From: Aubrey Li <[email protected]>
Under some latency intensive workloads, short idle periods occurs very
common, so that idle entry and exit path starts to dominate. It's important
to optimize them for the short idle period pattern. A fast idle path proposal
is introduced here for this purpose.
This proposal uses two factors in idle menu governor to predict the next
idle period. The one is energy break even point, the other is repeatable
interval detector. These two factors are generic to all arches.
If the next idle period is longer than the predefined threshold, that means
the next idle will be a long idle, then the idle thread will enter the
original normal idle path. Otherwise, the coming idle will be a short idle,
the idle thread will enter the fast idle path, which is supposed to enter
and exit faster than the normal path.
The predicted idle period is already computed in the cpuidle framework, so
pass it directly to menu governor to select the next c-state. Menu governor
does not need to compute again.
We measured 3%~5% improvemnt in disk IO workload, and 8%~20% improvement in
network workload.
Aubrey Li (11):
sched/idle: create a fast path for short idle periods
cpuidle: attach cpuidle governor statistics to the per-CPU device
cpuidle: introduce cpuidle governor for idle prediction
sched/idle: make the fast idle path for short idle periods
cpuidle: update idle statistics before cpuidle governor
timers: keep sleep length updated as needed
cpuidle: make idle residency update more generic
cpuidle: menu: remove reduplicative implementation
cpuidle: menu: feed cpuidle prediction to menu governor
cpuidle: update cpuidle governor when needed
sched/idle: Add a tuning knob to allow changing fast idle threshold
drivers/cpuidle/cpuidle.c | 241 +++++++++++++++++++++++++++++++++++++++
drivers/cpuidle/governors/menu.c | 192 +------------------------------
include/linux/cpuidle.h | 35 ++++++
include/linux/sched/sysctl.h | 1 +
kernel/sched/idle.c | 81 +++++++++++--
kernel/sysctl.c | 10 ++
kernel/time/tick-sched.c | 3 +
7 files changed, 366 insertions(+), 197 deletions(-)
--
2.7.4
From: Aubrey Li <[email protected]>
Short idle periods occur common under some workloads, and the idle
entry and exit path starts to dominate, so it's important to optimize
them. A fast idle routine is introduced here for short idle periods.
- tick nohz enter/exit are exclued
- RCU idle enter/exit are excluded since tick won't be stopped
- idle governor will be leveraged, hardware idle state selection
on some arches is excluded
- default system idle is used
- any deferrable work will be excluded
---
kernel/sched/idle.c | 59 ++++++++++++++++++++++++++++++++++++++++++++---------
1 file changed, 49 insertions(+), 10 deletions(-)
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index ac6d517..cf6c11f 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -202,22 +202,39 @@ static void cpuidle_idle_call(void)
}
/*
- * Generic idle loop implementation
- *
- * Called with polling cleared.
+ * fast idle loop implementation
*/
-static void do_idle(void)
+static void cpuidle_fast(void)
{
+ while (!need_resched()) {
+ check_pgt_cache();
+ rmb();
+
+ if (cpu_is_offline(smp_processor_id())) {
+ cpuhp_report_idle_dead();
+ arch_cpu_idle_dead();
+ }
+
+ local_irq_disable();
+ arch_cpu_idle_enter();
+
+ default_idle_call();
+
+ arch_cpu_idle_exit();
+ }
+
/*
- * If the arch has a polling bit, we maintain an invariant:
+ * Since we fell out of the loop above, we know TIF_NEED_RESCHED must
+ * be set, propagate it into PREEMPT_NEED_RESCHED.
*
- * Our polling bit is clear if we're not scheduled (i.e. if rq->curr !=
- * rq->idle). This means that, if rq->idle has the polling bit set,
- * then setting need_resched is guaranteed to cause the CPU to
- * reschedule.
+ * This is required because for polling idle loops we will not have had
+ * an IPI to fold the state for us.
*/
+ preempt_set_need_resched();
+}
- __current_set_polling();
+static void cpuidle_generic(void)
+{
tick_nohz_idle_enter();
while (!need_resched()) {
@@ -254,6 +271,28 @@ static void do_idle(void)
*/
preempt_set_need_resched();
tick_nohz_idle_exit();
+}
+
+/*
+ * Generic idle loop implementation
+ *
+ * Called with polling cleared.
+ */
+static void do_idle(void)
+{
+ /*
+ * If the arch has a polling bit, we maintain an invariant:
+ *
+ * Our polling bit is clear if we're not scheduled (i.e. if rq->curr !=
+ * rq->idle). This means that, if rq->idle has the polling bit set,
+ * then setting need_resched is guaranteed to cause the CPU to
+ * reschedule.
+ */
+
+ __current_set_polling();
+
+ cpuidle_generic();
+
__current_clr_polling();
/*
--
2.7.4
From: Aubrey Li <[email protected]>
A generic CPU idle governor is required to make the prediction of
how long the coming idle. The statistic data taken from the existing
menu governor is attached to the per-CPU device data structure
---
include/linux/cpuidle.h | 30 ++++++++++++++++++++++++++++++
1 file changed, 30 insertions(+)
diff --git a/include/linux/cpuidle.h b/include/linux/cpuidle.h
index fc1e5d7..f17a53b 100644
--- a/include/linux/cpuidle.h
+++ b/include/linux/cpuidle.h
@@ -61,6 +61,34 @@ struct cpuidle_state {
int index);
};
+/*
+ * Please note when changing the tuning values:
+ * If (MAX_INTERESTING-1) * RESOLUTION > UINT_MAX, the result of
+ * a scaling operation multiplication may overflow on 32 bit platforms.
+ * In that case, #define RESOLUTION as ULL to get 64 bit result:
+ * #define RESOLUTION 1024ULL
+ *
+ * The default values do not overflow.
+ */
+#define BUCKETS 12
+#define INTERVAL_SHIFT 3
+#define INTERVALS (1UL << INTERVAL_SHIFT)
+#define RESOLUTION 1024
+#define DECAY 8
+#define MAX_INTERESTING 50000
+
+struct cpuidle_governor_stat {
+ int last_state_idx;
+
+ unsigned int next_timer_us;
+ unsigned int predicted_us;
+ unsigned int bucket;
+ unsigned int correction_factor[BUCKETS];
+ unsigned int intervals[INTERVALS];
+ int interval_ptr;
+};
+
+
/* Idle State Flags */
#define CPUIDLE_FLAG_NONE (0x00)
#define CPUIDLE_FLAG_COUPLED (0x02) /* state applies to multiple cpus */
@@ -89,8 +117,10 @@ struct cpuidle_device {
cpumask_t coupled_cpus;
struct cpuidle_coupled *coupled;
#endif
+ struct cpuidle_governor_stat gov_stat;
};
+
DECLARE_PER_CPU(struct cpuidle_device *, cpuidle_devices);
DECLARE_PER_CPU(struct cpuidle_device, cpuidle_dev);
--
2.7.4
From: Aubrey Li <[email protected]>
The system will enter a fast idle loop if the predicted idle period
is shorter than the threshold.
---
kernel/sched/idle.c | 9 ++++++++-
1 file changed, 8 insertions(+), 1 deletion(-)
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index cf6c11f..16a766c 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -280,6 +280,8 @@ static void cpuidle_generic(void)
*/
static void do_idle(void)
{
+ unsigned int predicted_idle_us;
+ unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
/*
* If the arch has a polling bit, we maintain an invariant:
*
@@ -291,7 +293,12 @@ static void do_idle(void)
__current_set_polling();
- cpuidle_generic();
+ predicted_idle_us = cpuidle_predict();
+
+ if (likely(predicted_idle_us < short_idle_threshold))
+ cpuidle_fast();
+ else
+ cpuidle_generic();
__current_clr_polling();
--
2.7.4
From: Aubrey Li <[email protected]>
sleep length indicates how long we'll be idle. Currently, it's updated
only when tick nohz enters. These patch series make a new requirement
with tick, so we should keep sleep length updated as needed
---
kernel/time/tick-sched.c | 3 +++
1 file changed, 3 insertions(+)
diff --git a/kernel/time/tick-sched.c b/kernel/time/tick-sched.c
index 7fe53be..8bf6e8b 100644
--- a/kernel/time/tick-sched.c
+++ b/kernel/time/tick-sched.c
@@ -988,8 +988,11 @@ void tick_nohz_irq_exit(void)
*/
ktime_t tick_nohz_get_sleep_length(void)
{
+ struct clock_event_device *dev = __this_cpu_read(tick_cpu_device.evtdev);
struct tick_sched *ts = this_cpu_ptr(&tick_cpu_sched);
+ ts->sleep_length = ktime_sub(dev->next_event, ktime_get());
+
return ts->sleep_length;
}
--
2.7.4
From: Aubrey Li <[email protected]>
Short idle periods varies from different workload, make the switch
tunable
---
include/linux/sched/sysctl.h | 1 +
kernel/sched/idle.c | 5 +++--
kernel/sysctl.c | 10 ++++++++++
3 files changed, 14 insertions(+), 2 deletions(-)
diff --git a/include/linux/sched/sysctl.h b/include/linux/sched/sysctl.h
index 0f5ecd4..9771506 100644
--- a/include/linux/sched/sysctl.h
+++ b/include/linux/sched/sysctl.h
@@ -65,6 +65,7 @@ extern unsigned int sysctl_sched_autogroup_enabled;
extern int sysctl_sched_rr_timeslice;
extern int sched_rr_timeslice;
+extern unsigned int sysctl_fast_idle_threshold;
extern int sched_rr_handler(struct ctl_table *table, int write,
void __user *buffer, size_t *lenp,
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index 3358db2..555b02d 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -287,6 +287,8 @@ static void cpuidle_generic(void)
tick_nohz_idle_exit();
}
+unsigned int sysctl_fast_idle_threshold = USEC_PER_SEC / HZ / 2;
+
/*
* Generic idle loop implementation
*
@@ -295,7 +297,6 @@ static void cpuidle_generic(void)
static void do_idle(void)
{
unsigned int predicted_idle_us;
- unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
/*
* If the arch has a polling bit, we maintain an invariant:
*
@@ -309,7 +310,7 @@ static void do_idle(void)
predicted_idle_us = cpuidle_predict();
- if (likely(predicted_idle_us < short_idle_threshold))
+ if (likely(predicted_idle_us < sysctl_fast_idle_threshold))
cpuidle_fast();
else
cpuidle_generic();
diff --git a/kernel/sysctl.c b/kernel/sysctl.c
index 8c8714f..0acf81d 100644
--- a/kernel/sysctl.c
+++ b/kernel/sysctl.c
@@ -128,6 +128,7 @@ static int __maybe_unused four = 4;
static unsigned long one_ul = 1;
static int one_hundred = 100;
static int one_thousand = 1000;
+static int one_tick_to_us = USEC_PER_SEC / HZ;
#ifdef CONFIG_PRINTK
static int ten_thousand = 10000;
#endif
@@ -1201,6 +1202,15 @@ static struct ctl_table kern_table[] = {
.extra2 = &one,
},
#endif
+ {
+ .procname = "sched_fast_idle_threshold",
+ .data = &sysctl_fast_idle_threshold,
+ .maxlen = sizeof(unsigned int),
+ .mode = 0644,
+ .proc_handler = proc_dointvec_minmax,
+ .extra1 = &zero,
+ .extra2 = &one_tick_to_us,
+ },
{ }
};
--
2.7.4
From: Aubrey Li <[email protected]>
Promote menu governor update functionality into cpuidle governor,
so that cpuidle can make a prediction based on the fresh data.
---
drivers/cpuidle/cpuidle.c | 77 +++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 77 insertions(+)
diff --git a/drivers/cpuidle/cpuidle.c b/drivers/cpuidle/cpuidle.c
index 0be7f75..2b7d7bf 100644
--- a/drivers/cpuidle/cpuidle.c
+++ b/drivers/cpuidle/cpuidle.c
@@ -297,6 +297,79 @@ static unsigned int get_typical_interval(struct cpuidle_device *dev)
}
/**
+ * cpuidle_update - attempts to guess what happened after entry
+ * @drv: cpuidle driver containing state data
+ * @dev: the CPU
+ */
+static void cpuidle_update(struct cpuidle_driver *drv,
+ struct cpuidle_device *dev)
+{
+ struct cpuidle_governor_stat *gov_stat =
+ (struct cpuidle_governor_stat *)&(dev->gov_stat);
+ int last_idx = gov_stat->last_state_idx;
+ struct cpuidle_state *target = &drv->states[last_idx];
+ unsigned int measured_us;
+ unsigned int new_factor;
+
+ /*
+ * Try to figure out how much time passed between entry to low
+ * power state and occurrence of the wakeup event.
+ *
+ * If the entered idle state didn't support residency measurements,
+ * we use them anyway if they are short, and if long,
+ * truncate to the whole expected time.
+ *
+ * Any measured amount of time will include the exit latency.
+ * Since we are interested in when the wakeup begun, not when it
+ * was completed, we must subtract the exit latency. However, if
+ * the measured amount of time is less than the exit latency,
+ * assume the state was never reached and the exit latency is 0.
+ */
+
+ /* measured value */
+ measured_us = cpuidle_get_last_residency(dev);
+
+ /* Deduct exit latency */
+ if (measured_us > 2 * target->exit_latency)
+ measured_us -= target->exit_latency;
+ else
+ measured_us /= 2;
+
+ /* Make sure our coefficients do not exceed unity */
+ if (measured_us > gov_stat->next_timer_us)
+ measured_us = gov_stat->next_timer_us;
+
+ /* Update our correction ratio */
+ new_factor = gov_stat->correction_factor[gov_stat->bucket];
+ new_factor -= new_factor / DECAY;
+
+ if (gov_stat->next_timer_us > 0 && measured_us < MAX_INTERESTING)
+ new_factor += RESOLUTION * measured_us / gov_stat->next_timer_us;
+ else
+ /*
+ * we were idle so long that we count it as a perfect
+ * prediction
+ */
+ new_factor += RESOLUTION;
+
+ /*
+ * We don't want 0 as factor; we always want at least
+ * a tiny bit of estimated time. Fortunately, due to rounding,
+ * new_factor will stay nonzero regardless of measured_us values
+ * and the compiler can eliminate this test as long as DECAY > 1.
+ */
+ if (DECAY == 1 && unlikely(new_factor == 0))
+ new_factor = 1;
+
+ gov_stat->correction_factor[gov_stat->bucket] = new_factor;
+
+ /* update the repeating-pattern data */
+ gov_stat->intervals[gov_stat->interval_ptr++] = measured_us;
+ if (gov_stat->interval_ptr >= INTERVALS)
+ gov_stat->interval_ptr = 0;
+}
+
+/**
* cpuidle_predict - predict the next idle duration, in micro-second.
* There are two factors in the cpu idle governor, taken from menu:
* 1) Energy break even point
@@ -319,6 +392,10 @@ unsigned int cpuidle_predict(void)
if (cpuidle_not_available(drv, dev))
return -ENODEV;
+ /*
+ * Give the governor an opportunity to update on the outcome
+ */
+ cpuidle_update(drv, dev);
gov_stat = (struct cpuidle_governor_stat *)&(dev->gov_stat);
--
2.7.4
From: Aubrey Li <[email protected]>
Reflect the data to cpuidle governor when there is an update
---
drivers/cpuidle/cpuidle.c | 6 ++++--
include/linux/cpuidle.h | 1 +
kernel/sched/idle.c | 14 ++++++++++++++
3 files changed, 19 insertions(+), 2 deletions(-)
diff --git a/drivers/cpuidle/cpuidle.c b/drivers/cpuidle/cpuidle.c
index 97aacab..9c84c5c 100644
--- a/drivers/cpuidle/cpuidle.c
+++ b/drivers/cpuidle/cpuidle.c
@@ -387,9 +387,11 @@ unsigned int cpuidle_predict(void)
/*
* Give the governor an opportunity to update on the outcome
*/
- cpuidle_update(drv, dev);
-
gov_stat = (struct cpuidle_governor_stat *)&(dev->gov_stat);
+ if (gov_stat->needs_update) {
+ cpuidle_update(drv, dev);
+ gov_stat->needs_update = 0;
+ }
gov_stat->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
get_iowait_load(&nr_iowaiters, &cpu_load);
diff --git a/include/linux/cpuidle.h b/include/linux/cpuidle.h
index b9964ec..c6a805f 100644
--- a/include/linux/cpuidle.h
+++ b/include/linux/cpuidle.h
@@ -79,6 +79,7 @@ struct cpuidle_state {
struct cpuidle_governor_stat {
int last_state_idx;
+ int needs_update;
unsigned int next_timer_us;
unsigned int predicted_us;
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index 16a766c..3358db2 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -187,6 +187,7 @@ static void cpuidle_idle_call(void)
* Give the governor an opportunity to reflect on the outcome
*/
cpuidle_reflect(dev, entered_state);
+ dev->gov_stat.needs_update = 1;
}
exit_idle:
@@ -206,6 +207,10 @@ static void cpuidle_idle_call(void)
*/
static void cpuidle_fast(void)
{
+ struct cpuidle_device *dev = cpuidle_get_device();
+ ktime_t time_start, time_end;
+ s64 diff;
+
while (!need_resched()) {
check_pgt_cache();
rmb();
@@ -218,7 +223,16 @@ static void cpuidle_fast(void)
local_irq_disable();
arch_cpu_idle_enter();
+ time_start = ns_to_ktime(local_clock());
default_idle_call();
+ time_end = ns_to_ktime(local_clock());
+
+ diff = ktime_us_delta(time_end, time_start);
+ if (diff > INT_MAX)
+ diff = INT_MAX;
+
+ dev->last_residency = (int) diff;
+ dev->gov_stat.needs_update = 1;
arch_cpu_idle_exit();
}
--
2.7.4
From: Aubrey Li <[email protected]>
cpuidle already makes the prediction of how long the coming idle is.
We take it as the input for menu governor to select the target c-state.
---
drivers/cpuidle/governors/menu.c | 29 +++++------------------------
1 file changed, 5 insertions(+), 24 deletions(-)
diff --git a/drivers/cpuidle/governors/menu.c b/drivers/cpuidle/governors/menu.c
index f90c1a8..46f3d3f 100644
--- a/drivers/cpuidle/governors/menu.c
+++ b/drivers/cpuidle/governors/menu.c
@@ -199,9 +199,10 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
struct menu_device *data = this_cpu_ptr(&menu_devices);
struct device *device = get_cpu_device(dev->cpu);
int latency_req = pm_qos_request(PM_QOS_CPU_DMA_LATENCY);
+ struct cpuidle_governor_stat *gov_stat =
+ (struct cpuidle_governor_stat *)&(dev->gov_stat);
int i;
unsigned int interactivity_req;
- unsigned int expected_interval;
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
@@ -213,23 +214,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
if (unlikely(latency_req == 0))
return 0;
- /* determine the expected residency time, round up */
- data->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
-
get_iowait_load(&nr_iowaiters, &cpu_load);
- data->bucket = which_bucket(data->next_timer_us, nr_iowaiters);
-
- /*
- * Force the result of multiplication to be 64 bits even if both
- * operands are 32 bits.
- * Make sure to round up for half microseconds.
- */
- data->predicted_us = DIV_ROUND_CLOSEST_ULL((uint64_t)data->next_timer_us *
- data->correction_factor[data->bucket],
- RESOLUTION * DECAY);
-
- expected_interval = get_typical_interval(data);
- expected_interval = min(expected_interval, data->next_timer_us);
if (CPUIDLE_DRIVER_STATE_START > 0) {
struct cpuidle_state *s = &drv->states[CPUIDLE_DRIVER_STATE_START];
@@ -252,15 +237,11 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
}
/*
- * Use the lowest expected idle interval to pick the idle state.
- */
- data->predicted_us = min(data->predicted_us, expected_interval);
-
- /*
* Use the performance multiplier and the user-configurable
* latency_req to determine the maximum exit latency.
*/
- interactivity_req = data->predicted_us / performance_multiplier(nr_iowaiters, cpu_load);
+ interactivity_req = gov_stat->predicted_us /
+ performance_multiplier(nr_iowaiters, cpu_load);
if (latency_req > interactivity_req)
latency_req = interactivity_req;
@@ -274,7 +255,7 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
if (s->disabled || su->disable)
continue;
- if (s->target_residency > data->predicted_us)
+ if (s->target_residency > gov_stat->predicted_us)
break;
if (s->exit_latency > latency_req)
break;
--
2.7.4
From: Aubrey Li <[email protected]>
Current cpuidle governor updates the last idle residency with the
hardware c-state exit latency, which is not applicable for fast
idle path, so we update idle residency in idle routine instead.
---
drivers/cpuidle/cpuidle.c | 13 +++++--------
1 file changed, 5 insertions(+), 8 deletions(-)
diff --git a/drivers/cpuidle/cpuidle.c b/drivers/cpuidle/cpuidle.c
index 2b7d7bf..97aacab 100644
--- a/drivers/cpuidle/cpuidle.c
+++ b/drivers/cpuidle/cpuidle.c
@@ -306,8 +306,6 @@ static void cpuidle_update(struct cpuidle_driver *drv,
{
struct cpuidle_governor_stat *gov_stat =
(struct cpuidle_governor_stat *)&(dev->gov_stat);
- int last_idx = gov_stat->last_state_idx;
- struct cpuidle_state *target = &drv->states[last_idx];
unsigned int measured_us;
unsigned int new_factor;
@@ -329,12 +327,6 @@ static void cpuidle_update(struct cpuidle_driver *drv,
/* measured value */
measured_us = cpuidle_get_last_residency(dev);
- /* Deduct exit latency */
- if (measured_us > 2 * target->exit_latency)
- measured_us -= target->exit_latency;
- else
- measured_us /= 2;
-
/* Make sure our coefficients do not exceed unity */
if (measured_us > gov_stat->next_timer_us)
measured_us = gov_stat->next_timer_us;
@@ -481,6 +473,11 @@ int cpuidle_enter_state(struct cpuidle_device *dev, struct cpuidle_driver *drv,
diff = ktime_us_delta(time_end, time_start);
if (diff > INT_MAX)
diff = INT_MAX;
+ else if (diff > 2 * target_state->exit_latency)
+ /* Deduct exit latency */
+ diff -= target_state->exit_latency;
+ else
+ diff /= 2;
dev->last_residency = (int) diff;
--
2.7.4
From: Aubrey Li <[email protected]>
For what cpuidle governor already does, we remove them from menu governor
---
drivers/cpuidle/governors/menu.c | 163 ---------------------------------------
1 file changed, 163 deletions(-)
diff --git a/drivers/cpuidle/governors/menu.c b/drivers/cpuidle/governors/menu.c
index b2330fd..f90c1a8 100644
--- a/drivers/cpuidle/governors/menu.c
+++ b/drivers/cpuidle/governors/menu.c
@@ -122,7 +122,6 @@
struct menu_device {
int last_state_idx;
- int needs_update;
unsigned int next_timer_us;
unsigned int predicted_us;
@@ -190,91 +189,6 @@ static inline int performance_multiplier(unsigned long nr_iowaiters, unsigned lo
static DEFINE_PER_CPU(struct menu_device, menu_devices);
-static void menu_update(struct cpuidle_driver *drv, struct cpuidle_device *dev);
-
-/*
- * Try detecting repeating patterns by keeping track of the last 8
- * intervals, and checking if the standard deviation of that set
- * of points is below a threshold. If it is... then use the
- * average of these 8 points as the estimated value.
- */
-static unsigned int get_typical_interval(struct menu_device *data)
-{
- int i, divisor;
- unsigned int max, thresh, avg;
- uint64_t sum, variance;
-
- thresh = UINT_MAX; /* Discard outliers above this value */
-
-again:
-
- /* First calculate the average of past intervals */
- max = 0;
- sum = 0;
- divisor = 0;
- for (i = 0; i < INTERVALS; i++) {
- unsigned int value = data->intervals[i];
- if (value <= thresh) {
- sum += value;
- divisor++;
- if (value > max)
- max = value;
- }
- }
- if (divisor == INTERVALS)
- avg = sum >> INTERVAL_SHIFT;
- else
- avg = div_u64(sum, divisor);
-
- /* Then try to determine variance */
- variance = 0;
- for (i = 0; i < INTERVALS; i++) {
- unsigned int value = data->intervals[i];
- if (value <= thresh) {
- int64_t diff = (int64_t)value - avg;
- variance += diff * diff;
- }
- }
- if (divisor == INTERVALS)
- variance >>= INTERVAL_SHIFT;
- else
- do_div(variance, divisor);
-
- /*
- * The typical interval is obtained when standard deviation is
- * small (stddev <= 20 us, variance <= 400 us^2) or standard
- * deviation is small compared to the average interval (avg >
- * 6*stddev, avg^2 > 36*variance). The average is smaller than
- * UINT_MAX aka U32_MAX, so computing its square does not
- * overflow a u64. We simply reject this candidate average if
- * the standard deviation is greater than 715 s (which is
- * rather unlikely).
- *
- * Use this result only if there is no timer to wake us up sooner.
- */
- if (likely(variance <= U64_MAX/36)) {
- if ((((u64)avg*avg > variance*36) && (divisor * 4 >= INTERVALS * 3))
- || variance <= 400) {
- return avg;
- }
- }
-
- /*
- * If we have outliers to the upside in our distribution, discard
- * those by setting the threshold to exclude these outliers, then
- * calculate the average and standard deviation again. Once we get
- * down to the bottom 3/4 of our samples, stop excluding samples.
- *
- * This can deal with workloads that have long pauses interspersed
- * with sporadic activity with a bunch of short pauses.
- */
- if ((divisor * 4) <= INTERVALS * 3)
- return UINT_MAX;
-
- thresh = max - 1;
- goto again;
-}
-
/**
* menu_select - selects the next idle state to enter
* @drv: cpuidle driver containing state data
@@ -291,11 +205,6 @@ static int menu_select(struct cpuidle_driver *drv, struct cpuidle_device *dev)
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
- if (data->needs_update) {
- menu_update(drv, dev);
- data->needs_update = 0;
- }
-
/* resume_latency is 0 means no restriction */
if (resume_latency && resume_latency < latency_req)
latency_req = resume_latency;
@@ -389,78 +298,6 @@ static void menu_reflect(struct cpuidle_device *dev, int index)
struct menu_device *data = this_cpu_ptr(&menu_devices);
data->last_state_idx = index;
- data->needs_update = 1;
-}
-
-/**
- * menu_update - attempts to guess what happened after entry
- * @drv: cpuidle driver containing state data
- * @dev: the CPU
- */
-static void menu_update(struct cpuidle_driver *drv, struct cpuidle_device *dev)
-{
- struct menu_device *data = this_cpu_ptr(&menu_devices);
- int last_idx = data->last_state_idx;
- struct cpuidle_state *target = &drv->states[last_idx];
- unsigned int measured_us;
- unsigned int new_factor;
-
- /*
- * Try to figure out how much time passed between entry to low
- * power state and occurrence of the wakeup event.
- *
- * If the entered idle state didn't support residency measurements,
- * we use them anyway if they are short, and if long,
- * truncate to the whole expected time.
- *
- * Any measured amount of time will include the exit latency.
- * Since we are interested in when the wakeup begun, not when it
- * was completed, we must subtract the exit latency. However, if
- * the measured amount of time is less than the exit latency,
- * assume the state was never reached and the exit latency is 0.
- */
-
- /* measured value */
- measured_us = cpuidle_get_last_residency(dev);
-
- /* Deduct exit latency */
- if (measured_us > 2 * target->exit_latency)
- measured_us -= target->exit_latency;
- else
- measured_us /= 2;
-
- /* Make sure our coefficients do not exceed unity */
- if (measured_us > data->next_timer_us)
- measured_us = data->next_timer_us;
-
- /* Update our correction ratio */
- new_factor = data->correction_factor[data->bucket];
- new_factor -= new_factor / DECAY;
-
- if (data->next_timer_us > 0 && measured_us < MAX_INTERESTING)
- new_factor += RESOLUTION * measured_us / data->next_timer_us;
- else
- /*
- * we were idle so long that we count it as a perfect
- * prediction
- */
- new_factor += RESOLUTION;
-
- /*
- * We don't want 0 as factor; we always want at least
- * a tiny bit of estimated time. Fortunately, due to rounding,
- * new_factor will stay nonzero regardless of measured_us values
- * and the compiler can eliminate this test as long as DECAY > 1.
- */
- if (DECAY == 1 && unlikely(new_factor == 0))
- new_factor = 1;
-
- data->correction_factor[data->bucket] = new_factor;
-
- /* update the repeating-pattern data */
- data->intervals[data->interval_ptr++] = measured_us;
- if (data->interval_ptr >= INTERVALS)
- data->interval_ptr = 0;
}
/**
--
2.7.4
From: Aubrey Li <[email protected]>
Two factors taken from menu governor for idle prediction in the cpu
idle governor:
- Energy break even point
- Repeatable interval detector
Based on the actual known "next timer event" time, and coordinate with
the algorithm in the above two factors, we'll make a prediction of how
long we'll be idle
---
drivers/cpuidle/cpuidle.c | 165 ++++++++++++++++++++++++++++++++++++++++++++++
include/linux/cpuidle.h | 4 ++
2 files changed, 169 insertions(+)
diff --git a/drivers/cpuidle/cpuidle.c b/drivers/cpuidle/cpuidle.c
index 2706be7..0be7f75 100644
--- a/drivers/cpuidle/cpuidle.c
+++ b/drivers/cpuidle/cpuidle.c
@@ -13,6 +13,8 @@
#include <linux/mutex.h>
#include <linux/sched.h>
#include <linux/sched/clock.h>
+#include <linux/sched/loadavg.h>
+#include <linux/sched/stat.h>
#include <linux/notifier.h>
#include <linux/pm_qos.h>
#include <linux/cpu.h>
@@ -179,6 +181,169 @@ int cpuidle_enter_freeze(struct cpuidle_driver *drv, struct cpuidle_device *dev)
}
#endif /* CONFIG_SUSPEND */
+static inline int which_bucket(unsigned int duration,
+ unsigned long nr_iowaiters)
+{
+ int bucket = 0;
+
+ /*
+ * We keep two groups of stats; one with no
+ * IO pending, one without.
+ * This allows us to calculate
+ * E(duration)|iowait
+ */
+ if (nr_iowaiters)
+ bucket = BUCKETS/2;
+
+ if (duration < 10)
+ return bucket;
+ if (duration < 100)
+ return bucket + 1;
+ if (duration < 1000)
+ return bucket + 2;
+ if (duration < 10000)
+ return bucket + 3;
+ if (duration < 100000)
+ return bucket + 4;
+ return bucket + 5;
+}
+
+/*
+ * Try detecting repeating patterns by keeping track of the last 8
+ * intervals, and checking if the standard deviation of that set
+ * of points is below a threshold. If it is... then use the
+ * average of these 8 points as the estimated value.
+ */
+static unsigned int get_typical_interval(struct cpuidle_device *dev)
+{
+ struct cpuidle_governor_stat *gov_stat =
+ (struct cpuidle_governor_stat *)&(dev->gov_stat);
+ int i, divisor;
+ unsigned int max, thresh, avg;
+ uint64_t sum, variance;
+
+ thresh = UINT_MAX; /* Discard outliers above this value */
+
+again:
+
+ /* First calculate the average of past intervals */
+ max = 0;
+ sum = 0;
+ divisor = 0;
+ for (i = 0; i < INTERVALS; i++) {
+ unsigned int value = gov_stat->intervals[i];
+
+ if (value <= thresh) {
+ sum += value;
+ divisor++;
+ if (value > max)
+ max = value;
+ }
+ }
+ if (divisor == INTERVALS)
+ avg = sum >> INTERVAL_SHIFT;
+ else
+ avg = div_u64(sum, divisor);
+
+ /* Then try to determine variance */
+ variance = 0;
+ for (i = 0; i < INTERVALS; i++) {
+ unsigned int value = gov_stat->intervals[i];
+
+ if (value <= thresh) {
+ int64_t diff = (int64_t)value - avg;
+
+ variance += diff * diff;
+ }
+ }
+ if (divisor == INTERVALS)
+ variance >>= INTERVAL_SHIFT;
+ else
+ do_div(variance, divisor);
+
+ /*
+ * The typical interval is obtained when standard deviation is
+ * small (stddev <= 20 us, variance <= 400 us^2) or standard
+ * deviation is small compared to the average interval (avg >
+ * 6*stddev, avg^2 > 36*variance). The average is smaller than
+ * UINT_MAX aka U32_MAX, so computing its square does not
+ * overflow a u64. We simply reject this candidate average if
+ * the standard deviation is greater than 715 s (which is
+ * rather unlikely).
+ *
+ * Use this result only if there is no timer to wake us up sooner.
+ */
+ if (likely(variance <= U64_MAX/36)) {
+ if ((((u64)avg*avg > variance*36) &&
+ (divisor * 4 >= INTERVALS * 3)) || variance <= 400) {
+ return avg;
+ }
+ }
+
+ /*
+ * If we have outliers to the upside in our distribution, discard
+ * those by setting the threshold to exclude these outliers, then
+ * calculate the average and standard deviation again. Once we get
+ * down to the bottom 3/4 of our samples, stop excluding samples.
+ *
+ * This can deal with workloads that have long pauses interspersed
+ * with sporadic activity with a bunch of short pauses.
+ */
+ if ((divisor * 4) <= INTERVALS * 3)
+ return UINT_MAX;
+
+ thresh = max - 1;
+ goto again;
+}
+
+/**
+ * cpuidle_predict - predict the next idle duration, in micro-second.
+ * There are two factors in the cpu idle governor, taken from menu:
+ * 1) Energy break even point
+ * 2) Repeatable interval detector
+ *
+ * Based on the actual known "next timer event" time, and coordinate with
+ * the algorithm in the two factors, we'll make a prediction of how long
+ * we'll be idle
+ */
+unsigned int cpuidle_predict(void)
+{
+ struct cpuidle_device *dev = cpuidle_get_device();
+ struct cpuidle_driver *drv = cpuidle_get_cpu_driver(dev);
+ struct cpuidle_governor_stat *gov_stat;
+ unsigned int expected_interval;
+ unsigned long nr_iowaiters, cpu_load;
+
+ if (need_resched())
+ return 0;
+
+ if (cpuidle_not_available(drv, dev))
+ return -ENODEV;
+
+ gov_stat = (struct cpuidle_governor_stat *)&(dev->gov_stat);
+
+ gov_stat->next_timer_us = ktime_to_us(tick_nohz_get_sleep_length());
+ get_iowait_load(&nr_iowaiters, &cpu_load);
+ gov_stat->bucket = which_bucket(gov_stat->next_timer_us, nr_iowaiters);
+
+ /*
+ * Force the result of multiplication to be 64 bits even if both
+ * operands are 32 bits.
+ * Make sure to round up for half microseconds.
+ */
+ gov_stat->predicted_us = DIV_ROUND_CLOSEST_ULL(
+ (uint64_t)gov_stat->next_timer_us *
+ gov_stat->correction_factor[gov_stat->bucket],
+ RESOLUTION * DECAY);
+
+ expected_interval = get_typical_interval(dev);
+ expected_interval = min(expected_interval, gov_stat->next_timer_us);
+
+ gov_stat->predicted_us = min(gov_stat->predicted_us, expected_interval);
+
+ return gov_stat->predicted_us;
+}
+
/**
* cpuidle_enter_state - enter the state and update stats
* @dev: cpuidle device for this cpu
diff --git a/include/linux/cpuidle.h b/include/linux/cpuidle.h
index f17a53b..b9964ec 100644
--- a/include/linux/cpuidle.h
+++ b/include/linux/cpuidle.h
@@ -164,6 +164,7 @@ extern int cpuidle_select(struct cpuidle_driver *drv,
extern int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index);
extern void cpuidle_reflect(struct cpuidle_device *dev, int index);
+extern unsigned int cpuidle_predict(void);
extern int cpuidle_register_driver(struct cpuidle_driver *drv);
extern struct cpuidle_driver *cpuidle_get_driver(void);
@@ -198,6 +199,9 @@ static inline int cpuidle_enter(struct cpuidle_driver *drv,
struct cpuidle_device *dev, int index)
{return -ENODEV; }
static inline void cpuidle_reflect(struct cpuidle_device *dev, int index) { }
+static inline unsigned int cpuidle_predict(struct cpuidle_device *dev,
+ struct cpuidle_driver *drv)
+{return -ENODEV; }
static inline int cpuidle_register_driver(struct cpuidle_driver *drv)
{return -ENODEV; }
static inline struct cpuidle_driver *cpuidle_get_driver(void) {return NULL; }
--
2.7.4
On Mon, Jul 10, 2017 at 09:38:30AM +0800, Aubrey Li wrote:
> We measured 3%~5% improvemnt in disk IO workload, and 8%~20% improvement in
> network workload.
Argh, what a mess :/
So how much of the gain is simply due to skipping NOHZ? Mike used to
carry a patch that would throttle NOHZ. And that is a _far_ smaller and
simpler patch to do.
2017-07-10 16:46 GMT+08:00 Peter Zijlstra <[email protected]>:
> On Mon, Jul 10, 2017 at 09:38:30AM +0800, Aubrey Li wrote:
>> We measured 3%~5% improvemnt in disk IO workload, and 8%~20% improvement in
>> network workload.
>
> Argh, what a mess :/
Agreed, this patchset is a variant of
https://lkml.org/lkml/2017/6/22/296 As I mentioned before, we should
not churn the core path.
Regards,
Wanpeng Li
>
> So how much of the gain is simply due to skipping NOHZ? Mike used to
> carry a patch that would throttle NOHZ. And that is a _far_ smaller and
> simpler patch to do.
On 2017/7/10 16:46, Peter Zijlstra wrote:
> On Mon, Jul 10, 2017 at 09:38:30AM +0800, Aubrey Li wrote:
>> We measured 3%~5% improvemnt in disk IO workload, and 8%~20% improvement in
>> network workload.
>
> Argh, what a mess :/
>
> So how much of the gain is simply due to skipping NOHZ?
netperf reports 6~7% improvement due to skipping NOHZ, but still have 2~3%
improvement due to excluding RCU idle enter/exit, c-state selection and other
deferrable items. Also a shallow HW c-state is used in the idle loop, which
means faster HW sleep enter and exit.
> Mike used to carry a patch that would throttle NOHZ. And that is a _far_ small
> and simpler patch to do.
>
Can you please point me to the link of Mike's patch?
Thanks,
-Aubrey
On Mon, Jul 10, 2017 at 10:46:47AM +0200, Peter Zijlstra wrote:
> On Mon, Jul 10, 2017 at 09:38:30AM +0800, Aubrey Li wrote:
> > We measured 3%~5% improvemnt in disk IO workload, and 8%~20% improvement in
> > network workload.
>
> Argh, what a mess :/
The mess is really the current idle entry path. People keep putting more
and more slow stuff there, not realizing it's really a critical fast path.
>
> So how much of the gain is simply due to skipping NOHZ? Mike used to
> carry a patch that would throttle NOHZ. And that is a _far_ smaller and
> simpler patch to do.
Have you ever looked at a ftrace or PT trace of the idle entry?
There's just too much stuff going on there. NOHZ is just the tip
of the iceberg.
-Andi
On Mon, Jul 10, 2017 at 07:46:09AM -0700, Andi Kleen wrote:
> > So how much of the gain is simply due to skipping NOHZ? Mike used to
> > carry a patch that would throttle NOHZ. And that is a _far_ smaller and
> > simpler patch to do.
>
> Have you ever looked at a ftrace or PT trace of the idle entry?
>
> There's just too much stuff going on there. NOHZ is just the tip
> of the iceberg.
I have, and last time I did the actual poking at the LAPIC (to make NOHZ
happen) was by far the slowest thing happening.
Data to indicate what hurts how much would be a very good addition to
the Changelogs. Clearly you have some, you really should have shared.
On Mon, Jul 10, 2017 at 06:42:06PM +0200, Peter Zijlstra wrote:
> On Mon, Jul 10, 2017 at 07:46:09AM -0700, Andi Kleen wrote:
> > > So how much of the gain is simply due to skipping NOHZ? Mike used to
> > > carry a patch that would throttle NOHZ. And that is a _far_ smaller and
> > > simpler patch to do.
> >
> > Have you ever looked at a ftrace or PT trace of the idle entry?
> >
> > There's just too much stuff going on there. NOHZ is just the tip
> > of the iceberg.
>
> I have, and last time I did the actual poking at the LAPIC (to make NOHZ
> happen) was by far the slowest thing happening.
That must have been a long time ago because modern systems use TSC deadline
for a very long time ...
It's still slow, but not as slow as the LAPIC.
> Data to indicate what hurts how much would be a very good addition to
> the Changelogs. Clearly you have some, you really should have shared.
Aubrey?
-Andi
On 2017/7/11 1:27, Andi Kleen wrote:
> On Mon, Jul 10, 2017 at 06:42:06PM +0200, Peter Zijlstra wrote:
>> On Mon, Jul 10, 2017 at 07:46:09AM -0700, Andi Kleen wrote:
>>>> So how much of the gain is simply due to skipping NOHZ? Mike used to
>>>> carry a patch that would throttle NOHZ. And that is a _far_ smaller and
>>>> simpler patch to do.
>>>
>>> Have you ever looked at a ftrace or PT trace of the idle entry?
>>>
>>> There's just too much stuff going on there. NOHZ is just the tip
>>> of the iceberg.
>>
>> I have, and last time I did the actual poking at the LAPIC (to make NOHZ
>> happen) was by far the slowest thing happening.
>
> That must have been a long time ago because modern systems use TSC deadline
> for a very long time ...
>
> It's still slow, but not as slow as the LAPIC.
>
>> Data to indicate what hurts how much would be a very good addition to
>> the Changelogs. Clearly you have some, you really should have shared.
>
Here is an article indicates why we need to improve this:
https://cacm.acm.org/magazines/2017/4/215032-attack-of-the-killer-microseconds/fulltext
Given that we have a few new low-latency I/O devices like Xpoint 3D memory,
25/40GB Ethernet, etc, this proposal targets to improve the latency of
microsecond(us)-scale events as well.
Basically we are looking at how much we can improve(instead of what hurts),
the data is against v4.8.8.
In the idle loop,
- quiet_vmstat costs 5562ns - 6296ns
- tick_nohz_idle_enter costs 7058ns - 10726ns
- totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
9122ns - 15318ns.
--In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
1813ns - 3507ns
- tick_nohz_idle_exit costs 8372ns - 20850ns
Benchmark fio on a NVMe disk shows 3-4% improvement due to skipping nohz, extra
1-2% improvement overall
Benchmark netperf loopback in TCP Request-Response mode shows 6-7% improvement
due to skipping nohz, extra 2-3% improvement overall
Note, the data includes measurement overhead, and it could be varied on the
different platforms, different CPU frequency, and different workload, but they
are consistent once the testing configuration is fixed.
Thanks,
-Aubrey
On Mon, Jul 10, 2017 at 10:27:05AM -0700, Andi Kleen wrote:
> On Mon, Jul 10, 2017 at 06:42:06PM +0200, Peter Zijlstra wrote:
> > I have, and last time I did the actual poking at the LAPIC (to make NOHZ
> > happen) was by far the slowest thing happening.
>
> That must have been a long time ago because modern systems use TSC deadline
> for a very long time ...
Its been a while, but I didn't use the very latest chip when I did.
> It's still slow, but not as slow as the LAPIC.
Deadline TSC is a LAPIC timer mode. Sure the MSR might be slightly
cheaper than the MMIO, but its still painful.
On Tue, Jul 11, 2017 at 12:40:06PM +0800, Li, Aubrey wrote:
> > On Mon, Jul 10, 2017 at 06:42:06PM +0200, Peter Zijlstra wrote:
> >> Data to indicate what hurts how much would be a very good addition to
> >> the Changelogs. Clearly you have some, you really should have shared.
> In the idle loop,
>
> - quiet_vmstat costs 5562ns - 6296ns
Urgh, that thing is horrible, also I think its placed wrong. The comment
near that function says it should be called when we enter NOHZ.
Which suggests something like so:
---
kernel/sched/idle.c | 1 -
kernel/time/tick-sched.c | 1 +
2 files changed, 1 insertion(+), 1 deletion(-)
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index 6c23e30c0e5c..ef63adce0c9c 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -219,7 +219,6 @@ static void do_idle(void)
*/
__current_set_polling();
- quiet_vmstat();
tick_nohz_idle_enter();
while (!need_resched()) {
diff --git a/kernel/time/tick-sched.c b/kernel/time/tick-sched.c
index c7a899c5ce64..eb0e9753db8f 100644
--- a/kernel/time/tick-sched.c
+++ b/kernel/time/tick-sched.c
@@ -787,6 +787,7 @@ static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
if (!ts->tick_stopped) {
calc_load_nohz_start();
cpu_load_update_nohz_start();
+ quiet_vmstat();
ts->last_tick = hrtimer_get_expires(&ts->sched_timer);
ts->tick_stopped = 1;
> - tick_nohz_idle_enter costs 7058ns - 10726ns
> - tick_nohz_idle_exit costs 8372ns - 20850ns
Right, those are horrible expensive, but skipping them isn't 'hard', the
only tricky bit is finding a condition that makes sense.
See Mike's patch: https://patchwork.kernel.org/patch/2839221/
Combined with the above, and possibly a better condition, that should
get rid of most of this.
> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> 9122ns - 15318ns.
> --In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
> 1813ns - 3507ns
Is that the POPF being painful? or something else?
On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
> From: Aubrey Li <[email protected]>
>
> The system will enter a fast idle loop if the predicted idle period
> is shorter than the threshold.
> ---
> kernel/sched/idle.c | 9 ++++++++-
> 1 file changed, 8 insertions(+), 1 deletion(-)
>
> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> index cf6c11f..16a766c 100644
> --- a/kernel/sched/idle.c
> +++ b/kernel/sched/idle.c
> @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
> */
> static void do_idle(void)
> {
> + unsigned int predicted_idle_us;
> + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
> /*
> * If the arch has a polling bit, we maintain an invariant:
> *
> @@ -291,7 +293,12 @@ static void do_idle(void)
>
> __current_set_polling();
>
> - cpuidle_generic();
> + predicted_idle_us = cpuidle_predict();
> +
> + if (likely(predicted_idle_us < short_idle_threshold))
> + cpuidle_fast();
What if we get here from nohz_full usermode execution? In that
case, if I remember correctly, the scheduling-clock interrupt
will still be disabled, and would have to be re-enabled before
we could safely invoke cpuidle_fast().
Or am I missing something here?
Thanx, Paul
> + else
> + cpuidle_generic();
>
> __current_clr_polling();
>
> --
> 2.7.4
>
On Tue, Jul 11, 2017 at 11:41:57AM +0200, Peter Zijlstra wrote:
> On Tue, Jul 11, 2017 at 12:40:06PM +0800, Li, Aubrey wrote:
> > > On Mon, Jul 10, 2017 at 06:42:06PM +0200, Peter Zijlstra wrote:
>
> > >> Data to indicate what hurts how much would be a very good addition to
> > >> the Changelogs. Clearly you have some, you really should have shared.
>
> > In the idle loop,
> >
> > - quiet_vmstat costs 5562ns - 6296ns
>
> Urgh, that thing is horrible, also I think its placed wrong. The comment
> near that function says it should be called when we enter NOHZ.
>
> Which suggests something like so:
>
> ---
> kernel/sched/idle.c | 1 -
> kernel/time/tick-sched.c | 1 +
> 2 files changed, 1 insertion(+), 1 deletion(-)
>
> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> index 6c23e30c0e5c..ef63adce0c9c 100644
> --- a/kernel/sched/idle.c
> +++ b/kernel/sched/idle.c
> @@ -219,7 +219,6 @@ static void do_idle(void)
> */
>
> __current_set_polling();
> - quiet_vmstat();
> tick_nohz_idle_enter();
>
> while (!need_resched()) {
> diff --git a/kernel/time/tick-sched.c b/kernel/time/tick-sched.c
> index c7a899c5ce64..eb0e9753db8f 100644
> --- a/kernel/time/tick-sched.c
> +++ b/kernel/time/tick-sched.c
> @@ -787,6 +787,7 @@ static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
> if (!ts->tick_stopped) {
> calc_load_nohz_start();
> cpu_load_update_nohz_start();
> + quiet_vmstat();
This patch seems to make sense. Christoph?
>
> ts->last_tick = hrtimer_get_expires(&ts->sched_timer);
> ts->tick_stopped = 1;
>
>
> > - tick_nohz_idle_enter costs 7058ns - 10726ns
> > - tick_nohz_idle_exit costs 8372ns - 20850ns
>
> Right, those are horrible expensive, but skipping them isn't 'hard', the
> only tricky bit is finding a condition that makes sense.
Note you can statically disable it with nohz=0 boot parameter.
>
> See Mike's patch: https://patchwork.kernel.org/patch/2839221/
>
> Combined with the above, and possibly a better condition, that should
> get rid of most of this.
Such a patch could work well if the decision from the scheduler to not stop the tick
happens on idle entry.
Now if sched_needs_cpu() first allows to stop the tick then refuses it later
in the end of an idle IRQ, this won't have the desired effect. As long as ts->tick_stopped=1,
it stays so until we really restart the tick. So the whole costly nohz machinery stays on.
I guess it doesn't matter though, as we are talking about making fast idle entry so the
decision not to stop the tick is likely to be done once on idle entry, when ts->tick_stopped=0.
One exception though: if the tick is already stopped when we enter idle (full nohz case). And
BTW stopping the tick outside idle shouldn't be concerned here.
So I'd rather put that on can_stop_idle_tick().
>
> > - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> > 9122ns - 15318ns.
> > --In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
> > 1813ns - 3507ns
>
> Is that the POPF being painful? or something else?
Probably that and the atomic_add_return().
Thanks.
On Tue, Jul 11, 2017 at 05:58:47AM -0700, Paul E. McKenney wrote:
> On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
> > From: Aubrey Li <[email protected]>
> >
> > The system will enter a fast idle loop if the predicted idle period
> > is shorter than the threshold.
> > ---
> > kernel/sched/idle.c | 9 ++++++++-
> > 1 file changed, 8 insertions(+), 1 deletion(-)
> >
> > diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> > index cf6c11f..16a766c 100644
> > --- a/kernel/sched/idle.c
> > +++ b/kernel/sched/idle.c
> > @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
> > */
> > static void do_idle(void)
> > {
> > + unsigned int predicted_idle_us;
> > + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
> > /*
> > * If the arch has a polling bit, we maintain an invariant:
> > *
> > @@ -291,7 +293,12 @@ static void do_idle(void)
> >
> > __current_set_polling();
> >
> > - cpuidle_generic();
> > + predicted_idle_us = cpuidle_predict();
> > +
> > + if (likely(predicted_idle_us < short_idle_threshold))
> > + cpuidle_fast();
>
> What if we get here from nohz_full usermode execution? In that
> case, if I remember correctly, the scheduling-clock interrupt
> will still be disabled, and would have to be re-enabled before
> we could safely invoke cpuidle_fast().
>
> Or am I missing something here?
That's a good point. It's partially ok because if the tick is needed
for something specific, it is not entirely stopped but programmed to that
deadline.
Now there is some idle specific code when we enter dynticks-idle. See
tick_nohz_start_idle(), tick_nohz_stop_idle(), sched_clock_idle_wakeup_event()
and some subsystems that react differently when we enter dyntick idle
mode (scheduler_tick_max_deferment) so the tick may need a reevaluation.
For now I'd rather suggest that we treat full nohz as an exception case here
and do:
if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
cpuidle_fast();
Ugly but safer!
Thanks.
On Tue, Jul 11, 2017 at 06:09:27PM +0200, Frederic Weisbecker wrote:
> > > - tick_nohz_idle_enter costs 7058ns - 10726ns
> > > - tick_nohz_idle_exit costs 8372ns - 20850ns
> >
> > Right, those are horrible expensive, but skipping them isn't 'hard', the
> > only tricky bit is finding a condition that makes sense.
>
> Note you can statically disable it with nohz=0 boot parameter.
Yeah, but that's bad for power usage, nobody wants that.
> > See Mike's patch: https://patchwork.kernel.org/patch/2839221/
> >
> > Combined with the above, and possibly a better condition, that should
> > get rid of most of this.
>
> Such a patch could work well if the decision from the scheduler to not stop the tick
> happens on idle entry.
>
> Now if sched_needs_cpu() first allows to stop the tick then refuses it later
> in the end of an idle IRQ, this won't have the desired effect. As long as ts->tick_stopped=1,
> it stays so until we really restart the tick. So the whole costly nohz machinery stays on.
>
> I guess it doesn't matter though, as we are talking about making fast idle entry so the
> decision not to stop the tick is likely to be done once on idle entry, when ts->tick_stopped=0.
>
> One exception though: if the tick is already stopped when we enter idle (full nohz case). And
> BTW stopping the tick outside idle shouldn't be concerned here.
>
> So I'd rather put that on can_stop_idle_tick().
Mike's patch much predates the existence of that function I think ;-) But
sure..
> >
> > > - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> > > 9122ns - 15318ns.
> > > --In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
> > > 1813ns - 3507ns
> >
> > Is that the POPF being painful? or something else?
>
> Probably that and the atomic_add_return().
I got properly lost in the RCU machinery. It wasn't at all clear to me
if rcu_eqs_enter_common() was a slow-path function or not.
Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
what's the state of that thing, do we actually want that or not?
But I think we can at the very least do this; it only gets called from
kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
that point.
diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
index 51d4c3acf32d..dccf2dc8155a 100644
--- a/kernel/rcu/tree.c
+++ b/kernel/rcu/tree.c
@@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
*/
void rcu_idle_enter(void)
{
- unsigned long flags;
-
- local_irq_save(flags);
rcu_eqs_enter(false);
- local_irq_restore(flags);
}
-EXPORT_SYMBOL_GPL(rcu_idle_enter);
#ifdef CONFIG_NO_HZ_FULL
/**
On Tue, 11 Jul 2017, Frederic Weisbecker wrote:
> > --- a/kernel/time/tick-sched.c
> > +++ b/kernel/time/tick-sched.c
> > @@ -787,6 +787,7 @@ static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
> > if (!ts->tick_stopped) {
> > calc_load_nohz_start();
> > cpu_load_update_nohz_start();
> > + quiet_vmstat();
>
> This patch seems to make sense. Christoph?
Ok makes sense to me too. Was never entirely sure where the proper place
would be to call it.
On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> On Tue, Jul 11, 2017 at 06:09:27PM +0200, Frederic Weisbecker wrote:
>
> > > > - tick_nohz_idle_enter costs 7058ns - 10726ns
> > > > - tick_nohz_idle_exit costs 8372ns - 20850ns
> > >
> > > Right, those are horrible expensive, but skipping them isn't 'hard', the
> > > only tricky bit is finding a condition that makes sense.
> >
> > Note you can statically disable it with nohz=0 boot parameter.
>
> Yeah, but that's bad for power usage, nobody wants that.
>
> > > See Mike's patch: https://patchwork.kernel.org/patch/2839221/
> > >
> > > Combined with the above, and possibly a better condition, that should
> > > get rid of most of this.
> >
> > Such a patch could work well if the decision from the scheduler to not stop the tick
> > happens on idle entry.
> >
> > Now if sched_needs_cpu() first allows to stop the tick then refuses it later
> > in the end of an idle IRQ, this won't have the desired effect. As long as ts->tick_stopped=1,
> > it stays so until we really restart the tick. So the whole costly nohz machinery stays on.
> >
> > I guess it doesn't matter though, as we are talking about making fast idle entry so the
> > decision not to stop the tick is likely to be done once on idle entry, when ts->tick_stopped=0.
> >
> > One exception though: if the tick is already stopped when we enter idle (full nohz case). And
> > BTW stopping the tick outside idle shouldn't be concerned here.
> >
> > So I'd rather put that on can_stop_idle_tick().
>
> Mike's patch much predates the existence of that function I think ;-) But
> sure..
>
> > >
> > > > - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> > > > 9122ns - 15318ns.
> > > > --In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
> > > > 1813ns - 3507ns
> > >
> > > Is that the POPF being painful? or something else?
> >
> > Probably that and the atomic_add_return().
>
> I got properly lost in the RCU machinery. It wasn't at all clear to me
> if rcu_eqs_enter_common() was a slow-path function or not.
It is called on pretty much every transition to idle.
> Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
> what's the state of that thing, do we actually want that or not?
If you are battery powered and don't have tight real-time latency
constraints, you want it -- it has represent a 30-40% boost in battery
lifetime for some low-utilization battery-powered devices. Otherwise,
probably not.
> But I think we can at the very least do this; it only gets called from
> kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
> that point.
>
>
> diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> index 51d4c3acf32d..dccf2dc8155a 100644
> --- a/kernel/rcu/tree.c
> +++ b/kernel/rcu/tree.c
> @@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
> */
> void rcu_idle_enter(void)
> {
> - unsigned long flags;
> -
> - local_irq_save(flags);
With this addition, I am all for it:
RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
If you are OK with this addition, may I please have your Signed-off-by?
Thanx, Paul
> rcu_eqs_enter(false);
> - local_irq_restore(flags);
> }
> -EXPORT_SYMBOL_GPL(rcu_idle_enter);
>
> #ifdef CONFIG_NO_HZ_FULL
> /**
>
On Tue, Jul 11, 2017 at 06:33:55PM +0200, Frederic Weisbecker wrote:
> On Tue, Jul 11, 2017 at 05:58:47AM -0700, Paul E. McKenney wrote:
> > On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
> > > From: Aubrey Li <[email protected]>
> > >
> > > The system will enter a fast idle loop if the predicted idle period
> > > is shorter than the threshold.
> > > ---
> > > kernel/sched/idle.c | 9 ++++++++-
> > > 1 file changed, 8 insertions(+), 1 deletion(-)
> > >
> > > diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> > > index cf6c11f..16a766c 100644
> > > --- a/kernel/sched/idle.c
> > > +++ b/kernel/sched/idle.c
> > > @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
> > > */
> > > static void do_idle(void)
> > > {
> > > + unsigned int predicted_idle_us;
> > > + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
> > > /*
> > > * If the arch has a polling bit, we maintain an invariant:
> > > *
> > > @@ -291,7 +293,12 @@ static void do_idle(void)
> > >
> > > __current_set_polling();
> > >
> > > - cpuidle_generic();
> > > + predicted_idle_us = cpuidle_predict();
> > > +
> > > + if (likely(predicted_idle_us < short_idle_threshold))
> > > + cpuidle_fast();
> >
> > What if we get here from nohz_full usermode execution? In that
> > case, if I remember correctly, the scheduling-clock interrupt
> > will still be disabled, and would have to be re-enabled before
> > we could safely invoke cpuidle_fast().
> >
> > Or am I missing something here?
>
> That's a good point. It's partially ok because if the tick is needed
> for something specific, it is not entirely stopped but programmed to that
> deadline.
>
> Now there is some idle specific code when we enter dynticks-idle. See
> tick_nohz_start_idle(), tick_nohz_stop_idle(), sched_clock_idle_wakeup_event()
> and some subsystems that react differently when we enter dyntick idle
> mode (scheduler_tick_max_deferment) so the tick may need a reevaluation.
>
> For now I'd rather suggest that we treat full nohz as an exception case here
> and do:
>
> if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
> cpuidle_fast();
>
> Ugly but safer!
Works for me!
Thanx, Paul
On 2017/7/12 1:58, Christoph Lameter wrote:
> On Tue, 11 Jul 2017, Frederic Weisbecker wrote:
>
>>> --- a/kernel/time/tick-sched.c
>>> +++ b/kernel/time/tick-sched.c
>>> @@ -787,6 +787,7 @@ static ktime_t tick_nohz_stop_sched_tick(struct tick_sched *ts,
>>> if (!ts->tick_stopped) {
>>> calc_load_nohz_start();
>>> cpu_load_update_nohz_start();
>>> + quiet_vmstat();
>>
>> This patch seems to make sense. Christoph?
>
> Ok makes sense to me too. Was never entirely sure where the proper place
> would be to call it.
>
Do we have another path to invoke tick_nohz_stop_sched_tick() in the interrupt exit context
for nohz full case?
Thanks,
-Aubrey
On 2017/7/12 0:09, Frederic Weisbecker wrote:
> On Tue, Jul 11, 2017 at 11:41:57AM +0200, Peter Zijlstra wrote:
>>
>>> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
>>> 9122ns - 15318ns.
>>> --In this period, rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit costs
>>> 1813ns - 3507ns
>>
>> Is that the POPF being painful? or something else?
>
> Probably that and the atomic_add_return().
> We thought RCU idle cost is high, but it seems not. But it still has few microseconds
can be saved if we can remove them from fast idle path.
Thanks,
-Aubrey
On 2017/7/12 2:11, Paul E. McKenney wrote:
> On Tue, Jul 11, 2017 at 06:33:55PM +0200, Frederic Weisbecker wrote:
>> On Tue, Jul 11, 2017 at 05:58:47AM -0700, Paul E. McKenney wrote:
>>> On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
>>>> From: Aubrey Li <[email protected]>
>>>>
>>>> The system will enter a fast idle loop if the predicted idle period
>>>> is shorter than the threshold.
>>>> ---
>>>> kernel/sched/idle.c | 9 ++++++++-
>>>> 1 file changed, 8 insertions(+), 1 deletion(-)
>>>>
>>>> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
>>>> index cf6c11f..16a766c 100644
>>>> --- a/kernel/sched/idle.c
>>>> +++ b/kernel/sched/idle.c
>>>> @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
>>>> */
>>>> static void do_idle(void)
>>>> {
>>>> + unsigned int predicted_idle_us;
>>>> + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
>>>> /*
>>>> * If the arch has a polling bit, we maintain an invariant:
>>>> *
>>>> @@ -291,7 +293,12 @@ static void do_idle(void)
>>>>
>>>> __current_set_polling();
>>>>
>>>> - cpuidle_generic();
>>>> + predicted_idle_us = cpuidle_predict();
>>>> +
>>>> + if (likely(predicted_idle_us < short_idle_threshold))
>>>> + cpuidle_fast();
>>>
>>> What if we get here from nohz_full usermode execution? In that
>>> case, if I remember correctly, the scheduling-clock interrupt
>>> will still be disabled, and would have to be re-enabled before
>>> we could safely invoke cpuidle_fast().
>>>
>>> Or am I missing something here?
>>
>> That's a good point. It's partially ok because if the tick is needed
>> for something specific, it is not entirely stopped but programmed to that
>> deadline.
>>
>> Now there is some idle specific code when we enter dynticks-idle. See
>> tick_nohz_start_idle(), tick_nohz_stop_idle(), sched_clock_idle_wakeup_event()
>> and some subsystems that react differently when we enter dyntick idle
>> mode (scheduler_tick_max_deferment) so the tick may need a reevaluation.
>>
>> For now I'd rather suggest that we treat full nohz as an exception case here
>> and do:
>>
>> if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
>> cpuidle_fast();
>>
>> Ugly but safer!
>
> Works for me!
>
I guess who enabled full nohz(for example the financial guys who need the system
response as fast as possible) does not like this compromise, ;)
How about add rcu_idle enter/exit back only for full nohz case in fast idle? RCU idle
is the only risky ops if removing them from fast idle path. Comparing to adding RCU
idle back, going to normal idle path has more overhead IMHO.
Thanks,
-Aubrey
On 2017/7/12 0:34, Peter Zijlstra wrote:
> On Tue, Jul 11, 2017 at 06:09:27PM +0200, Frederic Weisbecker wrote:
>
>>>> - tick_nohz_idle_enter costs 7058ns - 10726ns
>>>> - tick_nohz_idle_exit costs 8372ns - 20850ns
>>>
>>> Right, those are horrible expensive, but skipping them isn't 'hard', the
>>> only tricky bit is finding a condition that makes sense.
>>
>> Note you can statically disable it with nohz=0 boot parameter.
>
> Yeah, but that's bad for power usage, nobody wants that.
>
>>> See Mike's patch: https://patchwork.kernel.org/patch/2839221/
>>>
>>> Combined with the above, and possibly a better condition, that should
>>> get rid of most of this.
>>
>> Such a patch could work well if the decision from the scheduler to not stop the tick
>> happens on idle entry.
>>
>> Now if sched_needs_cpu() first allows to stop the tick then refuses it later
>> in the end of an idle IRQ, this won't have the desired effect. As long as ts->tick_stopped=1,
>> it stays so until we really restart the tick. So the whole costly nohz machinery stays on.
>>
>> I guess it doesn't matter though, as we are talking about making fast idle entry so the
>> decision not to stop the tick is likely to be done once on idle entry, when ts->tick_stopped=0.
>>
>> One exception though: if the tick is already stopped when we enter idle (full nohz case). And
>> BTW stopping the tick outside idle shouldn't be concerned here.
>>
>> So I'd rather put that on can_stop_idle_tick().
>
> Mike's patch much predates the existence of that function I think ;-) But
> sure..
>
Okay, the difference is that Mike's patch uses a very simple algorithm to make the decision.
/*
* delta is wakeup_timestamp - idle_timestamp
*/
update_avg(&rq->avg_idle, delta);
...
static void update_avg(u64 *avg, u64 sample)
{
s64 diff = sample - *avg;
*avg += diff >> 3;
}
While my proposal is trying to leverage the prediction functionality of the existing idle menu
governor, which works very well for a long time.
I know the the code change is big and the running overhead is a bit higher than rq->avg_idle, but
should we make a comparison for some typical workloads?
Thanks,
-Aubrey
On Wed, Jul 12, 2017 at 11:19:59AM +0800, Li, Aubrey wrote:
> On 2017/7/12 2:11, Paul E. McKenney wrote:
> > On Tue, Jul 11, 2017 at 06:33:55PM +0200, Frederic Weisbecker wrote:
> >> On Tue, Jul 11, 2017 at 05:58:47AM -0700, Paul E. McKenney wrote:
> >>> On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
> >>>> From: Aubrey Li <[email protected]>
> >>>>
> >>>> The system will enter a fast idle loop if the predicted idle period
> >>>> is shorter than the threshold.
> >>>> ---
> >>>> kernel/sched/idle.c | 9 ++++++++-
> >>>> 1 file changed, 8 insertions(+), 1 deletion(-)
> >>>>
> >>>> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> >>>> index cf6c11f..16a766c 100644
> >>>> --- a/kernel/sched/idle.c
> >>>> +++ b/kernel/sched/idle.c
> >>>> @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
> >>>> */
> >>>> static void do_idle(void)
> >>>> {
> >>>> + unsigned int predicted_idle_us;
> >>>> + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
> >>>> /*
> >>>> * If the arch has a polling bit, we maintain an invariant:
> >>>> *
> >>>> @@ -291,7 +293,12 @@ static void do_idle(void)
> >>>>
> >>>> __current_set_polling();
> >>>>
> >>>> - cpuidle_generic();
> >>>> + predicted_idle_us = cpuidle_predict();
> >>>> +
> >>>> + if (likely(predicted_idle_us < short_idle_threshold))
> >>>> + cpuidle_fast();
> >>>
> >>> What if we get here from nohz_full usermode execution? In that
> >>> case, if I remember correctly, the scheduling-clock interrupt
> >>> will still be disabled, and would have to be re-enabled before
> >>> we could safely invoke cpuidle_fast().
> >>>
> >>> Or am I missing something here?
> >>
> >> That's a good point. It's partially ok because if the tick is needed
> >> for something specific, it is not entirely stopped but programmed to that
> >> deadline.
> >>
> >> Now there is some idle specific code when we enter dynticks-idle. See
> >> tick_nohz_start_idle(), tick_nohz_stop_idle(), sched_clock_idle_wakeup_event()
> >> and some subsystems that react differently when we enter dyntick idle
> >> mode (scheduler_tick_max_deferment) so the tick may need a reevaluation.
> >>
> >> For now I'd rather suggest that we treat full nohz as an exception case here
> >> and do:
> >>
> >> if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
> >> cpuidle_fast();
> >>
> >> Ugly but safer!
> >
> > Works for me!
>
> I guess who enabled full nohz(for example the financial guys who need the system
> response as fast as possible) does not like this compromise, ;)
And some HPC guys and some real-time guys with CPU-bound real-time
processing, so there are likely quite a few different views on this
compromise.
> How about add rcu_idle enter/exit back only for full nohz case in fast idle? RCU idle
> is the only risky ops if removing them from fast idle path. Comparing to adding RCU
> idle back, going to normal idle path has more overhead IMHO.
That might work, but I would need to see the actual patch. Frederic
Weisbecker should look at it as well.
Thanx, Paul
On 2017/7/12 13:03, Paul E. McKenney wrote:
> On Wed, Jul 12, 2017 at 11:19:59AM +0800, Li, Aubrey wrote:
>> On 2017/7/12 2:11, Paul E. McKenney wrote:
>>> On Tue, Jul 11, 2017 at 06:33:55PM +0200, Frederic Weisbecker wrote:
>>>> On Tue, Jul 11, 2017 at 05:58:47AM -0700, Paul E. McKenney wrote:
>>>>> On Mon, Jul 10, 2017 at 09:38:34AM +0800, Aubrey Li wrote:
>>>>>> From: Aubrey Li <[email protected]>
>>>>>>
>>>>>> The system will enter a fast idle loop if the predicted idle period
>>>>>> is shorter than the threshold.
>>>>>> ---
>>>>>> kernel/sched/idle.c | 9 ++++++++-
>>>>>> 1 file changed, 8 insertions(+), 1 deletion(-)
>>>>>>
>>>>>> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
>>>>>> index cf6c11f..16a766c 100644
>>>>>> --- a/kernel/sched/idle.c
>>>>>> +++ b/kernel/sched/idle.c
>>>>>> @@ -280,6 +280,8 @@ static void cpuidle_generic(void)
>>>>>> */
>>>>>> static void do_idle(void)
>>>>>> {
>>>>>> + unsigned int predicted_idle_us;
>>>>>> + unsigned int short_idle_threshold = jiffies_to_usecs(1) / 2;
>>>>>> /*
>>>>>> * If the arch has a polling bit, we maintain an invariant:
>>>>>> *
>>>>>> @@ -291,7 +293,12 @@ static void do_idle(void)
>>>>>>
>>>>>> __current_set_polling();
>>>>>>
>>>>>> - cpuidle_generic();
>>>>>> + predicted_idle_us = cpuidle_predict();
>>>>>> +
>>>>>> + if (likely(predicted_idle_us < short_idle_threshold))
>>>>>> + cpuidle_fast();
>>>>>
>>>>> What if we get here from nohz_full usermode execution? In that
>>>>> case, if I remember correctly, the scheduling-clock interrupt
>>>>> will still be disabled, and would have to be re-enabled before
>>>>> we could safely invoke cpuidle_fast().
>>>>>
>>>>> Or am I missing something here?
>>>>
>>>> That's a good point. It's partially ok because if the tick is needed
>>>> for something specific, it is not entirely stopped but programmed to that
>>>> deadline.
>>>>
>>>> Now there is some idle specific code when we enter dynticks-idle. See
>>>> tick_nohz_start_idle(), tick_nohz_stop_idle(), sched_clock_idle_wakeup_event()
>>>> and some subsystems that react differently when we enter dyntick idle
>>>> mode (scheduler_tick_max_deferment) so the tick may need a reevaluation.
>>>>
>>>> For now I'd rather suggest that we treat full nohz as an exception case here
>>>> and do:
>>>>
>>>> if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
>>>> cpuidle_fast();
>>>>
>>>> Ugly but safer!
>>>
>>> Works for me!
>>
>> I guess who enabled full nohz(for example the financial guys who need the system
>> response as fast as possible) does not like this compromise, ;)
>
> And some HPC guys and some real-time guys with CPU-bound real-time
> processing, so there are likely quite a few different views on this
> compromise.
>
>> How about add rcu_idle enter/exit back only for full nohz case in fast idle? RCU idle
>> is the only risky ops if removing them from fast idle path. Comparing to adding RCU
>> idle back, going to normal idle path has more overhead IMHO.
>
> That might work, but I would need to see the actual patch. Frederic
> Weisbecker should look at it as well.
>
Okay, let me address the first round of comments and deliver v2 soon.
Thanks,
-Aubrey
On Wed, Jul 12, 2017 at 12:15:08PM +0800, Li, Aubrey wrote:
> Okay, the difference is that Mike's patch uses a very simple algorithm to make the decision.
No, the difference is that we don't end up with duplication of a metric
ton of code.
It uses the normal idle path, it just makes the NOHZ enter fail.
The condition Mike uses is why that patch never really went anywhere and
needs work.
For the condition I tend to prefer something auto-adjusting vs a tunable
threshold that everybody + dog needs to manually adjust.
So add something that measures the cost of tick_nohz_idle_{enter,exit}()
and base the threshold off of that. Then of course, there's the question
which of the idle estimates to use.
The cpuidle idle estimate includes IRQs, which is important for actual
idle states, but not all interrupts re-enable the tick.
The scheduler idle estimate only considers task activity, which tends to
re-enable the tick.
So the cpuidle estimate is pessimistic in that it'll vastly under
estimate the actual nohz period, while the scheduler estimate will over
estimate. I suspsect the scheduler one is closer to the actual nohz
duration, but this is something we'll have to play with.
On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > But I think we can at the very least do this; it only gets called from
> > kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
> > that point.
> >
> >
> > diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> > index 51d4c3acf32d..dccf2dc8155a 100644
> > --- a/kernel/rcu/tree.c
> > +++ b/kernel/rcu/tree.c
> > @@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
> > */
> > void rcu_idle_enter(void)
> > {
> > - unsigned long flags;
> > -
> > - local_irq_save(flags);
>
> With this addition, I am all for it:
>
> RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
>
> If you are OK with this addition, may I please have your Signed-off-by?
Sure,
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
>
> > rcu_eqs_enter(false);
> > - local_irq_restore(flags);
> > }
> > -EXPORT_SYMBOL_GPL(rcu_idle_enter);
> >
> > #ifdef CONFIG_NO_HZ_FULL
> > /**
> >
>
On Wed, Jul 12, 2017 at 12:15:08PM +0800, Li, Aubrey wrote:
> While my proposal is trying to leverage the prediction functionality
> of the existing idle menu governor, which works very well for a long
> time.
Oh, so you've missed the emails where people say its shit? ;-)
Look for the emails of Daniel Lezcano who has been working on better
estimating the IRQ periodicity. Some of that has recently been merged
but it hasn't got any users yet afaik.
But as said before, I'm not convinced the actual idle time is the right
measure for NOHZ, because many interrupts do not in fact re-enable the
tick.
On Mon, Jul 10, 2017 at 09:38:33AM +0800, Aubrey Li wrote:
> + get_iowait_load(&nr_iowaiters, &cpu_load);
NAK, see commit e33a9bba85a86, that's just drug induced voodoo
programming.
On Tue, Jul 11, 2017 at 06:33:55PM +0200, Frederic Weisbecker wrote:
> if (!tick_nohz_full_cpu(smp_processor_id()) && likely(predicted_idle_us < short_idle_threshold))
> cpuidle_fast();
>
> Ugly but safer!
I'd not overly worry about this, cpuidle_fast() isn't anything that's
likely to ever happen.
On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
> > what's the state of that thing, do we actually want that or not?
>
> If you are battery powered and don't have tight real-time latency
> constraints, you want it -- it has represent a 30-40% boost in battery
> lifetime for some low-utilization battery-powered devices. Otherwise,
> probably not.
Would it make sense to hook that off of tick_nohz_idle_enter(); in
specific the part where we actually stop the tick; instead of every
idle?
On Wed, Jul 12, 2017 at 02:22:49PM +0200, Peter Zijlstra wrote:
> On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > > Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
> > > what's the state of that thing, do we actually want that or not?
> >
> > If you are battery powered and don't have tight real-time latency
> > constraints, you want it -- it has represent a 30-40% boost in battery
> > lifetime for some low-utilization battery-powered devices. Otherwise,
> > probably not.
>
> Would it make sense to hook that off of tick_nohz_idle_enter(); in
> specific the part where we actually stop the tick; instead of every
> idle?
The actions RCU takes on RCU_FAST_NO_HZ depend on the current state of
the CPU's callback lists, so it seems to me that the decision has to
be made on each idle entry.
Now it might be possible to make the checks more efficient, and doing
that is on my list.
Or am I missing your point?
Thanx, Paul
On Wed, Jul 12, 2017 at 01:54:51PM +0200, Peter Zijlstra wrote:
> On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
>
> > > But I think we can at the very least do this; it only gets called from
> > > kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
> > > that point.
> > >
> > >
> > > diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> > > index 51d4c3acf32d..dccf2dc8155a 100644
> > > --- a/kernel/rcu/tree.c
> > > +++ b/kernel/rcu/tree.c
> > > @@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
> > > */
> > > void rcu_idle_enter(void)
> > > {
> > > - unsigned long flags;
> > > -
> > > - local_irq_save(flags);
> >
> > With this addition, I am all for it:
> >
> > RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
> >
> > If you are OK with this addition, may I please have your Signed-off-by?
>
> Sure,
>
> Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Very good, I have queued the patch below. I left out the removal of
the export as I need to work out why the export was there. If it turns
out not to be needed, I will remove the related ones as well.
Fair enough?
Thanx, Paul
------------------------------------------------------------------------
commit 95f3e587ce6388028a51f0c852800fca944e7032
Author: Peter Zijlstra (Intel) <[email protected]>
Date: Wed Jul 12 07:59:54 2017 -0700
rcu: Make rcu_idle_enter() rely on callers disabling irqs
All callers to rcu_idle_enter() have irqs disabled, so there is no
point in rcu_idle_enter disabling them again. This commit therefore
replaces the irq disabling with a RCU_LOCKDEP_WARN().
Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
Signed-off-by: Paul E. McKenney <[email protected]>
diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
index 6de6b1c5ee53..c78b076653ce 100644
--- a/kernel/rcu/tree.c
+++ b/kernel/rcu/tree.c
@@ -840,11 +840,8 @@ static void rcu_eqs_enter(bool user)
*/
void rcu_idle_enter(void)
{
- unsigned long flags;
-
- local_irq_save(flags);
+ RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
rcu_eqs_enter(false);
- local_irq_restore(flags);
}
EXPORT_SYMBOL_GPL(rcu_idle_enter);
On Wed, Jul 12, 2017 at 08:54:58AM -0700, Paul E. McKenney wrote:
> On Wed, Jul 12, 2017 at 02:22:49PM +0200, Peter Zijlstra wrote:
> > On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > > > Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
> > > > what's the state of that thing, do we actually want that or not?
> > >
> > > If you are battery powered and don't have tight real-time latency
> > > constraints, you want it -- it has represent a 30-40% boost in battery
> > > lifetime for some low-utilization battery-powered devices. Otherwise,
> > > probably not.
> >
> > Would it make sense to hook that off of tick_nohz_idle_enter(); in
> > specific the part where we actually stop the tick; instead of every
> > idle?
>
> The actions RCU takes on RCU_FAST_NO_HZ depend on the current state of
> the CPU's callback lists, so it seems to me that the decision has to
> be made on each idle entry.
>
> Now it might be possible to make the checks more efficient, and doing
> that is on my list.
>
> Or am I missing your point?
Could be I'm just not remembering how all that works.. But I was
wondering if we can do the expensive bits if we've decided to actually
go NOHZ and avoid doing it on every idle entry.
IIRC the RCU fast NOHZ bits try and flush the callback list (or paw it
off to another CPU?) such that we can go NOHZ sooner. Having a !empty
callback list avoid NOHZ from happening.
Now if we've already decided we can't in fact go NOHZ due to other
concerns, flushing the callback list is pointless work. So I'm thinking
we can find a better place to do this.
On Wed, Jul 12, 2017 at 08:56:51AM -0700, Paul E. McKenney wrote:
> Very good, I have queued the patch below. I left out the removal of
> the export as I need to work out why the export was there. If it turns
> out not to be needed, I will remove the related ones as well.
'git grep rcu_idle_enter' shows no callers other than
kernel/sched/idle.c. Which seems a clear indication its not needed.
You also have to ask yourself, do I want joe module author to ever call
this. To which I suspect the answer is: hell no ;-)
On Wed, Jul 12, 2017 at 07:17:56PM +0200, Peter Zijlstra wrote:
> Could be I'm just not remembering how all that works.. But I was
> wondering if we can do the expensive bits if we've decided to actually
> go NOHZ and avoid doing it on every idle entry.
>
> IIRC the RCU fast NOHZ bits try and flush the callback list (or paw it
> off to another CPU?) such that we can go NOHZ sooner. Having a !empty
> callback list avoid NOHZ from happening.
>
> Now if we've already decided we can't in fact go NOHZ due to other
> concerns, flushing the callback list is pointless work. So I'm thinking
> we can find a better place to do this.
I'm a wee bit confused by the split between rcu_prepare_for_idle() and
rcu_needs_cpu().
There's a fair amount overlap there.. that said, I'm thinking we should
be calling rcu_needs_cpu() as the very last test, not the very first,
such that we can bail out of tick_nohz_stop_sched_tick() without having
to incur the penalty of flushing callbacks.
On Tue, Jul 11, 2017 at 06:09:27PM +0200, Frederic Weisbecker wrote:
> So I'd rather put that on can_stop_idle_tick().
That function needs a fix.. That's not in fact an identity (although it
turns out it is for the 4 default HZ values).
diff --git a/kernel/time/tick-sched.c b/kernel/time/tick-sched.c
index c7a899c5ce64..91433bc4a723 100644
--- a/kernel/time/tick-sched.c
+++ b/kernel/time/tick-sched.c
@@ -882,7 +882,7 @@ static bool can_stop_idle_tick(int cpu, struct tick_sched *ts)
}
if (unlikely(ts->nohz_mode == NOHZ_MODE_INACTIVE)) {
- ts->sleep_length = NSEC_PER_SEC / HZ;
+ ts->sleep_length = TICK_NSEC;
return false;
}
On Wed, Jul 12, 2017 at 07:17:56PM +0200, Peter Zijlstra wrote:
> On Wed, Jul 12, 2017 at 08:54:58AM -0700, Paul E. McKenney wrote:
> > On Wed, Jul 12, 2017 at 02:22:49PM +0200, Peter Zijlstra wrote:
> > > On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > > > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > > > > Also, RCU_FAST_NO_HZ will make a fairly large difference here.. Paul
> > > > > what's the state of that thing, do we actually want that or not?
> > > >
> > > > If you are battery powered and don't have tight real-time latency
> > > > constraints, you want it -- it has represent a 30-40% boost in battery
> > > > lifetime for some low-utilization battery-powered devices. Otherwise,
> > > > probably not.
> > >
> > > Would it make sense to hook that off of tick_nohz_idle_enter(); in
> > > specific the part where we actually stop the tick; instead of every
> > > idle?
> >
> > The actions RCU takes on RCU_FAST_NO_HZ depend on the current state of
> > the CPU's callback lists, so it seems to me that the decision has to
> > be made on each idle entry.
> >
> > Now it might be possible to make the checks more efficient, and doing
> > that is on my list.
> >
> > Or am I missing your point?
>
> Could be I'm just not remembering how all that works.. But I was
> wondering if we can do the expensive bits if we've decided to actually
> go NOHZ and avoid doing it on every idle entry.
>
> IIRC the RCU fast NOHZ bits try and flush the callback list (or paw it
> off to another CPU?) such that we can go NOHZ sooner. Having a !empty
> callback list avoid NOHZ from happening.
The code did indeed attempt to flush the callback list back in the day,
but that proved to not actually save any power. There were several
variations in the meantime, but what it does now is to check to see if
there are callbacks at rcu_needs_cpu() time:
1. If there are none, RCU tells the caller that it doesn't need
the CPU.
2. If there are some, and some of them are non-lazy (as in doing
something other than just freeing memory), RCU updates its idea
of which grace period the callbacks are waiting for, otherwise
leaves the callbacks alone, but returns saying that it needs
the CPU around four jiffies (by default), but rounded to allow
one wakeup to handle all CPUs in the power domain. Use the
rcu_idle_gp_delay boot/sysfs parameter to adjust the wait
duration if required. (I haven't heard of adjustment ever
being required.)
Note that a non-lazy callback might well be synchronize_rcu(),
so we cannot wait too long, or we will be delaying things
too much.
3. If there are some callbacks, and all of them are lazy, RCU
again updates its idea of which grace period the callbacks are
waiting for, otherwise leaves the callbacks alone, but returns
saying that it needs the CPU around six seconds (by default)
in the future, but using round_jiffies(), again to share wakeups
within a power domain. Use the rcu_idle_lazy_gp_delay
boot/sysfs parameter to adjust the wait, and again, as far as
I know adjustment never has been necessary.
When the CPU is awakened, it will update its callback based on any
grace periods that have elapsed in the meantime. There is a bit
of work later at rcu_idle_enter() time, but it is quite small.
> Now if we've already decided we can't in fact go NOHZ due to other
> concerns, flushing the callback list is pointless work. So I'm thinking
> we can find a better place to do this.
True, if the tick will still be happening, there is little point
in bothering RCU about it. And if CPUs tend to go idle with RCU
callbacks, then it would be cheaper to check arch_needs_cpu() and
irq_work_needs_cpu() first. If CPUs tend to be free of callbacks
when they go idle, this won't help, and might be counterproductive.
But if rcu_needs_cpu() or rcu_prepare_for_idle() is showing up on
profiles, I could adjust things. This would include making
rcu_prepare_for_idle() no longer expect that rcu_needs_cpu() had
previously been called on the current path to idle. (Not a big
deal, just that the obvious chnage to tick_nohz_stop_sched_tick()
won't necessarily do what you want.)
So please let me know if rcu_needs_cpu() or rcu_prepare_for_idle() are
prominent contributors to to-idle latency.
Thanx, Paul
On Wed, Jul 12, 2017 at 07:57:32PM +0200, Peter Zijlstra wrote:
> On Wed, Jul 12, 2017 at 07:17:56PM +0200, Peter Zijlstra wrote:
> > Could be I'm just not remembering how all that works.. But I was
> > wondering if we can do the expensive bits if we've decided to actually
> > go NOHZ and avoid doing it on every idle entry.
> >
> > IIRC the RCU fast NOHZ bits try and flush the callback list (or paw it
> > off to another CPU?) such that we can go NOHZ sooner. Having a !empty
> > callback list avoid NOHZ from happening.
> >
> > Now if we've already decided we can't in fact go NOHZ due to other
> > concerns, flushing the callback list is pointless work. So I'm thinking
> > we can find a better place to do this.
>
> I'm a wee bit confused by the split between rcu_prepare_for_idle() and
> rcu_needs_cpu().
>
> There's a fair amount overlap there.. that said, I'm thinking we should
> be calling rcu_needs_cpu() as the very last test, not the very first,
> such that we can bail out of tick_nohz_stop_sched_tick() without having
> to incur the penalty of flushing callbacks.
Maybe or maybe not, please see my earlier email for more details.
TL;DR: No, callbacks are no longer flushed. Yes, there is dependency.
Not hard to make rcu_prepare_for_idle() deal with rcu_needs_cpu() not
having been called, but it does need to happen. Putting rcu_needs_cpu()
last is not necessarily a good thing. If CPUs going idle normally
don't have callbacks, it won't help. So we need hard evidence that
rcu_needs_cpu() is consuming significant time before hacking.
Thanx, Paul
On Wed, Jul 12, 2017 at 07:46:42PM +0200, Peter Zijlstra wrote:
> On Wed, Jul 12, 2017 at 08:56:51AM -0700, Paul E. McKenney wrote:
> > Very good, I have queued the patch below. I left out the removal of
> > the export as I need to work out why the export was there. If it turns
> > out not to be needed, I will remove the related ones as well.
>
> 'git grep rcu_idle_enter' shows no callers other than
> kernel/sched/idle.c. Which seems a clear indication its not needed.
>
> You also have to ask yourself, do I want joe module author to ever call
> this. To which I suspect the answer is: hell no ;-)
The other question is "why did I do this in the first place".
The only case where there will turn out to have been a still-valid reason
is if I remove it without checking first. ;-)
Thanx, Paul
On Wed, Jul 12, 2017 at 11:53:06AM -0700, Paul E. McKenney wrote:
> On Wed, Jul 12, 2017 at 07:46:42PM +0200, Peter Zijlstra wrote:
> > On Wed, Jul 12, 2017 at 08:56:51AM -0700, Paul E. McKenney wrote:
> > > Very good, I have queued the patch below. I left out the removal of
> > > the export as I need to work out why the export was there. If it turns
> > > out not to be needed, I will remove the related ones as well.
> >
> > 'git grep rcu_idle_enter' shows no callers other than
> > kernel/sched/idle.c. Which seems a clear indication its not needed.
> >
> > You also have to ask yourself, do I want joe module author to ever call
> > this. To which I suspect the answer is: hell no ;-)
>
> The other question is "why did I do this in the first place".
>
> The only case where there will turn out to have been a still-valid reason
> is if I remove it without checking first. ;-)
And I have now checked. Please see below.
Thanx, Paul
------------------------------------------------------------------------
commit 31b2fd02abe5f036d7e83461bd19bbca3636d62e
Author: Paul E. McKenney <[email protected]>
Date: Wed Jul 12 11:55:21 2017 -0700
rcu: Remove exports from rcu_idle_exit() and rcu_idle_enter()
The rcu_idle_exit() and rcu_idle_enter() functions are exported because
they were originally used by RCU_NONIDLE(), which was intended to
be usable from modules. However, RCU_NONIDLE() now instead uses
rcu_irq_enter_irqson() and rcu_irq_exit_irqson(), which are not
exported, and there have been no complaints.
This commit therefore removes the exports from rcu_idle_exit() and
rcu_idle_enter().
Reported-by: Peter Zijlstra <[email protected]>
Signed-off-by: Paul E. McKenney <[email protected]>
diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
index 0798d2585e87..860d1c147606 100644
--- a/kernel/rcu/tree.c
+++ b/kernel/rcu/tree.c
@@ -843,7 +843,6 @@ void rcu_idle_enter(void)
RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
rcu_eqs_enter(false);
}
-EXPORT_SYMBOL_GPL(rcu_idle_enter);
#ifdef CONFIG_NO_HZ_FULL
/**
@@ -976,7 +975,6 @@ void rcu_idle_exit(void)
rcu_eqs_exit(false);
local_irq_restore(flags);
}
-EXPORT_SYMBOL_GPL(rcu_idle_exit);
#ifdef CONFIG_NO_HZ_FULL
/**
On Wed, Jul 12, 2017 at 10:34:10AM +0200, Peter Zijlstra wrote:
> On Wed, Jul 12, 2017 at 12:15:08PM +0800, Li, Aubrey wrote:
> > Okay, the difference is that Mike's patch uses a very simple algorithm to make the decision.
>
> No, the difference is that we don't end up with duplication of a metric
> ton of code.
What do you mean? There isn't much duplication from the fast path
in Aubrey's patch kit.
It just moves some code around from the cpuidle governor to be generic,
that accounts for the bulk of the changes. It's just moving however,
not adding.
> It uses the normal idle path, it just makes the NOHZ enter fail.
Which is only a small part of the problem.
-Andi
On Wed, Jul 12, 2017 at 11:46:17AM -0700, Paul E. McKenney wrote:
> So please let me know if rcu_needs_cpu() or rcu_prepare_for_idle() are
> prominent contributors to to-idle latency.
Right, some actual data would be good.
On Wed, Jul 12, 2017 at 02:32:40PM -0700, Andi Kleen wrote:
> On Wed, Jul 12, 2017 at 10:34:10AM +0200, Peter Zijlstra wrote:
> > On Wed, Jul 12, 2017 at 12:15:08PM +0800, Li, Aubrey wrote:
> > > Okay, the difference is that Mike's patch uses a very simple algorithm to make the decision.
> >
> > No, the difference is that we don't end up with duplication of a metric
> > ton of code.
>
> What do you mean? There isn't much duplication from the fast path
> in Aubrey's patch kit.
A whole second idle path is one too many. We're not going to have
duplicate idle paths.
> It just moves some code around from the cpuidle governor to be generic,
> that accounts for the bulk of the changes. It's just moving however,
> not adding.
It wasn't at first glance evident it was a pure move because he does it
over a bunch of patches. Also, that code will not be moved to the
generic code, people are working on alternatives and very much rely on
this being a governor thing.
> > It uses the normal idle path, it just makes the NOHZ enter fail.
>
> Which is only a small part of the problem.
Given the data so far provided it was by far the biggest problem. If you
want more things changed, you really have to give more data.
On 2017/7/13 16:36, Peter Zijlstra wrote:
> On Wed, Jul 12, 2017 at 02:32:40PM -0700, Andi Kleen wrote:
>
>>> It uses the normal idle path, it just makes the NOHZ enter fail.
>>
>> Which is only a small part of the problem.
>
> Given the data so far provided it was by far the biggest problem. If you
> want more things changed, you really have to give more data.
>
I have a data between arch_cpu_idle_enter and arch_cpu_idle_exit, this already
excluded HW sleep.
- totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
9122ns - 15318ns.
---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
costs 1813ns - 3507ns
Besides RCU, the period includes c-state selection on X86, a few timestamp updates
and a few computations in menu governor. Also, deep HW-cstate latency can be up
to 100+ microseconds, even if the system is very busy, CPU still has chance to enter
deep cstate, which I guess some outburst workloads are not happy with it.
That's my major concern without a fast idle path.
Thanks,
-Aubrey
On Thu, Jul 13, 2017 at 10:48:55PM +0800, Li, Aubrey wrote:
> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> 9122ns - 15318ns.
> ---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
> costs 1813ns - 3507ns
>
> Besides RCU,
So Paul wants more details on where RCU hurts so we can try to fix.
> the period includes c-state selection on X86, a few timestamp updates
> and a few computations in menu governor. Also, deep HW-cstate latency can be up
> to 100+ microseconds, even if the system is very busy, CPU still has chance to enter
> deep cstate, which I guess some outburst workloads are not happy with it.
>
> That's my major concern without a fast idle path.
Fixing C-state selection by creating an alternative idle path sounds so
very wrong.
On 2017/7/13 22:53, Peter Zijlstra wrote:
> On Thu, Jul 13, 2017 at 10:48:55PM +0800, Li, Aubrey wrote:
>
>> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
>> 9122ns - 15318ns.
>> ---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
>> costs 1813ns - 3507ns
>>
>> Besides RCU,
>
> So Paul wants more details on where RCU hurts so we can try to fix.
>
If we can call RCU idle enter/exit after tick is really stopped, instead of
call it every idle, I think it's fine. Then we can skip stopping tick if we need
fast idle.
>> the period includes c-state selection on X86, a few timestamp updates
>> and a few computations in menu governor. Also, deep HW-cstate latency can be up
>> to 100+ microseconds, even if the system is very busy, CPU still has chance to enter
>> deep cstate, which I guess some outburst workloads are not happy with it.
>>
>> That's my major concern without a fast idle path.
>
> Fixing C-state selection by creating an alternative idle path sounds so
> very wrong.
This only happens on the arch which has multiple hardware idle cstates, like
Intel's processor. As long as we want to support multiple cstates, we have to
make a selection(with cost of timestamp update and computation). That's fine
in the normal idle path, but if we want a fast idle switch, we can make a
tradeoff to use a low-latency one directly, that's why I proposed a fast idle
path, so that we don't need to mix fast idle condition judgement in both idle
entry and idle exit path.
Thanks,
-Aubrey
On Thu, Jul 13, 2017 at 04:53:11PM +0200, Peter Zijlstra wrote:
> On Thu, Jul 13, 2017 at 10:48:55PM +0800, Li, Aubrey wrote:
>
> > - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> > 9122ns - 15318ns.
> > ---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
> > costs 1813ns - 3507ns
> >
> > Besides RCU,
>
> So Paul wants more details on where RCU hurts so we can try to fix.
More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
rcu_cleanup_after_idle()) should not be significant unless you have
CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
and rcu_cleanup_after_idle(), as this can raise softirq. Also
rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
Knowing which of these is causing the most trouble might help me
reduce the overhead in the current idle path.
Also, how big is this system? If you can say, about what is the cost
of a cache miss to some other CPU's cache?
Thanx, Paul
> > the period includes c-state selection on X86, a few timestamp updates
> > and a few computations in menu governor. Also, deep HW-cstate latency can be up
> > to 100+ microseconds, even if the system is very busy, CPU still has chance to enter
> > deep cstate, which I guess some outburst workloads are not happy with it.
> >
> > That's my major concern without a fast idle path.
>
> Fixing C-state selection by creating an alternative idle path sounds so
> very wrong.
>
On Thu, Jul 13, 2017 at 11:13:28PM +0800, Li, Aubrey wrote:
> On 2017/7/13 22:53, Peter Zijlstra wrote:
> > Fixing C-state selection by creating an alternative idle path sounds so
> > very wrong.
>
> This only happens on the arch which has multiple hardware idle cstates, like
> Intel's processor. As long as we want to support multiple cstates, we have to
> make a selection(with cost of timestamp update and computation). That's fine
> in the normal idle path, but if we want a fast idle switch, we can make a
> tradeoff to use a low-latency one directly, that's why I proposed a fast idle
> path, so that we don't need to mix fast idle condition judgement in both idle
> entry and idle exit path.
That doesn't make sense. If you can decide to pick a shallow C state in
any way, you can fix the general selection too.
On 2017/7/13 23:20, Paul E. McKenney wrote:
> On Thu, Jul 13, 2017 at 04:53:11PM +0200, Peter Zijlstra wrote:
>> On Thu, Jul 13, 2017 at 10:48:55PM +0800, Li, Aubrey wrote:
>>
>>> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
>>> 9122ns - 15318ns.
>>> ---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
>>> costs 1813ns - 3507ns
>>>
>>> Besides RCU,
>>
>> So Paul wants more details on where RCU hurts so we can try to fix.
>
> More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
> rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
> rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
> rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
> rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
>
> The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
> rcu_cleanup_after_idle()) should not be significant unless you have
> CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
> how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
> and rcu_cleanup_after_idle(), as this can raise softirq. Also
> rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
>
> Knowing which of these is causing the most trouble might help me
> reduce the overhead in the current idle path.
>
I don't have details of these functions, I can measure if you want.
Do you have preferred workload for the measurement?
> Also, how big is this system? If you can say, about what is the cost
> of a cache miss to some other CPU's cache?
>
The system has two NUMA nodes. nproc returns 104. local memory access is
~100 ns and remote memory access is ~200ns, reported by mgen. Does this
address your question?
Thanks,
-Aubrey
On 2017/7/14 2:28, Peter Zijlstra wrote:
> On Thu, Jul 13, 2017 at 11:13:28PM +0800, Li, Aubrey wrote:
>> On 2017/7/13 22:53, Peter Zijlstra wrote:
>
>>> Fixing C-state selection by creating an alternative idle path sounds so
>>> very wrong.
>>
>> This only happens on the arch which has multiple hardware idle cstates, like
>> Intel's processor. As long as we want to support multiple cstates, we have to
>> make a selection(with cost of timestamp update and computation). That's fine
>> in the normal idle path, but if we want a fast idle switch, we can make a
>> tradeoff to use a low-latency one directly, that's why I proposed a fast idle
>> path, so that we don't need to mix fast idle condition judgement in both idle
>> entry and idle exit path.
>
> That doesn't make sense. If you can decide to pick a shallow C state in
> any way, you can fix the general selection too.
>
Okay, maybe something like the following make sense? Give a hint to
cpuidle_idle_call() to indicate a fast idle.
--------------------------------------------------------
diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
index ef63adc..3165e99 100644
--- a/kernel/sched/idle.c
+++ b/kernel/sched/idle.c
@@ -152,7 +152,7 @@ static void cpuidle_idle_call(void)
*/
rcu_idle_enter();
- if (cpuidle_not_available(drv, dev)) {
+ if (cpuidle_not_available(drv, dev) || this_is_a_fast_idle) {
default_idle_call();
goto exit_idle;
}
On Fri, Jul 14, 2017 at 11:47:32AM +0800, Li, Aubrey wrote:
> On 2017/7/13 23:20, Paul E. McKenney wrote:
> > On Thu, Jul 13, 2017 at 04:53:11PM +0200, Peter Zijlstra wrote:
> >> On Thu, Jul 13, 2017 at 10:48:55PM +0800, Li, Aubrey wrote:
> >>
> >>> - totally from arch_cpu_idle_enter entry to arch_cpu_idle_exit return costs
> >>> 9122ns - 15318ns.
> >>> ---- In this period(arch idle), rcu_idle_enter costs 1985ns - 2262ns, rcu_idle_exit
> >>> costs 1813ns - 3507ns
> >>>
> >>> Besides RCU,
> >>
> >> So Paul wants more details on where RCU hurts so we can try to fix.
> >
> > More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
> > rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
> > rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
> > rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
> > rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
> >
> > The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
> > rcu_cleanup_after_idle()) should not be significant unless you have
> > CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
> > how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
> > and rcu_cleanup_after_idle(), as this can raise softirq. Also
> > rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
> >
> > Knowing which of these is causing the most trouble might help me
> > reduce the overhead in the current idle path.
> >
> I don't have details of these functions, I can measure if you want.
> Do you have preferred workload for the measurement?
I do not have a specific workload in mind. Could you please choose
one with very frequent transitions to and from idle?
> > Also, how big is this system? If you can say, about what is the cost
> > of a cache miss to some other CPU's cache?
> >
> The system has two NUMA nodes. nproc returns 104. local memory access is
> ~100 ns and remote memory access is ~200ns, reported by mgen. Does this
> address your question?
Very much so, thank you! This will allow me to correctly interpret
time spent in the above functions.
Thanx, Paul
On Fri, Jul 14, 2017 at 11:56:33AM +0800, Li, Aubrey wrote:
> On 2017/7/14 2:28, Peter Zijlstra wrote:
> > On Thu, Jul 13, 2017 at 11:13:28PM +0800, Li, Aubrey wrote:
> >> On 2017/7/13 22:53, Peter Zijlstra wrote:
> >
> >>> Fixing C-state selection by creating an alternative idle path sounds so
> >>> very wrong.
> >>
> >> This only happens on the arch which has multiple hardware idle cstates, like
> >> Intel's processor. As long as we want to support multiple cstates, we have to
> >> make a selection(with cost of timestamp update and computation). That's fine
> >> in the normal idle path, but if we want a fast idle switch, we can make a
> >> tradeoff to use a low-latency one directly, that's why I proposed a fast idle
> >> path, so that we don't need to mix fast idle condition judgement in both idle
> >> entry and idle exit path.
> >
> > That doesn't make sense. If you can decide to pick a shallow C state in
> > any way, you can fix the general selection too.
> >
>
> Okay, maybe something like the following make sense? Give a hint to
> cpuidle_idle_call() to indicate a fast idle.
>
> --------------------------------------------------------
> diff --git a/kernel/sched/idle.c b/kernel/sched/idle.c
> index ef63adc..3165e99 100644
> --- a/kernel/sched/idle.c
> +++ b/kernel/sched/idle.c
> @@ -152,7 +152,7 @@ static void cpuidle_idle_call(void)
> */
> rcu_idle_enter();
>
> - if (cpuidle_not_available(drv, dev)) {
> + if (cpuidle_not_available(drv, dev) || this_is_a_fast_idle) {
> default_idle_call();
> goto exit_idle;
> }
No, that's wrong. We want to fix the normal C state selection process to
pick the right C state.
The fast-idle criteria could cut off a whole bunch of available C
states. We need to understand why our current C state pick is wrong and
amend the algorithm to do better. Not just bolt something on the side.
On 7/14/2017 8:38 AM, Peter Zijlstra wrote:
> No, that's wrong. We want to fix the normal C state selection process to
> pick the right C state.
>
> The fast-idle criteria could cut off a whole bunch of available C
> states. We need to understand why our current C state pick is wrong and
> amend the algorithm to do better. Not just bolt something on the side.
I can see a fast path through selection if you know the upper bound of any
selection is just 1 state.
But also, how much of this is about "C1 be fast" versus "selecting C1 is slow"
a lot of the patches in the thread seem to be about making a lighter/faster C1,
which is reasonable (you can even argue we might end up with 2 C1s, one fast
one full feature)
> > - if (cpuidle_not_available(drv, dev)) {
> > + if (cpuidle_not_available(drv, dev) || this_is_a_fast_idle) {
> > default_idle_call();
> > goto exit_idle;
> > }
>
> No, that's wrong. We want to fix the normal C state selection process to
> pick the right C state.
>
> The fast-idle criteria could cut off a whole bunch of available C
> states. We need to understand why our current C state pick is wrong and
> amend the algorithm to do better. Not just bolt something on the side.
Fast idle uses the same predictor as the current C state governor.
The only difference is that it uses a different threshold for C1.
Likely that's the cause. If it was using the same threshold the
decision would be the same.
The thresholds are coming either from the tables in intel idle,
or from ACPI (let's assume the first)
That means either: the intel idle C1 threshold on the system Aubrey
tested on is too high, or the fast idle threshold is too low.
But that would be only true for the workload he tested.
It may well be that it's not that great for another.
The numbers in the standard intel_idle are reasonably tested
with many workloads, so I guess it would be safer to pick that one.
Unless someone wants to revisit these tables.
-Andi
On Fri, Jul 14, 2017 at 08:52:28AM -0700, Arjan van de Ven wrote:
> On 7/14/2017 8:38 AM, Peter Zijlstra wrote:
> > No, that's wrong. We want to fix the normal C state selection process to
> > pick the right C state.
> >
> > The fast-idle criteria could cut off a whole bunch of available C
> > states. We need to understand why our current C state pick is wrong and
> > amend the algorithm to do better. Not just bolt something on the side.
>
> I can see a fast path through selection if you know the upper bound of any
> selection is just 1 state.
>
> But also, how much of this is about "C1 be fast" versus "selecting C1 is slow"
I got the impression its about we need to select C1 for longer. But the
fact that the patches don't in fact answer any of these questions,
they're wrong in principle ;-)
On Fri, Jul 14, 2017 at 05:58:53PM +0200, Peter Zijlstra wrote:
> On Fri, Jul 14, 2017 at 08:52:28AM -0700, Arjan van de Ven wrote:
> > On 7/14/2017 8:38 AM, Peter Zijlstra wrote:
> > > No, that's wrong. We want to fix the normal C state selection process to
> > > pick the right C state.
> > >
> > > The fast-idle criteria could cut off a whole bunch of available C
> > > states. We need to understand why our current C state pick is wrong and
> > > amend the algorithm to do better. Not just bolt something on the side.
> >
> > I can see a fast path through selection if you know the upper bound of any
> > selection is just 1 state.
fast idle doesn't have an upper bound.
If the prediction exceeds the fast idle threshold any C state can be used.
It's just another state (fast C1), but right now it has an own threshold
which may be different from standard C1.
> >
> > But also, how much of this is about "C1 be fast" versus "selecting C1 is slow"
>
> I got the impression its about we need to select C1 for longer. But the
> fact that the patches don't in fact answer any of these questions,
> they're wrong in principle ;-)
For that workload. Tuning idle thresholds is a complex trade off.
-Andi
On Fri, Jul 14, 2017 at 08:53:56AM -0700, Andi Kleen wrote:
> > > - if (cpuidle_not_available(drv, dev)) {
> > > + if (cpuidle_not_available(drv, dev) || this_is_a_fast_idle) {
> > > default_idle_call();
> > > goto exit_idle;
> > > }
> >
> > No, that's wrong. We want to fix the normal C state selection process to
> > pick the right C state.
> >
> > The fast-idle criteria could cut off a whole bunch of available C
> > states. We need to understand why our current C state pick is wrong and
> > amend the algorithm to do better. Not just bolt something on the side.
>
> Fast idle uses the same predictor as the current C state governor.
>
> The only difference is that it uses a different threshold for C1.
> Likely that's the cause. If it was using the same threshold the
> decision would be the same.
Right, so its selecting C1 for longer. That in turn means we could now
never select C2; because the fast-idle threshold is longer than our C2
time.
Which I feel is wrong; because if we're getting C1 wrong, what says
we're then getting the rest right.
> The thresholds are coming either from the tables in intel idle,
> or from ACPI (let's assume the first)
>
> That means either: the intel idle C1 threshold on the system Aubrey
> tested on is too high, or the fast idle threshold is too low.
Or our predictor is doing it wrong. It could be its over-estimating idle
duration. For example, suppose we have an idle distribution of:
40% < C1
60% > C2
And we end up selecting C2. Even though in many of our sleeps we really
wanted C1.
And as said; Daniel has been working on a better predictor -- now he's
probably not used it on the network workload you're looking at, so that
might be something to consider.
> And as said; Daniel has been working on a better predictor -- now he's
> probably not used it on the network workload you're looking at, so that
> might be something to consider.
Deriving a better idle predictor is a bit orthogonal to fast idle.
It would be a good idea to set the fast idle threshold to be the
same as intel_idle would use on that platform and rerun the benchmarks
Then the Cx pattern should be mostly identical, and fast idle can be
evaluated on its own benefits.
-Andi
On Fri, Jul 14, 2017 at 09:03:14AM -0700, Andi Kleen wrote:
> fast idle doesn't have an upper bound.
>
> If the prediction exceeds the fast idle threshold any C state can be used.
>
> It's just another state (fast C1), but right now it has an own threshold
> which may be different from standard C1.
Given it uses the same estimate we end up with:
select_c_state(idle_est)
{
if (idle_est < fast_threshold)
return C1;
if (idle_est < C1_threshold)
return C1;
if (idle_est < C2_threshold)
return C2;
/* ... */
return C6
}
Now, unless you're mister Turnbull, C2 will never get selected when
fast_threshold > C2_threshold.
Which is wrong. If you want to effectively scale the selection of C1,
why not also change the C2 and further criteria.
On 2017/7/14 12:05, Paul E. McKenney wrote:
>
> More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
> rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
> rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
> rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
> rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
>
> The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
> rcu_cleanup_after_idle()) should not be significant unless you have
> CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
> how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
> and rcu_cleanup_after_idle(), as this can raise softirq. Also
> rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
>
> Knowing which of these is causing the most trouble might help me
> reduce the overhead in the current idle path.
I measured two cases, nothing notable found.
The one is CONFIG_NO_HZ_IDLE=y, so the following function is just empty.
rcu_prepare_for_idle(): NULL
rcu_cleanup_after_idle(): NULL
do_nocb_deferred_wakeup(): NULL
rcu_dynticks_task_enter(): NULL
rcu_dynticks_task_exit(): NULL
And the following functions are traced separately, for each function I
traced 3 times by intel_PT, for each time the sampling period is 1-second.
num means the times the function is invoked in 1-second. (min, max, avg) is
the function duration, the unit is nano-second.
rcu_needs_cpu():
1) num: 6110 min: 3 max: 564 avg: 17.0
2) num: 16535 min: 3 max: 683 avg: 18.0
3) num: 8815 min: 3 max: 394 avg: 20.0
rcu_eqs_enter():
1) num: 7956 min: 17 max: 656 avg: 32.0
2) num: 9170 min: 17 max: 1075 avg: 35.0
3) num: 8604 min: 17 max: 859 avg: 29.0
rcu_eqs_enter_common():
1) num: 14676 min: 15 max: 620 avg: 28.0
2) num: 11180 min: 15 max: 795 avg: 30.0
3) num: 11484 min: 15 max: 725 avg: 29.0
rcu_dynticks_eqs_enter():
1) num: 11035 min: 10 max: 580 avg: 17.0
2) num: 15518 min: 10 max: 456 avg: 16.0
3) num: 15320 min: 10 max: 454 avg: 19.0
rcu_eqs_exit():
1) num: 11080 min: 14 max: 893 avg: 23.0
2) num: 13526 min: 14 max: 640 avg: 23.0
3) num: 12534 min: 14 max: 630 avg: 22.0
rcu_eqs_exit_common():
1) num: 18002 min: 12 max: 553 avg: 17.0
2) num: 10570 min: 11 max: 485 avg: 17.0
3) num: 13628 min: 11 max: 567 avg: 16.0
rcu_dynticks_eqs_exit():
1) num: 11195 min: 11 max: 436 avg: 16.0
2) num: 11808 min: 10 max: 506 avg: 16.0
3) num: 8132 min: 10 max: 546 avg: 15.0
==============================================================================
The other case is CONFIG_NO_HZ_FULL, I also enabled the required config to make
all the functions not empty.
rcu_needs_cpu():
1) num: 8530 min: 5 max: 770 avg: 13.0
2) num: 9965 min: 5 max: 518 avg: 12.0
3) num: 12503 min: 5 max: 755 avg: 16.0
rcu_prepare_for_idle():
1) num: 11662 min: 5 max: 684 avg: 9.0
2) num: 15294 min: 5 max: 676 avg: 9.0
3) num: 14332 min: 5 max: 524 avg: 9.0
rcu_cleanup_after_idle():
1) num: 13584 min: 4 max: 657 avg: 6.0
2) num: 9102 min: 4 max: 529 avg: 5.0
3) num: 10648 min: 4 max: 471 avg: 6.0
rcu_eqs_enter():
1) num: 14222 min: 26 max: 745 avg: 54.0
2) num: 12502 min: 26 max: 650 avg: 53.0
3) num: 11834 min: 26 max: 863 avg: 52.0
rcu_eqs_enter_common():
1) num: 16792 min: 24 max: 973 avg: 43.0
2) num: 19755 min: 24 max: 898 avg: 45.0
3) num: 8167 min: 24 max: 722 avg: 42.0
rcu_dynticks_eqs_enter():
1) num: 11605 min: 10 max: 532 avg: 14.0
2) num: 10438 min: 9 max: 554 avg: 14.0
3) num: 19816 min: 9 max: 701 avg: 14.0
do_nocb_deferred_wakeup():
1) num: 15348 min: 1 max: 459 avg: 3.0
2) num: 12822 min: 1 max: 564 avg: 4.0
3) num: 8272 min: 0 max: 458 avg: 3.0
rcu_dynticks_task_enter():
1) num: 6358 min: 1 max: 268 avg: 1.0
2) num: 11128 min: 1 max: 360 avg: 1.0
3) num: 20516 min: 1 max: 214 avg: 1.0
rcu_eqs_exit():
1) num: 16117 min: 20 max: 782 avg: 43.0
2) num: 11042 min: 20 max: 775 avg: 47.0
3) num: 16499 min: 20 max: 752 avg: 46.0
rcu_eqs_exit_common():
1) num: 12584 min: 17 max: 703 avg: 28.0
2) num: 17412 min: 17 max: 759 avg: 28.0
3) num: 16733 min: 17 max: 798 avg: 29.0
rcu_dynticks_task_exit():
1) num: 11730 min: 1 max: 528 avg: 4.0
2) num: 18840 min: 1 max: 581 avg: 5.0
3) num: 9815 min: 1 max: 381 avg: 4.0
rcu_dynticks_eqs_exit():
1) num: 10902 min: 9 max: 557 avg: 13.0
2) num: 19474 min: 9 max: 563 avg: 13.0
3) num: 11865 min: 9 max: 672 avg: 12.0
Please let me know if there is some data not reasonable, I can revisit again.
Thanks,
-Aubrey
On 2017/7/17 17:21, Peter Zijlstra wrote:
> On Fri, Jul 14, 2017 at 09:03:14AM -0700, Andi Kleen wrote:
>> fast idle doesn't have an upper bound.
>>
>> If the prediction exceeds the fast idle threshold any C state can be used.
>>
>> It's just another state (fast C1), but right now it has an own threshold
>> which may be different from standard C1.
>
> Given it uses the same estimate we end up with:
>
>
> Now, unless you're mister Turnbull, C2 will never get selected when
> fast_threshold > C2_threshold.
>
> Which is wrong. If you want to effectively scale the selection of C1,
> why not also change the C2 and further criteria.
>
That's not our intention, I think. As long as the predicted coming idle
period > threshold, we'll enter normal idle path, you can select any supported
c-states, tick can also be turned off for power saving. Any deferrable stuff
can be invoke as well because we'll sleep long enough.
Thanks,
-Aubrey
On Mon, Jul 17, 2017 at 09:24:51PM +0800, Li, Aubrey wrote:
> On 2017/7/14 12:05, Paul E. McKenney wrote:
> >
> > More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
> > rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
> > rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
> > rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
> > rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
> >
> > The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
> > rcu_cleanup_after_idle()) should not be significant unless you have
> > CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
> > how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
> > and rcu_cleanup_after_idle(), as this can raise softirq. Also
> > rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
> >
> > Knowing which of these is causing the most trouble might help me
> > reduce the overhead in the current idle path.
>
> I measured two cases, nothing notable found.
So skipping rcu_idle_{enter,exit}() is not in fact needed at all?
On 2017/7/17 21:58, Peter Zijlstra wrote:
> On Mon, Jul 17, 2017 at 09:24:51PM +0800, Li, Aubrey wrote:
>> On 2017/7/14 12:05, Paul E. McKenney wrote:
>>>
>>> More specifically: rcu_needs_cpu(), rcu_prepare_for_idle(),
>>> rcu_cleanup_after_idle(), rcu_eqs_enter(), rcu_eqs_enter_common(),
>>> rcu_dynticks_eqs_enter(), do_nocb_deferred_wakeup(),
>>> rcu_dynticks_task_enter(), rcu_eqs_exit(), rcu_eqs_exit_common(),
>>> rcu_dynticks_task_exit(), rcu_dynticks_eqs_exit().
>>>
>>> The first three (rcu_needs_cpu(), rcu_prepare_for_idle(), and
>>> rcu_cleanup_after_idle()) should not be significant unless you have
>>> CONFIG_RCU_FAST_NO_HZ=y. If you do, it would be interesting to learn
>>> how often invoke_rcu_core() is invoked from rcu_prepare_for_idle()
>>> and rcu_cleanup_after_idle(), as this can raise softirq. Also
>>> rcu_accelerate_cbs() and rcu_try_advance_all_cbs().
>>>
>>> Knowing which of these is causing the most trouble might help me
>>> reduce the overhead in the current idle path.
>>
>> I measured two cases, nothing notable found.
>
> So skipping rcu_idle_{enter,exit}() is not in fact needed at all?
>
I think it would make more sense if we still put them under the case
where tick is really stopped.
Thanks,
-Aubrey
On Fri, Jul 14, 2017 at 09:26:19AM -0700, Andi Kleen wrote:
> > And as said; Daniel has been working on a better predictor -- now he's
> > probably not used it on the network workload you're looking at, so that
> > might be something to consider.
>
> Deriving a better idle predictor is a bit orthogonal to fast idle.
No. If you want a different C state selected we need to fix the current
C state selector. We're not going to tinker.
And the predictor is probably the most fundamental part of the whole C
state selection logic.
Now I think the problem is that the current predictor goes for an
average idle duration. This means that we, on average, get it wrong 50%
of the time. For performance that's bad.
If you want to improve the worst case, we need to consider a cumulative
distribution function, and staying with the Gaussian assumption already
present, that would mean using:
1 x - mu
CDF(x) = - [ 1 + erf(-------------) ]
2 sigma sqrt(2)
Where, per the normal convention mu is the average and sigma^2 the
variance. See also:
https://en.wikipedia.org/wiki/Normal_distribution
We then solve CDF(x) = n% to find the x for which we get it wrong n% of
the time (IIRC something like: 'mu - 2sigma' ends up being 5% or so).
This conceptually gets us better exit latency for the cases where we got
it wrong before, and practically pushes down the estimate which gets us
C1 longer.
Of course, this all assumes a Gaussian distribution to begin with, if we
get bimodal (or worse) distributions we can still get it wrong. To fix
that, we'd need to do something better than what we currently have.
On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
> Now I think the problem is that the current predictor goes for an
> average idle duration. This means that we, on average, get it wrong 50%
> of the time. For performance that's bad.
that's not really what it does; it looks at next tick
and then discounts that based on history;
(with different discounts for different order of magnitude)
On Mon, 17 Jul 2017, Arjan van de Ven wrote:
> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
> > Now I think the problem is that the current predictor goes for an
> > average idle duration. This means that we, on average, get it wrong 50%
> > of the time. For performance that's bad.
>
> that's not really what it does; it looks at next tick
> and then discounts that based on history;
> (with different discounts for different order of magnitude)
next tick is the worst thing to look at for interrupt heavy workloads as
the next tick (as computed by the nohz code) can be far away, while the I/O
interrupts come in at a high frequency.
That's where Daniel Lezcanos work of predicting interrupts comes in and
that's the right solution to the problem. The core infrastructure has been
merged, just the idle/cpufreq users are not there yet. All you need to do
is to select CONFIG_IRQ_TIMINGS and use the statistics generated there.
Thanks,
tglx
On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
> Of course, this all assumes a Gaussian distribution to begin with, if we
> get bimodal (or worse) distributions we can still get it wrong. To fix
> that, we'd need to do something better than what we currently have.
>
fwiw some time ago I made a chart for predicted vs actual so you can sort
of judge the distribution of things visually
http://git.fenrus.org/tmp/linux2.png
On 7/17/2017 12:46 PM, Thomas Gleixner wrote:
> On Mon, 17 Jul 2017, Arjan van de Ven wrote:
>> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
>>> Now I think the problem is that the current predictor goes for an
>>> average idle duration. This means that we, on average, get it wrong 50%
>>> of the time. For performance that's bad.
>>
>> that's not really what it does; it looks at next tick
>> and then discounts that based on history;
>> (with different discounts for different order of magnitude)
>
> next tick is the worst thing to look at for interrupt heavy workloads as
well it was better than what was there before (without discount and without detecting
repeated patterns)
> the next tick (as computed by the nohz code) can be far away, while the I/O
> interrupts come in at a high frequency.
>
> That's where Daniel Lezcanos work of predicting interrupts comes in and
> that's the right solution to the problem. The core infrastructure has been
> merged, just the idle/cpufreq users are not there yet. All you need to do
> is to select CONFIG_IRQ_TIMINGS and use the statistics generated there.
>
yes ;-)
also note that the predictor does not need to perfect, on most systems C states are
an order of magnitude apart in terms of power/performance/latency so if you get the general
order of magnitude right the predictor is doing its job.
(this is not universally true, but physics of power gating/etc tend to drive to this conclusion;
the cost of implementing an extra state very close to another state means that the HW folks are unlikely
to do the less power saving state of the two to save their cost and testing effort)
On Mon, 17 Jul 2017, Arjan van de Ven wrote:
> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
> > Of course, this all assumes a Gaussian distribution to begin with, if we
> > get bimodal (or worse) distributions we can still get it wrong. To fix
> > that, we'd need to do something better than what we currently have.
> >
>
> fwiw some time ago I made a chart for predicted vs actual so you can sort
> of judge the distribution of things visually
Predicted by what?
Thanks,
tglx
On 7/17/2017 12:53 PM, Thomas Gleixner wrote:
> On Mon, 17 Jul 2017, Arjan van de Ven wrote:
>> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
>>> Of course, this all assumes a Gaussian distribution to begin with, if we
>>> get bimodal (or worse) distributions we can still get it wrong. To fix
>>> that, we'd need to do something better than what we currently have.
>>>
>>
>> fwiw some time ago I made a chart for predicted vs actual so you can sort
>> of judge the distribution of things visually
>
> Predicted by what?
this chart was with the current linux predictor
http://git.fenrus.org/tmp/timer.png is what you get if you JUST use the next timer ;-)
(which way back linux was doing)
On Mon, 17 Jul 2017, Arjan van de Ven wrote:
> On 7/17/2017 12:46 PM, Thomas Gleixner wrote:
> > That's where Daniel Lezcanos work of predicting interrupts comes in and
> > that's the right solution to the problem. The core infrastructure has been
> > merged, just the idle/cpufreq users are not there yet. All you need to do
> > is to select CONFIG_IRQ_TIMINGS and use the statistics generated there.
> >
> yes ;-)
:)
> also note that the predictor does not need to perfect, on most systems C
> states are an order of magnitude apart in terms of
> power/performance/latency so if you get the general order of magnitude
> right the predictor is doing its job.
So it would be interesting just to enable the irq timings stuff and compare
the outcome as a first step. That should be reasonably simple to implement
and would give us also some information of how that code behaves on larger
systems.
Thanks,
tglx
On 2017/7/18 3:23, Peter Zijlstra wrote:
> On Fri, Jul 14, 2017 at 09:26:19AM -0700, Andi Kleen wrote:
>>> And as said; Daniel has been working on a better predictor -- now he's
>>> probably not used it on the network workload you're looking at, so that
>>> might be something to consider.
>>
>> Deriving a better idle predictor is a bit orthogonal to fast idle.
>
> No. If you want a different C state selected we need to fix the current
> C state selector. We're not going to tinker.
>
> And the predictor is probably the most fundamental part of the whole C
> state selection logic.
>
> Now I think the problem is that the current predictor goes for an
> average idle duration. This means that we, on average, get it wrong 50%
> of the time. For performance that's bad.
>
> If you want to improve the worst case, we need to consider a cumulative
> distribution function, and staying with the Gaussian assumption already
> present, that would mean using:
>
> 1 x - mu
> CDF(x) = - [ 1 + erf(-------------) ]
> 2 sigma sqrt(2)
>
> Where, per the normal convention mu is the average and sigma^2 the
> variance. See also:
>
> https://en.wikipedia.org/wiki/Normal_distribution
>
> We then solve CDF(x) = n% to find the x for which we get it wrong n% of
> the time (IIRC something like: 'mu - 2sigma' ends up being 5% or so).
>
> This conceptually gets us better exit latency for the cases where we got
> it wrong before, and practically pushes down the estimate which gets us
> C1 longer.
>
> Of course, this all assumes a Gaussian distribution to begin with, if we
> get bimodal (or worse) distributions we can still get it wrong. To fix
> that, we'd need to do something better than what we currently have.
>
Maybe you are talking about applying some machine learning algorithm online
to fit a multivariate normal distribution, :)
Well, back to the problem, when the scheduler picks up idle thread, it does
not look at the history, nor make the prediction. So it's possible it has
to switch back a task ASAP when it's going into idle(very common under some
workloads).
That is, (idle_entry + idle_exit) > idle. If the system has multiple
hardware idle states, then:
(idle_entry + idle_exit + HW_entry + HW_exit) > HW_sleep
So we eventually want the idle path lighter than what we currently have.
A complex predictor may have high accuracy, but the cost could be high as well.
We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
it's better than menu governor.
Thanks,
-Aubrey
On 2017/7/18 3:48, Arjan van de Ven wrote:
> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
>> Of course, this all assumes a Gaussian distribution to begin with, if we
>> get bimodal (or worse) distributions we can still get it wrong. To fix
>> that, we'd need to do something better than what we currently have.
>>
>
> fwiw some time ago I made a chart for predicted vs actual so you can sort
> of judge the distribution of things visually
>
> http://git.fenrus.org/tmp/linux2.png
>
>
This does not look like a Gaussian, does it? I mean abs(expected - actual).
Thanks,
-Aubrey
> We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> it's better than menu governor.
I still would like to see how the fast path without the C1 heuristic works.
Fast pathing is a different concept from a better predictor. IMHO we need
both, but the first is likely lower hanging fruit.
-Andi
On Mon, 17 Jul 2017, Andi Kleen wrote:
> > We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> > it's better than menu governor.
>
> I still would like to see how the fast path without the C1 heuristic works.
>
> Fast pathing is a different concept from a better predictor. IMHO we need
> both, but the first is likely lower hanging fruit.
Hacking something on the side is always the lower hanging fruit as it
avoids solving the hard problems. As Peter said already, that's not going
to happen unless there is a real technical reason why the general path
cannot be fixed. So far there is no proof for that.
Thanks,
tglx
On 2017/7/18 14:43, Thomas Gleixner wrote:
> On Mon, 17 Jul 2017, Andi Kleen wrote:
>
>>> We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
>>> it's better than menu governor.
>>
>> I still would like to see how the fast path without the C1 heuristic works.
>>
>> Fast pathing is a different concept from a better predictor. IMHO we need
>> both, but the first is likely lower hanging fruit.
>
> Hacking something on the side is always the lower hanging fruit as it
> avoids solving the hard problems. As Peter said already, that's not going
> to happen unless there is a real technical reason why the general path
> cannot be fixed. So far there is no proof for that.
>
Let me try to make a summary, please correct me if I was wrong.
1) for quiet_vmstat, we are agreed to move to another place where tick is
really stopped.
2) for rcu idle enter/exit, I measured the details which Paul provided, and
the result matches with what I have measured before, nothing notable found.
But it still makes more sense if we can make rcu idle enter/exit hooked with
tick off. (it's possible other workloads behave differently)
3) for tick nohz idle, we want to skip if the coming idle is short. If we can
skip the tick nohz idle, we then skip all the items depending on it. But, there
are two hard points:
3.1) how to compute the period of the coming idle. My current proposal is to
use two factors in the current idle menu governor. There are two possible
options from Peter and Thomas, the one is to use scheduler idle estimate, which
is task activity based, the other is to use the statistics generated from irq
timings work.
3.2) how to determine if the idle is short or long. My current proposal is to
use a tunable value via /sys, while Peter prefers an auto-adjust mechanism. I
didn't get the details of an auto-adjust mechanism yet
4) for idle loop, my proposal introduces a simple one to use default idle
routine directly, while Peter and Thomas suggest we fix c-state selection
in the existing idle path.
Thanks,
-Aubrey
On Tue, Jul 18, 2017 at 08:43:53AM +0200, Thomas Gleixner wrote:
> On Mon, 17 Jul 2017, Andi Kleen wrote:
>
> > > We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> > > it's better than menu governor.
> >
> > I still would like to see how the fast path without the C1 heuristic works.
> >
> > Fast pathing is a different concept from a better predictor. IMHO we need
> > both, but the first is likely lower hanging fruit.
>
> Hacking something on the side is always the lower hanging fruit as it
> avoids solving the hard problems. As Peter said already, that's not going
> to happen unless there is a real technical reason why the general path
> cannot be fixed. So far there is no proof for that.
You didn't look at Aubrey's data?
There are some unavoidable slow operations in the current path -- e.g.
reprograming the timer for NOHZ. But we don't need that for really
short idle periods, because as you pointed out they never get woken
up by the tick.
Similar for other things like RCU.
I don't see how you can avoid that other than without a fast path mechanism.
Clearly these operations are eventually needed, just not all the time
for short sleeps.
Now in theory you could have lots of little fast paths in all the individual
operations that check this individually, but I don't see how that is better than
a single simple fast path.
-Andi
On Mon, 17 Jul 2017, Andi Kleen wrote:
> On Tue, Jul 18, 2017 at 08:43:53AM +0200, Thomas Gleixner wrote:
> > On Mon, 17 Jul 2017, Andi Kleen wrote:
> >
> > > > We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> > > > it's better than menu governor.
> > >
> > > I still would like to see how the fast path without the C1 heuristic works.
> > >
> > > Fast pathing is a different concept from a better predictor. IMHO we need
> > > both, but the first is likely lower hanging fruit.
> >
> > Hacking something on the side is always the lower hanging fruit as it
> > avoids solving the hard problems. As Peter said already, that's not going
> > to happen unless there is a real technical reason why the general path
> > cannot be fixed. So far there is no proof for that.
>
> You didn't look at Aubrey's data?
>
> There are some unavoidable slow operations in the current path -- e.g.
> reprograming the timer for NOHZ. But we don't need that for really
> short idle periods, because as you pointed out they never get woken
> up by the tick.
>
> Similar for other things like RCU.
>
> I don't see how you can avoid that other than without a fast path mechanism.
You can very well avoid it by taking the irq timings or whatever other
information into account for the NOHZ decision.
Thanks,
tglx
On Mon, 17 Jul 2017, Andi Kleen wrote:
> On Tue, Jul 18, 2017 at 08:43:53AM +0200, Thomas Gleixner wrote:
> > On Mon, 17 Jul 2017, Andi Kleen wrote:
> >
> > > > We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> > > > it's better than menu governor.
> > >
> > > I still would like to see how the fast path without the C1 heuristic works.
> > >
> > > Fast pathing is a different concept from a better predictor. IMHO we need
> > > both, but the first is likely lower hanging fruit.
> >
> > Hacking something on the side is always the lower hanging fruit as it
> > avoids solving the hard problems. As Peter said already, that's not going
> > to happen unless there is a real technical reason why the general path
> > cannot be fixed. So far there is no proof for that.
>
> You didn't look at Aubrey's data?
I did, but that data is no proof that it is unfixable. It's just data
describing the current situation, not more not less.
> There are some unavoidable slow operations in the current path -- e.g.
That's the whole point: current path, IOW current implementation.
This implementation is not set in stone and we rather fix it than just
creating a side channel and leave everything else as is.
Thanks,
tglx
On Tue, Jul 18, 2017 at 11:14:57AM +0800, Li, Aubrey wrote:
> On 2017/7/18 3:23, Peter Zijlstra wrote:
> > On Fri, Jul 14, 2017 at 09:26:19AM -0700, Andi Kleen wrote:
> >>> And as said; Daniel has been working on a better predictor -- now he's
> >>> probably not used it on the network workload you're looking at, so that
> >>> might be something to consider.
> >>
> >> Deriving a better idle predictor is a bit orthogonal to fast idle.
> >
> > No. If you want a different C state selected we need to fix the current
> > C state selector. We're not going to tinker.
> >
> > And the predictor is probably the most fundamental part of the whole C
> > state selection logic.
> >
> > Now I think the problem is that the current predictor goes for an
> > average idle duration. This means that we, on average, get it wrong 50%
> > of the time. For performance that's bad.
> >
> > If you want to improve the worst case, we need to consider a cumulative
> > distribution function, and staying with the Gaussian assumption already
> > present, that would mean using:
> >
> > 1 x - mu
> > CDF(x) = - [ 1 + erf(-------------) ]
> > 2 sigma sqrt(2)
> >
> > Where, per the normal convention mu is the average and sigma^2 the
> > variance. See also:
> >
> > https://en.wikipedia.org/wiki/Normal_distribution
> >
> > We then solve CDF(x) = n% to find the x for which we get it wrong n% of
> > the time (IIRC something like: 'mu - 2sigma' ends up being 5% or so).
> >
> > This conceptually gets us better exit latency for the cases where we got
> > it wrong before, and practically pushes down the estimate which gets us
> > C1 longer.
> >
> > Of course, this all assumes a Gaussian distribution to begin with, if we
> > get bimodal (or worse) distributions we can still get it wrong. To fix
> > that, we'd need to do something better than what we currently have.
> >
> Maybe you are talking about applying some machine learning algorithm online
> to fit a multivariate normal distribution, :)
Nah, nothing that fancy..
Something that _could_ work and deals with arbitrary distributions is
buckets divided on the actual C-state selection boundaries and a
(cyclic) array of the N most recent idle times.
Something like so:
struct est_data {
u8 array[64]
u8 *dist;
u8 idx;
}
DEFINE_PER_CPU(struct est_data, est_data);
void est_init(void)
{
int size = drv->state_count;
int cpu;
for_each_possible_cpu(cpu) {
per_cpu(est_data, cpu).dist = kzalloc(size);
// handle errors
}
}
u8 est_duration_2_state(u64 duration)
{
for (i=0; i<drv->state_count; i++) {
if (duration/1024 < drv->state[i].target_residency)
return i;
}
return i-1;
}
void est_contemplate(u64 duration)
{
struct est_data *ed = this_cpu_ptr(&est_data);
int state = est_duration_2_state(duration);
int idx = (ed->idx++ % ARRAY_SIZE(ed->array);
ed->dist[ed->array[idx]]--;
ed->array[idx] = state;
ed->dist[ed->array[idx]]++;
}
int est_state(int pct)
{
struct est_data *ed = this_cpu_ptr(&est_data);
int limit = pct * ARRAY_SIZE(ed->array) / 100; /* XXX move div out of line */
int cnt, last = 0;
/* CDF */
for (i=0; i<drv->state_count; i++) {
cnt += ed->dist[i];
if (cnt > limit)
break;
last = i;
}
return last;
}
> Well, back to the problem, when the scheduler picks up idle thread, it does
> not look at the history, nor make the prediction. So it's possible it has
> to switch back a task ASAP when it's going into idle(very common under some
> workloads).
>
> That is, (idle_entry + idle_exit) > idle. If the system has multiple
> hardware idle states, then:
>
> (idle_entry + idle_exit + HW_entry + HW_exit) > HW_sleep
>
> So we eventually want the idle path lighter than what we currently have.
> A complex predictor may have high accuracy, but the cost could be high as well.
I never suggested anything complex. The current menu thing uses an
average, all I said is if instead of the average you use something less,
say 'avg - 2*stdev' (it already computes the stdev) you get something,
which assuming Gaussian, is less than ~5 wrong on exit latency.
The above, also simple thing, uses a generic distribution function,
which works because it uses the exact boundaries we're limited to
anyway.
Of course, the above needs to be augmented with IRQ bits etc..
On Tue, Jul 18, 2017 at 02:56:47PM +0800, Li, Aubrey wrote:
> On 2017/7/18 14:43, Thomas Gleixner wrote:
> > On Mon, 17 Jul 2017, Andi Kleen wrote:
> >
> >>> We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
> >>> it's better than menu governor.
> >>
> >> I still would like to see how the fast path without the C1 heuristic works.
> >>
> >> Fast pathing is a different concept from a better predictor. IMHO we need
> >> both, but the first is likely lower hanging fruit.
> >
> > Hacking something on the side is always the lower hanging fruit as it
> > avoids solving the hard problems. As Peter said already, that's not going
> > to happen unless there is a real technical reason why the general path
> > cannot be fixed. So far there is no proof for that.
> >
> Let me try to make a summary, please correct me if I was wrong.
>
> 1) for quiet_vmstat, we are agreed to move to another place where tick is
> really stopped.
>
> 2) for rcu idle enter/exit, I measured the details which Paul provided, and
> the result matches with what I have measured before, nothing notable found.
> But it still makes more sense if we can make rcu idle enter/exit hooked with
> tick off. (it's possible other workloads behave differently)
Again, assuming that RCU is informed of CPUs in the kernel, regardless
of whether or not the tick is on that that point in time.
Thanx, Paul
> 3) for tick nohz idle, we want to skip if the coming idle is short. If we can
> skip the tick nohz idle, we then skip all the items depending on it. But, there
> are two hard points:
>
> 3.1) how to compute the period of the coming idle. My current proposal is to
> use two factors in the current idle menu governor. There are two possible
> options from Peter and Thomas, the one is to use scheduler idle estimate, which
> is task activity based, the other is to use the statistics generated from irq
> timings work.
>
> 3.2) how to determine if the idle is short or long. My current proposal is to
> use a tunable value via /sys, while Peter prefers an auto-adjust mechanism. I
> didn't get the details of an auto-adjust mechanism yet
>
> 4) for idle loop, my proposal introduces a simple one to use default idle
> routine directly, while Peter and Thomas suggest we fix c-state selection
> in the existing idle path.
>
> Thanks,
> -Aubrey
>
On 7/18/2017 8:20 AM, Paul E. McKenney wrote:
> 3.2) how to determine if the idle is short or long. My current proposal is to
> use a tunable value via /sys, while Peter prefers an auto-adjust mechanism. I
> didn't get the details of an auto-adjust mechanism yet
the most obvious way to do this (for me, maybe I'm naive) is to add another
C state, lets call it "C1-lite" with its own thresholds and power levels etc,
and just let that be picked naturally based on the heuristics.
(if we want to improve the heuristics, that's fine and always welcome but that
is completely orthogonal in my mind)
this C1-lite would then skip some of the idle steps like the nohz logic. How we
plumb that ... might end up being a flag or whatever, we'll figure that out easily.
as long as "real C1" has a break even time that is appropriate compared to C1-lite,
we'll only pick C1-lite for very very short idles like is desired...
but we don't end up creating a parallel infra for picking states, that part just does
not make sense to me tbh.... I have yet to see any reason why C1-lite couldn't be just
another C-state for everything except the actual place where we do the "go idle" last
bit of logic.
(Also note that for extreme short idles, today we just spinloop (C0), so by this argument
we should also do a C0-lite.. or make this C0 always the lite variant)
On Tue, Jul 18, 2017 at 08:29:40AM -0700, Arjan van de Ven wrote:
>
> the most obvious way to do this (for me, maybe I'm naive) is to add another
> C state, lets call it "C1-lite" with its own thresholds and power levels etc,
> and just let that be picked naturally based on the heuristics.
> (if we want to improve the heuristics, that's fine and always welcome but that
> is completely orthogonal in my mind)
C1-lite would then have a threshold < C1, whereas I understood the
desire to be for the fast-idle crud to have a larger threshold than C1
currently has.
That is, from what I understood, they want C1 selected *longer*.
On 7/18/2017 9:36 AM, Peter Zijlstra wrote:
> On Tue, Jul 18, 2017 at 08:29:40AM -0700, Arjan van de Ven wrote:
>>
>> the most obvious way to do this (for me, maybe I'm naive) is to add another
>> C state, lets call it "C1-lite" with its own thresholds and power levels etc,
>> and just let that be picked naturally based on the heuristics.
>> (if we want to improve the heuristics, that's fine and always welcome but that
>> is completely orthogonal in my mind)
>
> C1-lite would then have a threshold < C1, whereas I understood the
> desire to be for the fast-idle crud to have a larger threshold than C1
> currently has.
>
> That is, from what I understood, they want C1 selected *longer*.
that's just a matter of fixing the C1 and later thresholds to line up right.
shrug that's the most trivial thing to do, it's a number in a table.
some distros do those tunings anyway when they don't like the upstream tunings
On Tue, Jul 18, 2017 at 02:56:47PM +0800, Li, Aubrey wrote:
> 3) for tick nohz idle, we want to skip if the coming idle is short. If we can
> skip the tick nohz idle, we then skip all the items depending on it. But, there
> are two hard points:
>
> 3.1) how to compute the period of the coming idle. My current proposal is to
> use two factors in the current idle menu governor. There are two possible
> options from Peter and Thomas, the one is to use scheduler idle estimate, which
> is task activity based, the other is to use the statistics generated from irq
> timings work.
>
> 3.2) how to determine if the idle is short or long. My current proposal is to
> use a tunable value via /sys, while Peter prefers an auto-adjust mechanism. I
> didn't get the details of an auto-adjust mechanism yet
So the problem is that the cost of NOHZ enter/exit are for a large part
determined by (micro) architecture costs of programming timer hardware.
A single static threshold will never be the right value across all the
various machines we run Linux on.
So my suggestion was simply timing the cost of doing those functions
ever time we do them and keeping a running average of their cost. Then
use that measured cost as a basis for selecting when to skip them. For
example if the estimated idle period (by whatever estimate we end up
using) is less than 4 times the cost of doing NOHZ, don't do NOHZ.
Note how both tick_nohz_idle_{enter,exit}() already take a timestamp at
entry; all you need to do is take another one at exit and subtract.
On Tue, Jul 18, 2017 at 09:37:57AM -0700, Arjan van de Ven wrote:
> that's just a matter of fixing the C1 and later thresholds to line up right.
> shrug that's the most trivial thing to do, it's a number in a table.
Well, they represent a physical measure, namely the break-even-time. If
you go muck with them you don't have anything left. This is tinkering
of the worst possible kind.
Fix the estimator if you want behavioural changes.
> some distros do those tunings anyway when they don't like the upstream tunings
*shudder*
On Mon, Jul 17, 2017 at 12:48:38PM -0700, Arjan van de Ven wrote:
> On 7/17/2017 12:23 PM, Peter Zijlstra wrote:
> > Of course, this all assumes a Gaussian distribution to begin with, if we
> > get bimodal (or worse) distributions we can still get it wrong. To fix
> > that, we'd need to do something better than what we currently have.
> >
>
> fwiw some time ago I made a chart for predicted vs actual so you can sort
> of judge the distribution of things visually
>
> http://git.fenrus.org/tmp/linux2.png
That shows we get it wrong a lot of times (about 50%, as per the
average) and moving the line has benefit. Since for performance you
really don't want to pick the deeper idle state, so you want to bias
your pick towards a shallower state.
Using the CDF approach you can quantify by how much you want it moved.
On 2017/7/18 23:20, Paul E. McKenney wrote:
>> 2) for rcu idle enter/exit, I measured the details which Paul provided, and
>> the result matches with what I have measured before, nothing notable found.
>> But it still makes more sense if we can make rcu idle enter/exit hooked with
>> tick off. (it's possible other workloads behave differently)
>
> Again, assuming that RCU is informed of CPUs in the kernel, regardless
> of whether or not the tick is on that that point in time.
>
Yeah, I see, no problem for a normal idle.
But for a short idle, we want to return to the task ASAP. Even though RCU cost
is not notable, it would still be better for me if we can save some cycles in
idle entry and idle exit.
Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
My understanding is, if tick is not stopped, then we don't need inform RCU in
idle path, it can be informed in irq exit.
Thanks,
-Aubrey
On 2017/7/18 15:19, Thomas Gleixner wrote:
> On Mon, 17 Jul 2017, Andi Kleen wrote:
>> On Tue, Jul 18, 2017 at 08:43:53AM +0200, Thomas Gleixner wrote:
>>> On Mon, 17 Jul 2017, Andi Kleen wrote:
>>>
>>>>> We need a tradeoff here IMHO. I'll check Daniel's work to understand how/if
>>>>> it's better than menu governor.
>>>>
>>>> I still would like to see how the fast path without the C1 heuristic works.
>>>>
>>>> Fast pathing is a different concept from a better predictor. IMHO we need
>>>> both, but the first is likely lower hanging fruit.
>>>
>>> Hacking something on the side is always the lower hanging fruit as it
>>> avoids solving the hard problems. As Peter said already, that's not going
>>> to happen unless there is a real technical reason why the general path
>>> cannot be fixed. So far there is no proof for that.
>>
>> You didn't look at Aubrey's data?
>>
>> There are some unavoidable slow operations in the current path -- e.g.
>> reprograming the timer for NOHZ. But we don't need that for really
>> short idle periods, because as you pointed out they never get woken
>> up by the tick.
>>
>> Similar for other things like RCU.
>>
>> I don't see how you can avoid that other than without a fast path mechanism.
>
> You can very well avoid it by taking the irq timings or whatever other
> information into account for the NOHZ decision.
>
If I read the source correctly, irq timing statistics computation happens at
idle time. Sadly, this is what Andi Kleen worried about. People keep putting
more and more slow stuff in idle path, not realizing it could be a critical path.
/*
* The computation happens at idle time. When the CPU is not idle, the
* interrupts' timestamps are stored in the circular buffer, when the
* CPU goes idle and this routine is called, all the buffer's values
* are injected in the statistical model continuing to extend the
* statistics from the previous busy-idle cycle.
*/
Thanks,
-Aubrey
On Wed, 19 Jul 2017, Li, Aubrey wrote:
> On 2017/7/18 15:19, Thomas Gleixner wrote:
> > You can very well avoid it by taking the irq timings or whatever other
> > information into account for the NOHZ decision.
> >
> If I read the source correctly, irq timing statistics computation happens at
> idle time. Sadly, this is what Andi Kleen worried about. People keep putting
> more and more slow stuff in idle path, not realizing it could be a critical path.
Can you please stop this right here? We all realize that there is an issue,
we are not as stupid as you might think.
But we disagree that the proper solution is to add an ad hoc hack which
shortcuts stuff and creates a maintenance problem in the long run.
Just dismissing a proposal based on 'oh this adds more code to the idle
path' and then yelling 'you all do not get it' is not going to solve this
in any way.
You simply refuse to look at the big picture and you are just not willing
to analyze the involved bits and pieces and find a solution which allows to
serve both the NOHZ power saving and the interrupt driven workloads best.
All you are doing is providing data about the status quo, and then
deferring from that, that you need an extra magic code path. That
information is just a inventory of the current behaviour and the current
behaviour is caused by the current implementation. There is nothing set in
stone with that implementation and it can be changed.
But you are just in refusal mode and instead of sitting down and doing the
hard work, you accuse other people that they are not realizing the problem
and insist on your sloppy hackery. That's simply not the way it works.
Thanks,
tglx
On Wed, Jul 12, 2017 at 08:56:51AM -0700, Paul E. McKenney wrote:
> On Wed, Jul 12, 2017 at 01:54:51PM +0200, Peter Zijlstra wrote:
> > On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> >
> > > > But I think we can at the very least do this; it only gets called from
> > > > kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
> > > > that point.
> > > >
> > > >
> > > > diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> > > > index 51d4c3acf32d..dccf2dc8155a 100644
> > > > --- a/kernel/rcu/tree.c
> > > > +++ b/kernel/rcu/tree.c
> > > > @@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
> > > > */
> > > > void rcu_idle_enter(void)
> > > > {
> > > > - unsigned long flags;
> > > > -
> > > > - local_irq_save(flags);
> > >
> > > With this addition, I am all for it:
> > >
> > > RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
> > >
> > > If you are OK with this addition, may I please have your Signed-off-by?
> >
> > Sure,
> >
> > Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
>
> Very good, I have queued the patch below. I left out the removal of
> the export as I need to work out why the export was there. If it turns
> out not to be needed, I will remove the related ones as well.
>
> Fair enough?
>
> Thanx, Paul
>
> ------------------------------------------------------------------------
>
> commit 95f3e587ce6388028a51f0c852800fca944e7032
> Author: Peter Zijlstra (Intel) <[email protected]>
> Date: Wed Jul 12 07:59:54 2017 -0700
>
> rcu: Make rcu_idle_enter() rely on callers disabling irqs
>
> All callers to rcu_idle_enter() have irqs disabled, so there is no
> point in rcu_idle_enter disabling them again. This commit therefore
> replaces the irq disabling with a RCU_LOCKDEP_WARN().
>
> Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> Signed-off-by: Paul E. McKenney <[email protected]>
>
> diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> index 6de6b1c5ee53..c78b076653ce 100644
> --- a/kernel/rcu/tree.c
> +++ b/kernel/rcu/tree.c
> @@ -840,11 +840,8 @@ static void rcu_eqs_enter(bool user)
> */
> void rcu_idle_enter(void)
> {
> - unsigned long flags;
> -
> - local_irq_save(flags);
> + RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
Nice! I really need to make that LOCKDEP_ASSERT_IRQS_DISABLED() patchset because there
are many places where either we have WARN_ON_ONCE(!irqs_disabled()) or we need it but we were too
shy to do it for performance reason.
> rcu_eqs_enter(false);
> - local_irq_restore(flags);
> }
> EXPORT_SYMBOL_GPL(rcu_idle_enter);
>
>
On Tue, Jul 18, 2017 at 11:14:57AM +0800, Li, Aubrey wrote:
> On 2017/7/18 3:23, Peter Zijlstra wrote:
> > On Fri, Jul 14, 2017 at 09:26:19AM -0700, Andi Kleen wrote:
> >>> And as said; Daniel has been working on a better predictor -- now he's
> >>> probably not used it on the network workload you're looking at, so that
> >>> might be something to consider.
> >>
> >> Deriving a better idle predictor is a bit orthogonal to fast idle.
> >
> > No. If you want a different C state selected we need to fix the current
> > C state selector. We're not going to tinker.
> >
> > And the predictor is probably the most fundamental part of the whole C
> > state selection logic.
> >
> > Now I think the problem is that the current predictor goes for an
> > average idle duration. This means that we, on average, get it wrong 50%
> > of the time. For performance that's bad.
> >
> > If you want to improve the worst case, we need to consider a cumulative
> > distribution function, and staying with the Gaussian assumption already
> > present, that would mean using:
> >
> > 1 x - mu
> > CDF(x) = - [ 1 + erf(-------------) ]
> > 2 sigma sqrt(2)
> >
> > Where, per the normal convention mu is the average and sigma^2 the
> > variance. See also:
> >
> > https://en.wikipedia.org/wiki/Normal_distribution
> >
> > We then solve CDF(x) = n% to find the x for which we get it wrong n% of
> > the time (IIRC something like: 'mu - 2sigma' ends up being 5% or so).
> >
> > This conceptually gets us better exit latency for the cases where we got
> > it wrong before, and practically pushes down the estimate which gets us
> > C1 longer.
> >
> > Of course, this all assumes a Gaussian distribution to begin with, if we
> > get bimodal (or worse) distributions we can still get it wrong. To fix
> > that, we'd need to do something better than what we currently have.
> >
> Maybe you are talking about applying some machine learning algorithm online
> to fit a multivariate normal distribution, :)
See here for an implementation of what I spoke about above:
https://lkml.kernel.org/r/[email protected]
Very much statistics 101.
On Wed, Jul 19, 2017 at 01:44:06PM +0800, Li, Aubrey wrote:
> On 2017/7/18 23:20, Paul E. McKenney wrote:
>
> >> 2) for rcu idle enter/exit, I measured the details which Paul provided, and
> >> the result matches with what I have measured before, nothing notable found.
> >> But it still makes more sense if we can make rcu idle enter/exit hooked with
> >> tick off. (it's possible other workloads behave differently)
> >
> > Again, assuming that RCU is informed of CPUs in the kernel, regardless
> > of whether or not the tick is on that that point in time.
> >
> Yeah, I see, no problem for a normal idle.
>
> But for a short idle, we want to return to the task ASAP. Even though RCU cost
> is not notable, it would still be better for me if we can save some cycles in
> idle entry and idle exit.
>
> Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
> My understanding is, if tick is not stopped, then we don't need inform RCU in
> idle path, it can be informed in irq exit.
Indeed, the problem arises when the tick is stopped.
Thanx, Paul
On Wed, Jul 19, 2017 at 03:43:07PM +0200, Frederic Weisbecker wrote:
> On Wed, Jul 12, 2017 at 08:56:51AM -0700, Paul E. McKenney wrote:
> > On Wed, Jul 12, 2017 at 01:54:51PM +0200, Peter Zijlstra wrote:
> > > On Tue, Jul 11, 2017 at 11:09:31AM -0700, Paul E. McKenney wrote:
> > > > On Tue, Jul 11, 2017 at 06:34:22PM +0200, Peter Zijlstra wrote:
> > >
> > > > > But I think we can at the very least do this; it only gets called from
> > > > > kernel/sched/idle.c and both callsites have IRQs explicitly disabled by
> > > > > that point.
> > > > >
> > > > >
> > > > > diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> > > > > index 51d4c3acf32d..dccf2dc8155a 100644
> > > > > --- a/kernel/rcu/tree.c
> > > > > +++ b/kernel/rcu/tree.c
> > > > > @@ -843,13 +843,8 @@ static void rcu_eqs_enter(bool user)
> > > > > */
> > > > > void rcu_idle_enter(void)
> > > > > {
> > > > > - unsigned long flags;
> > > > > -
> > > > > - local_irq_save(flags);
> > > >
> > > > With this addition, I am all for it:
> > > >
> > > > RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
> > > >
> > > > If you are OK with this addition, may I please have your Signed-off-by?
> > >
> > > Sure,
> > >
> > > Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> >
> > Very good, I have queued the patch below. I left out the removal of
> > the export as I need to work out why the export was there. If it turns
> > out not to be needed, I will remove the related ones as well.
> >
> > Fair enough?
> >
> > Thanx, Paul
> >
> > ------------------------------------------------------------------------
> >
> > commit 95f3e587ce6388028a51f0c852800fca944e7032
> > Author: Peter Zijlstra (Intel) <[email protected]>
> > Date: Wed Jul 12 07:59:54 2017 -0700
> >
> > rcu: Make rcu_idle_enter() rely on callers disabling irqs
> >
> > All callers to rcu_idle_enter() have irqs disabled, so there is no
> > point in rcu_idle_enter disabling them again. This commit therefore
> > replaces the irq disabling with a RCU_LOCKDEP_WARN().
> >
> > Signed-off-by: Peter Zijlstra (Intel) <[email protected]>
> > Signed-off-by: Paul E. McKenney <[email protected]>
> >
> > diff --git a/kernel/rcu/tree.c b/kernel/rcu/tree.c
> > index 6de6b1c5ee53..c78b076653ce 100644
> > --- a/kernel/rcu/tree.c
> > +++ b/kernel/rcu/tree.c
> > @@ -840,11 +840,8 @@ static void rcu_eqs_enter(bool user)
> > */
> > void rcu_idle_enter(void)
> > {
> > - unsigned long flags;
> > -
> > - local_irq_save(flags);
> > + RCU_LOCKDEP_WARN(!irqs_disabled(), "rcu_idle_enter() invoked with irqs enabled!!!");
>
> Nice! I really need to make that LOCKDEP_ASSERT_IRQS_DISABLED() patchset because there
> are many places where either we have WARN_ON_ONCE(!irqs_disabled()) or we need it but we were too
> shy to do it for performance reason.
If you create it, let me know, I could switch to it.
Thanx, Paul
> > rcu_eqs_enter(false);
> > - local_irq_restore(flags);
> > }
> > EXPORT_SYMBOL_GPL(rcu_idle_enter);
> >
> >
>
On Wed, 19 Jul 2017, Paul E. McKenney wrote:
> > Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
> > My understanding is, if tick is not stopped, then we don't need inform RCU in
> > idle path, it can be informed in irq exit.
>
> Indeed, the problem arises when the tick is stopped.
Well is there a boundary when you would want the notification calls? I
would think that even an idle period of a couple of seconds does not
necessarily require a callback to rcu. Had some brokenness here where RCU
calls did not occur for hours or so. At some point the system ran out of
memory but thats far off.
On Wed, Jul 19, 2017 at 10:03:22AM -0500, Christopher Lameter wrote:
> On Wed, 19 Jul 2017, Paul E. McKenney wrote:
>
> > > Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
> > > My understanding is, if tick is not stopped, then we don't need inform RCU in
> > > idle path, it can be informed in irq exit.
> >
> > Indeed, the problem arises when the tick is stopped.
>
> Well is there a boundary when you would want the notification calls? I
> would think that even an idle period of a couple of seconds does not
> necessarily require a callback to rcu. Had some brokenness here where RCU
> calls did not occur for hours or so. At some point the system ran out of
> memory but thats far off.
Yeah, I should spell this out more completely, shouldn't I? And get
it into the documentation if it isn't already there... Where it is
currently at best hinted at. :-/
1. If a CPU is either idle or executing in usermode, and RCU believes
it is non-idle, the scheduling-clock tick had better be running.
Otherwise, you will get RCU CPU stall warnings. Or at best,
very long (11-second) grace periods, with a pointless IPI waking
the CPU each time.
2. If a CPU is in a portion of the kernel that executes RCU read-side
critical sections, and RCU believes this CPU to be idle, you can get
random memory corruption. DON'T DO THIS!!!
This is one reason to test with lockdep, which will complain
about this sort of thing.
3. If a CPU is in a portion of the kernel that is absolutely
positively no-joking guaranteed to never execute any RCU read-side
critical sections, and RCU believes this CPU to to be idle,
no problem. This sort of thing is used by some architectures
for light-weight exception handlers, which can then avoid the
overhead of rcu_irq_enter() and rcu_irq_exit(). Some go further
and avoid the entireties of irq_enter() and irq_exit().
Just make very sure you are running some of your tests with
CONFIG_PROVE_RCU=y.
4. If a CPU is executing in the kernel with the scheduling-clock
interrupt disabled and RCU believes this CPU to be non-idle,
and if the CPU goes idle (from an RCU perspective) every few
jiffies, no problem. It is usually OK for there to be the
occasional gap between idle periods of up to a second or so.
If the gap grows too long, you get RCU CPU stall warnings.
5. If a CPU is either idle or executing in usermode, and RCU believes
it to be idle, of course no problem.
6. If a CPU is executing in the kernel, the kernel code
path is passing through quiescent states at a reasonable
frequency (preferably about once per few jiffies, but the
occasional excursion to a second or so is usually OK) and the
scheduling-clock interrupt is enabled, of course no problem.
If the gap between a successive pair of quiescent states grows
too long, you get RCU CPU stall warnings.
For purposes of comparison, the default time until RCU CPU stall warning
in mainline is 21 seconds. A number of distros set this to 60 seconds.
Back in the 90s, the analogous timeout for DYNIX/ptx was 1.5 seconds. :-/
Hence "a second or so" instead of your "a couple of seconds". ;-)
Please see below for the corresponding patch to RCU's requirements.
Thoughts?
Thanx, Paul
------------------------------------------------------------------------
commit 693c9bfa43f92570dd362d8834440b418bbb994a
Author: Paul E. McKenney <[email protected]>
Date: Wed Jul 19 09:52:58 2017 -0700
doc: Set down RCU's scheduling-clock-interrupt needs
This commit documents the situations in which RCU needs the
scheduling-clock interrupt to be enabled, along with the consequences
of failing to meet RCU's needs in this area.
Signed-off-by: Paul E. McKenney <[email protected]>
diff --git a/Documentation/RCU/Design/Requirements/Requirements.html b/Documentation/RCU/Design/Requirements/Requirements.html
index 95b30fa25d56..7980bee5607f 100644
--- a/Documentation/RCU/Design/Requirements/Requirements.html
+++ b/Documentation/RCU/Design/Requirements/Requirements.html
@@ -2080,6 +2080,8 @@ Some of the relevant points of interest are as follows:
<li> <a href="#Scheduler and RCU">Scheduler and RCU</a>.
<li> <a href="#Tracing and RCU">Tracing and RCU</a>.
<li> <a href="#Energy Efficiency">Energy Efficiency</a>.
+<li> <a href="#Scheduling-Clock Interrupts and RCU">
+ Scheduling-Clock Interrupts and RCU</a>.
<li> <a href="#Memory Efficiency">Memory Efficiency</a>.
<li> <a href="#Performance, Scalability, Response Time, and Reliability">
Performance, Scalability, Response Time, and Reliability</a>.
@@ -2532,6 +2534,113 @@ I learned of many of these requirements via angry phone calls:
Flaming me on the Linux-kernel mailing list was apparently not
sufficient to fully vent their ire at RCU's energy-efficiency bugs!
+<h3><a name="Scheduling-Clock Interrupts and RCU">
+Scheduling-Clock Interrupts and RCU</a></h3>
+
+<p>
+The kernel transitions between in-kernel non-idle execution, userspace
+execution, and the idle loop.
+Depending on kernel configuration, RCU handles these states differently:
+
+<table border=3>
+<tr><th><tt>HZ</tt> Kconfig</th>
+ <th>In-Kernel</th>
+ <th>Usermode</th>
+ <th>Idle</th></tr>
+<tr><th align="left"><tt>HZ_PERIODIC</tt></th>
+ <td>Can rely on scheduling-clock interrupt.</td>
+ <td>Can rely on scheduling-clock interrupt and its
+ detection of interrupt from usermode.</td>
+ <td>Can rely on RCU's dyntick-idle detection.</td></tr>
+<tr><th align="left"><tt>NO_HZ_IDLE</tt></th>
+ <td>Can rely on scheduling-clock interrupt.</td>
+ <td>Can rely on scheduling-clock interrupt and its
+ detection of interrupt from usermode.</td>
+ <td>Can rely on RCU's dyntick-idle detection.</td></tr>
+<tr><th align="left"><tt>NO_HZ_FULL</tt></th>
+ <td>Can only sometimes rely on scheduling-clock interrupt.
+ In other cases, it is necessary to bound kernel execution
+ times and/or use IPIs.</td>
+ <td>Can rely on RCU's dyntick-idle detection.</td>
+ <td>Can rely on RCU's dyntick-idle detection.</td></tr>
+</table>
+
+<table>
+<tr><th> </th></tr>
+<tr><th align="left">Quick Quiz:</th></tr>
+<tr><td>
+ Why can't <tt>NO_HZ_FULL</tt> in-kernel execution rely on the
+ scheduling-clock interrupt, just like <tt>HZ_PERIODIC</tt>
+ and <tt>NO_HZ_IDLE</tt> do?
+</td></tr>
+<tr><th align="left">Answer:</th></tr>
+<tr><td bgcolor="#ffffff"><font color="ffffff">
+ Because, as a performance optimization, <tt>NO_HZ_FULL</tt>
+ does not necessarily re-enable the scheduling-clock interrupt
+ on entry to each and every system call.
+</font></td></tr>
+<tr><td> </td></tr>
+</table>
+
+<p>
+However, RCU must be reliably informed as to whether any given
+CPU is currently in the idle loop, and, for <tt>NO_HZ_FULL</tt>,
+also whether that CPU is executing in usermode, as discussed
+<a href="#Energy Efficiency">earlier</a>.
+It also requires that the scheduling-clock interrupt be enabled when
+RCU needs it to be:
+
+<ol>
+<li> If a CPU is either idle or executing in usermode, and RCU believes
+ it is non-idle, the scheduling-clock tick had better be running.
+ Otherwise, you will get RCU CPU stall warnings. Or at best,
+ very long (11-second) grace periods, with a pointless IPI waking
+ the CPU from time to time.
+<li> If a CPU is in a portion of the kernel that executes RCU read-side
+ critical sections, and RCU believes this CPU to be idle, you will get
+ random memory corruption. <b>DON'T DO THIS!!!</b>
+
+ <br>This is one reason to test with lockdep, which will complain
+ about this sort of thing.
+<li> If a CPU is in a portion of the kernel that is absolutely
+ positively no-joking guaranteed to never execute any RCU read-side
+ critical sections, and RCU believes this CPU to to be idle,
+ no problem. This sort of thing is used by some architectures
+ for light-weight exception handlers, which can then avoid the
+ overhead of <tt>rcu_irq_enter()</tt> and <tt>rcu_irq_exit()</tt>
+ at exception entry and exit, respectively.
+ Some go further and avoid the entireties of <tt>irq_enter()</tt>
+ and <tt>irq_exit()</tt>.
+
+ <br>Just make very sure you are running some of your tests with
+ <tt>CONFIG_PROVE_RCU=y</tt>, just in case one of your code paths
+ was in fact joking about not doing RCU read-side critical sections.
+<li> If a CPU is executing in the kernel with the scheduling-clock
+ interrupt disabled and RCU believes this CPU to be non-idle,
+ and if the CPU goes idle (from an RCU perspective) every few
+ jiffies, no problem. It is usually OK for there to be the
+ occasional gap between idle periods of up to a second or so.
+
+ <br>If the gap grows too long, you get RCU CPU stall warnings.
+<li> If a CPU is either idle or executing in usermode, and RCU believes
+ it to be idle, of course no problem.
+<li> If a CPU is executing in the kernel, the kernel code
+ path is passing through quiescent states at a reasonable
+ frequency (preferably about once per few jiffies, but the
+ occasional excursion to a second or so is usually OK) and the
+ scheduling-clock interrupt is enabled, of course no problem.
+
+ <br>If the gap between a successive pair of quiescent states grows
+ too long, you get RCU CPU stall warnings.
+</ol>
+
+<p>
+But as long as RCU is properly informed of kernel state transitions between
+in-kernel execution, usermode execution, and idle, and as long as the
+scheduling-clock interrupt is enabled when RCU needs it to be, you
+can rest assured that the bugs you encounter will be in some other
+part of RCU or some other part of the kernel!
+
<h3><a name="Memory Efficiency">Memory Efficiency</a></h3>
<p>
On 2017/7/19 22:48, Paul E. McKenney wrote:
> On Wed, Jul 19, 2017 at 01:44:06PM +0800, Li, Aubrey wrote:
>> On 2017/7/18 23:20, Paul E. McKenney wrote:
>>
>>>> 2) for rcu idle enter/exit, I measured the details which Paul provided, and
>>>> the result matches with what I have measured before, nothing notable found.
>>>> But it still makes more sense if we can make rcu idle enter/exit hooked with
>>>> tick off. (it's possible other workloads behave differently)
>>>
>>> Again, assuming that RCU is informed of CPUs in the kernel, regardless
>>> of whether or not the tick is on that that point in time.
>>>
>> Yeah, I see, no problem for a normal idle.
>>
>> But for a short idle, we want to return to the task ASAP. Even though RCU cost
>> is not notable, it would still be better for me if we can save some cycles in
>> idle entry and idle exit.
>>
>> Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
>> My understanding is, if tick is not stopped, then we don't need inform RCU in
>> idle path, it can be informed in irq exit.
>
> Indeed, the problem arises when the tick is stopped.
My question is, does problem arise when the tick is *not* stopped (skipping nohz idle)?
instead of
static void cpuidle_idle_call()
{
rcu_idle_enter()
......
rcu_idle_exit()
}
I want
static void cpuidle_idle_call()
{
if (tick stopped)
rcu_idle_enter()
......
if (tick stopped)
rcu_idle_exit()
}
Or checking tick stop can be put into rcu_idle_enter/exit
Thanks,
-Aubrey
On 2017/7/19 15:55, Thomas Gleixner wrote:
> On Wed, 19 Jul 2017, Li, Aubrey wrote:
>> On 2017/7/18 15:19, Thomas Gleixner wrote:
>>> You can very well avoid it by taking the irq timings or whatever other
>>> information into account for the NOHZ decision.
>>>
>> If I read the source correctly, irq timing statistics computation happens at
>> idle time. Sadly, this is what Andi Kleen worried about. People keep putting
>> more and more slow stuff in idle path, not realizing it could be a critical path.
>
> Can you please stop this right here? We all realize that there is an issue,
> we are not as stupid as you might think.
>
> But we disagree that the proper solution is to add an ad hoc hack which
> shortcuts stuff and creates a maintenance problem in the long run.
>
> Just dismissing a proposal based on 'oh this adds more code to the idle
> path' and then yelling 'you all do not get it' is not going to solve this
> in any way.
>
> You simply refuse to look at the big picture and you are just not willing
> to analyze the involved bits and pieces and find a solution which allows to
> serve both the NOHZ power saving and the interrupt driven workloads best.
>
> All you are doing is providing data about the status quo, and then
> deferring from that, that you need an extra magic code path. That
> information is just a inventory of the current behaviour and the current
> behaviour is caused by the current implementation. There is nothing set in
> stone with that implementation and it can be changed.
>
> But you are just in refusal mode and instead of sitting down and doing the
> hard work, you accuse other people that they are not realizing the problem
> and insist on your sloppy hackery. That's simply not the way it works.
Don't get me wrong, even if a fast path is acceptable, we still need to
figure out if the coming idle is short and when to switch. I'm just worried
about if irq timings is not an ideal statistics, we have to skip it too.
Let me a little time to digest the details of irq timings and obtain some
data to see if it's suitable for my case.
Thanks,
-Aubrey
On Thu, 20 Jul 2017, Li, Aubrey wrote:
> Don't get me wrong, even if a fast path is acceptable, we still need to
> figure out if the coming idle is short and when to switch. I'm just worried
> about if irq timings is not an ideal statistics, we have to skip it too.
There is no ideal solution ever.
Lets sit back and look at that from the big picture first before dismissing
a particular item upfront.
The current NOHZ implementation does:
predict = nohz_predict(timers, rcu, arch, irqwork);
if ((predict - now) > X)
stop_tick()
The C-State machinery does something like:
predict = cstate_predict(next_timer, scheduler);
cstate = cstate_select(predict);
That disconnect is part of the problem. What we really want is:
predict = idle_predict(timers, rcu, arch, irqwork, scheduler, irq timings);
and use that prediction for both the NOHZ and the C-State decision
function. That's the first thing which needs to be addressed.
Once that is done, you can look into the prediction functions and optimize
that or tweak the bits and pieces there and decide which predictors work
best for a particular workload.
As long as you just look into a particular predictor function and do not
address the underlying conceptual issues first, the outcome is very much
predictable: It's going to be useless crap.
Thanks,
tglx
On Thu, Jul 20, 2017 at 09:40:49AM +0800, Li, Aubrey wrote:
> On 2017/7/19 22:48, Paul E. McKenney wrote:
> > On Wed, Jul 19, 2017 at 01:44:06PM +0800, Li, Aubrey wrote:
> >> On 2017/7/18 23:20, Paul E. McKenney wrote:
> >>
> >>>> 2) for rcu idle enter/exit, I measured the details which Paul provided, and
> >>>> the result matches with what I have measured before, nothing notable found.
> >>>> But it still makes more sense if we can make rcu idle enter/exit hooked with
> >>>> tick off. (it's possible other workloads behave differently)
> >>>
> >>> Again, assuming that RCU is informed of CPUs in the kernel, regardless
> >>> of whether or not the tick is on that that point in time.
> >>>
> >> Yeah, I see, no problem for a normal idle.
> >>
> >> But for a short idle, we want to return to the task ASAP. Even though RCU cost
> >> is not notable, it would still be better for me if we can save some cycles in
> >> idle entry and idle exit.
> >>
> >> Do we have any problem if we skip RCU idle enter/exit under a fast idle scenario?
> >> My understanding is, if tick is not stopped, then we don't need inform RCU in
> >> idle path, it can be informed in irq exit.
> >
> > Indeed, the problem arises when the tick is stopped.
>
> My question is, does problem arise when the tick is *not* stopped (skipping nohz idle)?
>
> instead of
>
> static void cpuidle_idle_call()
> {
> rcu_idle_enter()
> ......
> rcu_idle_exit()
> }
>
> I want
>
> static void cpuidle_idle_call()
> {
> if (tick stopped)
> rcu_idle_enter()
> ......
> if (tick stopped)
> rcu_idle_exit()
> }
>
> Or checking tick stop can be put into rcu_idle_enter/exit
The answer is the traditional "it depends".
If the above change was all that you did, that would be a bug in the
case where the predicted short idle time turned out to in reality be an
indefinite idle time. RCU would indefinitely believe that the CPU was
non-idle, and would wait for it to report a quiescent state, which it
would not, even given the scheduling-clock interrupt (it is idle, so it
knows RCU already knows that it is idle, you see). RCU would eventually
send it a resched IPI, which would probably get things going again,
but the best you could hope for was extra resched IPIs and excessively
long grace periods.
To make this work reasonably, you would also need some way to check for
the case where the prediction idle time is short but the real idle time
is very long.
Thanx, Paul
On 7/20/2017 5:50 AM, Paul E. McKenney wrote:
> To make this work reasonably, you would also need some way to check for
> the case where the prediction idle time is short but the real idle time
> is very long.
so the case where you predict very short but is actually "indefinite", the real
solution likely is that we set a timer some time in the future
(say 100msec, or some other value that is long but not indefinite)
where we wake up the system and make a new prediction,
since clearly we were insanely wrong in the prediction and should try
again.
that or we turn the prediction from a single value into a range of
(expected, upper bound)
where upper bound is likely the next timer or other going-to-happen events.
On 7/20/2017 1:11 AM, Thomas Gleixner wrote:
> On Thu, 20 Jul 2017, Li, Aubrey wrote:
>> Don't get me wrong, even if a fast path is acceptable, we still need to
>> figure out if the coming idle is short and when to switch. I'm just worried
>> about if irq timings is not an ideal statistics, we have to skip it too.
>
> There is no ideal solution ever.
>
> Lets sit back and look at that from the big picture first before dismissing
> a particular item upfront.
>
> The current NOHZ implementation does:
>
> predict = nohz_predict(timers, rcu, arch, irqwork);
>
> if ((predict - now) > X)
> stop_tick()
>
> The C-State machinery does something like:
>
> predict = cstate_predict(next_timer, scheduler);
>
> cstate = cstate_select(predict);
>
> That disconnect is part of the problem. What we really want is:
>
> predict = idle_predict(timers, rcu, arch, irqwork, scheduler, irq timings);
two separate predictors is clearly a recipe for badness.
(likewise, C and P states try to estimate "performance sensitivity" and sometimes estimate in opposite directions)
to be honest, performance sensitivity estimation is probably 10x more critical for C state
selection than idle duration; a lot of modern hardware will do the energy efficiency stuff
in a microcontroller when it coordinates between multiple cores in the system on C and P states.
(both x86 and ARM have such microcontroller nowadays, at least for the higher performance
designs)
On Thu, Jul 20, 2017 at 05:50:54AM -0700, Paul E. McKenney wrote:
> >
> > static void cpuidle_idle_call()
> > {
> > rcu_idle_enter()
> > ......
> > rcu_idle_exit()
> > }
> >
> > I want
> >
> > static void cpuidle_idle_call()
> > {
> > if (tick stopped)
> > rcu_idle_enter()
> > ......
> > if (tick stopped)
> > rcu_idle_exit()
> > }
> >
> > Or checking tick stop can be put into rcu_idle_enter/exit
>
> The answer is the traditional "it depends".
>
> If the above change was all that you did, that would be a bug in the
> case where the predicted short idle time turned out to in reality be an
> indefinite idle time.
Can't be, you didn't disable the tick after all, so you're guaranteed to
get interrupted by the tick and try again.
On Thu, Jul 20, 2017 at 04:19:40PM +0200, Peter Zijlstra wrote:
> On Thu, Jul 20, 2017 at 05:50:54AM -0700, Paul E. McKenney wrote:
> > >
> > > static void cpuidle_idle_call()
> > > {
> > > rcu_idle_enter()
> > > ......
> > > rcu_idle_exit()
> > > }
> > >
> > > I want
> > >
> > > static void cpuidle_idle_call()
> > > {
> > > if (tick stopped)
> > > rcu_idle_enter()
> > > ......
> > > if (tick stopped)
> > > rcu_idle_exit()
> > > }
> > >
> > > Or checking tick stop can be put into rcu_idle_enter/exit
> >
> > The answer is the traditional "it depends".
> >
> > If the above change was all that you did, that would be a bug in the
> > case where the predicted short idle time turned out to in reality be an
> > indefinite idle time.
>
> Can't be, you didn't disable the tick after all, so you're guaranteed to
> get interrupted by the tick and try again.
I will reserve judgment on that until I see the patch. But to your point,
I would indeed hope that it works that way. ;-)
Thanx, Paul
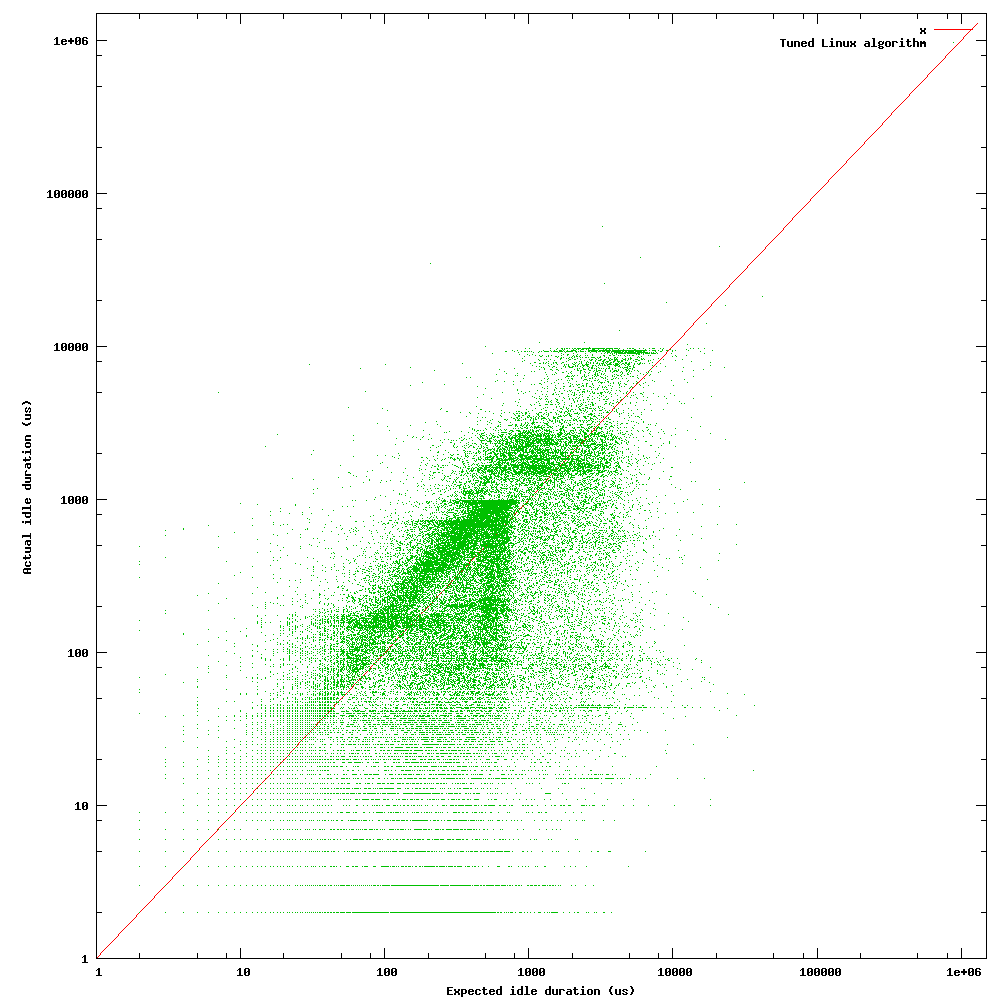{kind=link}
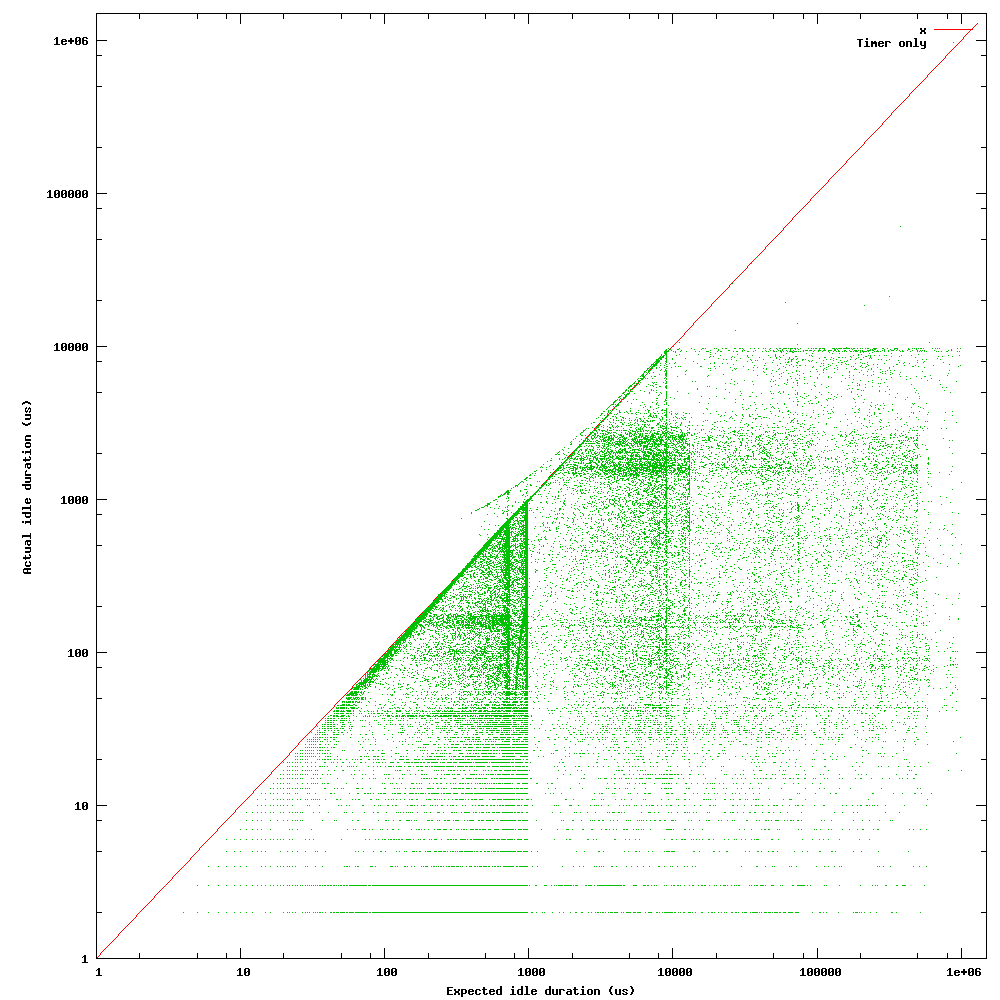{kind=link}