2
00c0-00df : dma2
00f0-00ff : fpu
0170-0177 : ide1
0184-0187 : MPU-401 UART
02f8-02ff : serial
0376-0376 : ide1
03c0-03df : vga+
03f8-03ff : serial
0530-0533 : Crystal audio controller
0800-083f : 0000:00:07.3
0800-0803 : PM1a_EVT_BLK
0804-0805 : PM1a_CNT_BLK
0808-080b : PM_TMR
080c-080f : GPE0_BLK
0840-085f : 0000:00:07.3
0850-0857 : piix4-smbus
0cf8-0cff : PCI conf1
c880-c8ff : 0000:00:11.0
c880-c8ff : 0000:00:11.0
cc40-cc7f : 0000:00:0e.0
cc40-cc47 : ide4
cc48-cc4f : ide5
cc50-cc7f : PDC20267
cca0-ccaf : 0000:00:0d.0
cca0-cca7 : ide2
cca8-ccaf : ide3
ccb0-ccb7 : 0000:00:0e.0
ccb0-ccb7 : ide5
ccb8-ccbb : 0000:00:0d.0
ccba-ccba : ide3
ccbc-ccbf : 0000:00:0e.0
ccbe-ccbe : ide5
ccc0-ccc7 : 0000:00:0d.0
ccc0-ccc7 : ide3
ccc8-cccf : 0000:00:0e.0
ccc8-cccf : ide4
ccd0-ccd3 : 0000:00:0d.0
ccd2-ccd2 : ide2
ccd4-ccd7 : 0000:00:0e.0
ccd6-ccd6 : ide4
ccd8-ccdf : 0000:00:0d.0
ccd8-ccdf : ide2
cce0-ccff : 0000:00:07.2
d000-dfff : PCI Bus #02
dc00-dc7f : 0000:02:0a.0
dc00-dc7f : 0000:02:0a.0
dc80-dcbf : 0000:02:0b.0
dc80-dcbf : 0000:02:0b.0
dcc0-dcff : 0000:02:09.0
dcc0-dcff : e1000
e000-efff : PCI Bus #01
ec00-ecff : 0000:01:00.0
ffa0-ffaf : 0000:00:07.1
ffa8-ffaf : ide1
[<c01ca635>] nfsd_open+0x45/0x190
[<c01cae1e>] nfsd_write+0x4e/0x390
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c036f9e2>] skb_drop_fraglist+0x42/0x50
[<c036faa6>] skb_release_data+0x96/0xc0
[<c01d335b>] nfsd3_proc_write+0xbb/0x120
[<c01c6663>] nfsd_dispatch+0xa3/0x250
[<c041f841>] svc_process+0x6e1/0x7f0
[<c01c6403>] nfsd+0x203/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
swapper: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c02d9471>] add_interrupt_randomness+0x31/0x40
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c0101df0>] default_idle+0x0/0x40
[<c0101e13>] default_idle+0x23/0x40
[<c0101e9f>] cpu_idle+0x2f/0x50
[<c04f2967>] start_kernel+0x157/0x180
[<c04f2540>] unknown_bootoption+0x0/0x180
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c038abd0>] ip_rcv_finish+0x0/0x2d0
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c038abd0>] ip_rcv_finish+0x0/0x2d0
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c01049c8>] common_interrupt+0x18/0x20
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c032c184>] boomerang_rx+0x254/0x490
[<c032b869>] boomerang_interrupt+0xb9/0x430
[<c0339798>] ide_intr+0x188/0x1e0
[<c01069fd>] handle_IRQ_event+0x3d/0x80
[<c0106e3f>] do_IRQ+0x8f/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013de66>] __kmalloc+0x56/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c01049c8>] common_interrupt+0x18/0x20
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
eth2: memory shortage
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c032c184>] boomerang_rx+0x254/0x490
[<c032b869>] boomerang_interrupt+0xb9/0x430
[<c0339798>] ide_intr+0x188/0x1e0
[<c01069fd>] handle_IRQ_event+0x3d/0x80
[<c0106e3f>] do_IRQ+0x8f/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013de66>] __kmalloc+0x56/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c01049c8>] common_interrupt+0x18/0x20
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c032c184>] boomerang_rx+0x254/0x490
[<c032b869>] boomerang_interrupt+0xb9/0x430
[<c0339798>] ide_intr+0x188/0x1e0
[<c01069fd>] handle_IRQ_event+0x3d/0x80
[<c0106e3f>] do_IRQ+0x8f/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013de66>] __kmalloc+0x56/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c01049c8>] common_interrupt+0x18/0x20
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
nfsd: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c011007b>] setup_pit_timer+0x2b/0x60
[<c0124d23>] sigprocmask+0x3/0xe0
[<c01c63f3>] nfsd+0x1f3/0x3c0
[<c01c6200>] nfsd+0x0/0x3c0
[<c010207d>] kernel_thread_helper+0x5/0x18
lftp: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
kswapd0: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c038abd0>] ip_rcv_finish+0x0/0x2d0
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c030941a>] __make_request+0x4ea/0x560
[<c0309563>] generic_make_request+0xd3/0x190
[<c0137b85>] mempool_alloc+0x85/0x190
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0309671>] submit_bio+0x51/0xf0
[<c01049c8>] common_interrupt+0x18/0x20
[<c015915b>] bio_alloc+0x17b/0x1f0
[<c0155ab0>] end_buffer_async_write+0x0/0x110
[<c0158925>] submit_bh+0xe5/0x140
[<c0289fa5>] xfs_submit_page+0xb5/0x100
[<c028a16a>] xfs_convert_page+0x17a/0x2b0
[<c01345b7>] find_trylock_page+0x27/0x60
[<c0289aef>] xfs_probe_delalloc_page+0x1f/0xa0
[<c028a30f>] xfs_cluster_write+0x6f/0x90
[<c028a633>] xfs_page_state_convert+0x303/0x6e0
[<c028b0f4>] linvfs_writepage+0x74/0x130
[<c013fe89>] pageout+0xb9/0x100
[<c0134290>] wake_up_page+0x10/0x30
[<c0140165>] shrink_list+0x295/0x4b0
[<c01404e3>] shrink_cache+0x163/0x380
[<c01150cd>] wake_up_process+0x1d/0x20
[<c028d1f5>] pagebuf_daemon_wakeup+0x15/0x20
[<c013fbc8>] shrink_slab+0x98/0x1a0
[<c0140c82>] shrink_zone+0xa2/0xd0
[<c01410c0>] balance_pgdat+0x1e0/0x2c0
[<c014125f>] kswapd+0xbf/0xe0
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0103f32>] ret_from_fork+0x6/0x14
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c01411a0>] kswapd+0x0/0xe0
[<c010207d>] kernel_thread_helper+0x5/0x18
kswapd0: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c032c184>] boomerang_rx+0x254/0x490
[<c032b869>] boomerang_interrupt+0xb9/0x430
[<c0339798>] ide_intr+0x188/0x1e0
[<c01069fd>] handle_IRQ_event+0x3d/0x80
[<c0106e3f>] do_IRQ+0x8f/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013de66>] __kmalloc+0x56/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c038abd0>] ip_rcv_finish+0x0/0x2d0
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c030941a>] __make_request+0x4ea/0x560
[<c0309563>] generic_make_request+0xd3/0x190
[<c0137b85>] mempool_alloc+0x85/0x190
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0309671>] submit_bio+0x51/0xf0
[<c01049c8>] common_interrupt+0x18/0x20
[<c015915b>] bio_alloc+0x17b/0x1f0
[<c0155ab0>] end_buffer_async_write+0x0/0x110
[<c0158925>] submit_bh+0xe5/0x140
[<c0289fa5>] xfs_submit_page+0xb5/0x100
[<c028a16a>] xfs_convert_page+0x17a/0x2b0
[<c01345b7>] find_trylock_page+0x27/0x60
[<c0289aef>] xfs_probe_delalloc_page+0x1f/0xa0
[<c028a30f>] xfs_cluster_write+0x6f/0x90
[<c028a633>] xfs_page_state_convert+0x303/0x6e0
[<c028b0f4>] linvfs_writepage+0x74/0x130
[<c013fe89>] pageout+0xb9/0x100
[<c0134290>] wake_up_page+0x10/0x30
[<c0140165>] shrink_list+0x295/0x4b0
[<c01404e3>] shrink_cache+0x163/0x380
[<c01150cd>] wake_up_process+0x1d/0x20
[<c028d1f5>] pagebuf_daemon_wakeup+0x15/0x20
[<c013fbc8>] shrink_slab+0x98/0x1a0
[<c0140c82>] shrink_zone+0xa2/0xd0
[<c01410c0>] balance_pgdat+0x1e0/0x2c0
[<c014125f>] kswapd+0xbf/0xe0
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0103f32>] ret_from_fork+0x6/0x14
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c01411a0>] kswapd+0x0/0xe0
[<c010207d>] kernel_thread_helper+0x5/0x18
eth2: memory shortage
kswapd0: page allocation failure. order:0, mode:0x20
[<c0139227>] __alloc_pages+0x247/0x3b0
[<c01393a8>] __get_free_pages+0x18/0x40
[<c013ca2f>] kmem_getpages+0x1f/0xc0
[<c013d770>] cache_grow+0xc0/0x1a0
[<c013da1b>] cache_alloc_refill+0x1cb/0x210
[<c013de81>] __kmalloc+0x71/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c032c184>] boomerang_rx+0x254/0x490
[<c032b869>] boomerang_interrupt+0xb9/0x430
[<c0339798>] ide_intr+0x188/0x1e0
[<c01069fd>] handle_IRQ_event+0x3d/0x80
[<c0106e3f>] do_IRQ+0x8f/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c013de66>] __kmalloc+0x56/0x80
[<c036f8f3>] alloc_skb+0x53/0x100
[<c031fe88>] e1000_alloc_rx_buffers+0x48/0xf0
[<c031fb8e>] e1000_clean_rx_irq+0x18e/0x440
[<c038abd0>] ip_rcv_finish+0x0/0x2d0
[<c031f76b>] e1000_clean+0x5b/0x100
[<c0375f7a>] net_rx_action+0x6a/0xf0
[<c011daa1>] __do_softirq+0x41/0x90
[<c011db17>] do_softirq+0x27/0x30
[<c0106ebc>] do_IRQ+0x10c/0x130
[<c01049c8>] common_interrupt+0x18/0x20
[<c030941a>] __make_request+0x4ea/0x560
[<c0309563>] generic_make_request+0xd3/0x190
[<c0137b85>] mempool_alloc+0x85/0x190
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0309671>] submit_bio+0x51/0xf0
[<c01049c8>] common_interrupt+0x18/0x20
[<c015915b>] bio_alloc+0x17b/0x1f0
[<c0155ab0>] end_buffer_async_write+0x0/0x110
[<c0158925>] submit_bh+0xe5/0x140
[<c0289fa5>] xfs_submit_page+0xb5/0x100
[<c028a16a>] xfs_convert_page+0x17a/0x2b0
[<c01345b7>] find_trylock_page+0x27/0x60
[<c0289aef>] xfs_probe_delalloc_page+0x1f/0xa0
[<c028a30f>] xfs_cluster_write+0x6f/0x90
[<c028a633>] xfs_page_state_convert+0x303/0x6e0
[<c028b0f4>] linvfs_writepage+0x74/0x130
[<c013fe89>] pageout+0xb9/0x100
[<c0134290>] wake_up_page+0x10/0x30
[<c0140165>] shrink_list+0x295/0x4b0
[<c01404e3>] shrink_cache+0x163/0x380
[<c01150cd>] wake_up_process+0x1d/0x20
[<c028d1f5>] pagebuf_daemon_wakeup+0x15/0x20
[<c013fbc8>] shrink_slab+0x98/0x1a0
[<c0140c82>] shrink_zone+0xa2/0xd0
[<c01410c0>] balance_pgdat+0x1e0/0x2c0
[<c014125f>] kswapd+0xbf/0xe0
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c0103f32>] ret_from_fork+0x6/0x14
[<c0116c60>] autoremove_wake_function+0x0/0x60
[<c01411a0>] kswapd+0x0/0xe0
[<c010207d>] kernel_thread_helper+0x5/0x18
On Mon, 25 Oct 2004, Nick Piggin wrote:
> Justin Piszcz wrote:
>> I guess people who get this should just stick with 2.6.8.1?
>>
>
> Does it cause any noticable problems? If not, then stay with
> 2.6.9.
>
> However, it would be nice to get to the bottom of it. It might
> just be happening by chance on 2.6.9 but not 2.6.8.1 though...
>
> Anyway, how often are you getting the messages? How many
> ethernet cards in the system?
>
> Can you run a kernel with sysrq support, and do `SysRq+M`
> (close to when the allocation failure happens if possible, but
> otherwise on a normally running system after it has been up
> for a while). Then send in the dmesg.
>
> Thanks,
> Nick
>
On Wed, 2004-10-27 at 17:40 -0400, Justin Piszcz wrote:
> Is there any chance Linus will freeze 2.6 and make the current development
> tree 2.7? It seems like ever since around 2.6.8 things have been getting
> progressively worse (page allocation failures/nvidia
> breakage/XFS-oops-when-copying-over-nfs-when-the-file-is-being-written-to)?
This not the kernel's problem when nvidia breaks. The kernel developers
make NO EFFORT to support binary only modules! Please, talk to nvidia
if this is a problem for you.
Lee
Andrew Morton <[email protected]> wrote:
> > swapper: page allocation failure. order:0, mode:0x20
> This should be harmless - networking will recover. The TSO fix was
> merged a week or so ago.
Ahem,
i don't think its all that harmless:
My machine got hundreds of the same in a row even after raising
vm.min_free_kbytes to 8192 and playing with vm.* in one direction and then in
the other one. Essentially the application took 2.2GB and cache was around
1.7GB of 4GB available memory. The machine swapping heavily at ~3m intervals
and setting swappiness to zero did not help.
I tried the following kernels: 2.6.9-mm1, 2.6.10-rc1-bk12, 2.6.9-rc3-bk6,
2.6.9-rc3-bk5 all of which froze at some point presenting me only with the
above page allocation failure. (no more sysrq)
2.6.9 gave me this in the end: http://zaphods.net/~zaphodb/recursive_die.png
Which was the point i decided to give 2.4 a try and guess what: This is
running faster and at higher packet rates than the 2.6 kernels achived and
is stable for the last three hours which at this load is more than the
abovementioned 2.6 kernels managed.
I got the impression there is another 2.6 vm-instability which made it in the
kernel after 2.6.7.
The machine is a Dual Opteron on Tyan K8S 4GB ECC-RAM running debian/unstable
(yes thats 32-bit only) from a 3ware 9000 Controller (SATA) - 8 250GB Disks
configured as single disks, no hw raid. Root-FS resides on SoftwareRAID,
Application uses xfs filesystems on the disks.
I attached some vmstat and slapinfo output during the swapping-phase. Dont
remember the exact kernel here but it was 2.6. (yes, the hostname is kernel.
;)
Stefan
On Wed, Nov 03, 2004 at 11:24:48PM +0100, Stefan Schmidt wrote:
> Andrew Morton <[email protected]> wrote:
> > > swapper: page allocation failure. order:0, mode:0x20
> > This should be harmless - networking will recover. The TSO fix was
> > merged a week or so ago.
> Ahem,
> i don't think its all that harmless:
> My machine got hundreds of the same in a row even after raising
> vm.min_free_kbytes to 8192 and playing with vm.* in one direction and then in
> the other one.
What is min_free_kbytes default on your machine?
> Essentially the application took 2.2GB and cache was around
> 1.7GB of 4GB available memory. The machine swapping heavily at ~3m intervals
> and setting swappiness to zero did not help.
> I tried the following kernels: 2.6.9-mm1, 2.6.10-rc1-bk12, 2.6.9-rc3-bk6,
> 2.6.9-rc3-bk5 all of which froze at some point presenting me only with the
> above page allocation failure. (no more sysrq)
> 2.6.9 gave me this in the end: http://zaphods.net/~zaphodb/recursive_die.png
This should be harmless as Andrew said - it would be helpful if you could
plug a serial cable to the box - this last oops on the picture doesnt say
much.
How intense is the network traffic you're generating?
> Which was the point i decided to give 2.4 a try and guess what: This is
> running faster and at higher packet rates than the 2.6 kernels achived and
> is stable for the last three hours which at this load is more than the
> abovementioned 2.6 kernels managed.
> I got the impression there is another 2.6 vm-instability which made it in the
> kernel after 2.6.7.
2.6.7 was stable under the same load?
2.4 keeps a higher amount of free pages around, but you should be able
to tune that with vm.min_free_kbytes...
For some reason the VM is not being able to keep enough pages free.
But then it shouldnt matter - if the tg3 driver can't allocate memory
it should drop the packet and not lockup.
Something is definately screwed, and there are quite an amount of
similar reports.
XFS also seems to be very memory hungry...
> The machine is a Dual Opteron on Tyan K8S 4GB ECC-RAM running debian/unstable
> (yes thats 32-bit only) from a 3ware 9000 Controller (SATA) - 8 250GB Disks
> configured as single disks, no hw raid. Root-FS resides on SoftwareRAID,
> Application uses xfs filesystems on the disks.
>
> I attached some vmstat and slapinfo output during the swapping-phase. Dont
> remember the exact kernel here but it was 2.6. (yes, the hostname is kernel.
> ;)
>
> Stefan
> Nov 2 17:12:26 kernel kernel: swapper: page allocation failure. order:0, mode:0x20
> Nov 2 17:12:26 kernel kernel: [__alloc_pages+417/800] __alloc_pages+0x1a1/0x320
> Nov 2 17:12:26 kernel kernel: [__get_free_pages+24/48] __get_free_pages+0x18/0x30
> Nov 2 17:12:26 kernel kernel: [kmem_getpages+24/192] kmem_getpages+0x18/0xc0
> Nov 2 17:12:26 kernel kernel: [cache_grow+157/304] cache_grow+0x9d/0x130
> Nov 2 17:12:26 kernel kernel: [nf_hook_slow+178/240] nf_hook_slow+0xb2/0xf0
> Nov 2 17:12:26 kernel kernel: [cache_alloc_refill+363/544] cache_alloc_refill+0x16b/0x220
> Nov 2 17:12:26 kernel kernel: [__kmalloc+122/144] __kmalloc+0x7a/0x90
> Nov 2 17:12:26 kernel kernel: [alloc_skb+50/208] alloc_skb+0x32/0xd0
> Nov 2 17:12:26 kernel kernel: [pg0+945331568/1068909568] tg3_alloc_rx_skb+0x70/0x130 [tg3]
> Nov 2 17:12:26 kernel kernel: [pg0+945332742/1068909568] tg3_rx+0x206/0x3b0 [tg3]
> Nov 2 17:12:26 kernel kernel: [pg0+945333307/1068909568] tg3_poll+0x8b/0x130 [tg3]
> Nov 2 17:12:26 kernel kernel: [net_rx_action+112/240] net_rx_action+0x70/0xf0
> Nov 2 17:12:26 kernel kernel: [__do_softirq+184/208] __do_softirq+0xb8/0xd0
> Nov 2 17:12:26 kernel kernel: [do_softirq+45/48] do_softirq+0x2d/0x30
> Nov 2 17:12:26 kernel kernel: [do_IRQ+43/64] do_IRQ+0x2b/0x40
> Nov 2 17:12:26 kernel kernel: [common_interrupt+24/32] common_interrupt+0x18/0x20
> Nov 2 17:12:26 kernel kernel: [default_idle+0/64] default_idle+0x0/0x40
> Nov 2 17:12:26 kernel kernel: [default_idle+44/64] default_idle+0x2c/0x40
> Nov 2 17:12:26 kernel kernel: [cpu_idle+51/64] cpu_idle+0x33/0x40
> Nov 2 17:12:26 kernel kernel: [start_kernel+332/368] start_kernel+0x14c/0x170
> Nov 2 17:12:26 kernel kernel: [unknown_bootoption+0/416] unknown_bootoption+0x0/0x1a0
>
>
> procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
> r b swpd free buff cache si so bi bo in cs us sy id wa
> 1 1 132964 3272 6420 1681888 0 0 1401 7668 15763 691 4 23 40 33
> 1 1 132964 3100 6380 1685256 0 0 1928 11176 16051 705 4 27 39 30
> 0 1 132964 3292 6212 1685288 0 0 1788 7575 16031 720 5 23 51 21
> 0 2 132964 4016 6432 1683368 0 0 1752 9379 16221 652 4 26 46 24
> 0 2 134180 197092 520 1496176 26 175 2473 12866 16302 1630 5 27 21 48
> 1 0 145608 89844 1476 1604432 56 1182 2672 9028 16248 822 4 26 37 32
> 1 0 145608 15148 2016 1675404 20 0 2127 4868 16193 612 4 26 48 22
> 0 1 146816 3152 2432 1688956 171 122 1872 6761 14757 583 2 15 29 53
> 0 2 146816 3972 2736 1693380 298 0 1982 7910 15626 666 3 23 48 27
> 1 0 146816 4028 2796 1689412 170 0 1759 7339 15586 597 2 18 35 45
> 0 1 146816 4136 2984 1690960 127 0 2091 7396 16146 557 3 26 43 27
> 0 3 146816 4320 3460 1685736 86 0 2042 7381 15981 597 3 23 32 41
> 0 1 146816 16820 3556 1672304 73 0 1082 9960 15361 777 2 18 34 46
> 0 1 146816 3348 3704 1686584 40 0 1762 8153 16247 633 4 26 42 28
> 0 2 146816 5700 3912 1683600 26 0 1973 9772 16120 669 4 24 42 30
> 0 0 146816 6096 4084 1674224 32 0 1478 7469 15378 569 2 18 33 47
> 0 3 146816 4284 4148 1680812 15 0 1052 8376 15717 576 3 24 43 30
> 0 1 146816 3572 4412 1684472 29 0 1660 10212 15740 597 3 22 38 37
> 0 0 146816 6220 4576 1680260 24 0 2256 8223 16015 656 4 25 47 25
> 0 1 146816 3448 4436 1683892 11 0 1526 8507 15820 628 4 21 38 37
> 0 0 146816 3152 4552 1687964 10 0 1609 9256 16244 665 4 25 52 18
> 0 0 146816 4212 4660 1683816 5 0 1524 8207 16066 545 3 25 42 30
>
> labinfo - version: 2.1
> # name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <batchcount> <limit> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
> ip_conntrack_expect 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> ip_conntrack 22024 23748 320 12 1 : tunables 54 27 8 : slabdata 1979 1979 85
> fib6_nodes 5 119 32 119 1 : tunables 120 60 8 : slabdata 1 1 0
> ip6_dst_cache 4 15 256 15 1 : tunables 120 60 8 : slabdata 1 1 0
> ndisc_cache 1 20 192 20 1 : tunables 120 60 8 : slabdata 1 1 0
> rawv6_sock 4 11 704 11 2 : tunables 54 27 8 : slabdata 1 1 0
> udpv6_sock 1 6 640 6 1 : tunables 54 27 8 : slabdata 1 1 0
> tcpv6_sock 5 6 1216 3 1 : tunables 24 12 8 : slabdata 2 2 0
> unix_sock 23 27 448 9 1 : tunables 54 27 8 : slabdata 3 3 0
> tcp_tw_bucket 6281 7192 128 31 1 : tunables 120 60 8 : slabdata 232 232 120
> tcp_bind_bucket 6 226 16 226 1 : tunables 120 60 8 : slabdata 1 1 0
> tcp_open_request 214 310 128 31 1 : tunables 120 60 8 : slabdata 10 10 0
> inet_peer_cache 2 61 64 61 1 : tunables 120 60 8 : slabdata 1 1 0
> secpath_cache 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> xfrm_dst_cache 0 0 256 15 1 : tunables 120 60 8 : slabdata 0 0 0
> ip_fib_alias 9 226 16 226 1 : tunables 120 60 8 : slabdata 1 1 0
> ip_fib_hash 9 119 32 119 1 : tunables 120 60 8 : slabdata 1 1 0
> ip_dst_cache 11007 13515 256 15 1 : tunables 120 60 8 : slabdata 901 901 0
> arp_cache 1 20 192 20 1 : tunables 120 60 8 : slabdata 1 1 0
> raw_sock 3 7 512 7 1 : tunables 54 27 8 : slabdata 1 1 0
> udp_sock 3 8 512 8 1 : tunables 54 27 8 : slabdata 1 1 0
> tcp_sock 7192 7910 1088 7 2 : tunables 24 12 8 : slabdata 1130 1130 72
> flow_cache 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> dm-snapshot-in 128 162 48 81 1 : tunables 120 60 8 : slabdata 2 2 0
> dm-snapshot-ex 0 0 16 226 1 : tunables 120 60 8 : slabdata 0 0 0
> dm-crypt_io 0 0 76 52 1 : tunables 120 60 8 : slabdata 0 0 0
> dm_tio 0 0 16 226 1 : tunables 120 60 8 : slabdata 0 0 0
> dm_io 0 0 16 226 1 : tunables 120 60 8 : slabdata 0 0 0
> scsi_cmd_cache 100 100 384 10 1 : tunables 54 27 8 : slabdata 10 10 27
> cfq_ioc_pool 0 0 24 156 1 : tunables 120 60 8 : slabdata 0 0 0
> cfq_pool 0 0 104 38 1 : tunables 120 60 8 : slabdata 0 0 0
> crq_pool 0 0 52 75 1 : tunables 120 60 8 : slabdata 0 0 0
> deadline_drq 0 0 48 81 1 : tunables 120 60 8 : slabdata 0 0 0
> as_arq 515 845 60 65 1 : tunables 120 60 8 : slabdata 13 13 300
> xfs_chashlist 583 740 20 185 1 : tunables 120 60 8 : slabdata 4 4 0
> xfs_ili 1873 2184 140 28 1 : tunables 120 60 8 : slabdata 78 78 0
> xfs_ifork 0 0 56 70 1 : tunables 120 60 8 : slabdata 0 0 0
> xfs_efi_item 15 15 260 15 1 : tunables 54 27 8 : slabdata 1 1 0
> xfs_efd_item 15 15 260 15 1 : tunables 54 27 8 : slabdata 1 1 0
> xfs_buf_item 639 783 148 27 1 : tunables 120 60 8 : slabdata 29 29 284
> xfs_dabuf 10 226 16 226 1 : tunables 120 60 8 : slabdata 1 1 0
> xfs_da_state 0 0 336 12 1 : tunables 54 27 8 : slabdata 0 0 0
> xfs_trans 260 260 596 13 2 : tunables 54 27 8 : slabdata 20 20 27
> xfs_inode 2212 3135 368 11 1 : tunables 54 27 8 : slabdata 285 285 0
> xfs_btree_cur 120 120 132 30 1 : tunables 120 60 8 : slabdata 4 4 0
> xfs_bmap_free_item 24 290 12 290 1 : tunables 120 60 8 : slabdata 1 1 0
> xfs_buf_t 690 870 256 15 1 : tunables 120 60 8 : slabdata 58 58 224
> linvfs_icache 2003 2673 344 11 1 : tunables 54 27 8 : slabdata 243 243 0
> hugetlbfs_inode_cache 1 12 312 12 1 : tunables 54 27 8 : slabdata 1 1 0
> ext2_inode_cache 0 0 448 9 1 : tunables 54 27 8 : slabdata 0 0 0
> ext2_xattr 0 0 44 88 1 : tunables 120 60 8 : slabdata 0 0 0
> journal_handle 135 135 28 135 1 : tunables 120 60 8 : slabdata 1 1 0
> journal_head 849 2835 48 81 1 : tunables 120 60 8 : slabdata 35 35 60
> revoke_table 2 290 12 290 1 : tunables 120 60 8 : slabdata 1 1 0
> revoke_record 109 226 16 226 1 : tunables 120 60 8 : slabdata 1 1 0
> ext3_inode_cache 414 707 508 7 1 : tunables 54 27 8 : slabdata 101 101 0
> ext3_xattr 0 0 44 88 1 : tunables 120 60 8 : slabdata 0 0 0
> dnotify_cache 0 0 20 185 1 : tunables 120 60 8 : slabdata 0 0 0
> eventpoll_pwq 0 0 36 107 1 : tunables 120 60 8 : slabdata 0 0 0
> eventpoll_epi 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> kioctx 0 0 192 20 1 : tunables 120 60 8 : slabdata 0 0 0
> kiocb 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> fasync_cache 0 0 16 226 1 : tunables 120 60 8 : slabdata 0 0 0
> shmem_inode_cache 7 9 408 9 1 : tunables 54 27 8 : slabdata 1 1 0
> posix_timers_cache 0 0 104 38 1 : tunables 120 60 8 : slabdata 0 0 0
> uid_cache 3 61 64 61 1 : tunables 120 60 8 : slabdata 1 1 0
> sgpool-128 32 33 2560 3 2 : tunables 24 12 8 : slabdata 11 11 0
> sgpool-64 32 33 1280 3 1 : tunables 24 12 8 : slabdata 11 11 0
> sgpool-32 102 102 640 6 1 : tunables 54 27 8 : slabdata 17 17 27
> sgpool-16 96 96 320 12 1 : tunables 54 27 8 : slabdata 8 8 0
> sgpool-8 200 200 192 20 1 : tunables 120 60 8 : slabdata 10 10 60
> blkdev_ioc 84 135 28 135 1 : tunables 120 60 8 : slabdata 1 1 0
> blkdev_queue 10 20 372 10 1 : tunables 54 27 8 : slabdata 2 2 0
> blkdev_requests 471 840 140 28 1 : tunables 120 60 8 : slabdata 30 30 240
> biovec-(256) 256 256 3072 2 2 : tunables 24 12 8 : slabdata 128 128 0
> biovec-128 256 260 1536 5 2 : tunables 24 12 8 : slabdata 52 52 0
> biovec-64 320 320 768 5 1 : tunables 54 27 8 : slabdata 64 64 0
> biovec-16 350 380 192 20 1 : tunables 120 60 8 : slabdata 19 19 0
> biovec-4 374 427 64 61 1 : tunables 120 60 8 : slabdata 7 7 0
> biovec-1 1456 3164 16 226 1 : tunables 120 60 8 : slabdata 14 14 480
> bio 1418 2196 64 61 1 : tunables 120 60 8 : slabdata 36 36 480
> file_lock_cache 23 43 92 43 1 : tunables 120 60 8 : slabdata 1 1 0
> sock_inode_cache 7064 7830 384 10 1 : tunables 54 27 8 : slabdata 783 783 135
> skbuff_head_cache 14636 23220 192 20 1 : tunables 120 60 8 : slabdata 1161 1161 420
> sock 3 10 384 10 1 : tunables 54 27 8 : slabdata 1 1 0
> proc_inode_cache 321 360 328 12 1 : tunables 54 27 8 : slabdata 30 30 0
> sigqueue 19 27 148 27 1 : tunables 120 60 8 : slabdata 1 1 0
> radix_tree_node 22347 28602 276 14 1 : tunables 54 27 8 : slabdata 2043 2043 27
> bdev_cache 30 45 448 9 1 : tunables 54 27 8 : slabdata 5 5 0
> mnt_cache 26 62 128 31 1 : tunables 120 60 8 : slabdata 2 2 0
> inode_cache 1040 1128 312 12 1 : tunables 54 27 8 : slabdata 94 94 0
> dentry_cache 10067 15400 140 28 1 : tunables 120 60 8 : slabdata 550 550 240
> filp 8189 9100 192 20 1 : tunables 120 60 8 : slabdata 455 455 60
> names_cache 26 26 4096 1 1 : tunables 24 12 8 : slabdata 26 26 0
> idr_layer_cache 112 116 136 29 1 : tunables 120 60 8 : slabdata 4 4 0
> buffer_head 345712 472959 48 81 1 : tunables 120 60 8 : slabdata 5839 5839 480
> mm_struct 91 91 576 7 1 : tunables 54 27 8 : slabdata 13 13 0
> vm_area_struct 1994 2205 88 45 1 : tunables 120 60 8 : slabdata 49 49 0
> fs_cache 86 183 64 61 1 : tunables 120 60 8 : slabdata 3 3 0
> files_cache 87 99 448 9 1 : tunables 54 27 8 : slabdata 11 11 0
> signal_cache 111 165 256 15 1 : tunables 120 60 8 : slabdata 11 11 0
> sighand_cache 104 108 1344 3 1 : tunables 24 12 8 : slabdata 36 36 0
> task_struct 111 111 1280 3 1 : tunables 24 12 8 : slabdata 37 37 0
> anon_vma 635 870 12 290 1 : tunables 120 60 8 : slabdata 3 3 0
> pgd 115 238 32 119 1 : tunables 120 60 8 : slabdata 2 2 0
> pmd 180 180 4096 1 1 : tunables 24 12 8 : slabdata 180 180 0
> size-131072(DMA) 0 0 131072 1 32 : tunables 8 4 0 : slabdata 0 0 0
> size-131072 0 0 131072 1 32 : tunables 8 4 0 : slabdata 0 0 0
> size-65536(DMA) 0 0 65536 1 16 : tunables 8 4 0 : slabdata 0 0 0
> size-65536 19 19 65536 1 16 : tunables 8 4 0 : slabdata 19 19 0
> size-32768(DMA) 0 0 32768 1 8 : tunables 8 4 0 : slabdata 0 0 0
> size-32768 139 139 32768 1 8 : tunables 8 4 0 : slabdata 139 139 0
> size-16384(DMA) 0 0 16384 1 4 : tunables 8 4 0 : slabdata 0 0 0
> size-16384 151 153 16384 1 4 : tunables 8 4 0 : slabdata 151 153 0
> size-8192(DMA) 0 0 8192 1 2 : tunables 8 4 0 : slabdata 0 0 0
> size-8192 365 365 8192 1 2 : tunables 8 4 0 : slabdata 365 365 0
> size-4096(DMA) 0 0 4096 1 1 : tunables 24 12 8 : slabdata 0 0 0
> size-4096 770 770 4096 1 1 : tunables 24 12 8 : slabdata 770 770 48
> size-2048(DMA) 0 0 2048 2 1 : tunables 24 12 8 : slabdata 0 0 0
> size-2048 14460 14556 2048 2 1 : tunables 24 12 8 : slabdata 7278 7278 12
> size-1024(DMA) 0 0 1024 4 1 : tunables 54 27 8 : slabdata 0 0 0
> size-1024 888 888 1024 4 1 : tunables 54 27 8 : slabdata 222 222 54
> size-512(DMA) 0 0 512 8 1 : tunables 54 27 8 : slabdata 0 0 0
> size-512 886 1352 512 8 1 : tunables 54 27 8 : slabdata 169 169 108
> size-256(DMA) 0 0 256 15 1 : tunables 120 60 8 : slabdata 0 0 0
> size-256 270 300 256 15 1 : tunables 120 60 8 : slabdata 20 20 0
> size-192(DMA) 0 0 192 20 1 : tunables 120 60 8 : slabdata 0 0 0
> size-192 156 180 192 20 1 : tunables 120 60 8 : slabdata 9 9 0
> size-128(DMA) 0 0 128 31 1 : tunables 120 60 8 : slabdata 0 0 0
> size-128 1921 2635 128 31 1 : tunables 120 60 8 : slabdata 85 85 0
> size-64(DMA) 0 0 64 61 1 : tunables 120 60 8 : slabdata 0 0 0
> size-64 7293 13603 64 61 1 : tunables 120 60 8 : slabdata 223 223 480
> size-32(DMA) 0 0 32 119 1 : tunables 120 60 8 : slabdata 0 0 0
> size-32 10802 19516 32 119 1 : tunables 120 60 8 : slabdata 164 164 120
> kmem_cache 160 160 192 20 1 : tunables 120 60 8 : slabdata 8 8 0
>
On Thu, Nov 04, 2004 at 10:17:22AM -0200, Marcelo Tosatti wrote:
> What is min_free_kbytes default on your machine?
I think it was 768, definitely around 700-800.
2.6.9 said:
Dentry cache hash table entries: 131072 (order: 7, 524288 bytes)
Inode-cache hash table entries: 65536 (order: 6, 262144 bytes)
Memory: 4058200k/4095936k available (2005k kernel code, 36816k reserved, 995k
data, 196k init, 3178432k highmem)
> > I tried the following kernels: 2.6.9-mm1, 2.6.10-rc1-bk12, 2.6.9-rc3-bk6,
> > 2.6.9-rc3-bk5 all of which froze at some point presenting me only with the
> > above page allocation failure. (no more sysrq)
> This should be harmless as Andrew said - it would be helpful if you could
> plug a serial cable to the box - this last oops on the picture doesnt say
> much.
Well right now the machine is running 2.4.28-rc1 with the 3w-9nnn patch by
Adam Radford from this list and i would like to see it run stable for about a
day before i give 2.6 another try. I think i'll have a terminal server hooked
up by then.
> How intense is the network traffic you're generating?
I was around 60-80 mbit/s each direction at i think 16k interrupts/s.
With 2.4.28-rc1 this is currently at 180mbit/s 27kpps up, 116mbit/s 24kpps down
still swapping a bit but no kernel messages on this, just around 1.7 rx
errors/s.
> 2.6.7 was stable under the same load?
No, sorry to give you this impression, 2.6.7 is just what some of my collegues
and i consider the more stable 2.6 kernel under heavy i/o load.
> Something is definately screwed, and there are quite an amount of
> similar reports.
Can i tell people its ok to see nf_hook_slow in the stack trace as it's
vm-related? A collegue was quite bluffed when i showed him. ;)
> XFS also seems to be very memory hungry...
I have 8 XFS-Filesystems in use here with several thousand files from some k to
your 'usual' 4GB DVD-image. XFS built as a module at first and then inline but
that did not change anything off course. 2x200 + 6x250GB that is.
Stefan
On Thu, Nov 04, 2004 at 07:18:57PM +0100, Stefan Schmidt wrote:
> On Thu, Nov 04, 2004 at 10:17:22AM -0200, Marcelo Tosatti wrote:
> > What is min_free_kbytes default on your machine?
> I think it was 768, definitely around 700-800.
> 2.6.9 said:
> Dentry cache hash table entries: 131072 (order: 7, 524288 bytes)
> Inode-cache hash table entries: 65536 (order: 6, 262144 bytes)
> Memory: 4058200k/4095936k available (2005k kernel code, 36816k reserved, 995k
> data, 196k init, 3178432k highmem)
>
> > > I tried the following kernels: 2.6.9-mm1, 2.6.10-rc1-bk12, 2.6.9-rc3-bk6,
> > > 2.6.9-rc3-bk5 all of which froze at some point presenting me only with the
> > > above page allocation failure. (no more sysrq)
> > This should be harmless as Andrew said - it would be helpful if you could
> > plug a serial cable to the box - this last oops on the picture doesnt say
> > much.
> Well right now the machine is running 2.4.28-rc1 with the 3w-9nnn patch by
> Adam Radford from this list and i would like to see it run stable for about a
> day before i give 2.6 another try. I think i'll have a terminal server hooked
> up by then.
>
> > How intense is the network traffic you're generating?
> I was around 60-80 mbit/s each direction at i think 16k interrupts/s.
>
> With 2.4.28-rc1 this is currently at 180mbit/s 27kpps up, 116mbit/s 24kpps down
> still swapping a bit but no kernel messages on this, just around 1.7 rx
> errors/s.
>
> > 2.6.7 was stable under the same load?
> No, sorry to give you this impression, 2.6.7 is just what some of my collegues
> and i consider the more stable 2.6 kernel under heavy i/o load.
>
> > Something is definately screwed, and there are quite an amount of
> > similar reports.
> Can i tell people its ok to see nf_hook_slow in the stack trace as it's
> vm-related? A collegue was quite bluffed when i showed him. ;)
>
> > XFS also seems to be very memory hungry...
> I have 8 XFS-Filesystems in use here with several thousand files from some k to
> your 'usual' 4GB DVD-image. XFS built as a module at first and then inline but
> that did not change anything off course. 2x200 + 6x250GB that is.
Stefan, Lukas,
Can you please run your workload which cause 0-order page allocation
failures with the following patch, pretty please?
We will have more information on the free areas state when the allocation
fails.
Andrew, please apply it to the next -mm, will you?
--- a/mm/page_alloc.c 2004-11-04 22:52:03.000000000 -0200
+++ b/mm/page_alloc.c 2004-11-09 16:57:04.823514992 -0200
@@ -902,6 +902,7 @@
" order:%d, mode:0x%x\n",
p->comm, order, gfp_mask);
dump_stack();
+ show_free_areas();
}
return NULL;
got_pg:
Hi all,
On Tue, Nov 09, 2004 at 02:41:13PM -0200, Marcelo Tosatti wrote:
> Stefan, Lukas,
>
> Can you please run your workload which cause 0-order page allocation
> failures with the following patch, pretty please?
>
> We will have more information on the free areas state when the allocation
> fails.
>
> Andrew, please apply it to the next -mm, will you?
here is the trace:
klogd: page allocation failure. order:0, mode: 0x20
[__alloc_pages+441/862] __alloc_pages+0x1b9/0x363
[__get_free_pages+42/63] __get_free_pages+0x25/0x3f
[kmem_getpages+37/201] kmem_getpages+0x21/0xc9
[cache_grow+175/333] cache_grow+0xab/0x14d
[cache_alloc_refill+376/537] cache_alloc_refill+0x174/0x219
[__kmalloc+137/140] __kmalloc+0x85/0x8c
[alloc_skb+75/224] alloc_skb+0x47/0xe0
[e1000_alloc_rx_buffers+72/227] e1000_alloc_rx_buffers+0x44/0xe3
[e1000_clean_rx_irq+402/1095] e1000_clean_rx_irq+0x18e/0x447
[e1000_clean+85/202] e1000_clean+0x51/0xca
[net_rx_action+123/246] net_rx_action+0x77/0xf6
[__do_softirq+183/198] __do_softirq+0xb7/0xc6
[do_softirq+45/47] do_softirq+0x2d/0x2f
[do_IRQ+274/304] do_IRQ+0x112/0x130
[common_interrupt+24/32] common_interrupt+0x18/0x20
[_spin_unlock_irq+13/28] _spin_unlock_irq+0x9/0x1c
[do_syslog+295/990] do_syslog+0x127/0x3de
[autoremove_wake_function+0/87] autoremove_wake_function+0x0/0x57
[autoremove_wake_function+0/87] autoremove_wake_function+0x0/0x57
[dnotify_parent+62/166] dnotify_parent+0x3a/0xa6
[vfs_read+180/281] vfs_read+0xb0/0x119
[sys_read+85/128] sys_read+0x51/0x80
[syscall_call+7/11] syscall_call+0x7/0xb
DMA per-cpu:
cpu 0 hot: low 2, high 6, batch 1
cpu 0 cold: low 0, high 2, batch 1
cpu 1 hot: low 2, high 6, batch 1
cpu 1 cold: low 0, high 2, batch 1
Normal per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
HighMem per-cpu:
cpu 0 hot: low 14, high 42, batch 7
cpu 0 cold: low 0, high 14, batch 7
cpu 1 hot: low 14, high 42, batch 7
cpu 1 cold: low 0, high 14, batch 7
Free pages: 348kB (112kB HighMem)
Active:38175 inactive:210615 dirty:95618 writeback:2461 unstable:0 free:87 slab:7706 mapped:14968 pagetables:404
DMA free:4kB min:12kB low:24kB high:36kB active:456kB inactive:11152kB present:16384kB
protections[]: 0 0 0
Normal free:232kB min:708kB low:1416kB high:384kB active:40264kB inactive:88296kB present:131008kB
protections[]: 0 0 0
HighMem free:112kB min:128kB low:256kB high:384kB active:40264kB inactive:88296kB present:131008kB
protections[]: 0 0 0
DMA: 1*4kB 0*8kB 0*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 4kB
Normal: 0*4kB 1*8kB 0*16kB 1*32kB 1*64kB 1*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 232kB
HighMem: 0*4kB 0*8kB 1*16kB 1*32kB 1*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 112kB
Swap cache: add 1, delete 1, find 0/0, race 0+0
--
Luk?? Hejtm?nek
Lukas Hejtmanek <[email protected]> wrote:
>
> Hi all,
>
> On Tue, Nov 09, 2004 at 02:41:13PM -0200, Marcelo Tosatti wrote:
> > Stefan, Lukas,
> >
> > Can you please run your workload which cause 0-order page allocation
> > failures with the following patch, pretty please?
> >
> > We will have more information on the free areas state when the allocation
> > fails.
> >
> > Andrew, please apply it to the next -mm, will you?
>
> here is the trace:
> klogd: page allocation failure. order:0, mode: 0x20
> [__alloc_pages+441/862] __alloc_pages+0x1b9/0x363
> [__get_free_pages+42/63] __get_free_pages+0x25/0x3f
> [kmem_getpages+37/201] kmem_getpages+0x21/0xc9
> [cache_grow+175/333] cache_grow+0xab/0x14d
> [cache_alloc_refill+376/537] cache_alloc_refill+0x174/0x219
> [__kmalloc+137/140] __kmalloc+0x85/0x8c
> [alloc_skb+75/224] alloc_skb+0x47/0xe0
> [e1000_alloc_rx_buffers+72/227] e1000_alloc_rx_buffers+0x44/0xe3
> [e1000_clean_rx_irq+402/1095] e1000_clean_rx_irq+0x18e/0x447
> [e1000_clean+85/202] e1000_clean+0x51/0xca
What kernel is in use here?
There was a problem related to e1000 and TSO which was leading to these
over-aggressive atomic allocations. That was fixed (within ./net/)
post-2.6.9.
On Tue, Nov 09, 2004 at 02:46:07PM -0800, Andrew Morton wrote:
> > > Can you please run your workload which cause 0-order page allocation
> > > failures with the following patch, pretty please?
> > >
> > > We will have more information on the free areas state when the allocation
> > > fails.
> > >
> > > Andrew, please apply it to the next -mm, will you?
> >
> > here is the trace:
> > klogd: page allocation failure. order:0, mode: 0x20
> > [__alloc_pages+441/862] __alloc_pages+0x1b9/0x363
> > [__get_free_pages+42/63] __get_free_pages+0x25/0x3f
> > [kmem_getpages+37/201] kmem_getpages+0x21/0xc9
> > [cache_grow+175/333] cache_grow+0xab/0x14d
> > [cache_alloc_refill+376/537] cache_alloc_refill+0x174/0x219
> > [__kmalloc+137/140] __kmalloc+0x85/0x8c
> > [alloc_skb+75/224] alloc_skb+0x47/0xe0
> > [e1000_alloc_rx_buffers+72/227] e1000_alloc_rx_buffers+0x44/0xe3
> > [e1000_clean_rx_irq+402/1095] e1000_clean_rx_irq+0x18e/0x447
> > [e1000_clean+85/202] e1000_clean+0x51/0xca
>
> What kernel is in use here?
>
> There was a problem related to e1000 and TSO which was leading to these
> over-aggressive atomic allocations. That was fixed (within ./net/)
> post-2.6.9.
I use vanilla 2.6.9.
--
Luk?? Hejtm?nek
On Tue, Nov 09, 2004 at 02:46:07PM -0800, Andrew Morton wrote:
> > here is the trace:
> > klogd: page allocation failure. order:0, mode: 0x20
...
> > [alloc_skb+75/224] alloc_skb+0x47/0xe0
> > [e1000_alloc_rx_buffers+72/227] e1000_alloc_rx_buffers+0x44/0xe3
> > [e1000_clean_rx_irq+402/1095] e1000_clean_rx_irq+0x18e/0x447
> > [e1000_clean+85/202] e1000_clean+0x51/0xca
> There was a problem related to e1000 and TSO which was leading to these
> over-aggressive atomic allocations. That was fixed (within ./net/)
> post-2.6.9.
I got the following with 2.6.10-rc1-mm4:
swapper: page allocation failure. order:0, mode:0x20
[<c013edfd>] __alloc_pages+0x20d/0x390
[<c013ef98>] __get_free_pages+0x18/0x30
[<c0141728>] kmem_getpages+0x18/0xc0
[<c01423ad>] cache_grow+0x9d/0x130
[<c01425bc>] cache_alloc_refill+0x17c/0x240
[<c0142874>] kmem_cache_alloc+0x44/0x50
[<c02e429e>] skb_clone+0xe/0x190
[<c031082e>] tcp_retransmit_skb+0x21e/0x300
[<c0308c96>] tcp_enter_loss+0x66/0x230
[<c031258f>] tcp_retransmit_timer+0xdf/0x400
[<c02ada31>] scsi_io_completion+0x111/0x480
[<c0127b52>] del_timer+0x62/0x80
[<c0312979>] tcp_write_timer+0xc9/0x100
[<c03128b0>] tcp_write_timer+0x0/0x100
[<c01281e2>] run_timer_softirq+0xe2/0x1c0
[<c02a8fe1>] scsi_finish_command+0x81/0xd0
[<c0124038>] __do_softirq+0xb8/0xd0
[<c012407d>] do_softirq+0x2d/0x30
[<c011324f>] smp_apic_timer_interrupt+0x5f/0xd0
[<c010498c>] apic_timer_interrupt+0x1c/0x24
[<c0102030>] default_idle+0x0/0x40
[<c010205c>] default_idle+0x2c/0x40
[<c01020e3>] cpu_idle+0x33/0x40
DMA per-cpu:
cpu 0 hot: low 2, high 6, batch 1
cpu 0 cold: low 0, high 2, batch 1
cpu 1 hot: low 2, high 6, batch 1
cpu 1 cold: low 0, high 2, batch 1
Normal per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
HighMem per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
Free pages: 4664kB (1600kB HighMem)
Active:489259 inactive:478496 dirty:105435 writeback:796 unstable:0 free:1166 slab:41902 mapped:481292 pagetables:1211
DMA free:56kB min:144kB low:288kB high:432kB active:4600kB inactive:3156kB present:16384kB pages_scanned:32 all_unreclaimable? no
protections[]: 0 0 0
Normal free:3008kB min:8044kB low:16088kB high:24132kB active:323776kB inactive:370488kB present:901120kB pages_scanned:64 all_unreclaimable? no
protections[]: 0 0 0
HighMem free:1600kB min:512kB low:1024kB high:1536kB active:1628660kB inactive:1540340kB present:3178432kB pages_scanned:0 all_unreclaimable? no
protections[]: 0 0 0
DMA: 0*4kB 1*8kB 1*16kB 1*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 56kB
Normal: 0*4kB 0*8kB 0*16kB 0*32kB 1*64kB 1*128kB 1*256kB 1*512kB 0*1024kB 1*2048kB 0*4096kB = 3008kB
HighMem: 24*4kB 24*8kB 14*16kB 8*32kB 5*64kB 0*128kB 0*256kB 1*512kB 0*1024kB 0*2048kB 0*4096kB = 1600kB
Swap cache: add 494, delete 439, find 171/197, race 0+0
Dual Opteron, 4GB, 3ware 9508, tg3 for BCM5704.
Offload parameters for eth0:
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp segmentation offload: off
Stefan
On Tue, Nov 09, 2004 at 11:44:23PM +0100, Lukas Hejtmanek wrote:
> On Tue, Nov 09, 2004 at 02:46:07PM -0800, Andrew Morton wrote:
> > > > Can you please run your workload which cause 0-order page allocation
> > > > failures with the following patch, pretty please?
> > > >
> > > > We will have more information on the free areas state when the allocation
> > > > fails.
> > > >
> > > > Andrew, please apply it to the next -mm, will you?
> > >
> > > here is the trace:
> > > klogd: page allocation failure. order:0, mode: 0x20
> > > [__alloc_pages+441/862] __alloc_pages+0x1b9/0x363
> > > [__get_free_pages+42/63] __get_free_pages+0x25/0x3f
> > > [kmem_getpages+37/201] kmem_getpages+0x21/0xc9
> > > [cache_grow+175/333] cache_grow+0xab/0x14d
> > > [cache_alloc_refill+376/537] cache_alloc_refill+0x174/0x219
> > > [__kmalloc+137/140] __kmalloc+0x85/0x8c
> > > [alloc_skb+75/224] alloc_skb+0x47/0xe0
> > > [e1000_alloc_rx_buffers+72/227] e1000_alloc_rx_buffers+0x44/0xe3
> > > [e1000_clean_rx_irq+402/1095] e1000_clean_rx_irq+0x18e/0x447
> > > [e1000_clean+85/202] e1000_clean+0x51/0xca
> >
> > What kernel is in use here?
> >
> > There was a problem related to e1000 and TSO which was leading to these
> > over-aggressive atomic allocations. That was fixed (within ./net/)
> > post-2.6.9.
>
> I use vanilla 2.6.9.
Lukas,
So you can be hitting the e1000/TSO issue - care to retest with
2.6.10-rc1-mm3/4 please?
Thanks a lot for testing!
Alright, i got a funny thing here that i suspect to be an(other?) vm issue:
We are running a third-party closed source software which handles many tcp
sessions and reads and writes that to/from several disks/partitions.
With 2.6.10-rc1-mm4 it is the first time we notice that, right after the kernel
throws a swapper: page allocation error thread (just like the ones you already
know), the interrupt rate, connection count and traffic decreases subsequently.
Here is part of a vmstat 10:
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 11312 19404 268 1896896 0 0 1091 17578 25463 1225 7 38 37 18
0 0 11312 26372 180 1892836 0 0 1182 21433 25576 1216 7 38 31 24
1 2 11308 23784 608 1890168 0 0 1252 20667 25532 1243 7 40 24 29
0 2 11308 23304 428 1890552 0 0 1174 20363 25948 1332 7 40 32 21
1 1 11304 18496 444 1893328 0 0 1630 20506 25840 1322 7 38 30 26
1 1 11304 8712 232 1905508 0 0 1528 19662 26245 1305 7 40 25 28
1 0 11304 18952 180 1894000 0 0 1595 19680 26275 1215 7 38 27 28
1 0 11304 22404 132 1896632 0 0 369 17724 24072 1045 7 37 49 7
1 0 11304 23956 492 1899876 0 0 504 19609 20829 1151 9 34 49 7
1 0 11304 25380 460 1908340 0 0 424 17983 16964 927 9 28 55 8
1 0 11304 18244 464 1922140 0 0 309 14431 13417 836 10 27 60 3
0 0 11304 17720 472 1928388 0 0 224 11868 9933 607 11 23 63 3
1 0 11304 25720 476 1924440 0 0 133 7663 6780 504 10 20 68 2
1 0 11304 24156 488 1928168 0 0 107 6244 5011 315 8 18 73 1
0 0 11304 19544 712 1934268 0 0 76 3191 4464 299 8 18 73 1
0 0 11304 19248 728 1936564 0 0 23 1802 4002 249 7 17 76 0
1 0 11304 27092 736 1929892 0 0 16 1336 3655 284 6 16 78 0
0 0 11304 26472 752 1931984 0 0 19 1508 3408 248 5 16 78 1
0 0 11304 19000 768 1940944 0 0 20 1398 3195 226 5 14 81 0
1 0 11304 21460 776 1938896 0 0 14 1084 3057 241 5 14 82 0
0 0 11304 26268 848 1934608 0 0 12 927 2906 218 5 13 82 0
1 1 11304 22076 900 1939860 0 0 18 679 2897 215 5 11 84 1
0 0 11304 25880 952 1936748 0 0 17 653 2713 251 4 13 82 1
0 0 11304 20436 976 1942368 0 0 8 1117 2703 229 5 11 83 1
...
strace shows:
01:38:50.316041 gettimeofday({1100047130, 316054}, NULL) = 0
01:38:50.316188 poll([{fd=5671, events=POLLIN}, {fd=2727, events=POLLIN}, {fd=6663, events=POLLIN}, {fd=197, events=POLLIN}, {fd=3978, events=POLLIN}, {fd=779, events=POLLIN}, ...{line continues like this}...
...
01:38:50.328056 accept(5, 0xbffd4ab8, [16]) = -1 EAGAIN (Resource temporarily unavailable) ...{an awful lot of these}...
...
01:38:50.329585 futex(0xaf1a698, FUTEX_WAIT, 92828, {0, 9964000}) = -1 ETIMEDOUT (Connection timed out) ...{some of these}...
...
Application says:
"n.n.n.n:p Client closed connection in body read"
To me it seems like suddently all those open sockets are suddenly 'temporarily
unavailable' to the application and so the connections time out.
I have not (yet?) seen this behaviour on 2.6.9, 2.6.9-mm1, 2.6.10-rc1-bk12 or
2.6.10-rc1-mm3.
I am able to reproduce the behaviour if under the same load iptraf or
tethereal are started. (First thought it might be because of the promisc mode.)
This seems to be what _might_ have triggered this although it was logged
happened 5m earlier than the traffic decay:
printk: 36 messages suppressed.
swapper: page allocation failure. order:0, mode:0x20
[__alloc_pages+525/912] __alloc_pages+0x20d/0x390
[__get_free_pages+24/48] __get_free_pages+0x18/0x30
[kmem_getpages+24/192] kmem_getpages+0x18/0xc0
[cache_grow+157/304] cache_grow+0x9d/0x130
[cache_alloc_refill+380/576] cache_alloc_refill+0x17c/0x240
[__kmalloc+122/144] __kmalloc+0x7a/0x90
[alloc_skb+50/208] alloc_skb+0x32/0xd0
[tg3_alloc_rx_skb+112/304] tg3_alloc_rx_skb+0x70/0x130
[tg3_rx+518/944] tg3_rx+0x206/0x3b0
[tg3_poll+139/336] tg3_poll+0x8b/0x150
[net_rx_action+125/288] net_rx_action+0x7d/0x120
[__do_softirq+184/208] __do_softirq+0xb8/0xd0
[do_softirq+45/48] do_softirq+0x2d/0x30
[do_IRQ+30/48] do_IRQ+0x1e/0x30
[common_interrupt+26/32] common_interrupt+0x1a/0x20
[default_idle+0/64] default_idle+0x0/0x40
[default_idle+44/64] default_idle+0x2c/0x40
[cpu_idle+51/64] cpu_idle+0x33/0x40
[start_kernel+331/368] start_kernel+0x14b/0x170
[unknown_bootoption+0/432] unknown_bootoption+0x0/0x1b0
DMA per-cpu:
cpu 0 hot: low 2, high 6, batch 1
cpu 0 cold: low 0, high 2, batch 1
cpu 1 hot: low 2, high 6, batch 1
cpu 1 cold: low 0, high 2, batch 1
Normal per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
HighMem per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
Free pages: 4616kB (1600kB HighMem)
Active:504159 inactive:454759 dirty:20020 writeback:115 unstable:0 free:1154 slab:50758 mapped:489095 pagetables:1222
DMA free:56kB min:144kB low:288kB high:432kB active:1936kB inactive:4932kB present:16384kB pages_scanned:32 all_unreclaimable? no
protections[]: 0 0 0
Normal free:2960kB min:8044kB low:16088kB high:24132kB active:492320kB inactive:166992kB present:901120kB pages_scanned:62 all_unreclaimable? no
protections[]: 0 0 0
HighMem free:1600kB min:512kB low:1024kB high:1536kB active:1522380kB inactive:1647112kB present:3178432kB pages_scanned:0 all_unreclaimable? no
protections[]: 0 0 0
DMA: 0*4kB 1*8kB 1*16kB 1*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 56kB
Normal: 0*4kB 0*8kB 1*16kB 0*32kB 2*64kB 0*128kB 1*256kB 1*512kB 0*1024kB 1*2048kB 0*4096kB = 2960kB
HighMem: 6*4kB 3*8kB 41*16kB 0*32kB 6*64kB 0*128kB 0*256kB 1*512kB 0*1024kB 0*2048kB 0*4096kB = 1600kB
Swap cache: add 154147, delete 151810, find 29532/39794, race 0+0
Stefan
Added netdev to Cc. Full cite.
Stefan Schmidt <[email protected]> wrote:
>
> Alright, i got a funny thing here that i suspect to be an(other?) vm issue:
>
> We are running a third-party closed source software which handles many tcp
> sessions and reads and writes that to/from several disks/partitions.
> With 2.6.10-rc1-mm4 it is the first time we notice that, right after the kernel
> throws a swapper: page allocation error thread (just like the ones you already
> know), the interrupt rate, connection count and traffic decreases subsequently.
>
> Here is part of a vmstat 10:
> procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
> r b swpd free buff cache si so bi bo in cs us sy id wa
> 1 0 11312 19404 268 1896896 0 0 1091 17578 25463 1225 7 38 37 18
> 0 0 11312 26372 180 1892836 0 0 1182 21433 25576 1216 7 38 31 24
> 1 2 11308 23784 608 1890168 0 0 1252 20667 25532 1243 7 40 24 29
> 0 2 11308 23304 428 1890552 0 0 1174 20363 25948 1332 7 40 32 21
> 1 1 11304 18496 444 1893328 0 0 1630 20506 25840 1322 7 38 30 26
> 1 1 11304 8712 232 1905508 0 0 1528 19662 26245 1305 7 40 25 28
> 1 0 11304 18952 180 1894000 0 0 1595 19680 26275 1215 7 38 27 28
> 1 0 11304 22404 132 1896632 0 0 369 17724 24072 1045 7 37 49 7
> 1 0 11304 23956 492 1899876 0 0 504 19609 20829 1151 9 34 49 7
> 1 0 11304 25380 460 1908340 0 0 424 17983 16964 927 9 28 55 8
> 1 0 11304 18244 464 1922140 0 0 309 14431 13417 836 10 27 60 3
> 0 0 11304 17720 472 1928388 0 0 224 11868 9933 607 11 23 63 3
> 1 0 11304 25720 476 1924440 0 0 133 7663 6780 504 10 20 68 2
> 1 0 11304 24156 488 1928168 0 0 107 6244 5011 315 8 18 73 1
> 0 0 11304 19544 712 1934268 0 0 76 3191 4464 299 8 18 73 1
> 0 0 11304 19248 728 1936564 0 0 23 1802 4002 249 7 17 76 0
> 1 0 11304 27092 736 1929892 0 0 16 1336 3655 284 6 16 78 0
> 0 0 11304 26472 752 1931984 0 0 19 1508 3408 248 5 16 78 1
> 0 0 11304 19000 768 1940944 0 0 20 1398 3195 226 5 14 81 0
> 1 0 11304 21460 776 1938896 0 0 14 1084 3057 241 5 14 82 0
> 0 0 11304 26268 848 1934608 0 0 12 927 2906 218 5 13 82 0
> 1 1 11304 22076 900 1939860 0 0 18 679 2897 215 5 11 84 1
> 0 0 11304 25880 952 1936748 0 0 17 653 2713 251 4 13 82 1
> 0 0 11304 20436 976 1942368 0 0 8 1117 2703 229 5 11 83 1
> ...
>
> strace shows:
> 01:38:50.316041 gettimeofday({1100047130, 316054}, NULL) = 0
> 01:38:50.316188 poll([{fd=5671, events=POLLIN}, {fd=2727, events=POLLIN}, {fd=6663, events=POLLIN}, {fd=197, events=POLLIN}, {fd=3978, events=POLLIN}, {fd=779, events=POLLIN}, ...{line continues like this}...
> ...
> 01:38:50.328056 accept(5, 0xbffd4ab8, [16]) = -1 EAGAIN (Resource temporarily unavailable) ...{an awful lot of these}...
> ...
> 01:38:50.329585 futex(0xaf1a698, FUTEX_WAIT, 92828, {0, 9964000}) = -1 ETIMEDOUT (Connection timed out) ...{some of these}...
> ...
> Application says:
> "n.n.n.n:p Client closed connection in body read"
>
> To me it seems like suddently all those open sockets are suddenly 'temporarily
> unavailable' to the application and so the connections time out.
> I have not (yet?) seen this behaviour on 2.6.9, 2.6.9-mm1, 2.6.10-rc1-bk12 or
> 2.6.10-rc1-mm3.
> I am able to reproduce the behaviour if under the same load iptraf or
> tethereal are started. (First thought it might be because of the promisc mode.)
>
> This seems to be what _might_ have triggered this although it was logged
> happened 5m earlier than the traffic decay:
>
> printk: 36 messages suppressed.
> swapper: page allocation failure. order:0, mode:0x20
> [__alloc_pages+525/912] __alloc_pages+0x20d/0x390
> [__get_free_pages+24/48] __get_free_pages+0x18/0x30
> [kmem_getpages+24/192] kmem_getpages+0x18/0xc0
> [cache_grow+157/304] cache_grow+0x9d/0x130
> [cache_alloc_refill+380/576] cache_alloc_refill+0x17c/0x240
> [__kmalloc+122/144] __kmalloc+0x7a/0x90
> [alloc_skb+50/208] alloc_skb+0x32/0xd0
> [tg3_alloc_rx_skb+112/304] tg3_alloc_rx_skb+0x70/0x130
> [tg3_rx+518/944] tg3_rx+0x206/0x3b0
> [tg3_poll+139/336] tg3_poll+0x8b/0x150
> [net_rx_action+125/288] net_rx_action+0x7d/0x120
> [__do_softirq+184/208] __do_softirq+0xb8/0xd0
> [do_softirq+45/48] do_softirq+0x2d/0x30
> [do_IRQ+30/48] do_IRQ+0x1e/0x30
> [common_interrupt+26/32] common_interrupt+0x1a/0x20
> [default_idle+0/64] default_idle+0x0/0x40
> [default_idle+44/64] default_idle+0x2c/0x40
> [cpu_idle+51/64] cpu_idle+0x33/0x40
> [start_kernel+331/368] start_kernel+0x14b/0x170
> [unknown_bootoption+0/432] unknown_bootoption+0x0/0x1b0
> DMA per-cpu:
> cpu 0 hot: low 2, high 6, batch 1
> cpu 0 cold: low 0, high 2, batch 1
> cpu 1 hot: low 2, high 6, batch 1
> cpu 1 cold: low 0, high 2, batch 1
> Normal per-cpu:
> cpu 0 hot: low 32, high 96, batch 16
> cpu 0 cold: low 0, high 32, batch 16
> cpu 1 hot: low 32, high 96, batch 16
> cpu 1 cold: low 0, high 32, batch 16
> HighMem per-cpu:
> cpu 0 hot: low 32, high 96, batch 16
> cpu 0 cold: low 0, high 32, batch 16
> cpu 1 hot: low 32, high 96, batch 16
> cpu 1 cold: low 0, high 32, batch 16
>
> Free pages: 4616kB (1600kB HighMem)
> Active:504159 inactive:454759 dirty:20020 writeback:115 unstable:0 free:1154 slab:50758 mapped:489095 pagetables:1222
> DMA free:56kB min:144kB low:288kB high:432kB active:1936kB inactive:4932kB present:16384kB pages_scanned:32 all_unreclaimable? no
> protections[]: 0 0 0
> Normal free:2960kB min:8044kB low:16088kB high:24132kB active:492320kB inactive:166992kB present:901120kB pages_scanned:62 all_unreclaimable? no
> protections[]: 0 0 0
> HighMem free:1600kB min:512kB low:1024kB high:1536kB active:1522380kB inactive:1647112kB present:3178432kB pages_scanned:0 all_unreclaimable? no
> protections[]: 0 0 0
> DMA: 0*4kB 1*8kB 1*16kB 1*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 56kB
> Normal: 0*4kB 0*8kB 1*16kB 0*32kB 2*64kB 0*128kB 1*256kB 1*512kB 0*1024kB 1*2048kB 0*4096kB = 2960kB
> HighMem: 6*4kB 3*8kB 41*16kB 0*32kB 6*64kB 0*128kB 0*256kB 1*512kB 0*1024kB 0*2048kB 0*4096kB = 1600kB
> Swap cache: add 154147, delete 151810, find 29532/39794, race 0+0
>
Well you've definitely used up all the memory which is available for atomic
allocations. Are you using an increased /proc/sys/vm/min_free_kbytes there?
As for the application collapse: dunno. Maybe networking broke. It would
be interesting to test Linus's current tree, at
ftp://ftp.kernel.org/pub/linux/kernel/v2.6/snapshots/patch-2.6.10-rc1-bk19.gz
On Tue, Nov 09, 2004 at 05:39:20PM -0800, Andrew Morton wrote:
> Well you've definitely used up all the memory which is available for atomic
> allocations. Are you using an increased /proc/sys/vm/min_free_kbytes there?
Yes, vm.min_free_kbytes=8192.
For other vm-settings find sysctl.conf attached.
Netdev: tg3 BCM5704r03, TSO off, ~32kpps rx, ~35kpps tx, ~2 rx errors/s
> As for the application collapse: dunno. Maybe networking broke. It would
> be interesting to test Linus's current tree, at
> ftp://ftp.kernel.org/pub/linux/kernel/v2.6/snapshots/patch-2.6.10-rc1-bk19.gz
Will try that tomorrow. Would you suggest printing out show_free_areas();
there too? I don't know what kind of an overhead that will generate on
subsequent stack traces.
Stefan
Stefan Schmidt <[email protected]> wrote:
>
> > As for the application collapse: dunno. Maybe networking broke. It would
> > be interesting to test Linus's current tree, at
> > ftp://ftp.kernel.org/pub/linux/kernel/v2.6/snapshots/patch-2.6.10-rc1-bk19.gz
> Will try that tomorrow. Would you suggest printing out show_free_areas();
> there too? I don't know what kind of an overhead that will generate on
> subsequent stack traces.
I don't think it'd help much - we know what's happening.
It would be interesting to keep increasing min_free_kbytes, see if you can
characterise the system's response to this setting.
Stefan Schmidt wrote:
>On Tue, Nov 09, 2004 at 05:39:20PM -0800, Andrew Morton wrote:
>
>>Well you've definitely used up all the memory which is available for atomic
>>allocations. Are you using an increased /proc/sys/vm/min_free_kbytes there?
>>
>Yes, vm.min_free_kbytes=8192.
>For other vm-settings find sysctl.conf attached.
>
>Netdev: tg3 BCM5704r03, TSO off, ~32kpps rx, ~35kpps tx, ~2 rx errors/s
>
>
>>As for the application collapse: dunno. Maybe networking broke. It would
>>be interesting to test Linus's current tree, at
>>ftp://ftp.kernel.org/pub/linux/kernel/v2.6/snapshots/patch-2.6.10-rc1-bk19.gz
>>
>Will try that tomorrow. Would you suggest printing out show_free_areas();
>there too? I don't know what kind of an overhead that will generate on
>subsequent stack traces.
>
>
Stefan,
Can you try the following patch, please? It is diffed against 2.6.10-rc1,
but I think it should apply to -mm kernels as well.
Basically 2.6.8 and earlier kernels had some quirks in the page allocator
that would allow for example, a large portion of "DMA" memory to be reserved
for network memory allocations (atomic allocations). After 'fixing' this
problem, 2.6.9 is effectively left with about a quarter the amount of memory
reserved for network allocations compared with 2.6.8.
The following patch roughly restores parity there. Thanks.
Nick
On Wed, Nov 10, 2004 at 03:24:10PM +1100, Nick Piggin wrote:
> Can you try the following patch, please? It is diffed against 2.6.10-rc1,
> but I think it should apply to -mm kernels as well.
>
> Basically 2.6.8 and earlier kernels had some quirks in the page allocator
> that would allow for example, a large portion of "DMA" memory to be reserved
> for network memory allocations (atomic allocations). After 'fixing' this
> problem, 2.6.9 is effectively left with about a quarter the amount of memory
> reserved for network allocations compared with 2.6.8.
>
> The following patch roughly restores parity there. Thanks.
I applied the patch to 2.6.10-rc1-mm4 and the application froze again, but i
just remembered that i changed a kernel-option in mm4 and forgot about that
yesterday:
I unset CONFIG_PACKET_MMAP and i suppose this could have this kind of effect
on high connection rates.
I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
for some hours at this load we can blame at least this issue (-1 EAGAIN) on
that parameter.
My variation of Harrisberger's Fourth Law of the Lab:
Experience is directly proportional to the amount of braincells ruined.
*ouch*,
Stefan
On Wed, Nov 10, 2004 at 11:28:54AM +0100, Stefan Schmidt wrote:
> > Can you try the following patch, please? It is diffed against 2.6.10-rc1,
> > but I think it should apply to -mm kernels as well.
I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will try
latest bk next.
> I unset CONFIG_PACKET_MMAP and i suppose this could have this kind of effect
> on high connection rates.
> I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
> for some hours at this load we can blame at least this issue (-1 EAGAIN) on
> that parameter.
Nope, that didn't change anything, still getting EAGAIN, checked two times.
Stefan
On Wed, Nov 10, 2004 at 01:06:24PM +0100, Stefan Schmidt wrote:
> On Wed, Nov 10, 2004 at 11:28:54AM +0100, Stefan Schmidt wrote:
> > > Can you try the following patch, please? It is diffed against 2.6.10-rc1,
> > > but I think it should apply to -mm kernels as well.
> I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will try
> latest bk next.
>
> > I unset CONFIG_PACKET_MMAP and i suppose this could have this kind of effect
> > on high connection rates.
> > I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
> > for some hours at this load we can blame at least this issue (-1 EAGAIN) on
> > that parameter.
> Nope, that didn't change anything, still getting EAGAIN, checked two times.
Hi Stefan,
Its not clear to me - do you have Nick's watermark patch in?
On Wed, Nov 10, 2004 at 06:58:31AM -0200, Marcelo Tosatti wrote:
> > > > Can you try the following patch, please? It is diffed against 2.6.10-rc1,
> > I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will try
> > latest bk next.
> > > I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
> > > for some hours at this load we can blame at least this issue (-1 EAGAIN) on
> > > that parameter.
> > Nope, that didn't change anything, still getting EAGAIN, checked two times.
> Its not clear to me - do you have Nick's watermark patch in?
Yes i have vm.min_free_kbytes=8192 and Nick's patch in mm4. I'll try
rc1-bk19 with his restore-atomic-buffer patch in a few minutes.
Stefan
--
The reason computer chips are so small is computers don't eat much.
On Wed, Nov 10, 2004 at 01:48:11PM +0100, Stefan Schmidt wrote:
> On Wed, Nov 10, 2004 at 06:58:31AM -0200, Marcelo Tosatti wrote:
> > > > > Can you try the following patch, please? It is diffed against 2.6.10-rc1,
> > > I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will try
> > > latest bk next.
>
> > > > I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
> > > > for some hours at this load we can blame at least this issue (-1 EAGAIN) on
> > > > that parameter.
> > > Nope, that didn't change anything, still getting EAGAIN, checked two times.
> > Its not clear to me - do you have Nick's watermark patch in?
> Yes i have vm.min_free_kbytes=8192 and Nick's patch in mm4. I'll try
> rc1-bk19 with his restore-atomic-buffer patch in a few minutes.
Stefan,
Please always run your tests with show_free_area() call at the
page allocation failure path.
I fully disagree with Andrew when he says
"I don't think it'd help much - we know what's happening."
> Lukas,
>
> So you can be hitting the e1000/TSO issue - care to retest with
> 2.6.10-rc1-mm3/4 please?
2.6.10-rc1-mm3 with CONFIG_PREEMPT=y and CONFIG_PREEMPT_BKL=y
results with: (and many more xfs related calls)
Nov 10 21:21:05 undomiel1 kernel: BUG: using smp_processor_id() in preemptible [00000001] code: swapper/1
Nov 10 21:21:05 undomiel1 kernel: caller is xfs_dir2_lookup+0x26/0x157
Nov 10 21:21:05 undomiel1 kernel: [<c025dbf4>] smp_processor_id+0xa8/0xb8
Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
Nov 10 21:21:05 undomiel1 kernel: [<c025a4e7>] send_uevent+0x148/0x1a0
Nov 10 21:21:05 undomiel1 kernel: [<c025a61a>] do_kobject_uevent+0xdb/0x109
Nov 10 21:21:05 undomiel1 kernel: [<c023ba15>] xfs_access+0x4d/0x5b
Nov 10 21:21:05 undomiel1 kernel: [<c023766e>] xfs_dir_lookup_int+0x4c/0x12b
Nov 10 21:21:05 undomiel1 kernel: [<c01611a3>] link_path_walk+0xd4a/0xe17
Nov 10 21:21:05 undomiel1 kernel: [<c023ce74>] xfs_lookup+0x50/0x88
Nov 10 21:21:05 undomiel1 kernel: [<c0249300>] linvfs_lookup+0x58/0x96
Nov 10 21:21:05 undomiel1 kernel: [<c016017a>] real_lookup+0xc20xe3
Nov 10 21:21:05 undomiel1 kernel: [<c016044e>] do_lookup+0x96/0xa1
--
Luk?? Hejtm?nek
Lukas Hejtmanek <[email protected]> wrote:
>
> 2.6.10-rc1-mm3 with CONFIG_PREEMPT=y and CONFIG_PREEMPT_BKL=y
> results with: (and many more xfs related calls)
>
> Nov 10 21:21:05 undomiel1 kernel: BUG: using smp_processor_id() in preemptible [00000001] code: swapper/1
> Nov 10 21:21:05 undomiel1 kernel: caller is xfs_dir2_lookup+0x26/0x157
> Nov 10 21:21:05 undomiel1 kernel: [<c025dbf4>] smp_processor_id+0xa8/0xb8
> Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
> Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
> Nov 10 21:21:05 undomiel1 kernel: [<c025a4e7>] send_uevent+0x148/0x1a0
That's XFS_STATS_INC() and friends.
I don't think there's really a bug here. It's a tiny bit racy, but that
will merely cause a small inaccuracy in the stats.
I think I'll just drop the debug patch. You can disable
CONFIG_DEBUG_PREEMPT to shut things up.
On Tue, Nov 09, 2004 at 06:33:48PM -0200, Marcelo Tosatti wrote:
> So you can be hitting the e1000/TSO issue - care to retest with
> 2.6.10-rc1-mm3/4 please?
>
> Thanks a lot for testing!
This is from 2.6.10-rc1-mm3: (i added show_free..)
swapper: page allocation failure. order:0, mode:0x20
[<c0137f28>] __alloc_pages+0x242/0x40e
[<c0138119>] __get_free_pages+0x25/0x3f
[<c032ed55>] tcp_v4_rcv+0x69a/0x9b5
[<c013b189>] kmem_getpages+0x21/0xc9
[<c013be3a>] cache_grow+0xab/0x14d
[<c013c05e>] cache_alloc_refill+0x182/0x244
[<c013c3ec>] __kmalloc+0x85/0x8c
[<c02fac89>] alloc_skb+0x47/0xe0
[<c02997ca>] e1000_alloc_rx_buffers+0x44/0xe3
[<c029944b>] e1000_clean_rx_irq+0x17c/0x4b7
[<c0298fd0>] e1000_clean+0x51/0xe7
[<c03010dc>] net_rx_action+0x7f/0x11f
[<c011daa3>] __do_softirq+0xb7/0xc6
[<c011dadf>] do_softirq+0x2d/0x2f
[<c010614e>] do_IRQ+0x1e/0x24
[<c0104756>] common_interrupt+0x1a/0x20
[<c0101eae>] default_idle+0x0/0x2c
[<c0101ed7>] default_idle+0x29/0x2c
[<c0101f40>] cpu_idle+0x33/0x3c
[<c0448a1f>] start_kernel+0x14c/0x165
[<c04484bd>] unknown_bootoption+0x0/0x1ab
DMA per-cpu:
cpu 0 hot: low 2, high 6, batch 1
cpu 0 cold: low 0, high 2, batch 1
cpu 1 hot: low 2, high 6, batch 1
cpu 1 cold: low 0, high 2, batch 1
Normal per-cpu:
cpu 0 hot: low 32, high 96, batch 16
cpu 0 cold: low 0, high 32, batch 16
cpu 1 hot: low 32, high 96, batch 16
cpu 1 cold: low 0, high 32, batch 16
HighMem per-cpu:
cpu 0 hot: low 14, high 42, batch 7
cpu 0 cold: low 0, high 14, batch 7
cpu 1 hot: low 14, high 42, batch 7
cpu 1 cold: low 0, high 14, batch 7
Free pages: 532kB (252kB HighMem)
Active:39820 inactive:208936 dirty:104508 writeback:672 unstable:0 free:133 slab:7779 mapped:15810 pagetables:410
DMA free:8kB min:12kB low:24kB high:36kB active:384kB inactive:11400kB present:16384kB pages_scanned:192 all_unreclaimable? no
protections[]: 0 0 0
DMA: 0*4kB 1*8kB 0*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 8kB
Normal: 0*4kB 0*8kB 1*16kB 0*32kB 0*64kB 0*128kB 1*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 272kB
HighMem: 15*4kB 8*8kB 2*16kB 1*32kB 1*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 252kB
Swap cache: add 1, delete 0, find 0/0, race 0+0
printk: 696 messages suppressed.
swapper: page allocation failure. order:0, mode:0x20
--
Luk?? Hejtm?nek
On Wed, Nov 10, 2004 at 01:09:43PM -0800, Andrew Morton wrote:
> Lukas Hejtmanek <[email protected]> wrote:
> >
> > 2.6.10-rc1-mm3 with CONFIG_PREEMPT=y and CONFIG_PREEMPT_BKL=y
> > results with: (and many more xfs related calls)
> >
> > Nov 10 21:21:05 undomiel1 kernel: BUG: using smp_processor_id() in preemptible [00000001] code: swapper/1
> > Nov 10 21:21:05 undomiel1 kernel: caller is xfs_dir2_lookup+0x26/0x157
> > Nov 10 21:21:05 undomiel1 kernel: [<c025dbf4>] smp_processor_id+0xa8/0xb8
> > Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
> > Nov 10 21:21:05 undomiel1 kernel: [<c020679b>] xfs_dir2_lookup+0x26/0x157
> > Nov 10 21:21:05 undomiel1 kernel: [<c025a4e7>] send_uevent+0x148/0x1a0
>
> That's XFS_STATS_INC() and friends.
>
> I don't think there's really a bug here. It's a tiny bit racy, but that
> will merely cause a small inaccuracy in the stats.
>
> I think I'll just drop the debug patch. You can disable
> CONFIG_DEBUG_PREEMPT to shut things up.
It did not help :( I had to disable CONFIG_PREEMPT to shut it up.
I had:
CONFIG_PREEMPT=y
CONFIG_PREEMPT_BKL=y
CONFIG_DEBUG_PREEMPT=y
It did what I wrote.
Then I had:
CONFIG_PREEMPT=y
#CONFIG_PREEMPT_BKL=y
#CONFIG_DEBUG_PREEMPT=y
and I had the same (or similar messages)
Now I have disabled all the preempt stuff and it is ok. (but not ok with
allocation failure, see next mail)
--
Luk?? Hejtm?nek
On Wed, Nov 10, 2004 at 10:28:18PM +0100, Lukas Hejtmanek wrote:
> On Tue, Nov 09, 2004 at 06:33:48PM -0200, Marcelo Tosatti wrote:
> > So you can be hitting the e1000/TSO issue - care to retest with
> > 2.6.10-rc1-mm3/4 please?
> >
> > Thanks a lot for testing!
>
> This is from 2.6.10-rc1-mm3: (i added show_free..)
>
> swapper: page allocation failure. order:0, mode:0x20
> [<c0137f28>] __alloc_pages+0x242/0x40e
> [<c0138119>] __get_free_pages+0x25/0x3f
> [<c032ed55>] tcp_v4_rcv+0x69a/0x9b5
> [<c013b189>] kmem_getpages+0x21/0xc9
> [<c013be3a>] cache_grow+0xab/0x14d
> [<c013c05e>] cache_alloc_refill+0x182/0x244
> [<c013c3ec>] __kmalloc+0x85/0x8c
> [<c02fac89>] alloc_skb+0x47/0xe0
> [<c02997ca>] e1000_alloc_rx_buffers+0x44/0xe3
> [<c029944b>] e1000_clean_rx_irq+0x17c/0x4b7
> [<c0298fd0>] e1000_clean+0x51/0xe7
> [<c03010dc>] net_rx_action+0x7f/0x11f
> [<c011daa3>] __do_softirq+0xb7/0xc6
> [<c011dadf>] do_softirq+0x2d/0x2f
> [<c010614e>] do_IRQ+0x1e/0x24
> [<c0104756>] common_interrupt+0x1a/0x20
> [<c0101eae>] default_idle+0x0/0x2c
> [<c0101ed7>] default_idle+0x29/0x2c
> [<c0101f40>] cpu_idle+0x33/0x3c
> [<c0448a1f>] start_kernel+0x14c/0x165
> [<c04484bd>] unknown_bootoption+0x0/0x1ab
> DMA per-cpu:
> cpu 0 hot: low 2, high 6, batch 1
> cpu 0 cold: low 0, high 2, batch 1
> cpu 1 hot: low 2, high 6, batch 1
> cpu 1 cold: low 0, high 2, batch 1
> Normal per-cpu:
> cpu 0 hot: low 32, high 96, batch 16
> cpu 0 cold: low 0, high 32, batch 16
> cpu 1 hot: low 32, high 96, batch 16
> cpu 1 cold: low 0, high 32, batch 16
> HighMem per-cpu:
> cpu 0 hot: low 14, high 42, batch 7
> cpu 0 cold: low 0, high 14, batch 7
> cpu 1 hot: low 14, high 42, batch 7
> cpu 1 cold: low 0, high 14, batch 7
> Free pages: 532kB (252kB HighMem)
> Active:39820 inactive:208936 dirty:104508 writeback:672 unstable:0 free:133 slab:7779 mapped:15810 pagetables:410
> DMA free:8kB min:12kB low:24kB high:36kB active:384kB inactive:11400kB present:16384kB pages_scanned:192 all_unreclaimable? no
> protections[]: 0 0 0
> DMA: 0*4kB 1*8kB 0*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 8kB
> Normal: 0*4kB 0*8kB 1*16kB 0*32kB 0*64kB 0*128kB 1*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 272kB
> HighMem: 15*4kB 8*8kB 2*16kB 1*32kB 1*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 252kB
> Swap cache: add 1, delete 0, find 0/0, race 0+0
> printk: 696 messages suppressed.
> swapper: page allocation failure. order:0, mode:0x20
OK, do you have Nick watermark fixes in?
They increase the GFP_ATOMIC buffer (memory reserved for GFP_ATOMIC allocations)
significantly, which is exactly the case here.
Its in Andrew's -mm tree already (the last -mm-bk contains it).
Its attached just in case - hope it ends this story.
Lukas Hejtmanek <[email protected]> wrote:
>
> > I don't think there's really a bug here. It's a tiny bit racy, but that
> > will merely cause a small inaccuracy in the stats.
> >
> > I think I'll just drop the debug patch. You can disable
> > CONFIG_DEBUG_PREEMPT to shut things up.
>
> It did not help :( I had to disable CONFIG_PREEMPT to shut it up.
>
> I had:
> CONFIG_PREEMPT=y
> CONFIG_PREEMPT_BKL=y
> CONFIG_DEBUG_PREEMPT=y
>
> It did what I wrote.
> Then I had:
> CONFIG_PREEMPT=y
> #CONFIG_PREEMPT_BKL=y
> #CONFIG_DEBUG_PREEMPT=y
>
> and I had the same (or similar messages)
Confused. Disabling CONFIG_DEBUG_PREEMPT should make those messages go
away. lib/kernel_lock.c has:
#if defined(CONFIG_PREEMPT) && defined(__smp_processor_id) && \
defined(CONFIG_DEBUG_PREEMPT)
/*
* Debugging check.
*/
unsigned int smp_processor_id(void)
{
...
printk(KERN_ERR "BUG: using smp_processor_id() in preemptible [%08x] code: %s/%d\n", preempt_count(), current->comm, current->pid);
print_symbol("caller is %s\n", (long)__builtin_return_address(0));
dump_stack();
On Wed, Nov 10, 2004 at 04:11:48PM -0200, Marcelo Tosatti wrote:
> OK, do you have Nick watermark fixes in?
Well I've applied it and it seems to be ok. Thanks.
Hope that fix will be included in 2.6.10 final.
--
Luk?? Hejtm?nek
Stefan Schmidt wrote:
>On Wed, Nov 10, 2004 at 06:58:31AM -0200, Marcelo Tosatti wrote:
>
>>>>>Can you try the following patch, please? It is diffed against 2.6.10-rc1,
>>>>>
>>>I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will try
>>>latest bk next.
>>>
>
>>>>I set it back to CONFIG_PACKET_MMAP=y and if the application does not freeze
>>>>for some hours at this load we can blame at least this issue (-1 EAGAIN) on
>>>>that parameter.
>>>>
>>>Nope, that didn't change anything, still getting EAGAIN, checked two times.
>>>
>>Its not clear to me - do you have Nick's watermark patch in?
>>
>Yes i have vm.min_free_kbytes=8192 and Nick's patch in mm4. I'll try
>rc1-bk19 with his restore-atomic-buffer patch in a few minutes.
>
>
You'll actually want to increase min_free_kbytes in order to have the same
amount of memory free as 2.6.8 did.
Start by applying my patch and using the default min_free_kbytes. Then
increase
it until the page allocation failures stop, and let us know what the end
result
was.
BTW we should probably have a message in the page allocation failure path
to tell people to try increasing /proc/sys/vm/min_free_kbytes...
On Thu, Nov 11, 2004 at 12:23:13PM +1100, Nick Piggin wrote:
>
>
> Stefan Schmidt wrote:
>
> >On Wed, Nov 10, 2004 at 06:58:31AM -0200, Marcelo Tosatti wrote:
> >
> >>>>>Can you try the following patch, please? It is diffed against
> >>>>>2.6.10-rc1,
> >>>>>
> >>>I did. No apparent change with mm4 and vm.min_free_kbytes = 8192. I will
> >>>try
> >>>latest bk next.
> >>>
> >
> >>>>I set it back to CONFIG_PACKET_MMAP=y and if the application does not
> >>>>freeze
> >>>>for some hours at this load we can blame at least this issue (-1
> >>>>EAGAIN) on
> >>>>that parameter.
> >>>>
> >>>Nope, that didn't change anything, still getting EAGAIN, checked two
> >>>times.
> >>>
> >>Its not clear to me - do you have Nick's watermark patch in?
> >>
> >Yes i have vm.min_free_kbytes=8192 and Nick's patch in mm4. I'll try
> >rc1-bk19 with his restore-atomic-buffer patch in a few minutes.
> >
> >
>
> You'll actually want to increase min_free_kbytes in order to have the same
> amount of memory free as 2.6.8 did.
>
> Start by applying my patch and using the default min_free_kbytes. Then
> increase
> it until the page allocation failures stop, and let us know what the end
> result
> was.
>
> BTW we should probably have a message in the page allocation failure path
> to tell people to try increasing /proc/sys/vm/min_free_kbytes...
>
We are having a similar problem (at least i think).
although I have up'd the min_free_kbytes to what was suggested in this
post and havent seen these messages _yet_.
Nov 7 13:02:23 aragorn kernel: swapper: page allocation failure.
order:1, mode:0x20
Nov 7 13:02:23 aragorn kernel: [<c01356f2>] __alloc_pages+0x1b3/0x358
Nov 7 13:02:23 aragorn kernel: [<c01358bc>] __get_free_pages+0x25/0x3f
Nov 7 13:02:23 aragorn kernel: [<c01389b0>] kmem_getpages+0x21/0xc9
Nov 7 13:02:23 aragorn kernel: [<c013968f>] cache_grow+0xab/0x14d
Nov 7 13:02:23 aragorn kernel: [<c01398a5>]
cache_alloc_refill+0x174/0x219
Nov 7 13:02:23 aragorn kernel: [<c0139b17>] kmem_cache_alloc+0x4b/0x4d
Nov 7 13:02:23 aragorn kernel: [<c0238118>] sk_alloc+0x34/0xa7
Nov 7 13:02:23 aragorn kernel: [<c026d485>]
tcp_create_openreq_child+0x34/0x558
Nov 7 13:02:23 aragorn kernel: [<c0269d81>]
tcp_v4_syn_recv_sock+0x47/0x2ea
Nov 7 13:02:23 aragorn kernel: [<c026db74>] tcp_check_req+0x1cb/0x4df
Nov 7 13:02:23 aragorn kernel: [<f88b64f0>] tg3_start_xmit+0x3f4/0x4f5
[tg3]
Nov 7 13:02:23 aragorn kernel: [<f88b64f0>] tg3_start_xmit+0x3f4/0x4f5
[tg3]
Nov 7 13:02:23 aragorn kernel: [<c023ec88>] dev_queue_xmit+0x120/0x284
Nov 7 13:02:23 aragorn kernel: [<c0248a0e>] qdisc_restart+0x17/0x1d9
Nov 7 13:02:23 aragorn kernel: [<c023ec88>] dev_queue_xmit+0x120/0x284
Nov 7 13:02:23 aragorn kernel: [<c0252a95>] ip_finish_output+0xbb/0x1b9
Nov 7 13:02:23 aragorn kernel: [<c025310d>] ip_queue_xmit+0x3f1/0x500
Nov 7 13:02:23 aragorn kernel: [<c01122a9>] try_to_wake_up+0x1de/0x26c
Nov 7 13:02:23 aragorn kernel: [<c0111c5c>] recalc_task_prio+0x93/0x188
Nov 7 13:02:23 aragorn kernel: [<c0111de1>] activate_task+0x90/0xa4
Nov 7 13:02:23 aragorn kernel: [<c01122a9>] try_to_wake_up+0x1de/0x26c
Nov 7 13:02:23 aragorn kernel: [<c0113c3d>] __wake_up_common+0x3f/0x5e
Nov 7 13:02:23 aragorn kernel: [<c0113c9c>] __wake_up+0x40/0x56
Nov 7 13:02:23 aragorn kernel: [<c026a08a>] tcp_v4_hnd_req+0x66/0x20a
Nov 7 13:02:23 aragorn kernel: [<c026dedb>] tcp_child_process+0x53/0xc4
Nov 7 13:02:23 aragorn kernel: [<c026a45e>] tcp_v4_do_rcv+0xd7/0x12d
Nov 7 13:02:23 aragorn kernel: [<c026ab8c>] tcp_v4_rcv+0x6d8/0x90f
Nov 7 13:02:23 aragorn kernel: [<c0111c5c>] recalc_task_prio+0x93/0x188
Nov 7 13:02:23 aragorn kernel: [<c024fd92>] ip_local_deliver+0xb5/0x201
Nov 7 13:02:23 aragorn kernel: [<c025021a>] ip_rcv+0x33c/0x47e
Nov 7 13:02:23 aragorn kernel: [<c0112fe8>]
find_busiest_group+0xe4/0x316
Nov 7 13:02:23 aragorn kernel: [<c023f2db>]
netif_receive_skb+0x1ac/0x242
Nov 7 13:02:23 aragorn kernel: [<c0239309>] alloc_skb+0x47/0xe0
Nov 7 13:02:23 aragorn kernel: [<f88b5a66>] tg3_rx+0x2a7/0x3fa [tg3]
Nov 7 13:02:23 aragorn kernel: [<f88b5c46>] tg3_poll+0x8d/0x130 [tg3]
Nov 7 13:02:23 aragorn kernel: [<c023f4f3>] net_rx_action+0x77/0xf6
Nov 7 13:02:23 aragorn kernel: [<c011b9cf>] __do_softirq+0xb7/0xc6
Nov 7 13:02:23 aragorn kernel: [<c011ba0b>] do_softirq+0x2d/0x2f
Nov 7 13:02:23 aragorn kernel: [<c0106adf>] do_IRQ+0x112/0x130
Nov 7 13:02:23 aragorn kernel: [<c010494c>] common_interrupt+0x18/0x20
Nov 7 13:02:23 aragorn kernel: [<c0101f1e>] default_idle+0x0/0x2c
Nov 7 13:02:23 aragorn kernel: [<c0101f47>] default_idle+0x29/0x2c
Nov 7 13:02:23 aragorn kernel: [<c0101fbc>] cpu_idle+0x3f/0x58
Nov 7 13:02:23 aragorn kernel: [<c031e9d5>] start_kernel+0x16e/0x189
Nov 7 13:02:23 aragorn kernel: [<c031e49f>]
unknown_bootoption+0x0/0x15c
Nov 7 13:02:23 aragorn kernel: swapper: page allocation failure.
order:1, mode:0x20
Nov 7 13:02:23 aragorn kernel: [<c01356f2>] __alloc_pages+0x1b3/0x358
Nov 7 13:02:23 aragorn kernel: [<c01358bc>] __get_free_pages+0x25/0x3f
Nov 7 13:02:23 aragorn kernel: [<c01389b0>] kmem_getpages+0x21/0xc9
Nov 7 13:02:23 aragorn syslog-ng[1574]: Error accepting AF_UNIX
connection, opened connections: 100, max: 100
Nov 7 13:02:23 aragorn kernel: [<c013968f>] cache_grow+0xab/0x14d
Nov 7 13:02:23 aragorn kernel: [<c01398a5>]
cache_alloc_refill+0x174/0x219
Nov 7 13:02:23 aragorn kernel: [<c0139b17>] kmem_cache_alloc+0x4b/0x4d
Nov 7 13:02:23 aragorn kernel: [<c0238118>] sk_alloc+0x34/0xa7
Nov 7 13:02:23 aragorn kernel: [<c026d485>]
tcp_create_openreq_child+0x34/0x558
Nov 7 13:02:23 aragorn kernel: [<c0269d81>]
tcp_v4_syn_recv_sock+0x47/0x2ea
Nov 7 13:02:23 aragorn kernel: [<c026db74>] tcp_check_req+0x1cb/0x4df
Nov 7 13:02:23 aragorn kernel: [<f88b64f0>] tg3_start_xmit+0x3f4/0x4f5
[tg3]
Nov 7 13:02:23 aragorn kernel: [<f88b64f0>] tg3_start_xmit+0x3f4/0x4f5
[tg3]
Nov 7 13:02:23 aragorn kernel: [<c023ec88>] dev_queue_xmit+0x120/0x284
Nov 7 13:02:23 aragorn kernel: [<c0248a0e>] qdisc_restart+0x17/0x1d9
Nov 7 13:02:23 aragorn kernel: [<c023ec88>] dev_queue_xmit+0x120/0x284
Nov 7 13:02:23 aragorn kernel: [<c0252a95>] ip_finish_output+0xbb/0x1b9
Nov 7 13:02:23 aragorn kernel: [<c0111c5c>] recalc_task_prio+0x93/0x188
Nov 7 13:02:23 aragorn kernel: [<c0111c5c>] recalc_task_prio+0x93/0x188
Nov 7 13:02:23 aragorn kernel: [<f88b64f0>] tg3_start_xmit+0x3f4/0x4f5
[tg3]
Nov 7 13:02:23 aragorn kernel: [<c027dc75>]
fib_validate_source+0x22c/0x257
Nov 7 13:02:23 aragorn kernel: [<c0248a0e>] qdisc_restart+0x17/0x1d9
Nov 7 13:02:23 aragorn kernel: [<c023ec88>] dev_queue_xmit+0x120/0x284
Nov 7 13:02:23 aragorn kernel: [<c0252a95>] ip_finish_output+0xbb/0x1b9
Nov 7 13:02:23 aragorn kernel: [<c025310d>] ip_queue_xmit+0x3f1/0x500
Nov 7 13:02:23 aragorn kernel: [<c026a08a>] tcp_v4_hnd_req+0x66/0x20a
Nov 7 13:02:23 aragorn kernel: [<c024ea28>]
ip_route_output_flow+0x2f/0x9d
Nov 7 13:02:23 aragorn kernel: [<c026a45e>] tcp_v4_do_rcv+0xd7/0x12d
Nov 7 13:02:23 aragorn kernel: [<c026ab8c>] tcp_v4_rcv+0x6d8/0x90f
Nov 7 13:02:23 aragorn kernel: [<c024fd92>] ip_local_deliver+0xb5/0x201
Nov 7 13:02:23 aragorn kernel: [<c025021a>] ip_rcv+0x33c/0x47e
Nov 7 13:02:23 aragorn kernel: [<c023f2db>]
netif_receive_skb+0x1ac/0x242
Nov 7 13:02:23 aragorn kernel: [<c0239309>] alloc_skb+0x47/0xe0
Nov 7 13:02:23 aragorn kernel: [<f88b5a66>] tg3_rx+0x2a7/0x3fa [tg3]
Nov 7 13:02:23 aragorn kernel: [<f88b5c46>] tg3_poll+0x8d/0x130 [tg3]
Nov 7 13:02:23 aragorn kernel: [<c023f4f3>] net_rx_action+0x77/0xf6
Nov 7 13:02:23 aragorn kernel: [<c011b9cf>] __do_softirq+0xb7/0xc6
Nov 7 13:02:23 aragorn kernel: [<c0106adf>] do_IRQ+0x112/0x130
Nov 7 13:02:23 aragorn kernel: [<c010494c>] common_interrupt+0x18/0x20
Nov 7 13:02:23 aragorn kernel: [<c0101f1e>] default_idle+0x0/0x2c
Nov 7 13:02:23 aragorn kernel: [<c0101f47>] default_idle+0x29/0x2c
Nov 7 13:02:23 aragorn kernel: [<c0101fbc>] cpu_idle+0x3f/0x58
Nov 7 13:02:23 aragorn kernel: [<c031e9d5>] start_kernel+0x16e/0x189
Nov 7 13:02:23 aragorn kernel: [<c031e49f>]
unknown_bootoption+0x0/0x15c
$ lspci
0000:00:00.0 Host bridge: ServerWorks CMIC-LE Host Bridge (GC-LE
chipset) (rev 33)
0000:00:00.1 Host bridge: ServerWorks CMIC-LE Host Bridge (GC-LE
chipset)
0000:00:00.2 Host bridge: ServerWorks CMIC-LE Host Bridge (GC-LE
chipset)
0000:00:0e.0 VGA compatible controller: ATI Technologies Inc Rage XL
(rev 27)
0000:00:0f.0 Host bridge: ServerWorks CSB5 South Bridge (rev 93)
0000:00:0f.1 IDE interface: ServerWorks CSB5 IDE Controller (rev 93)
0000:00:0f.2 USB Controller: ServerWorks OSB4/CSB5 OHCI USB Controller
(rev 05)
0000:00:0f.3 ISA bridge: ServerWorks CSB5 LPC bridge
0000:00:10.0 Host bridge: ServerWorks CIOB-E I/O Bridge with Gigabit
Ethernet (rev 12)
0000:00:10.2 Host bridge: ServerWorks CIOB-E I/O Bridge with Gigabit
Ethernet (rev 12)
0000:00:11.0 Host bridge: ServerWorks CIOB-X2 PCI-X I/O Bridge (rev 05)
0000:00:11.2 Host bridge: ServerWorks CIOB-X2 PCI-X I/O Bridge (rev 05)
0000:02:00.0 Ethernet controller: Broadcom Corporation NetXtreme BCM5704
Gigabit Ethernet (rev 02)
0000:02:00.1 Ethernet controller: Broadcom Corporation NetXtreme BCM5704
Gigabit Ethernet (rev 02)
0000:04:03.0 RAID bus controller: Dell PowerEdge Expandable RAID
controller 4/Di (rev 02)
On Wed, Nov 10, 2004 at 04:11:48PM -0200, Marcelo Tosatti wrote:
> OK, do you have Nick watermark fixes in?
>
> They increase the GFP_ATOMIC buffer (memory reserved for GFP_ATOMIC allocations)
> significantly, which is exactly the case here.
>
> Its in Andrew's -mm tree already (the last -mm-bk contains it).
>
> Its attached just in case - hope it ends this story.
Well today it reported page allocation failure again. I remind that I have
increased socket buffers:
/sbin/sysctl -w net/core/rmem_max=8388608
/sbin/sysctl -w net/core/wmem_max=8388608
/sbin/sysctl -w net/core/rmem_default=1048576
/sbin/sysctl -w net/core/wmem_default=1048576
/sbin/sysctl -w net/ipv4/tcp_window_scaling=1
/sbin/sysctl -w net/ipv4/tcp_rmem="4096 1048576 8388608"
/sbin/sysctl -w net/ipv4/tcp_wmem="4096 1048576 8388608"
/sbin/ifconfig eth0 txqueuelen 1000
I've tried to incdease min_free_kbytes to 10240 and it did not help :(
Nov 11 21:51:32 undomiel1 kernel: swapper: page allocation failure. order:0, mode:0x20
Nov 11 21:51:32 undomiel1 kernel: [<c0137f28>] __alloc_pages+0x242/0x40e
Nov 11 21:51:32 undomiel1 kernel: [<c0138119>] __get_free_pages+0x25/0x3f
Nov 11 21:51:32 undomiel1 kernel: [<c032ed61>] tcp_v4_rcv+0x69a/0x9b5
Nov 11 21:51:32 undomiel1 kernel: [<c013b195>] kmem_getpages+0x21/0xc9
Nov 11 21:51:32 undomiel1 kernel: [<c013be46>] cache_grow+0xab/0x14d
Nov 11 21:51:32 undomiel1 kernel: [<c013c06a>] cache_alloc_refill+0x182/0x244
Nov 11 21:51:32 undomiel1 kernel: [<c013c3f8>] __kmalloc+0x85/0x8c
Nov 11 21:51:32 undomiel1 kernel: [<c02fac95>] alloc_skb+0x47/0xe0
Nov 11 21:51:32 undomiel1 kernel: [<c02997d6>] e1000_alloc_rx_buffers+0x44/0xe3
Nov 11 21:51:32 undomiel1 kernel: [<c0299457>] e1000_clean_rx_irq+0x17c/0x4b7
....
Nov 11 21:51:32 undomiel1 kernel: DMA per-cpu:
Nov 11 21:51:32 undomiel1 kernel: cpu 0 hot: low 2, high 6, batch 1
Nov 11 21:51:32 undomiel1 kernel: cpu 0 cold: low 0, high 2, batch 1
Nov 11 21:51:32 undomiel1 kernel: cpu 1 hot: low 2, high 6, batch 1
Nov 11 21:51:32 undomiel1 kernel: cpu 1 cold: low 0, high 2, batch 1
Nov 11 21:51:32 undomiel1 kernel: Normal per-cpu:
Nov 11 21:51:32 undomiel1 kernel: cpu 0 hot: low 32, high 96, batch 16
Nov 11 21:51:32 undomiel1 kernel: cpu 0 cold: low 0, high 32, batch 16
Nov 11 21:51:32 undomiel1 kernel: cpu 1 hot: low 32, high 96, batch 16
Nov 11 21:51:32 undomiel1 kernel: cpu 1 cold: low 0, high 32, batch 16
Nov 11 21:51:32 undomiel1 kernel: HighMem per-cpu:
Nov 11 21:51:32 undomiel1 kernel: cpu 0 hot: low 14, high 42, batch 7
Nov 11 21:51:32 undomiel1 kernel: cpu 0 cold: low 0, high 14, batch 7
Nov 11 21:51:32 undomiel1 kernel: cpu 1 hot: low 14, high 42, batch 7
Nov 11 21:51:32 undomiel1 kernel: cpu 1 cold: low 0, high 14, batch 7
Nov 11 21:51:32 undomiel1 kernel:
Nov 11 21:51:32 undomiel1 kernel: Free pages: 1604kB (112kB HighMem)
Nov 11 21:51:32 undomiel1 kernel: Active:28524 inactive:219608 dirty:102206 writeback:2906 unstable:0 free:401 slab:8164 mapped:16804 pagetables:430
Nov 11 21:51:32 undomiel1 kernel: DMA free:28kB min:72kB low:88kB high:108kB active:1048kB inactive:10324kB present:16384kB pages_scanned:0 all_unreclaimable? no
Nov 11 21:51:32 undomiel1 kernel: protections[]: 0 0 0
Nov 11 21:51:32 undomiel1 kernel: Normal free:1464kB min:4020kB low:5024kB high:6028kB active:81152kB inactive:771468kB present:901120kB pages_scanned:0 all_unreclaimable? no
Nov 11 21:51:32 undomiel1 kernel: protections[]: 0 0 0
Nov 11 21:51:32 undomiel1 kernel: HighMem free:112kB min:128kB low:160kB high:192kB active:31896kB inactive:96640kB present:131008kB pages_scanned:0 all_unreclaimable? no
Nov 11 21:51:32 undomiel1 kernel: protections[]: 0 0 0
Nov 11 21:51:32 undomiel1 kernel: DMA: 1*4kB 1*8kB 1*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 28kB
Nov 11 21:51:32 undomiel1 kernel: Normal: 0*4kB 1*8kB 1*16kB 1*32kB 0*64kB 1*128kB 1*256kB 0*512kB 1*1024kB 0*2048kB 0*4096kB = 1464kB
Nov 11 21:51:32 undomiel1 kernel: HighMem: 0*4kB 0*8kB 1*16kB 1*32kB 1*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 112kB
Nov 11 21:51:32 undomiel1 kernel: Swap cache: add 10, delete 10, find 0/0, race 0+0
--
Luk?? Hejtm?nek
Lukas Hejtmanek wrote:
>On Wed, Nov 10, 2004 at 04:11:48PM -0200, Marcelo Tosatti wrote:
>
>>OK, do you have Nick watermark fixes in?
>>
>>They increase the GFP_ATOMIC buffer (memory reserved for GFP_ATOMIC allocations)
>>significantly, which is exactly the case here.
>>
>>Its in Andrew's -mm tree already (the last -mm-bk contains it).
>>
>>Its attached just in case - hope it ends this story.
>>
>
>Well today it reported page allocation failure again. I remind that I have
>increased socket buffers:
>/sbin/sysctl -w net/core/rmem_max=8388608
>/sbin/sysctl -w net/core/wmem_max=8388608
>/sbin/sysctl -w net/core/rmem_default=1048576
>/sbin/sysctl -w net/core/wmem_default=1048576
>/sbin/sysctl -w net/ipv4/tcp_window_scaling=1
>/sbin/sysctl -w net/ipv4/tcp_rmem="4096 1048576 8388608"
>/sbin/sysctl -w net/ipv4/tcp_wmem="4096 1048576 8388608"
>/sbin/ifconfig eth0 txqueuelen 1000
>
>I've tried to incdease min_free_kbytes to 10240 and it did not help :(
>
>
OK. Occasional page allocation failures are not a problem, although
if it is an order-0 allocation it may be an idea to increase
min_free_kbytes a bit more.
I think you said earlier that you had min_free_kbytes set to 8192?
Well after applying my patch, the memory watermarks get squashed
down, so you'd want to set it to at least 16384 afterward. Maybe
more.
That shouldn't cause it to actually keep more memory free than
2.6.8 did with an 8192 setting.
On Fri, Nov 12, 2004 at 11:09:29PM +1100, Nick Piggin wrote:
> OK. Occasional page allocation failures are not a problem, although
> if it is an order-0 allocation it may be an idea to increase
> min_free_kbytes a bit more.
What about more than occasional but more like constant errors? ;)
> I think you said earlier that you had min_free_kbytes set to 8192?
> Well after applying my patch, the memory watermarks get squashed
> down, so you'd want to set it to at least 16384 afterward. Maybe
> more.
I took the default from 2.6.10-rc1-bk19 with your patch and doubled it. No
luck with the following values subsequently applied:
#vm.min_free_kbytes=3831
#vm.min_free_kbytes=7662
#vm.min_free_kbytes=15324
#vm.min_free_kbytes=61296
vm.min_free_kbytes=65535
Did not help against the page allocation errors or boosting up the machines
performance.
I got XFS filesystem corruption in the end which (just) perhaps was triggered by
page allocation errors for it says:
XFS internal error XFS_WANT_CORRUPTED_RETURN after several page allocation
errors for the application having XFS in its stack trace leading to:
kernel: xfs_force_shutdown(sdd5,0x8) called from line 1091 of file
fs/xfs/xfs_trans.c. Return address = 0xc0212e5c
kernel: Filesystem "sdd5": Corruption of in-memory data detected.
Shutting down filesystem: sdd5
kernel: Please umount the filesystem, and rectify the problem(s)
Corruption of in-memory data sounds like something we would not want to
happen, right?
I attached full traces to http://oss.sgi.com/bugzilla/show_bug.cgi?id=345 which
is an rather old ticket dealing with page allocation errors and xfs but
perhaps it does fit.
Stefan
On Sat, Nov 13, 2004 at 03:47:43PM +0100, Stefan Schmidt wrote:
> On Fri, Nov 12, 2004 at 11:09:29PM +1100, Nick Piggin wrote:
> > OK. Occasional page allocation failures are not a problem, although
> > if it is an order-0 allocation it may be an idea to increase
> > min_free_kbytes a bit more.
> What about more than occasional but more like constant errors? ;)
>
> > I think you said earlier that you had min_free_kbytes set to 8192?
> > Well after applying my patch, the memory watermarks get squashed
> > down, so you'd want to set it to at least 16384 afterward. Maybe
> > more.
> I took the default from 2.6.10-rc1-bk19 with your patch and doubled it. No
> luck with the following values subsequently applied:
> #vm.min_free_kbytes=3831
> #vm.min_free_kbytes=7662
> #vm.min_free_kbytes=15324
> #vm.min_free_kbytes=61296
> vm.min_free_kbytes=65535
> Did not help against the page allocation errors or boosting up the machines
> performance.
Nick, such high reservations should have protected the system from OOM.
> I got XFS filesystem corruption in the end which (just) perhaps was triggered by
> page allocation errors for it says:
> XFS internal error XFS_WANT_CORRUPTED_RETURN after several page allocation
> errors for the application having XFS in its stack trace leading to:
> kernel: xfs_force_shutdown(sdd5,0x8) called from line 1091 of file
> fs/xfs/xfs_trans.c. Return address = 0xc0212e5c
> kernel: Filesystem "sdd5": Corruption of in-memory data detected.
> Shutting down filesystem: sdd5
> kernel: Please umount the filesystem, and rectify the problem(s)
>
> Corruption of in-memory data sounds like something we would not want to
> happen, right?
Definately. I suspect XFS is unable to handle OOM graciously, or some other
problem.
> I attached full traces to http://oss.sgi.com/bugzilla/show_bug.cgi?id=345 which
> is an rather old ticket dealing with page allocation errors and xfs but
> perhaps it does fit.
>
> Stefan
On Tue, Nov 16, 2004 at 07:33:11AM -0200, Marcelo Tosatti wrote:
> > I took the default from 2.6.10-rc1-bk19 with your patch and doubled it. No
> > luck with the following values subsequently applied:
> > #vm.min_free_kbytes=3831
> > #vm.min_free_kbytes=7662
> > #vm.min_free_kbytes=15324
> > #vm.min_free_kbytes=61296
> > vm.min_free_kbytes=65535
> > Did not help against the page allocation errors or boosting up the machines
> > performance.
>
> Nick, such high reservations should have protected the system from OOM.
> Definately. I suspect XFS is unable to handle OOM graciously, or some other
> problem.
It seems that both Stefan and me are using XFS. Does someone have this problems
with another filesystem? Unfortunately I cannot change fs. Can you Stefen?
--
Luk?? Hejtm?nek
On Sun, Nov 21, 2004 at 02:43:50AM +0100, Stefan Schmidt wrote:
> > It seems that both Stefan and me are using XFS. Does someone have this problems
> > with another filesystem? Unfortunately I cannot change fs. Can you Stefen?
> Yes, i'll switch to EXT2 now. We'll see. Needs about 1d to fill up again and
> i think if there is no filesystem corruption after say 5d i'll blame xfs. ;)
Err, later...
After aborting badblocks on the first disks xfs partition (ctrl-c) and then
running "mkfs.ext2 -v -T largefile4 -O dir_index,sparse_super -m 0" i got a
"Kernel panic - not syncing: Attempting to free lock on active lock list"
via serial. Still on 2.6.10-rc1-bk23-watermark. I will provide you with a
screenshot monday morning if there is any.
I just updated the debian/unstable i386 installation so it should be debian
version 1.35-8 of the e2fsprogs package.
*sigh*,
Stefan
On Tue, Nov 16, 2004 at 06:05:27PM +0100, Lukas Hejtmanek wrote:
> > Definately. I suspect XFS is unable to handle OOM graciously, or some other
> > problem.
> It seems that both Stefan and me are using XFS. Does someone have this problems
> with another filesystem? Unfortunately I cannot change fs. Can you Stefen?
Yes, i'll switch to EXT2 now. We'll see. Needs about 1d to fill up again and
i think if there is no filesystem corruption after say 5d i'll blame xfs. ;)
Stefan
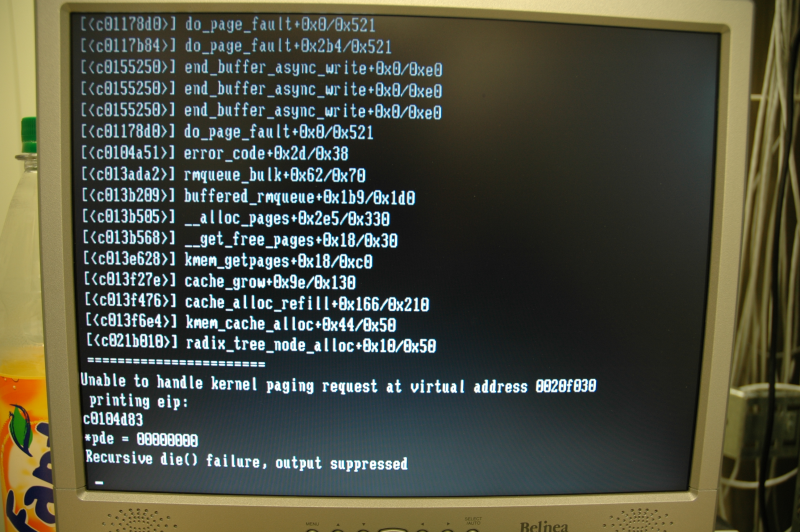{kind=link}