[Please excuse me for the resend, --
picked the wrong address for netdev again]
Hello.
This is a resend (sort of) of several months old email.
Previous email about this issue has been mostly ignored.
The situation is very simple: with an RTL8169 (probably
onboard) GigE card which, by default, is configured to
have MTU (maximal transmission unit) to be 1500 bytes,
it's *trivial* to instantly crash the machine by sending
it a *single* packet of size >1500 bytes (provided the
network switch can handle jumbo frames).
I verified with on several different machines - all I were
able to find with this card - and all behaves exactly the
same.
When sending a packet of size, say, 3000 bytes (ping -s 3000)
from another machine to a machine running rtl8169 with no
MTU configured, kernel OOPSes.
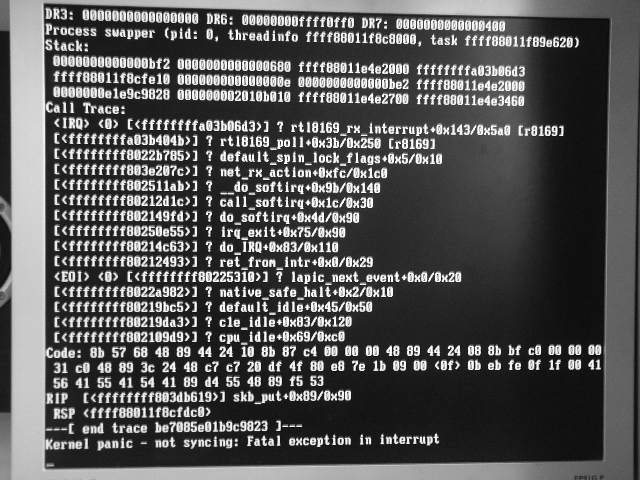
I captured one such OOPS (unfortunately without the first
line few lines) here:
http://www.corpit.ru/mjt/r8169-mtu-oops.jpg
(since the network goes boom at that time, no network console
is working).
But for anyone familiar with the driver's internals it
should be easy to figure the issue out.
This is, in my opinion, quite a serious issue. And I've no
idea why it is being ignored for several months.
Thanks.
/mjt
Michael Tokarev a ?crit :
> [Please excuse me for the resend, --
> picked the wrong address for netdev again]
>
> Hello.
>
> This is a resend (sort of) of several months old email.
> Previous email about this issue has been mostly ignored.
>
> The situation is very simple: with an RTL8169 (probably
> onboard) GigE card which, by default, is configured to
> have MTU (maximal transmission unit) to be 1500 bytes,
> it's *trivial* to instantly crash the machine by sending
> it a *single* packet of size >1500 bytes (provided the
> network switch can handle jumbo frames).
>
> I verified with on several different machines - all I were
> able to find with this card - and all behaves exactly the
> same.
>
> When sending a packet of size, say, 3000 bytes (ping -s 3000)
> from another machine to a machine running rtl8169 with no
> MTU configured, kernel OOPSes.
>
> I captured one such OOPS (unfortunately without the first
> line few lines) here:
>
> http://www.corpit.ru/mjt/r8169-mtu-oops.jpg
>
> (since the network goes boom at that time, no network console
> is working).
>
> But for anyone familiar with the driver's internals it
> should be easy to figure the issue out.
>
> This is, in my opinion, quite a serious issue. And I've no
> idea why it is being ignored for several months.
I suppose you use a recent kernel ?
Could you please try following patch ?
Thank you
diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
index e94316b..c08b97a 100644
--- a/drivers/net/r8169.c
+++ b/drivers/net/r8169.c
@@ -3468,7 +3468,7 @@ static int rtl8169_rx_interrupt(struct net_device *dev,
if (status & DescOwn)
break;
- if (unlikely(status & RxRES)) {
+ if (unlikely(status & (RxRES | RxRWT | RxRUNT | RxCRC | RxFOVF))) {
if (netif_msg_rx_err(tp)) {
printk(KERN_INFO
"%s: Rx ERROR. status = %08x\n",
Thank you Eric for the reply.
Eric Dumazet wrote:
> Michael Tokarev a ?crit :
[]
>> The situation is very simple: with an RTL8169 (probably
>> onboard) GigE card which, by default, is configured to
>> have MTU (maximal transmission unit) to be 1500 bytes,
>> it's *trivial* to instantly crash the machine by sending
>> it a *single* packet of size >1500 bytes (provided the
>> network switch can handle jumbo frames).
[]
>> http://www.corpit.ru/mjt/r8169-mtu-oops.jpg
> I suppose you use a recent kernel ?
http://marc.info/?t=123462473200002 -- here's my first attempt,
at Feb this year. It was 2.6.27 or so. Right now I'm running
2.6.29[.4]. So I think yes, I use a recent kernel.
> Could you please try following patch ?
[]
> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
> index e94316b..c08b97a 100644
> --- a/drivers/net/r8169.c
> +++ b/drivers/net/r8169.c
> @@ -3468,7 +3468,7 @@ static int rtl8169_rx_interrupt(struct net_device *dev,
>
> if (status & DescOwn)
> break;
> - if (unlikely(status & RxRES)) {
> + if (unlikely(status & (RxRES | RxRWT | RxRUNT | RxCRC | RxFOVF))) {
> if (netif_msg_rx_err(tp)) {
> printk(KERN_INFO
> "%s: Rx ERROR. status = %08x\n",
Tried that one, got no printk (at least not a visible one) and exactly
the same OOPS as before. Trivial test with
ping -c1 -s3000 $my_ip_addr
(learned to add -c1 because the previous time my machine crashed several times
in a row till I figured out what's going on and unplugged the ethernet cord --
even if ping were running from an xterm executed from the machine to which I
were pinging to! :)
Also got ext4fs corruption when rebooted (it's a staging area so nothing important
is there but still.. "interesting").
Also tried 32bit kernel (were using 64bits -- exactly the same result).
I wish I had a serial cable or even a serial port on this machine.... But I guess
it'd not help anyway, because the machine locks hard.
Thanks!
/mjt
Michael Tokarev a ?crit :
> Thank you Eric for the reply.
>
> Eric Dumazet wrote:
>> Michael Tokarev a ?crit :
> []
>>> The situation is very simple: with an RTL8169 (probably
>>> onboard) GigE card which, by default, is configured to
>>> have MTU (maximal transmission unit) to be 1500 bytes,
>>> it's *trivial* to instantly crash the machine by sending
>>> it a *single* packet of size >1500 bytes (provided the
>>> network switch can handle jumbo frames).
> []
>>> http://www.corpit.ru/mjt/r8169-mtu-oops.jpg
>
>> I suppose you use a recent kernel ?
>
> http://marc.info/?t=123462473200002 -- here's my first attempt,
> at Feb this year. It was 2.6.27 or so. Right now I'm running
> 2.6.29[.4]. So I think yes, I use a recent kernel.
>
>> Could you please try following patch ?
> []
>> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
>> index e94316b..c08b97a 100644
>> --- a/drivers/net/r8169.c
>> +++ b/drivers/net/r8169.c
>> @@ -3468,7 +3468,7 @@ static int rtl8169_rx_interrupt(struct
>> net_device *dev,
>>
>> if (status & DescOwn)
>> break;
>> - if (unlikely(status & RxRES)) {
>> + if (unlikely(status & (RxRES | RxRWT | RxRUNT | RxCRC |
>> RxFOVF))) {
>> if (netif_msg_rx_err(tp)) {
>> printk(KERN_INFO
>> "%s: Rx ERROR. status = %08x\n",
>
> Tried that one, got no printk (at least not a visible one) and exactly
> the same OOPS as before. Trivial test with
>
> ping -c1 -s3000 $my_ip_addr
>
> (learned to add -c1 because the previous time my machine crashed several
> times
> in a row till I figured out what's going on and unplugged the ethernet
> cord --
> even if ping were running from an xterm executed from the machine to
> which I
> were pinging to! :)
>
> Also got ext4fs corruption when rebooted (it's a staging area so nothing
> important
> is there but still.. "interesting").
>
> Also tried 32bit kernel (were using 64bits -- exactly the same result).
>
> I wish I had a serial cable or even a serial port on this machine....
> But I guess
> it'd not help anyway, because the machine locks hard.
>
> Thanks!
>
> /mjt
OK, 2nd try then :)
Thanks
diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
index e94316b..9080b08 100644
--- a/drivers/net/r8169.c
+++ b/drivers/net/r8169.c
@@ -3495,7 +3495,8 @@ static int rtl8169_rx_interrupt(struct net_device *dev,
* frames. They are seen as a symptom of over-mtu
* sized frames.
*/
- if (unlikely(rtl8169_fragmented_frame(status))) {
+ if (unlikely(rtl8169_fragmented_frame(status) ||
+ (unsigned int)pkt_size > tp->rx_buf_sz)) {
dev->stats.rx_dropped++;
dev->stats.rx_length_errors++;
rtl8169_mark_to_asic(desc, tp->rx_buf_sz);
Eric Dumazet wrote:
> Michael Tokarev a ?crit :
[]
>>>> The situation is very simple: with an RTL8169 (probably
>>>> onboard) GigE card which, by default, is configured to
>>>> have MTU (maximal transmission unit) to be 1500 bytes,
>>>> it's *trivial* to instantly crash the machine by sending
>>>> it a *single* packet of size >1500 bytes (provided the
>>>> network switch can handle jumbo frames).
[]
> OK, 2nd try then :)
> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
> index e94316b..9080b08 100644
> --- a/drivers/net/r8169.c
> +++ b/drivers/net/r8169.c
> @@ -3495,7 +3495,8 @@ static int rtl8169_rx_interrupt(struct net_device *dev,
> * frames. They are seen as a symptom of over-mtu
> * sized frames.
> */
> - if (unlikely(rtl8169_fragmented_frame(status))) {
> + if (unlikely(rtl8169_fragmented_frame(status) ||
> + (unsigned int)pkt_size > tp->rx_buf_sz)) {
> dev->stats.rx_dropped++;
> dev->stats.rx_length_errors++;
> rtl8169_mark_to_asic(desc, tp->rx_buf_sz);
This one behaves much better. There's no instant crash anymore, and the
'dropped' and 'frame' stats in ifconfig gets incremented with each ping.
It fails down the line however. I wasn't able to reply to this email after
doing the ping test with the above change (no more large packets were sent).
With OOPSes like this one:
general protection fault: 0000 [#1] SMP
last sysfs file: /sys/devices/pci0000:00/0000:00:01.0/0000:01:05.0/drm/card0/dev
CPU 0
Modules linked in: radeon drm r8169 powernow_k8 autofs4 nfsd nfs lockd nfs_acl auth_rpcgss sunrpc quota_v2
Pid: 10917, comm: icedove-bin Not tainted 2.6.29-x86-64 #2.6.29.4 System Product Name
RIP: 0010:[<ffffffff8029889b>] [<ffffffff8029889b>] put_page+0x1b/0x170
RSP: 0018:ffff8800cd8fdb88 EFLAGS: 00210296
RAX: 0000000000000020 RBX: 6d6c6b6a69686766 RCX: 0000000000000760
RDX: ffff88011d9f1680 RSI: ffff88011d9f139b RDI: 6d6c6b6a69686766
RBP: ffff88011c936ac0 R08: 0000000000000001 R09: 0000000000000000
R10: ffffffff80552840 R11: 0000000000200293 R12: ffff88011d03e080
R13: 0000000000000030 R14: ffff88011d03e4bc R15: 0000000000000000
FS: 0000000000000000(0000) GS:ffffffff80608000(0063) knlGS:00000000f220bb90
CS: 0010 DS: 002b ES: 002b CR0: 0000000080050033
CR2: 000000000820302c CR3: 0000000116c57000 CR4: 00000000000006e0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
Process icedove-bin (pid: 10917, threadinfo ffff8800cd8fc000, task ffff8801158d8820)
Stack:
0000000000000000 0000000000000001 ffff88011c936ac0 ffff88011d03e080
0000000000000030 ffffffff803dbc7f 0000000000000319 ffff88011c936ac0
0000000000000000 ffffffff803db911 ffff88011c936ac0 ffffffff80418a88
Call Trace:
[<ffffffff803dbc7f>] ? skb_release_data+0xaf/0xe0
[<ffffffff803db911>] ? __kfree_skb+0x11/0xa0
[<ffffffff80418a88>] ? tcp_recvmsg+0x6d8/0x950
[<ffffffff8046f91e>] ? _spin_lock_irqsave+0x2e/0x40
[<ffffffff803d61b0>] ? sock_common_recvmsg+0x30/0x50
[<ffffffff803d4365>] ? sock_recvmsg+0xd5/0x110
[<ffffffff80244640>] ? default_wake_function+0x0/0x10
[<ffffffff802d5019>] ? file_update_time+0x59/0x140
[<ffffffff80261e90>] ? autoremove_wake_function+0x0/0x30
[<ffffffff8046fa25>] ? _spin_lock+0x5/0x10
[<ffffffff8026f109>] ? futex_wake+0x129/0x140
[<ffffffff803d3ab2>] ? sockfd_lookup_light+0x22/0x90
[<ffffffff803d56e9>] ? sys_recvfrom+0xe9/0x180
[<ffffffff80261e90>] ? autoremove_wake_function+0x0/0x30
[<ffffffff8046d8c5>] ? thread_return+0x3d/0x6d8
[<ffffffff803f6c86>] ? compat_sys_socketcall+0x136/0x1f0
[<ffffffff80238c47>] ? cstar_dispatch+0x7/0x4a
Code: 2c fd ff ff eb db 66 2e 0f 1f 84 00 00 00 00 00 48 83 ec 28 48 89 5c 24 08 48 89 6c 24 10 48 89 fb 4c
RIP [<ffffffff8029889b>] put_page+0x1b/0x170
RSP <ffff8800cd8fdb88>
---[ end trace c2d84c667e0d946d ]---
(it probably has nothing to do with radeon drm sysfs file
(it is NOT the binary fglrx module by the way)).
Looks like some memory corruption. And most probably it is in
that error path in r8169 driver - it is the only new codepath
which were executed here. The problem is quite repeatable -
after sending a single large ping system starts behaving like
the above at random.
So we're on a right way it seems, but there's more than one
issue here.
By the way, is there anything else we can do here but drop the
packet? Or is there any REASON to do something else?
Thanks!
/mjt
Michael Tokarev a ?crit :
> Eric Dumazet wrote:
>> Michael Tokarev a ?crit :
> []
>>>>> The situation is very simple: with an RTL8169 (probably
>>>>> onboard) GigE card which, by default, is configured to
>>>>> have MTU (maximal transmission unit) to be 1500 bytes,
>>>>> it's *trivial* to instantly crash the machine by sending
>>>>> it a *single* packet of size >1500 bytes (provided the
>>>>> network switch can handle jumbo frames).
> []
>> OK, 2nd try then :)
>
>> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
>> index e94316b..9080b08 100644
>> --- a/drivers/net/r8169.c
>> +++ b/drivers/net/r8169.c
>> @@ -3495,7 +3495,8 @@ static int rtl8169_rx_interrupt(struct
>> net_device *dev,
>> * frames. They are seen as a symptom of over-mtu
>> * sized frames.
>> */
>> - if (unlikely(rtl8169_fragmented_frame(status))) {
>> + if (unlikely(rtl8169_fragmented_frame(status) ||
>> + (unsigned int)pkt_size > tp->rx_buf_sz)) {
>> dev->stats.rx_dropped++;
>> dev->stats.rx_length_errors++;
>> rtl8169_mark_to_asic(desc, tp->rx_buf_sz);
>
> This one behaves much better. There's no instant crash anymore, and the
> 'dropped' and 'frame' stats in ifconfig gets incremented with each ping.
>
> It fails down the line however. I wasn't able to reply to this email after
> doing the ping test with the above change (no more large packets were
> sent).
> With OOPSes like this one:
>
> general protection fault: 0000 [#1] SMP
> last sysfs file:
> /sys/devices/pci0000:00/0000:00:01.0/0000:01:05.0/drm/card0/dev
> CPU 0
> Modules linked in: radeon drm r8169 powernow_k8 autofs4 nfsd nfs lockd
> nfs_acl auth_rpcgss sunrpc quota_v2
> Pid: 10917, comm: icedove-bin Not tainted 2.6.29-x86-64 #2.6.29.4
> System Product Name
> RIP: 0010:[<ffffffff8029889b>] [<ffffffff8029889b>] put_page+0x1b/0x170
> RSP: 0018:ffff8800cd8fdb88 EFLAGS: 00210296
> RAX: 0000000000000020 RBX: 6d6c6b6a69686766 RCX: 0000000000000760
> RDX: ffff88011d9f1680 RSI: ffff88011d9f139b RDI: 6d6c6b6a69686766
> RBP: ffff88011c936ac0 R08: 0000000000000001 R09: 0000000000000000
> R10: ffffffff80552840 R11: 0000000000200293 R12: ffff88011d03e080
> R13: 0000000000000030 R14: ffff88011d03e4bc R15: 0000000000000000
> FS: 0000000000000000(0000) GS:ffffffff80608000(0063)
> knlGS:00000000f220bb90
> CS: 0010 DS: 002b ES: 002b CR0: 0000000080050033
> CR2: 000000000820302c CR3: 0000000116c57000 CR4: 00000000000006e0
> DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
> DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
> Process icedove-bin (pid: 10917, threadinfo ffff8800cd8fc000, task
> ffff8801158d8820)
> Stack:
> 0000000000000000 0000000000000001 ffff88011c936ac0 ffff88011d03e080
> 0000000000000030 ffffffff803dbc7f 0000000000000319 ffff88011c936ac0
> 0000000000000000 ffffffff803db911 ffff88011c936ac0 ffffffff80418a88
> Call Trace:
> [<ffffffff803dbc7f>] ? skb_release_data+0xaf/0xe0
> [<ffffffff803db911>] ? __kfree_skb+0x11/0xa0
> [<ffffffff80418a88>] ? tcp_recvmsg+0x6d8/0x950
> [<ffffffff8046f91e>] ? _spin_lock_irqsave+0x2e/0x40
> [<ffffffff803d61b0>] ? sock_common_recvmsg+0x30/0x50
> [<ffffffff803d4365>] ? sock_recvmsg+0xd5/0x110
> [<ffffffff80244640>] ? default_wake_function+0x0/0x10
> [<ffffffff802d5019>] ? file_update_time+0x59/0x140
> [<ffffffff80261e90>] ? autoremove_wake_function+0x0/0x30
> [<ffffffff8046fa25>] ? _spin_lock+0x5/0x10
> [<ffffffff8026f109>] ? futex_wake+0x129/0x140
> [<ffffffff803d3ab2>] ? sockfd_lookup_light+0x22/0x90
> [<ffffffff803d56e9>] ? sys_recvfrom+0xe9/0x180
> [<ffffffff80261e90>] ? autoremove_wake_function+0x0/0x30
> [<ffffffff8046d8c5>] ? thread_return+0x3d/0x6d8
> [<ffffffff803f6c86>] ? compat_sys_socketcall+0x136/0x1f0
> [<ffffffff80238c47>] ? cstar_dispatch+0x7/0x4a
> Code: 2c fd ff ff eb db 66 2e 0f 1f 84 00 00 00 00 00 48 83 ec 28 48 89
> 5c 24 08 48 89 6c 24 10 48 89 fb 4c
> RIP [<ffffffff8029889b>] put_page+0x1b/0x170
> RSP <ffff8800cd8fdb88>
> ---[ end trace c2d84c667e0d946d ]---
>
> (it probably has nothing to do with radeon drm sysfs file
> (it is NOT the binary fglrx module by the way)).
>
> Looks like some memory corruption. And most probably it is in
> that error path in r8169 driver - it is the only new codepath
> which were executed here. The problem is quite repeatable -
> after sending a single large ping system starts behaving like
> the above at random.
>
> So we're on a right way it seems, but there's more than one
> issue here.
>
> By the way, is there anything else we can do here but drop the
> packet? Or is there any REASON to do something else?
>
Hmm... this code path is not new, I believe your adapter is buggy, because it
is overwriting part of memory it should not touch at all.
When this driver queues a skb in rx queue, it tells NIC the max size of the skb,
and apparently NIC happily delivers packets with larger sizes, so probably DMA
wrote data past end of skb data.
Try to change
static void rtl_set_rx_max_size(void __iomem *ioaddr)
RTL_W16(RxMaxSize, 16383);
to ->
RTL_W16(RxMaxSize, RX_BUF_SIZE);
(But it will probably break jumbo frames rx as well)
Eric Dumazet wrote:
> Michael Tokarev a ?crit :
>> Eric Dumazet wrote:
>>> Michael Tokarev a ?crit :
>> []
>>>>>> The situation is very simple: with an RTL8169 (probably
>>>>>> onboard) GigE card which, by default, is configured to
>>>>>> have MTU (maximal transmission unit) to be 1500 bytes,
>>>>>> it's *trivial* to instantly crash the machine by sending
>>>>>> it a *single* packet of size >1500 bytes (provided the
>>>>>> network switch can handle jumbo frames).
>> []
>>> OK, 2nd try then :)
>>> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
>>> index e94316b..9080b08 100644
>>> --- a/drivers/net/r8169.c
>>> +++ b/drivers/net/r8169.c
>>> @@ -3495,7 +3495,8 @@ static int rtl8169_rx_interrupt(struct
>>> net_device *dev,
>>> * frames. They are seen as a symptom of over-mtu
>>> * sized frames.
>>> */
>>> - if (unlikely(rtl8169_fragmented_frame(status))) {
>>> + if (unlikely(rtl8169_fragmented_frame(status) ||
>>> + (unsigned int)pkt_size > tp->rx_buf_sz)) {
>>> dev->stats.rx_dropped++;
>>> dev->stats.rx_length_errors++;
>>> rtl8169_mark_to_asic(desc, tp->rx_buf_sz);
>> This one behaves much better. There's no instant crash anymore, and the
>> 'dropped' and 'frame' stats in ifconfig gets incremented with each ping.
>>
>> It fails down the line however. I wasn't able to reply to this email after
>> doing the ping test with the above change (no more large packets were
>> sent).
>> With OOPSes like this one:
>>
>> general protection fault: 0000 [#1] SMP
[]
>> [<ffffffff803dbc7f>] ? skb_release_data+0xaf/0xe0
>> [<ffffffff803db911>] ? __kfree_skb+0x11/0xa0
>> [<ffffffff80418a88>] ? tcp_recvmsg+0x6d8/0x950
[]
>> Looks like some memory corruption. And most probably it is in
>> that error path in r8169 driver - it is the only new codepath
>> which were executed here. The problem is quite repeatable -
>> after sending a single large ping system starts behaving like
>> the above at random.
[]
> Hmm... this code path is not new, I believe your adapter is buggy, because it
> is overwriting part of memory it should not touch at all.
>
> When this driver queues a skb in rx queue, it tells NIC the max size of the skb,
> and apparently NIC happily delivers packets with larger sizes, so probably DMA
> wrote data past end of skb data.
That's a very likely situation.
> Try to change
>
> static void rtl_set_rx_max_size(void __iomem *ioaddr)
> RTL_W16(RxMaxSize, 16383);
>
> to ->
>
> RTL_W16(RxMaxSize, RX_BUF_SIZE);
>
> (But it will probably break jumbo frames rx as well)
(RX_BUF_SIZE is defined as 1536).
Aha, so it should set some flags instead (as were tested in your
first try), for packets larger than that. Makes sense.
But if we told the NIC that we can receive 16K buffers, and it
delivered 3K packet to us, we've got some memory corruption...
I.e., the problem is that we told the driver that we can handle
16k buffers but actually we had only 1500, no?
Lemme check this all...
Setting RxMaxSize to RX_BUF_SIZE indeed solved the problem, --
I don't see random corruptions like the last one above.
But after setting RxMaxSize to 2500, I can trigger your 2nd
check/patch condition (for pkt_size > tp->rx_buf_sz) for
packets <2500 in size, and your *first* check/patch condition
(RxRES | RxRWT | RxRUNT | RxCRC | RxFOVF) for packets >2500
in size.
So to me (who has no knowledge about hardware at all), it looks
like the card behaves quite correctly.
Also note that I've seen this behavior on several different
machines. Here @home where I'm doing this all testing I've
Asus M3A78-EM motherboard (AMD780), and the second one is
Gigabyte GA-MA74GM-S2H (AMD740) - both behaves very similarly.
Both are AMD7xx, but I've seen the same problem on Intel-based
machines too.
I'll try out some more tests later today. (And there's another
issue with these NICs -- the famous, quite frequent under load
"NETDEV WATCHDOG: eth0 (r8169): transmit timed out" errors, which
are quite annoying... Also shown by both the above-mentioned mobos
and by other machines).
Thanks!
/mjt
Michael Tokarev a ?crit :
> Eric Dumazet wrote:
>> Michael Tokarev a ?crit :
>>> Eric Dumazet wrote:
>>>> Michael Tokarev a ?crit :
>>> []
>>>>>>> The situation is very simple: with an RTL8169 (probably
>>>>>>> onboard) GigE card which, by default, is configured to
>>>>>>> have MTU (maximal transmission unit) to be 1500 bytes,
>>>>>>> it's *trivial* to instantly crash the machine by sending
>>>>>>> it a *single* packet of size >1500 bytes (provided the
>>>>>>> network switch can handle jumbo frames).
>>> []
>>>> OK, 2nd try then :)
>>>> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
>>>> index e94316b..9080b08 100644
>>>> --- a/drivers/net/r8169.c
>>>> +++ b/drivers/net/r8169.c
>>>> @@ -3495,7 +3495,8 @@ static int rtl8169_rx_interrupt(struct
>>>> net_device *dev,
>>>> * frames. They are seen as a symptom of over-mtu
>>>> * sized frames.
>>>> */
>>>> - if (unlikely(rtl8169_fragmented_frame(status))) {
>>>> + if (unlikely(rtl8169_fragmented_frame(status) ||
>>>> + (unsigned int)pkt_size > tp->rx_buf_sz)) {
>>>> dev->stats.rx_dropped++;
>>>> dev->stats.rx_length_errors++;
>>>> rtl8169_mark_to_asic(desc, tp->rx_buf_sz);
>>> This one behaves much better. There's no instant crash anymore, and the
>>> 'dropped' and 'frame' stats in ifconfig gets incremented with each ping.
>>>
>>> It fails down the line however. I wasn't able to reply to this email
>>> after
>>> doing the ping test with the above change (no more large packets were
>>> sent).
>>> With OOPSes like this one:
>>>
>>> general protection fault: 0000 [#1] SMP
> []
>>> [<ffffffff803dbc7f>] ? skb_release_data+0xaf/0xe0
>>> [<ffffffff803db911>] ? __kfree_skb+0x11/0xa0
>>> [<ffffffff80418a88>] ? tcp_recvmsg+0x6d8/0x950
> []
>>> Looks like some memory corruption. And most probably it is in
>>> that error path in r8169 driver - it is the only new codepath
>>> which were executed here. The problem is quite repeatable -
>>> after sending a single large ping system starts behaving like
>>> the above at random.
> []
>> Hmm... this code path is not new, I believe your adapter is buggy,
>> because it
>> is overwriting part of memory it should not touch at all.
>>
>> When this driver queues a skb in rx queue, it tells NIC the max size
>> of the skb,
>> and apparently NIC happily delivers packets with larger sizes, so
>> probably DMA
>> wrote data past end of skb data.
>
> That's a very likely situation.
>
>> Try to change
>> static void rtl_set_rx_max_size(void __iomem *ioaddr)
>> RTL_W16(RxMaxSize, 16383);
>> to ->
>>
>> RTL_W16(RxMaxSize, RX_BUF_SIZE);
>>
>> (But it will probably break jumbo frames rx as well)
>
> (RX_BUF_SIZE is defined as 1536).
> Aha, so it should set some flags instead (as were tested in your
> first try), for packets larger than that. Makes sense.
>
> But if we told the NIC that we can receive 16K buffers, and it
> delivered 3K packet to us, we've got some memory corruption...
> I.e., the problem is that we told the driver that we can handle
> 16k buffers but actually we had only 1500, no?
>
> Lemme check this all...
>
> Setting RxMaxSize to RX_BUF_SIZE indeed solved the problem, --
> I don't see random corruptions like the last one above.
>
> But after setting RxMaxSize to 2500, I can trigger your 2nd
> check/patch condition (for pkt_size > tp->rx_buf_sz) for
> packets <2500 in size, and your *first* check/patch condition
> (RxRES | RxRWT | RxRUNT | RxCRC | RxFOVF) for packets >2500
> in size.
>
> So to me (who has no knowledge about hardware at all), it looks
> like the card behaves quite correctly.
>
> Also note that I've seen this behavior on several different
> machines. Here @home where I'm doing this all testing I've
> Asus M3A78-EM motherboard (AMD780), and the second one is
> Gigabyte GA-MA74GM-S2H (AMD740) - both behaves very similarly.
> Both are AMD7xx, but I've seen the same problem on Intel-based
> machines too.
>
> I'll try out some more tests later today. (And there's another
> issue with these NICs -- the famous, quite frequent under load
> "NETDEV WATCHDOG: eth0 (r8169): transmit timed out" errors, which
> are quite annoying... Also shown by both the above-mentioned mobos
> and by other machines).
>
> Thanks!
>
OK I suspect driver is buggy since 2.6.10 days :)
Could you try this patch ?
Thanks
diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
index 8247a94..c5ab5a8 100644
--- a/drivers/net/r8169.c
+++ b/drivers/net/r8169.c
@@ -2357,10 +2357,10 @@ static u16 rtl_rw_cpluscmd(void __iomem *ioaddr)
return cmd;
}
-static void rtl_set_rx_max_size(void __iomem *ioaddr)
+static void rtl_set_rx_max_size(void __iomem *ioaddr, unsigned int rx_buf_sz)
{
/* Low hurts. Let's disable the filtering. */
- RTL_W16(RxMaxSize, 16383);
+ RTL_W16(RxMaxSize, rx_buf_sz);
}
static void rtl8169_set_magic_reg(void __iomem *ioaddr, unsigned mac_version)
@@ -2407,7 +2407,7 @@ static void rtl_hw_start_8169(struct net_device *dev)
RTL_W8(EarlyTxThres, EarlyTxThld);
- rtl_set_rx_max_size(ioaddr);
+ rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
if ((tp->mac_version == RTL_GIGA_MAC_VER_01) ||
(tp->mac_version == RTL_GIGA_MAC_VER_02) ||
@@ -2668,7 +2668,7 @@ static void rtl_hw_start_8168(struct net_device *dev)
RTL_W8(EarlyTxThres, EarlyTxThld);
- rtl_set_rx_max_size(ioaddr);
+ rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
tp->cp_cmd |= RTL_R16(CPlusCmd) | PktCntrDisable | INTT_1;
@@ -2846,7 +2846,7 @@ static void rtl_hw_start_8101(struct net_device *dev)
RTL_W8(EarlyTxThres, EarlyTxThld);
- rtl_set_rx_max_size(ioaddr);
+ rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
tp->cp_cmd |= rtl_rw_cpluscmd(ioaddr) | PCIMulRW;
Eric Dumazet wrote:
> OK I suspect driver is buggy since 2.6.10 days :)
I browsed the git history for a while but don't see since
when it might be broken. But again, I don't know the code
nor the hardware.
> Could you try this patch ?
That makes quite some sense, except of two comments - pure
speculation/guesses really, since I don't know the hw.
The patch does not re-program the card when we change MTU
(where we merely set internal rx_buf_sz, but don't tell the
card about this). Maybe we should call this method in
rtl8169_set_rxbufsize() too?
I don't know almost anything about things like vlans for
example, but guess they use some additional headers. Does
those need some space too? Maybe its better to allocate
"a bit" more room in skb for that stuff?
Recompiling the driver now...
/mjt
Eric Dumazet wrote:
[]
> OK I suspect driver is buggy since 2.6.10 days :)
>
> Could you try this patch ?
Tried it, and it appears to work. Tried various MTU combinations
and packet sizes. Checked iperf too, with and without the patch
and with different MTU too, to be sure the patch does not introduce
any slowdowns - everything looks sane. In case the incoming packet
is larger than the RX buffer size, `errors' and `frames' RX stats
gets incremented.
The only somewhat odd thing is that rx path accepts packets larger
than MTU by 3 bytes. For example, if I set mtu to 2000, the
largest packet I can send is 2003 bytes; with mtu=2002, largest
actual packet size is 2005 bytes. This is complete frame - in
terms of ping size (ping -s) it's 1975 and 1977 bytes. That to
say, maybe we still have some corner case somewhere, for packets
larger than mtu by 1, 2 or 3 bytes.
Also I didn't try MTU < 1500.
Other than that,
Tested-By: Michael Tokarev <[email protected]>
And by the way, your email client uses quoted-printable encoding.
I had to use trivial perl one-liner to convert your patches to
plaintext. JFYI.
Thanks!
/mjt
> diff --git a/drivers/net/r8169.c b/drivers/net/r8169.c
> index 8247a94..c5ab5a8 100644
> --- a/drivers/net/r8169.c
> +++ b/drivers/net/r8169.c
> @@ -2357,10 +2357,10 @@ static u16 rtl_rw_cpluscmd(void __iomem *ioaddr)
> return cmd;
> }
>
> -static void rtl_set_rx_max_size(void __iomem *ioaddr)
> +static void rtl_set_rx_max_size(void __iomem *ioaddr, unsigned int rx_buf_sz)
> {
> /* Low hurts. Let's disable the filtering. */
> - RTL_W16(RxMaxSize, 16383);
> + RTL_W16(RxMaxSize, rx_buf_sz);
> }
>
> static void rtl8169_set_magic_reg(void __iomem *ioaddr, unsigned mac_version)
> @@ -2407,7 +2407,7 @@ static void rtl_hw_start_8169(struct net_device *dev)
>
> RTL_W8(EarlyTxThres, EarlyTxThld);
>
> - rtl_set_rx_max_size(ioaddr);
> + rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
>
> if ((tp->mac_version == RTL_GIGA_MAC_VER_01) ||
> (tp->mac_version == RTL_GIGA_MAC_VER_02) ||
> @@ -2668,7 +2668,7 @@ static void rtl_hw_start_8168(struct net_device *dev)
>
> RTL_W8(EarlyTxThres, EarlyTxThld);
>
> - rtl_set_rx_max_size(ioaddr);
> + rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
>
> tp->cp_cmd |= RTL_R16(CPlusCmd) | PktCntrDisable | INTT_1;
>
> @@ -2846,7 +2846,7 @@ static void rtl_hw_start_8101(struct net_device *dev)
>
> RTL_W8(EarlyTxThres, EarlyTxThld);
>
> - rtl_set_rx_max_size(ioaddr);
> + rtl_set_rx_max_size(ioaddr, tp->rx_buf_sz);
>
> tp->cp_cmd |= rtl_rw_cpluscmd(ioaddr) | PCIMulRW;
>
>
>
> --
> To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
> the body of a message to [email protected]
> More majordomo info at http://vger.kernel.org/majordomo-info.html
> Please read the FAQ at http://www.tux.org/lkml/
Michael Tokarev a ?crit :
> Eric Dumazet wrote:
> []
>> OK I suspect driver is buggy since 2.6.10 days :)
>>
>> Could you try this patch ?
>
> Tried it, and it appears to work. Tried various MTU combinations
> and packet sizes. Checked iperf too, with and without the patch
> and with different MTU too, to be sure the patch does not introduce
> any slowdowns - everything looks sane. In case the incoming packet
> is larger than the RX buffer size, `errors' and `frames' RX stats
> gets incremented.
>
> The only somewhat odd thing is that rx path accepts packets larger
> than MTU by 3 bytes. For example, if I set mtu to 2000, the
> largest packet I can send is 2003 bytes; with mtu=2002, largest
> actual packet size is 2005 bytes. This is complete frame - in
> terms of ping size (ping -s) it's 1975 and 1977 bytes. That to
> say, maybe we still have some corner case somewhere, for packets
> larger than mtu by 1, 2 or 3 bytes.
>
> Also I didn't try MTU < 1500.
>
> Other than that,
>
> Tested-By: Michael Tokarev <[email protected]>
Could you confirm this last patch was ok without former two patches ?
>
> And by the way, your email client uses quoted-printable encoding.
> I had to use trivial perl one-liner to convert your patches to
> plaintext. JFYI.
Ah yes, this is when I reply to one of your mail, thank you for the hint.
When submitting a new mail, my thunderbird agent uses a regular "Content-Transfer-Encoding: 7bit"
BTW, this driver uses NAPI, but still calls dev_kfree_skb_irq() in rtl8169_tx_interrupt()
You probably can get better performance calling dev_kfree_skb(tx_skb->skb); instead
@@ -3372,7 +3372,7 @@ static void rtl8169_tx_interrupt(struct net_device *dev,
rtl8169_unmap_tx_skb(tp->pci_dev, tx_skb, tp->TxDescArray + entry);
if (status & LastFrag) {
- dev_kfree_skb_irq(tx_skb->skb);
+ dev_kfree_skb(tx_skb->skb);
tx_skb->skb = NULL;
}
dirty_tx++;
Eric Dumazet wrote:
> Michael Tokarev a écrit :
>> Eric Dumazet wrote:
>> []
>>> OK I suspect driver is buggy since 2.6.10 days :)
>>>
>>> Could you try this patch ?
>> Tried it, and it appears to work. Tried various MTU combinations
>> and packet sizes. Checked iperf too, with and without the patch
>> and with different MTU too, to be sure the patch does not introduce
>> any slowdowns - everything looks sane. In case the incoming packet
>> is larger than the RX buffer size, `errors' and `frames' RX stats
>> gets incremented.
>>
>> The only somewhat odd thing is that rx path accepts packets larger
>> than MTU by 3 bytes. For example, if I set mtu to 2000, the
>> largest packet I can send is 2003 bytes; with mtu=2002, largest
>> actual packet size is 2005 bytes. This is complete frame - in
>> terms of ping size (ping -s) it's 1975 and 1977 bytes. That to
>> say, maybe we still have some corner case somewhere, for packets
>> larger than mtu by 1, 2 or 3 bytes.
>>
>> Also I didn't try MTU < 1500.
>>
>> Other than that,
>>
>> Tested-By: Michael Tokarev <[email protected]>
>
> Could you confirm this last patch was ok without former two patches ?
Yes, it's the last patch without former two which were for
debugging as I understand them. Got fresh 2.6.29.4 source
and applied your last patch to it, recompiled. All the testing
above were done this way.
>> And by the way, your email client uses quoted-printable encoding.
>> I had to use trivial perl one-liner to convert your patches to
>> plaintext. JFYI.
>
> Ah yes, this is when I reply to one of your mail, thank you for the hint.
>
> When submitting a new mail, my thunderbird agent uses a regular "Content-Transfer-Encoding: 7bit"
Heh. I know why it's this way. Due to your
"Michael Tokarev a écrit" in first line. Which
gets added by Thunderbird, and which causes it
to force quoted-printable instead of 7bit, because
of this "é". Mine offers "пишет" instead of "écrit"
("wrote" in English) and the result is similar.
> BTW, this driver uses NAPI, but still calls dev_kfree_skb_irq() in rtl8169_tx_interrupt()
>
> You probably can get better performance calling dev_kfree_skb(tx_skb->skb); instead
>
> @@ -3372,7 +3372,7 @@ static void rtl8169_tx_interrupt(struct net_device *dev,
> rtl8169_unmap_tx_skb(tp->pci_dev, tx_skb, tp->TxDescArray + entry);
>
> if (status & LastFrag) {
> - dev_kfree_skb_irq(tx_skb->skb);
> + dev_kfree_skb(tx_skb->skb);
> tx_skb->skb = NULL;
> }
> dirty_tx++;
Well, the performance is quite good -- 935Mb/sec according to iperf
for TCP. With UDP I got 1.05Gb/sec, but CPU usage is 100% during
all test time (for TCP test the CPU is in use for less than 5%).
I'll try the change tomorrow (it's 01:27 here now already).
Thank you for the good work!
/mjt
Michael Tokarev <[email protected]> :
[...]
> I'll try out some more tests later today. (And there's another
> issue with these NICs -- the famous, quite frequent under load
> "NETDEV WATCHDOG: eth0 (r8169): transmit timed out" errors, which
> are quite annoying... Also shown by both the above-mentioned mobos
> and by other machines).
This one should be fixed by commit f11a377b3f4e897d11f0e8d1fc688667e2f19708
in mainline.
--
Ueimor
Michael Tokarev <[email protected]> writes:
> Well, the performance is quite good -- 935Mb/sec according to iperf
> for TCP. With UDP I got 1.05Gb/sec, but CPU usage is 100% during
> all test time (for TCP test the CPU is in use for less than 5%).
BTW you may want to try pktgen for TX bandwidth tests (a kernel module).
In "clone" mode a slow IXP425 (ARM XScale) 533 MHz + Intel's 82541xx
E1000 chip are able to transmit 1500-byte packets at full gigabit speed.
--
Krzysztof Halasa
{kind=link}