Possibly related to the flush-processes-taking-CPU issues I saw
previously, I thought this was interesting. I found a log-crunching box
that does all of its work via NFS and spends most of the day sleeping.
It has been using a linearly-increasing amount of system time during the
time where is sleeping. munin graph:
http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
top shows:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4767 root 20 0 0 0 0 S 16 0.0 2413:29 flush-0:69
22385 root 20 0 0 0 0 S 10 0.0 1320:23 flush-0:70
(rest idle)
perf top shows:
-------------------------------------------------------------------------------------------
PerfTop: 252 irqs/sec kernel:97.2% exact: 0.0% [1000Hz cycles], (all, 2 CPUs)
-------------------------------------------------------------------------------------------
samples pcnt function DSO
_______ _____ _______________________________ ___________
912.00 21.2% _raw_spin_lock [kernel]
592.00 13.8% nfs_writepages [kernel]
474.00 11.0% queue_io [kernel]
428.00 10.0% writeback_single_inode [kernel]
379.00 8.8% writeback_sb_inodes [kernel]
237.00 5.5% bit_waitqueue [kernel]
184.00 4.3% do_writepages [kernel]
169.00 3.9% __iget [kernel]
132.00 3.1% redirty_tail [kernel]
85.00 2.0% iput [kernel]
72.00 1.7% _atomic_dec_and_lock [kernel]
67.00 1.6% write_cache_pages [kernel]
63.00 1.5% port_inb [ipmi_si]
62.00 1.4% __mark_inode_dirty [kernel]
48.00 1.1% __wake_up_bit [kernel]
32.00 0.7% nfs_write_inode [kernel]
26.00 0.6% native_read_tsc [kernel]
25.00 0.6% radix_tree_gang_lookup_tag_slot [kernel]
25.00 0.6% schedule [kernel]
24.00 0.6% wake_up_bit [kernel]
20.00 0.5% apic_timer_interrupt [kernel]
19.00 0.4% ia32_syscall [kernel]
16.00 0.4% find_get_pages_tag [kernel]
15.00 0.3% _raw_spin_lock_irqsave [kernel]
15.00 0.3% load_balance [kernel]
13.00 0.3% ktime_get [kernel]
12.00 0.3% shrink_icache_memory [kernel]
11.00 0.3% semop libc-2.7.so
9.00 0.2% nfs_pageio_doio [kernel]
8.00 0.2% dso__find_symbol perf
8.00 0.2% down_read [kernel]
7.00 0.2% __switch_to [kernel]
7.00 0.2% __phys_addr [kernel]
7.00 0.2% nfs_pageio_init [kernel]
7.00 0.2% pagevec_lookup_tag [kernel]
7.00 0.2% _cond_resched [kernel]
7.00 0.2% up_read [kernel]
6.00 0.1% sched_clock_local [kernel]
5.00 0.1% rb_erase [kernel]
5.00 0.1% page_fault [kernel]
"tcpdump -i any -n port 2049" and "nfsstat" shows this work does not actually result
in any NFS packets.
Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the
munin graphs. I'll try 2.6.37-rc an see if it changes.
Simon-
On Wed, Dec 15, 2010 at 06:58:09PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 17:55 -0500, J. Bruce Fields wrote:
> > On Wed, Dec 15, 2010 at 05:29:28PM -0500, J. Bruce Fields wrote:
> > > On Wed, Dec 15, 2010 at 05:15:46PM -0500, Trond Myklebust wrote:
> > > > I'm quite happy to accept that my user may map to completely different
> > > > identities on the server as I switch authentication schemes. Fixing that
> > > > is indeed the administrator's problem.
> > > >
> > > > I'm thinking of the simple case of creating a file, and then expecting
> > > > to see that file appear labelled with the correct user id when I do 'ls
> > > > -l'. That should work irrespectively of the authentication scheme that I
> > > > choose.
> > > >
> > > > In other words, if I authenticate as 'trond' on my client or to the
> > > > kerberos server, then do
> > > >
> > > > touch foo
> > > > ls -l foo
> > > >
> > > > I should see a file that is owned by 'trond'.
> > >
> > > Thanks, understood; but then, this isn't about behavior that occurs when
> > > a user *changes* authentication flavors.
> > >
> > > It's about what happens when someone sets nfs4_disable_idmapping but
> > > shouldn't have.
> >
> > In other words, to make sure I understand:
> >
> > - Is this switching-on-auth flavor *just* there to protect
> > confused administrators against themselves?
> > - Or is there some reasons someone who knew what they were doing
> > would actually *need* that behavior?
>
> It is there to ensure that you can use different type of authentication
> when speaking to different servers, and still have it work without the
> administrator having to add special mount options.
Oh, OK--now I understand, thanks! Then it really is just a restricted
sort of per-mountpoint idmapping.
As such I'm not sure I understand the relative merits of that versus
(possibly per-server) idmapd configuration. But at least it seems
tolerable.
The biggest remaining problem either way is that the user experience on
an NFSv3->NFSv4 upgrade is still:
- oh, look, file owners look all wrong.
- go find documentation of the needed configuration
(domain setting in /etc/idmapd.conf, or nfs4_disable_idmapping
option)
--b.
> As I've said before, the uid-on-the-wire behaviour only makes sense with
> AUTH_SYS. It adds no value when authenticating using principals, and
> will in many (most?) cases end up doing the wrong thing.
>
> Trond
>
> --
> Trond Myklebust
> Linux NFS client maintainer
>
> NetApp
> [email protected]
> http://www.netapp.com
>
On Wed, 2010-12-15 at 17:55 -0500, J. Bruce Fields wrote:
> On Wed, Dec 15, 2010 at 05:29:28PM -0500, J. Bruce Fields wrote:
> > On Wed, Dec 15, 2010 at 05:15:46PM -0500, Trond Myklebust wrote:
> > > On Wed, 2010-12-15 at 16:48 -0500, J. Bruce Fields wrote:
> > > > On Wed, Dec 15, 2010 at 03:32:08PM -0500, Trond Myklebust wrote:
> > > > > On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
> > > > >
> > > > > > Could you give an example of a case in which all of the following are
> > > > > > true?:
> > > > > > - the administrator explicitly requests numeric id's (for
> > > > > > example by setting nfs4_disable_idmapping).
> > > > > > - numeric id's work as long as the client uses auth_sys.
> > > > > > - they no longer work if that same client switches to krb5.
> > > > >
> > > > > Trivially:
> > > > >
> > > > > Server /etc/passwd maps trondmy to uid 1000
> > > > > Client /etc/passwd maps trondmy to uid 500
> > > >
> > > > I understand that any problematic case would involve different
> > > > name<->id mappings on the two sides.
> > > >
> > > > What I don't understand--and apologies if I'm being dense!--is what
> > > > sequence of operations exactly would work in this situation if we
> > > > automatically switch idmapping based on auth flavor, and would not work
> > > > without it.
> > > >
> > > > Are you imagining a future client that is also able to switch auth
> > > > flavors on the fly (say, based on whether a krb5 ticket exists or not),
> > > > or just unmounting and remounting to change the security flavor?
> > > >
> > > > Are you thinking of creating a file under one flavor and accessing it
> > > > under another?
> > >
> > > Neither.
> > >
> > > I'm quite happy to accept that my user may map to completely different
> > > identities on the server as I switch authentication schemes. Fixing that
> > > is indeed the administrator's problem.
> > >
> > > I'm thinking of the simple case of creating a file, and then expecting
> > > to see that file appear labelled with the correct user id when I do 'ls
> > > -l'. That should work irrespectively of the authentication scheme that I
> > > choose.
> > >
> > > In other words, if I authenticate as 'trond' on my client or to the
> > > kerberos server, then do
> > >
> > > touch foo
> > > ls -l foo
> > >
> > > I should see a file that is owned by 'trond'.
> >
> > Thanks, understood; but then, this isn't about behavior that occurs when
> > a user *changes* authentication flavors.
> >
> > It's about what happens when someone sets nfs4_disable_idmapping but
> > shouldn't have.
>
> In other words, to make sure I understand:
>
> - Is this switching-on-auth flavor *just* there to protect
> confused administrators against themselves?
> - Or is there some reasons someone who knew what they were doing
> would actually *need* that behavior?
It is there to ensure that you can use different type of authentication
when speaking to different servers, and still have it work without the
administrator having to add special mount options.
As I've said before, the uid-on-the-wire behaviour only makes sense with
AUTH_SYS. It adds no value when authenticating using principals, and
will in many (most?) cases end up doing the wrong thing.
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
>
> > I'm just about to try
> > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > half-merged and uploaded as -git3 but not pushed to his public git)
>
> Ignore this; I was just confusing myself by having the leak fixes already
> applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> merging again.
>
> Do you have a git branch exposed with the "Allow the admin to turn off
> NFSv4 uid/gid mapping" patches applied?
Hm, the fixes were merged for -git4, and it seems to work fine there.
As for the nfs4 uid/gid mapping patch, it seems the server side support
for this is still neded?
Simon-
On Wed, 2010-12-08 at 13:25 -0800, Simon Kirby wrote:
> Possibly related to the flush-processes-taking-CPU issues I saw
> previously, I thought this was interesting. I found a log-crunching box
> that does all of its work via NFS and spends most of the day sleeping.
> It has been using a linearly-increasing amount of system time during the
> time where is sleeping. munin graph:
>
> http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
>
> top shows:
>
> PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
> 4767 root 20 0 0 0 0 S 16 0.0 2413:29 flush-0:69
> 22385 root 20 0 0 0 0 S 10 0.0 1320:23 flush-0:70
> (rest idle)
>
> perf top shows:
>
> -------------------------------------------------------------------------------------------
> PerfTop: 252 irqs/sec kernel:97.2% exact: 0.0% [1000Hz cycles], (all, 2 CPUs)
> -------------------------------------------------------------------------------------------
>
> samples pcnt function DSO
> _______ _____ _______________________________ ___________
>
> 912.00 21.2% _raw_spin_lock [kernel]
> 592.00 13.8% nfs_writepages [kernel]
> 474.00 11.0% queue_io [kernel]
> 428.00 10.0% writeback_single_inode [kernel]
> 379.00 8.8% writeback_sb_inodes [kernel]
> 237.00 5.5% bit_waitqueue [kernel]
> 184.00 4.3% do_writepages [kernel]
> 169.00 3.9% __iget [kernel]
> 132.00 3.1% redirty_tail [kernel]
> 85.00 2.0% iput [kernel]
> 72.00 1.7% _atomic_dec_and_lock [kernel]
> 67.00 1.6% write_cache_pages [kernel]
> 63.00 1.5% port_inb [ipmi_si]
> 62.00 1.4% __mark_inode_dirty [kernel]
> 48.00 1.1% __wake_up_bit [kernel]
> 32.00 0.7% nfs_write_inode [kernel]
> 26.00 0.6% native_read_tsc [kernel]
> 25.00 0.6% radix_tree_gang_lookup_tag_slot [kernel]
> 25.00 0.6% schedule [kernel]
> 24.00 0.6% wake_up_bit [kernel]
> 20.00 0.5% apic_timer_interrupt [kernel]
> 19.00 0.4% ia32_syscall [kernel]
> 16.00 0.4% find_get_pages_tag [kernel]
> 15.00 0.3% _raw_spin_lock_irqsave [kernel]
> 15.00 0.3% load_balance [kernel]
> 13.00 0.3% ktime_get [kernel]
> 12.00 0.3% shrink_icache_memory [kernel]
> 11.00 0.3% semop libc-2.7.so
> 9.00 0.2% nfs_pageio_doio [kernel]
> 8.00 0.2% dso__find_symbol perf
> 8.00 0.2% down_read [kernel]
> 7.00 0.2% __switch_to [kernel]
> 7.00 0.2% __phys_addr [kernel]
> 7.00 0.2% nfs_pageio_init [kernel]
> 7.00 0.2% pagevec_lookup_tag [kernel]
> 7.00 0.2% _cond_resched [kernel]
> 7.00 0.2% up_read [kernel]
> 6.00 0.1% sched_clock_local [kernel]
> 5.00 0.1% rb_erase [kernel]
> 5.00 0.1% page_fault [kernel]
>
> "tcpdump -i any -n port 2049" and "nfsstat" shows this work does not actually result
> in any NFS packets.
>
> Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the
> munin graphs. I'll try 2.6.37-rc an see if it changes.
Possibly a side effect of the fs/fs-writeback.c changes in 2.6.36? You
do appear to be hitting a lot of spinlock contention, but I suspect that
a lot of it is coming from writeback_sb_inodes, writeback_single_inode
and queue_io, all of which seem unnaturally high on your stats above.
I don't see how you can be seeing no traffic on the wire. You are
certainly hitting some page writeout (0.2% nfs_pageio_doio).
Cheers
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, 2010-12-08 at 14:36 -0800, Simon Kirby wrote:
> On Wed, Dec 08, 2010 at 04:53:09PM -0500, Trond Myklebust wrote:
>
> > Possibly a side effect of the fs/fs-writeback.c changes in 2.6.36? You
> > do appear to be hitting a lot of spinlock contention, but I suspect that
> > a lot of it is coming from writeback_sb_inodes, writeback_single_inode
> > and queue_io, all of which seem unnaturally high on your stats above.
> >
> > I don't see how you can be seeing no traffic on the wire. You are
> > certainly hitting some page writeout (0.2% nfs_pageio_doio).
>
> It really seems to not be doing anything. I ran nfsstat -Zcv for 5
> minutes, and the only non-zero counters are rpc calls and authrefrsh,
> even though perf top shows similar profiles the whole time.
That sounds like a bug in nfsstat, then. As I said, your trace results
definitely indicate that you are doing page writeout. I'd cross check
using wireshark...
Cheers
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, Dec 08, 2010 at 01:25:05PM -0800, Simon Kirby wrote:
> Possibly related to the flush-processes-taking-CPU issues I saw
> previously, I thought this was interesting. I found a log-crunching box
> that does all of its work via NFS and spends most of the day sleeping.
> It has been using a linearly-increasing amount of system time during the
> time where is sleeping. munin graph:
>
> http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
>...
> Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the
> munin graphs. I'll try 2.6.37-rc an see if it changes.
So, back on this topic,
It seems that system CPU from "flush" processes is still increasing
during and after periods of NFS activity, even with 2.6.37-rc5-git4:
http://0x.ca/sim/ref/2.6.37/cpu_nfs.png
Something is definitely going on while NFS is active, and then keeps
happening in the idle periods. top and perf top look the same as in
2.6.36. No userland activity at all, but the kernel keeps doing stuff.
I could bisect this, but I have to wait a day for each build, unless I
can come up with a way to reproduce it more quickly. The mount points
for which the flush processes are active are the two mount points where
the logs are read from, rotated, compressed, and unlinked, and where the
reports are written, running in parallel under an xargs -P 15.
I'm pretty sure the only syscalls that are reproducing this are read(),
readdir(), lstat(), write(), rename(), unlink(), and close(). There's
nothing special happening here...
Simon-
On Wed, 2010-12-15 at 13:38 -0500, J. Bruce Fields wrote:
> On Wed, Dec 15, 2010 at 01:22:13PM -0500, Trond Myklebust wrote:
> > On Wed, 2010-12-15 at 13:08 -0500, J. Bruce Fields wrote:
> > > On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> > > > On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> > > >
> > > > > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> > > > >
> > > > > > I'm just about to try
> > > > > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > > > > half-merged and uploaded as -git3 but not pushed to his public git)
> > > > >
> > > > > Ignore this; I was just confusing myself by having the leak fixes already
> > > > > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > > > > merging again.
> > > > >
> > > > > Do you have a git branch exposed with the "Allow the admin to turn off
> > > > > NFSv4 uid/gid mapping" patches applied?
> > > >
> > > > Hm, the fixes were merged for -git4, and it seems to work fine there.
> > > >
> > > > As for the nfs4 uid/gid mapping patch, it seems the server side support
> > > > for this is still neded?
> > >
> > > I'm not convinced that this behavior should depend on the security
> > > flavor, so I'm assuming that something like steved's libnfsidmap patches
> > > should do the job.
> >
> > Don't assume.
> >
> > Those patches do not fix the problem that if uid(name@server) !=
> > uid(name@client), then the client will be creating files with the 'wrong
> > username' on the server.
>
> I don't see any obviously correct solution in cases where the mapping
> disagrees between client and server sides, so prefer to stick to the
> NFSv3 behavior.
>
> The only reason I see to do this anyway is to provide compatibility with
> NFSv3.
>
> > In that case, everything from setuid applications through open(O_CREAT)
> > to 'chown' will be broken because your authentication and authorisation
> > models do not match up.
>
> Those are preexisting problems from NFSv3, and it's up to the
> administrator to fix them.
>
> The best we can do is provide backwards-compatible behavior so that
> things that worked before continue working.
No. There are two cases here:
1) The user is authenticating using uids and gids (AUTH_SYS). In that
case, the server is using those uids and gids to authorise user
behaviour, and so file/directory creation/access/deletion/... will
depend only on the numeric values of those uids and gids. It doesn't
matter if the client belongs to a different domain, 'cos AUTH_SYS has no
concept of a domain. It doesn't matter whether or mot there exists a
name@domain mapping on the client, and server. Only the numbers matter.
NFSv2 and NFSv3 got this case right, and NFSv4 got it wrong (or didn't
consider it).
2) The user is authenticating using a principal name@DOMAIN. In this
case, either there is a mapping between name@DOMAIN and a owner@domain
+groupname@domain on the server, or there isn't. In the latter case, the
server treats the principal as the anonymous user. In the former case,
then if the client and server map owner@domain and groupname@domain to
the same uid and gid, then it is safe to pass uids and gids back and
forth. If they don't have identical mappings, then it is still safe to
pass owner@domain and groupname@domain, but passing uids and gids is now
wrong. NFSv4 gets this case right, but NFSv2/v3 get it wrong.
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, Dec 15, 2010 at 01:22:13PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 13:08 -0500, J. Bruce Fields wrote:
> > On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> > > On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> > >
> > > > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> > > >
> > > > > I'm just about to try
> > > > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > > > half-merged and uploaded as -git3 but not pushed to his public git)
> > > >
> > > > Ignore this; I was just confusing myself by having the leak fixes already
> > > > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > > > merging again.
> > > >
> > > > Do you have a git branch exposed with the "Allow the admin to turn off
> > > > NFSv4 uid/gid mapping" patches applied?
> > >
> > > Hm, the fixes were merged for -git4, and it seems to work fine there.
> > >
> > > As for the nfs4 uid/gid mapping patch, it seems the server side support
> > > for this is still neded?
> >
> > I'm not convinced that this behavior should depend on the security
> > flavor, so I'm assuming that something like steved's libnfsidmap patches
> > should do the job.
>
> Don't assume.
>
> Those patches do not fix the problem that if uid(name@server) !=
> uid(name@client), then the client will be creating files with the 'wrong
> username' on the server.
I don't see any obviously correct solution in cases where the mapping
disagrees between client and server sides, so prefer to stick to the
NFSv3 behavior.
The only reason I see to do this anyway is to provide compatibility with
NFSv3.
> In that case, everything from setuid applications through open(O_CREAT)
> to 'chown' will be broken because your authentication and authorisation
> models do not match up.
Those are preexisting problems from NFSv3, and it's up to the
administrator to fix them.
The best we can do is provide backwards-compatible behavior so that
things that worked before continue working.
--b.
On Wed, Dec 08, 2010 at 04:53:09PM -0500, Trond Myklebust wrote:
> Possibly a side effect of the fs/fs-writeback.c changes in 2.6.36? You
> do appear to be hitting a lot of spinlock contention, but I suspect that
> a lot of it is coming from writeback_sb_inodes, writeback_single_inode
> and queue_io, all of which seem unnaturally high on your stats above.
>
> I don't see how you can be seeing no traffic on the wire. You are
> certainly hitting some page writeout (0.2% nfs_pageio_doio).
It really seems to not be doing anything. I ran nfsstat -Zcv for 5
minutes, and the only non-zero counters are rpc calls and authrefrsh,
even though perf top shows similar profiles the whole time.
Simon-
On Wed, Dec 15, 2010 at 03:32:08PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
>
> > Could you give an example of a case in which all of the following are
> > true?:
> > - the administrator explicitly requests numeric id's (for
> > example by setting nfs4_disable_idmapping).
> > - numeric id's work as long as the client uses auth_sys.
> > - they no longer work if that same client switches to krb5.
>
> Trivially:
>
> Server /etc/passwd maps trondmy to uid 1000
> Client /etc/passwd maps trondmy to uid 500
I understand that any problematic case would involve different
name<->id mappings on the two sides.
What I don't understand--and apologies if I'm being dense!--is what
sequence of operations exactly would work in this situation if we
automatically switch idmapping based on auth flavor, and would not work
without it.
Are you imagining a future client that is also able to switch auth
flavors on the fly (say, based on whether a krb5 ticket exists or not),
or just unmounting and remounting to change the security flavor?
Are you thinking of creating a file under one flavor and accessing it
under another?
--b.
On Wed, 2010-12-15 at 14:49 -0500, J. Bruce Fields wrote:
> On Wed, Dec 15, 2010 at 02:33:50PM -0500, Trond Myklebust wrote:
> > On Wed, 2010-12-15 at 13:38 -0500, J. Bruce Fields wrote:
> > > On Wed, Dec 15, 2010 at 01:22:13PM -0500, Trond Myklebust wrote:
> > > > On Wed, 2010-12-15 at 13:08 -0500, J. Bruce Fields wrote:
> > > > > On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> > > > > > On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> > > > > >
> > > > > > > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> > > > > > >
> > > > > > > > I'm just about to try
> > > > > > > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > > > > > > half-merged and uploaded as -git3 but not pushed to his public git)
> > > > > > >
> > > > > > > Ignore this; I was just confusing myself by having the leak fixes already
> > > > > > > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > > > > > > merging again.
> > > > > > >
> > > > > > > Do you have a git branch exposed with the "Allow the admin to turn off
> > > > > > > NFSv4 uid/gid mapping" patches applied?
> > > > > >
> > > > > > Hm, the fixes were merged for -git4, and it seems to work fine there.
> > > > > >
> > > > > > As for the nfs4 uid/gid mapping patch, it seems the server side support
> > > > > > for this is still neded?
> > > > >
> > > > > I'm not convinced that this behavior should depend on the security
> > > > > flavor, so I'm assuming that something like steved's libnfsidmap patches
> > > > > should do the job.
> > > >
> > > > Don't assume.
> > > >
> > > > Those patches do not fix the problem that if uid(name@server) !=
> > > > uid(name@client), then the client will be creating files with the 'wrong
> > > > username' on the server.
> > >
> > > I don't see any obviously correct solution in cases where the mapping
> > > disagrees between client and server sides, so prefer to stick to the
> > > NFSv3 behavior.
> > >
> > > The only reason I see to do this anyway is to provide compatibility with
> > > NFSv3.
> > >
> > > > In that case, everything from setuid applications through open(O_CREAT)
> > > > to 'chown' will be broken because your authentication and authorisation
> > > > models do not match up.
> > >
> > > Those are preexisting problems from NFSv3, and it's up to the
> > > administrator to fix them.
> > >
> > > The best we can do is provide backwards-compatible behavior so that
> > > things that worked before continue working.
> >
> > No. There are two cases here:
> >
> > 1) The user is authenticating using uids and gids (AUTH_SYS). In that
> > case, the server is using those uids and gids to authorise user
> > behaviour, and so file/directory creation/access/deletion/... will
> > depend only on the numeric values of those uids and gids. It doesn't
> > matter if the client belongs to a different domain, 'cos AUTH_SYS has no
> > concept of a domain. It doesn't matter whether or mot there exists a
> > name@domain mapping on the client, and server. Only the numbers matter.
> > NFSv2 and NFSv3 got this case right, and NFSv4 got it wrong (or didn't
> > consider it).
> >
> > 2) The user is authenticating using a principal name@DOMAIN. In this
> > case, either there is a mapping between name@DOMAIN and a owner@domain
> > +groupname@domain on the server, or there isn't. In the latter case, the
> > server treats the principal as the anonymous user. In the former case,
> > then if the client and server map owner@domain and groupname@domain to
> > the same uid and gid, then it is safe to pass uids and gids back and
> > forth. If they don't have identical mappings, then it is still safe to
> > pass owner@domain and groupname@domain,
>
> Not necessarily; for example, there could be just a one-off mapping
> between root/client@DOMAIN and root on the server. And that would be
> sufficient to do something like a dumb
>
> cp -ax / /nfs
>
> backup, where you're just saving/restoring id's using chown/stat.
>
> I don't know if those sorts of cases are common. But they work under
> v3, and I don't see a reason to break them on upgrade to v4.
See above. It's about fixing what is broken with NFSv3.
> Certainly I don't see any motivation for going out of our way to break
> that case when an administrator explicitly requests numeric id's.
What do you mean by 'explicitly requests numeric ids'? If you mean
'decides to use NFSv3' then that works today.
What is the point of bending over backwards to make NFSv4 bug-compatible
with NFSv3? If people want NFSv3 they can use it. You can even mount an
NFSv3 partition while someone else is using NFSv4 on the same machine.
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
> Could you give an example of a case in which all of the following are
> true?:
> - the administrator explicitly requests numeric id's (for
> example by setting nfs4_disable_idmapping).
> - numeric id's work as long as the client uses auth_sys.
> - they no longer work if that same client switches to krb5.
Trivially:
Server /etc/passwd maps trondmy to uid 1000
Client /etc/passwd maps trondmy to uid 500
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, 2010-12-15 at 13:08 -0500, J. Bruce Fields wrote:
> On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> > On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> >
> > > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> > >
> > > > I'm just about to try
> > > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > > half-merged and uploaded as -git3 but not pushed to his public git)
> > >
> > > Ignore this; I was just confusing myself by having the leak fixes already
> > > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > > merging again.
> > >
> > > Do you have a git branch exposed with the "Allow the admin to turn off
> > > NFSv4 uid/gid mapping" patches applied?
> >
> > Hm, the fixes were merged for -git4, and it seems to work fine there.
> >
> > As for the nfs4 uid/gid mapping patch, it seems the server side support
> > for this is still neded?
>
> I'm not convinced that this behavior should depend on the security
> flavor, so I'm assuming that something like steved's libnfsidmap patches
> should do the job.
Don't assume.
Those patches do not fix the problem that if uid(name@server) !=
uid(name@client), then the client will be creating files with the 'wrong
username' on the server.
In that case, everything from setuid applications through open(O_CREAT)
to 'chown' will be broken because your authentication and authorisation
models do not match up.
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Wed, Dec 15, 2010 at 05:29:28PM -0500, J. Bruce Fields wrote:
> On Wed, Dec 15, 2010 at 05:15:46PM -0500, Trond Myklebust wrote:
> > On Wed, 2010-12-15 at 16:48 -0500, J. Bruce Fields wrote:
> > > On Wed, Dec 15, 2010 at 03:32:08PM -0500, Trond Myklebust wrote:
> > > > On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
> > > >
> > > > > Could you give an example of a case in which all of the following are
> > > > > true?:
> > > > > - the administrator explicitly requests numeric id's (for
> > > > > example by setting nfs4_disable_idmapping).
> > > > > - numeric id's work as long as the client uses auth_sys.
> > > > > - they no longer work if that same client switches to krb5.
> > > >
> > > > Trivially:
> > > >
> > > > Server /etc/passwd maps trondmy to uid 1000
> > > > Client /etc/passwd maps trondmy to uid 500
> > >
> > > I understand that any problematic case would involve different
> > > name<->id mappings on the two sides.
> > >
> > > What I don't understand--and apologies if I'm being dense!--is what
> > > sequence of operations exactly would work in this situation if we
> > > automatically switch idmapping based on auth flavor, and would not work
> > > without it.
> > >
> > > Are you imagining a future client that is also able to switch auth
> > > flavors on the fly (say, based on whether a krb5 ticket exists or not),
> > > or just unmounting and remounting to change the security flavor?
> > >
> > > Are you thinking of creating a file under one flavor and accessing it
> > > under another?
> >
> > Neither.
> >
> > I'm quite happy to accept that my user may map to completely different
> > identities on the server as I switch authentication schemes. Fixing that
> > is indeed the administrator's problem.
> >
> > I'm thinking of the simple case of creating a file, and then expecting
> > to see that file appear labelled with the correct user id when I do 'ls
> > -l'. That should work irrespectively of the authentication scheme that I
> > choose.
> >
> > In other words, if I authenticate as 'trond' on my client or to the
> > kerberos server, then do
> >
> > touch foo
> > ls -l foo
> >
> > I should see a file that is owned by 'trond'.
>
> Thanks, understood; but then, this isn't about behavior that occurs when
> a user *changes* authentication flavors.
>
> It's about what happens when someone sets nfs4_disable_idmapping but
> shouldn't have.
In other words, to make sure I understand:
- Is this switching-on-auth flavor *just* there to protect
confused administrators against themselves?
- Or is there some reasons someone who knew what they were doing
would actually *need* that behavior?
--b.
On Wed, Dec 15, 2010 at 02:57:08PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 14:49 -0500, J. Bruce Fields wrote:
> > On Wed, Dec 15, 2010 at 02:33:50PM -0500, Trond Myklebust wrote:
> > > 1) The user is authenticating using uids and gids (AUTH_SYS). In that
> > > case, the server is using those uids and gids to authorise user
> > > behaviour, and so file/directory creation/access/deletion/... will
> > > depend only on the numeric values of those uids and gids. It doesn't
> > > matter if the client belongs to a different domain, 'cos AUTH_SYS has no
> > > concept of a domain. It doesn't matter whether or mot there exists a
> > > name@domain mapping on the client, and server. Only the numbers matter.
> > > NFSv2 and NFSv3 got this case right, and NFSv4 got it wrong (or didn't
> > > consider it).
> > >
> > > 2) The user is authenticating using a principal name@DOMAIN. In this
> > > case, either there is a mapping between name@DOMAIN and a owner@domain
> > > +groupname@domain on the server, or there isn't. In the latter case, the
> > > server treats the principal as the anonymous user. In the former case,
> > > then if the client and server map owner@domain and groupname@domain to
> > > the same uid and gid, then it is safe to pass uids and gids back and
> > > forth. If they don't have identical mappings, then it is still safe to
> > > pass owner@domain and groupname@domain,
> >
> > Not necessarily; for example, there could be just a one-off mapping
> > between root/client@DOMAIN and root on the server. And that would be
> > sufficient to do something like a dumb
> >
> > cp -ax / /nfs
> >
> > backup, where you're just saving/restoring id's using chown/stat.
> >
> > I don't know if those sorts of cases are common. But they work under
> > v3, and I don't see a reason to break them on upgrade to v4.
>
> See above. It's about fixing what is broken with NFSv3.
The practical result in this particular example would be to break
something under NFSv4 that worked under NFSv3.
Could you give an example of a case in which all of the following are
true?:
- the administrator explicitly requests numeric id's (for
example by setting nfs4_disable_idmapping).
- numeric id's work as long as the client uses auth_sys.
- they no longer work if that same client switches to krb5.
If so, that would help me to understand why switching automatically from
numeric to string-based uid's in this case would be useful.
> > Certainly I don't see any motivation for going out of our way to break
> > that case when an administrator explicitly requests numeric id's.
>
> What do you mean by 'explicitly requests numeric ids'?
For example, if they set "nfs4_disable_idmapping".
> If you mean 'decides to use NFSv3' then that works today.
>
> What is the point of bending over backwards to make NFSv4 bug-compatible
> with NFSv3?
The advantage of supporting numeric user id's would be that it would
allow upgrades from NFSv3 to NFSv4 which would be transparent to the
user in more cases.
> If people want NFSv3 they can use it. You can even mount an
> NFSv3 partition while someone else is using NFSv4 on the same machine.
NFSv4 also has other advantages, which we would like to be able to bring
to people without requiring them to jump through unnecessary hoops.
--b.
On Wed, Dec 08, 2010 at 11:37:17PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-08 at 14:36 -0800, Simon Kirby wrote:
> > On Wed, Dec 08, 2010 at 04:53:09PM -0500, Trond Myklebust wrote:
> >
> > > Possibly a side effect of the fs/fs-writeback.c changes in 2.6.36? You
> > > do appear to be hitting a lot of spinlock contention, but I suspect that
> > > a lot of it is coming from writeback_sb_inodes, writeback_single_inode
> > > and queue_io, all of which seem unnaturally high on your stats above.
> > >
> > > I don't see how you can be seeing no traffic on the wire. You are
> > > certainly hitting some page writeout (0.2% nfs_pageio_doio).
> >
> > It really seems to not be doing anything. I ran nfsstat -Zcv for 5
> > minutes, and the only non-zero counters are rpc calls and authrefrsh,
> > even though perf top shows similar profiles the whole time.
>
> That sounds like a bug in nfsstat, then. As I said, your trace results
> definitely indicate that you are doing page writeout. I'd cross check
> using wireshark...
I know it's weird, but it really isn't writing anything. Confirmed with
tcpdump and tshark. Maybe it writes a single thing after a lot of
trying, or something.
2.6.36.1 is also doing the same thing when completely idle, after
finishing a bunch of log crunching. I'm just about to try
2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
half-merged and uploaded as -git3 but not pushed to his public git) and
your NFSv4 UID patch, which I will be testing shortly. If it works, this
should show if the same flush issue exists there or not.
Also, I just saw something similar in from 2.6.37-rc4-git1 plus your leak
fixes (this ver of top's %sys cpu is broken, ignore):
top - 16:54:44 up 8 days, 16:04, 1 user, load average: 40.11, 43.36, 24.71
Tasks: 490 total, 28 running, 461 sleeping, 0 stopped, 1 zombie
Cpu(s): 17.8%us, 6.9%sy, 0.0%ni, 60.2%id, 13.1%wa, 0.0%hi, 2.0%si, 0.0%st
Mem: 4051256k total, 1717004k used, 2334252k free, 17112k buffers
Swap: 979960k total, 268756k used, 711204k free, 362940k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2221 root 20 0 0 0 0 R 16 0.0 4:37.71 flush-0:65
10557 root 20 0 0 0 0 R 16 0.0 2:54.90 flush-0:46
7240 root 20 0 0 0 0 R 15 0.0 7:46.64 flush-0:31
8682 root 20 0 0 0 0 R 15 0.0 3:04.89 flush-0:34
13915 root 20 0 0 0 0 R 15 0.0 4:37.43 flush-0:27
17778 root 20 0 0 0 0 R 15 0.0 4:53.57 flush-0:83
19281 root 20 0 0 0 0 R 15 0.0 3:59.55 flush-0:56
19484 root 20 0 0 0 0 R 15 0.0 17:12.80 flush-0:77
19693 root 20 0 0 0 0 R 15 0.0 6:16.20 flush-0:71
25272 root 20 0 0 0 0 R 15 0.0 3:47.70 flush-0:68
5494 root 20 0 0 0 0 R 13 0.0 28:23.03 flush-0:75
7095 root 20 0 0 0 0 R 13 0.0 1:55.52 flush-0:42
10298 root 20 0 0 0 0 R 13 0.0 3:39.00 flush-0:61
13900 root 20 0 0 0 0 R 13 0.0 8:38.14 flush-0:80
14389 root 20 0 0 0 0 R 13 0.0 4:52.59 flush-0:81
16412 root 20 0 0 0 0 R 13 0.0 2:52.46 flush-0:33
17225 root 20 0 0 0 0 R 13 0.0 4:01.92 flush-0:78
20985 root 20 0 0 0 0 R 13 0.0 3:09.37 flush-0:29
24424 root 20 0 0 0 0 R 13 0.0 2:01.69 flush-0:20
25273 root 20 0 0 0 0 R 13 0.0 4:08.11 flush-0:70
25560 root 20 0 0 0 0 R 13 0.0 3:40.00 flush-0:69
27578 root 20 0 0 0 0 R 13 0.0 6:17.51 flush-0:57
25270 root 20 0 0 0 0 R 12 0.0 5:15.30 flush-0:26
25392 root 20 0 0 0 0 R 12 0.0 2:39.36 flush-0:82
27488 root 20 0 0 0 0 R 12 0.0 3:35.94 flush-0:76
31283 root 20 0 0 0 0 R 12 0.0 2:58.57 flush-0:18
28461 root 20 0 29556 2404 1544 R 4 0.1 0:00.04 top
6426 root 20 0 0 0 0 S 1 0.0 1:57.74 flush-0:73
14639 root 20 0 0 0 0 S 1 0.0 2:41.38 flush-0:58
20081 root 20 0 0 0 0 S 1 0.0 1:51.78 flush-0:60
24845 root 20 0 0 0 0 S 1 0.0 2:55.30 flush-0:32
1 root 20 0 10364 332 328 S 0 0.0 0:10.35 init
PerfTop: 3886 irqs/sec kernel:98.8% exact: 0.0% [1000Hz cycles], (all, 4 CPUs)
----------------------------------------------------------------------------------------
samples pcnt function DSO
_______ _____ _______________________________ __________________________
17772.00 80.6% _raw_spin_lock [kernel.kallsyms]
770.00 3.5% nfs_writepages [kernel.kallsyms]
530.00 2.4% writeback_sb_inodes [kernel.kallsyms]
463.00 2.1% writeback_single_inode [kernel.kallsyms]
364.00 1.7% queue_io [kernel.kallsyms]
283.00 1.3% nfs_write_inode [kernel.kallsyms]
210.00 1.0% bit_waitqueue [kernel.kallsyms]
185.00 0.8% redirty_tail [kernel.kallsyms]
182.00 0.8% do_writepages [kernel.kallsyms]
155.00 0.7% __iget [kernel.kallsyms]
129.00 0.6% iput [kernel.kallsyms]
122.00 0.6% __mark_inode_dirty [kernel.kallsyms]
102.00 0.5% write_cache_pages [kernel.kallsyms]
89.00 0.4% file_softmagic /usr/lib/libmagic.so.1.0.0
67.00 0.3% _atomic_dec_and_lock [kernel.kallsyms]
53.00 0.2% is_bad_inode [kernel.kallsyms]
48.00 0.2% page_fault [kernel.kallsyms]
44.00 0.2% __wake_up_bit [kernel.kallsyms]
32.00 0.1% find_get_pages_tag [kernel.kallsyms]
25.00 0.1% wake_up_bit [kernel.kallsyms]
17.00 0.1% copy_page_c [kernel.kallsyms]
17.00 0.1% clear_page_c [kernel.kallsyms]
13.00 0.1% radix_tree_gang_lookup_tag_slot [kernel.kallsyms]
12.00 0.1% ktime_get [kernel.kallsyms]
12.00 0.1% symbol_filter /usr/local/bin/perf
12.00 0.1% pagevec_lookup_tag [kernel.kallsyms]
11.00 0.0% mapping_tagged [kernel.kallsyms]
10.00 0.0% do_page_fault [kernel.kallsyms]
10.00 0.0% unmap_vmas [kernel.kallsyms]
9.00 0.0% find_get_page [kernel.kallsyms]
9.00 0.0% dso__load_sym /usr/local/bin/perf
9.00 0.0% __phys_addr [kernel.kallsyms]
8.00 0.0% nfs_pageio_init [kernel.kallsyms]
8.00 0.0% __d_lookup [kernel.kallsyms]
8.00 0.0% filemap_fault [kernel.kallsyms]
7.00 0.0% sched_clock_local [kernel.kallsyms]
7.00 0.0% memset /lib/libc-2.7.so
7.00 0.0% number [kernel.kallsyms]
6.00 0.0% handle_mm_fault [kernel.kallsyms]
6.00 0.0% symbols__insert /usr/local/bin/perf
6.00 0.0% radix_tree_tagged [kernel.kallsyms]
5.00 0.0% perf_event_task_tick [kernel.kallsyms]
5.00 0.0% native_write_msr_safe [kernel.kallsyms]
5.00 0.0% kfree [kernel.kallsyms]
5.00 0.0% __switch_to [kernel.kallsyms]
5.00 0.0% strlen /lib/libc-2.7.so
5.00 0.0% _cond_resched [kernel.kallsyms]
5.00 0.0% format_decode [kernel.kallsyms]
5.00 0.0% nfs_pageio_doio [kernel.kallsyms]
# cat /proc/5494/stack
[<ffffffff81052025>] __cond_resched+0x25/0x40
[<ffffffff81135459>] writeback_sb_inodes+0xb9/0x140
[<ffffffff81135efc>] writeback_inodes_wb+0xcc/0x140
[<ffffffff8113629b>] wb_writeback+0x32b/0x370
[<ffffffff811363b4>] wb_do_writeback+0xd4/0x1d0
[<ffffffff8113658b>] bdi_writeback_thread+0xdb/0x240
[<ffffffff81075046>] kthread+0x96/0xb0
[<ffffffff8100bca4>] kernel_thread_helper+0x4/0x10
[<ffffffffffffffff>] 0xffffffffffffffff
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
24 0 256484 2346524 26168 385584 0 1 33 26 5 14 18 9 60 13
25 0 256320 2346528 26168 385676 4 0 156 0 2041 2900 2 98 0 0
24 0 256144 2348916 26168 385968 32 0 172 8 2030 2879 3 97 0 0
24 0 255984 2349260 26168 386136 8 0 156 4 2080 2970 1 99 0 0
24 0 255360 2351216 26176 386168 128 0 272 44 2082 2942 0 100 0 0
25 0 255152 2351352 26184 386248 52 0 196 44 2071 3030 2 98 0 0
23 0 254880 2353400 26192 386660 144 0 296 84 2249 2960 3 97 0 0
23 0 254660 2354028 26192 386756 40 0 200 8 2060 3114 1 100 0 0
Gradually, the flush processes go back to sleeping, and then everything
works again, as if nothing happened. This is in contrast to what we
are seeing on the log crunching server, where system time just keeps
increasing forever with each log cruching run. These two cases may or
may not be the same problem.
See longer vmstat, nfsstat output, etc. here:
http://0x.ca/sim/ref/2.6.37-rc4-git1_flushy_nfs/
Simon-
On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> I'm just about to try
> 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> half-merged and uploaded as -git3 but not pushed to his public git)
Ignore this; I was just confusing myself by having the leak fixes already
applied. Otoh, I got this Oops while trying NFSv4. I'll check my
merging again.
Do you have a git branch exposed with the "Allow the admin to turn off
NFSv4 uid/gid mapping" patches applied?
Simon-
[ 89.312786] BUG: unable to handle kernel NULL pointer dereference at 0000000000000018
[ 89.316758] IP: [<ffffffff8120ed82>] nfs_follow_remote_path+0x212/0x3c0
[ 89.316758] PGD 2221c5067 PUD 225324067 PMD 0
[ 89.316758] Oops: 0000 [#1] SMP
[ 89.316758] last sysfs file: /sys/devices/platform/dcdbas/smi_data_buf_phys_addr
[ 89.316758] CPU 0
[ 89.316758] Modules linked in: ipmi_devintf ipmi_si ipmi_msghandler bnx2
[ 89.316758]
[ 89.316758] Pid: 4632, comm: mount.nfs Not tainted 2.6.37-rc5-git3-hw #1 0NH278/PowerEdge 2950
[ 89.316758] RIP: 0010:[<ffffffff8120ed82>] [<ffffffff8120ed82>] nfs_follow_remote_path+0x212/0x3c0
[ 89.316758] RSP: 0018:ffff880222073c98 EFLAGS: 00010246
[ 89.316758] RAX: ffff880222069a40 RBX: ffff8802222e0000 RCX: 0000000000000003
[ 89.316758] RDX: ffff8802222e0000 RSI: 0000000000000002 RDI: 0000000000000000
[ 89.316758] RBP: ffff880222073cd8 R08: ffff8800cfc16548 R09: ffffffff81a0c950
[ 89.316758] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000000
[ 89.316758] R13: 0000000000000000 R14: ffff880226698d00 R15: ffff8802252df180
[ 89.316758] FS: 00007f6626f176e0(0000) GS:ffff8800cfc00000(0000) knlGS:0000000000000000
[ 89.316758] CS: 0010 DS: 0000 ES: 0000 CR0: 000000008005003b
[ 89.316758] CR2: 0000000000000018 CR3: 000000022516d000 CR4: 00000000000006f0
[ 89.316758] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 89.316758] DR3: 0000000000000000 DR6: 00000000ffff0ff0 DR7: 0000000000000400
[ 89.316758] Process mount.nfs (pid: 4632, threadinfo ffff880222072000, task ffff8802222e0000)
[ 89.316758] Stack:
[ 89.316758] ffff880226699800 ffff880222007040 ffff880222337f40 0000000026698d00
[ 89.316758] ffff880222007040 0000000000000000 ffff880226699800 ffff880222040c00
[ 89.316758] ffff880222073d08 ffffffff8120f09e 0000000000000000 ffff8802220eea00
[ 89.316758] Call Trace:
[ 89.316758] [<ffffffff8120f09e>] nfs4_try_mount+0x9e/0xe0
[ 89.316758] [<ffffffff812100b0>] nfs_get_sb+0x500/0xae0
[ 89.316758] [<ffffffff810e76bb>] ? pcpu_alloc+0x7ab/0x950
[ 89.316758] [<ffffffff81387551>] ? ida_get_new_above+0x151/0x220
[ 89.316758] [<ffffffff810e787b>] ? __alloc_percpu+0xb/0x10
[ 89.316758] [<ffffffff81114d5f>] vfs_kern_mount+0x11f/0x1a0
[ 89.316758] [<ffffffff81114e4e>] do_kern_mount+0x4e/0x110
[ 89.316758] [<ffffffff8112f7a1>] do_mount+0x241/0x870
[ 89.316758] [<ffffffff8112da72>] ? copy_mount_options+0xf2/0x190
[ 89.316758] [<ffffffff8112fe83>] sys_mount+0xb3/0xe0
[ 89.316758] [<ffffffff8100af12>] system_call_fastpath+0x16/0x1b
[ 89.316758] Code: 65 48 8b 14 25 40 cc 00 00 eb 0f 66 0f 1f 44 00 00 48 39 57 10 74 14 48 89 c7 48 8b 07 48 81 ff f0 20 9a 81 0f 18 08 75 e8 31 ff <8b> 47 18 83 e8 01 85 c0 89 47 18 0f 84 c5 00 00 00 31 ff fe 05
[ 89.316758] RIP [<ffffffff8120ed82>] nfs_follow_remote_path+0x212/0x3c0
[ 89.316758] RSP <ffff880222073c98>
[ 89.316758] CR2: 0000000000000018
[ 89.845673] ---[ end trace 2be6416a581974cc ]---
On Wed, Dec 15, 2010 at 02:33:50PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 13:38 -0500, J. Bruce Fields wrote:
> > On Wed, Dec 15, 2010 at 01:22:13PM -0500, Trond Myklebust wrote:
> > > On Wed, 2010-12-15 at 13:08 -0500, J. Bruce Fields wrote:
> > > > On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> > > > > On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
> > > > >
> > > > > > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> > > > > >
> > > > > > > I'm just about to try
> > > > > > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > > > > > half-merged and uploaded as -git3 but not pushed to his public git)
> > > > > >
> > > > > > Ignore this; I was just confusing myself by having the leak fixes already
> > > > > > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > > > > > merging again.
> > > > > >
> > > > > > Do you have a git branch exposed with the "Allow the admin to turn off
> > > > > > NFSv4 uid/gid mapping" patches applied?
> > > > >
> > > > > Hm, the fixes were merged for -git4, and it seems to work fine there.
> > > > >
> > > > > As for the nfs4 uid/gid mapping patch, it seems the server side support
> > > > > for this is still neded?
> > > >
> > > > I'm not convinced that this behavior should depend on the security
> > > > flavor, so I'm assuming that something like steved's libnfsidmap patches
> > > > should do the job.
> > >
> > > Don't assume.
> > >
> > > Those patches do not fix the problem that if uid(name@server) !=
> > > uid(name@client), then the client will be creating files with the 'wrong
> > > username' on the server.
> >
> > I don't see any obviously correct solution in cases where the mapping
> > disagrees between client and server sides, so prefer to stick to the
> > NFSv3 behavior.
> >
> > The only reason I see to do this anyway is to provide compatibility with
> > NFSv3.
> >
> > > In that case, everything from setuid applications through open(O_CREAT)
> > > to 'chown' will be broken because your authentication and authorisation
> > > models do not match up.
> >
> > Those are preexisting problems from NFSv3, and it's up to the
> > administrator to fix them.
> >
> > The best we can do is provide backwards-compatible behavior so that
> > things that worked before continue working.
>
> No. There are two cases here:
>
> 1) The user is authenticating using uids and gids (AUTH_SYS). In that
> case, the server is using those uids and gids to authorise user
> behaviour, and so file/directory creation/access/deletion/... will
> depend only on the numeric values of those uids and gids. It doesn't
> matter if the client belongs to a different domain, 'cos AUTH_SYS has no
> concept of a domain. It doesn't matter whether or mot there exists a
> name@domain mapping on the client, and server. Only the numbers matter.
> NFSv2 and NFSv3 got this case right, and NFSv4 got it wrong (or didn't
> consider it).
>
> 2) The user is authenticating using a principal name@DOMAIN. In this
> case, either there is a mapping between name@DOMAIN and a owner@domain
> +groupname@domain on the server, or there isn't. In the latter case, the
> server treats the principal as the anonymous user. In the former case,
> then if the client and server map owner@domain and groupname@domain to
> the same uid and gid, then it is safe to pass uids and gids back and
> forth. If they don't have identical mappings, then it is still safe to
> pass owner@domain and groupname@domain,
Not necessarily; for example, there could be just a one-off mapping
between root/client@DOMAIN and root on the server. And that would be
sufficient to do something like a dumb
cp -ax / /nfs
backup, where you're just saving/restoring id's using chown/stat.
I don't know if those sorts of cases are common. But they work under
v3, and I don't see a reason to break them on upgrade to v4.
Certainly I don't see any motivation for going out of our way to break
that case when an administrator explicitly requests numeric id's.
--b.
> but passing uids and gids is now
> wrong. NFSv4 gets this case right, but NFSv2/v3 get it wrong.
>
> Trond
>
> --
> Trond Myklebust
> Linux NFS client maintainer
>
> NetApp
> [email protected]
> http://www.netapp.com
>
On Fri, Dec 17, 2010 at 05:08:01PM -0800, Simon Kirby wrote:
> On Wed, Dec 08, 2010 at 01:25:05PM -0800, Simon Kirby wrote:
>
> > Possibly related to the flush-processes-taking-CPU issues I saw
> > previously, I thought this was interesting. I found a log-crunching box
> > that does all of its work via NFS and spends most of the day sleeping.
> > It has been using a linearly-increasing amount of system time during the
> > time where is sleeping. munin graph:
> >
> > http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
> >...
> > Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the
> > munin graphs. I'll try 2.6.37-rc an see if it changes.
>
> So, back on this topic,
>
> It seems that system CPU from "flush" processes is still increasing
> during and after periods of NFS activity, even with 2.6.37-rc5-git4:
>
> http://0x.ca/sim/ref/2.6.37/cpu_nfs.png
>
> Something is definitely going on while NFS is active, and then keeps
> happening in the idle periods. top and perf top look the same as in
> 2.6.36. No userland activity at all, but the kernel keeps doing stuff.
>
> I could bisect this, but I have to wait a day for each build, unless I
> can come up with a way to reproduce it more quickly. The mount points
> for which the flush processes are active are the two mount points where
> the logs are read from, rotated, compressed, and unlinked, and where the
> reports are written, running in parallel under an xargs -P 15.
>
> I'm pretty sure the only syscalls that are reproducing this are read(),
> readdir(), lstat(), write(), rename(), unlink(), and close(). There's
> nothing special happening here...
I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
2562514 2541520 99% 0.95K 78739 33 2519648K nfs_inode_cache
467200 285110 61% 0.02K 1825 256 7300K kmalloc-16
299397 242350 80% 0.19K 14257 21 57028K dentry
217434 131978 60% 0.55K 7767 28 124272K radix_tree_node
215232 81522 37% 0.06K 3363 64 13452K kmalloc-64
183027 136802 74% 0.10K 4693 39 18772K buffer_head
101120 71184 70% 0.03K 790 128 3160K kmalloc-32
79616 59713 75% 0.12K 2488 32 9952K kmalloc-128
66560 41257 61% 0.01K 130 512 520K kmalloc-8
42126 26650 63% 0.75K 2006 21 32096K ext3_inode_cache
http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
try to track this down without having to wait too long, unless somebody
can see what is happening here.
Simon-
On Wed, 2010-12-15 at 16:48 -0500, J. Bruce Fields wrote:
> On Wed, Dec 15, 2010 at 03:32:08PM -0500, Trond Myklebust wrote:
> > On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
> >
> > > Could you give an example of a case in which all of the following are
> > > true?:
> > > - the administrator explicitly requests numeric id's (for
> > > example by setting nfs4_disable_idmapping).
> > > - numeric id's work as long as the client uses auth_sys.
> > > - they no longer work if that same client switches to krb5.
> >
> > Trivially:
> >
> > Server /etc/passwd maps trondmy to uid 1000
> > Client /etc/passwd maps trondmy to uid 500
>
> I understand that any problematic case would involve different
> name<->id mappings on the two sides.
>
> What I don't understand--and apologies if I'm being dense!--is what
> sequence of operations exactly would work in this situation if we
> automatically switch idmapping based on auth flavor, and would not work
> without it.
>
> Are you imagining a future client that is also able to switch auth
> flavors on the fly (say, based on whether a krb5 ticket exists or not),
> or just unmounting and remounting to change the security flavor?
>
> Are you thinking of creating a file under one flavor and accessing it
> under another?
Neither.
I'm quite happy to accept that my user may map to completely different
identities on the server as I switch authentication schemes. Fixing that
is indeed the administrator's problem.
I'm thinking of the simple case of creating a file, and then expecting
to see that file appear labelled with the correct user id when I do 'ls
-l'. That should work irrespectively of the authentication scheme that I
choose.
In other words, if I authenticate as 'trond' on my client or to the
kerberos server, then do
touch foo
ls -l foo
I should see a file that is owned by 'trond'.
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Fri, Dec 17, 2010 at 5:08 PM, Simon Kirby <[email protected]> wrote:
> On Wed, Dec 08, 2010 at 01:25:05PM -0800, Simon Kirby wrote:
>
>> Possibly related to the flush-processes-taking-CPU issues I saw
>> previously, I thought this was interesting. ?I found a log-crunching box
>> that does all of its work via NFS and spends most of the day sleeping.
>> It has been using a linearly-increasing amount of system time during the
>> time where is sleeping. ?munin graph:
>>
>> http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
>>...
>> Known 2.6.36 issue? ?This did not occur on 2.6.35.4, according to the
>> munin graphs. ?I'll try 2.6.37-rc an see if it changes.
>
> So, back on this topic,
>
> It seems that system CPU from "flush" processes is still increasing
> during and after periods of NFS activity, even with 2.6.37-rc5-git4:
>
> ? ? ? ?http://0x.ca/sim/ref/2.6.37/cpu_nfs.png
>
> Something is definitely going on while NFS is active, and then keeps
> happening in the idle periods. ?top and perf top look the same as in
> 2.6.36. ?No userland activity at all, but the kernel keeps doing stuff.
>
> I could bisect this, but I have to wait a day for each build, unless I
> can come up with a way to reproduce it more quickly. ?The mount points
> for which the flush processes are active are the two mount points where
> the logs are read from, rotated, compressed, and unlinked, and where the
> reports are written, running in parallel under an xargs -P 15.
>
> I'm pretty sure the only syscalls that are reproducing this are read(),
> readdir(), lstat(), write(), rename(), unlink(), and close(). ?There's
> nothing special happening here...
I'm running 2.6.36 on a number of mail servers that do a great deal of
write I/O to NFS (all Netapps, NFSv3, UDP). I've seen this exact same
behaviour a number of times since moving to 2.6.36. I just had to
powercycle a box a minute ago doing the same thing. Any time I've seen
this, the only remedy is reboot. These boxes were last running a
2.6.32.x kernel and had no such behaviour. I didn't think to check
nfsstat before rebooting but I can next time if it'd be useful.
'top' consistently showed 6 flush threads tying up 100% total of the CPU:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4853 root 20 0 0 0 0 R 33 0.0 36:47.13
flush-0:26
4854 root 20 0 0 0 0 R 33 0.0 38:56.89
flush-0:27
4855 root 20 0 0 0 0 R 33 0.0 38:35.01
flush-0:28
4856 root 20 0 0 0 0 R 33 0.0 39:00.11
flush-0:29
4857 root 20 0 0 0 0 R 33 0.0 37:39.08
flush-0:30
4858 root 20 0 0 0 0 R 31 0.0 37:04.30 flush-0:31
perf top consistently showed _raw_spin_lock at over 50% (these boxes
are only 2 cores though). shrink_icache_memory was usually near the
top and nfs_writepages hung around the top 5 or 6. Looking at tcpdump,
there was no actual packets getting sent to those Netapps (I was
looking at all ports too, not just 2049). This 'perf top' is fairly
representative of what I was seeing:
------------------------------------------------------------------------------
PerfTop: 23638 irqs/sec kernel:97.3% [100000 cycles], (all, 2 CPUs)
------------------------------------------------------------------------------
samples pcnt RIP kernel function
______ _______ _____ ________________ _______________
330867.00 - 62.5% - 00000000003cc97a : _raw_spin_lock
19496.00 - 3.7% - 00000000000c83e8 : shrink_icache_memory
13634.00 - 2.6% - 00000000003cc12c : down_read
12064.00 - 2.3% - 000000000004d817 : up_read
7807.00 - 1.5% - 0000000000022c38 : kunmap_atomic_notypecheck
7496.00 - 1.4% - 0000000000168258 : nfs_writepages
7343.00 - 1.4% - 00000000000d0244 : writeback_single_inode
5528.00 - 1.0% - 0000000000022d36 : kmap_atomic_prot
4915.00 - 0.9% - 00000000000c75c4 : __iget
3933.00 - 0.7% - 00000000000d0708 : writeback_sb_inodes
3793.00 - 0.7% - 0000000000049d27 : wake_up_bit
3579.00 - 0.7% - 00000000000c805c : dispose_list
3487.00 - 0.7% - 00000000000d08cf : __mark_inode_dirty
3144.00 - 0.6% - 00000000003cd890 : page_fault
2539.00 - 0.5% - 00000000001d6afc : _atomic_dec_and_lock
On Tue, Dec 14, 2010 at 05:56:09PM -0800, Simon Kirby wrote:
> On Tue, Dec 14, 2010 at 05:10:21PM -0800, Simon Kirby wrote:
>
> > On Tue, Dec 14, 2010 at 03:38:43PM -0800, Simon Kirby wrote:
> >
> > > I'm just about to try
> > > 2.6.37-rc5-git3 on there plus your NFS fixes (which Linus seems to have
> > > half-merged and uploaded as -git3 but not pushed to his public git)
> >
> > Ignore this; I was just confusing myself by having the leak fixes already
> > applied. Otoh, I got this Oops while trying NFSv4. I'll check my
> > merging again.
> >
> > Do you have a git branch exposed with the "Allow the admin to turn off
> > NFSv4 uid/gid mapping" patches applied?
>
> Hm, the fixes were merged for -git4, and it seems to work fine there.
>
> As for the nfs4 uid/gid mapping patch, it seems the server side support
> for this is still neded?
I'm not convinced that this behavior should depend on the security
flavor, so I'm assuming that something like steved's libnfsidmap patches
should do the job.
--b.
On Wed, Dec 15, 2010 at 05:15:46PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-15 at 16:48 -0500, J. Bruce Fields wrote:
> > On Wed, Dec 15, 2010 at 03:32:08PM -0500, Trond Myklebust wrote:
> > > On Wed, 2010-12-15 at 15:19 -0500, J. Bruce Fields wrote:
> > >
> > > > Could you give an example of a case in which all of the following are
> > > > true?:
> > > > - the administrator explicitly requests numeric id's (for
> > > > example by setting nfs4_disable_idmapping).
> > > > - numeric id's work as long as the client uses auth_sys.
> > > > - they no longer work if that same client switches to krb5.
> > >
> > > Trivially:
> > >
> > > Server /etc/passwd maps trondmy to uid 1000
> > > Client /etc/passwd maps trondmy to uid 500
> >
> > I understand that any problematic case would involve different
> > name<->id mappings on the two sides.
> >
> > What I don't understand--and apologies if I'm being dense!--is what
> > sequence of operations exactly would work in this situation if we
> > automatically switch idmapping based on auth flavor, and would not work
> > without it.
> >
> > Are you imagining a future client that is also able to switch auth
> > flavors on the fly (say, based on whether a krb5 ticket exists or not),
> > or just unmounting and remounting to change the security flavor?
> >
> > Are you thinking of creating a file under one flavor and accessing it
> > under another?
>
> Neither.
>
> I'm quite happy to accept that my user may map to completely different
> identities on the server as I switch authentication schemes. Fixing that
> is indeed the administrator's problem.
>
> I'm thinking of the simple case of creating a file, and then expecting
> to see that file appear labelled with the correct user id when I do 'ls
> -l'. That should work irrespectively of the authentication scheme that I
> choose.
>
> In other words, if I authenticate as 'trond' on my client or to the
> kerberos server, then do
>
> touch foo
> ls -l foo
>
> I should see a file that is owned by 'trond'.
Thanks, understood; but then, this isn't about behavior that occurs when
a user *changes* authentication flavors.
It's about what happens when someone sets nfs4_disable_idmapping but
shouldn't have.
Is that an important case to care about?
--b.
On Fri, Jan 07, 2011 at 10:05:39AM -0800, Mark Moseley wrote:
> NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
> about in case there's something you'd like me to look at.
>
> Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
> bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
> first time doing bisect, so I'll preemptively apologize for doing
That's a merge commit, so that doesn't sound right (it doesn't contain
changes by itself). How were you running the bisect? Were you
definitely seeing a good case since v2.6.35? Could you post your
"git bisect log" so I can see if I can follow it?
> anything silly) both went berserk within 15 mins of each other, after
> an uptime of around 63 hours for 2.6.36.2 and 65 hours for the
> bisected box. The 2.6.36.2 one is still running with all the various
> flush-0:xx threads spinning wildly. The bisected box just keeled over
> and died, but is back up now. The only kernel messages logged are just
> of the "task kworker/4:1:359 blocked for more than 120 seconds"
> variety, all with _raw_spin_lock_irq at the top of the stack trace.
>
> Looking at slabinfo, specifically, this: stats=$(grep nfs_inode_cache
> /proc/slabinfo | awk '{ print $2, $3 }')
> the active_objs and num_objs both increase to over a million (these
> boxes are delivering mail to NFS-mounted mailboxes, so that's
> perfectly reasonable). On both boxes, looking at sar, things start to
> go awry around 10am today EST. At that time on the 2.6.36.2 box, the
> NFS numbers look like this:
>
> Fri Jan 7 09:58:00 2011: 1079433 1079650
> Fri Jan 7 09:59:00 2011: 1079632 1080300
> Fri Jan 7 10:00:00 2011: 1080196 1080300
> Fri Jan 7 10:01:01 2011: 1080599 1080716
> Fri Jan 7 10:02:01 2011: 1081074 1081288
>
> on the bisected, like this:
>
> Fri Jan 7 09:59:34 2011: 1162786 1165320
> Fri Jan 7 10:00:34 2011: 1163301 1165320
> Fri Jan 7 10:01:34 2011: 1164369 1165450
> Fri Jan 7 10:02:35 2011: 1164179 1165450
> Fri Jan 7 10:03:35 2011: 1165795 1166958
>
> When the bisected box finally died, the last numbers were:
>
> Fri Jan 7 10:40:33 2011: 1177156 1177202
> Fri Jan 7 10:42:21 2011: 1177157 1177306
> Fri Jan 7 10:44:55 2011: 1177201 1177324
> Fri Jan 7 10:45:55 2011: 1177746 1177826
Yeah, I was seeing load proportional to these, but I don't think their
growth is anything wrong. It just seems to be something that is taking
up CPU from flush proceses as they grow, and something which is causing a
thundering herd of reclaim with lots of spinlock contention.
Hmmm.. I tried to see if drop_caches would clear nfs_inode_cache and thus
the CPU usage. The top of slabtop before doing anything:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1256343 1221799 97% 0.95K 38071 33 1218272K nfs_inode_cache
# echo 2 > /proc/sys/vm/drop_caches
this took about 40 seconds to execute, and perf top showed this for
pretty much the whole time:
samples pcnt function DSO
_______ _____ ________________________ ___________
1188.00 45.1% _raw_spin_lock [kernel]
797.00 30.2% rpcauth_cache_shrinker [kernel]
132.00 5.0% shrink_slab [kernel]
60.00 2.3% queue_io [kernel]
59.00 2.2% _cond_resched [kernel]
44.00 1.7% nfs_writepages [kernel]
35.00 1.3% writeback_single_inode [kernel]
34.00 1.3% writeback_sb_inodes [kernel]
23.00 0.9% do_writepages [kernel]
20.00 0.8% bit_waitqueue [kernel]
15.00 0.6% redirty_tail [kernel]
11.00 0.4% __iget [kernel]
11.00 0.4% __GI_strstr libc-2.7.so
slabtop then showed:
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
1256211 531720 42% 0.95K 38067 33 1218144K nfs_inode_cache
and this doesn't change further with drop_caches=3 or 1. It's strange
that most of them were freed, but not all... We do actually have
RPC_CREDCACHE_DEFAULT_HASHBITS set to 10 at build time, which might
explain a bigger credcache and time to free that. Did you change your
auth_hashtable_size at all? Anyway, even with all of that, system CPU
doesn't change.
Ok, weird, Running "sync" actually caused "vmstat 1" to go from 25% CPU
spikes every 5 seconds with nfs_writepages in the "perf top" every 5
seconds to being idle! /proc/vmstat showed only nr_dirty 8 and
nr_writeback 0 before I ran "sync". Either that, or it was just good
timing.
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 0 6767892 9696 41088 0 0 5 180 15 70 62 7 29 1
0 0 0 6767892 9696 41088 0 0 0 0 1124 1978 0 0 100 0
0 0 0 6767892 9696 41088 0 0 0 0 1105 1967 0 0 100 0
0 0 0 6767892 9696 41088 0 0 0 0 1180 1984 0 2 98 0
2 0 0 6767892 9696 41088 0 0 0 0 2102 1968 0 22 78 0
0 0 0 6767768 9704 41084 0 0 0 52 1504 2022 0 8 91 1
0 0 0 6767768 9704 41084 0 0 0 0 1059 1965 0 0 100 0
0 0 0 6767768 9704 41088 0 0 0 0 1077 1982 0 0 100 0
0 0 0 6767768 9704 41088 0 0 0 0 1166 1972 1 2 97 0
0 0 0 6767768 9704 41088 0 0 0 0 1353 1990 0 6 94 0
0 0 0 6767644 9704 41100 0 0 0 0 2531 2050 0 27 72 0
0 0 0 6767644 9704 41100 0 0 0 0 1065 1974 0 0 100 0
1 0 0 6767644 9704 41100 0 0 0 0 1090 1967 0 0 100 0
0 0 0 6767644 9704 41100 0 0 0 0 1175 1971 0 2 98 0
0 0 0 6767644 9704 41100 0 0 0 0 1321 1967 0 6 94 0
1 0 0 6767644 9712 41100 0 0 0 52 1995 1995 0 18 81 1
0 0 0 6767644 9712 41100 0 0 0 0 1342 1964 0 6 94 0
0 0 0 6767644 9712 41100 0 0 0 0 1064 1974 0 0 100 0
0 0 0 6767644 9712 41100 0 0 0 0 1163 1968 0 2 98 0
0 0 0 6767644 9712 41100 0 0 0 0 1390 1976 1 6 94 0
0 0 0 6767768 9712 41112 0 0 0 0 1282 2018 0 1 99 0
0 0 0 6767768 9712 41112 0 0 0 0 2166 1972 0 24 76 0
0 0 0 6786260 9712 41112 0 0 0 0 1092 1989 0 0 100 0
0 0 0 6786260 9712 41112 0 0 0 0 1039 2003 0 2 98 0
0 0 0 6774588 9712 41112 0 0 0 0 1524 2015 3 9 89 0
0 1 0 6770124 9716 41112 0 0 0 48 1315 1990 3 0 87 11
1 0 0 6769628 9720 41112 0 0 0 4 2196 1966 0 20 79 0
0 0 0 6768364 9724 41108 0 0 36 0 1403 2031 1 5 94 1
0 0 0 6768388 9724 41144 0 0 0 0 1185 1969 0 2 98 0
0 0 0 6768388 9724 41144 0 0 0 0 1351 1975 0 6 94 0
0 0 0 6768140 9724 41156 0 0 0 0 1261 2020 0 1 99 0
0 0 0 6768140 9724 41156 0 0 0 0 1053 1973 0 0 100 0
1 0 0 6768140 9724 41156 0 0 0 0 2194 1971 1 26 73 0
0 0 0 6768140 9732 41148 0 0 0 52 1283 2088 0 4 96 0
2 0 0 6768140 9732 41156 0 0 0 0 1184 1965 0 2 98 0
0 0 0 6786368 9732 41156 0 0 0 0 1297 2000 0 4 97 0
0 0 0 6786384 9732 41156 0 0 0 0 998 1949 0 0 100 0
(stop vmstat 1, run sync, restart vmstat 1)
1 0 0 6765304 9868 41736 0 0 0 0 1239 1967 0 0 100 0
0 0 0 6765304 9868 41736 0 0 0 0 1174 2035 0 0 100 0
0 0 0 6765304 9868 41736 0 0 0 0 1084 1976 0 0 100 0
1 0 0 6765172 9868 41736 0 0 0 0 1100 1975 0 0 100 0
0 0 0 6765304 9868 41760 0 0 0 0 1501 1997 1 1 98 0
0 0 0 6765304 9868 41760 0 0 0 0 1092 1964 0 0 100 0
1 0 0 6765304 9868 41760 0 0 0 0 1096 1963 0 0 100 0
0 0 0 6765304 9868 41760 0 0 0 0 1083 1967 0 0 100 0
0 0 0 6765304 9876 41752 0 0 0 76 1101 1980 0 0 99 1
0 0 0 6765304 9876 41760 0 0 0 4 1199 2097 0 2 98 0
0 0 0 6765304 9876 41760 0 0 0 0 1055 1964 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1064 1977 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1073 1968 0 0 100 0
0 0 0 6765304 9876 41760 0 0 0 0 1080 1976 0 0 100 0
0 0 0 6765156 9884 41772 0 0 0 20 1329 2034 1 1 98 1
0 0 0 6765180 9884 41780 0 0 0 0 1097 1971 0 1 99 0
0 0 0 6765180 9884 41780 0 0 0 0 1073 1960 0 0 100 0
0 0 0 6765180 9884 41780 0 0 0 0 1079 1976 0 0 100 0
0 0 0 6765172 9884 41780 0 0 0 0 1120 1980 0 0 100 0
0 0 0 6765180 9892 41772 0 0 0 60 1097 1982 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1067 1969 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1063 1973 0 0 100 0
0 0 0 6765180 9892 41780 0 0 0 0 1064 1969 0 1 100 0
Hmmm. I'll watch it and see if it climbs back up again. That would mean
that for now, echo 2 > /proc/sys/vm/drop_caches ; sync is a workaround
for the problem we're seeing with system CPU slowly creeping up since
2.6.36. I have no idea if this affects the sudden flush process spinlock
contention and attempted writeback without much progress during normal
load, but it certainly changes things here.
http://0x.ca/sim/ref/2.6.37/cpu_after_drop_caches_2_and_sync.png
Simon-
On Fri, Jan 7, 2011 at 4:52 PM, Simon Kirby <[email protected]> wrote:
> On Fri, Jan 07, 2011 at 10:05:39AM -0800, Mark Moseley wrote:
>
>> NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
>> about in case there's something you'd like me to look at.
>>
>> Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
>> bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
>> first time doing bisect, so I'll preemptively apologize for doing
>
> That's a merge commit, so that doesn't sound right (it doesn't contain
> changes by itself). ?How were you running the bisect? ?Were you
> definitely seeing a good case since v2.6.35? ?Could you post your
> "git bisect log" so I can see if I can follow it?
Here's 'git bisect log':
# git bisect log
git bisect start
# bad: [f6f94e2ab1b33f0082ac22d71f66385a60d8157f] Linux 2.6.36
git bisect bad f6f94e2ab1b33f0082ac22d71f66385a60d8157f
# good: [9fe6206f400646a2322096b56c59891d530e8d51] Linux 2.6.35
git bisect good 9fe6206f400646a2322096b56c59891d530e8d51
# good: [78417334b5cb6e1f915b8fdcc4fce3f1a1b4420c] Merge branch
'bkl/core' of git://git.kernel.org/pub/scm/linux/kernel/git/frederic/random-tracing
git bisect good 78417334b5cb6e1f915b8fdcc4fce3f1a1b4420c
# good: [14a4fa20a10d76eb98b7feb25be60735217929ba] Merge branch
'for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tiwai/sound-2.6
git bisect good 14a4fa20a10d76eb98b7feb25be60735217929ba
# bad: [ce7db282a3830f57f5b05ec48288c23a5c4d66d5] Merge branch
'for-linus' of git://git.kernel.org/pub/scm/linux/kernel/git/tj/percpu
git bisect bad ce7db282a3830f57f5b05ec48288c23a5c4d66d5
I did an initial checkout of stable
(git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git)
and (after git bisect start), did a 'git bisect good v2.6.35; git
bisect bad v2.6.36' but that seemed to be way too old. I tried to
approximate 2.6.35.9->2.6.36 by doing 'git bisect good
ea8a52f9f4bcc3420c38ae07f8378a2f18443970; git bisect bad
f6f94e2ab1b33f0082ac22d71f66385a60d8157f' but that had compilation
errors so I did 'git bisect good
9fe6206f400646a2322096b56c59891d530e8d51' which compiled ok -- heh,
did I mention this was my first outing with 'git bisect' :)
> Yeah, I was seeing load proportional to these, but I don't think their
> growth is anything wrong. ?It just seems to be something that is taking
> up CPU from flush proceses as they grow, and something which is causing a
> thundering herd of reclaim with lots of spinlock contention.
>
> Hmmm.. I tried to see if drop_caches would clear nfs_inode_cache and thus
> the CPU usage. ?The top of slabtop before doing anything:
>
> ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
> 1256343 1221799 ?97% ? ?0.95K ?38071 ? ? ? 33 ? 1218272K nfs_inode_cache
>
> # echo 2 > /proc/sys/vm/drop_caches
>
> this took about 40 seconds to execute, and perf top showed this for
> pretty much the whole time:
>
> ? ? ? ? ? ? samples ?pcnt function ? ? ? ? ? ? ? ? DSO
> ? ? ? ? ? ? _______ _____ ________________________ ___________
>
> ? ? ? ? ? ? 1188.00 45.1% _raw_spin_lock ? ? ? ? ? [kernel]
> ? ? ? ? ? ? ?797.00 30.2% rpcauth_cache_shrinker ? [kernel]
> ? ? ? ? ? ? ?132.00 ?5.0% shrink_slab ? ? ? ? ? ? ?[kernel]
> ? ? ? ? ? ? ? 60.00 ?2.3% queue_io ? ? ? ? ? ? ? ? [kernel]
> ? ? ? ? ? ? ? 59.00 ?2.2% _cond_resched ? ? ? ? ? ?[kernel]
> ? ? ? ? ? ? ? 44.00 ?1.7% nfs_writepages ? ? ? ? ? [kernel]
> ? ? ? ? ? ? ? 35.00 ?1.3% writeback_single_inode ? [kernel]
> ? ? ? ? ? ? ? 34.00 ?1.3% writeback_sb_inodes ? ? ?[kernel]
> ? ? ? ? ? ? ? 23.00 ?0.9% do_writepages ? ? ? ? ? ?[kernel]
> ? ? ? ? ? ? ? 20.00 ?0.8% bit_waitqueue ? ? ? ? ? ?[kernel]
> ? ? ? ? ? ? ? 15.00 ?0.6% redirty_tail ? ? ? ? ? ? [kernel]
> ? ? ? ? ? ? ? 11.00 ?0.4% __iget ? ? ? ? ? ? ? ? ? [kernel]
> ? ? ? ? ? ? ? 11.00 ?0.4% __GI_strstr ? ? ? ? ? ? ?libc-2.7.so
>
> slabtop then showed:
>
> ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
> 1256211 531720 ?42% ? ?0.95K ?38067 ? ? ? 33 ? 1218144K nfs_inode_cache
>
> and this doesn't change further with drop_caches=3 or 1. ?It's strange
> that most of them were freed, but not all... ?We do actually have
> RPC_CREDCACHE_DEFAULT_HASHBITS set to 10 at build time, which might
> explain a bigger credcache and time to free that. ?Did you change your
> auth_hashtable_size at all? ?Anyway, even with all of that, system CPU
> doesn't change.
Oh, now that's interesting. I'm setting RPC_CREDCACHE_DEFAULT_HASHBITS
to 8 (and have been since Jan, so like 2.6.33 or something) -- I was
having the same issue as in this thread,
http://www.spinics.net/lists/linux-nfs/msg09261.html. Bumping up
RPC_CREDCACHE_DEFAULT_HASHBITS was like a miracle on some of our
systems. I was going to get around to switching to the 'right way' to
do that as a boot param one of these days, instead of a hack.
In the bisected kernel, I definitely did *not* touch
RPC_CREDCACHE_DEFAULT_HASHBITS and it blew up anyway. If it hadn't
completely died, it'd have been nice to see what 'perf top' said.
> Ok, weird, Running "sync" actually caused "vmstat 1" to go from 25% CPU
> spikes every 5 seconds with nfs_writepages in the "perf top" every 5
> seconds to being idle! ?/proc/vmstat showed only nr_dirty 8 and
> nr_writeback 0 before I ran "sync". ?Either that, or it was just good
> timing.
>
> procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
> ?r ?b ? swpd ? free ? buff ?cache ? si ? so ? ?bi ? ?bo ? in ? cs us sy id wa
> ?0 ?0 ? ? ?0 6767892 ? 9696 ?41088 ? ?0 ? ?0 ? ? 5 ? 180 ? 15 ? 70 62 ?7 29 ?1
> ?0 ?0 ? ? ?0 6767892 ? 9696 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1124 1978 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767892 ? 9696 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1105 1967 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767892 ? 9696 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1180 1984 ?0 ?2 98 ?0
> ?2 ?0 ? ? ?0 6767892 ? 9696 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 2102 1968 ?0 22 78 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9704 ?41084 ? ?0 ? ?0 ? ? 0 ? ?52 1504 2022 ?0 ?8 91 ?1
> ?0 ?0 ? ? ?0 6767768 ? 9704 ?41084 ? ?0 ? ?0 ? ? 0 ? ? 0 1059 1965 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9704 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1077 1982 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9704 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1166 1972 ?1 ?2 97 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9704 ?41088 ? ?0 ? ?0 ? ? 0 ? ? 0 1353 1990 ?0 ?6 94 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9704 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 2531 2050 ?0 27 72 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9704 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1065 1974 ?0 ?0 100 ?0
> ?1 ?0 ? ? ?0 6767644 ? 9704 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1090 1967 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9704 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1175 1971 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9704 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1321 1967 ?0 ?6 94 ?0
> ?1 ?0 ? ? ?0 6767644 ? 9712 ?41100 ? ?0 ? ?0 ? ? 0 ? ?52 1995 1995 ?0 18 81 ?1
> ?0 ?0 ? ? ?0 6767644 ? 9712 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1342 1964 ?0 ?6 94 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9712 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1064 1974 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9712 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1163 1968 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6767644 ? 9712 ?41100 ? ?0 ? ?0 ? ? 0 ? ? 0 1390 1976 ?1 ?6 94 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9712 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 0 1282 2018 ?0 ?1 99 ?0
> ?0 ?0 ? ? ?0 6767768 ? 9712 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 0 2166 1972 ?0 24 76 ?0
> ?0 ?0 ? ? ?0 6786260 ? 9712 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 0 1092 1989 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6786260 ? 9712 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 0 1039 2003 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6774588 ? 9712 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 0 1524 2015 ?3 ?9 89 ?0
> ?0 ?1 ? ? ?0 6770124 ? 9716 ?41112 ? ?0 ? ?0 ? ? 0 ? ?48 1315 1990 ?3 ?0 87 11
> ?1 ?0 ? ? ?0 6769628 ? 9720 ?41112 ? ?0 ? ?0 ? ? 0 ? ? 4 2196 1966 ?0 20 79 ?0
> ?0 ?0 ? ? ?0 6768364 ? 9724 ?41108 ? ?0 ? ?0 ? ?36 ? ? 0 1403 2031 ?1 ?5 94 ?1
> ?0 ?0 ? ? ?0 6768388 ? 9724 ?41144 ? ?0 ? ?0 ? ? 0 ? ? 0 1185 1969 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6768388 ? 9724 ?41144 ? ?0 ? ?0 ? ? 0 ? ? 0 1351 1975 ?0 ?6 94 ?0
> ?0 ?0 ? ? ?0 6768140 ? 9724 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 1261 2020 ?0 ?1 99 ?0
> ?0 ?0 ? ? ?0 6768140 ? 9724 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 1053 1973 ?0 ?0 100 ?0
> ?1 ?0 ? ? ?0 6768140 ? 9724 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 2194 1971 ?1 26 73 ?0
> ?0 ?0 ? ? ?0 6768140 ? 9732 ?41148 ? ?0 ? ?0 ? ? 0 ? ?52 1283 2088 ?0 ?4 96 ?0
> ?2 ?0 ? ? ?0 6768140 ? 9732 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 1184 1965 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6786368 ? 9732 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 1297 2000 ?0 ?4 97 ?0
> ?0 ?0 ? ? ?0 6786384 ? 9732 ?41156 ? ?0 ? ?0 ? ? 0 ? ? 0 ?998 1949 ?0 ?0 100 ?0
> (stop vmstat 1, run sync, restart vmstat 1)
> ?1 ?0 ? ? ?0 6765304 ? 9868 ?41736 ? ?0 ? ?0 ? ? 0 ? ? 0 1239 1967 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9868 ?41736 ? ?0 ? ?0 ? ? 0 ? ? 0 1174 2035 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9868 ?41736 ? ?0 ? ?0 ? ? 0 ? ? 0 1084 1976 ?0 ?0 100 ?0
> ?1 ?0 ? ? ?0 6765172 ? 9868 ?41736 ? ?0 ? ?0 ? ? 0 ? ? 0 1100 1975 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9868 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1501 1997 ?1 ?1 98 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9868 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1092 1964 ?0 ?0 100 ?0
> ?1 ?0 ? ? ?0 6765304 ? 9868 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1096 1963 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9868 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1083 1967 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41752 ? ?0 ? ?0 ? ? 0 ? ?76 1101 1980 ?0 ?0 99 ?1
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 4 1199 2097 ?0 ?2 98 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1055 1964 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1064 1977 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1073 1968 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765304 ? 9876 ?41760 ? ?0 ? ?0 ? ? 0 ? ? 0 1080 1976 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765156 ? 9884 ?41772 ? ?0 ? ?0 ? ? 0 ? ?20 1329 2034 ?1 ?1 98 ?1
> ?0 ?0 ? ? ?0 6765180 ? 9884 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1097 1971 ?0 ?1 99 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9884 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1073 1960 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9884 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1079 1976 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765172 ? 9884 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1120 1980 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9892 ?41772 ? ?0 ? ?0 ? ? 0 ? ?60 1097 1982 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9892 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1067 1969 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9892 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1063 1973 ?0 ?0 100 ?0
> ?0 ?0 ? ? ?0 6765180 ? 9892 ?41780 ? ?0 ? ?0 ? ? 0 ? ? 0 1064 1969 ?0 ?1 100 ?0
>
> Hmmm. ?I'll watch it and see if it climbs back up again. ?That would mean
> that for now, echo 2 > /proc/sys/vm/drop_caches ; sync is a workaround
> for the problem we're seeing with system CPU slowly creeping up since
> 2.6.36. ?I have no idea if this affects the sudden flush process spinlock
> contention and attempted writeback without much progress during normal
> load, but it certainly changes things here.
>
> http://0x.ca/sim/ref/2.6.37/cpu_after_drop_caches_2_and_sync.png
That's pretty painful to have to do though (less painful than the box
becoming unusable, I'll admit). I wonder if when I did a umount on
mine (which must've sync'd at least that mount), it gave something a
big enough kick for the flush-0:xx threads to unstick themselves,
presumably what happened with your sync (though I didn't drop the
cache).
On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
> On Fri, Dec 17, 2010 at 05:08:01PM -0800, Simon Kirby wrote:
>
>> On Wed, Dec 08, 2010 at 01:25:05PM -0800, Simon Kirby wrote:
>>
>> > Possibly related to the flush-processes-taking-CPU issues I saw
>> > previously, I thought this was interesting. ?I found a log-crunching box
>> > that does all of its work via NFS and spends most of the day sleeping.
>> > It has been using a linearly-increasing amount of system time during the
>> > time where is sleeping. ?munin graph:
>> >
>> > http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
>> >...
>> > Known 2.6.36 issue? ?This did not occur on 2.6.35.4, according to the
>> > munin graphs. ?I'll try 2.6.37-rc an see if it changes.
>>
>> So, back on this topic,
>>
>> It seems that system CPU from "flush" processes is still increasing
>> during and after periods of NFS activity, even with 2.6.37-rc5-git4:
>>
>> ? ? ? ? http://0x.ca/sim/ref/2.6.37/cpu_nfs.png
>>
>> Something is definitely going on while NFS is active, and then keeps
>> happening in the idle periods. ?top and perf top look the same as in
>> 2.6.36. ?No userland activity at all, but the kernel keeps doing stuff.
>>
>> I could bisect this, but I have to wait a day for each build, unless I
>> can come up with a way to reproduce it more quickly. ?The mount points
>> for which the flush processes are active are the two mount points where
>> the logs are read from, rotated, compressed, and unlinked, and where the
>> reports are written, running in parallel under an xargs -P 15.
>>
>> I'm pretty sure the only syscalls that are reproducing this are read(),
>> readdir(), lstat(), write(), rename(), unlink(), and close(). ?There's
>> nothing special happening here...
>
> I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
>
> ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
> 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
> 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
> 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
> 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
> 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
> 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
> 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
> ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
> ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
> ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
>
> http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
> http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
>
> Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
> try to track this down without having to wait too long, unless somebody
> can see what is happening here.
I'll get started bisecting too, since this is something of a
show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
now have to be powercycled every couple of days (which is about how
long it takes for this behavior to show up). This is across-the-board
for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
Simon: It's probably irrelevant since these are kernel threads, but
I'm curious what distro your boxes are running. Ours are Debian Lenny,
i386, Dell Poweredge 850s. Just trying to figure out any
commonalities. I'll get my boxes back on 2.6.36.2 and start watching
nfs_inode_cache as well.
On Tue, Jan 4, 2011 at 1:40 PM, Simon Kirby <[email protected]> wrote:
> On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote:
>
>> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
>>
>> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
>> >
>> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
>> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
>> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
>> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
>> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
>> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
>> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
>> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
>> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
>> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
>> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
>> >
>> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
>> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
>> >
>> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
>> > try to track this down without having to wait too long, unless somebody
>> > can see what is happening here.
>>
>> I'll get started bisecting too, since this is something of a
>> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
>> now have to be powercycled every couple of days (which is about how
>> long it takes for this behavior to show up). This is across-the-board
>> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
>>
>> Simon: It's probably irrelevant since these are kernel threads, but
>> I'm curious what distro your boxes are running. Ours are Debian Lenny,
>> i386, Dell Poweredge 850s. Just trying to figure out any
>> commonalities. I'll get my boxes back on 2.6.36.2 and start watching
>> nfs_inode_cache as well.
>
> Same distro, x86_64, similar servers.
>
> I'm not sure if the two cases I am seeing are exactly the same problem,
> but on the log crunching boxes, system time seems proportional to
> nfs_inode_cache and nfs_inode_cache just keeps growing forever; however,
> if I stop the load and unmount the NFS mount points, all of the
> nfs_inode_cache objects do actually go away (after umount finishes).
>
> It seems the shrinker callback might not be working as intended here.
>
> On the shared server case, the crazy spinlock contention from all of the
> flusher processes happens suddenly and overloads the boxes for 10-15
> minutes, and then everything recovers. ?Over 21 of these boxes, they
> each have about 500k-700k nfs_inode_cache objects. ?The log cruncher hit
> 3.3 million nfs_inode_cache objects before I unmounted.
>
> Are your boxes repeating this behaviour at any predictable interval?
Simon:
My boxes definitely fall into the latter category, with spinlock
regularly sitting at 60-80% CPU (according to 'perf top'). As far as
predictability, not strictly, but it's typically after an uptime of
2-3 days. They take so long to get into this state that I've never
seen the actual transition in person, just the after-effects of
flush-0:xx gone crazy. These boxes have a number of other NFS mounts,
but it's on the flush-0:xx's for the heavily written-to NFS mounts
that are spinning wildly, which you'd expect to be the case. The
infrequently written-to NFS servers' flush-0:xx isn't to be found in
'top' output.
I'd booted into older kernels after my initial reply, so I'm 14 hrs
into booting a box back into 2.6.36.2 and another box into a
double-bisected 2.6.35-2.6.36 kernel (my first bisect hit compile
errors). Both are running normally but that fits with the pattern so
far.
NFS Guys:
Anything else we can be digging up to help debug this? This is a
pretty ugly issue.
On Fri, Jan 7, 2011 at 10:05 AM, Mark Moseley <[email protected]> wrote:
> On Wed, Jan 5, 2011 at 11:43 AM, Mark Moseley <[email protected]> wrote:
>> On Tue, Jan 4, 2011 at 1:40 PM, Simon Kirby <[email protected]> wrote:
>>> On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote:
>>>
>>>> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
>>>>
>>>> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
>>>> >
>>>> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
>>>> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
>>>> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
>>>> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
>>>> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
>>>> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
>>>> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
>>>> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
>>>> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
>>>> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
>>>> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
>>>> >
>>>> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
>>>> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
>>>> >
>>>> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
>>>> > try to track this down without having to wait too long, unless somebody
>>>> > can see what is happening here.
>>>>
>>>> I'll get started bisecting too, since this is something of a
>>>> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
>>>> now have to be powercycled every couple of days (which is about how
>>>> long it takes for this behavior to show up). This is across-the-board
>>>> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
>>>>
>>>> Simon: It's probably irrelevant since these are kernel threads, but
>>>> I'm curious what distro your boxes are running. Ours are Debian Lenny,
>>>> i386, Dell Poweredge 850s. Just trying to figure out any
>>>> commonalities. I'll get my boxes back on 2.6.36.2 and start watching
>>>> nfs_inode_cache as well.
>>>
>>> Same distro, x86_64, similar servers.
>>>
>>> I'm not sure if the two cases I am seeing are exactly the same problem,
>>> but on the log crunching boxes, system time seems proportional to
>>> nfs_inode_cache and nfs_inode_cache just keeps growing forever; however,
>>> if I stop the load and unmount the NFS mount points, all of the
>>> nfs_inode_cache objects do actually go away (after umount finishes).
>>>
>>> It seems the shrinker callback might not be working as intended here.
>>>
>>> On the shared server case, the crazy spinlock contention from all of the
>>> flusher processes happens suddenly and overloads the boxes for 10-15
>>> minutes, and then everything recovers. ?Over 21 of these boxes, they
>>> each have about 500k-700k nfs_inode_cache objects. ?The log cruncher hit
>>> 3.3 million nfs_inode_cache objects before I unmounted.
>>>
>>> Are your boxes repeating this behaviour at any predictable interval?
>>
>> Simon:
>> My boxes definitely fall into the latter category, with spinlock
>> regularly sitting at 60-80% CPU (according to 'perf top'). As far as
>> predictability, not strictly, but it's typically after an uptime of
>> 2-3 days. They take so long to get into this state that I've never
>> seen the actual transition in person, just the after-effects of
>> flush-0:xx gone crazy. These boxes have a number of other NFS mounts,
>> but it's on the flush-0:xx's for the heavily written-to NFS mounts
>> that are spinning wildly, which you'd expect to be the case. The
>> infrequently written-to NFS servers' flush-0:xx isn't to be found in
>> 'top' output.
>>
>> I'd booted into older kernels after my initial reply, so I'm 14 hrs
>> into booting a box back into 2.6.36.2 and another box into a
>> double-bisected 2.6.35-2.6.36 kernel (my first bisect hit compile
>> errors). Both are running normally but that fits with the pattern so
>> far.
>>
>> NFS Guys:
>> Anything else we can be digging up to help debug this? This is a
>> pretty ugly issue.
>>
>
> NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
> about in case there's something you'd like me to look at.
>
> Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
> bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
> first time doing bisect, so I'll preemptively apologize for doing
> anything silly) both went berserk within 15 mins of each other, after
> an uptime of around 63 hours for 2.6.36.2 and 65 hours for the
> bisected box. The 2.6.36.2 one is still running with all the various
> flush-0:xx threads spinning wildly. The bisected box just keeled over
> and died, but is back up now. The only kernel messages logged are just
> of the "task kworker/4:1:359 blocked for more than 120 seconds"
> variety, all with _raw_spin_lock_irq at the top of the stack trace.
>
> Looking at slabinfo, specifically, this: stats=$(grep nfs_inode_cache
> /proc/slabinfo | awk '{ print $2, $3 }')
> the active_objs and num_objs both increase to over a million (these
> boxes are delivering mail to NFS-mounted mailboxes, so that's
> perfectly reasonable). On both boxes, looking at sar, things start to
> go awry around 10am today EST. At that time on the 2.6.36.2 box, the
> NFS numbers look like this:
>
> Fri Jan ?7 09:58:00 2011: 1079433 1079650
> Fri Jan ?7 09:59:00 2011: 1079632 1080300
> Fri Jan ?7 10:00:00 2011: 1080196 1080300
> Fri Jan ?7 10:01:01 2011: 1080599 1080716
> Fri Jan ?7 10:02:01 2011: 1081074 1081288
>
> on the bisected, like this:
>
> Fri Jan ?7 09:59:34 2011: 1162786 1165320
> Fri Jan ?7 10:00:34 2011: 1163301 1165320
> Fri Jan ?7 10:01:34 2011: 1164369 1165450
> Fri Jan ?7 10:02:35 2011: 1164179 1165450
> Fri Jan ?7 10:03:35 2011: 1165795 1166958
>
> When the bisected box finally died, the last numbers were:
>
> Fri Jan ?7 10:40:33 2011: 1177156 1177202
> Fri Jan ?7 10:42:21 2011: 1177157 1177306
> Fri Jan ?7 10:44:55 2011: 1177201 1177324
> Fri Jan ?7 10:45:55 2011: 1177746 1177826
>
> On the still-thrashing 2.6.36.2 box, the highwater mark is:
>
> Fri Jan ?7 10:23:30 2011: 1084020 1084070
>
> and once things went awry, the active_objs started falling away and
> the number_objs has stayed at 1084070. Last numbers were:
>
> Fri Jan ?7 12:19:34 2011: 826623 1084070
>
> The bisected box had reached 1mil entries (or more significantly
> 1048576 entries) by y'day evening. The 2.6.36.2 box hit that by 7am
> EST today. So in neither case was there a big spike in entries.
>
> These boxes have identical workloads. They're not accessible from the
> net, so there's no chance of a DDoS or something. The significance of
> 10am EST could be either uptime-related (all these have gone down
> after 2-3 days) or just due to the to-be-expected early morning spike
> in mail flow.
>
Actually, I shouldn't say 'perfectly reasonable'. On other boxes in
that pool, doing the same workload (but running 2.6.32.27), the number
is more like:
117196 120756
after 9 days of uptime. So maybe 8 x that isn't quite reasonable
after only 2.5 days of uptime.
On Fri, Jan 7, 2011 at 10:12 AM, Mark Moseley <[email protected]> wrote:
> On Fri, Jan 7, 2011 at 10:05 AM, Mark Moseley <[email protected]> wrote:
>> On Wed, Jan 5, 2011 at 11:43 AM, Mark Moseley <[email protected]> wrote:
>>> On Tue, Jan 4, 2011 at 1:40 PM, Simon Kirby <[email protected]> wrote:
>>>> On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote:
>>>>
>>>>> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
>>>>>
>>>>> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
>>>>> >
>>>>> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
>>>>> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
>>>>> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
>>>>> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
>>>>> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
>>>>> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
>>>>> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
>>>>> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
>>>>> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
>>>>> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
>>>>> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
>>>>> >
>>>>> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
>>>>> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
>>>>> >
>>>>> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
>>>>> > try to track this down without having to wait too long, unless somebody
>>>>> > can see what is happening here.
>>>>>
>>>>> I'll get started bisecting too, since this is something of a
>>>>> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
>>>>> now have to be powercycled every couple of days (which is about how
>>>>> long it takes for this behavior to show up). This is across-the-board
>>>>> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
>>>>>
>>>>> Simon: It's probably irrelevant since these are kernel threads, but
>>>>> I'm curious what distro your boxes are running. Ours are Debian Lenny,
>>>>> i386, Dell Poweredge 850s. Just trying to figure out any
>>>>> commonalities. I'll get my boxes back on 2.6.36.2 and start watching
>>>>> nfs_inode_cache as well.
>>>>
>>>> Same distro, x86_64, similar servers.
>>>>
>>>> I'm not sure if the two cases I am seeing are exactly the same problem,
>>>> but on the log crunching boxes, system time seems proportional to
>>>> nfs_inode_cache and nfs_inode_cache just keeps growing forever; however,
>>>> if I stop the load and unmount the NFS mount points, all of the
>>>> nfs_inode_cache objects do actually go away (after umount finishes).
>>>>
>>>> It seems the shrinker callback might not be working as intended here.
>>>>
>>>> On the shared server case, the crazy spinlock contention from all of the
>>>> flusher processes happens suddenly and overloads the boxes for 10-15
>>>> minutes, and then everything recovers. ?Over 21 of these boxes, they
>>>> each have about 500k-700k nfs_inode_cache objects. ?The log cruncher hit
>>>> 3.3 million nfs_inode_cache objects before I unmounted.
>>>>
>>>> Are your boxes repeating this behaviour at any predictable interval?
>>>
>>> Simon:
>>> My boxes definitely fall into the latter category, with spinlock
>>> regularly sitting at 60-80% CPU (according to 'perf top'). As far as
>>> predictability, not strictly, but it's typically after an uptime of
>>> 2-3 days. They take so long to get into this state that I've never
>>> seen the actual transition in person, just the after-effects of
>>> flush-0:xx gone crazy. These boxes have a number of other NFS mounts,
>>> but it's on the flush-0:xx's for the heavily written-to NFS mounts
>>> that are spinning wildly, which you'd expect to be the case. The
>>> infrequently written-to NFS servers' flush-0:xx isn't to be found in
>>> 'top' output.
>>>
>>> I'd booted into older kernels after my initial reply, so I'm 14 hrs
>>> into booting a box back into 2.6.36.2 and another box into a
>>> double-bisected 2.6.35-2.6.36 kernel (my first bisect hit compile
>>> errors). Both are running normally but that fits with the pattern so
>>> far.
>>>
>>> NFS Guys:
>>> Anything else we can be digging up to help debug this? This is a
>>> pretty ugly issue.
>>>
>>
>> NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
>> about in case there's something you'd like me to look at.
>>
>> Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
>> bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
>> first time doing bisect, so I'll preemptively apologize for doing
>> anything silly) both went berserk within 15 mins of each other, after
>> an uptime of around 63 hours for 2.6.36.2 and 65 hours for the
>> bisected box. The 2.6.36.2 one is still running with all the various
>> flush-0:xx threads spinning wildly. The bisected box just keeled over
>> and died, but is back up now. The only kernel messages logged are just
>> of the "task kworker/4:1:359 blocked for more than 120 seconds"
>> variety, all with _raw_spin_lock_irq at the top of the stack trace.
>>
>> Looking at slabinfo, specifically, this: stats=$(grep nfs_inode_cache
>> /proc/slabinfo | awk '{ print $2, $3 }')
>> the active_objs and num_objs both increase to over a million (these
>> boxes are delivering mail to NFS-mounted mailboxes, so that's
>> perfectly reasonable). On both boxes, looking at sar, things start to
>> go awry around 10am today EST. At that time on the 2.6.36.2 box, the
>> NFS numbers look like this:
>>
>> Fri Jan ?7 09:58:00 2011: 1079433 1079650
>> Fri Jan ?7 09:59:00 2011: 1079632 1080300
>> Fri Jan ?7 10:00:00 2011: 1080196 1080300
>> Fri Jan ?7 10:01:01 2011: 1080599 1080716
>> Fri Jan ?7 10:02:01 2011: 1081074 1081288
>>
>> on the bisected, like this:
>>
>> Fri Jan ?7 09:59:34 2011: 1162786 1165320
>> Fri Jan ?7 10:00:34 2011: 1163301 1165320
>> Fri Jan ?7 10:01:34 2011: 1164369 1165450
>> Fri Jan ?7 10:02:35 2011: 1164179 1165450
>> Fri Jan ?7 10:03:35 2011: 1165795 1166958
>>
>> When the bisected box finally died, the last numbers were:
>>
>> Fri Jan ?7 10:40:33 2011: 1177156 1177202
>> Fri Jan ?7 10:42:21 2011: 1177157 1177306
>> Fri Jan ?7 10:44:55 2011: 1177201 1177324
>> Fri Jan ?7 10:45:55 2011: 1177746 1177826
>>
>> On the still-thrashing 2.6.36.2 box, the highwater mark is:
>>
>> Fri Jan ?7 10:23:30 2011: 1084020 1084070
>>
>> and once things went awry, the active_objs started falling away and
>> the number_objs has stayed at 1084070. Last numbers were:
>>
>> Fri Jan ?7 12:19:34 2011: 826623 1084070
>>
>> The bisected box had reached 1mil entries (or more significantly
>> 1048576 entries) by y'day evening. The 2.6.36.2 box hit that by 7am
>> EST today. So in neither case was there a big spike in entries.
>>
>> These boxes have identical workloads. They're not accessible from the
>> net, so there's no chance of a DDoS or something. The significance of
>> 10am EST could be either uptime-related (all these have gone down
>> after 2-3 days) or just due to the to-be-expected early morning spike
>> in mail flow.
>>
>
> Actually, I shouldn't say 'perfectly reasonable'. On other boxes in
> that pool, doing the same workload (but running 2.6.32.27), the number
> is more like:
>
> 117196 120756
>
> after 9 days of uptime. So maybe 8 x that ?isn't quite reasonable
> after only 2.5 days of uptime.
>
On the 2.6.36.2 box, after shutting down everything else that'd touch
NFS, I let the flush threads spin for a long time with nfs and rpc
debug turned up to 65535. I also tried unmounting one of the NFS
partitions which hung for a very very long time. As they spun there
was no debug logging except the occasional thing. It eventually spit
out 197903 messages of "NFS: clear cookie (0xeadd3288/0x(nil))"
(different addresses in each line, obviously) and since then things
quieted back down. The flush-0:xx threads don't even show up in 'top'
output anymore and _raw_spin_lock in 'perf top' has gone back down to
its usual area of 3-5%.
On Wed, Jan 5, 2011 at 11:43 AM, Mark Moseley <[email protected]> wrote:
> On Tue, Jan 4, 2011 at 1:40 PM, Simon Kirby <[email protected]> wrote:
>> On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote:
>>
>>> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
>>>
>>> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
>>> >
>>> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
>>> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
>>> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
>>> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
>>> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
>>> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
>>> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
>>> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
>>> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
>>> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
>>> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
>>> >
>>> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
>>> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
>>> >
>>> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
>>> > try to track this down without having to wait too long, unless somebody
>>> > can see what is happening here.
>>>
>>> I'll get started bisecting too, since this is something of a
>>> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
>>> now have to be powercycled every couple of days (which is about how
>>> long it takes for this behavior to show up). This is across-the-board
>>> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
>>>
>>> Simon: It's probably irrelevant since these are kernel threads, but
>>> I'm curious what distro your boxes are running. Ours are Debian Lenny,
>>> i386, Dell Poweredge 850s. Just trying to figure out any
>>> commonalities. I'll get my boxes back on 2.6.36.2 and start watching
>>> nfs_inode_cache as well.
>>
>> Same distro, x86_64, similar servers.
>>
>> I'm not sure if the two cases I am seeing are exactly the same problem,
>> but on the log crunching boxes, system time seems proportional to
>> nfs_inode_cache and nfs_inode_cache just keeps growing forever; however,
>> if I stop the load and unmount the NFS mount points, all of the
>> nfs_inode_cache objects do actually go away (after umount finishes).
>>
>> It seems the shrinker callback might not be working as intended here.
>>
>> On the shared server case, the crazy spinlock contention from all of the
>> flusher processes happens suddenly and overloads the boxes for 10-15
>> minutes, and then everything recovers. ?Over 21 of these boxes, they
>> each have about 500k-700k nfs_inode_cache objects. ?The log cruncher hit
>> 3.3 million nfs_inode_cache objects before I unmounted.
>>
>> Are your boxes repeating this behaviour at any predictable interval?
>
> Simon:
> My boxes definitely fall into the latter category, with spinlock
> regularly sitting at 60-80% CPU (according to 'perf top'). As far as
> predictability, not strictly, but it's typically after an uptime of
> 2-3 days. They take so long to get into this state that I've never
> seen the actual transition in person, just the after-effects of
> flush-0:xx gone crazy. These boxes have a number of other NFS mounts,
> but it's on the flush-0:xx's for the heavily written-to NFS mounts
> that are spinning wildly, which you'd expect to be the case. The
> infrequently written-to NFS servers' flush-0:xx isn't to be found in
> 'top' output.
>
> I'd booted into older kernels after my initial reply, so I'm 14 hrs
> into booting a box back into 2.6.36.2 and another box into a
> double-bisected 2.6.35-2.6.36 kernel (my first bisect hit compile
> errors). Both are running normally but that fits with the pattern so
> far.
>
> NFS Guys:
> Anything else we can be digging up to help debug this? This is a
> pretty ugly issue.
>
NOTE: NFS/Kernel guys: I've left the 2.6.36.2 box still thrashing
about in case there's something you'd like me to look at.
Ok, both my 2.6.36.2 kernel box and my 2.6.35->2.6.36 bisect box (was
bisected to ce7db282a3830f57f5b05ec48288c23a5c4d66d5 -- this is my
first time doing bisect, so I'll preemptively apologize for doing
anything silly) both went berserk within 15 mins of each other, after
an uptime of around 63 hours for 2.6.36.2 and 65 hours for the
bisected box. The 2.6.36.2 one is still running with all the various
flush-0:xx threads spinning wildly. The bisected box just keeled over
and died, but is back up now. The only kernel messages logged are just
of the "task kworker/4:1:359 blocked for more than 120 seconds"
variety, all with _raw_spin_lock_irq at the top of the stack trace.
Looking at slabinfo, specifically, this: stats=$(grep nfs_inode_cache
/proc/slabinfo | awk '{ print $2, $3 }')
the active_objs and num_objs both increase to over a million (these
boxes are delivering mail to NFS-mounted mailboxes, so that's
perfectly reasonable). On both boxes, looking at sar, things start to
go awry around 10am today EST. At that time on the 2.6.36.2 box, the
NFS numbers look like this:
Fri Jan 7 09:58:00 2011: 1079433 1079650
Fri Jan 7 09:59:00 2011: 1079632 1080300
Fri Jan 7 10:00:00 2011: 1080196 1080300
Fri Jan 7 10:01:01 2011: 1080599 1080716
Fri Jan 7 10:02:01 2011: 1081074 1081288
on the bisected, like this:
Fri Jan 7 09:59:34 2011: 1162786 1165320
Fri Jan 7 10:00:34 2011: 1163301 1165320
Fri Jan 7 10:01:34 2011: 1164369 1165450
Fri Jan 7 10:02:35 2011: 1164179 1165450
Fri Jan 7 10:03:35 2011: 1165795 1166958
When the bisected box finally died, the last numbers were:
Fri Jan 7 10:40:33 2011: 1177156 1177202
Fri Jan 7 10:42:21 2011: 1177157 1177306
Fri Jan 7 10:44:55 2011: 1177201 1177324
Fri Jan 7 10:45:55 2011: 1177746 1177826
On the still-thrashing 2.6.36.2 box, the highwater mark is:
Fri Jan 7 10:23:30 2011: 1084020 1084070
and once things went awry, the active_objs started falling away and
the number_objs has stayed at 1084070. Last numbers were:
Fri Jan 7 12:19:34 2011: 826623 1084070
The bisected box had reached 1mil entries (or more significantly
1048576 entries) by y'day evening. The 2.6.36.2 box hit that by 7am
EST today. So in neither case was there a big spike in entries.
These boxes have identical workloads. They're not accessible from the
net, so there's no chance of a DDoS or something. The significance of
10am EST could be either uptime-related (all these have gone down
after 2-3 days) or just due to the to-be-expected early morning spike
in mail flow.
On Tue, Jan 04, 2011 at 09:42:14AM -0800, Mark Moseley wrote:
> On Wed, Dec 29, 2010 at 2:03 PM, Simon Kirby <[email protected]> wrote:
>
> > I've noticed nfs_inode_cache is ever-increasing as well with 2.6.37:
> >
> > ?OBJS ACTIVE ?USE OBJ SIZE ?SLABS OBJ/SLAB CACHE SIZE NAME
> > 2562514 2541520 ?99% ? ?0.95K ?78739 ? ? ? 33 ? 2519648K nfs_inode_cache
> > 467200 285110 ?61% ? ?0.02K ? 1825 ? ? ?256 ? ? ?7300K kmalloc-16
> > 299397 242350 ?80% ? ?0.19K ?14257 ? ? ? 21 ? ? 57028K dentry
> > 217434 131978 ?60% ? ?0.55K ? 7767 ? ? ? 28 ? ?124272K radix_tree_node
> > 215232 ?81522 ?37% ? ?0.06K ? 3363 ? ? ? 64 ? ? 13452K kmalloc-64
> > 183027 136802 ?74% ? ?0.10K ? 4693 ? ? ? 39 ? ? 18772K buffer_head
> > 101120 ?71184 ?70% ? ?0.03K ? ?790 ? ? ?128 ? ? ?3160K kmalloc-32
> > ?79616 ?59713 ?75% ? ?0.12K ? 2488 ? ? ? 32 ? ? ?9952K kmalloc-128
> > ?66560 ?41257 ?61% ? ?0.01K ? ?130 ? ? ?512 ? ? ? 520K kmalloc-8
> > ?42126 ?26650 ?63% ? ?0.75K ? 2006 ? ? ? 21 ? ? 32096K ext3_inode_cache
> >
> > http://0x.ca/sim/ref/2.6.37/inodes_nfs.png
> > http://0x.ca/sim/ref/2.6.37/cpu2_nfs.png
> >
> > Perhaps I could bisect just fs/nfs changes between 2.6.35 and 2.6.36 to
> > try to track this down without having to wait too long, unless somebody
> > can see what is happening here.
>
> I'll get started bisecting too, since this is something of a
> show-stopper. Boxes that pre-2.6.36 would stay up for months at a time
> now have to be powercycled every couple of days (which is about how
> long it takes for this behavior to show up). This is across-the-board
> for about 50 boxes, ranging from 2.6.36 to 2.6.36.2.
>
> Simon: It's probably irrelevant since these are kernel threads, but
> I'm curious what distro your boxes are running. Ours are Debian Lenny,
> i386, Dell Poweredge 850s. Just trying to figure out any
> commonalities. I'll get my boxes back on 2.6.36.2 and start watching
> nfs_inode_cache as well.
Same distro, x86_64, similar servers.
I'm not sure if the two cases I am seeing are exactly the same problem,
but on the log crunching boxes, system time seems proportional to
nfs_inode_cache and nfs_inode_cache just keeps growing forever; however,
if I stop the load and unmount the NFS mount points, all of the
nfs_inode_cache objects do actually go away (after umount finishes).
It seems the shrinker callback might not be working as intended here.
On the shared server case, the crazy spinlock contention from all of the
flusher processes happens suddenly and overloads the boxes for 10-15
minutes, and then everything recovers. Over 21 of these boxes, they
each have about 500k-700k nfs_inode_cache objects. The log cruncher hit
3.3 million nfs_inode_cache objects before I unmounted.
Are your boxes repeating this behaviour at any predictable interval?
Simon-
On Tue, 2011-09-27 at 09:49 -0700, Simon Kirby wrote:
> On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
>
> > On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > > Hello!
> > >
> > > Following up on "System CPU increasing on idle 2.6.36", this issue is
> > > still happening even on 3.1-rc7. So, since it has been 9 months since I
> > > reported this, I figured I'd bisect this issue. The first bisection ended
> > > in an IPMI regression that looked like the problem, so I had to start
> > > again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > > which made it into 2.6.34-rc4.
> > >
> > > With this commit, system CPU keeps rising as the log crunch box runs
> > > (reads log files via NFS and spews out HTML files into NFS-mounted report
> > > directories). When it finishes the daily run, the system time stays
> > > non-zero and continues to be higher and higher after each run, until the
> > > box never completes a run within a day due to all of the wasted cycles.
> >
> > So reverting that commit fixes the problem on 3.1-rc7?
> >
> > As far as I can see, doing so should be safe thanks to commit
> > 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update dirty flags
> > in two steps) which fixes the original problem at the VFS level.
>
> Hmm, I went to git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2, but
> for some reason git left the nfs_mark_request_dirty(req); line in
> nfs_writepage_setup(), even though the original commit had that. Is that
> OK or should I remove that as well?
>
> Once that is sorted, I'll build it and let it run for a day and let you
> know. Thanks!
It shouldn't make any difference whether you leave it or remove it. The
resulting second call to __set_page_dirty_nobuffers() will always be a
no-op since the page will already be marked as dirty.
Cheers
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> Hello!
>
> Following up on "System CPU increasing on idle 2.6.36", this issue is
> still happening even on 3.1-rc7. So, since it has been 9 months since I
> reported this, I figured I'd bisect this issue. The first bisection ended
> in an IPMI regression that looked like the problem, so I had to start
> again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> which made it into 2.6.34-rc4.
>
> With this commit, system CPU keeps rising as the log crunch box runs
> (reads log files via NFS and spews out HTML files into NFS-mounted report
> directories). When it finishes the daily run, the system time stays
> non-zero and continues to be higher and higher after each run, until the
> box never completes a run within a day due to all of the wasted cycles.
So reverting that commit fixes the problem on 3.1-rc7?
As far as I can see, doing so should be safe thanks to commit
5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update dirty flags
in two steps) which fixes the original problem at the VFS level.
Cheers
Trond
--
Trond Myklebust
Linux NFS client maintainer
NetApp
[email protected]
http://www.netapp.com
On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
> On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > Hello!
> >
> > Following up on "System CPU increasing on idle 2.6.36", this issue is
> > still happening even on 3.1-rc7. So, since it has been 9 months since I
> > reported this, I figured I'd bisect this issue. The first bisection ended
> > in an IPMI regression that looked like the problem, so I had to start
> > again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > which made it into 2.6.34-rc4.
> >
> > With this commit, system CPU keeps rising as the log crunch box runs
> > (reads log files via NFS and spews out HTML files into NFS-mounted report
> > directories). When it finishes the daily run, the system time stays
> > non-zero and continues to be higher and higher after each run, until the
> > box never completes a run within a day due to all of the wasted cycles.
>
> So reverting that commit fixes the problem on 3.1-rc7?
>
> As far as I can see, doing so should be safe thanks to commit
> 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update dirty flags
> in two steps) which fixes the original problem at the VFS level.
Hmm, I went to git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2, but
for some reason git left the nfs_mark_request_dirty(req); line in
nfs_writepage_setup(), even though the original commit had that. Is that
OK or should I remove that as well?
Once that is sorted, I'll build it and let it run for a day and let you
know. Thanks!
Simon-
Hello!
Following up on "System CPU increasing on idle 2.6.36", this issue is
still happening even on 3.1-rc7. So, since it has been 9 months since I
reported this, I figured I'd bisect this issue. The first bisection ended
in an IPMI regression that looked like the problem, so I had to start
again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
which made it into 2.6.34-rc4.
With this commit, system CPU keeps rising as the log crunch box runs
(reads log files via NFS and spews out HTML files into NFS-mounted report
directories). When it finishes the daily run, the system time stays
non-zero and continues to be higher and higher after each run, until the
box never completes a run within a day due to all of the wasted cycles.
I previously posted a munin CPU graph picture here:
http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
Here is the most recent graph of me bisecting, roughly one day at a time:
http://0x.ca/sim/ref/2.6.34/cpu.png
Running a kernel built on this commit, I can actually make the problem
stop by just typing "sync". CPU then goes down to 0 and everything is
fine. Future kernel versions, such as 2.6.36, do not change with just a
"sync", but "sync;echo 3 > /proc/sys/vm/drop_caches;sync" _does_ stop
the system CPU usage. I can bisect this change, too, if that would help.
Here is the commit:
commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
Author: Trond Myklebust <[email protected]>
Date: Fri Apr 9 19:07:07 2010 -0400
NFS: Ensure that writeback_single_inode() calls write_inode() when syncing
Since writeback_single_inode() checks the inode->i_state flags _before_ it
flushes out the data, we need to ensure that the I_DIRTY_DATASYNC flag is
already set. Otherwise we risk not seeing a call to write_inode(), which
again means that we break fsync() et al...
Signed-off-by: Trond Myklebust <[email protected]>
diff --git a/fs/nfs/write.c b/fs/nfs/write.c
index 53ff70e..7f40ea3 100644
--- a/fs/nfs/write.c
+++ b/fs/nfs/write.c
@@ -421,6 +421,7 @@ static void
nfs_mark_request_dirty(struct nfs_page *req)
{
__set_page_dirty_nobuffers(req->wb_page);
+ __mark_inode_dirty(req->wb_page->mapping->host, I_DIRTY_DATASYNC);
}
#if defined(CONFIG_NFS_V3) || defined(CONFIG_NFS_V4)
@@ -660,6 +661,7 @@ static int nfs_writepage_setup(struct nfs_open_context *ctx, struct page *page,
req = nfs_setup_write_request(ctx, page, offset, count);
if (IS_ERR(req))
return PTR_ERR(req);
+ nfs_mark_request_dirty(req);
/* Update file length */
nfs_grow_file(page, offset, count);
nfs_mark_uptodate(page, req->wb_pgbase, req->wb_bytes);
@@ -739,8 +741,6 @@ int nfs_updatepage(struct file *file, struct page *page,
status = nfs_writepage_setup(ctx, page, offset, count);
if (status < 0)
nfs_set_pageerror(page);
- else
- __set_page_dirty_nobuffers(page);
dprintk("NFS: nfs_updatepage returns %d (isize %lld)\n",
status, (long long)i_size_read(inode));
With the build before this commit, the system time stays low always and
returns to 0% after every daily run.
Simon-
On Wed, Dec 08, 2010 at 04:53:09PM -0500, Trond Myklebust wrote:
> On Wed, 2010-12-08 at 13:25 -0800, Simon Kirby wrote:
> > Possibly related to the flush-processes-taking-CPU issues I saw
> > previously, I thought this was interesting. I found a log-crunching box
> > that does all of its work via NFS and spends most of the day sleeping.
> > It has been using a linearly-increasing amount of system time during the
> > time where is sleeping. munin graph:
> >
> > http://0x.ca/sim/ref/2.6.36/cpu_logcrunch_nfs.png
> >
> > top shows:
> >
> > PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
> > 4767 root 20 0 0 0 0 S 16 0.0 2413:29 flush-0:69
> > 22385 root 20 0 0 0 0 S 10 0.0 1320:23 flush-0:70
> > (rest idle)
> >
> > perf top shows:
> >
> > -------------------------------------------------------------------------------------------
> > PerfTop: 252 irqs/sec kernel:97.2% exact: 0.0% [1000Hz cycles], (all, 2 CPUs)
> > -------------------------------------------------------------------------------------------
> >
> > samples pcnt function DSO
> > _______ _____ _______________________________ ___________
> >
> > 912.00 21.2% _raw_spin_lock [kernel]
> > 592.00 13.8% nfs_writepages [kernel]
> > 474.00 11.0% queue_io [kernel]
> > 428.00 10.0% writeback_single_inode [kernel]
> > 379.00 8.8% writeback_sb_inodes [kernel]
> > 237.00 5.5% bit_waitqueue [kernel]
> > 184.00 4.3% do_writepages [kernel]
> > 169.00 3.9% __iget [kernel]
> > 132.00 3.1% redirty_tail [kernel]
> > 85.00 2.0% iput [kernel]
> > 72.00 1.7% _atomic_dec_and_lock [kernel]
> > 67.00 1.6% write_cache_pages [kernel]
> > 63.00 1.5% port_inb [ipmi_si]
> > 62.00 1.4% __mark_inode_dirty [kernel]
> > 48.00 1.1% __wake_up_bit [kernel]
> > 32.00 0.7% nfs_write_inode [kernel]
> > 26.00 0.6% native_read_tsc [kernel]
> > 25.00 0.6% radix_tree_gang_lookup_tag_slot [kernel]
> > 25.00 0.6% schedule [kernel]
> > 24.00 0.6% wake_up_bit [kernel]
> > 20.00 0.5% apic_timer_interrupt [kernel]
> > 19.00 0.4% ia32_syscall [kernel]
> > 16.00 0.4% find_get_pages_tag [kernel]
> > 15.00 0.3% _raw_spin_lock_irqsave [kernel]
> > 15.00 0.3% load_balance [kernel]
> > 13.00 0.3% ktime_get [kernel]
> > 12.00 0.3% shrink_icache_memory [kernel]
> > 11.00 0.3% semop libc-2.7.so
> > 9.00 0.2% nfs_pageio_doio [kernel]
> > 8.00 0.2% dso__find_symbol perf
> > 8.00 0.2% down_read [kernel]
> > 7.00 0.2% __switch_to [kernel]
> > 7.00 0.2% __phys_addr [kernel]
> > 7.00 0.2% nfs_pageio_init [kernel]
> > 7.00 0.2% pagevec_lookup_tag [kernel]
> > 7.00 0.2% _cond_resched [kernel]
> > 7.00 0.2% up_read [kernel]
> > 6.00 0.1% sched_clock_local [kernel]
> > 5.00 0.1% rb_erase [kernel]
> > 5.00 0.1% page_fault [kernel]
> >
> > "tcpdump -i any -n port 2049" and "nfsstat" shows this work does not actually result
> > in any NFS packets.
> >
> > Known 2.6.36 issue? This did not occur on 2.6.35.4, according to the
> > munin graphs. I'll try 2.6.37-rc an see if it changes.
>
> Possibly a side effect of the fs/fs-writeback.c changes in 2.6.36? You
> do appear to be hitting a lot of spinlock contention, but I suspect that
> a lot of it is coming from writeback_sb_inodes, writeback_single_inode
> and queue_io, all of which seem unnaturally high on your stats above.
>
> I don't see how you can be seeing no traffic on the wire. You are
> certainly hitting some page writeout (0.2% nfs_pageio_doio).
>
> Cheers
> Trond
> --
> Trond Myklebust
> Linux NFS client maintainer
>
> NetApp
> [email protected]
> http://www.netapp.com
On Wed, Sep 28, 2011 at 12:58:35PM -0700, Simon Kirby wrote:
> On Tue, Sep 27, 2011 at 01:04:15PM -0400, Trond Myklebust wrote:
>
> > On Tue, 2011-09-27 at 09:49 -0700, Simon Kirby wrote:
> > > On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
> > >
> > > > On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > > > > Hello!
> > > > >
> > > > > Following up on "System CPU increasing on idle 2.6.36", this issue is
> > > > > still happening even on 3.1-rc7. So, since it has been 9 months since I
> > > > > reported this, I figured I'd bisect this issue. The first bisection ended
> > > > > in an IPMI regression that looked like the problem, so I had to start
> > > > > again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > > > > which made it into 2.6.34-rc4.
> > > > >
> > > > > With this commit, system CPU keeps rising as the log crunch box runs
> > > > > (reads log files via NFS and spews out HTML files into NFS-mounted report
> > > > > directories). When it finishes the daily run, the system time stays
> > > > > non-zero and continues to be higher and higher after each run, until the
> > > > > box never completes a run within a day due to all of the wasted cycles.
> > > >
> > > > So reverting that commit fixes the problem on 3.1-rc7?
> > > >
> > > > As far as I can see, doing so should be safe thanks to commit
> > > > 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update dirty flags
> > > > in two steps) which fixes the original problem at the VFS level.
> > >
> > > Hmm, I went to git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2, but
> > > for some reason git left the nfs_mark_request_dirty(req); line in
> > > nfs_writepage_setup(), even though the original commit had that. Is that
> > > OK or should I remove that as well?
> > >
> > > Once that is sorted, I'll build it and let it run for a day and let you
> > > know. Thanks!
> >
> > It shouldn't make any difference whether you leave it or remove it. The
> > resulting second call to __set_page_dirty_nobuffers() will always be a
> > no-op since the page will already be marked as dirty.
>
> Ok, confirmed, git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2 on
> 3.1-rc7 fixes the problem for me. Does this make sense, then, or do we
> need further investigation and/or testing?
Just to clear up what I said before, it seems that on plain 3.1-rc8, I am
actually able to clear the endless CPU use in nfs_writepages by just
running "sync". I am not sure when this changed, but I'm pretty sure that
some versions between 2.6.34 and 3.1-rc used to not be affected by just
"sync" unless it was paired with drop_caches. Maybe this makes the
problem more obvious...
Simon-
On Tue, Sep 27, 2011 at 01:04:15PM -0400, Trond Myklebust wrote:
> On Tue, 2011-09-27 at 09:49 -0700, Simon Kirby wrote:
> > On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
> >
> > > On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > > > Hello!
> > > >
> > > > Following up on "System CPU increasing on idle 2.6.36", this issue is
> > > > still happening even on 3.1-rc7. So, since it has been 9 months since I
> > > > reported this, I figured I'd bisect this issue. The first bisection ended
> > > > in an IPMI regression that looked like the problem, so I had to start
> > > > again. Eventually, I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > > > which made it into 2.6.34-rc4.
> > > >
> > > > With this commit, system CPU keeps rising as the log crunch box runs
> > > > (reads log files via NFS and spews out HTML files into NFS-mounted report
> > > > directories). When it finishes the daily run, the system time stays
> > > > non-zero and continues to be higher and higher after each run, until the
> > > > box never completes a run within a day due to all of the wasted cycles.
> > >
> > > So reverting that commit fixes the problem on 3.1-rc7?
> > >
> > > As far as I can see, doing so should be safe thanks to commit
> > > 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update dirty flags
> > > in two steps) which fixes the original problem at the VFS level.
> >
> > Hmm, I went to git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2, but
> > for some reason git left the nfs_mark_request_dirty(req); line in
> > nfs_writepage_setup(), even though the original commit had that. Is that
> > OK or should I remove that as well?
> >
> > Once that is sorted, I'll build it and let it run for a day and let you
> > know. Thanks!
>
> It shouldn't make any difference whether you leave it or remove it. The
> resulting second call to __set_page_dirty_nobuffers() will always be a
> no-op since the page will already be marked as dirty.
Ok, confirmed, git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2 on
3.1-rc7 fixes the problem for me. Does this make sense, then, or do we
need further investigation and/or testing?
Simon-
> -----Original Message-----
> From: Simon Kirby [mailto:[email protected]]
> Sent: Thursday, September 29, 2011 8:58 PM
> To: Myklebust, Trond
> Cc: [email protected]; [email protected]
> Subject: Re: NFS client growing system CPU
>
> On Wed, Sep 28, 2011 at 12:58:35PM -0700, Simon Kirby wrote:
>
> > On Tue, Sep 27, 2011 at 01:04:15PM -0400, Trond Myklebust wrote:
> >
> > > On Tue, 2011-09-27 at 09:49 -0700, Simon Kirby wrote:
> > > > On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
> > > >
> > > > > On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > > > > > Hello!
> > > > > >
> > > > > > Following up on "System CPU increasing on idle 2.6.36", this
> > > > > > issue is still happening even on 3.1-rc7. So, since it has
> > > > > > been 9 months since I reported this, I figured I'd bisect
this
> > > > > > issue. The first bisection ended in an IPMI regression that
> > > > > > looked like the problem, so I had to start again.
Eventually,
> > > > > > I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > > > > > which made it into 2.6.34-rc4.
> > > > > >
> > > > > > With this commit, system CPU keeps rising as the log crunch
> > > > > > box runs (reads log files via NFS and spews out HTML files
> > > > > > into NFS-mounted report directories). When it finishes the
> > > > > > daily run, the system time stays non-zero and continues to
be
> > > > > > higher and higher after each run, until the box never
completes a
> run within a day due to all of the wasted cycles.
> > > > >
> > > > > So reverting that commit fixes the problem on 3.1-rc7?
> > > > >
> > > > > As far as I can see, doing so should be safe thanks to commit
> > > > > 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update
> > > > > dirty flags in two steps) which fixes the original problem at
the VFS
> level.
> > > >
> > > > Hmm, I went to git revert
> > > > b80c3cb628f0ebc241b02e38dd028969fb8026a2, but for some reason
git
> > > > left the nfs_mark_request_dirty(req); line in
> > > > nfs_writepage_setup(), even though the original commit had that.
Is
> that OK or should I remove that as well?
> > > >
> > > > Once that is sorted, I'll build it and let it run for a day and
> > > > let you know. Thanks!
> > >
> > > It shouldn't make any difference whether you leave it or remove
it.
> > > The resulting second call to __set_page_dirty_nobuffers() will
> > > always be a no-op since the page will already be marked as dirty.
> >
> > Ok, confirmed, git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2
on
> > 3.1-rc7 fixes the problem for me. Does this make sense, then, or do
we
> > need further investigation and/or testing?
>
> Just to clear up what I said before, it seems that on plain 3.1-rc8, I
am actually
> able to clear the endless CPU use in nfs_writepages by just running
"sync". I
> am not sure when this changed, but I'm pretty sure that some versions
> between 2.6.34 and 3.1-rc used to not be affected by just "sync"
unless it
> was paired with drop_caches. Maybe this makes the problem more
> obvious...
Hi Simon,
I think you are just finding yourself cycling through the VFS writeback
routines all the time because we dirty the inode for COMMIT at the same
time as we dirty a new page. Usually, we want to wait until after the
WRITE rpc call has completed, and so it was only the vfs race that
forced us to write this workaround so that we can guarantee reliable
fsync() behaviour.
My only concern at this point is to make sure that in reverting that
patch, we haven't overlooked some other fsync() bug that this patch
fixed. So far, it looks as if Dmitry's patch is sufficient to deal with
any issues that I can see.
Cheers
Trond
On Thu, Sep 29, 2011 at 06:11:17PM -0700, Myklebust, Trond wrote:
> > -----Original Message-----
> > From: Simon Kirby [mailto:[email protected]]
> > Sent: Thursday, September 29, 2011 8:58 PM
> > To: Myklebust, Trond
> > Cc: [email protected]; [email protected]
> > Subject: Re: NFS client growing system CPU
> >
> > On Wed, Sep 28, 2011 at 12:58:35PM -0700, Simon Kirby wrote:
> >
> > > On Tue, Sep 27, 2011 at 01:04:15PM -0400, Trond Myklebust wrote:
> > >
> > > > On Tue, 2011-09-27 at 09:49 -0700, Simon Kirby wrote:
> > > > > On Tue, Sep 27, 2011 at 07:42:53AM -0400, Trond Myklebust wrote:
> > > > >
> > > > > > On Mon, 2011-09-26 at 17:39 -0700, Simon Kirby wrote:
> > > > > > > Hello!
> > > > > > >
> > > > > > > Following up on "System CPU increasing on idle 2.6.36", this
> > > > > > > issue is still happening even on 3.1-rc7. So, since it has
> > > > > > > been 9 months since I reported this, I figured I'd bisect
> this
> > > > > > > issue. The first bisection ended in an IPMI regression that
> > > > > > > looked like the problem, so I had to start again.
> Eventually,
> > > > > > > I got commit b80c3cb628f0ebc241b02e38dd028969fb8026a2
> > > > > > > which made it into 2.6.34-rc4.
> > > > > > >
> > > > > > > With this commit, system CPU keeps rising as the log crunch
> > > > > > > box runs (reads log files via NFS and spews out HTML files
> > > > > > > into NFS-mounted report directories). When it finishes the
> > > > > > > daily run, the system time stays non-zero and continues to
> be
> > > > > > > higher and higher after each run, until the box never
> completes a
> > run within a day due to all of the wasted cycles.
> > > > > >
> > > > > > So reverting that commit fixes the problem on 3.1-rc7?
> > > > > >
> > > > > > As far as I can see, doing so should be safe thanks to commit
> > > > > > 5547e8aac6f71505d621a612de2fca0dd988b439 (writeback: Update
> > > > > > dirty flags in two steps) which fixes the original problem at
> the VFS
> > level.
> > > > >
> > > > > Hmm, I went to git revert
> > > > > b80c3cb628f0ebc241b02e38dd028969fb8026a2, but for some reason
> git
> > > > > left the nfs_mark_request_dirty(req); line in
> > > > > nfs_writepage_setup(), even though the original commit had that.
> Is
> > that OK or should I remove that as well?
> > > > >
> > > > > Once that is sorted, I'll build it and let it run for a day and
> > > > > let you know. Thanks!
> > > >
> > > > It shouldn't make any difference whether you leave it or remove
> it.
> > > > The resulting second call to __set_page_dirty_nobuffers() will
> > > > always be a no-op since the page will already be marked as dirty.
> > >
> > > Ok, confirmed, git revert b80c3cb628f0ebc241b02e38dd028969fb8026a2
> on
> > > 3.1-rc7 fixes the problem for me. Does this make sense, then, or do
> we
> > > need further investigation and/or testing?
> >
> > Just to clear up what I said before, it seems that on plain 3.1-rc8, I
> am actually
> > able to clear the endless CPU use in nfs_writepages by just running
> "sync". I
> > am not sure when this changed, but I'm pretty sure that some versions
> > between 2.6.34 and 3.1-rc used to not be affected by just "sync"
> unless it
> > was paired with drop_caches. Maybe this makes the problem more
> > obvious...
>
> Hi Simon,
>
> I think you are just finding yourself cycling through the VFS writeback
> routines all the time because we dirty the inode for COMMIT at the same
> time as we dirty a new page. Usually, we want to wait until after the
> WRITE rpc call has completed, and so it was only the vfs race that
> forced us to write this workaround so that we can guarantee reliable
> fsync() behaviour.
>
> My only concern at this point is to make sure that in reverting that
> patch, we haven't overlooked some other fsync() bug that this patch
> fixed. So far, it looks as if Dmitry's patch is sufficient to deal with
> any issues that I can see.
Hello!
So, this is a regression that has caused uptime issues for us since
2.6.34-rc4. Dmitry's patch went into 2.6.35, so I think this revert
should be committed and be a stable candidate for 2.6.35 - 3.1.
We have not seen any problems resulting from the revert, but our loads
are not particularly fsync()-heavy. How did things work before this
patch, anyway?
Here is another graph showing the revert fixing the problem on this box
with relatively simple workload (revert applied Tuesday evening):
http://0x.ca/sim/ref/3.1-rc8/cpu-analog02-revert-b80c3cb6.png
It is helping on many other boxes, too, but they get various spurts of
memory pressure and other CPU spikes that cause the difference to be
harder to see. We're still running your sunrpc/clnt.c debugging patch as
well, but haven't hit the hang again yet.
Simon-
{kind=link}
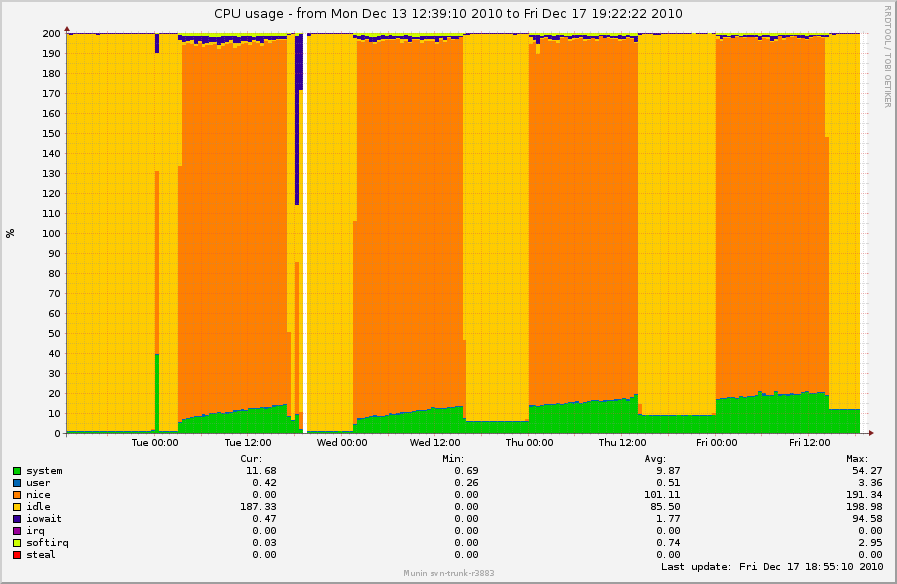{kind=link}
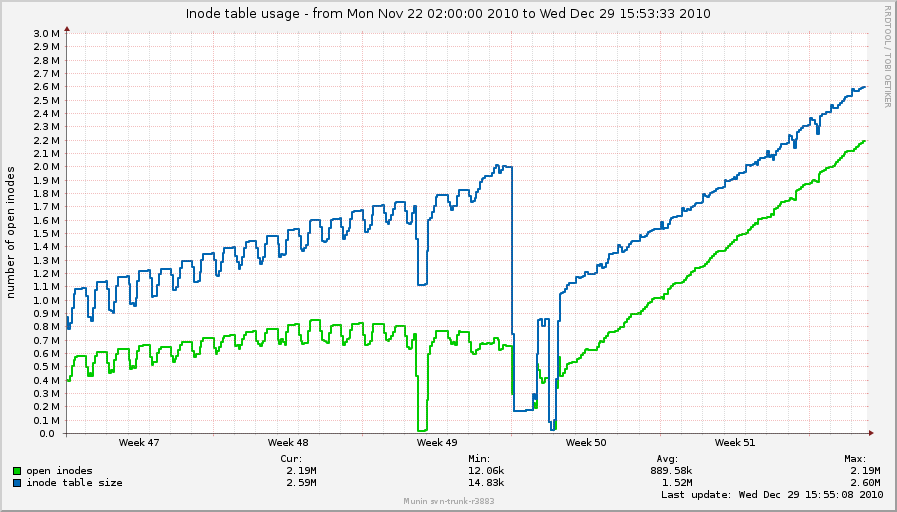{kind=link}
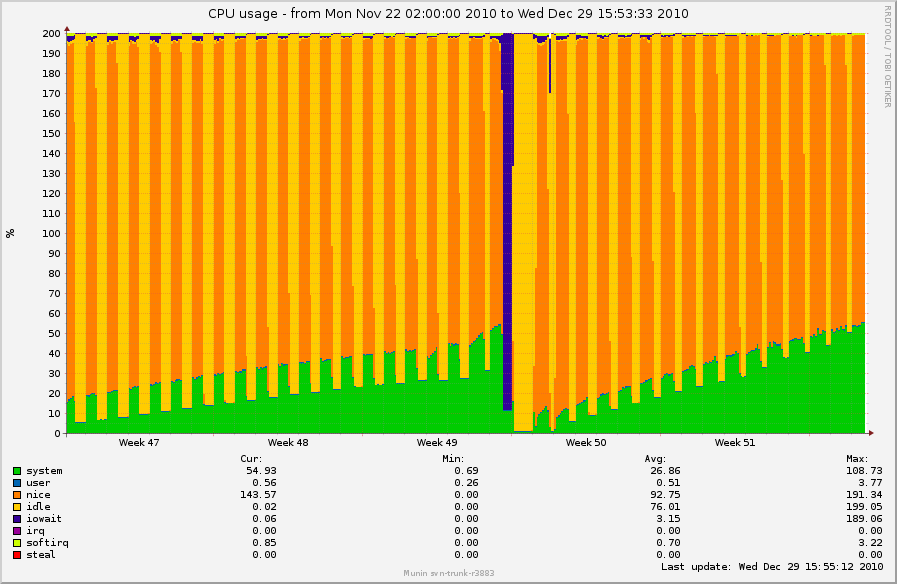{kind=link}
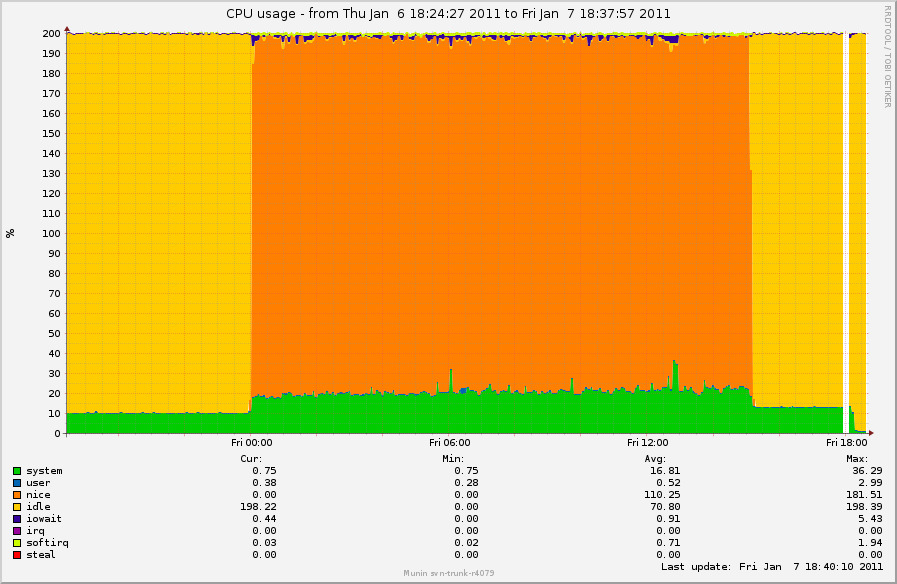{kind=link}
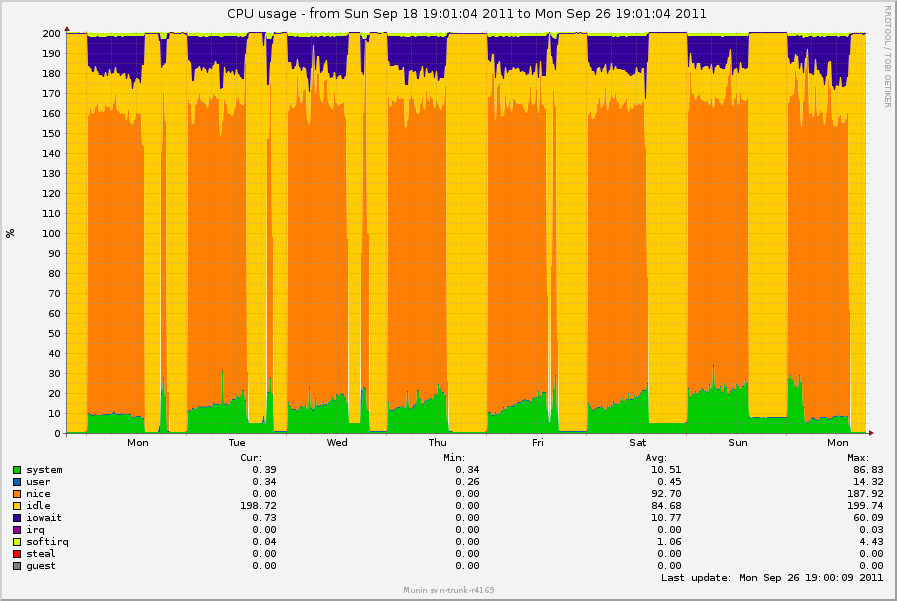{kind=link}
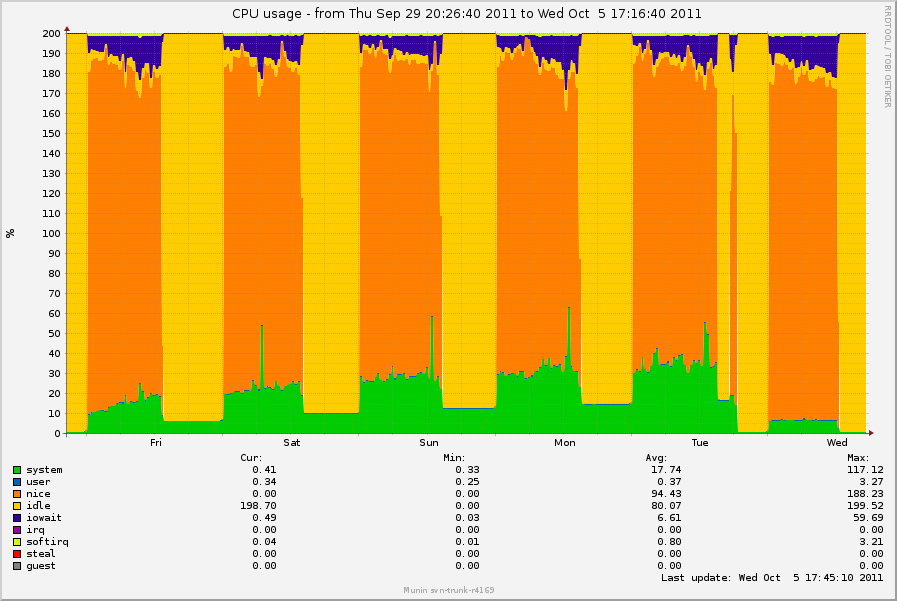{kind=link}