I saw a 4.8->4.9 regression (details below) that I attributed to:
9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues
That commit took the bitlock waitqueues from being dynamically-allocated
per-zone to being statically allocated and global. As suggested by
Linus, this makes them per-node, but keeps them statically-allocated.
It leaves us with more waitqueues than the global approach, inherently
scales it up as we gain nodes, and avoids generating code for
page_zone() which was evidently quite ugly. The patch is pretty darn
tiny too.
This turns what was a ~40% 4.8->4.9 regression into a 17% gain over
what on 4.8 did. That gain is a _bit_ surprising, but not entirely
unexpected since we now get much simpler code from no page_zone() and a
fixed-size array for which we don't have to follow a pointer (and get to
do power-of-2 math).
This boots in a small VM and on a multi-node NUMA system, but has not
been tested widely. It definitely needs to be validated to make sure
it properly initialzes the new structure in the various node hotplug
cases before anybody goes applying it.
Original report below (sent privately by accident).
include/linux/mmzone.h | 5 +++++
kernel/sched/core.c | 16 ----------------
mm/filemap.c | 22 +++++++++++++++++++++-
mm/page_alloc.c | 5 +++++
4 files changed, 31 insertions(+), 17 deletions(-)
---
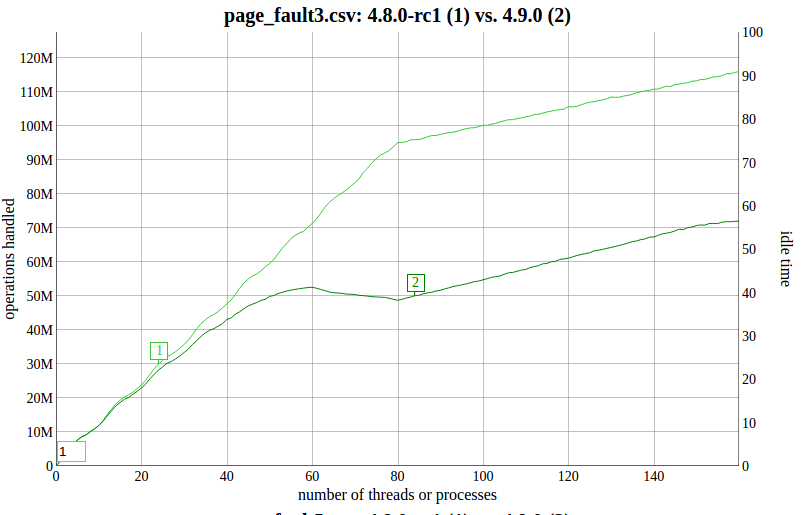
I'm seeing a 4.8->4.9 regression:
https://www.sr71.net/~dave/intel/2016-12-19-page_fault_3.processes.png
This is on a 160-thread 8-socket system. The workloads is a bunch of
processes faulting in pages to separate MAP_SHARED mappings:
https://github.com/antonblanchard/will-it-scale/blob/master/tests/page_fault3.c
The smoking gun in the profiles is that __wake_up_bit() (called via
unlock_page()) goes from ~1% to 4% in the profiles.
The workload is pretty maniacally touching random parts of the
waitqueue, and missing the cache heavily. Now that it is shared, I
suspect we're transferring cachelines across node boundaries in a way
that we were not with the per-zone waitqueues.
This is *only* showing up with MAP_SHARED pages, not with anonymous
pages. I think we do a lock_page()/unlock_page() pair in
do_shared_fault(), which we avoid in the anonymous case. Reverting:
9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues
restores things to 4.8 behavior. The fact that automated testing didn't
catch this probably means that it's pretty rare to find hardware that
actually shows the problem, so I don't think it's worth reverting
anything in mainline.
ut, the commit says:
> As part of that earlier discussion, we had a much better solution for
> the NUMA scalability issue - by just making the page lock have a
> separate contention bit, the waitqueue doesn't even have to be looked at
> for the normal case.
So, maybe we should do that moving forward since we at least found one
case that's pretty aversely affected.
Cc: Andreas Gruenbacher <[email protected]>
Cc: Bob Peterson <[email protected]>
Cc: Mel Gorman <[email protected]>
Cc: Peter Zijlstra <[email protected]>
Cc: Andy Lutomirski <[email protected]>
Cc: Steven Whitehouse <[email protected]>
Cc: Linus Torvalds <[email protected]>
---
b/include/linux/mmzone.h | 5 +++++
b/kernel/sched/core.c | 16 ----------------
b/mm/filemap.c | 22 +++++++++++++++++++++-
b/mm/page_alloc.c | 5 +++++
4 files changed, 31 insertions(+), 17 deletions(-)
diff -puN include/linux/mmzone.h~static-per-zone-waitqueue include/linux/mmzone.h
--- a/include/linux/mmzone.h~static-per-zone-waitqueue 2016-12-19 11:35:12.210823059 -0800
+++ b/include/linux/mmzone.h 2016-12-19 13:11:53.335170271 -0800
@@ -27,6 +27,9 @@
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
+#define WAIT_TABLE_BITS 8
+#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS)
+
/*
* PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed
* costly to service. That is between allocation orders which should
@@ -662,6 +665,8 @@ typedef struct pglist_data {
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
+ wait_queue_head_t wait_table[WAIT_TABLE_SIZE];
+
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
diff -puN kernel/sched/core.c~static-per-zone-waitqueue kernel/sched/core.c
--- a/kernel/sched/core.c~static-per-zone-waitqueue 2016-12-19 11:35:12.212823149 -0800
+++ b/kernel/sched/core.c 2016-12-19 11:35:12.225823738 -0800
@@ -7509,27 +7509,11 @@ static struct kmem_cache *task_group_cac
DECLARE_PER_CPU(cpumask_var_t, load_balance_mask);
DECLARE_PER_CPU(cpumask_var_t, select_idle_mask);
-#define WAIT_TABLE_BITS 8
-#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS)
-static wait_queue_head_t bit_wait_table[WAIT_TABLE_SIZE] __cacheline_aligned;
-
-wait_queue_head_t *bit_waitqueue(void *word, int bit)
-{
- const int shift = BITS_PER_LONG == 32 ? 5 : 6;
- unsigned long val = (unsigned long)word << shift | bit;
-
- return bit_wait_table + hash_long(val, WAIT_TABLE_BITS);
-}
-EXPORT_SYMBOL(bit_waitqueue);
-
void __init sched_init(void)
{
int i, j;
unsigned long alloc_size = 0, ptr;
- for (i = 0; i < WAIT_TABLE_SIZE; i++)
- init_waitqueue_head(bit_wait_table + i);
-
#ifdef CONFIG_FAIR_GROUP_SCHED
alloc_size += 2 * nr_cpu_ids * sizeof(void **);
#endif
diff -puN mm/filemap.c~static-per-zone-waitqueue mm/filemap.c
--- a/mm/filemap.c~static-per-zone-waitqueue 2016-12-19 11:35:12.215823285 -0800
+++ b/mm/filemap.c 2016-12-19 14:51:23.881814379 -0800
@@ -779,6 +779,26 @@ EXPORT_SYMBOL(__page_cache_alloc);
#endif
/*
+ * We need 'nid' because page_waitqueue() needs to get the waitqueue
+ * for memory where virt_to_page() does not work, like highmem.
+ */
+static wait_queue_head_t *__bit_waitqueue(void *word, int bit, int nid)
+{
+ const int shift = BITS_PER_LONG == 32 ? 5 : 6;
+ unsigned long val = (unsigned long)word << shift | bit;
+
+ return &NODE_DATA(nid)->wait_table[hash_long(val, WAIT_TABLE_BITS)];
+}
+
+wait_queue_head_t *bit_waitqueue(void *word, int bit)
+{
+ const int __maybe_unused nid = page_to_nid(virt_to_page(word));
+
+ return __bit_waitqueue(word, bit, nid);
+}
+EXPORT_SYMBOL(bit_waitqueue);
+
+/*
* In order to wait for pages to become available there must be
* waitqueues associated with pages. By using a hash table of
* waitqueues where the bucket discipline is to maintain all
@@ -790,7 +810,7 @@ EXPORT_SYMBOL(__page_cache_alloc);
*/
wait_queue_head_t *page_waitqueue(struct page *page)
{
- return bit_waitqueue(page, 0);
+ return __bit_waitqueue(page, 0, page_to_nid(page));
}
EXPORT_SYMBOL(page_waitqueue);
diff -puN mm/page_alloc.c~static-per-zone-waitqueue mm/page_alloc.c
--- a/mm/page_alloc.c~static-per-zone-waitqueue 2016-12-19 11:35:12.219823466 -0800
+++ b/mm/page_alloc.c 2016-12-19 13:10:56.587613213 -0800
@@ -5872,6 +5872,7 @@ void __paginginit free_area_init_node(in
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
+ int i;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
@@ -5892,6 +5893,10 @@ void __paginginit free_area_init_node(in
zones_size, zholes_size);
alloc_node_mem_map(pgdat);
+
+ /* per-node page waitqueue initialization: */
+ for (i = 0; i < WAIT_TABLE_SIZE; i++)
+ init_waitqueue_head(&pgdat->wait_table[i]);
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
_
On 12/19/2016 03:07 PM, Linus Torvalds wrote:
> +wait_queue_head_t *bit_waitqueue(void *word, int bit)
> +{
> + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
> +
> + return __bit_waitqueue(word, bit, nid);
>
> No can do. Part of the problem with the old coffee was that it did that
> virt_to_page() crud. That doesn't work with the virtually mapped stack.
Ahhh, got it.
So, what did you have in mind? Just redirect bit_waitqueue() to the
"first_online_node" waitqueues?
wait_queue_head_t *bit_waitqueue(void *word, int bit)
{
return __bit_waitqueue(word, bit, first_online_node);
}
We could do some fancy stuff like only do virt_to_page() for things in
the linear map, but I'm not sure we'll see much of a gain for it. None
of the other waitqueue users look as pathological as the 'struct page'
ones. Maybe:
wait_queue_head_t *bit_waitqueue(void *word, int bit)
{
int nid
if (word >= VMALLOC_START) /* all addrs not in linear map */
nid = first_online_node;
else
nid = page_to_nid(virt_to_page(word));
return __bit_waitqueue(word, bit, nid);
}
On Mon, 19 Dec 2016 14:58:26 -0800
Dave Hansen <[email protected]> wrote:
> I saw a 4.8->4.9 regression (details below) that I attributed to:
>
> 9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues
>
> That commit took the bitlock waitqueues from being dynamically-allocated
> per-zone to being statically allocated and global. As suggested by
> Linus, this makes them per-node, but keeps them statically-allocated.
>
> It leaves us with more waitqueues than the global approach, inherently
> scales it up as we gain nodes, and avoids generating code for
> page_zone() which was evidently quite ugly. The patch is pretty darn
> tiny too.
>
> This turns what was a ~40% 4.8->4.9 regression into a 17% gain over
> what on 4.8 did. That gain is a _bit_ surprising, but not entirely
> unexpected since we now get much simpler code from no page_zone() and a
> fixed-size array for which we don't have to follow a pointer (and get to
> do power-of-2 math).
I'll have to respin the PageWaiters patch and resend it. There were
just a couple of small issues picked up in review. I've just got side
tracked with getting a few other things done and haven't had time to
benchmark it properly.
I'd still like to see what per-node waitqueues does on top of that. If
it's significant for realistic workloads then it could be done for the
page waitqueues as Linus said.
Thanks,
Nick
On Mon, 19 Dec 2016 16:20:05 -0800
Dave Hansen <[email protected]> wrote:
> On 12/19/2016 03:07 PM, Linus Torvalds wrote:
> > +wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > +{
> > + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
> > +
> > + return __bit_waitqueue(word, bit, nid);
> >
> > No can do. Part of the problem with the old coffee was that it did that
> > virt_to_page() crud. That doesn't work with the virtually mapped stack.
>
> Ahhh, got it.
>
> So, what did you have in mind? Just redirect bit_waitqueue() to the
> "first_online_node" waitqueues?
>
> wait_queue_head_t *bit_waitqueue(void *word, int bit)
> {
> return __bit_waitqueue(word, bit, first_online_node);
> }
>
> We could do some fancy stuff like only do virt_to_page() for things in
> the linear map, but I'm not sure we'll see much of a gain for it. None
> of the other waitqueue users look as pathological as the 'struct page'
> ones. Maybe:
>
> wait_queue_head_t *bit_waitqueue(void *word, int bit)
> {
> int nid
> if (word >= VMALLOC_START) /* all addrs not in linear map */
> nid = first_online_node;
> else
> nid = page_to_nid(virt_to_page(word));
> return __bit_waitqueue(word, bit, nid);
> }
I think he meant just make the page_waitqueue do the per-node thing
and leave bit_waitqueue as the global bit.
It would be cool if CPUs had an instruction that translates an address
though. You could avoid all that lookup and just do it with the TLB :)
Thanks,
Nick
On Tue, Dec 20, 2016 at 12:31:13PM +1000, Nicholas Piggin wrote:
> On Mon, 19 Dec 2016 16:20:05 -0800
> Dave Hansen <[email protected]> wrote:
>
> > On 12/19/2016 03:07 PM, Linus Torvalds wrote:
> > > +wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > > +{
> > > + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
> > > +
> > > + return __bit_waitqueue(word, bit, nid);
> > >
> > > No can do. Part of the problem with the old coffee was that it did that
> > > virt_to_page() crud. That doesn't work with the virtually mapped stack.
> >
> > Ahhh, got it.
> >
> > So, what did you have in mind? Just redirect bit_waitqueue() to the
> > "first_online_node" waitqueues?
> >
> > wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > {
> > return __bit_waitqueue(word, bit, first_online_node);
> > }
> >
> > We could do some fancy stuff like only do virt_to_page() for things in
> > the linear map, but I'm not sure we'll see much of a gain for it. None
> > of the other waitqueue users look as pathological as the 'struct page'
> > ones. Maybe:
> >
> > wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > {
> > int nid
> > if (word >= VMALLOC_START) /* all addrs not in linear map */
> > nid = first_online_node;
> > else
> > nid = page_to_nid(virt_to_page(word));
> > return __bit_waitqueue(word, bit, nid);
> > }
>
> I think he meant just make the page_waitqueue do the per-node thing
> and leave bit_waitqueue as the global bit.
>
I'm pressed for time but at a glance, that might require a separate
structure of wait_queues for page waitqueue. Most users of bit_waitqueue
are not operating with pages. The first user is based on a word inside
a block_device for example. All non-page users could assume node-0. It
shrinks the available hash table space but as before, maybe collisions
are not common enough to actually matter. That would be worth checking
out. Alternatively, careful auditing to pick a node when it's known it's
safe to call virt_to_page may work but it would be fragile.
Unfortunately I won't be able to review or test any patches until January
3rd after I'm back online properly. Right now, I have intermittent internet
access at best. During the next 4 days, I know I definitely will not have
any internet access.
The last time around, there were three patch sets to avoid the overhead for
pages in particular. One was dropped (mine, based on Nick's old work) as
it was too complicated. Peter had some patches but after enough hammering
it failed due to a missed wakup that I didn't pin down before having to
travel to a conference.
I hadn't tested Nick's prototype although it looked fine because others
reviewed it before I looked and I was waiting for another version to
appear. If one appears, I'll take a closer look and bash it across a few
machines to see if it has any lost wakeup problems.
--
Mel Gorman
SUSE Labs
On Tue, 20 Dec 2016 12:58:25 +0000
Mel Gorman <[email protected]> wrote:
> On Tue, Dec 20, 2016 at 12:31:13PM +1000, Nicholas Piggin wrote:
> > On Mon, 19 Dec 2016 16:20:05 -0800
> > Dave Hansen <[email protected]> wrote:
> >
> > > On 12/19/2016 03:07 PM, Linus Torvalds wrote:
> > > > +wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > > > +{
> > > > + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
> > > > +
> > > > + return __bit_waitqueue(word, bit, nid);
> > > >
> > > > No can do. Part of the problem with the old coffee was that it did that
> > > > virt_to_page() crud. That doesn't work with the virtually mapped stack.
> > >
> > > Ahhh, got it.
> > >
> > > So, what did you have in mind? Just redirect bit_waitqueue() to the
> > > "first_online_node" waitqueues?
> > >
> > > wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > > {
> > > return __bit_waitqueue(word, bit, first_online_node);
> > > }
> > >
> > > We could do some fancy stuff like only do virt_to_page() for things in
> > > the linear map, but I'm not sure we'll see much of a gain for it. None
> > > of the other waitqueue users look as pathological as the 'struct page'
> > > ones. Maybe:
> > >
> > > wait_queue_head_t *bit_waitqueue(void *word, int bit)
> > > {
> > > int nid
> > > if (word >= VMALLOC_START) /* all addrs not in linear map */
> > > nid = first_online_node;
> > > else
> > > nid = page_to_nid(virt_to_page(word));
> > > return __bit_waitqueue(word, bit, nid);
> > > }
> >
> > I think he meant just make the page_waitqueue do the per-node thing
> > and leave bit_waitqueue as the global bit.
> >
>
> I'm pressed for time but at a glance, that might require a separate
> structure of wait_queues for page waitqueue. Most users of bit_waitqueue
> are not operating with pages. The first user is based on a word inside
> a block_device for example. All non-page users could assume node-0.
Yes it would require something or other like that. Trivial to keep things
balanced (if not local) over nodes by take a simple hash of the virtual
address to spread over the nodes. Or just keep using this separate global
table for the bit_waitqueue...
But before Linus grumps at me again, let's try to do the waitqueue
avoidance bit first before we worry about that :)
> It
> shrinks the available hash table space but as before, maybe collisions
> are not common enough to actually matter. That would be worth checking
> out. Alternatively, careful auditing to pick a node when it's known it's
> safe to call virt_to_page may work but it would be fragile.
>
> Unfortunately I won't be able to review or test any patches until January
> 3rd after I'm back online properly. Right now, I have intermittent internet
> access at best. During the next 4 days, I know I definitely will not have
> any internet access.
>
> The last time around, there were three patch sets to avoid the overhead for
> pages in particular. One was dropped (mine, based on Nick's old work) as
> it was too complicated. Peter had some patches but after enough hammering
> it failed due to a missed wakup that I didn't pin down before having to
> travel to a conference.
>
> I hadn't tested Nick's prototype although it looked fine because others
> reviewed it before I looked and I was waiting for another version to
> appear. If one appears, I'll take a closer look and bash it across a few
> machines to see if it has any lost wakeup problems.
>
Sure I'll respin it this week.
Thanks,
Nick
On Mon, Dec 19, 2016 at 4:20 PM, Dave Hansen
<[email protected]> wrote:
> On 12/19/2016 03:07 PM, Linus Torvalds wrote:
>> +wait_queue_head_t *bit_waitqueue(void *word, int bit)
>> +{
>> + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
>> +
>> + return __bit_waitqueue(word, bit, nid);
>>
>> No can do. Part of the problem with the old coffee was that it did that
>> virt_to_page() crud. That doesn't work with the virtually mapped stack.
>
> Ahhh, got it.
>
> So, what did you have in mind? Just redirect bit_waitqueue() to the
> "first_online_node" waitqueues?
That was my initial thought, but now that I'm back home and look at
the code, I realize:
- we never merged the PageWaiters patch. I thought we already did,
because I didn't think there was any confusion left, but that was
clearly just in my dreams.
I was surprised that you'd see the cache ping-pong with per-page
contention bit, but thought that maybe your benchmark was some kind of
broken "fault in the same page over and over again on multiple nodes"
thing. But it was simpler than that - you simply don't have the
per-page contention bit at all.
And quite frankly, I still suspect that just doing the per-page
contention bit will solve everything, and we don't want to do the
numa-spreading bit_waitqueue() at all.
- but if I'm wrong, and you can still see numa issues even with the
per-page contention bit in place, we should just treat
"bit_waitqueue()" separately from the page waitqueue, and just have a
separate (non-node) array for the bit-waitqueue.
I'll go back and try to see why the page flag contention patch didn't
get applied.
Linus
On Tue, Dec 20, 2016 at 9:31 AM, Linus Torvalds
<[email protected]> wrote:
>
> I'll go back and try to see why the page flag contention patch didn't
> get applied.
Ahh, a combination of warring patches by Nick and PeterZ, and worry
about the page flag bits.
Damn. I had mentally marked this whole issue as "solved". But the fact
that we know how to solve it doesn't mean it's done.
Linus
On Tue, Dec 20, 2016 at 10:02:46AM -0800, Linus Torvalds wrote:
> On Tue, Dec 20, 2016 at 9:31 AM, Linus Torvalds
> <[email protected]> wrote:
> >
> > I'll go back and try to see why the page flag contention patch didn't
> > get applied.
>
> Ahh, a combination of warring patches by Nick and PeterZ, and worry
> about the page flag bits.
I think Nick actually had a patch freeing up a pageflag, although Hugh
had a comment on that.
That said, I'm not a huge fan of his waiters patch, I'm still not sure
why he wants to write another whole wait loop, but whatever. Whichever
you prefer I suppose.
On Wed, Dec 21, 2016 at 09:09:31AM +0100, Peter Zijlstra wrote:
> On Tue, Dec 20, 2016 at 10:02:46AM -0800, Linus Torvalds wrote:
> > On Tue, Dec 20, 2016 at 9:31 AM, Linus Torvalds
> > <[email protected]> wrote:
> > >
> > > I'll go back and try to see why the page flag contention patch didn't
> > > get applied.
> >
> > Ahh, a combination of warring patches by Nick and PeterZ, and worry
> > about the page flag bits.
>
> I think Nick actually had a patch freeing up a pageflag, although Hugh
> had a comment on that.
>
> That said, I'm not a huge fan of his waiters patch, I'm still not sure
> why he wants to write another whole wait loop, but whatever. Whichever
> you prefer I suppose.
FWIW, here's mine.. compiles and boots on a NUMA x86_64 machine.
---
Subject: mm: Avoid slow path for unlock_page()
From: Peter Zijlstra <[email protected]>
Date: Thu, 27 Oct 2016 10:08:52 +0200
Currently we uncontidionally look up the page waitqueue and issue the
wakeup for unlock_page(), even though there might not be anybody
waiting.
Use another pageflag (PG_waiters) to keep track of the waitqueue state
such that we can avoid the work when there are in fact no waiters
queued.
Currently guarded by CONFIG_NUMA, which is not strictly correct as
I've been told there actually are 32bit architectures that have NUMA.
Ideally Nick manages to reclaim a pageflag and we can make this
unconditional.
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
---
include/linux/page-flags.h | 19 ++++++++
include/linux/pagemap.h | 25 ++++++++--
include/trace/events/mmflags.h | 7 +++
mm/filemap.c | 94 +++++++++++++++++++++++++++++++++++++----
4 files changed, 130 insertions(+), 15 deletions(-)
--- a/include/linux/page-flags.h
+++ b/include/linux/page-flags.h
@@ -73,6 +73,14 @@
*/
enum pageflags {
PG_locked, /* Page is locked. Don't touch. */
+#ifdef CONFIG_NUMA
+ /*
+ * This bit must end up in the same word as PG_locked (or any other bit
+ * we're waiting on), as per all architectures their bitop
+ * implementations.
+ */
+ PG_waiters, /* The hashed waitqueue has waiters */
+#endif
PG_error,
PG_referenced,
PG_uptodate,
@@ -231,6 +239,9 @@ static __always_inline int TestClearPage
#define TESTPAGEFLAG_FALSE(uname) \
static inline int Page##uname(const struct page *page) { return 0; }
+#define TESTPAGEFLAG_TRUE(uname) \
+static inline int Page##uname(const struct page *page) { return 1; }
+
#define SETPAGEFLAG_NOOP(uname) \
static inline void SetPage##uname(struct page *page) { }
@@ -249,10 +260,18 @@ static inline int TestClearPage##uname(s
#define PAGEFLAG_FALSE(uname) TESTPAGEFLAG_FALSE(uname) \
SETPAGEFLAG_NOOP(uname) CLEARPAGEFLAG_NOOP(uname)
+#define PAGEFLAG_TRUE(uname) TESTPAGEFLAG_TRUE(uname) \
+ SETPAGEFLAG_NOOP(uname) CLEARPAGEFLAG_NOOP(uname)
+
#define TESTSCFLAG_FALSE(uname) \
TESTSETFLAG_FALSE(uname) TESTCLEARFLAG_FALSE(uname)
__PAGEFLAG(Locked, locked, PF_NO_TAIL)
+#ifdef CONFIG_NUMA
+PAGEFLAG(Waiters, waiters, PF_NO_TAIL)
+#else
+PAGEFLAG_TRUE(Waiters);
+#endif
PAGEFLAG(Error, error, PF_NO_COMPOUND) TESTCLEARFLAG(Error, error, PF_NO_COMPOUND)
PAGEFLAG(Referenced, referenced, PF_HEAD)
TESTCLEARFLAG(Referenced, referenced, PF_HEAD)
--- a/include/linux/pagemap.h
+++ b/include/linux/pagemap.h
@@ -436,7 +436,7 @@ extern void __lock_page(struct page *pag
extern int __lock_page_killable(struct page *page);
extern int __lock_page_or_retry(struct page *page, struct mm_struct *mm,
unsigned int flags);
-extern void unlock_page(struct page *page);
+extern void __unlock_page(struct page *page);
static inline int trylock_page(struct page *page)
{
@@ -467,6 +467,20 @@ static inline int lock_page_killable(str
return 0;
}
+static inline void unlock_page(struct page *page)
+{
+ page = compound_head(page);
+ VM_BUG_ON_PAGE(!PageLocked(page), page);
+ clear_bit_unlock(PG_locked, &page->flags);
+ /*
+ * Since PG_locked and PG_waiters are in the same word, Program-Order
+ * ensures the load of PG_waiters must not observe a value earlier
+ * than our clear_bit() store.
+ */
+ if (PageWaiters(page))
+ __unlock_page(page);
+}
+
/*
* lock_page_or_retry - Lock the page, unless this would block and the
* caller indicated that it can handle a retry.
@@ -491,11 +505,11 @@ extern int wait_on_page_bit_killable(str
extern int wait_on_page_bit_killable_timeout(struct page *page,
int bit_nr, unsigned long timeout);
+extern int wait_on_page_lock(struct page *page, int mode);
+
static inline int wait_on_page_locked_killable(struct page *page)
{
- if (!PageLocked(page))
- return 0;
- return wait_on_page_bit_killable(compound_head(page), PG_locked);
+ return wait_on_page_lock(page, TASK_KILLABLE);
}
extern wait_queue_head_t *page_waitqueue(struct page *page);
@@ -513,8 +527,7 @@ static inline void wake_up_page(struct p
*/
static inline void wait_on_page_locked(struct page *page)
{
- if (PageLocked(page))
- wait_on_page_bit(compound_head(page), PG_locked);
+ wait_on_page_lock(page, TASK_UNINTERRUPTIBLE);
}
/*
--- a/include/trace/events/mmflags.h
+++ b/include/trace/events/mmflags.h
@@ -55,6 +55,12 @@
__def_gfpflag_names \
) : "none"
+#ifdef CONFIG_NUMA
+#define IF_HAVE_PG_WAITERS(flag,string) {1UL << flag, string},
+#else
+#define IF_HAVE_PG_WAITERS(flag,string)
+#endif
+
#ifdef CONFIG_MMU
#define IF_HAVE_PG_MLOCK(flag,string) ,{1UL << flag, string}
#else
@@ -81,6 +87,7 @@
#define __def_pageflag_names \
{1UL << PG_locked, "locked" }, \
+IF_HAVE_PG_WAITERS(PG_waiters, "waiters" ) \
{1UL << PG_error, "error" }, \
{1UL << PG_referenced, "referenced" }, \
{1UL << PG_uptodate, "uptodate" }, \
--- a/mm/filemap.c
+++ b/mm/filemap.c
@@ -809,15 +809,30 @@ EXPORT_SYMBOL_GPL(add_page_wait_queue);
* The mb is necessary to enforce ordering between the clear_bit and the read
* of the waitqueue (to avoid SMP races with a parallel wait_on_page_locked()).
*/
-void unlock_page(struct page *page)
+void __unlock_page(struct page *page)
{
- page = compound_head(page);
- VM_BUG_ON_PAGE(!PageLocked(page), page);
- clear_bit_unlock(PG_locked, &page->flags);
- smp_mb__after_atomic();
- wake_up_page(page, PG_locked);
+ wait_queue_head_t *wq = page_waitqueue(page);
+ unsigned long flags;
+
+ spin_lock_irqsave(&wq->lock, flags);
+ if (waitqueue_active(wq)) {
+ struct wait_bit_key key =
+ __WAIT_BIT_KEY_INITIALIZER(&page->flags, PG_locked);
+
+ __wake_up_locked_key(wq, TASK_NORMAL, &key);
+ } else {
+ /*
+ * We need to do ClearPageWaiters() under wq->lock such that
+ * we serialize against prepare_to_wait() adding waiters and
+ * setting task_struct::state.
+ *
+ * See lock_page_wait().
+ */
+ ClearPageWaiters(page);
+ }
+ spin_unlock_irqrestore(&wq->lock, flags);
}
-EXPORT_SYMBOL(unlock_page);
+EXPORT_SYMBOL(__unlock_page);
/**
* end_page_writeback - end writeback against a page
@@ -870,6 +885,55 @@ void page_endio(struct page *page, bool
}
EXPORT_SYMBOL_GPL(page_endio);
+static int lock_page_wait(struct wait_bit_key *word, int mode)
+{
+ struct page *page = container_of(word->flags, struct page, flags);
+
+ /*
+ * We cannot go sleep without having PG_waiters set. This would mean
+ * nobody would issue a wakeup and we'd be stuck.
+ */
+ if (!PageWaiters(page)) {
+
+ /*
+ * There are two orderings of importance:
+ *
+ * 1)
+ *
+ * [unlock] [wait]
+ *
+ * clear PG_locked set PG_waiters
+ * test PG_waiters test (and-set) PG_locked
+ *
+ * Since these are in the same word, and the clear/set
+ * operation are atomic, they are ordered against one another.
+ * Program-Order further constraints a CPU from speculating the
+ * later load to not be earlier than the RmW. So this doesn't
+ * need an explicit barrier. Also see unlock_page().
+ *
+ * 2)
+ *
+ * [unlock] [wait]
+ *
+ * LOCK wq->lock LOCK wq->lock
+ * __wake_up_locked || list-add
+ * clear PG_waiters set_current_state()
+ * UNLOCK wq->lock UNLOCK wq->lock
+ * set PG_waiters
+ *
+ * Since we're added to the waitqueue, we cannot get
+ * PG_waiters cleared without also getting TASK_RUNNING set,
+ * which will then void the schedule() call and we'll loop.
+ * Here wq->lock is sufficient ordering. See __unlock_page().
+ */
+ SetPageWaiters(page);
+
+ return 0;
+ }
+
+ return bit_wait_io(word, mode);
+}
+
/**
* __lock_page - get a lock on the page, assuming we need to sleep to get it
* @page: the page to lock
@@ -879,7 +943,7 @@ void __lock_page(struct page *page)
struct page *page_head = compound_head(page);
DEFINE_WAIT_BIT(wait, &page_head->flags, PG_locked);
- __wait_on_bit_lock(page_waitqueue(page_head), &wait, bit_wait_io,
+ __wait_on_bit_lock(page_waitqueue(page_head), &wait, lock_page_wait,
TASK_UNINTERRUPTIBLE);
}
EXPORT_SYMBOL(__lock_page);
@@ -890,10 +954,22 @@ int __lock_page_killable(struct page *pa
DEFINE_WAIT_BIT(wait, &page_head->flags, PG_locked);
return __wait_on_bit_lock(page_waitqueue(page_head), &wait,
- bit_wait_io, TASK_KILLABLE);
+ lock_page_wait, TASK_KILLABLE);
}
EXPORT_SYMBOL_GPL(__lock_page_killable);
+int wait_on_page_lock(struct page *page, int mode)
+{
+ struct page __always_unused *__page = (page = compound_head(page));
+ DEFINE_WAIT_BIT(wait, &page->flags, PG_locked);
+
+ if (!PageLocked(page))
+ return 0;
+
+ return __wait_on_bit(page_waitqueue(page), &wait, lock_page_wait, mode);
+}
+EXPORT_SYMBOL(wait_on_page_lock);
+
/*
* Return values:
* 1 - page is locked; mmap_sem is still held.
On Wed, 21 Dec 2016 09:09:31 +0100
Peter Zijlstra <[email protected]> wrote:
> On Tue, Dec 20, 2016 at 10:02:46AM -0800, Linus Torvalds wrote:
> > On Tue, Dec 20, 2016 at 9:31 AM, Linus Torvalds
> > <[email protected]> wrote:
> > >
> > > I'll go back and try to see why the page flag contention patch didn't
> > > get applied.
> >
> > Ahh, a combination of warring patches by Nick and PeterZ, and worry
> > about the page flag bits.
>
> I think Nick actually had a patch freeing up a pageflag, although Hugh
> had a comment on that.
Yeah I think he basically acked it. It had a small compound debug
false positive but I think it's okay. I'm just testing it again.
> That said, I'm not a huge fan of his waiters patch, I'm still not sure
> why he wants to write another whole wait loop, but whatever. Whichever
> you prefer I suppose.
Ah, I was waiting for some feedback, thanks.
Well I wanted to do it that way to keep the manipulation of the new
bit under the same lock as the waitqueue, so as not to introduce new
memory orderings vs testing waitqueue_active.
Thanks,
Nick
On Mon, 19 Dec 2016 14:58:26 -0800
Dave Hansen <[email protected]> wrote:
> I saw a 4.8->4.9 regression (details below) that I attributed to:
>
> 9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues
>
> That commit took the bitlock waitqueues from being dynamically-allocated
> per-zone to being statically allocated and global. As suggested by
> Linus, this makes them per-node, but keeps them statically-allocated.
>
> It leaves us with more waitqueues than the global approach, inherently
> scales it up as we gain nodes, and avoids generating code for
> page_zone() which was evidently quite ugly. The patch is pretty darn
> tiny too.
>
> This turns what was a ~40% 4.8->4.9 regression into a 17% gain over
> what on 4.8 did. That gain is a _bit_ surprising, but not entirely
> unexpected since we now get much simpler code from no page_zone() and a
> fixed-size array for which we don't have to follow a pointer (and get to
> do power-of-2 math).
>
> This boots in a small VM and on a multi-node NUMA system, but has not
> been tested widely. It definitely needs to be validated to make sure
> it properly initialzes the new structure in the various node hotplug
> cases before anybody goes applying it.
>
> Original report below (sent privately by accident).
>
> include/linux/mmzone.h | 5 +++++
> kernel/sched/core.c | 16 ----------------
> mm/filemap.c | 22 +++++++++++++++++++++-
> mm/page_alloc.c | 5 +++++
> 4 files changed, 31 insertions(+), 17 deletions(-)
>
> ---
>
> I'm seeing a 4.8->4.9 regression:
>
> https://www.sr71.net/~dave/intel/2016-12-19-page_fault_3.processes.png
>
> This is on a 160-thread 8-socket system. The workloads is a bunch of
> processes faulting in pages to separate MAP_SHARED mappings:
>
> https://github.com/antonblanchard/will-it-scale/blob/master/tests/page_fault3.c
>
> The smoking gun in the profiles is that __wake_up_bit() (called via
> unlock_page()) goes from ~1% to 4% in the profiles.
>
> The workload is pretty maniacally touching random parts of the
> waitqueue, and missing the cache heavily. Now that it is shared, I
> suspect we're transferring cachelines across node boundaries in a way
> that we were not with the per-zone waitqueues.
>
> This is *only* showing up with MAP_SHARED pages, not with anonymous
> pages. I think we do a lock_page()/unlock_page() pair in
> do_shared_fault(), which we avoid in the anonymous case. Reverting:
>
> 9dcb8b685f mm: remove per-zone hashtable of bitlock waitqueues
>
> restores things to 4.8 behavior. The fact that automated testing didn't
> catch this probably means that it's pretty rare to find hardware that
> actually shows the problem, so I don't think it's worth reverting
> anything in mainline.
I've been doing a bit of testing, and I don't know why you're seeing
this.
I don't think I've been able to trigger any actual page lock contention
so nothing gets put on the waitqueue to really bounce cache lines around
that I can see. Yes there are some loads to check the waitqueue, but
those should be cached read shared among CPUs so not cause interconnect
traffic I would have thought.
After testing my PageWaiters patch, I'm maybe seeing 2% improvment on
this workload (although powerpc doesn't do so well on this one due to
virtual memory management overheads -- maybe x86 will show a bit more)
But the point is that after this, there should be no waitqueue activity
at all. I haven't chased up a system with a lot of IOPS connected that
would be needed to realistically test contended cases (which I thought
I needed to show an improvement from per-node tables, but your test
suggests not...)
Thanks,
Nick
>
> ut, the commit says:
>
> > As part of that earlier discussion, we had a much better solution for
> > the NUMA scalability issue - by just making the page lock have a
> > separate contention bit, the waitqueue doesn't even have to be looked at
> > for the normal case.
>
> So, maybe we should do that moving forward since we at least found one
> case that's pretty aversely affected.
>
> Cc: Andreas Gruenbacher <[email protected]>
> Cc: Bob Peterson <[email protected]>
> Cc: Mel Gorman <[email protected]>
> Cc: Peter Zijlstra <[email protected]>
> Cc: Andy Lutomirski <[email protected]>
> Cc: Steven Whitehouse <[email protected]>
> Cc: Linus Torvalds <[email protected]>
>
> ---
>
> b/include/linux/mmzone.h | 5 +++++
> b/kernel/sched/core.c | 16 ----------------
> b/mm/filemap.c | 22 +++++++++++++++++++++-
> b/mm/page_alloc.c | 5 +++++
> 4 files changed, 31 insertions(+), 17 deletions(-)
>
> diff -puN include/linux/mmzone.h~static-per-zone-waitqueue include/linux/mmzone.h
> --- a/include/linux/mmzone.h~static-per-zone-waitqueue 2016-12-19 11:35:12.210823059 -0800
> +++ b/include/linux/mmzone.h 2016-12-19 13:11:53.335170271 -0800
> @@ -27,6 +27,9 @@
> #endif
> #define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
>
> +#define WAIT_TABLE_BITS 8
> +#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS)
> +
> /*
> * PAGE_ALLOC_COSTLY_ORDER is the order at which allocations are deemed
> * costly to service. That is between allocation orders which should
> @@ -662,6 +665,8 @@ typedef struct pglist_data {
> unsigned long min_slab_pages;
> #endif /* CONFIG_NUMA */
>
> + wait_queue_head_t wait_table[WAIT_TABLE_SIZE];
> +
> /* Write-intensive fields used by page reclaim */
> ZONE_PADDING(_pad1_)
> spinlock_t lru_lock;
> diff -puN kernel/sched/core.c~static-per-zone-waitqueue kernel/sched/core.c
> --- a/kernel/sched/core.c~static-per-zone-waitqueue 2016-12-19 11:35:12.212823149 -0800
> +++ b/kernel/sched/core.c 2016-12-19 11:35:12.225823738 -0800
> @@ -7509,27 +7509,11 @@ static struct kmem_cache *task_group_cac
> DECLARE_PER_CPU(cpumask_var_t, load_balance_mask);
> DECLARE_PER_CPU(cpumask_var_t, select_idle_mask);
>
> -#define WAIT_TABLE_BITS 8
> -#define WAIT_TABLE_SIZE (1 << WAIT_TABLE_BITS)
> -static wait_queue_head_t bit_wait_table[WAIT_TABLE_SIZE] __cacheline_aligned;
> -
> -wait_queue_head_t *bit_waitqueue(void *word, int bit)
> -{
> - const int shift = BITS_PER_LONG == 32 ? 5 : 6;
> - unsigned long val = (unsigned long)word << shift | bit;
> -
> - return bit_wait_table + hash_long(val, WAIT_TABLE_BITS);
> -}
> -EXPORT_SYMBOL(bit_waitqueue);
> -
> void __init sched_init(void)
> {
> int i, j;
> unsigned long alloc_size = 0, ptr;
>
> - for (i = 0; i < WAIT_TABLE_SIZE; i++)
> - init_waitqueue_head(bit_wait_table + i);
> -
> #ifdef CONFIG_FAIR_GROUP_SCHED
> alloc_size += 2 * nr_cpu_ids * sizeof(void **);
> #endif
> diff -puN mm/filemap.c~static-per-zone-waitqueue mm/filemap.c
> --- a/mm/filemap.c~static-per-zone-waitqueue 2016-12-19 11:35:12.215823285 -0800
> +++ b/mm/filemap.c 2016-12-19 14:51:23.881814379 -0800
> @@ -779,6 +779,26 @@ EXPORT_SYMBOL(__page_cache_alloc);
> #endif
>
> /*
> + * We need 'nid' because page_waitqueue() needs to get the waitqueue
> + * for memory where virt_to_page() does not work, like highmem.
> + */
> +static wait_queue_head_t *__bit_waitqueue(void *word, int bit, int nid)
> +{
> + const int shift = BITS_PER_LONG == 32 ? 5 : 6;
> + unsigned long val = (unsigned long)word << shift | bit;
> +
> + return &NODE_DATA(nid)->wait_table[hash_long(val, WAIT_TABLE_BITS)];
> +}
> +
> +wait_queue_head_t *bit_waitqueue(void *word, int bit)
> +{
> + const int __maybe_unused nid = page_to_nid(virt_to_page(word));
> +
> + return __bit_waitqueue(word, bit, nid);
> +}
> +EXPORT_SYMBOL(bit_waitqueue);
> +
> +/*
> * In order to wait for pages to become available there must be
> * waitqueues associated with pages. By using a hash table of
> * waitqueues where the bucket discipline is to maintain all
> @@ -790,7 +810,7 @@ EXPORT_SYMBOL(__page_cache_alloc);
> */
> wait_queue_head_t *page_waitqueue(struct page *page)
> {
> - return bit_waitqueue(page, 0);
> + return __bit_waitqueue(page, 0, page_to_nid(page));
> }
> EXPORT_SYMBOL(page_waitqueue);
>
> diff -puN mm/page_alloc.c~static-per-zone-waitqueue mm/page_alloc.c
> --- a/mm/page_alloc.c~static-per-zone-waitqueue 2016-12-19 11:35:12.219823466 -0800
> +++ b/mm/page_alloc.c 2016-12-19 13:10:56.587613213 -0800
> @@ -5872,6 +5872,7 @@ void __paginginit free_area_init_node(in
> pg_data_t *pgdat = NODE_DATA(nid);
> unsigned long start_pfn = 0;
> unsigned long end_pfn = 0;
> + int i;
>
> /* pg_data_t should be reset to zero when it's allocated */
> WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
> @@ -5892,6 +5893,10 @@ void __paginginit free_area_init_node(in
> zones_size, zholes_size);
>
> alloc_node_mem_map(pgdat);
> +
> + /* per-node page waitqueue initialization: */
> + for (i = 0; i < WAIT_TABLE_SIZE; i++)
> + init_waitqueue_head(&pgdat->wait_table[i]);
> #ifdef CONFIG_FLAT_NODE_MEM_MAP
> printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
> nid, (unsigned long)pgdat,
> _
>
> --
> To unsubscribe, send a message with 'unsubscribe linux-mm' in
> the body to [email protected]. For more info on Linux MM,
> see: http://www.linux-mm.org/ .
> Don't email: <a href=mailto:"[email protected]"> [email protected] </a>
On Wed, Dec 21, 2016 at 12:32 AM, Peter Zijlstra <[email protected]> wrote:
>
> FWIW, here's mine.. compiles and boots on a NUMA x86_64 machine.
So I like how your patch is smaller, but your patch is also broken.
First off, the whole contention bit is *not* NUMA-specific. It should
help non-NUMA too, by avoiding the stupid extra cache miss.
Secondly, CONFIG_NUMA is a broken thing to test anyway, since adding a
bit for the NUMA case can overflow the page flags as far as I can tell
(MIPS seems to support NUMA on 32-bit, for example, but I didn't
really check the Kconfig details). Making it dependent on 64-bit might
be ok (and would fix the issue above - I don't think we really need to
care too much about 32-bit any more)
But making it conditional at all means that now you have those two
different cases for this, which is a maintenance nightmare. So don't
do it even if we could say "screw 32-bit".
Anyway, the conditional thing could be fixed by just taking Nick's
patch 1/2, and your patch (with the conditional bits stripped out).
I do think your approach of just re-using the existing bit waiting
with just a page-specific waiting function is nicer than Nick's "let's
just roll new waiting functions" approach. It also avoids the extra
initcall.
Nick, comments?
Hugh - mind testing PeterZ's patch too? My comments about the
conditional PG_waiters bit and page bit overflow are not relevant for
your particular scenario, so you can ignore that part, and just take
PaterZ's patch directly.
Linus
On Wed, Dec 21, 2016 at 4:30 AM, Nicholas Piggin <[email protected]> wrote:
>
> I've been doing a bit of testing, and I don't know why you're seeing
> this.
>
> I don't think I've been able to trigger any actual page lock contention
> so nothing gets put on the waitqueue to really bounce cache lines around
> that I can see.
The "test is the waitqueue is empty" is going to cause cache misses
even if there is no contention.
In fact, that's why I want the contention bit in the struct page - not
because of any NUMA issues, but simply due to cache misses.
And yes, with no contention the bit waiting should hopefully be able
to cache things shared - which should make the bouncing much less -
but there's going to be a shitload of false sharing with any actual
IO, so you will get bouncing due to that.
And then regular bouncing due simply to capacity misses (rather than
the CPU's wanting exclusive access).
With the contention bit in place, the only people actually looking at
the wait queues are the ones doing IO. At which point false sharing is
going to go down dramatically, but even if it were to happen it goes
from a "big issue" to "who cares, the cachemiss is not noticeable
compared to the IO, even with a fast SSD".
Linus
On Wed, 21 Dec 2016 10:02:27 -0800
Linus Torvalds <[email protected]> wrote:
> On Wed, Dec 21, 2016 at 12:32 AM, Peter Zijlstra <[email protected]> wrote:
> >
> > FWIW, here's mine.. compiles and boots on a NUMA x86_64 machine.
>
> So I like how your patch is smaller, but your patch is also broken.
>
> First off, the whole contention bit is *not* NUMA-specific. It should
> help non-NUMA too, by avoiding the stupid extra cache miss.
>
> Secondly, CONFIG_NUMA is a broken thing to test anyway, since adding a
> bit for the NUMA case can overflow the page flags as far as I can tell
> (MIPS seems to support NUMA on 32-bit, for example, but I didn't
> really check the Kconfig details). Making it dependent on 64-bit might
> be ok (and would fix the issue above - I don't think we really need to
> care too much about 32-bit any more)
>
> But making it conditional at all means that now you have those two
> different cases for this, which is a maintenance nightmare. So don't
> do it even if we could say "screw 32-bit".
>
> Anyway, the conditional thing could be fixed by just taking Nick's
> patch 1/2, and your patch (with the conditional bits stripped out).
>
> I do think your approach of just re-using the existing bit waiting
> with just a page-specific waiting function is nicer than Nick's "let's
> just roll new waiting functions" approach. It also avoids the extra
> initcall.
>
> Nick, comments?
Well yes we should take my patch 1 and use the new bit for this
purpose regardless of what way we go with patch 2. I'll reply to
that in the other mail.
Thanks,
Nick
On Wed, 21 Dec 2016 10:12:36 -0800
Linus Torvalds <[email protected]> wrote:
> On Wed, Dec 21, 2016 at 4:30 AM, Nicholas Piggin <[email protected]> wrote:
> >
> > I've been doing a bit of testing, and I don't know why you're seeing
> > this.
> >
> > I don't think I've been able to trigger any actual page lock contention
> > so nothing gets put on the waitqueue to really bounce cache lines around
> > that I can see.
>
> The "test is the waitqueue is empty" is going to cause cache misses
> even if there is no contention.
>
> In fact, that's why I want the contention bit in the struct page - not
> because of any NUMA issues, but simply due to cache misses.
>
> And yes, with no contention the bit waiting should hopefully be able
> to cache things shared - which should make the bouncing much less -
> but there's going to be a shitload of false sharing with any actual
> IO, so you will get bouncing due to that.
Well that's what I'm actually interested in, but I could not get it to
do much bouncing at all. There was a significant amount of writes going
through when having the backing store files on writeback filesystem,
but even that was not really triggering a lot of actual waiters.
Not that I don't believe it could happen, and Dave's system is a lot
bigger and faster and more NUMA than the one I was testing on. I'm
just curious.
Thanks,
Nick
On Thu, 22 Dec 2016 04:33:31 +1000
Nicholas Piggin <[email protected]> wrote:
> On Wed, 21 Dec 2016 10:02:27 -0800
> Linus Torvalds <[email protected]> wrote:
>
> > I do think your approach of just re-using the existing bit waiting
> > with just a page-specific waiting function is nicer than Nick's "let's
> > just roll new waiting functions" approach. It also avoids the extra
> > initcall.
> >
> > Nick, comments?
>
> Well yes we should take my patch 1 and use the new bit for this
> purpose regardless of what way we go with patch 2. I'll reply to
> that in the other mail.
Actually when I hit send, I thought your next mail was addressing a
different subject. So back here.
Peter's patch is less code and in that regard a bit nicer. I tried
going that way once, but I just thought it was a bit too sloppy to
do nicely with wait bit APIs.
- The page can be added to waitqueue without PageWaiters being set.
This is transient condition where the lock is retested, but it
remains that PageWaiters is not quite the same as waitqueue_active
to some degree.
- This set + retest means every time a page gets a waiter, the cost
is 2 test-and-set for the lock bit plus 2 spin_lock+spin_unlock for
the waitqueue.
- Setting PageWaiters is done outside the waitqueue lock, so you also
have a new interleavings to think about versus clearing the bit.
- It fails to clear up the bit and return to fastpath when there are
hash collisions. Yes I know this is a rare case and on average it
probably does not matter. But jitter is important, but also we
really *want* to keep the waitqueue table small and lean like you
have made it if possible. None of this 100KB per zone crap -- I do
want to keep it small and tolerating collisions better would help
that.
Anyway that's about my 2c. Keep in mind Mel just said he might have
seen a lockup with Peter's patch, and mine has not been hugely tested
either, so let's wait for a bit more testing before merging either.
Although we could start pipelining the process by merging patch 1 if
Hugh acks it (cc'ed), then I'll resend with SOB and Ack.
Thanks,
Nick
On Wed, Dec 21, 2016 at 11:01 AM, Nicholas Piggin <[email protected]> wrote:
> Peter's patch is less code and in that regard a bit nicer. I tried
> going that way once, but I just thought it was a bit too sloppy to
> do nicely with wait bit APIs.
So I have to admit that when I read through your and PeterZ's patches
back-to-back, yours was easier to understand.
PeterZ's is smaller but kind of subtle. The whole "return zero from
lock_page_wait() and go around again" and the locking around that
isn't exactly clear. In contrast, yours has the obvious waitqueue
spinlock.
I'll think about it. And yes, it would be good to have more testing,
but at the same time xmas is imminent, and waiting around too much
isn't going to help either..
Linus
On Wed, 21 Dec 2016 11:50:49 -0800
Linus Torvalds <[email protected]> wrote:
> On Wed, Dec 21, 2016 at 11:01 AM, Nicholas Piggin <[email protected]> wrote:
> > Peter's patch is less code and in that regard a bit nicer. I tried
> > going that way once, but I just thought it was a bit too sloppy to
> > do nicely with wait bit APIs.
>
> So I have to admit that when I read through your and PeterZ's patches
> back-to-back, yours was easier to understand.
>
> PeterZ's is smaller but kind of subtle. The whole "return zero from
> lock_page_wait() and go around again" and the locking around that
> isn't exactly clear. In contrast, yours has the obvious waitqueue
> spinlock.
>
> I'll think about it. And yes, it would be good to have more testing,
> but at the same time xmas is imminent, and waiting around too much
> isn't going to help either..
Sure. Let's see if Dave and Mel get a chance to do some testing.
It might be a squeeze before Christmas. I realize we're going to fix
it anyway so on one hand might as well get something in. On the other
I didn't want to add a subtle bug then have everyone go on vacation.
How about I send up the page flag patch by Friday and that can bake
while the main patch gets more testing / review?
Thanks,
Nick
On Wed, 21 Dec 2016, Linus Torvalds wrote:
> On Wed, Dec 21, 2016 at 12:32 AM, Peter Zijlstra <[email protected]> wrote:
> >
> > FWIW, here's mine.. compiles and boots on a NUMA x86_64 machine.
>
> So I like how your patch is smaller, but your patch is also broken.
>
> First off, the whole contention bit is *not* NUMA-specific. It should
> help non-NUMA too, by avoiding the stupid extra cache miss.
>
> Secondly, CONFIG_NUMA is a broken thing to test anyway, since adding a
> bit for the NUMA case can overflow the page flags as far as I can tell
> (MIPS seems to support NUMA on 32-bit, for example, but I didn't
> really check the Kconfig details). Making it dependent on 64-bit might
> be ok (and would fix the issue above - I don't think we really need to
> care too much about 32-bit any more)
>
> But making it conditional at all means that now you have those two
> different cases for this, which is a maintenance nightmare. So don't
> do it even if we could say "screw 32-bit".
>
> Anyway, the conditional thing could be fixed by just taking Nick's
> patch 1/2, and your patch (with the conditional bits stripped out).
Yup.
>
> I do think your approach of just re-using the existing bit waiting
> with just a page-specific waiting function is nicer than Nick's "let's
> just roll new waiting functions" approach. It also avoids the extra
> initcall.
>
> Nick, comments?
>
> Hugh - mind testing PeterZ's patch too? My comments about the
> conditional PG_waiters bit and page bit overflow are not relevant for
> your particular scenario, so you can ignore that part, and just take
> PaterZ's patch directly.
Right, I put them both through some loads yesterday and overnight:
Peter's patch and Nick's patch each work fine here, no issues seen
with either (but I didn't attempt to compare them, aesthetically
nor in performance).
Hugh
{kind=link}