Hi!
We're seeing cases on a number of servers where cache never fully grows
to use all available memory. Sometimes we see servers with 4 GB of
memory that never seem to have less than 1.5 GB free, even with a
constantly-active VM. In some cases, these servers also swap out while
this happens, even though they are constantly reading the working set
into memory. We have been seeing this happening for a long time;
I don't think it's anything recent, and it still happens on 2.6.36.
I noticed that CONFIG_NUMA seems to enable some more complicated
reclaiming bits and figured it might help since most stock kernels seem
to ship with it now. This seems to have helped, but it may just be
wishful thinking. We still see this happening, though maybe to a lesser
degree. (The following observations are with CONFIG_NUMA enabled.)
I was eyeballing "vmstat 1" and "watch -n.2 -d cat /proc/vmstat" at the
same time, and I can see distinctly that the page cache is growing nicely
until a sudden event where 400 MB is freed within 1 second, leaving
this particular box with 700 MB free again. kswapd numbers increase in
/proc/vmstat, which leads me to believe that __alloc_pages_slowpath() has
been called, since it seems to be the thing that wakes up kswapd.
Previous patterns and watching of "vmstat 1" show that the swapping out
also seems to occur during the times that memory is quickly freed.
These are all x86_64, and so there is no highmem garbage going on.
The only zones would be for DMA, right? Is the combination of memory
fragmentation and large-order allocations the only thing that would be
causing this reclaim here? Is there some easy bake knob for finding what
is causing the free memory jumps each time this happens?
Kernel config and munin graph of free memory here:
http://0x.ca/sim/ref/2.6.36/
I notice CONFIG_COMPACTION is still "EXPERIMENTAL". Would it be worth
trying here? It seems to enable defrag before reclaim, but that sounds
kind of ...complicated...
Cheers,
Simon-
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 11496 401684 40364 2531844 0 0 4540 773 7890 16291 13 9 77 1
3 0 11492 400180 40372 2534204 0 0 5572 699 8544 14856 25 9 66 1
0 0 11492 394344 40372 2540796 0 0 5256 345 8239 16723 17 7 73 2
0 0 11492 388524 40372 2546236 0 0 5216 393 8687 17289 14 9 76 1
4 1 11684 716296 40244 2218612 0 220 6868 1837 11124 27368 28 20 51 0
1 0 11732 753992 40248 2181468 0 120 5240 647 9542 15609 38 11 50 1
1 0 11712 736864 40260 2197788 0 0 5872 9147 9838 16373 41 11 47 1
0 0 11712 738096 40260 2196984 0 0 4628 493 7980 15536 22 10 67 1
2 0 11712 733508 40260 2201756 0 0 4404 418 7265 16867 10 9 80 2
(cc linux-mm, where all the suckiness ends up)
On Mon, 15 Nov 2010 11:52:46 -0800
Simon Kirby <[email protected]> wrote:
> Hi!
>
> We're seeing cases on a number of servers where cache never fully grows
> to use all available memory. Sometimes we see servers with 4 GB of
> memory that never seem to have less than 1.5 GB free, even with a
> constantly-active VM. In some cases, these servers also swap out while
> this happens, even though they are constantly reading the working set
> into memory. We have been seeing this happening for a long time;
> I don't think it's anything recent, and it still happens on 2.6.36.
>
> I noticed that CONFIG_NUMA seems to enable some more complicated
> reclaiming bits and figured it might help since most stock kernels seem
> to ship with it now. This seems to have helped, but it may just be
> wishful thinking. We still see this happening, though maybe to a lesser
> degree. (The following observations are with CONFIG_NUMA enabled.)
>
> I was eyeballing "vmstat 1" and "watch -n.2 -d cat /proc/vmstat" at the
> same time, and I can see distinctly that the page cache is growing nicely
> until a sudden event where 400 MB is freed within 1 second, leaving
> this particular box with 700 MB free again. kswapd numbers increase in
> /proc/vmstat, which leads me to believe that __alloc_pages_slowpath() has
> been called, since it seems to be the thing that wakes up kswapd.
>
> Previous patterns and watching of "vmstat 1" show that the swapping out
> also seems to occur during the times that memory is quickly freed.
>
> These are all x86_64, and so there is no highmem garbage going on.
> The only zones would be for DMA, right? Is the combination of memory
> fragmentation and large-order allocations the only thing that would be
> causing this reclaim here? Is there some easy bake knob for finding what
> is causing the free memory jumps each time this happens?
>
> Kernel config and munin graph of free memory here:
>
> http://0x.ca/sim/ref/2.6.36/
>
> I notice CONFIG_COMPACTION is still "EXPERIMENTAL". Would it be worth
> trying here? It seems to enable defrag before reclaim, but that sounds
> kind of ...complicated...
>
> Cheers,
>
> Simon-
>
> procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
> r b swpd free buff cache si so bi bo in cs us sy id wa
> 1 0 11496 401684 40364 2531844 0 0 4540 773 7890 16291 13 9 77 1
> 3 0 11492 400180 40372 2534204 0 0 5572 699 8544 14856 25 9 66 1
> 0 0 11492 394344 40372 2540796 0 0 5256 345 8239 16723 17 7 73 2
> 0 0 11492 388524 40372 2546236 0 0 5216 393 8687 17289 14 9 76 1
> 4 1 11684 716296 40244 2218612 0 220 6868 1837 11124 27368 28 20 51 0
> 1 0 11732 753992 40248 2181468 0 120 5240 647 9542 15609 38 11 50 1
> 1 0 11712 736864 40260 2197788 0 0 5872 9147 9838 16373 41 11 47 1
> 0 0 11712 738096 40260 2196984 0 0 4628 493 7980 15536 22 10 67 1
> 2 0 11712 733508 40260 2201756 0 0 4404 418 7265 16867 10 9 80 2
Uploaded a new graph with maybe more useful pixels.
( http://0x.ca/sim/ref/2.6.36/memory_long.png ) Units are day-of-month.
On this same server, dovecot is probably leaking a bit, but it seems to
be backing off on the page cache at the same time. Disk usage grows all
day and not much is unlink()ed until the middle of the night, so I don't
see any reason things shouldn't stay around in page cache.
We then restarted dovecot (with old processes left around), and it seems
it started swapping to /dev/sda and throwing out pages from running apps
which came from /dev/sda (disks) while churning through mail on /dev/md0
(/dev/sd[bc]) which is SSD. Killing the old processes seemed to make it
happy to keep enough in page cache again to make /dev/sda idle again.
I guess the vm has no idea about the relative expensiveness of reads from
the SSD versus conventional disks connected to the same box?
Anyway, we turned off swap to try to stop load on /dev/sda. sysreq-M
showed this sort of output while kswapd was churning, if it helps:
SysRq : Show Memory
Mem-Info:
Node 0 DMA per-cpu:
CPU 0: hi: 0, btch: 1 usd: 0
CPU 1: hi: 0, btch: 1 usd: 0
CPU 2: hi: 0, btch: 1 usd: 0
CPU 3: hi: 0, btch: 1 usd: 0
Node 0 DMA32 per-cpu:
CPU 0: hi: 186, btch: 31 usd: 164
CPU 1: hi: 186, btch: 31 usd: 177
CPU 2: hi: 186, btch: 31 usd: 157
CPU 3: hi: 186, btch: 31 usd: 156
Node 0 Normal per-cpu:
CPU 0: hi: 186, btch: 31 usd: 51
CPU 1: hi: 186, btch: 31 usd: 152
CPU 2: hi: 186, btch: 31 usd: 57
CPU 3: hi: 186, btch: 31 usd: 157
active_anon:102749 inactive_anon:164705 isolated_anon:0
active_file:117584 inactive_file:132410 isolated_file:0
unevictable:7155 dirty:64 writeback:18 unstable:0
free:409953 slab_reclaimable:41904 slab_unreclaimable:10369
mapped:3980 shmem:698 pagetables:3947 bounce:0
Node 0 DMA free:15904kB min:28kB low:32kB high:40kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:15772kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB slab_unreclaimable:16kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? yes
lowmem_reserve[]: 0 3251 4009 4009
Node 0 DMA32 free:1477136kB min:6560kB low:8200kB high:9840kB active_anon:351928kB inactive_anon:512024kB active_file:405472kB inactive_file:361028kB unevictable:16kB isolated(anon):0kB isolated(file):0kB present:3329568kB mlocked:16kB dirty:128kB writeback:0kB mapped:9184kB shmem:1584kB slab_reclaimable:153108kB slab_unreclaimable:17180kB kernel_stack:808kB pagetables:5760kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? no
lowmem_reserve[]: 0 0 757 757
Node 0 Normal free:146772kB min:1528kB low:1908kB high:2292kB active_anon:59068kB inactive_anon:146796kB active_file:64864kB inactive_file:168464kB unevictable:28604kB isolated(anon):0kB isolated(file):92kB present:775680kB mlocked:28604kB dirty:128kB writeback:72kB mapped:6736kB shmem:1208kB slab_reclaimable:14508kB slab_unreclaimable:24280kB kernel_stack:1320kB pagetables:10028kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:236 all_unreclaimable? no
lowmem_reserve[]: 0 0 0 0
Node 0 DMA: 2*4kB 1*8kB 1*16kB 2*32kB 1*64kB 1*128kB 1*256kB 0*512kB 1*1024kB 1*2048kB 3*4096kB = 15904kB
Node 0 DMA32: 126783*4kB 85660*8kB 13612*16kB 2013*32kB 32*64kB 3*128kB 1*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 1477308kB
Node 0 Normal: 19801*4kB 8446*8kB 0*16kB 0*32kB 0*64kB 0*128kB 0*256kB 0*512kB 0*1024kB 0*2048kB 0*4096kB = 146772kB
252045 total pagecache pages
0 pages in swap cache
Swap cache stats: add 10390951, delete 10390951, find 21038039/22538430
Free swap = 0kB
Total swap = 0kB
1048575 pages RAM
35780 pages reserved
263717 pages shared
455184 pages non-shared
Simon-
On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> (cc linux-mm, where all the suckiness ends up)
>
> On Mon, 15 Nov 2010 11:52:46 -0800
> Simon Kirby <[email protected]> wrote:
>
> > Hi!
> >
> > We're seeing cases on a number of servers where cache never fully grows
> > to use all available memory. Sometimes we see servers with 4 GB of
> > memory that never seem to have less than 1.5 GB free, even with a
> > constantly-active VM. In some cases, these servers also swap out while
> > this happens, even though they are constantly reading the working set
> > into memory. We have been seeing this happening for a long time;
> > I don't think it's anything recent, and it still happens on 2.6.36.
> >
> > I noticed that CONFIG_NUMA seems to enable some more complicated
> > reclaiming bits and figured it might help since most stock kernels seem
> > to ship with it now. This seems to have helped, but it may just be
> > wishful thinking. We still see this happening, though maybe to a lesser
> > degree. (The following observations are with CONFIG_NUMA enabled.)
> >
> > I was eyeballing "vmstat 1" and "watch -n.2 -d cat /proc/vmstat" at the
> > same time, and I can see distinctly that the page cache is growing nicely
> > until a sudden event where 400 MB is freed within 1 second, leaving
> > this particular box with 700 MB free again. kswapd numbers increase in
> > /proc/vmstat, which leads me to believe that __alloc_pages_slowpath() has
> > been called, since it seems to be the thing that wakes up kswapd.
> >
> > Previous patterns and watching of "vmstat 1" show that the swapping out
> > also seems to occur during the times that memory is quickly freed.
> >
> > These are all x86_64, and so there is no highmem garbage going on.
> > The only zones would be for DMA, right? Is the combination of memory
> > fragmentation and large-order allocations the only thing that would be
> > causing this reclaim here? Is there some easy bake knob for finding what
> > is causing the free memory jumps each time this happens?
> >
> > Kernel config and munin graph of free memory here:
> >
> > http://0x.ca/sim/ref/2.6.36/
> >
> > I notice CONFIG_COMPACTION is still "EXPERIMENTAL". Would it be worth
> > trying here? It seems to enable defrag before reclaim, but that sounds
> > kind of ...complicated...
> >
> > Cheers,
> >
> > Simon-
> >
> > procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
> > r b swpd free buff cache si so bi bo in cs us sy id wa
> > 1 0 11496 401684 40364 2531844 0 0 4540 773 7890 16291 13 9 77 1
> > 3 0 11492 400180 40372 2534204 0 0 5572 699 8544 14856 25 9 66 1
> > 0 0 11492 394344 40372 2540796 0 0 5256 345 8239 16723 17 7 73 2
> > 0 0 11492 388524 40372 2546236 0 0 5216 393 8687 17289 14 9 76 1
> > 4 1 11684 716296 40244 2218612 0 220 6868 1837 11124 27368 28 20 51 0
> > 1 0 11732 753992 40248 2181468 0 120 5240 647 9542 15609 38 11 50 1
> > 1 0 11712 736864 40260 2197788 0 0 5872 9147 9838 16373 41 11 47 1
> > 0 0 11712 738096 40260 2196984 0 0 4628 493 7980 15536 22 10 67 1
> > 2 0 11712 733508 40260 2201756 0 0 4404 418 7265 16867 10 9 80 2
On Mon, 2010-11-22 at 15:44 -0800, Andrew Morton wrote:
> > These are all x86_64, and so there is no highmem garbage going on.
> > The only zones would be for DMA, right?
There shouldn't be any highmem-related action going on.
> Is the combination of memory fragmentation and large-order allocations
> the only thing that would be causing this reclaim here?
It does sound somewhat suspicious. Are you using hugetlbfs or
allocating large pages? What are your high-order allocations going to?
> Is there some easy bake knob for finding what
> is causing the free memory jumps each time this happens?
I wish. :) The best thing to do is to watch stuff like /proc/vmstat
along with its friends like /proc/{buddy,meminfo,slabinfo}. Could you
post some samples of those with some indication of where the bad
behavior was seen?
I've definitely seen swapping in the face of lots of free memory, but
only in cases where I was being a bit unfair about the numbers of
hugetlbfs pages I was trying to reserve.
-- Dave
On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> On Mon, 15 Nov 2010 11:52:46 -0800
> Simon Kirby <[email protected]> wrote:
>
> > I noticed that CONFIG_NUMA seems to enable some more complicated
> > reclaiming bits and figured it might help since most stock kernels seem
> > to ship with it now. This seems to have helped, but it may just be
> > wishful thinking. We still see this happening, though maybe to a lesser
> > degree. (The following observations are with CONFIG_NUMA enabled.)
> >
Hi,
As this is a NUMA machine, what is the value of
/proc/sys/vm/zone_reclaim_mode ? When enabled, this reclaims memory
local to the node in preference to using remote nodes. For certain
workloads this performs better but for users that expect all of memory
to be used, it has surprising results.
If set to 1, try testing with it set to 0 and see if it makes a
difference. Thanks
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Tue, Nov 23, 2010 at 10:04:03AM +0000, Mel Gorman wrote:
> On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> > On Mon, 15 Nov 2010 11:52:46 -0800
> > Simon Kirby <[email protected]> wrote:
> >
> > > I noticed that CONFIG_NUMA seems to enable some more complicated
> > > reclaiming bits and figured it might help since most stock kernels seem
> > > to ship with it now. This seems to have helped, but it may just be
> > > wishful thinking. We still see this happening, though maybe to a lesser
> > > degree. (The following observations are with CONFIG_NUMA enabled.)
> > >
>
> Hi,
>
> As this is a NUMA machine, what is the value of
> /proc/sys/vm/zone_reclaim_mode ? When enabled, this reclaims memory
> local to the node in preference to using remote nodes. For certain
> workloads this performs better but for users that expect all of memory
> to be used, it has surprising results.
>
> If set to 1, try testing with it set to 0 and see if it makes a
> difference. Thanks
Hi Mel,
It is set to 0. It's an Intel EM64T...I only enabled CONFIG_NUMA since
it seemed to enable some more complicated handling, and I figured it
might help, but it didn't seem to. It's also required for
CONFIG_COMPACTION, but that is still marked experimental.
Simon-
On Tue, Nov 23, 2010 at 12:35:31AM -0800, Dave Hansen wrote:
> I wish. :) The best thing to do is to watch stuff like /proc/vmstat
> along with its friends like /proc/{buddy,meminfo,slabinfo}. Could you
> post some samples of those with some indication of where the bad
> behavior was seen?
>
> I've definitely seen swapping in the face of lots of free memory, but
> only in cases where I was being a bit unfair about the numbers of
> hugetlbfs pages I was trying to reserve.
So, Dave and I spent quite some time today figuring out was going on
here. Once load picked up during the day, kswapd actually never slept
until late in the afternoon. During the evening now, it's still waking
up in bursts, and still keeping way too much memory free:
http://0x.ca/sim/ref/2.6.36/memory_tonight.png
(NOTE: we did swapoff -a to keep /dev/sda from overloading)
We have a much better idea on what is happening here, but more questions.
This x86_64 box has 4 GB of RAM; zones are set up as follows:
[ 0.000000] Zone PFN ranges:
[ 0.000000] DMA 0x00000001 -> 0x00001000
[ 0.000000] DMA32 0x00001000 -> 0x00100000
[ 0.000000] Normal 0x00100000 -> 0x00130000
...
[ 0.000000] On node 0 totalpages: 1047279
[ 0.000000] DMA zone: 56 pages used for memmap
[ 0.000000] DMA zone: 0 pages reserved
[ 0.000000] DMA zone: 3943 pages, LIFO batch:0
[ 0.000000] DMA32 zone: 14280 pages used for memmap
[ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
[ 0.000000] Normal zone: 2688 pages used for memmap
[ 0.000000] Normal zone: 193920 pages, LIFO batch:31
So, "Normal" is relatively small, and DMA32 contains most of the RAM.
Watermarks from /proc/zoneinfo are:
Node 0, zone DMA
min 7
low 8
high 10
protection: (0, 3251, 4009, 4009)
Node 0, zone DMA32
min 1640
low 2050
high 2460
protection: (0, 0, 757, 757)
Node 0, zone Normal
min 382
low 477
high 573
protection: (0, 0, 0, 0)
This box has a couple bnx2 NICs, which do about 60 Mbps each. Jumbo
frames were disabled for now (to try to stop big order allocations), but
this did not stop atomic allocations of order 3 coming in, as found with:
perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph -c 1 -a sleep 10
perf report
__alloc_pages_nodemask
alloc_pages_current
new_slab
__slab_alloc
__kmalloc_node_track_caller
__alloc_skb
__netdev_alloc_skb
bnx2_poll_work
>From my reading of this, it seems like __alloc_skb uses kmalloc(), and
kmalloc uses the kmalloc slab unless (unlikely(size > SLUB_MAX_SIZE)),
where SLUB_MAX_SIZE is 2 * PAGE_SIZE, in which case kmalloc_large is
called which allocates pages directly. This means that reception of
jumbo frames probably actually results in (consistent) smaller order
allocations! Anyway, these GFP_ATOMIC allocations don't seem to be
failing, BUT...
Right after kswapd goes to sleep, we're left with DMA32 with 421k or so
free pages, and Normal with 20k or so free pages (about 1.8 GB free).
Immediately, zone Normal starts being used until it reaches about 468
pages free in order 0, nothing else free. kswapd is not woken here,
but allocations just start coming from zone DMA32 instead. While this
happens, the occasional order=3 allocations coming in via the slab from
__alloc_skb seem to be picking away at the available order=3 chunks.
/proc/buddyinfo shows that there are 10k or so when it starts, so this
succeeds easily.
After a minute or so, available order-3 start reaching a lower number,
like 20 or so. order-4 then starts dropping as it is split into order-3,
until it reaches 20 or so as well. Then, order-3 hits 0, and kswapd is
woken. When this occurs, there are still a few order-5, order-6, etc.,
available. I presume the GFP_ATOMIC allocation can still split buddies
here, still making order-3 available without sleeping, because there is
no allocation failure message that I can see.
Here is a "while true; do sleep 1; grep -v 'DMA ' /proc/buddyinfo; done"
("DMA" zone is totally untouched, always, so excluded; white space
crushed to avoid wrapping), while it happens:
Node 0, zone DMA 2 1 1 2 1 1 1 0 1 1 3
Node 0, zone DMA32 25770 29441 14512 10426 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
...
Node 0, zone DMA32 23343 29405 6062 6478 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 23187 29358 6047 5960 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 23000 29372 6047 5411 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 22714 29391 6076 4225 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 22354 29459 6059 3178 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 22202 29388 6035 2395 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21971 29411 6036 1032 1901 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21514 29388 6019 433 1796 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21334 29387 6019 240 1464 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21237 29421 6052 216 1336 123 4 0 0 0 0
Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20968 29378 6020 244 751 123 4 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 24388 33261 1985 6 10 4 2 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 25358 34080 1068 0 4 4 2 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 75985 68954 5345 87 1 4 2 0 0 0 0
Node 0, zone Normal 18249 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81117 71630 19261 429 3 4 2 0 0 0 0
Node 0, zone Normal 17908 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81226 71299 21038 569 19 4 2 0 0 0 0
Node 0, zone Normal 18559 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81347 71278 21068 640 19 4 2 0 0 0 0
Node 0, zone Normal 17928 21 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81370 71237 21241 1073 29 4 2 0 0 0 0
Node 0, zone Normal 18187 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81401 71237 21314 1139 29 4 2 0 0 0 0
Node 0, zone Normal 16978 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81410 71239 21314 1145 29 4 2 0 0 0 0
Node 0, zone Normal 18156 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81419 71232 21317 1160 30 4 2 0 0 0 0
Node 0, zone Normal 17536 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81347 71144 21443 1160 31 4 2 0 0 0 0
Node 0, zone Normal 18483 7 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81300 71059 21556 1178 38 4 2 0 0 0 0
Node 0, zone Normal 18528 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81315 71042 21577 1180 39 4 2 0 0 0 0
Node 0, zone Normal 18431 2 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81301 71002 21702 1202 39 4 2 0 0 0 0
Node 0, zone Normal 18487 5 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81301 70998 21702 1202 39 4 2 0 0 0 0
Node 0, zone Normal 18311 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81296 71025 21711 1208 45 4 2 0 0 0 0
Node 0, zone Normal 17092 5 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 81299 71023 21716 1226 45 4 2 0 0 0 0
Node 0, zone Normal 18225 12 0 0 0 0 0 0 0 0 0
Running a perf record on the kswapd wakeup right when it happens shows:
perf record --event vmscan:mm_vmscan_wakeup_kswapd -a --call-graph -c 1 -a sleep 10
perf trace
swapper-0 [002] 1323136.979119: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
swapper-0 [002] 1323136.979131: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
lmtp-20593 [003] 1323136.984066: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
lmtp-20593 [003] 1323136.984079: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
swapper-0 [001] 1323136.985511: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
swapper-0 [001] 1323136.985515: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
lmtp-20593 [003] 1323136.985673: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
lmtp-20593 [003] 1323136.985675: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
This causes kswapd to throw out a bunch of stuff from Normal and from
DMA32, to try to get zone_watermark_ok() to be happy for order=3.
However, we have a heavy read load from all of the email stored on SSDs
on this box, and kswapd ends up fighting to try to keep reclaiming the
allocations (mostly order-0). During the whole day, it never wins -- the
allocations are faster. At night, it wins after a minute or two. The
fighting is happening in all of the lines after it awakes above.
slabs_scanned, kswapd_steal, kswapd_inodesteal (slowly),
kswapd_skip_congestion_wait, and pageoutrun go up in vmstat while kswapd
is running. With the box up for 15 days, you can see it struggling on
pgscan_kswapd_normal (from /proc/vmstat):
pgfree 3329793080
pgactivate 643476431
pgdeactivate 155182710
pgfault 2649106647
pgmajfault 58157157
pgrefill_dma 0
pgrefill_dma32 19688032
pgrefill_normal 7600864
pgrefill_movable 0
pgsteal_dma 0
pgsteal_dma32 465191578
pgsteal_normal 651178518
pgsteal_movable 0
pgscan_kswapd_dma 0
pgscan_kswapd_dma32 768300403
pgscan_kswapd_normal 34614572907
pgscan_kswapd_movable 0
pgscan_direct_dma 0
pgscan_direct_dma32 2853983
pgscan_direct_normal 885799
pgscan_direct_movable 0
pginodesteal 191895
pgrotated 27290463
So, here are my questions.
Why do we care about order > 0 watermarks at all in the Normal zone?
Wouldn't it make a lot more sense to just make the DMA32 zone the only
one we care about for larger-order allocations? Or is this required for
the hugepage stuff?
The fact that so much stuff is evicted just because order-3 hits 0 is
crazy, especially when larger order pages are still free. It seems like
we're trying to keep large orders free here. Why? Maybe things would be
better if kswapd does not reclaim at all unless the requested order is
empty _and_ all orders above are empty. This would require hugepage
users to use CONFIG_COMPACT, and have _compaction_ occur the way the
watermark checks work now, but people without CONFIG_HUGETLB_PAGE could
just actually use the memory. Would this work?
There is logic at the end of balance_pgdat() to give up balancing order>0
and just try another loop with order = 0 if sc.nr_reclaimed is <
SWAP_CLUSTER_MAX. However, when this order=0 pass returns, the caller of
balance_pgdat(), kswapd(), gets true from sleeping_prematurely() and just
calls right back to balance_pgdat() again. I think this is why this
logic doesn't seem to work here.
Is my assumption about GFP_ATOMIC order=3 working even when order 3 is
empty, but order>3 is not? Regardless, shouldn't kswapd be woken before
order 3 is 0 since it may have nothing above order 3 to split from, thus
actually causing an allocation failure? Does something else do this?
Ok, that's enough for now.. :)
Simon-
On Tue, Nov 23, 2010 at 10:43:29PM -0800, Simon Kirby wrote:
> On Tue, Nov 23, 2010 at 10:04:03AM +0000, Mel Gorman wrote:
>
> > On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> > > On Mon, 15 Nov 2010 11:52:46 -0800
> > > Simon Kirby <[email protected]> wrote:
> > >
> > > > I noticed that CONFIG_NUMA seems to enable some more complicated
> > > > reclaiming bits and figured it might help since most stock kernels seem
> > > > to ship with it now. This seems to have helped, but it may just be
> > > > wishful thinking. We still see this happening, though maybe to a lesser
> > > > degree. (The following observations are with CONFIG_NUMA enabled.)
> > > >
> >
> > Hi,
> >
> > As this is a NUMA machine, what is the value of
> > /proc/sys/vm/zone_reclaim_mode ? When enabled, this reclaims memory
> > local to the node in preference to using remote nodes. For certain
> > workloads this performs better but for users that expect all of memory
> > to be used, it has surprising results.
> >
> > If set to 1, try testing with it set to 0 and see if it makes a
> > difference. Thanks
>
> Hi Mel,
>
> It is set to 0. It's an Intel EM64T...I only enabled CONFIG_NUMA since
> it seemed to enable some more complicated handling, and I figured it
> might help, but it didn't seem to. It's also required for
> CONFIG_COMPACTION, but that is still marked experimental.
>
I'm surprised a little that you are bringing compaction up because unless
there are high-order involved, it wouldn't make a difference. Is there
a constant source of high-order allocations in the system e.g. a network
card configured to use jumbo frames? A possible consequence of that is that
reclaim is kicking in early to free order-[2-4] pages that would prevent 100%
of memory being used.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Wed, Nov 24, 2010 at 09:27:53AM +0000, Mel Gorman wrote:
> On Tue, Nov 23, 2010 at 10:43:29PM -0800, Simon Kirby wrote:
> > On Tue, Nov 23, 2010 at 10:04:03AM +0000, Mel Gorman wrote:
> >
> > > On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> > > > On Mon, 15 Nov 2010 11:52:46 -0800
> > > > Simon Kirby <[email protected]> wrote:
> > > >
> > > > > I noticed that CONFIG_NUMA seems to enable some more complicated
> > > > > reclaiming bits and figured it might help since most stock kernels seem
> > > > > to ship with it now. This seems to have helped, but it may just be
> > > > > wishful thinking. We still see this happening, though maybe to a lesser
> > > > > degree. (The following observations are with CONFIG_NUMA enabled.)
> > > > >
> > >
> > > Hi,
> > >
> > > As this is a NUMA machine, what is the value of
> > > /proc/sys/vm/zone_reclaim_mode ? When enabled, this reclaims memory
> > > local to the node in preference to using remote nodes. For certain
> > > workloads this performs better but for users that expect all of memory
> > > to be used, it has surprising results.
> > >
> > > If set to 1, try testing with it set to 0 and see if it makes a
> > > difference. Thanks
> >
> > Hi Mel,
> >
> > It is set to 0. It's an Intel EM64T...I only enabled CONFIG_NUMA since
> > it seemed to enable some more complicated handling, and I figured it
> > might help, but it didn't seem to. It's also required for
> > CONFIG_COMPACTION, but that is still marked experimental.
> >
>
> I'm surprised a little that you are bringing compaction up because unless
> there are high-order involved, it wouldn't make a difference. Is there
> a constant source of high-order allocations in the system e.g. a network
> card configured to use jumbo frames? A possible consequence of that is that
> reclaim is kicking in early to free order-[2-4] pages that would prevent 100%
> of memory being used.
We /were/ using jumbo frames, but only over a local cross-over connection
to another node (for DRBD), so I disabled jumbo frames on this interface
and reconnected DRBD. Even with MTUs set to 1500, we saw GFP_ATOMIC
order=3 allocations coming from __alloc_skb:
perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph sleep 10
perf trace
imap-20599 [002] 1287672.803567: mm_page_alloc: page=0xffffea00004536c0 pfn=4536000 order=3 migratetype=0 gfp_flags=GFP_ATOMIC|GFP_NOWARN|GFP_NORETRY|GFP_COMP
perf report shows:
__alloc_pages_nodemask
alloc_pages_current
new_slab
__slab_alloc
__kmalloc_node_track_caller
__alloc_skb
__netdev_alloc_skb
bnx2_poll_work
Dave was seeing these on his laptop with an Intel NIC as well. Ralf
noted that the slab cache grows in higher order blocks, so this is
normal. The GFP_ATOMIC bubbles up from *alloc_skb, I guess.
Simon-
On Wed, 2010-11-24 at 16:46 +0800, Simon Kirby wrote:
> On Tue, Nov 23, 2010 at 12:35:31AM -0800, Dave Hansen wrote:
>
> > I wish. :) The best thing to do is to watch stuff like /proc/vmstat
> > along with its friends like /proc/{buddy,meminfo,slabinfo}. Could you
> > post some samples of those with some indication of where the bad
> > behavior was seen?
> >
> > I've definitely seen swapping in the face of lots of free memory, but
> > only in cases where I was being a bit unfair about the numbers of
> > hugetlbfs pages I was trying to reserve.
>
> So, Dave and I spent quite some time today figuring out was going on
> here. Once load picked up during the day, kswapd actually never slept
> until late in the afternoon. During the evening now, it's still waking
> up in bursts, and still keeping way too much memory free:
>
> http://0x.ca/sim/ref/2.6.36/memory_tonight.png
>
> (NOTE: we did swapoff -a to keep /dev/sda from overloading)
>
> We have a much better idea on what is happening here, but more questions.
>
> This x86_64 box has 4 GB of RAM; zones are set up as follows:
>
> [ 0.000000] Zone PFN ranges:
> [ 0.000000] DMA 0x00000001 -> 0x00001000
> [ 0.000000] DMA32 0x00001000 -> 0x00100000
> [ 0.000000] Normal 0x00100000 -> 0x00130000
> ...
> [ 0.000000] On node 0 totalpages: 1047279
> [ 0.000000] DMA zone: 56 pages used for memmap
> [ 0.000000] DMA zone: 0 pages reserved
> [ 0.000000] DMA zone: 3943 pages, LIFO batch:0
> [ 0.000000] DMA32 zone: 14280 pages used for memmap
> [ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
> [ 0.000000] Normal zone: 2688 pages used for memmap
> [ 0.000000] Normal zone: 193920 pages, LIFO batch:31
>
> So, "Normal" is relatively small, and DMA32 contains most of the RAM.
> Watermarks from /proc/zoneinfo are:
>
> Node 0, zone DMA
> min 7
> low 8
> high 10
> protection: (0, 3251, 4009, 4009)
> Node 0, zone DMA32
> min 1640
> low 2050
> high 2460
> protection: (0, 0, 757, 757)
> Node 0, zone Normal
> min 382
> low 477
> high 573
> protection: (0, 0, 0, 0)
>
> This box has a couple bnx2 NICs, which do about 60 Mbps each. Jumbo
> frames were disabled for now (to try to stop big order allocations), but
> this did not stop atomic allocations of order 3 coming in, as found with:
>
> perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph -c 1 -a sleep 10
> perf report
>
> __alloc_pages_nodemask
> alloc_pages_current
> new_slab
> __slab_alloc
> __kmalloc_node_track_caller
> __alloc_skb
> __netdev_alloc_skb
> bnx2_poll_work
>
> From my reading of this, it seems like __alloc_skb uses kmalloc(), and
> kmalloc uses the kmalloc slab unless (unlikely(size > SLUB_MAX_SIZE)),
> where SLUB_MAX_SIZE is 2 * PAGE_SIZE, in which case kmalloc_large is
> called which allocates pages directly. This means that reception of
> jumbo frames probably actually results in (consistent) smaller order
> allocations! Anyway, these GFP_ATOMIC allocations don't seem to be
> failing, BUT...
>
> Right after kswapd goes to sleep, we're left with DMA32 with 421k or so
> free pages, and Normal with 20k or so free pages (about 1.8 GB free).
>
> Immediately, zone Normal starts being used until it reaches about 468
> pages free in order 0, nothing else free. kswapd is not woken here,
> but allocations just start coming from zone DMA32 instead. While this
> happens, the occasional order=3 allocations coming in via the slab from
> __alloc_skb seem to be picking away at the available order=3 chunks.
> /proc/buddyinfo shows that there are 10k or so when it starts, so this
> succeeds easily.
>
> After a minute or so, available order-3 start reaching a lower number,
> like 20 or so. order-4 then starts dropping as it is split into order-3,
> until it reaches 20 or so as well. Then, order-3 hits 0, and kswapd is
> woken. When this occurs, there are still a few order-5, order-6, etc.,
> available. I presume the GFP_ATOMIC allocation can still split buddies
> here, still making order-3 available without sleeping, because there is
> no allocation failure message that I can see.
>
> Here is a "while true; do sleep 1; grep -v 'DMA ' /proc/buddyinfo; done"
> ("DMA" zone is totally untouched, always, so excluded; white space
> crushed to avoid wrapping), while it happens:
>
> Node 0, zone DMA 2 1 1 2 1 1 1 0 1 1 3
> Node 0, zone DMA32 25770 29441 14512 10426 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> ...
> Node 0, zone DMA32 23343 29405 6062 6478 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 23187 29358 6047 5960 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 23000 29372 6047 5411 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 22714 29391 6076 4225 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 22354 29459 6059 3178 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 22202 29388 6035 2395 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 21971 29411 6036 1032 1901 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 21514 29388 6019 433 1796 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 21334 29387 6019 240 1464 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 21237 29421 6052 216 1336 123 4 0 0 0 0
> Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 20968 29378 6020 244 751 123 4 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 24388 33261 1985 6 10 4 2 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 25358 34080 1068 0 4 4 2 0 0 0 0
> Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 75985 68954 5345 87 1 4 2 0 0 0 0
> Node 0, zone Normal 18249 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81117 71630 19261 429 3 4 2 0 0 0 0
> Node 0, zone Normal 17908 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81226 71299 21038 569 19 4 2 0 0 0 0
> Node 0, zone Normal 18559 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81347 71278 21068 640 19 4 2 0 0 0 0
> Node 0, zone Normal 17928 21 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81370 71237 21241 1073 29 4 2 0 0 0 0
> Node 0, zone Normal 18187 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81401 71237 21314 1139 29 4 2 0 0 0 0
> Node 0, zone Normal 16978 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81410 71239 21314 1145 29 4 2 0 0 0 0
> Node 0, zone Normal 18156 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81419 71232 21317 1160 30 4 2 0 0 0 0
> Node 0, zone Normal 17536 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81347 71144 21443 1160 31 4 2 0 0 0 0
> Node 0, zone Normal 18483 7 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81300 71059 21556 1178 38 4 2 0 0 0 0
> Node 0, zone Normal 18528 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81315 71042 21577 1180 39 4 2 0 0 0 0
> Node 0, zone Normal 18431 2 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81301 71002 21702 1202 39 4 2 0 0 0 0
> Node 0, zone Normal 18487 5 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81301 70998 21702 1202 39 4 2 0 0 0 0
> Node 0, zone Normal 18311 0 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81296 71025 21711 1208 45 4 2 0 0 0 0
> Node 0, zone Normal 17092 5 0 0 0 0 0 0 0 0 0
> Node 0, zone DMA32 81299 71023 21716 1226 45 4 2 0 0 0 0
> Node 0, zone Normal 18225 12 0 0 0 0 0 0 0 0 0
>
> Running a perf record on the kswapd wakeup right when it happens shows:
> perf record --event vmscan:mm_vmscan_wakeup_kswapd -a --call-graph -c 1 -a sleep 10
> perf trace
> swapper-0 [002] 1323136.979119: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> swapper-0 [002] 1323136.979131: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> lmtp-20593 [003] 1323136.984066: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> lmtp-20593 [003] 1323136.984079: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> swapper-0 [001] 1323136.985511: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> swapper-0 [001] 1323136.985515: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> lmtp-20593 [003] 1323136.985673: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> lmtp-20593 [003] 1323136.985675: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
>
> This causes kswapd to throw out a bunch of stuff from Normal and from
> DMA32, to try to get zone_watermark_ok() to be happy for order=3.
> However, we have a heavy read load from all of the email stored on SSDs
> on this box, and kswapd ends up fighting to try to keep reclaiming the
> allocations (mostly order-0). During the whole day, it never wins -- the
> allocations are faster. At night, it wins after a minute or two. The
> fighting is happening in all of the lines after it awakes above.
>
> slabs_scanned, kswapd_steal, kswapd_inodesteal (slowly),
> kswapd_skip_congestion_wait, and pageoutrun go up in vmstat while kswapd
> is running. With the box up for 15 days, you can see it struggling on
> pgscan_kswapd_normal (from /proc/vmstat):
>
> pgfree 3329793080
> pgactivate 643476431
> pgdeactivate 155182710
> pgfault 2649106647
> pgmajfault 58157157
> pgrefill_dma 0
> pgrefill_dma32 19688032
> pgrefill_normal 7600864
> pgrefill_movable 0
> pgsteal_dma 0
> pgsteal_dma32 465191578
> pgsteal_normal 651178518
> pgsteal_movable 0
> pgscan_kswapd_dma 0
> pgscan_kswapd_dma32 768300403
> pgscan_kswapd_normal 34614572907
> pgscan_kswapd_movable 0
> pgscan_direct_dma 0
> pgscan_direct_dma32 2853983
> pgscan_direct_normal 885799
> pgscan_direct_movable 0
> pginodesteal 191895
> pgrotated 27290463
>
> So, here are my questions.
>
> Why do we care about order > 0 watermarks at all in the Normal zone?
> Wouldn't it make a lot more sense to just make the DMA32 zone the only
> one we care about for larger-order allocations? Or is this required for
> the hugepage stuff?
>
> The fact that so much stuff is evicted just because order-3 hits 0 is
> crazy, especially when larger order pages are still free. It seems like
> we're trying to keep large orders free here. Why? Maybe things would be
> better if kswapd does not reclaim at all unless the requested order is
> empty _and_ all orders above are empty. This would require hugepage
> users to use CONFIG_COMPACT, and have _compaction_ occur the way the
> watermark checks work now, but people without CONFIG_HUGETLB_PAGE could
> just actually use the memory. Would this work?
>
> There is logic at the end of balance_pgdat() to give up balancing order>0
> and just try another loop with order = 0 if sc.nr_reclaimed is <
> SWAP_CLUSTER_MAX. However, when this order=0 pass returns, the caller of
> balance_pgdat(), kswapd(), gets true from sleeping_prematurely() and just
> calls right back to balance_pgdat() again. I think this is why this
> logic doesn't seem to work here.
>
> Is my assumption about GFP_ATOMIC order=3 working even when order 3 is
> empty, but order>3 is not? Regardless, shouldn't kswapd be woken before
> order 3 is 0 since it may have nothing above order 3 to split from, thus
> actually causing an allocation failure? Does something else do this?
even kswapd is woken after order>3 is empty, the issue will occur since
the order > 3 pages will be used soon and kswapd still needs to reclaim
some pages. So the issue is there is high order page allocation and
lumpy reclaim wrongly reclaims some pages. maybe you should use slab
instead of slub to avoid high order allocation.
> On Wed, Nov 24, 2010 at 09:27:53AM +0000, Mel Gorman wrote:
>
> > On Tue, Nov 23, 2010 at 10:43:29PM -0800, Simon Kirby wrote:
> > > On Tue, Nov 23, 2010 at 10:04:03AM +0000, Mel Gorman wrote:
> > >
> > > > On Mon, Nov 22, 2010 at 03:44:19PM -0800, Andrew Morton wrote:
> > > > > On Mon, 15 Nov 2010 11:52:46 -0800
> > > > > Simon Kirby <[email protected]> wrote:
> > > > >
> > > > > > I noticed that CONFIG_NUMA seems to enable some more complicated
> > > > > > reclaiming bits and figured it might help since most stock kernels seem
> > > > > > to ship with it now. This seems to have helped, but it may just be
> > > > > > wishful thinking. We still see this happening, though maybe to a lesser
> > > > > > degree. (The following observations are with CONFIG_NUMA enabled.)
> > > > > >
> > > >
> > > > Hi,
> > > >
> > > > As this is a NUMA machine, what is the value of
> > > > /proc/sys/vm/zone_reclaim_mode ? When enabled, this reclaims memory
> > > > local to the node in preference to using remote nodes. For certain
> > > > workloads this performs better but for users that expect all of memory
> > > > to be used, it has surprising results.
> > > >
> > > > If set to 1, try testing with it set to 0 and see if it makes a
> > > > difference. Thanks
> > >
> > > Hi Mel,
> > >
> > > It is set to 0. It's an Intel EM64T...I only enabled CONFIG_NUMA since
> > > it seemed to enable some more complicated handling, and I figured it
> > > might help, but it didn't seem to. It's also required for
> > > CONFIG_COMPACTION, but that is still marked experimental.
> > >
> >
> > I'm surprised a little that you are bringing compaction up because unless
> > there are high-order involved, it wouldn't make a difference. Is there
> > a constant source of high-order allocations in the system e.g. a network
> > card configured to use jumbo frames? A possible consequence of that is that
> > reclaim is kicking in early to free order-[2-4] pages that would prevent 100%
> > of memory being used.
>
> We /were/ using jumbo frames, but only over a local cross-over connection
> to another node (for DRBD), so I disabled jumbo frames on this interface
> and reconnected DRBD. Even with MTUs set to 1500, we saw GFP_ATOMIC
> order=3 allocations coming from __alloc_skb:
>
> perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph sleep 10
> perf trace
>
> imap-20599 [002] 1287672.803567: mm_page_alloc: page=0xffffea00004536c0 pfn=4536000 order=3 migratetype=0 gfp_flags=GFP_ATOMIC|GFP_NOWARN|GFP_NORETRY|GFP_COMP
>
> perf report shows:
>
> __alloc_pages_nodemask
> alloc_pages_current
> new_slab
> __slab_alloc
> __kmalloc_node_track_caller
> __alloc_skb
> __netdev_alloc_skb
> bnx2_poll_work
>
> Dave was seeing these on his laptop with an Intel NIC as well. Ralf
> noted that the slab cache grows in higher order blocks, so this is
> normal. The GFP_ATOMIC bubbles up from *alloc_skb, I guess.
Please try SLAB instead SLUB (it can be switched by kernel build option).
SLUB try to use high order allocation implicitly.
On Thu, Nov 25, 2010 at 09:07:54AM +0800, Shaohua Li wrote:
> On Wed, 2010-11-24 at 16:46 +0800, Simon Kirby wrote:
> > On Tue, Nov 23, 2010 at 12:35:31AM -0800, Dave Hansen wrote:
> >
> > > I wish. :) The best thing to do is to watch stuff like /proc/vmstat
> > > along with its friends like /proc/{buddy,meminfo,slabinfo}. Could you
> > > post some samples of those with some indication of where the bad
> > > behavior was seen?
> > >
> > > I've definitely seen swapping in the face of lots of free memory, but
> > > only in cases where I was being a bit unfair about the numbers of
> > > hugetlbfs pages I was trying to reserve.
> >
> > So, Dave and I spent quite some time today figuring out was going on
> > here. Once load picked up during the day, kswapd actually never slept
> > until late in the afternoon. During the evening now, it's still waking
> > up in bursts, and still keeping way too much memory free:
> >
> > http://0x.ca/sim/ref/2.6.36/memory_tonight.png
> >
> > (NOTE: we did swapoff -a to keep /dev/sda from overloading)
> >
> > We have a much better idea on what is happening here, but more questions.
> >
> > This x86_64 box has 4 GB of RAM; zones are set up as follows:
> >
> > [ 0.000000] Zone PFN ranges:
> > [ 0.000000] DMA 0x00000001 -> 0x00001000
> > [ 0.000000] DMA32 0x00001000 -> 0x00100000
> > [ 0.000000] Normal 0x00100000 -> 0x00130000
> > ...
> > [ 0.000000] On node 0 totalpages: 1047279
> > [ 0.000000] DMA zone: 56 pages used for memmap
> > [ 0.000000] DMA zone: 0 pages reserved
> > [ 0.000000] DMA zone: 3943 pages, LIFO batch:0
> > [ 0.000000] DMA32 zone: 14280 pages used for memmap
> > [ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
> > [ 0.000000] Normal zone: 2688 pages used for memmap
> > [ 0.000000] Normal zone: 193920 pages, LIFO batch:31
> >
> > So, "Normal" is relatively small, and DMA32 contains most of the RAM.
> > Watermarks from /proc/zoneinfo are:
> >
> > Node 0, zone DMA
> > min 7
> > low 8
> > high 10
> > protection: (0, 3251, 4009, 4009)
> > Node 0, zone DMA32
> > min 1640
> > low 2050
> > high 2460
> > protection: (0, 0, 757, 757)
> > Node 0, zone Normal
> > min 382
> > low 477
> > high 573
> > protection: (0, 0, 0, 0)
> >
> > This box has a couple bnx2 NICs, which do about 60 Mbps each. Jumbo
> > frames were disabled for now (to try to stop big order allocations), but
> > this did not stop atomic allocations of order 3 coming in, as found with:
> >
> > perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph -c 1 -a sleep 10
> > perf report
> >
> > __alloc_pages_nodemask
> > alloc_pages_current
> > new_slab
> > __slab_alloc
> > __kmalloc_node_track_caller
> > __alloc_skb
> > __netdev_alloc_skb
> > bnx2_poll_work
> >
> > From my reading of this, it seems like __alloc_skb uses kmalloc(), and
> > kmalloc uses the kmalloc slab unless (unlikely(size > SLUB_MAX_SIZE)),
> > where SLUB_MAX_SIZE is 2 * PAGE_SIZE, in which case kmalloc_large is
> > called which allocates pages directly. This means that reception of
> > jumbo frames probably actually results in (consistent) smaller order
> > allocations! Anyway, these GFP_ATOMIC allocations don't seem to be
> > failing, BUT...
> >
> > Right after kswapd goes to sleep, we're left with DMA32 with 421k or so
> > free pages, and Normal with 20k or so free pages (about 1.8 GB free).
> >
> > Immediately, zone Normal starts being used until it reaches about 468
> > pages free in order 0, nothing else free. kswapd is not woken here,
> > but allocations just start coming from zone DMA32 instead. While this
> > happens, the occasional order=3 allocations coming in via the slab from
> > __alloc_skb seem to be picking away at the available order=3 chunks.
> > /proc/buddyinfo shows that there are 10k or so when it starts, so this
> > succeeds easily.
> >
> > After a minute or so, available order-3 start reaching a lower number,
> > like 20 or so. order-4 then starts dropping as it is split into order-3,
> > until it reaches 20 or so as well. Then, order-3 hits 0, and kswapd is
> > woken. When this occurs, there are still a few order-5, order-6, etc.,
> > available. I presume the GFP_ATOMIC allocation can still split buddies
> > here, still making order-3 available without sleeping, because there is
> > no allocation failure message that I can see.
> >
> > Here is a "while true; do sleep 1; grep -v 'DMA ' /proc/buddyinfo; done"
> > ("DMA" zone is totally untouched, always, so excluded; white space
> > crushed to avoid wrapping), while it happens:
> >
> > Node 0, zone DMA 2 1 1 2 1 1 1 0 1 1 3
> > Node 0, zone DMA32 25770 29441 14512 10426 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > ...
> > Node 0, zone DMA32 23343 29405 6062 6478 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 23187 29358 6047 5960 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 23000 29372 6047 5411 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 22714 29391 6076 4225 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 22354 29459 6059 3178 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 22202 29388 6035 2395 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 21971 29411 6036 1032 1901 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 21514 29388 6019 433 1796 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 21334 29387 6019 240 1464 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 21237 29421 6052 216 1336 123 4 0 0 0 0
> > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 20968 29378 6020 244 751 123 4 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 24388 33261 1985 6 10 4 2 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 25358 34080 1068 0 4 4 2 0 0 0 0
> > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 75985 68954 5345 87 1 4 2 0 0 0 0
> > Node 0, zone Normal 18249 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81117 71630 19261 429 3 4 2 0 0 0 0
> > Node 0, zone Normal 17908 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81226 71299 21038 569 19 4 2 0 0 0 0
> > Node 0, zone Normal 18559 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81347 71278 21068 640 19 4 2 0 0 0 0
> > Node 0, zone Normal 17928 21 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81370 71237 21241 1073 29 4 2 0 0 0 0
> > Node 0, zone Normal 18187 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81401 71237 21314 1139 29 4 2 0 0 0 0
> > Node 0, zone Normal 16978 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81410 71239 21314 1145 29 4 2 0 0 0 0
> > Node 0, zone Normal 18156 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81419 71232 21317 1160 30 4 2 0 0 0 0
> > Node 0, zone Normal 17536 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81347 71144 21443 1160 31 4 2 0 0 0 0
> > Node 0, zone Normal 18483 7 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81300 71059 21556 1178 38 4 2 0 0 0 0
> > Node 0, zone Normal 18528 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81315 71042 21577 1180 39 4 2 0 0 0 0
> > Node 0, zone Normal 18431 2 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81301 71002 21702 1202 39 4 2 0 0 0 0
> > Node 0, zone Normal 18487 5 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81301 70998 21702 1202 39 4 2 0 0 0 0
> > Node 0, zone Normal 18311 0 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81296 71025 21711 1208 45 4 2 0 0 0 0
> > Node 0, zone Normal 17092 5 0 0 0 0 0 0 0 0 0
> > Node 0, zone DMA32 81299 71023 21716 1226 45 4 2 0 0 0 0
> > Node 0, zone Normal 18225 12 0 0 0 0 0 0 0 0 0
> >
> > Running a perf record on the kswapd wakeup right when it happens shows:
> > perf record --event vmscan:mm_vmscan_wakeup_kswapd -a --call-graph -c 1 -a sleep 10
> > perf trace
> > swapper-0 [002] 1323136.979119: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > swapper-0 [002] 1323136.979131: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > lmtp-20593 [003] 1323136.984066: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > lmtp-20593 [003] 1323136.984079: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > swapper-0 [001] 1323136.985511: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > swapper-0 [001] 1323136.985515: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > lmtp-20593 [003] 1323136.985673: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > lmtp-20593 [003] 1323136.985675: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> >
> > This causes kswapd to throw out a bunch of stuff from Normal and from
> > DMA32, to try to get zone_watermark_ok() to be happy for order=3.
> > However, we have a heavy read load from all of the email stored on SSDs
> > on this box, and kswapd ends up fighting to try to keep reclaiming the
> > allocations (mostly order-0). During the whole day, it never wins -- the
> > allocations are faster. At night, it wins after a minute or two. The
> > fighting is happening in all of the lines after it awakes above.
> >
> > slabs_scanned, kswapd_steal, kswapd_inodesteal (slowly),
> > kswapd_skip_congestion_wait, and pageoutrun go up in vmstat while kswapd
> > is running. With the box up for 15 days, you can see it struggling on
> > pgscan_kswapd_normal (from /proc/vmstat):
> >
> > pgfree 3329793080
> > pgactivate 643476431
> > pgdeactivate 155182710
> > pgfault 2649106647
> > pgmajfault 58157157
> > pgrefill_dma 0
> > pgrefill_dma32 19688032
> > pgrefill_normal 7600864
> > pgrefill_movable 0
> > pgsteal_dma 0
> > pgsteal_dma32 465191578
> > pgsteal_normal 651178518
> > pgsteal_movable 0
> > pgscan_kswapd_dma 0
> > pgscan_kswapd_dma32 768300403
> > pgscan_kswapd_normal 34614572907
> > pgscan_kswapd_movable 0
> > pgscan_direct_dma 0
> > pgscan_direct_dma32 2853983
> > pgscan_direct_normal 885799
> > pgscan_direct_movable 0
> > pginodesteal 191895
> > pgrotated 27290463
> >
> > So, here are my questions.
> >
> > Why do we care about order > 0 watermarks at all in the Normal zone?
> > Wouldn't it make a lot more sense to just make the DMA32 zone the only
> > one we care about for larger-order allocations? Or is this required for
> > the hugepage stuff?
> >
> > The fact that so much stuff is evicted just because order-3 hits 0 is
> > crazy, especially when larger order pages are still free. It seems like
> > we're trying to keep large orders free here. Why? Maybe things would be
> > better if kswapd does not reclaim at all unless the requested order is
> > empty _and_ all orders above are empty. This would require hugepage
> > users to use CONFIG_COMPACT, and have _compaction_ occur the way the
> > watermark checks work now, but people without CONFIG_HUGETLB_PAGE could
> > just actually use the memory. Would this work?
> >
> > There is logic at the end of balance_pgdat() to give up balancing order>0
> > and just try another loop with order = 0 if sc.nr_reclaimed is <
> > SWAP_CLUSTER_MAX. However, when this order=0 pass returns, the caller of
> > balance_pgdat(), kswapd(), gets true from sleeping_prematurely() and just
> > calls right back to balance_pgdat() again. I think this is why this
> > logic doesn't seem to work here.
> >
> > Is my assumption about GFP_ATOMIC order=3 working even when order 3 is
> > empty, but order>3 is not? Regardless, shouldn't kswapd be woken before
> > order 3 is 0 since it may have nothing above order 3 to split from, thus
> > actually causing an allocation failure? Does something else do this?
>
> even kswapd is woken after order>3 is empty, the issue will occur since
> the order > 3 pages will be used soon and kswapd still needs to reclaim
> some pages. So the issue is there is high order page allocation and
> lumpy reclaim wrongly reclaims some pages. maybe you should use slab
> instead of slub to avoid high order allocation.
There are actually a few problems here. I think they are worth looking
at them separately, unless "don't use order 3 allocations" is a valid
statement, in which case we should fix slub.
The funny thing here is that slub.c's allocate_slab() calls alloc_pages()
with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a
lower order allocation automatically if it fails. This is why there is
no allocation failure warning when this happens. However, it is too late
-- kswapd is woken and it ties to bring order 3 up to the watermark.
If we hacked __alloc_pages_slowpath() to not wake kswapd when
__GFP_NOWARN is set, we would never see this problem and the slub
optimization might still mostly work. Either way, we should "fix" slub
or "fix" order-3 allocations, so that other people who are using slub
don't hit the same problem.
kswapd is throwing out many times what is needed for the order 3
watermark to be met. It seems to be not as bad now, but look at these
pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
followed by nr_pages_free calculation and final order-3 watermark test,
kswapd woken after the second sample):
Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
DMA32 20374 35116 975 1 2 5 1 0 0 0 0 94770 257 <= 256
DMA32 20480 35211 870 1 1 5 1 0 0 0 0 94630 241 <= 256
(kswapd wakes, gobble gobble)
DMA32 24387 37009 2910 297 100 5 1 0 0 0 0 114245 4193 <= 256
DMA32 36169 37787 4676 637 110 5 1 0 0 0 0 137527 7073 <= 256
DMA32 63443 40620 5716 982 144 5 1 0 0 0 0 177931 10377 <= 256
DMA32 65866 57006 6462 1180 158 5 1 0 0 0 0 217918 12185 <= 256
DMA32 67188 66779 9328 1893 208 5 1 0 0 0 0 256754 18689 <= 256
DMA32 67909 67356 18307 2268 235 5 1 0 0 0 0 297977 22121 <= 256
DMA32 68333 67419 20786 4192 298 7 1 0 0 0 0 324907 38585 <= 256
DMA32 69872 68096 21580 5141 326 7 1 0 0 0 0 339016 46625 <= 256
DMA32 69959 67970 22339 5657 371 10 1 0 0 0 0 346831 51569 <= 256
DMA32 70017 67946 22363 6078 417 11 1 0 0 0 0 351073 55705 <= 256
DMA32 70023 67949 22376 6204 439 12 1 0 0 0 0 352529 57097 <= 256
DMA32 70045 67937 22380 6262 451 12 1 0 0 0 0 353199 57753 <= 256
DMA32 70062 67939 22378 6298 456 12 1 0 0 0 0 353580 58121 <= 256
DMA32 70079 67959 22388 6370 458 12 1 0 0 0 0 354285 58729 <= 256
DMA32 70079 67959 22388 6387 460 12 1 0 0 0 0 354453 58897 <= 256
DMA32 70076 67954 22387 6393 460 12 1 0 0 0 0 354484 58945 <= 256
DMA32 70105 67975 22385 6466 468 12 1 0 0 0 0 355259 59657 <= 256
DMA32 70110 67972 22387 6466 470 12 1 0 0 0 0 355298 59689 <= 256
DMA32 70152 67989 22393 6476 470 12 1 0 0 0 0 355478 59769 <= 256
DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
DMA32 70192 67990 22401 6495 471 12 1 0 0 0 0 355720 59937 <= 256
DMA32 70192 67988 22401 6496 471 12 1 0 0 0 0 355724 59945 <= 256
DMA32 70099 68061 22467 6602 477 12 1 0 0 0 0 356985 60889 <= 256
DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
DMA32 70099 68062 22467 6603 477 12 1 0 0 0 0 356995 60897 <= 256
(kswapd sleeps)
Normal zone at the same time (shown separately for clarity):
Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
(kswapd wakes)
Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
(kswapd sleeps -- maybe too much turkey)
DMA32 get so much reclaimed that the watermark test succeeded long ago.
Meanwhile, Normal is being reclaimed as well, but because it's fighting
with allocations, it tries for a while and eventually succeeds (I think),
but the 200ms samples didn't catch it.
KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
to be similar to this problem, but your change is not working here.
We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
is increasing (so has_under_min_watermark_zone is true), and pageoutrun
increasing all the time. This means that balance_pgdat() keeps being
called, but sleeping_prematurely() is returning true, so kswapd() just
keeps re-calling balance_pgdat(). If your approach is correct to stop
kswapd here, the problem seems to be that balance_pgdat's copy of order
and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
kswapd never really sleeps. How is this supposed to work?
Our allocation load here is mostly file pages, some anon pages, and
relatively little slab and anything else.
Simon-
> There are actually a few problems here. I think they are worth looking
> at them separately, unless "don't use order 3 allocations" is a valid
> statement, in which case we should fix slub.
>
> The funny thing here is that slub.c's allocate_slab() calls alloc_pages()
> with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a
> lower order allocation automatically if it fails. This is why there is
> no allocation failure warning when this happens. However, it is too late
> -- kswapd is woken and it ties to bring order 3 up to the watermark.
> If we hacked __alloc_pages_slowpath() to not wake kswapd when
> __GFP_NOWARN is set, we would never see this problem and the slub
> optimization might still mostly work. Either way, we should "fix" slub
> or "fix" order-3 allocations, so that other people who are using slub
> don't hit the same problem.
This?
Subject: [PATCH] slub: use no __GFP_WAIT instead __GFP_NORETRY
---
mm/slub.c | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/mm/slub.c b/mm/slub.c
index 8c66aef..0c77399 100644
--- a/mm/slub.c
+++ b/mm/slub.c
@@ -1134,7 +1134,7 @@ static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
* Let the initial higher-order allocation fail under memory pressure
* so we fall-back to the minimum order allocation.
*/
- alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
+ alloc_gfp = (flags | __GFP_NOWARN) & ~(__GFP_NOFAIL | __GFP_WAIT);
page = alloc_slab_page(alloc_gfp, node, oo);
if (unlikely(!page)) {
--
1.6.5.2
> kswapd is throwing out many times what is needed for the order 3
> watermark to be met. It seems to be not as bad now, but look at these
> pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
> followed by nr_pages_free calculation and final order-3 watermark test,
> kswapd woken after the second sample):
>
> Normal zone at the same time (shown separately for clarity):
>
> Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
>
> Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> (kswapd wakes)
> Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
> Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
> Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
> Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
> Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
> Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
> Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
> Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
> Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
> Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
> Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
> Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
> Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
> Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
> Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
> Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
> Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> (kswapd sleeps -- maybe too much turkey)
>
> DMA32 get so much reclaimed that the watermark test succeeded long ago.
> Meanwhile, Normal is being reclaimed as well, but because it's fighting
> with allocations, it tries for a while and eventually succeeds (I think),
> but the 200ms samples didn't catch it.
>
> KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
> to be similar to this problem, but your change is not working here.
> We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
> is increasing (so has_under_min_watermark_zone is true), and pageoutrun
> increasing all the time. This means that balance_pgdat() keeps being
> called, but sleeping_prematurely() is returning true, so kswapd() just
> keeps re-calling balance_pgdat(). If your approach is correct to stop
> kswapd here, the problem seems to be that balance_pgdat's copy of order
> and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
> kswapd never really sleeps. How is this supposed to work?
Um. this seems regression since commit f50de2d381 (vmscan: have kswapd sleep
for a short interval and double check it should be asleep)
Can you please try this?
Subject: [PATCH] vmscan: don't rewakeup kswapd if zone memory was exhaust
---
mm/vmscan.c | 18 +++++++++++-------
1 files changed, 11 insertions(+), 7 deletions(-)
diff --git a/mm/vmscan.c b/mm/vmscan.c
index 1fcadaf..2945c74 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2148,7 +2148,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
* For kswapd, balance_pgdat() will work across all this node's zones until
* they are all at high_wmark_pages(zone).
*
- * Returns the number of pages which were actually freed.
+ * Return 1 if balancing was suceeded, otherwise 0.
*
* There is special handling here for zones which are full of pinned pages.
* This can happen if the pages are all mlocked, or if they are all used by
@@ -2165,7 +2165,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
* interoperates with the page allocator fallback scheme to ensure that aging
* of pages is balanced across the zones.
*/
-static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
+static int balance_pgdat(pg_data_t *pgdat, int order)
{
int all_zones_ok;
int priority;
@@ -2361,10 +2361,10 @@ out:
goto loop_again;
}
- return sc.nr_reclaimed;
+ return (sc.nr_reclaimed >= SWAP_CLUSTER_MAX);
}
-static void kswapd_try_to_sleep(pg_data_t *pgdat, int order)
+static void kswapd_try_to_sleep(pg_data_t *pgdat, int order, int force)
{
long remaining = 0;
DEFINE_WAIT(wait);
@@ -2374,6 +2374,9 @@ static void kswapd_try_to_sleep(pg_data_t *pgdat, int order)
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
+ if (force)
+ goto sleep:
+
/* Try to sleep for a short interval */
if (!sleeping_prematurely(pgdat, order, remaining)) {
remaining = schedule_timeout(HZ/10);
@@ -2386,6 +2389,7 @@ static void kswapd_try_to_sleep(pg_data_t *pgdat, int order)
* go fully to sleep until explicitly woken up.
*/
if (!sleeping_prematurely(pgdat, order, remaining)) {
+ sleep:
trace_mm_vmscan_kswapd_sleep(pgdat->node_id);
/*
@@ -2426,11 +2430,11 @@ static int kswapd(void *p)
unsigned long order;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
-
struct reclaim_state reclaim_state = {
.reclaimed_slab = 0,
};
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
+ int balanced = 0;
lockdep_set_current_reclaim_state(GFP_KERNEL);
@@ -2467,7 +2471,7 @@ static int kswapd(void *p)
*/
order = new_order;
} else {
- kswapd_try_to_sleep(pgdat, order);
+ kswapd_try_to_sleep(pgdat, order, !balanced);
order = pgdat->kswapd_max_order;
}
@@ -2481,7 +2485,7 @@ static int kswapd(void *p)
*/
if (!ret) {
trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
- balance_pgdat(pgdat, order);
+ balanced = balance_pgdat(pgdat, order);
}
}
return 0;
--
1.6.5.2
On Thu, Nov 25, 2010 at 01:03:28AM -0800, Simon Kirby wrote:
> > > <SNIP>
> > >
> > > This x86_64 box has 4 GB of RAM; zones are set up as follows:
> > >
> > > [ 0.000000] Zone PFN ranges:
> > > [ 0.000000] DMA 0x00000001 -> 0x00001000
> > > [ 0.000000] DMA32 0x00001000 -> 0x00100000
> > > [ 0.000000] Normal 0x00100000 -> 0x00130000
> > > ...
> > > [ 0.000000] On node 0 totalpages: 1047279
> > > [ 0.000000] DMA zone: 56 pages used for memmap
> > > [ 0.000000] DMA zone: 0 pages reserved
> > > [ 0.000000] DMA zone: 3943 pages, LIFO batch:0
> > > [ 0.000000] DMA32 zone: 14280 pages used for memmap
> > > [ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
> > > [ 0.000000] Normal zone: 2688 pages used for memmap
> > > [ 0.000000] Normal zone: 193920 pages, LIFO batch:31
> > >
> > > So, "Normal" is relatively small, and DMA32 contains most of the RAM.
Ok. A consequence of this is that kswapd balancing a node will still try
to balance Normal even if DMA32 has enough memory. This could account
for some of kswapd being mean.
> > > Watermarks from /proc/zoneinfo are:
> > >
> > > Node 0, zone DMA
> > > min 7
> > > low 8
> > > high 10
> > > protection: (0, 3251, 4009, 4009)
> > > Node 0, zone DMA32
> > > min 1640
> > > low 2050
> > > high 2460
> > > protection: (0, 0, 757, 757)
> > > Node 0, zone Normal
> > > min 382
> > > low 477
> > > high 573
> > > protection: (0, 0, 0, 0)
> > >
> > > This box has a couple bnx2 NICs, which do about 60 Mbps each. Jumbo
> > > frames were disabled for now (to try to stop big order allocations), but
> > > this did not stop atomic allocations of order 3 coming in, as found with:
> > >
> > > perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph -c 1 -a sleep 10
> > > perf report
> > >
> > > __alloc_pages_nodemask
> > > alloc_pages_current
> > > new_slab
> > > __slab_alloc
> > > __kmalloc_node_track_caller
> > > __alloc_skb
> > > __netdev_alloc_skb
> > > bnx2_poll_work
> > >
> > > From my reading of this, it seems like __alloc_skb uses kmalloc(), and
> > > kmalloc uses the kmalloc slab unless (unlikely(size > SLUB_MAX_SIZE)),
> > > where SLUB_MAX_SIZE is 2 * PAGE_SIZE, in which case kmalloc_large is
> > > called which allocates pages directly. This means that reception of
> > > jumbo frames probably actually results in (consistent) smaller order
> > > allocations! Anyway, these GFP_ATOMIC allocations don't seem to be
> > > failing, BUT...
> > >
It's possible to reduce the maximum order that SLUB uses but lets not
resort to that as a workaround just yet. In case it needs to be
elminiated as a source of problems later, the relevant kernel parameter
is slub_max_order=.
> > > Right after kswapd goes to sleep, we're left with DMA32 with 421k or so
> > > free pages, and Normal with 20k or so free pages (about 1.8 GB free).
> > >
> > > Immediately, zone Normal starts being used until it reaches about 468
> > > pages free in order 0, nothing else free. kswapd is not woken here,
> > > but allocations just start coming from zone DMA32 instead.
kswapd is not woken up because we stay in the allocator fastpath once
that much memory hs been freed.
> > > While this
> > > happens, the occasional order=3 allocations coming in via the slab from
> > > __alloc_skb seem to be picking away at the available order=3 chunks.
> > > /proc/buddyinfo shows that there are 10k or so when it starts, so this
> > > succeeds easily.
> > >
> > > After a minute or so, available order-3 start reaching a lower number,
> > > like 20 or so. order-4 then starts dropping as it is split into order-3,
> > > until it reaches 20 or so as well. Then, order-3 hits 0, and kswapd is
> > > woken.
Allocator slowpath.
> > > When this occurs, there are still a few order-5, order-6, etc.,
> > > available.
Watermarks are probably not met though.
> > > I presume the GFP_ATOMIC allocation can still split buddies
> > > here, still making order-3 available without sleeping, because there is
> > > no allocation failure message that I can see.
> > >
Technically it could, but watermark maintenance is important.
> > > Here is a "while true; do sleep 1; grep -v 'DMA ' /proc/buddyinfo; done"
> > > ("DMA" zone is totally untouched, always, so excluded; white space
> > > crushed to avoid wrapping), while it happens:
> > >
> > > Node 0, zone DMA 2 1 1 2 1 1 1 0 1 1 3
> > > Node 0, zone DMA32 25770 29441 14512 10426 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > ...
> > > Node 0, zone DMA32 23343 29405 6062 6478 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 23187 29358 6047 5960 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 23000 29372 6047 5411 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 22714 29391 6076 4225 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 22354 29459 6059 3178 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 22202 29388 6035 2395 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 21971 29411 6036 1032 1901 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 21514 29388 6019 433 1796 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 21334 29387 6019 240 1464 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 21237 29421 6052 216 1336 123 4 0 0 0 0
> > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 20968 29378 6020 244 751 123 4 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 24388 33261 1985 6 10 4 2 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 25358 34080 1068 0 4 4 2 0 0 0 0
> > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 75985 68954 5345 87 1 4 2 0 0 0 0
> > > Node 0, zone Normal 18249 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81117 71630 19261 429 3 4 2 0 0 0 0
> > > Node 0, zone Normal 17908 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81226 71299 21038 569 19 4 2 0 0 0 0
> > > Node 0, zone Normal 18559 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81347 71278 21068 640 19 4 2 0 0 0 0
> > > Node 0, zone Normal 17928 21 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81370 71237 21241 1073 29 4 2 0 0 0 0
> > > Node 0, zone Normal 18187 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81401 71237 21314 1139 29 4 2 0 0 0 0
> > > Node 0, zone Normal 16978 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81410 71239 21314 1145 29 4 2 0 0 0 0
> > > Node 0, zone Normal 18156 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81419 71232 21317 1160 30 4 2 0 0 0 0
> > > Node 0, zone Normal 17536 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81347 71144 21443 1160 31 4 2 0 0 0 0
> > > Node 0, zone Normal 18483 7 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81300 71059 21556 1178 38 4 2 0 0 0 0
> > > Node 0, zone Normal 18528 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81315 71042 21577 1180 39 4 2 0 0 0 0
> > > Node 0, zone Normal 18431 2 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81301 71002 21702 1202 39 4 2 0 0 0 0
> > > Node 0, zone Normal 18487 5 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81301 70998 21702 1202 39 4 2 0 0 0 0
> > > Node 0, zone Normal 18311 0 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81296 71025 21711 1208 45 4 2 0 0 0 0
> > > Node 0, zone Normal 17092 5 0 0 0 0 0 0 0 0 0
> > > Node 0, zone DMA32 81299 71023 21716 1226 45 4 2 0 0 0 0
> > > Node 0, zone Normal 18225 12 0 0 0 0 0 0 0 0 0
> > >
> > > Running a perf record on the kswapd wakeup right when it happens shows:
> > > perf record --event vmscan:mm_vmscan_wakeup_kswapd -a --call-graph -c 1 -a sleep 10
> > > perf trace
> > > swapper-0 [002] 1323136.979119: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > swapper-0 [002] 1323136.979131: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > lmtp-20593 [003] 1323136.984066: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > lmtp-20593 [003] 1323136.984079: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > swapper-0 [001] 1323136.985511: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > swapper-0 [001] 1323136.985515: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > lmtp-20593 [003] 1323136.985673: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > lmtp-20593 [003] 1323136.985675: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > >
> > > This causes kswapd to throw out a bunch of stuff from Normal and from
> > > DMA32, to try to get zone_watermark_ok() to be happy for order=3.
Yep.
> > > However, we have a heavy read load from all of the email stored on SSDs
> > > on this box, and kswapd ends up fighting to try to keep reclaiming the
> > > allocations (mostly order-0). During the whole day, it never wins -- the
> > > allocations are faster. At night, it wins after a minute or two. The
> > > fighting is happening in all of the lines after it awakes above.
> > >
It's probably fighting to keep *all* zones happy even though it's not strictly
necessary. I suspect it's fighting the most for Normal.
> > > slabs_scanned, kswapd_steal, kswapd_inodesteal (slowly),
> > > kswapd_skip_congestion_wait, and pageoutrun go up in vmstat while kswapd
> > > is running. With the box up for 15 days, you can see it struggling on
> > > pgscan_kswapd_normal (from /proc/vmstat):
> > >
> > > pgfree 3329793080
> > > pgactivate 643476431
> > > pgdeactivate 155182710
> > > pgfault 2649106647
> > > pgmajfault 58157157
> > > pgrefill_dma 0
> > > pgrefill_dma32 19688032
> > > pgrefill_normal 7600864
> > > pgrefill_movable 0
> > > pgsteal_dma 0
> > > pgsteal_dma32 465191578
> > > pgsteal_normal 651178518
> > > pgsteal_movable 0
> > > pgscan_kswapd_dma 0
> > > pgscan_kswapd_dma32 768300403
> > > pgscan_kswapd_normal 34614572907
> > > pgscan_kswapd_movable 0
> > > pgscan_direct_dma 0
> > > pgscan_direct_dma32 2853983
> > > pgscan_direct_normal 885799
> > > pgscan_direct_movable 0
> > > pginodesteal 191895
> > > pgrotated 27290463
> > >
> > > So, here are my questions.
> > >
> > > Why do we care about order > 0 watermarks at all in the Normal zone?
> > > Wouldn't it make a lot more sense to just make the DMA32 zone the only
> > > one we care about for larger-order allocations? Or is this required for
> > > the hugepage stuff?
> > >
It's not required. The logic for kswapd is "balance all zones" and
Normal is one of the zones. Even though you know that DMA32 is just
fine, kswapd doesn't.
> > > The fact that so much stuff is evicted just because order-3 hits 0 is
> > > crazy, especially when larger order pages are still free. It seems like
> > > we're trying to keep large orders free here. Why?
Watermarks. The steady stream of order-3 allocations is telling the
allocator and kswapd that these size pages must be available. It doesn't
know that slub can happily fall back to smaller pages because that
information is lost. Even removing __GFP_WAIT won't help because kswapd
still gets woken up for atomic allocation requests.
> > > Maybe things would be
> > > better if kswapd does not reclaim at all unless the requested order is
> > > empty _and_ all orders above are empty. This would require hugepage
> > > users to use CONFIG_COMPACT, and have _compaction_ occur the way the
> > > watermark checks work now, but people without CONFIG_HUGETLB_PAGE could
> > > just actually use the memory. Would this work?
> > >
> > > There is logic at the end of balance_pgdat() to give up balancing order>0
> > > and just try another loop with order = 0 if sc.nr_reclaimed is <
> > > SWAP_CLUSTER_MAX. However, when this order=0 pass returns, the caller of
> > > balance_pgdat(), kswapd(), gets true from sleeping_prematurely() and just
> > > calls right back to balance_pgdat() again. I think this is why this
> > > logic doesn't seem to work here.
> > >
Ok, this is true. kswapd in balance_pgdat() has given up on the order
but that information is lost when sleeping_prematurely() is called so it
constantly loops. That is a mistake. balance_pgdat() could return the order
so sleeping_prematurely() doesn't do the wrong thing.
> > > Is my assumption about GFP_ATOMIC order=3 working even when order 3 is
> > > empty, but order>3 is not? Regardless, shouldn't kswapd be woken before
> > > order 3 is 0 since it may have nothing above order 3 to split from, thus
> > > actually causing an allocation failure? Does something else do this?
> >
> > even kswapd is woken after order>3 is empty, the issue will occur since
> > the order > 3 pages will be used soon and kswapd still needs to reclaim
> > some pages. So the issue is there is high order page allocation and
> > lumpy reclaim wrongly reclaims some pages. maybe you should use slab
> > instead of slub to avoid high order allocation.
>
> There are actually a few problems here. I think they are worth looking
> at them separately, unless "don't use order 3 allocations" is a valid
> statement, in which case we should fix slub.
>
SLUB can be forced to use smaller orders but I don't think that's the
right fix here.
> The funny thing here is that slub.c's allocate_slab() calls alloc_pages()
> with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a
> lower order allocation automatically if it fails. This is why there is
> no allocation failure warning when this happens. However, it is too late
> -- kswapd is woken and it ties to bring order 3 up to the watermark.
> If we hacked __alloc_pages_slowpath() to not wake kswapd when
> __GFP_NOWARN is set, we would never see this problem and the slub
> optimization might still mostly work.
Yes, but we'd see more high-order atomic allocation (e.g. jumbo frames)
failures as a result so that fix would cause other regressions.
> Either way, we should "fix" slub
> or "fix" order-3 allocations, so that other people who are using slub
> don't hit the same problem.
>
> kswapd is throwing out many times what is needed for the order 3
> watermark to be met. It seems to be not as bad now, but look at these
> pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
> followed by nr_pages_free calculation and final order-3 watermark test,
> kswapd woken after the second sample):
>
> Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
>
> DMA32 20374 35116 975 1 2 5 1 0 0 0 0 94770 257 <= 256
> DMA32 20480 35211 870 1 1 5 1 0 0 0 0 94630 241 <= 256
> (kswapd wakes, gobble gobble)
> DMA32 24387 37009 2910 297 100 5 1 0 0 0 0 114245 4193 <= 256
> DMA32 36169 37787 4676 637 110 5 1 0 0 0 0 137527 7073 <= 256
> DMA32 63443 40620 5716 982 144 5 1 0 0 0 0 177931 10377 <= 256
> DMA32 65866 57006 6462 1180 158 5 1 0 0 0 0 217918 12185 <= 256
> DMA32 67188 66779 9328 1893 208 5 1 0 0 0 0 256754 18689 <= 256
> DMA32 67909 67356 18307 2268 235 5 1 0 0 0 0 297977 22121 <= 256
> DMA32 68333 67419 20786 4192 298 7 1 0 0 0 0 324907 38585 <= 256
> DMA32 69872 68096 21580 5141 326 7 1 0 0 0 0 339016 46625 <= 256
> DMA32 69959 67970 22339 5657 371 10 1 0 0 0 0 346831 51569 <= 256
> DMA32 70017 67946 22363 6078 417 11 1 0 0 0 0 351073 55705 <= 256
> DMA32 70023 67949 22376 6204 439 12 1 0 0 0 0 352529 57097 <= 256
> DMA32 70045 67937 22380 6262 451 12 1 0 0 0 0 353199 57753 <= 256
> DMA32 70062 67939 22378 6298 456 12 1 0 0 0 0 353580 58121 <= 256
> DMA32 70079 67959 22388 6370 458 12 1 0 0 0 0 354285 58729 <= 256
> DMA32 70079 67959 22388 6387 460 12 1 0 0 0 0 354453 58897 <= 256
> DMA32 70076 67954 22387 6393 460 12 1 0 0 0 0 354484 58945 <= 256
> DMA32 70105 67975 22385 6466 468 12 1 0 0 0 0 355259 59657 <= 256
> DMA32 70110 67972 22387 6466 470 12 1 0 0 0 0 355298 59689 <= 256
> DMA32 70152 67989 22393 6476 470 12 1 0 0 0 0 355478 59769 <= 256
> DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> DMA32 70192 67990 22401 6495 471 12 1 0 0 0 0 355720 59937 <= 256
> DMA32 70192 67988 22401 6496 471 12 1 0 0 0 0 355724 59945 <= 256
> DMA32 70099 68061 22467 6602 477 12 1 0 0 0 0 356985 60889 <= 256
> DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
> DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
> DMA32 70099 68062 22467 6603 477 12 1 0 0 0 0 356995 60897 <= 256
> (kswapd sleeps)
>
> Normal zone at the same time (shown separately for clarity):
>
> Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> (kswapd wakes)
> Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
> Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
> Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
> Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
> Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
> Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
> Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
> Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
> Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
> Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
> Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
> Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
> Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
> Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
> Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
> Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
> Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
> Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> (kswapd sleeps -- maybe too much turkey)
>
> DMA32 get so much reclaimed that the watermark test succeeded long ago.
> Meanwhile, Normal is being reclaimed as well, but because it's fighting
> with allocations, it tries for a while and eventually succeeds (I think),
> but the 200ms samples didn't catch it.
>
So, the key here is kswapd didn't need to balance all zones, any one of
them would have been fine.
> KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
> to be similar to this problem, but your change is not working here.
It's not because sleeping_prematurely() interferes with it.
> We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
> is increasing (so has_under_min_watermark_zone is true), and pageoutrun
> increasing all the time. This means that balance_pgdat() keeps being
> called, but sleeping_prematurely() is returning true, so kswapd() just
> keeps re-calling balance_pgdat(). If your approach is correct to stop
> kswapd here, the problem seems to be that balance_pgdat's copy of order
> and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
> kswapd never really sleeps. How is this supposed to work?
>
It doesn't.
> Our allocation load here is mostly file pages, some anon pages, and
> relatively little slab and anything else.
>
I think there are at least two fixes required here.
1. sleeping_prematurely() must be aware that balance_pgdat() has dropped
the order.
2. kswapd is trying to balance all zones for higher orders even though
it doesn't really have to.
This patch has potential fixes for both of these problems. I have a split-out
series but I'm posting it as a single patch so see if it allows kswapd to
go to sleep as expected for you and whether it stops hammering the Normal
zone unnecessarily. I tested it locally here (albeit with compaction
enabled) and it did reduce the amount of time kswapd spent awake.
==== CUT HERE ====
diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
index 39c24eb..25fe08d 100644
--- a/include/linux/mmzone.h
+++ b/include/linux/mmzone.h
@@ -645,6 +645,7 @@ typedef struct pglist_data {
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
+ enum zone_type high_zoneidx;
} pg_data_t;
#define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
@@ -660,7 +661,7 @@ typedef struct pglist_data {
extern struct mutex zonelists_mutex;
void build_all_zonelists(void *data);
-void wakeup_kswapd(struct zone *zone, int order);
+void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx);
int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
int classzone_idx, int alloc_flags);
enum memmap_context {
diff --git a/mm/page_alloc.c b/mm/page_alloc.c
index 07a6544..344b597 100644
--- a/mm/page_alloc.c
+++ b/mm/page_alloc.c
@@ -1921,7 +1921,7 @@ void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
struct zone *zone;
for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
- wakeup_kswapd(zone, order);
+ wakeup_kswapd(zone, order, high_zoneidx);
}
static inline int
diff --git a/mm/vmscan.c b/mm/vmscan.c
index d31d7ce..00529a0 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2118,15 +2118,17 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
#endif
/* is kswapd sleeping prematurely? */
-static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
+static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
{
int i;
+ bool all_zones_ok = true;
+ bool any_zone_ok = false;
/* If a direct reclaimer woke kswapd within HZ/10, it's premature */
if (remaining)
return 1;
- /* If after HZ/10, a zone is below the high mark, it's premature */
+ /* Check the watermark levels */
for (i = 0; i < pgdat->nr_zones; i++) {
struct zone *zone = pgdat->node_zones + i;
@@ -2138,10 +2140,20 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
if (!zone_watermark_ok(zone, order, high_wmark_pages(zone),
0, 0))
- return 1;
+ all_zones_ok = false;
+ else
+ any_zone_ok = true;
}
- return 0;
+ /*
+ * For high-order requests, any zone meeting the watermark is enough
+ * to allow kswapd go back to sleep
+ * For order-0, all zones must be balanced
+ */
+ if (order)
+ return !any_zone_ok;
+ else
+ return !all_zones_ok;
}
/*
@@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
{
int all_zones_ok;
+ int any_zone_ok;
int priority;
int i;
unsigned long total_scanned;
@@ -2201,6 +2214,7 @@ loop_again:
disable_swap_token();
all_zones_ok = 1;
+ any_zone_ok = 0;
/*
* Scan in the highmem->dma direction for the highest
@@ -2310,10 +2324,12 @@ loop_again:
* spectulatively avoid congestion waits
*/
zone_clear_flag(zone, ZONE_CONGESTED);
+ if (i <= pgdat->high_zoneidx)
+ any_zone_ok = 1;
}
}
- if (all_zones_ok)
+ if (all_zones_ok || (order && any_zone_ok))
break; /* kswapd: all done */
/*
* OK, kswapd is getting into trouble. Take a nap, then take
@@ -2336,7 +2352,7 @@ loop_again:
break;
}
out:
- if (!all_zones_ok) {
+ if (!(all_zones_ok || (order && any_zone_ok))) {
cond_resched();
try_to_freeze();
@@ -2361,7 +2377,13 @@ out:
goto loop_again;
}
- return sc.nr_reclaimed;
+ /*
+ * Return the order we were reclaiming at so sleeping_prematurely()
+ * makes a decision on the order we were last reclaiming at. However,
+ * if another caller entered the allocator slow path while kswapd
+ * was awake, order will remain at the higher level
+ */
+ return order;
}
/*
@@ -2417,6 +2439,7 @@ static int kswapd(void *p)
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
new_order = pgdat->kswapd_max_order;
pgdat->kswapd_max_order = 0;
+ pgdat->high_zoneidx = MAX_ORDER;
if (order < new_order) {
/*
* Don't sleep if someone wants a larger 'order'
@@ -2464,7 +2487,7 @@ static int kswapd(void *p)
*/
if (!ret) {
trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
- balance_pgdat(pgdat, order);
+ order = balance_pgdat(pgdat, order);
}
}
return 0;
@@ -2473,7 +2496,7 @@ static int kswapd(void *p)
/*
* A zone is low on free memory, so wake its kswapd task to service it.
*/
-void wakeup_kswapd(struct zone *zone, int order)
+void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx)
{
pg_data_t *pgdat;
@@ -2483,8 +2506,10 @@ void wakeup_kswapd(struct zone *zone, int order)
pgdat = zone->zone_pgdat;
if (zone_watermark_ok(zone, order, low_wmark_pages(zone), 0, 0))
return;
- if (pgdat->kswapd_max_order < order)
+ if (pgdat->kswapd_max_order < order) {
pgdat->kswapd_max_order = order;
+ pgdat->high_zoneidx = min(pgdat->high_zoneidx, high_zoneidx);
+ }
trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order);
if (!cpuset_zone_allowed_hardwall(zone, GFP_KERNEL))
return;
On Thu, Nov 25, 2010 at 07:51:44PM +0900, KOSAKI Motohiro wrote:
> > kswapd is throwing out many times what is needed for the order 3
> > watermark to be met. It seems to be not as bad now, but look at these
> > pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
> > followed by nr_pages_free calculation and final order-3 watermark test,
> > kswapd woken after the second sample):
> >
> > Normal zone at the same time (shown separately for clarity):
> >
> > Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
> >
> > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > (kswapd wakes)
> > Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
> > Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
> > Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
> > Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
> > Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
> > Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
> > Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
> > Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
> > Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
> > Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
> > Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
> > Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
> > Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
> > Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
> > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
> > Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
> > Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > (kswapd sleeps -- maybe too much turkey)
> >
> > DMA32 get so much reclaimed that the watermark test succeeded long ago.
> > Meanwhile, Normal is being reclaimed as well, but because it's fighting
> > with allocations, it tries for a while and eventually succeeds (I think),
> > but the 200ms samples didn't catch it.
> >
> > KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
> > to be similar to this problem, but your change is not working here.
> > We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
> > is increasing (so has_under_min_watermark_zone is true), and pageoutrun
> > increasing all the time. This means that balance_pgdat() keeps being
> > called, but sleeping_prematurely() is returning true, so kswapd() just
> > keeps re-calling balance_pgdat(). If your approach is correct to stop
> > kswapd here, the problem seems to be that balance_pgdat's copy of order
> > and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
> > kswapd never really sleeps. How is this supposed to work?
>
> Um. this seems regression since commit f50de2d381 (vmscan: have kswapd sleep
> for a short interval and double check it should be asleep)
>
I wrote my own patch before I saw this but for one of the issues we are doing
something similar. You are checking if enough pages got reclaimed where as
my patch considers any zone being balanced for high-orders being sufficient
for kswapd to go to sleep. I think mine is a little stronger because
it's checking what state the zones are in for a given order regardless
of what has been reclaimed. Lets see what testing has to say.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Thu, Nov 25, 2010 at 07:18:49PM +0900, KOSAKI Motohiro wrote:
> This?
> - alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
> + alloc_gfp = (flags | __GFP_NOWARN) & ~(__GFP_NOFAIL | __GFP_WAIT);
kswapd still gets woken in the !__GFP_WAIT case, which is what I was
seeing anyway, because the order-3 allocatons were starting from
__alloc_skb().
Simon-
> Subject: [PATCH] vmscan: don't rewakeup kswapd if zone memory was exhaust
>
> ---
> mm/vmscan.c | 18 +++++++++++-------
> 1 files changed, 11 insertions(+), 7 deletions(-)
Ugh, this is buggy. please ignore.
sorry.
> On Thu, Nov 25, 2010 at 07:18:49PM +0900, KOSAKI Motohiro wrote:
>
> > This?
>
> > - alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
> > + alloc_gfp = (flags | __GFP_NOWARN) & ~(__GFP_NOFAIL | __GFP_WAIT);
>
> kswapd still gets woken in the !__GFP_WAIT case, which is what I was
> seeing anyway, because the order-3 allocatons were starting from
> __alloc_skb().
Oops, my fault.
We also need __GFP_NOKSWAPD. (Proposed by Andrea)
On Fri, 2010-11-26 at 00:12 +0800, Mel Gorman wrote:
> On Thu, Nov 25, 2010 at 01:03:28AM -0800, Simon Kirby wrote:
> > > > <SNIP>
> > > >
> > > > This x86_64 box has 4 GB of RAM; zones are set up as follows:
> > > >
> > > > [ 0.000000] Zone PFN ranges:
> > > > [ 0.000000] DMA 0x00000001 -> 0x00001000
> > > > [ 0.000000] DMA32 0x00001000 -> 0x00100000
> > > > [ 0.000000] Normal 0x00100000 -> 0x00130000
> > > > ...
> > > > [ 0.000000] On node 0 totalpages: 1047279
> > > > [ 0.000000] DMA zone: 56 pages used for memmap
> > > > [ 0.000000] DMA zone: 0 pages reserved
> > > > [ 0.000000] DMA zone: 3943 pages, LIFO batch:0
> > > > [ 0.000000] DMA32 zone: 14280 pages used for memmap
> > > > [ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
> > > > [ 0.000000] Normal zone: 2688 pages used for memmap
> > > > [ 0.000000] Normal zone: 193920 pages, LIFO batch:31
> > > >
> > > > So, "Normal" is relatively small, and DMA32 contains most of the RAM.
>
> Ok. A consequence of this is that kswapd balancing a node will still try
> to balance Normal even if DMA32 has enough memory. This could account
> for some of kswapd being mean.
>
> > > > Watermarks from /proc/zoneinfo are:
> > > >
> > > > Node 0, zone DMA
> > > > min 7
> > > > low 8
> > > > high 10
> > > > protection: (0, 3251, 4009, 4009)
> > > > Node 0, zone DMA32
> > > > min 1640
> > > > low 2050
> > > > high 2460
> > > > protection: (0, 0, 757, 757)
> > > > Node 0, zone Normal
> > > > min 382
> > > > low 477
> > > > high 573
> > > > protection: (0, 0, 0, 0)
> > > >
> > > > This box has a couple bnx2 NICs, which do about 60 Mbps each. Jumbo
> > > > frames were disabled for now (to try to stop big order allocations), but
> > > > this did not stop atomic allocations of order 3 coming in, as found with:
> > > >
> > > > perf record --event kmem:mm_page_alloc --filter 'order>=3' -a --call-graph -c 1 -a sleep 10
> > > > perf report
> > > >
> > > > __alloc_pages_nodemask
> > > > alloc_pages_current
> > > > new_slab
> > > > __slab_alloc
> > > > __kmalloc_node_track_caller
> > > > __alloc_skb
> > > > __netdev_alloc_skb
> > > > bnx2_poll_work
> > > >
> > > > From my reading of this, it seems like __alloc_skb uses kmalloc(), and
> > > > kmalloc uses the kmalloc slab unless (unlikely(size > SLUB_MAX_SIZE)),
> > > > where SLUB_MAX_SIZE is 2 * PAGE_SIZE, in which case kmalloc_large is
> > > > called which allocates pages directly. This means that reception of
> > > > jumbo frames probably actually results in (consistent) smaller order
> > > > allocations! Anyway, these GFP_ATOMIC allocations don't seem to be
> > > > failing, BUT...
> > > >
>
> It's possible to reduce the maximum order that SLUB uses but lets not
> resort to that as a workaround just yet. In case it needs to be
> elminiated as a source of problems later, the relevant kernel parameter
> is slub_max_order=.
>
> > > > Right after kswapd goes to sleep, we're left with DMA32 with 421k or so
> > > > free pages, and Normal with 20k or so free pages (about 1.8 GB free).
> > > >
> > > > Immediately, zone Normal starts being used until it reaches about 468
> > > > pages free in order 0, nothing else free. kswapd is not woken here,
> > > > but allocations just start coming from zone DMA32 instead.
>
> kswapd is not woken up because we stay in the allocator fastpath once
> that much memory hs been freed.
>
> > > > While this
> > > > happens, the occasional order=3 allocations coming in via the slab from
> > > > __alloc_skb seem to be picking away at the available order=3 chunks.
> > > > /proc/buddyinfo shows that there are 10k or so when it starts, so this
> > > > succeeds easily.
> > > >
> > > > After a minute or so, available order-3 start reaching a lower number,
> > > > like 20 or so. order-4 then starts dropping as it is split into order-3,
> > > > until it reaches 20 or so as well. Then, order-3 hits 0, and kswapd is
> > > > woken.
>
> Allocator slowpath.
>
> > > > When this occurs, there are still a few order-5, order-6, etc.,
> > > > available.
>
> Watermarks are probably not met though.
>
> > > > I presume the GFP_ATOMIC allocation can still split buddies
> > > > here, still making order-3 available without sleeping, because there is
> > > > no allocation failure message that I can see.
> > > >
>
> Technically it could, but watermark maintenance is important.
>
> > > > Here is a "while true; do sleep 1; grep -v 'DMA ' /proc/buddyinfo; done"
> > > > ("DMA" zone is totally untouched, always, so excluded; white space
> > > > crushed to avoid wrapping), while it happens:
> > > >
> > > > Node 0, zone DMA 2 1 1 2 1 1 1 0 1 1 3
> > > > Node 0, zone DMA32 25770 29441 14512 10426 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > ...
> > > > Node 0, zone DMA32 23343 29405 6062 6478 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 23187 29358 6047 5960 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 23000 29372 6047 5411 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 22714 29391 6076 4225 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 22354 29459 6059 3178 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 22202 29388 6035 2395 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 21971 29411 6036 1032 1901 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 21514 29388 6019 433 1796 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 21334 29387 6019 240 1464 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 21237 29421 6052 216 1336 123 4 0 0 0 0
> > > > Node 0, zone Normal 455 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 20968 29378 6020 244 751 123 4 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 24388 33261 1985 6 10 4 2 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 25358 34080 1068 0 4 4 2 0 0 0 0
> > > > Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 75985 68954 5345 87 1 4 2 0 0 0 0
> > > > Node 0, zone Normal 18249 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81117 71630 19261 429 3 4 2 0 0 0 0
> > > > Node 0, zone Normal 17908 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81226 71299 21038 569 19 4 2 0 0 0 0
> > > > Node 0, zone Normal 18559 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81347 71278 21068 640 19 4 2 0 0 0 0
> > > > Node 0, zone Normal 17928 21 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81370 71237 21241 1073 29 4 2 0 0 0 0
> > > > Node 0, zone Normal 18187 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81401 71237 21314 1139 29 4 2 0 0 0 0
> > > > Node 0, zone Normal 16978 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81410 71239 21314 1145 29 4 2 0 0 0 0
> > > > Node 0, zone Normal 18156 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81419 71232 21317 1160 30 4 2 0 0 0 0
> > > > Node 0, zone Normal 17536 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81347 71144 21443 1160 31 4 2 0 0 0 0
> > > > Node 0, zone Normal 18483 7 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81300 71059 21556 1178 38 4 2 0 0 0 0
> > > > Node 0, zone Normal 18528 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81315 71042 21577 1180 39 4 2 0 0 0 0
> > > > Node 0, zone Normal 18431 2 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81301 71002 21702 1202 39 4 2 0 0 0 0
> > > > Node 0, zone Normal 18487 5 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81301 70998 21702 1202 39 4 2 0 0 0 0
> > > > Node 0, zone Normal 18311 0 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81296 71025 21711 1208 45 4 2 0 0 0 0
> > > > Node 0, zone Normal 17092 5 0 0 0 0 0 0 0 0 0
> > > > Node 0, zone DMA32 81299 71023 21716 1226 45 4 2 0 0 0 0
> > > > Node 0, zone Normal 18225 12 0 0 0 0 0 0 0 0 0
> > > >
> > > > Running a perf record on the kswapd wakeup right when it happens shows:
> > > > perf record --event vmscan:mm_vmscan_wakeup_kswapd -a --call-graph -c 1 -a sleep 10
> > > > perf trace
> > > > swapper-0 [002] 1323136.979119: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > > swapper-0 [002] 1323136.979131: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > > lmtp-20593 [003] 1323136.984066: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > > lmtp-20593 [003] 1323136.984079: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > > swapper-0 [001] 1323136.985511: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > > swapper-0 [001] 1323136.985515: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > > lmtp-20593 [003] 1323136.985673: mm_vmscan_wakeup_kswapd: nid=0 zid=2 order=3
> > > > lmtp-20593 [003] 1323136.985675: mm_vmscan_wakeup_kswapd: nid=0 zid=1 order=3
> > > >
> > > > This causes kswapd to throw out a bunch of stuff from Normal and from
> > > > DMA32, to try to get zone_watermark_ok() to be happy for order=3.
>
> Yep.
>
> > > > However, we have a heavy read load from all of the email stored on SSDs
> > > > on this box, and kswapd ends up fighting to try to keep reclaiming the
> > > > allocations (mostly order-0). During the whole day, it never wins -- the
> > > > allocations are faster. At night, it wins after a minute or two. The
> > > > fighting is happening in all of the lines after it awakes above.
> > > >
>
> It's probably fighting to keep *all* zones happy even though it's not strictly
> necessary. I suspect it's fighting the most for Normal.
>
> > > > slabs_scanned, kswapd_steal, kswapd_inodesteal (slowly),
> > > > kswapd_skip_congestion_wait, and pageoutrun go up in vmstat while kswapd
> > > > is running. With the box up for 15 days, you can see it struggling on
> > > > pgscan_kswapd_normal (from /proc/vmstat):
> > > >
> > > > pgfree 3329793080
> > > > pgactivate 643476431
> > > > pgdeactivate 155182710
> > > > pgfault 2649106647
> > > > pgmajfault 58157157
> > > > pgrefill_dma 0
> > > > pgrefill_dma32 19688032
> > > > pgrefill_normal 7600864
> > > > pgrefill_movable 0
> > > > pgsteal_dma 0
> > > > pgsteal_dma32 465191578
> > > > pgsteal_normal 651178518
> > > > pgsteal_movable 0
> > > > pgscan_kswapd_dma 0
> > > > pgscan_kswapd_dma32 768300403
> > > > pgscan_kswapd_normal 34614572907
> > > > pgscan_kswapd_movable 0
> > > > pgscan_direct_dma 0
> > > > pgscan_direct_dma32 2853983
> > > > pgscan_direct_normal 885799
> > > > pgscan_direct_movable 0
> > > > pginodesteal 191895
> > > > pgrotated 27290463
> > > >
> > > > So, here are my questions.
> > > >
> > > > Why do we care about order > 0 watermarks at all in the Normal zone?
> > > > Wouldn't it make a lot more sense to just make the DMA32 zone the only
> > > > one we care about for larger-order allocations? Or is this required for
> > > > the hugepage stuff?
> > > >
>
> It's not required. The logic for kswapd is "balance all zones" and
> Normal is one of the zones. Even though you know that DMA32 is just
> fine, kswapd doesn't.
>
> > > > The fact that so much stuff is evicted just because order-3 hits 0 is
> > > > crazy, especially when larger order pages are still free. It seems like
> > > > we're trying to keep large orders free here. Why?
>
> Watermarks. The steady stream of order-3 allocations is telling the
> allocator and kswapd that these size pages must be available. It doesn't
> know that slub can happily fall back to smaller pages because that
> information is lost. Even removing __GFP_WAIT won't help because kswapd
> still gets woken up for atomic allocation requests.
>
> > > > Maybe things would be
> > > > better if kswapd does not reclaim at all unless the requested order is
> > > > empty _and_ all orders above are empty. This would require hugepage
> > > > users to use CONFIG_COMPACT, and have _compaction_ occur the way the
> > > > watermark checks work now, but people without CONFIG_HUGETLB_PAGE could
> > > > just actually use the memory. Would this work?
> > > >
> > > > There is logic at the end of balance_pgdat() to give up balancing order>0
> > > > and just try another loop with order = 0 if sc.nr_reclaimed is <
> > > > SWAP_CLUSTER_MAX. However, when this order=0 pass returns, the caller of
> > > > balance_pgdat(), kswapd(), gets true from sleeping_prematurely() and just
> > > > calls right back to balance_pgdat() again. I think this is why this
> > > > logic doesn't seem to work here.
> > > >
>
> Ok, this is true. kswapd in balance_pgdat() has given up on the order
> but that information is lost when sleeping_prematurely() is called so it
> constantly loops. That is a mistake. balance_pgdat() could return the order
> so sleeping_prematurely() doesn't do the wrong thing.
>
> > > > Is my assumption about GFP_ATOMIC order=3 working even when order 3 is
> > > > empty, but order>3 is not? Regardless, shouldn't kswapd be woken before
> > > > order 3 is 0 since it may have nothing above order 3 to split from, thus
> > > > actually causing an allocation failure? Does something else do this?
> > >
> > > even kswapd is woken after order>3 is empty, the issue will occur since
> > > the order > 3 pages will be used soon and kswapd still needs to reclaim
> > > some pages. So the issue is there is high order page allocation and
> > > lumpy reclaim wrongly reclaims some pages. maybe you should use slab
> > > instead of slub to avoid high order allocation.
> >
> > There are actually a few problems here. I think they are worth looking
> > at them separately, unless "don't use order 3 allocations" is a valid
> > statement, in which case we should fix slub.
> >
>
> SLUB can be forced to use smaller orders but I don't think that's the
> right fix here.
>
> > The funny thing here is that slub.c's allocate_slab() calls alloc_pages()
> > with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a
> > lower order allocation automatically if it fails. This is why there is
> > no allocation failure warning when this happens. However, it is too late
> > -- kswapd is woken and it ties to bring order 3 up to the watermark.
> > If we hacked __alloc_pages_slowpath() to not wake kswapd when
> > __GFP_NOWARN is set, we would never see this problem and the slub
> > optimization might still mostly work.
>
> Yes, but we'd see more high-order atomic allocation (e.g. jumbo frames)
> failures as a result so that fix would cause other regressions.
>
> > Either way, we should "fix" slub
> > or "fix" order-3 allocations, so that other people who are using slub
> > don't hit the same problem.
> >
> > kswapd is throwing out many times what is needed for the order 3
> > watermark to be met. It seems to be not as bad now, but look at these
> > pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
> > followed by nr_pages_free calculation and final order-3 watermark test,
> > kswapd woken after the second sample):
> >
> > Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
> >
> > DMA32 20374 35116 975 1 2 5 1 0 0 0 0 94770 257 <= 256
> > DMA32 20480 35211 870 1 1 5 1 0 0 0 0 94630 241 <= 256
> > (kswapd wakes, gobble gobble)
> > DMA32 24387 37009 2910 297 100 5 1 0 0 0 0 114245 4193 <= 256
> > DMA32 36169 37787 4676 637 110 5 1 0 0 0 0 137527 7073 <= 256
> > DMA32 63443 40620 5716 982 144 5 1 0 0 0 0 177931 10377 <= 256
> > DMA32 65866 57006 6462 1180 158 5 1 0 0 0 0 217918 12185 <= 256
> > DMA32 67188 66779 9328 1893 208 5 1 0 0 0 0 256754 18689 <= 256
> > DMA32 67909 67356 18307 2268 235 5 1 0 0 0 0 297977 22121 <= 256
> > DMA32 68333 67419 20786 4192 298 7 1 0 0 0 0 324907 38585 <= 256
> > DMA32 69872 68096 21580 5141 326 7 1 0 0 0 0 339016 46625 <= 256
> > DMA32 69959 67970 22339 5657 371 10 1 0 0 0 0 346831 51569 <= 256
> > DMA32 70017 67946 22363 6078 417 11 1 0 0 0 0 351073 55705 <= 256
> > DMA32 70023 67949 22376 6204 439 12 1 0 0 0 0 352529 57097 <= 256
> > DMA32 70045 67937 22380 6262 451 12 1 0 0 0 0 353199 57753 <= 256
> > DMA32 70062 67939 22378 6298 456 12 1 0 0 0 0 353580 58121 <= 256
> > DMA32 70079 67959 22388 6370 458 12 1 0 0 0 0 354285 58729 <= 256
> > DMA32 70079 67959 22388 6387 460 12 1 0 0 0 0 354453 58897 <= 256
> > DMA32 70076 67954 22387 6393 460 12 1 0 0 0 0 354484 58945 <= 256
> > DMA32 70105 67975 22385 6466 468 12 1 0 0 0 0 355259 59657 <= 256
> > DMA32 70110 67972 22387 6466 470 12 1 0 0 0 0 355298 59689 <= 256
> > DMA32 70152 67989 22393 6476 470 12 1 0 0 0 0 355478 59769 <= 256
> > DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> > DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> > DMA32 70175 67991 22401 6493 471 12 1 0 0 0 0 355689 59921 <= 256
> > DMA32 70192 67990 22401 6495 471 12 1 0 0 0 0 355720 59937 <= 256
> > DMA32 70192 67988 22401 6496 471 12 1 0 0 0 0 355724 59945 <= 256
> > DMA32 70099 68061 22467 6602 477 12 1 0 0 0 0 356985 60889 <= 256
> > DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
> > DMA32 70099 68062 22467 6602 477 12 1 0 0 0 0 356987 60889 <= 256
> > DMA32 70099 68062 22467 6603 477 12 1 0 0 0 0 356995 60897 <= 256
> > (kswapd sleeps)
> >
> > Normal zone at the same time (shown separately for clarity):
> >
> > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > (kswapd wakes)
> > Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
> > Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
> > Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
> > Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
> > Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
> > Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
> > Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
> > Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
> > Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
> > Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
> > Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
> > Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
> > Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
> > Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
> > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
> > Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
> > Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
> > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > (kswapd sleeps -- maybe too much turkey)
> >
> > DMA32 get so much reclaimed that the watermark test succeeded long ago.
> > Meanwhile, Normal is being reclaimed as well, but because it's fighting
> > with allocations, it tries for a while and eventually succeeds (I think),
> > but the 200ms samples didn't catch it.
> >
>
> So, the key here is kswapd didn't need to balance all zones, any one of
> them would have been fine.
>
> > KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
> > to be similar to this problem, but your change is not working here.
>
> It's not because sleeping_prematurely() interferes with it.
>
> > We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
> > is increasing (so has_under_min_watermark_zone is true), and pageoutrun
> > increasing all the time. This means that balance_pgdat() keeps being
> > called, but sleeping_prematurely() is returning true, so kswapd() just
> > keeps re-calling balance_pgdat(). If your approach is correct to stop
> > kswapd here, the problem seems to be that balance_pgdat's copy of order
> > and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
> > kswapd never really sleeps. How is this supposed to work?
> >
>
> It doesn't.
>
> > Our allocation load here is mostly file pages, some anon pages, and
> > relatively little slab and anything else.
> >
>
> I think there are at least two fixes required here.
>
> 1. sleeping_prematurely() must be aware that balance_pgdat() has dropped
> the order.
> 2. kswapd is trying to balance all zones for higher orders even though
> it doesn't really have to.
>
> This patch has potential fixes for both of these problems. I have a split-out
> series but I'm posting it as a single patch so see if it allows kswapd to
> go to sleep as expected for you and whether it stops hammering the Normal
> zone unnecessarily. I tested it locally here (albeit with compaction
> enabled) and it did reduce the amount of time kswapd spent awake.
>
> ==== CUT HERE ====
> diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
> index 39c24eb..25fe08d 100644
> --- a/include/linux/mmzone.h
> +++ b/include/linux/mmzone.h
> @@ -645,6 +645,7 @@ typedef struct pglist_data {
> wait_queue_head_t kswapd_wait;
> struct task_struct *kswapd;
> int kswapd_max_order;
> + enum zone_type high_zoneidx;
> } pg_data_t;
>
> #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
> @@ -660,7 +661,7 @@ typedef struct pglist_data {
>
> extern struct mutex zonelists_mutex;
> void build_all_zonelists(void *data);
> -void wakeup_kswapd(struct zone *zone, int order);
> +void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx);
> int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
> int classzone_idx, int alloc_flags);
> enum memmap_context {
> diff --git a/mm/page_alloc.c b/mm/page_alloc.c
> index 07a6544..344b597 100644
> --- a/mm/page_alloc.c
> +++ b/mm/page_alloc.c
> @@ -1921,7 +1921,7 @@ void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
> struct zone *zone;
>
> for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
> - wakeup_kswapd(zone, order);
> + wakeup_kswapd(zone, order, high_zoneidx);
> }
>
> static inline int
> diff --git a/mm/vmscan.c b/mm/vmscan.c
> index d31d7ce..00529a0 100644
> --- a/mm/vmscan.c
> +++ b/mm/vmscan.c
> @@ -2118,15 +2118,17 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> #endif
>
> /* is kswapd sleeping prematurely? */
> -static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> +static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> {
> int i;
> + bool all_zones_ok = true;
> + bool any_zone_ok = false;
>
> /* If a direct reclaimer woke kswapd within HZ/10, it's premature */
> if (remaining)
> return 1;
>
> - /* If after HZ/10, a zone is below the high mark, it's premature */
> + /* Check the watermark levels */
> for (i = 0; i < pgdat->nr_zones; i++) {
> struct zone *zone = pgdat->node_zones + i;
>
> @@ -2138,10 +2140,20 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
>
> if (!zone_watermark_ok(zone, order, high_wmark_pages(zone),
> 0, 0))
> - return 1;
> + all_zones_ok = false;
> + else
> + any_zone_ok = true;
> }
>
> - return 0;
> + /*
> + * For high-order requests, any zone meeting the watermark is enough
> + * to allow kswapd go back to sleep
> + * For order-0, all zones must be balanced
> + */
> + if (order)
> + return !any_zone_ok;
> + else
> + return !all_zones_ok;
> }
>
> /*
> @@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> {
> int all_zones_ok;
> + int any_zone_ok;
> int priority;
> int i;
> unsigned long total_scanned;
> @@ -2201,6 +2214,7 @@ loop_again:
> disable_swap_token();
>
> all_zones_ok = 1;
> + any_zone_ok = 0;
>
> /*
> * Scan in the highmem->dma direction for the highest
> @@ -2310,10 +2324,12 @@ loop_again:
> * spectulatively avoid congestion waits
> */
> zone_clear_flag(zone, ZONE_CONGESTED);
> + if (i <= pgdat->high_zoneidx)
> + any_zone_ok = 1;
> }
>
> }
> - if (all_zones_ok)
> + if (all_zones_ok || (order && any_zone_ok))
> break; /* kswapd: all done */
> /*
> * OK, kswapd is getting into trouble. Take a nap, then take
> @@ -2336,7 +2352,7 @@ loop_again:
> break;
> }
> out:
> - if (!all_zones_ok) {
> + if (!(all_zones_ok || (order && any_zone_ok))) {
> cond_resched();
>
> try_to_freeze();
> @@ -2361,7 +2377,13 @@ out:
> goto loop_again;
> }
>
> - return sc.nr_reclaimed;
> + /*
> + * Return the order we were reclaiming at so sleeping_prematurely()
> + * makes a decision on the order we were last reclaiming at. However,
> + * if another caller entered the allocator slow path while kswapd
> + * was awake, order will remain at the higher level
> + */
> + return order;
> }
This seems always fail. because you have the protect in the kswapd side,
but no in the page allocation side. so every time a high order
allocation occurs, the protect breaks and kswapd keeps running.
On Fri, Nov 26, 2010 at 09:05:56AM +0800, Shaohua Li wrote:
> > @@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> > {
> > int all_zones_ok;
> > + int any_zone_ok;
> > int priority;
> > int i;
> > unsigned long total_scanned;
> > @@ -2201,6 +2214,7 @@ loop_again:
> > disable_swap_token();
> >
> > all_zones_ok = 1;
> > + any_zone_ok = 0;
> >
> > /*
> > * Scan in the highmem->dma direction for the highest
> > @@ -2310,10 +2324,12 @@ loop_again:
> > * spectulatively avoid congestion waits
> > */
> > zone_clear_flag(zone, ZONE_CONGESTED);
> > + if (i <= pgdat->high_zoneidx)
> > + any_zone_ok = 1;
> > }
> >
> > }
> > - if (all_zones_ok)
> > + if (all_zones_ok || (order && any_zone_ok))
> > break; /* kswapd: all done */
> > /*
> > * OK, kswapd is getting into trouble. Take a nap, then take
> > @@ -2336,7 +2352,7 @@ loop_again:
> > break;
> > }
> > out:
> > - if (!all_zones_ok) {
> > + if (!(all_zones_ok || (order && any_zone_ok))) {
> > cond_resched();
> >
> > try_to_freeze();
> > @@ -2361,7 +2377,13 @@ out:
> > goto loop_again;
> > }
> >
> > - return sc.nr_reclaimed;
> > + /*
> > + * Return the order we were reclaiming at so sleeping_prematurely()
> > + * makes a decision on the order we were last reclaiming at. However,
> > + * if another caller entered the allocator slow path while kswapd
> > + * was awake, order will remain at the higher level
> > + */
> > + return order;
> > }
> This seems always fail. because you have the protect in the kswapd side,
> but no in the page allocation side. so every time a high order
> allocation occurs, the protect breaks and kswapd keeps running.
>
I don't understand your question. sc.nr_reclaimed was being unused. The
point of returning order was to tell kswapd that "the order you were
reclaiming at may or may not be still valid, make your decisions on the
order I am currently reclaiming at". The key here is if that multiple
allocation requests come in for higher orders, kswapd will get reworken
multiple times. Unless it gets rewoken multiple times, kswapd is willing
to go back to sleep to avoid reclaiming an excessive number of pages.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Fri, 2010-11-26 at 00:15 +0800, Mel Gorman wrote:
> On Thu, Nov 25, 2010 at 07:51:44PM +0900, KOSAKI Motohiro wrote:
> > > kswapd is throwing out many times what is needed for the order 3
> > > watermark to be met. It seems to be not as bad now, but look at these
> > > pages being reclaimed (200ms intervals, whitespace-packed buddyinfo
> > > followed by nr_pages_free calculation and final order-3 watermark test,
> > > kswapd woken after the second sample):
> > >
> > > Normal zone at the same time (shown separately for clarity):
> > >
> > > Zone order:0 1 2 3 4 5 6 7 8 9 A nr_free or3-low-chk
> > >
> > > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > > Normal 452 1 0 0 0 0 0 0 0 0 0 454 -5 <= 238
> > > (kswapd wakes)
> > > Normal 7618 76 0 0 0 0 0 0 0 0 0 7770 145 <= 238
> > > Normal 8860 73 1 0 0 0 0 0 0 0 0 9010 143 <= 238
> > > Normal 8929 25 0 0 0 0 0 0 0 0 0 8979 43 <= 238
> > > Normal 8917 0 0 0 0 0 0 0 0 0 0 8917 -7 <= 238
> > > Normal 8978 16 0 0 0 0 0 0 0 0 0 9010 25 <= 238
> > > Normal 9064 4 0 0 0 0 0 0 0 0 0 9072 1 <= 238
> > > Normal 9068 2 0 0 0 0 0 0 0 0 0 9072 -3 <= 238
> > > Normal 8992 9 0 0 0 0 0 0 0 0 0 9010 11 <= 238
> > > Normal 9060 6 0 0 0 0 0 0 0 0 0 9072 5 <= 238
> > > Normal 9010 0 0 0 0 0 0 0 0 0 0 9010 -7 <= 238
> > > Normal 8907 5 0 0 0 0 0 0 0 0 0 8917 3 <= 238
> > > Normal 8576 0 0 0 0 0 0 0 0 0 0 8576 -7 <= 238
> > > Normal 8018 0 0 0 0 0 0 0 0 0 0 8018 -7 <= 238
> > > Normal 6778 0 0 0 0 0 0 0 0 0 0 6778 -7 <= 238
> > > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > > Normal 6220 0 0 0 0 0 0 0 0 0 0 6220 -7 <= 238
> > > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > > Normal 6251 0 0 0 0 0 0 0 0 0 0 6251 -7 <= 238
> > > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > > Normal 6218 1 0 0 0 0 0 0 0 0 0 6220 -5 <= 238
> > > Normal 6034 0 0 0 0 0 0 0 0 0 0 6034 -7 <= 238
> > > Normal 6065 0 0 0 0 0 0 0 0 0 0 6065 -7 <= 238
> > > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > > Normal 6189 0 0 0 0 0 0 0 0 0 0 6189 -7 <= 238
> > > Normal 6096 0 0 0 0 0 0 0 0 0 0 6096 -7 <= 238
> > > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > > Normal 6158 0 0 0 0 0 0 0 0 0 0 6158 -7 <= 238
> > > Normal 6127 0 0 0 0 0 0 0 0 0 0 6127 -7 <= 238
> > > (kswapd sleeps -- maybe too much turkey)
> > >
> > > DMA32 get so much reclaimed that the watermark test succeeded long ago.
> > > Meanwhile, Normal is being reclaimed as well, but because it's fighting
> > > with allocations, it tries for a while and eventually succeeds (I think),
> > > but the 200ms samples didn't catch it.
> > >
> > > KOSAKI Motohiro, I'm interested in your commit 73ce02e9. This seems
> > > to be similar to this problem, but your change is not working here.
> > > We're seeing kswapd run without sleeping, KSWAPD_SKIP_CONGESTION_WAIT
> > > is increasing (so has_under_min_watermark_zone is true), and pageoutrun
> > > increasing all the time. This means that balance_pgdat() keeps being
> > > called, but sleeping_prematurely() is returning true, so kswapd() just
> > > keeps re-calling balance_pgdat(). If your approach is correct to stop
> > > kswapd here, the problem seems to be that balance_pgdat's copy of order
> > > and sc.order is being set to 0, but not pgdat->kswapd_max_order, so
> > > kswapd never really sleeps. How is this supposed to work?
> >
> > Um. this seems regression since commit f50de2d381 (vmscan: have kswapd sleep
> > for a short interval and double check it should be asleep)
> >
>
> I wrote my own patch before I saw this but for one of the issues we are doing
> something similar. You are checking if enough pages got reclaimed where as
> my patch considers any zone being balanced for high-orders being sufficient
> for kswapd to go to sleep. I think mine is a little stronger because
> it's checking what state the zones are in for a given order regardless
> of what has been reclaimed. Lets see what testing has to say.
record the order seems not sufficient. in balance_pgdat(), the for look
exit only when:
priority <0 or sc.nr_reclaimed >= SWAP_CLUSTER_MAX.
but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
order = sc.order = 0;
this means before we set order to 0, we already reclaimed a lot of
pages, so I thought we need set order to 0 earlier before there are
enough free pages. below is a debug patch.
diff --git a/mm/vmscan.c b/mm/vmscan.c
index d31d7ce..ee5d2ed 100644
--- a/mm/vmscan.c
+++ b/mm/vmscan.c
@@ -2117,6 +2117,26 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
}
#endif
+static int all_zone_enough_free_pages(pg_data_t *pgdat)
+{
+ int i;
+
+ for (i = 0; i < pgdat->nr_zones; i++) {
+ struct zone *zone = pgdat->node_zones + i;
+
+ if (!populated_zone(zone))
+ continue;
+
+ if (zone->all_unreclaimable)
+ continue;
+
+ if (!zone_watermark_ok(zone, 0, high_wmark_pages(zone) * 8,
+ 0, 0))
+ return 0;
+ }
+ return 1;
+}
+
/* is kswapd sleeping prematurely? */
static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
{
@@ -2355,7 +2375,8 @@ out:
* back to sleep. High-order users can still perform direct
* reclaim if they wish.
*/
- if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
+ if (sc.nr_reclaimed < SWAP_CLUSTER_MAX ||
+ (order > 0 && all_zone_enough_free_pages(pgdat)))
order = sc.order = 0;
goto loop_again;
On Fri, 2010-11-26 at 09:25 +0800, Mel Gorman wrote:
> On Fri, Nov 26, 2010 at 09:05:56AM +0800, Shaohua Li wrote:
> > > @@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > > static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> > > {
> > > int all_zones_ok;
> > > + int any_zone_ok;
> > > int priority;
> > > int i;
> > > unsigned long total_scanned;
> > > @@ -2201,6 +2214,7 @@ loop_again:
> > > disable_swap_token();
> > >
> > > all_zones_ok = 1;
> > > + any_zone_ok = 0;
> > >
> > > /*
> > > * Scan in the highmem->dma direction for the highest
> > > @@ -2310,10 +2324,12 @@ loop_again:
> > > * spectulatively avoid congestion waits
> > > */
> > > zone_clear_flag(zone, ZONE_CONGESTED);
> > > + if (i <= pgdat->high_zoneidx)
> > > + any_zone_ok = 1;
> > > }
> > >
> > > }
> > > - if (all_zones_ok)
> > > + if (all_zones_ok || (order && any_zone_ok))
> > > break; /* kswapd: all done */
> > > /*
> > > * OK, kswapd is getting into trouble. Take a nap, then take
> > > @@ -2336,7 +2352,7 @@ loop_again:
> > > break;
> > > }
> > > out:
> > > - if (!all_zones_ok) {
> > > + if (!(all_zones_ok || (order && any_zone_ok))) {
> > > cond_resched();
> > >
> > > try_to_freeze();
> > > @@ -2361,7 +2377,13 @@ out:
> > > goto loop_again;
> > > }
> > >
> > > - return sc.nr_reclaimed;
> > > + /*
> > > + * Return the order we were reclaiming at so sleeping_prematurely()
> > > + * makes a decision on the order we were last reclaiming at. However,
> > > + * if another caller entered the allocator slow path while kswapd
> > > + * was awake, order will remain at the higher level
> > > + */
> > > + return order;
> > > }
> > This seems always fail. because you have the protect in the kswapd side,
> > but no in the page allocation side. so every time a high order
> > allocation occurs, the protect breaks and kswapd keeps running.
> >
>
> I don't understand your question. sc.nr_reclaimed was being unused. The
> point of returning order was to tell kswapd that "the order you were
> reclaiming at may or may not be still valid, make your decisions on the
> order I am currently reclaiming at". The key here is if that multiple
> allocation requests come in for higher orders, kswapd will get reworken
> multiple times. Unless it gets rewoken multiple times, kswapd is willing
> to go back to sleep to avoid reclaiming an excessive number of pages.
yes, I thought is rewoken multiple times, in the workload Simon reported
Node 0, zone DMA32 20741 29383 6022 134 272 123 4 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20476 29370 6024 117 48 116 4 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 20343 29369 6020 110 23 10 2 0 0 0 0
Node 0, zone Normal 453 1 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32 21592 30477 4856 22 10 4 2 0 0 0 0
order >=3 pages are reduced a lot in a second
> record the order seems not sufficient. in balance_pgdat(), the for look
> exit only when:
> priority <0 or sc.nr_reclaimed >= SWAP_CLUSTER_MAX.
> but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> order = sc.order = 0;
> this means before we set order to 0, we already reclaimed a lot of
> pages, so I thought we need set order to 0 earlier before there are
> enough free pages. below is a debug patch.
>
>
> diff --git a/mm/vmscan.c b/mm/vmscan.c
> index d31d7ce..ee5d2ed 100644
> --- a/mm/vmscan.c
> +++ b/mm/vmscan.c
> @@ -2117,6 +2117,26 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> }
> #endif
>
> +static int all_zone_enough_free_pages(pg_data_t *pgdat)
> +{
> + int i;
> +
> + for (i = 0; i < pgdat->nr_zones; i++) {
> + struct zone *zone = pgdat->node_zones + i;
> +
> + if (!populated_zone(zone))
> + continue;
> +
> + if (zone->all_unreclaimable)
> + continue;
> +
> + if (!zone_watermark_ok(zone, 0, high_wmark_pages(zone) * 8,
> + 0, 0))
> + return 0;
> + }
> + return 1;
> +}
> +
> /* is kswapd sleeping prematurely? */
> static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> {
> @@ -2355,7 +2375,8 @@ out:
> * back to sleep. High-order users can still perform direct
> * reclaim if they wish.
> */
> - if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> + if (sc.nr_reclaimed < SWAP_CLUSTER_MAX ||
> + (order > 0 && all_zone_enough_free_pages(pgdat)))
> order = sc.order = 0;
Ummm. this doesn't work. this place is processed every 32 pages reclaimed.
(see below code and comment). Theresore your patch break high order reclaim
logic.
/*
* We do this so kswapd doesn't build up large priorities for
* example when it is freeing in parallel with allocators. It
* matches the direct reclaim path behaviour in terms of impact
* on zone->*_priority.
*/
if (sc.nr_reclaimed >= SWAP_CLUSTER_MAX)
break;
On Fri, 2010-11-26 at 10:31 +0800, KOSAKI Motohiro wrote:
> > record the order seems not sufficient. in balance_pgdat(), the for look
> > exit only when:
> > priority <0 or sc.nr_reclaimed >= SWAP_CLUSTER_MAX.
> > but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > order = sc.order = 0;
> > this means before we set order to 0, we already reclaimed a lot of
> > pages, so I thought we need set order to 0 earlier before there are
> > enough free pages. below is a debug patch.
> >
> >
> > diff --git a/mm/vmscan.c b/mm/vmscan.c
> > index d31d7ce..ee5d2ed 100644
> > --- a/mm/vmscan.c
> > +++ b/mm/vmscan.c
> > @@ -2117,6 +2117,26 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> > }
> > #endif
> >
> > +static int all_zone_enough_free_pages(pg_data_t *pgdat)
> > +{
> > + int i;
> > +
> > + for (i = 0; i < pgdat->nr_zones; i++) {
> > + struct zone *zone = pgdat->node_zones + i;
> > +
> > + if (!populated_zone(zone))
> > + continue;
> > +
> > + if (zone->all_unreclaimable)
> > + continue;
> > +
> > + if (!zone_watermark_ok(zone, 0, high_wmark_pages(zone) * 8,
> > + 0, 0))
> > + return 0;
> > + }
> > + return 1;
> > +}
> > +
> > /* is kswapd sleeping prematurely? */
> > static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > {
> > @@ -2355,7 +2375,8 @@ out:
> > * back to sleep. High-order users can still perform direct
> > * reclaim if they wish.
> > */
> > - if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > + if (sc.nr_reclaimed < SWAP_CLUSTER_MAX ||
> > + (order > 0 && all_zone_enough_free_pages(pgdat)))
> > order = sc.order = 0;
>
> Ummm. this doesn't work. this place is processed every 32 pages reclaimed.
> (see below code and comment). Theresore your patch break high order reclaim
> logic.
Yes, this will break high order reclaim, but we need a compromise.
wrongly reclaim pages is more worse. could increase the watermark in
all_zone_enough_free_pages() better?
> On Fri, 2010-11-26 at 10:31 +0800, KOSAKI Motohiro wrote:
> > > record the order seems not sufficient. in balance_pgdat(), the for look
> > > exit only when:
> > > priority <0 or sc.nr_reclaimed >= SWAP_CLUSTER_MAX.
> > > but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > order = sc.order = 0;
> > > this means before we set order to 0, we already reclaimed a lot of
> > > pages, so I thought we need set order to 0 earlier before there are
> > > enough free pages. below is a debug patch.
> > >
> > >
> > > diff --git a/mm/vmscan.c b/mm/vmscan.c
> > > index d31d7ce..ee5d2ed 100644
> > > --- a/mm/vmscan.c
> > > +++ b/mm/vmscan.c
> > > @@ -2117,6 +2117,26 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> > > }
> > > #endif
> > >
> > > +static int all_zone_enough_free_pages(pg_data_t *pgdat)
> > > +{
> > > + int i;
> > > +
> > > + for (i = 0; i < pgdat->nr_zones; i++) {
> > > + struct zone *zone = pgdat->node_zones + i;
> > > +
> > > + if (!populated_zone(zone))
> > > + continue;
> > > +
> > > + if (zone->all_unreclaimable)
> > > + continue;
> > > +
> > > + if (!zone_watermark_ok(zone, 0, high_wmark_pages(zone) * 8,
> > > + 0, 0))
> > > + return 0;
> > > + }
> > > + return 1;
> > > +}
> > > +
> > > /* is kswapd sleeping prematurely? */
> > > static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > > {
> > > @@ -2355,7 +2375,8 @@ out:
> > > * back to sleep. High-order users can still perform direct
> > > * reclaim if they wish.
> > > */
> > > - if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > + if (sc.nr_reclaimed < SWAP_CLUSTER_MAX ||
> > > + (order > 0 && all_zone_enough_free_pages(pgdat)))
> > > order = sc.order = 0;
> >
> > Ummm. this doesn't work. this place is processed every 32 pages reclaimed.
> > (see below code and comment). Theresore your patch break high order reclaim
> > logic.
> Yes, this will break high order reclaim, but we need a compromise.
> wrongly reclaim pages is more worse. could increase the watermark in
> all_zone_enough_free_pages() better?
>
Hmm..
I guess I haven't catch your mention. you wrote
> > > but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > order = sc.order = 0;
> > > this means before we set order to 0, we already reclaimed a lot of
> > > pages
and I wrote it's not a lot. So, I don't understand why you are talking
about watermark increasing now. Personally you seems to talk unrelated
topic. Can you please elablate your point more?
Two points.
> @@ -2310,10 +2324,12 @@ loop_again:
> * spectulatively avoid congestion waits
> */
> zone_clear_flag(zone, ZONE_CONGESTED);
> + if (i <= pgdat->high_zoneidx)
> + any_zone_ok = 1;
> }
>
> }
> - if (all_zones_ok)
> + if (all_zones_ok || (order && any_zone_ok))
> break; /* kswapd: all done */
> /*
> * OK, kswapd is getting into trouble. Take a nap, then take
> @@ -2336,7 +2352,7 @@ loop_again:
> break;
> }
> out:
> - if (!all_zones_ok) {
> + if (!(all_zones_ok || (order && any_zone_ok))) {
This doesn't work ;)
kswapd have to clear ZONE_CONGESTED flag before enter sleeping.
otherwise nobody can clear it.
Say, we have to fill below condition.
- All zone are successing zone_watermark_ok(order-0)
- At least one zone are successing zone_watermark_ok(high-order)
> @@ -2417,6 +2439,7 @@ static int kswapd(void *p)
> prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
> new_order = pgdat->kswapd_max_order;
> pgdat->kswapd_max_order = 0;
> + pgdat->high_zoneidx = MAX_ORDER;
I don't think MAX_ORDER is correct ;)
high_zoneidx = pgdat->high_zoneidx;
pgdat->high_zoneidx = pgdat->nr_zones - 1;
?
And, we have another kswapd_max_order reading place. (after kswapd_try_to_sleep)
We need it too.
On Fri, Nov 26, 2010 at 08:03:04PM +0900, KOSAKI Motohiro wrote:
> Two points.
>
> > @@ -2310,10 +2324,12 @@ loop_again:
> > * spectulatively avoid congestion waits
> > */
> > zone_clear_flag(zone, ZONE_CONGESTED);
> > + if (i <= pgdat->high_zoneidx)
> > + any_zone_ok = 1;
> > }
> >
> > }
> > - if (all_zones_ok)
> > + if (all_zones_ok || (order && any_zone_ok))
> > break; /* kswapd: all done */
> > /*
> > * OK, kswapd is getting into trouble. Take a nap, then take
> > @@ -2336,7 +2352,7 @@ loop_again:
> > break;
> > }
> > out:
> > - if (!all_zones_ok) {
> > + if (!(all_zones_ok || (order && any_zone_ok))) {
>
> This doesn't work ;)
> kswapd have to clear ZONE_CONGESTED flag before enter sleeping.
> otherwise nobody can clear it.
>
Does it not do it earlier in balance_pgdat() here
/*
* If a zone reaches its high watermark,
* consider it to be no longer congested. It's
* possible there are dirty pages backed by
* congested BDIs but as pressure is
* relieved, spectulatively avoid congestion waits
*/
zone_clear_flag(zone, ZONE_CONGESTED);
if (i <= pgdat->high_zoneidx)
any_zone_ok = 1;
> Say, we have to fill below condition.
> - All zone are successing zone_watermark_ok(order-0)
We should loop around at least once with order == 0 where all_zones_ok
is checked.
> - At least one zone are successing zone_watermark_ok(high-order)
>
This is preferable but it's possible for kswapd to go to sleep without
this condition being satisified.
>
>
> > @@ -2417,6 +2439,7 @@ static int kswapd(void *p)
> > prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
> > new_order = pgdat->kswapd_max_order;
> > pgdat->kswapd_max_order = 0;
> > + pgdat->high_zoneidx = MAX_ORDER;
>
> I don't think MAX_ORDER is correct ;)
>
> high_zoneidx = pgdat->high_zoneidx;
> pgdat->high_zoneidx = pgdat->nr_zones - 1;
>
> ?
>
Bah. It should have been MAX_NR_ZONES. This happens to still work because
MAX_ORDER will always be higher than MAX_NR_ZONES but it's wrong.
> And, we have another kswapd_max_order reading place. (after kswapd_try_to_sleep)
> We need it too.
>
I'm not quite sure what you mean here. kswapd_max_order is read again
after kswapd tries to sleep (or wakes for that matter) but it'll be in
response to another caller having tried to wake kswapd indicating that
those high orders really are needed.
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
On Thu, 25 Nov 2010, KOSAKI Motohiro wrote:
> Please try SLAB instead SLUB (it can be switched by kernel build option).
> SLUB try to use high order allocation implicitly.
SLAB uses orders 0-1. Order is fixed per slab cache and determined based
on object size at slab creation.
SLUB uses orders 0-3. Falls back to smallest order if alloc order cannot
be met by the page allocator.
One can reduce SLUB to SLAB orders by specifying the following kernel
commandline parameter:
slub_max_order=1
On Fri, 2010-11-26 at 17:18 +0800, KOSAKI Motohiro wrote:
> > On Fri, 2010-11-26 at 10:31 +0800, KOSAKI Motohiro wrote:
> > > > record the order seems not sufficient. in balance_pgdat(), the for look
> > > > exit only when:
> > > > priority <0 or sc.nr_reclaimed >= SWAP_CLUSTER_MAX.
> > > > but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > > order = sc.order = 0;
> > > > this means before we set order to 0, we already reclaimed a lot of
> > > > pages, so I thought we need set order to 0 earlier before there are
> > > > enough free pages. below is a debug patch.
> > > >
> > > >
> > > > diff --git a/mm/vmscan.c b/mm/vmscan.c
> > > > index d31d7ce..ee5d2ed 100644
> > > > --- a/mm/vmscan.c
> > > > +++ b/mm/vmscan.c
> > > > @@ -2117,6 +2117,26 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> > > > }
> > > > #endif
> > > >
> > > > +static int all_zone_enough_free_pages(pg_data_t *pgdat)
> > > > +{
> > > > + int i;
> > > > +
> > > > + for (i = 0; i < pgdat->nr_zones; i++) {
> > > > + struct zone *zone = pgdat->node_zones + i;
> > > > +
> > > > + if (!populated_zone(zone))
> > > > + continue;
> > > > +
> > > > + if (zone->all_unreclaimable)
> > > > + continue;
> > > > +
> > > > + if (!zone_watermark_ok(zone, 0, high_wmark_pages(zone) * 8,
> > > > + 0, 0))
> > > > + return 0;
> > > > + }
> > > > + return 1;
> > > > +}
> > > > +
> > > > /* is kswapd sleeping prematurely? */
> > > > static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> > > > {
> > > > @@ -2355,7 +2375,8 @@ out:
> > > > * back to sleep. High-order users can still perform direct
> > > > * reclaim if they wish.
> > > > */
> > > > - if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > > + if (sc.nr_reclaimed < SWAP_CLUSTER_MAX ||
> > > > + (order > 0 && all_zone_enough_free_pages(pgdat)))
> > > > order = sc.order = 0;
> > >
> > > Ummm. this doesn't work. this place is processed every 32 pages reclaimed.
> > > (see below code and comment). Theresore your patch break high order reclaim
> > > logic.
> > Yes, this will break high order reclaim, but we need a compromise.
> > wrongly reclaim pages is more worse. could increase the watermark in
> > all_zone_enough_free_pages() better?
> >
>
> Hmm..
> I guess I haven't catch your mention. you wrote
>
> > > > but we do if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> > > > order = sc.order = 0;
> > > > this means before we set order to 0, we already reclaimed a lot of
> > > > pages
>
> and I wrote it's not a lot. So, I don't understand why you are talking
> about watermark increasing now. Personally you seems to talk unrelated
> topic. Can you please elablate your point more
ok let me clarify, in the for-loop of balance_pgdat() we reclaim 32
pages one time. but we have
if (!all_zones_ok) {
...
if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
order = sc.order = 0;
goto loop_again;
}
only when sc.nr_reclaimed < SWAP_CLUSTER_MAX or priority < 0, we set
order to 0. before this, we still use high order for zone_watermark_ok()
and it will fail and we keep doing page reclaim. So in the proposed
patch by you or Mel, checking the freed pages or order in kswapd() is
later. so I suggest we check if there is enough free pages in
balance_pgdat() and break high order allocation if yes.
> ok let me clarify, in the for-loop of balance_pgdat() we reclaim 32
> pages one time. but we have
> if (!all_zones_ok) {
> ...
> if (sc.nr_reclaimed < SWAP_CLUSTER_MAX)
> order = sc.order = 0;
>
> goto loop_again;
> }
> only when sc.nr_reclaimed < SWAP_CLUSTER_MAX or priority < 0, we set
> order to 0. before this, we still use high order for zone_watermark_ok()
> and it will fail and we keep doing page reclaim. So in the proposed
> patch by you or Mel, checking the freed pages or order in kswapd() is
> later. so I suggest we check if there is enough free pages in
> balance_pgdat() and break high order allocation if yes.
Ok, got it. Thanks. But I think Mel's approach is more conservative. I don't
think a lot of order-0 pages are good sign to ignore high order shortage.
I think we should prevent overkill reclaim, but number of order-0 pages
are not related high order overkill.
My point is, many cheap device require high order GFP_ATOMIC allocation
and high order ignorerance may makes system unstabilization on laptop world.
At least, your patch need more conservative guard.
Hi
> On Tue, Nov 23, 2010 at 12:35:31AM -0800, Dave Hansen wrote:
>
> > I wish. :) The best thing to do is to watch stuff like /proc/vmstat
> > along with its friends like /proc/{buddy,meminfo,slabinfo}. Could you
> > post some samples of those with some indication of where the bad
> > behavior was seen?
> >
> > I've definitely seen swapping in the face of lots of free memory, but
> > only in cases where I was being a bit unfair about the numbers of
> > hugetlbfs pages I was trying to reserve.
>
> So, Dave and I spent quite some time today figuring out was going on
> here. Once load picked up during the day, kswapd actually never slept
> until late in the afternoon. During the evening now, it's still waking
> up in bursts, and still keeping way too much memory free:
>
> http://0x.ca/sim/ref/2.6.36/memory_tonight.png
>
> (NOTE: we did swapoff -a to keep /dev/sda from overloading)
>
> We have a much better idea on what is happening here, but more questions.
>
> This x86_64 box has 4 GB of RAM; zones are set up as follows:
>
> [ 0.000000] Zone PFN ranges:
> [ 0.000000] DMA 0x00000001 -> 0x00001000
> [ 0.000000] DMA32 0x00001000 -> 0x00100000
> [ 0.000000] Normal 0x00100000 -> 0x00130000
> ...
> [ 0.000000] On node 0 totalpages: 1047279
> [ 0.000000] DMA zone: 56 pages used for memmap
> [ 0.000000] DMA zone: 0 pages reserved
> [ 0.000000] DMA zone: 3943 pages, LIFO batch:0
> [ 0.000000] DMA32 zone: 14280 pages used for memmap
> [ 0.000000] DMA32 zone: 832392 pages, LIFO batch:31
> [ 0.000000] Normal zone: 2688 pages used for memmap
> [ 0.000000] Normal zone: 193920 pages, LIFO batch:31
This machine's zone size are
DMA32: 3250MB
NORMAL: 750MB
This inbalance zone size is one of root cause of the strange swapping
issue. I'm sure we certinally need to fix our VM heuristics. However
there is no perfect heuristics in the real world and we can't make it.
Also, I guess a bug reporter need practical workaround.
Then, I wrote following patch.
if you pass a following boot parameter, zone division change to
dma32=1G + normal=3G.
in grub.conf
kernel /boot/vmlinuz ro root=foobar .... zone_dma32_size=1G
I bet this one reduce your head pain a lot. Can you please try this?
Of cource, this is only workaround. not truth fix.
>From 1446c915fd59a5f123c2619d1f1f3b4e1bd0c648 Mon Sep 17 00:00:00 2001
From: KOSAKI Motohiro <[email protected]>
Date: Thu, 23 Dec 2010 08:57:27 +0900
Subject: [PATCH] x86: implement zone_dma32_size boot parameter
Signed-off-by: KOSAKI Motohiro <[email protected]>
---
Documentation/kernel-parameters.txt | 5 +++++
arch/x86/mm/init_64.c | 17 ++++++++++++++++-
2 files changed, 21 insertions(+), 1 deletions(-)
diff --git a/Documentation/kernel-parameters.txt b/Documentation/kernel-parameters.txt
index a5966c0..25b4a53 100644
--- a/Documentation/kernel-parameters.txt
+++ b/Documentation/kernel-parameters.txt
@@ -2686,6 +2686,11 @@ and is between 256 and 4096 characters. It is defined in the file
Format:
<irq>,<irq_mask>,<io>,<full_duplex>,<do_sound>,<lockup_hack>[,<irq2>[,<irq3>[,<irq4>]]]
+ zone_dma32_size=nn[KMG] [KNL,BOOT,X86-64]
+ forces the dma32 zone to have an exact size of <nn>.
+ This works to reduce dma32 zone (In other word, to
+ increase normal zone) size.
+
______________________________________________________________________
TODO:
diff --git a/arch/x86/mm/init_64.c b/arch/x86/mm/init_64.c
index 71a5929..12d813d 100644
--- a/arch/x86/mm/init_64.c
+++ b/arch/x86/mm/init_64.c
@@ -95,6 +95,21 @@ static int __init nonx32_setup(char *str)
}
__setup("noexec32=", nonx32_setup);
+static unsigned long max_dma32_pfn = MAX_DMA32_PFN;
+static int __init parse_zone_dma32_size(char *arg)
+{
+ unsigned long dma32_pages;
+
+ if (!arg)
+ return -EINVAL;
+
+ dma32_pages = memparse(arg, &arg) >> PAGE_SHIFT;
+ max_dma32_pfn = min(MAX_DMA_PFN + dma32_pages, MAX_DMA32_PFN);
+
+ return 0;
+}
+early_param("zone_dma32_size", parse_zone_dma32_size);
+
/*
* When memory was added/removed make sure all the processes MM have
* suitable PGD entries in the local PGD level page.
@@ -625,7 +640,7 @@ void __init paging_init(void)
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
max_zone_pfns[ZONE_DMA] = MAX_DMA_PFN;
- max_zone_pfns[ZONE_DMA32] = MAX_DMA32_PFN;
+ max_zone_pfns[ZONE_DMA32] = max_dma32_pfn;
max_zone_pfns[ZONE_NORMAL] = max_pfn;
sparse_memory_present_with_active_regions(MAX_NUMNODES);
--
1.6.5.2
> On Thu, 25 Nov 2010, KOSAKI Motohiro wrote:
> > Please try SLAB instead SLUB (it can be switched by kernel build option).
> > SLUB try to use high order allocation implicitly.
>
> SLAB uses orders 0-1. Order is fixed per slab cache and determined based
> on object size at slab creation.
>
> SLUB uses orders 0-3. Falls back to smallest order if alloc order cannot
> be met by the page allocator.
>
> One can reduce SLUB to SLAB orders by specifying the following kernel
> commandline parameter:
>
> slub_max_order=1
This?
>From 3edd305fc58ac89364806cd60140793d37422acc Mon Sep 17 00:00:00 2001
From: KOSAKI Motohiro <[email protected]>
Date: Fri, 24 Dec 2010 18:04:10 +0900
Subject: [PATCH] slub: reduce slub_max_order by default
slab is already using order-1.
Signed-off-by: KOSAKI Motohiro <[email protected]>
---
mm/slub.c | 3 ++-
1 files changed, 2 insertions(+), 1 deletions(-)
diff --git a/mm/slub.c b/mm/slub.c
index 8c66aef..babf359 100644
--- a/mm/slub.c
+++ b/mm/slub.c
@@ -1964,7 +1964,8 @@ static struct page *get_object_page(const void *x)
* take the list_lock.
*/
static int slub_min_order;
-static int slub_max_order = PAGE_ALLOC_COSTLY_ORDER;
+/* order-1 is maximum size which we can assume to exist always. */
+static int slub_max_order = 1;
static int slub_min_objects;
/*
--
1.6.5.2
Hi
> On Fri, Nov 26, 2010 at 08:03:04PM +0900, KOSAKI Motohiro wrote:
> > Two points.
> >
> > > @@ -2310,10 +2324,12 @@ loop_again:
> > > * spectulatively avoid congestion waits
> > > */
> > > zone_clear_flag(zone, ZONE_CONGESTED);
> > > + if (i <= pgdat->high_zoneidx)
> > > + any_zone_ok = 1;
> > > }
> > >
> > > }
> > > - if (all_zones_ok)
> > > + if (all_zones_ok || (order && any_zone_ok))
> > > break; /* kswapd: all done */
> > > /*
> > > * OK, kswapd is getting into trouble. Take a nap, then take
> > > @@ -2336,7 +2352,7 @@ loop_again:
> > > break;
> > > }
> > > out:
> > > - if (!all_zones_ok) {
> > > + if (!(all_zones_ok || (order && any_zone_ok))) {
> >
> > This doesn't work ;)
> > kswapd have to clear ZONE_CONGESTED flag before enter sleeping.
> > otherwise nobody can clear it.
> >
>
> Does it not do it earlier in balance_pgdat() here
>
> /*
> * If a zone reaches its high watermark,
> * consider it to be no longer congested. It's
> * possible there are dirty pages backed by
> * congested BDIs but as pressure is
> * relieved, spectulatively avoid congestion waits
> */
> zone_clear_flag(zone, ZONE_CONGESTED);
> if (i <= pgdat->high_zoneidx)
> any_zone_ok = 1;
zone_clear_flag(zone, ZONE_CONGESTED) only clear one zone status. other
zone remain old status.
> > Say, we have to fill below condition.
> > - All zone are successing zone_watermark_ok(order-0)
>
> We should loop around at least once with order == 0 where all_zones_ok
> is checked.
But no gurantee. IOW kswapd early stopping increase GFP_ATOMIC allocation
failure risk, I think.
> > - At least one zone are successing zone_watermark_ok(high-order)
>
> This is preferable but it's possible for kswapd to go to sleep without
> this condition being satisified.
Yes.
>
> >
> >
> > > @@ -2417,6 +2439,7 @@ static int kswapd(void *p)
> > > prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
> > > new_order = pgdat->kswapd_max_order;
> > > pgdat->kswapd_max_order = 0;
> > > + pgdat->high_zoneidx = MAX_ORDER;
> >
> > I don't think MAX_ORDER is correct ;)
> >
> > high_zoneidx = pgdat->high_zoneidx;
> > pgdat->high_zoneidx = pgdat->nr_zones - 1;
> >
> > ?
> >
>
> Bah. It should have been MAX_NR_ZONES. This happens to still work because
> MAX_ORDER will always be higher than MAX_NR_ZONES but it's wrong.
Well, no. balance_pgdat() shuldn't read pgdat->high_zoneidx. please remember why
balance balance_pgdat() don't read pgdat->kswapd_max_order directly. wakeup_kswapd()
change pgdat->kswapd_max_order and pgdat->high_zoneidx without any lock. so,
we need to afraid following bad scenario.
T1: wakeup_kswapd(order=0, HIGHMEM)
T2: enter balance_kswapd()
T1: wakeup_kswapd(order=1, DMA32)
T2: exit balance_kswapd()
kswapd() erase pgdat->high_zoneidx and decide to don't sleep (because
old-order=0, new-order=1). So now we will start unnecessary HIGHMEM
reclaim.
>
> > And, we have another kswapd_max_order reading place. (after kswapd_try_to_sleep)
> > We need it too.
> >
>
> I'm not quite sure what you mean here. kswapd_max_order is read again
> after kswapd tries to sleep (or wakes for that matter) but it'll be in
> response to another caller having tried to wake kswapd indicating that
> those high orders really are needed.
My expected bad scenario was written above.
Thanks.
On Thu, Nov 25, 2010 at 04:12:38PM +0000, Mel Gorman wrote:
> On Thu, Nov 25, 2010 at 01:03:28AM -0800, Simon Kirby wrote:
> > > > <SNIP>
> > > >
> > > > This x86_64 box has 4 GB of RAM; zones are set up as follows:
> > > >
> > > > [ 0.000000] Zone PFN ranges:
> > > > [ 0.000000] DMA 0x00000001 -> 0x00001000
> > > > [ 0.000000] DMA32 0x00001000 -> 0x00100000
> > > > [ 0.000000] Normal 0x00100000 -> 0x00130000
>
> Ok. A consequence of this is that kswapd balancing a node will still try
> to balance Normal even if DMA32 has enough memory. This could account
> for some of kswapd being mean.
This seemed to be the case. DMA32 would be freed until watermarks were
met, and then it would fight order-0 allocations in Normal to try to meet
the watermark there, even though DMA32 had more than enough free.
> > > > The fact that so much stuff is evicted just because order-3 hits 0 is
> > > > crazy, especially when larger order pages are still free. It seems like
> > > > we're trying to keep large orders free here. Why?
>
> Watermarks. The steady stream of order-3 allocations is telling the
> allocator and kswapd that these size pages must be available. It doesn't
> know that slub can happily fall back to smaller pages because that
> information is lost. Even removing __GFP_WAIT won't help because kswapd
> still gets woken up for atomic allocation requests.
Since slub has a fallback to s->min (order 0 in this case), I think it
makes sense to make a GFP_NOBALANCE / GFP_NOKSWAPD, or GFP_NORECLAIM
(allow compaction if compiled, since slub's purpose is to reduce object
container waste).
> > The funny thing here is that slub.c's allocate_slab() calls alloc_pages()
> > with flags | __GFP_NOWARN | __GFP_NORETRY, and intentionally tries a
> > lower order allocation automatically if it fails. This is why there is
> > no allocation failure warning when this happens. However, it is too late
> > -- kswapd is woken and it ties to bring order 3 up to the watermark.
> > If we hacked __alloc_pages_slowpath() to not wake kswapd when
> > __GFP_NOWARN is set, we would never see this problem and the slub
> > optimization might still mostly work.
>
> Yes, but we'd see more high-order atomic allocation (e.g. jumbo frames)
> failures as a result so that fix would cause other regressions.
The part of your patch that fixes the SWAP_CLUSTER_MAX also increases
this chance.
> I think there are at least two fixes required here.
>
> 1. sleeping_prematurely() must be aware that balance_pgdat() has dropped
> the order.
> 2. kswapd is trying to balance all zones for higher orders even though
> it doesn't really have to.
>
> This patch has potential fixes for both of these problems. I have a split-out
> series but I'm posting it as a single patch so see if it allows kswapd to
> go to sleep as expected for you and whether it stops hammering the Normal
> zone unnecessarily. I tested it locally here (albeit with compaction
> enabled) and it did reduce the amount of time kswapd spent awake.
Ok, so this patch has been running in production since Friday, and there
is a definite improvement in our case. The reading of daemons and core
system stuff back into memory all the time from /dev/sda has stopped,
since kswapd now actually sleeps. Since this allows caching to work, we
can keep swap enabled. However, my userspace reimplementation of
zone_watermark_ok(order=3) shows that order-3 is almost never reached
now. It's not freeing The Right Stuff, or not enough of it before
SWAP_CLUSTER_MAX.
Also, as the days go by, it is still keeping more and more free memory.
my whitespace-compressed buddyinfo+extras right now shows:
DMA32 234402 493 2 3 2 2 2 0 0 0 0 235644 249 <= 512
Normal 369 5 3 7 1 0 0 0 0 0 0 463 87 <= 238
So, the order-3 watermarks are still not met, and the free order-0 free
pages seems to keep rising. Here is the munin memory graph of the week:
http://0x.ca/sim/ref/2.6.36/memory_mel_patch_4days.png
Things seem to be drifting to kswapd reclaiming order-0 in a way that
doesn't add up to more order-3 blocks available, so fragmentation is
increasing.
You mentioned that there was some mechanism to have it actually target
allocations that could be made into higher order allocations?
Simon-
> ==== CUT HERE ====
> diff --git a/include/linux/mmzone.h b/include/linux/mmzone.h
> index 39c24eb..25fe08d 100644
> --- a/include/linux/mmzone.h
> +++ b/include/linux/mmzone.h
> @@ -645,6 +645,7 @@ typedef struct pglist_data {
> wait_queue_head_t kswapd_wait;
> struct task_struct *kswapd;
> int kswapd_max_order;
> + enum zone_type high_zoneidx;
> } pg_data_t;
>
> #define node_present_pages(nid) (NODE_DATA(nid)->node_present_pages)
> @@ -660,7 +661,7 @@ typedef struct pglist_data {
>
> extern struct mutex zonelists_mutex;
> void build_all_zonelists(void *data);
> -void wakeup_kswapd(struct zone *zone, int order);
> +void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx);
> int zone_watermark_ok(struct zone *z, int order, unsigned long mark,
> int classzone_idx, int alloc_flags);
> enum memmap_context {
> diff --git a/mm/page_alloc.c b/mm/page_alloc.c
> index 07a6544..344b597 100644
> --- a/mm/page_alloc.c
> +++ b/mm/page_alloc.c
> @@ -1921,7 +1921,7 @@ void wake_all_kswapd(unsigned int order, struct zonelist *zonelist,
> struct zone *zone;
>
> for_each_zone_zonelist(zone, z, zonelist, high_zoneidx)
> - wakeup_kswapd(zone, order);
> + wakeup_kswapd(zone, order, high_zoneidx);
> }
>
> static inline int
> diff --git a/mm/vmscan.c b/mm/vmscan.c
> index d31d7ce..00529a0 100644
> --- a/mm/vmscan.c
> +++ b/mm/vmscan.c
> @@ -2118,15 +2118,17 @@ unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *mem_cont,
> #endif
>
> /* is kswapd sleeping prematurely? */
> -static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> +static bool sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> {
> int i;
> + bool all_zones_ok = true;
> + bool any_zone_ok = false;
>
> /* If a direct reclaimer woke kswapd within HZ/10, it's premature */
> if (remaining)
> return 1;
>
> - /* If after HZ/10, a zone is below the high mark, it's premature */
> + /* Check the watermark levels */
> for (i = 0; i < pgdat->nr_zones; i++) {
> struct zone *zone = pgdat->node_zones + i;
>
> @@ -2138,10 +2140,20 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
>
> if (!zone_watermark_ok(zone, order, high_wmark_pages(zone),
> 0, 0))
> - return 1;
> + all_zones_ok = false;
> + else
> + any_zone_ok = true;
> }
>
> - return 0;
> + /*
> + * For high-order requests, any zone meeting the watermark is enough
> + * to allow kswapd go back to sleep
> + * For order-0, all zones must be balanced
> + */
> + if (order)
> + return !any_zone_ok;
> + else
> + return !all_zones_ok;
> }
>
> /*
> @@ -2168,6 +2180,7 @@ static int sleeping_prematurely(pg_data_t *pgdat, int order, long remaining)
> static unsigned long balance_pgdat(pg_data_t *pgdat, int order)
> {
> int all_zones_ok;
> + int any_zone_ok;
> int priority;
> int i;
> unsigned long total_scanned;
> @@ -2201,6 +2214,7 @@ loop_again:
> disable_swap_token();
>
> all_zones_ok = 1;
> + any_zone_ok = 0;
>
> /*
> * Scan in the highmem->dma direction for the highest
> @@ -2310,10 +2324,12 @@ loop_again:
> * spectulatively avoid congestion waits
> */
> zone_clear_flag(zone, ZONE_CONGESTED);
> + if (i <= pgdat->high_zoneidx)
> + any_zone_ok = 1;
> }
>
> }
> - if (all_zones_ok)
> + if (all_zones_ok || (order && any_zone_ok))
> break; /* kswapd: all done */
> /*
> * OK, kswapd is getting into trouble. Take a nap, then take
> @@ -2336,7 +2352,7 @@ loop_again:
> break;
> }
> out:
> - if (!all_zones_ok) {
> + if (!(all_zones_ok || (order && any_zone_ok))) {
> cond_resched();
>
> try_to_freeze();
> @@ -2361,7 +2377,13 @@ out:
> goto loop_again;
> }
>
> - return sc.nr_reclaimed;
> + /*
> + * Return the order we were reclaiming at so sleeping_prematurely()
> + * makes a decision on the order we were last reclaiming at. However,
> + * if another caller entered the allocator slow path while kswapd
> + * was awake, order will remain at the higher level
> + */
> + return order;
> }
>
> /*
> @@ -2417,6 +2439,7 @@ static int kswapd(void *p)
> prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
> new_order = pgdat->kswapd_max_order;
> pgdat->kswapd_max_order = 0;
> + pgdat->high_zoneidx = MAX_ORDER;
> if (order < new_order) {
> /*
> * Don't sleep if someone wants a larger 'order'
> @@ -2464,7 +2487,7 @@ static int kswapd(void *p)
> */
> if (!ret) {
> trace_mm_vmscan_kswapd_wake(pgdat->node_id, order);
> - balance_pgdat(pgdat, order);
> + order = balance_pgdat(pgdat, order);
> }
> }
> return 0;
> @@ -2473,7 +2496,7 @@ static int kswapd(void *p)
> /*
> * A zone is low on free memory, so wake its kswapd task to service it.
> */
> -void wakeup_kswapd(struct zone *zone, int order)
> +void wakeup_kswapd(struct zone *zone, int order, enum zone_type high_zoneidx)
> {
> pg_data_t *pgdat;
>
> @@ -2483,8 +2506,10 @@ void wakeup_kswapd(struct zone *zone, int order)
> pgdat = zone->zone_pgdat;
> if (zone_watermark_ok(zone, order, low_wmark_pages(zone), 0, 0))
> return;
> - if (pgdat->kswapd_max_order < order)
> + if (pgdat->kswapd_max_order < order) {
> pgdat->kswapd_max_order = order;
> + pgdat->high_zoneidx = min(pgdat->high_zoneidx, high_zoneidx);
> + }
> trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, zone_idx(zone), order);
> if (!cpuset_zone_allowed_hardwall(zone, GFP_KERNEL))
> return;
On Fri, Nov 26, 2010 at 09:48:14AM -0600, Christoph Lameter wrote:
> On Thu, 25 Nov 2010, KOSAKI Motohiro wrote:
> > Please try SLAB instead SLUB (it can be switched by kernel build option).
> > SLUB try to use high order allocation implicitly.
>
> SLAB uses orders 0-1. Order is fixed per slab cache and determined based
> on object size at slab creation.
>
> SLUB uses orders 0-3. Falls back to smallest order if alloc order cannot
> be met by the page allocator.
>
> One can reduce SLUB to SLAB orders by specifying the following kernel
> commandline parameter:
>
> slub_max_order=1
Can we also mess with these /sys files on the fly?
[/sys/kernel/slab]# grep . kmalloc-*/order | sort -n -k2 -t-
kmalloc-8/order:0
kmalloc-16/order:0
kmalloc-32/order:0
kmalloc-64/order:0
kmalloc-96/order:0
kmalloc-128/order:0
kmalloc-192/order:0
kmalloc-256/order:1
kmalloc-512/order:2
kmalloc-1024/order:3
kmalloc-2048/order:3
kmalloc-4096/order:3
kmalloc-8192/order:3
I'm not familiar with how slub works, but I assume there's some overhead
or some reason not to just use order 0 for <= kmalloc-4096? Or is it
purely just trying to reduce cpu by calling alloc_pages less often?
Simon-
On Tue, Nov 30, 2010 at 03:31:03PM +0900, KOSAKI Motohiro wrote:
> Hi
> > On Fri, Nov 26, 2010 at 08:03:04PM +0900, KOSAKI Motohiro wrote:
> > > Two points.
> > >
> > > > @@ -2310,10 +2324,12 @@ loop_again:
> > > > * spectulatively avoid congestion waits
> > > > */
> > > > zone_clear_flag(zone, ZONE_CONGESTED);
> > > > + if (i <= pgdat->high_zoneidx)
> > > > + any_zone_ok = 1;
> > > > }
> > > >
> > > > }
> > > > - if (all_zones_ok)
> > > > + if (all_zones_ok || (order && any_zone_ok))
> > > > break; /* kswapd: all done */
> > > > /*
> > > > * OK, kswapd is getting into trouble. Take a nap, then take
> > > > @@ -2336,7 +2352,7 @@ loop_again:
> > > > break;
> > > > }
> > > > out:
> > > > - if (!all_zones_ok) {
> > > > + if (!(all_zones_ok || (order && any_zone_ok))) {
> > >
> > > This doesn't work ;)
> > > kswapd have to clear ZONE_CONGESTED flag before enter sleeping.
> > > otherwise nobody can clear it.
> > >
> >
> > Does it not do it earlier in balance_pgdat() here
> >
> > /*
> > * If a zone reaches its high watermark,
> > * consider it to be no longer congested. It's
> > * possible there are dirty pages backed by
> > * congested BDIs but as pressure is
> > * relieved, spectulatively avoid congestion waits
> > */
> > zone_clear_flag(zone, ZONE_CONGESTED);
> > if (i <= pgdat->high_zoneidx)
> > any_zone_ok = 1;
>
> zone_clear_flag(zone, ZONE_CONGESTED) only clear one zone status. other
> zone remain old status.
>
Ah now I get you. kswapd does not necessarily balance all zones so it needs
to unconditionally clear them all before it goes to sleep in case. At
some time in the future, the tagging of ZONE_CONGESTED needs more
thinking about.
> > > Say, we have to fill below condition.
> > > - All zone are successing zone_watermark_ok(order-0)
> >
> > We should loop around at least once with order == 0 where all_zones_ok
> > is checked.
>
> But no gurantee. IOW kswapd early stopping increase GFP_ATOMIC allocation
> failure risk, I think.
>
Force all zones to be balanced for order-0?
>
> > > - At least one zone are successing zone_watermark_ok(high-order)
> >
> > This is preferable but it's possible for kswapd to go to sleep without
> > this condition being satisified.
>
> Yes.
>
> >
> > >
> > >
> > > > @@ -2417,6 +2439,7 @@ static int kswapd(void *p)
> > > > prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
> > > > new_order = pgdat->kswapd_max_order;
> > > > pgdat->kswapd_max_order = 0;
> > > > + pgdat->high_zoneidx = MAX_ORDER;
> > >
> > > I don't think MAX_ORDER is correct ;)
> > >
> > > high_zoneidx = pgdat->high_zoneidx;
> > > pgdat->high_zoneidx = pgdat->nr_zones - 1;
> > >
> > > ?
> > >
> >
> > Bah. It should have been MAX_NR_ZONES. This happens to still work because
> > MAX_ORDER will always be higher than MAX_NR_ZONES but it's wrong.
>
> Well, no. balance_pgdat() shuldn't read pgdat->high_zoneidx. please remember why
> balance balance_pgdat() don't read pgdat->kswapd_max_order directly. wakeup_kswapd()
> change pgdat->kswapd_max_order and pgdat->high_zoneidx without any lock. so,
> we need to afraid following bad scenario.
>
>
> T1: wakeup_kswapd(order=0, HIGHMEM)
> T2: enter balance_kswapd()
> T1: wakeup_kswapd(order=1, DMA32)
> T2: exit balance_kswapd()
> kswapd() erase pgdat->high_zoneidx and decide to don't sleep (because
> old-order=0, new-order=1). So now we will start unnecessary HIGHMEM
> reclaim.
>
Correct. I'll fix this up.
> > > And, we have another kswapd_max_order reading place. (after kswapd_try_to_sleep)
> > > We need it too.
> > >
> >
> > I'm not quite sure what you mean here. kswapd_max_order is read again
> > after kswapd tries to sleep (or wakes for that matter) but it'll be in
> > response to another caller having tried to wake kswapd indicating that
> > those high orders really are needed.
>
> My expected bad scenario was written above.
>
> Thanks.
>
>
>
--
Mel Gorman
Part-time Phd Student Linux Technology Center
University of Limerick IBM Dublin Software Lab
Hi
> > > > > out:
> > > > > - if (!all_zones_ok) {
> > > > > + if (!(all_zones_ok || (order && any_zone_ok))) {
> > > >
> > > > This doesn't work ;)
> > > > kswapd have to clear ZONE_CONGESTED flag before enter sleeping.
> > > > otherwise nobody can clear it.
> > > >
> > >
> > > Does it not do it earlier in balance_pgdat() here
> > >
> > > /*
> > > * If a zone reaches its high watermark,
> > > * consider it to be no longer congested. It's
> > > * possible there are dirty pages backed by
> > > * congested BDIs but as pressure is
> > > * relieved, spectulatively avoid congestion waits
> > > */
> > > zone_clear_flag(zone, ZONE_CONGESTED);
> > > if (i <= pgdat->high_zoneidx)
> > > any_zone_ok = 1;
> >
> > zone_clear_flag(zone, ZONE_CONGESTED) only clear one zone status. other
> > zone remain old status.
> >
>
> Ah now I get you. kswapd does not necessarily balance all zones so it needs
> to unconditionally clear them all before it goes to sleep in case. At
> some time in the future, the tagging of ZONE_CONGESTED needs more
> thinking about.
>
This is a option.
> > > > Say, we have to fill below condition.
> > > > - All zone are successing zone_watermark_ok(order-0)
> > >
> > > We should loop around at least once with order == 0 where all_zones_ok
> > > is checked.
> >
> > But no gurantee. IOW kswapd early stopping increase GFP_ATOMIC allocation
> > failure risk, I think.
> >
>
> Force all zones to be balanced for order-0?
Yes.
I think following change does.
if (i <= pgdat->high_zoneidx)
- any_zone_ok = 1;
+ order = sc.order = 0;
This is more conservative.
On Tue, 30 Nov 2010, KOSAKI Motohiro wrote:
> This?
Specifying a parameter to temporarily override to see if this has the
effect is ok. But this has worked for years now. There must be something
else going with with reclaim that causes these issues now.
On Tue, 30 Nov 2010, Simon Kirby wrote:
> Can we also mess with these /sys files on the fly?
Sure. Go ahead. These are runtime configurable.
> I'm not familiar with how slub works, but I assume there's some overhead
> or some reason not to just use order 0 for <= kmalloc-4096? Or is it
> purely just trying to reduce cpu by calling alloc_pages less often?
Using higher order pages reduces the memory overhead for objects (that
after all need to be packed into an order N page), decreases the amount
of metadata that needs to be managed and decreases the use of the
slowpaths. That implies also a reduction in the locking overhead.
> On Tue, 30 Nov 2010, KOSAKI Motohiro wrote:
>
> > This?
>
> Specifying a parameter to temporarily override to see if this has the
> effect is ok. But this has worked for years now. There must be something
> else going with with reclaim that causes these issues now.
I don't think this has worked. Simon have found the corner case recently,
but it is not new.
So I hope you realize that high order allocation is no free lunch. __GFP_NORETRY
makes no sense really. Even though we have compaction, high order reclaim is still
costly operation.
I don't think SLUB's high order allocation trying is bad idea. but now It
does more costly trying. that's bad. Also I'm worry about SLUB assume too
higher end machine. Now Both SLES and RHEL decided to don't use SLUB,
instead use SLAB. Now linux community is fragmented. If you are still
interesting SL*B unification, can you please consider to join corner
case smashing activity?
On Wed, 1 Dec 2010, KOSAKI Motohiro wrote:
> > Specifying a parameter to temporarily override to see if this has the
> > effect is ok. But this has worked for years now. There must be something
> > else going with with reclaim that causes these issues now.
>
> I don't think this has worked. Simon have found the corner case recently,
> but it is not new.
What has worked? If the reduction of the maximum allocation order did not
have the expected effect of fixing things here then the issue is not
related to the higher allocations from slub.
Higher order allocations are not only a slub issue but a general issue for
various subsystem that require higher order pages. This ranges from jumbo
frames, to particular needs for certain device drivers, to huge pages.
> So I hope you realize that high order allocation is no free lunch. __GFP_NORETRY
> makes no sense really. Even though we have compaction, high order reclaim is still
> costly operation.
Sure. There is a tradeoff between reclaim effort and the benefit of higher
allocations. The costliness of reclaim may have increased with the recent
changes to the reclaim logic. In fact reclaim gets more and more complex
over time and there may be subtle bugs in there given the recent flurry of
changes.
> I don't think SLUB's high order allocation trying is bad idea. but now It
> does more costly trying. that's bad. Also I'm worry about SLUB assume too
> higher end machine. Now Both SLES and RHEL decided to don't use SLUB,
> instead use SLAB. Now linux community is fragmented. If you are still
> interesting SL*B unification, can you please consider to join corner
> case smashing activity?
The problems with higher order reclaim get more difficult with small
memory sizes yes. We could reduce the maximum order automatically if memory
is too tight. There is nothing hindering us from tuning the max order
behavior of slub in a similar way that we now tune the thresholds of the
vm statistics.
But for that to be done we first need to have some feedback if the changes
to max order have indeed the desired effect in this corner case.
> On Wed, 1 Dec 2010, KOSAKI Motohiro wrote:
>
> > > Specifying a parameter to temporarily override to see if this has the
> > > effect is ok. But this has worked for years now. There must be something
> > > else going with with reclaim that causes these issues now.
> >
> > I don't think this has worked. Simon have found the corner case recently,
> > but it is not new.
>
> What has worked? If the reduction of the maximum allocation order did not
> have the expected effect of fixing things here then the issue is not
> related to the higher allocations from slub.
>
> Higher order allocations are not only a slub issue but a general issue for
> various subsystem that require higher order pages. This ranges from jumbo
> frames, to particular needs for certain device drivers, to huge pages.
Sure yes. However One big difference is there. Other user certinally need
such high order, but slub are using high order for only performance. but its
stragegy often shoot our own foot. It often makes worse than low order. IOW,
slub isn't always win against slab.
> > So I hope you realize that high order allocation is no free lunch. __GFP_NORETRY
> > makes no sense really. Even though we have compaction, high order reclaim is still
> > costly operation.
>
> Sure. There is a tradeoff between reclaim effort and the benefit of higher
> allocations. The costliness of reclaim may have increased with the recent
> changes to the reclaim logic. In fact reclaim gets more and more complex
> over time and there may be subtle bugs in there given the recent flurry of
> changes.
I can't insist reclaim is really complex. So maybe one of problem is now
reclaim can't know the request is must necessary or optimistic try. And,
allocation failure often makes disaster then we were working on fixint it.
But increasing high order allocation successful ratio sadly can makes slub
unhappy. umm..
So I think we have multiple option
1) reduce slub_max_order and slub only use safely order
2) slub don't invoke reclaim when high order tryal allocation
(ie turn off GFP_WAIT and turn on GFP_NOKSWAPD)
3) slub pass new hint to reclaim and reclaim don't work so aggressively if
such hint is passwd.
So I have one question. I thought (2) is most nature. but now slub doesn't.
Why don't you do that? As far as I know, reclaim haven't been lighweight
operation since linux was born. I'm curious your assumed cost threshold for
slub high order allocation.
> > I don't think SLUB's high order allocation trying is bad idea. but now It
> > does more costly trying. that's bad. Also I'm worry about SLUB assume too
> > higher end machine. Now Both SLES and RHEL decided to don't use SLUB,
> > instead use SLAB. Now linux community is fragmented. If you are still
> > interesting SL*B unification, can you please consider to join corner
> > case smashing activity?
>
> The problems with higher order reclaim get more difficult with small
> memory sizes yes. We could reduce the maximum order automatically if memory
> is too tight. There is nothing hindering us from tuning the max order
> behavior of slub in a similar way that we now tune the thresholds of the
> vm statistics.
Sound like really good idea. :)
> But for that to be done we first need to have some feedback if the changes
> to max order have indeed the desired effect in this corner case.
On Thu, 2 Dec 2010, KOSAKI Motohiro wrote:
> So I think we have multiple option
>
> 1) reduce slub_max_order and slub only use safely order
> 2) slub don't invoke reclaim when high order tryal allocation
> (ie turn off GFP_WAIT and turn on GFP_NOKSWAPD)
> 3) slub pass new hint to reclaim and reclaim don't work so aggressively if
> such hint is passwd.
>
>
> So I have one question. I thought (2) is most nature. but now slub doesn't.
2) so far has not been available. GFP_NOKSWAPD does not exist upstream.
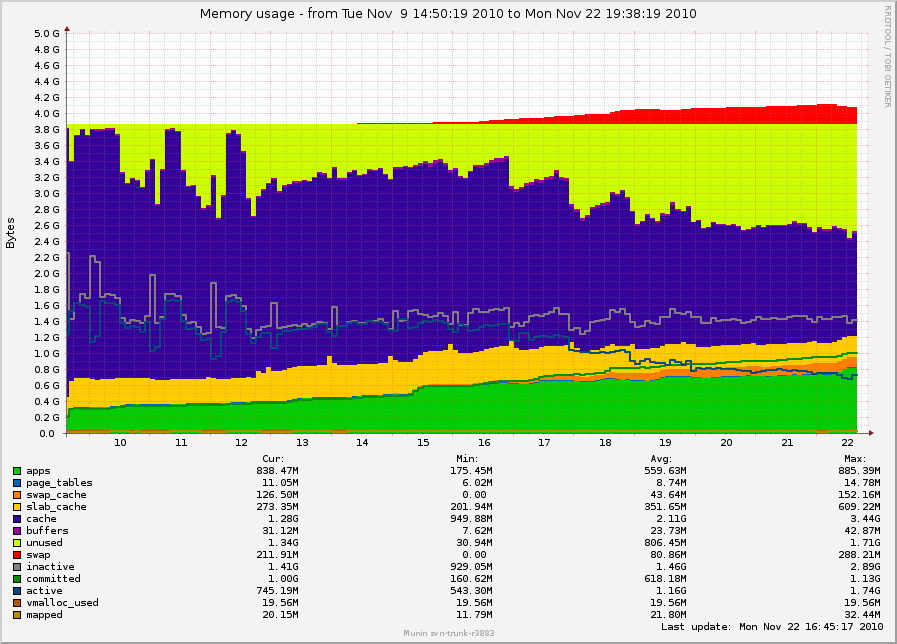{kind=link}
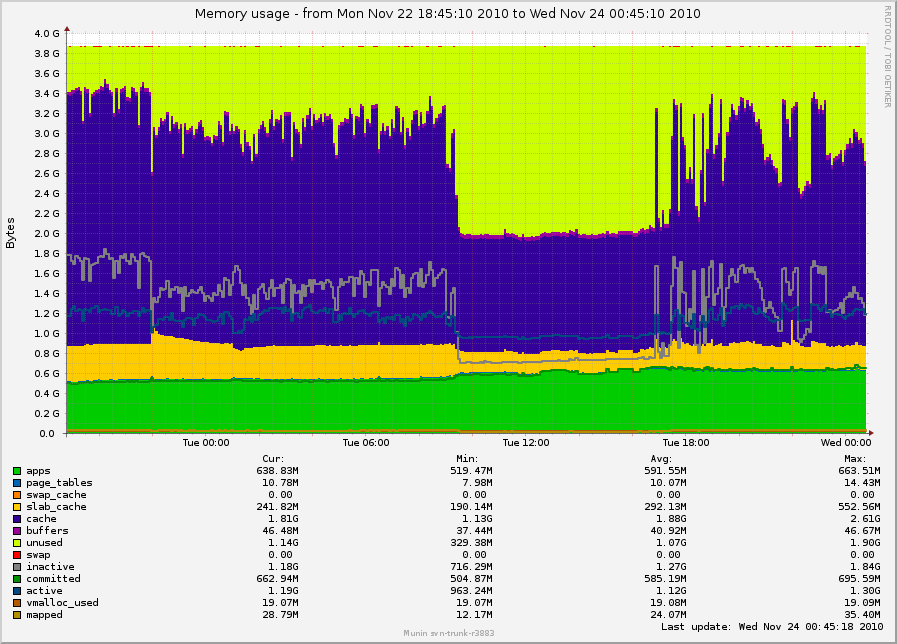{kind=link}
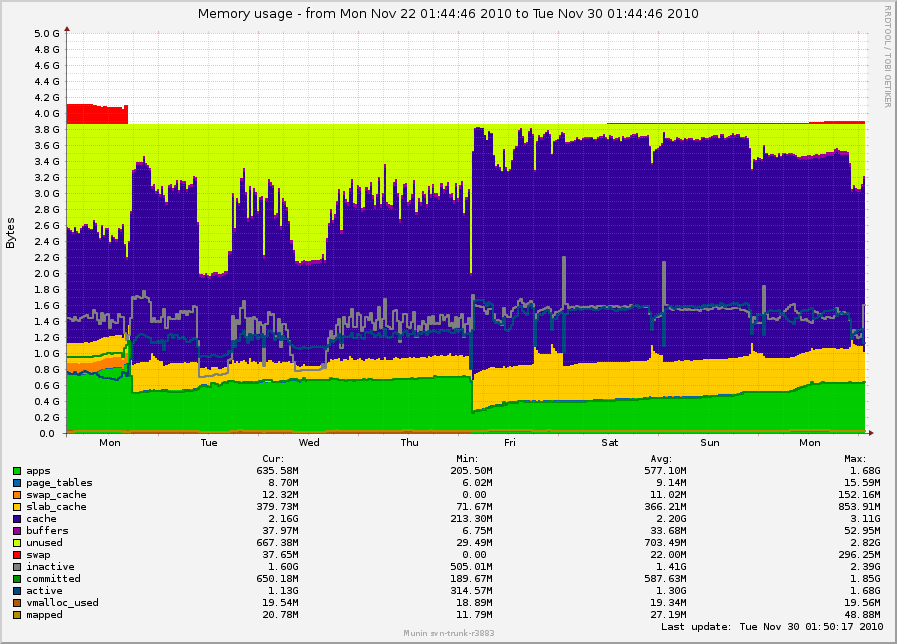{kind=link}