Proxy execution is an approach to implementing priority inheritance
based on distinguishing between a task's scheduler context (information
required in order to make scheduling decisions about when the task gets
to run, such as its scheduler class and priority) and its execution
context (information required to actually run the task, such as CPU
affinity). With proxy execution enabled, a task p1 that blocks on a
mutex remains on the runqueue, but its "blocked" status and the mutex on
which it blocks are recorded. If p1 is selected to run while still
blocked, the lock owner p2 can run "on its behalf", inheriting p1's
scheduler context. Execution context is not inherited, meaning that
e.g. the CPUs where p2 can run are still determined by its own affinity
and not p1's.
In practice a number of more complicated situations can arise: the mutex
owner might itself be blocked on another mutex, or it could be sleeping,
running on a different CPU, in the process of migrating between CPUs,
etc. Details on handling these various cases can be found in patch 7/11
("sched: Add proxy execution"), particularly in the implementation of
proxy() and accompanying comments.
Past discussions of proxy execution have often focused on the benefits
for deadline scheduling. Current interest for Android is based more on
desire for a broad solution to priority inversion on kernel mutexes,
including among CFS tasks. One notable scenario arises when cpu cgroups
are used to throttle less important background tasks. Priority inversion
can occur when an "important" unthrottled task blocks on a mutex held by
an "unimportant" task whose CPU time is constrained using cpu
shares. The result is higher worst case latencies for the unthrottled
task.[0] Testing by John Stultz with a simple reproducer [1] showed
promising results for this case, with proxy execution appearing to
eliminate the large latency spikes associated with priority
inversion.[2]
Proxy execution has been discussed over the past few years at several
conferences[3][4][5], but (as far as I'm aware) patches implementing the
concept have not been discussed on the list since Juri Lelli's RFC in
2018.[6] This series is an updated version of that patchset, seeking to
incorporate subsequent work by Juri[7], Valentin Schneider[8] and Peter
Zijlstra along with some new fixes.
Testing so far has focused on stability, mostly via mutex locktorture
with some tweaks to more quickly trigger proxy execution bugs. These
locktorture changes are included at the end of the series for
reference. The current series survives runs of >72 hours on QEMU without
crashes, deadlocks, etc. Testing on Pixel 6 with the android-mainline
kernel [9] yields similar results. In both cases, testing used >2 CPUs
and CONFIG_FAIR_GROUP_SCHED=y, a configuration Valentin Schneider
reported[10] showed stability problems with earlier versions of the
series.
That said, these are definitely still a work in progress, with some
known remaining issues (e.g. warnings while booting on Pixel 6,
suspicious looking min/max vruntime numbers) and likely others I haven't
found yet. I've done my best to eliminate checks and code paths made
redundant by new fixes but some probably remain. There's no attempt yet
to handle core scheduling. Performance testing so far has been limited
to the aforementioned priority inversion reproducer. The hope in sharing
now is to revive the discussion on proxy execution and get some early
input for continuing to revise & refine the patches.
[0] https://raw.githubusercontent.com/johnstultz-work/priority-inversion-demo/main/results/charts/6.0-rc7-throttling-starvation.png
[1] https://github.com/johnstultz-work/priority-inversion-demo
[2] https://raw.githubusercontent.com/johnstultz-work/priority-inversion-demo/main/results/charts/6.0-rc7-vanilla-vs-proxy.png
[3] https://lpc.events/event/2/contributions/62/
[4] https://lwn.net/Articles/793502/
[5] https://lwn.net/Articles/820575/
[6] https://lore.kernel.org/lkml/[email protected]/
[7] https://github.com/jlelli/linux/tree/experimental/deadline/proxy-rfc-v2
[8] https://gitlab.arm.com/linux-arm/linux-vs/-/tree/mainline/sched/proxy-rfc-v3/
[9] https://source.android.com/docs/core/architecture/kernel/android-common
[10] https://lpc.events/event/7/contributions/758/attachments/585/1036/lpc20-proxy.pdf#page=4
Connor O'Brien (2):
torture: support randomized shuffling for proxy exec testing
locktorture: support nested mutexes
Juri Lelli (3):
locking/mutex: make mutex::wait_lock irq safe
kernel/locking: Expose mutex_owner()
sched: Fixup task CPUs for potential proxies.
Peter Zijlstra (4):
locking/ww_mutex: Remove wakeups from under mutex::wait_lock
locking/mutex: Rework task_struct::blocked_on
sched: Split scheduler execution context
sched: Add proxy execution
Valentin Schneider (2):
kernel/locking: Add p->blocked_on wrapper
sched/rt: Fix proxy/current (push,pull)ability
include/linux/mutex.h | 2 +
include/linux/sched.h | 15 +-
include/linux/ww_mutex.h | 3 +
init/Kconfig | 7 +
init/init_task.c | 1 +
kernel/Kconfig.locks | 2 +-
kernel/fork.c | 6 +-
kernel/locking/locktorture.c | 20 +-
kernel/locking/mutex-debug.c | 9 +-
kernel/locking/mutex.c | 109 +++++-
kernel/locking/ww_mutex.h | 31 +-
kernel/sched/core.c | 679 +++++++++++++++++++++++++++++++++--
kernel/sched/deadline.c | 37 +-
kernel/sched/fair.c | 33 +-
kernel/sched/rt.c | 63 ++--
kernel/sched/sched.h | 42 ++-
kernel/torture.c | 10 +-
17 files changed, 955 insertions(+), 114 deletions(-)
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Peter Zijlstra <[email protected]>
In preparation to nest mutex::wait_lock under rq::lock we need to remove
wakeups from under it.
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Signed-off-by: Connor O'Brien <[email protected]>
---
include/linux/ww_mutex.h | 3 +++
kernel/locking/mutex.c | 8 ++++++++
kernel/locking/ww_mutex.h | 9 +++++++--
kernel/sched/core.c | 7 +++++++
4 files changed, 25 insertions(+), 2 deletions(-)
diff --git a/include/linux/ww_mutex.h b/include/linux/ww_mutex.h
index bb763085479a..9335b2202017 100644
--- a/include/linux/ww_mutex.h
+++ b/include/linux/ww_mutex.h
@@ -19,6 +19,7 @@
#include <linux/mutex.h>
#include <linux/rtmutex.h>
+#include <linux/sched/wake_q.h>
#if defined(CONFIG_DEBUG_MUTEXES) || \
(defined(CONFIG_PREEMPT_RT) && defined(CONFIG_DEBUG_RT_MUTEXES))
@@ -58,6 +59,7 @@ struct ww_acquire_ctx {
unsigned int acquired;
unsigned short wounded;
unsigned short is_wait_die;
+ struct wake_q_head wake_q;
#ifdef DEBUG_WW_MUTEXES
unsigned int done_acquire;
struct ww_class *ww_class;
@@ -137,6 +139,7 @@ static inline void ww_acquire_init(struct ww_acquire_ctx *ctx,
ctx->acquired = 0;
ctx->wounded = false;
ctx->is_wait_die = ww_class->is_wait_die;
+ wake_q_init(&ctx->wake_q);
#ifdef DEBUG_WW_MUTEXES
ctx->ww_class = ww_class;
ctx->done_acquire = 0;
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index d973fe6041bf..1582756914df 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -676,6 +676,8 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
}
raw_spin_unlock(&lock->wait_lock);
+ if (ww_ctx)
+ ww_ctx_wake(ww_ctx);
schedule_preempt_disabled();
first = __mutex_waiter_is_first(lock, &waiter);
@@ -725,6 +727,8 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
ww_mutex_lock_acquired(ww, ww_ctx);
raw_spin_unlock(&lock->wait_lock);
+ if (ww_ctx)
+ ww_ctx_wake(ww_ctx);
preempt_enable();
return 0;
@@ -736,6 +740,8 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
raw_spin_unlock(&lock->wait_lock);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, ip);
+ if (ww_ctx)
+ ww_ctx_wake(ww_ctx);
preempt_enable();
return ret;
}
@@ -946,9 +952,11 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
if (owner & MUTEX_FLAG_HANDOFF)
__mutex_handoff(lock, next);
+ preempt_disable();
raw_spin_unlock(&lock->wait_lock);
wake_up_q(&wake_q);
+ preempt_enable();
}
#ifndef CONFIG_DEBUG_LOCK_ALLOC
diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
index 56f139201f24..dfc174cd96c6 100644
--- a/kernel/locking/ww_mutex.h
+++ b/kernel/locking/ww_mutex.h
@@ -161,6 +161,11 @@ static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
#endif /* WW_RT */
+void ww_ctx_wake(struct ww_acquire_ctx *ww_ctx)
+{
+ wake_up_q(&ww_ctx->wake_q);
+}
+
/*
* Wait-Die:
* The newer transactions are killed when:
@@ -284,7 +289,7 @@ __ww_mutex_die(struct MUTEX *lock, struct MUTEX_WAITER *waiter,
#ifndef WW_RT
debug_mutex_wake_waiter(lock, waiter);
#endif
- wake_up_process(waiter->task);
+ wake_q_add(&ww_ctx->wake_q, waiter->task);
}
return true;
@@ -331,7 +336,7 @@ static bool __ww_mutex_wound(struct MUTEX *lock,
* wakeup pending to re-read the wounded state.
*/
if (owner != current)
- wake_up_process(owner);
+ wake_q_add(&ww_ctx->wake_q, owner);
return true;
}
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index ee28253c9ac0..617e737392be 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -1013,6 +1013,13 @@ void wake_up_q(struct wake_q_head *head)
wake_up_process(task);
put_task_struct(task);
}
+ /*
+ * XXX connoro: seems this is needed now that ww_ctx_wake() passes in a
+ * wake_q_head that is embedded in struct ww_acquire_ctx rather than
+ * declared locally.
+ */
+ head->first = node;
+ head->lastp = &head->first;
}
/*
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Juri Lelli <[email protected]>
When a mutex owner with potential proxies wakes up those proxies are
activated as well, on the same CPU of the owner. They might have been
sleeping on a different CPU however.
Fixup potential proxies CPU at wakeup time before activating them (or
they get woken up with a wrong CPU reference).
XXX connoro: plan is to fold this into "sched: Add proxy execution" in
future versions.
Signed-off-by: Juri Lelli <[email protected]>
[Fixed trivial rebase conflict]
Signed-off-by: Valentin Schneider <[email protected]>
[fix conflicts]
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/sched/core.c | 12 ++++++++++--
1 file changed, 10 insertions(+), 2 deletions(-)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 416e61182c17..ad2e7b49f98e 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -3733,8 +3733,15 @@ ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags,
raw_spin_unlock(&pp->blocked_lock);
break;
}
+ /* XXX can't call set_task_cpu() because we are not holding
+ * neither pp->pi_lock nor task's rq lock. This should however
+ * be fine as this task can't be woken up as it is blocked on
+ * this mutex atm.
+ * A problem however might be that __set_task_cpu() calls
+ * set_task_rq() which deals with groups and such...
+ */
+ __set_task_cpu(pp, cpu_of(rq));
activate_task(rq, pp, en_flags);
- pp->on_rq = TASK_ON_RQ_QUEUED;
resched_curr(rq);
raw_spin_unlock(&pp->blocked_lock);
}
@@ -7114,7 +7121,8 @@ static inline void sched_submit_work(struct task_struct *tsk)
* If a worker goes to sleep, notify and ask workqueue whether it
* wants to wake up a task to maintain concurrency.
*/
- if (task_flags & (PF_WQ_WORKER | PF_IO_WORKER)) {
+ if ((task_flags & (PF_WQ_WORKER | PF_IO_WORKER)) &&
+ !task_is_blocked(tsk)) {
if (task_flags & PF_WQ_WORKER)
wq_worker_sleeping(tsk);
else
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Juri Lelli <[email protected]>
mutex::wait_lock might be nested under rq->lock.
Make it irq safe then.
Signed-off-by: Juri Lelli <[email protected]>
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Link: https://lkml.kernel.org/r/[email protected]
[rebase & fix {un,}lock_wait_lock helpers in ww_mutex.h]
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/locking/mutex.c | 18 ++++++++++--------
kernel/locking/ww_mutex.h | 22 ++++++++++++----------
2 files changed, 22 insertions(+), 18 deletions(-)
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index 7800380219db..f39e9ee3c4d0 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -572,6 +572,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
{
struct mutex_waiter waiter;
struct ww_mutex *ww;
+ unsigned long flags;
int ret;
if (!use_ww_ctx)
@@ -614,7 +615,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
return 0;
}
- raw_spin_lock(&lock->wait_lock);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
/*
* After waiting to acquire the wait_lock, try again.
*/
@@ -676,7 +677,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
goto err;
}
- raw_spin_unlock(&lock->wait_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
if (ww_ctx)
ww_ctx_wake(ww_ctx);
schedule_preempt_disabled();
@@ -703,9 +704,9 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
trace_contention_begin(lock, LCB_F_MUTEX);
}
- raw_spin_lock(&lock->wait_lock);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
}
- raw_spin_lock(&lock->wait_lock);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
acquired:
__set_current_state(TASK_RUNNING);
@@ -732,7 +733,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
if (ww_ctx)
ww_mutex_lock_acquired(ww, ww_ctx);
- raw_spin_unlock(&lock->wait_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
if (ww_ctx)
ww_ctx_wake(ww_ctx);
preempt_enable();
@@ -743,7 +744,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
__mutex_remove_waiter(lock, &waiter);
err_early_kill:
trace_contention_end(lock, ret);
- raw_spin_unlock(&lock->wait_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, ip);
if (ww_ctx)
@@ -915,6 +916,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
struct task_struct *next = NULL;
DEFINE_WAKE_Q(wake_q);
unsigned long owner;
+ unsigned long flags;
mutex_release(&lock->dep_map, ip);
@@ -941,7 +943,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
}
}
- raw_spin_lock(&lock->wait_lock);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
debug_mutex_unlock(lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
@@ -959,7 +961,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
__mutex_handoff(lock, next);
preempt_disable();
- raw_spin_unlock(&lock->wait_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
wake_up_q(&wake_q);
preempt_enable();
diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
index dfc174cd96c6..7edd55d10f87 100644
--- a/kernel/locking/ww_mutex.h
+++ b/kernel/locking/ww_mutex.h
@@ -70,14 +70,14 @@ __ww_mutex_has_waiters(struct mutex *lock)
return atomic_long_read(&lock->owner) & MUTEX_FLAG_WAITERS;
}
-static inline void lock_wait_lock(struct mutex *lock)
+static inline void lock_wait_lock(struct mutex *lock, unsigned long *flags)
{
- raw_spin_lock(&lock->wait_lock);
+ raw_spin_lock_irqsave(&lock->wait_lock, *flags);
}
-static inline void unlock_wait_lock(struct mutex *lock)
+static inline void unlock_wait_lock(struct mutex *lock, unsigned long flags)
{
- raw_spin_unlock(&lock->wait_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
}
static inline void lockdep_assert_wait_lock_held(struct mutex *lock)
@@ -144,14 +144,14 @@ __ww_mutex_has_waiters(struct rt_mutex *lock)
return rt_mutex_has_waiters(&lock->rtmutex);
}
-static inline void lock_wait_lock(struct rt_mutex *lock)
+static inline void lock_wait_lock(struct rt_mutex *lock, unsigned long *flags)
{
- raw_spin_lock(&lock->rtmutex.wait_lock);
+ raw_spin_lock_irqsave(&lock->rtmutex.wait_lock, *flags);
}
-static inline void unlock_wait_lock(struct rt_mutex *lock)
+static inline void unlock_wait_lock(struct rt_mutex *lock, flags)
{
- raw_spin_unlock(&lock->rtmutex.wait_lock);
+ raw_spin_unlock_irqrestore(&lock->rtmutex.wait_lock, flags);
}
static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
@@ -382,6 +382,8 @@ __ww_mutex_check_waiters(struct MUTEX *lock, struct ww_acquire_ctx *ww_ctx)
static __always_inline void
ww_mutex_set_context_fastpath(struct ww_mutex *lock, struct ww_acquire_ctx *ctx)
{
+ unsigned long flags;
+
ww_mutex_lock_acquired(lock, ctx);
/*
@@ -409,9 +411,9 @@ ww_mutex_set_context_fastpath(struct ww_mutex *lock, struct ww_acquire_ctx *ctx)
* Uh oh, we raced in fastpath, check if any of the waiters need to
* die or wound us.
*/
- lock_wait_lock(&lock->base);
+ lock_wait_lock(&lock->base, &flags);
__ww_mutex_check_waiters(&lock->base, ctx);
- unlock_wait_lock(&lock->base);
+ unlock_wait_lock(&lock->base, flags);
}
static __always_inline int
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Peter Zijlstra <[email protected]>
A task currently holding a mutex (executing a critical section) might
find benefit in using scheduling contexts of other tasks blocked on the
same mutex if they happen to have higher priority of the current owner
(e.g., to prevent priority inversions).
Proxy execution lets a task do exactly that: if a mutex owner has
waiters, it can use waiters' scheduling context to potentially continue
running if preempted.
The basic mechanism is implemented by this patch, the core of which
resides in the proxy() function. Potential proxies (i.e., tasks blocked
on a mutex) are not dequeued, so, if one of them is actually selected by
schedule() as the next task to be put to run on a CPU, proxy() is used
to walk the blocked_on relation and find which task (mutex owner) might
be able to use the proxy's scheduling context.
Here come the tricky bits. In fact, owner task might be in all sort of
states when a proxy is found (blocked, executing on a different CPU,
etc.). Details on how to handle different situations are to be found in
proxy() code comments.
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
[rebased, added comments and changelog]
Signed-off-by: Juri Lelli <[email protected]>
[Fixed rebase conflicts]
[squashed sched: Ensure blocked_on is always guarded by blocked_lock]
Signed-off-by: Valentin Schneider <[email protected]>
[fix rebase conflicts, various fixes & tweaks commented inline]
[squashed sched: Use rq->curr vs rq->proxy checks]
Signed-off-by: Connor O'Brien <[email protected]>
Link: https://lore.kernel.org/all/[email protected]/
---
include/linux/sched.h | 2 +
init/Kconfig | 7 +
init/init_task.c | 1 +
kernel/Kconfig.locks | 2 +-
kernel/fork.c | 2 +
kernel/locking/mutex.c | 78 +++++-
kernel/sched/core.c | 585 +++++++++++++++++++++++++++++++++++++++-
kernel/sched/deadline.c | 2 +-
kernel/sched/fair.c | 13 +-
kernel/sched/rt.c | 3 +-
kernel/sched/sched.h | 21 +-
11 files changed, 694 insertions(+), 22 deletions(-)
diff --git a/include/linux/sched.h b/include/linux/sched.h
index 379e4c052644..1ccd0c1bde38 100644
--- a/include/linux/sched.h
+++ b/include/linux/sched.h
@@ -1132,6 +1132,8 @@ struct task_struct {
struct task_struct *blocked_proxy; /* task that is boosting us */
struct mutex *blocked_on; /* lock we're blocked on */
+ struct list_head blocked_entry; /* tasks blocked on us */
+ raw_spinlock_t blocked_lock;
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
int non_block_count;
diff --git a/init/Kconfig b/init/Kconfig
index 532362fcfe31..a341b9755a57 100644
--- a/init/Kconfig
+++ b/init/Kconfig
@@ -922,6 +922,13 @@ config NUMA_BALANCING_DEFAULT_ENABLED
If set, automatic NUMA balancing will be enabled if running on a NUMA
machine.
+config PROXY_EXEC
+ bool "Proxy Execution"
+ default n
+ help
+ This option enables proxy execution, a mechanism for mutex owning
+ tasks to inherit the scheduling context of higher priority waiters.
+
menuconfig CGROUPS
bool "Control Group support"
select KERNFS
diff --git a/init/init_task.c b/init/init_task.c
index ff6c4b9bfe6b..189ce67e9704 100644
--- a/init/init_task.c
+++ b/init/init_task.c
@@ -130,6 +130,7 @@ struct task_struct init_task
.journal_info = NULL,
INIT_CPU_TIMERS(init_task)
.pi_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.pi_lock),
+ .blocked_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.blocked_lock),
.timer_slack_ns = 50000, /* 50 usec default slack */
.thread_pid = &init_struct_pid,
.thread_group = LIST_HEAD_INIT(init_task.thread_group),
diff --git a/kernel/Kconfig.locks b/kernel/Kconfig.locks
index 4198f0273ecd..791c98f1d329 100644
--- a/kernel/Kconfig.locks
+++ b/kernel/Kconfig.locks
@@ -226,7 +226,7 @@ config ARCH_SUPPORTS_ATOMIC_RMW
config MUTEX_SPIN_ON_OWNER
def_bool y
- depends on SMP && ARCH_SUPPORTS_ATOMIC_RMW
+ depends on SMP && ARCH_SUPPORTS_ATOMIC_RMW && !PROXY_EXEC
config RWSEM_SPIN_ON_OWNER
def_bool y
diff --git a/kernel/fork.c b/kernel/fork.c
index 81e809c343fd..409f4d955537 100644
--- a/kernel/fork.c
+++ b/kernel/fork.c
@@ -2106,6 +2106,7 @@ static __latent_entropy struct task_struct *copy_process(
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
+ raw_spin_lock_init(&p->blocked_lock);
lockdep_assert_irqs_enabled();
#ifdef CONFIG_PROVE_LOCKING
@@ -2210,6 +2211,7 @@ static __latent_entropy struct task_struct *copy_process(
p->blocked_proxy = NULL; /* nobody is boosting us yet */
p->blocked_on = NULL; /* not blocked yet */
+ INIT_LIST_HEAD(&p->blocked_entry);
#ifdef CONFIG_BCACHE
p->sequential_io = 0;
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index 325fc9db5004..ba8bfac23c10 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -621,6 +621,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
}
raw_spin_lock_irqsave(&lock->wait_lock, flags);
+ raw_spin_lock(¤t->blocked_lock);
/*
* After waiting to acquire the wait_lock, try again.
*/
@@ -682,6 +683,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
goto err;
}
+ raw_spin_unlock(¤t->blocked_lock);
raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
if (ww_ctx)
ww_ctx_wake(ww_ctx);
@@ -689,6 +691,8 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
first = __mutex_waiter_is_first(lock, &waiter);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
+ raw_spin_lock(¤t->blocked_lock);
/*
* Gets reset by ttwu_runnable().
*/
@@ -703,15 +707,28 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
break;
if (first) {
+ bool acquired;
+
+ /*
+ * XXX connoro: mutex_optimistic_spin() can schedule, so
+ * we need to release these locks before calling it.
+ * This needs refactoring though b/c currently we take
+ * the locks earlier than necessary when proxy exec is
+ * disabled and release them unnecessarily when it's
+ * enabled. At a minimum, need to verify that releasing
+ * blocked_lock here doesn't create any races.
+ */
+ raw_spin_unlock(¤t->blocked_lock);
+ raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
trace_contention_begin(lock, LCB_F_MUTEX | LCB_F_SPIN);
- if (mutex_optimistic_spin(lock, ww_ctx, &waiter))
+ acquired = mutex_optimistic_spin(lock, ww_ctx, &waiter);
+ raw_spin_lock_irqsave(&lock->wait_lock, flags);
+ raw_spin_lock(¤t->blocked_lock);
+ if (acquired)
break;
trace_contention_begin(lock, LCB_F_MUTEX);
}
-
- raw_spin_lock_irqsave(&lock->wait_lock, flags);
}
- raw_spin_lock_irqsave(&lock->wait_lock, flags);
acquired:
__set_current_state(TASK_RUNNING);
@@ -738,6 +755,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
if (ww_ctx)
ww_mutex_lock_acquired(ww, ww_ctx);
+ raw_spin_unlock(¤t->blocked_lock);
raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
if (ww_ctx)
ww_ctx_wake(ww_ctx);
@@ -749,6 +767,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
__mutex_remove_waiter(lock, &waiter);
err_early_kill:
trace_contention_end(lock, ret);
+ raw_spin_unlock(¤t->blocked_lock);
raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, ip);
@@ -920,11 +939,22 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
{
struct task_struct *next = NULL;
DEFINE_WAKE_Q(wake_q);
- unsigned long owner;
+ /*
+ * XXX [juril] Proxy Exec forces always an HANDOFF (so that owner is
+ * never empty when there are waiters waiting?). Should we make this
+ * conditional on having proxy exec configured in?
+ */
+ unsigned long owner = MUTEX_FLAG_HANDOFF;
unsigned long flags;
mutex_release(&lock->dep_map, ip);
+ /*
+ * XXX must always handoff the mutex to avoid !owner in proxy().
+ * scheduler delay is minimal since we hand off to the task that
+ * is to be scheduled next.
+ */
+#ifndef CONFIG_PROXY_EXEC
/*
* Release the lock before (potentially) taking the spinlock such that
* other contenders can get on with things ASAP.
@@ -947,10 +977,41 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
return;
}
}
+#endif
raw_spin_lock_irqsave(&lock->wait_lock, flags);
debug_mutex_unlock(lock);
- if (!list_empty(&lock->wait_list)) {
+
+#ifdef CONFIG_PROXY_EXEC
+ raw_spin_lock(¤t->blocked_lock);
+ /*
+ * If we have a task boosting us, and that task was boosting us through
+ * this lock, hand the lock to that task, as that is the highest
+ * waiter, as selected by the scheduling function.
+ *
+ * XXX existence guarantee on ->blocked_task ?
+ */
+ next = current->blocked_proxy;
+ if (next) {
+ if (next->blocked_on != lock) {
+ next = NULL;
+ } else {
+ wake_q_add(&wake_q, next);
+ current->blocked_proxy = NULL;
+ }
+ }
+
+ /*
+ * XXX if there was no higher prio proxy, ->blocked_task will not have
+ * been set. Therefore lower prio contending tasks are serviced in
+ * FIFO order.
+ */
+#endif
+
+ /*
+ * Failing that, pick any on the wait list.
+ */
+ if (!next && !list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter =
list_first_entry(&lock->wait_list,
@@ -965,7 +1026,10 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
if (owner & MUTEX_FLAG_HANDOFF)
__mutex_handoff(lock, next);
- preempt_disable();
+ preempt_disable(); /* XXX connoro: why disable preemption here? */
+#ifdef CONFIG_PROXY_EXEC
+ raw_spin_unlock(¤t->blocked_lock);
+#endif
raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
wake_up_q(&wake_q);
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index c8bfa1ad9551..416e61182c17 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -510,6 +510,8 @@ sched_core_dequeue(struct rq *rq, struct task_struct *p, int flags) { }
*
* task_cpu(p): is changed by set_task_cpu(), the rules are:
*
+ * XXX connoro: does it matter that ttwu_do_activate now calls __set_task_cpu
+ * on blocked tasks?
* - Don't call set_task_cpu() on a blocked task:
*
* We don't care what CPU we're not running on, this simplifies hotplug,
@@ -2714,8 +2716,15 @@ static int affine_move_task(struct rq *rq, struct task_struct *p, struct rq_flag
struct set_affinity_pending my_pending = { }, *pending = NULL;
bool stop_pending, complete = false;
- /* Can the task run on the task's current CPU? If so, we're done */
- if (cpumask_test_cpu(task_cpu(p), &p->cpus_mask)) {
+ /*
+ * Can the task run on the task's current CPU? If so, we're done
+ *
+ * We are also done if the task is currently acting as proxy (and
+ * potentially has been migrated outside its current or previous
+ * affinity mask.
+ */
+ if (cpumask_test_cpu(task_cpu(p), &p->cpus_mask) ||
+ (task_current_proxy(rq, p) && !task_current(rq, p))) {
struct task_struct *push_task = NULL;
if ((flags & SCA_MIGRATE_ENABLE) &&
@@ -3681,7 +3690,55 @@ ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags,
atomic_dec(&task_rq(p)->nr_iowait);
}
+ /*
+ * XXX connoro: By calling activate_task with blocked_lock held, we order against
+ * the proxy() blocked_task case such that no more blocked tasks will
+ * be enqueued on p once we release p->blocked_lock.
+ */
+ raw_spin_lock(&p->blocked_lock);
+ /*
+ * XXX connoro: do we need to check p->on_rq here like we do for pp below?
+ * or does holding p->pi_lock ensure nobody else activates p first?
+ */
activate_task(rq, p, en_flags);
+ raw_spin_unlock(&p->blocked_lock);
+
+ /*
+ * A whole bunch of 'proxy' tasks back this blocked task, wake
+ * them all up to give this task its 'fair' share.
+ */
+ while (!list_empty(&p->blocked_entry)) {
+ struct task_struct *pp =
+ list_first_entry(&p->blocked_entry,
+ struct task_struct,
+ blocked_entry);
+ /*
+ * XXX connoro: proxy blocked_task case might be enqueuing more blocked tasks
+ * on pp. If those continue past when we delete pp from the list, we'll get an
+ * active with a non-empty blocked_entry list, which is no good. Locking
+ * pp->blocked_lock ensures either the blocked_task path gets the lock first and
+ * enqueues everything before we ever get the lock, or we get the lock first, the
+ * other path sees pp->on_rq != 0 and enqueues nothing.
+ */
+ raw_spin_lock(&pp->blocked_lock);
+ BUG_ON(pp->blocked_entry.prev != &p->blocked_entry);
+
+ list_del_init(&pp->blocked_entry);
+ if (READ_ONCE(pp->on_rq)) {
+ /*
+ * XXX connoro: We raced with a non mutex handoff activation of pp. That
+ * activation will also take care of activating all of the tasks after pp in
+ * the blocked_entry list, so we're done here.
+ */
+ raw_spin_unlock(&pp->blocked_lock);
+ break;
+ }
+ activate_task(rq, pp, en_flags);
+ pp->on_rq = TASK_ON_RQ_QUEUED;
+ resched_curr(rq);
+ raw_spin_unlock(&pp->blocked_lock);
+ }
+
ttwu_do_wakeup(rq, p, wake_flags, rf);
}
@@ -3717,12 +3774,96 @@ static int ttwu_runnable(struct task_struct *p, int wake_flags)
int ret = 0;
rq = __task_rq_lock(p, &rf);
- if (task_on_rq_queued(p)) {
- /* check_preempt_curr() may use rq clock */
- update_rq_clock(rq);
- ttwu_do_wakeup(rq, p, wake_flags, &rf);
- ret = 1;
+ if (!task_on_rq_queued(p)) {
+ BUG_ON(task_is_running(p));
+ goto out_unlock;
}
+
+ /*
+ * ttwu_do_wakeup()->
+ * check_preempt_curr() may use rq clock
+ */
+ update_rq_clock(rq);
+
+ /*
+ * XXX connoro: wrap this case with #ifdef CONFIG_PROXY_EXEC?
+ */
+ if (task_current(rq, p)) {
+ /*
+ * XXX connoro: p is currently running. 3 cases are possible:
+ * 1) p is blocked on a lock it owns, but we got the rq lock before
+ * it could schedule out. Kill blocked_on relation and call
+ * ttwu_do_wakeup
+ * 2) p is blocked on a lock it does not own. Leave blocked_on
+ * unchanged, don't call ttwu_do_wakeup, and return 0.
+ * 3) p is unblocked, but unless we hold onto blocked_lock while
+ * calling ttwu_do_wakeup, we could race with it becoming
+ * blocked and overwrite the correct p->__state with TASK_RUNNING.
+ */
+ raw_spin_lock(&p->blocked_lock);
+ if (task_is_blocked(p) && mutex_owner(p->blocked_on) == p)
+ set_task_blocked_on(p, NULL);
+ if (!task_is_blocked(p)) {
+ ttwu_do_wakeup(rq, p, wake_flags, &rf);
+ ret = 1;
+ }
+ raw_spin_unlock(&p->blocked_lock);
+ goto out_unlock;
+ }
+
+ /*
+ * Since we don't dequeue for blocked-on relations, we'll always
+ * trigger the on_rq_queued() clause for them.
+ */
+ if (task_is_blocked(p)) {
+ raw_spin_lock(&p->blocked_lock);
+
+ if (mutex_owner(p->blocked_on) != p) {
+ /*
+ * XXX connoro: p already woke, ran and blocked on
+ * another mutex. Since a successful wakeup already
+ * happened, we're done.
+ */
+ raw_spin_unlock(&p->blocked_lock);
+ goto out_unlock;
+ }
+
+ set_task_blocked_on(p, NULL);
+ if (!cpumask_test_cpu(cpu_of(rq), p->cpus_ptr)) {
+ /*
+ * proxy stuff moved us outside of the affinity mask
+ * 'sleep' now and fail the direct wakeup so that the
+ * normal wakeup path will fix things.
+ */
+ deactivate_task(rq, p, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
+ if (task_current_proxy(rq, p)) {
+ /*
+ * XXX connoro: If p is the proxy, then remove lingering
+ * references to it from rq and sched_class structs after
+ * dequeueing.
+ * can we get here while rq is inside __schedule?
+ * do any assumptions break if so?
+ */
+ put_prev_task(rq, p);
+ rq->proxy = rq->idle;
+ }
+ resched_curr(rq);
+ raw_spin_unlock(&p->blocked_lock);
+ goto out_unlock;
+ }
+
+ /*
+ * Must resched after killing a blocked_on relation. The currently
+ * executing context might not be the most elegible anymore.
+ */
+ resched_curr(rq);
+ raw_spin_unlock(&p->blocked_lock);
+ }
+
+ ttwu_do_wakeup(rq, p, wake_flags, &rf);
+ ret = 1;
+
+out_unlock:
__task_rq_unlock(rq, &rf);
return ret;
@@ -4126,6 +4267,23 @@ try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
if (READ_ONCE(p->on_rq) && ttwu_runnable(p, wake_flags))
goto unlock;
+ if (task_is_blocked(p)) {
+ /*
+ * XXX connoro: we are in one of 2 cases:
+ * 1) p is blocked on a mutex it doesn't own but is still
+ * enqueued on a rq. We definitely don't want to keep going
+ * (and potentially activate it elsewhere without ever
+ * dequeueing) but maybe this is more properly handled by
+ * having ttwu_runnable() return 1 in this case?
+ * 2) p was removed from its rq and added to a blocked_entry
+ * list by proxy(). It should not be woken until the task at
+ * the head of the list gets a mutex handoff wakeup.
+ * Should try_to_wake_up() return 1 in either of these cases?
+ */
+ success = 0;
+ goto unlock;
+ }
+
#ifdef CONFIG_SMP
/*
* Ensure we load p->on_cpu _after_ p->on_rq, otherwise it would be
@@ -5462,6 +5620,18 @@ void scheduler_tick(void)
rq_lock(rq, &rf);
+#ifdef CONFIG_PROXY_EXEC
+ /*
+ * XXX connoro: is this check needed? Why?
+ */
+ if (task_cpu(curr) != cpu) {
+ BUG_ON(!test_preempt_need_resched() &&
+ !tif_need_resched());
+ rq_unlock(rq, &rf);
+ return;
+ }
+#endif
+
update_rq_clock(rq);
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq));
update_thermal_load_avg(rq_clock_thermal(rq), rq, thermal_pressure);
@@ -6355,6 +6525,373 @@ pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
# define SM_MASK_PREEMPT SM_PREEMPT
#endif
+#ifdef CONFIG_PROXY_EXEC
+
+/*
+ * Find who @next (currently blocked on a mutex) can proxy for.
+ *
+ * Follow the blocked-on relation:
+ *
+ * ,-> task
+ * | | blocked-on
+ * | v
+ * proxied-by | mutex
+ * | | owner
+ * | v
+ * `-- task
+ *
+ * and set the proxied-by relation, this latter is used by the mutex code
+ * to find which (blocked) task to hand-off to.
+ *
+ * Lock order:
+ *
+ * p->pi_lock
+ * rq->lock
+ * mutex->wait_lock
+ * p->blocked_lock
+ *
+ * Returns the task that is going to be used as execution context (the one
+ * that is actually going to be put to run on cpu_of(rq)).
+ */
+static struct task_struct *
+proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
+{
+ struct task_struct *p = next;
+ struct task_struct *owner = NULL;
+ struct mutex *mutex;
+ struct rq *that_rq;
+ int this_cpu, that_cpu;
+ bool curr_in_chain = false;
+ LIST_HEAD(migrate_list);
+
+ this_cpu = cpu_of(rq);
+
+ /*
+ * Follow blocked_on chain.
+ *
+ * TODO: deadlock detection
+ */
+ for (p = next; p->blocked_on; p = owner) {
+ mutex = p->blocked_on;
+ /* Something changed in the chain, pick_again */
+ if (!mutex)
+ return NULL;
+
+ /*
+ * By taking mutex->wait_lock we hold off concurrent mutex_unlock()
+ * and ensure @owner sticks around.
+ */
+ raw_spin_lock(&mutex->wait_lock);
+ raw_spin_lock(&p->blocked_lock);
+
+ /* Check again that p is blocked with blocked_lock held */
+ if (!task_is_blocked(p) || mutex != p->blocked_on) {
+ /*
+ * Something changed in the blocked_on chain and
+ * we don't know if only at this level. So, let's
+ * just bail out completely and let __schedule
+ * figure things out (pick_again loop).
+ */
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+ return NULL;
+ }
+
+ if (task_current(rq, p))
+ curr_in_chain = true;
+
+ owner = mutex_owner(mutex);
+ /*
+ * XXX can't this be 0|FLAGS? See __mutex_unlock_slowpath for(;;)
+ * Mmm, OK, this can't probably happen because we force
+ * unlock to skip the for(;;) loop. Is this acceptable though?
+ */
+ if (task_cpu(owner) != this_cpu)
+ goto migrate_task;
+
+ if (task_on_rq_migrating(owner))
+ goto migrating_task;
+
+ if (owner == p)
+ goto owned_task;
+
+ if (!owner->on_rq)
+ goto blocked_task;
+
+ /*
+ * OK, now we're absolutely sure @owner is not blocked _and_
+ * on this rq, therefore holding @rq->lock is sufficient to
+ * guarantee its existence, as per ttwu_remote().
+ */
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+
+ owner->blocked_proxy = p;
+ }
+
+ WARN_ON_ONCE(!owner->on_rq);
+
+ return owner;
+
+migrate_task:
+ /*
+ * The blocked-on relation must not cross CPUs, if this happens
+ * migrate @p to the @owner's CPU.
+ *
+ * This is because we must respect the CPU affinity of execution
+ * contexts (@owner) but we can ignore affinity for scheduling
+ * contexts (@p). So we have to move scheduling contexts towards
+ * potential execution contexts.
+ *
+ * XXX [juril] what if @p is not the highest prio task once migrated
+ * to @owner's CPU?
+ *
+ * XXX [juril] also, after @p is migrated it is not migrated back once
+ * @owner releases the lock? Isn't this a potential problem w.r.t.
+ * @owner affinity settings?
+ * [juril] OK. It is migrated back into its affinity mask in
+ * ttwu_remote(), or by using wake_cpu via select_task_rq, guess we
+ * might want to add a comment about that here. :-)
+ *
+ * TODO: could optimize by finding the CPU of the final owner
+ * and migrating things there. Given:
+ *
+ * CPU0 CPU1 CPU2
+ *
+ * a ----> b ----> c
+ *
+ * the current scheme would result in migrating 'a' to CPU1,
+ * then CPU1 would migrate b and a to CPU2. Only then would
+ * CPU2 run c.
+ */
+ that_cpu = task_cpu(owner);
+ that_rq = cpu_rq(that_cpu);
+ /*
+ * @owner can disappear, simply migrate to @that_cpu and leave that CPU
+ * to sort things out.
+ */
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+
+ /*
+ * Since we're going to drop @rq, we have to put(@next) first,
+ * otherwise we have a reference that no longer belongs to us. Use
+ * @fake_task to fill the void and make the next pick_next_task()
+ * invocation happy.
+ *
+ * XXX double, triple think about this.
+ * XXX put doesn't work with ON_RQ_MIGRATE
+ *
+ * CPU0 CPU1
+ *
+ * B mutex_lock(X)
+ *
+ * A mutex_lock(X) <- B
+ * A __schedule()
+ * A pick->A
+ * A proxy->B
+ * A migrate A to CPU1
+ * B mutex_unlock(X) -> A
+ * B __schedule()
+ * B pick->A
+ * B switch_to (A)
+ * A ... does stuff
+ * A ... is still running here
+ *
+ * * BOOM *
+ */
+ put_prev_task(rq, next);
+ if (curr_in_chain) {
+ rq->proxy = rq->idle;
+ set_tsk_need_resched(rq->idle);
+ /*
+ * XXX [juril] don't we still need to migrate @next to
+ * @owner's CPU?
+ */
+ return rq->idle;
+ }
+ rq->proxy = rq->idle;
+
+ for (; p; p = p->blocked_proxy) {
+ int wake_cpu = p->wake_cpu;
+
+ WARN_ON(p == rq->curr);
+
+ deactivate_task(rq, p, 0);
+ set_task_cpu(p, that_cpu);
+ /*
+ * We can abuse blocked_entry to migrate the thing, because @p is
+ * still on the rq.
+ */
+ list_add(&p->blocked_entry, &migrate_list);
+
+ /*
+ * Preserve p->wake_cpu, such that we can tell where it
+ * used to run later.
+ */
+ p->wake_cpu = wake_cpu;
+ }
+
+ rq_unpin_lock(rq, rf);
+ raw_spin_rq_unlock(rq);
+ raw_spin_rq_lock(that_rq);
+
+ while (!list_empty(&migrate_list)) {
+ p = list_first_entry(&migrate_list, struct task_struct, blocked_entry);
+ list_del_init(&p->blocked_entry);
+
+ enqueue_task(that_rq, p, 0);
+ check_preempt_curr(that_rq, p, 0);
+ p->on_rq = TASK_ON_RQ_QUEUED;
+ /*
+ * check_preempt_curr has already called
+ * resched_curr(that_rq) in case it is
+ * needed.
+ */
+ }
+
+ raw_spin_rq_unlock(that_rq);
+ raw_spin_rq_lock(rq);
+ rq_repin_lock(rq, rf);
+
+ return NULL; /* Retry task selection on _this_ CPU. */
+
+migrating_task:
+ /*
+ * XXX connoro: one of the chain of mutex owners is currently
+ * migrating to this CPU, but has not yet been enqueued because
+ * we are holding the rq lock. As a simple solution, just schedule
+ * rq->idle to give the migration a chance to complete. Much like
+ * the migrate_task case we should end up back in proxy(), this
+ * time hopefully with all relevant tasks already enqueued.
+ */
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+ put_prev_task(rq, next);
+ rq->proxy = rq->idle;
+ set_tsk_need_resched(rq->idle);
+ return rq->idle;
+owned_task:
+ /*
+ * Its possible we interleave with mutex_unlock like:
+ *
+ * lock(&rq->lock);
+ * proxy()
+ * mutex_unlock()
+ * lock(&wait_lock);
+ * next(owner) = current->blocked_proxy;
+ * unlock(&wait_lock);
+ *
+ * wake_up_q();
+ * ...
+ * ttwu_runnable()
+ * __task_rq_lock()
+ * lock(&wait_lock);
+ * owner == p
+ *
+ * Which leaves us to finish the ttwu_runnable() and make it go.
+ *
+ * XXX is this happening in case of an HANDOFF to p?
+ * In any case, reading of the owner in __mutex_unlock_slowpath is
+ * done atomically outside wait_lock (only adding waiters to wake_q is
+ * done inside the critical section).
+ * Does this means we can get to proxy _w/o an owner_ if that was
+ * cleared before grabbing wait_lock? Do we account for this case?
+ * OK we actually do (see PROXY_EXEC ifdeffery in unlock function).
+ */
+
+ set_task_blocked_on(owner, NULL);
+
+ /*
+ * XXX connoro: previous versions would immediately run owner here if
+ * it's allowed to run on this CPU, but this creates potential races
+ * with the wakeup logic. Instead we can just take the blocked_task path
+ * when owner is already !on_rq, or else schedule rq->idle so that ttwu_runnable
+ * can get the rq lock and mark owner as running.
+ */
+ if (!owner->on_rq)
+ goto blocked_task;
+
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+ put_prev_task(rq, next);
+ rq->proxy = rq->idle;
+ set_tsk_need_resched(rq->idle);
+ return rq->idle;
+
+blocked_task:
+ /*
+ * XXX connoro: rq->curr must not be added to the blocked_entry list
+ * or else ttwu_do_activate could enqueue it elsewhere before it switches out
+ * here. The approach to avoiding this is the same as in the migrate_task case.
+ */
+ if (curr_in_chain) {
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+ put_prev_task(rq, next);
+ rq->proxy = rq->idle;
+ set_tsk_need_resched(rq->idle);
+ return rq->idle;
+ }
+ /*
+ * If !@owner->on_rq, holding @rq->lock will not pin the task,
+ * so we cannot drop @mutex->wait_lock until we're sure its a blocked
+ * task on this rq.
+ *
+ * We use @owner->blocked_lock to serialize against ttwu_activate().
+ * Either we see its new owner->on_rq or it will see our list_add().
+ */
+ if (owner != p) {
+ raw_spin_unlock(&p->blocked_lock);
+ raw_spin_lock(&owner->blocked_lock);
+ }
+
+ /*
+ * Walk back up the blocked_proxy relation and enqueue them all on @owner
+ *
+ * ttwu_activate() will pick them up and place them on whatever rq
+ * @owner will run next.
+ * XXX connoro: originally we would jump back into the main proxy() loop
+ * owner->on_rq !=0 path, but if we then end up taking the owned_task path
+ * then we can overwrite p->on_rq after ttwu_do_activate sets it to 1 which breaks
+ * the assumptions made in ttwu_do_activate.
+ */
+ if (!owner->on_rq) {
+ for (; p; p = p->blocked_proxy) {
+ if (p == owner)
+ continue;
+ BUG_ON(!p->on_rq);
+ deactivate_task(rq, p, DEQUEUE_SLEEP);
+ if (task_current_proxy(rq, p)) {
+ put_prev_task(rq, next);
+ rq->proxy = rq->idle;
+ }
+ /*
+ * XXX connoro: need to verify this is necessary. The rationale is that
+ * ttwu_do_activate must not have a chance to activate p elsewhere before
+ * it's fully extricated from its old rq.
+ */
+ smp_mb();
+ list_add(&p->blocked_entry, &owner->blocked_entry);
+ }
+ }
+ if (task_current_proxy(rq, next)) {
+ put_prev_task(rq, next);
+ rq->proxy = rq->idle;
+ }
+ raw_spin_unlock(&owner->blocked_lock);
+ raw_spin_unlock(&mutex->wait_lock);
+
+ return NULL; /* retry task selection */
+}
+#else /* PROXY_EXEC */
+static struct task_struct *
+proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
+{
+ return next;
+}
+#endif /* PROXY_EXEC */
+
/*
* __schedule() is the main scheduler function.
*
@@ -6447,7 +6984,7 @@ static void __sched notrace __schedule(unsigned int sched_mode)
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
- } else {
+ } else if (!task_is_blocked(prev)) {
prev->sched_contributes_to_load =
(prev_state & TASK_UNINTERRUPTIBLE) &&
!(prev_state & TASK_NOLOAD) &&
@@ -6473,11 +7010,37 @@ static void __sched notrace __schedule(unsigned int sched_mode)
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
+ } else {
+ /*
+ * XXX
+ * Let's make this task, which is blocked on
+ * a mutex, (push/pull)able (RT/DL).
+ * Unfortunately we can only deal with that by
+ * means of a dequeue/enqueue cycle. :-/
+ */
+ dequeue_task(rq, prev, 0);
+ enqueue_task(rq, prev, 0);
}
switch_count = &prev->nvcsw;
}
- rq->proxy = next = pick_next_task(rq, prev, &rf);
+pick_again:
+ /*
+ * If picked task is actually blocked it means that it can act as a
+ * proxy for the task that is holding the mutex picked task is blocked
+ * on. Get a reference to the blocked (going to be proxy) task here.
+ * Note that if next isn't actually blocked we will have rq->proxy ==
+ * rq->curr == next in the end, which is intended and means that proxy
+ * execution is currently "not in use".
+ */
+ rq->proxy = next = pick_next_task(rq, rq->proxy, &rf);
+ next->blocked_proxy = NULL;
+ if (unlikely(task_is_blocked(next))) {
+ next = proxy(rq, next, &rf);
+ if (!next)
+ goto pick_again;
+ }
+
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
#ifdef CONFIG_SCHED_DEBUG
@@ -6565,6 +7128,10 @@ static inline void sched_submit_work(struct task_struct *tsk)
*/
SCHED_WARN_ON(current->__state & TASK_RTLOCK_WAIT);
+ /* XXX still necessary? tsk_is_pi_blocked check here was deleted... */
+ if (task_is_blocked(tsk))
+ return;
+
/*
* If we are going to sleep and we have plugged IO queued,
* make sure to submit it to avoid deadlocks.
diff --git a/kernel/sched/deadline.c b/kernel/sched/deadline.c
index d5ab7ff64fbc..5416d61e87e7 100644
--- a/kernel/sched/deadline.c
+++ b/kernel/sched/deadline.c
@@ -1748,7 +1748,7 @@ static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags)
enqueue_dl_entity(&p->dl, flags);
- if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
+ if (!task_current(rq, p) && p->nr_cpus_allowed > 1 && !task_is_blocked(p))
enqueue_pushable_dl_task(rq, p);
}
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c
index d142f0611b34..2d8e9f9c6826 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -7370,7 +7370,9 @@ pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf
goto idle;
#ifdef CONFIG_FAIR_GROUP_SCHED
- if (!prev || prev->sched_class != &fair_sched_class)
+ if (!prev ||
+ prev->sched_class != &fair_sched_class ||
+ rq->curr != rq->proxy)
goto simple;
/*
@@ -7888,6 +7890,9 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
lockdep_assert_rq_held(env->src_rq);
+ if (task_is_blocked(p))
+ return 0;
+
/*
* We do not migrate tasks that are:
* 1) throttled_lb_pair, or
@@ -7938,7 +7943,11 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
/* Record that we found at least one task that could run on dst_cpu */
env->flags &= ~LBF_ALL_PINNED;
- if (task_running(env->src_rq, p)) {
+ /*
+ * XXX mutex unlock path may have marked proxy as unblocked allowing us to
+ * reach this point, but we still shouldn't migrate it.
+ */
+ if (task_running(env->src_rq, p) || task_current_proxy(env->src_rq, p)) {
schedstat_inc(p->stats.nr_failed_migrations_running);
return 0;
}
diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
index 116556f4fb0a..09385fcb1713 100644
--- a/kernel/sched/rt.c
+++ b/kernel/sched/rt.c
@@ -1548,7 +1548,8 @@ enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
enqueue_rt_entity(rt_se, flags);
- if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
+ if (!task_current(rq, p) && p->nr_cpus_allowed > 1 &&
+ !task_is_blocked(p))
enqueue_pushable_task(rq, p);
}
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index 0ef59dc7b8ea..354e75587fed 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -2079,6 +2079,19 @@ static inline int task_current_proxy(struct rq *rq, struct task_struct *p)
return rq->proxy == p;
}
+#ifdef CONFIG_PROXY_EXEC
+static inline bool task_is_blocked(struct task_struct *p)
+{
+ return !!p->blocked_on;
+}
+#else /* !PROXY_EXEC */
+static inline bool task_is_blocked(struct task_struct *p)
+{
+ return false;
+}
+
+#endif /* PROXY_EXEC */
+
static inline int task_running(struct rq *rq, struct task_struct *p)
{
#ifdef CONFIG_SMP
@@ -2233,12 +2246,18 @@ struct sched_class {
static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
{
- WARN_ON_ONCE(rq->proxy != prev);
+ WARN_ON_ONCE(rq->curr != prev && prev != rq->proxy);
+
+ /* XXX connoro: is this check necessary? */
+ if (prev == rq->proxy && task_cpu(prev) != cpu_of(rq))
+ return;
+
prev->sched_class->put_prev_task(rq, prev);
}
static inline void set_next_task(struct rq *rq, struct task_struct *next)
{
+ WARN_ON_ONCE(!task_current_proxy(rq, next));
next->sched_class->set_next_task(rq, next, false);
}
--
2.38.0.rc1.362.ged0d419d3c-goog
Quick hack to better surface bugs in proxy execution.
Shuffling sets the same cpu affinities for all tasks, which makes us
less likely to hit paths involving migrating blocked tasks onto a cpu
where they can't run. Add an element of randomness to allow affinities
of different writer tasks to diverge.
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/torture.c | 10 ++++++++--
1 file changed, 8 insertions(+), 2 deletions(-)
diff --git a/kernel/torture.c b/kernel/torture.c
index 789aeb0e1159..1d0dd88369e3 100644
--- a/kernel/torture.c
+++ b/kernel/torture.c
@@ -54,6 +54,9 @@ module_param(verbose_sleep_frequency, int, 0444);
static int verbose_sleep_duration = 1;
module_param(verbose_sleep_duration, int, 0444);
+static int random_shuffle;
+module_param(random_shuffle, int, 0444);
+
static char *torture_type;
static int verbose;
@@ -518,6 +521,7 @@ static void torture_shuffle_task_unregister_all(void)
*/
static void torture_shuffle_tasks(void)
{
+ DEFINE_TORTURE_RANDOM(rand);
struct shuffle_task *stp;
cpumask_setall(shuffle_tmp_mask);
@@ -537,8 +541,10 @@ static void torture_shuffle_tasks(void)
cpumask_clear_cpu(shuffle_idle_cpu, shuffle_tmp_mask);
mutex_lock(&shuffle_task_mutex);
- list_for_each_entry(stp, &shuffle_task_list, st_l)
- set_cpus_allowed_ptr(stp->st_t, shuffle_tmp_mask);
+ list_for_each_entry(stp, &shuffle_task_list, st_l) {
+ if (!random_shuffle || torture_random(&rand) & 0x1)
+ set_cpus_allowed_ptr(stp->st_t, shuffle_tmp_mask);
+ }
mutex_unlock(&shuffle_task_mutex);
cpus_read_unlock();
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Valentin Schneider <[email protected]>
Proxy execution forms atomic pairs of tasks: a proxy (scheduling context)
and an owner (execution context). The proxy, along with the rest of the
blocked chain, follows the owner wrt CPU placement.
They can be the same task, in which case push/pull doesn't need any
modification. When they are different, however,
FIFO1 & FIFO42:
,-> RT42
| | blocked-on
| v
proxied-by | mutex
| | owner
| v
`-- RT1
RT1
RT42
CPU0 CPU1
^ ^
| |
overloaded !overloaded
rq prio = 42 rq prio = 0
RT1 is eligible to be pushed to CPU1, but should that happen it will
"carry" RT42 along. Clearly here neither RT1 nor RT42 must be seen as
push/pullable.
Furthermore, tasks becoming blocked on a mutex don't need an explicit
dequeue/enqueue cycle to be made (push/pull)able: they have to be running
to block on a mutex, thus they will eventually hit put_prev_task().
XXX: pinned tasks becoming unblocked should be removed from the push/pull
lists, but those don't get to see __schedule() straight away.
Signed-off-by: Valentin Schneider <[email protected]>
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/sched/core.c | 36 ++++++++++++++++++++++++++----------
kernel/sched/rt.c | 22 +++++++++++++++++-----
2 files changed, 43 insertions(+), 15 deletions(-)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index ad2e7b49f98e..88a5fa34dc06 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -6891,12 +6891,28 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
return NULL; /* retry task selection */
}
+
+static inline void proxy_tag_curr(struct rq *rq, struct task_struct *next)
+{
+ /*
+ * pick_next_task() calls set_next_task() on the proxy at some
+ * point, which ensures it is not push/pullable. However, the
+ * proxy *and* the owner form an atomic pair wrt push/pull.
+ *
+ * Make sure owner is not pushable. Unfortunately we can only
+ * deal with that by means of a dequeue/enqueue cycle. :-/
+ */
+ dequeue_task(rq, next, DEQUEUE_NOCLOCK | DEQUEUE_SAVE);
+ enqueue_task(rq, next, ENQUEUE_NOCLOCK | ENQUEUE_RESTORE);
+}
#else /* PROXY_EXEC */
static struct task_struct *
proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
{
return next;
}
+
+static inline void proxy_tag_curr(struct rq *rq, struct task_struct *next) { }
#endif /* PROXY_EXEC */
/*
@@ -6945,6 +6961,7 @@ static void __sched notrace __schedule(unsigned int sched_mode)
unsigned long prev_state;
struct rq_flags rf;
struct rq *rq;
+ bool proxied;
int cpu;
cpu = smp_processor_id();
@@ -7017,20 +7034,11 @@ static void __sched notrace __schedule(unsigned int sched_mode)
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
- } else {
- /*
- * XXX
- * Let's make this task, which is blocked on
- * a mutex, (push/pull)able (RT/DL).
- * Unfortunately we can only deal with that by
- * means of a dequeue/enqueue cycle. :-/
- */
- dequeue_task(rq, prev, 0);
- enqueue_task(rq, prev, 0);
}
switch_count = &prev->nvcsw;
}
+ proxied = !!prev->blocked_proxy;
pick_again:
/*
* If picked task is actually blocked it means that it can act as a
@@ -7061,6 +7069,10 @@ static void __sched notrace __schedule(unsigned int sched_mode)
* changes to task_struct made by pick_next_task().
*/
RCU_INIT_POINTER(rq->curr, next);
+
+ if (unlikely(!task_current_proxy(rq, next)))
+ proxy_tag_curr(rq, next);
+
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
@@ -7085,6 +7097,10 @@ static void __sched notrace __schedule(unsigned int sched_mode)
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
+ /* In case next was already curr but just got blocked_proxy */
+ if (unlikely(!proxied && next->blocked_proxy))
+ proxy_tag_curr(rq, next);
+
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unpin_lock(rq, &rf);
diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
index 09385fcb1713..a99a59b2b246 100644
--- a/kernel/sched/rt.c
+++ b/kernel/sched/rt.c
@@ -1548,9 +1548,21 @@ enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
enqueue_rt_entity(rt_se, flags);
- if (!task_current(rq, p) && p->nr_cpus_allowed > 1 &&
- !task_is_blocked(p))
- enqueue_pushable_task(rq, p);
+ /*
+ * Current can't be pushed away. Proxy is tied to current, so don't
+ * push it either.
+ */
+ if (task_current(rq, p) || task_current_proxy(rq, p))
+ return;
+
+ /*
+ * Pinned tasks can't be pushed.
+ * Affinity of blocked tasks doesn't matter.
+ */
+ if (!task_is_blocked(p) && p->nr_cpus_allowed == 1)
+ return;
+
+ enqueue_pushable_task(rq, p);
}
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
@@ -1841,9 +1853,9 @@ static void put_prev_task_rt(struct rq *rq, struct task_struct *p)
/*
* The previous task needs to be made eligible for pushing
- * if it is still active
+ * if it is still active. Affinity of blocked task doesn't matter.
*/
- if (on_rt_rq(&p->rt) && p->nr_cpus_allowed > 1)
+ if (on_rt_rq(&p->rt) && (p->nr_cpus_allowed > 1 || task_is_blocked(p)))
enqueue_pushable_task(rq, p);
}
--
2.38.0.rc1.362.ged0d419d3c-goog
Quick hack to better surface bugs in proxy execution.
The single lock used by locktorture does not reliably exercise proxy
exec code paths for handling chains of blocked tasks involving >1
mutex. Add 2 more mutexes and randomize whether they are taken.
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/locking/locktorture.c | 20 ++++++++++++++++++--
1 file changed, 18 insertions(+), 2 deletions(-)
diff --git a/kernel/locking/locktorture.c b/kernel/locking/locktorture.c
index 9c2fb613a55d..bc3557677eed 100644
--- a/kernel/locking/locktorture.c
+++ b/kernel/locking/locktorture.c
@@ -48,6 +48,8 @@ torture_param(int, stat_interval, 60,
torture_param(int, stutter, 5, "Number of jiffies to run/halt test, 0=disable");
torture_param(int, verbose, 1,
"Enable verbose debugging printk()s");
+torture_param(int, nlocks, 1,
+ "Number of locks");
static char *torture_type = "spin_lock";
module_param(torture_type, charp, 0444);
@@ -327,6 +329,8 @@ static struct lock_torture_ops rw_lock_irq_ops = {
};
static DEFINE_MUTEX(torture_mutex);
+static DEFINE_MUTEX(torture_mutex2);
+static DEFINE_MUTEX(torture_mutex3);
static int torture_mutex_lock(int tid __maybe_unused)
__acquires(torture_mutex)
@@ -666,6 +670,7 @@ static struct lock_torture_ops percpu_rwsem_lock_ops = {
*/
static int lock_torture_writer(void *arg)
{
+ bool twolocks = false, threelocks = false;
struct lock_stress_stats *lwsp = arg;
int tid = lwsp - cxt.lwsa;
DEFINE_TORTURE_RANDOM(rand);
@@ -677,6 +682,12 @@ static int lock_torture_writer(void *arg)
if ((torture_random(&rand) & 0xfffff) == 0)
schedule_timeout_uninterruptible(1);
+ twolocks = nlocks > 1 ? (torture_random(&rand) & 0x1) : 0;
+ if (twolocks)
+ mutex_lock(&torture_mutex2);
+ threelocks = nlocks > 2 ? (torture_random(&rand) & 0x2) : 0;
+ if (threelocks)
+ mutex_lock(&torture_mutex3);
cxt.cur_ops->task_boost(&rand);
cxt.cur_ops->writelock(tid);
if (WARN_ON_ONCE(lock_is_write_held))
@@ -691,6 +702,11 @@ static int lock_torture_writer(void *arg)
WRITE_ONCE(last_lock_release, jiffies);
cxt.cur_ops->writeunlock(tid);
+ if (threelocks)
+ mutex_unlock(&torture_mutex3);
+ if (twolocks)
+ mutex_unlock(&torture_mutex2);
+
stutter_wait("lock_torture_writer");
} while (!torture_must_stop());
@@ -830,11 +846,11 @@ lock_torture_print_module_parms(struct lock_torture_ops *cur_ops,
const char *tag)
{
pr_alert("%s" TORTURE_FLAG
- "--- %s%s: nwriters_stress=%d nreaders_stress=%d stat_interval=%d verbose=%d shuffle_interval=%d stutter=%d shutdown_secs=%d onoff_interval=%d onoff_holdoff=%d\n",
+ "--- %s%s: nwriters_stress=%d nreaders_stress=%d stat_interval=%d verbose=%d shuffle_interval=%d stutter=%d shutdown_secs=%d onoff_interval=%d onoff_holdoff=%d nlocks=%d\n",
torture_type, tag, cxt.debug_lock ? " [debug]": "",
cxt.nrealwriters_stress, cxt.nrealreaders_stress, stat_interval,
verbose, shuffle_interval, stutter, shutdown_secs,
- onoff_interval, onoff_holdoff);
+ onoff_interval, onoff_holdoff, nlocks);
}
static void lock_torture_cleanup(void)
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Valentin Schneider <[email protected]>
This lets us assert p->blocked_lock is held whenever we access
p->blocked_on.
XXX: just make a pointer return, so we can also check at get's.
Signed-off-by: Valentin Schneider <[email protected]>
[fix conflicts]
Signed-off-by: Connor O'Brien <[email protected]>
---
include/linux/sched.h | 7 +++++++
kernel/locking/mutex.c | 6 +++---
2 files changed, 10 insertions(+), 3 deletions(-)
diff --git a/include/linux/sched.h b/include/linux/sched.h
index bd995e66d7d6..379e4c052644 100644
--- a/include/linux/sched.h
+++ b/include/linux/sched.h
@@ -2201,6 +2201,13 @@ static inline int rwlock_needbreak(rwlock_t *lock)
#endif
}
+static inline void set_task_blocked_on(struct task_struct *p, struct mutex *m)
+{
+ lockdep_assert_held(&p->blocked_lock);
+
+ p->blocked_on = m;
+}
+
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index f05cd2d216c7..7800380219db 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -645,7 +645,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
goto err_early_kill;
}
- current->blocked_on = lock;
+ set_task_blocked_on(current, lock);
set_current_state(state);
trace_contention_begin(lock, LCB_F_MUTEX);
for (;;) {
@@ -686,7 +686,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
/*
* Gets reset by ttwu_runnable().
*/
- current->blocked_on = lock;
+ set_task_blocked_on(current, lock);
set_current_state(state);
/*
* Here we order against unlock; we must either see it change
@@ -720,7 +720,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
}
__mutex_remove_waiter(lock, &waiter);
- current->blocked_on = NULL;
+ set_task_blocked_on(current, NULL);
debug_mutex_free_waiter(&waiter);
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Juri Lelli <[email protected]>
Implementing proxy execution requires that scheduler code be able to
identify the current owner of a mutex. Expose a new helper
mutex_owner() for this purpose.
Signed-off-by: Juri Lelli <[email protected]>
[Removed the EXPORT_SYMBOL]
Signed-off-by: Valentin Schneider <[email protected]>
Signed-off-by: Connor O'Brien <[email protected]>
---
include/linux/mutex.h | 2 ++
kernel/locking/mutex.c | 5 +++++
2 files changed, 7 insertions(+)
diff --git a/include/linux/mutex.h b/include/linux/mutex.h
index 8f226d460f51..ebdc59cb0bf6 100644
--- a/include/linux/mutex.h
+++ b/include/linux/mutex.h
@@ -118,6 +118,8 @@ do { \
extern void __mutex_init(struct mutex *lock, const char *name,
struct lock_class_key *key);
+extern struct task_struct *mutex_owner(struct mutex *lock);
+
/**
* mutex_is_locked - is the mutex locked
* @lock: the mutex to be queried
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index f39e9ee3c4d0..325fc9db5004 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -81,6 +81,11 @@ static inline struct task_struct *__mutex_owner(struct mutex *lock)
return (struct task_struct *)(atomic_long_read(&lock->owner) & ~MUTEX_FLAGS);
}
+struct task_struct *mutex_owner(struct mutex *lock)
+{
+ return __mutex_owner(lock);
+}
+
static inline struct task_struct *__owner_task(unsigned long owner)
{
return (struct task_struct *)(owner & ~MUTEX_FLAGS);
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Peter Zijlstra <[email protected]>
Lets define the scheduling context as all the scheduler state in
task_struct and the execution context as all state required to run the
task.
Currently both are intertwined in task_struct. We want to logically
split these such that we can run the execution context of one task
with the scheduling context of another.
To this purpose introduce rq::proxy to point to the task_struct used
for scheduler state and preserve rq::curr to denote the execution
context.
XXX connoro: A couple cases here may need more discussion:
- sched_yield() and yield_to(): whether we call the sched_class
methods for rq->curr or rq->proxy, there seem to be cases where
proxy exec could cause a yielding mutex owner to run again
immediately. How much of a concern is this?
- push_rt_task() calls find_lowest_rq() which can only be invoked on
RT tasks (scheduler context) but considers CPU affinity (execution
context). For now we call find_lowest_rq() on rq->curr, bailing out
when it is not RT, but does this give the desired behavior?
[added lot of comments/questions - identifiable by XXX]
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Signed-off-by: Juri Lelli <[email protected]>
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Link: https://lkml.kernel.org/r/[email protected]
[add additional comments and update more sched_class code to use
rq::proxy]
Signed-off-by: Connor O'Brien <[email protected]>
---
kernel/sched/core.c | 63 +++++++++++++++++++++++++++++++----------
kernel/sched/deadline.c | 35 ++++++++++++-----------
kernel/sched/fair.c | 20 +++++++------
kernel/sched/rt.c | 42 ++++++++++++++++-----------
kernel/sched/sched.h | 23 +++++++++++++--
5 files changed, 124 insertions(+), 59 deletions(-)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 617e737392be..c8bfa1ad9551 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -772,12 +772,13 @@ static enum hrtimer_restart hrtick(struct hrtimer *timer)
{
struct rq *rq = container_of(timer, struct rq, hrtick_timer);
struct rq_flags rf;
+ struct task_struct *curr = rq->proxy;
WARN_ON_ONCE(cpu_of(rq) != smp_processor_id());
rq_lock(rq, &rf);
update_rq_clock(rq);
- rq->curr->sched_class->task_tick(rq, rq->curr, 1);
+ curr->sched_class->task_tick(rq, curr, 1);
rq_unlock(rq, &rf);
return HRTIMER_NORESTART;
@@ -2186,16 +2187,18 @@ static inline void check_class_changed(struct rq *rq, struct task_struct *p,
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
- if (p->sched_class == rq->curr->sched_class)
- rq->curr->sched_class->check_preempt_curr(rq, p, flags);
- else if (sched_class_above(p->sched_class, rq->curr->sched_class))
+ struct task_struct *curr = rq->proxy;
+
+ if (p->sched_class == curr->sched_class)
+ curr->sched_class->check_preempt_curr(rq, p, flags);
+ else if (sched_class_above(p->sched_class, curr->sched_class))
resched_curr(rq);
/*
* A queue event has occurred, and we're going to schedule. In
* this case, we can save a useless back to back clock update.
*/
- if (task_on_rq_queued(rq->curr) && test_tsk_need_resched(rq->curr))
+ if (task_on_rq_queued(curr) && test_tsk_need_resched(rq->curr))
rq_clock_skip_update(rq);
}
@@ -2571,7 +2574,11 @@ __do_set_cpus_allowed(struct task_struct *p, const struct cpumask *new_mask, u32
lockdep_assert_held(&p->pi_lock);
queued = task_on_rq_queued(p);
- running = task_current(rq, p);
+ /*
+ * XXX is changing affinity of a proxy a problem?
+ * Consider for example put_prev_ set_curr_ below...
+ */
+ running = task_current_proxy(rq, p);
if (queued) {
/*
@@ -5376,7 +5383,7 @@ unsigned long long task_sched_runtime(struct task_struct *p)
* project cycles that may never be accounted to this
* thread, breaking clock_gettime().
*/
- if (task_current(rq, p) && task_on_rq_queued(p)) {
+ if (task_current_proxy(rq, p) && task_on_rq_queued(p)) {
prefetch_curr_exec_start(p);
update_rq_clock(rq);
p->sched_class->update_curr(rq);
@@ -5444,10 +5451,11 @@ void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
- struct task_struct *curr = rq->curr;
struct rq_flags rf;
unsigned long thermal_pressure;
u64 resched_latency;
+ /* accounting goes to the proxy task */
+ struct task_struct *curr = rq->proxy;
arch_scale_freq_tick();
sched_clock_tick();
@@ -5539,6 +5547,13 @@ static void sched_tick_remote(struct work_struct *work)
if (cpu_is_offline(cpu))
goto out_unlock;
+ /*
+ * XXX don't we need to account to rq->proxy?
+ * Maybe, since this is a remote tick for full dynticks mode, we are
+ * always sure that there is no proxy (only a single task is running.
+ */
+ SCHED_WARN_ON(rq->curr != rq->proxy);
+
update_rq_clock(rq);
if (!is_idle_task(curr)) {
@@ -6462,7 +6477,7 @@ static void __sched notrace __schedule(unsigned int sched_mode)
switch_count = &prev->nvcsw;
}
- next = pick_next_task(rq, prev, &rf);
+ rq->proxy = next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
#ifdef CONFIG_SCHED_DEBUG
@@ -6929,7 +6944,10 @@ void rt_mutex_setprio(struct task_struct *p, struct task_struct *pi_task)
prev_class = p->sched_class;
queued = task_on_rq_queued(p);
- running = task_current(rq, p);
+ /*
+ * XXX how does (proxy exec) mutexes and RT_mutexes work together?!
+ */
+ running = task_current_proxy(rq, p);
if (queued)
dequeue_task(rq, p, queue_flag);
if (running)
@@ -7017,7 +7035,10 @@ void set_user_nice(struct task_struct *p, long nice)
goto out_unlock;
}
queued = task_on_rq_queued(p);
- running = task_current(rq, p);
+ /*
+ * XXX see concerns about do_set_cpus_allowed, rt_mutex_prio & Co.
+ */
+ running = task_current_proxy(rq, p);
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE | DEQUEUE_NOCLOCK);
if (running)
@@ -7581,7 +7602,10 @@ static int __sched_setscheduler(struct task_struct *p,
}
queued = task_on_rq_queued(p);
- running = task_current(rq, p);
+ /*
+ * XXX and again, how is this safe w.r.t. proxy exec?
+ */
+ running = task_current_proxy(rq, p);
if (queued)
dequeue_task(rq, p, queue_flags);
if (running)
@@ -8276,6 +8300,11 @@ static void do_sched_yield(void)
rq = this_rq_lock_irq(&rf);
schedstat_inc(rq->yld_count);
+ /*
+ * XXX how about proxy exec?
+ * If a task currently proxied by some other task yields, should we
+ * apply the proxy or the current yield "behaviour" ?
+ */
current->sched_class->yield_task(rq);
preempt_disable();
@@ -8625,6 +8654,10 @@ EXPORT_SYMBOL(yield);
*/
int __sched yield_to(struct task_struct *p, bool preempt)
{
+ /*
+ * XXX what about current being proxied?
+ * Should we use proxy->sched_class methods in this case?
+ */
struct task_struct *curr = current;
struct rq *rq, *p_rq;
unsigned long flags;
@@ -8984,7 +9017,7 @@ void __init init_idle(struct task_struct *idle, int cpu)
__set_task_cpu(idle, cpu);
rcu_read_unlock();
- rq->idle = idle;
+ rq->proxy = rq->idle = idle;
rcu_assign_pointer(rq->curr, idle);
idle->on_rq = TASK_ON_RQ_QUEUED;
#ifdef CONFIG_SMP
@@ -9087,7 +9120,7 @@ void sched_setnuma(struct task_struct *p, int nid)
rq = task_rq_lock(p, &rf);
queued = task_on_rq_queued(p);
- running = task_current(rq, p);
+ running = task_current_proxy(rq, p);
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE);
@@ -10209,7 +10242,7 @@ void sched_move_task(struct task_struct *tsk)
rq = task_rq_lock(tsk, &rf);
update_rq_clock(rq);
- running = task_current(rq, tsk);
+ running = task_current_proxy(rq, tsk);
queued = task_on_rq_queued(tsk);
if (queued)
diff --git a/kernel/sched/deadline.c b/kernel/sched/deadline.c
index 0ab79d819a0d..d5ab7ff64fbc 100644
--- a/kernel/sched/deadline.c
+++ b/kernel/sched/deadline.c
@@ -1176,7 +1176,7 @@ static enum hrtimer_restart dl_task_timer(struct hrtimer *timer)
#endif
enqueue_task_dl(rq, p, ENQUEUE_REPLENISH);
- if (dl_task(rq->curr))
+ if (dl_task(rq->proxy))
check_preempt_curr_dl(rq, p, 0);
else
resched_curr(rq);
@@ -1303,7 +1303,7 @@ static u64 grub_reclaim(u64 delta, struct rq *rq, struct sched_dl_entity *dl_se)
*/
static void update_curr_dl(struct rq *rq)
{
- struct task_struct *curr = rq->curr;
+ struct task_struct *curr = rq->proxy;
struct sched_dl_entity *dl_se = &curr->dl;
u64 delta_exec, scaled_delta_exec;
int cpu = cpu_of(rq);
@@ -1819,7 +1819,7 @@ static int find_later_rq(struct task_struct *task);
static int
select_task_rq_dl(struct task_struct *p, int cpu, int flags)
{
- struct task_struct *curr;
+ struct task_struct *curr, *proxy;
bool select_rq;
struct rq *rq;
@@ -1830,6 +1830,7 @@ select_task_rq_dl(struct task_struct *p, int cpu, int flags)
rcu_read_lock();
curr = READ_ONCE(rq->curr); /* unlocked access */
+ proxy = READ_ONCE(rq->proxy);
/*
* If we are dealing with a -deadline task, we must
@@ -1840,9 +1841,9 @@ select_task_rq_dl(struct task_struct *p, int cpu, int flags)
* other hand, if it has a shorter deadline, we
* try to make it stay here, it might be important.
*/
- select_rq = unlikely(dl_task(curr)) &&
+ select_rq = unlikely(dl_task(proxy)) &&
(curr->nr_cpus_allowed < 2 ||
- !dl_entity_preempt(&p->dl, &curr->dl)) &&
+ !dl_entity_preempt(&p->dl, &proxy->dl)) &&
p->nr_cpus_allowed > 1;
/*
@@ -1907,7 +1908,7 @@ static void check_preempt_equal_dl(struct rq *rq, struct task_struct *p)
* let's hope p can move out.
*/
if (rq->curr->nr_cpus_allowed == 1 ||
- !cpudl_find(&rq->rd->cpudl, rq->curr, NULL))
+ !cpudl_find(&rq->rd->cpudl, rq->proxy, NULL))
return;
/*
@@ -1946,7 +1947,7 @@ static int balance_dl(struct rq *rq, struct task_struct *p, struct rq_flags *rf)
static void check_preempt_curr_dl(struct rq *rq, struct task_struct *p,
int flags)
{
- if (dl_entity_preempt(&p->dl, &rq->curr->dl)) {
+ if (dl_entity_preempt(&p->dl, &rq->proxy->dl)) {
resched_curr(rq);
return;
}
@@ -1956,7 +1957,7 @@ static void check_preempt_curr_dl(struct rq *rq, struct task_struct *p,
* In the unlikely case current and p have the same deadline
* let us try to decide what's the best thing to do...
*/
- if ((p->dl.deadline == rq->curr->dl.deadline) &&
+ if (p->dl.deadline == rq->proxy->dl.deadline &&
!test_tsk_need_resched(rq->curr))
check_preempt_equal_dl(rq, p);
#endif /* CONFIG_SMP */
@@ -1991,7 +1992,7 @@ static void set_next_task_dl(struct rq *rq, struct task_struct *p, bool first)
if (hrtick_enabled_dl(rq))
start_hrtick_dl(rq, p);
- if (rq->curr->sched_class != &dl_sched_class)
+ if (rq->proxy->sched_class != &dl_sched_class)
update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0);
deadline_queue_push_tasks(rq);
@@ -2311,8 +2312,8 @@ static int push_dl_task(struct rq *rq)
* can move away, it makes sense to just reschedule
* without going further in pushing next_task.
*/
- if (dl_task(rq->curr) &&
- dl_time_before(next_task->dl.deadline, rq->curr->dl.deadline) &&
+ if (dl_task(rq->proxy) &&
+ dl_time_before(next_task->dl.deadline, rq->proxy->dl.deadline) &&
rq->curr->nr_cpus_allowed > 1) {
resched_curr(rq);
return 0;
@@ -2439,7 +2440,7 @@ static void pull_dl_task(struct rq *this_rq)
* deadline than the current task of its runqueue.
*/
if (dl_time_before(p->dl.deadline,
- src_rq->curr->dl.deadline))
+ src_rq->proxy->dl.deadline))
goto skip;
if (is_migration_disabled(p)) {
@@ -2478,9 +2479,9 @@ static void task_woken_dl(struct rq *rq, struct task_struct *p)
if (!task_running(rq, p) &&
!test_tsk_need_resched(rq->curr) &&
p->nr_cpus_allowed > 1 &&
- dl_task(rq->curr) &&
+ dl_task(rq->proxy) &&
(rq->curr->nr_cpus_allowed < 2 ||
- !dl_entity_preempt(&p->dl, &rq->curr->dl))) {
+ !dl_entity_preempt(&p->dl, &rq->proxy->dl))) {
push_dl_tasks(rq);
}
}
@@ -2644,12 +2645,12 @@ static void switched_to_dl(struct rq *rq, struct task_struct *p)
return;
}
- if (rq->curr != p) {
+ if (rq->proxy != p) {
#ifdef CONFIG_SMP
if (p->nr_cpus_allowed > 1 && rq->dl.overloaded)
deadline_queue_push_tasks(rq);
#endif
- if (dl_task(rq->curr))
+ if (dl_task(rq->proxy))
check_preempt_curr_dl(rq, p, 0);
else
resched_curr(rq);
@@ -2665,7 +2666,7 @@ static void switched_to_dl(struct rq *rq, struct task_struct *p)
static void prio_changed_dl(struct rq *rq, struct task_struct *p,
int oldprio)
{
- if (task_on_rq_queued(p) || task_current(rq, p)) {
+ if (task_on_rq_queued(p) || task_current_proxy(rq, p)) {
#ifdef CONFIG_SMP
/*
* This might be too much, but unfortunately
diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c
index 914096c5b1ae..d142f0611b34 100644
--- a/kernel/sched/fair.c
+++ b/kernel/sched/fair.c
@@ -924,7 +924,7 @@ static void update_curr(struct cfs_rq *cfs_rq)
static void update_curr_fair(struct rq *rq)
{
- update_curr(cfs_rq_of(&rq->curr->se));
+ update_curr(cfs_rq_of(&rq->proxy->se));
}
static inline void
@@ -5645,7 +5645,7 @@ static void hrtick_start_fair(struct rq *rq, struct task_struct *p)
s64 delta = slice - ran;
if (delta < 0) {
- if (task_current(rq, p))
+ if (task_current_proxy(rq, p))
resched_curr(rq);
return;
}
@@ -5660,7 +5660,7 @@ static void hrtick_start_fair(struct rq *rq, struct task_struct *p)
*/
static void hrtick_update(struct rq *rq)
{
- struct task_struct *curr = rq->curr;
+ struct task_struct *curr = rq->proxy;
if (!hrtick_enabled_fair(rq) || curr->sched_class != &fair_sched_class)
return;
@@ -7229,7 +7229,7 @@ static void set_skip_buddy(struct sched_entity *se)
*/
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
- struct task_struct *curr = rq->curr;
+ struct task_struct *curr = rq->proxy;
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
int scale = cfs_rq->nr_running >= sched_nr_latency;
@@ -7263,7 +7263,7 @@ static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_
* prevents us from potentially nominating it as a false LAST_BUDDY
* below.
*/
- if (test_tsk_need_resched(curr))
+ if (test_tsk_need_resched(rq->curr))
return;
/* Idle tasks are by definition preempted by non-idle tasks. */
@@ -8260,7 +8260,7 @@ static bool __update_blocked_others(struct rq *rq, bool *done)
* update_load_avg() can call cpufreq_update_util(). Make sure that RT,
* DL and IRQ signals have been updated before updating CFS.
*/
- curr_class = rq->curr->sched_class;
+ curr_class = rq->proxy->sched_class;
thermal_pressure = arch_scale_thermal_pressure(cpu_of(rq));
@@ -11416,6 +11416,10 @@ static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
entity_tick(cfs_rq, se, queued);
}
+ /*
+ * XXX need to use execution context (rq->curr) for task_tick_numa and
+ * update_misfit_status?
+ */
if (static_branch_unlikely(&sched_numa_balancing))
task_tick_numa(rq, curr);
@@ -11479,7 +11483,7 @@ prio_changed_fair(struct rq *rq, struct task_struct *p, int oldprio)
* our priority decreased, or if we are not currently running on
* this runqueue and our priority is higher than the current's
*/
- if (task_current(rq, p)) {
+ if (task_current_proxy(rq, p)) {
if (p->prio > oldprio)
resched_curr(rq);
} else
@@ -11621,7 +11625,7 @@ static void switched_to_fair(struct rq *rq, struct task_struct *p)
* kick off the schedule if running, otherwise just see
* if we can still preempt the current task.
*/
- if (task_current(rq, p))
+ if (task_current_proxy(rq, p))
resched_curr(rq);
else
check_preempt_curr(rq, p, 0);
diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
index 55f39c8f4203..116556f4fb0a 100644
--- a/kernel/sched/rt.c
+++ b/kernel/sched/rt.c
@@ -574,7 +574,7 @@ static void dequeue_rt_entity(struct sched_rt_entity *rt_se, unsigned int flags)
static void sched_rt_rq_enqueue(struct rt_rq *rt_rq)
{
- struct task_struct *curr = rq_of_rt_rq(rt_rq)->curr;
+ struct task_struct *curr = rq_of_rt_rq(rt_rq)->proxy;
struct rq *rq = rq_of_rt_rq(rt_rq);
struct sched_rt_entity *rt_se;
@@ -1044,7 +1044,7 @@ static int sched_rt_runtime_exceeded(struct rt_rq *rt_rq)
*/
static void update_curr_rt(struct rq *rq)
{
- struct task_struct *curr = rq->curr;
+ struct task_struct *curr = rq->proxy;
struct sched_rt_entity *rt_se = &curr->rt;
u64 delta_exec;
u64 now;
@@ -1602,7 +1602,7 @@ static int find_lowest_rq(struct task_struct *task);
static int
select_task_rq_rt(struct task_struct *p, int cpu, int flags)
{
- struct task_struct *curr;
+ struct task_struct *curr, *proxy;
struct rq *rq;
bool test;
@@ -1614,6 +1614,7 @@ select_task_rq_rt(struct task_struct *p, int cpu, int flags)
rcu_read_lock();
curr = READ_ONCE(rq->curr); /* unlocked access */
+ proxy = READ_ONCE(rq->proxy);
/*
* If the current task on @p's runqueue is an RT task, then
@@ -1642,8 +1643,8 @@ select_task_rq_rt(struct task_struct *p, int cpu, int flags)
* systems like big.LITTLE.
*/
test = curr &&
- unlikely(rt_task(curr)) &&
- (curr->nr_cpus_allowed < 2 || curr->prio <= p->prio);
+ unlikely(rt_task(proxy)) &&
+ (curr->nr_cpus_allowed < 2 || proxy->prio <= p->prio);
if (test || !rt_task_fits_capacity(p, cpu)) {
int target = find_lowest_rq(p);
@@ -1677,8 +1678,9 @@ static void check_preempt_equal_prio(struct rq *rq, struct task_struct *p)
* Current can't be migrated, useless to reschedule,
* let's hope p can move out.
*/
+ /* XXX connoro: should we also bail out in the proxy != curr case? */
if (rq->curr->nr_cpus_allowed == 1 ||
- !cpupri_find(&rq->rd->cpupri, rq->curr, NULL))
+ !cpupri_find(&rq->rd->cpupri, rq->proxy, NULL))
return;
/*
@@ -1721,7 +1723,9 @@ static int balance_rt(struct rq *rq, struct task_struct *p, struct rq_flags *rf)
*/
static void check_preempt_curr_rt(struct rq *rq, struct task_struct *p, int flags)
{
- if (p->prio < rq->curr->prio) {
+ struct task_struct *curr = rq->proxy;
+
+ if (p->prio < curr->prio) {
resched_curr(rq);
return;
}
@@ -1739,7 +1743,7 @@ static void check_preempt_curr_rt(struct rq *rq, struct task_struct *p, int flag
* to move current somewhere else, making room for our non-migratable
* task.
*/
- if (p->prio == rq->curr->prio && !test_tsk_need_resched(rq->curr))
+ if (p->prio == curr->prio && !test_tsk_need_resched(rq->curr))
check_preempt_equal_prio(rq, p);
#endif
}
@@ -1764,7 +1768,7 @@ static inline void set_next_task_rt(struct rq *rq, struct task_struct *p, bool f
* utilization. We only care of the case where we start to schedule a
* rt task
*/
- if (rq->curr->sched_class != &rt_sched_class)
+ if (rq->proxy->sched_class != &rt_sched_class)
update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 0);
rt_queue_push_tasks(rq);
@@ -2037,7 +2041,7 @@ static struct task_struct *pick_next_pushable_task(struct rq *rq)
struct task_struct, pushable_tasks);
BUG_ON(rq->cpu != task_cpu(p));
- BUG_ON(task_current(rq, p));
+ BUG_ON(task_current(rq, p) || task_current_proxy(rq, p));
BUG_ON(p->nr_cpus_allowed <= 1);
BUG_ON(!task_on_rq_queued(p));
@@ -2070,7 +2074,7 @@ static int push_rt_task(struct rq *rq, bool pull)
* higher priority than current. If that's the case
* just reschedule current.
*/
- if (unlikely(next_task->prio < rq->curr->prio)) {
+ if (unlikely(next_task->prio < rq->proxy->prio)) {
resched_curr(rq);
return 0;
}
@@ -2091,6 +2095,10 @@ static int push_rt_task(struct rq *rq, bool pull)
* Note that the stoppers are masqueraded as SCHED_FIFO
* (cf. sched_set_stop_task()), so we can't rely on rt_task().
*/
+ /* XXX connoro: we still want to call find_lowest_rq on curr because
+ * it considers CPU affinity, so curr still has to be RT. But should
+ * we bail out if proxy is not also RT?
+ */
if (rq->curr->sched_class != &rt_sched_class)
return 0;
@@ -2423,7 +2431,7 @@ static void pull_rt_task(struct rq *this_rq)
* p if it is lower in priority than the
* current task on the run queue
*/
- if (p->prio < src_rq->curr->prio)
+ if (p->prio < src_rq->proxy->prio)
goto skip;
if (is_migration_disabled(p)) {
@@ -2465,9 +2473,9 @@ static void task_woken_rt(struct rq *rq, struct task_struct *p)
bool need_to_push = !task_running(rq, p) &&
!test_tsk_need_resched(rq->curr) &&
p->nr_cpus_allowed > 1 &&
- (dl_task(rq->curr) || rt_task(rq->curr)) &&
+ (dl_task(rq->proxy) || rt_task(rq->proxy)) &&
(rq->curr->nr_cpus_allowed < 2 ||
- rq->curr->prio <= p->prio);
+ rq->proxy->prio <= p->prio);
if (need_to_push)
push_rt_tasks(rq);
@@ -2551,7 +2559,7 @@ static void switched_to_rt(struct rq *rq, struct task_struct *p)
if (p->nr_cpus_allowed > 1 && rq->rt.overloaded)
rt_queue_push_tasks(rq);
#endif /* CONFIG_SMP */
- if (p->prio < rq->curr->prio && cpu_online(cpu_of(rq)))
+ if (p->prio < rq->proxy->prio && cpu_online(cpu_of(rq)))
resched_curr(rq);
}
}
@@ -2566,7 +2574,7 @@ prio_changed_rt(struct rq *rq, struct task_struct *p, int oldprio)
if (!task_on_rq_queued(p))
return;
- if (task_current(rq, p)) {
+ if (task_current_proxy(rq, p)) {
#ifdef CONFIG_SMP
/*
* If our priority decreases while running, we
@@ -2592,7 +2600,7 @@ prio_changed_rt(struct rq *rq, struct task_struct *p, int oldprio)
* greater than the current running task
* then reschedule.
*/
- if (p->prio < rq->curr->prio)
+ if (p->prio < rq->proxy->prio)
resched_curr(rq);
}
}
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index e26688d387ae..0ef59dc7b8ea 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -1014,7 +1014,12 @@ struct rq {
*/
unsigned int nr_uninterruptible;
- struct task_struct __rcu *curr;
+ /*
+ * XXX connoro: could different names (e.g. exec_ctx and sched_ctx) help
+ * with readability?
+ */
+ struct task_struct __rcu *curr; /* Execution context */
+ struct task_struct *proxy; /* Scheduling context (policy) */
struct task_struct *idle;
struct task_struct *stop;
unsigned long next_balance;
@@ -2055,11 +2060,25 @@ static inline u64 global_rt_runtime(void)
return (u64)sysctl_sched_rt_runtime * NSEC_PER_USEC;
}
+/*
+ * Is p the current execution context?
+ */
static inline int task_current(struct rq *rq, struct task_struct *p)
{
return rq->curr == p;
}
+/*
+ * Is p the current scheduling context?
+ *
+ * Note that it might be the current execution context at the same time if
+ * rq->curr == rq->proxy == p.
+ */
+static inline int task_current_proxy(struct rq *rq, struct task_struct *p)
+{
+ return rq->proxy == p;
+}
+
static inline int task_running(struct rq *rq, struct task_struct *p)
{
#ifdef CONFIG_SMP
@@ -2214,7 +2233,7 @@ struct sched_class {
static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
{
- WARN_ON_ONCE(rq->curr != prev);
+ WARN_ON_ONCE(rq->proxy != prev);
prev->sched_class->put_prev_task(rq, prev);
}
--
2.38.0.rc1.362.ged0d419d3c-goog
From: Peter Zijlstra <[email protected]>
Track the blocked-on relation for mutexes, this allows following this
relation at schedule time.
task
| blocked-on
v
mutex
| owner
v
task
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
[minor changes while rebasing]
Signed-off-by: Juri Lelli <[email protected]>
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Signed-off-by: Connor O'Brien <[email protected]>
Link: https://lkml.kernel.org/r/[email protected]
---
include/linux/sched.h | 6 ++----
kernel/fork.c | 4 ++--
kernel/locking/mutex-debug.c | 9 +++++----
kernel/locking/mutex.c | 6 ++++++
4 files changed, 15 insertions(+), 10 deletions(-)
diff --git a/include/linux/sched.h b/include/linux/sched.h
index e7b2f8a5c711..bd995e66d7d6 100644
--- a/include/linux/sched.h
+++ b/include/linux/sched.h
@@ -1130,10 +1130,8 @@ struct task_struct {
struct rt_mutex_waiter *pi_blocked_on;
#endif
-#ifdef CONFIG_DEBUG_MUTEXES
- /* Mutex deadlock detection: */
- struct mutex_waiter *blocked_on;
-#endif
+ struct task_struct *blocked_proxy; /* task that is boosting us */
+ struct mutex *blocked_on; /* lock we're blocked on */
#ifdef CONFIG_DEBUG_ATOMIC_SLEEP
int non_block_count;
diff --git a/kernel/fork.c b/kernel/fork.c
index 2b6bd511c6ed..81e809c343fd 100644
--- a/kernel/fork.c
+++ b/kernel/fork.c
@@ -2208,9 +2208,9 @@ static __latent_entropy struct task_struct *copy_process(
lockdep_init_task(p);
#endif
-#ifdef CONFIG_DEBUG_MUTEXES
+ p->blocked_proxy = NULL; /* nobody is boosting us yet */
p->blocked_on = NULL; /* not blocked yet */
-#endif
+
#ifdef CONFIG_BCACHE
p->sequential_io = 0;
p->sequential_io_avg = 0;
diff --git a/kernel/locking/mutex-debug.c b/kernel/locking/mutex-debug.c
index bc8abb8549d2..7228909c3e62 100644
--- a/kernel/locking/mutex-debug.c
+++ b/kernel/locking/mutex-debug.c
@@ -52,17 +52,18 @@ void debug_mutex_add_waiter(struct mutex *lock, struct mutex_waiter *waiter,
{
lockdep_assert_held(&lock->wait_lock);
- /* Mark the current thread as blocked on the lock: */
- task->blocked_on = waiter;
+ /* Current thread can't be already blocked (since it's executing!) */
+ DEBUG_LOCKS_WARN_ON(task->blocked_on);
}
void debug_mutex_remove_waiter(struct mutex *lock, struct mutex_waiter *waiter,
struct task_struct *task)
{
+ struct mutex *blocked_on = READ_ONCE(task->blocked_on);
+
DEBUG_LOCKS_WARN_ON(list_empty(&waiter->list));
DEBUG_LOCKS_WARN_ON(waiter->task != task);
- DEBUG_LOCKS_WARN_ON(task->blocked_on != waiter);
- task->blocked_on = NULL;
+ DEBUG_LOCKS_WARN_ON(blocked_on && blocked_on != lock);
INIT_LIST_HEAD(&waiter->list);
waiter->task = NULL;
diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
index 1582756914df..f05cd2d216c7 100644
--- a/kernel/locking/mutex.c
+++ b/kernel/locking/mutex.c
@@ -645,6 +645,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
goto err_early_kill;
}
+ current->blocked_on = lock;
set_current_state(state);
trace_contention_begin(lock, LCB_F_MUTEX);
for (;;) {
@@ -682,6 +683,10 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
first = __mutex_waiter_is_first(lock, &waiter);
+ /*
+ * Gets reset by ttwu_runnable().
+ */
+ current->blocked_on = lock;
set_current_state(state);
/*
* Here we order against unlock; we must either see it change
@@ -715,6 +720,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
}
__mutex_remove_waiter(lock, &waiter);
+ current->blocked_on = NULL;
debug_mutex_free_waiter(&waiter);
--
2.38.0.rc1.362.ged0d419d3c-goog
On 10/3/22 17:44, Connor O'Brien wrote:
> diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
> index 56f139201f24..dfc174cd96c6 100644
> --- a/kernel/locking/ww_mutex.h
> +++ b/kernel/locking/ww_mutex.h
> @@ -161,6 +161,11 @@ static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
>
> #endif /* WW_RT */
>
> +void ww_ctx_wake(struct ww_acquire_ctx *ww_ctx)
> +{
> + wake_up_q(&ww_ctx->wake_q);
> +}
> +
> /*
> * Wait-Die:
> * The newer transactions are killed when:
> @@ -284,7 +289,7 @@ __ww_mutex_die(struct MUTEX *lock, struct MUTEX_WAITER *waiter,
> #ifndef WW_RT
> debug_mutex_wake_waiter(lock, waiter);
> #endif
> - wake_up_process(waiter->task);
> + wake_q_add(&ww_ctx->wake_q, waiter->task);
> }
>
> return true;
> @@ -331,7 +336,7 @@ static bool __ww_mutex_wound(struct MUTEX *lock,
> * wakeup pending to re-read the wounded state.
> */
> if (owner != current)
> - wake_up_process(owner);
> + wake_q_add(&ww_ctx->wake_q, owner);
>
> return true;
> }
> diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> index ee28253c9ac0..617e737392be 100644
> --- a/kernel/sched/core.c
> +++ b/kernel/sched/core.c
> @@ -1013,6 +1013,13 @@ void wake_up_q(struct wake_q_head *head)
> wake_up_process(task);
> put_task_struct(task);
> }
> + /*
> + * XXX connoro: seems this is needed now that ww_ctx_wake() passes in a
> + * wake_q_head that is embedded in struct ww_acquire_ctx rather than
> + * declared locally.
> + */
> + head->first = node;
> + head->lastp = &head->first;
> }
>
You shouldn't do wake_q_init() here in wake_up_q(). Instead, you should
do it in ww_ctx_wake() right after the wake_up_q() call.
Cheers,
Longman
Hi Connor,
Thanks a lot for reviving this!
On 03/10/22 21:44, Connor O'Brien wrote:
...
> Past discussions of proxy execution have often focused on the benefits
> for deadline scheduling. Current interest for Android is based more on
> desire for a broad solution to priority inversion on kernel mutexes,
> including among CFS tasks. One notable scenario arises when cpu cgroups
> are used to throttle less important background tasks. Priority inversion
> can occur when an "important" unthrottled task blocks on a mutex held by
> an "unimportant" task whose CPU time is constrained using cpu
> shares. The result is higher worst case latencies for the unthrottled
> task.[0] Testing by John Stultz with a simple reproducer [1] showed
> promising results for this case, with proxy execution appearing to
> eliminate the large latency spikes associated with priority
> inversion.[2]
Uh, interesting. :)
...
> Testing so far has focused on stability, mostly via mutex locktorture
> with some tweaks to more quickly trigger proxy execution bugs. These
> locktorture changes are included at the end of the series for
> reference. The current series survives runs of >72 hours on QEMU without
> crashes, deadlocks, etc. Testing on Pixel 6 with the android-mainline
> kernel [9] yields similar results. In both cases, testing used >2 CPUs
> and CONFIG_FAIR_GROUP_SCHED=y, a configuration Valentin Schneider
> reported[10] showed stability problems with earlier versions of the
> series.
Cool. I started playing with it again and don't have much to report yet
(guess it's a good sign). I'll continue testing.
> That said, these are definitely still a work in progress, with some
> known remaining issues (e.g. warnings while booting on Pixel 6,
> suspicious looking min/max vruntime numbers) and likely others I haven't
> found yet. I've done my best to eliminate checks and code paths made
> redundant by new fixes but some probably remain. There's no attempt yet
> to handle core scheduling. Performance testing so far has been limited
> to the aforementioned priority inversion reproducer. The hope in sharing
> now is to revive the discussion on proxy execution and get some early
> input for continuing to revise & refine the patches.
I think another fundamental question I'm not sure we spent much time on
yet is how to deal with rtmutexes. I understand you are not particularly
interested in them for your usecase, but we'll need to come up with a
story/implementation that considers rtmutexes as well (possibly
replacing the current PI implementation?). The need for thinking about
this "from the start" is quite important as soon as PREEMPT_RT is
enabled (I tried to port this series on latest RT) and in general for
usecases relying on rtmutexes running mainline. Not sure if you already
thought about it and/or if we first want to address open questions of
the current implementation. Just wondering if we might be missing
important details if we don't look at the full picture right away.
Thanks!
Juri
On Thu, Oct 06, 2022 at 11:59:31AM +0200, Juri Lelli wrote:
> I think another fundamental question I'm not sure we spent much time on
> yet is how to deal with rtmutexes.
Delete them ;-) If PE works, they have no value left.
On 06/10/22 12:07, Peter Zijlstra wrote:
> On Thu, Oct 06, 2022 at 11:59:31AM +0200, Juri Lelli wrote:
>
> > I think another fundamental question I'm not sure we spent much time on
> > yet is how to deal with rtmutexes.
>
> Delete them ;-) If PE works, they have no value left.
>
Oh, OK. :)
On 03/10/22 21:44, Connor O'Brien wrote:
> From: Valentin Schneider <[email protected]>
This was one of my attempts at fixing RT load balancing (the BUG_ON in
pick_next_pushable_task() was quite easy to trigger), but I ended up
convincing myself this was insufficient - this only "tags" the donor and
the proxy, the entire blocked chain needs tagging. Hopefully not all of
what I'm about to write is nonsense, some of the neurons I need for this
haven't been used in a while - to be taken with a grain of salt.
Consider pick_highest_pushable_task() - we don't want any task in a blocked
chain to be pickable. There's no point in migrating it, we'll just hit
schedule()->proxy(), follow p->blocked_on and most likely move it back to
where the rest of the chain is. This applies any sort of balancing (CFS,
RT, DL).
ATM I think PE breaks the "run the N highest priority task on our N CPUs"
policy. Consider:
p0 (FIFO42)
|
| blocked_on
v
p1 (FIFO41)
|
| blocked_on
v
p2 (FIFO40)
Add on top p3 an unrelated FIFO1 task, and p4 an unrelated CFS task.
CPU0
current: p0
proxy: p2
enqueued: p0, p1, p2, p3
CPU1
current: p4
proxy: p4
enqueued: p4
pick_next_pushable_task() on CPU0 would pick p1 as the next highest
priority task to push away to e.g. CPU1, but that would be undone as soon
as proxy() happens on CPU1: we'd notice the CPU boundary and punt it back
to CPU0. What we would want here is to pick p3 instead to have it run on
CPU1.
I *think* we want only the proxy of an entire blocked-chain to be visible
to load-balance, unfortunately PE gathers the blocked-chain onto the
donor's CPU which kinda undoes that.
Having the blocked tasks remain in the rq is very handy as it directly
gives us the scheduling context and we can unwind the blocked chain for the
execution context, but it does wreak havock in load-balancing :/
Hi,
On Mon, Oct 03, 2022 at 09:44:57PM +0000, Connor O'Brien wrote:
> From: Peter Zijlstra <[email protected]>
>
> A task currently holding a mutex (executing a critical section) might
> find benefit in using scheduling contexts of other tasks blocked on the
> same mutex if they happen to have higher priority of the current owner
> (e.g., to prevent priority inversions).
>
> Proxy execution lets a task do exactly that: if a mutex owner has
> waiters, it can use waiters' scheduling context to potentially continue
> running if preempted.
>
> The basic mechanism is implemented by this patch, the core of which
> resides in the proxy() function. Potential proxies (i.e., tasks blocked
> on a mutex) are not dequeued, so, if one of them is actually selected by
> schedule() as the next task to be put to run on a CPU, proxy() is used
> to walk the blocked_on relation and find which task (mutex owner) might
> be able to use the proxy's scheduling context.
>
> Here come the tricky bits. In fact, owner task might be in all sort of
> states when a proxy is found (blocked, executing on a different CPU,
> etc.). Details on how to handle different situations are to be found in
> proxy() code comments.
>
> Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> [rebased, added comments and changelog]
> Signed-off-by: Juri Lelli <[email protected]>
> [Fixed rebase conflicts]
> [squashed sched: Ensure blocked_on is always guarded by blocked_lock]
> Signed-off-by: Valentin Schneider <[email protected]>
> [fix rebase conflicts, various fixes & tweaks commented inline]
> [squashed sched: Use rq->curr vs rq->proxy checks]
> Signed-off-by: Connor O'Brien <[email protected]>
> Link: https://lore.kernel.org/all/[email protected]/
[..]
> +#ifdef CONFIG_PROXY_EXEC
> +
> +/*
> + * Find who @next (currently blocked on a mutex) can proxy for.
> + *
> + * Follow the blocked-on relation:
> + *
> + * ,-> task
> + * | | blocked-on
> + * | v
> + * proxied-by | mutex
> + * | | owner
> + * | v
> + * `-- task
> + *
> + * and set the proxied-by relation, this latter is used by the mutex code
> + * to find which (blocked) task to hand-off to.
> + *
> + * Lock order:
> + *
> + * p->pi_lock
> + * rq->lock
> + * mutex->wait_lock
> + * p->blocked_lock
> + *
> + * Returns the task that is going to be used as execution context (the one
> + * that is actually going to be put to run on cpu_of(rq)).
> + */
> +static struct task_struct *
> +proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
Dang, this is intense ;-) , but cool..
Just some inital high level questions / comments from me:
> +{
> + struct task_struct *p = next;
> + struct task_struct *owner = NULL;
> + struct mutex *mutex;
> + struct rq *that_rq;
> + int this_cpu, that_cpu;
> + bool curr_in_chain = false;
> + LIST_HEAD(migrate_list);
> +
> + this_cpu = cpu_of(rq);
> +
> + /*
> + * Follow blocked_on chain.
> + *
> + * TODO: deadlock detection
> + */
This function is awfully big and feels like it should be split up for
readability.
> + for (p = next; p->blocked_on; p = owner) {
> + mutex = p->blocked_on;
> + /* Something changed in the chain, pick_again */
> + if (!mutex)
> + return NULL;
> +
> + /*
> + * By taking mutex->wait_lock we hold off concurrent mutex_unlock()
> + * and ensure @owner sticks around.
> + */
> + raw_spin_lock(&mutex->wait_lock);
> + raw_spin_lock(&p->blocked_lock);
> +
> + /* Check again that p is blocked with blocked_lock held */
> + if (!task_is_blocked(p) || mutex != p->blocked_on) {
> + /*
> + * Something changed in the blocked_on chain and
> + * we don't know if only at this level. So, let's
> + * just bail out completely and let __schedule
> + * figure things out (pick_again loop).
> + */
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> + return NULL;
> + }
> +
> + if (task_current(rq, p))
> + curr_in_chain = true;
> +
> + owner = mutex_owner(mutex);
> + /*
> + * XXX can't this be 0|FLAGS? See __mutex_unlock_slowpath for(;;)
> + * Mmm, OK, this can't probably happen because we force
> + * unlock to skip the for(;;) loop. Is this acceptable though?
> + */
> + if (task_cpu(owner) != this_cpu)
> + goto migrate_task;
> +
> + if (task_on_rq_migrating(owner))
> + goto migrating_task;
> +
> + if (owner == p)
> + goto owned_task;
> +
> + if (!owner->on_rq)
> + goto blocked_task;
> +
> + /*
> + * OK, now we're absolutely sure @owner is not blocked _and_
> + * on this rq, therefore holding @rq->lock is sufficient to
> + * guarantee its existence, as per ttwu_remote().
> + */
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> +
> + owner->blocked_proxy = p;
> + }
> +
> + WARN_ON_ONCE(!owner->on_rq);
> +
> + return owner;
Here, for CFS, doesn't this mean that the ->vruntime of the blocked task does
not change while it is giving the owner a chance to run?
So that feels like if the blocked task is on the left-most node of the cfs
rbtree, then it will always proxy to the owner while not letting other
unrelated CFS tasks to run. That sounds like a breakage of fairness.
Or did I miss something?
> +
> +migrate_task:
> + /*
> + * The blocked-on relation must not cross CPUs, if this happens
> + * migrate @p to the @owner's CPU.
> + *
> + * This is because we must respect the CPU affinity of execution
> + * contexts (@owner) but we can ignore affinity for scheduling
> + * contexts (@p). So we have to move scheduling contexts towards
> + * potential execution contexts.
> + *
> + * XXX [juril] what if @p is not the highest prio task once migrated
> + * to @owner's CPU?
Then that sounds like the right thing is happening, and @p will not proxy()
to @owner. Why does @p need to be highest prio?
> + *
> + * XXX [juril] also, after @p is migrated it is not migrated back once
> + * @owner releases the lock? Isn't this a potential problem w.r.t.
> + * @owner affinity settings?
Juri, Do you mean here, '@p affinity settings' ? @p's affinity is being
ignored right?
> + * [juril] OK. It is migrated back into its affinity mask in
> + * ttwu_remote(), or by using wake_cpu via select_task_rq, guess we
> + * might want to add a comment about that here. :-)
Good idea!
I am also wondering, how much more run-queue lock contention do these
additional migrations add, that we did not have before. Do we have any data
on that? Too much migration should not negate benefits of PE hopefully.
thanks,
- Joel
> + * TODO: could optimize by finding the CPU of the final owner
> + * and migrating things there. Given:
> + *
> + * CPU0 CPU1 CPU2
> + *
> + * a ----> b ----> c
> + *
> + * the current scheme would result in migrating 'a' to CPU1,
> + * then CPU1 would migrate b and a to CPU2. Only then would
> + * CPU2 run c.
> + */
> + that_cpu = task_cpu(owner);
> + that_rq = cpu_rq(that_cpu);
> + /*
> + * @owner can disappear, simply migrate to @that_cpu and leave that CPU
> + * to sort things out.
> + */
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> +
> + /*
> + * Since we're going to drop @rq, we have to put(@next) first,
> + * otherwise we have a reference that no longer belongs to us. Use
> + * @fake_task to fill the void and make the next pick_next_task()
> + * invocation happy.
> + *
> + * XXX double, triple think about this.
> + * XXX put doesn't work with ON_RQ_MIGRATE
> + *
> + * CPU0 CPU1
> + *
> + * B mutex_lock(X)
> + *
> + * A mutex_lock(X) <- B
> + * A __schedule()
> + * A pick->A
> + * A proxy->B
> + * A migrate A to CPU1
> + * B mutex_unlock(X) -> A
> + * B __schedule()
> + * B pick->A
> + * B switch_to (A)
> + * A ... does stuff
> + * A ... is still running here
> + *
> + * * BOOM *
> + */
> + put_prev_task(rq, next);
> + if (curr_in_chain) {
> + rq->proxy = rq->idle;
> + set_tsk_need_resched(rq->idle);
> + /*
> + * XXX [juril] don't we still need to migrate @next to
> + * @owner's CPU?
> + */
> + return rq->idle;
> + }
> + rq->proxy = rq->idle;
> +
> + for (; p; p = p->blocked_proxy) {
> + int wake_cpu = p->wake_cpu;
> +
> + WARN_ON(p == rq->curr);
> +
> + deactivate_task(rq, p, 0);
> + set_task_cpu(p, that_cpu);
> + /*
> + * We can abuse blocked_entry to migrate the thing, because @p is
> + * still on the rq.
> + */
> + list_add(&p->blocked_entry, &migrate_list);
> +
> + /*
> + * Preserve p->wake_cpu, such that we can tell where it
> + * used to run later.
> + */
> + p->wake_cpu = wake_cpu;
> + }
> +
> + rq_unpin_lock(rq, rf);
> + raw_spin_rq_unlock(rq);
> + raw_spin_rq_lock(that_rq);
> +
> + while (!list_empty(&migrate_list)) {
> + p = list_first_entry(&migrate_list, struct task_struct, blocked_entry);
> + list_del_init(&p->blocked_entry);
> +
> + enqueue_task(that_rq, p, 0);
> + check_preempt_curr(that_rq, p, 0);
> + p->on_rq = TASK_ON_RQ_QUEUED;
> + /*
> + * check_preempt_curr has already called
> + * resched_curr(that_rq) in case it is
> + * needed.
> + */
> + }
> +
> + raw_spin_rq_unlock(that_rq);
> + raw_spin_rq_lock(rq);
> + rq_repin_lock(rq, rf);
> +
> + return NULL; /* Retry task selection on _this_ CPU. */
> +
> +migrating_task:
> + /*
> + * XXX connoro: one of the chain of mutex owners is currently
> + * migrating to this CPU, but has not yet been enqueued because
> + * we are holding the rq lock. As a simple solution, just schedule
> + * rq->idle to give the migration a chance to complete. Much like
> + * the migrate_task case we should end up back in proxy(), this
> + * time hopefully with all relevant tasks already enqueued.
> + */
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> + put_prev_task(rq, next);
> + rq->proxy = rq->idle;
> + set_tsk_need_resched(rq->idle);
> + return rq->idle;
> +owned_task:
> + /*
> + * Its possible we interleave with mutex_unlock like:
> + *
> + * lock(&rq->lock);
> + * proxy()
> + * mutex_unlock()
> + * lock(&wait_lock);
> + * next(owner) = current->blocked_proxy;
> + * unlock(&wait_lock);
> + *
> + * wake_up_q();
> + * ...
> + * ttwu_runnable()
> + * __task_rq_lock()
> + * lock(&wait_lock);
> + * owner == p
> + *
> + * Which leaves us to finish the ttwu_runnable() and make it go.
> + *
> + * XXX is this happening in case of an HANDOFF to p?
> + * In any case, reading of the owner in __mutex_unlock_slowpath is
> + * done atomically outside wait_lock (only adding waiters to wake_q is
> + * done inside the critical section).
> + * Does this means we can get to proxy _w/o an owner_ if that was
> + * cleared before grabbing wait_lock? Do we account for this case?
> + * OK we actually do (see PROXY_EXEC ifdeffery in unlock function).
> + */
> +
> + set_task_blocked_on(owner, NULL);
> +
> + /*
> + * XXX connoro: previous versions would immediately run owner here if
> + * it's allowed to run on this CPU, but this creates potential races
> + * with the wakeup logic. Instead we can just take the blocked_task path
> + * when owner is already !on_rq, or else schedule rq->idle so that ttwu_runnable
> + * can get the rq lock and mark owner as running.
> + */
> + if (!owner->on_rq)
> + goto blocked_task;
> +
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> + put_prev_task(rq, next);
> + rq->proxy = rq->idle;
> + set_tsk_need_resched(rq->idle);
> + return rq->idle;
> +
> +blocked_task:
> + /*
> + * XXX connoro: rq->curr must not be added to the blocked_entry list
> + * or else ttwu_do_activate could enqueue it elsewhere before it switches out
> + * here. The approach to avoiding this is the same as in the migrate_task case.
> + */
> + if (curr_in_chain) {
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> + put_prev_task(rq, next);
> + rq->proxy = rq->idle;
> + set_tsk_need_resched(rq->idle);
> + return rq->idle;
> + }
> + /*
> + * If !@owner->on_rq, holding @rq->lock will not pin the task,
> + * so we cannot drop @mutex->wait_lock until we're sure its a blocked
> + * task on this rq.
> + *
> + * We use @owner->blocked_lock to serialize against ttwu_activate().
> + * Either we see its new owner->on_rq or it will see our list_add().
> + */
> + if (owner != p) {
> + raw_spin_unlock(&p->blocked_lock);
> + raw_spin_lock(&owner->blocked_lock);
> + }
> +
> + /*
> + * Walk back up the blocked_proxy relation and enqueue them all on @owner
> + *
> + * ttwu_activate() will pick them up and place them on whatever rq
> + * @owner will run next.
> + * XXX connoro: originally we would jump back into the main proxy() loop
> + * owner->on_rq !=0 path, but if we then end up taking the owned_task path
> + * then we can overwrite p->on_rq after ttwu_do_activate sets it to 1 which breaks
> + * the assumptions made in ttwu_do_activate.
> + */
> + if (!owner->on_rq) {
> + for (; p; p = p->blocked_proxy) {
> + if (p == owner)
> + continue;
> + BUG_ON(!p->on_rq);
> + deactivate_task(rq, p, DEQUEUE_SLEEP);
> + if (task_current_proxy(rq, p)) {
> + put_prev_task(rq, next);
> + rq->proxy = rq->idle;
> + }
> + /*
> + * XXX connoro: need to verify this is necessary. The rationale is that
> + * ttwu_do_activate must not have a chance to activate p elsewhere before
> + * it's fully extricated from its old rq.
> + */
> + smp_mb();
> + list_add(&p->blocked_entry, &owner->blocked_entry);
> + }
> + }
> + if (task_current_proxy(rq, next)) {
> + put_prev_task(rq, next);
> + rq->proxy = rq->idle;
> + }
> + raw_spin_unlock(&owner->blocked_lock);
> + raw_spin_unlock(&mutex->wait_lock);
> +
> + return NULL; /* retry task selection */
> +}
> +#else /* PROXY_EXEC */
> +static struct task_struct *
> +proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> +{
> + return next;
> +}
> +#endif /* PROXY_EXEC */
> +
> /*
> * __schedule() is the main scheduler function.
> *
> @@ -6447,7 +6984,7 @@ static void __sched notrace __schedule(unsigned int sched_mode)
> if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
> if (signal_pending_state(prev_state, prev)) {
> WRITE_ONCE(prev->__state, TASK_RUNNING);
> - } else {
> + } else if (!task_is_blocked(prev)) {
> prev->sched_contributes_to_load =
> (prev_state & TASK_UNINTERRUPTIBLE) &&
> !(prev_state & TASK_NOLOAD) &&
> @@ -6473,11 +7010,37 @@ static void __sched notrace __schedule(unsigned int sched_mode)
> atomic_inc(&rq->nr_iowait);
> delayacct_blkio_start();
> }
> + } else {
> + /*
> + * XXX
> + * Let's make this task, which is blocked on
> + * a mutex, (push/pull)able (RT/DL).
> + * Unfortunately we can only deal with that by
> + * means of a dequeue/enqueue cycle. :-/
> + */
> + dequeue_task(rq, prev, 0);
> + enqueue_task(rq, prev, 0);
> }
> switch_count = &prev->nvcsw;
> }
>
> - rq->proxy = next = pick_next_task(rq, prev, &rf);
> +pick_again:
> + /*
> + * If picked task is actually blocked it means that it can act as a
> + * proxy for the task that is holding the mutex picked task is blocked
> + * on. Get a reference to the blocked (going to be proxy) task here.
> + * Note that if next isn't actually blocked we will have rq->proxy ==
> + * rq->curr == next in the end, which is intended and means that proxy
> + * execution is currently "not in use".
> + */
> + rq->proxy = next = pick_next_task(rq, rq->proxy, &rf);
> + next->blocked_proxy = NULL;
> + if (unlikely(task_is_blocked(next))) {
> + next = proxy(rq, next, &rf);
> + if (!next)
> + goto pick_again;
> + }
> +
> clear_tsk_need_resched(prev);
> clear_preempt_need_resched();
> #ifdef CONFIG_SCHED_DEBUG
> @@ -6565,6 +7128,10 @@ static inline void sched_submit_work(struct task_struct *tsk)
> */
> SCHED_WARN_ON(current->__state & TASK_RTLOCK_WAIT);
>
> + /* XXX still necessary? tsk_is_pi_blocked check here was deleted... */
> + if (task_is_blocked(tsk))
> + return;
> +
> /*
> * If we are going to sleep and we have plugged IO queued,
> * make sure to submit it to avoid deadlocks.
> diff --git a/kernel/sched/deadline.c b/kernel/sched/deadline.c
> index d5ab7ff64fbc..5416d61e87e7 100644
> --- a/kernel/sched/deadline.c
> +++ b/kernel/sched/deadline.c
> @@ -1748,7 +1748,7 @@ static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags)
>
> enqueue_dl_entity(&p->dl, flags);
>
> - if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
> + if (!task_current(rq, p) && p->nr_cpus_allowed > 1 && !task_is_blocked(p))
> enqueue_pushable_dl_task(rq, p);
> }
>
> diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c
> index d142f0611b34..2d8e9f9c6826 100644
> --- a/kernel/sched/fair.c
> +++ b/kernel/sched/fair.c
> @@ -7370,7 +7370,9 @@ pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf
> goto idle;
>
> #ifdef CONFIG_FAIR_GROUP_SCHED
> - if (!prev || prev->sched_class != &fair_sched_class)
> + if (!prev ||
> + prev->sched_class != &fair_sched_class ||
> + rq->curr != rq->proxy)
> goto simple;
>
> /*
> @@ -7888,6 +7890,9 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
>
> lockdep_assert_rq_held(env->src_rq);
>
> + if (task_is_blocked(p))
> + return 0;
> +
> /*
> * We do not migrate tasks that are:
> * 1) throttled_lb_pair, or
> @@ -7938,7 +7943,11 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
> /* Record that we found at least one task that could run on dst_cpu */
> env->flags &= ~LBF_ALL_PINNED;
>
> - if (task_running(env->src_rq, p)) {
> + /*
> + * XXX mutex unlock path may have marked proxy as unblocked allowing us to
> + * reach this point, but we still shouldn't migrate it.
> + */
> + if (task_running(env->src_rq, p) || task_current_proxy(env->src_rq, p)) {
> schedstat_inc(p->stats.nr_failed_migrations_running);
> return 0;
> }
> diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
> index 116556f4fb0a..09385fcb1713 100644
> --- a/kernel/sched/rt.c
> +++ b/kernel/sched/rt.c
> @@ -1548,7 +1548,8 @@ enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
>
> enqueue_rt_entity(rt_se, flags);
>
> - if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
> + if (!task_current(rq, p) && p->nr_cpus_allowed > 1 &&
> + !task_is_blocked(p))
> enqueue_pushable_task(rq, p);
> }
>
> diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
> index 0ef59dc7b8ea..354e75587fed 100644
> --- a/kernel/sched/sched.h
> +++ b/kernel/sched/sched.h
> @@ -2079,6 +2079,19 @@ static inline int task_current_proxy(struct rq *rq, struct task_struct *p)
> return rq->proxy == p;
> }
>
> +#ifdef CONFIG_PROXY_EXEC
> +static inline bool task_is_blocked(struct task_struct *p)
> +{
> + return !!p->blocked_on;
> +}
> +#else /* !PROXY_EXEC */
> +static inline bool task_is_blocked(struct task_struct *p)
> +{
> + return false;
> +}
> +
> +#endif /* PROXY_EXEC */
> +
> static inline int task_running(struct rq *rq, struct task_struct *p)
> {
> #ifdef CONFIG_SMP
> @@ -2233,12 +2246,18 @@ struct sched_class {
>
> static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
> {
> - WARN_ON_ONCE(rq->proxy != prev);
> + WARN_ON_ONCE(rq->curr != prev && prev != rq->proxy);
> +
> + /* XXX connoro: is this check necessary? */
> + if (prev == rq->proxy && task_cpu(prev) != cpu_of(rq))
> + return;
> +
> prev->sched_class->put_prev_task(rq, prev);
> }
>
> static inline void set_next_task(struct rq *rq, struct task_struct *next)
> {
> + WARN_ON_ONCE(!task_current_proxy(rq, next));
> next->sched_class->set_next_task(rq, next, false);
> }
>
> --
> 2.38.0.rc1.362.ged0d419d3c-goog
>
On 12/10/22 01:54, Joel Fernandes wrote:
...
> > +migrate_task:
> > + /*
> > + * The blocked-on relation must not cross CPUs, if this happens
> > + * migrate @p to the @owner's CPU.
> > + *
> > + * This is because we must respect the CPU affinity of execution
> > + * contexts (@owner) but we can ignore affinity for scheduling
> > + * contexts (@p). So we have to move scheduling contexts towards
> > + * potential execution contexts.
> > + *
> > + * XXX [juril] what if @p is not the highest prio task once migrated
> > + * to @owner's CPU?
>
> Then that sounds like the right thing is happening, and @p will not proxy()
> to @owner. Why does @p need to be highest prio?
No, indeed. I (now :) don't think the above is a problem.
> > + *
> > + * XXX [juril] also, after @p is migrated it is not migrated back once
> > + * @owner releases the lock? Isn't this a potential problem w.r.t.
> > + * @owner affinity settings?
>
> Juri, Do you mean here, '@p affinity settings' ? @p's affinity is being
> ignored right?
Yeah, @p affinity.
> > + * [juril] OK. It is migrated back into its affinity mask in
> > + * ttwu_remote(), or by using wake_cpu via select_task_rq, guess we
> > + * might want to add a comment about that here. :-)
>
> Good idea!
Connor, maybe you can add such a comment in the next version? Thanks!
> I am also wondering, how much more run-queue lock contention do these
> additional migrations add, that we did not have before. Do we have any data
> on that? Too much migration should not negate benefits of PE hopefully.
Looks like this is a sensible thing to measure.
Best,
Juri
On Tue, Oct 04, 2022 at 12:01:13PM -0400, Waiman Long wrote:
> On 10/3/22 17:44, Connor O'Brien wrote:
> > diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
> > index 56f139201f24..dfc174cd96c6 100644
> > --- a/kernel/locking/ww_mutex.h
> > +++ b/kernel/locking/ww_mutex.h
> > @@ -161,6 +161,11 @@ static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
> > #endif /* WW_RT */
> > +void ww_ctx_wake(struct ww_acquire_ctx *ww_ctx)
> > +{
> > + wake_up_q(&ww_ctx->wake_q);
> > +}
> > +
> > /*
> > * Wait-Die:
> > * The newer transactions are killed when:
> > @@ -284,7 +289,7 @@ __ww_mutex_die(struct MUTEX *lock, struct MUTEX_WAITER *waiter,
> > #ifndef WW_RT
> > debug_mutex_wake_waiter(lock, waiter);
> > #endif
> > - wake_up_process(waiter->task);
> > + wake_q_add(&ww_ctx->wake_q, waiter->task);
> > }
> > return true;
> > @@ -331,7 +336,7 @@ static bool __ww_mutex_wound(struct MUTEX *lock,
> > * wakeup pending to re-read the wounded state.
> > */
> > if (owner != current)
> > - wake_up_process(owner);
> > + wake_q_add(&ww_ctx->wake_q, owner);
> > return true;
> > }
> > diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> > index ee28253c9ac0..617e737392be 100644
> > --- a/kernel/sched/core.c
> > +++ b/kernel/sched/core.c
> > @@ -1013,6 +1013,13 @@ void wake_up_q(struct wake_q_head *head)
> > wake_up_process(task);
> > put_task_struct(task);
> > }
> > + /*
> > + * XXX connoro: seems this is needed now that ww_ctx_wake() passes in a
> > + * wake_q_head that is embedded in struct ww_acquire_ctx rather than
> > + * declared locally.
> > + */
> > + head->first = node;
> > + head->lastp = &head->first;
> > }
>
> You shouldn't do wake_q_init() here in wake_up_q(). Instead, you should do
> it in ww_ctx_wake() right after the wake_up_q() call.
> :
Exactly, it is also mentioned in the wake_q.h header:
* The DEFINE_WAKE_Q macro declares and initializes the list head.
* wake_up_q() does NOT reinitialize the list; it's expected to be
* called near the end of a function. Otherwise, the list can be
* re-initialized for later re-use by wake_q_init().
*
Thanks.
On Mon, Oct 3, 2022 at 5:45 PM Connor O'Brien <[email protected]> wrote:
>
> From: Juri Lelli <[email protected]>
>
> mutex::wait_lock might be nested under rq->lock.
>
> Make it irq safe then.
Hi Juri, can you give an example where not doing this is an issue?
When nested under rq->lock, interrupts should already be disabled,
otherwise try_to_wake_up() from an interrupt can cause a deadlock no?
Then, why do you need this patch?
Thanks.
> Signed-off-by: Juri Lelli <[email protected]>
> Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> Link: https://lkml.kernel.org/r/[email protected]
> [rebase & fix {un,}lock_wait_lock helpers in ww_mutex.h]
> Signed-off-by: Connor O'Brien <[email protected]>
> ---
> kernel/locking/mutex.c | 18 ++++++++++--------
> kernel/locking/ww_mutex.h | 22 ++++++++++++----------
> 2 files changed, 22 insertions(+), 18 deletions(-)
>
> diff --git a/kernel/locking/mutex.c b/kernel/locking/mutex.c
> index 7800380219db..f39e9ee3c4d0 100644
> --- a/kernel/locking/mutex.c
> +++ b/kernel/locking/mutex.c
> @@ -572,6 +572,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> {
> struct mutex_waiter waiter;
> struct ww_mutex *ww;
> + unsigned long flags;
> int ret;
>
> if (!use_ww_ctx)
> @@ -614,7 +615,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> return 0;
> }
>
> - raw_spin_lock(&lock->wait_lock);
> + raw_spin_lock_irqsave(&lock->wait_lock, flags);
> /*
> * After waiting to acquire the wait_lock, try again.
> */
> @@ -676,7 +677,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> goto err;
> }
>
> - raw_spin_unlock(&lock->wait_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
> if (ww_ctx)
> ww_ctx_wake(ww_ctx);
> schedule_preempt_disabled();
> @@ -703,9 +704,9 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> trace_contention_begin(lock, LCB_F_MUTEX);
> }
>
> - raw_spin_lock(&lock->wait_lock);
> + raw_spin_lock_irqsave(&lock->wait_lock, flags);
> }
> - raw_spin_lock(&lock->wait_lock);
> + raw_spin_lock_irqsave(&lock->wait_lock, flags);
> acquired:
> __set_current_state(TASK_RUNNING);
>
> @@ -732,7 +733,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> if (ww_ctx)
> ww_mutex_lock_acquired(ww, ww_ctx);
>
> - raw_spin_unlock(&lock->wait_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
> if (ww_ctx)
> ww_ctx_wake(ww_ctx);
> preempt_enable();
> @@ -743,7 +744,7 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> __mutex_remove_waiter(lock, &waiter);
> err_early_kill:
> trace_contention_end(lock, ret);
> - raw_spin_unlock(&lock->wait_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
> debug_mutex_free_waiter(&waiter);
> mutex_release(&lock->dep_map, ip);
> if (ww_ctx)
> @@ -915,6 +916,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
> struct task_struct *next = NULL;
> DEFINE_WAKE_Q(wake_q);
> unsigned long owner;
> + unsigned long flags;
>
> mutex_release(&lock->dep_map, ip);
>
> @@ -941,7 +943,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
> }
> }
>
> - raw_spin_lock(&lock->wait_lock);
> + raw_spin_lock_irqsave(&lock->wait_lock, flags);
> debug_mutex_unlock(lock);
> if (!list_empty(&lock->wait_list)) {
> /* get the first entry from the wait-list: */
> @@ -959,7 +961,7 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
> __mutex_handoff(lock, next);
>
> preempt_disable();
> - raw_spin_unlock(&lock->wait_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
>
> wake_up_q(&wake_q);
> preempt_enable();
> diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
> index dfc174cd96c6..7edd55d10f87 100644
> --- a/kernel/locking/ww_mutex.h
> +++ b/kernel/locking/ww_mutex.h
> @@ -70,14 +70,14 @@ __ww_mutex_has_waiters(struct mutex *lock)
> return atomic_long_read(&lock->owner) & MUTEX_FLAG_WAITERS;
> }
>
> -static inline void lock_wait_lock(struct mutex *lock)
> +static inline void lock_wait_lock(struct mutex *lock, unsigned long *flags)
> {
> - raw_spin_lock(&lock->wait_lock);
> + raw_spin_lock_irqsave(&lock->wait_lock, *flags);
> }
>
> -static inline void unlock_wait_lock(struct mutex *lock)
> +static inline void unlock_wait_lock(struct mutex *lock, unsigned long flags)
> {
> - raw_spin_unlock(&lock->wait_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
> }
>
> static inline void lockdep_assert_wait_lock_held(struct mutex *lock)
> @@ -144,14 +144,14 @@ __ww_mutex_has_waiters(struct rt_mutex *lock)
> return rt_mutex_has_waiters(&lock->rtmutex);
> }
>
> -static inline void lock_wait_lock(struct rt_mutex *lock)
> +static inline void lock_wait_lock(struct rt_mutex *lock, unsigned long *flags)
> {
> - raw_spin_lock(&lock->rtmutex.wait_lock);
> + raw_spin_lock_irqsave(&lock->rtmutex.wait_lock, *flags);
> }
>
> -static inline void unlock_wait_lock(struct rt_mutex *lock)
> +static inline void unlock_wait_lock(struct rt_mutex *lock, flags)
> {
> - raw_spin_unlock(&lock->rtmutex.wait_lock);
> + raw_spin_unlock_irqrestore(&lock->rtmutex.wait_lock, flags);
> }
>
> static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
> @@ -382,6 +382,8 @@ __ww_mutex_check_waiters(struct MUTEX *lock, struct ww_acquire_ctx *ww_ctx)
> static __always_inline void
> ww_mutex_set_context_fastpath(struct ww_mutex *lock, struct ww_acquire_ctx *ctx)
> {
> + unsigned long flags;
> +
> ww_mutex_lock_acquired(lock, ctx);
>
> /*
> @@ -409,9 +411,9 @@ ww_mutex_set_context_fastpath(struct ww_mutex *lock, struct ww_acquire_ctx *ctx)
> * Uh oh, we raced in fastpath, check if any of the waiters need to
> * die or wound us.
> */
> - lock_wait_lock(&lock->base);
> + lock_wait_lock(&lock->base, &flags);
> __ww_mutex_check_waiters(&lock->base, ctx);
> - unlock_wait_lock(&lock->base);
> + unlock_wait_lock(&lock->base, flags);
> }
>
> static __always_inline int
> --
> 2.38.0.rc1.362.ged0d419d3c-goog
>
Hi,
Just on the yield bits (my opinion):
On Mon, Oct 3, 2022 at 5:45 PM Connor O'Brien <[email protected]> wrote:
>
> From: Peter Zijlstra <[email protected]>
>
> Lets define the scheduling context as all the scheduler state in
> task_struct and the execution context as all state required to run the
> task.
>
> Currently both are intertwined in task_struct. We want to logically
> split these such that we can run the execution context of one task
> with the scheduling context of another.
>
> To this purpose introduce rq::proxy to point to the task_struct used
> for scheduler state and preserve rq::curr to denote the execution
> context.
>
> XXX connoro: A couple cases here may need more discussion:
> - sched_yield() and yield_to(): whether we call the sched_class
> methods for rq->curr or rq->proxy, there seem to be cases where
> proxy exec could cause a yielding mutex owner to run again
> immediately. How much of a concern is this?
A task chosen to run again after calling yield is not unprecedented.
From sched_yield manpage:
"If the calling thread is the only thread in the highest priority list
at that time, it will continue to run after a call to sched_yield()."
[...]
> @@ -8276,6 +8300,11 @@ static void do_sched_yield(void)
> rq = this_rq_lock_irq(&rf);
>
> schedstat_inc(rq->yld_count);
> + /*
> + * XXX how about proxy exec?
> + * If a task currently proxied by some other task yields, should we
> + * apply the proxy or the current yield "behaviour" ?
> + */
> current->sched_class->yield_task(rq);
I think we should keep it simple and keep the existing yield behavior.
If there was no priority inversion, and lock owner called yield, why
should it behave any differently?
>
> preempt_disable();
> @@ -8625,6 +8654,10 @@ EXPORT_SYMBOL(yield);
> */
> int __sched yield_to(struct task_struct *p, bool preempt)
> {
> + /*
> + * XXX what about current being proxied?
> + * Should we use proxy->sched_class methods in this case?
> + */
> struct task_struct *curr = current;
> struct rq *rq, *p_rq;
> unsigned long flags;
Ditto.
> @@ -8984,7 +9017,7 @@ void __init init_idle(struct task_struct *idle, int cpu)
[...]
Thanks,
- Joel
On Tue, Oct 11, 2022 at 9:54 PM Joel Fernandes <[email protected]> wrote:
>
> Hi,
>
> On Mon, Oct 03, 2022 at 09:44:57PM +0000, Connor O'Brien wrote:
> > From: Peter Zijlstra <[email protected]>
> >
> > A task currently holding a mutex (executing a critical section) might
> > find benefit in using scheduling contexts of other tasks blocked on the
> > same mutex if they happen to have higher priority of the current owner
> > (e.g., to prevent priority inversions).
> >
> > Proxy execution lets a task do exactly that: if a mutex owner has
> > waiters, it can use waiters' scheduling context to potentially continue
> > running if preempted.
> >
> > The basic mechanism is implemented by this patch, the core of which
> > resides in the proxy() function. Potential proxies (i.e., tasks blocked
> > on a mutex) are not dequeued, so, if one of them is actually selected by
> > schedule() as the next task to be put to run on a CPU, proxy() is used
> > to walk the blocked_on relation and find which task (mutex owner) might
> > be able to use the proxy's scheduling context.
> >
> > Here come the tricky bits. In fact, owner task might be in all sort of
> > states when a proxy is found (blocked, executing on a different CPU,
> > etc.). Details on how to handle different situations are to be found in
> > proxy() code comments.
> >
> > Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> > [rebased, added comments and changelog]
> > Signed-off-by: Juri Lelli <[email protected]>
> > [Fixed rebase conflicts]
> > [squashed sched: Ensure blocked_on is always guarded by blocked_lock]
> > Signed-off-by: Valentin Schneider <[email protected]>
> > [fix rebase conflicts, various fixes & tweaks commented inline]
> > [squashed sched: Use rq->curr vs rq->proxy checks]
> > Signed-off-by: Connor O'Brien <[email protected]>
> > Link: https://lore.kernel.org/all/[email protected]/
> [..]
> > + for (p = next; p->blocked_on; p = owner) {
> > + mutex = p->blocked_on;
> > + /* Something changed in the chain, pick_again */
> > + if (!mutex)
> > + return NULL;
> > +
> > + /*
> > + * By taking mutex->wait_lock we hold off concurrent mutex_unlock()
> > + * and ensure @owner sticks around.
> > + */
> > + raw_spin_lock(&mutex->wait_lock);
> > + raw_spin_lock(&p->blocked_lock);
> > +
> > + /* Check again that p is blocked with blocked_lock held */
> > + if (!task_is_blocked(p) || mutex != p->blocked_on) {
> > + /*
> > + * Something changed in the blocked_on chain and
> > + * we don't know if only at this level. So, let's
> > + * just bail out completely and let __schedule
> > + * figure things out (pick_again loop).
> > + */
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > + return NULL;
> > + }
> > +
> > + if (task_current(rq, p))
> > + curr_in_chain = true;
> > +
> > + owner = mutex_owner(mutex);
> > + /*
> > + * XXX can't this be 0|FLAGS? See __mutex_unlock_slowpath for(;;)
> > + * Mmm, OK, this can't probably happen because we force
> > + * unlock to skip the for(;;) loop. Is this acceptable though?
> > + */
> > + if (task_cpu(owner) != this_cpu)
> > + goto migrate_task;
> > +
> > + if (task_on_rq_migrating(owner))
> > + goto migrating_task;
> > +
> > + if (owner == p)
> > + goto owned_task;
> > +
> > + if (!owner->on_rq)
> > + goto blocked_task;
> > +
> > + /*
> > + * OK, now we're absolutely sure @owner is not blocked _and_
> > + * on this rq, therefore holding @rq->lock is sufficient to
> > + * guarantee its existence, as per ttwu_remote().
> > + */
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > +
> > + owner->blocked_proxy = p;
> > + }
> > +
> > + WARN_ON_ONCE(!owner->on_rq);
> > +
> > + return owner;
>
> Here, for CFS, doesn't this mean that the ->vruntime of the blocked task does
> not change while it is giving the owner a chance to run?
>
> So that feels like if the blocked task is on the left-most node of the cfs
> rbtree, then it will always proxy to the owner while not letting other
> unrelated CFS tasks to run. That sounds like a breakage of fairness.
>
> Or did I miss something?
And indeed I missed something that Peter does in "sched: Split
scheduler execution context". Where, the proxy of the task should have
its accounting updated in the scheduler tick path so in theory and
also cause preemption, so in theory at least this should not be an
issue. :-)
thanks,
- Joel
> > +
> > +migrate_task:
> > + /*
> > + * The blocked-on relation must not cross CPUs, if this happens
> > + * migrate @p to the @owner's CPU.
> > + *
> > + * This is because we must respect the CPU affinity of execution
> > + * contexts (@owner) but we can ignore affinity for scheduling
> > + * contexts (@p). So we have to move scheduling contexts towards
> > + * potential execution contexts.
> > + *
> > + * XXX [juril] what if @p is not the highest prio task once migrated
> > + * to @owner's CPU?
>
> Then that sounds like the right thing is happening, and @p will not proxy()
> to @owner. Why does @p need to be highest prio?
>
> > + *
> > + * XXX [juril] also, after @p is migrated it is not migrated back once
> > + * @owner releases the lock? Isn't this a potential problem w.r.t.
> > + * @owner affinity settings?
>
> Juri, Do you mean here, '@p affinity settings' ? @p's affinity is being
> ignored right?
>
> > + * [juril] OK. It is migrated back into its affinity mask in
> > + * ttwu_remote(), or by using wake_cpu via select_task_rq, guess we
> > + * might want to add a comment about that here. :-)
>
> Good idea!
>
> I am also wondering, how much more run-queue lock contention do these
> additional migrations add, that we did not have before. Do we have any data
> on that? Too much migration should not negate benefits of PE hopefully.
>
> thanks,
>
> - Joel
>
>
>
>
>
> > + * TODO: could optimize by finding the CPU of the final owner
> > + * and migrating things there. Given:
> > + *
> > + * CPU0 CPU1 CPU2
> > + *
> > + * a ----> b ----> c
> > + *
> > + * the current scheme would result in migrating 'a' to CPU1,
> > + * then CPU1 would migrate b and a to CPU2. Only then would
> > + * CPU2 run c.
> > + */
> > + that_cpu = task_cpu(owner);
> > + that_rq = cpu_rq(that_cpu);
> > + /*
> > + * @owner can disappear, simply migrate to @that_cpu and leave that CPU
> > + * to sort things out.
> > + */
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > +
> > + /*
> > + * Since we're going to drop @rq, we have to put(@next) first,
> > + * otherwise we have a reference that no longer belongs to us. Use
> > + * @fake_task to fill the void and make the next pick_next_task()
> > + * invocation happy.
> > + *
> > + * XXX double, triple think about this.
> > + * XXX put doesn't work with ON_RQ_MIGRATE
> > + *
> > + * CPU0 CPU1
> > + *
> > + * B mutex_lock(X)
> > + *
> > + * A mutex_lock(X) <- B
> > + * A __schedule()
> > + * A pick->A
> > + * A proxy->B
> > + * A migrate A to CPU1
> > + * B mutex_unlock(X) -> A
> > + * B __schedule()
> > + * B pick->A
> > + * B switch_to (A)
> > + * A ... does stuff
> > + * A ... is still running here
> > + *
> > + * * BOOM *
> > + */
> > + put_prev_task(rq, next);
> > + if (curr_in_chain) {
> > + rq->proxy = rq->idle;
> > + set_tsk_need_resched(rq->idle);
> > + /*
> > + * XXX [juril] don't we still need to migrate @next to
> > + * @owner's CPU?
> > + */
> > + return rq->idle;
> > + }
> > + rq->proxy = rq->idle;
> > +
> > + for (; p; p = p->blocked_proxy) {
> > + int wake_cpu = p->wake_cpu;
> > +
> > + WARN_ON(p == rq->curr);
> > +
> > + deactivate_task(rq, p, 0);
> > + set_task_cpu(p, that_cpu);
> > + /*
> > + * We can abuse blocked_entry to migrate the thing, because @p is
> > + * still on the rq.
> > + */
> > + list_add(&p->blocked_entry, &migrate_list);
> > +
> > + /*
> > + * Preserve p->wake_cpu, such that we can tell where it
> > + * used to run later.
> > + */
> > + p->wake_cpu = wake_cpu;
> > + }
> > +
> > + rq_unpin_lock(rq, rf);
> > + raw_spin_rq_unlock(rq);
> > + raw_spin_rq_lock(that_rq);
> > +
> > + while (!list_empty(&migrate_list)) {
> > + p = list_first_entry(&migrate_list, struct task_struct, blocked_entry);
> > + list_del_init(&p->blocked_entry);
> > +
> > + enqueue_task(that_rq, p, 0);
> > + check_preempt_curr(that_rq, p, 0);
> > + p->on_rq = TASK_ON_RQ_QUEUED;
> > + /*
> > + * check_preempt_curr has already called
> > + * resched_curr(that_rq) in case it is
> > + * needed.
> > + */
> > + }
> > +
> > + raw_spin_rq_unlock(that_rq);
> > + raw_spin_rq_lock(rq);
> > + rq_repin_lock(rq, rf);
> > +
> > + return NULL; /* Retry task selection on _this_ CPU. */
> > +
> > +migrating_task:
> > + /*
> > + * XXX connoro: one of the chain of mutex owners is currently
> > + * migrating to this CPU, but has not yet been enqueued because
> > + * we are holding the rq lock. As a simple solution, just schedule
> > + * rq->idle to give the migration a chance to complete. Much like
> > + * the migrate_task case we should end up back in proxy(), this
> > + * time hopefully with all relevant tasks already enqueued.
> > + */
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > + put_prev_task(rq, next);
> > + rq->proxy = rq->idle;
> > + set_tsk_need_resched(rq->idle);
> > + return rq->idle;
> > +owned_task:
> > + /*
> > + * Its possible we interleave with mutex_unlock like:
> > + *
> > + * lock(&rq->lock);
> > + * proxy()
> > + * mutex_unlock()
> > + * lock(&wait_lock);
> > + * next(owner) = current->blocked_proxy;
> > + * unlock(&wait_lock);
> > + *
> > + * wake_up_q();
> > + * ...
> > + * ttwu_runnable()
> > + * __task_rq_lock()
> > + * lock(&wait_lock);
> > + * owner == p
> > + *
> > + * Which leaves us to finish the ttwu_runnable() and make it go.
> > + *
> > + * XXX is this happening in case of an HANDOFF to p?
> > + * In any case, reading of the owner in __mutex_unlock_slowpath is
> > + * done atomically outside wait_lock (only adding waiters to wake_q is
> > + * done inside the critical section).
> > + * Does this means we can get to proxy _w/o an owner_ if that was
> > + * cleared before grabbing wait_lock? Do we account for this case?
> > + * OK we actually do (see PROXY_EXEC ifdeffery in unlock function).
> > + */
> > +
> > + set_task_blocked_on(owner, NULL);
> > +
> > + /*
> > + * XXX connoro: previous versions would immediately run owner here if
> > + * it's allowed to run on this CPU, but this creates potential races
> > + * with the wakeup logic. Instead we can just take the blocked_task path
> > + * when owner is already !on_rq, or else schedule rq->idle so that ttwu_runnable
> > + * can get the rq lock and mark owner as running.
> > + */
> > + if (!owner->on_rq)
> > + goto blocked_task;
> > +
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > + put_prev_task(rq, next);
> > + rq->proxy = rq->idle;
> > + set_tsk_need_resched(rq->idle);
> > + return rq->idle;
> > +
> > +blocked_task:
> > + /*
> > + * XXX connoro: rq->curr must not be added to the blocked_entry list
> > + * or else ttwu_do_activate could enqueue it elsewhere before it switches out
> > + * here. The approach to avoiding this is the same as in the migrate_task case.
> > + */
> > + if (curr_in_chain) {
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > + put_prev_task(rq, next);
> > + rq->proxy = rq->idle;
> > + set_tsk_need_resched(rq->idle);
> > + return rq->idle;
> > + }
> > + /*
> > + * If !@owner->on_rq, holding @rq->lock will not pin the task,
> > + * so we cannot drop @mutex->wait_lock until we're sure its a blocked
> > + * task on this rq.
> > + *
> > + * We use @owner->blocked_lock to serialize against ttwu_activate().
> > + * Either we see its new owner->on_rq or it will see our list_add().
> > + */
> > + if (owner != p) {
> > + raw_spin_unlock(&p->blocked_lock);
> > + raw_spin_lock(&owner->blocked_lock);
> > + }
> > +
> > + /*
> > + * Walk back up the blocked_proxy relation and enqueue them all on @owner
> > + *
> > + * ttwu_activate() will pick them up and place them on whatever rq
> > + * @owner will run next.
> > + * XXX connoro: originally we would jump back into the main proxy() loop
> > + * owner->on_rq !=0 path, but if we then end up taking the owned_task path
> > + * then we can overwrite p->on_rq after ttwu_do_activate sets it to 1 which breaks
> > + * the assumptions made in ttwu_do_activate.
> > + */
> > + if (!owner->on_rq) {
> > + for (; p; p = p->blocked_proxy) {
> > + if (p == owner)
> > + continue;
> > + BUG_ON(!p->on_rq);
> > + deactivate_task(rq, p, DEQUEUE_SLEEP);
> > + if (task_current_proxy(rq, p)) {
> > + put_prev_task(rq, next);
> > + rq->proxy = rq->idle;
> > + }
> > + /*
> > + * XXX connoro: need to verify this is necessary. The rationale is that
> > + * ttwu_do_activate must not have a chance to activate p elsewhere before
> > + * it's fully extricated from its old rq.
> > + */
> > + smp_mb();
> > + list_add(&p->blocked_entry, &owner->blocked_entry);
> > + }
> > + }
> > + if (task_current_proxy(rq, next)) {
> > + put_prev_task(rq, next);
> > + rq->proxy = rq->idle;
> > + }
> > + raw_spin_unlock(&owner->blocked_lock);
> > + raw_spin_unlock(&mutex->wait_lock);
> > +
> > + return NULL; /* retry task selection */
> > +}
> > +#else /* PROXY_EXEC */
> > +static struct task_struct *
> > +proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> > +{
> > + return next;
> > +}
> > +#endif /* PROXY_EXEC */
> > +
> > /*
> > * __schedule() is the main scheduler function.
> > *
> > @@ -6447,7 +6984,7 @@ static void __sched notrace __schedule(unsigned int sched_mode)
> > if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
> > if (signal_pending_state(prev_state, prev)) {
> > WRITE_ONCE(prev->__state, TASK_RUNNING);
> > - } else {
> > + } else if (!task_is_blocked(prev)) {
> > prev->sched_contributes_to_load =
> > (prev_state & TASK_UNINTERRUPTIBLE) &&
> > !(prev_state & TASK_NOLOAD) &&
> > @@ -6473,11 +7010,37 @@ static void __sched notrace __schedule(unsigned int sched_mode)
> > atomic_inc(&rq->nr_iowait);
> > delayacct_blkio_start();
> > }
> > + } else {
> > + /*
> > + * XXX
> > + * Let's make this task, which is blocked on
> > + * a mutex, (push/pull)able (RT/DL).
> > + * Unfortunately we can only deal with that by
> > + * means of a dequeue/enqueue cycle. :-/
> > + */
> > + dequeue_task(rq, prev, 0);
> > + enqueue_task(rq, prev, 0);
> > }
> > switch_count = &prev->nvcsw;
> > }
> >
> > - rq->proxy = next = pick_next_task(rq, prev, &rf);
> > +pick_again:
> > + /*
> > + * If picked task is actually blocked it means that it can act as a
> > + * proxy for the task that is holding the mutex picked task is blocked
> > + * on. Get a reference to the blocked (going to be proxy) task here.
> > + * Note that if next isn't actually blocked we will have rq->proxy ==
> > + * rq->curr == next in the end, which is intended and means that proxy
> > + * execution is currently "not in use".
> > + */
> > + rq->proxy = next = pick_next_task(rq, rq->proxy, &rf);
> > + next->blocked_proxy = NULL;
> > + if (unlikely(task_is_blocked(next))) {
> > + next = proxy(rq, next, &rf);
> > + if (!next)
> > + goto pick_again;
> > + }
> > +
> > clear_tsk_need_resched(prev);
> > clear_preempt_need_resched();
> > #ifdef CONFIG_SCHED_DEBUG
> > @@ -6565,6 +7128,10 @@ static inline void sched_submit_work(struct task_struct *tsk)
> > */
> > SCHED_WARN_ON(current->__state & TASK_RTLOCK_WAIT);
> >
> > + /* XXX still necessary? tsk_is_pi_blocked check here was deleted... */
> > + if (task_is_blocked(tsk))
> > + return;
> > +
> > /*
> > * If we are going to sleep and we have plugged IO queued,
> > * make sure to submit it to avoid deadlocks.
> > diff --git a/kernel/sched/deadline.c b/kernel/sched/deadline.c
> > index d5ab7ff64fbc..5416d61e87e7 100644
> > --- a/kernel/sched/deadline.c
> > +++ b/kernel/sched/deadline.c
> > @@ -1748,7 +1748,7 @@ static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags)
> >
> > enqueue_dl_entity(&p->dl, flags);
> >
> > - if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
> > + if (!task_current(rq, p) && p->nr_cpus_allowed > 1 && !task_is_blocked(p))
> > enqueue_pushable_dl_task(rq, p);
> > }
> >
> > diff --git a/kernel/sched/fair.c b/kernel/sched/fair.c
> > index d142f0611b34..2d8e9f9c6826 100644
> > --- a/kernel/sched/fair.c
> > +++ b/kernel/sched/fair.c
> > @@ -7370,7 +7370,9 @@ pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf
> > goto idle;
> >
> > #ifdef CONFIG_FAIR_GROUP_SCHED
> > - if (!prev || prev->sched_class != &fair_sched_class)
> > + if (!prev ||
> > + prev->sched_class != &fair_sched_class ||
> > + rq->curr != rq->proxy)
> > goto simple;
> >
> > /*
> > @@ -7888,6 +7890,9 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
> >
> > lockdep_assert_rq_held(env->src_rq);
> >
> > + if (task_is_blocked(p))
> > + return 0;
> > +
> > /*
> > * We do not migrate tasks that are:
> > * 1) throttled_lb_pair, or
> > @@ -7938,7 +7943,11 @@ int can_migrate_task(struct task_struct *p, struct lb_env *env)
> > /* Record that we found at least one task that could run on dst_cpu */
> > env->flags &= ~LBF_ALL_PINNED;
> >
> > - if (task_running(env->src_rq, p)) {
> > + /*
> > + * XXX mutex unlock path may have marked proxy as unblocked allowing us to
> > + * reach this point, but we still shouldn't migrate it.
> > + */
> > + if (task_running(env->src_rq, p) || task_current_proxy(env->src_rq, p)) {
> > schedstat_inc(p->stats.nr_failed_migrations_running);
> > return 0;
> > }
> > diff --git a/kernel/sched/rt.c b/kernel/sched/rt.c
> > index 116556f4fb0a..09385fcb1713 100644
> > --- a/kernel/sched/rt.c
> > +++ b/kernel/sched/rt.c
> > @@ -1548,7 +1548,8 @@ enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
> >
> > enqueue_rt_entity(rt_se, flags);
> >
> > - if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
> > + if (!task_current(rq, p) && p->nr_cpus_allowed > 1 &&
> > + !task_is_blocked(p))
> > enqueue_pushable_task(rq, p);
> > }
> >
> > diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
> > index 0ef59dc7b8ea..354e75587fed 100644
> > --- a/kernel/sched/sched.h
> > +++ b/kernel/sched/sched.h
> > @@ -2079,6 +2079,19 @@ static inline int task_current_proxy(struct rq *rq, struct task_struct *p)
> > return rq->proxy == p;
> > }
> >
> > +#ifdef CONFIG_PROXY_EXEC
> > +static inline bool task_is_blocked(struct task_struct *p)
> > +{
> > + return !!p->blocked_on;
> > +}
> > +#else /* !PROXY_EXEC */
> > +static inline bool task_is_blocked(struct task_struct *p)
> > +{
> > + return false;
> > +}
> > +
> > +#endif /* PROXY_EXEC */
> > +
> > static inline int task_running(struct rq *rq, struct task_struct *p)
> > {
> > #ifdef CONFIG_SMP
> > @@ -2233,12 +2246,18 @@ struct sched_class {
> >
> > static inline void put_prev_task(struct rq *rq, struct task_struct *prev)
> > {
> > - WARN_ON_ONCE(rq->proxy != prev);
> > + WARN_ON_ONCE(rq->curr != prev && prev != rq->proxy);
> > +
> > + /* XXX connoro: is this check necessary? */
> > + if (prev == rq->proxy && task_cpu(prev) != cpu_of(rq))
> > + return;
> > +
> > prev->sched_class->put_prev_task(rq, prev);
> > }
> >
> > static inline void set_next_task(struct rq *rq, struct task_struct *next)
> > {
> > + WARN_ON_ONCE(!task_current_proxy(rq, next));
> > next->sched_class->set_next_task(rq, next, false);
> > }
> >
> > --
> > 2.38.0.rc1.362.ged0d419d3c-goog
> >
On Mon, Oct 10, 2022 at 4:40 AM Valentin Schneider <[email protected]> wrote:
>
> On 03/10/22 21:44, Connor O'Brien wrote:
> > From: Valentin Schneider <[email protected]>
>
> This was one of my attempts at fixing RT load balancing (the BUG_ON in
> pick_next_pushable_task() was quite easy to trigger), but I ended up
> convincing myself this was insufficient - this only "tags" the donor and
> the proxy, the entire blocked chain needs tagging. Hopefully not all of
> what I'm about to write is nonsense, some of the neurons I need for this
> haven't been used in a while - to be taken with a grain of salt.
Made sense to me! Thanks, this was really helpful for understanding
the interactions between proxy execution & load balancing.
>
> Consider pick_highest_pushable_task() - we don't want any task in a blocked
> chain to be pickable. There's no point in migrating it, we'll just hit
> schedule()->proxy(), follow p->blocked_on and most likely move it back to
> where the rest of the chain is. This applies any sort of balancing (CFS,
> RT, DL).
>
> ATM I think PE breaks the "run the N highest priority task on our N CPUs"
> policy. Consider:
>
> p0 (FIFO42)
> |
> | blocked_on
> v
> p1 (FIFO41)
> |
> | blocked_on
> v
> p2 (FIFO40)
>
> Add on top p3 an unrelated FIFO1 task, and p4 an unrelated CFS task.
>
> CPU0
> current: p0
> proxy: p2
> enqueued: p0, p1, p2, p3
>
> CPU1
> current: p4
> proxy: p4
> enqueued: p4
>
>
> pick_next_pushable_task() on CPU0 would pick p1 as the next highest
> priority task to push away to e.g. CPU1, but that would be undone as soon
> as proxy() happens on CPU1: we'd notice the CPU boundary and punt it back
> to CPU0. What we would want here is to pick p3 instead to have it run on
> CPU1.
Given this point, is there any reason that blocked tasks should ever
be pushable, even if they are not part of the blocked chain for the
currently running task? If we could just check task_is_blocked()
rather than needing to know whether the task is in the middle of the
"active" chain, that would seem to simplify things greatly. I think
that approach might also require another dequeue/enqueue, in
ttwu_runnable(), to catch non-proxy blocked tasks becoming unblocked
(and therefore pushable), but that *seems* OK...though I could
certainly be missing something.
A related load balancing correctness question that caught my eye while
taking another look at this code: when we have rq->curr != rq->proxy
and then rq->curr is preempted and switches out, IIUC rq->curr should
become pushable immediately - but this does not seem to be the case
even with this patch. Is there a path that handles this case that I'm
just missing, or a reason that no special handling is needed?
Otherwise I wonder if __schedule() might need a dequeue/enqueue for
the prev task as well in this case.
>
> I *think* we want only the proxy of an entire blocked-chain to be visible
> to load-balance, unfortunately PE gathers the blocked-chain onto the
> donor's CPU which kinda undoes that.
>
> Having the blocked tasks remain in the rq is very handy as it directly
> gives us the scheduling context and we can unwind the blocked chain for the
> execution context, but it does wreak havock in load-balancing :/
>
On Wed, Oct 12, 2022 at 01:54:26AM +0000, Joel Fernandes wrote:
> Here, for CFS, doesn't this mean that the ->vruntime of the blocked task does
> not change while it is giving the owner a chance to run?
>
> So that feels like if the blocked task is on the left-most node of the cfs
> rbtree, then it will always proxy to the owner while not letting other
> unrelated CFS tasks to run. That sounds like a breakage of fairness.
>
> Or did I miss something?
So CFS will pick the leftmost task, if it happens to be the lock owner,
it will run as normal, owner time will advance.
When owner time is advanced enough to not be elegible anymore, it is
likely a blocked task is selected, at which time we'll advance it's
vruntime.
All this repeats until the whole block chain has advanced enough to make
the owner elegible again and the whole thing repeats.
From this it is easy to see that the critical secion executes with the
direct sum of the blockchain as a whole (all of them will have donated
their relative time to make the owner elegible again) -- provided the
critical section is of course long enough for this to matter (or it's
owner's weight small enough etc..).
On Mon, Oct 03, 2022 at 09:44:57PM +0000, Connor O'Brien wrote:
> @@ -965,7 +1026,10 @@ static noinline void __sched __mutex_unlock_slowpath(struct mutex *lock, unsigne
> if (owner & MUTEX_FLAG_HANDOFF)
> __mutex_handoff(lock, next);
>
> - preempt_disable();
> + preempt_disable(); /* XXX connoro: why disable preemption here? */
> +#ifdef CONFIG_PROXY_EXEC
> + raw_spin_unlock(¤t->blocked_lock);
> +#endif
> raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
Because if we wouldn't have preemption disabled it would preempt here,
before the wakeup:
> wake_up_q(&wake_q);
And you'd be stuck with a priority inversion.
On Mon, Oct 03, 2022 at 09:44:57PM +0000, Connor O'Brien wrote:
> @@ -703,15 +707,28 @@ __mutex_lock_common(struct mutex *lock, unsigned int state, unsigned int subclas
> break;
>
> if (first) {
> + bool acquired;
> +
> + /*
> + * XXX connoro: mutex_optimistic_spin() can schedule, so
I'm thinking it might be better to remove that schedule point for
PROXY_EXEC instead of doing this.
Getting preempted right after acquiring a lock is less of a problem with
PE on than it is without it.
> + * we need to release these locks before calling it.
> + * This needs refactoring though b/c currently we take
> + * the locks earlier than necessary when proxy exec is
> + * disabled and release them unnecessarily when it's
> + * enabled. At a minimum, need to verify that releasing
> + * blocked_lock here doesn't create any races.
> + */
> + raw_spin_unlock(¤t->blocked_lock);
> + raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
> trace_contention_begin(lock, LCB_F_MUTEX | LCB_F_SPIN);
> - if (mutex_optimistic_spin(lock, ww_ctx, &waiter))
> + acquired = mutex_optimistic_spin(lock, ww_ctx, &waiter);
> + raw_spin_lock_irqsave(&lock->wait_lock, flags);
> + raw_spin_lock(¤t->blocked_lock);
> + if (acquired)
> break;
> trace_contention_begin(lock, LCB_F_MUTEX);
> }
On Mon, Oct 03, 2022 at 09:44:57PM +0000, Connor O'Brien wrote:
> diff --git a/init/Kconfig b/init/Kconfig
> index 532362fcfe31..a341b9755a57 100644
> --- a/init/Kconfig
> +++ b/init/Kconfig
> @@ -922,6 +922,13 @@ config NUMA_BALANCING_DEFAULT_ENABLED
> If set, automatic NUMA balancing will be enabled if running on a NUMA
> machine.
>
> +config PROXY_EXEC
> + bool "Proxy Execution"
> + default n
> + help
> + This option enables proxy execution, a mechanism for mutex owning
> + tasks to inherit the scheduling context of higher priority waiters.
> +
I tihnk the way you have it here you should add something like:
depends on !SCHED_CORE
On Wed, Oct 12, 2022 at 01:54:26AM +0000, Joel Fernandes wrote:
> > +migrate_task:
> > + /*
> > + * The blocked-on relation must not cross CPUs, if this happens
> > + * migrate @p to the @owner's CPU.
> > + *
> > + * This is because we must respect the CPU affinity of execution
> > + * contexts (@owner) but we can ignore affinity for scheduling
> > + * contexts (@p). So we have to move scheduling contexts towards
> > + * potential execution contexts.
> > + *
> > + * XXX [juril] what if @p is not the highest prio task once migrated
> > + * to @owner's CPU?
>
> Then that sounds like the right thing is happening, and @p will not proxy()
> to @owner. Why does @p need to be highest prio?
So all this is a head-ache and definitely introduces some inversion
cases -- doubly so when combined with lovely things like
migrate_disable().
But even aside from the obvious affinity related pain; there is another
issue. Per:
--- a/kernel/sched/rt.c
+++ b/kernel/sched/rt.c
@@ -1548,7 +1548,8 @@ enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
enqueue_rt_entity(rt_se, flags);
- if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
+ if (!task_current(rq, p) && p->nr_cpus_allowed > 1 &&
+ !task_is_blocked(p))
enqueue_pushable_task(rq, p);
}
blocked entries are NOT put on the pushable list -- this means that the
normal mitigation for resolving a priority inversion like described
above (having both P_max and P_max-1 on the same CPU) no longer works.
That is, normally we would resolve the situation by pushing P_max-1 to
another CPU. But not with PE as it currently stands.
The reason we remove blocked entries from the pushable list is because
must migrate them towards the execution context (and respect the
execution context's affinity constraints).
Basically the whole push-pull RT balancer scheme is broken vs PE, and
that is a bit of a head-ache :/
On Mon, Oct 03, 2022 at 09:44:50PM +0000, Connor O'Brien wrote:
> Proxy execution has been discussed over the past few years at several
> conferences[3][4][5], but (as far as I'm aware) patches implementing the
> concept have not been discussed on the list since Juri Lelli's RFC in
> 2018.[6] This series is an updated version of that patchset, seeking to
> incorporate subsequent work by Juri[7], Valentin Schneider[8] and Peter
> Zijlstra along with some new fixes.
I actually did a forward port at some point after core-scheduling and
had a sort-of working version -- although I do remember it being an even
bigger pain in the arse than normal.
I think I handed those patches to Joel at some point...
On Sat, 15 Oct 2022 15:53:19 +0200
Peter Zijlstra <[email protected]> wrote:
> >From this it is easy to see that the critical secion executes with the
> direct sum of the blockchain as a whole (all of them will have donated
> their relative time to make the owner elegible again) -- provided the
> critical section is of course long enough for this to matter (or it's
> owner's weight small enough etc..).
Does this mean that a lower priority task could do a sort of DOS attack
on a high priority task, if it creates a bunch of threads that
constantly grabs a shared lock from the higher priority task? That is,
the higher priority task could possibly lose a lot of its quota due to
other tasks running on its behalf in the critical section?
-- Steve
On Mon, Oct 03, 2022 at 09:44:50PM +0000, Connor O'Brien wrote:
> Proxy execution is an approach to implementing priority inheritance
> based on distinguishing between a task's scheduler context (information
> required in order to make scheduling decisions about when the task gets
> to run, such as its scheduler class and priority) and its execution
> context (information required to actually run the task, such as CPU
> affinity). With proxy execution enabled, a task p1 that blocks on a
> mutex remains on the runqueue, but its "blocked" status and the mutex on
> which it blocks are recorded. If p1 is selected to run while still
> blocked, the lock owner p2 can run "on its behalf", inheriting p1's
> scheduler context. Execution context is not inherited, meaning that
> e.g. the CPUs where p2 can run are still determined by its own affinity
> and not p1's.
>
> In practice a number of more complicated situations can arise: the mutex
> owner might itself be blocked on another mutex, or it could be sleeping,
> running on a different CPU, in the process of migrating between CPUs,
> etc. Details on handling these various cases can be found in patch 7/11
> ("sched: Add proxy execution"), particularly in the implementation of
> proxy() and accompanying comments.
>
> Past discussions of proxy execution have often focused on the benefits
> for deadline scheduling. Current interest for Android is based more on
> desire for a broad solution to priority inversion on kernel mutexes,
> including among CFS tasks. One notable scenario arises when cpu cgroups
> are used to throttle less important background tasks. Priority inversion
> can occur when an "important" unthrottled task blocks on a mutex held by
> an "unimportant" task whose CPU time is constrained using cpu
> shares. The result is higher worst case latencies for the unthrottled
> task.[0] Testing by John Stultz with a simple reproducer [1] showed
> promising results for this case, with proxy execution appearing to
> eliminate the large latency spikes associated with priority
> inversion.[2]
>
> Proxy execution has been discussed over the past few years at several
> conferences[3][4][5], but (as far as I'm aware) patches implementing the
> concept have not been discussed on the list since Juri Lelli's RFC in
> 2018.[6] This series is an updated version of that patchset, seeking to
> incorporate subsequent work by Juri[7], Valentin Schneider[8] and Peter
> Zijlstra along with some new fixes.
>
> Testing so far has focused on stability, mostly via mutex locktorture
> with some tweaks to more quickly trigger proxy execution bugs. These
> locktorture changes are included at the end of the series for
> reference. The current series survives runs of >72 hours on QEMU without
> crashes, deadlocks, etc. Testing on Pixel 6 with the android-mainline
> kernel [9] yields similar results. In both cases, testing used >2 CPUs
> and CONFIG_FAIR_GROUP_SCHED=y, a configuration Valentin Schneider
> reported[10] showed stability problems with earlier versions of the
> series.
>
> That said, these are definitely still a work in progress, with some
> known remaining issues (e.g. warnings while booting on Pixel 6,
> suspicious looking min/max vruntime numbers) and likely others I haven't
> found yet. I've done my best to eliminate checks and code paths made
> redundant by new fixes but some probably remain. There's no attempt yet
> to handle core scheduling. Performance testing so far has been limited
> to the aforementioned priority inversion reproducer. The hope in sharing
> now is to revive the discussion on proxy execution and get some early
> input for continuing to revise & refine the patches.
I ran a test to check CFS time sharing. The accounting on top is confusing,
but ftrace confirms the proxying happening.
Task A - pid 122
Task B - pid 123
Task C - pid 121
Task D - pid 124
Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
spins all the time, while A blocks on the same in-kernel mutex and remains
blocked.
Then I did "top -H" while the test was running which gives below output.
The first column is PID, and the third-last column is CPU percentage.
Without PE:
121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
With PE:
PID
122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
in fact not running and proxying to the owner task so everything seems
working correctly, but the accounting seems confusing, as in, it is confusing
to see the D-state task task taking 25% CPU when it is obviously "sleeping".
Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
sleep state), so may be it is OK then, but I did want to bring this up :-)
thanks,
- Joel
> [0] https://raw.githubusercontent.com/johnstultz-work/priority-inversion-demo/main/results/charts/6.0-rc7-throttling-starvation.png
> [1] https://github.com/johnstultz-work/priority-inversion-demo
> [2] https://raw.githubusercontent.com/johnstultz-work/priority-inversion-demo/main/results/charts/6.0-rc7-vanilla-vs-proxy.png
> [3] https://lpc.events/event/2/contributions/62/
> [4] https://lwn.net/Articles/793502/
> [5] https://lwn.net/Articles/820575/
> [6] https://lore.kernel.org/lkml/[email protected]/
> [7] https://github.com/jlelli/linux/tree/experimental/deadline/proxy-rfc-v2
> [8] https://gitlab.arm.com/linux-arm/linux-vs/-/tree/mainline/sched/proxy-rfc-v3/
> [9] https://source.android.com/docs/core/architecture/kernel/android-common
> [10] https://lpc.events/event/7/contributions/758/attachments/585/1036/lpc20-proxy.pdf#page=4
>
> Connor O'Brien (2):
> torture: support randomized shuffling for proxy exec testing
> locktorture: support nested mutexes
>
> Juri Lelli (3):
> locking/mutex: make mutex::wait_lock irq safe
> kernel/locking: Expose mutex_owner()
> sched: Fixup task CPUs for potential proxies.
>
> Peter Zijlstra (4):
> locking/ww_mutex: Remove wakeups from under mutex::wait_lock
> locking/mutex: Rework task_struct::blocked_on
> sched: Split scheduler execution context
> sched: Add proxy execution
>
> Valentin Schneider (2):
> kernel/locking: Add p->blocked_on wrapper
> sched/rt: Fix proxy/current (push,pull)ability
>
> include/linux/mutex.h | 2 +
> include/linux/sched.h | 15 +-
> include/linux/ww_mutex.h | 3 +
> init/Kconfig | 7 +
> init/init_task.c | 1 +
> kernel/Kconfig.locks | 2 +-
> kernel/fork.c | 6 +-
> kernel/locking/locktorture.c | 20 +-
> kernel/locking/mutex-debug.c | 9 +-
> kernel/locking/mutex.c | 109 +++++-
> kernel/locking/ww_mutex.h | 31 +-
> kernel/sched/core.c | 679 +++++++++++++++++++++++++++++++++--
> kernel/sched/deadline.c | 37 +-
> kernel/sched/fair.c | 33 +-
> kernel/sched/rt.c | 63 ++--
> kernel/sched/sched.h | 42 ++-
> kernel/torture.c | 10 +-
> 17 files changed, 955 insertions(+), 114 deletions(-)
>
> --
> 2.38.0.rc1.362.ged0d419d3c-goog
>
Hello,
On 2022/10/4 05:44, Connor O'Brien wrote:
> Proxy execution is an approach to implementing priority inheritance
> based on distinguishing between a task's scheduler context (information
> required in order to make scheduling decisions about when the task gets
> to run, such as its scheduler class and priority) and its execution
> context (information required to actually run the task, such as CPU
> affinity). With proxy execution enabled, a task p1 that blocks on a
> mutex remains on the runqueue, but its "blocked" status and the mutex on
> which it blocks are recorded. If p1 is selected to run while still
> blocked, the lock owner p2 can run "on its behalf", inheriting p1's
> scheduler context. Execution context is not inherited, meaning that
> e.g. the CPUs where p2 can run are still determined by its own affinity
> and not p1's.
This is cool. We have a problem (others should have encountered it too) that
priority inversion happened when the rwsem writer is waiting for many readers
which held lock but are throttled by CFS bandwidth control. (In our use case,
the rwsem is the mm_struct->mmap_sem)
So I'm curious if this work can also solve this problem? If we don't dequeue
the rwsem writer when it blocked on the rwsem, then CFS scheduler pick it to
run, we can use blocked chain to find the readers to run?
Thanks!
> On Oct 16, 2022, at 11:25 PM, Chengming Zhou <[email protected]> wrote:
>
> Hello,
>
>> On 2022/10/4 05:44, Connor O'Brien wrote:
>> Proxy execution is an approach to implementing priority inheritance
>> based on distinguishing between a task's scheduler context (information
>> required in order to make scheduling decisions about when the task gets
>> to run, such as its scheduler class and priority) and its execution
>> context (information required to actually run the task, such as CPU
>> affinity). With proxy execution enabled, a task p1 that blocks on a
>> mutex remains on the runqueue, but its "blocked" status and the mutex on
>> which it blocks are recorded. If p1 is selected to run while still
>> blocked, the lock owner p2 can run "on its behalf", inheriting p1's
>> scheduler context. Execution context is not inherited, meaning that
>> e.g. the CPUs where p2 can run are still determined by its own affinity
>> and not p1's.
>
> This is cool. We have a problem (others should have encountered it too) that
> priority inversion happened when the rwsem writer is waiting for many readers
> which held lock but are throttled by CFS bandwidth control. (In our use case,
> the rwsem is the mm_struct->mmap_sem)
>
> So I'm curious if this work can also solve this problem? If we don't dequeue
> the rwsem writer when it blocked on the rwsem, then CFS scheduler pick it to
> run, we can use blocked chain to find the readers to run?
That seems a lot harder and unsupported by current patch set AFAICS (my exposure to this work is about a week so take it with a grain of salt). You could have multiple readers so how would you choose which reader to proxy for (round robin?). Also, you no longer have a chain but a tree of chains, with the leaves being each reader - so you have to track that somehow, then keep migrating the blocked tasks in the chain to each readers CPU. Possibly migrating a lot more than in the case of a single chain. Also it’s not clear if it will be beneficial as proxying for one reader does not mean you’re improving the situation if it is another reader that is in need of the boost.
Thanks.
>
> Thanks!
>
> On Oct 16, 2022, at 4:48 PM, Steven Rostedt <[email protected]> wrote:
>
> On Sat, 15 Oct 2022 15:53:19 +0200
> Peter Zijlstra <[email protected]> wrote:
>
>>> From this it is easy to see that the critical secion executes with the
>> direct sum of the blockchain as a whole (all of them will have donated
>> their relative time to make the owner elegible again) -- provided the
>> critical section is of course long enough for this to matter (or it's
>> owner's weight small enough etc..).
>
> Does this mean that a lower priority task could do a sort of DOS attack
> on a high priority task, if it creates a bunch of threads that
> constantly grabs a shared lock from the higher priority task? That is,
> the higher priority task could possibly lose a lot of its quota due to
> other tasks running on its behalf in the critical section?
Just my opinion: I can see that as a problem, but on the other hand, if a bunch of threads are acquiring a shared lock to block a high priority task, then they are probably causing a DOS-type of issue anyway whether PE is enabled or not. Even if a prio inheritance mechanism boosts them, they’re still making the progress of the blocking high priority tasks slower. Or, did I miss something in this use case?
Thanks.
On 2022/10/17 11:56, Joel Fernandes wrote:
>
>
>> On Oct 16, 2022, at 11:25 PM, Chengming Zhou <[email protected]> wrote:
>>
>> Hello,
>>
>>> On 2022/10/4 05:44, Connor O'Brien wrote:
>>> Proxy execution is an approach to implementing priority inheritance
>>> based on distinguishing between a task's scheduler context (information
>>> required in order to make scheduling decisions about when the task gets
>>> to run, such as its scheduler class and priority) and its execution
>>> context (information required to actually run the task, such as CPU
>>> affinity). With proxy execution enabled, a task p1 that blocks on a
>>> mutex remains on the runqueue, but its "blocked" status and the mutex on
>>> which it blocks are recorded. If p1 is selected to run while still
>>> blocked, the lock owner p2 can run "on its behalf", inheriting p1's
>>> scheduler context. Execution context is not inherited, meaning that
>>> e.g. the CPUs where p2 can run are still determined by its own affinity
>>> and not p1's.
>>
>> This is cool. We have a problem (others should have encountered it too) that
>> priority inversion happened when the rwsem writer is waiting for many readers
>> which held lock but are throttled by CFS bandwidth control. (In our use case,
>> the rwsem is the mm_struct->mmap_sem)
>>
>> So I'm curious if this work can also solve this problem? If we don't dequeue
>> the rwsem writer when it blocked on the rwsem, then CFS scheduler pick it to
>> run, we can use blocked chain to find the readers to run?
>
> That seems a lot harder and unsupported by current patch set AFAICS (my exposure to this work is about a week so take it with a grain of salt). You could have multiple readers so how would you choose which reader to proxy for (round robin?). Also, you no longer have a chain but a tree of chains, with the leaves being each reader - so you have to track that somehow, then keep migrating the blocked tasks in the chain to each readers CPU. Possibly migrating a lot more than in the case of a single chain. Also it’s not clear if it will be beneficial as proxying for one reader does not mean you’re improving the situation if it is another reader that is in need of the boost.
>
Thanks for your reply, it's indeed more complex than I think, and proxying for just one reader
is also less efficient.
But this rwsem priority inversion problem hurts us so much that we are afraid to use
CFS bandwidth control now. Imaging when 10 readers held mmap_sem then throttled for 20ms,
the writer will have to wait for at least 200ms, which become worse if the writer held other lock.
Thanks.
On Sun, Oct 16, 2022 at 04:48:09PM -0400, Steven Rostedt wrote:
> On Sat, 15 Oct 2022 15:53:19 +0200
> Peter Zijlstra <[email protected]> wrote:
>
> > >From this it is easy to see that the critical secion executes with the
> > direct sum of the blockchain as a whole (all of them will have donated
> > their relative time to make the owner elegible again) -- provided the
> > critical section is of course long enough for this to matter (or it's
> > owner's weight small enough etc..).
>
> Does this mean that a lower priority task could do a sort of DOS attack
> on a high priority task, if it creates a bunch of threads that
> constantly grabs a shared lock from the higher priority task? That is,
> the higher priority task could possibly lose a lot of its quota due to
> other tasks running on its behalf in the critical section?
Less than without PE; without PE the high prio task will be blocked and
starved, with PE at least they'll help push the low prio thing ahead and
get on with things.
Additionally, the highest priotiy waiter will get the lock next.
> On Oct 17, 2022, at 12:26 AM, Chengming Zhou <[email protected]> wrote:
>
> On 2022/10/17 11:56, Joel Fernandes wrote:
>>
>>
>>>> On Oct 16, 2022, at 11:25 PM, Chengming Zhou <[email protected]> wrote:
>>>
>>> Hello,
>>>
>>>> On 2022/10/4 05:44, Connor O'Brien wrote:
>>>> Proxy execution is an approach to implementing priority inheritance
>>>> based on distinguishing between a task's scheduler context (information
>>>> required in order to make scheduling decisions about when the task gets
>>>> to run, such as its scheduler class and priority) and its execution
>>>> context (information required to actually run the task, such as CPU
>>>> affinity). With proxy execution enabled, a task p1 that blocks on a
>>>> mutex remains on the runqueue, but its "blocked" status and the mutex on
>>>> which it blocks are recorded. If p1 is selected to run while still
>>>> blocked, the lock owner p2 can run "on its behalf", inheriting p1's
>>>> scheduler context. Execution context is not inherited, meaning that
>>>> e.g. the CPUs where p2 can run are still determined by its own affinity
>>>> and not p1's.
>>>
>>> This is cool. We have a problem (others should have encountered it too) that
>>> priority inversion happened when the rwsem writer is waiting for many readers
>>> which held lock but are throttled by CFS bandwidth control. (In our use case,
>>> the rwsem is the mm_struct->mmap_sem)
>>>
>>> So I'm curious if this work can also solve this problem? If we don't dequeue
>>> the rwsem writer when it blocked on the rwsem, then CFS scheduler pick it to
>>> run, we can use blocked chain to find the readers to run?
>>
>> That seems a lot harder and unsupported by current patch set AFAICS (my exposure to this work is about a week so take it with a grain of salt). You could have multiple readers so how would you choose which reader to proxy for (round robin?). Also, you no longer have a chain but a tree of chains, with the leaves being each reader - so you have to track that somehow, then keep migrating the blocked tasks in the chain to each readers CPU. Possibly migrating a lot more than in the case of a single chain. Also it’s not clear if it will be beneficial as proxying for one reader does not mean you’re improving the situation if it is another reader that is in need of the boost.
>>
>
> Thanks for your reply, it's indeed more complex than I think, and proxying for just one reader
> is also less efficient.
>
> But this rwsem priority inversion problem hurts us so much that we are afraid to use
> CFS bandwidth control now. Imaging when 10 readers held mmap_sem then throttled for 20ms,
> the writer will have to wait for at least 200ms, which become worse if the writer held other lock.
I hear you. But on the other hand with so many readers the writer is bound to starve anyway. Rwsem is unfair to the writer by definition. But yes, I agree PE (if made to) can help here. I suggest also look into the per-VMA locks and maple tree work that Suren et all are doing, to improve the situation.
Thanks.
>
> Thanks.
>
On 10/17/22 02:23, Joel Fernandes wrote:
> I ran a test to check CFS time sharing. The accounting on top is confusing,
> but ftrace confirms the proxying happening.
>
> Task A - pid 122
> Task B - pid 123
> Task C - pid 121
> Task D - pid 124
>
> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
> spins all the time, while A blocks on the same in-kernel mutex and remains
> blocked.
>
> Then I did "top -H" while the test was running which gives below output.
> The first column is PID, and the third-last column is CPU percentage.
>
> Without PE:
> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
>
> With PE:
> PID
> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
>
> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
> in fact not running and proxying to the owner task so everything seems
> working correctly, but the accounting seems confusing, as in, it is confusing
> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
>
> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
> sleep state), so may be it is OK then, but I did want to bring this up :-)
I seem to remember Valentin raised similar issue about how userspace view can
get confusing/misleading:
https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
Cheers
--
Qais Yousef
> On Oct 19, 2022, at 7:43 AM, Qais Yousef <[email protected]> wrote:
>
> On 10/17/22 02:23, Joel Fernandes wrote:
>
>> I ran a test to check CFS time sharing. The accounting on top is confusing,
>> but ftrace confirms the proxying happening.
>>
>> Task A - pid 122
>> Task B - pid 123
>> Task C - pid 121
>> Task D - pid 124
>>
>> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
>> spins all the time, while A blocks on the same in-kernel mutex and remains
>> blocked.
>>
>> Then I did "top -H" while the test was running which gives below output.
>> The first column is PID, and the third-last column is CPU percentage.
>>
>> Without PE:
>> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
>> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
>> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
>>
>> With PE:
>> PID
>> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
>> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
>> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
>> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
>>
>> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
>> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
>> in fact not running and proxying to the owner task so everything seems
>> working correctly, but the accounting seems confusing, as in, it is confusing
>> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
>>
>> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
>> sleep state), so may be it is OK then, but I did want to bring this up :-)
>
> I seem to remember Valentin raised similar issue about how userspace view can
> get confusing/misleading:
>
> https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
Thanks for the pointer! Glad to see the consensus was that this is not acceptable.
I think we ought to write a patch to fix the accounting, for this series. I propose adding 2 new entries to proc/pid/stat which I think Juri was also sort of was alluding to:
1. Donated time.
2. Proxied time.
User space can then add or subtract this, to calculate things correctly. Or just display them in new columns. I think it will also actually show how much the proxying is happening for a use case.
Thoughts?
Thanks.
> Cheers
>
> --
> Qais Yousef
On 19/10/22 08:23, Joel Fernandes wrote:
>
>
> > On Oct 19, 2022, at 7:43 AM, Qais Yousef <[email protected]> wrote:
> >
> > On 10/17/22 02:23, Joel Fernandes wrote:
> >
> >> I ran a test to check CFS time sharing. The accounting on top is confusing,
> >> but ftrace confirms the proxying happening.
> >>
> >> Task A - pid 122
> >> Task B - pid 123
> >> Task C - pid 121
> >> Task D - pid 124
> >>
> >> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
> >> spins all the time, while A blocks on the same in-kernel mutex and remains
> >> blocked.
> >>
> >> Then I did "top -H" while the test was running which gives below output.
> >> The first column is PID, and the third-last column is CPU percentage.
> >>
> >> Without PE:
> >> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
> >> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
> >> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
> >>
> >> With PE:
> >> PID
> >> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
> >> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
> >> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
> >> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
> >>
> >> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
> >> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
> >> in fact not running and proxying to the owner task so everything seems
> >> working correctly, but the accounting seems confusing, as in, it is confusing
> >> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
> >>
> >> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
> >> sleep state), so may be it is OK then, but I did want to bring this up :-)
> >
> > I seem to remember Valentin raised similar issue about how userspace view can
> > get confusing/misleading:
> >
> > https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
>
> Thanks for the pointer! Glad to see the consensus was that this is not
> acceptable.
>
> I think we ought to write a patch to fix the accounting, for this
> series. I propose adding 2 new entries to proc/pid/stat which I think
> Juri was also sort of was alluding to:
>
> 1. Donated time.
> 2. Proxied time.
Sounds like a useful addition, at least from a debugging point of view.
> User space can then add or subtract this, to calculate things
> correctly. Or just display them in new columns. I think it will also
> actually show how much the proxying is happening for a use case.
Guess we'll however need to be backward compatible with old userspace?
Probably reporting the owner as running while proxied (as in the
comparison case vs. rtmutexes Valentin showed).
On Wed, Oct 19, 2022 at 9:41 AM Juri Lelli <[email protected]> wrote:
>
> On 19/10/22 08:23, Joel Fernandes wrote:
> >
> >
> > > On Oct 19, 2022, at 7:43 AM, Qais Yousef <[email protected]> wrote:
> > >
> > > On 10/17/22 02:23, Joel Fernandes wrote:
> > >
> > >> I ran a test to check CFS time sharing. The accounting on top is confusing,
> > >> but ftrace confirms the proxying happening.
> > >>
> > >> Task A - pid 122
> > >> Task B - pid 123
> > >> Task C - pid 121
> > >> Task D - pid 124
> > >>
> > >> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
> > >> spins all the time, while A blocks on the same in-kernel mutex and remains
> > >> blocked.
> > >>
> > >> Then I did "top -H" while the test was running which gives below output.
> > >> The first column is PID, and the third-last column is CPU percentage.
> > >>
> > >> Without PE:
> > >> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
> > >> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
> > >> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
> > >>
> > >> With PE:
> > >> PID
> > >> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
> > >> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
> > >> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
> > >> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
> > >>
> > >> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
> > >> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
> > >> in fact not running and proxying to the owner task so everything seems
> > >> working correctly, but the accounting seems confusing, as in, it is confusing
> > >> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
> > >>
> > >> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
> > >> sleep state), so may be it is OK then, but I did want to bring this up :-)
> > >
> > > I seem to remember Valentin raised similar issue about how userspace view can
> > > get confusing/misleading:
> > >
> > > https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
> >
> > Thanks for the pointer! Glad to see the consensus was that this is not
> > acceptable.
> >
> > I think we ought to write a patch to fix the accounting, for this
> > series. I propose adding 2 new entries to proc/pid/stat which I think
> > Juri was also sort of was alluding to:
> >
> > 1. Donated time.
> > 2. Proxied time.
>
> Sounds like a useful addition, at least from a debugging point of view.
>
> > User space can then add or subtract this, to calculate things
> > correctly. Or just display them in new columns. I think it will also
> > actually show how much the proxying is happening for a use case.
>
> Guess we'll however need to be backward compatible with old userspace?
> Probably reporting the owner as running while proxied (as in the
> comparison case vs. rtmutexes Valentin showed).
Hi Juri,
Yes I was thinking of leaving the old metrics alone and just providing
the new ones as additional fields in /proc/pid/stats . Then the tools
adjust as needed with the new information. From kernel PoV we provide
the maximum information.
Thanks,
- Joel
On 14/10/22 15:32, Connor O'Brien wrote:
> On Mon, Oct 10, 2022 at 4:40 AM Valentin Schneider <[email protected]> wrote:
>> Consider:
>>
>> p0 (FIFO42)
>> |
>> | blocked_on
>> v
>> p1 (FIFO41)
>> |
>> | blocked_on
>> v
>> p2 (FIFO40)
>>
>> Add on top p3 an unrelated FIFO1 task, and p4 an unrelated CFS task.
>>
>> CPU0
>> current: p0
>> proxy: p2
>> enqueued: p0, p1, p2, p3
>>
>> CPU1
>> current: p4
>> proxy: p4
>> enqueued: p4
>>
>>
>> pick_next_pushable_task() on CPU0 would pick p1 as the next highest
>> priority task to push away to e.g. CPU1, but that would be undone as soon
>> as proxy() happens on CPU1: we'd notice the CPU boundary and punt it back
>> to CPU0. What we would want here is to pick p3 instead to have it run on
>> CPU1.
>
> Given this point, is there any reason that blocked tasks should ever
> be pushable, even if they are not part of the blocked chain for the
> currently running task? If we could just check task_is_blocked()
> rather than needing to know whether the task is in the middle of the
> "active" chain, that would seem to simplify things greatly. I think
> that approach might also require another dequeue/enqueue, in
> ttwu_runnable(), to catch non-proxy blocked tasks becoming unblocked
> (and therefore pushable), but that *seems* OK...though I could
> certainly be missing something.
>
So for an active chain yes we probably don't want any task in the chain to
be visible to load-balance - proxy and curr because they both make up the
currently-executed task (but there are active load balances in
e.g. CFS...), and the rest of the chain because of the above issues.
As for blocked tasks in a separate chain, ideally we would want them to be
picked up by load-balance. Consider:
blocked_on owner
p0 ------------> m0 -------> p1
FIFO4 FIFO3
blocked_on owner
p2 ------------> m1 -------> p3
FIFO2 FIFO1
If all those tasks end up on a single CPU for whatever reason, we'll pick
p0, go through proxy(), and run p1.
If p2 isn't made visible to load-balance, we'll try to move p3 away -
unfortunately nothing will make it bring p2 with it. So if all other CPUs
are running FIFO1 tasks, load-balance will do nothing.
If p2 is made visible to load-balance, we'll try to move it away, but
if/when we try to pick it we'll move it back to where p3 is...
One possible change here is to make the blocked chain migrate towards the
proxy rather than the owner - this makes scheduling priority considerations
a bit saner, but is bad towards the owner (migrating blocked tasks is
"cheap", migrating running tasks isn't).
> A related load balancing correctness question that caught my eye while
> taking another look at this code: when we have rq->curr != rq->proxy
> and then rq->curr is preempted and switches out, IIUC rq->curr should
> become pushable immediately - but this does not seem to be the case
> even with this patch. Is there a path that handles this case that I'm
> just missing, or a reason that no special handling is needed?
> Otherwise I wonder if __schedule() might need a dequeue/enqueue for
> the prev task as well in this case.
pick_next_task() does a put_prev_task() before picking the new highest
priority task, so if curr gets preempted (IOW pick_next_task() returns a p
!= curr) then it has had put_prev_task() done on it which which should make
it pushable.
>>
>> I *think* we want only the proxy of an entire blocked-chain to be visible
>> to load-balance, unfortunately PE gathers the blocked-chain onto the
>> donor's CPU which kinda undoes that.
>>
>> Having the blocked tasks remain in the rq is very handy as it directly
>> gives us the scheduling context and we can unwind the blocked chain for the
>> execution context, but it does wreak havock in load-balancing :/
>>
On 03/10/22 21:44, Connor O'Brien wrote:
> @@ -1303,7 +1303,7 @@ static u64 grub_reclaim(u64 delta, struct rq *rq, struct sched_dl_entity *dl_se)
> */
> static void update_curr_dl(struct rq *rq)
> {
> - struct task_struct *curr = rq->curr;
> + struct task_struct *curr = rq->proxy;
I found a note pointing out that Juri has a patch to unify the
update_curr*() functions as part of the deadline servers thing; I think it
could be picked as a standalone to at least unify the curr = rq->proxy
trickery - this will also (hopefully) remove redundancy for whatever we do
to expose sane runtime values to userspace.
Last iteration I could find is:
https://lore.kernel.org/all/[email protected]/
On 10/19/22 15:41, Juri Lelli wrote:
> On 19/10/22 08:23, Joel Fernandes wrote:
> >
> >
> > > On Oct 19, 2022, at 7:43 AM, Qais Yousef <[email protected]> wrote:
> > >
> > > On 10/17/22 02:23, Joel Fernandes wrote:
> > >
> > >> I ran a test to check CFS time sharing. The accounting on top is confusing,
> > >> but ftrace confirms the proxying happening.
> > >>
> > >> Task A - pid 122
> > >> Task B - pid 123
> > >> Task C - pid 121
> > >> Task D - pid 124
> > >>
> > >> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
> > >> spins all the time, while A blocks on the same in-kernel mutex and remains
> > >> blocked.
> > >>
> > >> Then I did "top -H" while the test was running which gives below output.
> > >> The first column is PID, and the third-last column is CPU percentage.
> > >>
> > >> Without PE:
> > >> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
> > >> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
> > >> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
> > >>
> > >> With PE:
> > >> PID
> > >> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
> > >> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
> > >> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
> > >> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
> > >>
> > >> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
> > >> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
> > >> in fact not running and proxying to the owner task so everything seems
> > >> working correctly, but the accounting seems confusing, as in, it is confusing
> > >> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
> > >>
> > >> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
> > >> sleep state), so may be it is OK then, but I did want to bring this up :-)
> > >
> > > I seem to remember Valentin raised similar issue about how userspace view can
> > > get confusing/misleading:
> > >
> > > https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
> >
> > Thanks for the pointer! Glad to see the consensus was that this is not
> > acceptable.
> >
> > I think we ought to write a patch to fix the accounting, for this
> > series. I propose adding 2 new entries to proc/pid/stat which I think
> > Juri was also sort of was alluding to:
> >
> > 1. Donated time.
> > 2. Proxied time.
>
> Sounds like a useful addition, at least from a debugging point of view.
They look useful addition to me too.
>
> > User space can then add or subtract this, to calculate things
> > correctly. Or just display them in new columns. I think it will also
> > actually show how much the proxying is happening for a use case.
>
> Guess we'll however need to be backward compatible with old userspace?
> Probably reporting the owner as running while proxied (as in the
> comparison case vs. rtmutexes Valentin showed).
>
Or invent a new task_state? Doesn't have to be a real one, just report a new
letter for tasks in PE state. We could use 'r' to indicate running BUT..
Cheers
--
Qais Yousef
> On Oct 19, 2022, at 3:30 PM, Qais Yousef <[email protected]> wrote:
>
> On 10/19/22 15:41, Juri Lelli wrote:
>>> On 19/10/22 08:23, Joel Fernandes wrote:
>>>
>>>
>>>> On Oct 19, 2022, at 7:43 AM, Qais Yousef <[email protected]> wrote:
>>>>
>>>> On 10/17/22 02:23, Joel Fernandes wrote:
>>>>
>>>>> I ran a test to check CFS time sharing. The accounting on top is confusing,
>>>>> but ftrace confirms the proxying happening.
>>>>>
>>>>> Task A - pid 122
>>>>> Task B - pid 123
>>>>> Task C - pid 121
>>>>> Task D - pid 124
>>>>>
>>>>> Here D and B just spin all the time. C is lock owner (in-kernel mutex) and
>>>>> spins all the time, while A blocks on the same in-kernel mutex and remains
>>>>> blocked.
>>>>>
>>>>> Then I did "top -H" while the test was running which gives below output.
>>>>> The first column is PID, and the third-last column is CPU percentage.
>>>>>
>>>>> Without PE:
>>>>> 121 root 20 0 99496 4 0 R 33.6 0.0 0:02.76 t (task C)
>>>>> 123 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task B)
>>>>> 124 root 20 0 99496 4 0 R 33.2 0.0 0:02.75 t (task D)
>>>>>
>>>>> With PE:
>>>>> PID
>>>>> 122 root 20 0 99496 4 0 D 25.3 0.0 0:22.21 t (task A)
>>>>> 121 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task C)
>>>>> 123 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task B)
>>>>> 124 root 20 0 99496 4 0 R 25.0 0.0 0:22.20 t (task D)
>>>>>
>>>>> With PE, I was expecting 2 threads with 25% and 1 thread with 50%. Instead I
>>>>> get 4 threads with 25% in the top. Ftrace confirms that the D-state task is
>>>>> in fact not running and proxying to the owner task so everything seems
>>>>> working correctly, but the accounting seems confusing, as in, it is confusing
>>>>> to see the D-state task task taking 25% CPU when it is obviously "sleeping".
>>>>>
>>>>> Yeah, yeah, I know D is proxying for C (while being in the uninterruptible
>>>>> sleep state), so may be it is OK then, but I did want to bring this up :-)
>>>>
>>>> I seem to remember Valentin raised similar issue about how userspace view can
>>>> get confusing/misleading:
>>>>
>>>> https://www.youtube.com/watch?v=UQNOT20aCEg&t=3h21m41s
>>>
>>> Thanks for the pointer! Glad to see the consensus was that this is not
>>> acceptable.
>>>
>>> I think we ought to write a patch to fix the accounting, for this
>>> series. I propose adding 2 new entries to proc/pid/stat which I think
>>> Juri was also sort of was alluding to:
>>>
>>> 1. Donated time.
>>> 2. Proxied time.
>>
>> Sounds like a useful addition, at least from a debugging point of view.
>
> They look useful addition to me too.
Thanks.
>>> User space can then add or subtract this, to calculate things
>>> correctly. Or just display them in new columns. I think it will also
>>> actually show how much the proxying is happening for a use case.
>>
>> Guess we'll however need to be backward compatible with old userspace?
>> Probably reporting the owner as running while proxied (as in the
>> comparison case vs. rtmutexes Valentin showed).
>>
>
> Or invent a new task_state? Doesn't have to be a real one, just report a new
> letter for tasks in PE state. We could use 'r' to indicate running BUT..
This is a good idea, especially for tracing. I still feel the time taken in the state
is also important to add so that top displays percentage properly.
Best,
-J
> Cheers
>
> --
> Qais Yousef
On 19/10/22 18:05, Valentin Schneider wrote:
> On 14/10/22 15:32, Connor O'Brien wrote:
> > On Mon, Oct 10, 2022 at 4:40 AM Valentin Schneider <[email protected]> wrote:
> >> Consider:
> >>
> >> p0 (FIFO42)
> >> |
> >> | blocked_on
> >> v
> >> p1 (FIFO41)
> >> |
> >> | blocked_on
> >> v
> >> p2 (FIFO40)
> >>
> >> Add on top p3 an unrelated FIFO1 task, and p4 an unrelated CFS task.
> >>
> >> CPU0
> >> current: p0
> >> proxy: p2
> >> enqueued: p0, p1, p2, p3
> >>
> >> CPU1
> >> current: p4
> >> proxy: p4
> >> enqueued: p4
> >>
> >>
> >> pick_next_pushable_task() on CPU0 would pick p1 as the next highest
> >> priority task to push away to e.g. CPU1, but that would be undone as soon
> >> as proxy() happens on CPU1: we'd notice the CPU boundary and punt it back
> >> to CPU0. What we would want here is to pick p3 instead to have it run on
> >> CPU1.
> >
> > Given this point, is there any reason that blocked tasks should ever
> > be pushable, even if they are not part of the blocked chain for the
> > currently running task? If we could just check task_is_blocked()
> > rather than needing to know whether the task is in the middle of the
> > "active" chain, that would seem to simplify things greatly. I think
> > that approach might also require another dequeue/enqueue, in
> > ttwu_runnable(), to catch non-proxy blocked tasks becoming unblocked
> > (and therefore pushable), but that *seems* OK...though I could
> > certainly be missing something.
> >
>
> So for an active chain yes we probably don't want any task in the chain to
> be visible to load-balance - proxy and curr because they both make up the
> currently-executed task (but there are active load balances in
> e.g. CFS...), and the rest of the chain because of the above issues.
>
> As for blocked tasks in a separate chain, ideally we would want them to be
> picked up by load-balance. Consider:
>
> blocked_on owner
> p0 ------------> m0 -------> p1
> FIFO4 FIFO3
>
> blocked_on owner
> p2 ------------> m1 -------> p3
> FIFO2 FIFO1
>
>
> If all those tasks end up on a single CPU for whatever reason, we'll pick
> p0, go through proxy(), and run p1.
>
> If p2 isn't made visible to load-balance, we'll try to move p3 away -
> unfortunately nothing will make it bring p2 with it. So if all other CPUs
> are running FIFO1 tasks, load-balance will do nothing.
>
> If p2 is made visible to load-balance, we'll try to move it away, but
> if/when we try to pick it we'll move it back to where p3 is...
> One possible change here is to make the blocked chain migrate towards the
> proxy rather than the owner - this makes scheduling priority considerations
> a bit saner, but is bad towards the owner (migrating blocked tasks is
> "cheap", migrating running tasks isn't).
Plus we need to consider owner's affinity, maybe it can't really migrate
towards proxy's CPU.
It looks like in general we would like to perform load balancing
decisions considering potential proxies attributes? Guess it might soon
turn into a mess to implement, though.
On 20/10/22 15:30, Juri Lelli wrote:
> On 19/10/22 18:05, Valentin Schneider wrote:
>> One possible change here is to make the blocked chain migrate towards the
>> proxy rather than the owner - this makes scheduling priority considerations
>> a bit saner, but is bad towards the owner (migrating blocked tasks is
>> "cheap", migrating running tasks isn't).
>
> Plus we need to consider owner's affinity, maybe it can't really migrate
> towards proxy's CPU.
>
Right, "little" detail I forgot...
> It looks like in general we would like to perform load balancing
> decisions considering potential proxies attributes? Guess it might soon
> turn into a mess to implement, though.
I can't think of anything clever right now, but we do need something like
that to get "feature parity" with rtmutexes.
On Wed, Oct 19, 2022 at 10:17 AM Valentin Schneider <[email protected]> wrote:
>
> On 03/10/22 21:44, Connor O'Brien wrote:
> > @@ -1303,7 +1303,7 @@ static u64 grub_reclaim(u64 delta, struct rq *rq, struct sched_dl_entity *dl_se)
> > */
> > static void update_curr_dl(struct rq *rq)
> > {
> > - struct task_struct *curr = rq->curr;
> > + struct task_struct *curr = rq->proxy;
>
> I found a note pointing out that Juri has a patch to unify the
> update_curr*() functions as part of the deadline servers thing; I think it
> could be picked as a standalone to at least unify the curr = rq->proxy
> trickery - this will also (hopefully) remove redundancy for whatever we do
> to expose sane runtime values to userspace.
>
> Last iteration I could find is:
>
> https://lore.kernel.org/all/[email protected]/
That makes sense, thanks for the pointer to this patch.
On Tue, Oct 4, 2022 at 9:01 AM Waiman Long <[email protected]> wrote:
>
> On 10/3/22 17:44, Connor O'Brien wrote:
> > diff --git a/kernel/locking/ww_mutex.h b/kernel/locking/ww_mutex.h
> > index 56f139201f24..dfc174cd96c6 100644
> > --- a/kernel/locking/ww_mutex.h
> > +++ b/kernel/locking/ww_mutex.h
> > @@ -161,6 +161,11 @@ static inline void lockdep_assert_wait_lock_held(struct rt_mutex *lock)
> >
> > #endif /* WW_RT */
> >
> > +void ww_ctx_wake(struct ww_acquire_ctx *ww_ctx)
> > +{
> > + wake_up_q(&ww_ctx->wake_q);
> > +}
> > +
> > /*
> > * Wait-Die:
> > * The newer transactions are killed when:
> > @@ -284,7 +289,7 @@ __ww_mutex_die(struct MUTEX *lock, struct MUTEX_WAITER *waiter,
> > #ifndef WW_RT
> > debug_mutex_wake_waiter(lock, waiter);
> > #endif
> > - wake_up_process(waiter->task);
> > + wake_q_add(&ww_ctx->wake_q, waiter->task);
> > }
> >
> > return true;
> > @@ -331,7 +336,7 @@ static bool __ww_mutex_wound(struct MUTEX *lock,
> > * wakeup pending to re-read the wounded state.
> > */
> > if (owner != current)
> > - wake_up_process(owner);
> > + wake_q_add(&ww_ctx->wake_q, owner);
> >
> > return true;
> > }
> > diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> > index ee28253c9ac0..617e737392be 100644
> > --- a/kernel/sched/core.c
> > +++ b/kernel/sched/core.c
> > @@ -1013,6 +1013,13 @@ void wake_up_q(struct wake_q_head *head)
> > wake_up_process(task);
> > put_task_struct(task);
> > }
> > + /*
> > + * XXX connoro: seems this is needed now that ww_ctx_wake() passes in a
> > + * wake_q_head that is embedded in struct ww_acquire_ctx rather than
> > + * declared locally.
> > + */
> > + head->first = node;
> > + head->lastp = &head->first;
> > }
> >
>
> You shouldn't do wake_q_init() here in wake_up_q(). Instead, you should
> do it in ww_ctx_wake() right after the wake_up_q() call.
Thanks, will fix this in the next version.
>
> Cheers,
> Longman
>
On Wed, Oct 19, 2022 at 10:05 AM Valentin Schneider <[email protected]> wrote:
>
> On 14/10/22 15:32, Connor O'Brien wrote:
> > On Mon, Oct 10, 2022 at 4:40 AM Valentin Schneider <[email protected]> wrote:
> >> Consider:
> >>
> >> p0 (FIFO42)
> >> |
> >> | blocked_on
> >> v
> >> p1 (FIFO41)
> >> |
> >> | blocked_on
> >> v
> >> p2 (FIFO40)
> >>
> >> Add on top p3 an unrelated FIFO1 task, and p4 an unrelated CFS task.
> >>
> >> CPU0
> >> current: p0
> >> proxy: p2
> >> enqueued: p0, p1, p2, p3
> >>
> >> CPU1
> >> current: p4
> >> proxy: p4
> >> enqueued: p4
> >>
> >>
> >> pick_next_pushable_task() on CPU0 would pick p1 as the next highest
> >> priority task to push away to e.g. CPU1, but that would be undone as soon
> >> as proxy() happens on CPU1: we'd notice the CPU boundary and punt it back
> >> to CPU0. What we would want here is to pick p3 instead to have it run on
> >> CPU1.
> >
> > Given this point, is there any reason that blocked tasks should ever
> > be pushable, even if they are not part of the blocked chain for the
> > currently running task? If we could just check task_is_blocked()
> > rather than needing to know whether the task is in the middle of the
> > "active" chain, that would seem to simplify things greatly. I think
> > that approach might also require another dequeue/enqueue, in
> > ttwu_runnable(), to catch non-proxy blocked tasks becoming unblocked
> > (and therefore pushable), but that *seems* OK...though I could
> > certainly be missing something.
> >
>
> So for an active chain yes we probably don't want any task in the chain to
> be visible to load-balance - proxy and curr because they both make up the
> currently-executed task (but there are active load balances in
> e.g. CFS...), and the rest of the chain because of the above issues.
>
> As for blocked tasks in a separate chain, ideally we would want them to be
> picked up by load-balance. Consider:
>
> blocked_on owner
> p0 ------------> m0 -------> p1
> FIFO4 FIFO3
>
> blocked_on owner
> p2 ------------> m1 -------> p3
> FIFO2 FIFO1
>
>
> If all those tasks end up on a single CPU for whatever reason, we'll pick
> p0, go through proxy(), and run p1.
>
> If p2 isn't made visible to load-balance, we'll try to move p3 away -
> unfortunately nothing will make it bring p2 with it. So if all other CPUs
> are running FIFO1 tasks, load-balance will do nothing.
Got it, makes sense & will need to think some more about this case.
Another case to consider: if we have another task p4 on the same CPU
also blocked on m0, should it be pushable? There might not be much
point in pushing it away from p1, but preventing that seems like it
would complicate things even further since it would require that the
entire tree of tasks blocked on p1 not be visible to load-balance.
>
> If p2 is made visible to load-balance, we'll try to move it away, but
> if/when we try to pick it we'll move it back to where p3 is...
> One possible change here is to make the blocked chain migrate towards the
> proxy rather than the owner - this makes scheduling priority considerations
> a bit saner, but is bad towards the owner (migrating blocked tasks is
> "cheap", migrating running tasks isn't).
>
> > A related load balancing correctness question that caught my eye while
> > taking another look at this code: when we have rq->curr != rq->proxy
> > and then rq->curr is preempted and switches out, IIUC rq->curr should
> > become pushable immediately - but this does not seem to be the case
> > even with this patch. Is there a path that handles this case that I'm
> > just missing, or a reason that no special handling is needed?
> > Otherwise I wonder if __schedule() might need a dequeue/enqueue for
> > the prev task as well in this case.
>
> pick_next_task() does a put_prev_task() before picking the new highest
> priority task, so if curr gets preempted (IOW pick_next_task() returns a p
> != curr) then it has had put_prev_task() done on it which which should make
> it pushable.
Right now, that call to put_prev_task() passes in rq->proxy rather
than rq->curr, which IIUC means that if the outgoing rq->proxy is
newly pushable due to no longer being the "donor" task/scheduling
context then that will be detected - but I don't see how this does
anything about the outgoing rq->curr. Consider if we have the
following tasks all on a single CPU with the p0->p1 chain currently
running, and then p2 is raised to FIFO3:
blocked_on owner
p0 ------------> m0 -------> p1
FIFO2 FIFO1
blocked_on owner
p2 ------------> m1 -------> p3
FIFO1 FIFO1
My understanding is that the p2->p3 chain would preempt and
__schedule() would call put_prev_task() on p0, set_next_task() on p2,
and proxy_tag_curr() on p3, all of which will appropriately update
those tasks' pushability. But p1 should become pushable now that it's
switching out, and I don't see how that occurs.
On 03/10/2022 23:44, Connor O'Brien wrote:
> From: Peter Zijlstra <[email protected]>
[...]
> + * Returns the task that is going to be used as execution context (the one
> + * that is actually going to be put to run on cpu_of(rq)).
> + */
> +static struct task_struct *
> +proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> +{
[...]
> +migrate_task:
[...]
> + /*
> + * Since we're going to drop @rq, we have to put(@next) first,
> + * otherwise we have a reference that no longer belongs to us. Use
> + * @fake_task to fill the void and make the next pick_next_task()
^^^^^^^^^^
There was a `static struct task_struct fake_task` in
https://lkml.kernel.org/r/[email protected]
but now IMHO we use `rq->idle` <-- (1)
> + * invocation happy.
> + *
> + * XXX double, triple think about this.
> + * XXX put doesn't work with ON_RQ_MIGRATE
> + *
> + * CPU0 CPU1
> + *
> + * B mutex_lock(X)
> + *
> + * A mutex_lock(X) <- B
> + * A __schedule()
> + * A pick->A
> + * A proxy->B
> + * A migrate A to CPU1
> + * B mutex_unlock(X) -> A
> + * B __schedule()
> + * B pick->A
> + * B switch_to (A)
> + * A ... does stuff
> + * A ... is still running here
> + *
> + * * BOOM *
> + */
> + put_prev_task(rq, next);
> + if (curr_in_chain) {
> + rq->proxy = rq->idle;
> + set_tsk_need_resched(rq->idle);
> + /*
> + * XXX [juril] don't we still need to migrate @next to
> + * @owner's CPU?
> + */
> + return rq->idle;
> + }
--> (1)
> + rq->proxy = rq->idle;
> +
> + for (; p; p = p->blocked_proxy) {
> + int wake_cpu = p->wake_cpu;
> +
> + WARN_ON(p == rq->curr);
> +
> + deactivate_task(rq, p, 0);
> + set_task_cpu(p, that_cpu);
> + /*
> + * We can abuse blocked_entry to migrate the thing, because @p is
> + * still on the rq.
> + */
> + list_add(&p->blocked_entry, &migrate_list);
> +
> + /*
> + * Preserve p->wake_cpu, such that we can tell where it
> + * used to run later.
> + */
> + p->wake_cpu = wake_cpu;
> + }
> +
> + rq_unpin_lock(rq, rf);
> + raw_spin_rq_unlock(rq);
Don't we run into rq_pin_lock()'s:
SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
&balance_push_callback)
by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
and __balance_callbacks()?
[...]
On 10/17/22 09:26, Peter Zijlstra wrote:
> Additionally, the highest priotiy waiter will get the lock next.
True for RT. But for CFS, priority is share and there will be no guarantee the
'highest priority' task will run as soon as the lock is released to grab it,
no?
For example I can envisage:
+--------+----------------+--------+--------
| p0 | p1 | p0 | p1
+--------+----------------+--------+--------
^ ^ ^ ^ ^
| | | | |
| | | | Fails to hold the lock
holds lock releases lock | and proxy execs for p0 again
| |
| |
tries to hold lock holds lock again
proxy execs for p0
The notion of priority in CFS as it stands doesn't help in providing any
guarantees in who will be able to hold the lock next. I haven't looked at the
patches closely, so this might be handled already. I think the situation will
be worse if there're more tasks contending for the lock. Priority will
influences the chances, but the end result who holds the lock next is
effectively random, AFAICT.
I had a conversation once with an app developer who came from iOS world and
they were confused why their higher priority task is not preempting the lower
priority one when they ported it to Android.
I wonder sometimes if we need to introduce a true notion of priority for CFS.
I don't see why an app developer who would like to create 3 tasks and give them
strict priority order relative to each others can't do that. At the moment they
have little option in controlling execution order.
Actually I think we need two types of priorities:
* global priorities for a sys admin to say which apps are more
important to run over other apps. Or fairly share it if
equal priority.
* local priorities for an app to control which of its tasks are more
important to run over other tasks it owns.
The concept of share doesn't allow controlling execution order - and forces us
to look at things like latency_nice to, somewhat, overcome this limitation.
Thanks
--
Qais Yousef
> On Oct 24, 2022, at 6:33 PM, Qais Yousef <[email protected]> wrote:
>
> On 10/17/22 09:26, Peter Zijlstra wrote:
>
>> Additionally, the highest priotiy waiter will get the lock next.
>
> True for RT. But for CFS, priority is share and there will be no guarantee the
> 'highest priority' task will run as soon as the lock is released to grab it,
> no?
But the mutex lock owner should have done a wake_up in the mutex unlock path, which is arranged in FIFO order, if I am not mistaken. Subsequently the scheduler will at least get a chance to see if the thing that is waiting for the lock is of higher priority, at the next preemption point.
If it did not get to run, I don’t think that’s an issue — it was not highest priority as far as the scheduler is concerned. No?
Steve was teaching me some of this code recently, he could chime in :)
> For example I can envisage:
>
> +--------+----------------+--------+--------
> | p0 | p1 | p0 | p1
> +--------+----------------+--------+--------
> ^ ^ ^ ^ ^
> | | | | |
> | | | | Fails to hold the lock
> holds lock releases lock | and proxy execs for p0 again
> | |
> | |
> tries to hold lock holds lock again
> proxy execs for p0
>
> The notion of priority in CFS as it stands doesn't help in providing any
> guarantees in who will be able to hold the lock next. I haven't looked at the
> patches closely, so this might be handled already. I think the situation will
> be worse if there're more tasks contending for the lock. Priority will
> influences the chances, but the end result who holds the lock next is
> effectively random, AFAICT.
The wake up during unlock is FIFO order of waiters though. So that’s deterministic.
> I had a conversation once with an app developer who came from iOS world and
> they were confused why their higher priority task is not preempting the lower
> priority one when they ported it to Android.
>
> I wonder sometimes if we need to introduce a true notion of priority for CFS.
> I don't see why an app developer who would like to create 3 tasks and give them
> strict priority order relative to each others can't do that. At the moment they
> have little option in controlling execution order.
I want to talk more about this with you, I am actually working on something similar. Let’s talk ;)
Thanks,
- Joel
>
> Actually I think we need two types of priorities:
>
> * global priorities for a sys admin to say which apps are more
> important to run over other apps. Or fairly share it if
> equal priority.
> * local priorities for an app to control which of its tasks are more
> important to run over other tasks it owns.
>
> The concept of share doesn't allow controlling execution order - and forces us
> to look at things like latency_nice to, somewhat, overcome this limitation.
>
>
> Thanks
>
> --
> Qais Yousef
On 10/25/22 07:19, Joel Fernandes wrote:
>
>
> > On Oct 24, 2022, at 6:33 PM, Qais Yousef <[email protected]> wrote:
> >
> > On 10/17/22 09:26, Peter Zijlstra wrote:
> >
> >> Additionally, the highest priotiy waiter will get the lock next.
> >
> > True for RT. But for CFS, priority is share and there will be no guarantee
> > the 'highest priority' task will run as soon as the lock is released to
> > grab it, no?
>
> But the mutex lock owner should have done a wake_up in the mutex unlock path,
I admit I'm a bit speculating in terms of how mutexes/futexes will behave.
I thought we could still end up with a situation where all (or some) waiters
could wake up and race to hold the lock. Which now thinking about it is bad
news for RT on SMP systems since lower priority tasks on other CPUs could get
the lock before higher priority ones on another CPU. So maybe this situation
can never happen..
> which is arranged in FIFO order, if I am not mistaken. Subsequently the
> scheduler will at least get a chance to see if the thing that is waiting for
> the lock is of higher priority, at the next preemption point.
Right. If it's always ticketed, then we guarantee the order of who holds the
lock first. But the order of which the lock is held/requested/locked is not the
same as priority. And I am not sure if all variations of locks/configs will
exhibit the same behavior TBH.
Again I haven't looked closely at the patches/code, but I only seen the notion
of priority in rt_mutex; probably something similar was done in the PE patches.
__waiter_prio() in rt_mutex.c returns DEFAULT_PRIO for !rt_prio(). So it seems
for me for CFS the prio will not influence the top_waiter and they will be just
queued at the bottom in-order. For rt_mutex that is; which apparently is
obsolete from PE perspective.
I probably have speculated based on that rt_mutex behavior. Apologies if
I jumped guns.
> If it did not get to run, I don’t think that’s an issue — it was not highest
> priority as far as the scheduler is concerned. No?
For CFS priority === share; but maybe you refer to some implementation detail
I missed here. IOW, for CFS highest priority is the most starved task, which is
influenced by nice, but doesn't guarantee who gets to run next?
> Steve was teaching me some of this code recently, he could chime in :)
Would be good for the rest of us to get enlightened too :-)
>
> > For example I can envisage:
> >
> > +--------+----------------+--------+-------- | p0 | p1
> > | p0 | p1 +--------+----------------+--------+--------
> > ^ ^ ^ ^ ^ | | | | | | | | | Fails
> > to hold the lock holds lock releases lock | and proxy execs for
> > p0 again | | | | tries to
> > hold lock holds lock again proxy execs for p0
> >
> > The notion of priority in CFS as it stands doesn't help in providing any
> > guarantees in who will be able to hold the lock next. I haven't looked at
> > the patches closely, so this might be handled already. I think the
> > situation will be worse if there're more tasks contending for the lock.
> > Priority will influences the chances, but the end result who holds the lock
> > next is effectively random, AFAICT.
>
> The wake up during unlock is FIFO order of waiters though. So that’s
> deterministic.
Deterministic in respecting the order the lock was held. But not deterministic
in terms of the priority of the tasks in that order. IOW, that order is based
on time rather than priority.
Say we have 4 CFS tasks, 3 are priority 0 and one is priority -19. If the
3 tasks @prio_0 try to hold the lock before the one @prio_-19; then the FIFO
order means the higher priority one will be the last to get the lock. And the
other tasks - depending how long they hold the lock for - could cause the
@prio_-19 task to run as a proxy for multiple slices first. Which is the
potential problem I was trying to highlight. The @prio_-19 task will not
appear to have been starved for multiple slices since it runs; but as
a proxy.
Again, maybe there's a devilish detail in the patches that addresses that and
it's not really a problem.
>
> > I had a conversation once with an app developer who came from iOS world and
> > they were confused why their higher priority task is not preempting the
> > lower priority one when they ported it to Android.
> >
> > I wonder sometimes if we need to introduce a true notion of priority for
> > CFS. I don't see why an app developer who would like to create 3 tasks and
> > give them strict priority order relative to each others can't do that. At
> > the moment they have little option in controlling execution order.
>
> I want to talk more about this with you, I am actually working on something
> similar. Let’s talk ;)
Oh. Yes, let us talk! :-)
Cheers
--
Qais Yousef
Hello Dietmar,
> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
>
> On 03/10/2022 23:44, Connor O'Brien wrote:
>> From: Peter Zijlstra <[email protected]>
>
> [...]
>
>> + * Returns the task that is going to be used as execution context (the one
>> + * that is actually going to be put to run on cpu_of(rq)).
>> + */
>> +static struct task_struct *
>> +proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
>> +{
>
> [...]
>
>> +migrate_task:
>
> [...]
>
>> + /*
>> + * Since we're going to drop @rq, we have to put(@next) first,
>> + * otherwise we have a reference that no longer belongs to us. Use
>> + * @fake_task to fill the void and make the next pick_next_task()
> ^^^^^^^^^^
>
> There was a `static struct task_struct fake_task` in
> https://lkml.kernel.org/r/[email protected]
> but now IMHO we use `rq->idle` <-- (1)
Ok.
>> + * invocation happy.
>> + *
>> + * XXX double, triple think about this.
>> + * XXX put doesn't work with ON_RQ_MIGRATE
>> + *
>> + * CPU0 CPU1
>> + *
>> + * B mutex_lock(X)
>> + *
>> + * A mutex_lock(X) <- B
>> + * A __schedule()
>> + * A pick->A
>> + * A proxy->B
>> + * A migrate A to CPU1
>> + * B mutex_unlock(X) -> A
>> + * B __schedule()
>> + * B pick->A
>> + * B switch_to (A)
>> + * A ... does stuff
>> + * A ... is still running here
>> + *
>> + * * BOOM *
>> + */
>> + put_prev_task(rq, next);
>> + if (curr_in_chain) {
>> + rq->proxy = rq->idle;
>> + set_tsk_need_resched(rq->idle);
>> + /*
>> + * XXX [juril] don't we still need to migrate @next to
>> + * @owner's CPU?
>> + */
>> + return rq->idle;
>> + }
>
> --> (1)
Sorry but what has this got to do with your comment below?
>> + rq->proxy = rq->idle;
>> +
>> + for (; p; p = p->blocked_proxy) {
>> + int wake_cpu = p->wake_cpu;
>> +
>> + WARN_ON(p == rq->curr);
>> +
>> + deactivate_task(rq, p, 0);
>> + set_task_cpu(p, that_cpu);
>> + /*
>> + * We can abuse blocked_entry to migrate the thing, because @p is
>> + * still on the rq.
>> + */
>> + list_add(&p->blocked_entry, &migrate_list);
>> +
>> + /*
>> + * Preserve p->wake_cpu, such that we can tell where it
>> + * used to run later.
>> + */
>> + p->wake_cpu = wake_cpu;
>> + }
>> +
>> + rq_unpin_lock(rq, rf);
>> + raw_spin_rq_unlock(rq);
>
> Don't we run into rq_pin_lock()'s:
>
> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> &balance_push_callback)
>
> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> and __balance_callbacks()?
Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
Thanks,
- Joel
>
> [...]
On 29/10/2022 05:31, Joel Fernandes wrote:
> Hello Dietmar,
>
>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
>>
>> On 03/10/2022 23:44, Connor O'Brien wrote:
>>> From: Peter Zijlstra <[email protected]>
[...]
>>> + put_prev_task(rq, next);
>>> + if (curr_in_chain) {
>>> + rq->proxy = rq->idle;
>>> + set_tsk_need_resched(rq->idle);
>>> + /*
>>> + * XXX [juril] don't we still need to migrate @next to
>>> + * @owner's CPU?
>>> + */
>>> + return rq->idle;
>>> + }
>>
>> --> (1)
>
> Sorry but what has this got to do with your comment below?
This was the place where fake_task was used in:
https://lkml.kernel.org/r/[email protected]
+migrate_task:
...
+ }
+ rq->proxy = &fake_task; <-- !!!
+
+ for (; p; p = p->blocked_task) {
>>> + rq->proxy = rq->idle;
We use `rq->idle` now,
[...]
>>> + rq_unpin_lock(rq, rf);
>>> + raw_spin_rq_unlock(rq);
>>
>> Don't we run into rq_pin_lock()'s:
>>
>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
>> &balance_push_callback)
>>
>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
>> and __balance_callbacks()?
>
> Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
True, but the code which sneaks in between proxy()'s
raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
__schedule()
rq->proxy = next = pick_next_task()
__pick_next_task()
pick_next_task_rt()
set_next_task_rt()
rt_queue_push_tasks()
queue_balance_callback(..., push_rt_tasks); <-- queue rt cb
proxy()
raw_spin_rq_unlock(rq)
... <-- other thread does rq_lock_XXX(rq)
raw_spin_rq_lock_XXX(rq)
rq_pin_lock(rq)
raw_spin_rq_lock(rq)
context_switch()
finish_task_switch()
finish_lock_switch()
__balance_callbacks(rq) <-- run rt cb here
__balance_callbacks(rq)() <-- or run rt cb here
On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
> On 29/10/2022 05:31, Joel Fernandes wrote:
> > Hello Dietmar,
> >
> >> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
> >>
> >> On 03/10/2022 23:44, Connor O'Brien wrote:
> >>> From: Peter Zijlstra <[email protected]>
>
> [...]
>
> >>> + put_prev_task(rq, next);
> >>> + if (curr_in_chain) {
> >>> + rq->proxy = rq->idle;
> >>> + set_tsk_need_resched(rq->idle);
> >>> + /*
> >>> + * XXX [juril] don't we still need to migrate @next to
> >>> + * @owner's CPU?
> >>> + */
> >>> + return rq->idle;
> >>> + }
> >>
> >> --> (1)
> >
> > Sorry but what has this got to do with your comment below?
>
> This was the place where fake_task was used in:
>
> https://lkml.kernel.org/r/[email protected]
>
> +migrate_task:
> ...
> + }
> + rq->proxy = &fake_task; <-- !!!
> +
> + for (; p; p = p->blocked_task) {
>
> >>> + rq->proxy = rq->idle;
>
> We use `rq->idle` now,
I see. I need to research that, but a comment below:
> [...]
>
> >>> + rq_unpin_lock(rq, rf);
> >>> + raw_spin_rq_unlock(rq);
> >>
> >> Don't we run into rq_pin_lock()'s:
> >>
> >> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> >> &balance_push_callback)
> >>
> >> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> >> and __balance_callbacks()?
> >
> > Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
>
> True, but the code which sneaks in between proxy()'s
> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
>
Got it now, thanks a lot for clarifying. Can this be fixed by do a
__balance_callbacks() at:
> __schedule()
>
> rq->proxy = next = pick_next_task()
>
> __pick_next_task()
>
> pick_next_task_rt()
>
> set_next_task_rt()
>
> rt_queue_push_tasks()
>
> queue_balance_callback(..., push_rt_tasks); <-- queue rt cb
>
> proxy()
>
... here, before doing the following unlock?
> raw_spin_rq_unlock(rq)
>
> ... <-- other thread does rq_lock_XXX(rq)
> raw_spin_rq_lock_XXX(rq)
> rq_pin_lock(rq)
>
> raw_spin_rq_lock(rq)
>
> context_switch()
>
> finish_task_switch()
>
> finish_lock_switch()
>
> __balance_callbacks(rq) <-- run rt cb here
>
> __balance_callbacks(rq)() <-- or run rt cb here
Hmm also Connor, does locktorture do hotplug? Maybe it should to reproduce
the balance issues.
thanks,
- Joel
On 31/10/2022 19:00, Joel Fernandes wrote:
> On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
>> On 29/10/2022 05:31, Joel Fernandes wrote:
>>> Hello Dietmar,
>>>
>>>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
>>>>
>>>> On 03/10/2022 23:44, Connor O'Brien wrote:
>>>>> From: Peter Zijlstra <[email protected]>
[...]
>>>>> + rq_unpin_lock(rq, rf);
>>>>> + raw_spin_rq_unlock(rq);
>>>>
>>>> Don't we run into rq_pin_lock()'s:
>>>>
>>>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
>>>> &balance_push_callback)
>>>>
>>>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
>>>> and __balance_callbacks()?
>>>
>>> Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
>>
>> True, but the code which sneaks in between proxy()'s
>> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
>>
>
> Got it now, thanks a lot for clarifying. Can this be fixed by do a
> __balance_callbacks() at:
I tried the:
head = splice_balance_callbacks(rq)
task_rq_unlock(rq, p, &rf);
...
balance_callbacks(rq, head);
separation known from __sched_setscheduler() in __schedule() (right
after pick_next_task()) but it doesn't work. Lot of `BUG: scheduling
while atomic:`
[ 0.384135] BUG: scheduling while atomic: swapper/0/1/0x00000002
[ 0.384198] INFO: lockdep is turned off.
[ 0.384241] Modules linked in:
[ 0.384289] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G W 6.1.0-rc2-00023-g8a4c0a9d97ce-dirty #166
[ 0.384375] Hardware name: ARM Juno development board (r0) (DT)
[ 0.384426] Call trace:
[ 0.384454] dump_backtrace.part.0+0xe4/0xf0
[ 0.384501] show_stack+0x18/0x40
[ 0.384540] dump_stack_lvl+0x8c/0xb8
[ 0.384582] dump_stack+0x18/0x34
[ 0.384622] __schedule_bug+0x88/0xa0
[ 0.384666] __schedule+0xae0/0xba4
[ 0.384711] schedule+0x5c/0xfc
[ 0.384754] schedule_timeout+0xcc/0x10c
[ 0.384798] __wait_for_common+0xe4/0x1f4
[ 0.384847] wait_for_completion+0x20/0x2c
[ 0.384897] kthread_park+0x58/0xd0
...
>
>> __schedule()
>>
>> rq->proxy = next = pick_next_task()
>>
>> __pick_next_task()
>>
>> pick_next_task_rt()
>>
>> set_next_task_rt()
>>
>> rt_queue_push_tasks()
>>
>> queue_balance_callback(..., push_rt_tasks); <-- queue rt cb
>>
>> proxy()
>>
>
> ... here, before doing the following unlock?
>
>> raw_spin_rq_unlock(rq)
>>
>> ... <-- other thread does rq_lock_XXX(rq)
>> raw_spin_rq_lock_XXX(rq)
>> rq_pin_lock(rq)
>>
>> raw_spin_rq_lock(rq)
>>
>> context_switch()
>>
>> finish_task_switch()
>>
>> finish_lock_switch()
>>
>> __balance_callbacks(rq) <-- run rt cb here
>>
>> __balance_callbacks(rq)() <-- or run rt cb here
>
>
> Hmm also Connor, does locktorture do hotplug? Maybe it should to reproduce
> the balance issues.
I can reproduce this reliably with making the locktorture writer realtime.
--%<--
diff --git a/kernel/locking/locktorture.c b/kernel/locking/locktorture.c
index bc3557677eed..23aabb4f34e5 100644
--- a/kernel/locking/locktorture.c
+++ b/kernel/locking/locktorture.c
@@ -676,7 +676,8 @@ static int lock_torture_writer(void *arg)
DEFINE_TORTURE_RANDOM(rand);
VERBOSE_TOROUT_STRING("lock_torture_writer task started");
- set_user_nice(current, MAX_NICE);
+ if (!rt_task(current))
+ set_user_nice(current, MAX_NICE);
do {
if ((torture_random(&rand) & 0xfffff) == 0)
diff --git a/kernel/torture.c b/kernel/torture.c
index 1d0dd88369e3..55d8ac417a4a 100644
--- a/kernel/torture.c
+++ b/kernel/torture.c
@@ -57,6 +57,9 @@ module_param(verbose_sleep_duration, int, 0444);
static int random_shuffle;
module_param(random_shuffle, int, 0444);
+static int lock_torture_writer_fifo;
+module_param(lock_torture_writer_fifo, int, 0444);
+
static char *torture_type;
static int verbose;
@@ -734,7 +737,7 @@ bool stutter_wait(const char *title)
cond_resched_tasks_rcu_qs();
spt = READ_ONCE(stutter_pause_test);
for (; spt; spt = READ_ONCE(stutter_pause_test)) {
- if (!ret) {
+ if (!ret && !rt_task(current)) {
sched_set_normal(current, MAX_NICE);
ret = true;
}
@@ -944,6 +947,11 @@ int _torture_create_kthread(int (*fn)(void *arg), void *arg, char *s, char *m,
*tp = NULL;
return ret;
}
+
+ if (lock_torture_writer_fifo &&
+ !strncmp(s, "lock_torture_writer", strlen(s)))
+ sched_set_fifo(*tp);
+
wake_up_process(*tp); // Process is sleeping, so ordering provided.
torture_shuffle_task_register(*tp);
return ret;
On Mon, Oct 03, 2022 at 09:45:00PM +0000, Connor O'Brien wrote:
> Quick hack to better surface bugs in proxy execution.
>
> Shuffling sets the same cpu affinities for all tasks, which makes us
> less likely to hit paths involving migrating blocked tasks onto a cpu
> where they can't run. Add an element of randomness to allow affinities
> of different writer tasks to diverge.
>
> Signed-off-by: Connor O'Brien <[email protected]>
> ---
> kernel/torture.c | 10 ++++++++--
> 1 file changed, 8 insertions(+), 2 deletions(-)
>
> diff --git a/kernel/torture.c b/kernel/torture.c
> index 789aeb0e1159..1d0dd88369e3 100644
> --- a/kernel/torture.c
> +++ b/kernel/torture.c
> @@ -54,6 +54,9 @@ module_param(verbose_sleep_frequency, int, 0444);
> static int verbose_sleep_duration = 1;
> module_param(verbose_sleep_duration, int, 0444);
>
> +static int random_shuffle;
> +module_param(random_shuffle, int, 0444);
> +
> static char *torture_type;
> static int verbose;
>
> @@ -518,6 +521,7 @@ static void torture_shuffle_task_unregister_all(void)
> */
> static void torture_shuffle_tasks(void)
> {
> + DEFINE_TORTURE_RANDOM(rand);
> struct shuffle_task *stp;
>
> cpumask_setall(shuffle_tmp_mask);
> @@ -537,8 +541,10 @@ static void torture_shuffle_tasks(void)
> cpumask_clear_cpu(shuffle_idle_cpu, shuffle_tmp_mask);
>
> mutex_lock(&shuffle_task_mutex);
> - list_for_each_entry(stp, &shuffle_task_list, st_l)
> - set_cpus_allowed_ptr(stp->st_t, shuffle_tmp_mask);
> + list_for_each_entry(stp, &shuffle_task_list, st_l) {
> + if (!random_shuffle || torture_random(&rand) & 0x1)
> + set_cpus_allowed_ptr(stp->st_t, shuffle_tmp_mask);
> + }
> mutex_unlock(&shuffle_task_mutex);
Instead of doing it this way, maybe another approach is to randomize the
sleep interval in:
*/
static int torture_shuffle(void *arg)
{
VERBOSE_TOROUT_STRING("torture_shuffle task started");
do {
schedule_timeout_interruptible(shuffle_interval);
torture_shuffle_tasks();
...
} while (...)
...
}
Right now with this patch you still wakeup the shuffle thread when skipping
the affinity set operation.
thanks,
- Joel
> Instead of doing it this way, maybe another approach is to randomize the
> sleep interval in:
>
> */
> static int torture_shuffle(void *arg)
> {
> VERBOSE_TOROUT_STRING("torture_shuffle task started");
> do {
> schedule_timeout_interruptible(shuffle_interval);
> torture_shuffle_tasks();
> ...
> } while (...)
> ...
> }
>
> Right now with this patch you still wakeup the shuffle thread when skipping
> the affinity set operation.
>
> thanks,
>
> - Joel
>
Wouldn't the affinities of all the tasks still change in lockstep
then? The intent with this patch is to get into situations where the
tasks have different affinity masks, which I think requires changing
the behavior of torture_shuffle_tasks() rather than how often it's
called.
On Mon, Nov 14, 2022 at 12:44:21PM -0800, Connor O'Brien wrote:
> > Instead of doing it this way, maybe another approach is to randomize the
> > sleep interval in:
> >
> > */
> > static int torture_shuffle(void *arg)
> > {
> > VERBOSE_TOROUT_STRING("torture_shuffle task started");
> > do {
> > schedule_timeout_interruptible(shuffle_interval);
> > torture_shuffle_tasks();
> > ...
> > } while (...)
> > ...
> > }
> >
> > Right now with this patch you still wakeup the shuffle thread when skipping
> > the affinity set operation.
> >
> > thanks,
> >
> > - Joel
> >
>
> Wouldn't the affinities of all the tasks still change in lockstep
> then? The intent with this patch is to get into situations where the
> tasks have different affinity masks, which I think requires changing
> the behavior of torture_shuffle_tasks() rather than how often it's
> called.
Correct me if I'm wrong, but you are still changing the affinities of all the
tasks at the same time (shuffle_task_list still has all the threads being set
to the same affinity). The difference is with your patch, you occasionally
skip punching a consecutive hole into shuffle_tmp_mask.
I was thinking how you could make this patch more upstreamable, you are right
calling less often is not what you are specifically looking for. However,
would a better approach be to:
a) randomize the shuffle duration.
b) Instead of skipping the set_cpus_allowed_ptr(), why not randomize
the number of times you call cpumask_next() to pick a random hole.
These are just some ideas.
thanks,
- Joel
Hello Dietmar,
On Fri, Nov 04, 2022 at 06:09:26PM +0100, Dietmar Eggemann wrote:
> On 31/10/2022 19:00, Joel Fernandes wrote:
> > On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
> >> On 29/10/2022 05:31, Joel Fernandes wrote:
> >>> Hello Dietmar,
> >>>
> >>>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
> >>>>
> >>>> On 03/10/2022 23:44, Connor O'Brien wrote:
> >>>>> From: Peter Zijlstra <[email protected]>
>
> [...]
>
> >>>>> + rq_unpin_lock(rq, rf);
> >>>>> + raw_spin_rq_unlock(rq);
> >>>>
> >>>> Don't we run into rq_pin_lock()'s:
> >>>>
> >>>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> >>>> &balance_push_callback)
> >>>>
> >>>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> >>>> and __balance_callbacks()?
> >>>
> >>> Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
> >>
> >> True, but the code which sneaks in between proxy()'s
> >> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
> >>
> >
> > Got it now, thanks a lot for clarifying. Can this be fixed by do a
> > __balance_callbacks() at:
>
> I tried the:
>
> head = splice_balance_callbacks(rq)
> task_rq_unlock(rq, p, &rf);
> ...
> balance_callbacks(rq, head);
>
> separation known from __sched_setscheduler() in __schedule() (right
> after pick_next_task()) but it doesn't work. Lot of `BUG: scheduling
> while atomic:`
How about something like the following? This should exclude concurrent
balance callback queues from other CPUs and let us release the rq lock early
in proxy(). I ran locktorture with your diff to make writer threads RT, and I
cannot reproduce any crash with it:
---8<-----------------------
From: "Joel Fernandes (Google)" <[email protected]>
Subject: [PATCH] Exclude balance callback queuing during proxy's migrate
In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
lock needs to be held when __balance_callbacks() in schedule() is called.
However, it is possible that because rq lock is dropped in proxy(), another
CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
issues.
To remedy this, exclude balance callback queuing on other CPUs, during the
proxy().
Reported-by: Dietmar Eggemann <[email protected]>
Signed-off-by: Joel Fernandes (Google) <[email protected]>
---
kernel/sched/core.c | 15 +++++++++++++++
kernel/sched/sched.h | 3 +++
2 files changed, 18 insertions(+)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 88a5fa34dc06..f1dac21fcd90 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -6739,6 +6739,10 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
p->wake_cpu = wake_cpu;
}
+ // Prevent other CPUs from queuing balance callbacks while we migrate
+ // tasks in the migrate_list with the rq lock released.
+ raw_spin_lock(&rq->balance_lock);
+
rq_unpin_lock(rq, rf);
raw_spin_rq_unlock(rq);
raw_spin_rq_lock(that_rq);
@@ -6758,7 +6762,18 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
}
raw_spin_rq_unlock(that_rq);
+
+ // This may make lockdep unhappy as we acquire rq->lock with balance_lock
+ // held. But that should be a false positive, as the following pattern
+ // happens only on the current CPU with interrupts disabled:
+ // rq_lock()
+ // balance_lock();
+ // rq_unlock();
+ // rq_lock();
raw_spin_rq_lock(rq);
+
+ raw_spin_unlock(&rq->balance_lock);
+
rq_repin_lock(rq, rf);
return NULL; /* Retry task selection on _this_ CPU. */
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index 354e75587fed..932d32bf9571 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -1057,6 +1057,7 @@ struct rq {
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
+ raw_spinlock_t balance_lock;
unsigned char nohz_idle_balance;
unsigned char idle_balance;
@@ -1748,6 +1749,7 @@ queue_balance_callback(struct rq *rq,
void (*func)(struct rq *rq))
{
lockdep_assert_rq_held(rq);
+ raw_spin_lock(&rq->balance_lock);
/*
* Don't (re)queue an already queued item; nor queue anything when
@@ -1760,6 +1762,7 @@ queue_balance_callback(struct rq *rq,
head->func = (void (*)(struct callback_head *))func;
head->next = rq->balance_callback;
rq->balance_callback = head;
+ raw_spin_unlock(&rq->balance_lock);
}
#define rcu_dereference_check_sched_domain(p) \
--
2.38.1.584.g0f3c55d4c2-goog
On Sun, Nov 20, 2022 at 7:22 PM Joel Fernandes <[email protected]> wrote:
>
> Hello Dietmar,
>
> On Fri, Nov 04, 2022 at 06:09:26PM +0100, Dietmar Eggemann wrote:
> > On 31/10/2022 19:00, Joel Fernandes wrote:
> > > On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
> > >> On 29/10/2022 05:31, Joel Fernandes wrote:
> > >>> Hello Dietmar,
> > >>>
> > >>>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
> > >>>>
> > >>>> On 03/10/2022 23:44, Connor O'Brien wrote:
> > >>>>> From: Peter Zijlstra <[email protected]>
> >
> > [...]
> >
> > >>>>> + rq_unpin_lock(rq, rf);
> > >>>>> + raw_spin_rq_unlock(rq);
> > >>>>
> > >>>> Don't we run into rq_pin_lock()'s:
> > >>>>
> > >>>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> > >>>> &balance_push_callback)
> > >>>>
> > >>>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> > >>>> and __balance_callbacks()?
> > >>>
> > >>> Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
> > >>
> > >> True, but the code which sneaks in between proxy()'s
> > >> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
> > >>
> > >
> > > Got it now, thanks a lot for clarifying. Can this be fixed by do a
> > > __balance_callbacks() at:
> >
> > I tried the:
> >
> > head = splice_balance_callbacks(rq)
> > task_rq_unlock(rq, p, &rf);
> > ...
> > balance_callbacks(rq, head);
> >
> > separation known from __sched_setscheduler() in __schedule() (right
> > after pick_next_task()) but it doesn't work. Lot of `BUG: scheduling
> > while atomic:`
>
> How about something like the following? This should exclude concurrent
> balance callback queues from other CPUs and let us release the rq lock early
> in proxy(). I ran locktorture with your diff to make writer threads RT, and I
> cannot reproduce any crash with it:
>
> ---8<-----------------------
>
> From: "Joel Fernandes (Google)" <[email protected]>
> Subject: [PATCH] Exclude balance callback queuing during proxy's migrate
>
> In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
> lock needs to be held when __balance_callbacks() in schedule() is called.
> However, it is possible that because rq lock is dropped in proxy(), another
> CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
> issues.
>
> To remedy this, exclude balance callback queuing on other CPUs, during the
> proxy().
>
> Reported-by: Dietmar Eggemann <[email protected]>
> Signed-off-by: Joel Fernandes (Google) <[email protected]>
> ---
> kernel/sched/core.c | 15 +++++++++++++++
> kernel/sched/sched.h | 3 +++
> 2 files changed, 18 insertions(+)
>
> diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> index 88a5fa34dc06..f1dac21fcd90 100644
> --- a/kernel/sched/core.c
> +++ b/kernel/sched/core.c
> @@ -6739,6 +6739,10 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> p->wake_cpu = wake_cpu;
> }
>
> + // Prevent other CPUs from queuing balance callbacks while we migrate
> + // tasks in the migrate_list with the rq lock released.
> + raw_spin_lock(&rq->balance_lock);
> +
> rq_unpin_lock(rq, rf);
> raw_spin_rq_unlock(rq);
> raw_spin_rq_lock(that_rq);
> @@ -6758,7 +6762,18 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> }
>
> raw_spin_rq_unlock(that_rq);
> +
> + // This may make lockdep unhappy as we acquire rq->lock with balance_lock
> + // held. But that should be a false positive, as the following pattern
> + // happens only on the current CPU with interrupts disabled:
> + // rq_lock()
> + // balance_lock();
> + // rq_unlock();
> + // rq_lock();
> raw_spin_rq_lock(rq);
Hmm, I think there's still a chance of deadlock here. I need to
rethink it a bit, but that's the idea I was going for.
thanks,
- Joel
> +
> + raw_spin_unlock(&rq->balance_lock);
> +
> rq_repin_lock(rq, rf);
>
> return NULL; /* Retry task selection on _this_ CPU. */
> diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
> index 354e75587fed..932d32bf9571 100644
> --- a/kernel/sched/sched.h
> +++ b/kernel/sched/sched.h
> @@ -1057,6 +1057,7 @@ struct rq {
> unsigned long cpu_capacity_orig;
>
> struct callback_head *balance_callback;
> + raw_spinlock_t balance_lock;
>
> unsigned char nohz_idle_balance;
> unsigned char idle_balance;
> @@ -1748,6 +1749,7 @@ queue_balance_callback(struct rq *rq,
> void (*func)(struct rq *rq))
> {
> lockdep_assert_rq_held(rq);
> + raw_spin_lock(&rq->balance_lock);
>
> /*
> * Don't (re)queue an already queued item; nor queue anything when
> @@ -1760,6 +1762,7 @@ queue_balance_callback(struct rq *rq,
> head->func = (void (*)(struct callback_head *))func;
> head->next = rq->balance_callback;
> rq->balance_callback = head;
> + raw_spin_unlock(&rq->balance_lock);
> }
>
> #define rcu_dereference_check_sched_domain(p) \
> --
> 2.38.1.584.g0f3c55d4c2-goog
>
On Sun, Nov 20, 2022 at 08:49:22PM -0500, Joel Fernandes wrote:
> On Sun, Nov 20, 2022 at 7:22 PM Joel Fernandes <[email protected]> wrote:
> >
> > Hello Dietmar,
> >
> > On Fri, Nov 04, 2022 at 06:09:26PM +0100, Dietmar Eggemann wrote:
> > > On 31/10/2022 19:00, Joel Fernandes wrote:
> > > > On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
> > > >> On 29/10/2022 05:31, Joel Fernandes wrote:
> > > >>> Hello Dietmar,
> > > >>>
> > > >>>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
> > > >>>>
> > > >>>> On 03/10/2022 23:44, Connor O'Brien wrote:
> > > >>>>> From: Peter Zijlstra <[email protected]>
> > >
> > > [...]
> > >
> > > >>>>> + rq_unpin_lock(rq, rf);
> > > >>>>> + raw_spin_rq_unlock(rq);
> > > >>>>
> > > >>>> Don't we run into rq_pin_lock()'s:
> > > >>>>
> > > >>>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> > > >>>> &balance_push_callback)
> > > >>>>
> > > >>>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> > > >>>> and __balance_callbacks()?
> > > >>>
> > > >>> Apologies, I’m a bit lost here. The code you are responding to inline does not call rq_pin_lock, it calls rq_unpin_lock. So what scenario does the warning trigger according to you?
> > > >>
> > > >> True, but the code which sneaks in between proxy()'s
> > > >> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
> > > >>
> > > >
> > > > Got it now, thanks a lot for clarifying. Can this be fixed by do a
> > > > __balance_callbacks() at:
> > >
> > > I tried the:
> > >
> > > head = splice_balance_callbacks(rq)
> > > task_rq_unlock(rq, p, &rf);
> > > ...
> > > balance_callbacks(rq, head);
> > >
> > > separation known from __sched_setscheduler() in __schedule() (right
> > > after pick_next_task()) but it doesn't work. Lot of `BUG: scheduling
> > > while atomic:`
> >
> > How about something like the following? This should exclude concurrent
> > balance callback queues from other CPUs and let us release the rq lock early
> > in proxy(). I ran locktorture with your diff to make writer threads RT, and I
> > cannot reproduce any crash with it:
> >
> > ---8<-----------------------
> >
> > From: "Joel Fernandes (Google)" <[email protected]>
> > Subject: [PATCH] Exclude balance callback queuing during proxy's migrate
> >
> > In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
> > lock needs to be held when __balance_callbacks() in schedule() is called.
> > However, it is possible that because rq lock is dropped in proxy(), another
> > CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
> > issues.
> >
> > To remedy this, exclude balance callback queuing on other CPUs, during the
> > proxy().
> >
> > Reported-by: Dietmar Eggemann <[email protected]>
> > Signed-off-by: Joel Fernandes (Google) <[email protected]>
> > ---
> > kernel/sched/core.c | 15 +++++++++++++++
> > kernel/sched/sched.h | 3 +++
> > 2 files changed, 18 insertions(+)
> >
> > diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> > index 88a5fa34dc06..f1dac21fcd90 100644
> > --- a/kernel/sched/core.c
> > +++ b/kernel/sched/core.c
> > @@ -6739,6 +6739,10 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> > p->wake_cpu = wake_cpu;
> > }
> >
> > + // Prevent other CPUs from queuing balance callbacks while we migrate
> > + // tasks in the migrate_list with the rq lock released.
> > + raw_spin_lock(&rq->balance_lock);
> > +
> > rq_unpin_lock(rq, rf);
> > raw_spin_rq_unlock(rq);
> > raw_spin_rq_lock(that_rq);
> > @@ -6758,7 +6762,18 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> > }
> >
> > raw_spin_rq_unlock(that_rq);
> > +
> > + // This may make lockdep unhappy as we acquire rq->lock with balance_lock
> > + // held. But that should be a false positive, as the following pattern
> > + // happens only on the current CPU with interrupts disabled:
> > + // rq_lock()
> > + // balance_lock();
> > + // rq_unlock();
> > + // rq_lock();
> > raw_spin_rq_lock(rq);
>
> Hmm, I think there's still a chance of deadlock here. I need to
> rethink it a bit, but that's the idea I was going for.
Took care of that, and came up with the below. Tested with locktorture and it
survives. Thoughts?
---8<-----------------------
From: "Joel Fernandes (Google)" <[email protected]>
Subject: [PATCH v2] Exclude balance callback queuing during proxy's migrate
In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
lock needs to be held when __balance_callbacks() in schedule() is called.
However, it is possible that because rq lock is dropped in proxy(), another
CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
issues.
To remedy this, exclude balance callback queuing on other CPUs, during the
proxy().
Reported-by: Dietmar Eggemann <[email protected]>
Signed-off-by: Joel Fernandes (Google) <[email protected]>
---
kernel/sched/core.c | 72 ++++++++++++++++++++++++++++++++++++++++++--
kernel/sched/sched.h | 3 ++
2 files changed, 73 insertions(+), 2 deletions(-)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 88a5fa34dc06..aba90b3dc3ef 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -633,6 +633,29 @@ struct rq *__task_rq_lock(struct task_struct *p, struct rq_flags *rf)
}
}
+/*
+ * Helper to call __task_rq_lock safely, in scenarios where we might be about to
+ * queue a balance callback on a remote CPU. That CPU might be in proxy(), and
+ * could have released its rq lock while holding balance_lock. So release rq
+ * lock in such a situation to avoid deadlock, and retry.
+ */
+struct rq *__task_rq_lock_balance(struct task_struct *p, struct rq_flags *rf)
+{
+ struct rq *rq;
+ bool locked = false;
+
+ do {
+ if (locked) {
+ __task_rq_unlock(rq, rf);
+ cpu_relax();
+ }
+ rq = __task_rq_lock(p, rf);
+ locked = true;
+ } while (raw_spin_is_locked(&rq->balance_lock));
+
+ return rq;
+}
+
/*
* task_rq_lock - lock p->pi_lock and lock the rq @p resides on.
*/
@@ -675,6 +698,29 @@ struct rq *task_rq_lock(struct task_struct *p, struct rq_flags *rf)
}
}
+/*
+ * Helper to call task_rq_lock safely, in scenarios where we might be about to
+ * queue a balance callback on a remote CPU. That CPU might be in proxy(), and
+ * could have released its rq lock while holding balance_lock. So release rq
+ * lock in such a situation to avoid deadlock, and retry.
+ */
+struct rq *task_rq_lock_balance(struct task_struct *p, struct rq_flags *rf)
+{
+ struct rq *rq;
+ bool locked = false;
+
+ do {
+ if (locked) {
+ task_rq_unlock(rq, p, rf);
+ cpu_relax();
+ }
+ rq = task_rq_lock(p, rf);
+ locked = true;
+ } while (raw_spin_is_locked(&rq->balance_lock));
+
+ return rq;
+}
+
/*
* RQ-clock updating methods:
*/
@@ -6739,6 +6785,12 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
p->wake_cpu = wake_cpu;
}
+ /*
+ * Prevent other CPUs from queuing balance callbacks while we migrate
+ * tasks in the migrate_list with the rq lock released.
+ */
+ raw_spin_lock(&rq->balance_lock);
+
rq_unpin_lock(rq, rf);
raw_spin_rq_unlock(rq);
raw_spin_rq_lock(that_rq);
@@ -6758,7 +6810,21 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
}
raw_spin_rq_unlock(that_rq);
+
+ /*
+ * This may make lockdep unhappy as we acquire rq->lock with
+ * balance_lock held. But that should be a false positive, as the
+ * following pattern happens only on the current CPU with interrupts
+ * disabled:
+ * rq_lock()
+ * balance_lock();
+ * rq_unlock();
+ * rq_lock();
+ */
raw_spin_rq_lock(rq);
+
+ raw_spin_unlock(&rq->balance_lock);
+
rq_repin_lock(rq, rf);
return NULL; /* Retry task selection on _this_ CPU. */
@@ -7489,7 +7555,7 @@ void rt_mutex_setprio(struct task_struct *p, struct task_struct *pi_task)
if (p->pi_top_task == pi_task && prio == p->prio && !dl_prio(prio))
return;
- rq = __task_rq_lock(p, &rf);
+ rq = __task_rq_lock_balance(p, &rf);
update_rq_clock(rq);
/*
* Set under pi_lock && rq->lock, such that the value can be used under
@@ -8093,7 +8159,8 @@ static int __sched_setscheduler(struct task_struct *p,
* To be able to change p->policy safely, the appropriate
* runqueue lock must be held.
*/
- rq = task_rq_lock(p, &rf);
+ rq = task_rq_lock_balance(p, &rf);
+
update_rq_clock(rq);
/*
@@ -10312,6 +10379,7 @@ void __init sched_init(void)
rq = cpu_rq(i);
raw_spin_lock_init(&rq->__lock);
+ raw_spin_lock_init(&rq->balance_lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index 354e75587fed..932d32bf9571 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -1057,6 +1057,7 @@ struct rq {
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
+ raw_spinlock_t balance_lock;
unsigned char nohz_idle_balance;
unsigned char idle_balance;
@@ -1748,6 +1749,7 @@ queue_balance_callback(struct rq *rq,
void (*func)(struct rq *rq))
{
lockdep_assert_rq_held(rq);
+ raw_spin_lock(&rq->balance_lock);
/*
* Don't (re)queue an already queued item; nor queue anything when
@@ -1760,6 +1762,7 @@ queue_balance_callback(struct rq *rq,
head->func = (void (*)(struct callback_head *))func;
head->next = rq->balance_callback;
rq->balance_callback = head;
+ raw_spin_unlock(&rq->balance_lock);
}
#define rcu_dereference_check_sched_domain(p) \
--
2.38.1.584.g0f3c55d4c2-goog
On Mon, Nov 21, 2022 at 03:59:58AM +0000, Joel Fernandes wrote:
> On Sun, Nov 20, 2022 at 08:49:22PM -0500, Joel Fernandes wrote:
> > On Sun, Nov 20, 2022 at 7:22 PM Joel Fernandes <[email protected]> wrote:
> > >
> > > Hello Dietmar,
> > >
> > > On Fri, Nov 04, 2022 at 06:09:26PM +0100, Dietmar Eggemann wrote:
> > > > On 31/10/2022 19:00, Joel Fernandes wrote:
> > > > > On Mon, Oct 31, 2022 at 05:39:45PM +0100, Dietmar Eggemann wrote:
> > > > >> On 29/10/2022 05:31, Joel Fernandes wrote:
> > > > >>> Hello Dietmar,
> > > > >>>
> > > > >>>> On Oct 24, 2022, at 6:13 AM, Dietmar Eggemann <[email protected]> wrote:
> > > > >>>>
> > > > >>>> On 03/10/2022 23:44, Connor O'Brien wrote:
> > > > >>>>> From: Peter Zijlstra <[email protected]>
> > > >
> > > > [...]
> > > >
> > > > >>>>> + rq_unpin_lock(rq, rf);
> > > > >>>>> + raw_spin_rq_unlock(rq);
> > > > >>>>
> > > > >>>> Don't we run into rq_pin_lock()'s:
> > > > >>>>
> > > > >>>> SCHED_WARN_ON(rq->balance_callback && rq->balance_callback !=
> > > > >>>> &balance_push_callback)
> > > > >>>>
> > > > >>>> by releasing rq lock between queue_balance_callback(, push_rt/dl_tasks)
> > > > >>>> and __balance_callbacks()?
> > > > >>>
> > > > >>> Apologies, I’m a bit lost here. The code you are responding to
> > > > >>> inline does not call rq_pin_lock, it calls rq_unpin_lock. So
> > > > >>> what scenario does the warning trigger according to you?
> > > > >>
> > > > >> True, but the code which sneaks in between proxy()'s
> > > > >> raw_spin_rq_unlock(rq) and raw_spin_rq_lock(rq) does.
> > > > >>
> > > > >
> > > > > Got it now, thanks a lot for clarifying. Can this be fixed by do a
> > > > > __balance_callbacks() at:
> > > >
> > > > I tried the:
> > > >
> > > > head = splice_balance_callbacks(rq)
> > > > task_rq_unlock(rq, p, &rf);
> > > > ...
> > > > balance_callbacks(rq, head);
> > > >
> > > > separation known from __sched_setscheduler() in __schedule() (right
> > > > after pick_next_task()) but it doesn't work. Lot of `BUG: scheduling
> > > > while atomic:`
> > >
> > > How about something like the following? This should exclude concurrent
> > > balance callback queues from other CPUs and let us release the rq lock early
> > > in proxy(). I ran locktorture with your diff to make writer threads RT, and I
> > > cannot reproduce any crash with it:
> > >
> > > ---8<-----------------------
> > >
> > > From: "Joel Fernandes (Google)" <[email protected]>
> > > Subject: [PATCH] Exclude balance callback queuing during proxy's migrate
> > >
> > > In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
> > > lock needs to be held when __balance_callbacks() in schedule() is called.
> > > However, it is possible that because rq lock is dropped in proxy(), another
> > > CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
> > > issues.
> > >
> > > To remedy this, exclude balance callback queuing on other CPUs, during the
> > > proxy().
> > >
> > > Reported-by: Dietmar Eggemann <[email protected]>
> > > Signed-off-by: Joel Fernandes (Google) <[email protected]>
> > > ---
> > > kernel/sched/core.c | 15 +++++++++++++++
> > > kernel/sched/sched.h | 3 +++
> > > 2 files changed, 18 insertions(+)
> > >
> > > diff --git a/kernel/sched/core.c b/kernel/sched/core.c
> > > index 88a5fa34dc06..f1dac21fcd90 100644
> > > --- a/kernel/sched/core.c
> > > +++ b/kernel/sched/core.c
> > > @@ -6739,6 +6739,10 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> > > p->wake_cpu = wake_cpu;
> > > }
> > >
> > > + // Prevent other CPUs from queuing balance callbacks while we migrate
> > > + // tasks in the migrate_list with the rq lock released.
> > > + raw_spin_lock(&rq->balance_lock);
> > > +
> > > rq_unpin_lock(rq, rf);
> > > raw_spin_rq_unlock(rq);
> > > raw_spin_rq_lock(that_rq);
> > > @@ -6758,7 +6762,18 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
> > > }
> > >
> > > raw_spin_rq_unlock(that_rq);
> > > +
> > > + // This may make lockdep unhappy as we acquire rq->lock with balance_lock
> > > + // held. But that should be a false positive, as the following pattern
> > > + // happens only on the current CPU with interrupts disabled:
> > > + // rq_lock()
> > > + // balance_lock();
> > > + // rq_unlock();
> > > + // rq_lock();
> > > raw_spin_rq_lock(rq);
> >
> > Hmm, I think there's still a chance of deadlock here. I need to
> > rethink it a bit, but that's the idea I was going for.
>
> Took care of that, and came up with the below. Tested with locktorture and it
> survives. Thoughts?
Found a new bug in my patch during locktorture + hotplug. I was missing an
unlock() during early return of queue_balance_callback(). Please try the
following version of the patch for testing. To trigger the bug in the v2, I
gave the following options to locktorture:
locktorture.stutter=5 locktorture.torture_type=mutex_lock
locktorture.onoff_interval=1 locktorture.onoff_holdoff=10
locktorture.nwriters_stress=10
Now it is fixed.
---8<-----------------------
From: "Joel Fernandes (Google)" <[email protected]>
Subject: [PATCH v3] Exclude balance callback queuing during proxy's migrate
In commit 565790d28b1e ("sched: Fix balance_callback()"), it is clear that rq
lock needs to be held when __balance_callbacks() in schedule() is called.
However, it is possible that because rq lock is dropped in proxy(), another
CPU, say in __sched_setscheduler() can queue balancing callbacks and cause
issues.
To remedy this, exclude balance callback queuing on other CPUs, during the
proxy().
Reported-by: Dietmar Eggemann <[email protected]>
Signed-off-by: Joel Fernandes (Google) <[email protected]>
---
kernel/sched/core.c | 72 ++++++++++++++++++++++++++++++++++++++++++--
kernel/sched/sched.h | 7 ++++-
2 files changed, 76 insertions(+), 3 deletions(-)
diff --git a/kernel/sched/core.c b/kernel/sched/core.c
index 88a5fa34dc06..aba90b3dc3ef 100644
--- a/kernel/sched/core.c
+++ b/kernel/sched/core.c
@@ -633,6 +633,29 @@ struct rq *__task_rq_lock(struct task_struct *p, struct rq_flags *rf)
}
}
+/*
+ * Helper to call __task_rq_lock safely, in scenarios where we might be about to
+ * queue a balance callback on a remote CPU. That CPU might be in proxy(), and
+ * could have released its rq lock while holding balance_lock. So release rq
+ * lock in such a situation to avoid deadlock, and retry.
+ */
+struct rq *__task_rq_lock_balance(struct task_struct *p, struct rq_flags *rf)
+{
+ struct rq *rq;
+ bool locked = false;
+
+ do {
+ if (locked) {
+ __task_rq_unlock(rq, rf);
+ cpu_relax();
+ }
+ rq = __task_rq_lock(p, rf);
+ locked = true;
+ } while (raw_spin_is_locked(&rq->balance_lock));
+
+ return rq;
+}
+
/*
* task_rq_lock - lock p->pi_lock and lock the rq @p resides on.
*/
@@ -675,6 +698,29 @@ struct rq *task_rq_lock(struct task_struct *p, struct rq_flags *rf)
}
}
+/*
+ * Helper to call task_rq_lock safely, in scenarios where we might be about to
+ * queue a balance callback on a remote CPU. That CPU might be in proxy(), and
+ * could have released its rq lock while holding balance_lock. So release rq
+ * lock in such a situation to avoid deadlock, and retry.
+ */
+struct rq *task_rq_lock_balance(struct task_struct *p, struct rq_flags *rf)
+{
+ struct rq *rq;
+ bool locked = false;
+
+ do {
+ if (locked) {
+ task_rq_unlock(rq, p, rf);
+ cpu_relax();
+ }
+ rq = task_rq_lock(p, rf);
+ locked = true;
+ } while (raw_spin_is_locked(&rq->balance_lock));
+
+ return rq;
+}
+
/*
* RQ-clock updating methods:
*/
@@ -6739,6 +6785,12 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
p->wake_cpu = wake_cpu;
}
+ /*
+ * Prevent other CPUs from queuing balance callbacks while we migrate
+ * tasks in the migrate_list with the rq lock released.
+ */
+ raw_spin_lock(&rq->balance_lock);
+
rq_unpin_lock(rq, rf);
raw_spin_rq_unlock(rq);
raw_spin_rq_lock(that_rq);
@@ -6758,7 +6810,21 @@ proxy(struct rq *rq, struct task_struct *next, struct rq_flags *rf)
}
raw_spin_rq_unlock(that_rq);
+
+ /*
+ * This may make lockdep unhappy as we acquire rq->lock with
+ * balance_lock held. But that should be a false positive, as the
+ * following pattern happens only on the current CPU with interrupts
+ * disabled:
+ * rq_lock()
+ * balance_lock();
+ * rq_unlock();
+ * rq_lock();
+ */
raw_spin_rq_lock(rq);
+
+ raw_spin_unlock(&rq->balance_lock);
+
rq_repin_lock(rq, rf);
return NULL; /* Retry task selection on _this_ CPU. */
@@ -7489,7 +7555,7 @@ void rt_mutex_setprio(struct task_struct *p, struct task_struct *pi_task)
if (p->pi_top_task == pi_task && prio == p->prio && !dl_prio(prio))
return;
- rq = __task_rq_lock(p, &rf);
+ rq = __task_rq_lock_balance(p, &rf);
update_rq_clock(rq);
/*
* Set under pi_lock && rq->lock, such that the value can be used under
@@ -8093,7 +8159,8 @@ static int __sched_setscheduler(struct task_struct *p,
* To be able to change p->policy safely, the appropriate
* runqueue lock must be held.
*/
- rq = task_rq_lock(p, &rf);
+ rq = task_rq_lock_balance(p, &rf);
+
update_rq_clock(rq);
/*
@@ -10312,6 +10379,7 @@ void __init sched_init(void)
rq = cpu_rq(i);
raw_spin_lock_init(&rq->__lock);
+ raw_spin_lock_init(&rq->balance_lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
diff --git a/kernel/sched/sched.h b/kernel/sched/sched.h
index 354e75587fed..17947a4009de 100644
--- a/kernel/sched/sched.h
+++ b/kernel/sched/sched.h
@@ -1057,6 +1057,7 @@ struct rq {
unsigned long cpu_capacity_orig;
struct callback_head *balance_callback;
+ raw_spinlock_t balance_lock;
unsigned char nohz_idle_balance;
unsigned char idle_balance;
@@ -1748,18 +1749,22 @@ queue_balance_callback(struct rq *rq,
void (*func)(struct rq *rq))
{
lockdep_assert_rq_held(rq);
+ raw_spin_lock(&rq->balance_lock);
/*
* Don't (re)queue an already queued item; nor queue anything when
* balance_push() is active, see the comment with
* balance_push_callback.
*/
- if (unlikely(head->next || rq->balance_callback == &balance_push_callback))
+ if (unlikely(head->next || rq->balance_callback == &balance_push_callback)) {
+ raw_spin_unlock(&rq->balance_lock);
return;
+ }
head->func = (void (*)(struct callback_head *))func;
head->next = rq->balance_callback;
rq->balance_callback = head;
+ raw_spin_unlock(&rq->balance_lock);
}
#define rcu_dereference_check_sched_domain(p) \
--
2.38.1.584.g0f3c55d4c2-goog
On 2022-10-03 at 21:44:57 +0000, Connor O'Brien wrote:
> From: Peter Zijlstra <[email protected]>
>
> A task currently holding a mutex (executing a critical section) might
> find benefit in using scheduling contexts of other tasks blocked on the
> same mutex if they happen to have higher priority of the current owner
> (e.g., to prevent priority inversions).
>
> Proxy execution lets a task do exactly that: if a mutex owner has
> waiters, it can use waiters' scheduling context to potentially continue
> running if preempted.
>
> The basic mechanism is implemented by this patch, the core of which
> resides in the proxy() function. Potential proxies (i.e., tasks blocked
> on a mutex) are not dequeued, so, if one of them is actually selected by
> schedule() as the next task to be put to run on a CPU, proxy() is used
> to walk the blocked_on relation and find which task (mutex owner) might
> be able to use the proxy's scheduling context.
>
> Here come the tricky bits. In fact, owner task might be in all sort of
> states when a proxy is found (blocked, executing on a different CPU,
> etc.). Details on how to handle different situations are to be found in
> proxy() code comments.
>
> Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> [rebased, added comments and changelog]
> Signed-off-by: Juri Lelli <[email protected]>
> [Fixed rebase conflicts]
> [squashed sched: Ensure blocked_on is always guarded by blocked_lock]
> Signed-off-by: Valentin Schneider <[email protected]>
> [fix rebase conflicts, various fixes & tweaks commented inline]
> [squashed sched: Use rq->curr vs rq->proxy checks]
> Signed-off-by: Connor O'Brien <[email protected]>
> Link: https://lore.kernel.org/all/[email protected]/
>
While we are evaluating linux scalability on high core count system, we found
that hackbench pipe mode is sensitive to mutex_lock(). So we looked at this patch
set to see if it makes any difference.
Tested on a system with 112 online CPUs. The hackbench launches 8 groups, each
group has 14 pairs of sender/receiver. Every sender sends data via pipe to each
receiver in the same group, thus it is a 14 * 14 reproducer/consumer matrix in
every group, and 14 * 14 * 8 concurrent read/write in total. With pe patch applied,
we observed some throughput regression. According to perf profiling, the system has
higher idle time(raised from 16% to 39%).
And one hot path is:
do_idle() -> schedule_idle() -> __schedule() -> pick_next_task_fair() -> newidle_balance()
It seems that the systems spends quite some time in newidle_balance() which
is costly on a 112 CPUs system. My understanding is that, if the CPU
quits idle in do_idle(), it is very likely to have a pending ttwu request. So
when this CPU further reaches schedule_idle()->pick_next_task_fair(),
it should find a candidate task. But unfortunately in our case it fails to find any
runnable task, thus has to pick the idle task, which triggers the costly
load balance. Is this caused by a race condition that someone else migtate the runnable
task to the other CPU? Besides, a more generic question is, if the mutex lock owners/blockers
have the same priority, is proxy execution suitible for this scenario?
I'm glad to test with what you suggest, appreciated for any suggestion.
The flamegraph of vanilla 6.0-rc7:
https://raw.githubusercontent.com/yu-chen-surf/schedtests/master/results/proxy_execution/flamegraph_vanilla_6.0.0-rc7.svg
The flamegraph of vanilla 6.0-rc7 + proxy execution:
https://raw.githubusercontent.com/yu-chen-surf/schedtests/master/results/proxy_execution/flamegraph_pe_6.0.0-rc7.svg
thanks,
Chenyu
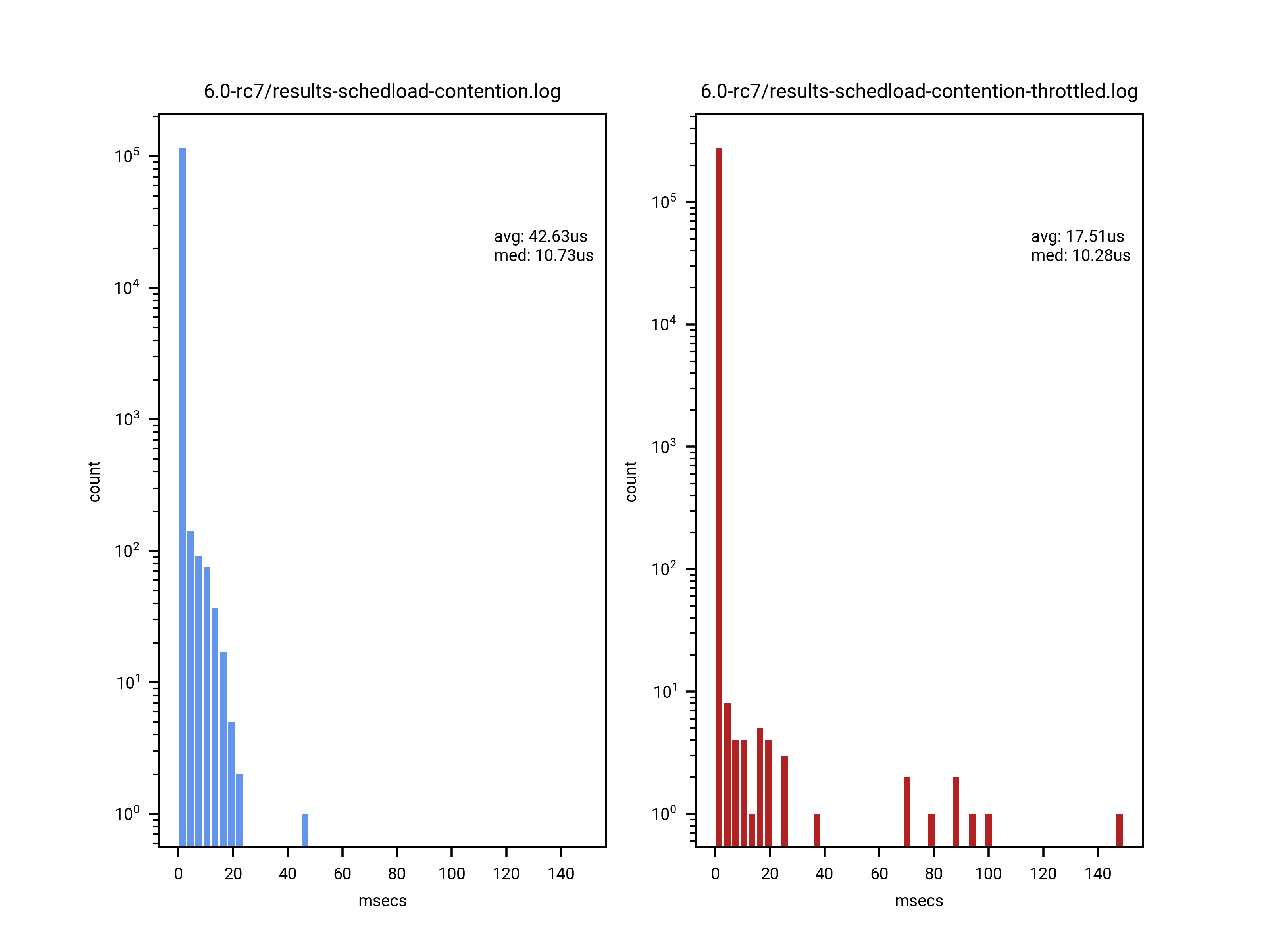{kind=link}
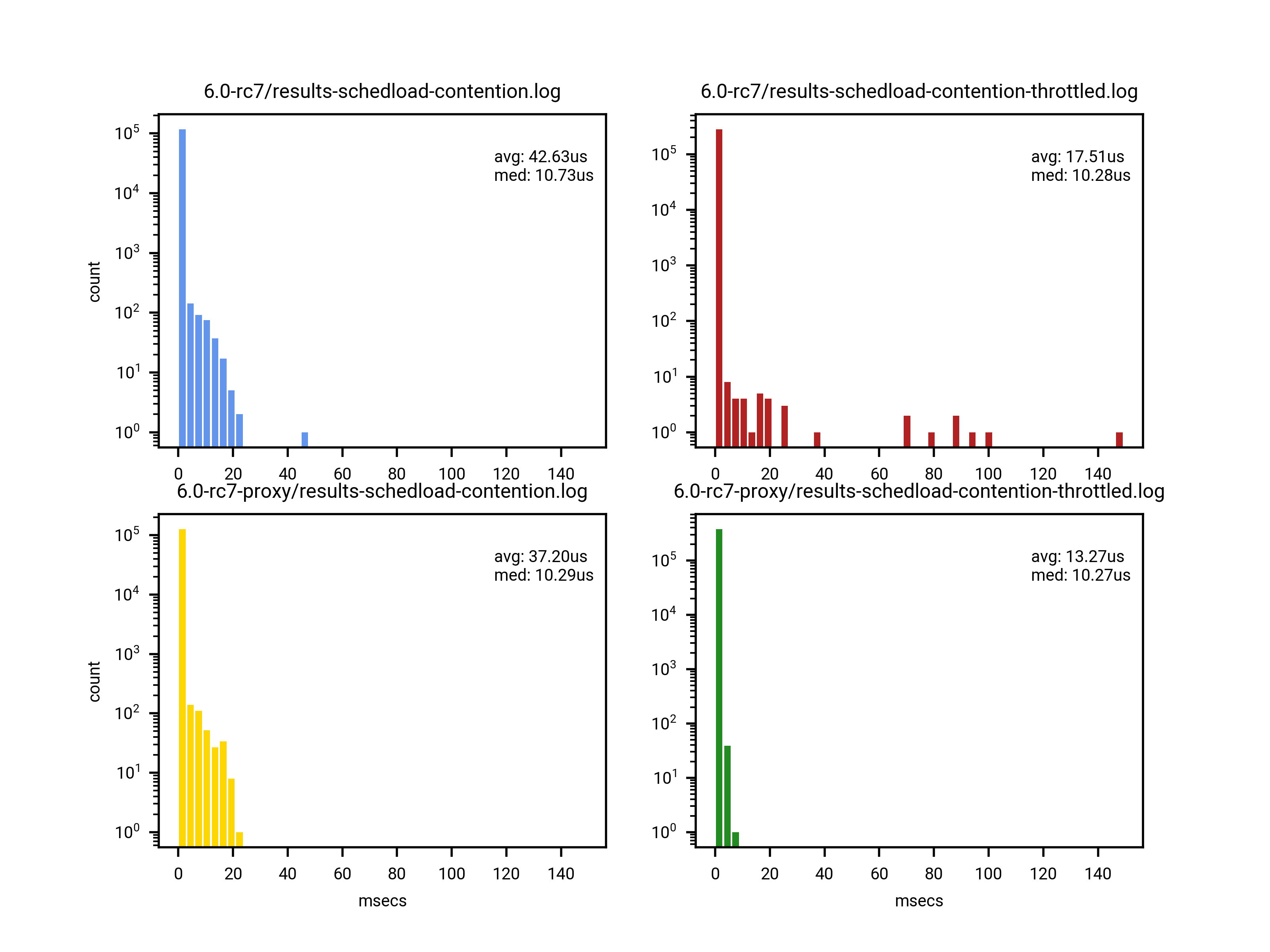{kind=link}
{kind=link}
{kind=link}