Hi Paul,
I'm seeing a regression when comparing 3.15 to Linus's current tree.
I'm using Anton Blanchard's will-it-scale "open1" test which creates a
bunch of processes and does open()/close() in a tight loop:
> https://github.com/antonblanchard/will-it-scale/blob/master/tests/open1.c
At about 50 cores worth of processes, 3.15 and the pre-3.16 code start
to diverge, with 3.15 scaling better:
http://sr71.net/~dave/intel/3.16-open1regression-0.png
Some profiles point to a big increase in contention inside slub.c's
get_partial_node() (the allocation side of the slub code) causing the
regression. That particular open() test is known to do a lot of slab
operations. But, the odd part is that the slub code hasn't been touched
much.
So, I bisected it down to this:
> commit ac1bea85781e9004da9b3e8a4b097c18492d857c
> Author: Paul E. McKenney <[email protected]>
> Date: Sun Mar 16 21:36:25 2014 -0700
>
> sched,rcu: Make cond_resched() report RCU quiescent states
Specifically, if I raise RCU_COND_RESCHED_LIM, things get back to their
3.15 levels.
Could the additional RCU quiescent states be causing us to be doing more
RCU frees that we were before, and getting less benefit from the lock
batching that RCU normally provides?
The top RCU functions in the profiles are as follows:
> 3.15.0-xxx: 2.58% open1_processes [kernel.kallsyms] [k] file_free_rcu
> 3.15.0-xxx: 2.45% open1_processes [kernel.kallsyms] [k] __d_lookup_rcu
> 3.15.0-xxx: 2.41% open1_processes [kernel.kallsyms] [k] rcu_process_callbacks
> 3.15.0-xxx: 1.87% open1_processes [kernel.kallsyms] [k] __call_rcu.constprop.10
> 3.16.0-rc0: 2.68% open1_processes [kernel.kallsyms] [k] rcu_process_callbacks
> 3.16.0-rc0: 2.68% open1_processes [kernel.kallsyms] [k] file_free_rcu
> 3.16.0-rc0: 1.55% open1_processes [kernel.kallsyms] [k] __call_rcu.constprop.10
> 3.16.0-rc0: 1.28% open1_processes [kernel.kallsyms] [k] __d_lookup_rcu
With everything else equal, we'd expect to see all of these _higher_ in
the profiles on a the faster kernel (3.15) since it has more RCU work to do.
But, they're all _roughly_ the same. __d_lookup_rcu went up in the
profile on the fast one (3.15) probably because there _were_ more
lookups happening there.
rcu_process_callbacks makes me syspicious. It went up slightly
(probably in the noise), but it _should_ have dropped due to there being
less RCU work to do.
This supports the theory that there are more callbacks happening than
before, causing more slab lock contention, which is the actual trigger
for the performance drop.
I also hacked in an interface to make RCU_COND_RESCHED_LIM a tunable.
Making it huge instantly makes my test go fast, and dropping it to 256
instantly makes it slow. Some brief toying with it shows that
RCU_COND_RESCHED_LIM has to be about 100,000 before performance gets
back to where it was before.
On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dave Hansen wrote:
> Hi Paul,
>
> I'm seeing a regression when comparing 3.15 to Linus's current tree.
> I'm using Anton Blanchard's will-it-scale "open1" test which creates a
> bunch of processes and does open()/close() in a tight loop:
>
> > https://github.com/antonblanchard/will-it-scale/blob/master/tests/open1.c
>
> At about 50 cores worth of processes, 3.15 and the pre-3.16 code start
> to diverge, with 3.15 scaling better:
>
> http://sr71.net/~dave/intel/3.16-open1regression-0.png
>
> Some profiles point to a big increase in contention inside slub.c's
> get_partial_node() (the allocation side of the slub code) causing the
> regression. That particular open() test is known to do a lot of slab
> operations. But, the odd part is that the slub code hasn't been touched
> much.
>
> So, I bisected it down to this:
>
> > commit ac1bea85781e9004da9b3e8a4b097c18492d857c
> > Author: Paul E. McKenney <[email protected]>
> > Date: Sun Mar 16 21:36:25 2014 -0700
> >
> > sched,rcu: Make cond_resched() report RCU quiescent states
>
> Specifically, if I raise RCU_COND_RESCHED_LIM, things get back to their
> 3.15 levels.
>
> Could the additional RCU quiescent states be causing us to be doing more
> RCU frees that we were before, and getting less benefit from the lock
> batching that RCU normally provides?
Quite possibly. One way to check would be to use the debugfs files
rcu/*/rcugp, which give a count of grace periods since boot for each
RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
for !CONFIG_PREEMPT.
Another possibility is that someone is invoking cond_reched() in an
incredibly tight loop.
> The top RCU functions in the profiles are as follows:
>
> > 3.15.0-xxx: 2.58% open1_processes [kernel.kallsyms] [k] file_free_rcu
> > 3.15.0-xxx: 2.45% open1_processes [kernel.kallsyms] [k] __d_lookup_rcu
> > 3.15.0-xxx: 2.41% open1_processes [kernel.kallsyms] [k] rcu_process_callbacks
> > 3.15.0-xxx: 1.87% open1_processes [kernel.kallsyms] [k] __call_rcu.constprop.10
>
> > 3.16.0-rc0: 2.68% open1_processes [kernel.kallsyms] [k] rcu_process_callbacks
> > 3.16.0-rc0: 2.68% open1_processes [kernel.kallsyms] [k] file_free_rcu
> > 3.16.0-rc0: 1.55% open1_processes [kernel.kallsyms] [k] __call_rcu.constprop.10
> > 3.16.0-rc0: 1.28% open1_processes [kernel.kallsyms] [k] __d_lookup_rcu
>
> With everything else equal, we'd expect to see all of these _higher_ in
> the profiles on a the faster kernel (3.15) since it has more RCU work to do.
>
> But, they're all _roughly_ the same. __d_lookup_rcu went up in the
> profile on the fast one (3.15) probably because there _were_ more
> lookups happening there.
>
> rcu_process_callbacks makes me syspicious. It went up slightly
> (probably in the noise), but it _should_ have dropped due to there being
> less RCU work to do.
>
> This supports the theory that there are more callbacks happening than
> before, causing more slab lock contention, which is the actual trigger
> for the performance drop.
>
> I also hacked in an interface to make RCU_COND_RESCHED_LIM a tunable.
> Making it huge instantly makes my test go fast, and dropping it to 256
> instantly makes it slow. Some brief toying with it shows that
> RCU_COND_RESCHED_LIM has to be about 100,000 before performance gets
> back to where it was before.
That is way bigger than I would expect. My bet is that someone is
invoking cond_resched() in a 10s-of-nanoseconds tight loop.
But please feel free to send along your patch, CCing LKML. Longer
term, I probably need to take a more algorithmic approach, but what
you have will be useful to benchmarkers until then.
Thanx, Paul
On 06/13/2014 03:45 PM, Paul E. McKenney wrote:
> On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dav
>> So, I bisected it down to this:
>>
>>> commit ac1bea85781e9004da9b3e8a4b097c18492d857c
>>> Author: Paul E. McKenney <[email protected]>
>>> Date: Sun Mar 16 21:36:25 2014 -0700
>>>
>>> sched,rcu: Make cond_resched() report RCU quiescent states
>>
>> Specifically, if I raise RCU_COND_RESCHED_LIM, things get back to their
>> 3.15 levels.
>>
>> Could the additional RCU quiescent states be causing us to be doing more
>> RCU frees that we were before, and getting less benefit from the lock
>> batching that RCU normally provides?
>
> Quite possibly. One way to check would be to use the debugfs files
> rcu/*/rcugp, which give a count of grace periods since boot for each
> RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
> for !CONFIG_PREEMPT.
>
> Another possibility is that someone is invoking cond_reched() in an
> incredibly tight loop.
open() does at least a couple of allocations in getname(),
get_empty_filp() and apparmor_file_alloc_security() in my kernel, and
each of those does a cond_resched() via the might_sleep() in the slub
code. This test is doing ~400k open/closes per second per CPU, so
that's ~1.2M cond_resched()/sec/CPU, but that's still hundreds of ns
between calls on average.
I'll do some more ftraces and dig in to those debugfs files early next week.
> But please feel free to send along your patch, CCing LKML. Longer
> term, I probably need to take a more algorithmic approach, but what
> you have will be useful to benchmarkers until then.
With the caveat that I exerted approximately 15 seconds of brainpower to
code it up...patch attached.
On Fri, Jun 13, 2014 at 04:35:01PM -0700, Dave Hansen wrote:
> On 06/13/2014 03:45 PM, Paul E. McKenney wrote:
> > On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dav
> >> So, I bisected it down to this:
> >>
> >>> commit ac1bea85781e9004da9b3e8a4b097c18492d857c
> >>> Author: Paul E. McKenney <[email protected]>
> >>> Date: Sun Mar 16 21:36:25 2014 -0700
> >>>
> >>> sched,rcu: Make cond_resched() report RCU quiescent states
> >>
> >> Specifically, if I raise RCU_COND_RESCHED_LIM, things get back to their
> >> 3.15 levels.
> >>
> >> Could the additional RCU quiescent states be causing us to be doing more
> >> RCU frees that we were before, and getting less benefit from the lock
> >> batching that RCU normally provides?
> >
> > Quite possibly. One way to check would be to use the debugfs files
> > rcu/*/rcugp, which give a count of grace periods since boot for each
> > RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
> > for !CONFIG_PREEMPT.
> >
> > Another possibility is that someone is invoking cond_reched() in an
> > incredibly tight loop.
>
> open() does at least a couple of allocations in getname(),
> get_empty_filp() and apparmor_file_alloc_security() in my kernel, and
> each of those does a cond_resched() via the might_sleep() in the slub
> code. This test is doing ~400k open/closes per second per CPU, so
> that's ~1.2M cond_resched()/sec/CPU, but that's still hundreds of ns
> between calls on average.
>
> I'll do some more ftraces and dig in to those debugfs files early next week.
>
> > But please feel free to send along your patch, CCing LKML. Longer
> > term, I probably need to take a more algorithmic approach, but what
> > you have will be useful to benchmarkers until then.
>
> With the caveat that I exerted approximately 15 seconds of brainpower to
> code it up...patch attached.
Thank you Dave! And if someone doesn't like it, they can always improve
upon it, right? ;-)
Thanx, Paul
> ---
>
> b/arch/x86/kernel/nmi.c | 3 +++
> b/include/linux/rcupdate.h | 2 +-
> 2 files changed, 4 insertions(+), 1 deletion(-)
>
> diff -puN arch/x86/kernel/nmi.c~dirty-rcu-hack arch/x86/kernel/nmi.c
> --- a/arch/x86/kernel/nmi.c~dirty-rcu-hack 2014-06-13 16:00:30.257183228 -0700
> +++ b/arch/x86/kernel/nmi.c 2014-06-13 16:00:30.261183407 -0700
> @@ -88,10 +88,13 @@ __setup("unknown_nmi_panic", setup_unkno
>
> static u64 nmi_longest_ns = 1 * NSEC_PER_MSEC;
>
> +u64 RCU_COND_RESCHED_LIM = 256;
> static int __init nmi_warning_debugfs(void)
> {
> debugfs_create_u64("nmi_longest_ns", 0644,
> arch_debugfs_dir, &nmi_longest_ns);
> + debugfs_create_u64("RCU_COND_RESCHED_LIM", 0644,
> + arch_debugfs_dir, &RCU_COND_RESCHED_LIM);
> return 0;
> }
> fs_initcall(nmi_warning_debugfs);
> diff -puN include/linux/rcupdate.h~dirty-rcu-hack include/linux/rcupdate.h
> --- a/include/linux/rcupdate.h~dirty-rcu-hack 2014-06-13 16:00:35.578421426 -0700
> +++ b/include/linux/rcupdate.h 2014-06-13 16:00:49.863060683 -0700
> @@ -303,7 +303,7 @@ bool __rcu_is_watching(void);
> * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
> */
>
> -#define RCU_COND_RESCHED_LIM 256 /* ms vs. 100s of ms. */
> +extern u64 RCU_COND_RESCHED_LIM /* ms vs. 100s of ms. */
> DECLARE_PER_CPU(int, rcu_cond_resched_count);
> void rcu_resched(void);
>
> _
On 06/13/2014 03:45 PM, Paul E. McKenney wrote:
>> > Could the additional RCU quiescent states be causing us to be doing more
>> > RCU frees that we were before, and getting less benefit from the lock
>> > batching that RCU normally provides?
> Quite possibly. One way to check would be to use the debugfs files
> rcu/*/rcugp, which give a count of grace periods since boot for each
> RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
> for !CONFIG_PREEMPT.
With the previously-mentioned workload, rcugp's "age" averages 9 with
the old kernel (or RCU_COND_RESCHED_LIM at a high value) and 2 with the
current kernel which contains this regression.
I also checked the rate and sources for how I'm calling cond_resched.
I'm calling it 5x for every open/close() pair in my test case, which
take about 7us. So, _cond_resched() is, on average, only being called
every microsecond. That doesn't seem _too_ horribly extreme.
> 3895.165846 | 8) | SyS_open() {
> 3895.165846 | 8) 0.065 us | _cond_resched();
> 3895.165847 | 8) 0.064 us | _cond_resched();
> 3895.165849 | 8) 2.406 us | }
> 3895.165849 | 8) 0.199 us | SyS_close();
> 3895.165850 | 8) | do_notify_resume() {
> 3895.165850 | 8) 0.063 us | _cond_resched();
> 3895.165851 | 8) 0.069 us | _cond_resched();
> 3895.165852 | 8) 0.060 us | _cond_resched();
> 3895.165852 | 8) 2.194 us | }
> 3895.165853 | 8) | SyS_open() {
The more I think about it, the more I think we can improve on a purely
call-based counter.
First, it couples the number of cond_resched() directly calls with the
benefits we see out of RCU. We really don't *need* to see more grace
periods if we have more cond_resched() calls.
It also ends up eating a new cacheline in a bunch of pretty hot paths.
It would be nice to be able to keep the fast path part of this as at
least read-only.
Could we do something (functionally) like the attached patch? Instead
of counting cond_resched() calls, we could just specify some future time
by which we want have a quiescent state. We could even push the time to
be something _just_ before we would have declared a stall.
On Tue, Jun 17, 2014 at 04:10:29PM -0700, Dave Hansen wrote:
> On 06/13/2014 03:45 PM, Paul E. McKenney wrote:
> >> > Could the additional RCU quiescent states be causing us to be doing more
> >> > RCU frees that we were before, and getting less benefit from the lock
> >> > batching that RCU normally provides?
> > Quite possibly. One way to check would be to use the debugfs files
> > rcu/*/rcugp, which give a count of grace periods since boot for each
> > RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
> > for !CONFIG_PREEMPT.
>
> With the previously-mentioned workload, rcugp's "age" averages 9 with
> the old kernel (or RCU_COND_RESCHED_LIM at a high value) and 2 with the
> current kernel which contains this regression.
>
> I also checked the rate and sources for how I'm calling cond_resched.
> I'm calling it 5x for every open/close() pair in my test case, which
> take about 7us. So, _cond_resched() is, on average, only being called
> every microsecond. That doesn't seem _too_ horribly extreme.
>
> > 3895.165846 | 8) | SyS_open() {
> > 3895.165846 | 8) 0.065 us | _cond_resched();
> > 3895.165847 | 8) 0.064 us | _cond_resched();
> > 3895.165849 | 8) 2.406 us | }
> > 3895.165849 | 8) 0.199 us | SyS_close();
> > 3895.165850 | 8) | do_notify_resume() {
> > 3895.165850 | 8) 0.063 us | _cond_resched();
> > 3895.165851 | 8) 0.069 us | _cond_resched();
> > 3895.165852 | 8) 0.060 us | _cond_resched();
> > 3895.165852 | 8) 2.194 us | }
> > 3895.165853 | 8) | SyS_open() {
>
> The more I think about it, the more I think we can improve on a purely
> call-based counter.
>
> First, it couples the number of cond_resched() directly calls with the
> benefits we see out of RCU. We really don't *need* to see more grace
> periods if we have more cond_resched() calls.
>
> It also ends up eating a new cacheline in a bunch of pretty hot paths.
> It would be nice to be able to keep the fast path part of this as at
> least read-only.
>
> Could we do something (functionally) like the attached patch? Instead
> of counting cond_resched() calls, we could just specify some future time
> by which we want have a quiescent state. We could even push the time to
> be something _just_ before we would have declared a stall.
Looks quite promising to me, as long as the CPU in question is actively
updating jiffies. I'd love to see some numbers from that approach.
- Josh Triplett
> It also ends up eating a new cacheline in a bunch of pretty hot paths.
> It would be nice to be able to keep the fast path part of this as at
> least read-only.
>
> Could we do something (functionally) like the attached patch? Instead
> of counting cond_resched() calls, we could just specify some future time
> by which we want have a quiescent state. We could even push the time to
> be something _just_ before we would have declared a stall.
I still think it's totally the wrong place. cond_resched() is in so
many fast paths (every lock, every allocation). It just doesn't
make sense to add non essential things like this to it.
I would be rather to just revert the original patch.
-Andi
On Tue, Jun 17, 2014 at 04:10:29PM -0700, Dave Hansen wrote:
> On 06/13/2014 03:45 PM, Paul E. McKenney wrote:
> >> > Could the additional RCU quiescent states be causing us to be doing more
> >> > RCU frees that we were before, and getting less benefit from the lock
> >> > batching that RCU normally provides?
> > Quite possibly. One way to check would be to use the debugfs files
> > rcu/*/rcugp, which give a count of grace periods since boot for each
> > RCU flavor. Here "*" is rcu_preempt for CONFIG_PREEMPT and rcu_sched
> > for !CONFIG_PREEMPT.
>
> With the previously-mentioned workload, rcugp's "age" averages 9 with
> the old kernel (or RCU_COND_RESCHED_LIM at a high value) and 2 with the
> current kernel which contains this regression.
>
> I also checked the rate and sources for how I'm calling cond_resched.
> I'm calling it 5x for every open/close() pair in my test case, which
> take about 7us. So, _cond_resched() is, on average, only being called
> every microsecond. That doesn't seem _too_ horribly extreme.
>
> > 3895.165846 | 8) | SyS_open() {
> > 3895.165846 | 8) 0.065 us | _cond_resched();
> > 3895.165847 | 8) 0.064 us | _cond_resched();
> > 3895.165849 | 8) 2.406 us | }
> > 3895.165849 | 8) 0.199 us | SyS_close();
> > 3895.165850 | 8) | do_notify_resume() {
> > 3895.165850 | 8) 0.063 us | _cond_resched();
> > 3895.165851 | 8) 0.069 us | _cond_resched();
> > 3895.165852 | 8) 0.060 us | _cond_resched();
> > 3895.165852 | 8) 2.194 us | }
> > 3895.165853 | 8) | SyS_open() {
>
> The more I think about it, the more I think we can improve on a purely
> call-based counter.
>
> First, it couples the number of cond_resched() directly calls with the
> benefits we see out of RCU. We really don't *need* to see more grace
> periods if we have more cond_resched() calls.
>
> It also ends up eating a new cacheline in a bunch of pretty hot paths.
> It would be nice to be able to keep the fast path part of this as at
> least read-only.
>
> Could we do something (functionally) like the attached patch? Instead
> of counting cond_resched() calls, we could just specify some future time
> by which we want have a quiescent state. We could even push the time to
> be something _just_ before we would have declared a stall.
Nice analysis!
So if I understand correctly, a goodly part of the regression is due not
to the overhead added to cond_resched(), but rather because grace periods
are now happening faster, thus incurring more overhead. Is that correct?
If this is the case, could you please let me know roughly how sensitive is
the performance to the time delay in RCU_COND_RESCHED_EVERY_THIS_JIFFIES?
The patch looks promising. I will probably drive the time-setup deeper
into the guts of RCU, which should allow moving the access to jiffies
and the comparison off of the fast path as well, but this appears to
me to be good and sufficient for others encountering this same problem
in the meantime.
And of course, if my attempt to drive things deeper into the guts of
RCU doesn't work out, something close to the below might also be the
eventual solution.
Thanx, Paul
> ---
>
> b/arch/x86/kernel/nmi.c | 6 +++---
> b/include/linux/rcupdate.h | 7 +++----
> b/kernel/rcu/update.c | 4 ++--
> 3 files changed, 8 insertions(+), 9 deletions(-)
>
> diff -puN include/linux/rcupdate.h~rcu-halfstall include/linux/rcupdate.h
> --- a/include/linux/rcupdate.h~rcu-halfstall 2014-06-17 14:08:19.596464173 -0700
> +++ b/include/linux/rcupdate.h 2014-06-17 14:15:40.335598696 -0700
> @@ -303,8 +303,8 @@ bool __rcu_is_watching(void);
> * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
> */
>
> -extern u64 RCU_COND_RESCHED_LIM; /* ms vs. 100s of ms. */
> -DECLARE_PER_CPU(int, rcu_cond_resched_count);
> +extern u64 RCU_COND_RESCHED_EVERY_THIS_JIFFIES;
> +DECLARE_PER_CPU(unsigned long, rcu_cond_resched_at_jiffies);
> void rcu_resched(void);
>
> /*
> @@ -321,8 +321,7 @@ void rcu_resched(void);
> */
> static inline bool rcu_should_resched(void)
> {
> - return raw_cpu_inc_return(rcu_cond_resched_count) >=
> - RCU_COND_RESCHED_LIM;
> + return raw_cpu_read(rcu_cond_resched_at_jiffies) >= jiffies;
> }
>
> /*
> diff -puN arch/x86/kernel/nmi.c~rcu-halfstall arch/x86/kernel/nmi.c
> --- a/arch/x86/kernel/nmi.c~rcu-halfstall 2014-06-17 14:11:28.442072042 -0700
> +++ b/arch/x86/kernel/nmi.c 2014-06-17 14:12:04.664723690 -0700
> @@ -88,13 +88,13 @@ __setup("unknown_nmi_panic", setup_unkno
>
> static u64 nmi_longest_ns = 1 * NSEC_PER_MSEC;
>
> -u64 RCU_COND_RESCHED_LIM = 256;
> +u64 RCU_COND_RESCHED_EVERY_THIS_JIFFIES = 100;
> static int __init nmi_warning_debugfs(void)
> {
> debugfs_create_u64("nmi_longest_ns", 0644,
> arch_debugfs_dir, &nmi_longest_ns);
> - debugfs_create_u64("RCU_COND_RESCHED_LIM", 0644,
> - arch_debugfs_dir, &RCU_COND_RESCHED_LIM);
> + debugfs_create_u64("RCU_COND_RESCHED_EVERY_THIS_JIFFIES", 0644,
> + arch_debugfs_dir, &RCU_COND_RESCHED_EVERY_THIS_JIFFIES);
> return 0;
> }
> fs_initcall(nmi_warning_debugfs);
> diff -puN kernel/rcu/update.c~rcu-halfstall kernel/rcu/update.c
> --- a/kernel/rcu/update.c~rcu-halfstall 2014-06-17 14:12:50.768834979 -0700
> +++ b/kernel/rcu/update.c 2014-06-17 14:17:14.166894075 -0700
> @@ -355,7 +355,7 @@ early_initcall(check_cpu_stall_init);
> * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
> */
>
> -DEFINE_PER_CPU(int, rcu_cond_resched_count);
> +DEFINE_PER_CPU(unsigned long, rcu_cond_resched_at_jiffies);
>
> /*
> * Report a set of RCU quiescent states, for use by cond_resched()
> @@ -364,7 +364,7 @@ DEFINE_PER_CPU(int, rcu_cond_resched_cou
> void rcu_resched(void)
> {
> preempt_disable();
> - __this_cpu_write(rcu_cond_resched_count, 0);
> + __this_cpu_write(rcu_cond_resched_at_jiffies, jiffies + RCU_COND_RESCHED_EVERY_THIS_JIFFIES);
> rcu_note_context_switch(smp_processor_id());
> preempt_enable();
> }
> _
On Tue, Jun 17, 2014 at 05:15:17PM -0700, Andi Kleen wrote:
> > It also ends up eating a new cacheline in a bunch of pretty hot paths.
> > It would be nice to be able to keep the fast path part of this as at
> > least read-only.
> >
> > Could we do something (functionally) like the attached patch? Instead
> > of counting cond_resched() calls, we could just specify some future time
> > by which we want have a quiescent state. We could even push the time to
> > be something _just_ before we would have declared a stall.
>
> I still think it's totally the wrong place. cond_resched() is in so
> many fast paths (every lock, every allocation). It just doesn't
> make sense to add non essential things like this to it.
>
> I would be rather to just revert the original patch.
OK. What would you suggest instead? If all we do is to revert the
original patch, we once again end up with long-running in-kernel code
paths stalling the RCU grace period. The cond_resched() calls sprinkled
through them once again won't help with this.
Or are you suggesting leveraging the now-deprecated set_need_resched()
so that the checks happen deeper in the scheduler? Looks like grabbing
the offending CPU's task and doing set_tsk_need_resched() on that task
is the replacement.
CCing Peter Zijlstra for his thoughts on this.
Thanx, Paul
> OK. What would you suggest instead? If all we do is to revert the
Hang checker should have two timer phases:
Timer fires first time:
- Save context switch counter on that. Force a reschedule to some
work queue. Rearm timer
Timer fires again:
- Check reschedule count. If the reschedule count changed
it was a real hang, otherwise ignore.
-Andi
On Tue, Jun 17, 2014 at 07:27:31PM -0700, Andi Kleen wrote:
> > OK. What would you suggest instead? If all we do is to revert the
>
> Hang checker should have two timer phases:
>
> Timer fires first time:
> - Save context switch counter on that. Force a reschedule to some
> work queue. Rearm timer
>
> Timer fires again:
> - Check reschedule count. If the reschedule count changed
> it was a real hang, otherwise ignore.
I could take that approach, but the RT guys aren't going to thank me for
the wakeup associated with the work queue. I suppose that I could use
one approach for real-time workloads and your workqueue-base approach
for other workloads.
Still, I bet I can drop the common-case cond_resched() overhead to a
single read of a per-CPU variable and a branch. But yes, that would be
in response to the second phase, FWIW. If that measurably too much
overhead, then one thing for realtime and another otherwise.
Thanx, Paul
On 06/17/2014 05:18 PM, Paul E. McKenney wrote:
> So if I understand correctly, a goodly part of the regression is due not
> to the overhead added to cond_resched(), but rather because grace periods
> are now happening faster, thus incurring more overhead. Is that correct?
Yes, that's the theory at least.
> If this is the case, could you please let me know roughly how sensitive is
> the performance to the time delay in RCU_COND_RESCHED_EVERY_THIS_JIFFIES?
This is the previous kernel, plus RCU tracing, so it's not 100%
apples-to-apples (and it peaks a bit lower than the other kernel). But
here's the will-it-scale open1 throughput on the y axis vs
RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
http://sr71.net/~dave/intel/jiffies-vs-openops.png
This was a quick and dirty single run with very little averaging, so I
expect there to be a good amount of noise. I ran it from 1->100, but it
seemed to peak at about 30.
> The patch looks promising. I will probably drive the time-setup deeper
> into the guts of RCU, which should allow moving the access to jiffies
> and the comparison off of the fast path as well, but this appears to
> me to be good and sufficient for others encountering this same problem
> in the meantime.
Yeah, the more overhead we can push out of cond_resched(), the better.
I had no idea how much we call it!
On Tue, Jun 17, 2014 at 09:47:45PM -0700, Paul E. McKenney wrote:
> On Tue, Jun 17, 2014 at 07:27:31PM -0700, Andi Kleen wrote:
> > > OK. What would you suggest instead? If all we do is to revert the
> >
> > Hang checker should have two timer phases:
> >
> > Timer fires first time:
> > - Save context switch counter on that. Force a reschedule to some
> > work queue. Rearm timer
> >
> > Timer fires again:
> > - Check reschedule count. If the reschedule count changed
> > it was a real hang, otherwise ignore.
>
> I could take that approach, but the RT guys aren't going to thank me for
> the wakeup associated with the work queue. I suppose that I could use
They can disable the hang timer if it's really problem.
If they cannot tolerate a single context switch they likely
cannot tolerate a timer firing either.
-Andi
On Wed, Jun 18, 2014 at 05:40:28AM -0700, Andi Kleen wrote:
> On Tue, Jun 17, 2014 at 09:47:45PM -0700, Paul E. McKenney wrote:
> > On Tue, Jun 17, 2014 at 07:27:31PM -0700, Andi Kleen wrote:
> > > > OK. What would you suggest instead? If all we do is to revert the
> > >
> > > Hang checker should have two timer phases:
> > >
> > > Timer fires first time:
> > > - Save context switch counter on that. Force a reschedule to some
> > > work queue. Rearm timer
> > >
> > > Timer fires again:
> > > - Check reschedule count. If the reschedule count changed
> > > it was a real hang, otherwise ignore.
> >
> > I could take that approach, but the RT guys aren't going to thank me for
> > the wakeup associated with the work queue. I suppose that I could use
>
> They can disable the hang timer if it's really problem.
>
> If they cannot tolerate a single context switch they likely
> cannot tolerate a timer firing either.
Ah, but I make the timer fire on some other CPU.
Thanx, Paul
On Tue, Jun 17, 2014 at 11:33:56PM -0700, Dave Hansen wrote:
> On 06/17/2014 05:18 PM, Paul E. McKenney wrote:
> > So if I understand correctly, a goodly part of the regression is due not
> > to the overhead added to cond_resched(), but rather because grace periods
> > are now happening faster, thus incurring more overhead. Is that correct?
>
> Yes, that's the theory at least.
>
> > If this is the case, could you please let me know roughly how sensitive is
> > the performance to the time delay in RCU_COND_RESCHED_EVERY_THIS_JIFFIES?
>
> This is the previous kernel, plus RCU tracing, so it's not 100%
> apples-to-apples (and it peaks a bit lower than the other kernel). But
> here's the will-it-scale open1 throughput on the y axis vs
> RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
>
> http://sr71.net/~dave/intel/jiffies-vs-openops.png
>
> This was a quick and dirty single run with very little averaging, so I
> expect there to be a good amount of noise. I ran it from 1->100, but it
> seemed to peak at about 30.
OK, so a default setting on the order of 20-30 jiffies looks promising.
> > The patch looks promising. I will probably drive the time-setup deeper
> > into the guts of RCU, which should allow moving the access to jiffies
> > and the comparison off of the fast path as well, but this appears to
> > me to be good and sufficient for others encountering this same problem
> > in the meantime.
>
> Yeah, the more overhead we can push out of cond_resched(), the better.
> I had no idea how much we call it!
Me neither!
Thanx, Paul
On Tue, 17 Jun 2014, Andi Kleen wrote:
> I still think it's totally the wrong place. cond_resched() is in so
> many fast paths (every lock, every allocation). It just doesn't
> make sense to add non essential things like this to it.
>
> I would be rather to just revert the original patch.
I fully agree.
On 06/18/2014 05:58 AM, Paul E. McKenney wrote:
>> > This is the previous kernel, plus RCU tracing, so it's not 100%
>> > apples-to-apples (and it peaks a bit lower than the other kernel). But
>> > here's the will-it-scale open1 throughput on the y axis vs
>> > RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
>> >
>> > http://sr71.net/~dave/intel/jiffies-vs-openops.png
>> >
>> > This was a quick and dirty single run with very little averaging, so I
>> > expect there to be a good amount of noise. I ran it from 1->100, but it
>> > seemed to peak at about 30.
> OK, so a default setting on the order of 20-30 jiffies looks promising.
For the biggest machine I have today, yeah. But, we need to be a bit
careful here. The CPUs I'm running it on were released 3 years ago and
I think we need to be planning at _least_ for today's large systems. I
would guess that by raising ...EVERY_THIS_JIFFIES, we're shifting this
curve out to the right:
http://sr71.net/~dave/intel/3.16-open1regression-0.png
so that we're _just_ before the regression hits us. But that just
guarantees I'll hit this again when I get new CPUs. :)
If we go this route, I think we should probably take it up in to the
100-200 range, or even scale it to something on the order of what the
rcu stall timeout is. Other than the stall detector, is there some
other reason to be forcing frequent quiescent states?
On Wed, Jun 18, 2014 at 10:36:25AM -0700, Dave Hansen wrote:
> On 06/18/2014 05:58 AM, Paul E. McKenney wrote:
> >> > This is the previous kernel, plus RCU tracing, so it's not 100%
> >> > apples-to-apples (and it peaks a bit lower than the other kernel). But
> >> > here's the will-it-scale open1 throughput on the y axis vs
> >> > RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
> >> >
> >> > http://sr71.net/~dave/intel/jiffies-vs-openops.png
> >> >
> >> > This was a quick and dirty single run with very little averaging, so I
> >> > expect there to be a good amount of noise. I ran it from 1->100, but it
> >> > seemed to peak at about 30.
> > OK, so a default setting on the order of 20-30 jiffies looks promising.
>
> For the biggest machine I have today, yeah. But, we need to be a bit
> careful here. The CPUs I'm running it on were released 3 years ago and
> I think we need to be planning at _least_ for today's large systems. I
> would guess that by raising ...EVERY_THIS_JIFFIES, we're shifting this
> curve out to the right:
>
> http://sr71.net/~dave/intel/3.16-open1regression-0.png
>
> so that we're _just_ before the regression hits us. But that just
> guarantees I'll hit this again when I get new CPUs. :)
Understood. One approach would be to scale this in a manner similar
to the scaling of the delay from the beginning of the grace period
to the start of quiescent-state forcing, which is about three jiffies
on small systems scaling up to about 20 jiffies on large systems.
> If we go this route, I think we should probably take it up in to the
> 100-200 range, or even scale it to something on the order of what the
> rcu stall timeout is. Other than the stall detector, is there some
> other reason to be forcing frequent quiescent states?
Yep. CONFIG_NO_HZ_FULL+nohz_full kernels running in kernel mode don't
progress RCU grace periods. But they should not need to be all that
frequent.
Thanx, Paul
On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dave Hansen wrote:
> Hi Paul,
>
> I'm seeing a regression when comparing 3.15 to Linus's current tree.
> I'm using Anton Blanchard's will-it-scale "open1" test which creates a
> bunch of processes and does open()/close() in a tight loop:
>
> > https://github.com/antonblanchard/will-it-scale/blob/master/tests/open1.c
>
> At about 50 cores worth of processes, 3.15 and the pre-3.16 code start
> to diverge, with 3.15 scaling better:
>
> http://sr71.net/~dave/intel/3.16-open1regression-0.png
>
> Some profiles point to a big increase in contention inside slub.c's
> get_partial_node() (the allocation side of the slub code) causing the
> regression. That particular open() test is known to do a lot of slab
> operations. But, the odd part is that the slub code hasn't been touched
> much.
Coming back to this... If the original was stalling RCU grace periods
for the duration of the test, then it would also be deferring any
freeing until after the end of the test. This is of course similar
to the usual Java benchmarking trick of making sure that the garbage
collector never runs. It would also mean that if a change caused RCU
grace periods to complete during the test, that change might appear to
reduce throughput when in fact it was simply causing the throughput to
be more accurately represented.
The reason I bring this possibility up is that it would account for the
increase in contention in slub -- by causing free operations to occur
concurrently.
Thanx, Paul
On 06/18/2014 02:48 PM, Paul E. McKenney wrote:
> On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dave Hansen wrote:
>> Hi Paul,
>>
>> I'm seeing a regression when comparing 3.15 to Linus's current tree.
>> I'm using Anton Blanchard's will-it-scale "open1" test which creates a
>> bunch of processes and does open()/close() in a tight loop:
>>
>>> https://github.com/antonblanchard/will-it-scale/blob/master/tests/open1.c
>>
>> At about 50 cores worth of processes, 3.15 and the pre-3.16 code start
>> to diverge, with 3.15 scaling better:
>>
>> http://sr71.net/~dave/intel/3.16-open1regression-0.png
>>
>> Some profiles point to a big increase in contention inside slub.c's
>> get_partial_node() (the allocation side of the slub code) causing the
>> regression. That particular open() test is known to do a lot of slab
>> operations. But, the odd part is that the slub code hasn't been touched
>> much.
>
> Coming back to this... If the original was stalling RCU grace periods
> for the duration of the test, then it would also be deferring any
> freeing until after the end of the test.
I run the test for pretty long periods of time, and I don't see any
consistent growth in the memory used. I'd expect if we were fully
stalling RCU grace periods that we'd see memory usage grow too.
Looking at rcu_sched/rcugp at 1-second intervals, we can see the gpnum
going up consistently (incrementing at a rate of about 15/second).
Does that rule out the possibility of stalling them until after the test?
> Wed Jun 18 14:46:32 PDT 2014: completed=7707 gpnum=7708 age=14 max=123, 7
> Wed Jun 18 14:46:33 PDT 2014: completed=7723 gpnum=7724 age=14 max=123, 7
> Wed Jun 18 14:46:34 PDT 2014: completed=7739 gpnum=7740 age=19 max=123, 7
> Wed Jun 18 14:46:35 PDT 2014: completed=7756 gpnum=7757 age=3 max=123, 6
> Wed Jun 18 14:46:36 PDT 2014: completed=7771 gpnum=7772 age=12 max=123, 5
> Wed Jun 18 14:46:37 PDT 2014: completed=7787 gpnum=7788 age=7 max=123, 5
> Wed Jun 18 14:46:39 PDT 2014: completed=7802 gpnum=7803 age=14 max=123, 5
> Wed Jun 18 14:46:40 PDT 2014: completed=7816 gpnum=7817 age=15 max=123, 5
> Wed Jun 18 14:46:41 PDT 2014: completed=7831 gpnum=7832 age=15 max=123, 6
> Wed Jun 18 14:46:42 PDT 2014: completed=7847 gpnum=7848 age=15 max=123, 6
> Wed Jun 18 14:46:43 PDT 2014: completed=7860 gpnum=7861 age=15 max=123, 6
> Wed Jun 18 14:46:44 PDT 2014: completed=7877 gpnum=7878 age=15 max=123, 6
> Wed Jun 18 14:46:45 PDT 2014: completed=7892 gpnum=7893 age=17 max=123, 6
> Wed Jun 18 14:46:46 PDT 2014: completed=7906 gpnum=7907 age=17 max=123, 7
> Wed Jun 18 14:46:47 PDT 2014: completed=7920 gpnum=7921 age=19 max=123, 7
> Wed Jun 18 14:46:48 PDT 2014: completed=7936 gpnum=7937 age=19 max=123, 7
> Wed Jun 18 14:46:49 PDT 2014: completed=7954 gpnum=7955 age=2 max=123, 7
> Wed Jun 18 14:46:50 PDT 2014: completed=7970 gpnum=7971 age=0 max=123, 7
> Wed Jun 18 14:46:51 PDT 2014: completed=7985 gpnum=7986 age=6 max=123, 7
> Wed Jun 18 14:46:52 PDT 2014: completed=8000 gpnum=8001 age=7 max=123, 8
> Wed Jun 18 14:46:53 PDT 2014: completed=8015 gpnum=8016 age=8 max=123, 8
> Wed Jun 18 14:46:54 PDT 2014: completed=8031 gpnum=8032 age=10 max=123, 7
On Wed, Jun 18, 2014 at 03:03:38PM -0700, Dave Hansen wrote:
> On 06/18/2014 02:48 PM, Paul E. McKenney wrote:
> > On Fri, Jun 13, 2014 at 01:04:28PM -0700, Dave Hansen wrote:
> >> Hi Paul,
> >>
> >> I'm seeing a regression when comparing 3.15 to Linus's current tree.
> >> I'm using Anton Blanchard's will-it-scale "open1" test which creates a
> >> bunch of processes and does open()/close() in a tight loop:
> >>
> >>> https://github.com/antonblanchard/will-it-scale/blob/master/tests/open1.c
> >>
> >> At about 50 cores worth of processes, 3.15 and the pre-3.16 code start
> >> to diverge, with 3.15 scaling better:
> >>
> >> http://sr71.net/~dave/intel/3.16-open1regression-0.png
> >>
> >> Some profiles point to a big increase in contention inside slub.c's
> >> get_partial_node() (the allocation side of the slub code) causing the
> >> regression. That particular open() test is known to do a lot of slab
> >> operations. But, the odd part is that the slub code hasn't been touched
> >> much.
> >
> > Coming back to this... If the original was stalling RCU grace periods
> > for the duration of the test, then it would also be deferring any
> > freeing until after the end of the test.
>
> I run the test for pretty long periods of time, and I don't see any
> consistent growth in the memory used. I'd expect if we were fully
> stalling RCU grace periods that we'd see memory usage grow too.
>
> Looking at rcu_sched/rcugp at 1-second intervals, we can see the gpnum
> going up consistently (incrementing at a rate of about 15/second).
>
> Does that rule out the possibility of stalling them until after the test?
That it does!
> > Wed Jun 18 14:46:32 PDT 2014: completed=7707 gpnum=7708 age=14 max=123, 7
> > Wed Jun 18 14:46:33 PDT 2014: completed=7723 gpnum=7724 age=14 max=123, 7
> > Wed Jun 18 14:46:34 PDT 2014: completed=7739 gpnum=7740 age=19 max=123, 7
> > Wed Jun 18 14:46:35 PDT 2014: completed=7756 gpnum=7757 age=3 max=123, 6
> > Wed Jun 18 14:46:36 PDT 2014: completed=7771 gpnum=7772 age=12 max=123, 5
> > Wed Jun 18 14:46:37 PDT 2014: completed=7787 gpnum=7788 age=7 max=123, 5
> > Wed Jun 18 14:46:39 PDT 2014: completed=7802 gpnum=7803 age=14 max=123, 5
> > Wed Jun 18 14:46:40 PDT 2014: completed=7816 gpnum=7817 age=15 max=123, 5
> > Wed Jun 18 14:46:41 PDT 2014: completed=7831 gpnum=7832 age=15 max=123, 6
> > Wed Jun 18 14:46:42 PDT 2014: completed=7847 gpnum=7848 age=15 max=123, 6
> > Wed Jun 18 14:46:43 PDT 2014: completed=7860 gpnum=7861 age=15 max=123, 6
> > Wed Jun 18 14:46:44 PDT 2014: completed=7877 gpnum=7878 age=15 max=123, 6
> > Wed Jun 18 14:46:45 PDT 2014: completed=7892 gpnum=7893 age=17 max=123, 6
> > Wed Jun 18 14:46:46 PDT 2014: completed=7906 gpnum=7907 age=17 max=123, 7
> > Wed Jun 18 14:46:47 PDT 2014: completed=7920 gpnum=7921 age=19 max=123, 7
> > Wed Jun 18 14:46:48 PDT 2014: completed=7936 gpnum=7937 age=19 max=123, 7
> > Wed Jun 18 14:46:49 PDT 2014: completed=7954 gpnum=7955 age=2 max=123, 7
> > Wed Jun 18 14:46:50 PDT 2014: completed=7970 gpnum=7971 age=0 max=123, 7
> > Wed Jun 18 14:46:51 PDT 2014: completed=7985 gpnum=7986 age=6 max=123, 7
> > Wed Jun 18 14:46:52 PDT 2014: completed=8000 gpnum=8001 age=7 max=123, 8
> > Wed Jun 18 14:46:53 PDT 2014: completed=8015 gpnum=8016 age=8 max=123, 8
> > Wed Jun 18 14:46:54 PDT 2014: completed=8031 gpnum=8032 age=10 max=123, 7
Thank you for checking!
Thanx, Paul
On Wed, Jun 18, 2014 at 01:30:52PM -0700, Paul E. McKenney wrote:
> On Wed, Jun 18, 2014 at 10:36:25AM -0700, Dave Hansen wrote:
> > On 06/18/2014 05:58 AM, Paul E. McKenney wrote:
> > >> > This is the previous kernel, plus RCU tracing, so it's not 100%
> > >> > apples-to-apples (and it peaks a bit lower than the other kernel). But
> > >> > here's the will-it-scale open1 throughput on the y axis vs
> > >> > RCU_COND_RESCHED_EVERY_THIS_JIFFIES on x:
> > >> >
> > >> > http://sr71.net/~dave/intel/jiffies-vs-openops.png
> > >> >
> > >> > This was a quick and dirty single run with very little averaging, so I
> > >> > expect there to be a good amount of noise. I ran it from 1->100, but it
> > >> > seemed to peak at about 30.
> > > OK, so a default setting on the order of 20-30 jiffies looks promising.
> >
> > For the biggest machine I have today, yeah. But, we need to be a bit
> > careful here. The CPUs I'm running it on were released 3 years ago and
> > I think we need to be planning at _least_ for today's large systems. I
> > would guess that by raising ...EVERY_THIS_JIFFIES, we're shifting this
> > curve out to the right:
> >
> > http://sr71.net/~dave/intel/3.16-open1regression-0.png
> >
> > so that we're _just_ before the regression hits us. But that just
> > guarantees I'll hit this again when I get new CPUs. :)
>
> Understood. One approach would be to scale this in a manner similar
> to the scaling of the delay from the beginning of the grace period
> to the start of quiescent-state forcing, which is about three jiffies
> on small systems scaling up to about 20 jiffies on large systems.
>
> > If we go this route, I think we should probably take it up in to the
> > 100-200 range, or even scale it to something on the order of what the
> > rcu stall timeout is. Other than the stall detector, is there some
> > other reason to be forcing frequent quiescent states?
>
> Yep. CONFIG_NO_HZ_FULL+nohz_full kernels running in kernel mode don't
> progress RCU grace periods. But they should not need to be all that
> frequent.
Here is an early version of a patch, which looks promising on short
rcutorture tests. It does not yet have control of the holdoff time
(I intend to add a module parameter for this), but it also avoids ever
having cond_resched() do a quiescent state if there is no grace period in
progress or if the current grace period is less than seven jiffies old.
(The constant "7" is the thing that will be made into a module parameter.)
These restrictions lead me to believe that "7" will perform well in your
tests, because normal workloads would almost never have cond_resched()
do anything other than a test of a per-CPU variable. But of course your
tests are the final judges of that.
Thoughts?
Thanx, Paul
------------------------------------------------------------------------
rcu: Reduce overhead of cond_resched() checks for RCU
Commit ac1bea85781e (Make cond_resched() report RCU quiescent states)
fixed a problem where a CPU looping in the kernel with but one runnable
task would give RCU CPU stall warnings, even if the in-kernel loop
contained cond_resched() calls. Unfortunately, in so doing, it introduced
performance regressions in Anton Blanchard's will-it-scale "open1" test.
The problem appears to be not so much the increased cond_resched() path
length as an increase in the rate at which grace periods complete, which
increased per-update grace-period overhead.
This commit takes a different approach to fixing this bug, mainly by
avoiding having cond_resched() do an RCU-visible quiescent state unless
there is a grace period that has been in flight for a significant period
of time. This commit also reduces the common-case cond_resched() overhead
to a check of a single per-CPU variable.
Reported-by: Dave Hansen <[email protected]>
Signed-off-by: Paul E. McKenney <[email protected]>
diff --git a/include/linux/rcupdate.h b/include/linux/rcupdate.h
index 063a6bf1a2b6..d5e40a42cc43 100644
--- a/include/linux/rcupdate.h
+++ b/include/linux/rcupdate.h
@@ -300,41 +300,6 @@ bool __rcu_is_watching(void);
#endif /* #if defined(CONFIG_DEBUG_LOCK_ALLOC) || defined(CONFIG_RCU_TRACE) || defined(CONFIG_SMP) */
/*
- * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
- */
-
-#define RCU_COND_RESCHED_LIM 256 /* ms vs. 100s of ms. */
-DECLARE_PER_CPU(int, rcu_cond_resched_count);
-void rcu_resched(void);
-
-/*
- * Is it time to report RCU quiescent states?
- *
- * Note unsynchronized access to rcu_cond_resched_count. Yes, we might
- * increment some random CPU's count, and possibly also load the result from
- * yet another CPU's count. We might even clobber some other CPU's attempt
- * to zero its counter. This is all OK because the goal is not precision,
- * but rather reasonable amortization of rcu_note_context_switch() overhead
- * and extremely high probability of avoiding RCU CPU stall warnings.
- * Note that this function has to be preempted in just the wrong place,
- * many thousands of times in a row, for anything bad to happen.
- */
-static inline bool rcu_should_resched(void)
-{
- return raw_cpu_inc_return(rcu_cond_resched_count) >=
- RCU_COND_RESCHED_LIM;
-}
-
-/*
- * Report quiscent states to RCU if it is time to do so.
- */
-static inline void rcu_cond_resched(void)
-{
- if (unlikely(rcu_should_resched()))
- rcu_resched();
-}
-
-/*
* Infrastructure to implement the synchronize_() primitives in
* TREE_RCU and rcu_barrier_() primitives in TINY_RCU.
*/
diff --git a/include/linux/rcutiny.h b/include/linux/rcutiny.h
index d40a6a451330..ff2ede319890 100644
--- a/include/linux/rcutiny.h
+++ b/include/linux/rcutiny.h
@@ -83,6 +83,19 @@ static inline void rcu_note_context_switch(int cpu)
rcu_sched_qs(cpu);
}
+static inline bool rcu_should_resched(void)
+{
+ return false;
+}
+
+static inline void rcu_cond_resched(void)
+{
+}
+
+static inline void rcu_resched(void)
+{
+}
+
/*
* Take advantage of the fact that there is only one CPU, which
* allows us to ignore virtualization-based context switches.
diff --git a/include/linux/rcutree.h b/include/linux/rcutree.h
index 3e2f5d432743..16780fed7155 100644
--- a/include/linux/rcutree.h
+++ b/include/linux/rcutree.h
@@ -46,6 +46,22 @@ static inline void rcu_virt_note_context_switch(int cpu)
rcu_note_context_switch(cpu);
}
+DECLARE_PER_CPU(int, rcu_cond_resched_mask);
+void rcu_resched(void);
+
+/* Is it time to report RCU quiescent states? */
+static inline bool rcu_should_resched(void)
+{
+ return raw_cpu_read(rcu_cond_resched_mask);
+}
+
+/* Report quiescent states to RCU if it is time to do so. */
+static inline void rcu_cond_resched(void)
+{
+ if (unlikely(rcu_should_resched()))
+ rcu_resched();
+}
+
void synchronize_rcu_bh(void);
void synchronize_sched_expedited(void);
void synchronize_rcu_expedited(void);
diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
index 777624e1329b..8c47d04ecdea 100644
--- a/kernel/rcu/tree.c
+++ b/kernel/rcu/tree.c
@@ -229,6 +229,58 @@ static DEFINE_PER_CPU(struct rcu_dynticks, rcu_dynticks) = {
#endif /* #ifdef CONFIG_NO_HZ_FULL_SYSIDLE */
};
+/*
+ * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
+ */
+
+DEFINE_PER_CPU(int, rcu_cond_resched_mask);
+
+/*
+ * Let the RCU core know that this CPU has gone through a cond_resched(),
+ * which is a quiescent state.
+ */
+void rcu_resched(void)
+{
+ unsigned long flags;
+ struct rcu_data *rdp;
+ struct rcu_dynticks *rdtp;
+ int resched_mask;
+ struct rcu_state *rsp;
+
+ local_irq_save(flags);
+
+ /*
+ * Yes, we can lose flag-setting operations. This is OK, because
+ * the flag will be set again after some delay.
+ */
+ resched_mask = raw_cpu_read(rcu_cond_resched_mask);
+ raw_cpu_write(rcu_cond_resched_mask, 0);
+
+ /* Find the flavor that needs a quiescent state. */
+ for_each_rcu_flavor(rsp) {
+ rdp = raw_cpu_ptr(rsp->rda);
+ if (!(resched_mask & rsp->flavor_mask))
+ continue;
+ smp_mb(); /* ->flavor_mask before ->cond_resched_completed. */
+ if (ACCESS_ONCE(rdp->mynode->completed) !=
+ ACCESS_ONCE(rdp->cond_resched_completed))
+ continue;
+
+ /*
+ * Pretend to be momentarily idle for the quiescent state.
+ * This allows the grace-period kthread to record the
+ * quiescent state, with no need for this CPU to do anything
+ * further.
+ */
+ rdtp = this_cpu_ptr(&rcu_dynticks);
+ smp_mb__before_atomic(); /* Earlier stuff before QS. */
+ atomic_add(2, &rdtp->dynticks); /* QS. */
+ smp_mb__after_atomic(); /* Later stuff after QS. */
+ break;
+ }
+ local_irq_restore(flags);
+}
+
static long blimit = 10; /* Maximum callbacks per rcu_do_batch. */
static long qhimark = 10000; /* If this many pending, ignore blimit. */
static long qlowmark = 100; /* Once only this many pending, use blimit. */
@@ -853,6 +905,7 @@ static int rcu_implicit_dynticks_qs(struct rcu_data *rdp,
bool *isidle, unsigned long *maxj)
{
unsigned int curr;
+ int *rcrmp;
unsigned int snap;
curr = (unsigned int)atomic_add_return(0, &rdp->dynticks->dynticks);
@@ -893,13 +946,20 @@ static int rcu_implicit_dynticks_qs(struct rcu_data *rdp,
}
/*
- * There is a possibility that a CPU in adaptive-ticks state
- * might run in the kernel with the scheduling-clock tick disabled
- * for an extended time period. Invoke rcu_kick_nohz_cpu() to
- * force the CPU to restart the scheduling-clock tick in this
- * CPU is in this state.
+ * A CPU running for an extended time within the kernel can
+ * delay RCU grace periods. When the CPU is in NO_HZ_FULL mode,
+ * even context-switching back and forth between a pair of
+ * in-kernel CPU-bound tasks cannot advance grace periods.
+ * So if the grace period is old enough, make the CPU pay attention.
*/
- rcu_kick_nohz_cpu(rdp->cpu);
+ if (ULONG_CMP_GE(jiffies, rdp->rsp->gp_start + 7)) {
+ rcrmp = &per_cpu(rcu_cond_resched_mask, rdp->cpu);
+ ACCESS_ONCE(rdp->cond_resched_completed) =
+ ACCESS_ONCE(rdp->mynode->completed);
+ smp_mb(); /* ->cond_resched_completed before *rcrmp. */
+ ACCESS_ONCE(*rcrmp) =
+ ACCESS_ONCE(*rcrmp) + rdp->rsp->flavor_mask;
+ }
/*
* Alternatively, the CPU might be running in the kernel
@@ -3504,6 +3564,7 @@ static void __init rcu_init_one(struct rcu_state *rsp,
"rcu_node_fqs_1",
"rcu_node_fqs_2",
"rcu_node_fqs_3" }; /* Match MAX_RCU_LVLS */
+ static u8 fl_mask = 0x1;
int cpustride = 1;
int i;
int j;
@@ -3522,6 +3583,8 @@ static void __init rcu_init_one(struct rcu_state *rsp,
for (i = 1; i < rcu_num_lvls; i++)
rsp->level[i] = rsp->level[i - 1] + rsp->levelcnt[i - 1];
rcu_init_levelspread(rsp);
+ rsp->flavor_mask = fl_mask;
+ fl_mask <<= 1;
/* Initialize the elements themselves, starting from the leaves. */
diff --git a/kernel/rcu/tree.h b/kernel/rcu/tree.h
index db3f096ed80b..60fb0eaa2d16 100644
--- a/kernel/rcu/tree.h
+++ b/kernel/rcu/tree.h
@@ -315,6 +315,9 @@ struct rcu_data {
/* 4) reasons this CPU needed to be kicked by force_quiescent_state */
unsigned long dynticks_fqs; /* Kicked due to dynticks idle. */
unsigned long offline_fqs; /* Kicked due to being offline. */
+ unsigned long cond_resched_completed;
+ /* Grace period that needs help */
+ /* from cond_resched(). */
/* 5) __rcu_pending() statistics. */
unsigned long n_rcu_pending; /* rcu_pending() calls since boot. */
@@ -400,6 +403,7 @@ struct rcu_state {
struct rcu_node *level[RCU_NUM_LVLS]; /* Hierarchy levels. */
u32 levelcnt[MAX_RCU_LVLS + 1]; /* # nodes in each level. */
u8 levelspread[RCU_NUM_LVLS]; /* kids/node in each level. */
+ u8 flavor_mask; /* bit in flavor mask. */
struct rcu_data __percpu *rda; /* pointer of percu rcu_data. */
void (*call)(struct rcu_head *head, /* call_rcu() flavor. */
void (*func)(struct rcu_head *head));
@@ -571,7 +575,7 @@ static bool rcu_nocb_need_deferred_wakeup(struct rcu_data *rdp);
static void do_nocb_deferred_wakeup(struct rcu_data *rdp);
static void rcu_boot_init_nocb_percpu_data(struct rcu_data *rdp);
static void rcu_spawn_nocb_kthreads(struct rcu_state *rsp);
-static void rcu_kick_nohz_cpu(int cpu);
+static void __maybe_unused rcu_kick_nohz_cpu(int cpu);
static bool init_nocb_callback_list(struct rcu_data *rdp);
static void rcu_sysidle_enter(struct rcu_dynticks *rdtp, int irq);
static void rcu_sysidle_exit(struct rcu_dynticks *rdtp, int irq);
diff --git a/kernel/rcu/tree_plugin.h b/kernel/rcu/tree_plugin.h
index 695ecf19dfc6..569b390daa15 100644
--- a/kernel/rcu/tree_plugin.h
+++ b/kernel/rcu/tree_plugin.h
@@ -2422,7 +2422,7 @@ static bool init_nocb_callback_list(struct rcu_data *rdp)
* if an adaptive-ticks CPU is failing to respond to the current grace
* period and has not be idle from an RCU perspective, kick it.
*/
-static void rcu_kick_nohz_cpu(int cpu)
+static void __maybe_unused rcu_kick_nohz_cpu(int cpu)
{
#ifdef CONFIG_NO_HZ_FULL
if (tick_nohz_full_cpu(cpu))
diff --git a/kernel/rcu/update.c b/kernel/rcu/update.c
index a2aeb4df0f60..d22309cae9f5 100644
--- a/kernel/rcu/update.c
+++ b/kernel/rcu/update.c
@@ -350,21 +350,3 @@ static int __init check_cpu_stall_init(void)
early_initcall(check_cpu_stall_init);
#endif /* #ifdef CONFIG_RCU_STALL_COMMON */
-
-/*
- * Hooks for cond_resched() and friends to avoid RCU CPU stall warnings.
- */
-
-DEFINE_PER_CPU(int, rcu_cond_resched_count);
-
-/*
- * Report a set of RCU quiescent states, for use by cond_resched()
- * and friends. Out of line due to being called infrequently.
- */
-void rcu_resched(void)
-{
- preempt_disable();
- __this_cpu_write(rcu_cond_resched_count, 0);
- rcu_note_context_switch(smp_processor_id());
- preempt_enable();
-}
I still think it's totally the wrong direction to pollute so
many fast paths with this obscure debugging check workaround
unconditionally.
cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
And these are really critical paths for many workloads.
If you really wanted to do this I think you would first need
to define a cond_resched_i_am_not_fast() or somesuch.
Or put it all behind some debugging ifdef.
-Andi
--
[email protected] -- Speaking for myself only
On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
>
> I still think it's totally the wrong direction to pollute so
> many fast paths with this obscure debugging check workaround
> unconditionally.
OOM prevention should count for something, I would hope.
> cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> And these are really critical paths for many workloads.
>
> If you really wanted to do this I think you would first need
> to define a cond_resched_i_am_not_fast() or somesuch.
>
> Or put it all behind some debugging ifdef.
My first thought was to put it behind CONFIG_NO_HZ_FULL, but everyone
seems to be enabling that one.
As mentioned earlier, I could potentially push the check behind
the need-resched check, which would get it off of the common case
of the code paths you call out above.
Thanx, Paul
On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> >
> > I still think it's totally the wrong direction to pollute so
> > many fast paths with this obscure debugging check workaround
> > unconditionally.
>
> OOM prevention should count for something, I would hope.
>
> > cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> > And these are really critical paths for many workloads.
> >
> > If you really wanted to do this I think you would first need
> > to define a cond_resched_i_am_not_fast() or somesuch.
> >
> > Or put it all behind some debugging ifdef.
>
> My first thought was to put it behind CONFIG_NO_HZ_FULL, but everyone
> seems to be enabling that one.
>
> As mentioned earlier, I could potentially push the check behind
> the need-resched check, which would get it off of the common case
> of the code paths you call out above.
Of course, it would also be good to measure this and see how much it
really hurts.
Thanx, Paul
On Wed, 2014-06-18 at 19:13 -0700, Paul E. McKenney wrote:
> On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> >
> > I still think it's totally the wrong direction to pollute so
> > many fast paths with this obscure debugging check workaround
> > unconditionally.
>
> OOM prevention should count for something, I would hope.
>
> > cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> > And these are really critical paths for many workloads.
> >
> > If you really wanted to do this I think you would first need
> > to define a cond_resched_i_am_not_fast() or somesuch.
> >
> > Or put it all behind some debugging ifdef.
>
> My first thought was to put it behind CONFIG_NO_HZ_FULL, but everyone
> seems to be enabling that one.
Not everybody, SUSE doesn't even have it enabled in factory.
-Mike
On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> >
> > I still think it's totally the wrong direction to pollute so
> > many fast paths with this obscure debugging check workaround
> > unconditionally.
>
> OOM prevention should count for something, I would hope.
OOM in what scenario? This is getting bizarre.
If something keeps looping forever in the kernel creating
RCU callbacks without any real quiescent states it's simply broken.
-Andi
On Wed, Jun 18, 2014 at 08:38:16PM -0700, Andi Kleen wrote:
> On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > >
> > > I still think it's totally the wrong direction to pollute so
> > > many fast paths with this obscure debugging check workaround
> > > unconditionally.
> >
> > OOM prevention should count for something, I would hope.
>
> OOM in what scenario? This is getting bizarre.
On the bizarre part, at least we agree on something. ;-)
CONFIG_NO_HZ_FULL booted with at least one nohz_full CPU. Said CPU
gets into the kernel and stays there, not necessarily generating RCU
callbacks. The other CPUs are very likely generating RCU callbacks.
Because the nohz_full CPU is in the kernel, and because there are no
scheduling-clock interrupts on that CPU, grace periods do not complete.
Eventually, the callbacks from the other CPUs (and perhaps also some
from the nohz_full CPU, for that matter) OOM the machine.
Now this scenario constitutes an abuse of CONFIG_NO_HZ_FULL, because it
is intended for CPUs that execute either in userspace (in which case
those CPUs are in extended quiescent states so that RCU can happily
ignore them) or for real-time workloads with low CPU untilization (in
which case RCU sees them go idle, which is also a quiescent state).
But that won't stop people from abusing their kernels and complaining
when things break.
This same thing can also happen without CONFIG_NO_HZ full, though
the system has to work a bit harder. In this case, the CPU looping
in the kernel has scheduling-clock interrupts, but if all it does
is cond_resched(), RCU is never informed of any quiescent states.
The whole point of this patch is to make those cond_resched() calls,
which are quiescent states, visible to RCU.
> If something keeps looping forever in the kernel creating
> RCU callbacks without any real quiescent states it's simply broken.
I could get behind that. But by that definition, there is a lot of
breakage in the current kernel, especially as we move to larger CPU
counts.
Thanx, Paul
On Thu, Jun 19, 2014 at 04:50:19AM +0200, Mike Galbraith wrote:
> On Wed, 2014-06-18 at 19:13 -0700, Paul E. McKenney wrote:
> > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > >
> > > I still think it's totally the wrong direction to pollute so
> > > many fast paths with this obscure debugging check workaround
> > > unconditionally.
> >
> > OOM prevention should count for something, I would hope.
> >
> > > cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> > > And these are really critical paths for many workloads.
> > >
> > > If you really wanted to do this I think you would first need
> > > to define a cond_resched_i_am_not_fast() or somesuch.
> > >
> > > Or put it all behind some debugging ifdef.
> >
> > My first thought was to put it behind CONFIG_NO_HZ_FULL, but everyone
> > seems to be enabling that one.
>
> Not everybody, SUSE doesn't even have it enabled in factory.
OK, apologies for the over-generalization.
But you would think that I would have learned this lesson with
CONFIG_RCU_FAST_NO_HZ, wouldn't you? :-/
Thanx, Paul
On Wed, 2014-06-18 at 20:38 -0700, Andi Kleen wrote:
> On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > >
> > > I still think it's totally the wrong direction to pollute so
> > > many fast paths with this obscure debugging check workaround
> > > unconditionally.
> >
> > OOM prevention should count for something, I would hope.
>
> OOM in what scenario? This is getting bizarre.
>
> If something keeps looping forever in the kernel creating
> RCU callbacks without any real quiescent states it's simply broken.
Typical problem we faced in the past is in exit() path when multi
thousands of files/sockets are rcu-freed, and qhimark is hit.
Huge latency alerts, as freeing 10000+ items takes a while (about 70 ns
per item...)
Maybe close_files() should use a
cond_resched_and_keep_rcu_queues_small_please() ;)
On Wed, Jun 18, 2014 at 09:52:25PM -0700, Eric Dumazet wrote:
> On Wed, 2014-06-18 at 20:38 -0700, Andi Kleen wrote:
> > On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> > > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > > >
> > > > I still think it's totally the wrong direction to pollute so
> > > > many fast paths with this obscure debugging check workaround
> > > > unconditionally.
> > >
> > > OOM prevention should count for something, I would hope.
> >
> > OOM in what scenario? This is getting bizarre.
> >
> > If something keeps looping forever in the kernel creating
> > RCU callbacks without any real quiescent states it's simply broken.
>
> Typical problem we faced in the past is in exit() path when multi
> thousands of files/sockets are rcu-freed, and qhimark is hit.
>
> Huge latency alerts, as freeing 10000+ items takes a while (about 70 ns
> per item...)
>
> Maybe close_files() should use a
> cond_resched_and_keep_rcu_queues_small_please() ;)
That sort of approach would work for me. Over time, I would guess
that the cond_resched_and_keep_rcu_queues_small_please() function would
find its way to where it needed to be. ;-)
Thanx, Paul
On Wed, 2014-06-18 at 21:19 -0700, Paul E. McKenney wrote:
> On Wed, Jun 18, 2014 at 08:38:16PM -0700, Andi Kleen wrote:
> > On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> > > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > > >
> > > > I still think it's totally the wrong direction to pollute so
> > > > many fast paths with this obscure debugging check workaround
> > > > unconditionally.
> > >
> > > OOM prevention should count for something, I would hope.
> >
> > OOM in what scenario? This is getting bizarre.
>
> On the bizarre part, at least we agree on something. ;-)
>
> CONFIG_NO_HZ_FULL booted with at least one nohz_full CPU. Said CPU
> gets into the kernel and stays there, not necessarily generating RCU
> callbacks. The other CPUs are very likely generating RCU callbacks.
> Because the nohz_full CPU is in the kernel, and because there are no
> scheduling-clock interrupts on that CPU, grace periods do not complete.
> Eventually, the callbacks from the other CPUs (and perhaps also some
> from the nohz_full CPU, for that matter) OOM the machine.
>
> Now this scenario constitutes an abuse of CONFIG_NO_HZ_FULL, because it
> is intended for CPUs that execute either in userspace (in which case
> those CPUs are in extended quiescent states so that RCU can happily
> ignore them) or for real-time workloads with low CPU untilization (in
> which case RCU sees them go idle, which is also a quiescent state).
> But that won't stop people from abusing their kernels and complaining
> when things break.
IMHO, those people can keep the pieces.
I don't even enable RCU_BOOST in -rt kernels, because that safety net
has a price. The instant Joe User picks up the -rt shovel, it's his
grave, and he gets to do the digging. Instead of trying to save his
bacon, I hand him a slightly better shovel, let him prioritize all
kthreads including workqueues. Joe can dig all he wants to, and it's on
him, I just make sure he has the means to bury himself properly :)
> This same thing can also happen without CONFIG_NO_HZ full, though
> the system has to work a bit harder. In this case, the CPU looping
> in the kernel has scheduling-clock interrupts, but if all it does
> is cond_resched(), RCU is never informed of any quiescent states.
> The whole point of this patch is to make those cond_resched() calls,
> which are quiescent states, visible to RCU.
>
> > If something keeps looping forever in the kernel creating
> > RCU callbacks without any real quiescent states it's simply broken.
>
> I could get behind that. But by that definition, there is a lot of
> breakage in the current kernel, especially as we move to larger CPU
> counts.
Not only larger CPU counts: skipping the -rq clock update on wakeup
(cycle saving optimization) turned out to be deadly to boxen with a
zillion disks because our wakeup latency can be so incredibly horrible
that falsely attributing wakeup latency to the next task to run
(watchdog) resulted in it being throttled for long enough that big IO
boxen panicked during boot.
The root cause of that wasn't the optimization, the root was the
horrific amounts of time we can spend locked up in the kernel.
-Mike
On Wed, 18 Jun 2014, Andi Kleen wrote:
> I still think it's totally the wrong direction to pollute so
> many fast paths with this obscure debugging check workaround
> unconditionally.
>
> cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> And these are really critical paths for many workloads.
>
> If you really wanted to do this I think you would first need
> to define a cond_resched_i_am_not_fast() or somesuch.
>
> Or put it all behind some debugging ifdef.
Again I am fully on Andi's side here. Please remove these frequent calls
to cond_resched. If one wants a fully preemptable kernel then please use
CONFIG_PREEMPT.
On Thu, Jun 19, 2014 at 09:42:18AM -0500, Christoph Lameter wrote:
> On Wed, 18 Jun 2014, Andi Kleen wrote:
>
> > I still think it's totally the wrong direction to pollute so
> > many fast paths with this obscure debugging check workaround
> > unconditionally.
> >
> > cond_resched() is in EVERY sleeping lock and in EVERY memory allocation!
> > And these are really critical paths for many workloads.
> >
> > If you really wanted to do this I think you would first need
> > to define a cond_resched_i_am_not_fast() or somesuch.
> >
> > Or put it all behind some debugging ifdef.
>
> Again I am fully on Andi's side here. Please remove these frequent calls
> to cond_resched. If one wants a fully preemptable kernel then please use
> CONFIG_PREEMPT.
That is a separate issue, but unnecessary calls to cond_resched()
should of course be removed -- no argument there.
Thanx, Paul
On Thu, Jun 19, 2014 at 07:24:18AM +0200, Mike Galbraith wrote:
> On Wed, 2014-06-18 at 21:19 -0700, Paul E. McKenney wrote:
> > On Wed, Jun 18, 2014 at 08:38:16PM -0700, Andi Kleen wrote:
> > > On Wed, Jun 18, 2014 at 07:13:37PM -0700, Paul E. McKenney wrote:
> > > > On Wed, Jun 18, 2014 at 06:42:00PM -0700, Andi Kleen wrote:
> > > > >
> > > > > I still think it's totally the wrong direction to pollute so
> > > > > many fast paths with this obscure debugging check workaround
> > > > > unconditionally.
> > > >
> > > > OOM prevention should count for something, I would hope.
> > >
> > > OOM in what scenario? This is getting bizarre.
> >
> > On the bizarre part, at least we agree on something. ;-)
> >
> > CONFIG_NO_HZ_FULL booted with at least one nohz_full CPU. Said CPU
> > gets into the kernel and stays there, not necessarily generating RCU
> > callbacks. The other CPUs are very likely generating RCU callbacks.
> > Because the nohz_full CPU is in the kernel, and because there are no
> > scheduling-clock interrupts on that CPU, grace periods do not complete.
> > Eventually, the callbacks from the other CPUs (and perhaps also some
> > from the nohz_full CPU, for that matter) OOM the machine.
> >
> > Now this scenario constitutes an abuse of CONFIG_NO_HZ_FULL, because it
> > is intended for CPUs that execute either in userspace (in which case
> > those CPUs are in extended quiescent states so that RCU can happily
> > ignore them) or for real-time workloads with low CPU untilization (in
> > which case RCU sees them go idle, which is also a quiescent state).
> > But that won't stop people from abusing their kernels and complaining
> > when things break.
>
> IMHO, those people can keep the pieces.
>
> I don't even enable RCU_BOOST in -rt kernels, because that safety net
> has a price. The instant Joe User picks up the -rt shovel, it's his
> grave, and he gets to do the digging. Instead of trying to save his
> bacon, I hand him a slightly better shovel, let him prioritize all
> kthreads including workqueues. Joe can dig all he wants to, and it's on
> him, I just make sure he has the means to bury himself properly :)
One of the nice things about NO_HZ_FULL is that it should reduce the
need for RCU_BOOST. One of the purposes of RCU_BOOST is for the guy
who has an infinite-loop bug in a high-priority RT-priority process,
because such processes can starve out low-priority RCU readers. But
with a properly configured NO_HZ_FULL system, the low-priority processes
aren't sharing CPUs with the RT-priority processes.
In fact, it might be worth making RCU_BOOST depend on !NO_HZ_FULL in -rt.
> > This same thing can also happen without CONFIG_NO_HZ full, though
> > the system has to work a bit harder. In this case, the CPU looping
> > in the kernel has scheduling-clock interrupts, but if all it does
> > is cond_resched(), RCU is never informed of any quiescent states.
> > The whole point of this patch is to make those cond_resched() calls,
> > which are quiescent states, visible to RCU.
> >
> > > If something keeps looping forever in the kernel creating
> > > RCU callbacks without any real quiescent states it's simply broken.
> >
> > I could get behind that. But by that definition, there is a lot of
> > breakage in the current kernel, especially as we move to larger CPU
> > counts.
>
> Not only larger CPU counts: skipping the -rq clock update on wakeup
> (cycle saving optimization) turned out to be deadly to boxen with a
> zillion disks because our wakeup latency can be so incredibly horrible
> that falsely attributing wakeup latency to the next task to run
> (watchdog) resulted in it being throttled for long enough that big IO
> boxen panicked during boot.
>
> The root cause of that wasn't the optimization, the root was the
> horrific amounts of time we can spend locked up in the kernel.
Completely agreed!
Thanx, Paul
On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> That is a separate issue, but unnecessary calls to cond_resched()
> should of course be removed -- no argument there.
It looks like we are fighting higher latencies by adding calls in most of
the critical sections which will in turn increase the latencies that we
are trying to reduce.
On Thu, Jun 19, 2014 at 03:31:56PM -0500, Christoph Lameter wrote:
> On Thu, 19 Jun 2014, Paul E. McKenney wrote:
>
> > That is a separate issue, but unnecessary calls to cond_resched()
> > should of course be removed -- no argument there.
>
> It looks like we are fighting higher latencies by adding calls in most of
> the critical sections which will in turn increase the latencies that we
> are trying to reduce.
That is on battle in a larger war. Another battle is to keep big systems
from choking and dying. We need to win both battles, though I understand
that you are focused primarily on latency reduction. I don't get that
luxury because RCU is used across the board.
Thanx, Paul
On Thu, Jun 19, 2014 at 01:42:20PM -0700, Paul E. McKenney wrote:
> On Thu, Jun 19, 2014 at 03:31:56PM -0500, Christoph Lameter wrote:
> > On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> >
> > > That is a separate issue, but unnecessary calls to cond_resched()
> > > should of course be removed -- no argument there.
> >
> > It looks like we are fighting higher latencies by adding calls in most of
> > the critical sections which will in turn increase the latencies that we
> > are trying to reduce.
>
> That is on battle in a larger war. Another battle is to keep big systems
> from choking and dying. We need to win both battles, though I understand
If we really need cond_resched() now to stop systems from dying
we did a really poor job at designing Linux. I hope it's not true,
that would be really bad and point to some severe design problems
elsewhere.
-Andi
On Thu, Jun 19, 2014 at 01:50:44PM -0700, Andi Kleen wrote:
> On Thu, Jun 19, 2014 at 01:42:20PM -0700, Paul E. McKenney wrote:
> > On Thu, Jun 19, 2014 at 03:31:56PM -0500, Christoph Lameter wrote:
> > > On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> > >
> > > > That is a separate issue, but unnecessary calls to cond_resched()
> > > > should of course be removed -- no argument there.
> > >
> > > It looks like we are fighting higher latencies by adding calls in most of
> > > the critical sections which will in turn increase the latencies that we
> > > are trying to reduce.
> >
> > That is on battle in a larger war. Another battle is to keep big systems
> > from choking and dying. We need to win both battles, though I understand
>
> If we really need cond_resched() now to stop systems from dying
> we did a really poor job at designing Linux. I hope it's not true,
> that would be really bad and point to some severe design problems
> elsewhere.
Or that systems are growing larger than anticipated by some of the
designs. And there are some truly huge systems out there running
Linux, as has been mentioned on this thread several times.
Thanx, Paul
On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> On Thu, Jun 19, 2014 at 03:31:56PM -0500, Christoph Lameter wrote:
> > On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> >
> > > That is a separate issue, but unnecessary calls to cond_resched()
> > > should of course be removed -- no argument there.
> >
> > It looks like we are fighting higher latencies by adding calls in most of
> > the critical sections which will in turn increase the latencies that we
> > are trying to reduce.
>
> That is on battle in a larger war. Another battle is to keep big systems
> from choking and dying. We need to win both battles, though I understand
> that you are focused primarily on latency reduction. I don't get that
> luxury because RCU is used across the board.
At least reduce the increased latencies to a processor or put it somewhere
outside of the regular execution paths. Sprinkling this throughout the
kernel via a inline function that did not generate code in the non debug
situation before is not that nice.
This looks very much like the CONFIG_PREEMPT problem in not so
extreme form. Maybe we need to add another config option:
CONFIG_REALLY_REALLY_NO_PREEMPT
to get the fastest code possible and those cond_rescheds removed from the
critical paths?
Or better
CONFIG_PREEMPT_HALF_WAY
to enable those cond_rescheds.
On Thu, Jun 19, 2014 at 04:16:34PM -0500, Christoph Lameter wrote:
> This looks very much like the CONFIG_PREEMPT problem in not so
> extreme form. Maybe we need to add another config option:
>
> CONFIG_REALLY_REALLY_NO_PREEMPT
>
> to get the fastest code possible and those cond_rescheds removed from the
> critical paths?
>
> Or better
>
> CONFIG_PREEMPT_HALF_WAY
>
> to enable those cond_rescheds.
That much actually does seem quite reasonable: making cond_resched() do
non-trivial work ought to have a config option to disable it.
On Thu, Jun 19, 2014 at 02:32:03PM -0700, [email protected] wrote:
> On Thu, Jun 19, 2014 at 04:16:34PM -0500, Christoph Lameter wrote:
> > This looks very much like the CONFIG_PREEMPT problem in not so
> > extreme form. Maybe we need to add another config option:
> >
> > CONFIG_REALLY_REALLY_NO_PREEMPT
> >
> > to get the fastest code possible and those cond_rescheds removed from the
> > critical paths?
> >
> > Or better
> >
> > CONFIG_PREEMPT_HALF_WAY
> >
> > to enable those cond_rescheds.
>
> That much actually does seem quite reasonable: making cond_resched() do
> non-trivial work ought to have a config option to disable it.
I am putting together patches based on Eric Dumazet's suggestion and on a
variant of the above approach. However, I do expect the distros to starve
to death between those two bales of hay. But perhaps the actual patches
will inspire a bit of light to go with this thread's heat and smoke.
Thanx, Paul
On Thu, 19 Jun 2014, Paul E. McKenney wrote:
> I am putting together patches based on Eric Dumazet's suggestion and on a
> variant of the above approach. However, I do expect the distros to starve
> to death between those two bales of hay. But perhaps the actual patches
> will inspire a bit of light to go with this thread's heat and smoke.
Yep. Note that the large systems are only a few and the smaller systems
are many. You are penalizing the overwhelming majority for support of a
few systems.
On Fri, Jun 20, 2014 at 10:20:36AM -0500, Christoph Lameter wrote:
> On Thu, 19 Jun 2014, Paul E. McKenney wrote:
>
> > I am putting together patches based on Eric Dumazet's suggestion and on a
> > variant of the above approach. However, I do expect the distros to starve
> > to death between those two bales of hay. But perhaps the actual patches
> > will inspire a bit of light to go with this thread's heat and smoke.
>
> Yep. Note that the large systems are only a few and the smaller systems
> are many. You are penalizing the overwhelming majority for support of a
> few systems.
And the fraction of the small systems that care that much about latency
is also quite small.
Of course, if you have performance results that show otherwise, please
share them.
Thanx, Paul
On Fri, 20 Jun 2014, Paul E. McKenney wrote:
> And the fraction of the small systems that care that much about latency
> is also quite small.
This also impacts general performance of course not only latency.
> Of course, if you have performance results that show otherwise, please
> share them.
We are discussing a performance problem right here.
On Fri, Jun 20, 2014 at 11:07:13AM -0500, Christoph Lameter wrote:
> On Fri, 20 Jun 2014, Paul E. McKenney wrote:
>
> > And the fraction of the small systems that care that much about latency
> > is also quite small.
>
> This also impacts general performance of course not only latency.
>
> > Of course, if you have performance results that show otherwise, please
> > share them.
>
> We are discussing a performance problem right here.
We are engaging in a lot of -speculation- about an -alleged- performance
problem. I have posted a fix to the actual performance problem, but the
guy reporting the original report of that problem has not yet reported
the performance of the fix. Which is fine, as I am getting ready to
post an updated fix, and besides which he might well have higher-priority
tasks requiring his attention. But without that performance information,
we are all just engaging in baseless speculation.
Thanx, Paul
On 06/20/2014 09:30 AM, Paul E. McKenney wrote:
> On Fri, Jun 20, 2014 at 11:07:13AM -0500, Christoph Lameter wrote:
>> On Fri, 20 Jun 2014, Paul E. McKenney wrote:
>>
>>> And the fraction of the small systems that care that much about latency
>>> is also quite small.
>>
>> This also impacts general performance of course not only latency.
>>
>>> Of course, if you have performance results that show otherwise, please
>>> share them.
>>
>> We are discussing a performance problem right here.
>
> We are engaging in a lot of -speculation- about an -alleged- performance
> problem. I have posted a fix to the actual performance problem, but the
> guy reporting the original report of that problem has not yet reported
> the performance of the fix. Which is fine, as I am getting ready to
> post an updated fix, and besides which he might well have higher-priority
> tasks requiring his attention. But without that performance information,
> we are all just engaging in baseless speculation.
The patch helps, but does not get us back to where we were before:
Baseline: 3c8fb5044 with ac1bea85781e9004d reverted:
root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
...
average:57710064
3c8fb5044 with Paul's early version with the magic 7:
root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
...
average:48363361
It was down at 43M or 44M without the new patch.
full spew:
3c8fb50445833b93f69b6b703a29aae3523cad0c
with ac1bea85781e9004d reverted:
root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
warmup
min:366329 max:421686 total:63727790
min:358758 max:406036 total:62561168
min:298435 max:340355 total:51711000
min:343707 max:383812 total:59554601
min:310652 max:356571 total:54016014
min:337738 max:382557 total:59146223
measurement
min:317628 max:363489 total:55230696
min:341875 max:392621 total:59910047
min:331979 max:376582 total:58074347
min:342835 max:388481 total:59644247
min:327282 max:374283 total:56897588
min:321668 max:373622 total:55799061
min:336575 max:387027 total:58948777
min:350269 max:397098 total:61510405
min:336949 max:382367 total:58640224
min:327913 max:371026 total:56833639
min:322377 max:375011 total:56923970
min:354508 max:399130 total:61628878
min:319998 max:367493 total:55624467
min:337322 max:379689 total:58425775
min:325701 max:369950 total:56382432
min:318423 max:364997 total:55662597
min:332930 max:374174 total:57881582
min:324787 max:371432 total:56881287
min:335136 max:381850 total:58661101
min:329253 max:377998 total:58146731
min:353550 max:399807 total:61031126
min:312443 max:358633 total:55092296
min:344435 max:396344 total:61129639
min:332426 max:394539 total:58307766
min:322235 max:367385 total:56477056
min:326722 max:362761 total:55421905
min:318183 max:366510 total:56260638
min:321812 max:372084 total:56639167
min:328016 max:379484 total:57794343
min:314929 max:364644 total:55440152
average:57710064
3c8fb50445833b93f69b6b703a29aae3523cad0c
with paul's early version and the magic 7:
root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
testcase:Separate file open/close
warmup
min:310891 max:364268 total:54015547
min:283886 max:333177 total:49992270
min:275451 max:314699 total:47775422
min:275164 max:316351 total:47720614
min:283434 max:326614 total:49156206
min:276475 max:320313 total:48469874
measurement
min:274589 max:323239 total:48149462
min:280194 max:328827 total:49338289
min:277830 max:327060 total:48962337
min:281689 max:325917 total:49211850
min:271332 max:308350 total:46813631
min:275384 max:319016 total:47366390
min:276728 max:318277 total:47752679
min:275616 max:317111 total:47955871
min:278882 max:319082 total:47864449
min:267076 max:312427 total:47225886
min:279400 max:322798 total:48561113
min:279140 max:317367 total:47762975
min:278772 max:325575 total:49001990
min:271660 max:311780 total:47349871
min:283508 max:326299 total:49516078
min:284946 max:327525 total:49468752
min:271924 max:316507 total:47867902
min:279669 max:313937 total:47582153
min:272887 max:319545 total:47725521
min:281685 max:323791 total:48620478
min:280714 max:324849 total:48804594
min:283307 max:327424 total:49153787
min:280186 max:323924 total:48618088
min:270821 max:311985 total:47194656
min:282145 max:327910 total:48728398
min:276035 max:326523 total:48895232
min:275433 max:317441 total:48054952
min:276840 max:320486 total:48297727
min:280297 max:320323 total:48736783
min:286099 max:327522 total:50318962
average:48363361
On Fri, Jun 20, 2014 at 10:39:50AM -0700, Dave Hansen wrote:
> On 06/20/2014 09:30 AM, Paul E. McKenney wrote:
> > On Fri, Jun 20, 2014 at 11:07:13AM -0500, Christoph Lameter wrote:
> >> On Fri, 20 Jun 2014, Paul E. McKenney wrote:
> >>
> >>> And the fraction of the small systems that care that much about latency
> >>> is also quite small.
> >>
> >> This also impacts general performance of course not only latency.
> >>
> >>> Of course, if you have performance results that show otherwise, please
> >>> share them.
> >>
> >> We are discussing a performance problem right here.
> >
> > We are engaging in a lot of -speculation- about an -alleged- performance
> > problem. I have posted a fix to the actual performance problem, but the
> > guy reporting the original report of that problem has not yet reported
> > the performance of the fix. Which is fine, as I am getting ready to
> > post an updated fix, and besides which he might well have higher-priority
> > tasks requiring his attention. But without that performance information,
> > we are all just engaging in baseless speculation.
>
> The patch helps, but does not get us back to where we were before:
>
> Baseline: 3c8fb5044 with ac1bea85781e9004d reverted:
> root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
> ...
> average:57710064
>
> 3c8fb5044 with Paul's early version with the magic 7:
> root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
> ...
> average:48363361
>
> It was down at 43M or 44M without the new patch.
Thank you for the info, Dave!
Thanx, Paul
> full spew:
>
> 3c8fb50445833b93f69b6b703a29aae3523cad0c
> with ac1bea85781e9004d reverted:
> root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
> warmup
> min:366329 max:421686 total:63727790
> min:358758 max:406036 total:62561168
> min:298435 max:340355 total:51711000
> min:343707 max:383812 total:59554601
> min:310652 max:356571 total:54016014
> min:337738 max:382557 total:59146223
> measurement
> min:317628 max:363489 total:55230696
> min:341875 max:392621 total:59910047
> min:331979 max:376582 total:58074347
> min:342835 max:388481 total:59644247
> min:327282 max:374283 total:56897588
> min:321668 max:373622 total:55799061
> min:336575 max:387027 total:58948777
> min:350269 max:397098 total:61510405
> min:336949 max:382367 total:58640224
> min:327913 max:371026 total:56833639
> min:322377 max:375011 total:56923970
> min:354508 max:399130 total:61628878
> min:319998 max:367493 total:55624467
> min:337322 max:379689 total:58425775
> min:325701 max:369950 total:56382432
> min:318423 max:364997 total:55662597
> min:332930 max:374174 total:57881582
> min:324787 max:371432 total:56881287
> min:335136 max:381850 total:58661101
> min:329253 max:377998 total:58146731
> min:353550 max:399807 total:61031126
> min:312443 max:358633 total:55092296
> min:344435 max:396344 total:61129639
> min:332426 max:394539 total:58307766
> min:322235 max:367385 total:56477056
> min:326722 max:362761 total:55421905
> min:318183 max:366510 total:56260638
> min:321812 max:372084 total:56639167
> min:328016 max:379484 total:57794343
> min:314929 max:364644 total:55440152
> average:57710064
>
> 3c8fb50445833b93f69b6b703a29aae3523cad0c
> with paul's early version and the magic 7:
> root@bigbox:~/will-it-scale# ./open1_processes -t 160 -s 30
> testcase:Separate file open/close
> warmup
> min:310891 max:364268 total:54015547
> min:283886 max:333177 total:49992270
> min:275451 max:314699 total:47775422
> min:275164 max:316351 total:47720614
> min:283434 max:326614 total:49156206
> min:276475 max:320313 total:48469874
> measurement
> min:274589 max:323239 total:48149462
> min:280194 max:328827 total:49338289
> min:277830 max:327060 total:48962337
> min:281689 max:325917 total:49211850
> min:271332 max:308350 total:46813631
> min:275384 max:319016 total:47366390
> min:276728 max:318277 total:47752679
> min:275616 max:317111 total:47955871
> min:278882 max:319082 total:47864449
> min:267076 max:312427 total:47225886
> min:279400 max:322798 total:48561113
> min:279140 max:317367 total:47762975
> min:278772 max:325575 total:49001990
> min:271660 max:311780 total:47349871
> min:283508 max:326299 total:49516078
> min:284946 max:327525 total:49468752
> min:271924 max:316507 total:47867902
> min:279669 max:313937 total:47582153
> min:272887 max:319545 total:47725521
> min:281685 max:323791 total:48620478
> min:280714 max:324849 total:48804594
> min:283307 max:327424 total:49153787
> min:280186 max:323924 total:48618088
> min:270821 max:311985 total:47194656
> min:282145 max:327910 total:48728398
> min:276035 max:326523 total:48895232
> min:275433 max:317441 total:48054952
> min:276840 max:320486 total:48297727
> min:280297 max:320323 total:48736783
> min:286099 max:327522 total:50318962
> average:48363361
>
>
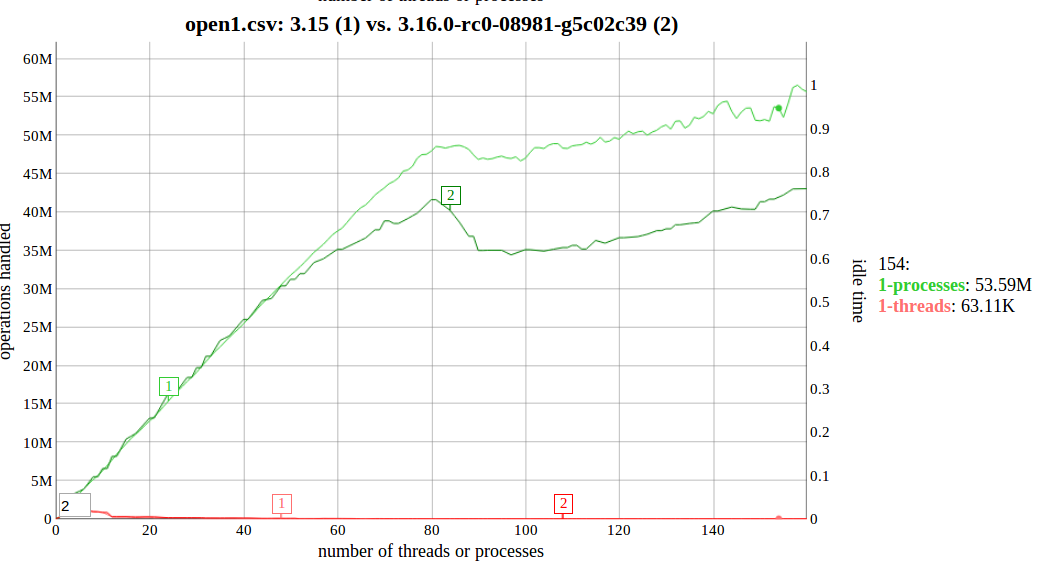{kind=link}
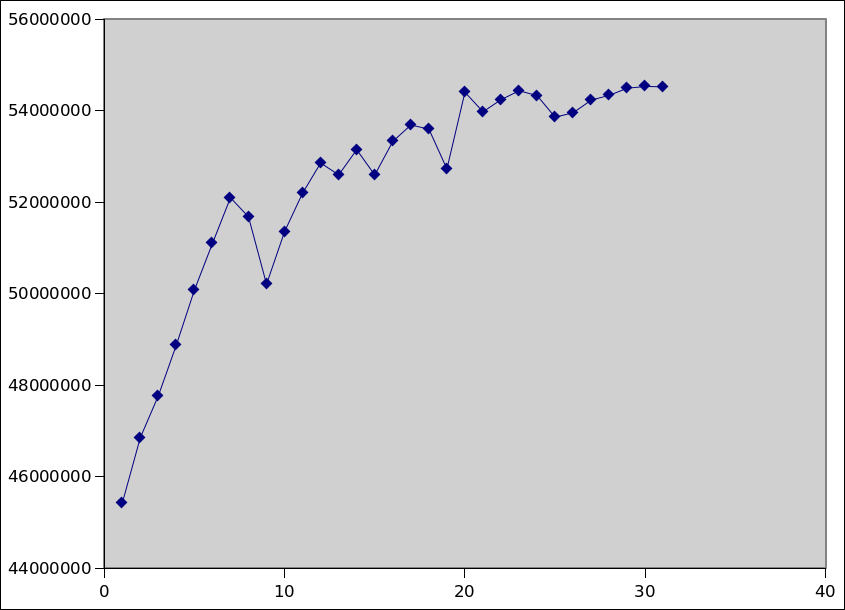{kind=link}