This is a minor update from the last version. The most notable
thing is that I was able to demonstrate that maintaining the
cmpxchg16 optimization has _some_ value.
Otherwise, the code changes are just a few minor cleanups.
---
SLUB depends on a 16-byte cmpxchg for an optimization which
allows it to not disable interrupts in its fast path. This
optimization has some small but measurable benefits:
http://lkml.kernel.org/r/[email protected]
In order to get guaranteed 16-byte alignment (required by the
hardware on x86), 'struct page' is padded out from 56 to 64
bytes.
Those 8-bytes matter. We've gone to great lengths to keep
'struct page' small in the past. It's a shame that we bloat it
now just for alignment reasons when we have extra space. Plus,
bloating such a commonly-touched structure *HAS* cache
footprint implications.
These patches attempt _internal_ alignment instead of external
alignment for slub.
I also got a bug report from some folks running a large database
benchmark. Their old kernel uses slab and their new one uses
slub. They were swapping and couldn't figure out why. It turned
out to be the 2GB of RAM that the slub padding wastes on their
system.
On my box, that 2GB cost about $200 to populate back when we
bought it. I want my $200 back.
This set takes me from 16909584K of reserved memory at boot
down to 14814472K, so almost *exactly* 2GB of savings! It also
helps performance, presumably because it touches 14% fewer
struct page cachelines. A 30GB dd to a ramfs file:
dd if=/dev/zero of=bigfile bs=$((1<<30)) count=30
is sped up by about 4.4% in my testing.
I've run this through its paces and have not had stability issues
with it. It definitely needs some more testing, but it's
definitely ready for a wider audience.
I also wrote up a document describing 'struct page's layout:
http://tinyurl.com/n6kmedz
From: Dave Hansen <[email protected]>
'struct page' has two list_head fields: 'lru' and 'list'.
Conveniently, they are unioned together. This means that code
can use them interchangably, which gets horribly confusing like
with this nugget from slab.c:
> list_del(&page->lru);
> if (page->active == cachep->num)
> list_add(&page->list, &n->slabs_full);
This patch makes the slab and slub code use page->list
universally instead of mixing ->list and ->lru.
It also adds some comments to attempt to keep new users from
picking up uses of ->list.
So, the new rule is: page->list is what the slabs use. page->lru
is for everybody else. This is a pretty arbitrary rule, but we
need _something_. Maybe we should just axe the ->list one and
make the sl?bs use ->lru.
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm_types.h | 5 ++
linux.git-davehans/mm/slab.c | 50 ++++++++++++++--------------
2 files changed, 29 insertions(+), 26 deletions(-)
diff -puN include/linux/mm_types.h~make-slab-use-page-lru-vs-list-consistently include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~make-slab-use-page-lru-vs-list-consistently 2014-01-02 13:40:29.087256768 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 13:40:29.093257038 -0800
@@ -124,6 +124,8 @@ struct page {
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
+ * Can be used as a generic list
+ * by the page owner.
*/
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
@@ -136,7 +138,8 @@ struct page {
#endif
};
- struct list_head list; /* slobs list of pages */
+ struct list_head list; /* sl[aou]bs list of pages.
+ * do not use outside of slabs */
struct slab *slab_page; /* slab fields */
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
diff -puN mm/slab.c~make-slab-use-page-lru-vs-list-consistently mm/slab.c
--- linux.git/mm/slab.c~make-slab-use-page-lru-vs-list-consistently 2014-01-02 13:40:29.090256903 -0800
+++ linux.git-davehans/mm/slab.c 2014-01-02 13:40:29.095257128 -0800
@@ -765,15 +765,15 @@ static void recheck_pfmemalloc_active(st
return;
spin_lock_irqsave(&n->list_lock, flags);
- list_for_each_entry(page, &n->slabs_full, lru)
+ list_for_each_entry(page, &n->slabs_full, list)
if (is_slab_pfmemalloc(page))
goto out;
- list_for_each_entry(page, &n->slabs_partial, lru)
+ list_for_each_entry(page, &n->slabs_partial, list)
if (is_slab_pfmemalloc(page))
goto out;
- list_for_each_entry(page, &n->slabs_free, lru)
+ list_for_each_entry(page, &n->slabs_free, list)
if (is_slab_pfmemalloc(page))
goto out;
@@ -1428,7 +1428,7 @@ void __init kmem_cache_init(void)
{
int i;
- BUILD_BUG_ON(sizeof(((struct page *)NULL)->lru) <
+ BUILD_BUG_ON(sizeof(((struct page *)NULL)->list) <
sizeof(struct rcu_head));
kmem_cache = &kmem_cache_boot;
setup_node_pointer(kmem_cache);
@@ -1624,15 +1624,15 @@ slab_out_of_memory(struct kmem_cache *ca
continue;
spin_lock_irqsave(&n->list_lock, flags);
- list_for_each_entry(page, &n->slabs_full, lru) {
+ list_for_each_entry(page, &n->slabs_full, list) {
active_objs += cachep->num;
active_slabs++;
}
- list_for_each_entry(page, &n->slabs_partial, lru) {
+ list_for_each_entry(page, &n->slabs_partial, list) {
active_objs += page->active;
active_slabs++;
}
- list_for_each_entry(page, &n->slabs_free, lru)
+ list_for_each_entry(page, &n->slabs_free, list)
num_slabs++;
free_objects += n->free_objects;
@@ -2424,11 +2424,11 @@ static int drain_freelist(struct kmem_ca
goto out;
}
- page = list_entry(p, struct page, lru);
+ page = list_entry(p, struct page, list);
#if DEBUG
BUG_ON(page->active);
#endif
- list_del(&page->lru);
+ list_del(&page->list);
/*
* Safe to drop the lock. The slab is no longer linked
* to the cache.
@@ -2721,7 +2721,7 @@ static int cache_grow(struct kmem_cache
spin_lock(&n->list_lock);
/* Make slab active. */
- list_add_tail(&page->lru, &(n->slabs_free));
+ list_add_tail(&page->list, &(n->slabs_free));
STATS_INC_GROWN(cachep);
n->free_objects += cachep->num;
spin_unlock(&n->list_lock);
@@ -2864,7 +2864,7 @@ retry:
goto must_grow;
}
- page = list_entry(entry, struct page, lru);
+ page = list_entry(entry, struct page, list);
check_spinlock_acquired(cachep);
/*
@@ -2884,7 +2884,7 @@ retry:
}
/* move slabp to correct slabp list: */
- list_del(&page->lru);
+ list_del(&page->list);
if (page->active == cachep->num)
list_add(&page->list, &n->slabs_full);
else
@@ -3163,7 +3163,7 @@ retry:
goto must_grow;
}
- page = list_entry(entry, struct page, lru);
+ page = list_entry(entry, struct page, list);
check_spinlock_acquired_node(cachep, nodeid);
STATS_INC_NODEALLOCS(cachep);
@@ -3175,12 +3175,12 @@ retry:
obj = slab_get_obj(cachep, page, nodeid);
n->free_objects--;
/* move slabp to correct slabp list: */
- list_del(&page->lru);
+ list_del(&page->list);
if (page->active == cachep->num)
- list_add(&page->lru, &n->slabs_full);
+ list_add(&page->list, &n->slabs_full);
else
- list_add(&page->lru, &n->slabs_partial);
+ list_add(&page->list, &n->slabs_partial);
spin_unlock(&n->list_lock);
goto done;
@@ -3337,7 +3337,7 @@ static void free_block(struct kmem_cache
page = virt_to_head_page(objp);
n = cachep->node[node];
- list_del(&page->lru);
+ list_del(&page->list);
check_spinlock_acquired_node(cachep, node);
slab_put_obj(cachep, page, objp, node);
STATS_DEC_ACTIVE(cachep);
@@ -3355,14 +3355,14 @@ static void free_block(struct kmem_cache
*/
slab_destroy(cachep, page);
} else {
- list_add(&page->lru, &n->slabs_free);
+ list_add(&page->list, &n->slabs_free);
}
} else {
/* Unconditionally move a slab to the end of the
* partial list on free - maximum time for the
* other objects to be freed, too.
*/
- list_add_tail(&page->lru, &n->slabs_partial);
+ list_add_tail(&page->list, &n->slabs_partial);
}
}
}
@@ -3404,7 +3404,7 @@ free_done:
while (p != &(n->slabs_free)) {
struct page *page;
- page = list_entry(p, struct page, lru);
+ page = list_entry(p, struct page, list);
BUG_ON(page->active);
i++;
@@ -4029,13 +4029,13 @@ void get_slabinfo(struct kmem_cache *cac
check_irq_on();
spin_lock_irq(&n->list_lock);
- list_for_each_entry(page, &n->slabs_full, lru) {
+ list_for_each_entry(page, &n->slabs_full, list) {
if (page->active != cachep->num && !error)
error = "slabs_full accounting error";
active_objs += cachep->num;
active_slabs++;
}
- list_for_each_entry(page, &n->slabs_partial, lru) {
+ list_for_each_entry(page, &n->slabs_partial, list) {
if (page->active == cachep->num && !error)
error = "slabs_partial accounting error";
if (!page->active && !error)
@@ -4043,7 +4043,7 @@ void get_slabinfo(struct kmem_cache *cac
active_objs += page->active;
active_slabs++;
}
- list_for_each_entry(page, &n->slabs_free, lru) {
+ list_for_each_entry(page, &n->slabs_free, list) {
if (page->active && !error)
error = "slabs_free accounting error";
num_slabs++;
@@ -4266,9 +4266,9 @@ static int leaks_show(struct seq_file *m
check_irq_on();
spin_lock_irq(&n->list_lock);
- list_for_each_entry(page, &n->slabs_full, lru)
+ list_for_each_entry(page, &n->slabs_full, list)
handle_slab(x, cachep, page);
- list_for_each_entry(page, &n->slabs_partial, lru)
+ list_for_each_entry(page, &n->slabs_partial, list)
handle_slab(x, cachep, page);
spin_unlock_irq(&n->list_lock);
}
_
From: Dave Hansen <[email protected]>
'struct page' has two list_head fields: 'lru' and 'list'.
Conveniently, they are unioned together. This means that code
can use them interchangably, which gets horribly confusing.
The blk-mq made the logical decision to try to use page->list.
But, that field was actually introduced just for the slub code.
->lru is the right field to use outside of slab/slub.
Signed-off-by: Dave Hansen <[email protected]>
Acked-by: David Rientjes <[email protected]>
Acked-by: Kirill A. Shutemov <[email protected]>
---
linux.git-davehans/block/blk-mq.c | 6 +++---
1 file changed, 3 insertions(+), 3 deletions(-)
diff -puN block/blk-mq.c~blk-mq-uses-page-list-incorrectly block/blk-mq.c
--- linux.git/block/blk-mq.c~blk-mq-uses-page-list-incorrectly 2014-01-02 13:40:29.388270304 -0800
+++ linux.git-davehans/block/blk-mq.c 2014-01-02 13:40:29.392270484 -0800
@@ -1091,8 +1091,8 @@ static void blk_mq_free_rq_map(struct bl
struct page *page;
while (!list_empty(&hctx->page_list)) {
- page = list_first_entry(&hctx->page_list, struct page, list);
- list_del_init(&page->list);
+ page = list_first_entry(&hctx->page_list, struct page, lru);
+ list_del_init(&page->lru);
__free_pages(page, page->private);
}
@@ -1156,7 +1156,7 @@ static int blk_mq_init_rq_map(struct blk
break;
page->private = this_order;
- list_add_tail(&page->list, &hctx->page_list);
+ list_add_tail(&page->lru, &hctx->page_list);
p = page_address(page);
entries_per_page = order_to_size(this_order) / rq_size;
_
From: Dave Hansen <[email protected]>
To make the layout of 'struct page' look nicer, I broke
up a few of the unions. But, this has a cost: things that
were guaranteed to line up before might not any more. To make up
for that, some BUILD_BUG_ON()s are added to manually check for
the alignment dependencies.
This makes it *MUCH* more clear how the first few fields of
'struct page' get used by the slab allocators.
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm_types.h | 101 ++++++++++++++--------------
linux.git-davehans/mm/slab.c | 6 -
linux.git-davehans/mm/slab_common.c | 17 ++++
linux.git-davehans/mm/slob.c | 25 +++---
4 files changed, 84 insertions(+), 65 deletions(-)
diff -puN include/linux/mm_types.h~rearrange-struct-page include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~rearrange-struct-page 2014-01-02 13:40:30.396315632 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 13:40:30.405316037 -0800
@@ -46,27 +46,60 @@ struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
- struct address_space *mapping; /* If low bit clear, points to
- * inode address_space, or NULL.
- * If page mapped as anonymous
- * memory, low bit is set, and
- * it points to anon_vma object:
- * see PAGE_MAPPING_ANON below.
- */
- void *s_mem; /* slab first object */
- };
-
- /* Second double word */
- struct {
- union {
+ struct /* the normal uses */ {
pgoff_t index; /* Our offset within mapping. */
- void *freelist; /* sl[aou]b first free object */
+ /*
+ * mapping: If low bit clear, points to
+ * inode address_space, or NULL. If page
+ * mapped as anonymous memory, low bit is
+ * set, and it points to anon_vma object:
+ * see PAGE_MAPPING_ANON below.
+ */
+ struct address_space *mapping;
+ /*
+ * Count of ptes mapped in mms, to show when page
+ * is mapped & limit reverse map searches.
+ *
+ * Used also for tail pages refcounting instead
+ * of _count. Tail pages cannot be mapped and
+ * keeping the tail page _count zero at all times
+ * guarantees get_page_unless_zero() will never
+ * succeed on tail pages.
+ */
+ atomic_t _mapcount;
+ atomic_t _count;
+ }; /* end of the "normal" use */
+
+ struct { /* SLUB */
+ void *unused;
+ void *freelist;
+ unsigned inuse:16;
+ unsigned objects:15;
+ unsigned frozen:1;
+ atomic_t dontuse_slub_count;
};
-
- union {
+ struct { /* SLAB */
+ void *s_mem;
+ void *slab_freelist;
+ unsigned int active;
+ atomic_t dontuse_slab_count;
+ };
+ struct { /* SLOB */
+ void *slob_unused;
+ void *slob_freelist;
+ unsigned int units;
+ atomic_t dontuse_slob_count;
+ };
+ /*
+ * This is here to help the slub code deal with
+ * its inuse/objects/frozen bitfields as a single
+ * blob.
+ */
+ struct { /* slub helpers */
+ void *slubhelp_unused;
+ void *slubhelp_freelist;
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- /* Used for cmpxchg_double in slub */
+ defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
unsigned long counters;
#else
/*
@@ -76,38 +109,6 @@ struct page {
*/
unsigned counters;
#endif
-
- struct {
-
- union {
- /*
- * Count of ptes mapped in
- * mms, to show when page is
- * mapped & limit reverse map
- * searches.
- *
- * Used also for tail pages
- * refcounting instead of
- * _count. Tail pages cannot
- * be mapped and keeping the
- * tail page _count zero at
- * all times guarantees
- * get_page_unless_zero() will
- * never succeed on tail
- * pages.
- */
- atomic_t _mapcount;
-
- struct { /* SLUB */
- unsigned inuse:16;
- unsigned objects:15;
- unsigned frozen:1;
- };
- int units; /* SLOB */
- };
- atomic_t _count; /* Usage count, see below. */
- };
- unsigned int active; /* SLAB */
};
};
diff -puN mm/slab.c~rearrange-struct-page mm/slab.c
--- linux.git/mm/slab.c~rearrange-struct-page 2014-01-02 13:40:30.398315722 -0800
+++ linux.git-davehans/mm/slab.c 2014-01-02 13:40:30.407316127 -0800
@@ -1955,7 +1955,7 @@ static void slab_destroy(struct kmem_cac
{
void *freelist;
- freelist = page->freelist;
+ freelist = page->slab_freelist;
slab_destroy_debugcheck(cachep, page);
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
struct rcu_head *head;
@@ -2543,7 +2543,7 @@ static void *alloc_slabmgmt(struct kmem_
static inline unsigned int *slab_freelist(struct page *page)
{
- return (unsigned int *)(page->freelist);
+ return (unsigned int *)(page->slab_freelist);
}
static void cache_init_objs(struct kmem_cache *cachep,
@@ -2648,7 +2648,7 @@ static void slab_map_pages(struct kmem_c
void *freelist)
{
page->slab_cache = cache;
- page->freelist = freelist;
+ page->slab_freelist = freelist;
}
/*
diff -puN mm/slab_common.c~rearrange-struct-page mm/slab_common.c
--- linux.git/mm/slab_common.c~rearrange-struct-page 2014-01-02 13:40:30.400315812 -0800
+++ linux.git-davehans/mm/slab_common.c 2014-01-02 13:40:30.407316127 -0800
@@ -658,3 +658,20 @@ static int __init slab_proc_init(void)
}
module_init(slab_proc_init);
#endif /* CONFIG_SLABINFO */
+#define SLAB_PAGE_CHECK(field1, field2) \
+ BUILD_BUG_ON(offsetof(struct page, field1) != \
+ offsetof(struct page, field2))
+/*
+ * To make the layout of 'struct page' look nicer, we've broken
+ * up a few of the unions. Folks declaring their own use of the
+ * first few fields need to make sure that their use does not
+ * interfere with page->_count. This ensures that the individual
+ * users' use actually lines up with the real ->_count.
+ */
+void slab_build_checks(void)
+{
+ SLAB_PAGE_CHECK(_count, dontuse_slab_count);
+ SLAB_PAGE_CHECK(_count, dontuse_slub_count);
+ SLAB_PAGE_CHECK(_count, dontuse_slob_count);
+}
+
diff -puN mm/slob.c~rearrange-struct-page mm/slob.c
--- linux.git/mm/slob.c~rearrange-struct-page 2014-01-02 13:40:30.402315902 -0800
+++ linux.git-davehans/mm/slob.c 2014-01-02 13:40:30.408316172 -0800
@@ -219,7 +219,8 @@ static void *slob_page_alloc(struct page
slob_t *prev, *cur, *aligned = NULL;
int delta = 0, units = SLOB_UNITS(size);
- for (prev = NULL, cur = sp->freelist; ; prev = cur, cur = slob_next(cur)) {
+ for (prev = NULL, cur = sp->slob_freelist; ;
+ prev = cur, cur = slob_next(cur)) {
slobidx_t avail = slob_units(cur);
if (align) {
@@ -243,12 +244,12 @@ static void *slob_page_alloc(struct page
if (prev)
set_slob(prev, slob_units(prev), next);
else
- sp->freelist = next;
+ sp->slob_freelist = next;
} else { /* fragment */
if (prev)
set_slob(prev, slob_units(prev), cur + units);
else
- sp->freelist = cur + units;
+ sp->slob_freelist = cur + units;
set_slob(cur + units, avail - units, next);
}
@@ -321,7 +322,7 @@ static void *slob_alloc(size_t size, gfp
spin_lock_irqsave(&slob_lock, flags);
sp->units = SLOB_UNITS(PAGE_SIZE);
- sp->freelist = b;
+ sp->slob_freelist = b;
INIT_LIST_HEAD(&sp->list);
set_slob(b, SLOB_UNITS(PAGE_SIZE), b + SLOB_UNITS(PAGE_SIZE));
set_slob_page_free(sp, slob_list);
@@ -368,7 +369,7 @@ static void slob_free(void *block, int s
if (!slob_page_free(sp)) {
/* This slob page is about to become partially free. Easy! */
sp->units = units;
- sp->freelist = b;
+ sp->slob_freelist = b;
set_slob(b, units,
(void *)((unsigned long)(b +
SLOB_UNITS(PAGE_SIZE)) & PAGE_MASK));
@@ -388,15 +389,15 @@ static void slob_free(void *block, int s
*/
sp->units += units;
- if (b < (slob_t *)sp->freelist) {
- if (b + units == sp->freelist) {
- units += slob_units(sp->freelist);
- sp->freelist = slob_next(sp->freelist);
+ if (b < (slob_t *)sp->slob_freelist) {
+ if (b + units == sp->slob_freelist) {
+ units += slob_units(sp->slob_freelist);
+ sp->slob_freelist = slob_next(sp->slob_freelist);
}
- set_slob(b, units, sp->freelist);
- sp->freelist = b;
+ set_slob(b, units, sp->slob_freelist);
+ sp->slob_freelist = b;
} else {
- prev = sp->freelist;
+ prev = sp->slob_freelist;
next = slob_next(prev);
while (b > next) {
prev = next;
_
From: Dave Hansen <[email protected]>
SLUB depends on a 16-byte cmpxchg for an optimization. In order
to get guaranteed 16-byte alignment (required by the hardware on
x86), 'struct page' is padded out from 56 to 64 bytes.
Those 8-bytes matter. We've gone to great lengths to keep
'struct page' small in the past. It's a shame that we bloat it
now just for alignment reasons when we have *extra* space. Also,
increasing the size of 'struct page' by 14% makes it 14% more
likely that we will miss a cacheline when fetching it.
This patch takes an unused 8-byte area of slub's 'struct page'
and reuses it to internally align to the 16-bytes that we need.
Note that this also gets rid of the ugly slub #ifdef that we use
to segregate ->counters and ->_count for cases where we need to
manipulate ->counters without the benefit of a hardware cmpxchg.
This patch takes me from 16909584K of reserved memory at boot
down to 14814472K, so almost *exactly* 2GB of savings! It also
helps performance, presumably because of that 14% fewer
cacheline effect. A 30GB dd to a ramfs file:
dd if=/dev/zero of=bigfile bs=$((1<<30)) count=30
is sped up by about 4.4% in my testing.
The value of maintaining the cmpxchg16 operation can be
demonstrated in some tiny little microbenchmarks, so it is
probably something we should keep around instead of just using
the spinlock for everything:
http://lkml.kernel.org/r/[email protected]
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/arch/Kconfig | 8 ----
linux.git-davehans/arch/s390/Kconfig | 1
linux.git-davehans/arch/x86/Kconfig | 1
linux.git-davehans/include/linux/mm_types.h | 55 +++++++---------------------
linux.git-davehans/init/Kconfig | 2 -
linux.git-davehans/mm/slab_common.c | 10 +++--
linux.git-davehans/mm/slub.c | 4 ++
7 files changed, 26 insertions(+), 55 deletions(-)
diff -puN arch/Kconfig~remove-struct-page-alignment-restrictions arch/Kconfig
--- linux.git/arch/Kconfig~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.071044198 -0800
+++ linux.git-davehans/arch/Kconfig 2014-01-02 14:56:39.086044872 -0800
@@ -289,14 +289,6 @@ config HAVE_RCU_TABLE_FREE
config ARCH_HAVE_NMI_SAFE_CMPXCHG
bool
-config HAVE_ALIGNED_STRUCT_PAGE
- bool
- help
- This makes sure that struct pages are double word aligned and that
- e.g. the SLUB allocator can perform double word atomic operations
- on a struct page for better performance. However selecting this
- might increase the size of a struct page by a word.
-
config HAVE_CMPXCHG_LOCAL
bool
diff -puN arch/s390/Kconfig~remove-struct-page-alignment-restrictions arch/s390/Kconfig
--- linux.git/arch/s390/Kconfig~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.073044287 -0800
+++ linux.git-davehans/arch/s390/Kconfig 2014-01-02 14:56:39.087044917 -0800
@@ -102,7 +102,6 @@ config S390
select GENERIC_FIND_FIRST_BIT
select GENERIC_SMP_IDLE_THREAD
select GENERIC_TIME_VSYSCALL
- select HAVE_ALIGNED_STRUCT_PAGE if SLUB
select HAVE_ARCH_JUMP_LABEL if !MARCH_G5
select HAVE_ARCH_SECCOMP_FILTER
select HAVE_ARCH_SECCOMP
diff -puN arch/x86/Kconfig~remove-struct-page-alignment-restrictions arch/x86/Kconfig
--- linux.git/arch/x86/Kconfig~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.075044377 -0800
+++ linux.git-davehans/arch/x86/Kconfig 2014-01-02 14:56:39.088044962 -0800
@@ -77,7 +77,6 @@ config X86
select HAVE_PERF_USER_STACK_DUMP
select HAVE_DEBUG_KMEMLEAK
select ANON_INODES
- select HAVE_ALIGNED_STRUCT_PAGE if SLUB
select HAVE_CMPXCHG_LOCAL
select HAVE_ARCH_KMEMCHECK
select HAVE_USER_RETURN_NOTIFIER
diff -puN include/linux/mm_types.h~remove-struct-page-alignment-restrictions include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.076044423 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 14:56:39.089045007 -0800
@@ -24,38 +24,30 @@
struct address_space;
struct slub_data {
- void *unused;
void *freelist;
union {
struct {
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
- atomic_t dontuse_slub_count;
};
- /*
- * ->counters is used to make it easier to copy
- * all of the above counters in one chunk.
- * The actual counts are never accessed via this.
- */
-#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
- unsigned long counters;
-#else
- /*
- * Keep _count separate from slub cmpxchg_double data.
- * As the rest of the double word is protected by
- * slab_lock but _count is not.
- */
struct {
- unsigned counters;
- /*
- * This isn't used directly, but declare it here
- * for clarity since it must line up with _count
- * from 'struct page'
- */
+ /* counters is just a helperfor the above bitfield */
+ unsigned long counters;
+ atomic_t padding;
atomic_t separate_count;
};
-#endif
+ /*
+ * the double-cmpxchg case:
+ * counters and _count overlap:
+ */
+ union {
+ unsigned long counters2;
+ struct {
+ atomic_t padding2;
+ atomic_t _count;
+ };
+ };
};
};
@@ -70,15 +62,8 @@ struct slub_data {
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
- *
- * The objects in struct page are organized in double word blocks in
- * order to allows us to use atomic double word operations on portions
- * of struct page. That is currently only used by slub but the arrangement
- * allows the use of atomic double word operations on the flags/mapping
- * and lru list pointers also.
*/
struct page {
- /* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
@@ -121,7 +106,6 @@ struct page {
};
};
- /* Third double word block */
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
@@ -150,7 +134,6 @@ struct page {
#endif
};
- /* Remainder is not double word aligned */
union {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
@@ -199,15 +182,7 @@ struct page {
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
-}
-/*
- * The struct page can be forced to be double word aligned so that atomic ops
- * on double words work. The SLUB allocator can make use of such a feature.
- */
-#ifdef CONFIG_HAVE_ALIGNED_STRUCT_PAGE
- __aligned(2 * sizeof(unsigned long))
-#endif
-;
+};
struct page_frag {
struct page *page;
diff -puN init/Kconfig~remove-struct-page-alignment-restrictions init/Kconfig
--- linux.git/init/Kconfig~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.078044513 -0800
+++ linux.git-davehans/init/Kconfig 2014-01-02 14:56:39.090045052 -0800
@@ -841,7 +841,7 @@ config SLUB_CPU_PARTIAL
config SLUB_ATTEMPT_CMPXCHG_DOUBLE
default y
- depends on SLUB && HAVE_CMPXCHG_DOUBLE && HAVE_ALIGNED_STRUCT_PAGE
+ depends on SLUB && HAVE_CMPXCHG_DOUBLE
bool "SLUB: attempt to use double-cmpxchg operations"
help
Some CPUs support instructions that let you do a large double-word
diff -puN mm/slab_common.c~remove-struct-page-alignment-restrictions mm/slab_common.c
--- linux.git/mm/slab_common.c~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.080044602 -0800
+++ linux.git-davehans/mm/slab_common.c 2014-01-02 14:56:39.090045052 -0800
@@ -674,7 +674,6 @@ module_init(slab_proc_init);
void slab_build_checks(void)
{
SLAB_PAGE_CHECK(_count, dontuse_slab_count);
- SLAB_PAGE_CHECK(_count, slub_data.dontuse_slub_count);
SLAB_PAGE_CHECK(_count, dontuse_slob_count);
/*
@@ -688,9 +687,12 @@ void slab_build_checks(void)
* carve out for _count in that case actually lines up
* with the real _count.
*/
-#if !(defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE))
SLAB_PAGE_CHECK(_count, slub_data.separate_count);
-#endif
+
+ /*
+ * We need at least three double-words worth of space to
+ * ensure that we can align to a double-wordk internally.
+ */
+ BUILD_BUG_ON(sizeof(struct slub_data) != sizeof(unsigned long) * 3);
}
diff -puN mm/slub.c~remove-struct-page-alignment-restrictions mm/slub.c
--- linux.git/mm/slub.c~remove-struct-page-alignment-restrictions 2014-01-02 14:56:39.082044693 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 14:56:39.092045142 -0800
@@ -239,7 +239,11 @@ static inline struct kmem_cache_node *ge
static inline struct slub_data *slub_data(struct page *page)
{
+ int doubleword_bytes = BITS_PER_LONG * 2 / 8;
void *ptr = &page->slub_data;
+#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
+ ptr = PTR_ALIGN(ptr, doubleword_bytes);
+#endif
return ptr;
}
_
From: Dave Hansen <[email protected]>
page->pfmemalloc does not deserve a spot in 'struct page'. It is
only used transiently _just_ after a page leaves the buddy
allocator.
Instead of declaring a union, we move its functionality behind a
few quick accessor functions. This way we could also much more
easily audit that it is being used correctly in debugging
scenarios. For instance, we could store a magic number in there
which could never get reused as a page->index and check that the
magic number exists in page_pfmemalloc().
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm.h | 17 +++++++++++++++++
linux.git-davehans/include/linux/mm_types.h | 9 ---------
linux.git-davehans/include/linux/skbuff.h | 10 +++++-----
linux.git-davehans/mm/page_alloc.c | 2 +-
linux.git-davehans/mm/slab.c | 4 ++--
linux.git-davehans/mm/slub.c | 2 +-
6 files changed, 26 insertions(+), 18 deletions(-)
diff -puN include/linux/mm.h~page_pfmemalloc-only-used-by-slab include/linux/mm.h
--- linux.git/include/linux/mm.h~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.673283120 -0800
+++ linux.git-davehans/include/linux/mm.h 2014-01-02 13:40:29.687283750 -0800
@@ -2011,5 +2011,22 @@ void __init setup_nr_node_ids(void);
static inline void setup_nr_node_ids(void) {}
#endif
+/*
+ * If set by the page allocator, ALLOC_NO_WATERMARKS was set and the
+ * low watermark was not met implying that the system is under some
+ * pressure. The caller should try ensure this page is only used to
+ * free other pages. Currently only used by sl[au]b. Note that
+ * this is only valid for a short time after the page returns
+ * from the allocator.
+ */
+static inline int page_pfmemalloc(struct page *page)
+{
+ return !!page->index;
+}
+static inline void set_page_pfmemalloc(struct page *page, int pfmemalloc)
+{
+ page->index = pfmemalloc;
+}
+
#endif /* __KERNEL__ */
#endif /* _LINUX_MM_H */
diff -puN include/linux/mm_types.h~page_pfmemalloc-only-used-by-slab include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.675283210 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 13:40:29.688283795 -0800
@@ -61,15 +61,6 @@ struct page {
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
- bool pfmemalloc; /* If set by the page allocator,
- * ALLOC_NO_WATERMARKS was set
- * and the low watermark was not
- * met implying that the system
- * is under some pressure. The
- * caller should try ensure
- * this page is only used to
- * free other pages.
- */
};
union {
diff -puN include/linux/skbuff.h~page_pfmemalloc-only-used-by-slab include/linux/skbuff.h
--- linux.git/include/linux/skbuff.h~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.677283300 -0800
+++ linux.git-davehans/include/linux/skbuff.h 2014-01-02 13:40:29.690283885 -0800
@@ -1322,11 +1322,11 @@ static inline void __skb_fill_page_desc(
skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
/*
- * Propagate page->pfmemalloc to the skb if we can. The problem is
+ * Propagate page_pfmemalloc() to the skb if we can. The problem is
* that not all callers have unique ownership of the page. If
* pfmemalloc is set, we check the mapping as a mapping implies
* page->index is set (index and pfmemalloc share space).
- * If it's a valid mapping, we cannot use page->pfmemalloc but we
+ * If it's a valid mapping, we cannot use page_pfmemalloc() but we
* do not lose pfmemalloc information as the pages would not be
* allocated using __GFP_MEMALLOC.
*/
@@ -1335,7 +1335,7 @@ static inline void __skb_fill_page_desc(
skb_frag_size_set(frag, size);
page = compound_head(page);
- if (page->pfmemalloc && !page->mapping)
+ if (page_pfmemalloc(page) && !page->mapping)
skb->pfmemalloc = true;
}
@@ -1922,7 +1922,7 @@ static inline struct page *__skb_alloc_p
gfp_mask |= __GFP_MEMALLOC;
page = alloc_pages_node(NUMA_NO_NODE, gfp_mask, order);
- if (skb && page && page->pfmemalloc)
+ if (skb && page && page_pfmemalloc(page))
skb->pfmemalloc = true;
return page;
@@ -1951,7 +1951,7 @@ static inline struct page *__skb_alloc_p
static inline void skb_propagate_pfmemalloc(struct page *page,
struct sk_buff *skb)
{
- if (page && page->pfmemalloc)
+ if (page && page_pfmemalloc(page))
skb->pfmemalloc = true;
}
diff -puN mm/page_alloc.c~page_pfmemalloc-only-used-by-slab mm/page_alloc.c
--- linux.git/mm/page_alloc.c~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.679283390 -0800
+++ linux.git-davehans/mm/page_alloc.c 2014-01-02 13:40:29.692283974 -0800
@@ -2040,7 +2040,7 @@ this_zone_full:
* memory. The caller should avoid the page being used
* for !PFMEMALLOC purposes.
*/
- page->pfmemalloc = !!(alloc_flags & ALLOC_NO_WATERMARKS);
+ set_page_pfmemalloc(page, alloc_flags & ALLOC_NO_WATERMARKS);
return page;
}
diff -puN mm/slab.c~page_pfmemalloc-only-used-by-slab mm/slab.c
--- linux.git/mm/slab.c~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.681283480 -0800
+++ linux.git-davehans/mm/slab.c 2014-01-02 13:40:29.694284064 -0800
@@ -1672,7 +1672,7 @@ static struct page *kmem_getpages(struct
}
/* Record if ALLOC_NO_WATERMARKS was set when allocating the slab */
- if (unlikely(page->pfmemalloc))
+ if (unlikely(page_pfmemalloc(page)))
pfmemalloc_active = true;
nr_pages = (1 << cachep->gfporder);
@@ -1683,7 +1683,7 @@ static struct page *kmem_getpages(struct
add_zone_page_state(page_zone(page),
NR_SLAB_UNRECLAIMABLE, nr_pages);
__SetPageSlab(page);
- if (page->pfmemalloc)
+ if (page_pfmemalloc(page))
SetPageSlabPfmemalloc(page);
memcg_bind_pages(cachep, cachep->gfporder);
diff -puN mm/slub.c~page_pfmemalloc-only-used-by-slab mm/slub.c
--- linux.git/mm/slub.c~page_pfmemalloc-only-used-by-slab 2014-01-02 13:40:29.683283570 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 13:40:29.696284154 -0800
@@ -1403,7 +1403,7 @@ static struct page *new_slab(struct kmem
memcg_bind_pages(s, order);
page->slab_cache = s;
__SetPageSlab(page);
- if (page->pfmemalloc)
+ if (page_pfmemalloc(page))
SetPageSlabPfmemalloc(page);
start = page_address(page);
_
From: Dave Hansen <[email protected]>
I added a bunch of longer than 80 column lines and other various
messes. But, doing line-to-line code replacements makes the
previous patch much easier to audit. I stuck the cleanups in
here instead.
The slub code also delcares a bunch of 'struct page's on the
stack. Now that 'struct slub_data' is separate, we can declare
those smaller structures instead. This ends up saving us a
couple hundred bytes in object size.
Doing all the work of doing the pointer alignment operations over
and over costs us some code size. In the end (not this patch
alone), we take slub.o's size from 26672->27168, so about 500
bytes. But, on an 8GB system, we saved about 256k in 'struct
page' overhead. That's a pretty good tradeoff.
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/mm/slub.c | 129 ++++++++++++++++++++++---------------------
1 file changed, 68 insertions(+), 61 deletions(-)
diff -puN mm/slub.c~slub-cleanups mm/slub.c
--- linux.git/mm/slub.c~slub-cleanups 2014-01-02 15:29:12.570949151 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 15:39:08.978812390 -0800
@@ -257,7 +257,8 @@ static inline int check_valid_pointer(st
return 1;
base = page_address(page);
- if (object < base || object >= base + slub_data(page)->objects * s->size ||
+ if (object < base ||
+ object >= base + slub_data(page)->objects * s->size ||
(object - base) % s->size) {
return 0;
}
@@ -374,16 +375,17 @@ static inline bool __cmpxchg_double_slab
VM_BUG_ON(!irqs_disabled());
#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
- freelist_old, counters_old,
- freelist_new, counters_new))
- return 1;
+ if (cmpxchg_double(&slub_data(page)->freelist,
+ &slub_data(page)->counters,
+ freelist_old, counters_old,
+ freelist_new, counters_new))
+ return 1;
} else
#endif
{
slab_lock(page);
if (slub_data(page)->freelist == freelist_old &&
- slub_data(page)->counters == counters_old) {
+ slub_data(page)->counters == counters_old) {
slub_data(page)->freelist = freelist_new;
slub_data(page)->counters = counters_new;
slab_unlock(page);
@@ -407,11 +409,12 @@ static inline bool cmpxchg_double_slab(s
void *freelist_new, unsigned long counters_new,
const char *n)
{
+ struct slub_data *sd = slub_data(page);
#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
- freelist_old, counters_old,
- freelist_new, counters_new))
+ if (cmpxchg_double(&sd->freelist, &sd->counters,
+ freelist_old, counters_old,
+ freelist_new, counters_new))
return 1;
} else
#endif
@@ -420,10 +423,10 @@ static inline bool cmpxchg_double_slab(s
local_irq_save(flags);
slab_lock(page);
- if (slub_data(page)->freelist == freelist_old &&
- slub_data(page)->counters == counters_old) {
- slub_data(page)->freelist = freelist_new;
- slub_data(page)->counters = counters_new;
+ if (sd->freelist == freelist_old &&
+ sd->counters == counters_old) {
+ sd->freelist = freelist_new;
+ sd->counters = counters_new;
slab_unlock(page);
local_irq_restore(flags);
return 1;
@@ -859,7 +862,8 @@ static int check_slab(struct kmem_cache
}
if (slub_data(page)->inuse > slub_data(page)->objects) {
slab_err(s, page, "inuse %u > max %u",
- s->name, slub_data(page)->inuse, slub_data(page)->objects);
+ s->name, slub_data(page)->inuse,
+ slub_data(page)->objects);
return 0;
}
/* Slab_pad_check fixes things up after itself */
@@ -890,7 +894,8 @@ static int on_freelist(struct kmem_cache
} else {
slab_err(s, page, "Freepointer corrupt");
slub_data(page)->freelist = NULL;
- slub_data(page)->inuse = slub_data(page)->objects;
+ slub_data(page)->inuse =
+ slub_data(page)->objects;
slab_fix(s, "Freelist cleared");
return 0;
}
@@ -913,7 +918,8 @@ static int on_freelist(struct kmem_cache
}
if (slub_data(page)->inuse != slub_data(page)->objects - nr) {
slab_err(s, page, "Wrong object count. Counter is %d but "
- "counted were %d", slub_data(page)->inuse, slub_data(page)->objects - nr);
+ "counted were %d", slub_data(page)->inuse,
+ slub_data(page)->objects - nr);
slub_data(page)->inuse = slub_data(page)->objects - nr;
slab_fix(s, "Object count adjusted.");
}
@@ -1550,7 +1556,7 @@ static inline void *acquire_slab(struct
{
void *freelist;
unsigned long counters;
- struct page new;
+ struct slub_data new;
/*
* Zap the freelist and set the frozen bit.
@@ -1795,8 +1801,8 @@ static void deactivate_slab(struct kmem_
enum slab_modes l = M_NONE, m = M_NONE;
void *nextfree;
int tail = DEACTIVATE_TO_HEAD;
- struct page new;
- struct page old;
+ struct slub_data new;
+ struct slub_data old;
if (slub_data(page)->freelist) {
stat(s, DEACTIVATE_REMOTE_FREES);
@@ -1819,13 +1825,13 @@ static void deactivate_slab(struct kmem_
prior = slub_data(page)->freelist;
counters = slub_data(page)->counters;
set_freepointer(s, freelist, prior);
- slub_data(&new)->counters = counters;
- slub_data(&new)->inuse--;
- VM_BUG_ON(!slub_data(&new)->frozen);
+ new.counters = counters;
+ new.inuse--;
+ VM_BUG_ON(!new.frozen);
} while (!__cmpxchg_double_slab(s, page,
prior, counters,
- freelist, slub_data(&new)->counters,
+ freelist, new.counters,
"drain percpu freelist"));
freelist = nextfree;
@@ -1847,24 +1853,24 @@ static void deactivate_slab(struct kmem_
*/
redo:
- slub_data(&old)->freelist = slub_data(page)->freelist;
- slub_data(&old)->counters = slub_data(page)->counters;
- VM_BUG_ON(!slub_data(&old)->frozen);
+ old.freelist = slub_data(page)->freelist;
+ old.counters = slub_data(page)->counters;
+ VM_BUG_ON(!old.frozen);
/* Determine target state of the slab */
- slub_data(&new)->counters = slub_data(&old)->counters;
+ new.counters = old.counters;
if (freelist) {
- slub_data(&new)->inuse--;
- set_freepointer(s, freelist, slub_data(&old)->freelist);
- slub_data(&new)->freelist = freelist;
+ new.inuse--;
+ set_freepointer(s, freelist, old.freelist);
+ new.freelist = freelist;
} else
- slub_data(&new)->freelist = slub_data(&old)->freelist;
+ new.freelist = old.freelist;
- slub_data(&new)->frozen = 0;
+ new.frozen = 0;
- if (!slub_data(&new)->inuse && n->nr_partial > s->min_partial)
+ if (!new.inuse && n->nr_partial > s->min_partial)
m = M_FREE;
- else if (slub_data(&new)->freelist) {
+ else if (new.freelist) {
m = M_PARTIAL;
if (!lock) {
lock = 1;
@@ -1913,8 +1919,8 @@ redo:
l = m;
if (!__cmpxchg_double_slab(s, page,
- slub_data(&old)->freelist, slub_data(&old)->counters,
- slub_data(&new)->freelist, slub_data(&new)->counters,
+ old.freelist, old.counters,
+ new.freelist, new.counters,
"unfreezing slab"))
goto redo;
@@ -1943,8 +1949,8 @@ static void unfreeze_partials(struct kme
struct page *page, *discard_page = NULL;
while ((page = c->partial)) {
- struct page new;
- struct page old;
+ struct slub_data new;
+ struct slub_data old;
c->partial = page->next;
@@ -1959,21 +1965,21 @@ static void unfreeze_partials(struct kme
do {
- slub_data(&old)->freelist = slub_data(page)->freelist;
- slub_data(&old)->counters = slub_data(page)->counters;
+ old.freelist = slub_data(page)->freelist;
+ old.counters = slub_data(page)->counters;
VM_BUG_ON(!slub_data(&old)->frozen);
- slub_data(&new)->counters = slub_data(&old)->counters;
- slub_data(&new)->freelist = slub_data(&old)->freelist;
+ new.counters = old.counters;
+ new.freelist = old.freelist;
slub_data(&new)->frozen = 0;
} while (!__cmpxchg_double_slab(s, page,
- slub_data(&old)->freelist, slub_data(&old)->counters,
- slub_data(&new)->freelist, slub_data(&new)->counters,
+ old.freelist, old.counters,
+ new.freelist, new.counters,
"unfreezing slab"));
- if (unlikely(!slub_data(&new)->inuse && n->nr_partial > s->min_partial)) {
+ if (unlikely(!new.inuse && n->nr_partial > s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {
@@ -2225,7 +2231,7 @@ static inline bool pfmemalloc_match(stru
*/
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
{
- struct page new;
+ struct slub_data new;
unsigned long counters;
void *freelist;
@@ -2233,15 +2239,15 @@ static inline void *get_freelist(struct
freelist = slub_data(page)->freelist;
counters = slub_data(page)->counters;
- slub_data(&new)->counters = counters;
- VM_BUG_ON(!slub_data(&new)->frozen);
+ new.counters = counters;
+ VM_BUG_ON(!new.frozen);
- slub_data(&new)->inuse = slub_data(page)->objects;
- slub_data(&new)->frozen = freelist != NULL;
+ new.inuse = slub_data(page)->objects;
+ new.frozen = freelist != NULL;
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
- NULL, slub_data(&new)->counters,
+ NULL, new.counters,
"get_freelist"));
return freelist;
@@ -2526,7 +2532,7 @@ static void __slab_free(struct kmem_cach
void *prior;
void **object = (void *)x;
int was_frozen;
- struct page new;
+ struct slub_data new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
@@ -2545,10 +2551,10 @@ static void __slab_free(struct kmem_cach
prior = slub_data(page)->freelist;
counters = slub_data(page)->counters;
set_freepointer(s, object, prior);
- slub_data(&new)->counters = counters;
- was_frozen = slub_data(&new)->frozen;
- slub_data(&new)->inuse--;
- if ((!slub_data(&new)->inuse || !prior) && !was_frozen) {
+ new.counters = counters;
+ was_frozen = new.frozen;
+ new.inuse--;
+ if ((!new.inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior)
@@ -2558,7 +2564,7 @@ static void __slab_free(struct kmem_cach
* We can defer the list move and instead
* freeze it.
*/
- slub_data(&new)->frozen = 1;
+ new.frozen = 1;
else { /* Needs to be taken off a list */
@@ -2578,7 +2584,7 @@ static void __slab_free(struct kmem_cach
} while (!cmpxchg_double_slab(s, page,
prior, counters,
- object, slub_data(&new)->counters,
+ object, new.counters,
"__slab_free"));
if (likely(!n)) {
@@ -2587,7 +2593,7 @@ static void __slab_free(struct kmem_cach
* If we just froze the page then put it onto the
* per cpu partial list.
*/
- if (slub_data(&new)->frozen && !was_frozen) {
+ if (new.frozen && !was_frozen) {
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
@@ -2600,7 +2606,7 @@ static void __slab_free(struct kmem_cach
return;
}
- if (unlikely(!slub_data(&new)->inuse && n->nr_partial > s->min_partial))
+ if (unlikely(!new.inuse && n->nr_partial > s->min_partial))
goto slab_empty;
/*
@@ -3423,7 +3429,8 @@ int kmem_cache_shrink(struct kmem_cache
* list_lock. ->inuse here is the upper limit.
*/
list_for_each_entry_safe(page, t, &n->partial, lru) {
- list_move(&page->lru, slabs_by_inuse + slub_data(page)->inuse);
+ list_move(&page->lru, slabs_by_inuse +
+ slub_data(page)->inuse);
if (!slub_data(page)->inuse)
n->nr_partial--;
}
_
From: Dave Hansen <[email protected]>
In order to simplify 'struct page', we will shortly be moving
some fields around. This causes slub's ->freelist usage to
impinge on page->mapping's storage space. The buddy allocator
wants ->mapping to be NULL when a page is handed back, so we have
to make sure that it is cleared.
Note that slab already doeds this, so just create a common helper
and have all the slabs do it this way. ->mapping is right next
to ->flags, so it's virtually guaranteed to be in the L1 at this
point, so this shouldn't cost very much to do in practice.
Other allocators and users of 'struct page' may also want to call
this if they use parts of 'struct page' for nonstandard purposes.
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm.h | 11 +++++++++++
linux.git-davehans/mm/slab.c | 3 +--
linux.git-davehans/mm/slob.c | 2 +-
linux.git-davehans/mm/slub.c | 2 +-
4 files changed, 14 insertions(+), 4 deletions(-)
diff -puN include/linux/mm.h~slub-reset-page-at-free include/linux/mm.h
--- linux.git/include/linux/mm.h~slub-reset-page-at-free 2014-01-02 13:40:30.057300388 -0800
+++ linux.git-davehans/include/linux/mm.h 2014-01-02 13:40:30.067300838 -0800
@@ -2028,5 +2028,16 @@ static inline void set_page_pfmemalloc(s
page->index = pfmemalloc;
}
+/*
+ * Custom allocators (like the slabs) use 'struct page' fields
+ * for all kinds of things. This resets the page's state so that
+ * the buddy allocator will be happy with it.
+ */
+static inline void allocator_reset_page(struct page *page)
+{
+ page->mapping = NULL;
+ page_mapcount_reset(page);
+}
+
#endif /* __KERNEL__ */
#endif /* _LINUX_MM_H */
diff -puN mm/slab.c~slub-reset-page-at-free mm/slab.c
--- linux.git/mm/slab.c~slub-reset-page-at-free 2014-01-02 13:40:30.060300523 -0800
+++ linux.git-davehans/mm/slab.c 2014-01-02 13:40:30.069300928 -0800
@@ -1718,8 +1718,7 @@ static void kmem_freepages(struct kmem_c
BUG_ON(!PageSlab(page));
__ClearPageSlabPfmemalloc(page);
__ClearPageSlab(page);
- page_mapcount_reset(page);
- page->mapping = NULL;
+ allocator_reset_page(page);
memcg_release_pages(cachep, cachep->gfporder);
if (current->reclaim_state)
diff -puN mm/slob.c~slub-reset-page-at-free mm/slob.c
--- linux.git/mm/slob.c~slub-reset-page-at-free 2014-01-02 13:40:30.061300568 -0800
+++ linux.git-davehans/mm/slob.c 2014-01-02 13:40:30.070300973 -0800
@@ -360,7 +360,7 @@ static void slob_free(void *block, int s
clear_slob_page_free(sp);
spin_unlock_irqrestore(&slob_lock, flags);
__ClearPageSlab(sp);
- page_mapcount_reset(sp);
+ allocator_reset_page(sp);
slob_free_pages(b, 0);
return;
}
diff -puN mm/slub.c~slub-reset-page-at-free mm/slub.c
--- linux.git/mm/slub.c~slub-reset-page-at-free 2014-01-02 13:40:30.063300658 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 13:40:30.071301017 -0800
@@ -1452,7 +1452,7 @@ static void __free_slab(struct kmem_cach
__ClearPageSlab(page);
memcg_release_pages(s, order);
- page_mapcount_reset(page);
+ allocator_reset_page(page);
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += pages;
__free_memcg_kmem_pages(page, order);
_
From: Dave Hansen <[email protected]>
I found this useful to have in my testing. I would like to have
it available for a bit, at least until other folks have had a
chance to do some testing with it.
We should probably just pull the help text and the description
out of this so that folks are not prompted for it instead of
ripping it out entirely.
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm_types.h | 3 +--
linux.git-davehans/init/Kconfig | 2 +-
linux.git-davehans/mm/slub.c | 9 +++------
3 files changed, 5 insertions(+), 9 deletions(-)
diff -puN include/linux/mm_types.h~abstract-out-slub-double-cmpxchg-operation include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~abstract-out-slub-double-cmpxchg-operation 2014-01-02 15:28:04.382877603 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 15:28:04.391878008 -0800
@@ -38,8 +38,7 @@ struct slub_data {
* all of the above counters in one chunk.
* The actual counts are never accessed via this.
*/
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
+#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
unsigned long counters;
#else
/*
diff -puN init/Kconfig~abstract-out-slub-double-cmpxchg-operation init/Kconfig
--- linux.git/init/Kconfig~abstract-out-slub-double-cmpxchg-operation 2014-01-02 15:28:04.384877693 -0800
+++ linux.git-davehans/init/Kconfig 2014-01-02 15:28:04.392878053 -0800
@@ -841,7 +841,7 @@ config SLUB_CPU_PARTIAL
config SLUB_ATTEMPT_CMPXCHG_DOUBLE
default y
- depends on SLUB && HAVE_CMPXCHG_DOUBLE
+ depends on SLUB && HAVE_CMPXCHG_DOUBLE && HAVE_ALIGNED_STRUCT_PAGE
bool "SLUB: attempt to use double-cmpxchg operations"
help
Some CPUs support instructions that let you do a large double-word
diff -puN mm/slub.c~abstract-out-slub-double-cmpxchg-operation mm/slub.c
--- linux.git/mm/slub.c~abstract-out-slub-double-cmpxchg-operation 2014-01-02 15:28:04.386877783 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 15:28:04.394878143 -0800
@@ -368,8 +368,7 @@ static inline bool __cmpxchg_double_slab
const char *n)
{
VM_BUG_ON(!irqs_disabled());
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
+#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
if (s->flags & __CMPXCHG_DOUBLE) {
if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
freelist_old, counters_old,
@@ -404,8 +403,7 @@ static inline bool cmpxchg_double_slab(s
void *freelist_new, unsigned long counters_new,
const char *n)
{
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
+#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
if (s->flags & __CMPXCHG_DOUBLE) {
if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
freelist_old, counters_old,
@@ -3085,8 +3083,7 @@ static int kmem_cache_open(struct kmem_c
}
}
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
+#if defined(CONFIG_SLUB_ATTEMPT_CMPXCHG_DOUBLE)
if (system_has_cmpxchg_double() && (s->flags & SLAB_DEBUG_FLAGS) == 0)
/* Enable fast mode */
s->flags |= __CMPXCHG_DOUBLE;
_
From: Dave Hansen <[email protected]>
SLUB has some very unique alignment constraints it places
on 'struct page'. Break those out in to a separate structure
which will not pollute 'struct page'.
This structure will be moved around inside 'struct page' at
runtime in the next patch, so it is necessary to break it out for
those uses as well.
Vim pattern used for the renames:
%s/\(page\|new\)\(->\|\.\)\(freelist\|counters\)/slub_data(\1)\2\3/g
Signed-off-by: Dave Hansen <[email protected]>
---
linux.git-davehans/include/linux/mm_types.h | 66 ++++---
linux.git-davehans/mm/slab_common.c | 29 ++-
linux.git-davehans/mm/slub.c | 253 ++++++++++++++--------------
3 files changed, 192 insertions(+), 156 deletions(-)
diff -puN include/linux/mm_types.h~slub-rearrange include/linux/mm_types.h
--- linux.git/include/linux/mm_types.h~slub-rearrange 2014-01-02 13:40:30.733330787 -0800
+++ linux.git-davehans/include/linux/mm_types.h 2014-01-02 15:24:43.756840049 -0800
@@ -23,6 +23,43 @@
struct address_space;
+struct slub_data {
+ void *unused;
+ void *freelist;
+ union {
+ struct {
+ unsigned inuse:16;
+ unsigned objects:15;
+ unsigned frozen:1;
+ atomic_t dontuse_slub_count;
+ };
+ /*
+ * ->counters is used to make it easier to copy
+ * all of the above counters in one chunk.
+ * The actual counts are never accessed via this.
+ */
+#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
+ defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
+ unsigned long counters;
+#else
+ /*
+ * Keep _count separate from slub cmpxchg_double data.
+ * As the rest of the double word is protected by
+ * slab_lock but _count is not.
+ */
+ struct {
+ unsigned counters;
+ /*
+ * This isn't used directly, but declare it here
+ * for clarity since it must line up with _count
+ * from 'struct page'
+ */
+ atomic_t separate_count;
+ };
+#endif
+ };
+};
+
#define USE_SPLIT_PTE_PTLOCKS (NR_CPUS >= CONFIG_SPLIT_PTLOCK_CPUS)
#define USE_SPLIT_PMD_PTLOCKS (USE_SPLIT_PTE_PTLOCKS && \
IS_ENABLED(CONFIG_ARCH_ENABLE_SPLIT_PMD_PTLOCK))
@@ -70,14 +107,7 @@ struct page {
atomic_t _count;
}; /* end of the "normal" use */
- struct { /* SLUB */
- void *unused;
- void *freelist;
- unsigned inuse:16;
- unsigned objects:15;
- unsigned frozen:1;
- atomic_t dontuse_slub_count;
- };
+ struct slub_data slub_data;
struct { /* SLAB */
void *s_mem;
void *slab_freelist;
@@ -90,26 +120,6 @@ struct page {
unsigned int units;
atomic_t dontuse_slob_count;
};
- /*
- * This is here to help the slub code deal with
- * its inuse/objects/frozen bitfields as a single
- * blob.
- */
- struct { /* slub helpers */
- void *slubhelp_unused;
- void *slubhelp_freelist;
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- unsigned long counters;
-#else
- /*
- * Keep _count separate from slub cmpxchg_double data.
- * As the rest of the double word is protected by
- * slab_lock but _count is not.
- */
- unsigned counters;
-#endif
- };
};
/* Third double word block */
diff -puN mm/slab_common.c~slub-rearrange mm/slab_common.c
--- linux.git/mm/slab_common.c~slub-rearrange 2014-01-02 13:40:30.735330876 -0800
+++ linux.git-davehans/mm/slab_common.c 2014-01-02 15:24:35.095449871 -0800
@@ -658,20 +658,39 @@ static int __init slab_proc_init(void)
}
module_init(slab_proc_init);
#endif /* CONFIG_SLABINFO */
+
#define SLAB_PAGE_CHECK(field1, field2) \
BUILD_BUG_ON(offsetof(struct page, field1) != \
offsetof(struct page, field2))
/*
* To make the layout of 'struct page' look nicer, we've broken
- * up a few of the unions. Folks declaring their own use of the
- * first few fields need to make sure that their use does not
- * interfere with page->_count. This ensures that the individual
- * users' use actually lines up with the real ->_count.
+ * up a few of the unions. But, this has made it hard to see if
+ * any given use will interfere with page->_count.
+ *
+ * To work around this, each user declares their own _count field
+ * and we check them at build time to ensure that the independent
+ * definitions actually line up with the real ->_count.
*/
void slab_build_checks(void)
{
SLAB_PAGE_CHECK(_count, dontuse_slab_count);
- SLAB_PAGE_CHECK(_count, dontuse_slub_count);
+ SLAB_PAGE_CHECK(_count, slub_data.dontuse_slub_count);
SLAB_PAGE_CHECK(_count, dontuse_slob_count);
+
+ /*
+ * When doing a double-cmpxchg, the slub code sucks in
+ * _count. But, this is harmless since if _count is
+ * modified, the cmpxchg will fail. When not using a
+ * real cmpxchg, the slub code uses a lock. But, _count
+ * is not modified under that lock and updates can be
+ * lost if they race with one of the "faked" cmpxchg
+ * under that lock. This makes sure that the space we
+ * carve out for _count in that case actually lines up
+ * with the real _count.
+ */
+#if !(defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
+ defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE))
+ SLAB_PAGE_CHECK(_count, slub_data.separate_count);
+#endif
}
diff -puN mm/slub.c~slub-rearrange mm/slub.c
--- linux.git/mm/slub.c~slub-rearrange 2014-01-02 13:40:30.737330966 -0800
+++ linux.git-davehans/mm/slub.c 2014-01-02 15:27:23.607040821 -0800
@@ -52,8 +52,8 @@
* The slab_lock is only used for debugging and on arches that do not
* have the ability to do a cmpxchg_double. It only protects the second
* double word in the page struct. Meaning
- * A. page->freelist -> List of object free in a page
- * B. page->counters -> Counters of objects
+ * A. slub_data(page)->freelist -> List of object free in a page
+ * B. slub_data(page)->counters -> Counters of objects
* C. page->frozen -> frozen state
*
* If a slab is frozen then it is exempt from list management. It is not
@@ -237,6 +237,12 @@ static inline struct kmem_cache_node *ge
return s->node[node];
}
+static inline struct slub_data *slub_data(struct page *page)
+{
+ void *ptr = &page->slub_data;
+ return ptr;
+}
+
/* Verify that a pointer has an address that is valid within a slab page */
static inline int check_valid_pointer(struct kmem_cache *s,
struct page *page, const void *object)
@@ -247,7 +253,7 @@ static inline int check_valid_pointer(st
return 1;
base = page_address(page);
- if (object < base || object >= base + page->objects * s->size ||
+ if (object < base || object >= base + slub_data(page)->objects * s->size ||
(object - base) % s->size) {
return 0;
}
@@ -365,7 +371,7 @@ static inline bool __cmpxchg_double_slab
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&page->freelist, &page->counters,
+ if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
freelist_old, counters_old,
freelist_new, counters_new))
return 1;
@@ -373,10 +379,10 @@ static inline bool __cmpxchg_double_slab
#endif
{
slab_lock(page);
- if (page->freelist == freelist_old &&
- page->counters == counters_old) {
- page->freelist = freelist_new;
- page->counters = counters_new;
+ if (slub_data(page)->freelist == freelist_old &&
+ slub_data(page)->counters == counters_old) {
+ slub_data(page)->freelist = freelist_new;
+ slub_data(page)->counters = counters_new;
slab_unlock(page);
return 1;
}
@@ -401,7 +407,7 @@ static inline bool cmpxchg_double_slab(s
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&page->freelist, &page->counters,
+ if (cmpxchg_double(&slub_data(page)->freelist, &slub_data(page)->counters,
freelist_old, counters_old,
freelist_new, counters_new))
return 1;
@@ -412,10 +418,10 @@ static inline bool cmpxchg_double_slab(s
local_irq_save(flags);
slab_lock(page);
- if (page->freelist == freelist_old &&
- page->counters == counters_old) {
- page->freelist = freelist_new;
- page->counters = counters_new;
+ if (slub_data(page)->freelist == freelist_old &&
+ slub_data(page)->counters == counters_old) {
+ slub_data(page)->freelist = freelist_new;
+ slub_data(page)->counters = counters_new;
slab_unlock(page);
local_irq_restore(flags);
return 1;
@@ -446,7 +452,7 @@ static void get_map(struct kmem_cache *s
void *p;
void *addr = page_address(page);
- for (p = page->freelist; p; p = get_freepointer(s, p))
+ for (p = slub_data(page)->freelist; p; p = get_freepointer(s, p))
set_bit(slab_index(p, s, addr), map);
}
@@ -557,7 +563,8 @@ static void print_page_info(struct page
{
printk(KERN_ERR
"INFO: Slab 0x%p objects=%u used=%u fp=0x%p flags=0x%04lx\n",
- page, page->objects, page->inuse, page->freelist, page->flags);
+ page, slub_data(page)->objects, slub_data(page)->inuse,
+ slub_data(page)->freelist, page->flags);
}
@@ -843,14 +850,14 @@ static int check_slab(struct kmem_cache
}
maxobj = order_objects(compound_order(page), s->size, s->reserved);
- if (page->objects > maxobj) {
+ if (slub_data(page)->objects > maxobj) {
slab_err(s, page, "objects %u > max %u",
- s->name, page->objects, maxobj);
+ s->name, slub_data(page)->objects, maxobj);
return 0;
}
- if (page->inuse > page->objects) {
+ if (slub_data(page)->inuse > slub_data(page)->objects) {
slab_err(s, page, "inuse %u > max %u",
- s->name, page->inuse, page->objects);
+ s->name, slub_data(page)->inuse, slub_data(page)->objects);
return 0;
}
/* Slab_pad_check fixes things up after itself */
@@ -869,8 +876,8 @@ static int on_freelist(struct kmem_cache
void *object = NULL;
unsigned long max_objects;
- fp = page->freelist;
- while (fp && nr <= page->objects) {
+ fp = slub_data(page)->freelist;
+ while (fp && nr <= slub_data(page)->objects) {
if (fp == search)
return 1;
if (!check_valid_pointer(s, page, fp)) {
@@ -880,8 +887,8 @@ static int on_freelist(struct kmem_cache
set_freepointer(s, object, NULL);
} else {
slab_err(s, page, "Freepointer corrupt");
- page->freelist = NULL;
- page->inuse = page->objects;
+ slub_data(page)->freelist = NULL;
+ slub_data(page)->inuse = slub_data(page)->objects;
slab_fix(s, "Freelist cleared");
return 0;
}
@@ -896,16 +903,16 @@ static int on_freelist(struct kmem_cache
if (max_objects > MAX_OBJS_PER_PAGE)
max_objects = MAX_OBJS_PER_PAGE;
- if (page->objects != max_objects) {
+ if (slub_data(page)->objects != max_objects) {
slab_err(s, page, "Wrong number of objects. Found %d but "
- "should be %d", page->objects, max_objects);
- page->objects = max_objects;
+ "should be %d", slub_data(page)->objects, max_objects);
+ slub_data(page)->objects = max_objects;
slab_fix(s, "Number of objects adjusted.");
}
- if (page->inuse != page->objects - nr) {
+ if (slub_data(page)->inuse != slub_data(page)->objects - nr) {
slab_err(s, page, "Wrong object count. Counter is %d but "
- "counted were %d", page->inuse, page->objects - nr);
- page->inuse = page->objects - nr;
+ "counted were %d", slub_data(page)->inuse, slub_data(page)->objects - nr);
+ slub_data(page)->inuse = slub_data(page)->objects - nr;
slab_fix(s, "Object count adjusted.");
}
return search == NULL;
@@ -918,8 +925,8 @@ static void trace(struct kmem_cache *s,
printk(KERN_INFO "TRACE %s %s 0x%p inuse=%d fp=0x%p\n",
s->name,
alloc ? "alloc" : "free",
- object, page->inuse,
- page->freelist);
+ object, slub_data(page)->inuse,
+ slub_data(page)->freelist);
if (!alloc)
print_section("Object ", (void *)object,
@@ -1085,8 +1092,8 @@ bad:
* as used avoids touching the remaining objects.
*/
slab_fix(s, "Marking all objects used");
- page->inuse = page->objects;
- page->freelist = NULL;
+ slub_data(page)->inuse = slub_data(page)->objects;
+ slub_data(page)->freelist = NULL;
}
return 0;
}
@@ -1366,7 +1373,7 @@ static struct page *allocate_slab(struct
if (!page)
return NULL;
- page->objects = oo_objects(oo);
+ slub_data(page)->objects = oo_objects(oo);
mod_zone_page_state(page_zone(page),
(s->flags & SLAB_RECLAIM_ACCOUNT) ?
NR_SLAB_RECLAIMABLE : NR_SLAB_UNRECLAIMABLE,
@@ -1399,7 +1406,7 @@ static struct page *new_slab(struct kmem
goto out;
order = compound_order(page);
- inc_slabs_node(s, page_to_nid(page), page->objects);
+ inc_slabs_node(s, page_to_nid(page), slub_data(page)->objects);
memcg_bind_pages(s, order);
page->slab_cache = s;
__SetPageSlab(page);
@@ -1412,7 +1419,7 @@ static struct page *new_slab(struct kmem
memset(start, POISON_INUSE, PAGE_SIZE << order);
last = start;
- for_each_object(p, s, start, page->objects) {
+ for_each_object(p, s, start, slub_data(page)->objects) {
setup_object(s, page, last);
set_freepointer(s, last, p);
last = p;
@@ -1420,9 +1427,9 @@ static struct page *new_slab(struct kmem
setup_object(s, page, last);
set_freepointer(s, last, NULL);
- page->freelist = start;
- page->inuse = page->objects;
- page->frozen = 1;
+ slub_data(page)->freelist = start;
+ slub_data(page)->inuse = slub_data(page)->objects;
+ slub_data(page)->frozen = 1;
out:
return page;
}
@@ -1437,7 +1444,7 @@ static void __free_slab(struct kmem_cach
slab_pad_check(s, page);
for_each_object(p, s, page_address(page),
- page->objects)
+ slub_data(page)->objects)
check_object(s, page, p, SLUB_RED_INACTIVE);
}
@@ -1498,7 +1505,7 @@ static void free_slab(struct kmem_cache
static void discard_slab(struct kmem_cache *s, struct page *page)
{
- dec_slabs_node(s, page_to_nid(page), page->objects);
+ dec_slabs_node(s, page_to_nid(page), slub_data(page)->objects);
free_slab(s, page);
}
@@ -1548,23 +1555,23 @@ static inline void *acquire_slab(struct
* The old freelist is the list of objects for the
* per cpu allocation list.
*/
- freelist = page->freelist;
- counters = page->counters;
- new.counters = counters;
- *objects = new.objects - new.inuse;
+ freelist = slub_data(page)->freelist;
+ counters = slub_data(page)->counters;
+ slub_data(&new)->counters = counters;
+ *objects = slub_data(&new)->objects - slub_data(&new)->inuse;
if (mode) {
- new.inuse = page->objects;
- new.freelist = NULL;
+ slub_data(&new)->inuse = slub_data(page)->objects;
+ slub_data(&new)->freelist = NULL;
} else {
- new.freelist = freelist;
+ slub_data(&new)->freelist = freelist;
}
- VM_BUG_ON(new.frozen);
- new.frozen = 1;
+ VM_BUG_ON(slub_data(&new)->frozen);
+ slub_data(&new)->frozen = 1;
if (!__cmpxchg_double_slab(s, page,
freelist, counters,
- new.freelist, new.counters,
+ slub_data(&new)->freelist, slub_data(&new)->counters,
"acquire_slab"))
return NULL;
@@ -1789,7 +1796,7 @@ static void deactivate_slab(struct kmem_
struct page new;
struct page old;
- if (page->freelist) {
+ if (slub_data(page)->freelist) {
stat(s, DEACTIVATE_REMOTE_FREES);
tail = DEACTIVATE_TO_TAIL;
}
@@ -1807,16 +1814,16 @@ static void deactivate_slab(struct kmem_
unsigned long counters;
do {
- prior = page->freelist;
- counters = page->counters;
+ prior = slub_data(page)->freelist;
+ counters = slub_data(page)->counters;
set_freepointer(s, freelist, prior);
- new.counters = counters;
- new.inuse--;
- VM_BUG_ON(!new.frozen);
+ slub_data(&new)->counters = counters;
+ slub_data(&new)->inuse--;
+ VM_BUG_ON(!slub_data(&new)->frozen);
} while (!__cmpxchg_double_slab(s, page,
prior, counters,
- freelist, new.counters,
+ freelist, slub_data(&new)->counters,
"drain percpu freelist"));
freelist = nextfree;
@@ -1838,24 +1845,24 @@ static void deactivate_slab(struct kmem_
*/
redo:
- old.freelist = page->freelist;
- old.counters = page->counters;
- VM_BUG_ON(!old.frozen);
+ slub_data(&old)->freelist = slub_data(page)->freelist;
+ slub_data(&old)->counters = slub_data(page)->counters;
+ VM_BUG_ON(!slub_data(&old)->frozen);
/* Determine target state of the slab */
- new.counters = old.counters;
+ slub_data(&new)->counters = slub_data(&old)->counters;
if (freelist) {
- new.inuse--;
- set_freepointer(s, freelist, old.freelist);
- new.freelist = freelist;
+ slub_data(&new)->inuse--;
+ set_freepointer(s, freelist, slub_data(&old)->freelist);
+ slub_data(&new)->freelist = freelist;
} else
- new.freelist = old.freelist;
+ slub_data(&new)->freelist = slub_data(&old)->freelist;
- new.frozen = 0;
+ slub_data(&new)->frozen = 0;
- if (!new.inuse && n->nr_partial > s->min_partial)
+ if (!slub_data(&new)->inuse && n->nr_partial > s->min_partial)
m = M_FREE;
- else if (new.freelist) {
+ else if (slub_data(&new)->freelist) {
m = M_PARTIAL;
if (!lock) {
lock = 1;
@@ -1904,8 +1911,8 @@ redo:
l = m;
if (!__cmpxchg_double_slab(s, page,
- old.freelist, old.counters,
- new.freelist, new.counters,
+ slub_data(&old)->freelist, slub_data(&old)->counters,
+ slub_data(&new)->freelist, slub_data(&new)->counters,
"unfreezing slab"))
goto redo;
@@ -1950,21 +1957,21 @@ static void unfreeze_partials(struct kme
do {
- old.freelist = page->freelist;
- old.counters = page->counters;
- VM_BUG_ON(!old.frozen);
+ slub_data(&old)->freelist = slub_data(page)->freelist;
+ slub_data(&old)->counters = slub_data(page)->counters;
+ VM_BUG_ON(!slub_data(&old)->frozen);
- new.counters = old.counters;
- new.freelist = old.freelist;
+ slub_data(&new)->counters = slub_data(&old)->counters;
+ slub_data(&new)->freelist = slub_data(&old)->freelist;
- new.frozen = 0;
+ slub_data(&new)->frozen = 0;
} while (!__cmpxchg_double_slab(s, page,
- old.freelist, old.counters,
- new.freelist, new.counters,
+ slub_data(&old)->freelist, slub_data(&old)->counters,
+ slub_data(&new)->freelist, slub_data(&new)->counters,
"unfreezing slab"));
- if (unlikely(!new.inuse && n->nr_partial > s->min_partial)) {
+ if (unlikely(!slub_data(&new)->inuse && n->nr_partial > s->min_partial)) {
page->next = discard_page;
discard_page = page;
} else {
@@ -2028,7 +2035,7 @@ static void put_cpu_partial(struct kmem_
}
pages++;
- pobjects += page->objects - page->inuse;
+ pobjects += slub_data(page)->objects - slub_data(page)->inuse;
page->pages = pages;
page->pobjects = pobjects;
@@ -2101,7 +2108,7 @@ static inline int node_match(struct page
static int count_free(struct page *page)
{
- return page->objects - page->inuse;
+ return slub_data(page)->objects - slub_data(page)->inuse;
}
static unsigned long count_partial(struct kmem_cache_node *n,
@@ -2184,8 +2191,8 @@ static inline void *new_slab_objects(str
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
- freelist = page->freelist;
- page->freelist = NULL;
+ freelist = slub_data(page)->freelist;
+ slub_data(page)->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
@@ -2205,7 +2212,7 @@ static inline bool pfmemalloc_match(stru
}
/*
- * Check the page->freelist of a page and either transfer the freelist to the
+ * Check the ->freelist of a page and either transfer the freelist to the
* per cpu freelist or deactivate the page.
*
* The page is still frozen if the return value is not NULL.
@@ -2221,18 +2228,18 @@ static inline void *get_freelist(struct
void *freelist;
do {
- freelist = page->freelist;
- counters = page->counters;
+ freelist = slub_data(page)->freelist;
+ counters = slub_data(page)->counters;
- new.counters = counters;
- VM_BUG_ON(!new.frozen);
+ slub_data(&new)->counters = counters;
+ VM_BUG_ON(!slub_data(&new)->frozen);
- new.inuse = page->objects;
- new.frozen = freelist != NULL;
+ slub_data(&new)->inuse = slub_data(page)->objects;
+ slub_data(&new)->frozen = freelist != NULL;
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
- NULL, new.counters,
+ NULL, slub_data(&new)->counters,
"get_freelist"));
return freelist;
@@ -2319,7 +2326,7 @@ load_freelist:
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
- VM_BUG_ON(!c->page->frozen);
+ VM_BUG_ON(!slub_data(c->page)->frozen);
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
local_irq_restore(flags);
@@ -2533,13 +2540,13 @@ static void __slab_free(struct kmem_cach
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
- prior = page->freelist;
- counters = page->counters;
+ prior = slub_data(page)->freelist;
+ counters = slub_data(page)->counters;
set_freepointer(s, object, prior);
- new.counters = counters;
- was_frozen = new.frozen;
- new.inuse--;
- if ((!new.inuse || !prior) && !was_frozen) {
+ slub_data(&new)->counters = counters;
+ was_frozen = slub_data(&new)->frozen;
+ slub_data(&new)->inuse--;
+ if ((!slub_data(&new)->inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior)
@@ -2549,7 +2556,7 @@ static void __slab_free(struct kmem_cach
* We can defer the list move and instead
* freeze it.
*/
- new.frozen = 1;
+ slub_data(&new)->frozen = 1;
else { /* Needs to be taken off a list */
@@ -2569,7 +2576,7 @@ static void __slab_free(struct kmem_cach
} while (!cmpxchg_double_slab(s, page,
prior, counters,
- object, new.counters,
+ object, slub_data(&new)->counters,
"__slab_free"));
if (likely(!n)) {
@@ -2578,7 +2585,7 @@ static void __slab_free(struct kmem_cach
* If we just froze the page then put it onto the
* per cpu partial list.
*/
- if (new.frozen && !was_frozen) {
+ if (slub_data(&new)->frozen && !was_frozen) {
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
@@ -2591,7 +2598,7 @@ static void __slab_free(struct kmem_cach
return;
}
- if (unlikely(!new.inuse && n->nr_partial > s->min_partial))
+ if (unlikely(!slub_data(&new)->inuse && n->nr_partial > s->min_partial))
goto slab_empty;
/*
@@ -2877,18 +2884,18 @@ static void early_kmem_cache_node_alloc(
"in order to be able to continue\n");
}
- n = page->freelist;
+ n = slub_data(page)->freelist;
BUG_ON(!n);
- page->freelist = get_freepointer(kmem_cache_node, n);
- page->inuse = 1;
- page->frozen = 0;
+ slub_data(page)->freelist = get_freepointer(kmem_cache_node, n);
+ slub_data(page)->inuse = 1;
+ slub_data(page)->frozen = 0;
kmem_cache_node->node[node] = n;
#ifdef CONFIG_SLUB_DEBUG
init_object(kmem_cache_node, n, SLUB_RED_ACTIVE);
init_tracking(kmem_cache_node, n);
#endif
init_kmem_cache_node(n);
- inc_slabs_node(kmem_cache_node, node, page->objects);
+ inc_slabs_node(kmem_cache_node, node, slub_data(page)->objects);
add_partial(n, page, DEACTIVATE_TO_HEAD);
}
@@ -3144,7 +3151,7 @@ static void list_slab_objects(struct kme
#ifdef CONFIG_SLUB_DEBUG
void *addr = page_address(page);
void *p;
- unsigned long *map = kzalloc(BITS_TO_LONGS(page->objects) *
+ unsigned long *map = kzalloc(BITS_TO_LONGS(slub_data(page)->objects) *
sizeof(long), GFP_ATOMIC);
if (!map)
return;
@@ -3152,7 +3159,7 @@ static void list_slab_objects(struct kme
slab_lock(page);
get_map(s, page, map);
- for_each_object(p, s, addr, page->objects) {
+ for_each_object(p, s, addr, slub_data(page)->objects) {
if (!test_bit(slab_index(p, s, addr), map)) {
printk(KERN_ERR "INFO: Object 0x%p @offset=%tu\n",
@@ -3175,7 +3182,7 @@ static void free_partial(struct kmem_cac
struct page *page, *h;
list_for_each_entry_safe(page, h, &n->partial, lru) {
- if (!page->inuse) {
+ if (!slub_data(page)->inuse) {
remove_partial(n, page);
discard_slab(s, page);
} else {
@@ -3412,11 +3419,11 @@ int kmem_cache_shrink(struct kmem_cache
* Build lists indexed by the items in use in each slab.
*
* Note that concurrent frees may occur while we hold the
- * list_lock. page->inuse here is the upper limit.
+ * list_lock. ->inuse here is the upper limit.
*/
list_for_each_entry_safe(page, t, &n->partial, lru) {
- list_move(&page->lru, slabs_by_inuse + page->inuse);
- if (!page->inuse)
+ list_move(&page->lru, slabs_by_inuse + slub_data(page)->inuse);
+ if (!slub_data(page)->inuse)
n->nr_partial--;
}
@@ -3855,12 +3862,12 @@ void *__kmalloc_node_track_caller(size_t
#ifdef CONFIG_SYSFS
static int count_inuse(struct page *page)
{
- return page->inuse;
+ return slub_data(page)->inuse;
}
static int count_total(struct page *page)
{
- return page->objects;
+ return slub_data(page)->objects;
}
#endif
@@ -3876,16 +3883,16 @@ static int validate_slab(struct kmem_cac
return 0;
/* Now we know that a valid freelist exists */
- bitmap_zero(map, page->objects);
+ bitmap_zero(map, slub_data(page)->objects);
get_map(s, page, map);
- for_each_object(p, s, addr, page->objects) {
+ for_each_object(p, s, addr, slub_data(page)->objects) {
if (test_bit(slab_index(p, s, addr), map))
if (!check_object(s, page, p, SLUB_RED_INACTIVE))
return 0;
}
- for_each_object(p, s, addr, page->objects)
+ for_each_object(p, s, addr, slub_data(page)->objects)
if (!test_bit(slab_index(p, s, addr), map))
if (!check_object(s, page, p, SLUB_RED_ACTIVE))
return 0;
@@ -4086,10 +4093,10 @@ static void process_slab(struct loc_trac
void *addr = page_address(page);
void *p;
- bitmap_zero(map, page->objects);
+ bitmap_zero(map, slub_data(page)->objects);
get_map(s, page, map);
- for_each_object(p, s, addr, page->objects)
+ for_each_object(p, s, addr, slub_data(page)->objects)
if (!test_bit(slab_index(p, s, addr), map))
add_location(t, s, get_track(s, p, alloc));
}
@@ -4288,9 +4295,9 @@ static ssize_t show_slab_objects(struct
node = page_to_nid(page);
if (flags & SO_TOTAL)
- x = page->objects;
+ x = slub_data(page)->objects;
else if (flags & SO_OBJECTS)
- x = page->inuse;
+ x = slub_data(page)->inuse;
else
x = 1;
_
On Fri, 03 Jan 2014 10:01:47 -0800 Dave Hansen <[email protected]> wrote:
> This is a minor update from the last version. The most notable
> thing is that I was able to demonstrate that maintaining the
> cmpxchg16 optimization has _some_ value.
>
> Otherwise, the code changes are just a few minor cleanups.
>
> ---
>
> SLUB depends on a 16-byte cmpxchg for an optimization which
> allows it to not disable interrupts in its fast path. This
> optimization has some small but measurable benefits:
>
> http://lkml.kernel.org/r/[email protected]
So really the only significant benefit from the cmpxchg16 is with
cache-cold eight-byte kmalloc/kfree? 8% faster in this case? But with
cache-hot kmalloc/kfree the benefit of cmpxchg16 is precisely zero.
This is really weird and makes me suspect a measurement glitch.
Even if this 8% is real, it's unclear that it's worth all the
complexity the cmpxchg16 adds.
It would be really useful (hint :)) if we were to know exactly where
that 8% is coming from - perhaps it's something which is not directly
related to the cmpxchg16, and we can fix it separately.
On Fri, Jan 03, 2014 at 02:18:16PM -0800, Andrew Morton wrote:
> On Fri, 03 Jan 2014 10:01:47 -0800 Dave Hansen <[email protected]> wrote:
>
> > This is a minor update from the last version. The most notable
> > thing is that I was able to demonstrate that maintaining the
> > cmpxchg16 optimization has _some_ value.
> >
> > Otherwise, the code changes are just a few minor cleanups.
> >
> > ---
> >
> > SLUB depends on a 16-byte cmpxchg for an optimization which
> > allows it to not disable interrupts in its fast path. This
> > optimization has some small but measurable benefits:
> >
> > http://lkml.kernel.org/r/[email protected]
>
> So really the only significant benefit from the cmpxchg16 is with
> cache-cold eight-byte kmalloc/kfree? 8% faster in this case? But with
> cache-hot kmalloc/kfree the benefit of cmpxchg16 is precisely zero.
Hello,
I guess that cmpxchg16 is not used in this cache-hot kmalloc/kfree test,
because kfree would be done in free fast-path. In this case,
this_cpu_cmpxchg_double() would be called, so you cannot find any effect
of cmpxchg16.
Thanks.
>
> This is really weird and makes me suspect a measurement glitch.
>
> Even if this 8% is real, it's unclear that it's worth all the
> complexity the cmpxchg16 adds.
>
> It would be really useful (hint :)) if we were to know exactly where
> that 8% is coming from - perhaps it's something which is not directly
> related to the cmpxchg16, and we can fix it separately.
>
>
> --
> To unsubscribe, send a message with 'unsubscribe linux-mm' in
> the body to [email protected]. For more info on Linux MM,
> see: http://www.linux-mm.org/ .
> Don't email: <a href=mailto:"[email protected]"> [email protected] </a>
On 01/05/2014 08:32 PM, Joonsoo Kim wrote:
> On Fri, Jan 03, 2014 at 02:18:16PM -0800, Andrew Morton wrote:
>> On Fri, 03 Jan 2014 10:01:47 -0800 Dave Hansen <[email protected]> wrote:
>>> SLUB depends on a 16-byte cmpxchg for an optimization which
>>> allows it to not disable interrupts in its fast path. This
>>> optimization has some small but measurable benefits:
>>>
>>> http://lkml.kernel.org/r/[email protected]
>>
>> So really the only significant benefit from the cmpxchg16 is with
>> cache-cold eight-byte kmalloc/kfree? 8% faster in this case? But with
>> cache-hot kmalloc/kfree the benefit of cmpxchg16 is precisely zero.
>
> I guess that cmpxchg16 is not used in this cache-hot kmalloc/kfree test,
> because kfree would be done in free fast-path. In this case,
> this_cpu_cmpxchg_double() would be called, so you cannot find any effect
> of cmpxchg16.
That's a good point. I also confirmed this theory with the
free_{fast,slow}path slub counters. So, I ran another round of tests.
One important difference from the last round: I'm now writing to each
allocation. I originally did this so that I could store the allocations
in a linked-list, but I also realized that it's important. It's rare in
practice to do an allocation and not write _something_ to it. This
change adds a bit of cache pressure which changed the results pretty
substantially.
I tested 4 cases, all of these on the "cache-cold kfree()" case. The
first 3 are with vanilla upstream kernel source. The 4th is patched
with my new slub code (all single-threaded):
http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
There are a few important takeaways here:
1. The double-cmpxchg optimization has a measurable benefit
2. 64-byte 'struct page' is faster than the 56-byte one independent of
the cmpxchg optimization. Maybe because foo/sizeof(struct page) is
then a simple shift.
3. My new code is probably _slightly_ slower than the existing code,
but still has the huge space savings
4. All of these deltas are greatly magnified here and are hard or
impossible to demonstrate in practice.
Why does the double-cmpxchg help? The extra cache references that it
takes to go out and touch the paravirt structures and task struct to
disable interrupts in the spinlock cases start to show up and hurt our
allocation rates by about 30%. This advantage starts to evaporate when
there is more noise in the caches, or when we start to run the tests
across more cores.
But the real question here is whether we can shrink 'struct page'. The
existing (64-byte struct page) slub code wins on allocations under 256b
by as much as 5% (the 32-byte kmalloc()), but my new code wins on
allocations over 1k. 4k allocations just happen to be the most common
on my systems, and they're also very near the "sweet spot" for the new
code. But, the delta here is _much_ smaller that it was in the spinlock
vs. cmpxchg cases. This advantage also evaporates when we run things
across more cores or in less synthetic benchmarks.
I also explored that 5% hit that my code caused in the 32-byte
allocation case. It looked to me to be mostly explained by the code
that I added. There were more instructions executed and the
cycles-per-instruction went down. This looks to be mostly due to a ~15%
increase in branch misses, probably from the increased code size and
complexity.
This is the perf stat output for a run doing 16.8M kmalloc(32)/kfree()'s:
vanilla:
> 883,412 LLC-loads # 0.296 M/sec [39.76%]
> 566,546 LLC-load-misses # 64.13% of all LL-cache hits [39.98%]
patched:
> 556,751 LLC-loads # 0.186 M/sec [39.86%]
> 339,106 LLC-load-misses # 60.91% of all LL-cache hits [39.72%]
My best guess is that most of the LLC references are going out and
touching the struct pages for slab management. It's why we see such a
big change.
On Fri, 10 Jan 2014 12:52:32 -0800 Dave Hansen <[email protected]> wrote:
> On 01/05/2014 08:32 PM, Joonsoo Kim wrote:
> > On Fri, Jan 03, 2014 at 02:18:16PM -0800, Andrew Morton wrote:
> >> On Fri, 03 Jan 2014 10:01:47 -0800 Dave Hansen <[email protected]> wrote:
> >>> SLUB depends on a 16-byte cmpxchg for an optimization which
> >>> allows it to not disable interrupts in its fast path. This
> >>> optimization has some small but measurable benefits:
> >>>
> >>> http://lkml.kernel.org/r/[email protected]
> >>
> >> So really the only significant benefit from the cmpxchg16 is with
> >> cache-cold eight-byte kmalloc/kfree? 8% faster in this case? But with
> >> cache-hot kmalloc/kfree the benefit of cmpxchg16 is precisely zero.
> >
> > I guess that cmpxchg16 is not used in this cache-hot kmalloc/kfree test,
> > because kfree would be done in free fast-path. In this case,
> > this_cpu_cmpxchg_double() would be called, so you cannot find any effect
> > of cmpxchg16.
>
> That's a good point. I also confirmed this theory with the
> free_{fast,slow}path slub counters. So, I ran another round of tests.
>
> One important difference from the last round: I'm now writing to each
> allocation. I originally did this so that I could store the allocations
> in a linked-list, but I also realized that it's important. It's rare in
> practice to do an allocation and not write _something_ to it. This
> change adds a bit of cache pressure which changed the results pretty
> substantially.
>
> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> first 3 are with vanilla upstream kernel source. The 4th is patched
> with my new slub code (all single-threaded):
>
> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
So we're converging on the most complex option. argh.
> There are a few important takeaways here:
> 1. The double-cmpxchg optimization has a measurable benefit
> 2. 64-byte 'struct page' is faster than the 56-byte one independent of
> the cmpxchg optimization. Maybe because foo/sizeof(struct page) is
> then a simple shift.
> 3. My new code is probably _slightly_ slower than the existing code,
> but still has the huge space savings
> 4. All of these deltas are greatly magnified here and are hard or
> impossible to demonstrate in practice.
>
> Why does the double-cmpxchg help? The extra cache references that it
> takes to go out and touch the paravirt structures and task struct to
> disable interrupts in the spinlock cases start to show up and hurt our
> allocation rates by about 30%.
So all this testing was performed in a VM? If so, how much is that
likely to have impacted the results?
> This advantage starts to evaporate when
> there is more noise in the caches, or when we start to run the tests
> across more cores.
>
> But the real question here is whether we can shrink 'struct page'. The
> existing (64-byte struct page) slub code wins on allocations under 256b
> by as much as 5% (the 32-byte kmalloc()), but my new code wins on
> allocations over 1k. 4k allocations just happen to be the most common
> on my systems, and they're also very near the "sweet spot" for the new
> code. But, the delta here is _much_ smaller that it was in the spinlock
> vs. cmpxchg cases. This advantage also evaporates when we run things
> across more cores or in less synthetic benchmarks.
>
> I also explored that 5% hit that my code caused in the 32-byte
> allocation case. It looked to me to be mostly explained by the code
> that I added. There were more instructions executed and the
> cycles-per-instruction went down. This looks to be mostly due to a ~15%
> increase in branch misses, probably from the increased code size and
> complexity.
>
> This is the perf stat output for a run doing 16.8M kmalloc(32)/kfree()'s:
> vanilla:
> > 883,412 LLC-loads # 0.296 M/sec [39.76%]
> > 566,546 LLC-load-misses # 64.13% of all LL-cache hits [39.98%]
> patched:
> > 556,751 LLC-loads # 0.186 M/sec [39.86%]
> > 339,106 LLC-load-misses # 60.91% of all LL-cache hits [39.72%]
>
> My best guess is that most of the LLC references are going out and
> touching the struct pages for slab management. It's why we see such a
> big change.
On 01/10/2014 03:39 PM, Andrew Morton wrote:
>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
>> first 3 are with vanilla upstream kernel source. The 4th is patched
>> with my new slub code (all single-threaded):
>>
>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
>
> So we're converging on the most complex option. argh.
Yeah, looks that way.
> So all this testing was performed in a VM? If so, how much is that
> likely to have impacted the results?
Nope, none of it was in a VM. All the results here are from bare-metal.
On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <[email protected]> wrote:
> On 01/10/2014 03:39 PM, Andrew Morton wrote:
>>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
>>> first 3 are with vanilla upstream kernel source. The 4th is patched
>>> with my new slub code (all single-threaded):
>>>
>>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
>>
>> So we're converging on the most complex option. argh.
>
> Yeah, looks that way.
Seems like a reasonable compromise between memory usage and allocation speed.
Christoph?
Pekka
On Sat, 11 Jan 2014, Pekka Enberg wrote:
> On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <[email protected]> wrote:
> > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> >>> with my new slub code (all single-threaded):
> >>>
> >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> >>
> >> So we're converging on the most complex option. argh.
> >
> > Yeah, looks that way.
>
> Seems like a reasonable compromise between memory usage and allocation speed.
>
> Christoph?
Fundamentally I think this is good. I need to look at the details but I am
only going to be able to do that next week when I am back in the office.
On Sat, Jan 11, 2014 at 06:55:39PM -0600, Christoph Lameter wrote:
> On Sat, 11 Jan 2014, Pekka Enberg wrote:
>
> > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <[email protected]> wrote:
> > > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> > >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> > >>> with my new slub code (all single-threaded):
> > >>>
> > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> > >>
> > >> So we're converging on the most complex option. argh.
> > >
> > > Yeah, looks that way.
> >
> > Seems like a reasonable compromise between memory usage and allocation speed.
> >
> > Christoph?
>
> Fundamentally I think this is good. I need to look at the details but I am
> only going to be able to do that next week when I am back in the office.
Hello,
I have another guess about the performance result although I didn't look at
these patches in detail. I guess that performance win of 64-byte sturct on
small allocations can be caused by low latency when accessing slub's metadata,
that is, struct page.
Following is pages per slab via '/proc/slabinfo'.
size pages per slab
...
256 1
512 1
1024 2
2048 4
4096 8
8192 8
We only touch one struct page on small allocation.
In 64-byte case, we always use one cacheline for touching struct page, since
it is aligned to cacheline size. However, in 56-byte case, we possibly use
two cachelines because struct page isn't aligned to cacheline size.
This aspect can change on large allocation cases. For example, consider
4096-byte allocation case. In 64-byte case, it always touches 8 cachelines
for metadata, however, in 56-byte case, it touches 7 or 8 cachelines since
8 struct page occupies 8 * 56 bytes memory, that is, 7 cacheline size.
This guess may be wrong, so if you think it wrong, please ignore it. :)
And I have another opinion on this patchset. Diminishing struct page size
will affect other usecases beside the slub. As we know, Dave found this
by doing sequential 'dd'. I think that it may be the best case for 56-byte case.
If we randomly touch the struct page, this un-alignment can cause regression
since touching the struct page will cause two cachline misses. So, I think
that it is better to get more benchmark results to this patchset for convincing
ourselves. If possible, how about asking Fengguang to run whole set of
his benchmarks before going forward?
Thanks.
On Mon, 2014-01-13 at 10:44 +0900, Joonsoo Kim wrote:
> On Sat, Jan 11, 2014 at 06:55:39PM -0600, Christoph Lameter wrote:
> > On Sat, 11 Jan 2014, Pekka Enberg wrote:
> >
> > > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <[email protected]> wrote:
> > > > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> > > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> > > >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> > > >>> with my new slub code (all single-threaded):
> > > >>>
> > > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> > > >>
> > > >> So we're converging on the most complex option. argh.
> > > >
> > > > Yeah, looks that way.
> > >
> > > Seems like a reasonable compromise between memory usage and allocation speed.
> > >
> > > Christoph?
> >
> > Fundamentally I think this is good. I need to look at the details but I am
> > only going to be able to do that next week when I am back in the office.
>
> Hello,
>
> I have another guess about the performance result although I didn't look at
> these patches in detail. I guess that performance win of 64-byte sturct on
> small allocations can be caused by low latency when accessing slub's metadata,
> that is, struct page.
>
> Following is pages per slab via '/proc/slabinfo'.
>
> size pages per slab
> ...
> 256 1
> 512 1
> 1024 2
> 2048 4
> 4096 8
> 8192 8
>
> We only touch one struct page on small allocation.
> In 64-byte case, we always use one cacheline for touching struct page, since
> it is aligned to cacheline size. However, in 56-byte case, we possibly use
> two cachelines because struct page isn't aligned to cacheline size.
>
> This aspect can change on large allocation cases. For example, consider
> 4096-byte allocation case. In 64-byte case, it always touches 8 cachelines
> for metadata, however, in 56-byte case, it touches 7 or 8 cachelines since
> 8 struct page occupies 8 * 56 bytes memory, that is, 7 cacheline size.
>
> This guess may be wrong, so if you think it wrong, please ignore it. :)
>
> And I have another opinion on this patchset. Diminishing struct page size
> will affect other usecases beside the slub. As we know, Dave found this
> by doing sequential 'dd'. I think that it may be the best case for 56-byte case.
> If we randomly touch the struct page, this un-alignment can cause regression
> since touching the struct page will cause two cachline misses. So, I think
> that it is better to get more benchmark results to this patchset for convincing
> ourselves. If possible, how about asking Fengguang to run whole set of
> his benchmarks before going forward?
Cc'ing him.
> > So, I think
> > that it is better to get more benchmark results to this patchset for convincing
> > ourselves. If possible, how about asking Fengguang to run whole set of
> > his benchmarks before going forward?
>
> Cc'ing him.
My pleasure. Is there a git tree for the patches? Git trees
are most convenient for running automated tests and bisects.
Thanks,
Fengguang
On 01/13/2014 05:46 AM, Fengguang Wu wrote:
>>> So, I think
>>> that it is better to get more benchmark results to this patchset for convincing
>>> ourselves. If possible, how about asking Fengguang to run whole set of
>>> his benchmarks before going forward?
>>
>> Cc'ing him.
>
> My pleasure. Is there a git tree for the patches? Git trees
> are most convenient for running automated tests and bisects.
Here's a branch:
https://github.com/hansendc/linux/tree/slub-reshrink-for-Fengguang-20140113
My patches are not broken out in there, but that's all the code that
needs to get tested.
On 01/12/2014 05:44 PM, Joonsoo Kim wrote:
> We only touch one struct page on small allocation.
> In 64-byte case, we always use one cacheline for touching struct page, since
> it is aligned to cacheline size. However, in 56-byte case, we possibly use
> two cachelines because struct page isn't aligned to cacheline size.
I think you're completely correct that this can _happen_, but I'm a bit
unconvinced that what you're talking about is the thing which dominates
the results. I'm sure it plays a role, but the tests I was doing were
doing tens of millions of allocations and touching a _lot_ of 'struct
pages'. I would not expect these effects to be observable across such a
large sample of pages.
Dave: Please resend the newest form of the patchset. I do not have patch 0
and 1 and I do not see them on linux-mm.
On Sat, 11 Jan 2014, Christoph Lameter wrote:
> On Sat, 11 Jan 2014, Pekka Enberg wrote:
>
> > On Sat, Jan 11, 2014 at 1:42 AM, Dave Hansen <[email protected]> wrote:
> > > On 01/10/2014 03:39 PM, Andrew Morton wrote:
> > >>> I tested 4 cases, all of these on the "cache-cold kfree()" case. The
> > >>> first 3 are with vanilla upstream kernel source. The 4th is patched
> > >>> with my new slub code (all single-threaded):
> > >>>
> > >>> http://www.sr71.net/~dave/intel/slub/slub-perf-20140109.png
> > >>
> > >> So we're converging on the most complex option. argh.
> > >
> > > Yeah, looks that way.
> >
> > Seems like a reasonable compromise between memory usage and allocation speed.
> >
> > Christoph?
>
> Fundamentally I think this is good. I need to look at the details but I am
> only going to be able to do that next week when I am back in the office.
One easy way to shrink struct page is to simply remove the feature. The
patchset looked a bit complicated and does many other things.
Subject: slub: Remove struct page alignment restriction by dropping cmpxchg_double on struct page fields
Remove the logic that will do cmpxchg_doubles on struct page fields with
the requirement of double word alignment. This allows struct page
to shrink by 8 bytes.
Signed-off-by: Christoph Lameter <[email protected]>
Index: linux/include/linux/mm_types.h
===================================================================
--- linux.orig/include/linux/mm_types.h 2014-01-14 13:55:00.611838185 -0600
+++ linux/include/linux/mm_types.h 2014-01-14 13:55:00.601838496 -0600
@@ -73,18 +73,12 @@ struct page {
};
union {
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- /* Used for cmpxchg_double in slub */
- unsigned long counters;
-#else
/*
* Keep _count separate from slub cmpxchg_double data.
* As the rest of the double word is protected by
* slab_lock but _count is not.
*/
unsigned counters;
-#endif
struct {
@@ -195,15 +189,7 @@ struct page {
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
-}
-/*
- * The struct page can be forced to be double word aligned so that atomic ops
- * on double words work. The SLUB allocator can make use of such a feature.
- */
-#ifdef CONFIG_HAVE_ALIGNED_STRUCT_PAGE
- __aligned(2 * sizeof(unsigned long))
-#endif
-;
+};
struct page_frag {
struct page *page;
Index: linux/mm/slub.c
===================================================================
--- linux.orig/mm/slub.c 2014-01-14 13:55:00.611838185 -0600
+++ linux/mm/slub.c 2014-01-14 14:03:31.025903976 -0600
@@ -185,7 +185,6 @@ static inline bool kmem_cache_has_cpu_pa
/* Internal SLUB flags */
#define __OBJECT_POISON 0x80000000UL /* Poison object */
-#define __CMPXCHG_DOUBLE 0x40000000UL /* Use cmpxchg_double */
#ifdef CONFIG_SMP
static struct notifier_block slab_notifier;
@@ -362,34 +361,19 @@ static inline bool __cmpxchg_double_slab
const char *n)
{
VM_BUG_ON(!irqs_disabled());
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&page->freelist, &page->counters,
- freelist_old, counters_old,
- freelist_new, counters_new))
- return 1;
- } else
-#endif
- {
- slab_lock(page);
- if (page->freelist == freelist_old &&
- page->counters == counters_old) {
- page->freelist = freelist_new;
- page->counters = counters_new;
- slab_unlock(page);
- return 1;
- }
+
+ slab_lock(page);
+ if (page->freelist == freelist_old &&
+ page->counters == counters_old) {
+ page->freelist = freelist_new;
+ page->counters = counters_new;
slab_unlock(page);
+ return 1;
}
-
- cpu_relax();
stat(s, CMPXCHG_DOUBLE_FAIL);
-
#ifdef SLUB_DEBUG_CMPXCHG
printk(KERN_INFO "%s %s: cmpxchg double redo ", n, s->name);
#endif
-
return 0;
}
@@ -398,40 +382,14 @@ static inline bool cmpxchg_double_slab(s
void *freelist_new, unsigned long counters_new,
const char *n)
{
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- if (s->flags & __CMPXCHG_DOUBLE) {
- if (cmpxchg_double(&page->freelist, &page->counters,
- freelist_old, counters_old,
- freelist_new, counters_new))
- return 1;
- } else
-#endif
- {
- unsigned long flags;
-
- local_irq_save(flags);
- slab_lock(page);
- if (page->freelist == freelist_old &&
- page->counters == counters_old) {
- page->freelist = freelist_new;
- page->counters = counters_new;
- slab_unlock(page);
- local_irq_restore(flags);
- return 1;
- }
- slab_unlock(page);
- local_irq_restore(flags);
- }
-
- cpu_relax();
- stat(s, CMPXCHG_DOUBLE_FAIL);
-
-#ifdef SLUB_DEBUG_CMPXCHG
- printk(KERN_INFO "%s %s: cmpxchg double redo ", n, s->name);
-#endif
+ unsigned long flags;
+ int r;
- return 0;
+ local_irq_save(flags);
+ r = __cmpxchg_double_slab(s, page, freelist_old, counters_old,
+ freelist_new, counters_new, n);
+ local_irq_restore(flags);
+ return r;
}
#ifdef CONFIG_SLUB_DEBUG
@@ -3078,13 +3036,6 @@ static int kmem_cache_open(struct kmem_c
}
}
-#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
- defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
- if (system_has_cmpxchg_double() && (s->flags & SLAB_DEBUG_FLAGS) == 0)
- /* Enable fast mode */
- s->flags |= __CMPXCHG_DOUBLE;
-#endif
-
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
@@ -4608,10 +4559,8 @@ static ssize_t sanity_checks_store(struc
const char *buf, size_t length)
{
s->flags &= ~SLAB_DEBUG_FREE;
- if (buf[0] == '1') {
- s->flags &= ~__CMPXCHG_DOUBLE;
+ if (buf[0] == '1')
s->flags |= SLAB_DEBUG_FREE;
- }
return length;
}
SLAB_ATTR(sanity_checks);
@@ -4625,10 +4574,8 @@ static ssize_t trace_store(struct kmem_c
size_t length)
{
s->flags &= ~SLAB_TRACE;
- if (buf[0] == '1') {
- s->flags &= ~__CMPXCHG_DOUBLE;
+ if (buf[0] == '1')
s->flags |= SLAB_TRACE;
- }
return length;
}
SLAB_ATTR(trace);
@@ -4645,10 +4592,8 @@ static ssize_t red_zone_store(struct kme
return -EBUSY;
s->flags &= ~SLAB_RED_ZONE;
- if (buf[0] == '1') {
- s->flags &= ~__CMPXCHG_DOUBLE;
+ if (buf[0] == '1')
s->flags |= SLAB_RED_ZONE;
- }
calculate_sizes(s, -1);
return length;
}
@@ -4666,10 +4611,8 @@ static ssize_t poison_store(struct kmem_
return -EBUSY;
s->flags &= ~SLAB_POISON;
- if (buf[0] == '1') {
- s->flags &= ~__CMPXCHG_DOUBLE;
+ if (buf[0] == '1')
s->flags |= SLAB_POISON;
- }
calculate_sizes(s, -1);
return length;
}
@@ -4687,10 +4630,9 @@ static ssize_t store_user_store(struct k
return -EBUSY;
s->flags &= ~SLAB_STORE_USER;
- if (buf[0] == '1') {
- s->flags &= ~__CMPXCHG_DOUBLE;
+ if (buf[0] == '1')
s->flags |= SLAB_STORE_USER;
- }
+
calculate_sizes(s, -1);
return length;
}
Index: linux/arch/Kconfig
===================================================================
--- linux.orig/arch/Kconfig 2014-01-14 13:55:00.611838185 -0600
+++ linux/arch/Kconfig 2014-01-14 13:55:00.601838496 -0600
@@ -289,14 +289,6 @@ config HAVE_RCU_TABLE_FREE
config ARCH_HAVE_NMI_SAFE_CMPXCHG
bool
-config HAVE_ALIGNED_STRUCT_PAGE
- bool
- help
- This makes sure that struct pages are double word aligned and that
- e.g. the SLUB allocator can perform double word atomic operations
- on a struct page for better performance. However selecting this
- might increase the size of a struct page by a word.
-
config HAVE_CMPXCHG_LOCAL
bool
Index: linux/arch/s390/Kconfig
===================================================================
--- linux.orig/arch/s390/Kconfig 2014-01-14 13:55:00.611838185 -0600
+++ linux/arch/s390/Kconfig 2014-01-14 13:55:00.601838496 -0600
@@ -102,7 +102,6 @@ config S390
select GENERIC_FIND_FIRST_BIT
select GENERIC_SMP_IDLE_THREAD
select GENERIC_TIME_VSYSCALL
- select HAVE_ALIGNED_STRUCT_PAGE if SLUB
select HAVE_ARCH_JUMP_LABEL if !MARCH_G5
select HAVE_ARCH_SECCOMP_FILTER
select HAVE_ARCH_TRACEHOOK
Index: linux/arch/x86/Kconfig
===================================================================
--- linux.orig/arch/x86/Kconfig 2014-01-14 13:55:00.611838185 -0600
+++ linux/arch/x86/Kconfig 2014-01-14 13:55:00.601838496 -0600
@@ -77,7 +77,6 @@ config X86
select HAVE_PERF_USER_STACK_DUMP
select HAVE_DEBUG_KMEMLEAK
select ANON_INODES
- select HAVE_ALIGNED_STRUCT_PAGE if SLUB
select HAVE_CMPXCHG_LOCAL
select HAVE_CMPXCHG_DOUBLE
select HAVE_ARCH_KMEMCHECK
On 01/14/2014 12:07 PM, Christoph Lameter wrote:
> One easy way to shrink struct page is to simply remove the feature. The
> patchset looked a bit complicated and does many other things.
Sure. There's a clear path if you only care about 'struct page' size,
or if you only care about making the slub fast path as fast as possible.
We've got three variables, though:
1. slub fast path speed
2. space overhead from 'struct page'
3. code complexity.
Arranged in three basic choices:
1. Big 'struct page', fast, medium complexity code
2. Small 'struct page', slow, lowest complexity
3. Small 'struct page', fast, highest complexity, risk of new code
The question is what we should do by _default_, and what we should be
recommending for our customers via the distros. Are you saying that you
think we should completely rule out even having option 1 in mainline?
On Tue, 14 Jan 2014, Dave Hansen wrote:
> On 01/14/2014 12:07 PM, Christoph Lameter wrote:
> > One easy way to shrink struct page is to simply remove the feature. The
> > patchset looked a bit complicated and does many other things.
>
> Sure. There's a clear path if you only care about 'struct page' size,
> or if you only care about making the slub fast path as fast as possible.
> We've got three variables, though:
>
> 1. slub fast path speed
The fast path does use this_cpu_cmpxchg_double which is something
different from a cmpxchg_double and its not used on struct page.
> Arranged in three basic choices:
>
> 1. Big 'struct page', fast, medium complexity code
> 2. Small 'struct page', slow, lowest complexity
The numbers that I see seem to indicate that a big struct page means slow.
> The question is what we should do by _default_, and what we should be
> recommending for our customers via the distros. Are you saying that you
> think we should completely rule out even having option 1 in mainline?
If option 1 is slower than option 2 then we do not need it.
On 01/16/2014 08:44 AM, Christoph Lameter wrote:
> On Tue, 14 Jan 2014, Dave Hansen wrote:
>
>> On 01/14/2014 12:07 PM, Christoph Lameter wrote:
>>> One easy way to shrink struct page is to simply remove the feature. The
>>> patchset looked a bit complicated and does many other things.
>>
>> Sure. There's a clear path if you only care about 'struct page' size,
>> or if you only care about making the slub fast path as fast as possible.
>> We've got three variables, though:
>>
>> 1. slub fast path speed
>
> The fast path does use this_cpu_cmpxchg_double which is something
> different from a cmpxchg_double and its not used on struct page.
Yeah, I'm confusing the two. I might as well say: "slub speed when
touching 'struct page'"
>> Arranged in three basic choices:
>>
>> 1. Big 'struct page', fast, medium complexity code
>> 2. Small 'struct page', slow, lowest complexity
>
> The numbers that I see seem to indicate that a big struct page means slow.
This was a really tight loop where the caches are really hot, but it did
show the large 'struct page' winning:
http://sr71.net/~dave/intel/slub/slub-perf-20140109.png
As I said in the earlier description, the paravirt code doing interrupt
disabling was what really hurt the two spinlock cases.
On Thu, 16 Jan 2014, Dave Hansen wrote:
> This was a really tight loop where the caches are really hot, but it did
> show the large 'struct page' winning:
>
> http://sr71.net/~dave/intel/slub/slub-perf-20140109.png
>
> As I said in the earlier description, the paravirt code doing interrupt
> disabling was what really hurt the two spinlock cases.
Hrm... Ok. in that case the additional complexity may be justified.
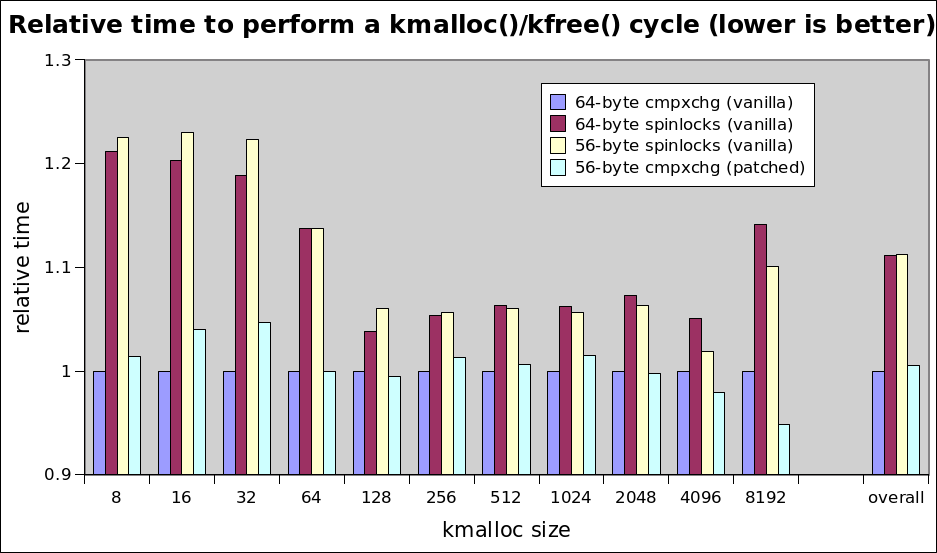{kind=link}
{kind=link}