Please look at http://www.namesys.com/benchmarks/v4marks.html
In brief, V4 is way faster than V3, and the wandering logs are indeed
twice as fast as fixed location logs when performing writes in large
batches.
We are able to perform all filesystem operations fully atomically, while
getting dramatic performance improvements. (Other attempts at
introducing transactions into filesystems are said to have failed for
performance reasons.)
Balancing at flush time works well, not using blobs works well,
allocating at flush time works well. CPU time is good enough to get by,
and it will improve over the next few months as we tweak a lot of little
details, but the IO performance is what matters, and this performance is
quite good enough to use. In all the places where V3 sacrifices
performance to save disk space, V4 saves more disk space and gains
rather than loses performance.
The plugin infrastructure works well, expect lots of plugins over the
next year or two.
Look for a repacker to come out in a few weeks that will make these
numbers especially good for filesystems that have 80% of their files
unmoving for long periods of time (which is to say most systems), and
might otherwise suffer from fragmentation.
These benchmarks mean to me that our performance is now good enough to
ship V4 to users (which means we need persons willing to try to crash it
so that the stability can become good enough to ship to users).
Sometime during the next week or two we will probably send a patch in,
and ask for inclusion. We need to run another round of stress tests
after our latest tweaks, and kill off two bugs that got added just
recently, and then we will ask for testers.
I will be going to Budapest to discuss filesystem semantics with Peter
Foldiak for a week, so V4 may get sent in for inclusion by members of my
team while I am absent. If so, please include it in 2.5/2.6.
--
Hans
Hans Reiser wrote:
> Please look at http://www.namesys.com/benchmarks/v4marks.html
>
> In brief, V4 is way faster than V3, and the wandering logs are indeed
> twice as fast as fixed location logs when performing writes in large
> batches.
>
<snip>
I am interested in testing this out, but the latest patch on the namesys
sight appears to be against 2.5.60 which was never usable on my
hardware. If there is a later patch, or if somebody has adapted it to
work against 2.6.0-test1(or anything comparably recent), please let me know.
-Tupshin
This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
On Wed, 2003-07-23 at 23:26, Tupshin Harper wrote:
> Hans Reiser wrote:
>
> > Please look at http://www.namesys.com/benchmarks/v4marks.html
> >
> > In brief, V4 is way faster than V3, and the wandering logs are indeed
> > twice as fast as fixed location logs when performing writes in large
> > batches.
> >
> <snip>
> I am interested in testing this out, but the latest patch on the namesys
> sight appears to be against 2.5.60 which was never usable on my
> hardware. If there is a later patch, or if somebody has adapted it to
> work against 2.6.0-test1(or anything comparably recent), please let me know.
>
> -Tupshin
>
> -
> To unsubscribe from this list: send the line "unsubscribe linux-kernel" in
> the body of a message to [email protected]
> More majordomo info at http://vger.kernel.org/majordomo-info.html
> Please read the FAQ at http://www.tux.org/lkml/
Shawn wrote:
>This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
>
Thanks, but I tried applying the
2.6.0-test1-reiser4-2.6.0-test1.diff from that location with a lack of
success.
It applied cleanly, but it doesn't add a fs/reiser4 directory and
asociated contents. Is there an additional patch, or is this one broken?
-Tupshin
Looks like the 2.5.74 is the last one of any respectable size. I'm
thinking someone forgot a diff switch (N?) over at namesys...
Hans? Time to long-distance spank someone?
On Wed, 2003-07-23 at 23:56, Tupshin Harper wrote:
> Shawn wrote:
>
> >This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
> >
> Thanks, but I tried applying the
> 2.6.0-test1-reiser4-2.6.0-test1.diff from that location with a lack of
> success.
>
> It applied cleanly, but it doesn't add a fs/reiser4 directory and
> asociated contents. Is there an additional patch, or is this one broken?
>
> -Tupshin
>
Hmmm... Maybe he can get one of those swirly color guys on the namesys
website to administer the spanking.
(http://www.namesys.com/v4/r4pics/finegrainingJ.jpg) I want to see video
of that...
BTW Hans, I have a new swirly guy idea for the "Extensibility through
plugins" graphic... ;P
On Thu, 2003-07-24 at 00:21, Shawn wrote:
> Looks like the 2.5.74 is the last one of any respectable size. I'm
> thinking someone forgot a diff switch (N?) over at namesys...
>
> Hans? Time to long-distance spank someone?
>
> On Wed, 2003-07-23 at 23:56, Tupshin Harper wrote:
> > Shawn wrote:
> >
> > >This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
> > >
> > Thanks, but I tried applying the
> > 2.6.0-test1-reiser4-2.6.0-test1.diff from that location with a lack of
> > success.
> >
> > It applied cleanly, but it doesn't add a fs/reiser4 directory and
> > asociated contents. Is there an additional patch, or is this one broken?
> >
> > -Tupshin
Shawn writes:
> Looks like the 2.5.74 is the last one of any respectable size. I'm
> thinking someone forgot a diff switch (N?) over at namesys...
>
> Hans? Time to long-distance spank someone?
Can you try following the instructions on the
http://www.namesys.com/code.html (requires bitkeeper)?
Nikita.
>
> On Wed, 2003-07-23 at 23:56, Tupshin Harper wrote:
> > Shawn wrote:
> >
> > >This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
> > >
> > Thanks, but I tried applying the
> > 2.6.0-test1-reiser4-2.6.0-test1.diff from that location with a lack of
> > success.
> >
> > It applied cleanly, but it doesn't add a fs/reiser4 directory and
> > asociated contents. Is there an additional patch, or is this one broken?
> >
> > -Tupshin
> >
Nikita Danilov wrote:
>Shawn writes:
> > Looks like the 2.5.74 is the last one of any respectable size. I'm
> > thinking someone forgot a diff switch (N?) over at namesys...
> >
> > Hans? Time to long-distance spank someone?
>
>Can you try following the instructions on the
>http://www.namesys.com/code.html (requires bitkeeper)?
>
>Nikita.
>
I'm sorry, but I don't have a bitkeeper license. Please let me know if a
fixed patch is available.
-Tupshin
On Thu, Jul 24, 2003 at 08:10:19AM -0700, Tupshin Harper wrote:
> Nikita Danilov wrote:
>
> >Shawn writes:
> >> Looks like the 2.5.74 is the last one of any respectable size. I'm
> >> thinking someone forgot a diff switch (N?) over at namesys...
> >>
> >> Hans? Time to long-distance spank someone?
> >
> >Can you try following the instructions on the
> >http://www.namesys.com/code.html (requires bitkeeper)?
> >
> >Nikita.
> >
> I'm sorry, but I don't have a bitkeeper license. Please let me know if a
> fixed patch is available.
If someone can tell me what it is that you need and I'll do it and send you
a patch. I'm cloning that tree now.
--
---
Larry McVoy lm at bitmover.com http://www.bitmover.com/lm
Larry McVoy wrote:
>On Thu, Jul 24, 2003 at 08:10:19AM -0700, Tupshin Harper wrote:
>
>
>>Nikita Danilov wrote:
>>
>>
>>
>>>Shawn writes:
>>>
>>>
>>>>Looks like the 2.5.74 is the last one of any respectable size. I'm
>>>>thinking someone forgot a diff switch (N?) over at namesys...
>>>>
>>>>Hans? Time to long-distance spank someone?
>>>>
>>>>
>>>Can you try following the instructions on the
>>>http://www.namesys.com/code.html (requires bitkeeper)?
>>>
>>>Nikita.
>>>
>>>
>>>
>>I'm sorry, but I don't have a bitkeeper license. Please let me know if a
>>fixed patch is available.
>>
>>
>
>If someone can tell me what it is that you need and I'll do it and send you
>a patch. I'm cloning that tree now.
>
>
Thanks...I'm just interested in a working version of the reiser 4
patches to apply against 2.6.0-test1 or any other very recent tree. The
version at ftp://ftp.namesys.com/pub/tmp is incomplete.
-Tupshin
Wow, it seems rather involved just to get a udiff against bk-cur. Pull
kernel sources with reiser4 mods, then pull fs/reiser4/*, then generate
a diff.
Well, at least I understand it now...
On Thu, 2003-07-24 at 10:26, Larry McVoy wrote:
> On Thu, Jul 24, 2003 at 08:10:19AM -0700, Tupshin Harper wrote:
> > Nikita Danilov wrote:
> >
> > >Shawn writes:
> > >> Looks like the 2.5.74 is the last one of any respectable size. I'm
> > >> thinking someone forgot a diff switch (N?) over at namesys...
> > >>
> > >> Hans? Time to long-distance spank someone?
> > >
> > >Can you try following the instructions on the
> > >http://www.namesys.com/code.html (requires bitkeeper)?
> > >
> > >Nikita.
> > >
> > I'm sorry, but I don't have a bitkeeper license. Please let me know if a
> > fixed patch is available.
>
> If someone can tell me what it is that you need and I'll do it and send you
> a patch. I'm cloning that tree now.
On Thu, Jul 24, 2003 at 08:26:49AM -0700, Larry McVoy wrote:
> > >http://www.namesys.com/code.html (requires bitkeeper)?
>
> If someone can tell me what it is that you need and I'll do it and send you
> a patch. I'm cloning that tree now.
I pulled the r4 tree into linux-2.5 (2.6) top of trunk, merged it (it all
automerged, ya gotta love that, see below), and sent out a patch. If someone
else needs that patch let me know.
takepatch: 2782 new revisions, 8 conflicts in 357 files
440459 bytes uncompressed to 2455963, 5.58X expansion
Running resolve to apply new work ...
resolve: found 25 renames in pass 1
resolve: resolved 25 renames in pass 2
Content merge of Makefile OK
Content merge of arch/um/drivers/ubd_kern.c OK
Content merge of fs/jbd/transaction.c OK
Content merge of fs/proc/proc_misc.c OK
Content merge of include/linux/sched.h OK
Content merge of kernel/ksyms.c OK
Content merge of kernel/sched.c OK
resolve: resolved 7 conflicts in pass 3
--
---
Larry McVoy lm at bitmover.com http://www.bitmover.com/lm
Am Mit, 2003-07-23 um 23.02 schrieb Hans Reiser:
> In brief, V4 is way faster than V3, and the wandering logs are indeed
> twice as fast as fixed location logs when performing writes in large
> batches.
How do the wandering logs compare to the "wandering" logs of the log
structured filesystem JFFS2? Does this mean I can achieve an implicit
wear leveling for flash memory?
> We are able to perform all filesystem operations fully atomically,
> while getting dramatic performance improvements. (Other attempts at
> introducing transactions into filesystems are said to have failed for
> performance reasons.)
How failsafe is it to switch off the power several times? When the
filesystem really works atomically I should have either the old or the
new version but no mixture. Does it still need to fsck or is the
transaction replay done at mount time? In case one still needs fsck,
what's the probability of needing user interaction? How long does it
need to get a filesystem back into a consistent state after a powerloss
(approx. per MB/GB)?
Background: I'm doing systems on compactflash cards and need a reliable
filesystem for it. At the moment I'm using a compressed JFFS2 over the
mtd emulation driver for block devices which works quite well but has a
few catches...
--
Servus,
Daniel
Daniel Egger writes:
> Am Mit, 2003-07-23 um 23.02 schrieb Hans Reiser:
>
> > In brief, V4 is way faster than V3, and the wandering logs are indeed
> > twice as fast as fixed location logs when performing writes in large
> > batches.
>
> How do the wandering logs compare to the "wandering" logs of the log
> structured filesystem JFFS2? Does this mean I can achieve an implicit
> wear leveling for flash memory?
I don't know enough about jffs2, but you can read about reiser4's
"wandering logs" and transaction manager design at the
http://www.namesys.com/txn-doc.html.
Briefly speaking, in usual WAL (write-ahead logging) transaction system,
whenever block is modified, journal record, describing changes to this
block is forced to the on-disk journal before modified block is allowed
to be written. In the worst case this means that data are written twice.
But if modified block is accessible through "pointer" of some kind
stored in its "parent" block (one can think of ext2 inode addressing
data blocks for example), we can
1. allocate new block location on the disk ("wandered location").
2. update parent block to point to the wandered location.
3. store modified block content to the wandered location.
4. add old block location to the journal. Old block is now journal
record for the modified version.
>
> > We are able to perform all filesystem operations fully atomically,
> > while getting dramatic performance improvements. (Other attempts at
> > introducing transactions into filesystems are said to have failed for
> > performance reasons.)
>
> How failsafe is it to switch off the power several times? When the
> filesystem really works atomically I should have either the old or the
> new version but no mixture. Does it still need to fsck or is the
> transaction replay done at mount time? In case one still needs fsck,
> what's the probability of needing user interaction? How long does it
> need to get a filesystem back into a consistent state after a powerloss
> (approx. per MB/GB)?
I should warn everybody that reiser4 is _highly_ _experimental_ at this
moment. Don't use it for production.
>
> Background: I'm doing systems on compactflash cards and need a reliable
> filesystem for it. At the moment I'm using a compressed JFFS2 over the
> mtd emulation driver for block devices which works quite well but has a
> few catches...
>
> --
> Servus,
> Daniel
Calculemus!
Nikita.
Nikita Danilov wrote:
>Daniel Egger writes:
> >
> > How failsafe is it to switch off the power several times? When the
> > filesystem really works atomically I should have either the old or the
> > new version but no mixture. Does it still need to fsck or is the
> > transaction replay done at mount time? In case one still needs fsck,
> > what's the probability of needing user interaction? How long does it
> > need to get a filesystem back into a consistent state after a powerloss
> > (approx. per MB/GB)?
>
>I should warn everybody that reiser4 is _highly_ _experimental_ at this
>moment. Don't use it for production.
>
I'd like to ask this question differently: How failsafe is reiserfs4
*theoretically*. Assuming no bugs in implementation, what is the true
import of its atomic nature? Strengths and potential weaknesses?
-Thanks
-Tupshin
Am Don, 2003-07-24 um 19.07 schrieb Nikita Danilov:
> I don't know enough about jffs2, but you can read about reiser4's
> "wandering logs" and transaction manager design at the
> http://www.namesys.com/txn-doc.html.
I've read it by now, thanks for the reference.
> Briefly speaking, in usual WAL (write-ahead logging) transaction system,
> whenever block is modified, journal record, describing changes to this
> block is forced to the on-disk journal before modified block is allowed
> to be written. In the worst case this means that data are written twice.
Is there way to influence what is considered free space for the
wandering blocks or is it a fixed algorithm? If the latter, what is the
access pattern on the free space (like pseudorandom, cyclic linear,
hashed)?
> I should warn everybody that reiser4 is _highly_ _experimental_ at this
> moment. Don't use it for production.
That certainly doesn't stop me from trying... :)
Have you ran any tests to test the durabilty of your "transcrash" system
for instance against sudden power dropouts?
Is the filesystem selfhealing or does one need fsck.reiserfs for it? If
the latter: will it do the right thing (i.e. automatically bring the
system into consistent shape not like ext3) when invoked with "-y"?
--
Servus,
Daniel
Tupshin Harper writes:
> Nikita Danilov wrote:
>
> >Daniel Egger writes:
> > >
> > > How failsafe is it to switch off the power several times? When the
> > > filesystem really works atomically I should have either the old or the
> > > new version but no mixture. Does it still need to fsck or is the
> > > transaction replay done at mount time? In case one still needs fsck,
> > > what's the probability of needing user interaction? How long does it
> > > need to get a filesystem back into a consistent state after a powerloss
> > > (approx. per MB/GB)?
> >
> >I should warn everybody that reiser4 is _highly_ _experimental_ at this
> >moment. Don't use it for production.
> >
> I'd like to ask this question differently: How failsafe is reiserfs4
> *theoretically*. Assuming no bugs in implementation, what is the true
> import of its atomic nature? Strengths and potential weaknesses?
Assuming no bugs in implementation it is very safe. :-)
This is lengthy topic. You may wish to read documents on the
namesys.com. For example,
http://www.namesys.com/v4/reiser4_the_atomic_fs.html
>
> -Thanks
> -Tupshin
>
Nikita.
Daniel Egger writes:
> Am Don, 2003-07-24 um 19.07 schrieb Nikita Danilov:
>
> > I don't know enough about jffs2, but you can read about reiser4's
> > "wandering logs" and transaction manager design at the
> > http://www.namesys.com/txn-doc.html.
>
> I've read it by now, thanks for the reference.
>
> > Briefly speaking, in usual WAL (write-ahead logging) transaction system,
> > whenever block is modified, journal record, describing changes to this
> > block is forced to the on-disk journal before modified block is allowed
> > to be written. In the worst case this means that data are written twice.
>
> Is there way to influence what is considered free space for the
> wandering blocks or is it a fixed algorithm? If the latter, what is the
> access pattern on the free space (like pseudorandom, cyclic linear,
> hashed)?
No special measures are taken to level block allocation. Wandered blocks
are allocated to improve packing i.e., place blocks of the same file
close to each other. Actually, it tries to place tree nodes in the
parent-first order.
>
> > I should warn everybody that reiser4 is _highly_ _experimental_ at this
> > moment. Don't use it for production.
>
> That certainly doesn't stop me from trying... :)
> Have you ran any tests to test the durabilty of your "transcrash" system
> for instance against sudden power dropouts?
> Is the filesystem selfhealing or does one need fsck.reiserfs for it? If
> the latter: will it do the right thing (i.e. automatically bring the
> system into consistent shape not like ext3) when invoked with "-y"?
It should automatically replay journal on the mount. fsck.reiser4 is
still needed owing to the bugs in the implementation, but, I am afraid,
it cannot do much at the moment.
>
> --
> Servus,
> Daniel
Nikita.
Am Fre, 2003-07-25 um 15.02 schrieb Nikita Danilov:
> No special measures are taken to level block allocation. Wandered blocks
> are allocated to improve packing i.e., place blocks of the same file
> close to each other. Actually, it tries to place tree nodes in the
> parent-first order.
So the new blocks are created as close as possible to the old blocks
instead of say spreading them as far as possible. This is pretty bad for
usage in the embedded world but I guess this is not the market you're
aiming at. :(
--
Servus,
Daniel
On Fri, 2003-07-25 at 18:20, Daniel Egger wrote:
> Am Fre, 2003-07-25 um 15.02 schrieb Nikita Danilov:
>
> > No special measures are taken to level block allocation. Wandered blocks
> > are allocated to improve packing i.e., place blocks of the same file
> > close to each other. Actually, it tries to place tree nodes in the
> > parent-first order.
>
> So the new blocks are created as close as possible to the old blocks
> instead of say spreading them as far as possible. This is pretty bad for
> usage in the embedded world but I guess this is not the market you're
> aiming at. :(
Reiser4 has plugin-based architecture. So, anybody is able to write new
block allocator plugin.
Speaking about possible embedded usage... What kind of embedded devices
do you mean. Reiser4 driver is big enough in size for some of them (for
instance, for mine MPIO MP3 player :))
--
We're flying high, we're watching the world passes by...
Am Fre, 2003-07-25 um 16.39 schrieb Yury Umanets:
> Reiser4 has plugin-based architecture. So, anybody is able to write new
> block allocator plugin.
Cool.
> Speaking about possible embedded usage... What kind of embedded devices
> do you mean. Reiser4 driver is big enough in size for some of them (for
> instance, for mine MPIO MP3 player :))
I'm talking about pretty standard ix86 hardware which has embedded like
properties such as fanless and motorless use, hardware watchdog, flash
memory but only few of the typical limitations like restricted memory
(we are using 256 or 512 MB), slow CPU, few connectors.
So basically we do have pretty powerful hardware with huge storage and
memory and now need a FS which is fast and reliable even on flash
memory. JFFS2 is nice but way too slow once one has bigger sizes.
--
Servus,
Daniel
On Sat, 2003-07-26 at 05:08, Daniel Egger wrote:
> Am Fre, 2003-07-25 um 16.39 schrieb Yury Umanets:
>
> > Reiser4 has plugin-based architecture. So, anybody is able to write new
> > block allocator plugin.
>
> Cool.
>
> > Speaking about possible embedded usage... What kind of embedded devices
> > do you mean. Reiser4 driver is big enough in size for some of them (for
> > instance, for mine MPIO MP3 player :))
>
> I'm talking about pretty standard ix86 hardware which has embedded like
> properties such as fanless and motorless use, hardware watchdog, flash
> memory but only few of the typical limitations like restricted memory
> (we are using 256 or 512 MB), slow CPU, few connectors.
>
> So basically we do have pretty powerful hardware with huge storage and
> memory and now need a FS which is fast and reliable even on flash
> memory. JFFS2 is nice but way too slow once one has bigger sizes.
I think this is more then enough for running reiser4. Reiser4 is a linux
filesystem first of all, and linux is able to be ran on even worse
hardware then you have.
--
We're flying high, we're watching the world passes by...
Hans Reiser <[email protected]> wrote:
>
> Please look at http://www.namesys.com/benchmarks/v4marks.html
It says "but since most users use ext3 with only meta-data journaling"
which isn't really correct. ext3's metadata-only journalling mode is
writeback mode.
Most people in fact use ext3's ordered mode, which provides the same data
consistency guarantees on recovery as data journalling.
Please compare against the ext3 in -mm. It has tweaks which aren't yet
merged, but which will be submitted soon.
Am Sam, 2003-07-26 um 09.19 schrieb Yury Umanets:
> I think this is more then enough for running reiser4. Reiser4 is a linux
> filesystem first of all, and linux is able to be ran on even worse
> hardware then you have.
Linux is running just fine one the system, thanks. My question is
whether reiserfs is suitable for flash devices. The chances to get some
usable answers seem to be incredible low though...
--
Servus,
Daniel
On Sat, 2003-07-26 at 18:13, Daniel Egger wrote:
> Am Sam, 2003-07-26 um 09.19 schrieb Yury Umanets:
>
> > I think this is more then enough for running reiser4. Reiser4 is a linux
> > filesystem first of all, and linux is able to be ran on even worse
> > hardware then you have.
>
> Linux is running just fine one the system, thanks. My question is
> whether reiserfs is suitable for flash devices. The chances to get some
> usable answers seem to be incredible low though...
Reiserfs cannot be used efficiently with flash, as it uses block size 4K
(by default) and usual flash block size is in range 64K - 256K.
Also reiserfs does not use compression, that would be very nice of it
:), because flash has limited number of erase cycles per block (in range
100.000) and it is about three times as expensive as SDRAM.
So, it is better to use something more convenient. For instance jffs2.
But, if you are still want to use reiserfs for flash device, you should
do at least the following:
(1) Make the journal substantial smaller of size.
(2) Don't turn tails off. This is useful to prolong flash live.
Regards.
--
We're flying high, we're watching the world passes by...
On Sat, 2003-07-26 at 10:19, Yury Umanets wrote:
> > So basically we do have pretty powerful hardware with huge storage and
> > memory and now need a FS which is fast and reliable even on flash
> > memory. JFFS2 is nice but way too slow once one has bigger sizes.
>
> I think this is more then enough for running reiser4. Reiser4 is a linux
> filesystem first of all, and linux is able to be ran on even worse
> hardware then you have.
Most Linux filesystems can't be used properly with flash devices because
of unability to handle write errors caused by flash wearing out. FS
should mark the block as bad and relocate the data. Some devices report
"read correctly, but had ECC" and when such happens data should also be
relocated to not worn-out place and block marked as bad.
--
Jussi Laako <[email protected]>
Am Sam, 2003-07-26 um 16.54 schrieb Yury Umanets:
Now we're talking. :)
> Reiserfs cannot be used efficiently with flash, as it uses block size 4K
> (by default) and usual flash block size is in range 64K - 256K.
Don't confuse block size with erase size. The former is the layout of
the fs' data on the medium while the latter is the granulariy of the
erase command which is important insofar that flash has to be erased (in
most cases) before one can write new data on it.
However since you said that one can plug in a different block allocation
scheme, I think it might be possible to work around that limitation by
writing a block allocator which works around the limitations of the
erase size.
> Also reiserfs does not use compression, that would be very nice of it
> :), because flash has limited number of erase cycles per block (in range
> 100.000)
I don't see what the compression has to do with the limited number of
erase/write cycles.
> and it is about three times as expensive as SDRAM.
That's true but not important to us. The system right now fits nicely on
a 128MB CF card when using ext2 or on 64MB when using JFFS2. The latter
is far more stable and reliable but dogslow. Since the price difference
between 128MB and 64CF is rather small and the cost of the overall
system relatively high this is no argument for us.
> So, it is better to use something more convenient. For instance jffs2.
Convenient only insofar that it's more reliable. It's a pain in the neck
to setup for non hardwired flash chips and to boot, it also takes
forever to mount and to write on it.
> (1) Make the journal substantial smaller of size.
> (2) Don't turn tails off. This is useful to prolong flash live.
Thanks. But first I'll have a look at your plugin architecture to see
how feasible a different implementation of block allocation especially
for flash devices would be.
--
Servus,
Daniel
On Sat, 26 Jul 2003 17:21:37 +0200, Daniel Egger said:
> > Also reiserfs does not use compression, that would be very nice of it
> > :), because flash has limited number of erase cycles per block (in range
> > 100.000)
>
> I don't see what the compression has to do with the limited number of
> erase/write cycles.
It's a subtle point - let's say you have a 32K blob of data and a 4K block/
erase/whatever size on the flash. If you write it uncompressed, then 8 blocks
are going to get an erase cycle. If however you can compress it down to 12K
(not at all unusual for text), then only 3 blocks get an erase cycle, and the
other 5 blocks get to live longer...
On Sat, 2003-07-26 at 19:21, Daniel Egger wrote:
> Am Sam, 2003-07-26 um 16.54 schrieb Yury Umanets:
>
> Now we're talking. :)
>
> > Reiserfs cannot be used efficiently with flash, as it uses block size 4K
> > (by default) and usual flash block size is in range 64K - 256K.
>
> Don't confuse block size with erase size. The former is the layout of
> the fs' data on the medium while the latter is the granulariy of the
> erase command which is important insofar that flash has to be erased (in
> most cases) before one can write new data on it.
So what? I mean, that if an IO request size does not equal to flash
erase size, then corresponding block device driver can't just submit
data to flash, but need maintain some cache, and cache size the same as
erase size for particular flash device. And in the case when WRITE
request is encountered, and write sector does not equal to start sector
of cached data or cache is empty, block device driver should read data
from flash first to fill cache up. This is redundant IO operation.
>
> However since you said that one can plug in a different block allocation
> scheme, I think it might be possible to work around that limitation by
> writing a block allocator which works around the limitations of the
> erase size.
This is some misunderstanding :) First we've spoken about reiser4, then
you asked how does reiserfs behave on flash devices and is it convenient
for flash at all.
Just make sure, that we're speaking about the same thing:
Plugin-based architecture is used in reiser4, not in reiserfs (reiser3).
Reiser4 is fully different, written from the scratch filesystem.
>
> > Also reiserfs does not use compression, that would be very nice of it
> > :), because flash has limited number of erase cycles per block (in range
> > 100.000)
>
> I don't see what the compression has to do with the limited number of
> erase/write cycles.
Compressed data which should be written is smaller then uncompressed
one, thus, its writing affects smaller number of blocks. Each block will
be erased rarely, that will prolong flash live.
>
> > and it is about three times as expensive as SDRAM.
>
> That's true but not important to us. The system right now fits nicely on
> a 128MB CF card when using ext2 or on 64MB when using JFFS2. The latter
> is far more stable and reliable but dogslow. Since the price difference
> between 128MB and 64CF is rather small and the cost of the overall
> system relatively high this is no argument for us.
So, you prefer speed? What do you use for this x86 box with flash?
>
> > So, it is better to use something more convenient. For instance jffs2.
>
> Convenient only insofar that it's more reliable.
I'd not say, that ext2 is too reliable though.
> It's a pain in the neck
> to setup for non hardwired flash chips and to boot, it also takes
> forever to mount and to write on it.
>
> > (1) Make the journal substantial smaller of size.
> > (2) Don't turn tails off. This is useful to prolong flash live.
>
> Thanks. But first I'll have a look at your plugin architecture to see
> how feasible a different implementation of block allocation especially
> for flash devices would be.
You should take a look to reiser4, not to reiserfs. Don't forget :)
But I don't understand, why do you want to make changes in current block
allocator plugin? In other words, what is wrong with current
implementation, which is willing to allocate blocks closer one to
another one?
I thought, if blocks lie side by side, as current block allocator does,
this increases probability of flash block device cache hitting (take a
look to drivers/mtd/mtdblock.c), what is definitely good. Isn't it?
Regards.
--
We're flying high, we're watching the world passes by...
Am Son, 2003-07-27 um 12.30 schrieb Yury Umanets:
> So what? I mean, that if an IO request size does not equal to flash
> erase size, then corresponding block device driver can't just submit
> data to flash, but need maintain some cache, and cache size the same as
> erase size for particular flash device. And in the case when WRITE
> request is encountered, and write sector does not equal to start sector
> of cached data or cache is empty, block device driver should read data
> from flash first to fill cache up. This is redundant IO operation.
Right, but it should be possible to ensure (by using a special encoding)
that a part of the erased block can be detected as empty or already
occupied by reading just a few bytes. Sure this is a tradeoff but one
I'd be willing to make. :)
> This is some misunderstanding :) First we've spoken about reiser4, then
> you asked how does reiserfs behave on flash devices and is it convenient
> for flash at all.
> Just make sure, that we're speaking about the same thing:
> Plugin-based architecture is used in reiser4, not in reiserfs (reiser3).
> Reiser4 is fully different, written from the scratch filesystem.
My bad, I thought you're using the term reiserfs also for reiser4. I was
always talking about reiser4 when I said reiserfs.
> > I don't see what the compression has to do with the limited number of
> > erase/write cycles.
> Compressed data which should be written is smaller then uncompressed
> one, thus, its writing affects smaller number of blocks. Each block will
> be erased rarely, that will prolong flash live.
Only when the data is in motion. Considering that most of the data is
quite fixed with only some bytes of configuration being written a few
times and an update of a few packages every now and then I'm pretty sure
the wear affect will hardly hit. It's more important, that the
configuration bits are spread evenly over the full filesystem.
> So, you prefer speed?
Yes. Especially startup times are important to us but also execution
times for cachecold executables.
> What do you use for this x86 box with flash?
This are VIA Eden boxes with 667 Mhz fanless x86 compatible CPUs. They
come in a booksize chassis and deliver pretty impressive performance for
their size.
> > Convenient only insofar that it's more reliable.
> I'd not say, that ext2 is too reliable though.
No it's not. Especially the fsck annoyance is a real killer because we
can either not run it, thereby risking an inconsistent filesystem or run
it unattended thereby risking a loss of files.
> You should take a look to reiser4, not to reiserfs. Don't forget :)
I'm aware, thanks. :)
> But I don't understand, why do you want to make changes in current block
> allocator plugin? In other words, what is wrong with current
> implementation, which is willing to allocate blocks closer one to
> another one?
> I thought, if blocks lie side by side, as current block allocator does,
> this increases probability of flash block device cache hitting (take a
> look to drivers/mtd/mtdblock.c), what is definitely good. Isn't it?
I've some doubts that placing blocks close to another wears out all of
the flash equally. I imagine something like circular or hashed block
allocator which ensures equal wear leveling taking the erasesize of the
flash into account.
--
Servus,
Daniel
On Sun, 2003-07-27 at 15:05, Daniel Egger wrote:
> Am Son, 2003-07-27 um 12.30 schrieb Yury Umanets:
>
> > So what? I mean, that if an IO request size does not equal to flash
> > erase size, then corresponding block device driver can't just submit
> > data to flash, but need maintain some cache, and cache size the same as
> > erase size for particular flash device. And in the case when WRITE
> > request is encountered, and write sector does not equal to start sector
> > of cached data or cache is empty, block device driver should read data
> > from flash first to fill cache up. This is redundant IO operation.
>
> Right, but it should be possible to ensure (by using a special encoding)
> that a part of the erased block can be detected as empty or already
> occupied by reading just a few bytes. Sure this is a tradeoff but one
> I'd be willing to make. :)
This is probably tradeoff for flash producers first of all.
>
> > This is some misunderstanding :) First we've spoken about reiser4, then
> > you asked how does reiserfs behave on flash devices and is it convenient
> > for flash at all.
>
> > Just make sure, that we're speaking about the same thing:
>
> > Plugin-based architecture is used in reiser4, not in reiserfs (reiser3).
> > Reiser4 is fully different, written from the scratch filesystem.
>
> My bad, I thought you're using the term reiserfs also for reiser4. I was
> always talking about reiser4 when I said reiserfs.
Reiser4 will use compression. So, it will be more convenient or flash
devices. But using XIP is problematic in this case.
>
> > > I don't see what the compression has to do with the limited number of
> > > erase/write cycles.
>
> > Compressed data which should be written is smaller then uncompressed
> > one, thus, its writing affects smaller number of blocks. Each block will
> > be erased rarely, that will prolong flash live.
>
> Only when the data is in motion. Considering that most of the data is
> quite fixed with only some bytes of configuration being written a few
> times and an update of a few packages every now and then I'm pretty sure
> the wear affect will hardly hit. It's more important, that the
> configuration bits are spread evenly over the full filesystem.
>
> > So, you prefer speed?
>
> Yes. Especially startup times are important to us but also execution
> times for cachecold executables.
>
> > What do you use for this x86 box with flash?
>
> This are VIA Eden boxes with 667 Mhz fanless x86 compatible CPUs. They
> come in a booksize chassis and deliver pretty impressive performance for
> their size.
My friend used something like this for video player :)
>
> > > Convenient only insofar that it's more reliable.
> > I'd not say, that ext2 is too reliable though.
>
> No it's not. Especially the fsck annoyance is a real killer because we
> can either not run it, thereby risking an inconsistent filesystem or run
> it unattended thereby risking a loss of files.
>
> > You should take a look to reiser4, not to reiserfs. Don't forget :)
>
> I'm aware, thanks. :)
>
> > But I don't understand, why do you want to make changes in current block
> > allocator plugin? In other words, what is wrong with current
> > implementation, which is willing to allocate blocks closer one to
> > another one?
>
> > I thought, if blocks lie side by side, as current block allocator does,
> > this increases probability of flash block device cache hitting (take a
> > look to drivers/mtd/mtdblock.c), what is definitely good. Isn't it?
>
> I've some doubts that placing blocks close to another wears out all of
> the flash equally. I imagine something like circular or hashed block
> allocator which ensures equal wear leveling taking the erasesize of the
> flash into account.
Probably you are right in general.
But erasesize is block device driver abstraction level related issue.
General purpose filesystem should not be concerned about it.
--
We're flying high, we're watching the world passes by...
Nikita Danilov wrote:
>Shawn writes:
> > Looks like the 2.5.74 is the last one of any respectable size. I'm
> > thinking someone forgot a diff switch (N?) over at namesys...
> >
> > Hans? Time to long-distance spank someone?
>
>Can you try following the instructions on the
>http://www.namesys.com/code.html (requires bitkeeper)?
>
>Nikita.
>
> >
> > On Wed, 2003-07-23 at 23:56, Tupshin Harper wrote:
> > > Shawn wrote:
> > >
> > > >This is pretty f'ed, but it's on ftp://ftp.namesys.com/pub/tmp
> > > >
> > > Thanks, but I tried applying the
> > > 2.6.0-test1-reiser4-2.6.0-test1.diff from that location with a lack of
> > > success.
> > >
> > > It applied cleanly, but it doesn't add a fs/reiser4 directory and
> > > asociated contents. Is there an additional patch, or is this one broken?
> > >
> > > -Tupshin
> > >
>
>
>
>
Nikita, how about phrasing this as:
`Dear and esteemed potential Reiser4 user, I apologize that we put a
tarball on our website and let it get so obsolete, thereby wasting your
time. I am deleting it now, and will soon put a new one up. In the
meantime, can you use bitkeeper if that is convenient for you? Here is
the URL with the instructions for doing that.....'
It is the usual American business english used in such cases.;-)
--
Hans
Daniel Egger wrote:
>Am Mit, 2003-07-23 um 23.02 schrieb Hans Reiser:
>
>
>
>>In brief, V4 is way faster than V3, and the wandering logs are indeed
>>twice as fast as fixed location logs when performing writes in large
>>batches.
>>
>>
>
>How do the wandering logs compare to the "wandering" logs of the log
>structured filesystem JFFS2? Does this mean I can achieve an implicit
>wear leveling for flash memory?
>
Forgive me for answering your question with a question, but, wouldn't
you want to do it at the block device layer? If no, then it would not
be hard to code a block allocation plugin for it. Probably the main
problem would be with the super block and bitmaps, which have fixed
locations (and are written twice but we don't normally care because they
are small and insignificant to performance.)
>
>
>
>>We are able to perform all filesystem operations fully atomically,
>>while getting dramatic performance improvements. (Other attempts at
>>introducing transactions into filesystems are said to have failed for
>>performance reasons.)
>>
>>
>
>How failsafe is it to switch off the power several times? When the
>filesystem really works atomically I should have either the old or the
>new version but no mixture.
>
It is safe.
> Does it still need to fsck or is the
>transaction replay done at mount time?
>
mount time.
> In case one still needs fsck,
>what's the probability of needing user interaction?
>
0, but an application can still write to two files, and if it does not
use our atomic infrastructure (at this time none of them do;-) ), the
two separate files will not be certain to be updated as one atom atomically.
>How long does it
>need to get a filesystem back into a consistent state after a powerloss
>(approx. per MB/GB)?
>
I don't have numbers, someone else will have to answer/measure it for you.
>
>Background: I'm doing systems on compactflash cards and need a reliable
>filesystem for it. At the moment I'm using a compressed JFFS2 over the
>mtd emulation driver for block devices which works quite well but has a
>few catches...
>
>
>
--
Hans
> [[email protected]]
>
> Nikita, how about phrasing this as:
>
> `Dear and esteemed potential Reiser4 user, I apologize that we put a
> tarball on our website and let it get so obsolete, thereby wasting your
> time. I am deleting it now, and will soon put a new one up. In the
> meantime, can you use bitkeeper if that is convenient for you? Here is
> the URL with the instructions for doing that.....'
>
> It is the usual American business english used in such cases.;-)
Standard American puke inducing pretentious florid business
language if you want to be completely accurate. 8)
--
Tomas Szepe <[email protected]>
Daniel Egger wrote:
>Am Fre, 2003-07-25 um 15.02 schrieb Nikita Danilov:
>
>
>
>>No special measures are taken to level block allocation. Wandered blocks
>>are allocated to improve packing i.e., place blocks of the same file
>>close to each other. Actually, it tries to place tree nodes in the
>>parent-first order.
>>
>>
>
>So the new blocks are created as close as possible to the old blocks
>instead of say spreading them as far as possible. This is pretty bad for
>usage in the embedded world but I guess this is not the market you're
>aiming at. :(
>
>
>
I thought that close was fine, it was putting it in the same block that
was the problem?
Again, I think this is best solved in the device layer.
--
Hans
Andrew Morton wrote:
>Hans Reiser <[email protected]> wrote:
>
>
>>Please look at http://www.namesys.com/benchmarks/v4marks.html
>>
>>
>
>It says "but since most users use ext3 with only meta-data journaling"
>which isn't really correct. ext3's metadata-only journalling mode is
>writeback mode.
>
>Most people in fact use ext3's ordered mode, which provides the same data
>consistency guarantees on recovery as data journalling.
>
>Please compare against the ext3 in -mm. It has tweaks which aren't yet
>merged, but which will be submitted soon.
>
>
>
>
>
We are going to run a bunch more benchmarks when I get back, probably
doing things like turning on htrees and tail combining and stuff, in
lots of different combinations. Ordered mode will be added, as well as
making green have a uniform meaning for all the benchmarks;-). This
benchmark was just what could be done before I got on a plane.
--
Hans
Daniel Egger wrote:
>Am Sam, 2003-07-26 um 09.19 schrieb Yury Umanets:
>
>
>
>>I think this is more then enough for running reiser4. Reiser4 is a linux
>>filesystem first of all, and linux is able to be ran on even worse
>>hardware then you have.
>>
>>
>
>Linux is running just fine one the system, thanks. My question is
>whether reiserfs is suitable for flash devices. The chances to get some
>usable answers seem to be incredible low though...
>
>
>
it is suitable for any flash device that has wear leveling built into
the hardware (e.g. all compact flash cards), or for which a wear
leveling block device driver is used (I don't know if one exists for Linux).
--
Hans
Yury Umanets wrote:
>On Sat, 2003-07-26 at 18:13, Daniel Egger wrote:
>
>
>>Am Sam, 2003-07-26 um 09.19 schrieb Yury Umanets:
>>
>>
>>
>>>I think this is more then enough for running reiser4. Reiser4 is a linux
>>>filesystem first of all, and linux is able to be ran on even worse
>>>hardware then you have.
>>>
>>>
>
>
>
>>Linux is running just fine one the system, thanks. My question is
>>whether reiserfs is suitable for flash devices. The chances to get some
>>usable answers seem to be incredible low though...
>>
>>
>
>Reiserfs cannot be used efficiently with flash, as it uses block size 4K
>(by default) and usual flash block size is in range 64K - 256K.
>
This answer is incorrect. The device driver will hide this from us,
slum squeezing will tend to write in large batches, and things will
probably work. However, you should try it and see rather than theorize.
>
>Also reiserfs does not use compression, that would be very nice of it
>:), because flash has limited number of erase cycles per block (in range
>100.000) and it is about three times as expensive as SDRAM.
>
We have compression plugins that will be ready soon. Go ask Edward in
the chair behind you what he does for a living.;-)
>
>So, it is better to use something more convenient. For instance jffs2.
>
>But, if you are still want to use reiserfs for flash device, you should
>do at least the following:
>
>(1) Make the journal substantial smaller of size.
>(2) Don't turn tails off. This is useful to prolong flash live.
>
>
>Regards.
>
>
>
He is asking about reiser4, not reiserfs V3.
--
Hans
Jussi Laako wrote:
>On Sat, 2003-07-26 at 10:19, Yury Umanets wrote:
>
>
>
>>>So basically we do have pretty powerful hardware with huge storage and
>>>memory and now need a FS which is fast and reliable even on flash
>>>memory. JFFS2 is nice but way too slow once one has bigger sizes.
>>>
>>>
>>I think this is more then enough for running reiser4. Reiser4 is a linux
>>filesystem first of all, and linux is able to be ran on even worse
>>hardware then you have.
>>
>>
>
>Most Linux filesystems can't be used properly with flash devices because
>of unability to handle write errors caused by flash wearing out. FS
>should mark the block as bad and relocate the data. Some devices report
>"read correctly, but had ECC" and when such happens data should also be
>relocated to not worn-out place and block marked as bad.
>
>
>
>
I would be happy to accept a patch fixing that, or to fix it for a fee,
or to fix it if we somehow get more funding from somewhere next year.;-)
--
Hans
Tomas Szepe wrote:
>>[[email protected]]
>>
>>Nikita, how about phrasing this as:
>>
>> `Dear and esteemed potential Reiser4 user, I apologize that we put a
>>tarball on our website and let it get so obsolete, thereby wasting your
>>time. I am deleting it now, and will soon put a new one up. In the
>>meantime, can you use bitkeeper if that is convenient for you? Here is
>>the URL with the instructions for doing that.....'
>>
>>It is the usual American business english used in such cases.;-)
>>
>>
>
>Standard American puke inducing pretentious florid business
>language if you want to be completely accurate. 8)
>
>
>
Yeah, but Nikita really could have been more helpful....
--
Hans
On Sun, 2003-07-27 at 17:31, Hans Reiser wrote:
> Yury Umanets wrote:
>
> >On Sat, 2003-07-26 at 18:13, Daniel Egger wrote:
> >
> >
> >>Am Sam, 2003-07-26 um 09.19 schrieb Yury Umanets:
> >>
> >>
> >>
> >>>I think this is more then enough for running reiser4. Reiser4 is a linux
> >>>filesystem first of all, and linux is able to be ran on even worse
> >>>hardware then you have.
> >>>
> >>>
> >
> >
> >
> >>Linux is running just fine one the system, thanks. My question is
> >>whether reiserfs is suitable for flash devices. The chances to get some
> >>usable answers seem to be incredible low though...
> >>
> >>
> >
> >Reiserfs cannot be used efficiently with flash, as it uses block size 4K
> >(by default) and usual flash block size is in range 64K - 256K.
> >
> This answer is incorrect. The device driver will hide this from us,
> slum squeezing will tend to write in large batches, and things will
> probably work. However, you should try it and see rather than theorize.
See my explanation in last emails. Also I have not just theorized. I
have been developing block device driver for MPIO players (Smart Card
based one). And reiserfs does not use squeezing on flush (and I've
spoken about reiserfs here).
>
> >
> >Also reiserfs does not use compression, that would be very nice of it
> >:), because flash has limited number of erase cycles per block (in range
> >100.000) and it is about three times as expensive as SDRAM.
> >
> We have compression plugins that will be ready soon. Go ask Edward in
> the chair behind you what he does for a living.;-)
Yes, we have compression plugins in reiser4, but we have spoken about
reiserfs.
>
> >
> >So, it is better to use something more convenient. For instance jffs2.
> >
> >But, if you are still want to use reiserfs for flash device, you should
> >do at least the following:
> >
> >(1) Make the journal substantial smaller of size.
> >(2) Don't turn tails off. This is useful to prolong flash live.
> >
> >
> >Regards.
> >
> >
> >
> He is asking about reiser4, not reiserfs V3.
--
We're flying high, we're watching the world passes by...
Am Son, 2003-07-27 um 14.59 schrieb Hans Reiser:
> I thought that close was fine, it was putting it in the same block that
> was the problem?
This looks fine for normal harddrives put on flash you'd probably like
to write the data evenly over the free space in some already formatted
section still leaving the oportunity to format some other sectors to not
run out of space.
> Again, I think this is best solved in the device layer.
A device layer that shuffles around sectors would have interesting
semantics, like hardly being portable because one would have to use
exactly the same device driver with the same parameters to use the
filesystem and thus retrieve the data.
--
Servus,
Daniel
On Sun, 2003-07-27 at 18:10, Daniel Egger wrote:
> Am Son, 2003-07-27 um 15.28 schrieb Hans Reiser:
>
> > it is suitable for any flash device that has wear leveling built into
> > the hardware (e.g. all compact flash cards)
>
> Are you sure CF cards have wear leveling? I'm pretty confident that they
> have defect sector management but no wear leveling. There's a huge
> difference between those two.
>
> > or for which a wear leveling block device driver is used (I don't know
> > if one exists for Linux).
>
> This is normally done by the filesystem (e.g. JFFS2).
Normally device driver should be concerned about making wear out
smaller. It is up to it IMHO.
--
We're flying high, we're watching the world passes by...
Am Son, 2003-07-27 um 15.28 schrieb Hans Reiser:
> it is suitable for any flash device that has wear leveling built into
> the hardware (e.g. all compact flash cards)
Are you sure CF cards have wear leveling? I'm pretty confident that they
have defect sector management but no wear leveling. There's a huge
difference between those two.
> or for which a wear leveling block device driver is used (I don't know
> if one exists for Linux).
This is normally done by the filesystem (e.g. JFFS2).
--
Servus,
Daniel
On Sunday 27 July 2003 08:45, Tomas Szepe wrote:
>> [[email protected]]
>>
>> Nikita, how about phrasing this as:
>>
>> `Dear and esteemed potential Reiser4 user, I apologize that we
>> put a tarball on our website and let it get so obsolete, thereby
>> wasting your time. I am deleting it now, and will soon put a new
>> one up. In the meantime, can you use bitkeeper if that is
>> convenient for you? Here is the URL with the instructions for
>> doing that.....'
>>
>> It is the usual American business english used in such cases.;-)
>
>Standard American puke inducing pretentious florid business
>language if you want to be completely accurate. 8)
Huh? I thought Hans was being facetious, or was practicing his
standup comedy. I can see something like that coming out of a far
western oriental type when dealing with an american that isn't really
understanding his accent, but here in the states, after we've
explained it once in plain english, the next exchange will more than
likely go the other way, possibly even making it to the 'hey
dumbf*ck' stage on about the 4th reply.
And I do object, albeit somewhat tongue-in-cheek, to applying that
particular label/broad brush to all americans since I am one of those
creatures.
--
Cheers, Gene
AMD K6-III@500mhz 320M
Athlon1600XP@1400mhz 512M
99.27% setiathome rank, not too shabby for a WV hillbilly
Yahoo.com attornies please note, additions to this message
by Gene Heskett are:
Copyright 2003 by Maurice Eugene Heskett, all rights reserved.
In article <1059315015.10692.207.camel@sonja> you wrote:
> This is normally done by the filesystem (e.g. JFFS2).
why is jffs2 so slow, if the cpu overhead can be totally neglected when
writing to such slow media? I would asume a FS whic his optimized for not
wearing out flash cards would reduce the IOs to the absolute minimum and
therefore be fast be definition?
Greetings
Bernd
--
eckes privat - http://www.eckes.org/
Project Freefire - http://www.freefire.org/
In article <1059315409.10692.215.camel@sonja> you wrote:
> A device layer that shuffles around sectors would have interesting
> semantics, like hardly being portable because one would have to use
> exactly the same device driver with the same parameters to use the
> filesystem and thus retrieve the data.
In fact it should not shuffle around, but support the filesystem in
requesting new free blocks.
But I see that FS must support the flash by for example beeing prepared to
move often used blocks (super blocks, bitmaps, ... ) around.
Greetings
Bernd
--
eckes privat - http://www.eckes.org/
Project Freefire - http://www.freefire.org/
On Sul, 2003-07-27 at 16:30, Bernd Eckenfels wrote:
> why is jffs2 so slow, if the cpu overhead can be totally neglected when
> writing to such slow media? I would asume a FS whic his optimized for not
> wearing out flash cards would reduce the IOs to the absolute minimum and
> therefore be fast be definition?
Flash cards are -slow-. Also jffs2 is mostly synchronous so it writes
the long bit by bit. The flash wear is on erase not write. You could
certainly teach jffs2 a bit more about batching writes. The other issue
with jffs2 is startup because it is a log you have to read the entire
log to know what state you are in
Daniel Egger wrote:
>Are you sure CF cards have wear leveling? I'm pretty confident that they
>have defect sector management but no wear leveling. There's a huge
>difference between those two.
>
I am told that they do by flx. After all, they are most used for the
FAT filesystem.
--
Hans
Daniel Egger wrote:
>Am Son, 2003-07-27 um 14.59 schrieb Hans Reiser:
>
>
>
>>I thought that close was fine, it was putting it in the same block that
>>was the problem?
>>
>>
>
>This looks fine for normal harddrives put on flash you'd probably like
>to write the data evenly over the free space in some already formatted
>section still leaving the oportunity to format some other sectors to not
>run out of space.
>
I was not able to parse the sentence above.;-)
>
>
>
>>Again, I think this is best solved in the device layer.
>>
>>
>
>A device layer that shuffles around sectors would have interesting
>semantics, like hardly being portable because one would have to use
>exactly the same device driver with the same parameters to use the
>filesystem and thus retrieve the data.
>
>
>
No, you could be more clever than that.
--
Hans
Daniel Egger wrote:
>Am Mon, 2003-07-28 um 14.44 schrieb Hans Reiser:
>
>
>
>>>This looks fine for normal harddrives put on flash you'd probably like
>>>to write the data evenly over the free space in some already formatted
>>>section still leaving the oportunity to format some other sectors to not
>>>run out of space.
>>>
>>>
>
>
>
>>I was not able to parse the sentence above.;-)
>>
>>
>
>s/put/but/
>
>As already mentioned the flash chips have to be erased before they can
>be written. The erasesize is much larger than the typical block size
>which means that although a block doesn't contain valid data it still
>contains something which means that it cannot be written until it was
>erased. That's why JFFS2 is using garbage collection to reclaim unused
>but (at the moment) unusable space.
>
>
>
>>No, you could be more clever than that.
>>
>>
>
>Sure. :)
>
>
>
If you feel ambitious, try increasing the reiser4 node size to equal the
erase size. This requires changes to VM though.
--
Hans
Am Mon, 2003-07-28 um 14.44 schrieb Hans Reiser:
> >This looks fine for normal harddrives put on flash you'd probably like
> >to write the data evenly over the free space in some already formatted
> >section still leaving the oportunity to format some other sectors to not
> >run out of space.
> I was not able to parse the sentence above.;-)
s/put/but/
As already mentioned the flash chips have to be erased before they can
be written. The erasesize is much larger than the typical block size
which means that although a block doesn't contain valid data it still
contains something which means that it cannot be written until it was
erased. That's why JFFS2 is using garbage collection to reclaim unused
but (at the moment) unusable space.
> No, you could be more clever than that.
Sure. :)
--
Servus,
Daniel
So, in summary, reiser4 will do a good job of flushing in large batches
using large bios, and that is most of what you can do to optimize for
large erase size.
Things that could be added: improved compression for small files,
garbage collection based freeing of unused blocks, increasing node size
to equal erase size.
We can add such features for a fee, or you can code them yourself and
send us a patch.
If I am wrong about compact flashes all having hardware wear leveling so
that FAT can be used on them, then you can add wear leveling to the list
of features desirable.
--
Hans
On Sun, 2003-07-27 at 16:49, Alan Cox wrote:
> Flash cards are -slow-. Also jffs2 is mostly synchronous so it writes
> the long bit by bit. The flash wear is on erase not write. You could
> certainly teach jffs2 a bit more about batching writes. The other issue
> with jffs2 is startup because it is a log you have to read the entire
> log to know what state you are in
Startup in 2.5 is a _lot_ better than in 2.4 -- we stopped checking the
crc32 on every node during mount, and do it later instead. We also use a
pointer directly into the flash if it's possible, rather than memcpying
every node we look at during the mount.
The amount of state we need to rebuild during the mount isn't huge -- if
you ignore nlink for the moment, all we really need to do is build up a
list of
{ physical address, length, inode # to which it belongs }
tuples for each log entry on the medium -- for larger media, we could
add tailers to each eraseblock with a condensed version of that
information, to prevent the need to scan the whole of each block during
mount to work it out.
I suspect we're going to have to do that for the larger NAND devices,
including DiskOnChip, in the fairly near future. It takes 30 seconds to
mount a 144MiB DiskOnChip with JFFS2.
We already do some form of write batching on NAND flash too -- since we
can't always write more than once to any given 512-byte 'page' on the
flash, we have to have a write-back buffer and coalesce writes.
The other fairly simple thing we can do to improve runtime performance
and device lifetime is start being more intelligent about garbage
collection -- we should GC ancient and unchanged data to separate blocks
on the flash, rather than mixing it in with new writes; then we will end
up with more fully-clean eraseblocks (which can be ignored except for
once in a blue moon when we decide to GC them for wear levelling
purposes) and more mostly-dirty eraseblocks (on which we make rapid GC
progress since not a lot needs to be copied before the block can be
erased) -- and fewer of the 50%-dirty blocks we tend to see at the
moment.
--
dwmw2
On Sun, 2003-07-27 at 11:30, Yury Umanets wrote:
> I thought, if blocks lie side by side, as current block allocator does,
> this increases probability of flash block device cache hitting (take a
> look to drivers/mtd/mtdblock.c), what is definitely good. Isn't it?
Please do not use the word 'good' in the same sentence as mtdblock.
The mtdblock device is fundamentally not suitable for use in production
in write mode -- by design.
'Normal' file systems such as ext3/reiser{fs,4} do not operate on flash
directly. Flash is _different_ -- you can't atomically overwrite
small-sized 'sectors', and you have to care about wear levelling.
There are two types of flash. On the original and more common NOR flash,
the 'erase blocks' are typically of the order of 64KiB in size -- they
start off filled with 0xFF, and you can clear bits individually until
you're bored or they're all set to zero. At which point you can erase
the _whole_ eraseblock back to all ones again.
On the newer and cheaper NAND flash, there are more restrictions. The
eraseblocks are smaller (typ. 8KiB) and it's subdivided into 'pages' of
typ. 512 bytes -- while with NOR flash you can clear bits individually
in as many cycles as you like, with NAND you have a limited number of
write cycles to any given 'page', after which point current leakage
causes the contents of that page to become undefined.
Neither of these are suitable for use directly as a block device. You
need some kind of 'translation layer' to make them emulate a hard drive
in some way. Such a translation layer will ideally also handle wear
levelling and bad block management for you.
The most naïve such 'translation layer' is that implemented in
mtdblock.c. Upon a write request, it reads the eraseblock containing the
512-byte sector to be changed, modifies the in-memory copy, then erases
the flash eraseblock and writes it back again. There is some caching
present to prevent subsequent writes within the _same_ eraseblock from
causing more than one erase cycle, but there's no wear levelling and no
bad block management. There's a 1:1 mapping from 'logical' addresses
within the fake block device and physical addresses on the flash.
If you lose power or crash between the 'erase' and 'writeback' portions
of the above-described read/modify/erase/writeback cycle, you have lost
not only the contents of the sector you were trying to modify, but also
the 128KiB in which it was resident. This is _really_ not a good idea.
The mtdblock device should be used only for read-only operation (e.g.
with cramfs) in production, and for writing only during setup.
There also exist some more complicated 'translation layers', which are
basically pseudo-filesystems used to emulate a block device using flash
as backing store. They perform their own wear levelling and journalling
to ensure reliability. The ones supported by Linux are FTL (used for NOR
flash especially in PCMCIA devices) and NFTL (used on the NAND flash
found in DiskOnChip devices). Although these aren't _fundamentally_
broken as mtdblock is, they are still somewhat suboptimal. There's a
SmartMedia translation layer (SM is basically just NAND flash) too,
which nobody's bothered to implement yet.
They still need to do some form of garbage-collection, copying around
still-valid sectors from one place on the physical medium to another, to
allow an eraseblock which contained some obsolete data to be completely
obsoleted and hence erased to free up usable space. However, the block
device layer is never told by the file system when a sector is no longer
used -- so if you fill the file system with data then 'rm -rf *', the
_block_ device will still think it's entirely full of data, and
carefully copy that data around the physical medium for you in case you
want it back.
Also, your file system needs its _own_ journalling to ensure data
integrity at the higher level, since the block device 'translation
layer' only ensures the same form of data integrity that a normal hard
drive would achieve, and nothing more. So you (the file system) end up
writing data (or at least metadata) changes out to the physical medium
twice, once to the 'journal' on the faked block device, and once to the
real location on the faked block device, while the underlying
'translation layer' is performing its own journalling underneath you to
ensure integrity too. This is far from ideal for flash wear.
Hence the development of JFFS, JFFS2 and YAFFS -- file systems which
operate directly on the flash chips rather than introducing the
suboptimal 'fake' block devices. This isn't DOS any more -- we don't
need to provide INT 13h Disk BIOS emulation and then expect everyone to
use FAT atop it :)
For flash you can access directly as _flash_, a file system specifically
designed for the purpose is the better approach. JFFS2 performance is
being improved, and YAFFS (and soon YAFFS2) take different approaches to
the problem.
Some devices, however, are made of flash but do their best to hide it
from you.
CompactFlash may have flash internally but to all extents and purposes,
as far as the computer can tell, it really is a (somewhat unreliable)
IDE drive. It has a 'translation layer' built into its black box -- you
can't tell whether it does its own wear levelling or not, but in the
majority of cases we suspect not. Anecdotal evidence is that its
internal firmware also tends to get the journalling part of the
'translation layer' wrong too, and can get its internal
'pseudo-filesystem' into an inconsistent state from which it cannot
recover. Of course, since you can't access the flash directly from
software, you cannot do anything but bin the unit when this happens. I
assume the usb-storage devices are very similar.
The practice of using JFFS2 on CF (and other real block devices) isn't
really something I encourage, but it seems to have happened because
there isn't a 'real' block device based file system which is
powerfail-save, optimised for space and which uses compression. If
reiser4 can fill that gap, that would be pleasing to me.
--
dwmw2
On Sat, 2003-07-26 at 18:14, Jussi Laako wrote:
> Most Linux filesystems can't be used properly with flash devices because
> of unability to handle write errors caused by flash wearing out. FS
> should mark the block as bad and relocate the data.
This is typically done by the pseudo-filesystem (FTL, NFTL, etc.) which
is used to emulate a hard drive on flash storage; the 'real' file system
itself doesn't need to do it for itself.
--
dwmw2
On Sun, 2003-07-27 at 16:32, Bernd Eckenfels wrote:
> In article <1059315409.10692.215.camel@sonja> you wrote:
> > A device layer that shuffles around sectors would have interesting
> > semantics, like hardly being portable because one would have to use
> > exactly the same device driver with the same parameters to use the
> > filesystem and thus retrieve the data.
>
> In fact it should not shuffle around, but support the filesystem in
> requesting new free blocks.
In practice it _does_ shuffle around. It'll keep some kind of metadata
somewhere logging which physical 512-byte 'sectors' on the medium
contain data belonging to each logical 512-byte sector of the emulated
block device. Each time a logical sector is overwritten, it'll just
write it out elsewhere on the physical medium and adjust the metadata
accordingly, and the original copy of that sector becomes obsolete.
When it (almost) runs out of 'elsewhere', it needs to garbage collect --
it'll pick an eraseblock which contains mostly obsolete data, copy the
still-valid sectors into the remaining 'elsewhere' as if they'd been
rewritten with the same data again, then erase the eraseblock which now
_only_ contains obsolete sectors.
> But I see that FS must support the flash by for example beeing prepared to
> move often used blocks (super blocks, bitmaps, ... ) around.
And by telling it which blocks no longer contain relevant data, so that
the block 'translation layer' can discard them and stop copying them
around the physical medium as described above...
Basically, if you're going to teach the filesystem about flash, you
should teach it about flash properly and quit pretending to be a block
device altogether. The artificial extra layer just begs you to violate
the layering in _so_ many ways that you should just abolish it.
--
dwmw2
In article <[email protected]> you wrote:
> The practice of using JFFS2 on CF (and other real block devices) isn't
> really something I encourage, but it seems to have happened because
> there isn't a 'real' block device based file system which is
> powerfail-save, optimised for space and which uses compression. If
> reiser4 can fill that gap, that would be pleasing to me.
Thanks for that great article, would you care to describe where the slowness
of JFFS2 is coming from?
Do you have experiences with XFS and ext3 (datajournal) filesystems in terms
of power fail security?
Greetings
Bernd
--
eckes privat - http://www.eckes.org/
Project Freefire - http://www.freefire.org/
You didn't Cc me; there are 7240 unread messages in my linux-kernel
folder which are about to be read with the 'd' key... it's lucky I saw
your reply at all. Please don't drop recipients.
On Fri, 2003-08-08 at 15:28, Bernd Eckenfels wrote:
> In article <[email protected]> you wrote:
> > The practice of using JFFS2 on CF (and other real block devices) isn't
> > really something I encourage, but it seems to have happened because
> > there isn't a 'real' block device based file system which is
> > powerfail-save, optimised for space and which uses compression. If
> > reiser4 can fill that gap, that would be pleasing to me.
>
> Thanks for that great article, would you care to describe where the slowness
> of JFFS2 is coming from?
During mount, it comes from the fact that we need to find every single
log entry (node) in the file system. It's a purely log-structured file
system -- there is _no_ positional information; it's just a jumble of
log entries with version numbers to show ordering, and we need to find
them all and note which inode# they belong to.
We've already got about an order of magnitude improvement in mount time
from 2.4 to 2.5 by deferring much of the work (in particular crc32
checking on all those nodes) from the actual mount to later, and by
eliminating memcpy() into RAM of data on NOR flash where we can actually
just use pointers directly into flash instead.
The scan is still slow on NAND flash, which we can't directly
dereference and _have_ to copy from the flash to read it. As I said
elsewhere, it's about 30 seconds for a 30%-full 144MiB DiskOnChip
device. The fix for this, yet to be implemented, will be a 'tailer' at
the end of each flash eraseblock, containing all the information which
we would otherwise have to glean by scanning the whole of the eraseblock
looking for log entries. Then we just need to read the tailer from the
end of each block rather than reading the whole block.
In this way we trade off a small amount of space for a large improvement
in mount time. This seems like an eminently sensible tradeoff especially
given that it was the large size of these devices which caused the mount
time to become problematic in the first place -- there's room to spare.
It can also be a configurable option. For embedded devices which almost
never cold-boot and usually suspend to RAM instead, a very slow mount
isn't necessarily a show-stopper.
Performance during runtime isn't often cited as a problem, but can also
be improved somewhat. Currently, our garbage collection is rather naïve;
it picks a 'victim' eraseblock, generally one of the 'dirtiest' (i.e.
containing the most log entries which are obsoleted by subsequent writes
elsewhere). It then proceeds to obsolete all the nodes in that
eraseblock which remain valid, by just writing out the same data
elsewhere -- at which point it can erase the 'victim' and add it back to
the free_list.
Garbage collection is most efficient when the 'victim' block in fact
contains almost no still-valid nodes, and can just about be deleted
straight away. It's at its least efficient when we pick a completely
clean block in which _all_ the nodes need to be copied elsewhere -- we
copy and entire eraseblock without making _any_ extra free space in that
case (we do it very occasionally for wear levelling purposes).
This garbage collection is generally done in the background thread,
which has some primitive heuristics to tell it how much space to keep
available. But it's also done just-in-time, if you either kill the GC
thread or if you're saturating the FS with writes and the GC thread
hasn't had time to keep making space for you before you needed it.
The problem here is that GC writes which obsolete nodes in the victim
eraseblock are mingled with the ongoing new writes driven from
userspace. So we tend to end up writing out new eraseblocks full of data
nodes which are half new and volatile data, and half old stuff which
almost never changes like libraries and binaries. The new stuff like
temporary datafiles tends to get changed, overwritten or deleted -- and
the old stuff tends not to. So (referring to the paragraph on GC
efficiency above) our behaviour is such that we tend to end up with none
of the mostly-dirty blocks which are most efficient to garbage-collect
from; instead we have blocks which are roughly half-clean and
half-dirty.
The proposed fix for this is to split writes into two ongoing streams
instead of the current one stream -- we write new data into one
eraseblock while we write GC'd data into another. That way, the old
stable data nodes tend to get grouped together into 100% clean blocks
which we can just ignore (until we decide to wear level them), and 100%
_dirty_ blocks which are nice and quick to GC.
I worry about the memory usage sometimes, and play some rather
disgusting tricks to keep it down -- but in practice that's more of an
issue for the eCos port of JFFS2 than Linux; Linux boxen generally have
enough memory that it's not a problem.
> Do you have experiences with XFS and ext3 (datajournal) filesystems in terms
> of power fail security?
No. I've been at the receiving end of an automated powerfail script
which has been stress-testing JFFS2 and forcibly power cycling the
device in question every few minutes -- which gave rise to all kinds of
interesting observations about flash behaviour under those
circumstances. But I'm not aware of similar tests being done on XFS or
ext3 with repeated power failure and integrity tests.
--
dwmw2
Hello David,
In article <[email protected]> you wrote:
> I've been at the receiving end of an automated powerfail script
> which has been stress-testing JFFS2 and forcibly power cycling the
> device in question every few minutes
Is this needing some special hardware support, or is it kind of forcing
apm/apci power downs? Can you publish that script? I would need that for
some stress testing of applications and the kernel.
I also wonder, what the best method is to test those hard crashes,
especially interesting is the case, where disks get power interruption at
write, to see if the filesystem and block layer recovers from things like
half written (format needing) blocks.
Greetings
Bernd
--
eckes privat - http://www.eckes.org/
Project Freefire - http://www.freefire.org/
This box is IPv4 only -- your email address with only an AAAA record is
probably going to bounce again... :)
On Sat, 2003-08-09 at 01:29, Bernd Eckenfels wrote:
> Is this needing some special hardware support, or is it kind of forcing
> apm/apci power downs? Can you publish that script? I would need that for
> some stress testing of applications and the kernel.
I didn't do it myself -- I just got to fix the bugs which turned up ;)
I think it was done with X10 automated power switching stuff.
> I also wonder, what the best method is to test those hard crashes,
> especially interesting is the case, where disks get power interruption at
> write, to see if the filesystem and block layer recovers from things like
> half written (format needing) blocks.
Journal at application layer to external network-attached storage. Check
on-device fs integrity against your network journal at boot, continue
stress testing from where you left off.
--
dwmw2
On Sun, 27 Jul 2003, Yury Umanets wrote:
> On Sun, 2003-07-27 at 18:10, Daniel Egger wrote:
> > Am Son, 2003-07-27 um 15.28 schrieb Hans Reiser:
> > > or for which a wear leveling block device driver is used (I don't know
> > > if one exists for Linux).
> >
> > This is normally done by the filesystem (e.g. JFFS2).
>
> Normally device driver should be concerned about making wear out
> smaller. It is up to it IMHO.
The driver should do the logical to physical mapping, but the portability
vanishes if the filesystem to physical mapping is not the same for all
machines and operating systems. For pluggable devices this is important.
The leveling seems to be done by JFFs2 in a portable way, and that's as it
should be. If the leveling were in the driver I don't believe even FAT
would work.
--
bill davidsen <[email protected]>
CTO, TMR Associates, Inc
Doing interesting things with little computers since 1979.
On Thu, 2003-08-14 at 00:12, Bill Davidsen wrote:
> On Sun, 27 Jul 2003, Yury Umanets wrote:
>
> > On Sun, 2003-07-27 at 18:10, Daniel Egger wrote:
> > > Am Son, 2003-07-27 um 15.28 schrieb Hans Reiser:
>
> > > > or for which a wear leveling block device driver is used (I don't know
> > > > if one exists for Linux).
> > >
> > > This is normally done by the filesystem (e.g. JFFS2).
> >
> > Normally device driver should be concerned about making wear out
> > smaller. It is up to it IMHO.
>
> The driver should do the logical to physical mapping, but the portability
> vanishes if the filesystem to physical mapping is not the same for all
> machines and operating systems. For pluggable devices this is important.
>
> The leveling seems to be done by JFFs2 in a portable way, and that's as it
> should be. If the leveling were in the driver I don't believe even FAT
> would work.
Hello Bill,
Yes, you are right. Device driver cannot take care about leveling.
It is able only to take care about simple caching (one erase block) in
order to make wear out smaller and do not read/write whole block if one
sector should be written.
Part of a filesystem called "block allocator" should take care about
leveling.
On Wed, 2003-08-13 at 21:12, Bill Davidsen wrote:
> The driver should do the logical to physical mapping, but the portability
> vanishes if the filesystem to physical mapping is not the same for all
> machines and operating systems. For pluggable devices this is important.
The portability also vanishes if the file system layout is not the same
for all machines and operating systems... what's your point?
Just like there are standard file systems, there are also standard
'translation layers' -- pseudofilesystems which are used to emulate a
hard drive on flash storage -- and some of these are implemented for
Linux.
Take a PCMCIA flash card (real flash, not CF) with FTL and FAT on it,
and it'll work just fine under both Windows and Linux, because they both
use the standard FTL and FAT formats.
FTL provides the logical<->physical mapping and the wear levelling, FAT
is just normal FAT.
> The leveling seems to be done by JFFs2 in a portable way, and that's as it
> should be.
You seem to be very confused here. JFFS2 works on flash directly;
nothing's pretending to be a block device. It doesn't seem to be at all
relevant to this discussion.
JFFS2 does its own wear levelling and flash management, because it works
directly on the flash.
FAT can't do that -- it needs some other code (like the FTL code) to
emulate a normal hard drive for it, providing wear levelling and
logical<->physical translation for it.
See http://www.infradead.org/~dwmw2/mtd-upper-layers.jpeg
Wear levelling is not done in the driver -- the driver just drives the
flash, and in fact is below the bottom of the diagram since it's largely
irrelevant. It just gives you read/write/erase functions for the raw
flash.
Wear levelling is done either in the file system which works directly on
the flash (JFFS2, YAFFS), or in the 'translation layer' which uses the
flash to pretend to be a block device (FTL, NFTL, INFTL, SMTL). (In the
case of the extremely naïve 'mtdblock' translation layer, no translation
and no wear levelling is done at all.)
> If the leveling were in the driver I don't believe even FAT
> would work.
I think that by 'driver' you actually mean the 'translation layer' or
the combination of translation layer and underlying hardware driver, in
which case you would be incorrect to say that it wouldn't work. That
_is_ how it works, portably.
--
dwmw2
On Thu, 2003-08-14 at 06:04, Yury Umanets wrote:
> Yes, you are right. Device driver cannot take care about leveling.
The hardware device driver doesn't. The 'translation layer' does, in the
case where you are using a traditional block-based file system.
If you consider the translation layer and the underlying raw hardware
driver together to form the 'device driver' from the filesystem's
perspective and in the context of the above sentence, then you're
incorrect -- it can, and in general it _does_ take care of wear
levelling.
> It is able only to take care about simple caching (one erase block) in
> order to make wear out smaller and do not read/write whole block if one
> sector should be written.
Whatever meaning of 'device driver' you meant to use -- no.
The raw hardware driver provides only raw read/write/erase
functionality; no caching is appropriate.
The optional translation layer which simulates a block device provides
far more than simple caching -- it provides wear levelling, bad block
management, etc. All using a standard layout on the flash hardware for
portability.
(Except in the special case of the 'mtdblock' translation layer, which
is not suitable for anything but read-only operation on devices without
any bad blocks to be worked around.)
> Part of a filesystem called "block allocator" should take care about
> leveling.
That's insufficient. In a traditional file system, blocks get
overwritten without being freed and reallocated -- the allocator isn't
always involved.
If you want to teach a file system about flash and wear levelling, you
end up ditching the pretence that it's a block device entirely and
working directly with the flash hardware driver.
Either that or use a translation layer which does it _all_ for the file
system and then just use a standard file system on that simulated block
device.
Between those two extremes, very little actually makes sense.
If you introduce the gratuitous extra 'block device' abstraction layer
which doesn't really fit the reality of flash hardware very well at all,
you end up wanting to violate the layering in so many ways that you
realise you really shouldn't have been pretending to be a block device
in the first place.
--
dwmw2
On Thu, 2003-08-14 at 18:10, David Woodhouse wrote:
> On Thu, 2003-08-14 at 06:04, Yury Umanets wrote:
> > Yes, you are right. Device driver cannot take care about leveling.
>
> The hardware device driver doesn't. The 'translation layer' does, in the
> case where you are using a traditional block-based file system.
>
> If you consider the translation layer and the underlying raw hardware
> driver together to form the 'device driver' from the filesystem's
> perspective and in the context of the above sentence, then you're
> incorrect -- it can, and in general it _does_ take care of wear
> levelling.
>
> > It is able only to take care about simple caching (one erase block) in
> > order to make wear out smaller and do not read/write whole block if one
> > sector should be written.
>
> Whatever meaning of 'device driver' you meant to use -- no.
>
> The raw hardware driver provides only raw read/write/erase
> functionality; no caching is appropriate.
>
> The optional translation layer which simulates a block device provides
> far more than simple caching -- it provides wear levelling, bad block
> management, etc. All using a standard layout on the flash hardware for
> portability.
>
> (Except in the special case of the 'mtdblock' translation layer, which
> is not suitable for anything but read-only operation on devices without
> any bad blocks to be worked around.)
>
> > Part of a filesystem called "block allocator" should take care about
> > leveling.
>
> That's insufficient. In a traditional file system, blocks get
> overwritten without being freed and reallocated -- the allocator isn't
> always involved.
>
> If you want to teach a file system about flash and wear levelling, you
> end up ditching the pretence that it's a block device entirely and
> working directly with the flash hardware driver.
>
> Either that or use a translation layer which does it _all_ for the file
> system and then just use a standard file system on that simulated block
> device.
>
> Between those two extremes, very little actually makes sense.
>
> If you introduce the gratuitous extra 'block device' abstraction layer
> which doesn't really fit the reality of flash hardware very well at all,
> you end up wanting to violate the layering in so many ways that you
> realise you really shouldn't have been pretending to be a block device
> in the first place.
Agreed fully with you David. Thanks for explanation.
Only there are probably cannot be so fair borders between levels. Thus,
some functions of translation layer may be passed to filesystem level
(higher one). For instance some things about block allocating. And some
other functions may be passed to device driver layer (lower one).
Regards.
On Fri, 2003-08-15 at 15:32 -0400, Bill Davidsen wrote:
> On Thu, 14 Aug 2003, David Woodhouse wrote:
>
> > The raw hardware driver provides only raw read/write/erase
> > functionality; no caching is appropriate.
>
> Okay, that's the model I have in mind as the driver, assuming you included
> seek in that list.
No seek -- offsets are passed to the read/write methods, like
pread()/pwrite().
We have read(), which reads from the flash hardware, erase() which
resets an eraseblock to all 0xFF, and write() which performs an bitwise
AND operation between the contents of the flash and the buffer provided
(you can only clear bits on flash, you can't set them except by erasing;
qv.).
> > If you want to teach a file system about flash and wear levelling, you
> > end up ditching the pretence that it's a block device entirely and
> > working directly with the flash hardware driver.
>
> I don't think that's right. A file system may very well be *optimized* for
> performance on a certain class of device, but that doesn't make it device
> dependent. For example some early SysV filesystems had the directory in
> the middle of the platters to minimize seek distance when the partition
> was only partially filled. I'd bet I could run JFFS2 on a normal drive,
> and I know I can run FAT, ext2, etc on a CF. Now if Linux only knew how to
> read SysV.4 drives I could save some critical old data from the 90's, but
> that's another issue...
CF != flash. For the purpose of this discussion, 'CF' and 'normal drive'
are identical concepts. They are block devices; not MTD devices. JFFS2
does not work on them (without trickery) since JFFS2 is not written to
use block devices.
Conversely, you cannot use FAT/ext/etc on real flash without some kind
of 'translation layer' to make it pretend to be a block device.
CF just happens to have that translation layer built in to its hardware
rather than doing it in software -- so as far as the computer is
concerned, CF _is_ an IDE hard drive.
> > Either that or use a translation layer which does it _all_ for the file
> > system and then just use a standard file system on that simulated block
> > device.
>
> That sounds like a loopback mount, sort of. At least a feature which could
> be added fairly easily, like crypto mounts.
No, it's nothing like a loopback mount. It's a pseudo-filesystem. Three
sane implementations of such a thing are already in the kernel, and one
hopelessly trivial readonly one.
--
dwmw2
On Thu, 14 Aug 2003, David Woodhouse wrote:
> The raw hardware driver provides only raw read/write/erase
> functionality; no caching is appropriate.
Okay, that's the model I have in mind as the driver, assuming you included
seek in that list.
>
> The optional translation layer which simulates a block device provides
> far more than simple caching -- it provides wear levelling, bad block
> management, etc. All using a standard layout on the flash hardware for
> portability.
>
> (Except in the special case of the 'mtdblock' translation layer, which
> is not suitable for anything but read-only operation on devices without
> any bad blocks to be worked around.)
> If you want to teach a file system about flash and wear levelling, you
> end up ditching the pretence that it's a block device entirely and
> working directly with the flash hardware driver.
I don't think that's right. A file system may very well be *optimized* for
performance on a certain class of device, but that doesn't make it device
dependent. For example some early SysV filesystems had the directory in
the middle of the platters to minimize seek distance when the partition
was only partially filled. I'd bet I could run JFFS2 on a normal drive,
and I know I can run FAT, ext2, etc on a CF. Now if Linux only knew how to
read SysV.4 drives I could save some critical old data from the 90's, but
that's another issue...
>
> Either that or use a translation layer which does it _all_ for the file
> system and then just use a standard file system on that simulated block
> device.
That sounds like a loopback mount, sort of. At least a feature which could
be added fairly easily, like crypto mounts.
>
> Between those two extremes, very little actually makes sense.
>
> If you introduce the gratuitous extra 'block device' abstraction layer
> which doesn't really fit the reality of flash hardware very well at all,
> you end up wanting to violate the layering in so many ways that you
> realise you really shouldn't have been pretending to be a block device
> in the first place.
Agreed, if you're going to do that type of fakery it's probably better to
take some overhead and not give up good design in the name of performance
for something which is usually limited by other factors like device
performance, or seldom used. Slow and robust is easier to maintain.
--
bill davidsen <[email protected]>
CTO, TMR Associates, Inc
Doing interesting things with little computers since 1979.
){kind=link}
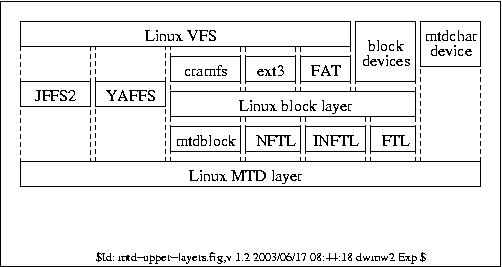{kind=link}