Hi All,
Thanks a lot for the feedback so far!
One more respin after the last batch of comments from Peter and Frederic.
The previous summary that still applies:
On Sunday, March 4, 2018 11:21:30 PM CET Rafael J. Wysocki wrote:
>
> The problem is that if we stop the sched tick in
> tick_nohz_idle_enter() and then the idle governor predicts short idle
> duration, we lose regardless of whether or not it is right.
>
> If it is right, we've lost already, because we stopped the tick
> unnecessarily. If it is not right, we'll lose going forward, because
> the idle state selected by the governor is going to be too shallow and
> we'll draw too much power (that has been reported recently to actually
> happen often enough for people to care).
>
> This patch series is an attempt to improve the situation and the idea
> here is to make the decision whether or not to stop the tick deeper in
> the idle loop and in particular after running the idle state selection
> in the path where the idle governor is invoked. This way the problem
> can be avoided, because the idle duration predicted by the idle governor
> can be used to decide whether or not to stop the tick so that the tick
> is only stopped if that value is large enough (and, consequently, the
> idle state selected by the governor is deep enough).
>
> The series tires to avoid adding too much new code, rather reorder the
> existing code and make it more fine-grained.
>
> Patch 1 prepares the tick-sched code for the subsequent modifications and it
> doesn't change the code's functionality (at least not intentionally).
>
> Patch 2 starts pushing the tick stopping decision deeper into the idle
> loop, but that is limited to do_idle() and tick_nohz_irq_exit().
>
> Patch 3 makes cpuidle_idle_call() decide whether or not to stop the tick
> and sets the stage for the subsequent changes.
>
> Patch 4 adds a bool pointer argument to cpuidle_select() and the ->select
> governor callback allowing them to return a "nohz" hint on whether or not to
> stop the tick to the caller. It also adds code to decide what value to
> return as "nohz" to the menu governor.
>
> Patch 5 reorders the idle state selection with respect to the stopping of
> the tick and causes the additional "nohz" hint from cpuidle_select() to be
> used for deciding whether or not to stop the tick.
>
> Patch 6 causes the menu governor to refine the state selection in case the
> tick is not going to be stopped and the already selected state may not fit
> before the next tick time.
>
> Patch 7 Deals with the situation in which the tick was stopped previously,
> but the idle governor still predicts short idle.
This series is complementary to the poll_idle() patch at
https://patchwork.kernel.org/patch/10282237/
Thanks,
Rafael
From: Rafael J. Wysocki <[email protected]>
If the scheduler tick has been stopped already and the governor
selects a shallow idle state, the CPU can spend a long time in that
state if the selection is based on an inaccurate prediction of idle
time. That effect turns out to be noticeable, so it needs to be
mitigated.
To that end, modify the menu governor to discard the result of the
idle time prediction if the tick is stopped and the predicted idle
time is less than the tick period length, unless the tick timer is
going to expire soon.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Rebase on top of the new [1-6/7].
* Never use the interactivity factor when the tick is stopped.
---
drivers/cpuidle/governors/menu.c | 29 ++++++++++++++++++++++-------
1 file changed, 22 insertions(+), 7 deletions(-)
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -353,13 +353,28 @@ static int menu_select(struct cpuidle_dr
*/
data->predicted_us = min(data->predicted_us, expected_interval);
- /*
- * Use the performance multiplier and the user-configurable
- * latency_req to determine the maximum exit latency.
- */
- interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
- if (latency_req > interactivity_req)
- latency_req = interactivity_req;
+ if (tick_nohz_tick_stopped()) {
+ /*
+ * If the tick is already stopped, the cost of possible short
+ * idle duration misprediction is much higher, because the CPU
+ * may be stuck in a shallow idle state for a long time as a
+ * result of it. In that case say we might mispredict and try
+ * to force the CPU into a state for which we would have stopped
+ * the tick, unless the tick timer is going to expire really
+ * soon anyway.
+ */
+ if (data->predicted_us < TICK_USEC_HZ)
+ data->predicted_us = min_t(unsigned int, TICK_USEC_HZ,
+ ktime_to_us(tick_time));
+ } else {
+ /*
+ * Use the performance multiplier and the user-configurable
+ * latency_req to determine the maximum exit latency.
+ */
+ interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
+ if (latency_req > interactivity_req)
+ latency_req = interactivity_req;
+ }
expected_interval = data->predicted_us;
/*
From: Rafael J. Wysocki <[email protected]>
Push the decision whether or not to stop the tick somewhat deeper
into the idle loop.
Stopping the tick upfront leads to unpleasant outcomes in case the
idle governor doesn't agree with the nohz code on the duration of the
upcoming idle period. Specifically, if the tick has been stopped and
the idle governor predicts short idle, the situation is bad regardless
of whether or not the prediction is accurate. If it is accurate, the
tick has been stopped unnecessarily which means excessive overhead.
If it is not accurate, the CPU is likely to spend too much time in
the (shallow, because short idle has been predicted) idle state
selected by the governor [1].
As the first step towards addressing this problem, change the code
to make the tick stopping decision inside of the loop in do_idle().
In particular, do not stop the tick in the cpu_idle_poll() code path.
Also don't do that in tick_nohz_irq_exit() which doesn't really have
enough information on whether or not to stop the tick.
Link: https://marc.info/?l=linux-pm&m=150116085925208&w=2 # [1]
Link: https://tu-dresden.de/zih/forschung/ressourcen/dateien/projekte/haec/powernightmares.pdf
Suggested-by: Frederic Weisbecker <[email protected]>
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Restart the tick before cpu_idle_poll() as suggested by Frederic.
---
include/linux/tick.h | 2 ++
kernel/sched/idle.c | 9 ++++++---
kernel/time/tick-sched.c | 26 ++++++++++++++++++--------
3 files changed, 26 insertions(+), 11 deletions(-)
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -221,13 +221,13 @@ static void do_idle(void)
__current_set_polling();
tick_nohz_idle_enter();
- tick_nohz_idle_stop_tick_protected();
while (!need_resched()) {
check_pgt_cache();
rmb();
if (cpu_is_offline(cpu)) {
+ tick_nohz_idle_stop_tick_protected();
cpuhp_report_idle_dead();
arch_cpu_idle_dead();
}
@@ -241,10 +241,13 @@ static void do_idle(void)
* broadcast device expired for us, we don't want to go deep
* idle as we know that the IPI is going to arrive right away.
*/
- if (cpu_idle_force_poll || tick_check_broadcast_expired())
+ if (cpu_idle_force_poll || tick_check_broadcast_expired()) {
+ tick_nohz_idle_restart_tick();
cpu_idle_poll();
- else
+ } else {
+ tick_nohz_idle_stop_tick();
cpuidle_idle_call();
+ }
arch_cpu_idle_exit();
}
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -984,12 +984,10 @@ void tick_nohz_irq_exit(void)
{
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
- if (ts->inidle) {
+ if (ts->inidle)
tick_nohz_start_idle(ts);
- __tick_nohz_idle_stop_tick(ts);
- } else {
+ else
tick_nohz_full_update_tick(ts);
- }
}
/**
@@ -1050,6 +1048,20 @@ static void tick_nohz_account_idle_ticks
#endif
}
+static void __tick_nohz_idle_restart_tick(struct tick_sched *ts, ktime_t now)
+{
+ tick_nohz_restart_sched_tick(ts, now);
+ tick_nohz_account_idle_ticks(ts);
+}
+
+void tick_nohz_idle_restart_tick(void)
+{
+ struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, ktime_get());
+}
+
/**
* tick_nohz_idle_exit - restart the idle tick from the idle task
*
@@ -1074,10 +1086,8 @@ void tick_nohz_idle_exit(void)
if (ts->idle_active)
tick_nohz_stop_idle(ts, now);
- if (ts->tick_stopped) {
- tick_nohz_restart_sched_tick(ts, now);
- tick_nohz_account_idle_ticks(ts);
- }
+ if (ts->tick_stopped)
+ __tick_nohz_idle_restart_tick(ts, now);
local_irq_enable();
}
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -115,6 +115,7 @@ enum tick_dep_bits {
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
extern void tick_nohz_idle_stop_tick(void);
+extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
@@ -135,6 +136,7 @@ static inline void tick_nohz_idle_stop_t
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
static inline void tick_nohz_idle_stop_tick(void) { }
+static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
From: Rafael J. Wysocki <[email protected]>
Prepare the scheduler tick code for reworking the idle loop to
avoid stopping the tick in some cases.
The idea is to split the nohz idle entry call to decouple the idle
time stats accounting and preparatory work from the actual tick stop
code, in order to later be able to delay the tick stop once we reach
more power-knowledgeable callers.
Move away the tick_nohz_start_idle() invocation from
__tick_nohz_idle_enter(), rename the latter to
__tick_nohz_idle_stop_tick() and define tick_nohz_idle_stop_tick()
as a wrapper around it for calling it from the outside.
Make tick_nohz_idle_enter() only call tick_nohz_start_idle() instead
of calling the entire __tick_nohz_idle_enter(), add another wrapper
disabling and enabling interrupts around tick_nohz_idle_stop_tick()
and make the current callers of tick_nohz_idle_enter() call it too
to retain their current functionality.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Add the high-level description to the changelog as suggested by
Frederic.
* Make tick_nohz_idle_stop_tick_protected() do nothing for
CONFIG_NO_HZ_COMMON unset.
---
arch/x86/xen/smp_pv.c | 1 +
include/linux/tick.h | 12 ++++++++++++
kernel/sched/idle.c | 1 +
kernel/time/tick-sched.c | 46 +++++++++++++++++++++++++---------------------
4 files changed, 39 insertions(+), 21 deletions(-)
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -114,6 +114,7 @@ enum tick_dep_bits {
#ifdef CONFIG_NO_HZ_COMMON
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
+extern void tick_nohz_idle_stop_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
@@ -122,9 +123,18 @@ extern unsigned long tick_nohz_get_idle_
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
extern u64 get_cpu_idle_time_us(int cpu, u64 *last_update_time);
extern u64 get_cpu_iowait_time_us(int cpu, u64 *last_update_time);
+
+static inline void tick_nohz_idle_stop_tick_protected(void)
+{
+ local_irq_disable();
+ tick_nohz_idle_stop_tick();
+ local_irq_enable();
+}
+
#else /* !CONFIG_NO_HZ_COMMON */
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
+static inline void tick_nohz_idle_stop_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
@@ -134,6 +144,8 @@ static inline ktime_t tick_nohz_get_slee
}
static inline u64 get_cpu_idle_time_us(int cpu, u64 *unused) { return -1; }
static inline u64 get_cpu_iowait_time_us(int cpu, u64 *unused) { return -1; }
+
+static inline void tick_nohz_idle_stop_tick_protected(void) { }
#endif /* !CONFIG_NO_HZ_COMMON */
#ifdef CONFIG_NO_HZ_FULL
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -539,14 +539,11 @@ static void tick_nohz_stop_idle(struct t
sched_clock_idle_wakeup_event();
}
-static ktime_t tick_nohz_start_idle(struct tick_sched *ts)
+static void tick_nohz_start_idle(struct tick_sched *ts)
{
- ktime_t now = ktime_get();
-
- ts->idle_entrytime = now;
+ ts->idle_entrytime = ktime_get();
ts->idle_active = 1;
sched_clock_idle_sleep_event();
- return now;
}
/**
@@ -911,19 +908,21 @@ static bool can_stop_idle_tick(int cpu,
return true;
}
-static void __tick_nohz_idle_enter(struct tick_sched *ts)
+static void __tick_nohz_idle_stop_tick(struct tick_sched *ts)
{
- ktime_t now, expires;
+ ktime_t expires;
int cpu = smp_processor_id();
- now = tick_nohz_start_idle(ts);
-
if (can_stop_idle_tick(cpu, ts)) {
int was_stopped = ts->tick_stopped;
ts->idle_calls++;
- expires = tick_nohz_stop_sched_tick(ts, now, cpu);
+ /*
+ * The idle entry time should be a sufficient approximation of
+ * the current time at this point.
+ */
+ expires = tick_nohz_stop_sched_tick(ts, ts->idle_entrytime, cpu);
if (expires > 0LL) {
ts->idle_sleeps++;
ts->idle_expires = expires;
@@ -937,16 +936,19 @@ static void __tick_nohz_idle_enter(struc
}
/**
- * tick_nohz_idle_enter - stop the idle tick from the idle task
+ * tick_nohz_idle_stop_tick - stop the idle tick from the idle task
*
* When the next event is more than a tick into the future, stop the idle tick
- * Called when we start the idle loop.
- *
- * The arch is responsible of calling:
+ */
+void tick_nohz_idle_stop_tick(void)
+{
+ __tick_nohz_idle_stop_tick(this_cpu_ptr(&tick_cpu_sched));
+}
+
+/**
+ * tick_nohz_idle_enter - prepare for entering idle on the current CPU
*
- * - rcu_idle_enter() after its last use of RCU before the CPU is put
- * to sleep.
- * - rcu_idle_exit() before the first use of RCU after the CPU is woken up.
+ * Called when we start the idle loop.
*/
void tick_nohz_idle_enter(void)
{
@@ -965,7 +967,7 @@ void tick_nohz_idle_enter(void)
ts = this_cpu_ptr(&tick_cpu_sched);
ts->inidle = 1;
- __tick_nohz_idle_enter(ts);
+ tick_nohz_start_idle(ts);
local_irq_enable();
}
@@ -982,10 +984,12 @@ void tick_nohz_irq_exit(void)
{
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
- if (ts->inidle)
- __tick_nohz_idle_enter(ts);
- else
+ if (ts->inidle) {
+ tick_nohz_start_idle(ts);
+ __tick_nohz_idle_stop_tick(ts);
+ } else {
tick_nohz_full_update_tick(ts);
+ }
}
/**
Index: linux-pm/arch/x86/xen/smp_pv.c
===================================================================
--- linux-pm.orig/arch/x86/xen/smp_pv.c
+++ linux-pm/arch/x86/xen/smp_pv.c
@@ -425,6 +425,7 @@ static void xen_pv_play_dead(void) /* us
* data back is to call:
*/
tick_nohz_idle_enter();
+ tick_nohz_idle_stop_tick_protected();
cpuhp_online_idle(CPUHP_AP_ONLINE_IDLE);
}
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -221,6 +221,7 @@ static void do_idle(void)
__current_set_polling();
tick_nohz_idle_enter();
+ tick_nohz_idle_stop_tick_protected();
while (!need_resched()) {
check_pgt_cache();
From: Rafael J. Wysocki <[email protected]>
Make cpuidle_idle_call() decide whether or not to stop the tick.
First, the cpuidle_enter_s2idle() path deals with the tick (and with
the entire timekeeping for that matter) by itself and it doesn't need
the tick to be stopped beforehand.
Second, to address the issue with short idle duration predictions
by the idle governor after the tick has been stopped, it will be
necessary to change the ordering of cpuidle_select() with respect
to tick_nohz_idle_stop_tick(). To prepare for that, put a
tick_nohz_idle_stop_tick() call in the same branch in which
cpuidle_select() is called.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Rebase on top of the new [1-3/7].
---
kernel/sched/idle.c | 19 +++++++++++++++----
1 file changed, 15 insertions(+), 4 deletions(-)
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -146,13 +146,15 @@ static void cpuidle_idle_call(void)
}
/*
- * Tell the RCU framework we are entering an idle section,
- * so no more rcu read side critical sections and one more
+ * The RCU framework needs to be told that we are entering an idle
+ * section, so no more rcu read side critical sections and one more
* step to the grace period
*/
- rcu_idle_enter();
if (cpuidle_not_available(drv, dev)) {
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
default_idle_call();
goto exit_idle;
}
@@ -169,16 +171,26 @@ static void cpuidle_idle_call(void)
if (idle_should_enter_s2idle() || dev->use_deepest_state) {
if (idle_should_enter_s2idle()) {
+ rcu_idle_enter();
+
entered_state = cpuidle_enter_s2idle(drv, dev);
if (entered_state > 0) {
local_irq_enable();
goto exit_idle;
}
+
+ rcu_idle_exit();
}
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ tick_nohz_idle_stop_tick();
+ rcu_idle_enter();
+
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
@@ -245,7 +257,6 @@ static void do_idle(void)
tick_nohz_idle_restart_tick();
cpu_idle_poll();
} else {
- tick_nohz_idle_stop_tick();
cpuidle_idle_call();
}
arch_cpu_idle_exit();
From: Rafael J. Wysocki <[email protected]>
If the tick isn't stopped, the target residency of the state selected
by the menu governor may be greater than the actual time to the next
tick and that means lost energy.
To avoid that, make tick_nohz_get_sleep_length() return the current
time to the next event (before stopping the tick) in addition to the
estimated one via an extra pointer argument and make menu_select()
use that value to refine the state selection when necessary.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Rebase on top of the new [4/7].
* Look for a new state only if the tick isn't stopped already.
---
drivers/cpuidle/governors/menu.c | 25 ++++++++++++++++++++++---
include/linux/tick.h | 2 +-
kernel/time/tick-sched.c | 7 +++++--
3 files changed, 28 insertions(+), 6 deletions(-)
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -120,7 +120,7 @@ extern void tick_nohz_idle_restart_tick(
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
-extern ktime_t tick_nohz_get_sleep_length(void);
+extern ktime_t tick_nohz_get_sleep_length(ktime_t *cur_ret);
extern unsigned long tick_nohz_get_idle_calls(void);
extern unsigned long tick_nohz_get_idle_calls_cpu(int cpu);
extern u64 get_cpu_idle_time_us(int cpu, u64 *last_update_time);
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -1031,10 +1031,11 @@ void tick_nohz_irq_exit(void)
/**
* tick_nohz_get_sleep_length - return the expected length of the current sleep
+ * @cur_ret: pointer for returning the current time to the next event
*
* Called from power state control code with interrupts disabled
*/
-ktime_t tick_nohz_get_sleep_length(void)
+ktime_t tick_nohz_get_sleep_length(ktime_t *cur_ret)
{
struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
@@ -1047,6 +1048,8 @@ ktime_t tick_nohz_get_sleep_length(void)
WARN_ON_ONCE(!ts->inidle);
+ *cur_ret = ktime_sub(dev->next_event, now);
+
if (can_stop_idle_tick(cpu, ts)) {
ktime_t next_event = tick_nohz_next_event(ts, cpu);
@@ -1054,7 +1057,7 @@ ktime_t tick_nohz_get_sleep_length(void)
return ktime_sub(next_event, now);
}
- return ktime_sub(dev->next_event, now);
+ return *cur_ret;
}
/**
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -296,6 +296,7 @@ static int menu_select(struct cpuidle_dr
unsigned int expected_interval;
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
+ ktime_t tick_time;
if (data->needs_update) {
menu_update(drv, dev);
@@ -313,7 +314,7 @@ static int menu_select(struct cpuidle_dr
}
/* determine the expected residency time, round up */
- data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
+ data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length(&tick_time));
get_iowait_load(&nr_iowaiters, &cpu_load);
data->bucket = which_bucket(data->next_timer_us, nr_iowaiters);
@@ -396,9 +397,27 @@ static int menu_select(struct cpuidle_dr
* Don't stop the tick if the selected state is a polling one or if the
* expected idle duration is shorter than the tick period length.
*/
- if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
- expected_interval < TICK_USEC_HZ)
+ if (drv->states[idx].flags & CPUIDLE_FLAG_POLLING) {
*nohz_ret = false;
+ } else if (expected_interval < TICK_USEC_HZ) {
+ *nohz_ret = false;
+
+ if (!tick_nohz_tick_stopped()) {
+ unsigned int tick_us = ktime_to_us(tick_time);
+
+ /*
+ * Because the tick is not going to be stopped, make
+ * sure that the target residency of the state to be
+ * returned is within the time to the next timer event
+ * including the tick.
+ */
+ while (idx > 0 &&
+ (drv->states[idx].target_residency > tick_us ||
+ drv->states[idx].disabled ||
+ dev->states_usage[idx].disable))
+ idx--;
+ }
+ }
data->last_state_idx = idx;
From: Rafael J. Wysocki <[email protected]>
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0,
(2) the selected state is a polling one, or
(3) the expected idle period duration is within the tick period
range.
Since the value returned through the new argument pointer is not
used yet, this change is not expected to alter the functionality of
the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Simplify the code deciding what to return as 'nohz_ret' in
cpuidle_select(), add comments to explain what is going on.
---
drivers/cpuidle/cpuidle.c | 10 ++++++++--
drivers/cpuidle/governors/ladder.c | 3 ++-
drivers/cpuidle/governors/menu.c | 30 ++++++++++++++++++++++++++----
include/linux/cpuidle.h | 8 +++++---
kernel/sched/idle.c | 4 +++-
5 files changed, 44 insertions(+), 11 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *nohz_ret);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *nohz_ret)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *nohz_ret);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool nohz = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &nohz);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @nohz_ret: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @nohz_ret is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *nohz_ret)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, nohz_ret);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -275,12 +275,16 @@ again:
goto again;
}
+#define TICK_USEC_HZ ((USEC_PER_SEC + HZ/2) / HZ)
+
/**
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @nohz_ret: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *nohz_ret)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +307,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *nohz_ret = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = data->predicted_us;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -369,15 +376,30 @@ static int menu_select(struct cpuidle_dr
idx = i; /* first enabled state */
if (s->target_residency > data->predicted_us)
break;
- if (s->exit_latency > latency_req)
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons, use
+ * the target residency of the selected state as the
+ * expected idle duration so that the tick is retained
+ * as long as that target residency is low enough.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or if the
+ * expected idle duration is shorter than the tick period length.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC_HZ)
+ *nohz_ret = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
From: Rafael J. Wysocki <[email protected]>
In order to address the issue with short idle duration predictions
by the idle governor after the tick has been stopped, reorder the
code in cpuidle_idle_call() so that the governor idle state selection
runs before tick_nohz_idle_go_idle() and use the "nohz" hint returned
by cpuidle_select() to decide whether or not to stop the tick.
This isn't straightforward, because menu_select() invokes
tick_nohz_get_sleep_length() to get the time to the next timer
event and the number returned by the latter comes from
__tick_nohz_idle_enter(). Fortunately, however, it is possible
to compute that number without actually stopping the tick and with
the help of the existing code.
Namely, notice that tick_nohz_stop_sched_tick() already computes the
next timer event time to reprogram the scheduler tick hrtimer and
that time can be used as a proxy for the actual next timer event
time in the idle duration predicition. Moreover, it is possible
to split tick_nohz_stop_sched_tick() into two separate routines,
one computing the time to the next timer event and the other
simply stopping the tick when the time to the next timer event
is known.
Accordingly, split tick_nohz_stop_sched_tick() into
tick_nohz_next_event() and tick_nohz_stop_tick() and use the
former in tick_nohz_get_sleep_length(). Add two new extra fields,
timer_expires and timer_expires_base, to struct tick_sched for
passing data between these two new functions and to indicate that
tick_nohz_next_event() has run and tick_nohz_stop_tick() can be
called now. Also drop the now redundant sleep_length field from
there.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v4 -> v5:
* Rebase on top of the new [1-4/7].
---
include/linux/tick.h | 2
kernel/sched/idle.c | 11 ++-
kernel/time/tick-sched.c | 156 +++++++++++++++++++++++++++++++----------------
kernel/time/tick-sched.h | 6 +
4 files changed, 120 insertions(+), 55 deletions(-)
Index: linux-pm/kernel/time/tick-sched.h
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.h
+++ linux-pm/kernel/time/tick-sched.h
@@ -38,7 +38,8 @@ enum tick_nohz_mode {
* @idle_exittime: Time when the idle state was left
* @idle_sleeptime: Sum of the time slept in idle with sched tick stopped
* @iowait_sleeptime: Sum of the time slept in idle with sched tick stopped, with IO outstanding
- * @sleep_length: Duration of the current idle sleep
+ * @timer_expires: Anticipated timer expiration time (in case sched tick is stopped)
+ * @timer_expires_base: Base time clock monotonic for @timer_expires
* @do_timer_lst: CPU was the last one doing do_timer before going idle
*/
struct tick_sched {
@@ -58,8 +59,9 @@ struct tick_sched {
ktime_t idle_exittime;
ktime_t idle_sleeptime;
ktime_t iowait_sleeptime;
- ktime_t sleep_length;
unsigned long last_jiffies;
+ u64 timer_expires;
+ u64 timer_expires_base;
u64 next_timer;
ktime_t idle_expires;
int do_timer_last;
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -190,13 +190,18 @@ static void cpuidle_idle_call(void)
} else {
bool nohz = true;
- tick_nohz_idle_stop_tick();
- rcu_idle_enter();
-
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
next_state = cpuidle_select(drv, dev, &nohz);
+
+ if (nohz)
+ tick_nohz_idle_stop_tick();
+ else
+ tick_nohz_idle_retain_tick();
+
+ rcu_idle_enter();
+
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/kernel/time/tick-sched.c
===================================================================
--- linux-pm.orig/kernel/time/tick-sched.c
+++ linux-pm/kernel/time/tick-sched.c
@@ -652,13 +652,10 @@ static inline bool local_timer_softirq_p
return local_softirq_pending() & TIMER_SOFTIRQ;
}
-static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
- ktime_t now, int cpu)
+static ktime_t tick_nohz_next_event(struct tick_sched *ts, int cpu)
{
- struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
u64 basemono, next_tick, next_tmr, next_rcu, delta, expires;
unsigned long seq, basejiff;
- ktime_t tick;
/* Read jiffies and the time when jiffies were updated last */
do {
@@ -667,6 +664,7 @@ static ktime_t tick_nohz_stop_sched_tick
basejiff = jiffies;
} while (read_seqretry(&jiffies_lock, seq));
ts->last_jiffies = basejiff;
+ ts->timer_expires_base = basemono;
/*
* Keep the periodic tick, when RCU, architecture or irq_work
@@ -711,31 +709,24 @@ static ktime_t tick_nohz_stop_sched_tick
* next period, so no point in stopping it either, bail.
*/
if (!ts->tick_stopped) {
- tick = 0;
+ ts->timer_expires = 0;
goto out;
}
}
/*
- * If this CPU is the one which updates jiffies, then give up
- * the assignment and let it be taken by the CPU which runs
- * the tick timer next, which might be this CPU as well. If we
- * don't drop this here the jiffies might be stale and
- * do_timer() never invoked. Keep track of the fact that it
- * was the one which had the do_timer() duty last. If this CPU
- * is the one which had the do_timer() duty last, we limit the
- * sleep time to the timekeeping max_deferment value.
+ * If this CPU is the one which had the do_timer() duty last, we limit
+ * the sleep time to the timekeeping max_deferment value.
* Otherwise we can sleep as long as we want.
*/
delta = timekeeping_max_deferment();
- if (cpu == tick_do_timer_cpu) {
- tick_do_timer_cpu = TICK_DO_TIMER_NONE;
- ts->do_timer_last = 1;
- } else if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
- delta = KTIME_MAX;
- ts->do_timer_last = 0;
- } else if (!ts->do_timer_last) {
- delta = KTIME_MAX;
+ if (cpu != tick_do_timer_cpu) {
+ if (tick_do_timer_cpu != TICK_DO_TIMER_NONE) {
+ delta = KTIME_MAX;
+ ts->do_timer_last = 0;
+ } else if (!ts->do_timer_last) {
+ delta = KTIME_MAX;
+ }
}
#ifdef CONFIG_NO_HZ_FULL
@@ -750,14 +741,40 @@ static ktime_t tick_nohz_stop_sched_tick
else
expires = KTIME_MAX;
- expires = min_t(u64, expires, next_tick);
- tick = expires;
+ ts->timer_expires = min_t(u64, expires, next_tick);
+
+out:
+ return ts->timer_expires;
+}
+
+static void tick_nohz_stop_tick(struct tick_sched *ts, int cpu)
+{
+ struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
+ u64 basemono = ts->timer_expires_base;
+ u64 expires = ts->timer_expires;
+ ktime_t tick = expires;
+
+ /* Make sure we won't be trying to stop it twice in a row. */
+ ts->timer_expires_base = 0;
+
+ /*
+ * If this CPU is the one which updates jiffies, then give up
+ * the assignment and let it be taken by the CPU which runs
+ * the tick timer next, which might be this CPU as well. If we
+ * don't drop this here the jiffies might be stale and
+ * do_timer() never invoked. Keep track of the fact that it
+ * was the one which had the do_timer() duty last.
+ */
+ if (cpu == tick_do_timer_cpu) {
+ tick_do_timer_cpu = TICK_DO_TIMER_NONE;
+ ts->do_timer_last = 1;
+ }
/* Skip reprogram of event if its not changed */
if (ts->tick_stopped && (expires == ts->next_tick)) {
/* Sanity check: make sure clockevent is actually programmed */
if (tick == KTIME_MAX || ts->next_tick == hrtimer_get_expires(&ts->sched_timer))
- goto out;
+ return;
WARN_ON_ONCE(1);
printk_once("basemono: %llu ts->next_tick: %llu dev->next_event: %llu timer->active: %d timer->expires: %llu\n",
@@ -791,7 +808,7 @@ static ktime_t tick_nohz_stop_sched_tick
if (unlikely(expires == KTIME_MAX)) {
if (ts->nohz_mode == NOHZ_MODE_HIGHRES)
hrtimer_cancel(&ts->sched_timer);
- goto out;
+ return;
}
hrtimer_set_expires(&ts->sched_timer, tick);
@@ -800,15 +817,23 @@ static ktime_t tick_nohz_stop_sched_tick
hrtimer_start_expires(&ts->sched_timer, HRTIMER_MODE_ABS_PINNED);
else
tick_program_event(tick, 1);
-out:
- /*
- * Update the estimated sleep length until the next timer
- * (not only the tick).
- */
- ts->sleep_length = ktime_sub(dev->next_event, now);
- return tick;
}
+static void tick_nohz_retain_tick(struct tick_sched *ts)
+{
+ ts->timer_expires_base = 0;
+}
+
+#ifdef CONFIG_NO_HZ_FULL
+static void tick_nohz_stop_sched_tick(struct tick_sched *ts, int cpu)
+{
+ if (tick_nohz_next_event(ts, cpu))
+ tick_nohz_stop_tick(ts, cpu);
+ else
+ tick_nohz_retain_tick(ts);
+}
+#endif /* CONFIG_NO_HZ_FULL */
+
static void tick_nohz_restart_sched_tick(struct tick_sched *ts, ktime_t now)
{
/* Update jiffies first */
@@ -844,7 +869,7 @@ static void tick_nohz_full_update_tick(s
return;
if (can_stop_full_tick(cpu, ts))
- tick_nohz_stop_sched_tick(ts, ktime_get(), cpu);
+ tick_nohz_stop_sched_tick(ts, cpu);
else if (ts->tick_stopped)
tick_nohz_restart_sched_tick(ts, ktime_get());
#endif
@@ -870,10 +895,8 @@ static bool can_stop_idle_tick(int cpu,
return false;
}
- if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE)) {
- ts->sleep_length = NSEC_PER_SEC / HZ;
+ if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE))
return false;
- }
if (need_resched())
return false;
@@ -913,25 +936,33 @@ static void __tick_nohz_idle_stop_tick(s
ktime_t expires;
int cpu = smp_processor_id();
- if (can_stop_idle_tick(cpu, ts)) {
+ /*
+ * If tick_nohz_get_sleep_length() ran tick_nohz_next_event(), the
+ * tick timer expiration time is known already.
+ */
+ if (ts->timer_expires_base)
+ expires = ts->timer_expires;
+ else if (can_stop_idle_tick(cpu, ts))
+ expires = tick_nohz_next_event(ts, cpu);
+ else
+ return;
+
+ ts->idle_calls++;
+
+ if (expires > 0LL) {
int was_stopped = ts->tick_stopped;
- ts->idle_calls++;
+ tick_nohz_stop_tick(ts, cpu);
- /*
- * The idle entry time should be a sufficient approximation of
- * the current time at this point.
- */
- expires = tick_nohz_stop_sched_tick(ts, ts->idle_entrytime, cpu);
- if (expires > 0LL) {
- ts->idle_sleeps++;
- ts->idle_expires = expires;
- }
+ ts->idle_sleeps++;
+ ts->idle_expires = expires;
if (!was_stopped && ts->tick_stopped) {
ts->idle_jiffies = ts->last_jiffies;
nohz_balance_enter_idle(cpu);
}
+ } else {
+ tick_nohz_retain_tick(ts);
}
}
@@ -945,6 +976,11 @@ void tick_nohz_idle_stop_tick(void)
__tick_nohz_idle_stop_tick(this_cpu_ptr(&tick_cpu_sched));
}
+void tick_nohz_idle_retain_tick(void)
+{
+ tick_nohz_retain_tick(this_cpu_ptr(&tick_cpu_sched));
+}
+
/**
* tick_nohz_idle_enter - prepare for entering idle on the current CPU
*
@@ -957,7 +993,7 @@ void tick_nohz_idle_enter(void)
lockdep_assert_irqs_enabled();
/*
* Update the idle state in the scheduler domain hierarchy
- * when tick_nohz_stop_sched_tick() is called from the idle loop.
+ * when tick_nohz_stop_tick() is called from the idle loop.
* State will be updated to busy during the first busy tick after
* exiting idle.
*/
@@ -966,6 +1002,9 @@ void tick_nohz_idle_enter(void)
local_irq_disable();
ts = this_cpu_ptr(&tick_cpu_sched);
+
+ WARN_ON_ONCE(ts->timer_expires_base);
+
ts->inidle = 1;
tick_nohz_start_idle(ts);
@@ -991,15 +1030,31 @@ void tick_nohz_irq_exit(void)
}
/**
- * tick_nohz_get_sleep_length - return the length of the current sleep
+ * tick_nohz_get_sleep_length - return the expected length of the current sleep
*
* Called from power state control code with interrupts disabled
*/
ktime_t tick_nohz_get_sleep_length(void)
{
+ struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+ int cpu = smp_processor_id();
+ /*
+ * The idle entry time is expected to be a sufficient approximation of
+ * the current time at this point.
+ */
+ ktime_t now = ts->idle_entrytime;
+
+ WARN_ON_ONCE(!ts->inidle);
+
+ if (can_stop_idle_tick(cpu, ts)) {
+ ktime_t next_event = tick_nohz_next_event(ts, cpu);
+
+ if (next_event)
+ return ktime_sub(next_event, now);
+ }
- return ts->sleep_length;
+ return ktime_sub(dev->next_event, now);
}
/**
@@ -1077,6 +1132,7 @@ void tick_nohz_idle_exit(void)
local_irq_disable();
WARN_ON_ONCE(!ts->inidle);
+ WARN_ON_ONCE(ts->timer_expires_base);
ts->inidle = 0;
Index: linux-pm/include/linux/tick.h
===================================================================
--- linux-pm.orig/include/linux/tick.h
+++ linux-pm/include/linux/tick.h
@@ -115,6 +115,7 @@ enum tick_dep_bits {
extern bool tick_nohz_enabled;
extern int tick_nohz_tick_stopped(void);
extern void tick_nohz_idle_stop_tick(void);
+extern void tick_nohz_idle_retain_tick(void);
extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
extern void tick_nohz_idle_exit(void);
@@ -136,6 +137,7 @@ static inline void tick_nohz_idle_stop_t
#define tick_nohz_enabled (0)
static inline int tick_nohz_tick_stopped(void) { return 0; }
static inline void tick_nohz_idle_stop_tick(void) { }
+static inline void tick_nohz_idle_retain_tick(void) { }
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
static inline void tick_nohz_idle_exit(void) { }
Over the last week I tested v4+pollv2 and now v5+pollv3. With v5, I
observe a particular idle behavior, that I have not seen before with
v4. On a dual-socket Skylake system the idle power increases from
74.1 W (system total) to 85.5 W with a 300 HZ build and even to
138.3 W with a 1000 HZ build. A similar Haswell-EP system is also
affected.
There are phases during which one core will keep switching to the
highest C-state, but not disable the sched tick. Every 4th sched tick,
a kworker on that core is scheduled shortly. Every wakeup from C6 of a
single core will more than double the package power consumption of
*both8 sockets for ~500 us resulting in the significantly increased
sustained power consumption.
This is illustrated in [1]. For a comparison of a "normal" phase
(samekernel), see [2]. For a global view of the effect on a 1000 Hz
build, see [3].
I have not yet found any particular triggers or the specific
interaction between the sched tick and the kworker. I'm not sure how
this was introduced in v5. I would guess it could be a feedback loop
that I was concerned about initially.
I have more findings from v4, but this seems much more impactful.
[1] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/rjwv5_idle_300Hz.png
[2] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/rjwv5_idle_300Hz_ok.png
[3] https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/rjwv5_idle_1000Hz.png
On 2018-03-15 22:59, Rafael J. Wysocki wrote:
> Hi All,
>
> Thanks a lot for the feedback so far!
>
> One more respin after the last batch of comments from Peter and Frederic.
>
> The previous summary that still applies:
>
> On Sunday, March 4, 2018 11:21:30 PM CET Rafael J. Wysocki wrote:
>>
>> The problem is that if we stop the sched tick in
>> tick_nohz_idle_enter() and then the idle governor predicts short idle
>> duration, we lose regardless of whether or not it is right.
>>
>> If it is right, we've lost already, because we stopped the tick
>> unnecessarily. If it is not right, we'll lose going forward, because
>> the idle state selected by the governor is going to be too shallow and
>> we'll draw too much power (that has been reported recently to actually
>> happen often enough for people to care).
>>
>> This patch series is an attempt to improve the situation and the idea
>> here is to make the decision whether or not to stop the tick deeper in
>> the idle loop and in particular after running the idle state selection
>> in the path where the idle governor is invoked. This way the problem
>> can be avoided, because the idle duration predicted by the idle governor
>> can be used to decide whether or not to stop the tick so that the tick
>> is only stopped if that value is large enough (and, consequently, the
>> idle state selected by the governor is deep enough).
>>
>> The series tires to avoid adding too much new code, rather reorder the
>> existing code and make it more fine-grained.
>>
>> Patch 1 prepares the tick-sched code for the subsequent modifications and it
>> doesn't change the code's functionality (at least not intentionally).
>>
>> Patch 2 starts pushing the tick stopping decision deeper into the idle
>> loop, but that is limited to do_idle() and tick_nohz_irq_exit().
>>
>> Patch 3 makes cpuidle_idle_call() decide whether or not to stop the tick
>> and sets the stage for the subsequent changes.
>>
>> Patch 4 adds a bool pointer argument to cpuidle_select() and the ->select
>> governor callback allowing them to return a "nohz" hint on whether or not to
>> stop the tick to the caller. It also adds code to decide what value to
>> return as "nohz" to the menu governor.
>>
>> Patch 5 reorders the idle state selection with respect to the stopping of
>> the tick and causes the additional "nohz" hint from cpuidle_select() to be
>> used for deciding whether or not to stop the tick.
>>
>> Patch 6 causes the menu governor to refine the state selection in case the
>> tick is not going to be stopped and the already selected state may not fit
>> before the next tick time.
>>
>> Patch 7 Deals with the situation in which the tick was stopped previously,
>> but the idle governor still predicts short idle.
>
> This series is complementary to the poll_idle() patch at
>
> https://patchwork.kernel.org/patch/10282237/
>
> Thanks,
> Rafael
>
--
Dipl. Inf. Thomas Ilsche
Computer Scientist
Highly Adaptive Energy-Efficient Computing
CRC 912 HAEC: http://tu-dresden.de/sfb912
Technische Universität Dresden
Center for Information Services and High Performance Computing (ZIH)
01062 Dresden, Germany
Phone: +49 351 463-42168
Fax: +49 351 463-37773
E-Mail: [email protected]
On 2018.03.17 Thomas Ilsche wrote:
> Over the last week I tested v4+pollv2 and now v5+pollv3. With v5, I
> observe a particular idle behavior, that I have not seen before with
> v4. On a dual-socket Skylake system the idle power increases from
> 74.1 W (system total) to 85.5 W with a 300 HZ build and even to
> 138.3 W with a 1000 HZ build. A similar Haswell-EP system is also
> affected.
I confirm your idle findings. There is a regression between V4 and V5.
The differences on my test computer are much less than on yours,
probably because I have only 8 CPUs.
http://fast.smythies.com/rjw_idle.png
1000 Hz kernel only.
... Doug
On Saturday, March 17, 2018 5:11:53 PM CET Doug Smythies wrote:
> On 2018.03.17 Thomas Ilsche wrote:
>
> > Over the last week I tested v4+pollv2 and now v5+pollv3. With v5, I
> > observe a particular idle behavior, that I have not seen before with
> > v4. On a dual-socket Skylake system the idle power increases from
> > 74.1 W (system total) to 85.5 W with a 300 HZ build and even to
> > 138.3 W with a 1000 HZ build. A similar Haswell-EP system is also
> > affected.
>
> I confirm your idle findings. There is a regression between V4 and V5.
> The differences on my test computer are much less than on yours,
> probably because I have only 8 CPUs.
>
> http://fast.smythies.com/rjw_idle.png
>
> 1000 Hz kernel only.
Doug, Thomas,
Thank you both for the reports, much appreciated!
Below is a drop-in v6 replacement for patch [4/7].
With this new patch applied instead of the [4/7] the behavior should be much
more in line with the v4 behavior, so please try it if you can and let me know
if that really is the case on your systems.
Patches [5-7/7] from the original v5 apply on top of it right away for me,
but I've also created a git branch you can use to pull all of the series
with the below included:
git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
idle-loop
Thanks!
---
From: Rafael J. Wysocki <[email protected]>
Subject: [PATCH v6] cpuidle: Return nohz hint from cpuidle_select()
Add a new pointer argument to cpuidle_select() and to the ->select
cpuidle governor callback to allow a boolean value indicating
whether or not the tick should be stopped before entering the
selected state to be returned from there.
Make the ladder governor ignore that pointer (to preserve its
current behavior) and make the menu governor return 'false" through
it if:
(1) the idle exit latency is constrained at 0,
(2) the selected state is a polling one, or
(3) the selected state is not deep enough.
Since the value returned through the new argument pointer is not
used yet, this change is not expected to alter the functionality of
the code.
Signed-off-by: Rafael J. Wysocki <[email protected]>
---
v5 -> v6: Change tick stopping conditions in the menu governor to
be more in line with the v4 behavior.
---
drivers/cpuidle/cpuidle.c | 10 ++++++--
drivers/cpuidle/governors/ladder.c | 3 +-
drivers/cpuidle/governors/menu.c | 44 ++++++++++++++++++++++++++++++++-----
include/linux/cpuidle.h | 8 ++++--
kernel/sched/idle.c | 4 ++-
5 files changed, 57 insertions(+), 12 deletions(-)
Index: linux-pm/include/linux/cpuidle.h
===================================================================
--- linux-pm.orig/include/linux/cpuidle.h
+++ linux-pm/include/linux/cpuidle.h
@@ -135,7 +135,8 @@ extern bool cpuidle_not_available(struct
struct cpuidle_device *dev);
extern int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *nohz_ret);
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
@@ -167,7 +168,7 @@ static inline bool cpuidle_not_available
struct cpuidle_device *dev)
{return true; }
static inline int cpuidle_select(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *nohz_ret)
{return -ENODEV; }
static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
@@ -250,7 +251,8 @@ struct cpuidle_governor {
struct cpuidle_device *dev);
int (*select) (struct cpuidle_driver *drv,
- struct cpuidle_device *dev);
+ struct cpuidle_device *dev,
+ bool *nohz_ret);
void (*reflect) (struct cpuidle_device *dev, int index);
};
Index: linux-pm/kernel/sched/idle.c
===================================================================
--- linux-pm.orig/kernel/sched/idle.c
+++ linux-pm/kernel/sched/idle.c
@@ -188,13 +188,15 @@ static void cpuidle_idle_call(void)
next_state = cpuidle_find_deepest_state(drv, dev);
call_cpuidle(drv, dev, next_state);
} else {
+ bool nohz = true;
+
tick_nohz_idle_stop_tick();
rcu_idle_enter();
/*
* Ask the cpuidle framework to choose a convenient idle state.
*/
- next_state = cpuidle_select(drv, dev);
+ next_state = cpuidle_select(drv, dev, &nohz);
entered_state = call_cpuidle(drv, dev, next_state);
/*
* Give the governor an opportunity to reflect on the outcome
Index: linux-pm/drivers/cpuidle/cpuidle.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/cpuidle.c
+++ linux-pm/drivers/cpuidle/cpuidle.c
@@ -272,12 +272,18 @@ int cpuidle_enter_state(struct cpuidle_d
*
* @drv: the cpuidle driver
* @dev: the cpuidle device
+ * @nohz_ret: indication on whether or not to stop the tick
*
* Returns the index of the idle state. The return value must not be negative.
+ *
+ * The memory location pointed to by @nohz_ret is expected to be written the
+ * 'false' boolean value if the scheduler tick should not be stopped before
+ * entering the returned state.
*/
-int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+int cpuidle_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *nohz_ret)
{
- return cpuidle_curr_governor->select(drv, dev);
+ return cpuidle_curr_governor->select(drv, dev, nohz_ret);
}
/**
Index: linux-pm/drivers/cpuidle/governors/ladder.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/ladder.c
+++ linux-pm/drivers/cpuidle/governors/ladder.c
@@ -63,9 +63,10 @@ static inline void ladder_do_selection(s
* ladder_select_state - selects the next state to enter
* @drv: cpuidle driver
* @dev: the CPU
+ * @dummy: not used
*/
static int ladder_select_state(struct cpuidle_driver *drv,
- struct cpuidle_device *dev)
+ struct cpuidle_device *dev, bool *dummy)
{
struct ladder_device *ldev = this_cpu_ptr(&ladder_devices);
struct device *device = get_cpu_device(dev->cpu);
Index: linux-pm/drivers/cpuidle/governors/menu.c
===================================================================
--- linux-pm.orig/drivers/cpuidle/governors/menu.c
+++ linux-pm/drivers/cpuidle/governors/menu.c
@@ -275,12 +275,16 @@ again:
goto again;
}
+#define TICK_USEC_HZ ((USEC_PER_SEC + HZ/2) / HZ)
+
/**
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
* @dev: the CPU
+ * @nohz_ret: indication on whether or not to stop the tick
*/
-static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
+static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
+ bool *nohz_ret)
{
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
@@ -303,8 +307,10 @@ static int menu_select(struct cpuidle_dr
latency_req = resume_latency;
/* Special case when user has set very strict latency requirement */
- if (unlikely(latency_req == 0))
+ if (unlikely(latency_req == 0)) {
+ *nohz_ret = false;
return 0;
+ }
/* determine the expected residency time, round up */
data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
@@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
if (latency_req > interactivity_req)
latency_req = interactivity_req;
+ expected_interval = TICK_USEC_HZ;
/*
* Find the idle state with the lowest power while satisfying
* our constraints.
@@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
continue;
if (idx == -1)
idx = i; /* first enabled state */
- if (s->target_residency > data->predicted_us)
+ if (s->target_residency > data->predicted_us) {
+ /*
+ * Retain the tick if the selected state is shallower
+ * than the deepest available one with target residency
+ * within the tick period range.
+ *
+ * This allows the tick to be stopped even if the
+ * predicted idle duration is within the tick period
+ * range to counter the effect by which the prediction
+ * may be skewed towards lower values due to the tick
+ * bias.
+ */
+ expected_interval = s->target_residency;
break;
- if (s->exit_latency > latency_req)
+ }
+ if (s->exit_latency > latency_req) {
+ /*
+ * If we break out of the loop for latency reasons,
+ * retain the tick unless the target residency of the
+ * selected state is too high.
+ */
+ expected_interval = drv->states[idx].target_residency;
break;
-
+ }
idx = i;
}
if (idx == -1)
idx = 0; /* No states enabled. Must use 0. */
+ /*
+ * Don't stop the tick if the selected state is a polling one or it is
+ * not deep enough.
+ */
+ if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
+ expected_interval < TICK_USEC_HZ)
+ *nohz_ret = false;
+
data->last_state_idx = idx;
return data->last_state_idx;
On 2018.03.18 04:01 Rafael J. Wysocki wrote:
> Below is a drop-in v6 replacement for patch [4/7].
>
> With this new patch applied instead of the [4/7] the behavior should be much
> more in line with the v4 behavior, so please try it if you can and let me know
> if that really is the case on your systems.
Yes, the idle power is back down to V4 levels. (I did not do a new graph).
Some other data from this week (7 patch set + poll fix verses kernel 4.16-rc5):
pipe-test: The not cross core test is the most dramatic. Using CPU's 3 and 7,
or core 3, uses 6% less power and 18% performance improvement.
Graphs:
http://fast.smythies.com/pipe-test-one-core-power.png
http://fast.smythies.com/pipe-test-one-core-times.png
A couple of Phoronix tests (I didn't get very far yet):
himeno: 11% performance improvement; 14% less power.
compress-lzma: small performance improvement; small power improvement.
mafft: performance similar; small power improvement.
... Doug
On Sun, Mar 18, 2018 at 4:30 PM, Doug Smythies <[email protected]> wrote:
> On 2018.03.18 04:01 Rafael J. Wysocki wrote:
>
>> Below is a drop-in v6 replacement for patch [4/7].
>>
>> With this new patch applied instead of the [4/7] the behavior should be much
>> more in line with the v4 behavior, so please try it if you can and let me know
>> if that really is the case on your systems.
>
> Yes, the idle power is back down to V4 levels. (I did not do a new graph).
Awesome, thanks!
> Some other data from this week (7 patch set + poll fix verses kernel 4.16-rc5):
>
> pipe-test: The not cross core test is the most dramatic. Using CPU's 3 and 7,
> or core 3, uses 6% less power and 18% performance improvement.
>
> Graphs:
> http://fast.smythies.com/pipe-test-one-core-power.png
> http://fast.smythies.com/pipe-test-one-core-times.png
>
> A couple of Phoronix tests (I didn't get very far yet):
> himeno: 11% performance improvement; 14% less power.
> compress-lzma: small performance improvement; small power improvement.
> mafft: performance similar; small power improvement.
Great news, thank you!
On Sun, Mar 18, 2018 at 12:00 PM, Rafael J. Wysocki <[email protected]> wrote:
> On Saturday, March 17, 2018 5:11:53 PM CET Doug Smythies wrote:
>> On 2018.03.17 Thomas Ilsche wrote:
>>
>> > Over the last week I tested v4+pollv2 and now v5+pollv3. With v5, I
>> > observe a particular idle behavior, that I have not seen before with
>> > v4. On a dual-socket Skylake system the idle power increases from
>> > 74.1 W (system total) to 85.5 W with a 300 HZ build and even to
>> > 138.3 W with a 1000 HZ build. A similar Haswell-EP system is also
>> > affected.
>>
>> I confirm your idle findings. There is a regression between V4 and V5.
>> The differences on my test computer are much less than on yours,
>> probably because I have only 8 CPUs.
>>
>> http://fast.smythies.com/rjw_idle.png
>>
>> 1000 Hz kernel only.
>
> Doug, Thomas,
>
> Thank you both for the reports, much appreciated!
>
> Below is a drop-in v6 replacement for patch [4/7].
>
> With this new patch applied instead of the [4/7] the behavior should be much
> more in line with the v4 behavior, so please try it if you can and let me know
> if that really is the case on your systems.
>
> Patches [5-7/7] from the original v5 apply on top of it right away for me,
> but I've also created a git branch you can use to pull all of the series
> with the below included:
>
> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
> idle-loop
>
> Thanks!
>
> ---
> From: Rafael J. Wysocki <[email protected]>
> Subject: [PATCH v6] cpuidle: Return nohz hint from cpuidle_select()
>
> Add a new pointer argument to cpuidle_select() and to the ->select
> cpuidle governor callback to allow a boolean value indicating
> whether or not the tick should be stopped before entering the
> selected state to be returned from there.
>
> Make the ladder governor ignore that pointer (to preserve its
> current behavior) and make the menu governor return 'false" through
> it if:
> (1) the idle exit latency is constrained at 0,
> (2) the selected state is a polling one, or
> (3) the selected state is not deep enough.
>
> Since the value returned through the new argument pointer is not
> used yet, this change is not expected to alter the functionality of
> the code.
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
[cut]
> @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
> if (latency_req > interactivity_req)
> latency_req = interactivity_req;
>
> + expected_interval = TICK_USEC_HZ;
> /*
> * Find the idle state with the lowest power while satisfying
> * our constraints.
> @@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
> continue;
> if (idx == -1)
> idx = i; /* first enabled state */
> - if (s->target_residency > data->predicted_us)
> + if (s->target_residency > data->predicted_us) {
> + /*
> + * Retain the tick if the selected state is shallower
> + * than the deepest available one with target residency
> + * within the tick period range.
> + *
> + * This allows the tick to be stopped even if the
> + * predicted idle duration is within the tick period
> + * range to counter the effect by which the prediction
> + * may be skewed towards lower values due to the tick
> + * bias.
> + */
> + expected_interval = s->target_residency;
> break;
BTW, I guess I need to explain the motivation here more thoroughly, so
here it goes.
The governor predicts idle duration under the assumption that the
tick will be stopped, so if the result of the prediction is within the tick
period range and it is not accurate, that needs to be taken into
account in the governor's statistics. However, if the tick is allowed
to run every time the governor predicts idle duration within the tick
period range, the governor will always see that it was "almost
right" and the correction factor applied by it to improve the
prediction next time will not be sufficient. For this reason, it
is better to stop the tick at least sometimes when the governor
predicts idle duration within the tick period range and the idea
here is to do that when the selected state is the deepest available
one with the target residency within the tick period range. This
allows the opportunity to save more energy to be seized which
balances the extra overhead of stopping the tick.
HTH
On Thu, Mar 15, 2018 at 11:11:35PM +0100, Rafael J. Wysocki wrote:
I would suggest s/nohz_ret/stop_tick/ throughout, because I keep
forgetting which way around the boolean works and the new name doesn't
confuse.
> Index: linux-pm/drivers/cpuidle/governors/menu.c
> ===================================================================
> --- linux-pm.orig/drivers/cpuidle/governors/menu.c
> +++ linux-pm/drivers/cpuidle/governors/menu.c
> @@ -275,12 +275,16 @@ again:
> goto again;
> }
>
> +#define TICK_USEC_HZ ((USEC_PER_SEC + HZ/2) / HZ)
Do we want to put that next to TICK_NSEC?
Also, there are only 2 users of the existing TICK_USEC, do we want to:
s/TICK_USEC/USER_&/
and then rename the new thing to TICK_USEC ?
> /**
> * menu_select - selects the next idle state to enter
> * @drv: cpuidle driver containing state data
> * @dev: the CPU
> + * @nohz_ret: indication on whether or not to stop the tick
> */
> +static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
> + bool *nohz_ret)
> {
> struct menu_device *data = this_cpu_ptr(&menu_devices);
> struct device *device = get_cpu_device(dev->cpu);
> @@ -303,8 +307,10 @@ static int menu_select(struct cpuidle_dr
> latency_req = resume_latency;
>
> /* Special case when user has set very strict latency requirement */
> + if (unlikely(latency_req == 0)) {
> + *nohz_ret = false;
> return 0;
> + }
>
> /* determine the expected residency time, round up */
> data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
> @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
> if (latency_req > interactivity_req)
> latency_req = interactivity_req;
>
> + expected_interval = data->predicted_us;
> /*
> * Find the idle state with the lowest power while satisfying
> * our constraints.
> @@ -369,15 +376,30 @@ static int menu_select(struct cpuidle_dr
> idx = i; /* first enabled state */
> if (s->target_residency > data->predicted_us)
> break;
> + if (s->exit_latency > latency_req) {
> + /*
> + * If we break out of the loop for latency reasons, use
> + * the target residency of the selected state as the
> + * expected idle duration so that the tick is retained
> + * as long as that target residency is low enough.
> + */
> + expected_interval = drv->states[idx].target_residency;
> break;
> + }
> idx = i;
> }
>
> if (idx == -1)
> idx = 0; /* No states enabled. Must use 0. */
>
> + /*
> + * Don't stop the tick if the selected state is a polling one or if the
> + * expected idle duration is shorter than the tick period length.
> + */
> + if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
> + expected_interval < TICK_USEC_HZ)
> + *nohz_ret = false;
> +
> data->last_state_idx = idx;
>
> return data->last_state_idx;
Yes, much clearer, Thanks!
On Thu, Mar 15, 2018 at 11:16:41PM +0100, Rafael J. Wysocki wrote:
> --- linux-pm.orig/kernel/time/tick-sched.c
> +++ linux-pm/kernel/time/tick-sched.c
> @@ -1031,10 +1031,11 @@ void tick_nohz_irq_exit(void)
>
> /**
> * tick_nohz_get_sleep_length - return the expected length of the current sleep
> + * @cur_ret: pointer for returning the current time to the next event
Both name and description are confusing, what it actually appears to
return is the duration until the next event. Which would suggest a name
like: delta_next or something along those lines.
But 'cur' short for current, is very misleading.
On Mon, Mar 19, 2018 at 10:45 AM, Peter Zijlstra <[email protected]> wrote:
> On Thu, Mar 15, 2018 at 11:16:41PM +0100, Rafael J. Wysocki wrote:
>
>> --- linux-pm.orig/kernel/time/tick-sched.c
>> +++ linux-pm/kernel/time/tick-sched.c
>> @@ -1031,10 +1031,11 @@ void tick_nohz_irq_exit(void)
>>
>> /**
>> * tick_nohz_get_sleep_length - return the expected length of the current sleep
>> + * @cur_ret: pointer for returning the current time to the next event
>
> Both name and description are confusing, what it actually appears to
> return is the duration until the next event. Which would suggest a name
> like: delta_next or something along those lines.
>
> But 'cur' short for current, is very misleading.
OK, I'll change that.
Thanks!
On Mon, Mar 19, 2018 at 10:11 AM, Peter Zijlstra <[email protected]> wrote:
> On Thu, Mar 15, 2018 at 11:11:35PM +0100, Rafael J. Wysocki wrote:
>
> I would suggest s/nohz_ret/stop_tick/ throughout, because I keep
> forgetting which way around the boolean works and the new name doesn't
> confuse.
OK
>> Index: linux-pm/drivers/cpuidle/governors/menu.c
>> ===================================================================
>> --- linux-pm.orig/drivers/cpuidle/governors/menu.c
>> +++ linux-pm/drivers/cpuidle/governors/menu.c
>> @@ -275,12 +275,16 @@ again:
>> goto again;
>> }
>>
>> +#define TICK_USEC_HZ ((USEC_PER_SEC + HZ/2) / HZ)
>
> Do we want to put that next to TICK_NSEC?
That would be one change too far IMHO.
> Also, there are only 2 users of the existing TICK_USEC, do we want to:
>
> s/TICK_USEC/USER_&/
>
> and then rename the new thing to TICK_USEC ?
Well, that can be done.
>> /**
>> * menu_select - selects the next idle state to enter
>> * @drv: cpuidle driver containing state data
>> * @dev: the CPU
>> + * @nohz_ret: indication on whether or not to stop the tick
>> */
>> +static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev,
>> + bool *nohz_ret)
>> {
>> struct menu_device *data = this_cpu_ptr(&menu_devices);
>> struct device *device = get_cpu_device(dev->cpu);
>> @@ -303,8 +307,10 @@ static int menu_select(struct cpuidle_dr
>> latency_req = resume_latency;
>>
>> /* Special case when user has set very strict latency requirement */
>> + if (unlikely(latency_req == 0)) {
>> + *nohz_ret = false;
>> return 0;
>> + }
>>
>> /* determine the expected residency time, round up */
>> data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
>> @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
>> if (latency_req > interactivity_req)
>> latency_req = interactivity_req;
>>
>> + expected_interval = data->predicted_us;
>> /*
>> * Find the idle state with the lowest power while satisfying
>> * our constraints.
>> @@ -369,15 +376,30 @@ static int menu_select(struct cpuidle_dr
>> idx = i; /* first enabled state */
>> if (s->target_residency > data->predicted_us)
>> break;
>> + if (s->exit_latency > latency_req) {
>> + /*
>> + * If we break out of the loop for latency reasons, use
>> + * the target residency of the selected state as the
>> + * expected idle duration so that the tick is retained
>> + * as long as that target residency is low enough.
>> + */
>> + expected_interval = drv->states[idx].target_residency;
>> break;
>> + }
>> idx = i;
>> }
>>
>> if (idx == -1)
>> idx = 0; /* No states enabled. Must use 0. */
>>
>> + /*
>> + * Don't stop the tick if the selected state is a polling one or if the
>> + * expected idle duration is shorter than the tick period length.
>> + */
>> + if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
>> + expected_interval < TICK_USEC_HZ)
>> + *nohz_ret = false;
>> +
>> data->last_state_idx = idx;
>>
>> return data->last_state_idx;
>
> Yes, much clearer, Thanks!
But this has regressed since the v4, please see
https://patchwork.kernel.org/patch/10291097/
Thanks!
On Sun, Mar 18, 2018 at 05:15:22PM +0100, Rafael J. Wysocki wrote:
> On Sun, Mar 18, 2018 at 12:00 PM, Rafael J. Wysocki <[email protected]> wrote:
> > @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
> > if (latency_req > interactivity_req)
> > latency_req = interactivity_req;
> >
> > + expected_interval = TICK_USEC_HZ;
> > /*
> > * Find the idle state with the lowest power while satisfying
> > * our constraints.
> > @@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
> > continue;
> > if (idx == -1)
> > idx = i; /* first enabled state */
> > - if (s->target_residency > data->predicted_us)
> > + if (s->target_residency > data->predicted_us) {
> > + /*
> > + * Retain the tick if the selected state is shallower
> > + * than the deepest available one with target residency
> > + * within the tick period range.
> > + *
> > + * This allows the tick to be stopped even if the
> > + * predicted idle duration is within the tick period
> > + * range to counter the effect by which the prediction
> > + * may be skewed towards lower values due to the tick
> > + * bias.
> > + */
> > + expected_interval = s->target_residency;
> > break;
>
> BTW, I guess I need to explain the motivation here more thoroughly, so
> here it goes.
>
> The governor predicts idle duration under the assumption that the
> tick will be stopped, so if the result of the prediction is within the tick
> period range and it is not accurate, that needs to be taken into
> account in the governor's statistics. However, if the tick is allowed
> to run every time the governor predicts idle duration within the tick
> period range, the governor will always see that it was "almost
> right" and the correction factor applied by it to improve the
> prediction next time will not be sufficient. For this reason, it
> is better to stop the tick at least sometimes when the governor
> predicts idle duration within the tick period range and the idea
> here is to do that when the selected state is the deepest available
> one with the target residency within the tick period range. This
> allows the opportunity to save more energy to be seized which
> balances the extra overhead of stopping the tick.
My brain is just not willing to understand how that work this morning.
Also it sounds really dodgy.
Should we not look to something like this instead?
---
--- a/include/linux/tick.h
+++ b/include/linux/tick.h
@@ -119,6 +119,7 @@ extern void tick_nohz_idle_stop_tick(voi
extern void tick_nohz_idle_retain_tick(void);
extern void tick_nohz_idle_restart_tick(void);
extern void tick_nohz_idle_enter(void);
+extern bool tick_nohz_idle_got_tick(void);
extern void tick_nohz_idle_exit(void);
extern void tick_nohz_irq_exit(void);
extern ktime_t tick_nohz_get_sleep_length(void);
@@ -142,6 +143,7 @@ static inline void tick_nohz_idle_stop_t
static inline void tick_nohz_idle_retain_tick(void) { }
static inline void tick_nohz_idle_restart_tick(void) { }
static inline void tick_nohz_idle_enter(void) { }
+static inline bool tick_nohz_idle_got_tick(void) { return false; }
static inline void tick_nohz_idle_exit(void) { }
static inline ktime_t tick_nohz_get_sleep_length(void)
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -198,10 +198,13 @@ static void cpuidle_idle_call(void)
rcu_idle_enter();
entered_state = call_cpuidle(drv, dev, next_state);
- /*
- * Give the governor an opportunity to reflect on the outcome
- */
- cpuidle_reflect(dev, entered_state);
+
+ if (!tick_nohz_idle_got_tick()) {
+ /*
+ * Give the governor an opportunity to reflect on the outcome
+ */
+ cpuidle_reflect(dev, entered_state);
+ }
}
exit_idle:
--- a/kernel/time/tick-sched.c
+++ b/kernel/time/tick-sched.c
@@ -996,6 +996,21 @@ void tick_nohz_idle_enter(void)
local_irq_enable();
}
+bool tick_nohz_idle_got_tick(void)
+{
+ struct tick_sched *ts;
+ bool got_tick = false;
+
+ ts = this_cpu_ptr(&tick_cpu_sched);
+
+ if (ts->inidle == 2) {
+ got_tick = true;
+ ts->inidle = 1;
+ }
+
+ return got_tick;
+}
+
/**
* tick_nohz_irq_exit - update next tick event from interrupt exit
*
@@ -1142,6 +1157,9 @@ static void tick_nohz_handler(struct clo
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
dev->next_event = KTIME_MAX;
tick_sched_do_timer(now);
@@ -1239,6 +1257,9 @@ static enum hrtimer_restart tick_sched_t
struct pt_regs *regs = get_irq_regs();
ktime_t now = ktime_get();
+ if (ts->inidle)
+ ts->inidle = 2;
+
tick_sched_do_timer(now);
/*
On Mon, Mar 19, 2018 at 11:49 AM, Peter Zijlstra <[email protected]> wrote:
> On Sun, Mar 18, 2018 at 05:15:22PM +0100, Rafael J. Wysocki wrote:
>> On Sun, Mar 18, 2018 at 12:00 PM, Rafael J. Wysocki <[email protected]> wrote:
>> > @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
>> > if (latency_req > interactivity_req)
>> > latency_req = interactivity_req;
>> >
>> > + expected_interval = TICK_USEC_HZ;
>> > /*
>> > * Find the idle state with the lowest power while satisfying
>> > * our constraints.
>> > @@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
>> > continue;
>> > if (idx == -1)
>> > idx = i; /* first enabled state */
>> > - if (s->target_residency > data->predicted_us)
>> > + if (s->target_residency > data->predicted_us) {
>> > + /*
>> > + * Retain the tick if the selected state is shallower
>> > + * than the deepest available one with target residency
>> > + * within the tick period range.
>> > + *
>> > + * This allows the tick to be stopped even if the
>> > + * predicted idle duration is within the tick period
>> > + * range to counter the effect by which the prediction
>> > + * may be skewed towards lower values due to the tick
>> > + * bias.
>> > + */
>> > + expected_interval = s->target_residency;
>> > break;
>>
>> BTW, I guess I need to explain the motivation here more thoroughly, so
>> here it goes.
>>
>> The governor predicts idle duration under the assumption that the
>> tick will be stopped, so if the result of the prediction is within the tick
>> period range and it is not accurate, that needs to be taken into
>> account in the governor's statistics. However, if the tick is allowed
>> to run every time the governor predicts idle duration within the tick
>> period range, the governor will always see that it was "almost
>> right" and the correction factor applied by it to improve the
>> prediction next time will not be sufficient. For this reason, it
>> is better to stop the tick at least sometimes when the governor
>> predicts idle duration within the tick period range and the idea
>> here is to do that when the selected state is the deepest available
>> one with the target residency within the tick period range. This
>> allows the opportunity to save more energy to be seized which
>> balances the extra overhead of stopping the tick.
>
> My brain is just not willing to understand how that work this morning.
> Also it sounds really dodgy.
Well, I guess I can't really explain it better. :-)
The reason why this works better than the original v5 is because of
how menu_update() works AFAICS.
> Should we not look to something like this instead?
>
> ---
> --- a/include/linux/tick.h
> +++ b/include/linux/tick.h
> @@ -119,6 +119,7 @@ extern void tick_nohz_idle_stop_tick(voi
> extern void tick_nohz_idle_retain_tick(void);
> extern void tick_nohz_idle_restart_tick(void);
> extern void tick_nohz_idle_enter(void);
> +extern bool tick_nohz_idle_got_tick(void);
> extern void tick_nohz_idle_exit(void);
> extern void tick_nohz_irq_exit(void);
> extern ktime_t tick_nohz_get_sleep_length(void);
> @@ -142,6 +143,7 @@ static inline void tick_nohz_idle_stop_t
> static inline void tick_nohz_idle_retain_tick(void) { }
> static inline void tick_nohz_idle_restart_tick(void) { }
> static inline void tick_nohz_idle_enter(void) { }
> +static inline bool tick_nohz_idle_got_tick(void) { return false; }
> static inline void tick_nohz_idle_exit(void) { }
>
> static inline ktime_t tick_nohz_get_sleep_length(void)
> --- a/kernel/sched/idle.c
> +++ b/kernel/sched/idle.c
> @@ -198,10 +198,13 @@ static void cpuidle_idle_call(void)
> rcu_idle_enter();
>
> entered_state = call_cpuidle(drv, dev, next_state);
> - /*
> - * Give the governor an opportunity to reflect on the outcome
> - */
> - cpuidle_reflect(dev, entered_state);
> +
> + if (!tick_nohz_idle_got_tick()) {
> + /*
> + * Give the governor an opportunity to reflect on the outcome
> + */
> + cpuidle_reflect(dev, entered_state);
> + }
So I guess the idea is to only invoke menu_update() if the CPU was not
woken up by the tick, right?
I would check that in menu_reflect() (as the problem is really with
the menu governor and not general).
Also, do we really want to always disregard wakeups from the tick?
Say, if the governor predicted idle duration of a few microseconds and
the CPU is woken up by the tick, we want it to realize that it was way
off, don't we?
> }
>
> exit_idle:
> --- a/kernel/time/tick-sched.c
> +++ b/kernel/time/tick-sched.c
> @@ -996,6 +996,21 @@ void tick_nohz_idle_enter(void)
> local_irq_enable();
> }
>
> +bool tick_nohz_idle_got_tick(void)
> +{
> + struct tick_sched *ts;
> + bool got_tick = false;
> +
> + ts = this_cpu_ptr(&tick_cpu_sched);
> +
> + if (ts->inidle == 2) {
> + got_tick = true;
> + ts->inidle = 1;
> + }
> +
> + return got_tick;
> +}
Looks simple enough. :-)
> +
> /**
> * tick_nohz_irq_exit - update next tick event from interrupt exit
> *
> @@ -1142,6 +1157,9 @@ static void tick_nohz_handler(struct clo
> struct pt_regs *regs = get_irq_regs();
> ktime_t now = ktime_get();
>
> + if (ts->inidle)
> + ts->inidle = 2;
> +
> dev->next_event = KTIME_MAX;
>
> tick_sched_do_timer(now);
> @@ -1239,6 +1257,9 @@ static enum hrtimer_restart tick_sched_t
> struct pt_regs *regs = get_irq_regs();
> ktime_t now = ktime_get();
>
> + if (ts->inidle)
> + ts->inidle = 2;
> +
Why do we need to do it here?
> tick_sched_do_timer(now);
>
> /*
On Mon, Mar 19, 2018 at 12:36 PM, Rafael J. Wysocki <[email protected]> wrote:
> On Mon, Mar 19, 2018 at 11:49 AM, Peter Zijlstra <[email protected]> wrote:
>> On Sun, Mar 18, 2018 at 05:15:22PM +0100, Rafael J. Wysocki wrote:
>>> On Sun, Mar 18, 2018 at 12:00 PM, Rafael J. Wysocki <[email protected]> wrote:
>>> > @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
>>> > if (latency_req > interactivity_req)
>>> > latency_req = interactivity_req;
>>> >
>>> > + expected_interval = TICK_USEC_HZ;
>>> > /*
>>> > * Find the idle state with the lowest power while satisfying
>>> > * our constraints.
>>> > @@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
>>> > continue;
>>> > if (idx == -1)
>>> > idx = i; /* first enabled state */
>>> > - if (s->target_residency > data->predicted_us)
>>> > + if (s->target_residency > data->predicted_us) {
>>> > + /*
>>> > + * Retain the tick if the selected state is shallower
>>> > + * than the deepest available one with target residency
>>> > + * within the tick period range.
>>> > + *
>>> > + * This allows the tick to be stopped even if the
>>> > + * predicted idle duration is within the tick period
>>> > + * range to counter the effect by which the prediction
>>> > + * may be skewed towards lower values due to the tick
>>> > + * bias.
>>> > + */
>>> > + expected_interval = s->target_residency;
>>> > break;
>>>
>>> BTW, I guess I need to explain the motivation here more thoroughly, so
>>> here it goes.
>>>
>>> The governor predicts idle duration under the assumption that the
>>> tick will be stopped, so if the result of the prediction is within the tick
>>> period range and it is not accurate, that needs to be taken into
>>> account in the governor's statistics. However, if the tick is allowed
>>> to run every time the governor predicts idle duration within the tick
>>> period range, the governor will always see that it was "almost
>>> right" and the correction factor applied by it to improve the
>>> prediction next time will not be sufficient. For this reason, it
>>> is better to stop the tick at least sometimes when the governor
>>> predicts idle duration within the tick period range and the idea
>>> here is to do that when the selected state is the deepest available
>>> one with the target residency within the tick period range. This
>>> allows the opportunity to save more energy to be seized which
>>> balances the extra overhead of stopping the tick.
>>
>> My brain is just not willing to understand how that work this morning.
>> Also it sounds really dodgy.
>
> Well, I guess I can't really explain it better. :-)
>
> The reason why this works better than the original v5 is because of
> how menu_update() works AFAICS.
Actually, it looks like menu_update() doesn't do the right thing when
the tick isn't stopped at all, because data->next_timer_us is useless
then.
Let me try to fix that in a new respin of the series.
On 2018-03-15 23:19, Rafael J. Wysocki wrote:
> From: Rafael J. Wysocki <[email protected]>
>
> If the scheduler tick has been stopped already and the governor
> selects a shallow idle state, the CPU can spend a long time in that
> state if the selection is based on an inaccurate prediction of idle
> time. That effect turns out to be noticeable, so it needs to be
> mitigated.
What are some common causes for that situation?
How could I trigger this for testing?
> To that end, modify the menu governor to discard the result of the
> idle time prediction if the tick is stopped and the predicted idle
> time is less than the tick period length, unless the tick timer is
> going to expire soon.
This seems dangerous. Using a C-state that is too deep could be
problematic for soft latency, caches and overall energy.
Would it be viable to re-enable the sched tick to act as a fallback?
Generally, would it be feasible to modify the upcoming sched tick
timer to be a better time for a fallback wakeup in certain situations?
>
> Signed-off-by: Rafael J. Wysocki <[email protected]>
> ---
>
> v4 -> v5:
> * Rebase on top of the new [1-6/7].
> * Never use the interactivity factor when the tick is stopped.
>
> ---
> drivers/cpuidle/governors/menu.c | 29 ++++++++++++++++++++++-------
> 1 file changed, 22 insertions(+), 7 deletions(-)
>
> Index: linux-pm/drivers/cpuidle/governors/menu.c
> ===================================================================
> --- linux-pm.orig/drivers/cpuidle/governors/menu.c
> +++ linux-pm/drivers/cpuidle/governors/menu.c
> @@ -353,13 +353,28 @@ static int menu_select(struct cpuidle_dr
> */
> data->predicted_us = min(data->predicted_us, expected_interval);
>
> - /*
> - * Use the performance multiplier and the user-configurable
> - * latency_req to determine the maximum exit latency.
> - */
> - interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
> - if (latency_req > interactivity_req)
> - latency_req = interactivity_req;
> + if (tick_nohz_tick_stopped()) {
> + /*
> + * If the tick is already stopped, the cost of possible short
> + * idle duration misprediction is much higher, because the CPU
> + * may be stuck in a shallow idle state for a long time as a
> + * result of it. In that case say we might mispredict and try
> + * to force the CPU into a state for which we would have stopped
> + * the tick, unless the tick timer is going to expire really
> + * soon anyway.
> + */
> + if (data->predicted_us < TICK_USEC_HZ)
> + data->predicted_us = min_t(unsigned int, TICK_USEC_HZ,
> + ktime_to_us(tick_time));
This applies to the heuristic (expected_interval) and the (heuristically
corrected) next timer. Should this modification be applied only to the
expected_interval under the assumption that the next_timer_us * correction
is never totally wrong.
> + } else {
> + /*
> + * Use the performance multiplier and the user-configurable
> + * latency_req to determine the maximum exit latency.
> + */
> + interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
> + if (latency_req > interactivity_req)
> + latency_req = interactivity_req;
> + }
>
> expected_interval = data->predicted_us;
> /*
>
On Mon, Mar 19, 2018 at 12:36:52PM +0100, Rafael J. Wysocki wrote:
> > My brain is just not willing to understand how that work this morning.
> > Also it sounds really dodgy.
>
> Well, I guess I can't really explain it better. :-)
I'll try again once my brain decides to wake up.
> The reason why this works better than the original v5 is because of
> how menu_update() works AFAICS.
I'll have to go read that first then.
> > + if (!tick_nohz_idle_got_tick()) {
> > + /*
> > + * Give the governor an opportunity to reflect on the outcome
> > + */
> > + cpuidle_reflect(dev, entered_state);
> > + }
>
> So I guess the idea is to only invoke menu_update() if the CPU was not
> woken up by the tick, right?
>
> I would check that in menu_reflect() (as the problem is really with
> the menu governor and not general).
>
> Also, do we really want to always disregard wakeups from the tick?
>
> Say, if the governor predicted idle duration of a few microseconds and
> the CPU is woken up by the tick, we want it to realize that it was way
> off, don't we?
The way I look at it is that we should always disregard the tick for
wakeups. Such that we can make an unbiased decision on disabling it.
If the above simple method is the best way to achieve that, probably
not. Because now we 'loose' the idle time, instead of accumulating it.
> > }
> >
> > exit_idle:
> > --- a/kernel/time/tick-sched.c
> > +++ b/kernel/time/tick-sched.c
> > @@ -996,6 +996,21 @@ void tick_nohz_idle_enter(void)
> > local_irq_enable();
> > }
> >
> > +bool tick_nohz_idle_got_tick(void)
> > +{
> > + struct tick_sched *ts;
> > + bool got_tick = false;
> > +
> > + ts = this_cpu_ptr(&tick_cpu_sched);
> > +
> > + if (ts->inidle == 2) {
> > + got_tick = true;
> > + ts->inidle = 1;
> > + }
> > +
> > + return got_tick;
> > +}
>
> Looks simple enough. :-)
Yes, the obvious fail is that it will not be able to tell if it was the
only wakeup source. Suppose two interrupts fire, the tick and something
else, the above will disregard the idle time, even though it maybe
should not have.
> > +
> > /**
> > * tick_nohz_irq_exit - update next tick event from interrupt exit
> > *
> > @@ -1142,6 +1157,9 @@ static void tick_nohz_handler(struct clo
> > struct pt_regs *regs = get_irq_regs();
> > ktime_t now = ktime_get();
> >
> > + if (ts->inidle)
> > + ts->inidle = 2;
> > +
> > dev->next_event = KTIME_MAX;
> >
> > tick_sched_do_timer(now);
> > @@ -1239,6 +1257,9 @@ static enum hrtimer_restart tick_sched_t
> > struct pt_regs *regs = get_irq_regs();
> > ktime_t now = ktime_get();
> >
> > + if (ts->inidle)
> > + ts->inidle = 2;
> > +
>
> Why do we need to do it here?
>
> > tick_sched_do_timer(now);
> >
> > /*
Both are tick handlers, one low-res one high-res. The idea it that the
tick flips the ts->inidle thing from 1->2, which then allows *got_tick()
to detect if we had a tick for wakeup.
On 2018.03.19 05:47 Thomas Ilsche wrote:
> On 2018-03-15 23:19, Rafael J. Wysocki wrote:
>> From: Rafael J. Wysocki <[email protected]>
>>
>> If the scheduler tick has been stopped already and the governor
>> selects a shallow idle state, the CPU can spend a long time in that
>> state if the selection is based on an inaccurate prediction of idle
>> time. That effect turns out to be noticeable, so it needs to be
>> mitigated.
>
> What are some common causes for that situation?
> How could I trigger this for testing?
It appeared quite readily with my simple 100% load
on one CPU test. Back then (V3) there only 6 patches in the set,
and before the re-spin there ended up being a patch 7 of 6, which
made a significant difference in both package power and the
histograms of times in each idle state.
Reference:
https://marc.info/?l=linux-pm&m=152075419526696&w=2
... Doug
On 2018-03-18 17:15, Rafael J. Wysocki wrote:
>> Doug, Thomas,
>>
>> Thank you both for the reports, much appreciated!
>>
>> Below is a drop-in v6 replacement for patch [4/7].
>>
>> With this new patch applied instead of the [4/7] the behavior should be much
>> more in line with the v4 behavior, so please try it if you can and let me know
>> if that really is the case on your systems.
>>
>> Patches [5-7/7] from the original v5 apply on top of it right away for me,
>> but I've also created a git branch you can use to pull all of the series
>> with the below included:
>>
>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>> idle-loop
Thanks for the git repo, that helps alot. I have tested v6 on a
Skylake desktop and server system as well as a Haswell server system.
The odd idle behavior of v5 is gone.
Some of the other findings may be obsolete by the upcoming respin,
I will retest.
Our originally observed Powernightmare pattern is effectively
prevented in both idle and with a synthetic trigger. However, I can
reproduce simple workloads under which the revised menu governor
wastes energy by going into *deeper* C-states than advisable.
Consider the Skylake server system which has residencies in C1E of
20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
unsynchronized pinned to each core. While this is an artificial
case, it is a very innocent one - easy to predict and regular. Between
vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
entirely in C1E. With the patches applied, the cores spend ~75% of
their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
C1E with the baseline). Generally the new menu governor seems to chose
C1E if the next timer is an enabled sched timer - which occasionally
interrupts the sleep-interval into two C1E sleeps rather than one C6.
Manually disabling C6, reduces power consumption back to 149.5 W.
This is far from what I expected, I did not yet figure out why the
patched menu governor decides to go to C6 under that workload. I
have tested this previously with v4 and saw this behavior even
without path "7/7".
The results from Haswell-EP and Skylake desktop are similar.
The tests are with a 1000 Hz kernel because I wanted to amplify
effects that happening when C-state residencies and tick timers are
closer together. But I suspect the results will be similar with
300 Hz as the impact from the sched tick interruption seems to be
minor compared to the odd C-state selection.
Some very raw illustrations, all from Skylake SP (2 == C1E, 3 == C6):
power consumption
trigger-10-10 is the synthetic Powernightmare
poller-omp-300 is the parallel usleep(300) loop:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v6_skl_sp_power.png
cstate utilization with usleep(300) loop
(as per /sys/.../stateN/time / wall time)
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v6_skl_sp_poll_300_utilization.png
average time spent in cstates
(as /sys/.../stateN/time / /sys/.../stateN/usage)
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v6_skl_sp_poll_300_avg_time.png
detailed look:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v6_poll_300_skl.png
>>
>> Thanks!
>>
>> ---
>> From: Rafael J. Wysocki <[email protected]>
>> Subject: [PATCH v6] cpuidle: Return nohz hint from cpuidle_select()
>>
>> Add a new pointer argument to cpuidle_select() and to the ->select
>> cpuidle governor callback to allow a boolean value indicating
>> whether or not the tick should be stopped before entering the
>> selected state to be returned from there.
>>
>> Make the ladder governor ignore that pointer (to preserve its
>> current behavior) and make the menu governor return 'false" through
>> it if:
>> (1) the idle exit latency is constrained at 0,
>> (2) the selected state is a polling one, or
>> (3) the selected state is not deep enough.
>>
>> Since the value returned through the new argument pointer is not
>> used yet, this change is not expected to alter the functionality of
>> the code.
>>
>> Signed-off-by: Rafael J. Wysocki <[email protected]>
>> ---
>
> [cut]
>
>> @@ -354,6 +360,7 @@ static int menu_select(struct cpuidle_dr
>> if (latency_req > interactivity_req)
>> latency_req = interactivity_req;
>>
>> + expected_interval = TICK_USEC_HZ;
>> /*
>> * Find the idle state with the lowest power while satisfying
>> * our constraints.
>> @@ -367,17 +374,44 @@ static int menu_select(struct cpuidle_dr
>> continue;
>> if (idx == -1)
>> idx = i; /* first enabled state */
>> - if (s->target_residency > data->predicted_us)
>> + if (s->target_residency > data->predicted_us) {
>> + /*
>> + * Retain the tick if the selected state is shallower
>> + * than the deepest available one with target residency
>> + * within the tick period range.
>> + *
>> + * This allows the tick to be stopped even if the
>> + * predicted idle duration is within the tick period
>> + * range to counter the effect by which the prediction
>> + * may be skewed towards lower values due to the tick
>> + * bias.
>> + */
>> + expected_interval = s->target_residency;
>> break;
>
> BTW, I guess I need to explain the motivation here more thoroughly, so
> here it goes.
>
> The governor predicts idle duration under the assumption that the
> tick will be stopped, so if the result of the prediction is within the tick
> period range and it is not accurate, that needs to be taken into
> account in the governor's statistics. However, if the tick is allowed
> to run every time the governor predicts idle duration within the tick
> period range, the governor will always see that it was "almost
> right" and the correction factor applied by it to improve the
> prediction next time will not be sufficient. For this reason, it
> is better to stop the tick at least sometimes when the governor
> predicts idle duration within the tick period range and the idea
> here is to do that when the selected state is the deepest available
> one with the target residency within the tick period range. This
> allows the opportunity to save more energy to be seized which
> balances the extra overhead of stopping the tick.
>
> HTH
>
--
Dipl. Inf. Thomas Ilsche
Computer Scientist
Highly Adaptive Energy-Efficient Computing
CRC 912 HAEC: http://tu-dresden.de/sfb912
Technische Universität Dresden
Center for Information Services and High Performance Computing (ZIH)
01062 Dresden, Germany
Phone: +49 351 463-42168
Fax: +49 351 463-37773
E-Mail: [email protected]
On Tue, Mar 20, 2018 at 11:01 AM, Thomas Ilsche
<[email protected]> wrote:
> On 2018-03-18 17:15, Rafael J. Wysocki wrote:
>>>
>>> Doug, Thomas,
>>>
>>> Thank you both for the reports, much appreciated!
>>>
>>> Below is a drop-in v6 replacement for patch [4/7].
>>>
>>> With this new patch applied instead of the [4/7] the behavior should be
>>> much
>>> more in line with the v4 behavior, so please try it if you can and let me
>>> know
>>> if that really is the case on your systems.
>>>
>>> Patches [5-7/7] from the original v5 apply on top of it right away for
>>> me,
>>> but I've also created a git branch you can use to pull all of the series
>>> with the below included:
>>>
>>> git://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git \
>>> idle-loop
>
>
> Thanks for the git repo, that helps alot. I have tested v6 on a
> Skylake desktop and server system as well as a Haswell server system.
> The odd idle behavior of v5 is gone.
Thank you for the report!
> Some of the other findings may be obsolete by the upcoming respin,
> I will retest.
>
> Our originally observed Powernightmare pattern is effectively
> prevented in both idle and with a synthetic trigger.
That's great!
> However, I can reproduce simple workloads under which the revised
> menu governor wastes energy by going into *deeper* C-states than
> advisable.
>
> Consider the Skylake server system which has residencies in C1E of
> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
> unsynchronized pinned to each core. While this is an artificial
> case, it is a very innocent one - easy to predict and regular. Between
> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
> entirely in C1E. With the patches applied, the cores spend ~75% of
> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
> C1E with the baseline). Generally the new menu governor seems to chose
> C1E if the next timer is an enabled sched timer - which occasionally
> interrupts the sleep-interval into two C1E sleeps rather than one C6.
>
> Manually disabling C6, reduces power consumption back to 149.5 W.
>
> This is far from what I expected, I did not yet figure out why the
> patched menu governor decides to go to C6 under that workload. I
> have tested this previously with v4 and saw this behavior even
> without path "7/7".
I see.
I'm not sure what the source of this effect is either. If that is
also present in the v7 I'm working on now, it should be easier to
diagnose in there.
> The results from Haswell-EP and Skylake desktop are similar.
>
> The tests are with a 1000 Hz kernel because I wanted to amplify
> effects that happening when C-state residencies and tick timers are
> closer together. But I suspect the results will be similar with
> 300 Hz as the impact from the sched tick interruption seems to be
> minor compared to the odd C-state selection.
OK
Thanks!
On 2018.03.20 11:22 Doug Smythies wrote:
> On 2018.03.19 05:47 Thomas Ilsche wrote:
>> On 2018-03-15 23:19, Rafael J. Wysocki wrote:
>>> From: Rafael J. Wysocki <[email protected]>
>>>
>>> If the scheduler tick has been stopped already and the governor
>>> selects a shallow idle state, the CPU can spend a long time in that
>>> state if the selection is based on an inaccurate prediction of idle
>>> time. That effect turns out to be noticeable, so it needs to be
>>> mitigated.
>>
>> What are some common causes for that situation?
>> How could I trigger this for testing?
>
> It appeared quite readily with my simple 100% load
> on one CPU test. Back then (V3) there only 6 patches in the set,
> and before the re-spin there ended up being a patch 7 of 6, which
> made a significant difference in both package power and the
> histograms of times in each idle state.
>
> Reference:
> https://marc.info/?l=linux-pm&m=152075419526696&w=2
I made a kernel (4.16-rc5) with only patches 1 to 6 of 7 (V6)
and also with the poll fix.
I took an old graph:
http://fast.smythies.com/rjwv3pp_100.png
and removed an obsolete line and added a line from this
kernel:
http://fast.smythies.com/rjwv6m_100.png
I also acquired a trace during the test and observe:
Report: Summary:
Idle State 0: Total Entries: 699 : PowerNightmares: 0 : Not PN time (seconds): 0.031169 : PN time: 0.000000 : Ratio: 0.000000
Idle State 1: Total Entries: 3855 : PowerNightmares: 106 : Not PN time (seconds): 0.123759 : PN time: 43.511914 : Ratio: 351.585856
Idle State 2: Total Entries: 3688 : PowerNightmares: 181 : Not PN time (seconds): 1.303237 : PN time: 63.241424 : Ratio: 48.526418
Idle State 3: Total Entries: 528 : PowerNightmares: 115 : Not PN time (seconds): 0.276290 : PN time: 44.764111 : Ratio: 162.018571
Where "PowerNightmare" is defined as spending excessive time in an idle state,
and arbitrarily defined for my processor as:
#define THRESHOLD_0 100 /* Idle state 0 PowerNightmare threshold in microseconds */
#define THRESHOLD_1 1000 /* Idle state 1 PowerNightmare threshold in microseconds */
#define THRESHOLD_2 2000 /* Idle state 2 PowerNightmare threshold in microseconds */
#define THRESHOLD_3 4000 /* Idle state 3 PowerNightmare threshold in microseconds */
While this trace file was only about 15 megabytes, I have several 10s of gigabytes of trace data for
V4 + poll fix and never see any excessive time spent in any idle state.
... Doug
On 2018.03.20 03:02 Thomas Ilsche wrote:
...[snip]...
> Consider the Skylake server system which has residencies in C1E of
> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
> unsynchronized pinned to each core. While this is an artificial
> case, it is a very innocent one - easy to predict and regular. Between
> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
> entirely in C1E. With the patches applied, the cores spend ~75% of
> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
> C1E with the baseline). Generally the new menu governor seems to chose
> C1E if the next timer is an enabled sched timer - which occasionally
> interrupts the sleep-interval into two C1E sleeps rather than one C6.
>
> Manually disabling C6, reduces power consumption back to 149.5 W.
...[snip]...
Note that one of the tests that I normally do is a work/sleep
frequency sweep from 100 to 2100 Hz, typically at a lowish
workload. I didn't notice anything odd with this test:
http://fast.smythies.com/rjw_freq_sweep.png
However, your test is at 3333 Hz (well, minus overheads).
I did the same as you. And was surprised to confirm
your power findings. In my case package power goes from
~8.6 watts to ~7.3 watts with idle state 4 (C6) disabled.
I am getting different residency times than you though.
I also observe different overheads between idle state 4
being disabled or not. i.e. my actual loop frequency
drops from ~2801 Hz to ~2754 Hz.
Example residencies over the previous minute:
Idle state 4 (C6) disabled (seconds):
Idle state 0: 0.001119
Idle state 1: 0.056638
Idle state 2: 13.100550
Idle state 3: 446.266744
Idle state 4: 0.000000
Idle state 4 (C6) enabled (seconds):
Idle state 0: 0.034502
Idle state 1: 1.949595
Idle state 2: 78.291793
Idle state 3: 96.467974
Idle state 4: 286.247524
... Doug
On Tue, Mar 20, 2018 at 6:15 PM, Doug Smythies <[email protected]> wrote:
> On 2018.03.20 11:22 Doug Smythies wrote:
>> On 2018.03.19 05:47 Thomas Ilsche wrote:
>>> On 2018-03-15 23:19, Rafael J. Wysocki wrote:
>>>> From: Rafael J. Wysocki <[email protected]>
>>>>
>>>> If the scheduler tick has been stopped already and the governor
>>>> selects a shallow idle state, the CPU can spend a long time in that
>>>> state if the selection is based on an inaccurate prediction of idle
>>>> time. That effect turns out to be noticeable, so it needs to be
>>>> mitigated.
>>>
>>> What are some common causes for that situation?
>>> How could I trigger this for testing?
>>
>> It appeared quite readily with my simple 100% load
>> on one CPU test. Back then (V3) there only 6 patches in the set,
>> and before the re-spin there ended up being a patch 7 of 6, which
>> made a significant difference in both package power and the
>> histograms of times in each idle state.
>>
>> Reference:
>> https://marc.info/?l=linux-pm&m=152075419526696&w=2
>
> I made a kernel (4.16-rc5) with only patches 1 to 6 of 7 (V6)
> and also with the poll fix.
>
> I took an old graph:
> http://fast.smythies.com/rjwv3pp_100.png
>
> and removed an obsolete line and added a line from this
> kernel:
>
> http://fast.smythies.com/rjwv6m_100.png
>
> I also acquired a trace during the test and observe:
>
> Report: Summary:
>
> Idle State 0: Total Entries: 699 : PowerNightmares: 0 : Not PN time (seconds): 0.031169 : PN time: 0.000000 : Ratio: 0.000000
> Idle State 1: Total Entries: 3855 : PowerNightmares: 106 : Not PN time (seconds): 0.123759 : PN time: 43.511914 : Ratio: 351.585856
> Idle State 2: Total Entries: 3688 : PowerNightmares: 181 : Not PN time (seconds): 1.303237 : PN time: 63.241424 : Ratio: 48.526418
> Idle State 3: Total Entries: 528 : PowerNightmares: 115 : Not PN time (seconds): 0.276290 : PN time: 44.764111 : Ratio: 162.018571
>
> Where "PowerNightmare" is defined as spending excessive time in an idle state,
> and arbitrarily defined for my processor as:
>
> #define THRESHOLD_0 100 /* Idle state 0 PowerNightmare threshold in microseconds */
> #define THRESHOLD_1 1000 /* Idle state 1 PowerNightmare threshold in microseconds */
> #define THRESHOLD_2 2000 /* Idle state 2 PowerNightmare threshold in microseconds */
> #define THRESHOLD_3 4000 /* Idle state 3 PowerNightmare threshold in microseconds */
>
> While this trace file was only about 15 megabytes, I have several 10s of gigabytes of trace data for
> V4 + poll fix and never see any excessive time spent in any idle state.
Thanks for this work!
I prefer it with patch [7/7]. :-)
Summary: My results with kernel 4.16-rc6 and V8 of the patch set
are completely different, and now show no clear difference
(a longer test might reveal something).
On 2018.03.20 10:16 Doug Smythies wrote:
> On 2018.03.20 03:02 Thomas Ilsche wrote:
>
>...[snip]...
>
>> Consider the Skylake server system which has residencies in C1E of
>> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
>> unsynchronized pinned to each core. While this is an artificial
>> case, it is a very innocent one - easy to predict and regular. Between
>> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
>> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
>> entirely in C1E. With the patches applied, the cores spend ~75% of
>> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
>> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
>> C1E with the baseline). Generally the new menu governor seems to chose
>> C1E if the next timer is an enabled sched timer - which occasionally
>> interrupts the sleep-interval into two C1E sleeps rather than one C6.
>>
>> Manually disabling C6, reduces power consumption back to 149.5 W.
>
> ...[snip]...
>
> Note that one of the tests that I normally do is a work/sleep
> frequency sweep from 100 to 2100 Hz, typically at a lowish
> workload. I didn't notice anything odd with this test:
>
> http://fast.smythies.com/rjw_freq_sweep.png
>
> However, your test is at 3333 Hz (well, minus overheads).
> I did the same as you. And was surprised to confirm
> your power findings. In my case package power goes from
> ~8.6 watts to ~7.3 watts with idle state 4 (C6) disabled.
>
> I am getting different residency times than you though.
> I also observe different overheads between idle state 4
> being disabled or not. i.e. my actual loop frequency
> drops from ~2801 Hz to ~2754 Hz.
>
> Example residencies over the previous minute:
>
> Idle state 4 (C6) disabled (seconds):
>
> Idle state 0: 0.001119
> Idle state 1: 0.056638
> Idle state 2: 13.100550
> Idle state 3: 446.266744
> Idle state 4: 0.000000
>
> Idle state 4 (C6) enabled (seconds):
>
> Idle state 0: 0.034502
> Idle state 1: 1.949595
> Idle state 2: 78.291793
> Idle state 3: 96.467974
> Idle state 4: 286.247524
Now, with kernel 4.16-rc6 and V8 of the patch set and the poll fix
I am unable to measure the processor package power difference
between idle state 0 enabled or disabled (i.e. it is in the noise).
also the loop time changes (overhead changes) are minimal. However,
the overall loop time has dropped to ~2730 Hz, so there seems to be
a little more overhead in general.
I increased my loop frequency to ~3316 Hz. Similar.
I increased my loop frequency to ~15474 Hz. Similar.
Compared to a stock 4.16-rc6 kernel: The loop rate dropped
to 15,209 Hz and it (the stock kernel) used about 0.3 more
watts (out of 10.97, or ~3% more).
... Doug
On Tuesday, March 20, 2018 10:03:50 PM CET Doug Smythies wrote:
> Summary: My results with kernel 4.16-rc6 and V8 of the patch set
> are completely different, and now show no clear difference
> (a longer test might reveal something).
Does this mean that you see the "powernightmares" pattern with the v8
again or are you referring to something else?
> On 2018.03.20 10:16 Doug Smythies wrote:
> > On 2018.03.20 03:02 Thomas Ilsche wrote:
> >
> >...[snip]...
> >
> >> Consider the Skylake server system which has residencies in C1E of
> >> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
> >> unsynchronized pinned to each core. While this is an artificial
> >> case, it is a very innocent one - easy to predict and regular. Between
> >> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
> >> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
> >> entirely in C1E. With the patches applied, the cores spend ~75% of
> >> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
> >> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
> >> C1E with the baseline). Generally the new menu governor seems to chose
> >> C1E if the next timer is an enabled sched timer - which occasionally
> >> interrupts the sleep-interval into two C1E sleeps rather than one C6.
> >>
> >> Manually disabling C6, reduces power consumption back to 149.5 W.
> >
> > ...[snip]...
> >
> > Note that one of the tests that I normally do is a work/sleep
> > frequency sweep from 100 to 2100 Hz, typically at a lowish
> > workload. I didn't notice anything odd with this test:
> >
> > http://fast.smythies.com/rjw_freq_sweep.png
Would it be possible to produce this graph with the v8 of the
patchset?
> > However, your test is at 3333 Hz (well, minus overheads).
> > I did the same as you. And was surprised to confirm
> > your power findings. In my case package power goes from
> > ~8.6 watts to ~7.3 watts with idle state 4 (C6) disabled.
> >
> > I am getting different residency times than you though.
> > I also observe different overheads between idle state 4
> > being disabled or not. i.e. my actual loop frequency
> > drops from ~2801 Hz to ~2754 Hz.
> >
> > Example residencies over the previous minute:
> >
> > Idle state 4 (C6) disabled (seconds):
> >
> > Idle state 0: 0.001119
> > Idle state 1: 0.056638
> > Idle state 2: 13.100550
> > Idle state 3: 446.266744
> > Idle state 4: 0.000000
> >
> > Idle state 4 (C6) enabled (seconds):
> >
> > Idle state 0: 0.034502
> > Idle state 1: 1.949595
> > Idle state 2: 78.291793
> > Idle state 3: 96.467974
> > Idle state 4: 286.247524
>
> Now, with kernel 4.16-rc6 and V8 of the patch set and the poll fix
> I am unable to measure the processor package power difference
> between idle state 0 enabled or disabled (i.e. it is in the noise).
> also the loop time changes (overhead changes) are minimal. However,
> the overall loop time has dropped to ~2730 Hz, so there seems to be
> a little more overhead in general.
>
> I increased my loop frequency to ~3316 Hz. Similar.
>
> I increased my loop frequency to ~15474 Hz. Similar.
> Compared to a stock 4.16-rc6 kernel: The loop rate dropped
> to 15,209 Hz and it (the stock kernel) used about 0.3 more
> watts (out of 10.97, or ~3% more).
So do you prefer v6 or v8? I guess the former?
On 2018.03.20 23:33 Rafael J. Wysocki wrote:
> On Tuesday, March 20, 2018 10:03:50 PM CET Doug Smythies wrote:
>> Summary: My results with kernel 4.16-rc6 and V8 of the patch set
>> are completely different, and now show no clear difference
>> (a longer test might reveal something).
>
> Does this mean that you see the "powernightmares" pattern with the v8
> again or are you referring to something else?
Sorry for not being clear.
I do not see any "powernightmares" at all with V8.
After this e-mail I did a 3 hour trace and saw none.
>> On 2018.03.20 10:16 Doug Smythies wrote:
>>> On 2018.03.20 03:02 Thomas Ilsche wrote:
>>>
>>>...[snip]...
>>>
>>>> Consider the Skylake server system which has residencies in C1E of
>>>> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
>>>> unsynchronized pinned to each core. While this is an artificial
>>>> case, it is a very innocent one - easy to predict and regular. Between
>>>> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
>>>> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
>>>> entirely in C1E. With the patches applied, the cores spend ~75% of
>>>> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
>>>> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
>>>> C1E with the baseline). Generally the new menu governor seems to chose
>>>> C1E if the next timer is an enabled sched timer - which occasionally
>>>> interrupts the sleep-interval into two C1E sleeps rather than one C6.
>>>>
>>>> Manually disabling C6, reduces power consumption back to 149.5 W.
>>>
>>> ...[snip]...
>>>
>>> Note that one of the tests that I normally do is a work/sleep
>>> frequency sweep from 100 to 2100 Hz, typically at a lowish
>>> workload. I didn't notice anything odd with this test:
>>>
>>> http://fast.smythies.com/rjw_freq_sweep.png
>
> Would it be possible to produce this graph with the v8 of the
> patchset?
Yes, sure.
>>> However, your test is at 3333 Hz (well, minus overheads).
>>> I did the same as you. And was surprised to confirm
>>> your power findings. In my case package power goes from
>>> ~8.6 watts to ~7.3 watts with idle state 4 (C6) disabled.
>>>
>>> I am getting different residency times than you though.
>>> I also observe different overheads between idle state 4
>>> being disabled or not. i.e. my actual loop frequency
>>> drops from ~2801 Hz to ~2754 Hz.
>>>
>>> Example residencies over the previous minute:
>>>
>>> Idle state 4 (C6) disabled (seconds):
>>>
>>> Idle state 0: 0.001119
>>> Idle state 1: 0.056638
>>> Idle state 2: 13.100550
>>> Idle state 3: 446.266744
>>> Idle state 4: 0.000000
>>>
>>> Idle state 4 (C6) enabled (seconds):
>>>
>>> Idle state 0: 0.034502
>>> Idle state 1: 1.949595
>>> Idle state 2: 78.291793
>>> Idle state 3: 96.467974
>>> Idle state 4: 286.247524
>>
>> Now, with kernel 4.16-rc6 and V8 of the patch set and the poll fix
>> I am unable to measure the processor package power difference
>> between idle state 0 enabled or disabled (i.e. it is in the noise).
>> also the loop time changes (overhead changes) are minimal. However,
>> the overall loop time has dropped to ~2730 Hz, so there seems to be
>> a little more overhead in general.
>>
>> I increased my loop frequency to ~3316 Hz. Similar.
>>
>> I increased my loop frequency to ~15474 Hz. Similar.
>> Compared to a stock 4.16-rc6 kernel: The loop rate dropped
>> to 15,209 Hz and it (the stock kernel) used about 0.3 more
>> watts (out of 10.97, or ~3% more).
>
> So do you prefer v6 or v8? I guess the former?
Again sorry for not being clear.
I was saying that V8 is great.
I did more tests after the original e-mail was sent,
and the noted slight overhead drop was not always there
(i.e. it was inconsistent).
... Doug
On Wednesday, March 21, 2018 2:51:13 PM CET Doug Smythies wrote:
> On 2018.03.20 23:33 Rafael J. Wysocki wrote:
> > On Tuesday, March 20, 2018 10:03:50 PM CET Doug Smythies wrote:
> >> Summary: My results with kernel 4.16-rc6 and V8 of the patch set
> >> are completely different, and now show no clear difference
> >> (a longer test might reveal something).
> >
> > Does this mean that you see the "powernightmares" pattern with the v8
> > again or are you referring to something else?
>
> Sorry for not being clear.
> I do not see any "powernightmares" at all with V8.
Great!
> After this e-mail I did a 3 hour trace and saw none.
>
> >> On 2018.03.20 10:16 Doug Smythies wrote:
> >>> On 2018.03.20 03:02 Thomas Ilsche wrote:
> >>>
> >>>...[snip]...
> >>>
> >>>> Consider the Skylake server system which has residencies in C1E of
> >>>> 20 us and C6 of 800 us. I use a small while(1) {usleep(300);}
> >>>> unsynchronized pinned to each core. While this is an artificial
> >>>> case, it is a very innocent one - easy to predict and regular. Between
> >>>> vanilla 4.16.0-rc5 and idle-loop/v6, the power consumption increases
> >>>> from 149.7 W to 158.1 W. On 4.16.0-rc5, the cores sleep almost
> >>>> entirely in C1E. With the patches applied, the cores spend ~75% of
> >>>> their sleep time in C6, ~25% in C1E. The average time/usage for C1E is
> >>>> also lower with v6 at ~350 us rather than the ~550 us in C6 (and in
> >>>> C1E with the baseline). Generally the new menu governor seems to chose
> >>>> C1E if the next timer is an enabled sched timer - which occasionally
> >>>> interrupts the sleep-interval into two C1E sleeps rather than one C6.
> >>>>
> >>>> Manually disabling C6, reduces power consumption back to 149.5 W.
> >>>
> >>> ...[snip]...
> >>>
> >>> Note that one of the tests that I normally do is a work/sleep
> >>> frequency sweep from 100 to 2100 Hz, typically at a lowish
> >>> workload. I didn't notice anything odd with this test:
> >>>
> >>> http://fast.smythies.com/rjw_freq_sweep.png
> >
> > Would it be possible to produce this graph with the v8 of the
> > patchset?
>
> Yes, sure.
Thanks!
> >>> However, your test is at 3333 Hz (well, minus overheads).
> >>> I did the same as you. And was surprised to confirm
> >>> your power findings. In my case package power goes from
> >>> ~8.6 watts to ~7.3 watts with idle state 4 (C6) disabled.
> >>>
> >>> I am getting different residency times than you though.
> >>> I also observe different overheads between idle state 4
> >>> being disabled or not. i.e. my actual loop frequency
> >>> drops from ~2801 Hz to ~2754 Hz.
> >>>
> >>> Example residencies over the previous minute:
> >>>
> >>> Idle state 4 (C6) disabled (seconds):
> >>>
> >>> Idle state 0: 0.001119
> >>> Idle state 1: 0.056638
> >>> Idle state 2: 13.100550
> >>> Idle state 3: 446.266744
> >>> Idle state 4: 0.000000
> >>>
> >>> Idle state 4 (C6) enabled (seconds):
> >>>
> >>> Idle state 0: 0.034502
> >>> Idle state 1: 1.949595
> >>> Idle state 2: 78.291793
> >>> Idle state 3: 96.467974
> >>> Idle state 4: 286.247524
> >>
> >> Now, with kernel 4.16-rc6 and V8 of the patch set and the poll fix
> >> I am unable to measure the processor package power difference
> >> between idle state 0 enabled or disabled (i.e. it is in the noise).
> >> also the loop time changes (overhead changes) are minimal. However,
> >> the overall loop time has dropped to ~2730 Hz, so there seems to be
> >> a little more overhead in general.
> >>
> >> I increased my loop frequency to ~3316 Hz. Similar.
> >>
> >> I increased my loop frequency to ~15474 Hz. Similar.
> >> Compared to a stock 4.16-rc6 kernel: The loop rate dropped
> >> to 15,209 Hz and it (the stock kernel) used about 0.3 more
> >> watts (out of 10.97, or ~3% more).
> >
> > So do you prefer v6 or v8? I guess the former?
>
> Again sorry for not being clear.
> I was saying that V8 is great.
OK, thanks!
It's v7, actually. :-)
> I did more tests after the original e-mail was sent,
> and the noted slight overhead drop was not always there
> (i.e. it was inconsistent).
If possible, please also try the v7.2 replacement for patch [5/8]:
https://patchwork.kernel.org/patch/10299429/
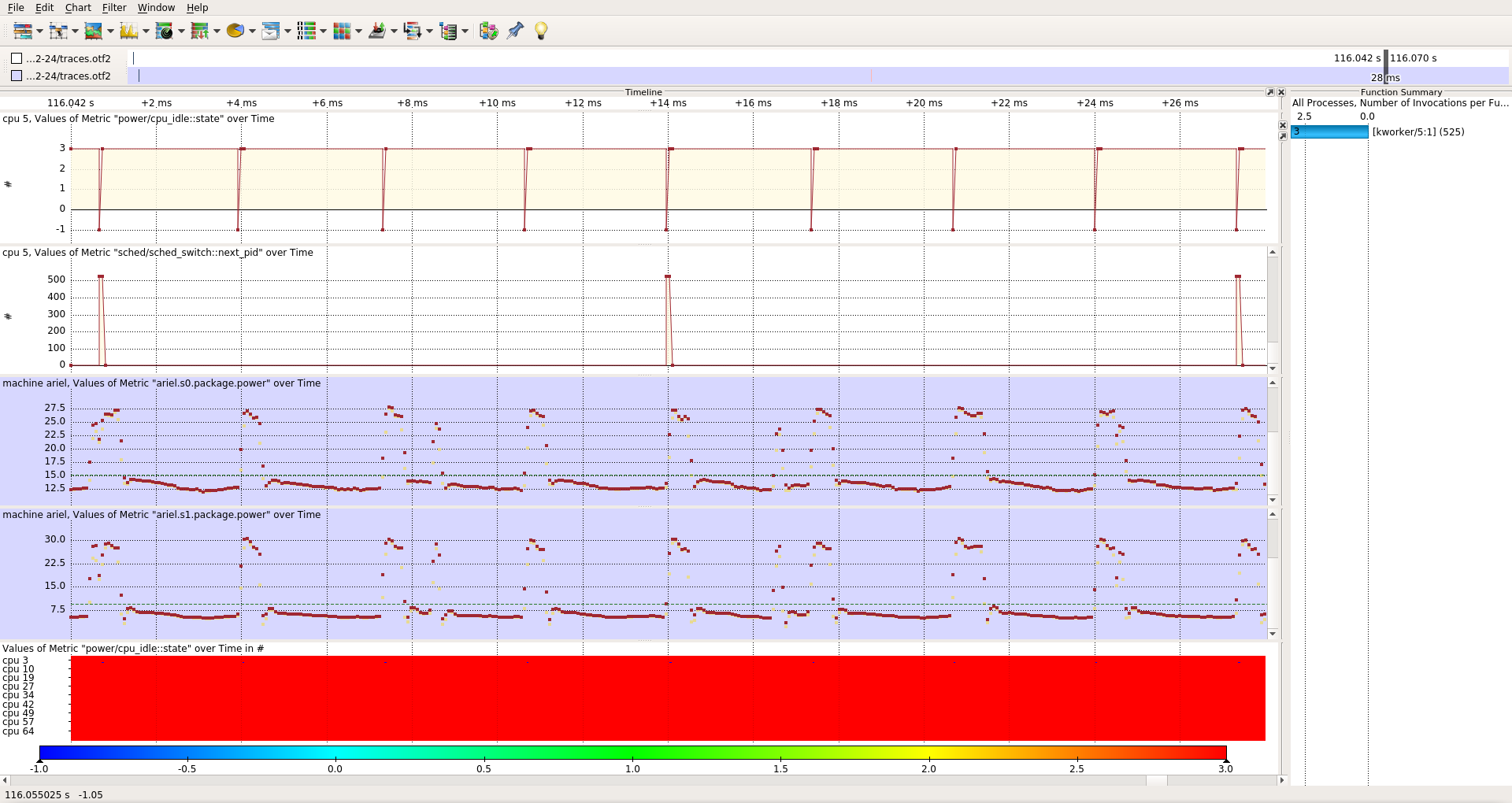{kind=link}
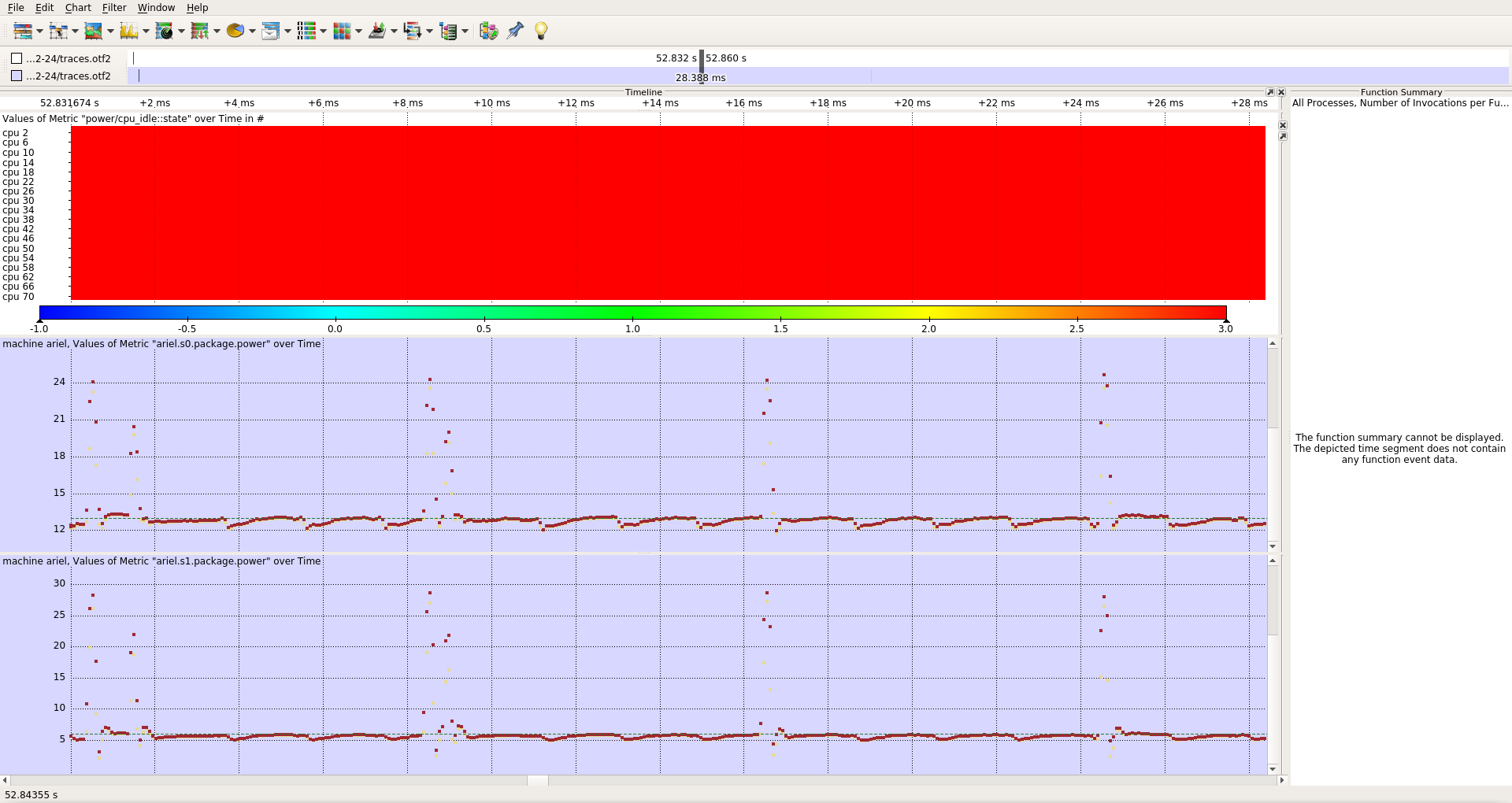{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
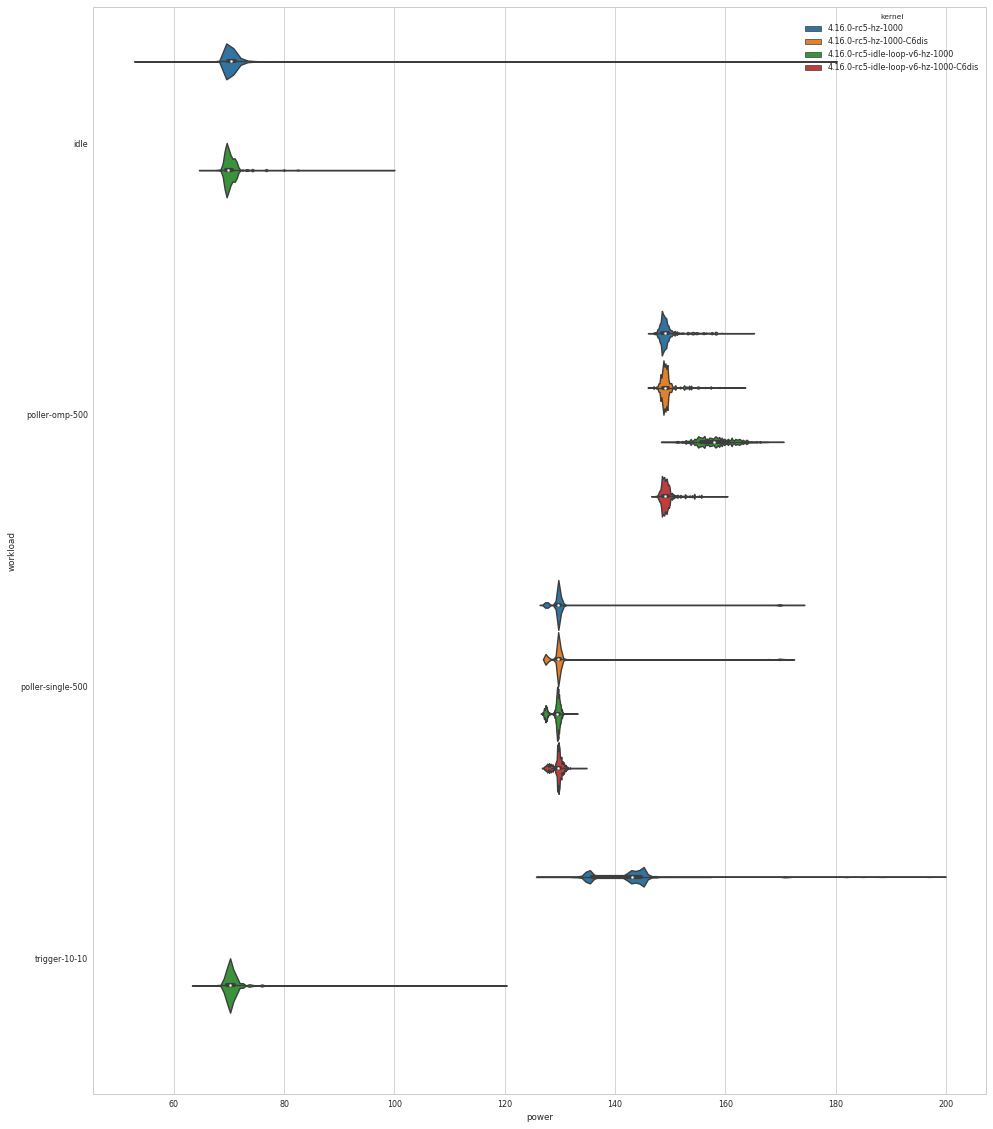{kind=link}
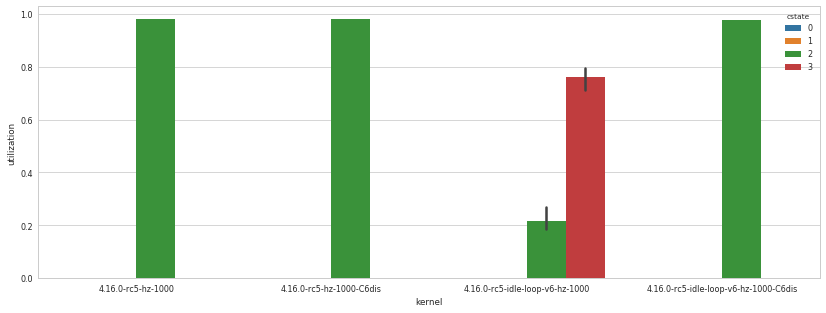{kind=link}
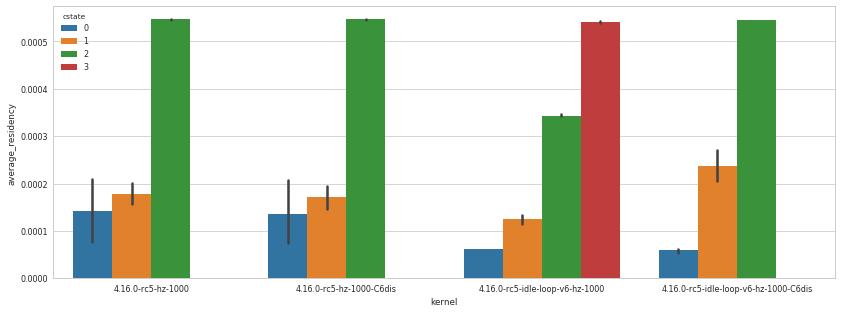{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}