Extended changelog at:
http://home.earthlink.net/~rwhron/kernel/andrea/2.4.19pre2aa1.html
--
Randy Hron
On Fri, Mar 08, 2002 at 01:22:39AM +0100, Andrea Arcangeli wrote:
> - "i" is the random not predictable input
> - "i" is generated by dropping the non random bits of the "page"
> with a cute trick that drops the bit with
> a shiftright with an immediate argument, it's not a
> division so it's faster it could been
> "page/sizeof(struct page)" but it would been slower
> - s(i) takes into account not just the last "wait_table->shift" bytes
> of the random information in "i", but also the next "shift"
> bytes, so it's more random even if some of those lower or higher
> bits is generating patterns for whatever reason
> - finally you mask out the resulting random information s(i) with
> size-1, so you fit into the wait_table->head memory.
> The result is that it exploits most of the random input, and physically
> consecutive pages are liekly to use the same cacheline in case there is
> some pattern. That looks a good algorithm to me.
I'm sorry, this reasoning is too flawed to address in detail. I'm a
programmer, not a schoolteacher. I'll drop a hint: "randomness" is not
the right word to use. The way to make a meaningful statement is a
statistical measurement of how close the resulting bucket distributions
are to uniform, as uniform distributions across buckets minimize collisions.
I suggest the usual chi^2 and Kolmogorov-Smirnov (and variants) tests.
The results of these tests are simple: they will compute the
probability that the difference between the measured distribution and a
true uniform distribution could not have occurred by chance (i.e.
whether its difference from the uniform distribution is statistically
significant). With these things in hand you should be able to make more
meaningful assertions about your hashing algorithms.
Cheers,
Bill
P.S.: The quality (or lack thereof) of this hash function is already
visible in histograms of the pagecache bucket distribution on
larger systems. Statistical measurements of its quality reflect
this very clearly as well. Someone needs to move the stable out
of the Sahara and closer to a lake.
http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
is a histogram of the pagecache hash function's bucket distribution
on an SMP ppc64 machine after some benchmark run.
http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
has a histogram of a Fibonacci hashing hash function's bucket
distribution on the same machine after an identical benchmark run.
(There is more to come from the hash table analysis front.)
On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
> http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
>
> is a histogram of the pagecache hash function's bucket distribution
> on an SMP ppc64 machine after some benchmark run.
>
> http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
>
> has a histogram of a Fibonacci hashing hash function's bucket
> distribution on the same machine after an identical benchmark run.
akpm just pointed out to me these histograms are not quite the best
comparisons as the tables differ in size. I'll get something webabble
soon with head-to-head comparisons. OTOH the general nature of things
should be clear and the behavior of that hash function visible.
Cheers,
Bill
On Tue, Mar 12, 2002 at 05:31:52AM +0000, [email protected] wrote:
> On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
> > http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
> >
> > is a histogram of the pagecache hash function's bucket distribution
> > on an SMP ppc64 machine after some benchmark run.
> >
> > http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
> >
> > has a histogram of a Fibonacci hashing hash function's bucket
> > distribution on the same machine after an identical benchmark run.
>
> akpm just pointed out to me these histograms are not quite the best
> comparisons as the tables differ in size. I'll get something webabble
yes, I also noticed it immediatly, 250000 buckets vs 8million buckets...
Not only that, now I also noticed it seems there is a different number
of entries into the two hashes.
> soon with head-to-head comparisons. OTOH the general nature of things
> should be clear and the behavior of that hash function visible.
I won't be really surprised if you can beat the pagecache hash with big
files. Fibonacci/mul may very well be better there. I'm not sure if you
can beat it on the small files though, and still one should always take
into account the cache effects, the monitoring of the hash distribution
isn't the end of the story.
I would be mostly interested to see a comparions for the hashfn of the
wait_table too, that is the thing we were discussing here.
Andrea
On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
> On Fri, Mar 08, 2002 at 01:22:39AM +0100, Andrea Arcangeli wrote:
> > - "i" is the random not predictable input
> > - "i" is generated by dropping the non random bits of the "page"
> > with a cute trick that drops the bit with
> > a shiftright with an immediate argument, it's not a
> > division so it's faster it could been
> > "page/sizeof(struct page)" but it would been slower
> > - s(i) takes into account not just the last "wait_table->shift" bytes
> > of the random information in "i", but also the next "shift"
> > bytes, so it's more random even if some of those lower or higher
> > bits is generating patterns for whatever reason
> > - finally you mask out the resulting random information s(i) with
> > size-1, so you fit into the wait_table->head memory.
> > The result is that it exploits most of the random input, and physically
> > consecutive pages are liekly to use the same cacheline in case there is
> > some pattern. That looks a good algorithm to me.
>
> I'm sorry, this reasoning is too flawed to address in detail. I'm a
Well, that's the same reasoning behind the hashfn that everybody using
linux computes at every read syscall. I didn't invented it, I only told
you what's the reasoning behind it.
btw, some year back also Chuck Lever did an very interesting extensive
research on hashing and he just evaluated the multiplicative hash
method.
The critical thing that araised from Chuck's extensive research on the
hashes is been the dynamic sizing of the hashes as boot. the hashfn
weren't changed. If we could have exploited a huge performance
optimization and if the current hashfn would been flawed how could you
explain that the hashfn are still unchanged? Because Linus dropped the
email with the patches and those emails weren't resent? Then why didn't
somebody piked them up in a different benchmark tree?
Said that I agree that for the pagecache hash, there could be
interesting patterns in input. If the inodes are allocated at nearly the
same time after boot, and you work on large files, then you'll likely
generate lots of collisions that may be avoided by the multiplicatve
hash. So it's not optimal for the big files handling only a few inodes.
But note that this email thread is about the wait_table hash, not the
pagecache hash, they're two completly different beasts, even if the
reasoning behind them is the same one.
> programmer, not a schoolteacher. I'll drop a hint: "randomness" is not
I studied the multiplicative hashes (i recall the div method) in
Introduction to Algorithms and what I think about them is that those
hashfns are been designed to work well in presence of non random
patterns in input. One example of an hashfn in linux that doesn't get
significantive random input, is the buffer cache hash. That's indexed
by offset and the blkdev. the blkdev is just fixed, no matter if it's a
pointer or a major/minor. The offset will definitely have huge patterns
that can lead to bad distribution (just like the "offset" in the
pagecache hash). I recall Chuck noticed that, and infact the hashfn of
the buffercache is the only one that I'm sure it's been replaced because
it was bad.
See what it become now:
#define _hashfn(dev,block) \
((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
(((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
((block) << (bh_hash_shift - 12))))
For the pagecache hashfn similar collisions can happen with big files and
only a few inodes allocated right after boot. The current pagecache hash
is optimal on the small files, like simultaneous kernel compile + kde
compile + gcc compile etc....
Also note that one thing that math doesn't contemplate is that it may be
faster to handle more collisions on a hot L2/L1 cache, rather than not
having collisons but to constantly run at the speed of the DRAM and the
current hashes definitely cares a lot about this bit. I only see you
looking at the distribution on the paper and not at the access pattern
to memory and cache effects.
But anyways we're not talking about the pagecache has here, the
randomness of the input of the wait_table isn't remotely comparable to
the randomness of the input of the pagecache hash: after load the free
pages in the freelists will become completly random, and if there's a
probability, the probability is that they're contigous (for example when
a kernel stack gets released for example, and two page of pagecahce gets
allocated while reading a file, and then we wait on both, and we want
both waitqueues in the same cacheline). It's not like with the
pagecacache that you can artificially generate collisions easily by
working on big files with two inodes allocated right after boot. Here
the pages are the random input and we can't ask for something better in
input for an hashfn.
If you assume a pure random input, I don't see how can you distribute it
better with a simple mul assembler instruction. That's my whole point.
Now if intuition doesn't work here, and you need a complex math
demonstration to proof it, please give post a poiner to a book or
pubblication and I will study it, I definitely want to understand how
the hell could a "mul" distribute better a pure random input because
intuitions tells me it's not possible.
> the right word to use. The way to make a meaningful statement is a
> statistical measurement of how close the resulting bucket distributions
> are to uniform, as uniform distributions across buckets minimize collisions.
> I suggest the usual chi^2 and Kolmogorov-Smirnov (and variants) tests.
>
> The results of these tests are simple: they will compute the
> probability that the difference between the measured distribution and a
> true uniform distribution could not have occurred by chance (i.e.
> whether its difference from the uniform distribution is statistically
> significant). With these things in hand you should be able to make more
> meaningful assertions about your hashing algorithms.
>
>
> Cheers,
> Bill
>
> P.S.: The quality (or lack thereof) of this hash function is already
> visible in histograms of the pagecache bucket distribution on
> larger systems. Statistical measurements of its quality reflect
> this very clearly as well. Someone needs to move the stable out
> of the Sahara and closer to a lake.
>
> http://www.samba.org/~anton/linux/pagecache/pagecache_before.png
>
> is a histogram of the pagecache hash function's bucket distribution
> on an SMP ppc64 machine after some benchmark run.
>
> http://www.samba.org/~anton/linux/pagecache/pagecache_after.png
>
> has a histogram of a Fibonacci hashing hash function's bucket
> distribution on the same machine after an identical benchmark run.
>
> (There is more to come from the hash table analysis front.)
from the graphs it seems the "before" had 250000 buckets, and the
"after" had 8 million buckets. Is that right? Or were all the other
8millions - 250000 buckets unused in the "before" test, if yes, then you
were definitely not monitorning a misc load with small files, but of
course for such a kind of workload the fibonacci hashing would very well
be better than the current pagecache hash, I completly agree. the
"after" graph also shows the hash is sized wrong, that's because we're
not using the bootmem allocator, Dave has a patch for that (but it's
highmem-not-aware still). btw, it's amazing that the hash is almost as
fast as the radix tree despite the fact the hash can at max be 2M in
size currently, on a >=4G box you really need it bigger or you'll be
guaranteed having to walk a bigger depth than the radix tree.
Andrea
On Tue, 12 Mar 2002, Andrea Arcangeli wrote:
> If you assume a pure random input, I don't see how can you distribute it
> better with a simple mul assembler instruction. That's my whole point.
Since you've just given two examples of common non-random
workloads yourself, I don't see how you can reasonably
expect a pure random input.
Rik
--
<insert bitkeeper endorsement here>
http://www.surriel.com/ http://distro.conectiva.com/
On Fri, Mar 08, 2002 at 01:22:39AM +0100, Andrea Arcangeli wrote:
>>> The result is that it exploits most of the random input, and physically
>>> consecutive pages are liekly to use the same cacheline in case there is
>>> some pattern. That looks a good algorithm to me.
On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
>> I'm sorry, this reasoning is too flawed to address in detail. I'm a
On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
> Well, that's the same reasoning behind the hashfn that everybody using
> linux computes at every read syscall. I didn't invented it, I only told
> you what's the reasoning behind it.
I maintain that this reasoning is fallacious and that the results are
suboptimal. The argument is by authority and the results I have measured.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> btw, some year back also Chuck Lever did an very interesting extensive
> research on hashing and he just evaluated the multiplicative hash
> method.
I cited Chuck Lever in my comments.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> The critical thing that araised from Chuck's extensive research on the
> hashes is been the dynamic sizing of the hashes as boot. the hashfn
> weren't changed. If we could have exploited a huge performance
> optimization and if the current hashfn would been flawed how could you
> explain that the hashfn are still unchanged? Because Linus dropped the
> email with the patches and those emails weren't resent? Then why didn't
> somebody piked them up in a different benchmark tree?
The pagecache hash function and the inode cache hash functions don't pass
statistical tests and performance improvements from using hash functions
that do are demonstrable.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> Said that I agree that for the pagecache hash, there could be
> interesting patterns in input. If the inodes are allocated at nearly the
> same time after boot, and you work on large files, then you'll likely
> generate lots of collisions that may be avoided by the multiplicatve
> hash. So it's not optimal for the big files handling only a few inodes.
-ESPECULATION
Q(chi^2|nu), the probability that a uniform distribution would give
rise to such measured distributions by chance, is vanishingly small for
the pagecache hash functions. I have measured this in various scenarios,
and am attempting to gather enough information to compute statistical
correlations between benchmarks and statistical tests for the
uniformity of the distribution across buckets in addition to statistical
properties of the bucket distributions themselves.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> But note that this email thread is about the wait_table hash, not the
> pagecache hash, they're two completly different beasts, even if the
> reasoning behind them is the same one.
Not really. The pagecache hash function proved itself so poor in the
pagecache setting it was not a worthwhile candidate.
On Tue, Mar 12, 2002 at 04:19:58AM +0000, [email protected] wrote:
>> programmer, not a schoolteacher. I'll drop a hint: "randomness" is not
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> I studied the multiplicative hashes (i recall the div method) in
> Introduction to Algorithms and what I think about them is that those
> hashfns are been designed to work well in presence of non random
> patterns in input. One example of an hashfn in linux that doesn't get
> significantive random input, is the buffer cache hash. That's indexed
> by offset and the blkdev. the blkdev is just fixed, no matter if it's a
> pointer or a major/minor. The offset will definitely have huge patterns
> that can lead to bad distribution (just like the "offset" in the
> pagecache hash). I recall Chuck noticed that, and infact the hashfn of
> the buffercache is the only one that I'm sure it's been replaced because
> it was bad.
CLR's mention of multiplicative hashing is little more than a citation
of Knuth with a brief computation of a bucket index (using floating
point arithmetic!) for an example. The div method is in the section
immediately preceding it and is described as slot = key % tablesize.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> See what it become now:
> #define _hashfn(dev,block) \
> ((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
> (((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
> ((block) << (bh_hash_shift - 12))))
I've actually measured the distributions of entries across buckets
resulting from this hash function and it has impressive statistical
properties. Fibonacci hashing falls flat on its face for the bcache,
which seems to be at variance with your sequential input assertion,
as that appears to be one of Fibonacci hashing's specialties (behold
ext2 inode number allocation).
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> For the pagecache hashfn similar collisions can happen with big files and
> only a few inodes allocated right after boot. The current pagecache hash
> is optimal on the small files, like simultaneous kernel compile + kde
> compile + gcc compile etc....
-ESPECULATION
The pagecache hash function has never passed a single statistical test
that I've put it through. Q(chi^2|nu) < 10**-200 etc. is typical.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> Also note that one thing that math doesn't contemplate is that it may be
> faster to handle more collisions on a hot L2/L1 cache, rather than not
> having collisons but to constantly run at the speed of the DRAM and the
> current hashes definitely cares a lot about this bit. I only see you
> looking at the distribution on the paper and not at the access pattern
> to memory and cache effects.
I'll humor you for a moment but point out that L2/L1 cache misses are
considerably cheaper than scheduling storms. Furthermore, the kinds of
proof you'd to establish this sort of assertion for ordinary bucket
disciplines appears to involve reading profiling registers to count
cache misses or perhaps tracing bus accesses using logic analyzers, or
simulation logging, which I doubt have been done.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> But anyways we're not talking about the pagecache has here, the
> randomness of the input of the wait_table isn't remotely comparable to
> the randomness of the input of the pagecache hash: after load the free
> pages in the freelists will become completly random, and if there's a
> probability, the probability is that they're contigous (for example when
> a kernel stack gets released for example, and two page of pagecahce gets
> allocated while reading a file, and then we wait on both, and we want
> both waitqueues in the same cacheline). It's not like with the
> pagecacache that you can artificially generate collisions easily by
> working on big files with two inodes allocated right after boot. Here
> the pages are the random input and we can't ask for something better in
> input for an hashfn.
This is pure speculation. Would you care demonstrate these phenomena by
means of tracing methods, e.g. simulator traces or instrumentation code?
My personal opinion on these sorts of assertions is that they are highly
workload dependent and involve interactions with the policies of the slab
and physical allocators with usage patterns, architectural formatting of
virtual addresses, and physical and virtual memory layouts, which in my
mind are complex enough and vary enough they are best modeled with
statistical and empirical methods.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> If you assume a pure random input, I don't see how can you distribute it
> better with a simple mul assembler instruction. That's my whole point.
> Now if intuition doesn't work here, and you need a complex math
> demonstration to proof it, please give post a poiner to a book or
> pubblication and I will study it, I definitely want to understand how
> the hell could a "mul" distribute better a pure random input because
> intuitions tells me it's not possible.
A random variable could have a distribution concentrated at a single
point (which would defeat any hashing scheme). You need to revise your
terminology at the very least.
I'd also love to hear what sort of distribution you believe your random
input variable to have, and measurements to compare it against.
For specific reasons why multiplication by a magic constant (related to
the golden ratio) should have particularly interesting scattering
properties, Knuth cites Vera Tur?n S?s, Acta Math. Acad. Sci. Hung. 8
(1957), 461-471; Ann. Univ. Sci. Budapest, E?tv?s Sect. Math 1 (1958),
127-134, and gives further details in exercises 8 and 9 in section 6.4,
TAOCP vol. 2 (2nd ed.). There are also some relevant lemmas around for
the connoisseur.
I don't take this to mean that Fibonacci hashing is gospel.
In my mind the advantages are specifically:
(1) the search process for good hash functions may be guided by sieving
(2) there is a comprehensible motivation behind the hashing scheme
(3) the hash functions actually pass the statistical tests I run
(4) they provide demonstrable benefits for the tables I use them in
Now, the proofs as they are carried out appear to involve sequential
natural numbers, yet one should notice that this is *not* a finite
process. Hence, it makes an assertion regarding all of the natural
numbers simultaneously, not sequential insertions.
On Tue, Mar 12, 2002 at 07:06:45AM +0100, Andrea Arcangeli wrote:
> from the graphs it seems the "before" had 250000 buckets, and the
> "after" had 8 million buckets. Is that right? Or were all the other
> 8millions - 250000 buckets unused in the "before" test, if yes, then you
> were definitely not monitorning a misc load with small files, but of
> course for such a kind of workload the fibonacci hashing would very well
> be better than the current pagecache hash, I completly agree. the
> "after" graph also shows the hash is sized wrong, that's because we're
> not using the bootmem allocator, Dave has a patch for that (but it's
> highmem-not-aware still). btw, it's amazing that the hash is almost as
> fast as the radix tree despite the fact the hash can at max be 2M in
> size currently, on a >=4G box you really need it bigger or you'll be
> guaranteed having to walk a bigger depth than the radix tree.
What you're noticing here is what I actually pointed you at was "before"
and "after" for pagecache alloc in bootmem. I don't actually know where
anton's comparisons for my Fibonacci hashing functions vs. that are,
and probably won't hear until hacker hours resume in .au
I will either sort out the results I have on the waitqueues or rerun
tests at my leisure.
Note I am only trying to help you avoid shooting yourself in the foot.
Cheers,
Bill
On Tue, Mar 12, 2002 at 07:46:51AM -0300, Rik van Riel wrote:
> On Tue, 12 Mar 2002, Andrea Arcangeli wrote:
>
> > If you assume a pure random input, I don't see how can you distribute it
> > better with a simple mul assembler instruction. That's my whole point.
>
> Since you've just given two examples of common non-random
> workloads yourself, I don't see how you can reasonably
> expect a pure random input.
It is not pure random of course, it can't be pure random there will be
always some influence for example from the I/O patterns, in particular
right after boot, but the randomness of the input is still excellent,
it's not an inode pointer that could have a very little change. I made
the example to say in the so unlikely case it happens, that's great,
we'll have the guarantee that those two pages won't collide in the same
waitqueue.
Infact above I said "If you _assume_ pure random input". That's what I'm
interested about, if you _assume_ pure random input (in practice there
will always be some infuence).
Bill said that "randomness" is not the right word to use, I instead
think it's the key. If it's pure random mul will make no difference to
the distribution. And the closer we're to pure random like in the
wait_table hash, the less mul will help and the more important will be
to just get right the two contigous pages in the same cacheline and
nothing else.
For the pagecache hash the thing is different, as said with the
pagecache some patological workload can really generate lots of
collisions reproducibly, big patterns can happen there, for example if
the inode happens to be allocated in a row right after boot, and then
some massive I/O starts on similar patterns. While in the
developer-workloads with lots of small files and VM activity, the
pagecache hash should be just good.
Andrea
On Tue, Mar 12, 2002 at 12:47:28PM +0100, Andrea Arcangeli wrote:
> Bill said that "randomness" is not the right word to use, I instead
> think it's the key. If it's pure random mul will make no difference to
> the distribution. And the closer we're to pure random like in the
> wait_table hash, the less mul will help and the more important will be
> to just get right the two contigous pages in the same cacheline and
> nothing else.
Aha! It's random! Is the distribution:
(1) Poisson
(2) singular
(3) binomial
(4) hypergeometric
or what?
Cheers,
Bill
On March 12, 2002 12:47 pm, Andrea Arcangeli wrote:
> If it's pure random mul will make no difference to
> the distribution. And the closer we're to pure random like in the
> wait_table hash, the less mul will help and the more important will be
> to just get right the two contigous pages in the same cacheline and
> nothing else.
You're ignoring the possibility (probability) of corner cases. I'm not
sure why you're beating away on this, Bill has done a fine job of coming
up with hashes that are both satisfactory for the common case and have
sound reasons for being resistant to corner cases.
--
Daniel
On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
> For specific reasons why multiplication by a magic constant (related to
> the golden ratio) should have particularly interesting scattering
> properties, Knuth cites Vera Tur?n S?s, Acta Math. Acad. Sci. Hung. 8
I know about the scattering properties of some number (that is been
measured empirically if I remeber well what I read). I was asking for
something else, I was asking if this magical number can scatter better a
random input as well or not. My answer is no. And I believe the nearest
you are to random input to the hashfn the less the mul can scatter
better than the input itself and it will just lose cache locality for
consecutive pages. So the nearest you are, the better if you avoid the
mul and you take full advantage of the randomness of the input, rather
than keeping assuming the input has pattenrs.
I mean, start reading from /dev/random and see how the distribution goes
with and without mul, it will be the same I think.
> I will either sort out the results I have on the waitqueues or rerun
> tests at my leisure.
I'm waiting for it, if you've monitor patches I can run something too.
I'd like to count the number of collisions over time in particular.
> Note I am only trying to help you avoid shooting yourself in the foot.
If I've rescheduling problems you're likely to have them too, I'm quite
sure, if something the fact I keep the hashtable large enough will make
me less bitten by the collisions. The only certain way to avoid riskying
regressions would be to backout the wait_table part that was merged in
mainline 19pre2. the page_zone thing cannot generate any regression for
instance (same is true for page_address), the wait_table part is gray
area instead, it's just an heuristic like all the hashes and you can
always have a corner case bitten hard, it's just that the probabiliy for
such a corner case to happen has to be small enough for it to be
acceptable, but you can always be unlucky, no matter if you mul or not,
you cannot predict the future of what's the next pages that the people
will wait on from userspace.
Andrea
On Tue, 12 Mar 2002, Andrea Arcangeli wrote:
> I know about the scattering properties of some number (that is been
> measured empirically if I remeber well what I read). I was asking for
> something else, I was asking if this magical number can scatter better a
> random input as well or not. My answer is no.
> I mean, start reading from /dev/random and see how the distribution goes
> with and without mul, it will be the same I think.
I think it's time we introduce a CS theory equivalent
of Godwin's Law.
You've just outknuthed yourself ;)
Rik
--
<insert bitkeeper endorsement here>
http://www.surriel.com/ http://distro.conectiva.com/
On Tue, 12 Mar 2002, Andrea Arcangeli wrote:
> On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
> > For specific reasons why multiplication by a magic constant (related to
> > the golden ratio) should have particularly interesting scattering
> > properties, Knuth cites Vera Tur?n S?s, Acta Math. Acad. Sci. Hung. 8
>
> I know about the scattering properties of some number (that is been
> measured empirically if I remeber well what I read). I was asking for
> something else, I was asking if this magical number can scatter better a
> random input as well or not. My answer is no. And I believe the nearest
> you are to random input to the hashfn the less the mul can scatter
> better than the input itself and it will just lose cache locality for
> consecutive pages. So the nearest you are, the better if you avoid the
> mul and you take full advantage of the randomness of the input, rather
> than keeping assuming the input has pattenrs.
>
> I mean, start reading from /dev/random and see how the distribution goes
> with and without mul, it will be the same I think.
>
> > I will either sort out the results I have on the waitqueues or rerun
> > tests at my leisure.
>
> I'm waiting for it, if you've monitor patches I can run something too.
> I'd like to count the number of collisions over time in particular.
>
> > Note I am only trying to help you avoid shooting yourself in the foot.
>
> If I've rescheduling problems you're likely to have them too, I'm quite
> sure, if something the fact I keep the hashtable large enough will make
> me less bitten by the collisions. The only certain way to avoid riskying
> regressions would be to backout the wait_table part that was merged in
> mainline 19pre2. the page_zone thing cannot generate any regression for
> instance (same is true for page_address), the wait_table part is gray
> area instead, it's just an heuristic like all the hashes and you can
> always have a corner case bitten hard, it's just that the probabiliy for
> such a corner case to happen has to be small enough for it to be
> acceptable, but you can always be unlucky, no matter if you mul or not,
> you cannot predict the future of what's the next pages that the people
> will wait on from userspace.
>
> Andrea
This is a simple random number generator. It takes a pointer to your
own private long, somewhere in your code, and returns a long random
number with a period of 0xfffd4011. I ran a program for about a
year, trying to find a magic number that will produce a longer
period.
You could add a ldiv and return the modulus to set hash-table limits.
ANDs are not good because, in principle, you could get many numbers
in which all the low bits are zero.
The advantage of this simple code is it works quickly. The disadvantages
are, of course, its not portable and a rotation of a binary number
is not a mathematical function, lending itself to rigorous analysis.
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
#
# File rnd.S Created 04-FEB-2000 Richard B. Johnson
# [email protected]
#
# Simple random number generator.
#
#
MAGIC = 0xd0047077
INTPTR = 0x08
.section .text
.global rnd
.type rnd,@function
.align 0x04
pushl %ebx
movl INTPTR(%esp), %ebx
movl (%ebx), %eax
rorl $3, %eax
addl $MAGIC, %eax
movl %eax, (%ebx)
popl %ebx
ret
.end
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
#-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
Cheers,
Dick Johnson
Penguin : Linux version 2.4.18 on an i686 machine (797.90 BogoMips).
Bill Gates? Who?
On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
>> For specific reasons why multiplication by a magic constant (related to
>> the golden ratio) should have particularly interesting scattering
>> properties, Knuth cites Vera Tur?n S?s, Acta Math. Acad. Sci. Hung. 8
On Tue, Mar 12, 2002 at 01:56:05PM +0100, Andrea Arcangeli wrote:
> I know about the scattering properties of some number (that is been
> measured empirically if I remeber well what I read). I was asking for
> something else, I was asking if this magical number can scatter better a
> random input as well or not. My answer is no. And I believe the nearest
> you are to random input to the hashfn the less the mul can scatter
> better than the input itself and it will just lose cache locality for
> consecutive pages. So the nearest you are, the better if you avoid the
> mul and you take full advantage of the randomness of the input, rather
> than keeping assuming the input has pattenrs.
> I mean, start reading from /dev/random and see how the distribution goes
> with and without mul, it will be the same I think.
The assumption here is then that the input distribution is uniform.
This is, in fact the input distribution Fibonacci hashing is
designed for (i.e. uniform distribution on the natural numbers, which
arises quite naturally from considering all of \mathbb{N} as input).
On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
>> I will either sort out the results I have on the waitqueues or rerun
>> tests at my leisure.
On Tue, Mar 12, 2002 at 01:56:05PM +0100, Andrea Arcangeli wrote:
> I'm waiting for it, if you've monitor patches I can run something too.
> I'd like to count the number of collisions over time in particular.
This is a fairly crude statistic but one that I'm collecting. The
hashtable profiling is something I've been treating as a userspace
issue with the state dumps done by mmapping /dev/kmem, and in fact,
I did not write that myself, that is due to Anton Blanchard and Rusty
Russell, who initiated this area of study, and have made the more
important contributions to it. In this instance, you can see as well
as I that the references date to the 50's and 60's, and that accurate
measurement is the truly difficult aspect of the problem. Formulae to
grind statistics into single numbers are nothing but following
directions, and these have been precisely the portions of the effort
for which I've been responsible, aside from perhaps some of the sieving
routines, with which I had assistance from Krystof and Fare from OPN,
and these are not especially significant in terms of effort either.
Anton and Rusty have been the ones with the insight to identify the
problematic areas and also to find methods of collecting data.
On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
>> Note I am only trying to help you avoid shooting yourself in the foot.
On Tue, Mar 12, 2002 at 01:56:05PM +0100, Andrea Arcangeli wrote:
> If I've rescheduling problems you're likely to have them too, I'm quite
> sure, if something the fact I keep the hashtable large enough will make
> me less bitten by the collisions. The only certain way to avoid riskying
> regressions would be to backout the wait_table part that was merged in
> mainline 19pre2. the page_zone thing cannot generate any regression for
> instance (same is true for page_address), the wait_table part is gray
> area instead, it's just an heuristic like all the hashes and you can
> always have a corner case bitten hard, it's just that the probabiliy for
> such a corner case to happen has to be small enough for it to be
> acceptable, but you can always be unlucky, no matter if you mul or not,
> you cannot predict the future of what's the next pages that the people
> will wait on from userspace.
I have some small reservations about these assertions.
(1) the scheduling storms are direct results of collisions in the hash
tables, which are direct consequences of the hash function quality.
OTOH increasing table size is one method of collision reduction,
albeit one I would like extremely strict control over, and one
that should not truly be considered until the load is high
(.e.g. 0.75 or thereabouts)
(2) page_address() has been seen to cause small regressions on
architectures where the additional memory reference in comparison
to a __va((page - mem_map) << PAGE_SHIFT) implementation is
measurable. In my mind, several generic variants are required for
optimality and I will either personally implement them or endorse
any suitably clean implementations of them (clean is the hard part).
(3) Hashing is not mere heuristics. A hash function is a sufficiently
small portion of an implementation of a table lookup scheme
that the search may be guided by statistical measurements of
both the effectiveness of the hash function in distributing
keys across buckets and net profiling results. The fact I
restricted the space I searched to Fibonacci hashing is
irrelevant; it was merely a tractable search subspace.
(4) The notion that a hashing scheme may be defeated by a sufficiently
unlucky input distribution is irrelevant. This has been known
(and I suppose feared) since its invention in the early 1950's.
Hash tables are nondeterministic data structures by design, and
their metrics of performance are either expected or amortized
running time, not worst case, which always equal to linear search.
(5) Last, but not least, the /dev/random argument is bogus. Mass
readings of pseudorandom number generators do not make for
necessarily uniformly distributed trials or samples. By and
large the methods by which pseudorandom number generators are
judged (and rightly so) are various kinds of statistical relations
between some (fixed for the duration of the trial) number of
successively generated numbers. For instance, groups of N (where
N is small and fixed for the duration of the trial) consecutively
generated numbers should not lie within the same hyperplane for
some applications. These have no relation to the properties
which would cause a distribution of a set of numbers which is
measured as a snapshot in time to pass a test for uniformity.
Otherwise we appear to be largely in agreement.
Cheers,
Bill
On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote:
> This is a simple random number generator. It takes a pointer to your
> own private long, somewhere in your code, and returns a long random
> number with a period of 0xfffd4011. I ran a program for about a
> year, trying to find a magic number that will produce a longer
> period.
>
> You could add a ldiv and return the modulus to set hash-table limits.
> ANDs are not good because, in principle, you could get many numbers
> in which all the low bits are zero.
>
>
> The advantage of this simple code is it works quickly. The disadvantages
> are, of course, its not portable and a rotation of a binary number
> is not a mathematical function, lending itself to rigorous analysis.
Would you mind explaining what the point of this is? AFAICT this is
meaningless noise inspired by the words "/dev/random".
Bill
On Tue, Mar 12, 2002 at 01:21:35PM +0100, Daniel Phillips wrote:
> On March 12, 2002 12:47 pm, Andrea Arcangeli wrote:
> > If it's pure random mul will make no difference to
> > the distribution. And the closer we're to pure random like in the
> > wait_table hash, the less mul will help and the more important will be
> > to just get right the two contigous pages in the same cacheline and
> > nothing else.
>
> You're ignoring the possibility (probability) of corner cases. I'm not
The corner cases cannot go away with a mul. If what you care about are
corner cases you shouldn't have dropped page->wait.
I changed the hashfn to make it better IMHO, Bill says it is suboptimal,
but I would prefer to see it happening on real load too before returning
to the mul. Counting the number of collisions per second under load
should be good enough measurement, nominal performance would be the
other variable but I doubt there's anything to measure in real time
differences.
If I'm generating visibly more collisions, I will be very glad to return
to the mul hashfn of course.
AFIK my current hashfn is never been tested in precendence on this kind
of random input of the wait_table pages.
Andrea
On Tue, 12 Mar 2002 [email protected] wrote:
> On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote:
> > This is a simple random number generator. It takes a pointer to your
> > own private long, somewhere in your code, and returns a long random
> > number with a period of 0xfffd4011. I ran a program for about a
> > year, trying to find a magic number that will produce a longer
> > period.
> >
> > You could add a ldiv and return the modulus to set hash-table limits.
> > ANDs are not good because, in principle, you could get many numbers
> > in which all the low bits are zero.
> >
> >
> > The advantage of this simple code is it works quickly. The disadvantages
> > are, of course, its not portable and a rotation of a binary number
> > is not a mathematical function, lending itself to rigorous analysis.
>
> Would you mind explaining what the point of this is? AFAICT this is
> meaningless noise inspired by the words "/dev/random".
>
>
> Bill
>
Really?
Cheers,
Dick Johnson
Penguin : Linux version 2.4.18 on an i686 machine (797.90 BogoMips).
Windows-2000/Professional isn't.
On March 12, 2002 03:25 pm, Andrea Arcangeli wrote:
> On Tue, Mar 12, 2002 at 01:21:35PM +0100, Daniel Phillips wrote:
> > On March 12, 2002 12:47 pm, Andrea Arcangeli wrote:
> > > If it's pure random mul will make no difference to
> > > the distribution. And the closer we're to pure random like in the
> > > wait_table hash, the less mul will help and the more important will be
> > > to just get right the two contigous pages in the same cacheline and
> > > nothing else.
> >
> > You're ignoring the possibility (probability) of corner cases. I'm not
>
> The corner cases cannot go away with a mul.
Oh but they do[1]. If there's a major point you're missing it has to be that.
[1] Not entirely of course, which Bill already pointed out clearly enough.
'Go away' always means 'get less common' with respect to hash functions,
that's the best you can do.
--
Daniel
On Tue, Mar 12, 2002 at 02:14:39PM +0000, [email protected] wrote:
> The assumption here is then that the input distribution is uniform.
Yes.
> On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
> >> I will either sort out the results I have on the waitqueues or rerun
> >> tests at my leisure.
>
> On Tue, Mar 12, 2002 at 01:56:05PM +0100, Andrea Arcangeli wrote:
> > I'm waiting for it, if you've monitor patches I can run something too.
> > I'd like to count the number of collisions over time in particular.
>
> This is a fairly crude statistic but one that I'm collecting. The
> hashtable profiling is something I've been treating as a userspace
> issue with the state dumps done by mmapping /dev/kmem, and in fact,
I'm not sure if the collisions will be frequent enough to show up in
kmem. I think collisions in this hash should never happen except in very
unlikely cases (one collision every few seconds would be ok for
example). So I guess we'd better use a synchronous method to count the
number of collisions with proper kernel code for that.
> I did not write that myself, that is due to Anton Blanchard and Rusty
> Russell, who initiated this area of study, and have made the more
> important contributions to it. In this instance, you can see as well
> as I that the references date to the 50's and 60's, and that accurate
> measurement is the truly difficult aspect of the problem. Formulae to
> grind statistics into single numbers are nothing but following
> directions, and these have been precisely the portions of the effort
> for which I've been responsible, aside from perhaps some of the sieving
> routines, with which I had assistance from Krystof and Fare from OPN,
> and these are not especially significant in terms of effort either.
> Anton and Rusty have been the ones with the insight to identify the
> problematic areas and also to find methods of collecting data.
>
>
> On Tue, Mar 12, 2002 at 11:29:00AM +0000, [email protected] wrote:
> >> Note I am only trying to help you avoid shooting yourself in the foot.
>
> On Tue, Mar 12, 2002 at 01:56:05PM +0100, Andrea Arcangeli wrote:
> > If I've rescheduling problems you're likely to have them too, I'm quite
> > sure, if something the fact I keep the hashtable large enough will make
> > me less bitten by the collisions. The only certain way to avoid riskying
> > regressions would be to backout the wait_table part that was merged in
> > mainline 19pre2. the page_zone thing cannot generate any regression for
> > instance (same is true for page_address), the wait_table part is gray
> > area instead, it's just an heuristic like all the hashes and you can
> > always have a corner case bitten hard, it's just that the probabiliy for
> > such a corner case to happen has to be small enough for it to be
> > acceptable, but you can always be unlucky, no matter if you mul or not,
> > you cannot predict the future of what's the next pages that the people
> > will wait on from userspace.
>
> I have some small reservations about these assertions.
> (1) the scheduling storms are direct results of collisions in the hash
> tables, which are direct consequences of the hash function quality.
you mean in _the_ hash table (wait_table hash table). Collisions in all
other hash tables in the kernel doesn't lead to scheduling storms of
course.
> OTOH increasing table size is one method of collision reduction,
> albeit one I would like extremely strict control over, and one
> that should not truly be considered until the load is high
> (.e.g. 0.75 or thereabouts)
yes, however strict control over 52k on a 256G machine when spending
some more minor ram would reduce a lot the probability of collisions
looked a bit excessive. I'm all for spending ram _if_ it pays off
singificantly.
> (2) page_address() has been seen to cause small regressions on
> architectures where the additional memory reference in comparison
That's a minor global regression, but linear without corner cases,
and the additional ram available to userspace may make more difference
as well depending on the workload and the size of the ram.
> to a __va((page - mem_map) << PAGE_SHIFT) implementation is
> measurable. In my mind, several generic variants are required for
> optimality and I will either personally implement them or endorse
> any suitably clean implementations of them (clean is the hard part).
> (3) Hashing is not mere heuristics. A hash function is a sufficiently
> small portion of an implementation of a table lookup scheme
> that the search may be guided by statistical measurements of
> both the effectiveness of the hash function in distributing
> keys across buckets and net profiling results. The fact I
> restricted the space I searched to Fibonacci hashing is
> irrelevant; it was merely a tractable search subspace.
> (4) The notion that a hashing scheme may be defeated by a sufficiently
> unlucky input distribution is irrelevant. This has been known
> (and I suppose feared) since its invention in the early 1950's.
> Hash tables are nondeterministic data structures by design, and
> their metrics of performance are either expected or amortized
> running time, not worst case, which always equal to linear search.
> (5) Last, but not least, the /dev/random argument is bogus. Mass
> readings of pseudorandom number generators do not make for
> necessarily uniformly distributed trials or samples. By and
> large the methods by which pseudorandom number generators are
> judged (and rightly so) are various kinds of statistical relations
> between some (fixed for the duration of the trial) number of
> successively generated numbers. For instance, groups of N (where
> N is small and fixed for the duration of the trial) consecutively
> generated numbers should not lie within the same hyperplane for
> some applications. These have no relation to the properties
> which would cause a distribution of a set of numbers which is
> measured as a snapshot in time to pass a test for uniformity.
/dev/random is not a pseudorandom number generator. /dev/urandom is.
>
>
> Otherwise we appear to be largely in agreement.
Yes.
Andrea
On Tue, Mar 12, 2002 at 02:14:39PM +0000, [email protected] wrote:
>> The assumption here is then that the input distribution is uniform.
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> Yes.
This is a much stronger assertion than random. Random variables
may have distributions concentrated on low-dimensional surfaces
(or even singleton points!) which is a case that should be excluded.
Various other distributions are probably not what you want either.
To be clear, I am not operating under the assumption that the input
distribution is uniform (or anything in particular).
At some point in the past, I wrote:
>> This is a fairly crude statistic but one that I'm collecting. The
>> hashtable profiling is something I've been treating as a userspace
>> issue with the state dumps done by mmapping /dev/kmem, and in fact,
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> I'm not sure if the collisions will be frequent enough to show up in
> kmem. I think collisions in this hash should never happen except in very
> unlikely cases (one collision every few seconds would be ok for
> example). So I guess we'd better use a synchronous method to count the
> number of collisions with proper kernel code for that.
That is pretty easy to do.
At some point in the past, I wrote:
>> I have some small reservations about these assertions.
>> (1) the scheduling storms are direct results of collisions in the hash
>> tables, which are direct consequences of the hash function quality.
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> you mean in _the_ hash table (wait_table hash table). Collisions in all
> other hash tables in the kernel doesn't lead to scheduling storms of
> course.
There is more than one wait_table, one per node or per zone.
At some point in the past, I wrote:
>> OTOH increasing table size is one method of collision reduction,
>> albeit one I would like extremely strict control over, and one
>> that should not truly be considered until the load is high
>> (.e.g. 0.75 or thereabouts)
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> yes, however strict control over 52k on a 256G machine when spending
> some more minor ram would reduce a lot the probability of collisions
> looked a bit excessive. I'm all for spending ram _if_ it pays off
> singificantly.
Also, there are already too many boot-time allocations proportional to
memory. At the very least consider setting a hard constant upper bound
with some small constant of proportionality to PID_MAX.
If I may wander (further?) off-topic and stand on the soapbox for a moment:
I personally believe this is serious enough various actions should be
taken so that we don't die a death by a thousand "every mickey mouse
hash table in the kernel allocating 0.5% of RAM at boot time" cuts.
Note that we are already in such dire straits that sufficiently large
physical memory sizes on 36-bit physically-addressed 32-bit machines
alone will experience consumption of the entire kernel virtual address
space by various boot-time allocations. This is a bug.
The lower bound of 256 looks intriguing; if it's needed then it should
be done, but if it is needed it begins to raise the question of whether
this fragment of physical memory is worthwhile or should be ignored. On
i386 this would be a fragment of size 1MB or smaller packaged into a
pgdat or zone. There is also an open question as to how much overhead
introducing nodes with tiny amounts of memory like this creates. I
think there may be a reason why they're commonly ignored. I suspect the
real issue here may be that contention for memory doesn't decrease with
the shrinking size of a region of physical memory either.
At some point in the past, I wrote:
>> (2) page_address() has been seen to cause small regressions on
>> architectures where the additional memory reference in comparison
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> That's a minor global regression, but linear without corner cases,
> and the additional ram available to userspace may make more difference
> as well depending on the workload and the size of the ram.
True, and (aside from how I would phrase it) this is my rationale for
not taking immediate action. For architectures where the interaction of
the address calculation arithmetic, arithmetic feature sets, and
numerical properties of structure sizes and so on are particularly
unfortunate around this code (I believe SPARC is one example and there
may be others), something will have to be done whether it's using a
different computation or just using the memory.
At some point in the past, I wrote:
>> (5) Last, but not least, the /dev/random argument is bogus. Mass
>> readings of pseudorandom number generators do not make for
>> necessarily uniformly distributed trials or samples. By and
>> large the methods by which pseudorandom number generators are
>> judged (and rightly so) are various kinds of statistical relations
>> between some (fixed for the duration of the trial) number of
>> successively generated numbers. For instance, groups of N (where
>> N is small and fixed for the duration of the trial) consecutively
>> generated numbers should not lie within the same hyperplane for
>> some applications. These have no relation to the properties
>> which would cause a distribution of a set of numbers which is
>> measured as a snapshot in time to pass a test for uniformity.
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> /dev/random is not a pseudorandom number generator. /dev/urandom is.
Right right. Random number generation is a different problem regardless.
At some point in the past, I wrote:
>> Otherwise we appear to be largely in agreement.
On Tue, Mar 12, 2002 at 04:04:30PM +0100, Andrea Arcangeli wrote:
> Yes.
We're getting down to details too minor to bother with.
Enough for now? Shall we meet with benchmarks next time?
Cheers,
Bill
P.S.: Note that I do maintain my code. If you do have demonstrable
improvements or even cleanups I will review them and endorse
them if they pass my review. These changes did not. Also,
these changes to the hashing scheme were not separated out
from the rest of the VM patch, so the usual "break this up
into a separate patch please" applies.
[email protected] wrote:
>
> Also, these changes to the hashing scheme were not separated out
> from the rest of the VM patch, so the usual "break this up
> into a separate patch please" applies.
FYI, I am doing that at present. It look like Andrea's 10_vm-30
patch will end up as twenty or thirty separate patches. I won't
be testing every darn patch individually - I'll batch them up into
maybe four groups for testing and merging.
Andrea introduced some subtly changed buffer locking rules, and
this causes ext3 to deadlock under heavy load. Until we sort
this out, I'm afraid that the -aa VM is not suitable for production
use with ext3.
ext2 is OK and I *assume* it's OK with reiserfs. The problem occurs
when a filesystem performs:
lock_buffer(dirty_bh);
allocate_something(GFP_NOFS);
without having locked the buffer's page. sync_page_buffers()
can perform a wait_on_buffer() against dirty_bh. (I think.
I'm not quite up-to-speed with the new buffer state bits yet).
-
[email protected] wrote:
>> Also, these changes to the hashing scheme were not separated out
>> from the rest of the VM patch, so the usual "break this up
>> into a separate patch please" applies.
On Tue, Mar 12, 2002 at 04:09:22PM -0800, Andrew Morton wrote:
> FYI, I am doing that at present. It look like Andrea's 10_vm-30
> patch will end up as twenty or thirty separate patches. I won't
> be testing every darn patch individually - I'll batch them up into
> maybe four groups for testing and merging.
There are some okay parts to aa's hashing changes but we need to
work together to get the patch to perform those and drop the rest,
and also address some style issues. Some of the constants are
adjustable (though it's not clear how they should be adjusted) and the
wait_table_t ADT is fine. The hash function change is not and moving
the table from per-zone to per-node is questionable, as its effects are
not well-understood.
Perhaps understandably so, I'd like to take a hands-on role in
guiding this patch into a form suitable for the mainline kernel.
On Tue, Mar 12, 2002 at 04:09:22PM -0800, Andrew Morton wrote:
> Andrea introduced some subtly changed buffer locking rules, and
> this causes ext3 to deadlock under heavy load. Until we sort
> this out, I'm afraid that the -aa VM is not suitable for production
> use with ext3.
> ext2 is OK and I *assume* it's OK with reiserfs. The problem occurs
> when a filesystem performs:
> lock_buffer(dirty_bh);
> allocate_something(GFP_NOFS);
> without having locked the buffer's page. sync_page_buffers()
> can perform a wait_on_buffer() against dirty_bh. (I think.
> I'm not quite up-to-speed with the new buffer state bits yet).
This looks like a change of invariants that could generate a fair
amount of audit work. Ugh...
Cheers,
Bill
[email protected] wrote:
>
> Perhaps understandably so, I'd like to take a hands-on role in
> guiding this patch into a form suitable for the mainline kernel.
The hashing changes will become the topmost (ie: last-applied) diff
for that reason...
> This looks like a change of invariants that could generate a fair
> amount of audit work. Ugh...
In a better world, the VM wouldn't know anything at all about
these "buffer" thingies.
-
On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote:
> This is a simple random number generator. It takes a pointer to your
> own private long, somewhere in your code, and returns a long random
> number with a period of 0xfffd4011. I ran a program for about a
> year, trying to find a magic number that will produce a longer
> period.
Random number generators are not hash functions. Where is the relevance?
I think you're generating a stream of uniform deviates to test whether
a given hash function performs well with random input.
I'm far more concerned about how the hash function behaves on real input
data and I've been measuring that from the start, and as far as I'm
concerned this microbenchmark is fairly useless. If it defeats it, it
doesn't demonstrate that the hash function behaves poorly on the input
distribution I'm interested in. If it doesn't defeat it it doesn't
demonstrate that the hash function behaves well on the input distribution
I'm interested in. If you want to generate useful random numbers for
simulating workloads for hash table benchmarking you should attempt to
measure and simulate the distribution of hash keys from the hash tables
you're interested in and use statistical tests to verify that you're
actually generating numbers with similar distributions. One easy way
to get those might be, say, dumping all the elements of a hash table
by traversing all the collision chains and sampling the keys' fields.
On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote:
> You could add a ldiv and return the modulus to set hash-table limits.
> ANDs are not good because, in principle, you could get many numbers
> in which all the low bits are zero.
It sounds like you're generating a stream of random deviates and then
hashing them by mapping to their least residues mod the hash table size
with perhaps a division thrown in. With a long period you're going to
get quite impressive statistics, not that it means anything. =)
On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote:
> The advantage of this simple code is it works quickly. The disadvantages
> are, of course, its not portable and a rotation of a binary number
> is not a mathematical function, lending itself to rigorous analysis.
Rigorous mathematical analysis does not require analyticity =) or
number-theoretic tractability. There are things called statistical
analysis and asymptotic analysis, which go great together and are
quite wonderful in combination with empirical testing.
On Tue, Mar 12, 2002 at 08:33:23AM -0500, Richard B. Johnson wrote
(and I added comments to):
> MAGIC = 0xd0047077
> INTPTR = 0x08
> .section .text
> .global rnd
> .type rnd,@function
> .align 0x04
> pushl %ebx # save %ebx
> movl INTPTR(%esp), %ebx # load argument from stack to %ebx
> movl (%ebx), %eax # deref arg, loading to %eax
> rorl $3, %eax # roll %eax right by 3
> addl $MAGIC, %eax # add $MAGIC to %eax
> movl %eax, (%ebx) # save result
> popl %ebx # restore %ebx
> ret
> .end
So you've invented the following function:
f(n) = 2**29 * (n % 8) + floor(n/8) + 0xd0047077
I wonder what several tests will look like for this, but you should
really test your own random number generator.
I have my own patches to work on.
Cheers,
Bill
On Tue, Mar 12, 2002 at 04:09:22PM -0800, Andrew Morton wrote:
> [email protected] wrote:
> >
> > Also, these changes to the hashing scheme were not separated out
> > from the rest of the VM patch, so the usual "break this up
> > into a separate patch please" applies.
>
> FYI, I am doing that at present. It look like Andrea's 10_vm-30
> patch will end up as twenty or thirty separate patches. I won't
> be testing every darn patch individually - I'll batch them up into
> maybe four groups for testing and merging.
>
> Andrea introduced some subtly changed buffer locking rules, and
> this causes ext3 to deadlock under heavy load. Until we sort
> this out, I'm afraid that the -aa VM is not suitable for production
> use with ext3.
>
> ext2 is OK and I *assume* it's OK with reiserfs. The problem occurs
> when a filesystem performs:
>
> lock_buffer(dirty_bh);
> allocate_something(GFP_NOFS);
>
> without having locked the buffer's page. sync_page_buffers()
> can perform a wait_on_buffer() against dirty_bh. (I think.
> I'm not quite up-to-speed with the new buffer state bits yet).
The deadlock I fixed with BH_Pending_IO was only related to
write_some_buffers. What you found now is an additional deadlock that is
been fixed by further changes in mainline, alternative to the
BH_Pending_IO, but less restrictive.
The reason I kept using BH_Pending_IO is that without it the VM cannot
throttle correctly on locked buffers. With BH_launder the VM is only
able to throttle on buffers that the VM submitted by itself (and
incidentally it doesn't deadlock for you). So an excessive amount of
locked buffers submitted by bdflush/kupdate would lead the VM not to be
able to proper throttle. This is most important for the lowmem machines
where the amount of locked memory can be substantial thanks to the
fairly large I/O queues (mostly with more than on disk).
You can see the attached emails for historical reference.
Now, I think the best fix is to just drop the BH_Pending_IO and to add a
BH_launder similar mainline, but used in a completly different manner.
The way used by mainline is too permissive for those locked buffers just
submitted to the I/O layer.
In short I will set BH_launder in submit_bh, instead of
sync_page_buffers, this way I'll be sure if BH_launder is set I can
safely wait on the locked buffer because it's just visible to the I/O
layer and unplugging the queue will be enough to get it unlocked
eventually. BH_launder will be cleared in unlock_buffer as usual. That
is the _right_ usage of BH_launder, I simply weren't doing that because
I didn't noticed this further deadlock yet, I was only aware of the
write_some_buffers vs GFP_NOHIGHIO deadlock so far. In short this new
usage is the complemental information of my BH_Pending_IO. So now I can
wait if BH_Launder is set, while previously I couldn't wait if
BH_Pending_IO was set. But now the difference is that BH_Pending_IO
wasn't covering all the cases while BH_Launder used in my manner really
cover all the cases (the BH_launder in mainline doesn't cover all the
cases either, but the only downside is that it won't be able to write
throttle, while I could deadlock).
What do you think about this patch against 2.4.19pre3aa1?
Unless somebody finds anything wrong, I will release a new -aa tree and
vm-32 with it applied. I think it's the best approch to cure the
deadlock and to still be able to throttle on the locked buffers.
diff -urN ref/drivers/block/ll_rw_blk.c launder/drivers/block/ll_rw_blk.c
--- ref/drivers/block/ll_rw_blk.c Wed Mar 13 08:24:07 2002
+++ launder/drivers/block/ll_rw_blk.c Wed Mar 13 08:12:40 2002
@@ -1025,6 +1025,7 @@
BUG();
set_bit(BH_Req, &bh->b_state);
+ set_bit(BH_Launder, &bh->b_state);
/*
* First step, 'identity mapping' - RAID or LVM might
diff -urN ref/fs/buffer.c launder/fs/buffer.c
--- ref/fs/buffer.c Wed Mar 13 08:24:07 2002
+++ launder/fs/buffer.c Wed Mar 13 08:26:02 2002
@@ -171,6 +171,7 @@
brelse(bh);
if (ret == 0) {
clear_bit(BH_Wait_IO, &bh->b_state);
+ clear_bit(BH_Launder, &bh->b_state);
smp_mb__after_clear_bit();
if (waitqueue_active(&bh->b_wait)) {
wake_up(&bh->b_wait);
@@ -184,6 +185,7 @@
{
clear_bit(BH_Wait_IO, &bh->b_state);
clear_bit(BH_Lock, &bh->b_state);
+ clear_bit(BH_Launder, &bh->b_state);
smp_mb__after_clear_bit();
if (waitqueue_active(&bh->b_wait))
wake_up(&bh->b_wait);
@@ -238,7 +240,6 @@
do {
struct buffer_head * bh = *array++;
bh->b_end_io = end_buffer_io_sync;
- clear_bit(BH_Pending_IO, &bh->b_state);
submit_bh(WRITE, bh);
} while (--count);
}
@@ -278,7 +279,6 @@
if (atomic_set_buffer_clean(bh)) {
__refile_buffer(bh);
get_bh(bh);
- set_bit(BH_Pending_IO, &bh->b_state);
array[count++] = bh;
if (count < NRSYNC)
continue;
@@ -2704,13 +2704,12 @@
continue;
}
- if (unlikely(buffer_pending_IO(bh))) {
- tryagain = 0;
- continue;
- }
-
/* Second time through we start actively writing out.. */
if (test_and_set_bit(BH_Lock, &bh->b_state)) {
+ if (unlikely(!buffer_launder(bh))) {
+ tryagain = 0;
+ continue;
+ }
wait_on_buffer(bh);
tryagain = 1;
continue;
diff -urN ref/include/linux/fs.h launder/include/linux/fs.h
--- ref/include/linux/fs.h Wed Mar 13 08:24:11 2002
+++ launder/include/linux/fs.h Wed Mar 13 08:23:59 2002
@@ -232,7 +232,7 @@
BH_New, /* 1 if the buffer is new and not yet written out */
BH_Async, /* 1 if the buffer is under end_buffer_io_async I/O */
BH_Wait_IO, /* 1 if we should write out this buffer */
- BH_Pending_IO, /* 1 if the buffer is locked but not in the I/O queue yet */
+ BH_Launder, /* 1 if we can throttle on this buffer */
BH_JBD, /* 1 if it has an attached journal_head */
BH_Delay, /* 1 if the buffer is delayed allocate */
@@ -295,7 +295,7 @@
#define buffer_mapped(bh) __buffer_state(bh,Mapped)
#define buffer_new(bh) __buffer_state(bh,New)
#define buffer_async(bh) __buffer_state(bh,Async)
-#define buffer_pending_IO(bh) __buffer_state(bh,Pending_IO)
+#define buffer_launder(bh) __buffer_state(bh,Launder)
#define buffer_delay(bh) __buffer_state(bh,Delay)
#define bh_offset(bh) ((unsigned long)(bh)->b_data & ~PAGE_MASK)
Andrea
On March 13, 2002 02:24 am, Andrew Morton wrote:
> [email protected] wrote:
> > This looks like a change of invariants that could generate a fair
> > amount of audit work. Ugh...
>
> In a better world, the VM wouldn't know anything at all about
> these "buffer" thingies.
;-)
--
Daniel
Andrea Arcangeli wrote:
>
> ...
> What do you think about this patch against 2.4.19pre3aa1?
Well it won't apply on 10_vm-30, but that's OK...
So BH_Launder is set when we start I/O and is cleared on
I/O completion. That sounds fine - clearly it is always
safe to throttle on these buffers.
Thanks - I'll stress-test it tomorrow.
-
On Tue, Mar 12, 2002 at 11:55:27PM -0800, Andrew Morton wrote:
> Andrea Arcangeli wrote:
> >
> > ...
> > What do you think about this patch against 2.4.19pre3aa1?
>
> Well it won't apply on 10_vm-30, but that's OK...
Yes, I will make a new vm-31 shortly anyways.
> So BH_Launder is set when we start I/O and is cleared on
> I/O completion. That sounds fine - clearly it is always
> safe to throttle on these buffers.
>
> Thanks - I'll stress-test it tomorrow.
Fine, thanks again!
Andrea
On March 13, 2002 01:09 am, Andrew Morton wrote:
> Andrea introduced some subtly changed buffer locking rules, and
> this causes ext3 to deadlock under heavy load. Until we sort
> this out, I'm afraid that the -aa VM is not suitable for production
> use with ext3.
>
> ext2 is OK and I *assume* it's OK with reiserfs. The problem occurs
> when a filesystem performs:
>
> lock_buffer(dirty_bh);
> allocate_something(GFP_NOFS);
>
> without having locked the buffer's page. sync_page_buffers()
> can perform a wait_on_buffer() against dirty_bh. (I think.
> I'm not quite up-to-speed with the new buffer state bits yet).
Note that this is a perfect example of the tangle-of-states problem we
discussed on IRC. This problem comes up because of the uholy way in
which pages and buffers are tangled together (page->buffer->page...).
The solution imho is to get rid of buffer_heads and divide their
current functionality between struct page and struct bio.
Cleaning up the state mess is just one of the reasons for doing it, of
course, but it's not all that unimportant.
--
Daniel
On Wed, Mar 13, 2002 at 08:30:55AM +0100, Andrea Arcangeli wrote:
> {
> clear_bit(BH_Wait_IO, &bh->b_state);
> clear_bit(BH_Lock, &bh->b_state);
> + clear_bit(BH_Launder, &bh->b_state);
> smp_mb__after_clear_bit();
> if (waitqueue_active(&bh->b_wait))
actually, while refining the patch and integrating it, I audited it some
more carefully and the above was wrong, we must ensure nobody is able to
acquire BH_Lock before BH_Launder. So we must also enforce ordering at
the cpu level. This is the correct version.
clear_bit(BH_Wait_IO, &bh->b_state);
clear_bit(BH_Launder, &bh->b_state);
/* nobody must acquire BH_Lock again before BH_Launder is clear */
smp_mb__after_clear_bit();
clear_bit(BH_Lock, &bh->b_state);
The race would been nearly impossible to trigger during stress testing,
you'd need to BH_Lock + GFP_NOFS + alloc_pages + shrink_cache + the
interesting page is near the end of the lru + try_to_free_buffers +
sync_page_buffers + wait_on_buffer all in a few cycles (irq handlers
could trigger it :), but with the huge userbase somebody I don't exclude
somebody could been really hurted by and anyways it would be still a
common code bug even if it would not be possible to reproduce it with
current available hardware.
Note that the above very same race can happen in mainline too on
architectures where a clear_bit doesn't imply a strong CPU barrier.
So on the paper your same kind of deadlock could happen on mainline as
well but there it is reduced to an SMP race and it would affect only
alpha, ppc and s390. So I'm glad my deadlock is been useful to fix
another SMP race condition at least :)
Andrea
On Wed, 13 Mar 2002, Andrea Arcangeli wrote:
> On Wed, Mar 13, 2002 at 08:30:55AM +0100, Andrea Arcangeli wrote:
> > {
> > clear_bit(BH_Wait_IO, &bh->b_state);
> > clear_bit(BH_Lock, &bh->b_state);
> > + clear_bit(BH_Launder, &bh->b_state);
> > smp_mb__after_clear_bit();
> > if (waitqueue_active(&bh->b_wait))
>
> actually, while refining the patch and integrating it, I audited it some
> more carefully and the above was wrong,
It's complex.
Would there be a way to simplify the thing so the author
of the code can at least get it right and there's a chance
of other people understanding it too ? ;)
Rik
--
<insert bitkeeper endorsement here>
http://www.surriel.com/ http://distro.conectiva.com/
On Wed, Mar 13, 2002 at 10:51:26AM -0300, Rik van Riel wrote:
> On Wed, 13 Mar 2002, Andrea Arcangeli wrote:
> > On Wed, Mar 13, 2002 at 08:30:55AM +0100, Andrea Arcangeli wrote:
> > > {
> > > clear_bit(BH_Wait_IO, &bh->b_state);
> > > clear_bit(BH_Lock, &bh->b_state);
> > > + clear_bit(BH_Launder, &bh->b_state);
> > > smp_mb__after_clear_bit();
> > > if (waitqueue_active(&bh->b_wait))
> >
> > actually, while refining the patch and integrating it, I audited it some
> > more carefully and the above was wrong,
>
> It's complex.
The SMP kernel is complex, preempt+SMP is even more complex. If you find
a design solution more simple or/and more efficient to be able to
identify which locked buffers are just been submitted for I/O let me
know ASAP, I can't think for a better/simpler one and the locking rules
IMHO here are very simple, nothing remotely comparable to other parts of
the kernel. Infact I think it is the simplicity of this fix that renders
is so obviously right and why Andrew as well could reply to me this
morning with an agreement that that is the right fix.
It is as simple as:
when a locked buffer is visible to the I/O layer BH_Launder is set
This means before unlocking we must clear BH_Launder, mb() on alpha and
then clear BH_Lock, so no reader can see BH_Launder set on an unlocked
buffer and then risk to deadlock.
I think it is very simple and clean. If you want to know something way
more complex than that just ask or alternatively grep for:
grep preempt 2.5.7-pre1/kernel/sched.c
Andrea
On Wed, 13 Mar 2002 [email protected] wrote:
[SNIPPED..]
You might want to look at http://www.eece.unm.edu/faculty/heileman/hash/hash.html
rather than assuming everyone is uninformed. Source-code is provided
for several hashing functions as well as source-code for tests. This
is a relatively old reference although it addresses both the chaos
and fractal methods discussed here, plus chaotic probe strategies
in address hashing.
A fast random number generator is essential to produce meaningful
tests within a reasonable period of time. It is also used within one
of the hashing functions to 'guess' at the direction of displacement
when an insertion slot is not immediately located, as well as the
displacement mechanism for several chaotic methods discussed.
Using your own hash-function as a template for tests of the same
hash-function, as you propose, is unlikely to provide meaningful
results.
Cheers,
Dick Johnson
Penguin : Linux version 2.4.18 on an i686 machine (797.90 BogoMips).
Windows-2000/Professional isn't.
Rik van Riel wrote:
>
> On Wed, 13 Mar 2002, Andrea Arcangeli wrote:
> > On Wed, Mar 13, 2002 at 08:30:55AM +0100, Andrea Arcangeli wrote:
> > > {
> > > clear_bit(BH_Wait_IO, &bh->b_state);
> > > clear_bit(BH_Lock, &bh->b_state);
> > > + clear_bit(BH_Launder, &bh->b_state);
> > > smp_mb__after_clear_bit();
> > > if (waitqueue_active(&bh->b_wait))
> >
> > actually, while refining the patch and integrating it, I audited it some
> > more carefully and the above was wrong,
>
> It's complex.
>
> Would there be a way to simplify the thing so the author
> of the code can at least get it right and there's a chance
> of other people understanding it too ? ;)
I'll be documenting the BH state bits, and sync_page_buffers(),
when it settles down.
> ...
> <insert bitkeeper endorsement here>
You should lubricate it first.
-
On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> [SNIPPED..]
Nice move. No one will have the foggiest idea without hunting for
my prior message whether your comments on what I said are accurate.
On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> You might want to look at http://www.eece.unm.edu/faculty/heileman/hash/hash.html
> rather than assuming everyone is uninformed. Source-code is provided
> for several hashing functions as well as source-code for tests. This
> is a relatively old reference although it addresses both the chaos
> and fractal methods discussed here, plus chaotic probe strategies
> in address hashing.
You've presented a paper that attempts to establish a connection
between chaos theory and hashing by open addressing. I'm not convinced
chaos theory is all that, but some of their measurement techniques
appear useful, and I'll probably try using them, despite the fact Linux
appears to favor hashing by separate chaining.
This URL has not convinced me you are informed, and I don't really want
to be convinced whether you're informed or not. Your contributions to
these threads have been far less than enlightening or helpful thus far.
On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> A fast random number generator is essential to produce meaningful
> tests within a reasonable period of time. It is also used within one
> of the hashing functions to 'guess' at the direction of displacement
> when an insertion slot is not immediately located, as well as the
> displacement mechanism for several chaotic methods discussed.
I don't buy this, and the reason why is that hashing is obviously
sensitive to the input distribution. To defeat any hash function,
you need only produce a distribution concentrated on a set hashing
to the same number. If your distribution is literally uniform, then
you'll never do better (by one measure) than least residue mod hash
table size. You need to produce a realistic set of test keys. The key
distributions you actually want to hash will be neither of the above.
(Though one should verify it doesn't do poorly on uniform input, it's
little more than a sanity check.)
On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> Using your own hash-function as a template for tests of the same
> hash-function, as you propose, is unlikely to provide meaningful
> results.
I'm not proposing that. I have no idea why you think I am.
If I may summarize, if you're going to use random number generation
to simulate test inputs, verify the distribution of the test inputs
you generate actually resembles the thing you're trying to simulate.
It's far more productive to get samples of kernel virtual addresses
of the objects whose addresses you're hashing, or inode numbers from
real filesystems, or filenames, or whatever, than to just feed it a
stream of numbers spewed by some random number generator no one's
heard of, and that's not going to change in the least. For a Monte
Carlo simulation of its usage in the kernel, you're going to need to
actually figure out how to simulate those things' distributions.
Hmm, I wouldn't be suprised to get a bunch of "YHBT" messages after
this but the chaos theory paper does have some useful stuff for
analyzing hash table performance. Distributions' entropies and Lyapunov
exponents of hash functions should be easy enough to compute.
Bill
On Wed, 13 Mar 2002 [email protected] wrote:
> On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> > [SNIPPED..]
>
> Nice move. No one will have the foggiest idea without hunting for
> my prior message whether your comments on what I said are accurate.
>
>
> On Wed, Mar 13, 2002 at 02:06:48PM -0500, Richard B. Johnson wrote:
> > You might want to look at http://www.eece.unm.edu/faculty/heileman/hash/hash.html
> > rather than assuming everyone is uninformed. Source-code is provided
> > for several hashing functions as well as source-code for tests. This
> > is a relatively old reference although it addresses both the chaos
> > and fractal methods discussed here, plus chaotic probe strategies
> > in address hashing.
>
> You've presented a paper that attempts to establish a connection
> between chaos theory and hashing by open addressing. I'm not convinced
> chaos theory is all that, but some of their measurement techniques
> appear useful, and I'll probably try using them, despite the fact Linux
> appears to favor hashing by separate chaining.
>
> This URL has not convinced me you are informed, and I don't really want
> to be convinced whether you're informed or not. Your contributions to
> these threads have been far less than enlightening or helpful thus far.
>
[SNIPPED rest of diatribe...]
Listen you incompetent amoeba. I attempted to tell you in a nice
way that your apparent mastery of technical mumbo-jumbo will be
detected by many who have actual knowledge and expertise in the
area in which you pretend to be competent.
That said, have a nice day.
Dick Johnson
Penguin : Linux version 2.4.18 on an i686 machine (797.90 BogoMips).
Windows-2000/Professional isn't.
On March 14, 2002 01:18 pm, Richard B. Johnson wrote:
> On Wed, 13 Mar 2002 [email protected] wrote:
> > [big swinging math stuff]
>
> Listen you incompetent amoeba. I attempted to tell you in a nice
> way that your apparent mastery of technical mumbo-jumbo will be
> detected by many who have actual knowledge and expertise in the
> area in which you pretend to be competent.
You were way wide of the mark, though admittedly Bill reacted more
agressively than necessary, it's what happens when you use steroids to build
up your math muscles ;-)
Bill knows what a pseudorandom generator is, and how to use it for testing
hash functions, so do I. I don't really like the one you showed, though I
appeciate the fact it's a couple of assembly instructions and has a decent
period. Did you run a spectral test[1] on it? I'd be surprised if the
results are pretty, though pleasantly surprised. I have one myself sitting
around somewhere that's 2 or 3 instructions long, based on an LSR, which does
have some analyzable properties. Though for serious testing I wouldn't use
it - I'd crack my Numerical Recipes in C or use urandom, taking it on faith
that the coder was duly diligent. A few cycles saved evaluating the hash
just isn't worth it if you then have to wonder if patterns in your generator
are showing through to your test results.
You missed a lot if you didn't notice the quality of Bill's work on the hash.
I 100% agree with his approach[2]. The fact he managed to satisfy davem
should tell you a lot - we now have nice, short multiplicative hashes to use
that get evaluated as fast shift-adds on sparc. These hashes have *provably*
good behavior. Thanks Bill.
[1] see Knuth
[2] well, I sort of put him up to it...
--
Daniel
On Thu, 14 Mar 2002, Richard B. Johnson wrote:
> [SNIPPED rest of diatribe...]
>
> Listen you incompetent amoeba.
Likewise. Lets go over this again:
1) the idea is to have a hashing function that
performs well for the page cache and/or the
hashed wait queues
2) input for these two hash functions is not at
all guaranteed to be random or uniformly spread
3) this means we need a hash function that performs
well on very much non-random inputs
Now, where does your random number generator fit in this
scenario ?
regards,
Rik
--
<insert bitkeeper endorsement here>
http://www.surriel.com/ http://distro.conectiva.com/
On March 14, 2002 02:59 pm, Rik van Riel wrote:
> Now, where does your random number generator fit in this
> scenario ?
He was offering it up as a means of testing the hash, a well intentioned
thought. What he didn't seem to realize is, that's like telling Linus how to
read an oops.
--
Daniel
Andrea Arcangeli <[email protected]> said:
[...]
> AFIK my current hashfn is never been tested in precendence on this kind
> of random input of the wait_table pages.
If the input is really random, anything will do. I.e., just chopping off a
few not guaranteed-zero bits (probably better low-end) and using that would
be enough.
--
Dr. Horst H. von Brand User #22616 counter.li.org
Departamento de Informatica Fono: +56 32 654431
Universidad Tecnica Federico Santa Maria +56 32 654239
Casilla 110-V, Valparaiso, Chile Fax: +56 32 797513
On Fri, Mar 15, 2002 at 01:20:29PM -0400, Horst von Brand wrote:
> Andrea Arcangeli <[email protected]> said:
>
> [...]
>
> > AFIK my current hashfn is never been tested in precendence on this kind
> > of random input of the wait_table pages.
>
> If the input is really random, anything will do. I.e., just chopping off a
> few not guaranteed-zero bits (probably better low-end) and using that would
> be enough.
indeed, that's basically what I'm doing there (plus a "+ >>" just to use
more of the random bits).
Andrea
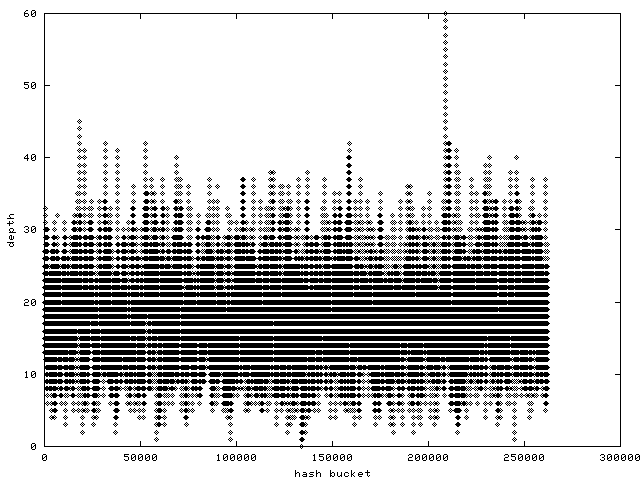{kind=link}
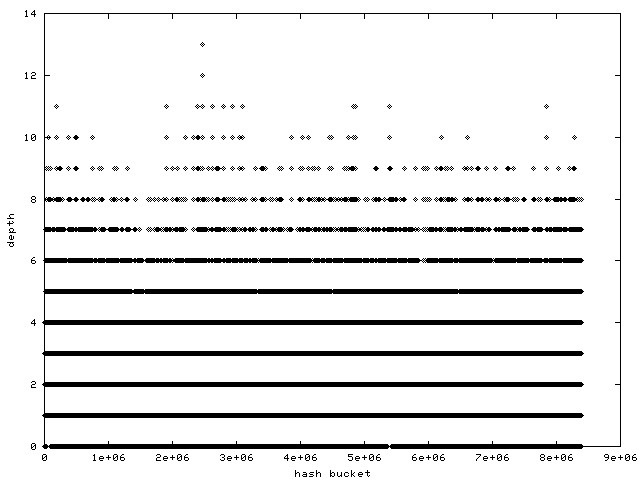{kind=link}