On Wed, 2013-03-06 at 15:27 +0400, [email protected] wrote:
[...]
> Stack trace picture is here:
> http://vmx.yourcmc.ru/var/pics/IMG_20130306_141045.jpg
Vitaliy reported that his system crashes when suspending to disk. This
was a regression from 3.2 to 3.7, and remains in 3.8. Some details of
this system are in the bug log at <http://bugs.debian.org/700333>.
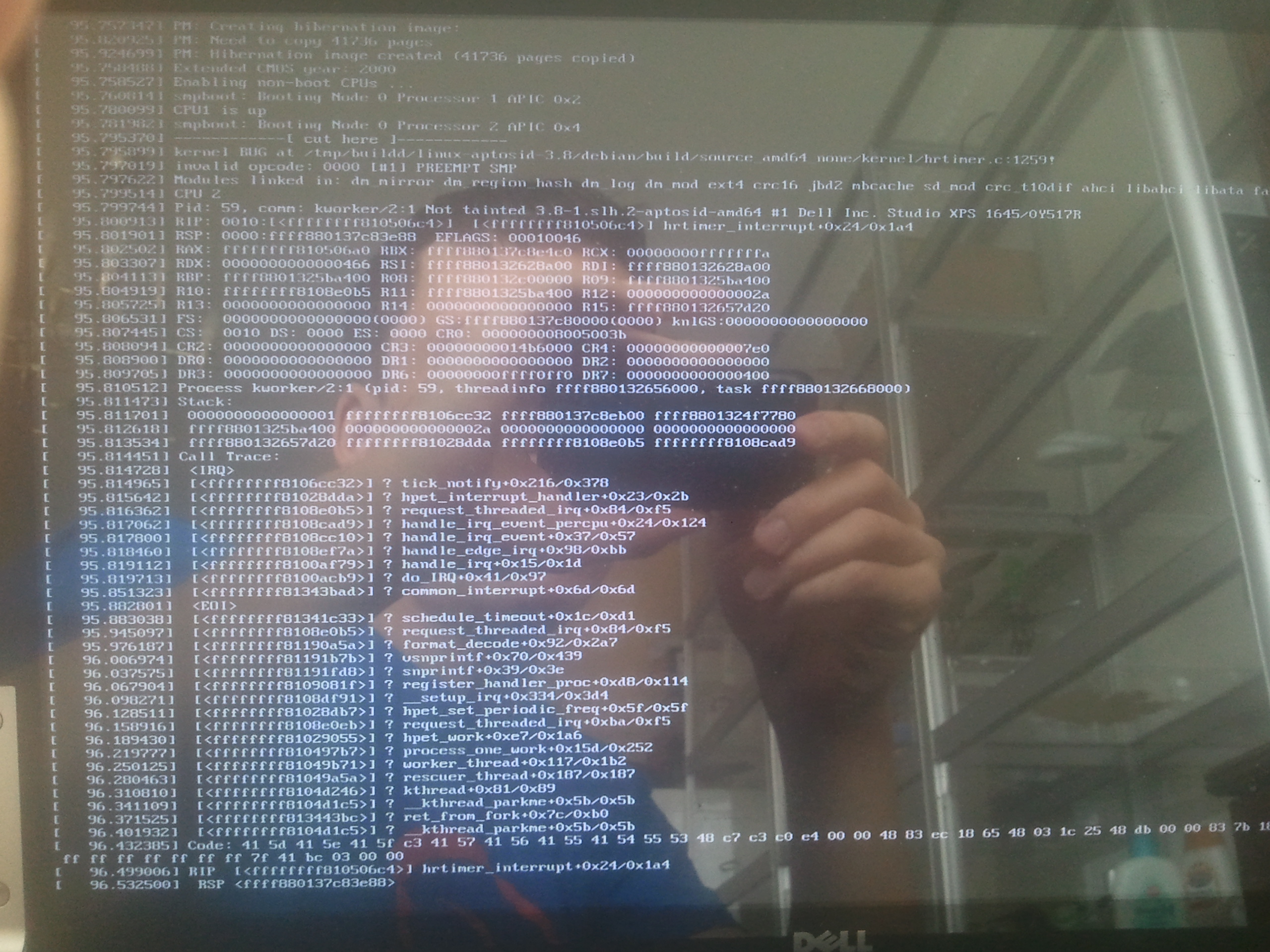
The photo shows a BUG in hrtimer_interrupt() after making the
hibernation image and while resuming the non-boot CPUs. The HPET
interrupt handler was called immediately after it was registered for CPU
2 (?), before the corresponding clock_event_device was registered.
Seems like an obvious race condition, but then shouldn't the HPET have
been stopped while the CPU was previously offlined? And it's strange
that this system apparently hits the race quite reliably.
Ben.
--
Ben Hutchings
The obvious mathematical breakthrough [to break modern encryption] would be
development of an easy way to factor large prime numbers. - Bill Gates
>> Stack trace picture is here:
>> http://vmx.yourcmc.ru/var/pics/IMG_20130306_141045.jpg
>
> Vitaliy reported that his system crashes when suspending to disk.
> This
> was a regression from 3.2 to 3.7, and remains in 3.8. Some details
> of
> this system are in the bug log at <http://bugs.debian.org/700333>.
>
> The photo shows a BUG in hrtimer_interrupt() after making the
> hibernation image and while resuming the non-boot CPUs. The HPET
> interrupt handler was called immediately after it was registered for
> CPU
> 2 (?), before the corresponding clock_event_device was registered.
>
> Seems like an obvious race condition, but then shouldn't the HPET
> have
> been stopped while the CPU was previously offlined? And it's strange
> that this system apparently hits the race quite reliably.
Anyone?
+ tglx.
On Sun, Apr 21, 2013 at 01:38:33AM +0400, [email protected] wrote:
> >>Stack trace picture is here:
> >>http://vmx.yourcmc.ru/var/pics/IMG_20130306_141045.jpg
> >
> >Vitaliy reported that his system crashes when suspending to disk.
> >This
> >was a regression from 3.2 to 3.7, and remains in 3.8. Some
> >details of
> >this system are in the bug log at <http://bugs.debian.org/700333>.
> >
> >The photo shows a BUG in hrtimer_interrupt() after making the
> >hibernation image and while resuming the non-boot CPUs. The HPET
> >interrupt handler was called immediately after it was registered
> >for CPU
> >2 (?), before the corresponding clock_event_device was registered.
> >
> >Seems like an obvious race condition, but then shouldn't the HPET
> >have
> >been stopped while the CPU was previously offlined? And it's strange
> >that this system apparently hits the race quite reliably.
>
> Anyone?
--
Regards/Gruss,
Boris.
Sent from a fat crate under my desk. Formatting is fine.
--
On Sun, 21 Apr 2013, Borislav Petkov wrote:
> + tglx.
>
> On Sun, Apr 21, 2013 at 01:38:33AM +0400, [email protected] wrote:
> > >>Stack trace picture is here:
> > >>http://vmx.yourcmc.ru/var/pics/IMG_20130306_141045.jpg
> > >
> > >Vitaliy reported that his system crashes when suspending to disk.
> > >This
> > >was a regression from 3.2 to 3.7, and remains in 3.8. Some
> > >details of
> > >this system are in the bug log at <http://bugs.debian.org/700333>.
> > >
> > >The photo shows a BUG in hrtimer_interrupt() after making the
> > >hibernation image and while resuming the non-boot CPUs. The HPET
> > >interrupt handler was called immediately after it was registered
> > >for CPU
> > >2 (?), before the corresponding clock_event_device was registered.
> > >
> > >Seems like an obvious race condition, but then shouldn't the HPET
> > >have
> > >been stopped while the CPU was previously offlined? And it's strange
> > >that this system apparently hits the race quite reliably.
> >
> > Anyone?
So what happens is, that the HPET seems to have an interrupt pending
and this gets immediately fired, when the handler is installed. The
core code does not remove the hpet->event_handler, so it calls into
the hrtimer_interrupt where it hits the BUG and dies.
With the patch below, the box should survive and we should see a
"Spurious HPET timer interrupt on HPET timer..." entry in dmesg.
That's a first workaround to confirm my theory. I'll look into the
HPET code how we can avoid that at all.
Thanks,
tglx
diff --git a/kernel/time/tick-common.c b/kernel/time/tick-common.c
index b1600a6..0f0ce6e 100644
--- a/kernel/time/tick-common.c
+++ b/kernel/time/tick-common.c
@@ -323,6 +323,7 @@ static void tick_shutdown(unsigned int *cpup)
*/
dev->mode = CLOCK_EVT_MODE_UNUSED;
clockevents_exchange_device(dev, NULL);
+ dev->event_handler = NULL;
td->evtdev = NULL;
}
raw_spin_unlock_irqrestore(&tick_device_lock, flags);
On Mon, 22 Apr 2013, Thomas Gleixner wrote:
> With the patch below, the box should survive and we should see a
>
> "Spurious HPET timer interrupt on HPET timer..." entry in dmesg.
>
> That's a first workaround to confirm my theory. I'll look into the
> HPET code how we can avoid that at all.
Looks like we can't do anything about that in the HPET code itself.
Vitaliy, could you try that patch ?
Thanks,
tglx
On Sat, Apr 27, 2013 at 07:08:42PM +0400, [email protected] wrote:
> >Looks like we can't do anything about that in the HPET code itself.
> >
> >Vitaliy, could you try that patch ?
>
> Thanks, I've tried it several days ago (and still using a patched
> kernel :)) - the box survives.
> But at which moment should I check for "Spurious interrupt" in dmesg?
When you do a suspend/resume cycle.
The bug says "The photo shows a BUG in hrtimer_interrupt() after making
the hibernation image and while resuming the non-boot CPUs." so I'm
guessing with Thomas' patch it suspends fine now?
--
Regards/Gruss,
Boris.
Sent from a fat crate under my desk. Formatting is fine.
--
> Looks like we can't do anything about that in the HPET code itself.
>
> Vitaliy, could you try that patch ?
Thanks, I've tried it several days ago (and still using a patched
kernel :)) - the box survives.
But at which moment should I check for "Spurious interrupt" in dmesg?
> When you do a suspend/resume cycle.
OK, yes, I've found it there.
> The bug says "The photo shows a BUG in hrtimer_interrupt() after
> making
> the hibernation image and while resuming the non-boot CPUs." so I'm
> guessing with Thomas' patch it suspends fine now?
Yeah, now I'm using a patched kernel and it's OK.
So, does it mean the problem is fixed by this patch or it's just
confirmed and should be fixed by another one?
On Sun, Apr 28, 2013 at 05:26:07PM +0400, [email protected] wrote:
> >When you do a suspend/resume cycle.
>
> OK, yes, I've found it there.
>
> >The bug says "The photo shows a BUG in hrtimer_interrupt() after
> >making
> >the hibernation image and while resuming the non-boot CPUs." so I'm
> >guessing with Thomas' patch it suspends fine now?
>
> Yeah, now I'm using a patched kernel and it's OK.
>
> So, does it mean the problem is fixed by this patch or it's just
> confirmed and should be fixed by another one?
Well, it makes sense to me, at least: we remove the handler on suspend
so that the HPET interrupt doesn't fire. If, when the box comes up
again, the pending interrupt is cleared, then all is fine - we can
safely register the handler again and everyone goes about their merry
way.
But don't worry, if Thomas has an idea, it is almost guaranteed you'll
get a proper fix soon. :-)
--
Regards/Gruss,
Boris.
Sent from a fat crate under my desk. Formatting is fine.
--
On Sun, 28 Apr 2013, Borislav Petkov wrote:
> On Sun, Apr 28, 2013 at 05:26:07PM +0400, [email protected] wrote:
> > >When you do a suspend/resume cycle.
> >
> > OK, yes, I've found it there.
> >
> > >The bug says "The photo shows a BUG in hrtimer_interrupt() after
> > >making
> > >the hibernation image and while resuming the non-boot CPUs." so I'm
> > >guessing with Thomas' patch it suspends fine now?
> >
> > Yeah, now I'm using a patched kernel and it's OK.
> >
> > So, does it mean the problem is fixed by this patch or it's just
> > confirmed and should be fixed by another one?
>
> Well, it makes sense to me, at least: we remove the handler on suspend
> so that the HPET interrupt doesn't fire. If, when the box comes up
> again, the pending interrupt is cleared, then all is fine - we can
> safely register the handler again and everyone goes about their merry
> way.
>
> But don't worry, if Thomas has an idea, it is almost guaranteed you'll
> get a proper fix soon. :-)
I merged a slightly better fix, you all were on cc. It's going into
3.10 and it's tagged stable, so it will show up in stable kernels
soon.
Thanks,
tglx
> I merged a slightly better fix, you all were on cc. It's going into
> 3.10 and it's tagged stable, so it will show up in stable kernels
> soon.
Thanks for the fix!
But where did you post it - on LKML?
(I didn't see it because I'm not subscribed to LKML?)
{kind=link}